| ЪТЮяЗЩЫйЗЂеЙжЎЪБЃЌЭљЭљашвЊФуЭЃЯТНХВНЃЌЛиЙЫздМКЫљДІЕФЮЛжУЃЌЗёдђФуЛсКмШнвзЯнШыЖдЯИНкЕФаЫЗмжЎжаЁЃЙЙГЩШЫЙЄжЧФмЛљДЁЕФЪ§ОнПЦММе§вдВЛЭЌЕФЗНЪНЯђЧАЗЂеЙЃЌЖјЧвЫйЖШЗЩПьЁЃвђДЫЃЌдкФуИФБфжАвЕжЎЧАЃЌЛђепОіЖЈЪЙгУШЫЙЄжЧФмРЉеЙвЕЮёЪБЃЌШУЮвУЧЪзЯШЖдШЫЙЄжЧФмзівЛИіФёюЋЃЌвдАяжњРэНтЮвУЧЫљДІЕФЮЛжУвдМАЮДРДзпЯђЁЃ

ШЫЙЄжЧФмЕФШ§ИіНзЖЮ
ЮвУЧЧуЯђгкАбШЫЙЄжЧФмПДзіаТЪТЮяЃЌгШЦфЪЧаТММЪѕвдМАКЭЩюЖШбЇЯАЯрЙиЕФаТММЧЩЁЃШЛЖјЃЌШЫЙЄжЧФмвбОЙ§Ъ§ЪЎФъЕФЗЂеЙЃЌЗёШЯЙ§ЭљЕФГЩЙІЫЦКѕВЛКЯТпМЃЌвђЮЊММЪѕзмЪЧВЛЖЯЯђЧАЗЂеЙЁЃ
ЕБЮвЗбСІЯђЦфЫћШЫНтЪЭШЫЙЄжЧФмжЎЪБЃЌЮвВЛЖЯЮЊдЄВтЗжЮібАеввЛаЉЗжНчЯпЃЌетаЉЗжЮіЮвУЧвбОЪЕМљСЫЯрЕБвЛЖЮЪБМфЃЌвВЪЧДѓжкЖдШЫЙЄжЧФмГжгаЕФЙлЕуЁЃзюНќЮвЖСЕНСЫвЛБОУћНаЁЖШЫЙЄжЧФмЕФШ§ДЮРЫГБЃЈThree
Waves of AIЃЉЁЗЕФЪщЃЌзїепЪЧ DARPA аХЯЂДДаТАьЙЋЪвжїЙм John LaunchburyЃЌЫћДгвЛИіИќГЄдЖКЭПэЙуЕФЪгНЧЃЌНЋШЫЙЄжЧФмЕФРњЪЗгыЮДРДЛЎЗжЮЊСЫШ§ИіНзЖЮЃК
1. ЪжЙЄжЊЪЖЃЈHandcrafted KnowledgeЃЉНзЖЮ
2. ЭГМЦбЇЯАЃЈStatistical LearningЃЉНзЖЮ
3. гяОГЫГгІЃЈContextual AdaptationЃЉНзЖЮ
Launchbury ЕФЙлЕуЖдЮвАяжњМЋДѓЁЃОЁЙмНзЖЮЃЈagesЃЉЕФБШгїКмгагУЃЌЕЋЪЧетКмШнвзШУШЫЮѓНтЮЊвЛИіНзЖЮНсЪјСЫЯТвЛИіНзЖЮзїЮЊЬцДњВХПЊЪМЁЃгыДЫЯрЗДЃЌЮвАбШЫЙЄжЧФмПДзївЛИіН№зжЫўЃЌЦфжаЯТвЛНзЖЮЕФЗЂеЙЕьЖЈдкЧАвЛНзЖЮжЎЩЯЁЃетвВЧхЮњЕиБэУїСЫМДЪЙЪЧзюЙХРЯЕФШЫЙЄжЧФмММЪѕвВВЛЛсЙ§ЪБЃЌЧвЪЕМЪЩЯвРШЛдкЪЙгУжЎжаЁЃ
ЖдгкЕкЖўИіНзЖЮЭГМЦбЇЯАЃЈStatistical LearningЃЉЃЌМДЮвУЧФПЧАЫљДІЕФНзЖЮЃЌЮвЗжЮЊСЫвЛаЉИќЯИЕФНзЖЮЃЌвђЮЊЕкЖўИіНзЖЮжЎжагавЛаЉжиДѓЭЛЦЦжЕЕУЕЅЖРзїНтЪЭЁЃ
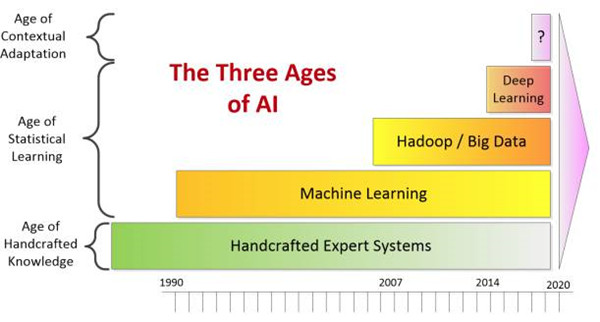
ЕквЛНзЖЮЃКЪжЙЄжЊЪЖ
ЕквЛИіНзЖЮЕФЕфаЭДњБэЪЧЁИзЈМвЯЕЭГЁЙЃЈexpert systemsЃЉЃЌЦфАбДѓСПжЊЪЖзЊЛЏЮЊгЩжааЁЦѓвЕЭХЖгОЋаФжЦЖЈЕФОіВпЪїРДдіЧПШЫРрЕФжЧФмЁЃзЈМвЯЕЭГЕФДњБэР§згЪЧ
TurboTax ЛђепзіЕїЖШЕФЮяСїГЬађЃЌЫќУЧдкЩЯЪРМЭ 80 ФъДњвбОГіЯжЃЌЧвКмгаПЩФмИќдчЁЃ
ОЁЙмЮвУЧгаФмСІдЫгУЛњЦїбЇЯАЭГМЦЫуЗЈжюШчЛиЙщЁЂSVMЁЂЫцЛњЩСжвдМАЩёОЭјТчЃЌЧветаЉЫуЗЈздЩЯЪРМЭ 90
ФъДњвдРДЛёЕУСЫЗЩЫйРЉеЙЃЌЕЋЪжЙЄЯЕЭГЕФгІгУВЂЮДЭъШЋЯћЪЇЁЃзюНќ Launchbury ЬсМАЕНИУЯЕЭГЕФвЛИігІгУГЩЙІЗРгљСЫЭјТчЙЅЛїЁЃДѓдМдк
2004 ФъжЎЧАЃЌЯрЫЦЕФЯЕЭГЪЕМЪЩЯвбОГЩЮЊздЖЏМнЪЛГЕЕФКЫаФЃЈЦфЪЇАмЕФжївЊдвђЪЧВЛФмНтЪЭЫљгаЕФЯжЪЕЮЪЬтЃЉЁЃ
Launchbury ШЯЮЊзЈМвЯЕЭГдкЭЦРэЗНУцБэЯжВЛЫзЃЌЕЋНіЯогкМИИібЯИёЖЈвхЕФЮЪЬтЃЌЧвУЛгабЇЯАФмСІЃЌВЛФмДІРэВЛШЗЖЈадЮЪЬтЁЃ
ЕкЖўНзЖЮЃКЭГМЦбЇЯА
ЕкЖўИіНзЖЮЪЧЮвУЧЯждкЫљДІЕФНзЖЮЁЃОЁЙм Launchbury ЧуЯђгкЙизЂЩюЖШбЇЯАЗНУцЕФНјВНЃЌЪЕМЪЩЯдчдкЮвУЧЪЙгУМЦЫуЛњбАевЪ§ОнжаЕФаХКХжЎЪБОЭвбОВНШыСЫЕкЖўНзЖЮЁЃЭГМЦбЇЯАНзЖЮПЊЪМгкЪ§ЪЎФъжЎЧАЃЌЕЋЪЧдкЩЯЪРМЭ
90 ФъДњЛёЕУСЫЧЃв§СІЃЌВЂЭЈЙ§ДІРэаТЪ§ОнЁЂШнСПЩѕжСЪЧЪ§ОнСїЖјВЛЖЯЛёЕУРЉеЙЁЃ
гЩгкВЛЖЯдіМгЕФЩюЖШбЇЯАММЪѕЙЄОпЯфЃЈБШШчЛиЙщЁЂЩёОЭјТчЁЂЫцЛњЩСжЁЂSVMЁЂGBMЃЉЃЌЭГМЦбЇЯАНзЖЮАщЫцзХДгЪ§ОнжЎжабАеваХКХФмСІЕФБЌеЈаддіГЄгІдЫЖјЩњЁЃ
етЪЧвЛжжВЛЛсЯћЪЇЕФЛљДЁЪ§ОнПЦбЇЪЕМљЃЌЫќПЩвдНтЪЭЯћЗбепЃЈЫћУЧЮЊЪВУДРДЁЂЮЊЪВУДСєЁЂЮЊЪВУДзпЃЉЁЂНЛвзЃЈЪЧЗёДцдкЦлеЉЃЉЁЂзАжУЃЈЫќЪЧЗёгаЮЪЬтЃЉЁЂЪ§ОнСїЃЈ30
ЬьжЎКѓЦфМлжЕЪЧЪВУДЃЉЕФЫљгаааЮЊЮЪЬтЁЃЭГМЦбЇЯЕЖдШЫРржЧФмЕФдіЧПЪЧВЛЖЯЗЂеЙЕФШЫЙЄжЧФмЕФВПЗжжЎвЛЁЃ
дкЕкЖўНзЖЮжЎжаЃЌжСЩйгаСэЭтСНИіжиДѓЭЛЦЦМЋДѓЕиЬсЩ§СЫШЫРрЕФФмСІЁЃЕквЛИіЪЧ Hadoop гыДѓЪ§ОнЁЃЯждкЮвУЧвбОгаСЫДѓЙцФЃВЂааДІРэвдМАДЂДцКЭВщбЏДѓЕФЗЧНсЙЙПьЫйвЦЖЏЪ§ОнМЏЕФЗНЗЈЁЃ2007
Фъ Hadoop ЪзДЮПЊдДЃЌжБЕНЯждкЁЃЕкЖўИіаЁЕФЭЛЦЦЪЧЯжДњШЫЙЄжЧФмЙЄОпМЏЕФаЫЦ№ЃЌЦфгЩвдЯТ 6 жжММЪѕзщГЩЃК
1. здШЛгябдДІРэ
2. ЭМЯёЪЖБ№
3. ЧПЛЏбЇЯА
4. ЮЪД№Лњ
5. ЖдПЙЪНбЕСЗ
6. ЛњЦїШЫ
Г§СЫЩйЪ§Р§ЭтЃЌетаЉММЪѕПЩБЛећКЯЮЊвРРЕгкЩюЖШбЇЯАЕФвЛРрЃЌЕЋЪЧШчЙћФуВщПДЩюЖШбЇЯАЙЄзїЗНЪНвдМАЩюЖШЩёОЭјТчдЫааЗНЪНЕФЯъЧщЃЌФуКмПьЛсвтЪЖЕНетаЉВЂВЛЪЧЮЪЬтЕФКЫаФЁЃ
дкОэЛ§ЩёОЭјТчЁЂбЛЗЩёОЭјТчЁЂЩњГЩЖдПЙЩёОЭјТчЁЂЧПЛЏбЇЯАжЎжаЕФНјЛЏЩёОЭјТчМАЦфЫљгаБфЬхжЎжаЭЈГЃгаКмЩйЃЛЗДЙ§РДдкЮЪД№ЛњЃЈWatsonЃЉЁЂЛњЦїШЫЛђепВЛЪЙгУЩюЖШЩёОЭјТчЕФЧПЛЏбЇЯАБфЬхжЎжаДцдкИќЩйЁЃ
гЩгкетаЉММЪѕЕФЙВЭЌжЎДІЪЧЫќУЧЩњГЩздМКЕФЬиеїЃЌвВаэЮвУЧгІИУГЦжЎЮЊЮоЬиеїНЈФЃЕФНзЖЮЃЈEra of Featureless
ModelingЃЉЁЃФуШдШЛВЛЕУВЛЪЙгУвбжЊЕФБъзЂЪЕР§НјаабЕСЗЃЌЕЋЪЧФуВЛБидкСажаЬюШыдЄЖЈвхЕФБфЬхКЭЪєадЁЃЫќУЧдкМЋЦфДѓЕФМЦЫуеѓСаЩЯвВашвЊДѓЙцФЃВЂааДІРэЃЌКмЖрДЮашвЊзЈвЕаОЦЌЃЈБШШч
GPUЁЂFPGAЃЉвддкШЫРрЪБМфГпЖШЩЯИуЖЈвЛЧаЁЃ
вђДЫЃЌживЊЕФЧјБ№ОЭЪЧЕкЖўНзЖЮЕФШЫЙЄжЧФмПЩвдбгајМИЪЎФъЃЌВЂЧвЦфжївЊДгЛњЦїбЇЯАЁЂДѓЪ§Он/Hadoop КЭЮоЬиеїНЈФЃШ§ИіЗНУцвбОЖдаТММЪѕНјааСЫШ§ДЮДѓЕФБфИяЁЃЕЋетаЉЭЛЦЦШдШЛдкЭГМЦбЇЯАЗНЗЈетвЛНзЖЮФкЃЌИУНзЖЮЛЙЛсМЬајЗЂеЙВЂВњЩњИќЖрЕФЭЛЦЦЁЃ
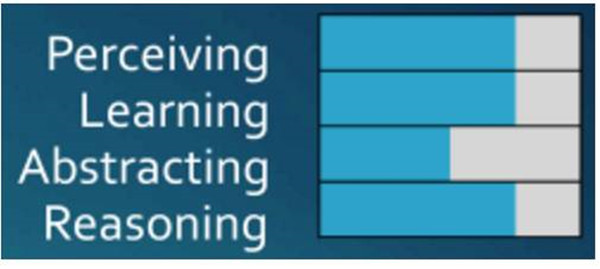
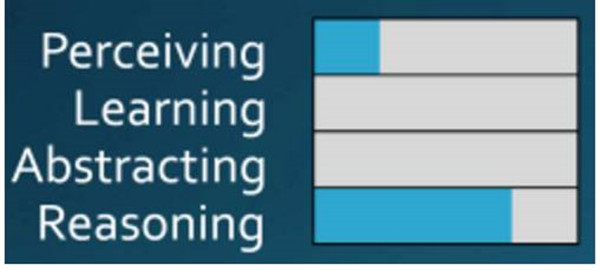
Launchbury БэУїЃЌЕНФПЧАЮЊжЙЃЌЮвУЧвбОгЕгаЗЧГЃЯШНјЁЂЯИЗжКЭЧПДѓдЄВтФмСІЕФЯЕЭГЃЌЕЋЪЧШдШЛЛЙУЛгаРэНтгяОГКЭзюаЁЭЦРэФмСІЁЃвђЮЊЮвУЧЕФММЪѕЖдЪ§ОнгаИќДѓСПЕФашЧѓЃЌетвбОГЩЮЊСЫвЛИіеЯАЃЌЖјЖдЮвУЧШдШЛгаМлжЕКЭИпаЇЕФдЄВтЗжЮіММЪѕВЂВЛгІИУЪЧетбљЕФЁЃЕЋЮвУЧдкетИіНзЖЮдчЦкЮоЗЈНтОіЕФРЇФбЃЌАќРЈздЖЏМнЪЛЦћГЕЁЂЛњЦїгЎЕУШевцИДдггЮЯЗЕФФмСІЁЂЭМЯёЁЂЮФБОКЭздШЛгябдДІРэЕШЗНУцФПЧАЖМвбОШЁЕУСЫжиДѓЕФЭЛЦЦЁЃ
ЕкШ§НзЖЮЃКгяОГЫГгІЃЈcontextual adaptionЃЉ
НгЯТРДФиЃПLauchbury ЫЕЃЌЕБЧАЭГМЦбЇЯАЪБДњГіЯжСЫСНИіЮЪЬтЃЌЕкШ§ИіНзЖЮвЊНтОіСНИіЮЪЬтЁЃ
НтЪЭЭЦРэааЮЊЕФФЃаЭЃКЫфШЛЮвУЧЕФЩюЖШЩёОЭјТчЩЦгкЗжРрЃЌБШШчЭМЦЌЃЌЕЋЪЧДІРэдРэШдШЛЯдЕУЩёУиФЊВтЁЃЮвУЧашвЊМШПЩвдНјааЗжРрвВПЩвдЕУЕННтЪЭЕФЯЕЭГЁЃРэНтЭЦРэОЭФмШУЖдДІРэЙ§ГЬЕФаое§еце§гааЇЁЃ
ЩњГЩФЃаЭЃКетаЉФЃаЭПЩвдДгЧБдкгяОГжаНјаабЇЯАЃЌБШШчвЛИіФЃаЭЃЌеЦЮеСЫУПИізжФИЕФБЪЛЃЌЖјВЛЪЧЛљгкДѓСПдуИтЕФЪщаДбљБОНјааДжБЉЗжРрЁЃЮвУЧНёЬьЪЙгУЕФЩњГЩФЃаЭгаЭћЯджјМѕЩйЖдбЕСЗЪ§ОнЕФашЧѓЁЃ
МјгкетаЉЬиЕуЃЌДІдкетвЛНзЖЮЕФШЫЙЄжЧФмЯЕЭГОЭФмЪЙгУгяОГФЃаЭЃЈcontextual modelsЃЉНјааИажЊЁЂбЇЯАЁЂЭЦРэвдМАГщЯѓЃЌНЋДгвЛИіЯЕЭГжабЇЯАЕНЕФЖЋЮїгІгУЕНвЛИіЭъШЋВЛЭЌЕФгяОГжаЁЃ
ШЋОАЪгвА
аТНзЖЮЕФПЊЪМВЂВЛвтЮЖзХЧАвЛНзЖЮЛсъЉШЛЖјжЙЁЃвЛаЉММЪѕЁЂЙІФмЕФгагУадЛђаэЛсНЕЕЭЃЌЕЋЪЧЭъШЋБЛЬдЬГіОжвВВЛЬЋЯжЪЕЁЃБШШчЃЌзюаТММЪѕЫљашЕФДѓСПМЦЫуСІЁЂбаЗЂЕФИДдгадвдМАбЕСЗЖМЛсжЦдМетаЉММЪѕЭЫГіРњЪЗЮшЬЈЃЌНЋРДФГИіЪБКђГіЯжЕФИпМлжЕЕФЮЪЬтПЩФмЛЙЛсгУЕНетаЉММЪѕЁЃ
ЦфЫћЧщПіЃЌБШШчгяОГВЩгУНзЖЮЃЌЮвУЧПЩФмВЛЕУВЛЕШД§аТвЛДњаОЦЌЕФГіЯжЃЌетРраОЦЌИќМгРрЫЦШЫФдЁЃетаЉБЛГЦЮЊЩёОаЮЬЌЛђепТіГхЩёОЭјТчЕФЕкШ§ДњЩёОЭјТчЖМЛсгУЕНЯждкбаЗЂзюдчНзЖЮЕФФЧаЉаОЦЌЁЃ
ЯждкЃЌЮвУЧДІдкЕкЖўНзЖЮЃЈЭГМЦбЇЯАЃЉЕФЪВУДЮЛжУЃП
ЕБЧАНзЖЮЕФШ§еТФкШнжаЃЌШЫУЧПЩФмзюЙизЂЕФЪЧаТЖЋЮїЃЌЩюЖШбЇЯАЁЂЧПЛЏбЇЯАвдМАЩЯЪіЙЙГЩИУНзЖЮЕФСљжжММЪѕжЎМфЕФЦНКтЁЃ
етЪЧвЛГЁбнЛЏЕФМшФбЙ§ГЬЃЌИеПЊЪМНсГіЙћЪЕЃЌЕЋетаЉаТЕФЗЂеЙжаОјДѓВПЗжШдШЛУЛгазМБИКУПЊЛЈНсЙћЁЃОЁЙмПЩвдПДЕНетаЉММЪѕЛсЭљФФИіЗНЯђЗЂеЙЃЌЕЋЪЧЃЌжЛгаСНЕНШ§ИіММЪѕгаЭћПЩППЩЬвЕЛЏЃЈЭМЯёДІРэЁЂЮФБОКЭгявєДІРэЃЌРрЫЦ
Watson QAMs ЕФгаЯоАцБОЁЃЃЉ
ЕБФуЪдзХНЋетаЉММЪѕХЁдквЛЦ№ЪБЃЌетаЉММЪѕвВВЛЙ§ЪЧЫЩЩЂЕидквЛЦ№ЃЌМЏГЩетаЉММЪѕШдШЛЪЧзюОпЬєеНадЕФЪТЧщжЎвЛЁЃЮвУЧзмЛсЯыЕНАьЗЈЕФЃЌжЛЪЧЛЙУЛЕНетвЛВНЁЃ
ЮвУЧзмЛсзпЕНФЧвЛВНЕФЃЌЩѕжСНјШыЕкШ§НзЖЮЁЃВЛЙ§ЃЌзпЙ§етвЛНзЖЮжЎЧАЃЌЛђаэЛЙЛсГіЯжЮвУЧЮДдјдЄСЯЕФбнЛЏЛђепБфИяЁЃ
|









