| БОЮФЮЊДѓЪ§ОндгЬИ4дТ20ШеЮЂаХЩчШКЗжЯэФкШнећРэЁЃ
НёЬьЕФФПБъЪЧЪЙгУCaffeЭъГЩЩюЖШбЇЯАбЕСЗЕФШЋЙ§ГЬЁЃCaffeЪЧвЛПюЪЎЗжжЊУћЕФЩюЖШбЇЯАПђМмЃЌгЩМгжнДѓбЇВЎПЫРћЗжаЃЕФМжбяЧхВЉЪПгк2013ФъдкGithubЩЯЗЂВМЁЃздФЧЪБЦ№ЃЌCaffeдкбаОПНчКЭЙЄвЕНчЖМЪмЕНСЫМЋДѓЕФЙизЂЁЃCaffeЕФЪЙгУБШНЯМђЕЅЃЌДњТывзгкРЉеЙЃЌдЫааЫйЖШЕУЕНСЫЙЄвЕНчЕФШЯПЩЃЌЭЌЪБЛЙгаЪЎЗжГЩЪьЕФЩчЧјЁЃ
ЖдгкИеПЊЪМбЇЯАЩюЖШбЇЯАЕФЭЌбЇРДЫЕЃЌCaffeЪЧвЛПюЪЎЗжЪЎЗжЪЪКЯЕФПЊдДПђМмЁЃПЩЦфЫћЭЌРраЭЕФПђМмЃЌЫќгжвЛИізюДѓЕФЬиЕуЃЌОЭЪЧДњТыКЭПђМмБШНЯМђЕЅЃЌЪЪКЯЩюШыСЫНтЗжЮіЁЃНёЬьНЋвЊНщЩмЕФФкШнЖМЪЧCaffeжаГЩаЭКмОУЕФФкШнЃЌШчНёОјДѓЖрЪ§АцБОЕФCaffeЖМАќКЌетаЉЙІФмЁЃЙигкCaffeЯТдиКЭАВзАЕФФкШнЧыИїЮЛИљОнЙйЗНЭјеОжИЕМНјааЯТдиКЭАВзАЃЌетРяОЭВЛдйзИЪіСЫЁЃ

вЛИіГЃЙцЕФМрЖНбЇЯАШЮЮёжївЊАќКЌбЕСЗгыдЄВтСНИіДѓЕФВНжшЃЌетРяЛЙЪЧвдCaffeжаздДјЕФР§згЁЊЁЊMNISTЪ§ОнМЏЪжаДЪ§зжЪЖБ№ЮЊР§ЃЌРДНщЩмвЛЯТЫќОпЬхЕФЪЙгУЗНЗЈЁЃ
ШчЙћАбЩЯУцЬсЕНЕФЩюЖШбЇЯАбЕСЗВНжшЗжНтЕУИќЯИжТвЛаЉЃЌФЧУДетИіГЃЙцСїГЬНЋЗжГЩетМИИізгВНжшЃК
Ъ§ОндЄДІРэЃЈНЈСЂЪ§ОнПтЃЉ
ЭјТчНсЙЙгыФЃаЭбЕСЗЕФХфжУ
бЕСЗгыдкбЕСЗ
бЕСЗШежОЗжЮі
дЄВтМьбщгыЗжЮі
адФмВтЪд
ЯТУцОЭРДвЛвЛНщЩмЁЃ
1 Ъ§ОндЄДІРэ
ЪзЯШЪЧбЕСЗЪ§ОнКЭдЄВтЪ§ОнЕФдЄДІРэЁЃетРяЕФЙЄзївЛАуЪЧАбД§ЗжЮіЪЖБ№ЕФЭМЯёНјааМђЕЅЕФдЄДІРэЃЌШЛКѓБЃДцЕНЪ§ОнПтжаЁЃЮЊЪВУДвЊЭъГЩетвЛВНЖјВЛЪЧжБНгДгЭМЯёЮФМўжаЖСШЁЪ§ОнФиЃПвђЮЊЪЕМЪШЮЮёжабЕСЗЪ§ОнЕФЪ§СППЩФмЗЧГЃДѓЃЌДгЭМЯёЮФМўжаЖСШЁЪ§ОнВЂНјааГѕЪМЛЏЕФаЇТЪЪЧЗЧГЃЕЭЕФЃЌЫљвдКмгаБивЊАбЪ§ОндЄЯШБЃДцдкЪ§ОнПтжаЃЌРДМгПьбЕСЗЕФНкзрЁЃ
вдЯТЕФВйзїНЋШЋВПдкжеЖЫЭъГЩЁЃЕквЛВНЪЧНЋЪ§ОнЯТдиЕНБОЕиЃЌКУдкMNISTЕФЪ§ОнСПВЛЫуДѓЃЌШчЙћДѓМвЕФЭјТчЛЗОГКУЃЌетвЛВНЕФЫйЖШЛсЗЧГЃПьЁЃЪзЯШРДЕНcaffeЕФАВзАИљФПТМЁЊЁЊCAFFE_HOMEЃЌШЛКѓжДааЯТУцЕФУќСюЃК
cd data/mnist
./get_mnist.sh |
ГЬађжДааЭъГЩКѓЃЌЮФМўМаЯТгІИУЛсЖрГіРДЫФИіЮФМўЃЌетЫФИіЮФМўОЭЪЧЮвУЧЯТдиЕФЪ§ОнЮФМўЁЃЕкЖўВНЮвУЧашвЊЕїгУexampleжаЕФЪ§ОнПтДДНЈГЬађЃК
cd $CAFFE_HOME
./examples/mnist/create_mnist.sh |
ГЬађжДааЭъГЩКѓЃЌexamples/mnistЮФМўМаЯТУцОЭЛсЖрГіСНИіЮФМўМаЃЌЗжБ№БЃДцСЫMNISTЕФбЕСЗКЭВтЪдЪ§ОнЁЃжЕЕУвЛЬсЕФЪЧЃЌЪ§ОнПтЕФИёЪНПЩвдЭЈЙ§аоИФНХБОЕФBACKENDБфСПРДИќЛЛЁЃФПЧАЪ§ОнПтгаСНжжжїСїбЁдёЃК
LevelDB
LmDB
етСНжжЪ§ОнПтдкДцДЂЪ§ОнКЭВйзнЩЯгавЛаЉВЛЭЌЃЌЪзЯШЪЧЫќУЧЕФЪ§ОнзщжЏЗНЪНВЛЭЌЃЌетЪЧLevelDBЕФФкШнЃК
етЪЧLMDBЕФФкШнЃК

ДгНсЙЙПЩвдПДГіLevelDBЕФЮФМўБШНЯЖрЃЌLMDBЕФЮФМўИќЮЊНєДеЁЃ
ЦфДЮЪЧЫќУЧЕФЖСШЁЪ§ОнЕФНгПкЃЌФГаЉГЁОАашвЊБщРњЪ§ОнПтЭъГЩвЛаЉдЪМЭМЯёЕФЗжЮіДІРэЃЌвђДЫСЫНтЫќУЧЕФЪ§ОнЖСШЁЗНЗЈвВЪЎЗжгаБивЊЁЃЪзЯШЪЧLMDBЖСШЁЪ§ОнЕФДњТыЃК

ЦфДЮЪЧLevelDBЖСШЁЕФДњТыЃК
зюКѓЛиЕНБОаЁНкЕФЮЪЬтЃКЮЊЪВУДвЊВЩгУЪ§ОнПтЕФЗНЪНДцДЂЪ§ОнЖјВЛЪЧжБНгЖСШЁЭМЯёЃПетРяПЩвдМђЕЅВтЪдвЛЯТгУMNISTЪ§ОнЙЙНЈЕФетСНИіЪ§ОнПтАДађЖСШЁЕФЫйЖШЃЌетРягУЯЕЭГКЏЪ§timeНјааМЦЪБЃЌНсЙћШчЯТЃК
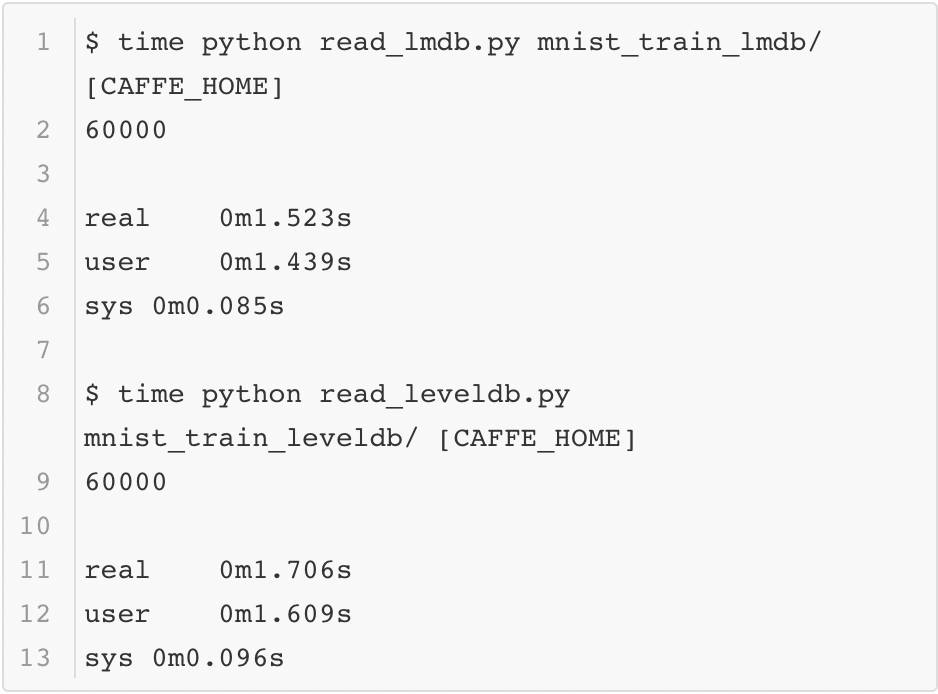
ЮЊСЫБШНЯдЪМЭМЯёЖСШыЕФЫйЖШЃЌетРяНЋMNISTЕФЪ§ОнвдjpegЕФИёЪНБЃДцГЩЭМЯёЃЌВЂВтЪдЫќЕФЖСШЁаЇТЪЃЈвдCaffe
pythonЪЙгУЕФscikit imageЮЊР§ЃЉЃЌДњТыШчЯТЫљЪОЃК

зюжеЕФЪБМфШчЯТЫљЪОЃК

гЩДЫПЩвдПДГіЃЌдЪМЭМЯёКЭЪ§ОнПтЯрБШЃЌЖСШЁЪ§ОнЕФаЇТЪВюОрЛЙЪЧТљДѓЕФЁЃЫфШЛдкCaffeбЕСЗжаЪ§ОнЖСШыЪЧвьВНЭъГЩЕФЃЌЕЋЪЧЫќЛЙЪЧВЛФмЙЛЬЋТ§ЃЌЫљвдетвВЪЧдкбЕСЗЪБбЁдёЪ§ОнПтЕФдвђЁЃ
жСгкетСНИіЪ§ОнПтжЎМфЕФБШНЯЃЌетРяОЭВЛдйЖрзіСЫЁЃИааЫШЄЕФИїЮЛПЩвддквЛаЉДѓаЭЕФЪ§ОнМЏЩЯзівЛаЉЪЕбщЃЌФЧбљИќШнвзПДГіСНИіЪ§ОнМЏжЎМфЕФЧјБ№ЁЃ
2 ЭјТчНсЙЙгыФЃаЭбЕСЗЕФХфжУ
ЩЯвЛНкЭъГЩСЫЪ§ОнПтЕФДДНЈЃЌЯТУцОЭвЊЮЊбЕСЗФЃаЭзізМБИСЫЁЃвЛАуРДЫЕCaffeВЩгУЖСШыХфжУЮФМўЕФЗНЪННјаабЕСЗЁЃCaffeЕФХфжУЮФМўвЛАугЩСНВПЗжзщГЩЃКsolver.prototxtКЭnet.prototxtЃЈгаЪБЛсгаЖрИіnet.prototxtЃЉЁЃЫќУЧЪЕМЪЩЯЖдгІСЫCaffeЯЕЭГМмЙЙжаСНИіЪЎЗжЙиМќЕФЪЕЬхЁЊЁЊЭјТчНсЙЙNetКЭЧѓНтЦїSolverЁЃЯШРДПДПДвЛАуРДЫЕЯрЖдМђЖЬЕФsolver.prototxtЕФФкШнЃЌЮЊСЫЗНБуДѓМвРэНтЃЌЫљгаХфжУаХЯЂЖМвбОМгШыСЫзЂЪЭЃК

ЮЊСЫЗНБуДѓМвРэНтЃЌетРяНЋexamples/mnist/lenet_solver.prototxtжаЕФФкШнНјаажиаТХХађЃЌећИіХфжУЮФМўЯрЕБгкЛиД№СЫЯТУцМИИіЮЪЬтЃК
ЭјТчНсЙЙЕФЮФМўдкФФЃП
гУЪВУДМЦЫузЪдДбЕСЗЃПCPUЛЙЪЧGPUЃП
бЕСЗЖрОУЃПбЕСЗКЭВтЪдЕФБШР§ЪЧШчКЮАВХХЕФЃЌЪВУДЪБКђЪфГіаЉИјЮвУЧЧЦЧЦЃП
гХЛЏЕФбЇЯАТЪдѕУДЩшЖЈЃПЛЙгаЦфЫћЕФгХЛЏВЮЪ§ЁЊЁЊШчЖЏСПКЭе§дђФиЃП
вЊЪБПЬМЧЕУДцЕЕАЁЃЌВЛШЛДѓЯРЕУДгЭЗРДЙ§СЫЁЁ
НгЯТРДОЭЪЧnet.prototxtСЫЃЌетРяКіТдСЫУПИіЭјТчВуЕФВЮЪ§ХфжУЃЌжЛАбБэЪОЭјТчЕФЛљБОНсЙЙКЭРраЭХфжУеЙЪОГіРДЃК
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
} |
етРяжЛеЙЪОСЫЭјТчНсЙЙЕФЛљДЁХфжУЃЌвВеМгУСЫДѓСПЕФЦЊЗљЁЃвЛАуРДЫЕЃЌетИіЮФМўжаЕФФкШнГЌЙ§100ааЖМЪЧдйГЃМћВЛЙ§ЕФЪТЁЃЖјЯёДѓУћЖІЖІЕФResNetЭјТчЃЌЫќЕФЮФМўГЄЖШЭЈГЃдкЧЇаавдЩЯЃЌИќЪЧШУШЫФбвддФЖСЁЃФЧУДЮЪЬтРДСЫЃЌФЧУДДѓЕФЭјТчЮФМўЖМЪЧППШЫжБНгБрМГіРДЕФУДЃПВЛвЛЖЈЁЃгаЕФШЫЛсБШНЯгаФЭаФЕивЛЕуЕуаДЭъЃЌЖјгаЕФШЫдђВЛЛсдИвтзіетбљЕФПрСІЛюЁЃЪЕМЪЩЯCaffeЬсЙЉСЫвЛЬзНгПкЃЌДѓМвПЩвдЭЈЙ§аДДњТыЕФаЮЪНЩњГЩетИіЮФМўЁЃетбљвЛРДЃЌБраДФЃаЭХфжУЕФЙЄзївВБфЕУМђЕЅВЛЩйЁЃЯТУцеЙЪОСЫвЛЖЮЩњГЩLeNetЭјТчНсЙЙЕФДњТыЃК

зюжеЩњГЩЕФНсЙћДѓМвЖМЪьжЊЃЌетРяОЭВЛИјГіСЫЁЃ
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
transform_param {
scale: 0.00390625
mirror: false
}
data_param {
source: "123"
batch_size: 128
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
} |
ДѓМвПЩФмОѕЕУЩЯУцЕФДњТыВЂУЛгаНкЪЁЬЋЖрЦЊЗљЃЌЪЕМЪЩЯШчЙћНЋЩЯУцЕФДњТыФЃПщЛЏзіЕУИќКУаЉЃЌЫќОЭЛсБфЕУЗЧГЃМђНрЁЃетРяОЭВЛзібнЪОСЫЃЌЛЖгДѓМвздааГЂЪдЁЃ
3 бЕСЗгыдйбЕСЗ
зМБИКУСЫЪ§ОнЃЌвВШЗЖЈСЫбЕСЗЯрЙиЕФХфжУЃЌЯТУце§ЪНПЊЪМбЕСЗЁЃбЕСЗашвЊЦєЖЏетИіНХБОЃК

ШЛКѓОЙ§вЛЖЮЪБМфЕФбЕСЗЃЌУќСюааВњЩњСЫДѓСПШежОЃЌбЕСЗЙ§ГЬвВаћИцЭъГЩЁЃетЪБбЕСЗКУЕФФЃаЭФПТМЖрГіСЫетМИИіЮФМўЃК

КмЯдШЛЃЌетМИИіЮФМўБЃДцСЫбЕСЗЙ§ГЬжаЕФвЛаЉФкШнЃЌФЧУДЫќУЧЖМЪЧзіЪВУДЕФФиЃП*caffemodel*ЮФМўБЃДцСЫcaffeФЃаЭжаЕФВЮЪ§ЃЌ*solverstate*ЮФМўБЃДцСЫбЕСЗЙ§ГЬжаЕФвЛаЉжаМфНсЙћЁЃБЃДцВЮЪ§етМўЪТЧщКмШнвзЯыЯѓЃЌЕЋЪЧБЃДцбЕСЗжаЕФжаМфНсЙћОЭгааЉГщЯѓСЫЁЃsolverstateРяУцОПОЙБЃДцСЫЪВУДЃПЛиД№етИіЮЪЬтОЭашвЊевЕНsolverstateЕФФкШнЖЈвхЃЌетИіЖЈвхРДздsrc/caffe/proto/caffe.protoЮФМўЃК

ДгЖЈвхжаПЩвдКмЧхГўЕФПДГіЦфФкШнЕФКЌвхЁЃЦфжаhistoryЪЧвЛИіБШНЯгавтЫМЕФаХЯЂЃЌЫћДцДЂСЫРњЪЗЕФВЮЪ§гХЛЏаХЯЂЁЃетИіаХЯЂгаЪВУДзїгУФиЃПгЩгкКмЖрЫуЗЈЖМвРРЕРњЪЗИќаТаХЯЂЃЌШчЙћгавЛИіФЃаЭбЕСЗСЫвЛАыЭЃжЙСЫЯТРДЃЌЯждкЯыЛљгкжЎЧАбЕСЗЕФГЩЙћМЬајбЕСЗЃЌФЧУДашвЊРњЪЗЕФгХЛЏаХЯЂАяжњМЬајбЕСЗЁЃШчЙћФЃаЭбЕСЗЭЛШЛжаЖЯбЕСЗЖјРњЪЗаХЯЂгжЖЊЪЇСЫЃЌФЧУДФЃаЭжЛФмДгЭЗбЕСЗЁЃетбљЕФЩюЖШбЇЯАПђМмОЭВЛОпБИЁАЖЯЕубЕСЗЁБЕФЙІФмСЫЃЌжЛга"жиЭЗдйРД"ЕФЙІФмЁЃЯждкЕФДѓаЭЩюЖШбЇЯАФЃаЭЖМашвЊКмГЄЕФЪБМфбЕСЗЃЌгаЕФашвЊбЕСЗКУМИЬьЃЌШчЙћПђМмВЛЬсЙЉЖЯЕубЕСЗЕФЙІФмЃЌвЛЕЉЛњЦїГіЯжЮЪЬтЕМжТГЬађБРРЃЃЌФЃаЭОЭВЛЕУВЛжиЭЗПЊЪМбЕСЗЃЌетЛсЖдЙЄГЬЪІЕФЩэаФдьГЩОоДѓДђЛїЁЁЫљвдетИіДцЕЕЛњжЦМЋДѓЕиЬсИпСЫФЃаЭбЕСЗЕФПЩППадЁЃ
ДгСэвЛИіЗНУцПМТЧЃЌШчЙћФЃаЭбЕСЗГЙЕзНсЪјЃЌетаЉРњЪЗаХЯЂОЭБфЕУЮогУСЫЁЃcaffemodelЮФМўашвЊБЃДцЯТРДЃЌЖјsolverstateетИіЮФМўПЩвдБЛжБНгЖЊЦњЁЃвђДЫетжжЗжРыДцДЂЕФЗНЪНЬиБ№ЗНБуВйзїЁЃ
ДгИеВХЬсЕНЕФЁАЖЯЕубЕСЗЁБПЩвдПДГіЃЌЩюЖШбЇЯАЦфЪЕАќКЌСЫЁАдйбЕСЗЁБетИіИХФюЁЃвЛАуРДЫЕЁАдйбЕСЗЁБАќКЌСНжжФЃЪНЃЌЦфжавЛжжОЭЪЧЩЯУцЬсЕНЕФЁАЖЯЕубЕСЗЁБЁЃДгЧАУцЕФХфжУЮФМўжаПЩвдПДГіЃЌбЕСЗЕФзмЕќДњТжЪ§ЪЧ10000ТжЃЌУПбЕСЗ5000ТжЃЌФЃаЭОЭЛсБЛБЃДцвЛДЮЁЃШчЙћФЃаЭдкбЕСЗЕФЙ§ГЬжаБЛвЛаЉВЛПЩПЙСІДђЖЯСЫЃЈБШЗНЫЕЛњЦїЖЯЕчСЫЃЉЃЌФЧУДДѓМвПЩвдДг5000ТжЕќДњЪББЃДцЕФФЃаЭКЭРњЪЗИќаТВЮЪ§ЛжИДГіРДЃЌУќСюШчЯТЫљЪОЃК

етРяВЛЗСдйЩюШывЛЕуЗжЮіЁЃЫфШЛФЃаЭЕФРњЪЗИќаТаХЯЂБЛБЃДцСЫЯТРДЃЌЕЋЕБЪБЕФбЕСЗГЁОАецЕФБЛЭъШЋЛжИДСЫУДЃПЫЦКѕУЛгаЃЌЛЙгавЛИігАЯьбЕСЗЕФЙиМќвђЫиУЛгаЛжИДЁЊЁЊЪ§ОнЃЌетИіЪЧВЛШнвзБЛбЕСЗЙ§ГЬОЋШЗПижЦЕФЁЃвВОЭЪЧЫЕЃЌЪзДЮбЕСЗЪБЕк5001ТжЕќДњбЕСЗЕФЪ§ОнКЭЯждкЁАЖЯЕубЕСЗЁБЕФЪ§ОнЪЧВЛвЛбљЕФЁЃЕЋЪЧвЛАуРДЫЕЃЌжЛвЊБЃжЄУПИібЕСЗХњДЮЃЈbatchЃЉФкЪ§ОнЕФЗжВМЯрНќЃЌВЛЛсгаЬЋДѓЕФВювьЃЌСНжжбЕСЗЖМПЩвдГЏзХе§ШЗЕФЗНЯђЧАНјЃЌЦфжаДцдкЕФЮЂаЁВюОрПЩвдКіТдВЛМЦЁЃ
ЕкЖўжжЁАдйбЕСЗЁБЕФЗНЪНдђЪЧгаРэТлЛљДЁжЇГХЕФбЕСЗФЃЪНЁЃетИіФЃЪНЛсдкжЎЧАбЕСЗЕФЛљДЁЩЯЃЌЖдФЃаЭНсЙЙзівЛЖЈЕФаоИФЃЌШЛКѓгІгУЕНЦфЫћЕФФЃаЭжаЁЃетжжбЇЯАЗНЪНБЛГЦзїЧЈвЦбЇЯАЃЈTransfer
LearningЃЉЁЃетРяОйвЛИіМђЕЅЕФР§згЃЌдкЕБЧАФЃаЭбЕСЗЭъГЩжЎКѓЃЌФЃаЭВЮЪ§НЋБЛжБНгИГжЕЕНвЛИіаТЕФФЃаЭЩЯЃЌШЛКѓШУетИіаТФЃаЭжиЭЗПЊЪМбЕСЗЁЃетИіВйзїПЩвдЭЈЙ§ЯТУцетИіУќСюЭъГЩЃК

жДааУќСюКѓCaffeЛсЯёЭљГЃвЛбљПЊЪМбЕСЗВЂЪфГіДѓСПШежОЃЌЕЋЪЧдкЭъГЩГѕЪМЛЏжЎКѓЃЌЫќЛсЪфГіетбљвЛЬѕШежОЃК

етЬѕШежООЭЪЧдкИцЫпЮвУЧЃЌЕБЧАЕФбЕСЗЪЧдкетИіТЗОЖЯТЕФФЃаЭЩЯНјаа"Finetune"ЁЃ
4 бЕСЗШежОЗжЮі
бЕСЗЙ§ГЬжаCaffeВњЩњСЫДѓСПЕФШежОЃЌетаЉШежОАќКЌКмЖрбЕСЗЙ§ГЬЕФаХЯЂЃЌЗЧГЃКмжЕЕУЗжЮіЁЃЗжЮіЕФФкШнгаКмЖрЃЌЦфжажЎвЛОЭЪЧЗжЮібЕСЗЙ§ГЬжаФПБъКЏЪ§lossЕФБфЛЏЧњЯпЁЃдкетИіР§згжаЃЌПЩвдЗжЮіЫцзХЕќДњТжЪ§ВЛЖЯдіМгЃЌSoftmax
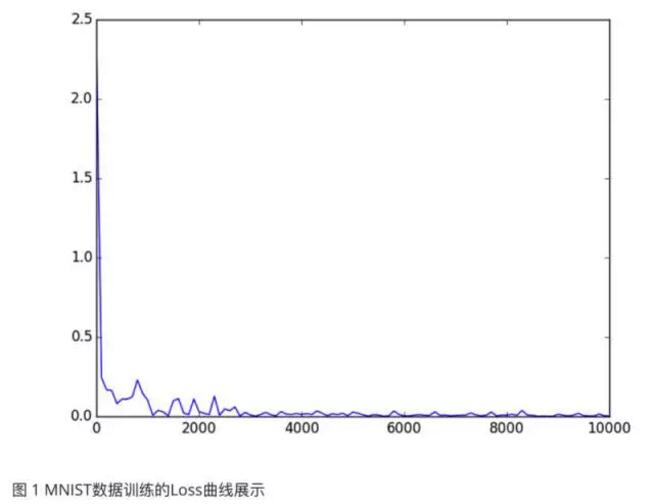
LossЕФБфЛЏЧщПіЁЃЪзЯШНЋбЕСЗЙ§ГЬЕФШежОаХЯЂБЃДцЯТРДЃЌБШЗНЫЕШежОаХЯЂБЛБЃДцЕНmnist.logЮФМўжаЃЌШЛКѓгУЯТУцЕФУќСюПЩвдНЋIterationКЭLossЕФаХЯЂЬсШЁВЂБЃДцЯТРДЃК

ЬсШЁКѓЕФаХЯЂПЩвдгУСэвЛИіНХБОЭъГЩLossЧњЯпЕФЛцЭМЙЄзїЃК
import matplotlib.pyplot
as plt
x = []
y = []
with open('loss_data') as f:
for line in f:
sps = line[:-1].split()
x.append(int(sps[0]))
y.append(float(sps[1]))
plt.plot(x,y)
plt.show() |
НсЙћШчЭМ1ЫљЪОЃЌПЩМћLossКмПьОЭНЕЕНСЫКмЕЭЕФЕиЗНЃЌФЃаЭЕФбЕСЗЫйЖШКмПьЁЃетИігХвьЕФБэЯжПЩвдЫЕУїКмЖрЮЪЬтЃЌЕЋетРяОЭВЛзіЙ§ЖрЕиЗжЮіСЫЁЃ
Г§ДЫжЎЭтЃЌШежОжаЪфГіЕФЦфЫћаХЯЂвВПЩвдБЛЙлВьЗжЮіЃЌБШЗНЫЕВтЪдЛЗНкЕФОЋШЗЖШЕШЃЌЫќУЧвВПЩвдЭЈЙ§ЩЯУцЕФЗНЗЈНтЮіГіРДЁЃгЩгкВЩгУЕФЗНЗЈЛљБОЯрЭЌЃЌетРягаВЛШЅзИЪіСЫЃЌИїЮЛПЩвдздааГЂЪдЁЃ
е§ГЃбЕСЗЙ§ГЬжаЃЌШежОРяжЛЛсЯдЪОУПвЛзщЕќДњКѓФЃаЭбЕСЗЕФећЬхаХЯЂЃЌШчЙћЯывЊСЫНтИќЖрЯъЯИЕФаХЯЂЃЌОЭвЊНЋsolver.prototxtжаЕФЕїЪдаХЯЂДђПЊЃЌетбљОЭПЩвдЛёЕУИќЖргагУЕФаХЯЂЙЉДѓМвЗжЮіЃК
ЕїЪдаХЯЂДђПЊКѓЃЌУПвЛзщЕќДњКѓУПвЛВуЭјТчЕФЧАЯђКѓЯђМЦЫуЙ§ГЬжаЕФЯъЯИаХЯЂЖМПЩвдБЛЙлВтЕНЁЃетРяНиШЁЦфжавЛзщЕќДњКѓЕФШежОаХЯЂеЙЪОГіРДЃК

ШчЙћЯывЊЖдЭјТчЕФБэЯжзіИќЖрЕиСЫНтЃЌФЧУДЗжЮіетаЉФкШнБиВЛПЩЩйЁЃ
5 дЄВтМьбщгыЗжЮі
ФЃаЭЭъГЩбЕСЗКѓЃЌОЭвЊЖдЫќЕФбЕСЗБэЯжзібщжЄЃЌПДПДЫќдкЦфЫћВтЪдЪ§ОнМЏЩЯЕФе§ШЗадЁЃCaffeЬсЙЉСЫСэЭтвЛИіЙІФмгУгкЪфГіВтЪдЕФНсЙћЁЃвдЯТОЭЪЧЫќЕФНХБОЃК

НХБОЕФЪфГіНсЙћШчЯТЫљЪОЃК

Г§СЫЭъГЩВтЪдЕФбщжЄЃЌгаЪБДѓМвЛЙашвЊжЊЕРФЃаЭИќЖрЕФдЫЫуЯИНкЃЌетОЭашвЊЩюШыФЃаЭФкВПШЅЙлВьФЃаЭВњЩњЕФжаМфНсЙћЁЃЪЙгУCaffeЬсЙЉЕФНшПкЃЌУПвЛВуЭјТчЪфГіЕФжаМфНсЙћЖМПЩвдгУПЩЪгЛЏЕФЗНЗЈЯдЪОГіРДЃЌЙЉДѓМвЙлВтЁЂЗжЮіФЃаЭУПвЛВуЕФзїгУЁЃЦфжаЕФДњТыШчЯТЫљЪОЃК

жДааЩЯУцЕФДњТыОЭПЩвдЩњГЩШчЭМ2ЕНЭМ5етМИеХЭМЯёЃЌЫќУЧИїДњБэвЛИіФЃаЭВуЕФЪфГіЭМЯёЃК




етвЛзщЭМеЙЪОСЫОэЛ§ЩёОЭјТчЪЧШчКЮАбвЛИіЪ§зжзЊБфГЩЬиеїБрТыЕФЁЃетбљЕФЗНЗЈЫфШЛПЩвдКмКУЕиПДЕНФЃаЭФкВПЕФБэЯжЃЌБШЗНЫЕconv1ЕФНсЙћЭМжагаЕФЬсШЁСЫЪ§зжЕФБпНчЃЌгаЕФУїШЗСЫЧАОАЯёЫиЫљдкЕФЮЛжУЃЌетИіЯжЯѓКЭЕк3еТжаОйР§ЕФОэЛ§аЇЙћгаМИЗжЯрЫЦЁЃЕЋЪЧЕНСЫconv2ЕФНсЙћЭМжаЃЌФЃаЭЕФЪфГіОЭБфЕУШУШЫгааЉПДВЛЖЎСЫЁЃЪЕМЪЩЯЯывЊеце§ПДЖЎетаЉЭМЯёЯыБэДяЕФФкШнШЗЪЕгааЉРЇФбЕФЁЃ
6 адФмВтЪд
Г§СЫдкВтЪдЪ§ОнЩЯЕФзМШЗТЪЃЌФЃаЭЕФдЫааЪБМфвВЗЧГЃжЕЕУЙиаФЁЃШчЙћФЃаЭЕФдЫааЪБМфЬЋГЄЃЌЩѕжСЕНСЫВЛПЩгУЕФГЬЖШЃЌФЧУДМДЪЙЫќОЋЖШКмИпвВУЛгаЪЕМЪвтвхЁЃВтЪдЪБМфЕФНХБОШчЯТЫљЪОЃК

CaffeЛсе§ГЃЕФЭъГЩЧАЯђКѓЯђЕФМЦЫуЃЌВЂМЧТМЦфжаЕФЪБМфЁЃвдЯТЪЧЪЙвЛДЮВтЪдНсЙћЕФЪБМфМЧТМЃК
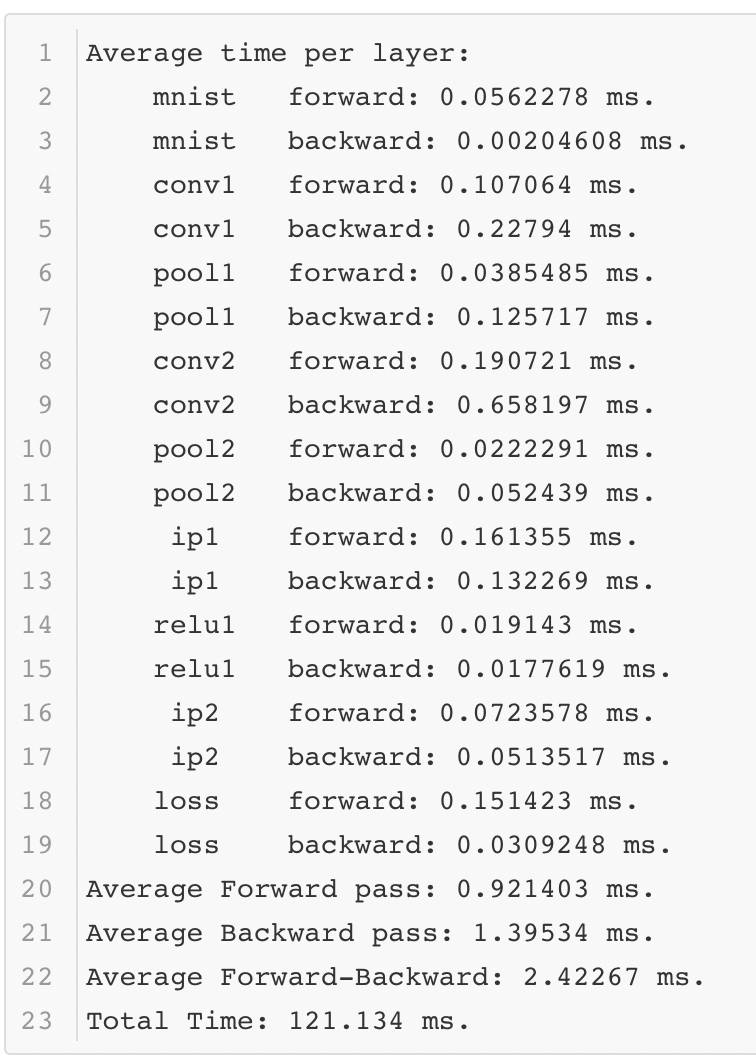
ПЩвдПДГідкадФмВтЪдЕФЙ§ГЬжаЃЌLenetФЃаЭжЛашвЊВЛЕН1КСУыЕФЪБМфОЭПЩвдЭъГЩЧАЯђМЦЫуЃЌетИіЫйЖШЛЙЪЧКмПьЕФЁЃЕБШЛетЪЧдквЛИіЯрЖдВЛДэЕФGPUЩЯдЫааЕФЃЌФЧУДШчЙћдквЛИіЬѕМўВюЕФGPUЩЯдЫааЃЌНсЙћШчКЮФиЃП
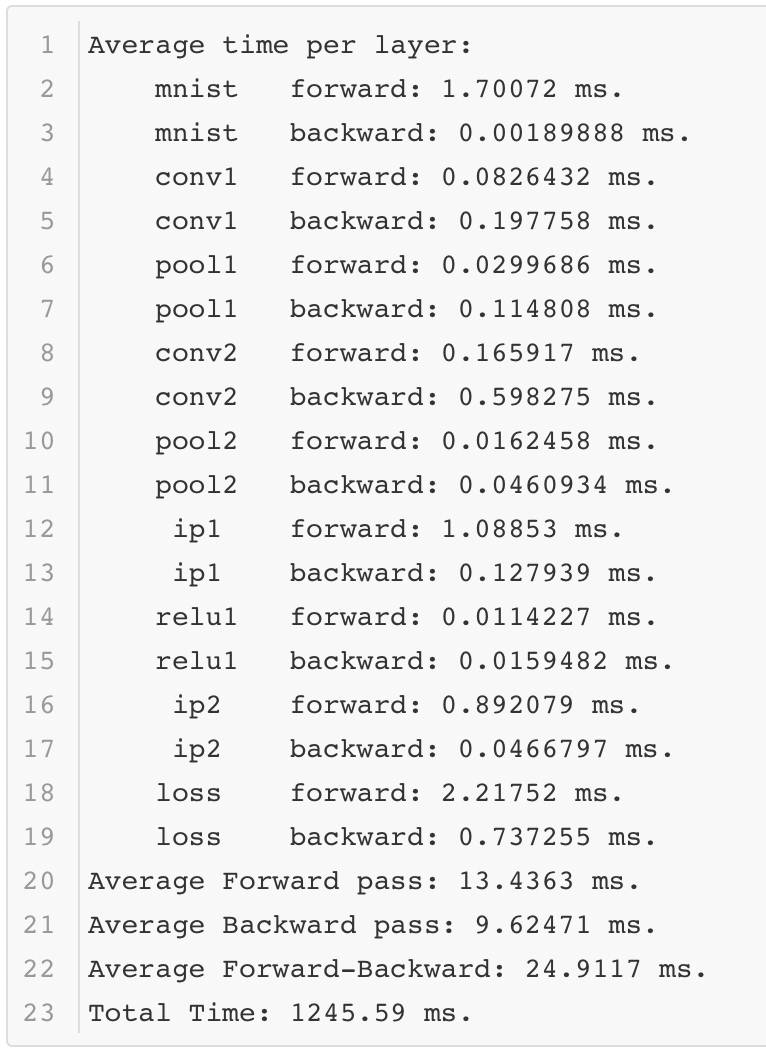
ПЩвдПДЕНВЛЭЌЕФЛЗОГЖдгкФЃаЭдЫааЕФЪБМфгАЯьКмДѓЁЃ
вдЩЯОЭЪЧФЃаЭбЕСЗЕФвЛИіЭъећЙ§ГЬЁЃЯждкЯраХДѓМвЖдЩюЖШбЇЯАФЃаЭЕФбЕСЗКЭЪЙгУгаСЫЛљБОЕФСЫНтЁЃЪЕМЪЩЯПДЕНетРяДѓМвЩѕжСПЩвдШгЯТЪщШЅЧзздЪЕМљВЛЭЌФЃаЭЕФаЇЙћЃЌПЊЪМЩюЖШбЇЯАЕФЪЕеНжЎТУЁЃ
зюКѓЗХвЛеХCaffeдДДњТыЕФМмЙЙЭМЃЌвдЗНБуДѓМвбаОПCaffeдДТыЁЃ
Д№вЩЛЗНк
Q1. CaffeКЭЦфЫћЩюЖШбЇЯАПђЖШ(ШчMxNet, TensorflowЕШ)БШгаЪВУДгХШБЕуЃП
ЗыГЌЃКCaffeзїЮЊЁАРЯвЛДњЁБЕФЩюЖШбЇЯАПђМмЃЌДгМмЙЙЩЯРДЫЕгавЛИіКмДѓЕФВЛЭЌжЎДІЃЌФЧОЭЪЧЫќВЛЪЧВЩгУЗћКХдЫЫуЕФЗНЪННјааЩшМЦЕФЃЌетбљДјРДСЫвЛаЉгХЕуКЭШБЕуЁЃ
гХЕуЪЧCaffeдкМЦЫуЙ§ГЬжаЃЌдкФкДцЪЙгУКЭдЫЫуЫйЖШЗНУцЖМгавЛЖЈЕФгХЪЦЃЌФкДцЪЙгУНЯаЁЃЌЫйЖШвВБШНЯгаБЃжЄЃЌЯрЖдЖјбдЃЌЛљгкЗћКХМЦЫуЕФПђМмдкетСНЗНУцЛсЩдШѕвЛаЉЁЃ
ШБЕуЪЧCaffeФЃаЭСщЛюадНЯШѕЁЃЖдгквЛаЉаТГіЯжЕФЭјТчФЃаЭНсЙЙЃЌCaffeЪЪХфЦ№РДашвЊвЛаЉММЧЩЃЌашвЊвЛЖЈЕФОбщЃЌЖјMXNetЃЌTensorFlowетбљЕФФЃаЭОЭМђЕЅКмЖрЁЃ
ЫљвдвЛАуРДЫЕЃЌMXNetЁЂTensorflowИќЪЪКЯЪЕбщЛЗОГЃЌCaffeБШНЯЪЪКЯЙЄвЕНчЯпЩЯЪЙгУЁЃЦфЫћЗНУцЃЌЯждкCaffeЕФЩчЧјЯрБШTensorflowПЩФмвЊШѕаЉЃЌЕЋвРШЛЪЧЗЧГЃжїСїЕФПЊдДПђМмЁЃ
Q2. ШчКЮПДД§facebookаТЗЂВМЕФcaffe2ЩюЖШбЇЯАПђМмЃПЫќБШЯжгаЕФcaffeгаЪВУДбљЕФИФНјЃПИњЯждкЕФTensorFlowЯрБШШчКЮЃП
ЗыГЌЃКcaffe2зюНќБШНЯШШЃЌжЎЧАЮвУЛгаЖрПДЙ§ЃЌетСНЬьМЏжаПДСЫПДЃЌДѓИХгавдЯТвЛаЉИаЪмЃК
гаСЫCaffe2КЭCaffeЯрБШБфЛЏДѓУДЃПprototxtКЭcaffemodelКЃЖЗПЩвдгУЃЌЛљБОЩЯЫуЯђЯТМцШнЃЌCaffeЕФвЛаЉжЊЪЖММФмЛЙПЩвдгУЁЃ
Caffe2ЕФВйзїЗНЪНЃПДгЙйЗНЮФЕЕжаПДЃЌCaffe2ЕФpythonНгПкгаСЫКмДѓЕФНјВНЁЃИјГіЕФЪОР§жївЊЪЧгУpythonДњТыУшЪіЭјТчНсЙЙЃЈКЭtfКмЯёЃЌвВгаcheckpointЕШИХФюЃЉ->ЩњГЩФкДцАцЕФЭјТчФЃаЭ->ЙЙНЈnetКЭЯрЙиЛЗОГ->жДааДњТыЃЌЫљвдГ§СЫЧАУцЕФpythonНгПкЃЌКѓУцЕФСїГЬКЭcaffe1КмЯёЁЃ
ФкВПМмЙЙЩЯЕФБфЛЏЃПCaffe2НшМјСЫTensorflowЕФвЛаЉИХФюЃЌНЋЙ§ШЅЕФNetВ№ГЩСНВПЗжЃКЪ§ОнКЭЭјТчЭМЁЃЪ§ОнВПЗжЪЧWorkspaceЃЌКЭtfЕФsessionКмЯёЃЌСэЭтвЛВПЗжЪЧЭјТчЭМnetЁЃСэЭтЃЌCaffe2ФкВПвВНЋLayerИФГЩСЫOpЁЃ
ЯждкОЭЩЯЪжCaffe2ЃПМИКѕгаЕудчЃЌФПЧАЙйЗНИјГіЕФФкШнЛЙБШНЯЩйЃЌДѓМввВВЛБиЬЋаФМБЁЃ
зюКѓЫЕЫЕCaffe2ЙйЗНИјГіЕФвЛаЉССЕуЙІФмЃКПчЦНЬЈЁЃетвЛДЮЕФCaffe2ПЩвддкИїжжВЛЭЌЕФЦНЬЈЩЯВПЪ№дЫааЃЌетЫуЪЧвЛИіССЕуЁЃ
Q3. caffeeКЭpytorchЖМЪЧfacebookдкЭЦЃЌФЧетСНИіПђМмгаЪВУДВЛЭЌФиЃП
ЗыГЌЃКЛљБОЩЯЪЕбщЛЗОГЯТжївЊгУpytorch,ЯпЩЯЛЗОГгУCaffeЁЃ
Q4. caffeгаУЛгаЬсЙЉвЛаЉpreTrainingЕФвЛаЉФЃаЭ ЗНБуИќПьЕиЕїгУЭјТчФиЃП
ЗыГЌЃКCaffeгаздМКЕФModel zooЃЌЯъЧщПЩвдЩЯШЅПДвЛПДЁЃ
Q5. caffeдквЦЖЏЖЫЪЕМљЕФЪЕМЪАИР§Т№ЃП
ЗыГЌЃКОЭЮвЩэБпгаЯоЕФСЫНтЃЌвЛаЉЙЋЫОзівЦЖЏЖЫГЂЪдЛЙЪЧЪЙгУСЫTensorflowЃЌВЂУЛгагУCaffeЁЃ |









