| 自然语言处理是人工智能研究的核心问题之一。近日,已宣布被
Salesforce 收购的深度学习公司 MetaMind 在其官方网站上发表了一篇文章,深度剖析了
LSTM 和词袋模型在自然语言处理上的应用。
机器学习、深度学习和更广义上的人工智能的兴起是毫无疑问的,而且其已经对计算机科学领域产生巨大的影响。你可能已经听说过,目前深度学习已经在图像识别和围棋等很多任务上实现了对人类的超越。
深度学习社区目前将自然语言处理(NLP)看作是下一个研究和应用的前沿。
深度学习的一大优势是其进步往往是非常通用的。比如说,使深度学习在一个领域有效的技术往往不需要太多修改就能迁移到另一个领域。更具体而言,为图像和语音识别所开发的构建大规模、高计算成本的深度学习模型的方法也能被用于自然语言处理。最近的最先进的翻译系统就是其中一例,该系统的表现超越了所有以往的系统,但所需的计算机能力也要多得多。这样的高要求的系统能够在真实世界数据中发现偶然出现的非常复杂的模式,但这也让很多人将这样的大规模模型用在各种各样的任务上。这又带来了一个问题:
是否所有的任务都具有需要这种模型才能处理的复杂度?
让我们看看一个用于情感分析的在词袋嵌入(bag-of-words embeddings)上训练的一个两层多层感知器(two
layered MLP)的内部情况:
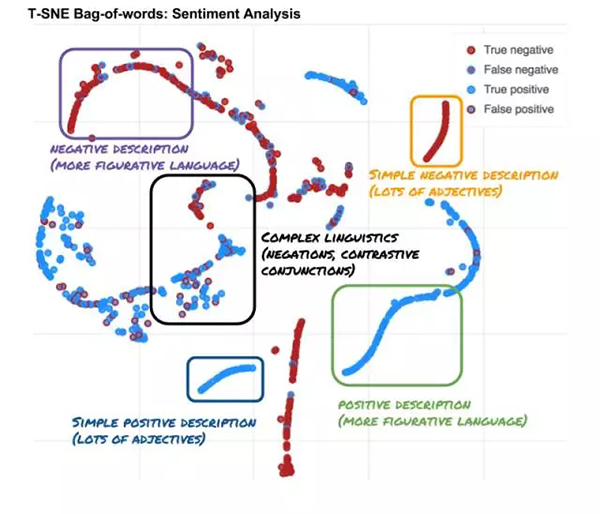
用于情感分析的在词袋嵌入(bag-of-words embeddings)上训练的一个两层多层感知器(two
layered MLP)的内部情况
一个被称为词袋(bag-of-words)的简单深度学习系统的内部情况,其可以将句子分类为积极的(positive)或消极的(negative)。这张图是来自在一个词袋上的一个
2 层 MLP 最后一个隐藏层的一个 T-SNE。其中每个数据点对应于一个句子,不同的颜色分别对应于该深度学习系统的预测和真实目标。实线框表示句子的不同语义内容。后面你可以通过一张交互式图表来了解它们。
上图中的实线框提供了一些重要的见解。而真实世界数据的难度远不止此,一些句子可以被轻松分类,但另一些却包含了复杂的语义结构。在可以轻松分类的句子的案例中,高容量的系统可能并不是必需的。也许一个简单得多的模型就能完成同样的工作。这篇博客文章探讨了这种情况是否属实,并将说明我们其实往往使用简单模型就能完成任务。
一、对文本的深度学习
大多数深度学习方法需要浮点数作为输入,如果你没使用过文本,你可能会疑问:
我怎么使用一段文本来进行深度学习?
对于文本,其核心问题是在给定材料的长度的情况下如何表征任意大量的信息。一种流行的方法是将文本切分(tokenize)成词(word)、子词(sub-word)甚至字符(character)。然后每一个词都可以通过
word2vec 或 Glove 等经过了充分研究的方法而转换成一个浮点向量。这种方法可以通过不同词之前的隐含关系来提高对词的有意义的表征。
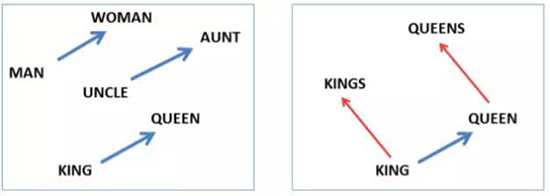
取一个词,将其转换成一个高维嵌入(比如 300 维),然后使用 PCA 或 T-SNE(流行的降维工具,在这个案例中是降为
2 维),你就可以找到词之间的有趣关系。比如,在上图中你可以看到 uncle 与 aunt 之间的距离和
man 与 woman 之间的距离差不多相等(来自 Mikolov et al., 2013)
通过使用 tokenization 和 word2vec 方法,我们可以将一段文本转换为词的浮点表示的一个序列。
现在,一个词表征的序列有什么用?
二、词袋(bag-of-words)
现在我们来探讨一下词袋(BoW),这也许是最简单的机器学习算法了!
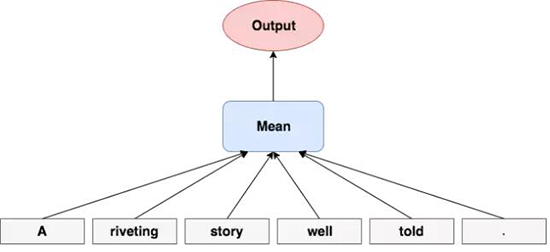
取一些词表征(图下部的灰色框),然后通过加(sum)或平均(average)得到一个共同的表征(蓝色框),这个共同表征(common
representation)包含了每个词的一些信息。在这篇文章中,该共同表征被用于预测一个句子是积极的还是消极的(红色框)。
在每个特征维(feature dimension)上简单地取词的平均(mean)。事实证明简单地对词嵌入(word
embedding)进行平均(尽管这完全忽略了句子的顺序)就足以在许多简单的实际案例中取得良好的效果,而且也能在与深度神经网络结合时提供一个强大的基准(后面会解释)。
此外,取平均的计算成本很低,而且可以将句子的降维成固定大小的向量。
三、循环神经网络
一些句子需要很高的准确度或依赖于句子结构。使用词袋来解决这些问题可能不能满足要求。不过,你可以考虑使用让人惊叹的循环神经网络(Recurrent
Neural Networks)。
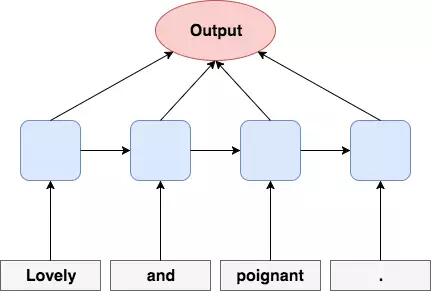
在每一个时间步骤(从左到右),一个输入(比如一个词)被馈送入 RNN(灰色框),并整合之前的内部记忆(蓝色框)。然后该
RNN 执行一些计算,得到新的内部记忆(蓝色框),该记忆表示了所有之前见过的单元(如,所有之前的词)。该
RNN 现在应该已经包含了一个句子层面的信息,让其可以更好地预测一个句子是积极的还是消极的(红色框)。
每个词嵌入都按顺序被送入一个循环神经网络,然后该网络可以存储之前见过的信息并将其与新的词结合起来。当使用长短期记忆(LSTM)或门控循环单元(GRU)等著名的记忆单元来驱动
RNN 时,该 RNN 能够记住具有很多个词的句子中所发生的情况!(因为 LSTM 的成功,带有 LSTM
记忆单元的 RNN 常被称为 LSTM。)这类模型中最大的模型将这样的结构堆叠了 8 次。
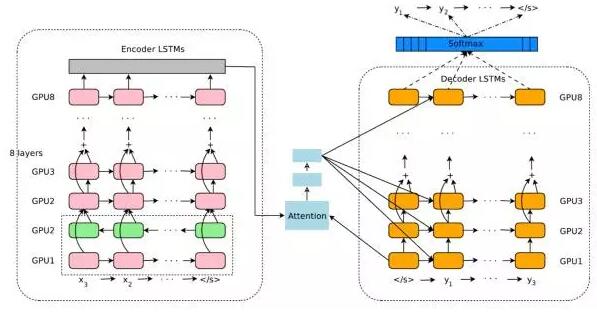
都表示带有 LSTM 单元的循环神经网络。它们也应用了一些权衡的技巧,比如跳过 LSTM 层之间的连接和一种被称为注意(attention)的方法。另外要注意绿色的
LSTM 指向了相反的方向。当与一个普通的 LSTM 结合时,这被称为双向 LSTM(bidirectional
LSTM),因为其可以在数据序列的两个方向上都获取信息。更多信息可参阅 Stephen Merity
的博客(即机器之心文章《深度 | 逐层剖析,谷歌机器翻译突破背后的神经网络架构是怎样的?》)(来源:Wu
et al., 2016)。
但是,和简单的词袋模型比起来,LSTM 的计算成本要高得多,而且需要经验丰富的深度学习工程师使用高性能的计算硬件来实现和提供支持。
四、例子:情感分析
情感分析(sentiment analysis)是一种量化主观性文章的极性的文档分类任务。给定一个句子,模型去评估它的情感是积极、消极还是中性的。
想要在事态严重前先发现 Twitter 上的愤怒客户吗?那么,情感分析可能正是你想要的!
一个极佳的实现此目的的数据集(我们接下来会用到)是 Stanford sentiment treebank(SST):
https://nlp.stanford.edu/sentiment/treebank.html
我们已经公开了一个 PyTorch 的数据加载器:
https://github.com/pytorch/text
STT 不仅可以给句子分类(积极、消极),而且也可以给每个句子提供符合语法的子短语(subphrases)。然而,在我们的系统中,我们不使用任何树信息(tree
information)。
原始的 SST 由 5 类构成:非常积极、积极、中性、消极、非常消极。我们认为二值分类任务更加简单,其中积极与非常积极结合、消极与非常消极结合,没有中性。
我们为我们的模型架构提供了一个简略且技术化的描述。重点不是它到底如何被构建,而是计算成本低的模型达到了
82% 的验证精度,一个 64 大小的批任务用了 10 毫秒,而计算成本高的 LSTM 架构虽然验证精度达到了
88% 但是需耗时 87 毫秒才能处理完同样的任务量(最好的模型大概精度在 88-90%)。
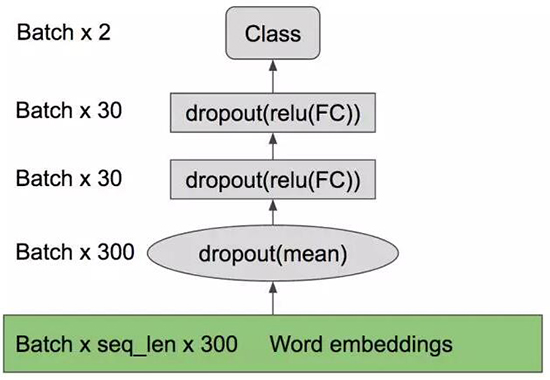
下面的绿色框表示词嵌入,使用 GloVe 进行了初始化,然后是取词的平均(词袋)和带有 dropout
的 2 层 MLP。
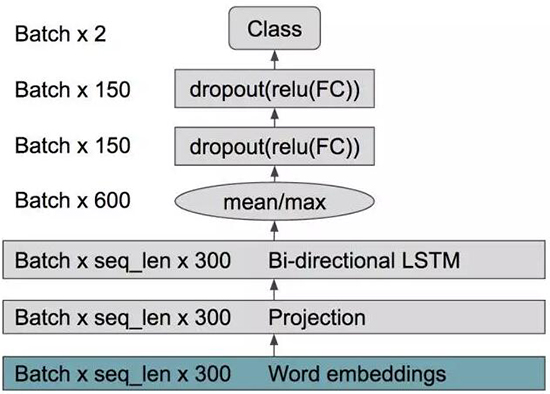
下面的蓝绿色框表示词嵌入,使用 GloVe 进行了初始化。在整个词嵌入中没有跟踪梯度。我们使用了一个带有
LSTM 单元的双向 RNN,使用的方式类似于词袋,我们使用了该 RNN 隐藏状态来提取均值和最大值,之后是一个带
dropout 的 2 层 MLP。
五、低计算成本的跳读阅读器(skim reader)
在某些任务中,算法可以展现出接近人类水平的精度,但是要达到这种效果,你的服务器预算恐怕得非常高。你也知道,不一定总是需要使用有真实世界数据的
LSTM,用低成本的词袋(BoW)或许也没问题。
当然,顺序不可知的词袋(BoW)会将大量消极词汇错误分类。完全切换到一个劣质的词袋(BoW)会降低我们的总体性能,让它听上去就不那么令人信服了。所以问题就变成了:
我们能否学会区分「简单」和「困难」的句子。
而且为了节省时间,我们能否用低成本的模型来完成这项任务?
六、探索内部
探索深度学习模型的一种流行的方法是了解每个句子在隐藏层中是如何表示的。但是,因为隐藏层常常是高维的,所以我们可以使用
T-SNE 这样的算法来将其降至 2 维,从而让我们可以绘制图表供人类观察。
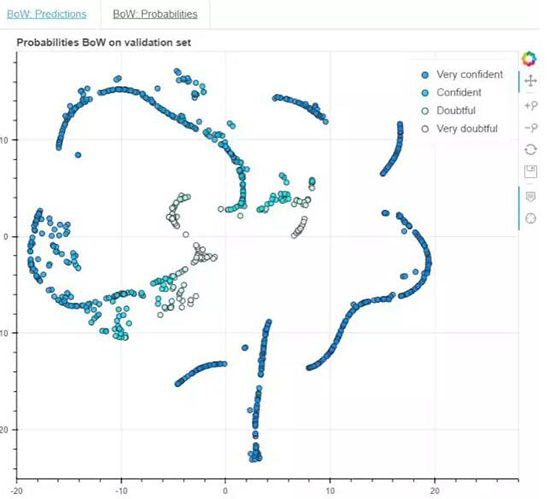
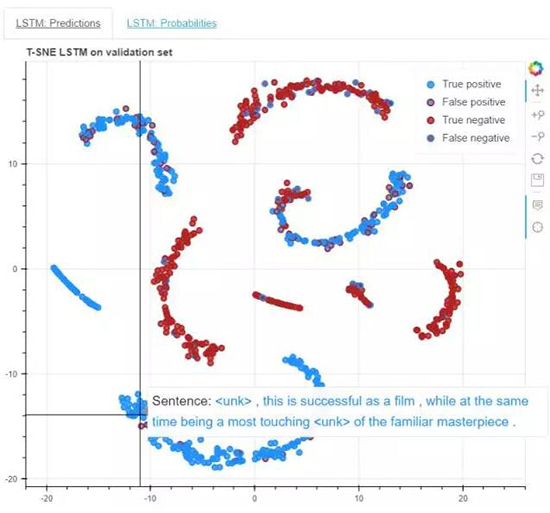
上面两张图是原文中可交互的图示的截图。在原交互图中,你可以将光标移动、缩放和悬停在数据点上来查看这些数据点的信息。在图中,你可以看到在词袋(BoW)中的最后一个隐藏层。当悬停在任何数据点上时,你可以看到表示该数据点的句子。句子的颜色取决于其标签(label)。
Predictions 标签页:该模型的系统预测与实际标签的比较。数据点的中心表示其预测(蓝色表示积极,红色表示消极),周围的线表示实际的标签。让我们可以了解系统什么时候是正确的,什么时候是错误的。
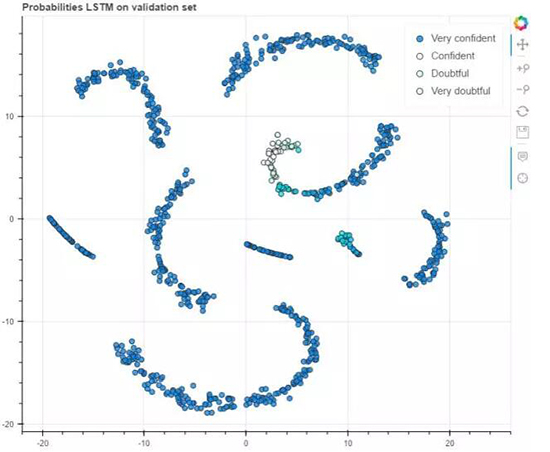
Probabilities 标签页:我们绘制了在输出层中被预测的类别的概率。这表示了该模型对其预测的信息。此外,当悬停在数据点上时,也将能看到给定数据点的概率,其颜色表示了模型的预测。注意因为该任务是二元分类,所以其概率是从
0.5 开始的,在这个案例中的最小置信度为 50/50.
T-SNE 图容易受到许多过度解读的破坏,但这可能能让你了解一些趋势。
七、T-SNE 的解读
句子变成聚类(cluster),聚类构成不同的语义类型。
一些聚类具有简单的形式,而且具有很高的置信度和准确度。
其它聚类更加分散,带有更低的准确度和置信度。
带有积极成分和消极成分的句子是很困难的。
现在让我们看看在 LSTM 上的相似的图: 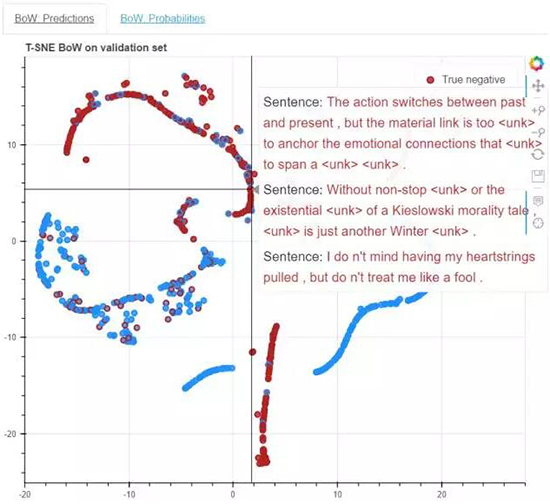
上面两张图是原文中可交互的图示的截图。在原交互图中,你可以将光标移动、缩放和悬停在数据点上来查看这些数据点的信息。设置和词袋的交互图类似,快来探索
LSTM 的内部吧!
我们可以认为其中许多观察也对 LSTM 有效。但是,LSTM 只有相对较少的样本,置信度也相对较低,而且句子中同时出现积极和消极的成分时,对
LSTM 来说的挑战性也要低于对词袋的挑战性。
看起来词袋可以聚类句子,并使用其概率来识别是否有可能给那个聚类中的句子提供一个正确的预测。对于这些观察,可以做出一个合理的假设:置信度更高的答案更正确。
为了研究这个假设,我们可以看看概率阈值(probability thresholds)。
八、概率阈值
人们训练词袋和 LSTM 为每一个类提供概率,以度量确定性。这是什么意思?如果词袋返回一个 1,那么表示它对其预测很自信。通常在预测时我们采用由我们的模型提供且带有最高可能性的类。在这种二元分类的情况下(积极或消极),概率必须超过
0.5(否则我们会预测相反的类)。但是一个被预测类的低概率也许表明该模型存疑。例如,一个模型预测的积极概率为
0.51,消极概率为 0.49,那么说这个结论是积极的就不太可信。当使用「阈值」时,我们是指将预测出的概率与一个值相比较,并评估要不要使用它。例如,我们可以决定使用概率全部超过
0.7 的句子。或者我们也可以看看 0.5-0.55 的区间给预测置信度带来什么影响,而这正是在下图所要精确调查的。
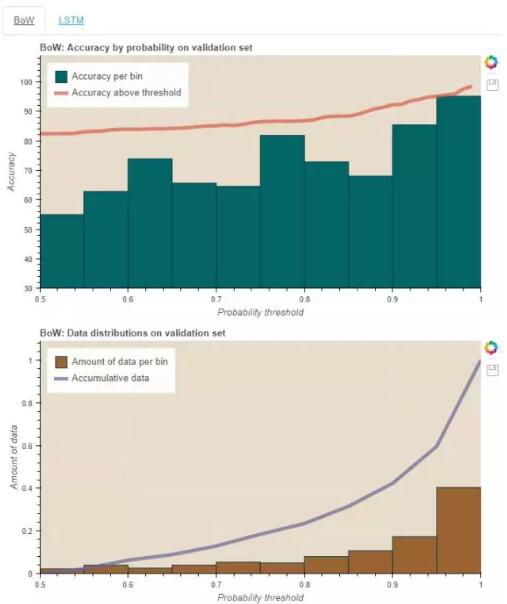
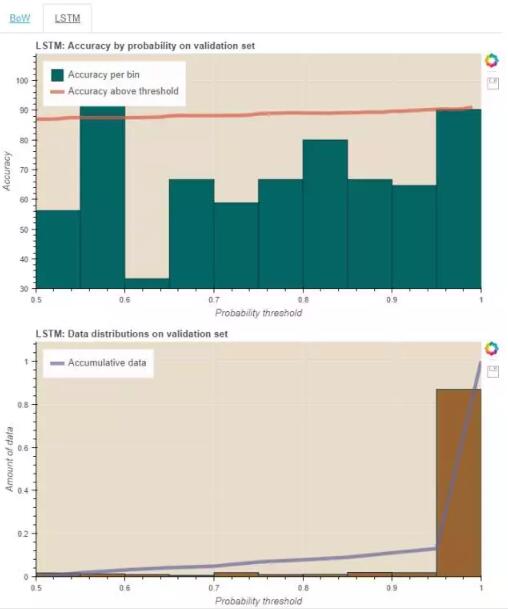
在这张阈值图中,柱的高度对应于两个阈值内的数据点的精确度;线表示当所有的数据点超出给定的阈值时的类似的精确度。在数据数量图中,柱的高度对应于两个阈值内
data reciding 的量,线则是每个阈值仓积累的数据。
从每个词袋图中你也许发现增加概率阈值性能也会随之提升。当 LSTM 过拟合训练集并只提供置信度高的答案时,上述情况在
LSTM 图中并不明显就似乎很正常了。
在容易的样本上使用 BoW,在困难的样本上使用原始 LSTM
因此,简单使用输出概率就能向我们表明什么时候一个句子是容易的,什么时候需要来自更强系统(比如强大的
LSTM)的指导。
我们使用概率阈值创建了一种「概率策略」(probability strategy),从而可为词袋系统的概率设置阈值,并在所有没有达到阈值的数据点上使用
LSTM。这样做为我们提供了用于词袋的那么多的数据(在阈值之上的句子)和一系列数据点,其中我们要么选择
BoW(在阈值之上),要么选择 LSTM(在阈值之下),我们可以用此发现一个精度和计算成本。接着我们会获得
BoW 和 LSTM 之间的一个从 0.0(仅使用 LSTM)到 1.0(仅使用 BoW)的比率,并可借此计算精度和计算时间。
九、基线(Baseline)
为了构建基线(baseline),我们需要考虑两个模型之间的比率。例如词袋(BoW)使用 0.1 的数据就相当于
0.9 倍 LSTM 的准确率和 0.1 倍 BoW 的准确率。其目的是取得没有指导策略(guided
strategy)的基线,从而在句子中使用 BoW 或 LSTM 的选择是随机分配的。然而,使用策略时是有成本的。我们必须首先通过
BoW 模型处理所有的句子,从而确定我们是否该使用 BoW 或 LSTM。在没有句子达到概率阀值(probability
threshold)的情况下,我们可以不需要什么理由运行额外的模型。为了体现这一点,我们从以下方式计算策略成本与比率。
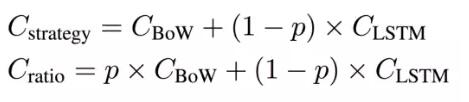
其中 C 代表着成本,p 代表着 BoW 使用数据的比例。
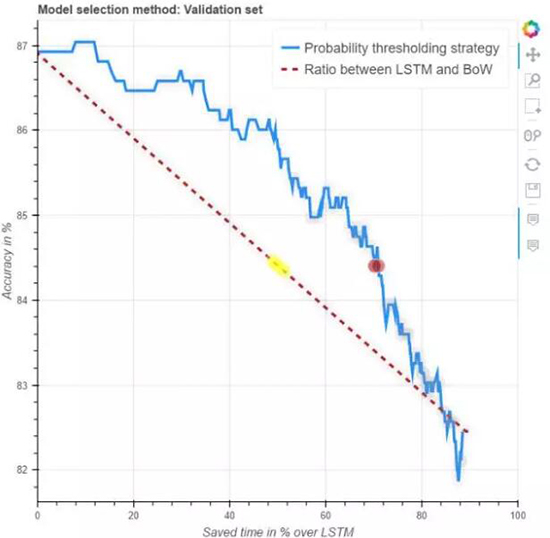
上图是验证集上的结果,其比较了 BoW、LSTM(红线)和概率阀值策略(蓝线)之间不同组合比率的精度和速度,最左侧的数据点对应于只使用
LSTM,最右边的只使用 BoW,中间的对应着使用两者的组合。蓝线代表着没有指导策略的 CBOW 和
LSTM 组合,红线描述了使用 BoW 概率作为策略指导哪个系统使用多大比例。注意最大的时间节省超过了
90%,因为其仅仅只使用了 BoW。有趣的是,我们发现使用 BoW 阀值要显著优于没有使用指导策略(guided
strategy)的情况。
我们随后测量了曲线的均值,我们称之为曲线下速度(Speed Under the Curve /SUC),其就如下表所示。

以上是在验证集中离散地选择使用 BoW 还是 LSTM 的策略结果。每一个模型会在不同 seed 的情况下计算十次。该表格中的结果是
SUC 的均值。概率策略(probability strategy)也会和比率(Ratio)相比较。
十、学习何时跳读何时阅读
知道什么时候在两个不同模型之间转换还不够,因为我们要构建一个更通用的系统,学习在所有不同模型之间转换。这样的系统将帮助我们处理更复杂的行为。
在监督学习中当阅读完胜于跳读时,我们可以学习吗?
LSTM 自左到右地「阅读」我们,每一步都存储一个记忆,而「跳读」则使用 BoW 模型。在来自词袋模型上的概率操作时,我们基于不变量做决策,这个不变量是指当词袋系统遭到质疑时,更强大的
LSTM 工作地更好。但是情况总是如此吗?

当词袋和 LSTM 关于一个句子是正确或错误的时候的「混淆矩阵」(confusion matrix)。相似于来自之前的词袋和
LSTM 之间的混淆 T-SNE 图。
事实上,结果证明这种情况只适用于 12% 的句子,而 6% 的句子中,词袋和 LSTM 都错了。在这种情况下,我们没有理由再运行
LSTM,而只使用词袋以节省时间。
十一、学习跳读,配置
当 BoW 遭受质疑时我们并不总是应该使用 LSTM。当 LSTM 也犯错并且我们要保留珍贵的计算资源时,我们可以使词袋模型理解吗?
让我们再一次看看 T-SNE 图,但是现在再加上 BoW 和 LSTM 之间的混淆矩阵图。我们希望找到混淆矩阵不同元素之间的关系,尤其是当
BoW 错误时。
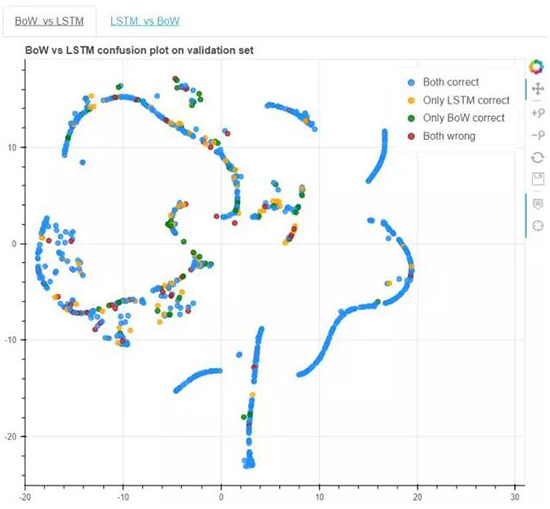
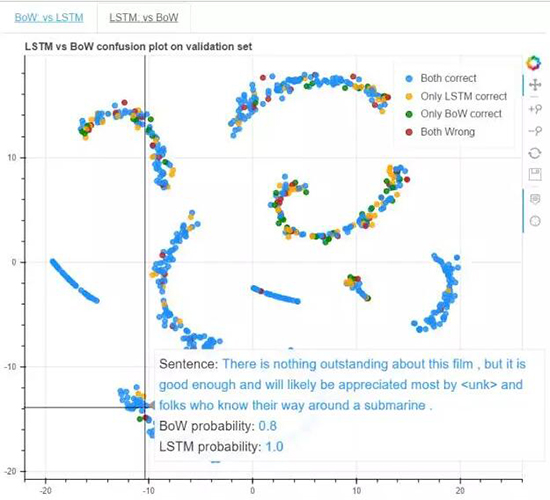
从对比图中,我们发现当 BoW 是正确的,并遭受怀疑时,我们很容易判决出来。然而,当 LSTM 可能是对或错时,BoW
与 LSTM 之间并没有明确的关系。
1. 我们能学习这种关系吗?
另外,因为概率策略依赖于二元决策并要求概率,其是有很大的限制性的。相反,我们提出了一个基于神经网络的可训练决策网络(decision
network)。如果我们查看混淆矩阵(confusion matrix),那么我们就能使用这些信息为监督决策网络生成标签。因此,我们就能在
LSTM 正确且 BoW 错误的情况下使用 LSTM。
为了生成数据集,我们需要一个句子集,其包含了词袋和 LSTM 的真实、潜在的预测。然而在训练 LSTM
的过程中,其经常实现了超过 99% 的训练准确度,并显然对训练集存在过拟合现象。为了避免这一点,我们将训练集分割成模型训练集(80%
的训练数据)和决策训练集(余下 20% 的训练数据),其中决策训练集是模型之前所没有见过的。之后,我们使用余下的
20% 数据微调了模型,并期望决策网络能泛化到这一个新的、没见过的但又十分相关的数据集,并让系统更好一些。
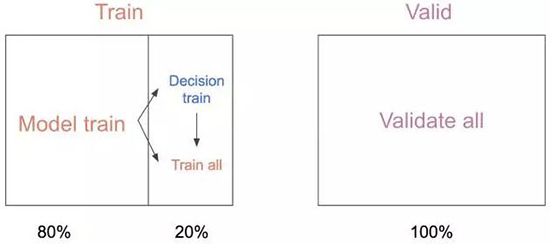
词袋和 LSTM 最初都是在「Model train」上先进行训练(80% 训练数据),随后这些模型被用于生成决策网络的标签,再进行完整数据集的训练。验证集在这段时间一直被使用。
为了构建我们的决策网络,我们进入我们低成本的词袋系统的最后一个隐藏层(用来生成 T-SNE 图的同一层)。我们在模型训练集上的词袋训练之上叠加一个两层
MLP。我们发现,如果我们不遵循这个方法,决策网络将无法了解 BoW 模型的趋势,并且不能很好地进行泛化。
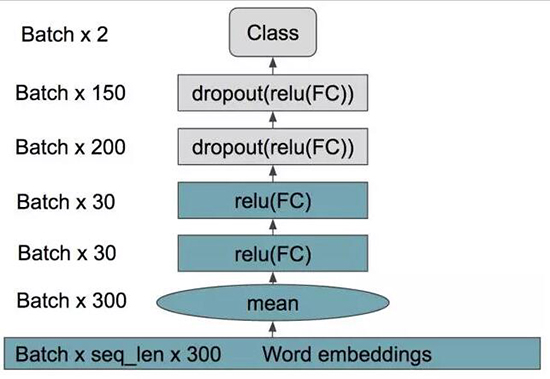
底部的长条状代表词袋系统的层,不包含 dropout。一个双层的 MLP 被加在顶部,一个类用于是否选择词袋或卓越的
LSTM。
由决策网络在验证集上选择的类别(在模型训练集上训练过的模型基础上)接着被应用于完全训练集上训练过但非常相关的模型上。为什么要应用到一个完全训练集训练过的模型上?因为模型训练集上的模型通常较差,因此准确度会比较低。该决策网络是基于在验证集上的
SUC 最大化而利用早停(early stopping)训练的。
2. 决策网络的表现如何?
让我们从观察决策网络的预测开始。
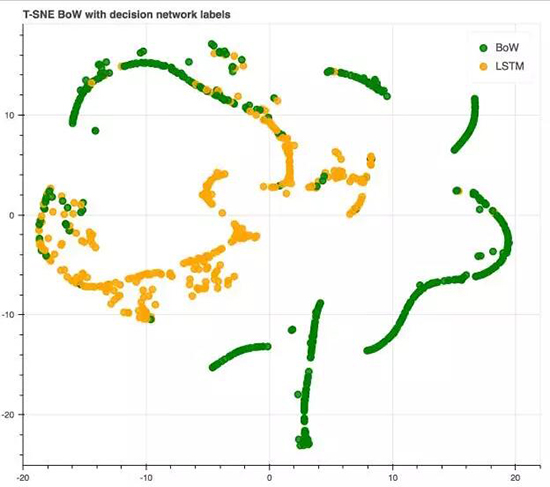
数据点和之前使用词袋模型时的 T-SNE 图相同。绿色点代表使用词袋预测的句子,黄色点代表 LSTM。
注意:这有多近似词袋的概率截止(probability cutoff)。让我们看看决策网络最后一个隐藏层的
T-SNE 是否能够真的聚集一些关于 LSTM 什么时候正确或错误的信息。
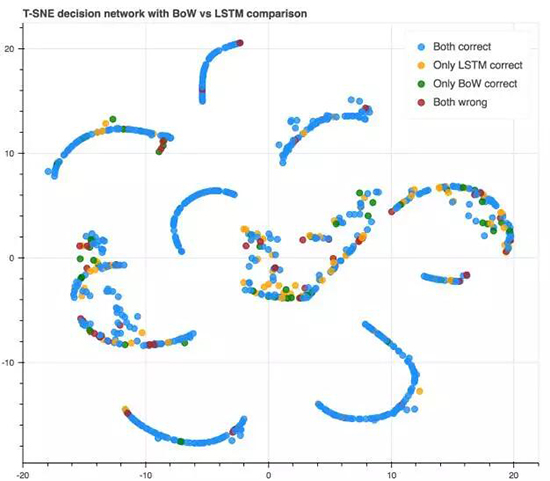
3. 网络如何执行我们的决策?
让我们从决策网络的预测开始。
数据点基于决策网络最后隐藏状态的语句表征,源自验证语句。颜色和之前的比较图相同。
看起来决策网络能够从词袋的隐藏状态中拾取聚类。然而,它似乎不能理解何时 LSTM 可能是错误的(将黄色和红色聚类分开)。
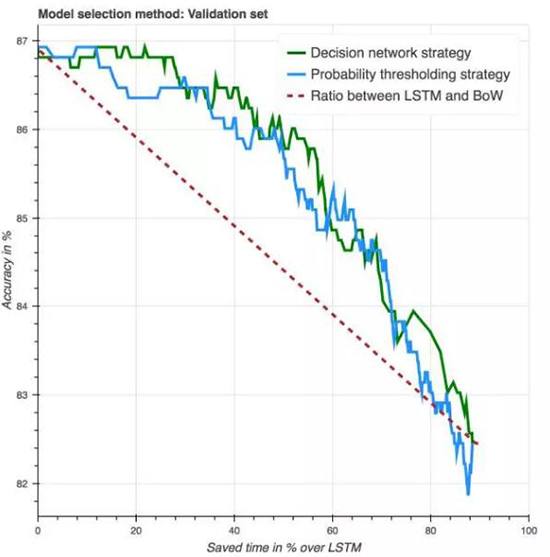
紫色曲线代表在验证集上新引入的决策网络,注意决策网络如何实现接近但略微不同于概率阈值的解决方案。从时间曲线和数据精度来看,决策网络的优势并不明显。
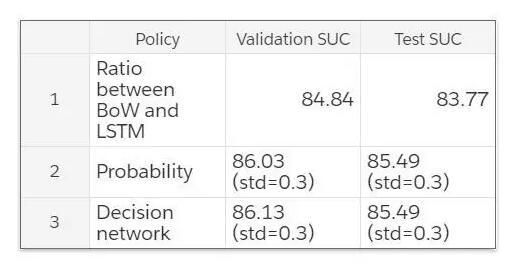
Bow 与 LSTM 在测试集和验证集中的表现。SUC 基于准确率与速度图的平均值。每个模型都用不同种子计算了十次。表中结果来自
SUC 的平均数。标准偏差基于与比率的差异。
从预测图、数据量、准确率和 SUC 分数中,我们可以推断决策网络很善于了解 BoW 何时正确,何时不正确。而且,它允许我们构建一个更通用的系统,挖掘深度学习模型的隐藏状态。然而,它也表明让决策网络了解它无法访问的系统行为是非常困难的,例如更复杂的
LSTM。
十二、讨论
我们现在终于明白了 LSTM 的真正实力,它可以在文本上达到接近人类的水平,同时为了达到这一水平,训练也不需要接近真实世界的数据量。我们可以训练一个词袋模型(bag-of-words
model)用于理解简单的句子,这可以节省大量的计算资源,整个系统的性能损失微乎其微(取决于词袋阈值的大小程度)。
这个方法与平均相关,该平均通常是当类似于带有高置信度的模型将被使用时而执行的。但是,只要有一个可调整置信度的词袋,并且不需要运行
LSTM,我们就可以自行权衡计算时间和准确度的重要性并调整相应参数。我们相信这种方法对于那些寻求在不牺牲性能的前提下节省计算资源的深度学习开发者会非常有帮助。
文章中有一些交互式图示,感兴趣的读者可以浏览原网页查阅。本文作者为 MetaMind 研究科学家 Alexander
Rosenberg Johansen。据介绍,该研究的相关论文将会很快发布到 arXiv 上。
|









