| 机器学习最近大红大紫,既有这个契机为何不乘机好好学习一番。本文不是科普文,本人作为初学者也没有能力教别人,仅仅用此篇文章记录自己学习及尝试结合业务场景进行的一些实验过程。
机器学习与平时编程解决问题的区别
我们平时编程解决问题,主要是基于规则,而通过机器学习来解决问题是通过建立模型。
基于规则
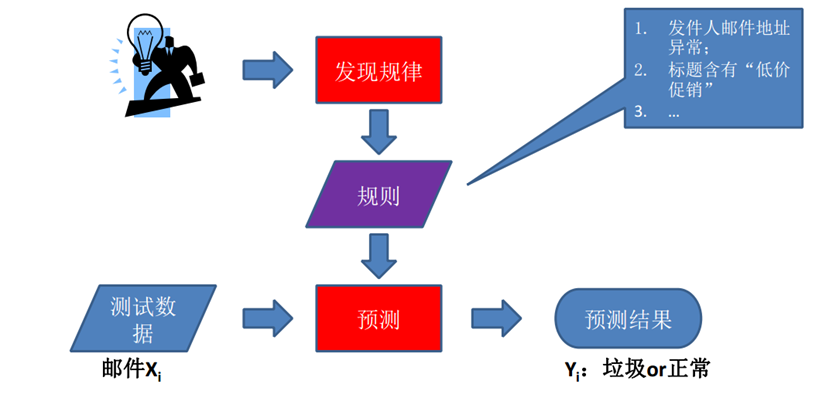
我们通过经验或者智慧,主动发掘可以解决问题的规则(也许就是一条条 if 语句),然后将许多规则结合在一起形成解决问题的方案。就比如图中判断垃圾邮件的过程,标题是否包含某种词……等就是明确的规则。这种方法修改起来非常方便,只要根据场景的演变,不断修正规则集。
基于模型
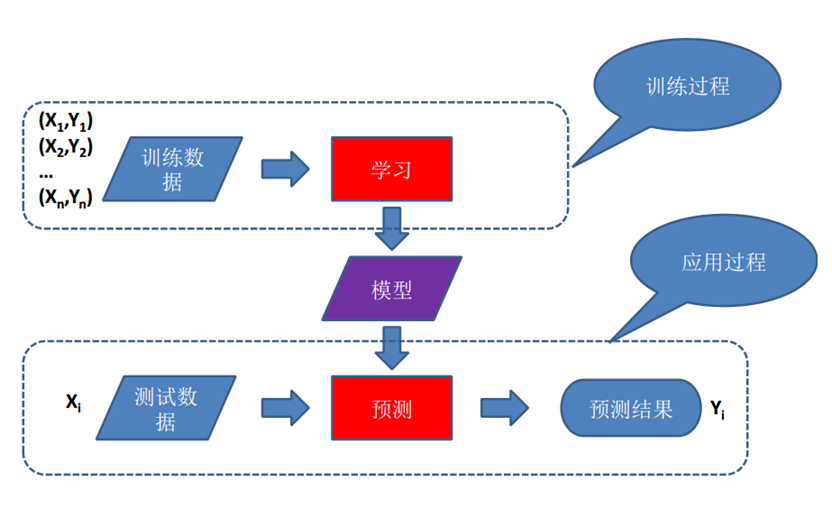
机器学习就是通过模型来解决问题,首先需要一堆数据(假设为 X),然后通过某一种算法进行学习(这里的某种算法多种多样,需要了解但不需要精通,毕竟不是专业人士),数据+学习算法
就会产生一个模型(模型这里我们认为是一个复杂的函数 f)。有了这个函数,当有新的数据来需要预测的时候,就代入函数得到函数的结果(函数结果也即为问题结果)。
这里有两个问题:
1.这个模型是由算法+数据 训练产生的,而不是人工干预形成的,所以当你觉得模型不满意的时候,你没法直接调整模型,因为模型对于你来说是一个黑盒。你只能通过调整数据或者调整算法来间接调整模型,已达到优化解决方案的目的。所以有一个尴尬是,当你遇到一个新的问题场景,你想说像基于规则的程序那样,我们快点给模型加一个规则来修正模型以解决新问题吧,抱歉,臣妾做不到……必须重新训练模型。
2.通过模型计算出的结果往往不太好解释,不像规则产生的结果可追溯形成的过程,从而完成修正
机器学习问题类型
对问题进行分类,能够帮助我们更好的找到适合机器学习发挥的场景,一般有四大类型:
分类(classification):在训练数据上建模,对于新样本,判断它的类别。如垃圾邮件识别中判断是否垃圾邮件(二分类)、tensoflow
的入门教程-手写数字识别(多分类) 等
回归(regression):在训练数据上建模,对于新样本,判断它的标注值。标注值与分类问题不同,分类问题的标注是离散值,而回归问题中的标注是实数(连续的)。如股价预测、房价预测、监控曲线预测等
聚类(clustering):给出了一些相似度衡量标准,用来判断两个不同数据的相似程度,然后根据这些标准将数据进行划分。如在一堆未给出名字的照片中,自动的将同一个人的照片聚集到一块。
规则抽取(rule extraction):发现数据中属性之间的统计关系,而不只是预测一些事情。如啤酒和尿布的关系。商品推荐就是最典型的应用场景
然后,针对这些问题能够用来建立模型的算法更多,算法分类可以参考 机器学习算法概览
尝试的场景
运维的工作中,经常需要对重要的指标曲线进行观察,来判断系统是否正常 or 异常。这个场景广泛发生在包括监控告警、运营变更、容灾演练等情况下,但是通过一些固定阀值+特定检测算法的方法并不能满足不断变化的情况。所以第一个尝试的场景就是:
根据某一指标曲线的历史数据判断当前/未来数据点是否异常
在实践上述问题的过程中,发现因为机器学习毕竟是基于历史预测未来,如果历史本就没有值得学习的价值,那判断是否异常就会导致不可理解的结果(就是某些指标图形效果不好),继而产生另一场景:
把指标曲线进行分类,把不同图形特征的指标曲线分成若干类,分而治之
指标曲线异常检测
1.提前想清楚的问题
数据有哪些?针对某一条指标曲线,假设是每一分钟为一个 slot,那么一天就是 1440 slot。又因为我们秒级监控的数据是保存两周,那么
14×1440 个 slot
数据需要提取特征吗?常规的机器学习都需要通过专门设计、特征工程等方法来提取特征。(直接怼原始数据这种适用于深度学习的方法,应该是基于海量数据,略过…)
指标曲线异常检测是什么类型的问题?二分类问题,判断 slot 是否异常
应该使用什么算法?因为数据本身并不具备标记,且通过设计方法来标记数据的成本也很高(slot 太多,每个都要标记),所以只能采用无监督算法来建立模型
每一个指标曲线都建立一个唯一模型?理论上,针对异常分类,每个指标曲线单独一个模型肯定是最优的,因为可以避免其他指标曲线的干扰。但是因为实时性、资源等实际情况,需要针对应用场景自己决定,此处单独建模。
2.特征提取
时序数据如何提取有关于异常检测的特征。采取的方法是:每个 slot 单独提取特征向量(可能变化 slot
时间窗口为 5min)。每个 slot 提取特征的过程,是使用很多比较“流行”的异常检测器来完成。slot
经过每个检测器的提取之后,会得到一些被检查器量化过的,可以衡量数据异常程度的数值,称为 serverity,然后采各种不同的
serverity 组合形成 slot 对应的特征向量。举例 servertiy 的方法:
比如常见的正态分布的方法,假设某一时间点(纵向上看,不同天但同时同分) 的数据符合正太分布,即 14
个 slot 符合正太分布,计算 14 个点的μ和σ,然后对于某个点 x 的 serverity=|x-μ|
/ σ。另外其他能够预测指标曲线值的方法可以使用 serverity = |预测值 - 实际值| /
(max -min) 的方法来度量异常程度。
如下图所示的思想,把每一个 slot 分别转换为不同的检测器产生的 serverity。这样做的思考是,通过聚集不同检测器的能力,检测出不同情况下的异常,再通过机器学习来区分哪些是真正的异常点。经过转化之后有效的去除了时间、数值等带来的影响。
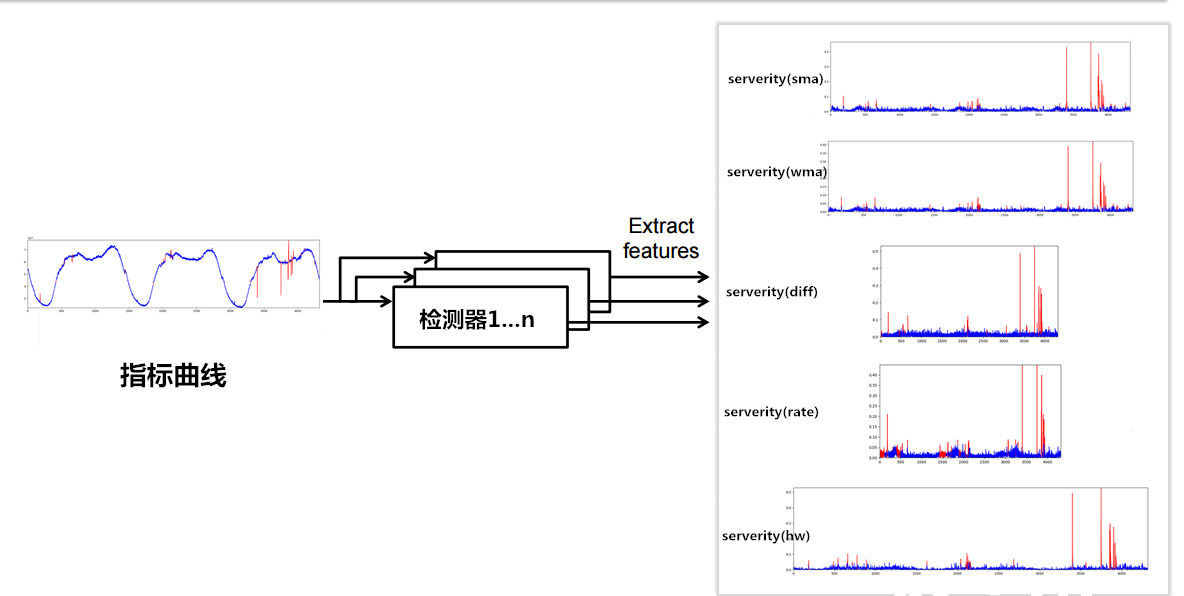
我们最终实现了的检测器包括:sma(移动平均法)、wma(加权移动平均)、tsd(时间序列分解法)、diff(差分)、rate(同环比)、gasi(高斯分布)、ema(一次指数平滑)、hw(三次指数平滑)、arima(自回归积分华东平均)
等
3.训练模型
训练模型,采用是 sklearn 的 python 库来实现。经过对比和实验,选取的机器学习算法是无监督的分类异常检测算法
isolationForest(孤异森林)。该算法的特点是:无监督、速度快、效果好(ps:已经有 wxg
同学在登录异常检测中尝试过)。放一张某天 tdp 系统异常时某核心指标曲线的检测效果:
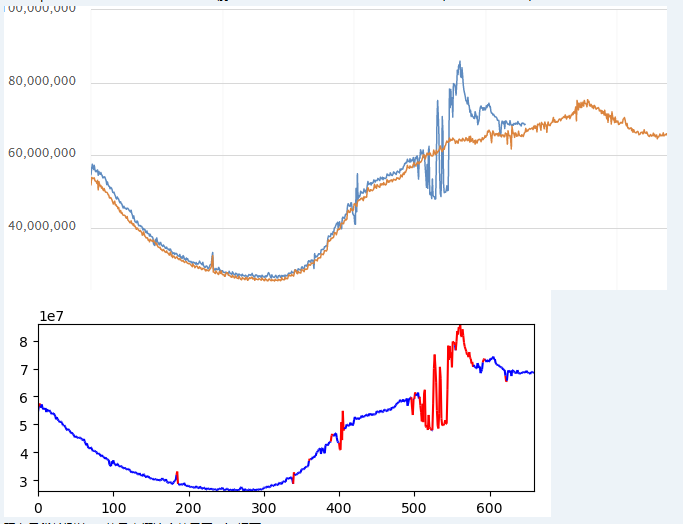
上图为当日异常曲线与昨日正常曲线对比图,下图为经过模型判断之后的图,红色表示判断为异常点。该模型已经尝试在一体化流程系统的上线验证模块使用。
指标曲线分类
曲线分类,同样是机器学习中典型的分类问题,而且针对这个问题已经有同学进行过尝试,可参考智能告警算法-曲线识别模型。接下来简单描述下不同的地方:
特征的设计:采用了开源工程提取特征和人工设计特征相结合的方法,开源时序特征工程为 cesium 和
tsfresh。因为开源特征较多,可以使用一个特征选择的方法,进行筛选之后使用,第一版本的模型,使用了
19 个特征。
标记的训练数据:并没有采用 kmeans 的方法来形成标记数据,反而使用了人工标记的方法(标记了
200 个不同的曲线,花了一天时间)。之前也参考其他同学的方法先用 kmeans 聚类打标,但是效果一直不太好,且聚类完成之后也要人工挑选确认样本,所以一不做二不休直接人工了,23333333
监督分类算法:监督分类算法很多,比如 svm、LR、神经网络等。因为我们训练数据不多,最后采用的是随机森林
人工划分了 4 个类别:周期较光滑曲线、周期较粗糙曲线、类心跳曲线(整体起伏不大,在某一个范围内反复上线跳动)、类错误率曲线(绝大部分情况为恒定值,比如
0,偶尔有异常突起或下陷)。该模型在脚本大师上建立了一个体验任务,可是输入秒级监控的曲线体验分类。
总结
1 .特征很重要:”数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。“由此可见,特征工程尤其是特征选择在机器学习中占有相当重要的地位。在实践中,大部分时间也都花在了特征选择与提取上。怪不得深度学习如此火,跳过这步还是很伟大的,23333
2 .数据难获得:实践中,数据的获取,特别是有标记的数据获取,感觉是十分困难的。看似有很多数据,但是不知道怎么把看似大量数据变成问题所需要且能够使用的数据,还真是个世界难题
3 .应用场景难选取:想在运维实践中运用机器学习获得良好的效果,需要丰富的运维经验,又要深厚的机器学习功底。21
世纪什么最重要?人才、人才、人才。 |









