| вђЮЊ
AlphaGo ЕФГіЯжЃЌЙ§ШЅЕФ 2016 ФъПЩЮНЪЧШЫЙЄжЧФмдЊФъЁЃМЧЕУЕБЪБЮвУЧе§дкЫежнЗтБебаЗЂThe
PlatformЃЌЙЄзїжЎгрЬжТлЕНШЫЛњЖдеНЕФеце§втвхЃЌВЂВЛдкгкММЪѕЩЯЕФЭЛЦЦЃЌЖјдкгкЖдШЫУЧЙЬгажЊЪЖЕФгАЯьЃЌШЫЙЄжЧФмЕФгІгУЛсШчгъКѓДКЫёАуЕЎЩњЃЌвдКѓУЛгаШЫЙЄжЧФмЕФШэМўвдКѓФуЖМВЛКУвтЫМПЊПкСЫЁЃДѓМвЖМдкЮЪЃЌздМКЕФЙЄзїгыШЫЙЄжЧФмгаЪВУДЙиЯЕЃЌШчКЮдкздМКЕФЙЄзїжагІгУШЫЙЄжЧФмЃЌШчКЮдкШэМўжажВШыШЫЙЄжЧФмЕФЛљвђЃЌЪЙгУШЫЙЄжЧФмгІИУДгКЮДІШыЪжЃЌбЇЯАШЫЙЄжЧФмгІИУДгФФРяПЊЪМЃЌИќЩюВуДЮЕФЮЪЬтЪЧШЫЙЄжЧФмФмЗёДњЬцШЫРрЃЌзїЮЊвЛИіГЬађдБЃЌШЫЙЄжЧФмЪЧЗёЛсДњЬцШЫРраДГЬађЁЄЁЄЁЄетРяИљОнЮвУЧЭХЖгЕФЪЕМљНщЩмвЛЯТШчКЮдкШэМўжагІгУШЫЙЄжЧФмЁЃ
ШЫЙЄжЧФмЃЈAIЃЉЕФФПБъЪЧдіЧПжЧФмЃЈIAЃЉЃЌЖјВЛЪЧЬцДњШЫРр
ШЫЙЄжЧФмВЂВЛЪЧвЛИіаТИХФюЃЌ40ФъДњЮЌФЩЕФЁЖПижЦТлЁЊЁЊЙигкдкЖЏЮяКЭЛњЦїжаПижЦКЭЭЈбЖЕФПЦбЇЁЗОЭЪЧШЫЙЄжЧФмЁЃЕЋдчФъЕФШЫЙЄжЧФмЪмЯогкМЦЫуФмСІЃЌИќЖрдкНтОіФЃаЭЕФМЦЫуЫйЖШКЭОЋЖШЩЯДцдкзХжюЖрЮЪЬтЁЃНќФъРДЫцзХдЦМЦЫуММЪѕЕФЗЂеЙЃЌМЦЫуЛњЕФМЦЫуФмСІЬсИпСЫЃЌЭЌЪБЫцзХДѓЪ§ОнЕФЗЂеЙЃЌИќИДдгЕФМЦЫуЮЪЬтПЩвдгУИќЖрЕФЪ§ОнНјаааое§ЃЌШЫЙЄжЧФмЕФПЩгУадДѓДѓЬсИпЁЃЕЋЪЧЮвУЧДгФПЧАШЫЙЄжЧФмгІгУЕФЧщПіПЩвдПДЕНЃЌШЫЙЄжЧФмВЂВЛФмЬцДњШЫРрЃЌР§ШчдкЭМЯёЪЖБ№ЁЂгявєЪЖБ№ЕШЗНУцЕФЭЛЦЦЃЌНіНіЪЧШУЛњЦїИќМгДЯУїЖјвбЃЌЛЙдЖдЖУЛгаДяЕНШЫРрЕФГЬЖШЃЌзїЮЊШЫРрЕФжЧФмжњЪжИќМгКЯЪЪЁЃ
РэЧхШЫЙЄжЧФмЁЂЛњЦїбЇЯАЁЂЩюЖШбЇЯАЁЂЭГМЦЕШЛљБОИХФюжЎМфЕФЙиЯЕ
АбШЫЙЄжЧФмЕФЗНЗЈгІгУЕНШэМўжаЃЌЮвУЧЯШЪсРэЧхГўМИИіИХФюжЎМфЕФЙиЯЕЃК
ШЫЙЄжЧФмЃЈArtificial IntelligenceЃЉЪЧвЛИіДѓЕФИХФюЃЌЪЧШУЛњЦїЯёШЫвЛбљЫМПМЩѕжСГЌдНШЫРрЃЛ ЛњЦїбЇЯАЃЈMechine LearningЃЉЪЧЪЕЯжШЫЙЄжЧФмЕФвЛжжЗНЗЈЃЌЛњЦїбЇЯАзюЛљБОЕФзіЗЈЃЌЪЧЪЙгУЫуЗЈРДНтЮіЪ§ОнЁЂДгжабЇЯАЃЌШЛКѓЖдецЪЕЪРНчжаЕФЪТМўзіГіОіВпКЭдЄВтЃЛ ЩюЖШбЇЯАЃЈDeep learningЃЉгжЪЧЛњЦїбЇЯАЕФвЛжжЪЕЯжЗНЪНЃЌЫћЪЧФЃФтШЫЩёОЭјТчЕФЗНЪНЃЌгУИќЖрЕФВуЪ§ЃЌИќЖрЕФЩёОдЊЃЌШЛКѓИјЯЕЭГЪфШыКЃСПЕФЪ§ОнЃЌРДбЕСЗЭјТчЃЛ
ЭГМЦбЇЪЧЛњЦїбЇЯАКЭЩёОЭјТчЕФвЛжжЛљДЁжЊЪЖЃЌДгДЋЭГЗжЙЄРДПДЃЌЭГМЦбЇвЛАуЪЧЪ§бЇЁЂЭГМЦЕШзЈвЕбаОПЕФЗНЯђЃЌЖјЛњЦїбЇЯАЪЧМЦЫуЛњПЦбЇЕФбаОПЗНЯђЃЌЕЋЪЧФПЧАДѓМвЕФбаОПГЩЙћдНРДдНЪтЭОЭЌЙщЃЌгаЭГМЦбЇЕФДѓЪІОЭШЯЮЊЭГМЦЪЕМЪЩЯвЛжБдкДгЪТЛњЦїбЇЯАЕФЙЄзїЁЃ

ЖдгкЩюЖШбЇЯАЁЂЭГМЦЕФзЈМвРДЫЕЃЌЫћУЧИќМгЙизЂгкФЃаЭЁЂЫуЗЈЕШЕШЃЌевЕНПЩвдЦеЪЪадНтОіЮЪЬтЕФАьЗЈЁЃЖјЖдгкЮвУЧгІгУРДЫЕЃЌОпЬхЕФЫуЗЈЪЕЯжВЛашвЊЮвУЧПМТЧЬЋЖрЃЌЖјЪЧевЕНЪЪКЯЕФГЁОАЁЂКЯЪЪЕФФЃаЭЁЂЦЅХфЕФЫуЗЈЃЌЫљвдгІгУШЫЙЄжЧФмЪЕМЪЩЯЪЧвЛИіМЦЫуЛњЁЂЭГМЦЁЂжЊЪЖЙЄГЬЁЂаавЕжЊЪЖЕФвЛИіНЛВцгІгУЁЃдкОГЃЩцМАЕНЕФгІгУжаЃЌЮввЛАудкДІРэНсЙЙЛЏЁЂАыНсЙЙЛЏЪ§ОнЪБгХЯШПМТЧДЋЭГЭГМЦбЇЕФЗНЗЈЃЌР§ШчЗжРрЁЂЪ§ОнЯрЙиадЁЂЛиЙщЕШЃЌЖјДІРэЗЧНсЙЙЛЏЪ§ОнЪБЃЈР§ШчЭМЯёЁЂЪгЦЕЁЂЮФБОЃЉгХЯШПМТЧЩюЖШбЇЯАЕФЗНЗЈЃЌЕЋетаЉЗНЗЈвВашвЊгаЭГМЦбЇжЊЪЖЁЃЫљвдЃЌашвЊВЙПЮЃКЯпадДњЪ§ЁЂЪ§РэЭГМЦЁЂPythonЃЌЮвОѕЕУЁЖЛњЦїбЇЯАЪЕеНЁЗетЪщШыУХВЛДэЃЌЩЯЪіМИЗНУцжЊЪЖЖМНщЩмСЫЁЃ
гІгУШЫЙЄжЧФмЪЕЯждіЧПжЧФмЕФШ§ИіВуУц
гІгУШЫЙЄжЧФмЕФЪБКђЃЌШЫУЧЛсгавЛИіЮѓЧјЃЌзмЪЧЯЃЭћЕУЕНвЛИівтЯыВЛЕНЕФНсЙћЃЌвВОЭЪЧЯЃЭћЬНЫїГіаТжЊЪЖЁЃОГЃгаШЫЮЪЮвЃЌЕУЕНЕФНсЙћКУЯёУЛгаЪВУДЮвВЛжЊЕРЕФЃЌЮвЫЕетОЭЖдСЫЃЌвђЮЊФуЪЧзЈМвЃЌвЊЪЧМЦЫуЛњЕУЕНЕФНсЙћЖМЪЧВЛПЩжЊЕФЃЌФудѕУДФмЯраХЫћЃПР§ШчAlphaGoЯТЕФЦхЃЌОјДѓЖрЪ§ЖМЪЧШЫРрвбжЊЕФЃЌЗЧГЃЩйЗЧГЃЩйЕФЧщПіЯТЃЌЯТГівЛеаСэРрЃЌетвбОЪЧвЛИіЖЅЬьаЧЕФЫЎЦНСЫЁЃКмЖрШЫЪЇЭћСЫЃЌетЛЙгаЩЖвтЫМЃЌЦфЪЕвтвхКмДѓЃК
ЃЈ1ЃЉМЦЫуЛњПЩвдШУГЃШЫПьЫйЛёЕУвдЭљзЈМвВХФмОпБИЕФжЊЪЖ
Р§ШчгаОбщЕФПЭЛЇОРэЃЌПЯЖЈЗЧГЃСЫНтПЭЛЇЕФЧщПіЃЌЫЪЧгХжЪПЭЛЇЃЌЫашвЊЪВУДВњЦЗЕШЕШЃЌВЛашвЊМЦЫуЛњЁЃЕЋЪЧЭЈЙ§гУЛЇЛЯёЕШШЫЙЄжЧФмЕФЪжЖЮЃЌМЦЫуЛњПЩвдШУОбщВЛЙЛЗсИЛЕФШЫЃЌвВОпБИСЫЩЯЪіОбщЃЌетИізіЗЈМлжЕОЭЗЧГЃИпЃЌБЯОЙзЈМвЪЧЩйЕФЃЛ
ЃЈ2ЃЉАяжњзЈМвМѕЩйжиИДадЕФЙЄзї
Р§ШчвНЩњдкзіВЁРэМьВтЪБЃЌОјДѓЖрЪ§УЛгаЩњВЁЕФЧщПіКЭгаЕфаЭВЁРэЬиеїЕФЧщПіЃЌЛњЦїЖМПЩвдЬсабвНЩњЃЌНкдМвНЩњЕФБІЙѓЪБМфЁЃШчДЫПДРДЃЌЮвУЧОЭЛсРэНтЃЌШЫЙЄжЧФмВЛЪЧЬцДњШЫЃЌЖјЪЧИјШЫРрдіМгвЛИіжЧФмЕФжњЪжЃЌЪЧдіЧПжЧФмЃЈIA
Intelligence AugmentationЃЉЁЃ МЦЫуЛњзїЮЊвЛИіжЧФмжњЪжЃЌПЩвддкВЛЭЌВуУцКЭЪжЖЮАяжњЮвУЧЃЌЮвАбЫћЗжЮЊЛњаЕжЧФмЁЂЪЕЯжвтЭМЕФжЧФмКЭДДдьвтЭМЕФжЧФмШ§ИіЗНУцЃК
ЃЈ1ЃЉЛњаЕжЧФм
ЮвУЧФПЧАДгЪТЕФжївЊЙЄзїЖМЪЧетИіЃЌЪТЯШЩшЖЈЙцдђЃЈДњТывВЪЧЙцдђЃЉЃЌШУМЦЫуЛњЭъГЩДѓСПжиИДМЦЫуЃЌГфЗжРћгУМЦЫуЛњЕФМЦЫуФмСІЃЌЬцДњШЫЕФЪжЙЄРЭЖЏЃЌетЪЧвЛИівдЙцдђЮЊКЫаФЕФФЃЪНЃЌЖјетаЉЙцдђРДздгкШЫЯжгаЕФжЊЪЖЃЛ
ЃЈ2ЃЉЪЕЯжвтЭМжЧФм
ШЫжЊЕРзюжеНсЙћЪЧЪВУДЃЌЕЋЪЧВЂВЛИцЫпМЦЫуЛњВЩгУЪВУДбљЕФЙцдђМЦЫуЃЌЭЈЙ§ДѓСПЪ§ОнбЕСЗМЦЫуЛњевЕНЙцдђЃЌШЛКѓдйШУМЦЫуЛњЭъГЩДѓСПжиИДМЦЫуЃЌМЦЫуЛњОПОЙевЕНЕФЙцдђЪЧЪВУДЃЌгаПЩФмШЫВЂВЛвЛЖЈФмРэНтЃЌЦфЪЕЭљЭљвВВЛашвЊРэНтЃЌАбМЦЫуЛњЕБГЩСЫКкКаЃЛ
ЃЈ3ЃЉДДдьвтЭМжЧФм
вВОЭЪЧШУМЦЫуЛњздМКевЕНШЫВЂВЛжЊЕРЕФаТжЊЪЖЃЌетвВЪЧЮвУЧзюЯђЭљЕФГЁОАЁЃ ДгОпЬхЕФЪЕЯжВуУцПДЃЌЕквЛжжЧщПіЮовЩЪЧзюЖрЕФЃЌЮвУЧашвЊЬсСЖзмНсЙцдђЃЌгУКУЕквЛжжЧщПіКмживЊЃЛЕкЖўжжЧщПівдЧАЯрЖдЩйвЛаЉЃЌЕЋЧЁЧЁЪЧФПЧАашвЊИФНјЕФЃЌдкЕкЖўжжЧщПіЯТЮвУЧЭљЭљгХЯШгУЭГМЦбЇЕФЗНЗЈДІРэНсЙЙЛЏЁЂАыНсЙЙЛЏЪ§ОнЃЈР§ШчИёЪНЛЏШежОЃЉЃЌгУЩюЖШбЇЯАЕФЗНЗЈДІРэЗЧНсЙЙЛЏЪ§ОнЃЌетОЭашвЊШУЮвУЧЕФЭХЖгОпБИШЫЙЄжЧФмЕФЫМЮЌЁЃ
ЪЕМљШЫЙЄжЧФмгІгУашвЊаТЫМЮЌЃЌВЛФмдйгУЙцдђРэНтМЦЫуЛњЪЕЯжжЧФмЕФЗНЪН
ЪЕМљШЫЙЄжЧФмЃЌашвЊдкдкЫМЮЌЩЯНјааЕїећЁЃЮвУЧЭљЭљЯАЙпгкгУжЦЖЈЙцдђЕФЗНЪНжИЛгМЦЫуЛњЃЌЪфШыМЦЫуЙцдђКЭЪфГіНсЙћЖМЪЧвбжЊЕФЃЌвВОЭЪЧЮвЩЯУцЫЕЕФЛњаЕжЧФмЗНЪНЁЃЕЋКѓСНжжФЃЪНОЭВЛЪЧЙцдђЗНЪНСЫЃЌвђЮЊЙцдђЪЧМЦЫуЛњевЕНЕФЃЌетвВОЭЪЧОГЃЫЕЕФЪ§ОнбЕСЗЁЃ етРяЮвОйвЛИіЮвУЧздМКЪЕЯжЕФР§згЃЌШУДѓМвРэНтвЛЯТЪВУДЪЧФЃаЭЁЂЫуЗЈКЭЪ§ОнбЕСЗЁЃ ЯШЫЕвЛИіБГОАЃЌЮвУЧдкЪсРэЯжгаЦѓвЕЪ§ОнМмЙЙЕФЪБКђЃЌашвЊНЈСЂЪ§ОнМфЕФЙиСЊЃЌгУШЫНјааЪсРэЗбЙЄЗбСІЃЌЮвУЧОЭДђЫугУМЦЫуЛњздЖЏЭъГЩвЛВПЗжЃЌШЛКѓШЫЙЄаое§ЃЌетОЭЪЧвЛИідіЧПжЧФмЃЈIAЃЉЕФР§згЁЃетРяУцОЭгавЛИіЧщПіЃЌШчЙћЪ§ОнПтжаУЛгаНЈСЂЭтМќЃЌШчКЮАбетжжЪЕМЪЕФЭтМќЙиЯЕевГіРДЃЌЮвУЧОЭгУетИіР§згНтЪЭвЛЯТЛњаЕжЧФмКЭЪЕЯжвтЭМжЧФмЕФЗНЗЈЃК
ЃЈ1ЃЉгУЙцдђЕФЗНЪНВщевЭтМќЙиЯЕ
ЪзЯШвЊЖЈвхЙцдђЃЌЭтМќЙиСЊЕФЙцдђАќРЈзжЖЮРраЭвЛжТЁЂГЄЖШвЛжТЁЂАќКЌЯрЭЌЪ§ОнЕШЕШЃЌШЛКѓдкЫљгаЪ§ОнжаБщРњЃЌНјааЦЅХфЁЃетжжЗНЪНашвЊгаЭъећЕФЪ§ОнЃЌЖјЧвЪЧЗёЮЊЭтМќЙиЯЕЕФХаЖЯЙцдђЭљЭљгааЉФЃК§ЃЌдкУЛгаЕУЕНШЋСПЪ§ОнЪБгавЛЖЈОжЯоадЃЛ
ЃЈ2ЃЉгУЭГМЦбЇЗНЗЈВщевЭтМќЙиЯЕ
ЪзЯШЃЌЮвУЧЖЈвхГізжЖЮЕФЬиеїЃЈРрЫЦгУЛЇЛЯёЃЉЃЌзжЖЮЬиеїЪЧвЛИіЯђСПЃЌОЭЪЧвЛИівЛЮЌЪ§зщЃЌАќРЈБэУћЁЂзжЖЮУћЁЂзжЖЮРраЭЁЂзЂЪЭЁЂбљР§Ъ§ОнзюДѓГЄЖШЁЂбљР§Ъ§ОнзюаЁГЄЖШЕШЕШЃЌгЩгкБэУћЁЂзжЖЮУћВЛЪЧЪ§жЕЃЌЮвУЧвЊАбЫћУЧБфГЩЪ§жЕЃЌПЩвдКЭЭЌвЛИіБъзМзжЗћДЎзїБШНЯЃЌвВОЭЪЧЭЈЙ§вЦЮЛЕФЗНЪНАбзжЗћДЎвЦЖЏГЩБъзМзжЗћДЎЃЌвЦЖЏДЮЪ§дНЩйЃЌЯрЫЦЖШОЭдНИпЃЌетбљОЭЕУЕНСЫвЛИіеце§ЕФвЛЮЌЪ§зщЃЈЯђСПЃЉСЫЁЃ ЦфДЮЃЌЮвУЧФУГівЛВПЗжвбжЊЙиЯЕЕФБэКЭзжЖЮЃЌзїЮЊбЕСЗбљБОЃЌж№вЛМЦЫуСНИізжЖЮжЎМфЕФЯрЙиЯЕЪ§ЃЈЯрЙиЯЕЪ§ЕФМЦЫуЗНЗЈЪЧЯжГЩЕФЃЌЮветРяОЭВЛНщЩмСЫЃЌвЛЩЯЙЋЪНЮвОЭдЮЃЌPythonЕФЗЂааАцAnacondaРяУцОЭгаЃЌгУСЫетИіОЭЬхЛсЕН
Python ЪЧзюКУЕФгябдСЫЃЉЃЌЯрЙиЯЕЪ§ИпЕФЫЕУїЬиеїРрЫЦЃЌШЯЖЈЮЊЭтМќЙиЯЕЁЃетЪБКђШЫЙЄХаЖЯвЛЯТЃЌШчЙћНсЙћВЛДэЃЌФЧетИіФЃаЭОЭЪЧе§ШЗЕФЃЌШчЙћНсЙћВЛКУОЭЛЛвЛжжЯрЙиЯЕЪ§МЦЫуЗНЗЈЃЌЛђепИФБфЪ§ОнЬиеїЃЌЛђепЖдЪ§ОнЬиеїНјааМгЙЄЃЌзмжЎЃЌЭтМќЬиеїзїЮЊвЛИіПЭЙлДцдкЃЌвЛЖЈФмЙЛевЕНЗћКЯЕФЬиеїЃЌетОЭЪЧЪ§ОнбЕСЗЁЃЭЈЙ§Ъ§ОнбЕСЗЃЌевЕНКЯЪЪЕФзжЖЮЬиеїЃЈФЃаЭЃЉКЭМЦЫуЗНЗЈЃЈЫуЗЈЃЉЃЌвВПЩвдНЛИјМЦЫуЛњзіДІРэСЫЃЌАбЫљгаЕФЭтМќевГіРДЁЃ ФуПДЃЌетРяУЛгаЖЈвхЙцдђЃЌДІРэЗНЗЈЪЧЭЈЙ§Ъ§ОнбЕСЗЕФЗНЪНЃЌШУМЦЫуЛњздМКевГіРДЕФЃЌЮвВЛашвЊжЊЕРЯрЙиЯЕЪ§етЭцвтЕНЕзЪЧЪВУДвтЫМЃЌетОЭЪЧЩЯУцЫЕЕФЃЌМЦЫуЛњЪЧвЛИіКкКаЁЃ ашвЊЫЕУїЕФЪТЃЌдкЩЯЪіР§згжаЃЌЮвМђЛЏСЫВЛЩйЖЏзїЃЌЪЕМЪЩЯзюПЊЪМЛЙевГіРДКмЖрВЛЪЧЭтМќЙиЯЕЕФзжЖЮЃЌР§Шч createTimeЃЌЮвУЧЛЙвЊАбетжждывєзжЖЮЕФЬиеїбЕСЗГіРДЃЌЬоГ§дывєЁЃ етИіЪОР§ЫЕУїСЫгІгУШЫЙЄжЧФмЪБВЛЭЌЕФСНжжЫМЮЌФЃЪНЃЌМђЕЅЕФЫЕВЛФмдйгУДДдьЙцдђЕФЗНЪНжИЛгМЦЫуЛњЃЌЖјЪЧбЕСЗМЦЫуЛњздМКевГіЙцТЩЁЃ ЩЯУцЮвУЧЗжЮіСЫШЫЙЄжЧФмЯргІЕФЛљБОИХФюЃЌШЫЙЄжЧФмЕФМИжжФЃЪНвдМАгІгУШЫЙЄжЧФмЪБашвЊЕФЫМЮЌЭЛЦЦЃЌЯТУцЮвУЧДгШэМўМмЙЙЗЂеЙКЭУцСйЕФЬєеНЃЌПДПДгІгУШЫЙЄжЧФмЪБЕФЧаШыЕудкФФРяЃЌФФРяИќШнвзБЌЗЂГіШЫЙЄжЧФмЕФЛ№ЛЈЁЃ
гІЖдШэМўМмЙЙЗжЖјжЮжЎДјРДМЏГЩЕФЬєеНЃЌЬНЫїжЧФмЕФСЌНг
ЪВУДЪЧШэМўМмЙЙЃЌдкInfoQГіАцЕФЁЖСФСФМмЙЙЁЗжаНВЕФКмЧхГўЃЈИааЛРЯЭѕЃЌзмНсЗЧГЃЕНЮЛЃЉЃЌШэМўМмЙЙОЭЪЧ ЃЈ1ЃЉИљОнЮЪЬтШЗЖЈЯЕЭГБпНчЃЛ ЃЈ2ЃЉАДвЛЖЈддђНјааЧаЗжЃЛ ЃЈ3ЃЉНЈСЂВЛЭЌФЃПщМфЕФЙЕЭЈЛњжЦЃЛ ЃЈ4ЃЉећЬхадНЛИЖШэМўЙІФмЁЃ ПЩМћЃЌМмЙЙЕФЙиМќЪЧЗжЖјжЮжЎЕФембЇЃЌЕЋЧаЗжЪЧЮЊСЫШэМўбаЗЂЁЂдЫЮЌЗНБуЃЌШэМўЕФФПБъЪЧећЬхНЛИЖЃЌЗжгыКЯДцдкетУЌЖмЃЌетвЛУЌЖмЪЧгЩМЏГЩНтОіЕФЃЌЕЋЪЧМЏГЩЭљЭљЪЧИДдгЕФЃЌДѓМвдкМмЙЙЗНУцЕФЗжЯэЃЌвВвдШчКЮЧаЗжОгЖрЃЌШчКЮМЏГЩЯрЖдНЯЩйЁЃ
МЏГЩЙЄзїЕФИДдгЖШгАЯьСЫИДдгЖШЯЕЭГЕФбаЗЂ
UnixЕФЪЕМљЮовЩЖдШэМўМмЙЙгазХОоДѓЕФгАЯьЃЌзівЛИіЪТЧщЃЌзіЕНзюКУЃЌвЛжБЪЧ Unix ЗчИёЫљГЋЕМЕФЃЌЕЋЁАдкРэЯыЪРНчжаЃЌUnixГЬађдБжЛдИвтЪжЙЄДђдьаЁЧЩЭъУРЕФШэМўБІЪЏЃЌУПИіЖМФЧУДаЁЧЩЁЂФЧУДгХбХЁЂФЧУДЭъУРЁЃШЛЖјЯдЪОжаКмВЛавЕФЪЧЃЌЬЋЖрИДдгЮЪЬташвЊИДдгЕФНтОіЗНАИЁЃНіНіЪЎааЕФГЬађЃЌдйгХбХвВЮоЗЈПижЦХчЦјЪНПЭЛњЁЃФЧЖљгаЬЋЖрЕФзАБИЁЂЬЋЖрЕФЭЈТЗКЭНчУцЃЌЬЋЖрВЛЭЌЕФДІРэЛњЃЌЬЋЖрВЛЭЌВйзїШЫдБЖЈвхЕФзгЯЕЭГЃЌЫћУЧЩѕжССЌЛљБОЕФдМЖЈЖМЮоЗЈЭГвЛЁЃМДЪЙФмЙЛГЩЙІЕиНЋКНПеЯЕЭГЫљгаЕФИіЬхШэМўВПЗжзіЕФгХбХЃЌЕЋЦДзАНсЙћКмПЩФмЪЧвЛЖбХгДѓЁЂИДдгЁЂдуИтЕФДњТыЁЄЁЄЁЄХчЦјПЭЛњЕФИДдгЪЧБиШЛЕФЁЃ Й§ШЅгаИіМтШёЕФЙлЕуЃЌВЛФмЮЊМђЕЅадЖјЮўЩќЙІФмЃЌвђЮЊЗЩЛњБиаывЊФмЗЩЁЃе§ЪЧетИіЪТЪЕЃЌКНПеПижЦЯЕЭГВЂВЛЛсВњЩњЙигкИДдгЖШЕФЪЅеН----UnixГЬађдБЭљЭљОДЖјдЖжЎЃЈеЊздЁЖUnixБрГЬвеЪѕЁЗЃЉЁЃ ВЛавЕФЪЧЃЌЮвУЧУцСйЕФЭљЭљЪЧИДдгадЕФЯЕЭГЃЌЦЌУцРэНтUnixЗчИёЗжЖјжЮжЎЭљЭљДјРДИќДѓЕФМЏГЩФбЖШЁЃЮЊСЫНЕЕЭМЏГЩЕФФбЖШЃЌЮвУЧЭљЭљВЩгУОоЪЏаЭЕФЯЕЭГМмЙЙЃЌгУвЛИіДѓвЛЭГЕФЗНЪНЩшМЦЯЕЭГЃЌНіНідкЯЕЭГФкВПНјааФЃПщЕФВ№ЗжЃЌгУcodebaseКЭЙцЗЖНјаадМЪјЃЌзпЩЯСЫКЭUnixЗчИёБГЕРЖјГлЕФЕРТЗЁЃЕБадФмКЭПЩЮЌЛЄадбЙСІЕНРДКѓЃЌетбљЕФЯЕЭГгжВЛЕУВЛНјааВ№ЗжЃКЮвЙ§ШЅГЃГЃПДЕНЃЌЕБШэМўЯЕЭГДяЕН
100 ЭђааДњТыЙцФЃЪБЃЌШЫУЧЛсОѕЕУЮЌЛЄРЇФбЃЌВњЩњСЫЧПСвЕФВ№ЗжФюЭЗЃЛЕБДяЕН 300 ЭђааДњТыЙцФЃЪБЃЌШЫУЧЭљЭљдйвВАДФЭВЛзЁВ№ЗжЕФгћЭћЃЛЕБДяЕН
500 ЭђааДњТыЙцФЃЪБЃЌдйБЃЪиЕФзщжЏвВЛсзїГіВ№ЗжЕФОіЖЈЁЃ
ШэМўМмЙЙжаИДдгЕФМЏГЩЙЄзїашвЊРћгУШЫЙЄжЧФмЗНЪНМђЛЏЯТРД
ЛиЙЫвЛЯТНтОіМЏГЩЮЪЬтЕФРњЪЗЃЌЮвУЧЛсЗЂЯжНЯдчЕФМЏГЩМмЙЙФЃЪНРДздгк UnixЃЌОЭЪЧжкЫЕжмжЊЕФЙмЕРЃЈPipeЃЉФЃЪНЁЃPipeФЃЪННЋЪ§ОнДЋЕнЕНвЛИіШЮЮёађСажаЃЌЙмЕРАчбнепСїЫЎЯпЕФНЧЩЋЃЌЪ§ОндкетРяБЛДІРэШЛКѓДЋЕнЕНЯТвЛИіВНжшЁЃ ЙмЕРФЃЪНзїЮЊвЛжжзюЛљБОЕФЗНЪНЃЌРэТлЩЯПЩвдНтОіЫљгаМЏГЩЮЪЬтЃЌЕЋЩцМАЕНОпЬхЮЪЬтЪБЃЌОЭашвЊеыЖдВЛЭЌЧщПізігІЖдЃЌеыЖдИїжжИДдгЕФЧщПіЃЌПЩвдзмНсГіИќЖрЕФФЃЪНЃЌЁЖЦѓвЕМЏГЩФЃЪНЁЗЃЈEIPЃЉвЛЪщжаЮЇШЦЯћЯЂМЏГЩЃЌзмНсГіШєИЩМЏГЩФЃЪНЃЌПЩЮНЪЧЯћЯЂМЏГЩЕФМЏДѓГЩЪНзмНсЁЃЕЋEIPЕФМЏГЩФЃЪНжївЊеыЖдЯЕЭГМфКѓЬЈЗўЮёЕФМЏГЩЃЌSOAМмЙЙЬсГіСЫвдPortalЃЈЧАЖЫМЏГЩЃЉЁЂBPMЃЈСїГЬМЏГЩЃЉЁЂESBЃЈЗўЮёМЏГЩЃЉЁЂDIЃЈЪ§ОнМЏГЩЃЉвдМАЪТМў/ЯћЯЂМЏГЩЕФЖрВуУцМЏГЩЬхЯЕЃЌИќМгЯЕЭГадЕФЮЊМЏГЩЙЄзїЬсЙЉжИЕМЁЃSOAЕФМЏГЩЗНЪНашвЊвЛЯЕСаЕФМЏГЩЛљДЁЩшЪЉжЇГжЃЌЪєгквЛжжжааФЛЏЕФМЏГЩЗНЪНЃЌЮвУЧПЩвдГЦжЎЮЊMiddleBoxЕФЗНЪНЃЌдкЮЂЗўЮёМмЙЙЬсГіКѓЃЌЮвУЧЛсВЩгУАбМЏГЩТпМгывЕЮёЙІФмВПЪ№дквЛЦ№ЕФШЅжааФЛЏМЏГЩЗНЪНЃЌПЩвдГЦжЎЮЊMiddlePipeЕФФЃЪНЁЃ МЏГЩЗНЪНвЛТЗбнНјЯТРДЃЌжївЊЪЧМЏГЩЕФЪжЖЮЩЯВЛЖЯЗаТЃЌЖржжПђМмКЭЛљДЁЩшЪЉдНРДдНЖрЕФНтОіСЫЗЧЙІФмашЧѓЃЌР§Шч
ESB ПЩвдНтОіТЗгЩЁЂАВШЋЁЂСїПиЕШЮЪЬтЃЌвЛЖЈГЬЖШЩЯМѕЩйСЫМЏГЩЕФЙЄзїСПЁЃЕЋМЏГЩЕФвЕЮёИДдгЖШЛЙДцдкКмЖрЃЌетРяЮвСаОйМИИіГЃМћЕФЮЪЬтЃК ЃЈ1ЃЉЪ§ОнЕФВщевЮЪЬт еыЖдвЕЮёашЧѓЃЌашвЊЪЙгУвбДцдкЕФЪ§ОнКЭЗўЮёЃЌЕЋдкЦѓвЕЛЗОГжаЃЌЯЕЭГЁЂЗўЮёЁЂЪ§ОнжкЖрЃЈЯыЯѓвЛЯТОпга10ЖрЭђЗўЮёЁЂ10ЖрЭђЪ§ОнБъзМЕФЧщПіЃЉЃЌЯыевЕНЪдгУЕФЗўЮёКЭЪ§ОнЃЌВЛЪЧвЛМўШнвзЕФЪТЧщЃЌвЛАуЮвУЧЖМвЊвРРЕзЈМвдкетЗНУцЕФжЊЪЖЃЌЭЈЙ§змЬхЩшМЦжИЖЈСЫЪ§ОнЕФСїЯђЃЌетвРРЕгкзЈМвЕФФмСІЃЌзЈМвЕФФмСІвВЪЧТ§Т§Л§РлЦ№РДЕФЁЃЮвУЧашвЊАяжњвЕЮёИќПьЫйЕФевЕНЪ§ОнКЭЗўЮёЃЌАяжњзЈМвПьЫйЪЕЯжЛ§РлЃЌМѕЩйжиИДРЭЖЏЁЃ ЃЈ2ЃЉЪ§ОнЕФЪЪХфЮЪЬт ЭЈЙ§ЗўЮёЗНЪННјааМЏГЩЃЌдзгЗўЮёЭљЭљашвЊДѓСПЕФЪфШыВЮЪ§ЁЃОйИіР§згЃЌЕїгУвЛИіЗЂЖЬаХЕФНгПкЃЌВЛНіНіЪЧЪеаХШЫЕчЛАКХТыКЭЖЬаХФкШнЃЌЛЙвЊАќРЈКмЖрвЕЮёКЌвхЕФВЮЪ§ЃЌР§ШчЗЂаХШЫЕФаеУћЁЂзщжЏЁЂЗЂаХЕФЯЕЭГЁЂЗЂаХЕФдвђЁЂЗЂаХЪБКЭПЭЛЇНгДЅЕФЧўЕРЃЈПЭЗўЧўЕРЁЂЭјЕуЧўЕРЁЂЭјвјЧўЕРЁЂзджњжеЖЫЕШЕШЃЉЁЂЗЂаХЪБЙиСЊЕФВњЦЗЃЌетаЉаХЯЂЪЧПЩвдгУРДМЦЫуГЩБОЁЂПижЦДЮЪ§ЁЂБмУтжиИДЩЇШХПЭЛЇЃЛгУЛЇУћЁЂУмТыЁЂбщжЄТыЁЂЗЂЫЭЪБМфЕШетЪЧгУзїАВШЋбщжЄЕФЃЛгХЯШМЖЁЂЗЂЫЭЧўЕРЕШЪЧгУРДзіСїСППижЦЕФЃЛСїЫЎКХЁЂШЋОжвЕЮёIDЁЂЧыЧѓIDЁЂЧыЧѓЪБМфЕШЕШЪЧгУРДзіМрПиЕФЁЃЩЯЪіаХЯЂРДздгыУПДЮЗЂЖЬаХЕФЩЯЯТЮФЃЌдкЪЕМЪПЊЗЂЦкМфОЭвЊзіКмЖрЕФИГжЕЁЂзЊЛЛЙЄзїЃЌНЋЩЯЯТЮФЕФаХЯЂДЋЕнИјЗўЮёЃЌетжжзЊЛЛОЭЯёЯТЭМФЧбљЃЌЕфаЭЕФУцЖрСЫМгЫЎЃЌЫЎЖрСЫМгУцЁЃЮвУЧашвЊИљОнЕБЧАЩЯЯТЮФКЭЗўЮёЕФЬиеїЃЌздЖЏЕФНјаавЛаЉЪЪХфЃЌБмУтШЫЙЄЕФжиИДадРЭЖЏЁЃ

ЃЈ3ЃЉЯЕЭГЕФСЊЖЏЮЪЬт ЕБвЛИівЕЮёЪТМўВњЩњЪБЃЌгаКмЖрЯрЙиСЊЕФЯЕЭГЖМЛсашвЊзїГіЙиСЊадЗДгГЃЌР§ШчвЛИіКНАрбгЮѓЃЌОЭЛсЩцМАЛњЦБЕФИФЧЉЁЂОЦЕъЕФИФЦкЁЂНгГЕЗўЮёЕФИФЦкЁЂЛсвщАВХХЕФБфИќЁЂШеГЬМЦЛЎЕФБфИќЁЃвЛАуЮвУЧЛсЩшМЦвЛИіЪТМўжааФЃЌЮЊИїИіЯЕЭГПЊЗЂГіМрЬ§ЕФГЬађЃЌЕБЪТМўЕНРДЪБХаЖЯЩЯЯТЮФаХЯЂЃЌОіЖЈВњЩњЕФЖЏзїЁЃШчЙћЪТЯШУЛгаЩшЖЈЕФЙцдђЃЌОЭЮоЗЈВњЩњСЊЖЏЃЌЮвУЧЦкД§ИќМгздЖЏЛЏЕФНЈСЂетжжСЊЖЏЙиЯЕЃЌШУМЦЫуЛњжЧФмЕФВњЩњЖЏзїЖјВЛНіНіЭЈЙ§ШЫЮЊЩшжУЁЃ РрЫЦЮЪЬтЛЙгаКмЖрЃЌЮвУЧЦкД§ФмЙЛИќМгжЧФмЕФМЏГЩЁЃ
ашвЊМЏГЩЕФВПЗжВЛжЛЪЧШэМўБОЩэЃЌШэМўЙ§ГЬвВЪЧвЛИіИДдгЕФМЏГЩ/азїЙЄзї
ЗжЖјжЮжЎЕФШэМўашвЊЭЈЙ§МЏГЩЗНЪНећЬхНЛИЖЃЌШэМўЕФЩњВњЙ§ГЬвВЪЧвЛИіЖрШЫЁЂЖрзщжЏазїЕФЙ§ГЬЃЌвВашвЊМЏГЩЁЃАбШэМўПДГЩЪЧвЛИіВњЦЗЃЌВњЦЗОЭгаВпЛЎЁЂбаЗЂЁЂдЫгЊКЭЭЫГіИїИіНзЖЮЃЌУПИіНзЖЮПЩФмгЩВЛЭЌЕФШЫЛђзщжЏЭъГЩЁЃШэМўЕФбаЗЂНзЖЮОЭЪЧвЛИівЛИіЯюФПЕФЪЕЪЉЙ§ГЬЃЌАќРЈСЂЯюЁЂжДааКЭЭъЙЄЁЃетбљЕФЙ§ГЬзщжЏЦ№РДЃЌОЭЪЧвЛЬѕШэМўЩњВњЕФСїЫЎЯпЁЃДгдчЦкЦйВМЪНЕФШэМўбаЗЂЃЌЕНКѓРДУєНнбаЗЂЙ§ГЬЁЂCMMЃЌЕНФПЧАЗчЭЗе§ОЂЕФDevOpsЃЌЖМЪЧдкНтОіШэМўЩњВњСїЫЎЯпВЛЭЌНзЖЮЕФазїЮЪЬтЃЌУєНнеыЖдШэМўЖЈвхЁЂЩшМЦЁЂЙЙНЈЃЈПЊЗЂЃЉНзЖЮЕФазїЃЌГжајМЏГЩЪЧЙЙНЈЃЈПЊЗЂЃЉгыВтЪдНзЖЮЕФазїЃЌГжајНЛИЖЪЧДгЖЈвхНзЖЮЕНВПЪ№ЃЈНЛИЖЃЉНзЖЮЕФазїЁЃ

азїжаУцСйЕФЮЪЬтЃЌОЭЪЧМЏГЩЕФЮЪЬтЃЌЮвУЧПЩвдЯыЕНКмЖрЃЌетРявВОйМИИіР§згЃК ЃЈ1ЃЉашЧѓЁЂЩшМЦгыЙЙНЈЃЈПЊЗЂЃЉЕФЙЕЭЈЮЪЬтЃКЮвУЧашвЊАбашЧѓ/ЩшМЦЕФжЊЪЖЭМЦзЛЏЁЂЬѕФПЛЏЃЌздЖЏгыПЊЗЂЙЄзїзівЛЖЈГЬЖШЕФЪЪХфЃЌМѕЩйашЧѓ/ЩшМЦЕНДњТыЕФзЊЛЛЙЄзїЃЛ ЃЈ2ЃЉЙЙНЈЃЈПЊЗЂЃЉгыВтЪдЕФЙЕЭЈЮЪЬтЃКЮвУЧашвЊИљОнЗўЮёКЭЪ§ОнЬиадвдМАЛ§РлЕФРњЪЗЪ§ОнЃЌздЖЏВњЩњВтЪдгУР§КЭВтЪдЗНЗЈЃЛ ЃЈ3ЃЉдЫгЊЕФЙЕЭЈЮЪЬтЃКЮвУЧашвЊЭЈЙ§гІгУЛЯёЁЂзЪдДЛЯёЕШЗНЪНЃЌЗўЮёгыЮяРэзЪдДжЎМфНЈСЂСЌНгЃЌПьЫйЖЈЮЛЮЪЬтЃЌНјааШнСПдЄВтЃЌЪЕЯжИќжЧФмЕФдЫЮЌЁЃ
дкШэМўМмЙЙжагІгУШЫЙЄжЧФмЕФФПБъЃКЭЈЙ§діЧПжЧФмЗНЪНЪЕЯжШэМўЯЕЭГгыШэМўЙЄГЬЕФжЧФмСЌНг
гІЖдИДдгМЏГЩЕФЬєеНЃЌЮвУЧПЩвдв§ШыШЫЙЄжЧФмЕФЫМТЗЃЌНЋШЫгыШэМўжЎМфЁЂЮяЬхгыШэМўжЎМфЁЂШэМўгыШэМўжЎМфЁЂШэМўЩњВњЯпИїЛЗНкжЎМфЭЈЙ§жЊЪЖЪЙФмЕФЗНЪНМЏГЩЦ№РДЃЌдкДЋЭГЭъШЋвРРЕЙцдђНјааМЏГЩЕФЗНЪНЛљДЁЩЯЃЌВЩгУаТЕФМЏГЩЗНЗЈЃКвдЩЯЯТЮФаХЯЂЮЊЪфШыЃЌРћгУзЈМввбгаЕФжЊЪЖЃЌЭЈЙ§Ъ§ОнбЕСЗКЭЧПЛЏбЇЯАЕФЗНЪНЃЌШУМЦЫуЛњФмЙЛРэНтМЏГЩЕФвтЭМЃЌГЩЮЊЮвУЧЕФжЧФмжњЪжЃЌАяжњЮвУЧЪЕЯжжЧФмЕФСЌНгЃЌНјЖјПЩвдШУМЦЫуЛњЬНЫїаТЕФСЌНгжЊЪЖЁЃетРяЃЌЮвАбСЌНгвВЗжЮЊШ§ИіВуУцЃКЛњаЕСЌНгЁЂЛљгкжЊЪЖСЌНгЁЂДДдьжЊЪЖСЌНгЁЃ
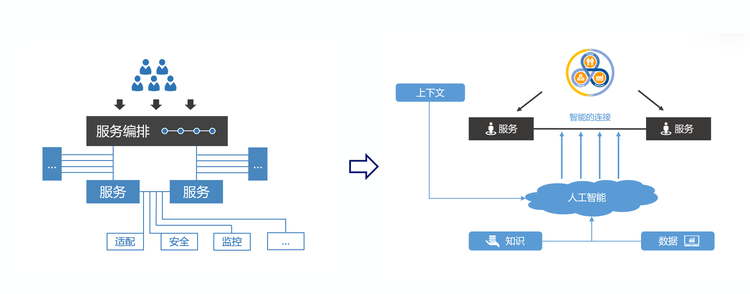
ДгжЧФмСЌНгШыЪжЬНЫїдкШэМўМмЙЙжагІгУШЫЙЄжЧФм
ДгКЮДІШыЪжЃЌЬНЫїШЫЙЄжЧФмдкШэМўжаЕФгІгУЃЌЪЧДѓМвзюЙизЂЕФЛАЬтЃЌетРяЮвАбЦедЊдкЬНЫїШЫЙЄжЧФмГѕЦкОРњЕФМИИіАИР§ЃЌИјДѓМвзівЛИіНщЩмЁЃЦедЊЖЪТГЄСѕбЧЖЋВЉЪПдчФъОЭДгЪТЩёОЭјТчЕФбаОПЃЌЫћжИГідкФПЧАВЂааМЦЫуЕШММЪѕГфЗжЗЂеЙЕФНёЬьЃЌЫуЗЈвбОВЛЪЧШЫЙЄжЧФмЕФЦПОБЃЌгІгУШЫЙЄжЧФмашвЊгаСНИіЭЛЦЦЃК ЃЈ1ЃЉевЕНШЫЙЄжЧФмгІгУЕФЧаШыЕу ЃЈ2ЃЉЭХЖгОпБИШЫЙЄжЧФмгІгУЕФЫМЮЌ ЫљвдЮвУЧдкгІгУШЫЙЄжЧФмЕФЪБКђЃЌВЛЪЧГЩСЂвЛИізЈУХЕФаЁзщзібаОПЃЌЖјЪЧАйЛЈЦыЗХЕФЗНЪНЁЃСЫНтЦедЊЕФХѓгбЛсжЊЕРЃЌЦедЊЕФбаЗЂЗжЮЊдЦМЦЫу&SOAЁЂДѓЪ§ОнЁЂвЦЖЏЁЂЙЄГЬаЇТЪгыММЪѕЦНЬЈЁЂВњЦЗжЇГжжааФМИИіЭХЖгЃЌЮвУЧШУУПИіЭХЖгДгЪ§Он+СЌНгЗНЯђЩЯШыЪжЃЌИїздЬНЫїШЫЙЄжЧФмдкСьгђЩЯЕФгІгУГЁОАЃЌЭЈЙ§евЕНЧаШыЕуКЭГѕВНЪЕМљЃЌж№ВННЈСЂЭХЖгЕФШЫЙЄжЧФмЫМЮЌЁЃЦфжадЦМЦЫу&SOAЭХЖгЕФЗНЯђЪЧЭЈЙ§ЗўЮёЛЯёЗНЪННтОіЮЂЗўЮёЕФжЧФмдЫЮЌгыжЧФмЦЅХфЃЌДѓЪ§ОнЭХЖгЕФЗНЯђЪЧЭЈЙ§жЊЪЖЭМЦзЪЕЯжЪ§ОнздЗўЮёЃЌвЦЖЏЭХЖгЕФЗНЯђЪЧUIЕФжЧФмЛЏПЊЗЂЃЌЙЄГЬаЇТЪгыММЪѕЦНЬЈЭХЖгЕФЗНЯђЪЧЩюЖШбЇЯАдкСїГЬгыжЧФмжЦдьЕФгІгУЁЃгЩгкЦЊЗљгаЯоЃЌетРяЮвжЛАбЦедЊДѓЪ§ОнЭХЖгКЭвЦЖЏЭХЖгЫљзіЕФЙЄзїзівЛИіНщЩмЁЃ
АИР§вЛЃКЛљгкжЊЪЖЭМЦзЃЌЪЕЯжЪ§ОнЕФздЗўЮёФмСІ
ЯШМђЕЅНщЩмвЛЯТБГОАЃКДѓМвОГЃЛсЬ§ЕНгаШЫЮЪЮвУЧгаФФаЉЪ§ОнЃЌетаЉЪ§ОндкФФРяЃЌШчКЮЛёШЁЪ§ОнЕФЮЪЬтЃЌФмЗёНЈСЂвЛИіЦНЬЈЃЌШУЮвУЧЯѓАйЖШЫбЫївЛбљЃЌИљОнЮвУЧЕФжЊЪЖЃЈвЕЮёЪѕгяЃЉевЕНЯрЙиЕФЪ§ОнЃЌЬсНЛЩъЧыЃЌЕУЕНЪ§ОнЃЌетОЭЪЧвЛИіЛёШЁЪ§ОнЕФзджњЗўЮёЁЃ вдЭљЪ§ОндкФФРяЭљЭљЭЈЙ§ШЫЙЄЪсРэЭъГЩЃЌЮвУЧЯЃЭћФмЙЛздЖЏЛЏвЛаЉЃЌЮЊзЈМвЬсЙЉвЛИіжЧФмЕФжњЪжЃЌетРяЕФЙЄзїЗжЮЊШ§ВПЗжЃК ЃЈ1ЃЉНЈСЂжЊЪЖЭМЦз ШЫНјааЪ§ОнЫбЫїЪЧЭЈЙ§вЕЮёЪѕгяЃЈжЊЪЖЃЉРДЫбЫїЕФЃЌЖјжЊЪЖжЎМфЪЧгаЯрЛЅСЊЯЕЕФЃЌР§ШчЫЎЙћКЭЮїКьЪСЪЧЩЯЯТЮЛЙиЯЕЃЈКѓепЪЧЧАепЕФОпЬхЬхЯжЃЉЃЌЫбЫїЪЧГ§СЫвЊСаГіжБНгНсЙћЃЌЛЙашвЊЯдЪОвЛаЉЙиСЊЕФжЊЪЖЃЌетОЭвЊНЈСЂжЊЪЖЭМЦзЁЃМђЕЅЫЕжЊЪЖЭМЦзОЭЪЧИХФюЁЂЪєадвдМАИХФюжЎМфЕФЙиСЊЙиЯЕЃЌ
етИіЙиЯЕПЩвдЪжЙЄНЈСЂЃЌЮвУЧЭЈЙ§ЖдеўВпЁЂЗЈЙцЁЂашЧѓЁЂЪ§ОнПтcommentsЁЂНчУцЕШЖржжРДдДЃЌВЩгУздШЛгябдДІРэЕШЗНЗЈЃЌПЩвдНЈСЂЦ№ВПЗжЕФжЊЪЖЭМЦзЃЌИЈжњзЈМвЕФЙЄзїЃЛ ЃЈ2ЃЉЪсРэММЪѕдЊЪ§Он ећРэИїИіЯЕЭГФкВПЪ§ОнЃЌвдМАЪ§ОнжЎМфЕФЙиЯЕЃЌаЮГЩЪ§ОнЕиЭМЁЃетРяЕФФбЖШЪЧЪ§ОнжЎМфЕФЙиЯЕЃЌР§ШчЪ§ОнЕФбЊдЕЙиЯЕЁЂгАЯьЖШЙиЯЕЁЂЙиСЊЙиЯЕЁЂжїЪ§ОнЙиЯЕЕШЃЌетРяЮвУЧВЩгУзжЖЮЬиеїЕФЯрЙиадЁЂЪ§ОнДІРэТпМЕФДЪЗЈ/гяЗЈЗжЮіЕШЪжЖЮЃЌХфКЯЧПЛЏбЇЯАРДЭъГЩЃЌЧАУцСаОйЕФВщевЭтМќЪОР§ЃЌОЭЪЧвЛВПЗжЃЛ ЃЈ3ЃЉНЈСЂжЊЪЖЭМЦзгыММЪѕдЊЪ§ОнжЎМфЕФЙиЯЕ етРяОЭвЊЭЈЙ§ЗжЮіНчУц/ЗўЮёгыДњТыжЎМфЕФЙиСЊЃЌНЈСЂЦ№гГЩфЙиЯЕЁЃзюжеаЇЙћОЭЪЧЃЌЪЙгУЪ§ОнЫбЫїЃЌТМШыЯЃЭћВщевЕФвЕЮёЪѕгяЃЌЕУЕНЯрЙиНсЙћЃЌВщПДбљР§Ъ§ОнЃЌШчЙћЪЧашвЊЕФЪ§ОнЃЌЬсНЛЪЙгУЩъЧыЃЌШчЙћВЛЪЧЃЌМЬајИљОнЯрЙижЊЪЖНјааЪ§ОнЬНЫїЁЃЬсЙЉЪ§ОнздЗўЮёФмСІЃЌОЭЪЧдкгІгУЕФЩшМЦЪІЁЂЪ§ОнПЦбЇМвЛђепвЕЮёЗжЮіЪІгыЪ§ОнжЎМфНЈСЂЦ№СЌНгЃЌЮвУЧЕФЭХЖгОЭЪЧДгСЌНгЕФЫМТЗГіЗЂЃЌевЕНСЫШЫЙЄжЧФмЕФЧаШыЕуЁЃ ЪЕМЪЩЯЃЌЪ§ОнздЗўЮёАќКЌгаевЁЂЛёЁЂгУЕШжкЖрЛЗНкЃЌЮветРяЫЕЕФЪЧевЕФЛЗНкШчКЮЪЕЯжЃЌетжжевЕФЗНЗЈЃЌвВВЛПЩФм100%зМШЗЃЌЛЙашвЊзЈМвНјааЕїећЃЌвдМАЭЈЙ§ЧПЛЏбЇЯАЕШЪжЖЮВЛЖЯаое§ЃЌПЩвдПДГіЃЌгІгУШЫЙЄжЧФмвВЪЧвЛИіНЅНјЭъЩЦЕФЙ§ГЬЁЃ
АИР§ЖўЃКЭЈЙ§ЩюЖШбЇЯАЃЌЪЕЯжвЦЖЏUIЕФжЧФмЛЏПЊЗЂ
вЦЖЏUIЕФжЧФмЛЏПЊЗЂЃЌЪЧЮвУЧвЦЖЏЭХЖггІгУШЫЙЄжЧФмЕФЕквЛИіГЂЪдЃЌЯждкПДРДЃЌОЭЪЧдкUIЩшМЦЪІгыПЊЗЂЙЄГЬЪІжЎМфНЈСЂСЌНгЁЃДѓМвЛсЗЂЯжЃЌЩшМЦЪІЕФЩшМЦдкБфГЩДњТыЪЕЯжЪБзмЛсгаЦЋВюЃЌМДЪЙвЛИіЯёЫиЕФВювьЃЌвВЛсгАЯьНчУцЕФаЇЙћЃЌвдЭљЮвУЧВЩШЁВЛЭЌвЕЮёФЃАхЕФЗНЪНЃЌНЈСЂвЛаЉЙцЗЖЖдЩшМЦКЭПЊЗЂзідМЪјЃЌКѓРДвЦЖЏЭХЖгОѕЕУЃЌПЩвдгУЩюЖШбЇЯАЕФЗНЪНзівЛаЉГЂЪдЃЌбАевВЛЭЌЕФНчУцЩшМЦаЇЙћЃЌЪзЯШЭЈЙ§Ъ§ОнБъЧЉЗНЪНШЗЖЈвГУцЕФЗчИёЃЌдйЭЈЙ§ЭМЯёЦЌЖЮЕФЗНЪНбЇЯАКЭЪЖБ№ЩшМЦИхжаЕФзщМўЃЌзюжеОЙ§ЖрДЮЕФДІРэЃЌБфГЩвЛИіЪїзДЕФНсЙЙЃЌАбетИіЪїзДНсЙЙгыДњТыНјаагГЩфЃЌОЭВњЩњСЫКЭЩшМЦЭМвЛжТЕФДњТыЁЃ етИіАИР§жаЃЌЛљгкЭМЦЌЕФЩёОЭјТчбЇЯАЪЧвЛИіЙиМќММЪѕЃЌЕЋЪЧШчЙћЕЅДПЪЙгУетИіММЪѕЃЌМЦЫуСПЛсЮоЗЈГаЪмЃЌЫљвдЮвУЧНЋДІРэЙ§ГЬЗжГЩСЫМИИіНзЖЮЃЌУПИіНзЖЮНјааЗжРрЃЌУПИіНзЖЮЖМПЩвдХфКЯЧПЛЏбЇЯАЕФЗНЪНЃЌгЩШЫЙЄжИЖЈВпТдЃЌжИЕММЦЫуЛњЕФбЇЯАЃЌЬсИпСЫЙЄГЬЛЏЕФФмСІЃЈРрЫЦзіЗЈдкЩюРЖЖдеѓПЈЫЙХСТоЗђЕФЪБКђОЭгагІгУЃЌгавЛЮЛЬиМЖДѓЪІЛсжИЕМЩюРЖЕБЧАЕФВпТдЃЌР§ШчНјЙЅЛЙЪЧЗРЪиЃЌОпЬхеаЪ§гЩЩюРЖОіЖЈЃЉЁЃ ЩЯЪіСНИіАИР§жаЃЌЮвУЧЪзЯШдкИїИіСьгђжаевЕНПЩФмЕФЧаШыЕуЃЌеыЖдВЛЭЌГЁОАЪЙгУСЫВЛЭЌЕФЗНАИЃЌВЂВЛЪЧЖМВЩгУСЫЩюЖШбЇЯА/ЩёОЭјТчЕФЗНЗЈЁЃЮвУЧУЛгаЪзЯШДгTensorflowЕШПђМмбЇЦ№ЃЌЖјЪЧдкНсЙЙЛЏЁЂАыНсЙЙЛЏгХЯШЪЙгУЭГМЦЗНЗЈЃЌЗЧНсЙЙЛЏЪ§ОндйЪЙгУЩюЖШбЇЯАЃЌЖјЪЧгУвЕЮёЧ§ЖЏЕФЗНЪНж№ВНЭЦНјЃЌгааЇЕФБмУтСЫЁАЩюЖШЗКРФЁБЁЃ
змНс
ЮДРДЕФШэМўБиНЋЪЧШЫЙЄжЧФмЕФШэМўЃЌЕЋШЫЙЄжЧФмЪЧЭЈЙ§ММЪѕЪжЖЮЪЕЯжжЧФмдіЧПЃЌАяжњЦеЭЈШЫбИЫйОпБИВПЗжзЈМвЕФММФмЃЌАяжњзЈМвМѕЩйжиИДадЕФРЭЖЏЃЌЬНЫїаТЕФжЊЪЖЃЌЖјВЛЪЧШЁДњШЫЁЃгІгУШЫЙЄжЧФмЃЌгІИУдкЪ§Он+СЌНгЕФФЃЪНЯТЃЌДгжЧФмМЏГЩШыЪжЃЌЬНЫїШЫЙЄжЧФмдкШэМўжаЕФгІгУЁЃЖјетжжЬНЫїЃЌМШАќРЈДЋЭГРћгУЙцдђЪЕЯжЕФЛњаЕжЧФмЃЌвВАќРЈРћгУЭГМЦбЇКЭЩюЖШбЇЯАЗНЗЈжЇГХЕФЪЕЯжвтЭМжЧФмЃЌЛЙгаДДдьвтЭМ/бАеваТжЊЪЖЕФЬНЫїЃЌЖјЭГМЦбЇЗНЗЈЭљЭљгУдкНсЙЙЛЏЪ§ОнКЭАыНсЙЙЛЏЕФЪ§ОнжаЃЌЩюЖШбЇЯАЭљЭљвЊРћгУЗЧНсЙЙЛЏЪ§ОнЁЃ змжЎЃЌШЫЙЄжЧФмЪЧМЦЫуЛњПЦбЇЁЂЭГМЦбЇЁЂжЊЪЖЙЄГЬЁЂСьгђжЊЪЖЕФвЛИіНЛВцбЇПЦЃЌВЛФмНіНіеОдкФГИіНЧЖШШЅРэНтКЭГЂЪдЃЌе§ЫљЮНЁАО§згВЛЦїЁБЁЃ |









