| 使用机器学习的方法可以解决越来越多的实际问题,它在现实世界中的应用越来越广泛,比如智能风控、欺诈检测、个性化推荐、机器翻译、模式识别、智能控制,等等。
机器学习分类
我们都知道,机器学习可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised
Learning)和强化学习(Reinforcement Learning),下面简单介绍一下它们含义:
监督学习
监督学习是根据给定的标签(Label)已知的训练数据集,通过选定的算法在该训练数据集上进行训练学习,最后得到一个可以描述该数据集规律的预测函数,也就是我们所说的模型。有了模型,对于未知标签的输入数据,可以通过该预测函数预测出它的标签。典型的监督学习方法,如分类、回归等。
无监督学习
无监督学习是根据给定的标签(Label)未知的训练数据集,通过训练学习从训练数据集中发现隐藏的模式或结构。典型的无监督学习方法,如聚类分析。
强化学习
强化学习是人工智能中的策略学习的一种,从动物学习、参数扰动自适应控制理论发展而来。这种学习方法是从环境状态到动作映射的学习方法,使动作从环境中获得的累计奖赏值最大。通过不断地试错来学习,从而发现最优行为策略。常用的强化学习算法,如Q学习算法、SARSA算法。
机器学习基本过程
基于上面介绍的机器学习的分类方法,我们可以从更广义的范围来总结出,构建一个完整的机器学习应用程序,通常应该包含的基本过程。下面,给出了构建机器学习应用一般需要经历的4个主要阶段:
数据准备
数据准备阶段,通常会有一个或者多个已经存在的数据集,数据集的状态可能距离生产该数据的源头非常近,数据格式多种多样,不规范、缺失值、错误值随处可见。还有可能,数据集包含多个不同类型的子数据集,单独拿出每一个子数据集对机器学习模型训练,都没有什么意义,除非我们就需要对这些子数据集进行一些处理。
对于这样的输入数据集,如果不加处理而直接拿来进行机器学习模型的训练,一个结果是根本无法使用这样数据集作为生产机器学习模型的输入;另一个结果是可以满足训练机器学习模型算法的输入格式等要求,但是训练出来的机器学习模型根本无法投入生产,带来期望的效果。
面向机器学习的数据准备阶段,可以看成是一个通用的数据ETL过程,这个ETL过程除了进行基础的规范数据格式、去除噪声、集成数据等,还包含一些机器学习特有的数据ETL过程,比如:特征抽取(TF-IDF/Word2Vec)、降维、主成分分析(PCA)等。而且,对一些面向机器学习的数据ETL过程,可能本身就需要生成一个机器学习模型来对输入数据集进行复杂的预处理。
可见,数据准备阶段主要是对数据进行ETL,在此基础上可能需要选择合适的数据分割策略,生成满足机器学习模型训练的训练集,和用于评估模型的测试集。
训练模型
训练模型是构建机器学习应用各个阶段中最核心的阶段。该阶段,我们首先会根据给定的问题域,选择一个适合解决该领域问题的模型,然后才会考虑基于所选择数据的规模和特点,使用特定的算法来计算生成最终我们需要的模型。
模型是什么呢?通俗地讲,模型可以理解为一个数学函数,该函数最终能够满足的效果是,根据我们给定的输入数据,就能得到或近似得到我们认为合理的结果。一个数学函数具有一个或多个参数,训练模型的结果就是确定这些参数的值。函数可能很简单,也可能很复杂。数据集可能有其特点,比如数据规模超大、数据在处理过程中精度的损失等等,我们要在所选择的数据集上进行训练学习,通常不能得到目标函数所有参数理论上的精确值。最终的目标是,能够在给定的数据集上具有很好地表现,我们可以根据实际情况做特殊处理。在实际应用中,往往提升精度会耗费大量资源和时间,再对比模型带来效果可能微乎其微,所以舍弃一定的精度也能很好地在实际应用中使用该模型。
训练模型,就是从给定的数据集学习得到数据中潜在的规律,通过以函数的形式表示,经过计算处理求得目标数学函数对应的全部参数。基于最终得到的参数所构造的函数,能够使函数很好地解决假设的问题(训练数据集),模拟给定训练数据集同时,又具备很好的泛化能力,即不会欠拟合或过拟合。
评估模型
训练模型得到了一组参数,能够模拟给定训练数据集,但是如果对于未来未知的数据,模型的表现会如何?为了解决这个疑问,我们需要将训练得到的模型,作用在给定的测试数据集上,根据结果进行分析,确定模型的精度是否能够满足应用需求。训练数据集和测试数据集唯一不同的就是是否已知标签,而对数据本身的处理逻辑基本都是相同的。
另外,评价模型的优劣,验证模型的好坏,需要选择适合特拟定领域的度量方法,从而对模型进行客观的评价。比如,离线模型的评估,常用准确率、精确率-召回率,而在线模型可能会使用CTR、A/B测试等。
应用模型
一个经过验证可以投入使用的模型,可能会提供一个特殊的结果数据集,我们根据应用的需要对其进行进一步处理,比如推荐模型中的物品集合很大,可以通过对推荐的物品结果集进行再加工处理,对支持的应用提供快速的查询服务。模型也可能是一个不可读的模型,这种情况我们可能需要基于该模型开发一个服务,直接对外提供模型服务。
具体的如何使用模型,这要依赖于实际应用的特点和使用方式。
Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在代码实现的级别管理好每一个处理步骤之间的先后运行关系,极大地简化了开发机器学习应用的难度。
Spark ML Pipeline使用DataFrame作为机器学习输入输出数据集的抽象。DataFrame来自Spark
SQL,表示对数据集的一种特殊抽象,它也是Dataset(它是Spark 1.6引入的表示分布式数据集的抽象接口),但是DataFrame通过为数据集中每行数据的每列指定列名的方式来组织Dataset,类似于关系数据库中的表,同时还在底层处理做了非常多的优化。DataFrame可以基于不同的数据源进行构建,比如结构化文件、Hive表、数据库、RDD等。或者更直白一点表达什么是DataFrame,可以认为它等价于Dataset[Row],表示DataFrame是一个Row类型数据对象的Dataset。
机器学习可以被应用于各种数据类型,例如向量、文本、图片、结构化数据。Spark ML API采用DataFrame的理由是,来自Spark
SQL中的DataFrame接口的抽象,可以支持非常广泛的类型,而且表达非常直观,便于在Spark中进行处理。所以说,DataFrame是Spark
ML最基础的对数据集的抽象,所有各种ML Pipeline组件都会基于DataFrame构建更加丰富、复杂的数据处理逻辑。
Spark ML Pipeline主要包含2个核心的数据处理组件:Transformer、Estimator,其中它们都是Pipeline中PipelineStage的子类,另外一些抽象,如Model、Predictor、Classifier、Regressor等都是基于这两个核心组件衍生出来,比如,Model是一个Transformer,Predictor是一个Estimator,它们的关系如下类图所示:
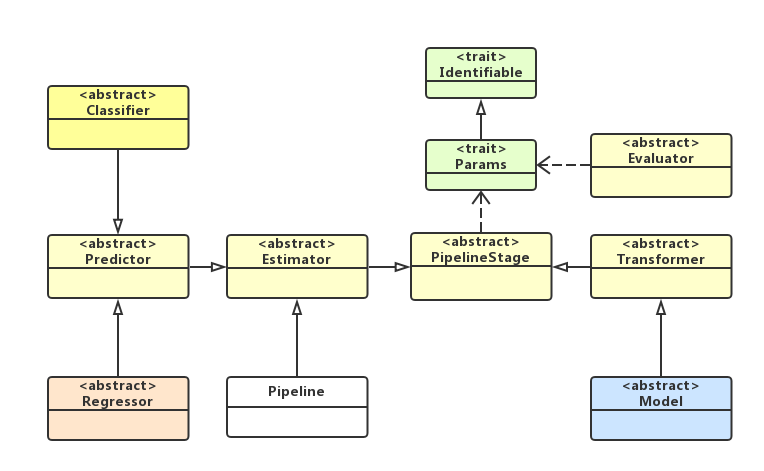
基于上图,我们对它们进行详细的说明,如下所示:
Transformer
Transformer对机器学习中要处理的数据集进行转换操作,类似于Spark中对RDD进行的Transformation操作(对一个输入RDD转换处理后生成一个新的RDD),Transformer是对DataFrame进行转换。我们可以从Transformer类的代码抽象定义,来看一下它定义的几个参数不同的transform方法,如下所示:
package org.apache.spark.ml
@DeveloperApi
abstract class Transformer extends PipelineStage
{
@Since("2.0.0")
@varargs
def transform(
dataset: Dataset[_],
firstParamPair: ParamPair[_],
otherParamPairs: ParamPair[_]*): DataFrame = {
val map = new ParamMap()
.put(firstParamPair)
.put(otherParamPairs: _*)
transform(dataset, map)
}
@Since("2.0.0")
def transform(dataset: Dataset[_], paramMap: ParamMap):
DataFrame = {
this.copy(paramMap).transform(dataset)
}
@Since("2.0.0")
def transform(dataset: Dataset[_]): DataFrame
override def copy(extra: ParamMap): Transformer
}
|
上面对应的多个transform方法,都会输入一个Dataset[_],经过转换处理后输出一个DataFrame,实际上你可以通过查看DataFrame的定义,其实它就是一个Dataset,如下所示:
| type DataFrame
= Dataset[Row] |
Transformer主要抽象了两类操作:一类是对特征进行转换,它可能会从一个DataFrame中读取某列数据,然后通过map算法将该列数据转换为新的列数据,比如,输入一个DataFrame,将输入的原始一列文本数据,转换成一列特征向量,最后输出的数据还是一个DataFrame,对该列数据转换处理后还映射到输入时的列名(通过该列名可以操作该列数据)。
下面,我们看一下,Spark MLLib中实现的Transformer类继承关系,如下类图所示:
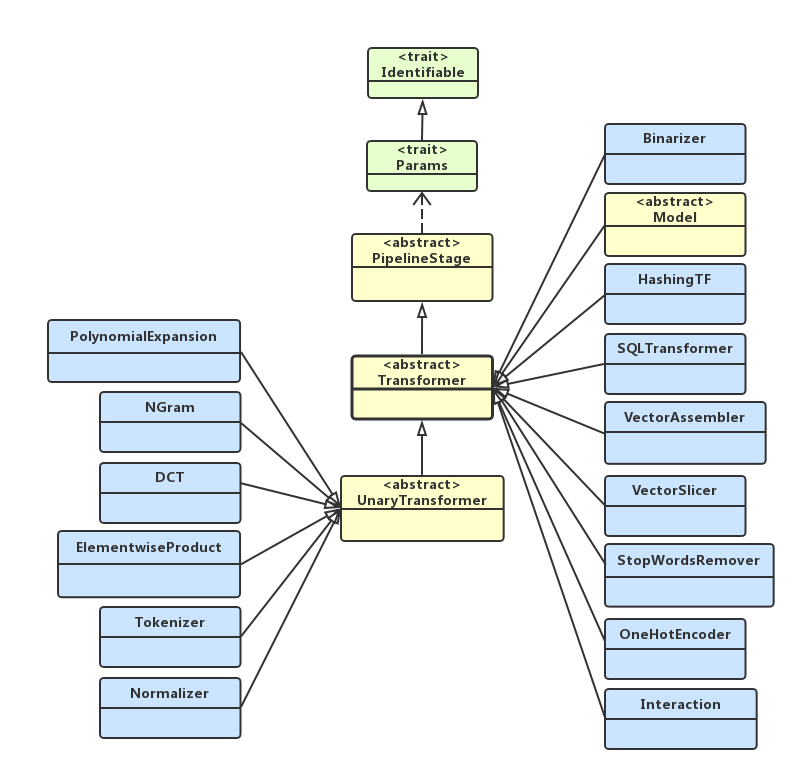
Estimator
Estimator用来训练模型,它的输入是一个DataFrame,输出是一个Model,Model是Spark
ML中对机器学习模型的抽象和定义,Model其实是一个Transformer。一个机器学习算法是基于一个数据集进行训练的,Estimator对基于该训练集的机器学习算法进行了抽象。所以它的输入是一个数据集DataFrame,经过训练最终得到一个模型Model。
Estimator类定了fit方法来实现对模型的训练,类的代码如下所示:
package org.apache.spark.ml
@DeveloperApi
abstract class Estimator[M <: Model[M]] extends
PipelineStage {
@Since("2.0.0")
@varargs
def fit(dataset: Dataset[_], firstParamPair: ParamPair[_],
otherParamPairs: ParamPair[_]*): M = {
val map = new ParamMap()
.put(firstParamPair)
.put(otherParamPairs: _*)
fit(dataset, map)
}
@Since("2.0.0")
def fit(dataset: Dataset[_], paramMap: ParamMap):
M = {
copy(paramMap).fit(dataset)
}
@Since("2.0.0")
def fit(dataset: Dataset[_]): M
@Since("2.0.0")
def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]):
Seq[M] = {
paramMaps.map(fit(dataset, _))
}
override def copy(extra: ParamMap): Estimator[M]
}
|
通过上面代码可以看到,Estimator调用fit方法以后,得到一个Model,也就是Transformer,一个Transformer又可以对输入的DataFrame执行变换操作。
下面,我们看一下,Spark MLLib中实现的Estimator类,如下类图所示:
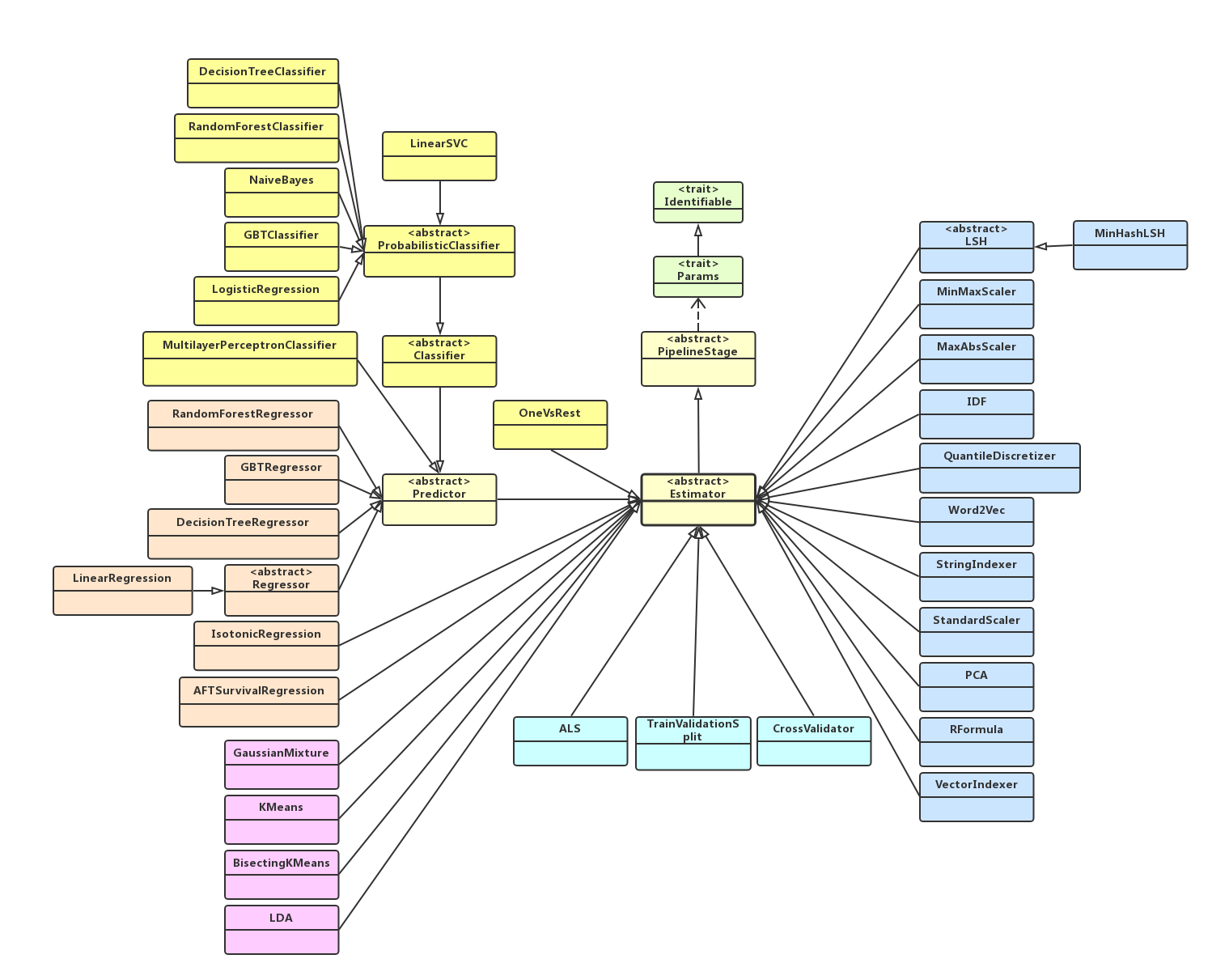
PipelineStage
PipelineStage是构建一个Pipeline的基本元素,它或者是一个Transformer,或者是一个Estimator。
Pipeline
Pipeline实际上是Estimator的实现类,一个Pipeline是基于多个PipelineStage构建而成的DAG图,简单一点可以使用线性的PipelineStage序列来完成机器学习应用的构建,当然也可以构建相对复杂一些的PipelineStage
DAG图。
调用Pipeline的fit方法,会生成一个PipelineModel,它是Model的子类,所以也就是一个Transformer。在训练过程中,Pipeline中的多个PipelineStage是运行在训练数据集上的,最后生成了一个Model。我们也可以看到,训练模型过程中,处于最后面的PipelineStage应该是一个或多个连续的Estimator,因为只有Estimator运行后才会生成Model。
接着,就是Pipeline中处于训练阶段和测试阶段之间,比较重要的一个PipelineStage了:PipelineModel,它起了承上启下的作用,调用PipelineModel的transform方法,按照和训练阶段类似的数据处理(转换)流程,经过相同的各个PipelineState对数据集进行变换,最后将训练阶段生成模型作用在测试数据集上,从而实现最终的预测目的。
基于Spark ML Pipeline,可以很容易地构建这种线性Pipeline,我们可以看到一个机器学习应用构建过程中(准备数据、训练模型、评估模型)的各个处理过程,可以通过一个同一个Pipeline
API进行线性组合,非常直观、容易管理。
Spark ML Pipeline实践
这里,我们直接根据Spark ML Pipeline官方文档给出的示例——基于Logistic回归实现文本分类,来详细说明通过Spark
ML Pipeline API构建机器学习应用,以及具体如何使用它。官网给出的这个例子非常直观,后续有关在实际业务场景中的实践,我们会单独在另一篇文章中进行分享。
场景描述
这个示例:
在训练阶段,需要根据给定的训练文本行数据集,将每个单词分离出来;然后根据得到的单词,生成特征向量;最后基于特征向量,选择Logistic回归算法,进行训练学习生成Logistic模型。
在测试阶段,需要按照如上相同的方式去处理给定的测试数据集,基于训练阶段得到的模型,进行预测。
训练阶段
训练阶段各个数据处理的步骤,如下图所示:
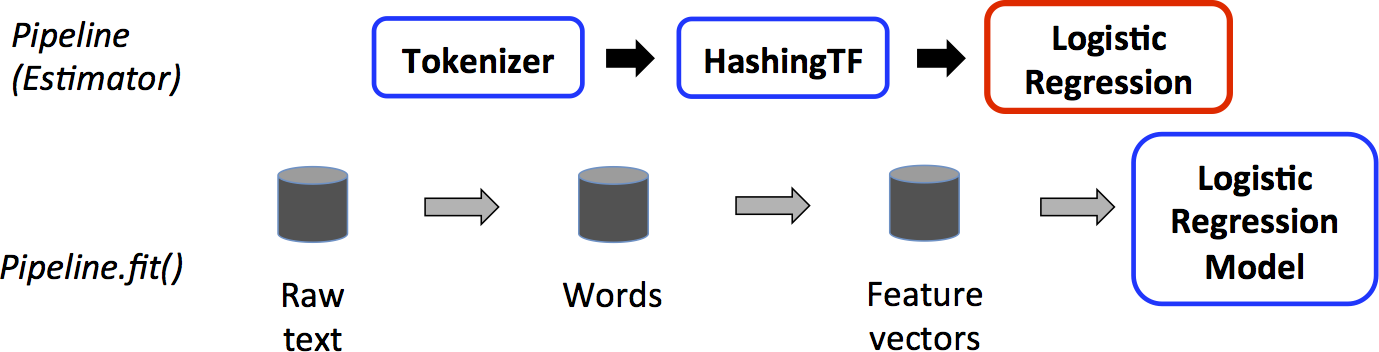
上图中,蓝色方框表示的都是Transformer,红色方框表示Estimator。
在训练阶段,通过Pipeline运行时,Tokenizer和HashingTF都会将输入的DataFrame进行转换,生成新的DataFrame;LogisticRegression是一个Estimator,当调用LogisticRegression的fit方法时,会生成一个LogisticRegressionModel,它是一个Transformer,可以在测试阶段使用。
测试阶段
上面的过程都是在调用Pipeline的fit方法时进行处理的,最后会生成一个PipelineModel,它是一个Transformer,会被用于测试阶段。测试阶段运行始于该PipelineModel,具体处理流程如下图所示:
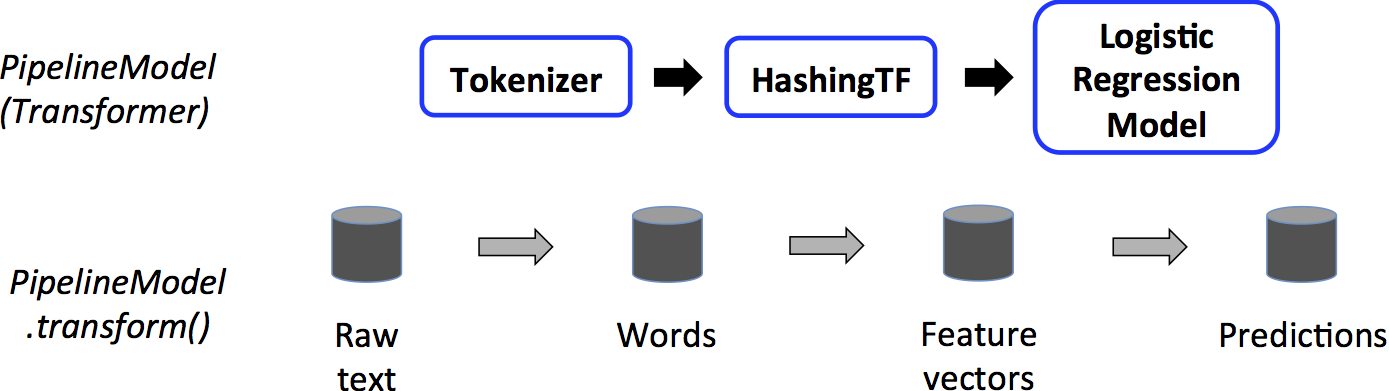
PipelineModel作为一个Transformer,首先也会对输入的测试数据集执行转换操作,对比训练阶段的处理流程,可以看到,在训练阶段的Estimator都变成了Transformer,因为我们在测试阶段的输出就是一个结果集DataFrame,而不需要训练阶段生成Model了。
示例代码
首先,准备模拟的训练数据集,代码如下所示:
val training =
spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
|
模拟的训练数据集中,有3个字段,分别为ID、文本内容、标签。在实际应用中,我们应该是从指定的文件系统中去读取数据,如HDFS,只需要根据需要修改即可。
其次,创建一个Pipeline对象,同时设置对应的多个顺序执行的PipelineStage,代码如下所示:
val tokenizer
= new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr)) //
包含3个PipelineStage
|
接着,就可以基于训练数据集进行训练操作了,代码如下所示:
val model = pipeline.fit(training)
|
调用Pipeline的fit方法生成了一个Model,我们可以根据实际情况,选择是否将生成模型进行保存(以便后续重新加载使用模型),如下所示:
// Now we can
optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
|
然后,创建一个模拟测试数据集,用来测试前面训练生成的模型,代码如下所示:
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
|
测试数据集中,标签(Label)都是未知的,通过将前面生成的模型作用在该测试数据集上,就会预测生成对应的标签数据,代码如下所示:
// Make predictions
on test documents.
model.transform(test)
.select("id", "text", "probability",
"prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob:
Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob,
prediction=$prediction")
}
|
这样就能够基于预测的结果,验证分类模型的准确性。
最后,可以将生成模型用于实际应用场景中,完成需要的功能。
有关更多使用Spark ML Pipeline的例子,可以参考Spark发行包中,examples里面src/main/scala/ml下面的很多示例代码,非常好的学习资源。 |









