| ЕквЛВПЗжНВНтздШЛгябдДІРэЕФдРэЃЌЕкЖўВПЗжНВНтСФЬьЛњЦїШЫЕФЪЕЯждРэЃЌНтОіЗНАИМАЬєеНЃЌзюКѓвд seq2seq+Attention
ЛњжЦНВНтФЃаЭНсЙЙЁЃЕкШ§ВПЗжНВНтШчКЮДг0ПЊЪМбЕСЗвЛИіСФЬьЛњЦїШЫЁЃ
вЛЁЂздШЛгябдДІРэЕФдРэ
ШЫЙЄжЧФмРэНтздШЛгябдЕФдРэЃЌвЊЛиД№етИіЮЪЬтЃЌЪзЯШашвЊНчЖЈЯТетИіЮЪЬтЕФКЌвхЃЌвЛжжЪЧЯСвхЕФЫЕШчКЮгУМЦЫуЛњРДДІРэКЭЗжЮіздШЛгябдЃЛСэвЛжжЪЧдђЪЧЙувхЕиРэНтЙигкЁИШЫЙЄжЧФмЁЙЁЂЁИздШЛгябдЁЙКЭЁИРэНтЁЙЕФКЌвхЁЃ
ЮвУЧЯШДгЙувхВуУцЬНЬжЁЃХЊЧхГўетМИИіУћДЪЁЃ
здШЛгябдЃКОЭЪЧШЫРрЩчЛсжаЗЂУїКЭбнБфЕФгУгкЙЕЭЈКЭНЛСїЕФгябдЁЃЖјШЫЙЄжЧФмдкЖдЪТЮяЃЈВЛНіНіЪЧздШЛгябдЃЉЕФРэНтЃЌЭљЭљАќКЌСНИіВуДЮЃКвЛЪЧбаОПФкШнЃЛЖўЪЧЗНЗЈТлЁЃ
баОПФкШнЩЯжївЊЪЧЯждкСїааЕФбаОППЮЬтЃЌР§ШчжЊЪЖЭМЦзЁЂCVЁЂгявєЪЖБ№ЁЂNLP ЕШЁЃ
ЗНЗЈТлЪЧжИЪЕЯжШЫЙЄжЧФмЕФЗНЗЈЃЌжївЊгаШ§жжЃКЗћКХжївхЁЂСЊНсжївхЁЂааЮЊжївхЁЃ
ЗћКХжївхЪЧгУЪ§РэТпМЕФЭЦРэРДФЃФтШЫЕФЫМЮЌжЧФмЃЌР§ШчзЈМвЯЕЭГЕФЪЕЯжЁЃСЊНсжївхЖдШЫФдЕФЗТЩњбЇбаОПЃЌзюГЃМћЕФОЭЪЧЩёОЭјТчФЃаЭЁЃ
ааЮЊжївхжиЕудкПЩдЄВтЕФШЫРрааЮЊЩЯЃЌШЯЮЊШЫРрЭЈЙ§гыЭтНчЛЗОГЕФНЛЛЅЖјЕУЕНздЪЪгІадЃЌЩцМАЕФЫуЗЈгавХДЋЫуЗЈЁЂЧПЛЏбЇЯАЕШЁЃ
ЯжгаЕФNLPжївЊЪЧвдЙцдђКЭЭГМЦЯрНсКЯРДДІРэЕФЁЃЫќЕФЙцдђвЛУцЦЋЯђгкЗћКХжївхЕФЪгНЧЃЛ
ЖјЭГМЦвЛУцЦЋЯђгкЭкОђвЛАуЙцТЩЃЌЪєгкЙщФЩЃЌФПЧАгУЕФЗНЗЈЃЌБШШчНЋздШЛгябдгУДЪЯђСПЕФЗНЗЈБэеїЃЌШЛКѓНгШыЩёОЭјТчжаНјаабЕСЗЃЌвВОЭЪЧСЊНсжївхЕФЫМЯыЁЃ
РэНтЃКЙигкЛњЦїЪЧЗёФмеце§РэНтгябдвЛжБгаељТлЁЃЯШХзПЊетИіЮЪЬтЃЌЮвУЧПДПДШЫРрЖдгябдЕФРэНтЪЧдѕУДбљЕФЁЃЪЕМЪЩЯЃЌШЫРрЖдРэНтетИіЪТЧщвВзіЕФВЛвЛЖЈКУЁЃ
БШШчЃЌФЯББЗНЖдЁИЖЙИЏФдЁЙЕФШЯжЊЪЧВЛЭЌЕФЃЌСНШЫНЛЬИПЩФмОЭЛсЖдЭЌвЛЮяЬхЕФРэНтВЛЭЌЁЃ
вђДЫЃЌРэНтЪЧашвЊгЩЯрЫЦЕФЩњЛюОРњЁЂЙВЭЌЛАЬтЁЂЩЯЯТЮФЁЂЛсЛАЕФЛЗОГЁЂЫЋЗНЕФжЊЪЖЕШКмЖрвђЫиОіЖЈЕФЁЃ
МШШЛЖдгкШЫРрРДЫЕЃЌеце§ФмРэНтЖдЗНЃЌашвЊетУДЖрЕФвўадвђЫиЃЌФЧЖдгкЛњЦїРДЫЕЃЌЮвУЧзюКУОЭВЛвЊЙиаФЛњЦїЪЧЗёеце§ФмРэНтЮЪЬтЕФКЌвхБОЩэЃЌЖјЪЧОЁПЩФмЕиШУЛњЦїЙизЂЩЯЪівђЫиЃЌРДФЃФтШЫЕФжЧФмЁЃ
ЯСвхЕФВуУцЪЧЮвУЧЙЄГЬЪІбаОПЕФжївЊЗНЯђЁЃ
вВОЭЪЧНЋздШЛгябдРэНтПДГЩЪЧгУМЦЫуЛњРДДІРэКЭЗжЮіздШЛгябдЃЌЫќЩцМАЕНгябдбЇЃЈДЪЁЂДЪадЁЂгяЗЈЃЉКЭМЦЫуЛњбЇПЦЃЈФЃаЭ/ЫуЗЈЃЉЕФЗЖГыЁЃ
ДггябдбЇЩЯРДПДЃЌбаОПЕФЗНЯђАќРЈДЪИЩЬсШЁЁЂДЪадЛЙдЁЂЗжДЪЁЂДЪадБъзЂЁЂУќУћЪЕЬхЪЖБ№ЁЂДЪадЯћЦчЁЂОфЗЈЗжЮіЁЂЦЊеТЗжЮіЕШЕШЁЃ
етЪєгкбаОПЕФЛљДЁЗЖГыЃЌдкетаЉЛљДЁЕФбаОПФкШнжЎЩЯЃЌУцЯђЕФЪЧОпЬхЕФЮФБОДІРэгІгУЃЌШчЃЌЛњЦїЗвыЁЂЮФБОеЊвЊЁЂЧщИаЗжРрЁЂЮЪД№ЯЕЭГЁЂСФЬьЛњЦїШЫЕШЁЃ
дкМЦЫуЛњЫуЗЈЕФбаОПЗНУцЃЌвЛАуЪЧвдЙцдђКЭЭГМЦЯрНсКЯЕФЗНЗЈЃЌвВОЭЪЧРэаджївхКЭОбщжївхЯрНсКЯЁЃ
здШЛгябдБОжЪЩЯЛЙЪЧЗћКХЯЕЭГЃЌвђДЫгавЛЖЈЕФЙцдђПЩбАЃЌЕЋЪЧЫќЕФИДдгадгжОіЖЈСЫУЛгаЙцдђПЩвдМШВЛЯрЛЅГхЭЛгжФмИВИЧЫљгаЕФгябдЯжЯѓЁЃ
КѓРДДѓЙцФЃгяСЯПтЕФЭъЩЦКЭЭГМЦЛњЦїбЇЯАЗНЗЈСїааЦ№РДКѓЃЌОЭЪЁШЅСЫКмЖрШЫЙЄБржЦЙцдђЕФИКЕЃЃЌЪЙФЃаЭЩњГЩздЖЏЩњГЩЬиеїЁЃ
ЫљвдЃЌЮвУЧбаОПЕФ NLP ОЭЪЧЪЙгУЪ§РэКЭЛњЦїбЇЯАЕФЗНЗЈЖдгябдНјааНЈФЃЁЃПЩвдЫЕЃЌNLP ВЛЪЧДяЕНеце§ЕФздШЛгябдРэНтЃЌЖјЪЧАбгябдЕБГЩЪЧвЛжжМЦЫуШЮЮёЁЃ
ЖўЁЂСФЬьЛњЦїШЫЕФЪЕЯждРэЃЌНтОіЗНАИМАЬєеН
ЮвУЧДгСФЬьЛњЦїШЫЕФЗжРрКЭЪЕЯждРэЗжБ№ЫЕЦ№ЁЃ
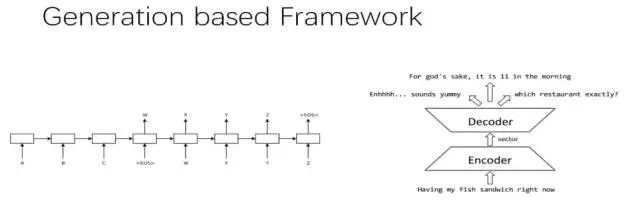
ФПЧАСФЬьЛњЦїШЫИљОнЖдЛАЕФВњЩњЗНЪНЃЌПЩвдЗжЮЊЛљгкМьЫїЕФФЃаЭЃЈRetrieval-Based
ModelsЃЉКЭЩњГЩЪНФЃаЭЃЈGenerative ModelsЃЉЁЃ
ЛљгкМьЫїЕФФЃаЭгавЛИідЄЯШЖЈвхЕФЛиД№МЏЃЌЮв
УЧашвЊЩшМЦвЛаЉЦєЗЂЪНЙцдђЃЌетаЉЙцдђФмЙЛИљОнЪфШыЕФЮЪОфМАЩЯЯТЮФЃЌЬєбЁГіКЯЪЪЕФЛиД№ЁЃ
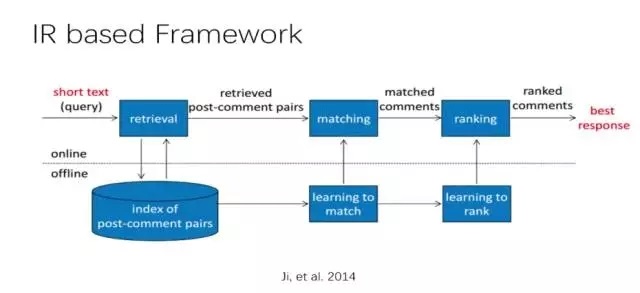
ЩњГЩЪНФЃаЭВЛвРРЕдЄЯШЖЈвхЕФЛиД№МЏЃЌЖјЪЧИљОнЪфШыЕФЮЪОфМАЩЯЯТЮФЃЌВњЩњвЛИіаТЕФЛиД№ЁЃ
СФЬьЛњЦїШЫЕФетСНЬѕММЪѕТЗЯпЃЌДгГЄдЖЕФНЧЖШПДФПЧАММЪѕЛЙЖМЛЙДІдкЩНЕзЃЌСНжжММЪѕТЗЯпЕФвьЭЌКЭгХЪЦШчЯТЃК
ЛљгкМьЫїЕФФЃаЭЕФгХЪЦЃК
Д№ОфПЩЖСадКУ
Д№ОфЖрбљадЧП
ГіЯжВЛЯрЙиЕФД№ОфЃЌШнвзЗжЮіЁЂЖЈЮЛ bug
ЕЋЪЧЫќЕФСгЪЦдкгкЃКашвЊЖдКђбЁЕФНсЙћзіХХађЃЌНјаабЁдё
ЛљгкЩњГЩЪНФЃаЭЕФгХЪЦЃК
ЖЫЕНЖЫЕФбЕСЗЃЌБШНЯШнвзЪЕЯж
БмУтЮЌЛЄвЛИіДѓЕФ Q-A Ъ§ОнМЏ
ВЛашвЊЖдУПвЛИіФЃПщЖюЭтНјааЕїгХЃЌБмУтСЫИїИіФЃПщжЎМфЕФЮѓВюМЖСЊаЇгІ
ЕЋЪЧЫќЕФСгЪЦдкгкЃКФбвдБЃжЄЩњГЩЕФНсЙћЪЧПЩЖСЕФЃЌЖрбљЕФЁЃ
вђДЫЃЌЩЯЪіЗНЗЈЙВЭЌУцСйЕФЬєеНгаЃК
ШчКЮРћгУЧАМИТжЖдЛАЕФаХЯЂЃЌгІгУЕНЕБТжЖдЛАЕБжа
КЯВЂЯжгаЕФжЊЪЖПтЕФФкШнНјРД
ФмЗёзіЕНИіадЛЏЃЌЧЇШЫЧЇУцЁЃ
етгаЕуРрЫЦгкЮвУЧЕФаХЯЂМьЫїЯЕЭГЃЌМШЯЃЭћдкДЙжБСьгђзіЕУИќКУЃЛвВЯЃЭћЖдВЛЭЌЕФШЫЕФ query гаВЛЭЌЕФХХађЦЋКУЁЃ
ДггІгУФПЕФЕФНЧЖШЧјЗжЃЌПЩвдЗжЮЊФПБъЧ§ЖЏЃЈGoal
DrivenЃЉЃЌгІгУгкПЭЗўжњРэЕШЃЌдкЗтБеЛАЬтГЁОАжаЃЛЮоФПБъЧ§ЖЏЃЈNon-Goal DrivenЃЉЃЌгІгУдкПЊЗХЛАЬтЕФГЁОАЯТЃЌетЪЧПЩЬИТлЕФжїЬтЪЧВЛЯоЕФЃЌЕЋЪЧашвЊЛњЦїШЫгавЛЖЈЕФЛљДЁГЃЪЖЁЃ
ОЁЙмФПЧАЙЄвЕНчгІгУЕФДѓЖрЪ§ЪЧЛљгкМьЫїЕФФЃаЭЃЌЪєгкФПБъЧ§ЖЏЕФЃЌР§ШчЃКАЂРяаЁУлЃЌгІгУЕФЛАЬтСьгђБШНЯеЃЌЩдЮЂНЋЛАЬтРЉДѓвЛЕуЃЌЫќОЭЛсВЛзХБпМЪЛиИДЛђепЮФВЛЖдЬтЁЃШчЯТЭМЃК
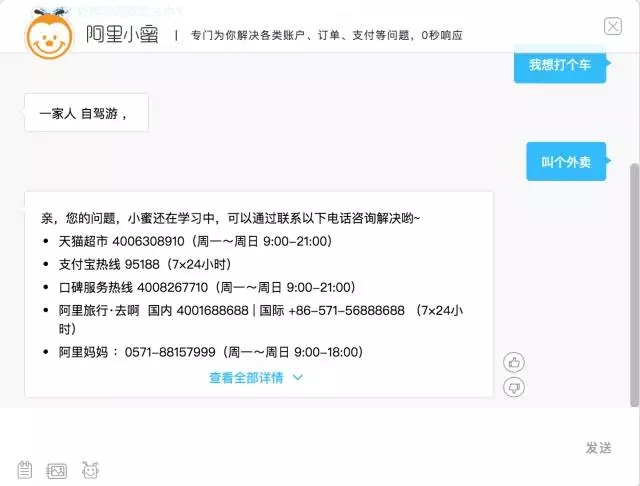
вЛИіПЊЗХЛАЬтГЁОАЯТЕФЩњГЩЪНФЃаЭгІИУЪЧзюжЧФмЁЂЗћКЯЮвУЧдЄЦкЕФСФЬьЛњЦїШЫЁЃвђДЫзмНсРДПД:
жЧФмСФЬьЛњЦїШЫЕФФПБъЃК
КЭШЫРрФмЙЛНјааГжајЕФЙЕЭЈ
ЖдВЛЭЌЕФЬсЮЪФмЙЛИјГіКЯЪЪЕФЛиД№
ПМТЧЕНШЫРрВЛЭЌИіадЛЏЕФВювьадЃЌИјГіВювьадЕФЛиД№ЃЈР§ШчЃЌЭЌвЛИіЮЪЬтЃЌЖдФаХЎРЯЩйВЛЭЌШКЬхЕФЛиД№гІИУТдгаВювьЃЉ
ФЧУДЖдгквЛИіжЧФмЛњЦїШЫРДЫЕЃЌЫќЕФСФЬьЕФЙІФмдкЦфжагІИУДІгкЪВУДЮЛжУЃПЪзЯШЃЌСФЬьгІИУЪЧвЛИіЛљДЁФЃПщЃЛЦфДЮЃЌСФЬьгІИУКЭЭъГЩШЮЮёЕФФЃПщгаКмКУЕФазїЃЛзюКѓЃЌСФЬьгІИУЪЙЛњЦїШЫПДЩЯШЅЯёФњЕФХѓгбЃЌЖјВЛЪЧФњЕФДњРэЛђепжњЪжЁЃ
ДгЩЯЪіНЧЖШРДЫЕЃЌЯждкгавЛаЉОГЃгыСФЬьЛњЦїШЫЛьЯ§ЕФИХФюЃЌвВЪЧвЛаЉСФЬьЯЕЭГЕФжмБпВњЦЗЃК
QA ЮЪД№ЯЕЭГЃКЪЧЛиД№ЪТЪЕЮЪЬтЃЈР§ШчжщЗхгаЖрИпЃЉвдМАЗЧЪТЪЕЮЪЬтЃЈР§Шч why, how, opinion
ЕШЙлЕуадЮЪЬтЃЉЕФСьгђЛњЦїШЫЁЃ
Dialog system ЖдЛАЯЕЭГЃКетжжДѓЖрЪЧФПБъЧ§ЖЏЕФЃЌЕЋЪЧНќМИФъЖМвВдкТ§Т§НгЪмСФЬьЛњЦїШЫЙІФм
Online customer service дкЯпПЭЗўЃКР§ШчЬдБІаЁУлЃЌЫќдкЖрЪ§ЧщПіЯТЯёвЛИіздЖЏЕФ
FAQЁЃ
вђДЫЃЌОЁЙмСФЬьЯЕЭГЖМЪЧеыЖдЮФБОРэНтЕФДѓЗНЯђЃЌЕЋФПБъВЛЭЌОіЖЈСЫММЪѕТЗЯпЛсгаЫљЦЋжиЃЌЕЋСФЬьЙІФмЪЧвЛИіЛљДЁЙІФмЁЃ
жЧФмСФЬьЛњЦїШЫПЩвдДгЩЯУцЕФжмБпЯЕЭГбаОПСьгђЕФЪ§ОнМЏгаЫљНшМјЃК
ЗЧЪТЪЕЮЪЬтЕФЮЪД№
ЩчЧјаЭЮЪД№ЯЕЭГЃЈР§ШчАйЖШжЊЕРЕШЃЌЖдЮЪЬтКЭД№АИМфгаНЯЧПЕФЦЅХфЃЛВЂЧввЛИіЮЪЬтЖрИіД№АИЪБгаЦРЗжЁЂХХађЃЉ
ДгдкЯпЯЕЭГжаЭкОђвЛаЉКУЕФ QA corpus
ФЧШчКЮРДЦРМлвЛИіСФЬьЛњЦїШЫЕФКУЛЕЃПзюживЊЕФЪЧЮЪОфКЭД№ОфЕФЯрЙиадЃЌвВОЭЪЧБОжЪЪЧЃКЖЬЮФБОЯрЙиЖШМЦЫуЁЃЕЋвЊзЂвтЃК
ЯрЫЦадКЭЯрЙиадЪЧВЛЭЌЕФЁЃгУгкЯрЫЦадМЦЫуЕФИїжжЗНЗЈВЂВЛЪЪгУгкЯрЙиадЁЃЮвУЧашвЊНЈСЂвЛЬзЖЬЮФБОЯрЙиадМЦЫуЗНЗЈЁЃ
ЯрЙиадМЦЫугавЛаЉдкдчЦкЕФСФЬьЛњЦїШЫЕФЙЙНЈжабгајЯТРДЕФЗНЗЈЃК
ДЪгяЙВЯжЕФЭГМЦ
ЛљгкЛњЦїЗвыЕФЯрЙиЖШМЦЫу
жїЬтФЃаЭЃЈLDA)ЕФЯрЫЦЖШМЦЫу
ФПЧАдкСФЬьЛњЦїШЫЩЯЪЙгУЕФЩюЖШбЇЯАЗНЗЈгаШчЯТетаЉЃК
Word2vec, Glove
CNN, LSTM, GRU
Seq2Seq
Attention mechanism
Deep Reinforcement Learning |
ЦфжаЃЌЩюЖШЧПЛЏбЇЯАЪЧАбЁАШчКЮЕУЕНвЛИізуЙЛШУШЫТњвтЕФЩњГЩЪННсЙћЁБСПЛЏГЩRewardЁЃетаЉвђЫиАќРЈЃК
ЪЧЗёШнвзБЛЛиД№ЃЈвЛИіКУЕФЩњГЩЪНЕФНсЙћгІИУЪЧИќШнвзШУШЫНгЯТШЅЕФЃЉ
вЛИіКУЕФЛиИДгІИУШУЖдЛАЧАНјЃЌБмУтжиИДад
БЃжЄгявхЕФСЌЙсадЁЃгУЩњГЩЪНЕФНсЙћЗДЭЦЛиqueryЕФПЩФмадгаЖрДѓЃЌФмБЃжЄдкгявхЩЯЪЧКЭаГЕФЁЂСЌЙсЕФЁЃ
ФЧУДШчКЮЪЕЯждкжЧФмСФЬьЛњЦїШЫЕФЕкШ§ИіФПБъЃЌВювьЛЏЛиД№ФиЃПвВОЭЪЧШчКЮдкЖдЛАРяШчКЮв§ШыИіадЛЏЃЈpersonalityЃЉаХЯЂЃП
ЪзЯШдЄбЕСЗвЛИіШЫЕФЯђСПЃЌШУЩњГЩЕФНсЙћЬљНќШЫЕФЬиЕуЁЃЭЈЙ§ word embedding НЋШЫЕФаХЯЂзїЮЊвЛИіДЪЯђСПЃЌдкЪфШыВПЗждіМгвЛзщШЫЕФЯђСПЃЛдкЩњГЩЛиД№ЕФЪБКђЃЌПМТЧВЛЭЌЕФШЫгІИУбЁЪВУДбљЕФДЪгяЁЃ
ФПЧАЃЌЮвУЧвЊзівЛИіеце§жЧФмЕФздЖЏСФЬьЛњЦїШЫЃЌШдШЛУцСйвЛаЉЬєеНЃК
ШБЗІЙЋЙВЕФбЕСЗЪ§ОнМЏЃЌФПЧАЪЙгУЙњЭтЕФЪ§ОнМЏНЯЖр
Ubuntu dialog corpusЃЈsubset of Ubuntu CorpusЃЉ
Reddit datasetЃЈПЩЖСадКЭжЪСПЖМВЛДэЃЉ
Corpora from Chinese SNS(ЮЂВЉЃЉ
ВтЪдМЏЛЙВЛЭГвЛ
ЦРЙРЖШСПЃКЖШСПКмФбЩшМЦЃЈФПЧАЪЧДгЛњЦїЗвыКЭздЖЏеЊвЊЕФBLEUЁЂROUGEРяНшМјЕФЃЌЕЋУцСйЮЪЬтЪЧЗёФмПЬЛСФЬьЛњЦїШЫЕФКУЛЕЃЌВЂЧвжИЕМСФЬьЛњЦїШЫЕФММЪѕГЏзХе§ЯђЕФЗНЯђЗЂеЙЃЉ
СФЬьЛњЦїШЫЕФвЛАуЖдЛАКЭШЮЮёЕМЯђЕФЖдЛАжЎМфШчКЮФмЙЛЦНЛЌЧаЛЛ
етжжЦНЛЌЧаЛЛЖдгУЛЇЕФЬхбщЗЧГЃживЊ
ЧаЛЛЕФММЪѕашвЊвРРЕЧщаїЗжЮіМАЩЯЯТЮФЗжЮі
гУЛЇВЛашвЊИјГіУїШЗЕФЗДРЁЁЃР§ШчЃЌЮвЧАвЛОфЫЕТЙъЯКУЃЌКѓвЛОфЫЕВЛЯВЛЖКЋЗЖЃЌашвЊСФЬьЛњЦїШЫФме§ШЗЪЖБ№
ШдШЛДцдкЕФЮЪЬт
ОфзгМЖЁЂЦЌЖЮМЖЕФгявхНЈФЃЛЙУЛгаДЪгяЕФНЈФЃЃЈword embeddingЃЉФЧУДКУ
ЩњГЩЪНШдШЛЛсВњЩњвЛаЉАВШЋЛиД№
дкжЊЪЖЕФБэЪОКЭв§ШыЩЯЛЙашвЊХЌСІ
зюКѓгавЛаЉПЩвдЦкД§ЕФНсТлКЭЧАОАЃК
ПЩвдШЯЮЊжЧФмСФЬьЛњЦїШЫЪЧвЛИіALL-NLPЮЪЬтЃЌЩюЖШбЇЯАЪЧДйНјСЫchatbotЕФЗЂеЙЃЌЕЋЛЙВЛЙЛЃЌашвЊКЭДЋЭГЛњЦїбЇЯАЯрНсКЯЁЃФПЧАЮвУЧШддкЬНЫївЛаЉЗНЗЈТлМАВтЪдЕФЦРМлЬхЯЕЁЃ
ВЂЧвЯЃЭћСФЬьЛњЦїШЫФмЙЛжїЖЏевШЫЫЕЛАЃЌР§ШчЫќЫЕЁАФузђЬьИњЮвЫЕЪВУДЁЁФуЩњШеПьЕНРВЁЁЁБЕШЕШЁЃ
етИіПЩвдгУЙцдђЪЕЯжЃЌашвЊАбЮЪЬтЖЈвхЧхГўЁЃИіадЛЏЕФСФЬьЛњЦїШЫЕФЪЕЯжЃЌзХСІЕуПЩФмИќЦЋЙЄГЬЁЃСФЬьЛњЦїШЫЕФбаОППЩФмдк2015ФъзѓгвВХПЊЪМХюВЊаЫЦ№ЃЌЫљвдДѓМвгаКмДѓЕФЛњЛсКЭЬєеНЁЃ
вЛаЉСФЬьЛњЦїШЫЕФВЮПМЮФЯзЃК
Neural Responding Machine for Short-Text Conversation
(2015-03)
A Neural Conversational Model (2015-06)
A Neural Network Approach to Context-Sensitive Generation
of Conversational Responses (2015-06)
The Ubuntu Dialogue Corpus: A Large Dataset for Research
in Unstructured Multi-Turn Dialogue - Systems (2015-06)
Building End-To-End Dialogue Systems Using Generative
Hierarchical Neural Network Models (2015-07)
A Diversity-Promoting Objective Function for Neural
Conversation Models (2015-10)
Attention with Intention for a Neural Network Conversation
Model (2015-10)
Improved Deep Learning Baselines for Ubuntu Corpus
Dialogs (2015-10)
A Survey of Available Corpora for Building Data-Driven
Dialogue Systems (2015-12)
Incorporating Copying Mechanism in Sequence-to-Sequence
Learning (2016-03)
A Persona-Based Neural Conversation Model (2016-03)
How NOT To Evaluate Your Dialogue System: An Empirical
Study of Unsupervised Evaluation Metrics for Dialogue
Response Generation (2016-03)
ЯТУцЪЧНВНтжЧФмСФЬьЛњЦїШЫЕФ Seq2Seq+Attention ЛњжЦЁЃ
ЖјЩњГЩЪНФЃаЭЯждкжївЊбаОПЗНЗЈЪЧ Sequence to Sequence+Attention ЕФФЃаЭЃЌвдМАзюаТГіЕФ
GANSeq ФЃаЭЁЃЃЈВЮПМТлЮФЃКSequence to Sequence Learning with
Neural NetworksЃЉ
seq2seq ФЃаЭЪЧвЛИіЗвыФЃаЭЃЌжївЊЪЧАбвЛИіађСаЗвыГЩСэвЛИіађСаЁЃЫќЕФЛљБОЫМЯыЪЧгУСНИі RNNLMЃЌвЛИізїЮЊБрТыЦїЃЌСэвЛИізїЮЊНтТыЦїЃЌзщГЩ
RNN БрТыЦї-НтТыЦїЁЃ
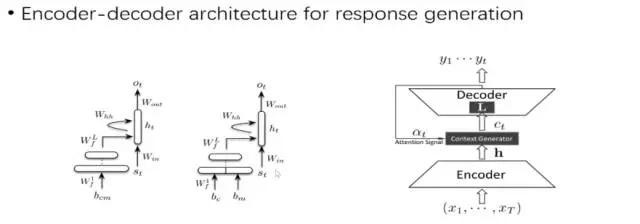
дкЮФБОДІРэСьгђЃЌЮвУЧГЃгУБрТыЦї-НтТыЦїЃЈencoder-decoderЃЉПђМмЁЃШчЯТЭМЃК
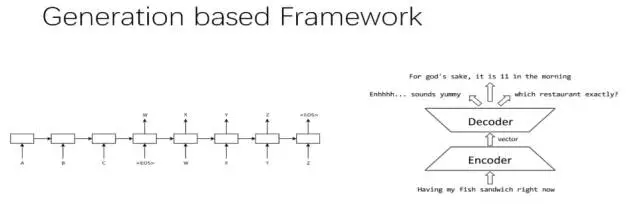
дкетИіФЃаЭжаЃЌУПвЛЪБМфЕФЪфШыКЭЪфГіЪЧВЛЭЌЕФЁЃЮвУЧЕФФПЕФЪЧАбЯжгаађСа ABC зїЮЊЪфШыЃЌгГЩфГЩ WXYZ
зїЮЊЪфГіЁЃБрТыЦїЖдЪфШыЕФ ABC НјааБрТыЃЌЩњГЩжаМфгявхБрТы CЁЃ
ШЛКѓНтТыЦїЖджаМфгявхБрТы C НјааНтТыЃЌдкУПИіiЪБПЬЃЌНсКЯвбОЩњГЩЕФ WXY ЕФРњЪЗаХЯЂЩњГЩ ZЁЃ
ЕЋЪЧЃЌетИіПђМмгавЛИіШБЕуЃЌОЭЪЧЩњГЩЕФОфзгжаУПвЛИіДЪВЩгУЕФжаМфгявхБрТыЪЧЯрЭЌЕФЃЌЖМЪЧ CЁЃ
вђДЫЃЌдкОфзгБШНЯЖЬЕФЪБКђЃЌЛЙФмБШНЯЬљЧаЃЌОфзгГЄЪБЃЌОЭУїЯдВЛКЯгявхСЫЁЃ
ЫќЕФЙ§ГЬЗжЮЊетСНВНЃК
ЃЈ1ЃЉБрТыЃЈEncodeЃЉ
ht ЪЧгЩЕБЧАЕФЪфШы xt КЭЩЯвЛДЮЕФвўВиВуЕФЪфГі ht-1ЃЌОЙ§ЗЧЯпадБфЛЛЕУЕНЕФЁЃ
ЯђСПcЭЈГЃЮЊRNNжаЕФзюКѓвЛИівўНкЕуЃЈhЃЌHidden stateЃЉЃЌЛђЪЧЖрИівўНкЕуЕФМгШЈзмКЭЃЈдкзЂвтСІЛњжЦРяЃЉЁЃ
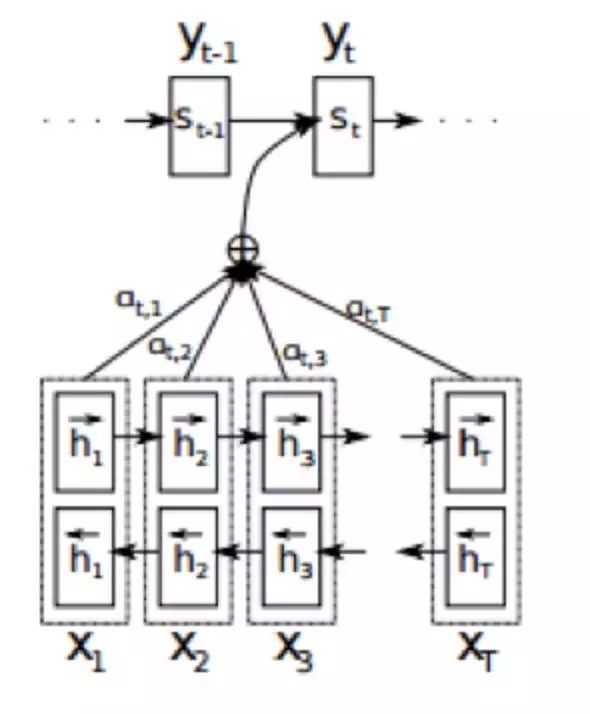
ЃЈ2ЃЉНтТыЃЈDecodeЃЉ
НтТыЕФЙ§ГЬГЃГЃЪЙгУЬАаФЫуЗЈЛђепМЏЪјЫбЫїЃЌРДЗЕЛиЖдгІИХТЪзюДѓЕФДЪЛуЁЃ
дкЪЕМЪЪЕЯжСФЬьЯЕЭГЕФЪБКђЃЌвЛАуБрТыЦїКЭНтТыЦїЖМВЩгУRNNФЃаЭвдМАRNNФЃаЭЕФИФНјФЃаЭ LSTMЁЃ
ЕБОфзгГЄЖШГЌЙ§30вдКѓЃЌLSTMФЃаЭЕФаЇЙћЛсМБОчЯТНЕЃЌвЛАуДЫЪБЛсв§Шы
Attention ФЃаЭЃЌЖдГЄОфзгРДЫЕФмЙЛУїЯдЬсЩ§ЯЕЭГаЇЙћЁЃ
Attention ЛњжЦЪЧШЯжЊаФРэбЇВуУцЕФвЛИіИХФюЃЌЫќЪЧжИЕБШЫдкзівЛМўЪТЧщЕФЪБКђЃЌЛсзЈзЂЕизіетМўЪТЖјКіТджмЮЇЕФЦфЫћЪТЁЃ
Р§ШчЃЌШЫдкзЈзЂЕиПДетБОЪщЃЌЛсКіТдХдБпШЫЫЕЛАЕФЩљвєЁЃетжжЛњжЦгІгУдкСФЬьЛњЦїШЫЁЂЛњЦїЗвыЕШСьгђЃЌОЭАбдДОфзгжаЖдЩњГЩОфзгживЊЕФЙиМќДЪЕФШЈжиЬсИпЃЌВњЩњГіИќзМШЗЕФгІД№ЁЃ
діМгСЫ Attention ФЃаЭЕФБрТыЦї-НтТыЦїПђМмШчЯТЭМЫљЪОЁЃSeq2Seq жаЕФБрТыЦїБЛЬцЛЛЮЊвЛИіЫЋЯђбЛЗЭјТчЃЈbidirectional
RNNЃЉЃЌдДађСа xЃН(x1,x2,Ё,xt) ЗжБ№БЛе§ЯђгыЗДЯђЕиЪфШыСЫФЃаЭжаЃЌНјЖјЕУЕНСЫе§ЗДСНВувўНкЕуЃЌгяОГЯђСПcдђгЩ
RNN жаЕФвўНкЕуhЭЈЙ§ВЛЭЌЕФШЈжи a МгШЈЖјГЩЁЃ
Ш§ЁЂЖЏЪжЪЕЯжвЛИіжЧФмЛњЦїШЫ
БОДЮДњТыЛљгкTF 1.1АцБОЪЕЯжЃЌЪЙгУЫЋЯђ LSTM+Attention ФЃаЭЁЃЗжЮЊ6ВНЃК
1ЃЉПтв§ШыМАГЌВЮЪ§ЖЈвх
import numpy as
np #matrix math
import tensorflow as tf #machine learningt
import helpers #for formatting data into batches
and generating random sequence data
tf.reset_default_graph() #Clears the default
graph stack and resets the global default graph.
sess = tf.InteractiveSession()
PAD = 0
EOS = 1
vocab_size = 10
input_embedding_size = 20 #character length
encoder_hidden_units = 20 #num neurons
decoder_hidden_units = encoder_hidden_units
* 2
#input placehodlers
encoder_inputs = tf.placeholder(shape=(None,
None), dtype=tf.int32, name='encoder_inputs')
encoder_inputs_length = tf.placeholder(shape=(None,),
dtype=tf.int32, name='encoder_inputs_length')
decoder_targets = tf.placeholder(shape=(None,
None), dtype=tf.int32, name='decoder_targets') |
2ЃЉЪфШыЮФБОЕФЯђСПБэЪО
embeddings =
tf.Variable(tf.random_uniform([vocab_size, input_embedding_size],
-1.0, 1.0), dtype=tf.float32)
#this thing could get huge in a real world
application
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings,
encoder_inputs) |
3ЃЉEncoder
from tensorflow.contrib.rnn
import LSTMCell, LSTMStateTuple
encoder_cell = LSTMCell(encoder_hidden_units)
((encoder_fw_outputs,
encoder_bw_outputs),
(encoder_fw_final_state,
encoder_bw_final_state)) = (
tf.nn.bidirectional_dynamic_rnn(cell_fw=encoder_cell,
cell_bw=encoder_cell,
inputs=encoder_inputs_embedded,
sequence_length=encoder_inputs_length,
dtype=tf.float64, time_major=True)
)
encoder_outputs = tf.concat((encoder_fw_outputs,
encoder_bw_outputs), 2)
encoder_final_state_c = tf.concat(
(encoder_fw_final_state.c, encoder_bw_final_state.c),
1)
encoder_final_state_h = tf.concat(
(encoder_fw_final_state.h, encoder_bw_final_state.h),
1)
encoder_final_state = LSTMStateTuple(
c=encoder_final_state_c,
h=encoder_final_state_h
) |
4ЃЉDecoder
decoder_cell
= LSTMCell(decoder_hidden_units)
encoder_max_time, batch_size = tf.unstack(tf.shape(encoder_inputs))
decoder_lengths = encoder_inputs_length + 3
#weights
W = tf.Variable(tf.random_uniform([decoder_hidden_units,
vocab_size], -1, 1), dtype=tf.float32)
#bias
b = tf.Variable(tf.zeros([vocab_size]), dtype=tf.float32)
assert EOS == 1 and PAD == 0
eos_time_slice = tf.ones([batch_size], dtype=tf.int32,
name='EOS')
pad_time_slice = tf.zeros([batch_size], dtype=tf.int32,
name='PAD')
#retrieves rows of the params tensor. The behavior
is similar to using indexing with arrays in
numpy
eos_step_embedded = tf.nn.embedding_lookup(embeddings,
eos_time_slice)
pad_step_embedded = tf.nn.embedding_lookup(embeddings,
pad_time_slice)
def loop_fn_initial():
initial_elements_finished = (0 >= decoder_lengths)
# all False at the initial step
#end of sentence
initial_input = eos_step_embedded
#last time steps cell state
initial_cell_state = encoder_final_state
#none
initial_cell_output = None
#none
initial_loop_state = None # we don't need to
pass any additional information
return (initial_elements_finished,
initial_input,
initial_cell_state,
initial_cell_output,
initial_loop_state)
def loop_fn_transition(time, previous_output,
previous_state, previous_loop_state):
def get_next_input():
output_logits = tf.add(tf.matmul(previous_output,
W), b)
#Returns the index with the largest value
across axes of a tensor.
prediction = tf.argmax(output_logits, axis=1)
#embed prediction for the next input
next_input = tf.nn.embedding_lookup(embeddings,
prediction)
return next_input
elements_finished = (time >= decoder_lengths)
# this operation produces boolean tensor of
[batch_size]
# defining if corresponding sequence has ended
#Computes the "logical and" of elements
across dimensions of a tensor.
finished = tf.reduce_all(elements_finished)
# -> boolean scalar
#Return either fn1() or fn2() based on the boolean
predicate pred.
input = tf.cond(finished, lambda: pad_step_embedded,
get_next_input)
#set previous to current
state = previous_state
output = previous_output
loop_state = None
return (elements_finished,
input,
state,
output,
loop_state)
def loop_fn(time, previous_output, previous_state,
previous_loop_state):
if previous_state is None: # time == 0
assert previous_output is None and previous_state
is None
return loop_fn_initial()
else:
return loop_fn_transition(time, previous_output,
previous_state, previous_loop_state)
decoder_outputs_ta, decoder_final_state, _
= tf.nn.raw_rnn(decoder_cell, loop_fn)
decoder_outputs = decoder_outputs_ta.stack()
decoder_max_steps, decoder_batch_size, decoder_dim
= tf.unstack(tf.shape(decoder_outputs))
#flettened output tensor
decoder_outputs_flat = tf.reshape(decoder_outputs,
(-1, decoder_dim))
#pass flattened tensor through decoder
decoder_logits_flat = tf.add(tf.matmul(decoder_outputs_flat,
W), b)
#prediction vals
decoder_logits = tf.reshape(decoder_logits_flat,
(decoder_max_steps, decoder_batch_size, vocab_size))
decoder_prediction = tf.argmax(decoder_logits,
2) |
5ЃЉOptimizer
stepwise_cross_entropy
= tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(decoder_targets, depth=vocab_size,
dtype=tf.float32),
logits=decoder_logits,
)
#loss function
loss = tf.reduce_mean(stepwise_cross_entropy)
#train it
train_op = tf.train.AdamOptimizer().minimize(loss)
sess.run(tf.global_variables_initializer()) |
6ЃЉTraining on the toy task
batch_size =
100
batches = helpers.random_sequences(length_from=3,
length_to=8,
vocab_lower=2, vocab_upper=10,
batch_size=batch_size)
print('head of the batch:')
for seq in next(batches)[:10]:
print(seq)
def next_feed():
batch = next(batches)
encoder_inputs_, encoder_input_lengths_ = helpers.batch(batch)
decoder_targets_, _ = helpers.batch(
[(sequence) + [EOS] + [PAD] * 2 for sequence
in batch]
)
return {
encoder_inputs: encoder_inputs_,
encoder_inputs_length: encoder_input_lengths_,
decoder_targets: decoder_targets_,
}
loss_track = []
max_batches = 3001
batches_in_epoch = 1000
try:
for batch in range(max_batches):
fd = next_feed()
_, l = sess.run([train_op, loss], fd)
loss_track.append(l)
if batch == 0 or batch % batches_in_epoch
== 0:
print('batch {}'.format(batch))
print(' minibatch loss: {}'.format(sess.run(loss,
fd)))
predict_ = sess.run(decoder_prediction, fd)
for i, (inp, pred) in enumerate(zip(fd[encoder_inputs].T,
predict_.T)):
print(' sample {}:'.format(i + 1))
print(' input > {}'.format(inp))
print('predicted > {}'.format(pred))
if i >= 2:
break
print()
except KeyboardInterrupt:
print(' training interrupted') |
дк30000ДЮЕќДњКѓЃЌloss жЕНЕЕНСЫ0.0869ЁЃ
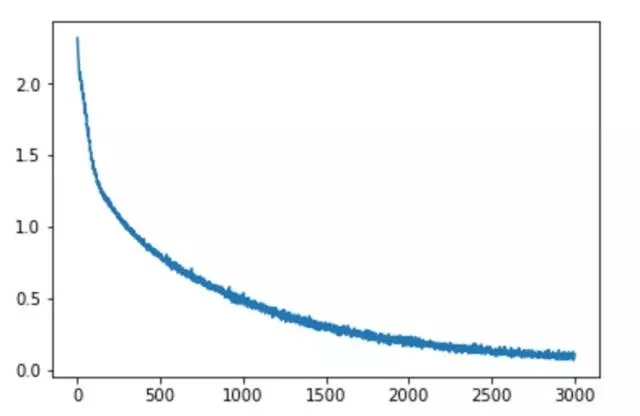
ДѓМвПЩвдГЂЪдвЛЯТЃЌашвЊдДТыЕФЛАЃЌЮвЩдКѓЗХдк github ЩЯЁЃ |









