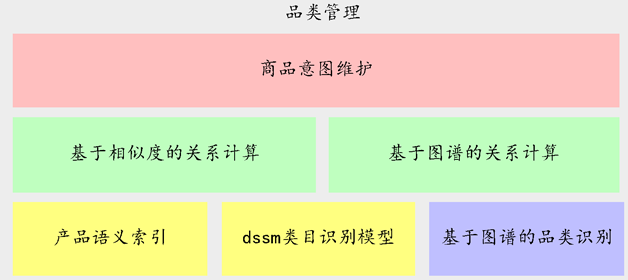
| ÷«ń‹»ňĽķĹĽĽ•Ńž”ÚĶńĹť…‹
––“Ķ∑÷ņŗľįńŅ«įĶń”¶”√◊īŅŲ
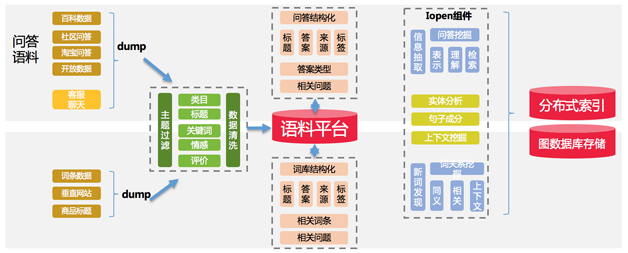
‘ŕ»ę«Ú»ňĻ§÷«ń‹Ńž”Ú≤Ľ∂Ō∑Ę’ĻĶńĹŮŐž£¨įŁņ®Google°ĘFacebook°ĘMicrosoft°ĘAmazon°ĘAppleĶ»Ľ•Ń™ÕÝĻęňĺŌŗľŐÕ∆≥ŲŃň◊‘ľļĶń÷«ń‹ňĹ»ň÷ķņŪļÕĽķ∆ų»ň∆ĹŐ®°£÷«ń‹»ňĽķĹĽĽ•Õ®Ļżń‚»ňĽĮĶńĹĽĽ•ŐŚ—ť÷ū≤Ĺ‘ŕ÷«ń‹ŅÕ∑Ģ°Ę»őőŮ÷ķņŪ°Ę÷«ń‹ľ“ĺ”°Ę÷«ń‹”≤ľĢ°ĘĽ•∂ĮŃńŐžĶ»Ńž”Ú∑ĘĽ”ĺřīůĶń◊ų”√ļÕľŘ÷Ķ°£“Úīň£¨łųīůĻęňĺ∂ľĹę÷«ń‹ŃńŐžĽķ∆ų»ň◊ųő™őīņī»ŽŅŕľ∂ĪūĶń”¶”√∂‘īż°£ĹŮŐžňś◊Ň –≥°ĶńĹÝ“Ľ≤Ĺ∑Ę’Ļ£¨ŃńŐžĽķ∆ų»ňįī’’≤ķ∆∑ļÕ∑ĢőŮĶńņŗ–Õ÷ų“™Ņ…∑÷ő™£ļŅÕ∑Ģ°Ę”ťņ÷°Ę÷ķņŪ°ĘĹŐ”ż°Ę∑ĢőŮĶ»ņŗ–Õ°£
Õľ1Ĺō»°Ńň≤Ņ∑÷ŃńŐžĽķ∆ų»ň°£

Õľ1 ChatbotĽ„◊‹
įĘņÔ–°√Ř‘ŕĶÁ…ŐŃž”ÚĶń◊īŅŲ
2015ńÍ7‘¬£¨įĘņÔÕ∆≥ŲŃň◊‘ľļĶń÷«ń‹ňĹ»ň÷ķņŪ°™°™įĘņÔ–°√Ř£¨“ĽłŲőß»∆◊ŇĶÁ◊”…ŐőŮŃž”Ú÷–Ķń∑ĢőŮ°ĘĶľĻļ“‘ľį»őőŮ÷ķņŪő™ļň–ńĶń÷«ń‹»ňĽķĹĽĽ•≤ķ∆∑°£Õ®ĻżĶÁ◊”…ŐőŮŃž”Ú”Ž÷«ń‹»ňĽķĹĽĽ•Ńž”ÚĶńĹŠļŌ£¨īÝņīīęÕ≥∑ĢőŮ––“Ķń£ ĹĶńĪšĽĮ”ŽŐŚ—ťĶńŐŠ…ż°£‘໕ńÍĶńňę ģ“Ľ∆ŕľš£¨įĘņÔ–°√Ř’ŻŐŚ÷«ń‹∑ĢőŮŃŅīÔĶĹ643ÕÚ£¨∆š÷–÷«ń‹Ĺ‚ĺŲ¬ īÔĶĹ95%£¨÷«ń‹∑ĢőŮ‘ŕ’ŻłŲ∑ĢőŮŃŅ£®◊‹∑ĢőŮŃŅ=÷«ń‹∑ĢőŮŃŅ+‘ŕŌŖ»ňĻ§∑ĢőŮŃŅ+ĶÁĽį∑ĢőŮŃŅ£©’ľĪ»“≤īÔĶĹ95%£¨≥…ő™Ńňňę ģ“Ľ∆ŕľš∑ĢőŮĶńĺÝ∂‘÷ųѶ°£
ĶÁ…ŐŃž”ÚŌ¬įĘņÔ–°√ŘĶńľľ ű Ķľý
ľľ űoverview
÷«ń‹»ňĽķĹĽĽ•ŌĶÕ≥£¨ň◊≥∆£ļChatbotŌĶÕ≥ĽÚ’ŖbotŌĶÕ≥£¨Õľ2 «»ňĽķĹĽĽ•ĶńŃų≥ŐÕľ°£
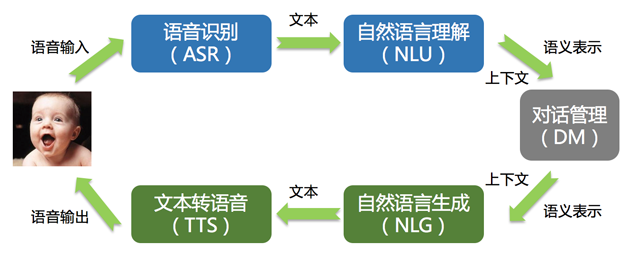
Õľ2 »ňĽķĹĽĽ•ĶńŃų≥Ő
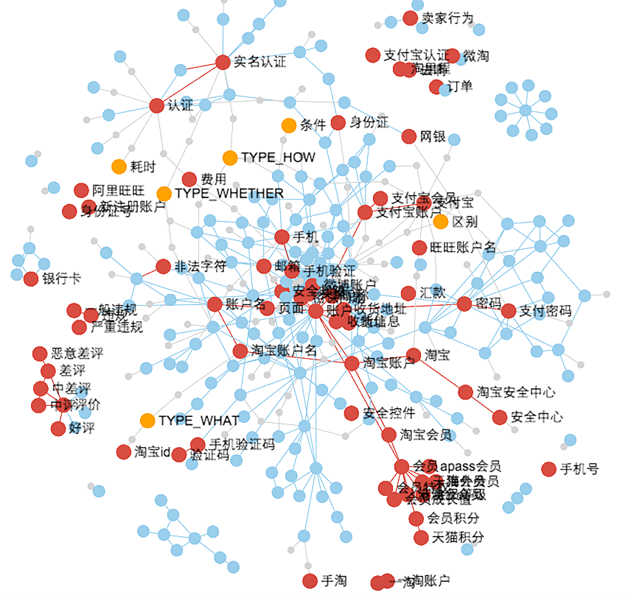
ļň–ń «NLU£®◊‘»Ľ”Ô—‘ņŪĹ‚£©£¨Õ®Ļż∂‘ĽįŌĶÕ≥ī¶ņŪ£¨◊ÓļůÕ®Ļż◊‘»Ľ”Ô—‘…ķ≥…Ķń∑Ĺ ĹłÝ≥Ųīūįł°£“Ľ∂ő”Ô—‘»ÁļőņŪĹ‚∂‘”ŕľ∆ň„ĽķņīňĶ «∑«≥£”–ń—∂»Ķń£¨ņż»Á£ļ°į∆ĽĻŻ°Ī’‚łŲī ĺÕĺŖĪł÷Ń…ŔŃĹłŲļ¨“Ś£¨“ĽłŲ «ňģĻŻ Ű–‘Ķń°į∆ĽĻŻ°Ī£¨ĽĻ”–“ĽłŲ «÷™√ŻĽ•Ń™ÕÝĻęňĺ Ű–‘Ķń°į∆ĽĻŻ°Ī°£
“‚Õľ”Ž∆•Ňš∑÷≤„Ķńľľ űľ‹ĻĻŐŚŌĶ
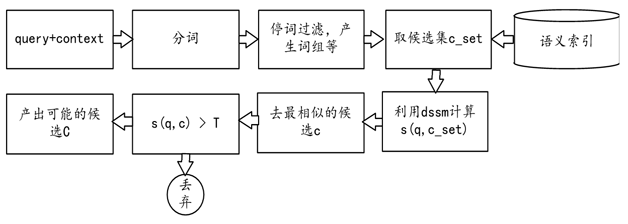
‘ŕįĘņÔ–°√Ř’‚—ýĶńĶÁ◊”…ŐőŮŃž”Ú≥°ĺį÷–£¨∂‘Ĺ”Ķń”–ŅÕ∑Ģ°Ę÷ķņŪ°ĘŃńŐžľłīůņŗĽķ∆ų»ň°£’‚–©Ľķ∆ų»ň£¨”…”ŕĪĺ…ŪĶńńŅĪÍ≤ĽÕ¨£¨ĺÕĶľ÷¬≤Ľń‹”√Õ¨“ĽŐ◊ľľ űŅÚľ‹ņīĹ‚ĺŲ°£“Úīň£¨Ō»≤…”√∑÷Ńž”Ú∑÷≤„∑÷≥°ĺįĶń∑Ĺ ĹĹÝ––ľ‹ĻĻ≥ťŌů£¨»Ľļů‘Ŕłýĺ›≤ĽÕ¨Ķń∑÷≤„ļÕ∑÷≥°ĺį≤…”√≤ĽÕ¨ĶńĽķ∆ų—ßŌį∑Ĺ∑®ĹÝ––ľľ ű…Ťľ∆°£ ◊Ō»ő“√«Ĺę∂‘ĽįŌĶÕ≥ī”∑÷≥…ŃĹ≤„£ļ
1.“‚Õľ ∂Īū≤„£ļ ∂Īū”Ô—‘Ķń’ś Ķ“‚Õľ£¨Ĺę“‚ÕľĹÝ––∑÷ņŗ≤ĘĹÝ––“‚Õľ Ű–‘≥ť»°°£“‚ÕľĺŲ∂®Ńňļů–ÝĶńŃž”Ú ∂ĪūŃų≥Ő£¨“Úīň“‚Õľ≤„ «“ĽłŲĹŠļŌ…ŌŌ¬őń żĺ›ń£–Õ”ŽŃž”Ú żĺ›ń£–Õ≤Ľ∂Ō∂‘“‚ÕľĹÝ––√ų»∑ļÕÕ∆ņŪĶńĻż≥Ő£Ľ
2.ő īū∆•Ňš≤„£ļ∂‘ő Ő‚ĹÝ––∆•Ňš ∂Īūľį…ķ≥…īūįłĶńĻż≥Ő°£‘ŕįĘņÔ–°√ŘĶń∂‘ĽįŐŚŌĶ÷–ő“√«įī’’“ĶőŮ≥°ĺįĹÝ––Ńň»ż÷÷Ķš–Õő Ő‚ņŗ–ÕĶńĽģ∑÷£¨≤Ę«““ņĺ›»ż÷÷ņŗ–Õ£¨≤…”√≤ĽÕ¨Ķń∆•ŇšŃų≥ŐļÕ∑Ĺ∑®£ļ
1.ő īū–Õ£ļņż»Á°į√‹¬ŽÕŁľ«‘ű√īįž£Ņ°Ī°ķ ≤…”√Ľý”ŕ÷™ ∂Õľ∆◊ĻĻĹ®+ľžňųń£–Õ∆•Ňš∑Ĺ Ĺ£Ľ
2.»őőŮ–Õ£ļņż»Á°įő“ŌŽ∂©“Ľ’Ň√ųŐžī”ļľ÷›ĶĹĪĪĺ©ĶńĽķ∆Ī°Ī°ķ “‚ÕľĺŲ≤Ŗ+slots
fillingĶń∆•Ňš“‘ľįĽý”ŕ…Ó∂»«ŅĽĮ—ßŌįĶń∑Ĺ Ĺ£Ľ
3.”ÔŃń–Õ£ļņż»Á°įő“–ń«ť≤Ľļ√°Ī°ķ ľžňųń£–Õ”ŽDeep LearningŌŗĹŠļŌĶń∑Ĺ Ĺ°£
Õľ3ĪŪ ĺŃňįĘņÔ–°√ŘĶń“‚ÕľļÕ∆•Ňš∑÷≤„Ķńľľ űľ‹ĻĻ°£
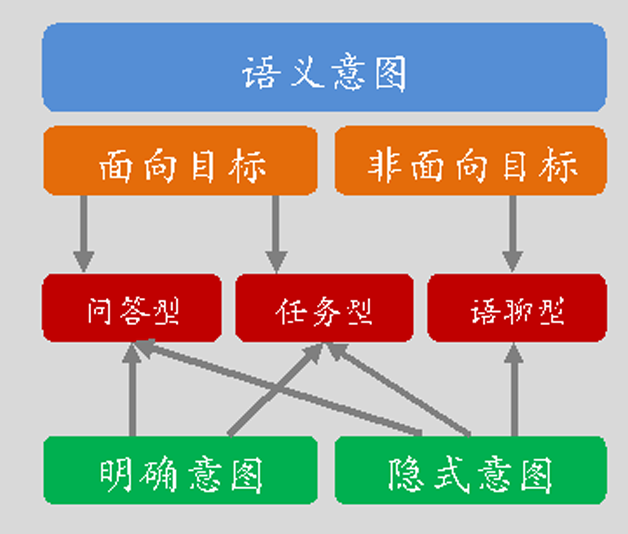
Õľ3 įĘņÔ–°√ŘĶń“‚ÕľļÕ∆•Ňš∑÷≤„Ķńľľ űľ‹ĻĻ
“‚Õľ ∂ĪūĹť…‹£ļĹŠļŌ”√Ľß––ő™Deep Learningń£–ÕĶń Ķľý
Õ®≥£Ĺę“‚Õľ ∂Īū≥ťŌů≥…Ľķ∆ų—ßŌį÷–Ķń∑÷ņŗő Ő‚£¨‘ŕįĘņÔ–°√ŘĶńľľ ű∑Ĺįł÷–≥żŃňīęÕ≥ĶńőńĪĺŐō’ų÷ģÕ‚£¨Ņľ¬«ĶĹĪĺ…Ū‘ŕ∂‘ĽįŃž”Ú÷–īś‘ŕ”Ô“Ś“‚Õľ≤ĽÕÍ’ŻĶń«ťŅŲ£¨ő“√«“≤ľ”»ŽŃň”√ Ķ Ī°ĘņŽŌŖ”√ĽßĪĺ…ŪĶń––ő™ľį”√ĽßĪĺ…ŪŌŗĻōĶńŐō’ų£¨Õ®Ļż…Ó∂»—ßŌį∑ĹįłĻĻĹ®ń£–Õ£¨∂‘”√Ľß“‚ÕľĹÝ––‘§≤‚,
ĺŖŐŚ»ÁÕľ4°£

Õľ4 ĹŠļŌ”√Ľß––ő™Ķń…Ó∂»—ßŌį“‚Õľ∑÷ņŗ
‘ŕĽý”ŕ…Ó∂»—ßŌįĶń∑÷ņŗ‘§≤‚ń£–Õ…Ō£¨ő“√«”–ŃĹ÷÷ĺŖŐŚĶń—°–Õ∑Ĺįł£ļ“Ľ÷÷ «∂ŗ∑÷ņŗń£–Õ£¨“Ľ÷÷ «∂Ģ∑÷ņŗń£–Õ°£∂ŗ∑÷ņŗń£–ÕĶń”ŇĶ„ «–‘ń‹Ņž£¨Ķę «∂‘”ŕ–Ť“™ņ©’Ļ∑÷ņŗŃž”Ú «’ŻłŲń£–Õ–Ť“™÷ō–¬—ĶŃ∑£Ľ∂Ý∂Ģ∑÷ņŗń£–ÕĶń”ŇĶ„ĺÕ «ņ©’ĻŃž”Ú≥°ĺį Ī‘≠ņīĶńń£–Õ∂ľŅ…“‘łī”√£¨Ņ…“‘∆ĹŐ®ĹÝ––ņ©’Ļ£¨»ĪĶ„“≤ļ‹√ųŌ‘–Ť“™≤Ľ∂ŌĹÝ––∂Ģ∑÷£¨’ŻŐŚ–‘ń‹…Ō≤Ľ»Á∂ŗ∑÷ņŗļ√£¨“Úīň‘ŕĺŖŐŚĶń≥°ĺįļÕ żĺ›ŃŅ…ŌŅ…“‘◊Ų≤ĽÕ¨Ķń—°–Õ°£
–°√Ř”√DL◊Ų“‚Õľ∑÷ņŗĶń’ŻŐŚľľ űňľ¬∑ «Ĺę––ő™“Ú◊””ŽőńĪĺŐō’ų∑÷ĪūĹÝ––Embeddingī¶ņŪ£¨Õ®ĻżŌÚŃŅĶĢľ”÷ģļů‘ŔĹÝ––∂ŗ∑÷ņŗĽÚ’Ŗ∂Ģ∑÷ņŗī¶ņŪ°£’‚ņÔĶńőńĪĺŐō’ųő¨∂»Ņ…“‘—°‘ŮÕ®ĻżīęÕ≥Ķńbag
of wordsĶń∑Ĺ∑®£¨“≤Ņ… Ļ”√Deep LearningĶń∑Ĺ∑®ĹÝ––ŌÚŃŅĽĮ£¨ĺŖŐŚ»ÁÕľ5°£
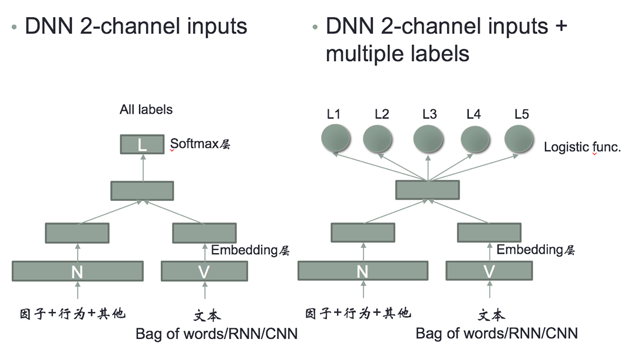
Õľ5 ĹŠļŌ”√Ľß––ő™Ķń…Ó∂»—ßŌį“‚Õľ∑÷ņŗĶńÕݬÁĹŠĻĻ
∆•Ňšń£–Õoverview£ļĹť…‹––“Ķ»żīů∆•Ňšń£–Õ
ńŅ«į÷ųŃųĶń÷«ń‹∆•Ňšľľ ű∑÷ő™»ÁŌ¬»ż÷÷∑Ĺ∑®£ļ
1.Ľý”ŕń£įŚ∆•Ňš£®Rule-Based£©
2.Ľý”ŕľžňųń£–Õ£®Retrieval Model£©
3.Ľý”ŕ…Ó∂»—ßŌįń£–Õ£®Deep Learning£©
‘ŕįĘņÔ–°√ŘĶńľľ ű≥°ĺįŌ¬£¨ő“√«≤…”√ŃňĽý”ŕń£įŚ∆•Ňš£¨ľžňųń£–Õ“‘ľį…Ó∂»—ßŌįń£–Õő™Ľýī°Ķń∑Ĺ∑®‘≠–ÕņīĹÝ––∑÷≥°ĺį£®ő īū–Õ°Ę»őőŮ–Õ°Ę”ÔŃń–Õ£©ĶńĽŠĽįŌĶÕ≥ĻĻĹ®°£
įĘņÔ–°√ŘĶń»żīůŃž”Ú≥°ĺįĶńľľ ű Ķľý
÷«ń‹ĶľĻļ£ļĽý”ŕ‘Ų«Ņ—ßŌįĶń÷«ń‹ĶľĻļ
÷«ń‹ĶľĻļ÷ų“™Õ®Ļż÷ß≥÷ļÕ”√ĽßĶń∂ŗ¬÷ĹĽĽ•£¨≤Ľ∂ŌĶńņŪĹ‚ļÕ√ų»∑”√ĽßĶń“‚Õľ°£≤Ę‘ŕīňĽýī°…ŌņŻ”√…Ó∂»«ŅĽĮ—ßŌį≤Ľ∂ŌĶō”ŇĽĮĶľĻļĶńĹĽĽ•Ļż≥Ő°£Õľ6’Ļ ĺŃň÷«ń‹ĶľĻļĶńľľ űľ‹ĻĻÕľ°£
Õľ6 ÷«ń‹ĶľĻļĶńľ‹ĻĻÕľ
’‚ņÔŃĹłŲļň–ńĶńő Ő‚£ļ
‘ŕ∂ŗ¬÷ĹĽĽ•÷–ņŪĹ‚”√ĽßĶń“‚Õľ°£
łýĺ›”√ĽßĶń“‚ÕľĹŠĻŻ£¨”ŇĽĮŇŇ–ÚĶńĹŠĻŻļÕĹĽĽ•ĶńĻż≥Ő°£
Ō¬√ś÷ų“™Ĺť…‹ĶľĻļ“‚ÕľņŪĹ‚°Ę“‘ľį…Ó∂»‘Ų«Ņ—ßŌįĶńĹĽĽ•≤Ŗ¬‘”ŇĽĮ°£
1.÷«ń‹ĶľĻļĶń“‚ÕľņŪĹ‚ļÕ“‚ÕľĻ‹ņŪ
÷«ń‹ĶľĻļŌ¬Ķń“‚ÕľņŪĹ‚÷ų“™ « ∂Īū”√ĽßŌŽ“™Ļļ¬ÚĶń…Ő∆∑“‘ľį…Ő∆∑∂‘”¶Ķń Ű–‘£¨Ōŗ∂‘”ŕīęÕ≥Ķń“‚ÕľņŪĹ‚£¨“≤īÝņīŃňňńłŲ–¬ĶńŐŰ’Ĺ£ļ
Ķŕ“Ľ£ļ”√Ľß∆ęŌÚ”ŕ∂ŐĺšĶńĪŪīÔ°£“Úīň£¨ ∂Īū”√ĽßĶń“‚Õľ£¨“™ĹŠļŌ”√ĽßĶń∂ŗ¬÷ĽŠĽįļÕ“‚ÕľĶńĪŖĹÁ°£
Ķŕ∂Ģ£ļ‘ŕ∂ŗ¬÷ĹĽĽ•÷–”√ĽßĽŠ≤Ľ∂ŌŐŪľ”ĽÚ–řłń“‚ÕľĶń◊”“‚Õľ£¨–Ť“™ő¨Ľ§“Ľ∑›ĶĪ«į ∂ĪūĶń“‚ÕľľĮļŌ°£
Ķ໿£ļ…Ő∆∑“‚Õľ÷ģľšīś‘ŕ◊ŇĽ•≥‚£¨Ōŗň∆£¨…ŌŌ¬őĽĶ»ĻōŌĶ°£≤ĽÕ¨ĶńĻōŌĶ∂‘”¶Ķń“‚ÕľĻ‹ņŪ“≤≤ĽÕ¨°£
Ķŕňń£ļ Ű–‘“‚Õľīś‘ŕ◊ŇĻťņŗļÕĽ•≥‚Ķńő Ő‚°£
’Ž∂‘∂Ő”ÔĪŪīÔ£¨ő“√«Õ®Ļż∆∑ņŗĻ‹ņŪļÕ Ű–‘Ļ‹ņŪő¨Ľ§Ńň“ĽłŲ“‚Õľ∂—£¨ī”∂ÝĹŌļ√ĶōĹ‚ĺŲŃň∂Ő”ÔĪŪ ĺ£¨“‚ÕľĪŖĹÁļÕĺŖŐŚĶń“‚Õľ«–ĽĽļÕ–řłń¬Ŗľ≠°£Õ¨ Ī£¨’Ž∂‘ĹŌīůĶń…Ő∆∑Ņ‚ő Ő‚£¨ő“√«≤…”√÷™ ∂Õľ∆◊ĹŠļŌ”Ô“Śňų“żĶń∑Ĺ Ĺ£¨ ĻĶ√…Ő∆∑Ķń ∂ĪūĪšĶ√∑«≥£łŖ–ß°£Ō¬√śő“√«∑÷ĪūĹť…‹∆∑ņŗĻ‹ņŪļÕ Ű–‘Ļ‹ņŪ°£
2.Ľý”ŕ÷™ ∂Õľ∆◊ļÕ”Ô“Śňų“żĶń∆∑ņŗĻ‹ņŪ
÷«ń‹ĶľĻļ≥°ĺįŌ¬Ķń∆∑ņŗĻ‹ņŪ∑÷ő™∆∑ņŗ ∂Īū£¨“‘ľį∆∑ņŗĶńĻōŌĶľ∆ň„£¨Õľ7 «∆∑ņŗĻōŌĶĶńľ‹ĻĻÕľ°£
Õľ7 ∆∑ņŗĻ‹ņŪľ‹ĻĻÕľ
3.∆∑ņŗ ∂Īū
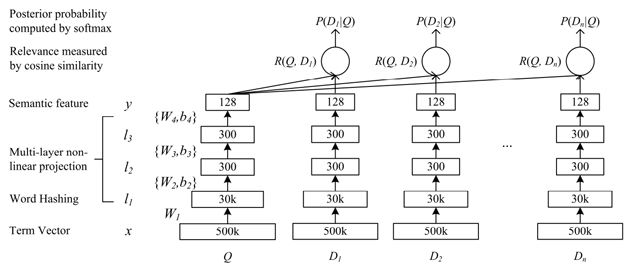
≤…”√ŃňĽý”ŕ÷™ ∂Õľ∆◊Ķń ∂Īū∑ĹįłļÕĽý”ŕ”Ô“Śňų“żľįdssmĶńŇ–Īūń£–Õ°£
1.Ľý”ŕ…Ő∆∑÷™ ∂Õľ∆◊Ķń ∂Īū∑Ĺįł£ļĽý”ŕ÷™ ∂Õľ∆◊łī‘”ĶńĹŠĻĻĽĮń‹Ń¶£¨◊Ų…Ő∆∑ĶńņŗńŅ ∂Īū£¨ «…Ő∆∑ ∂ĪūĶńĽýī°°£
2.Ľý”ŕ”Ô“Śňų“żľįdssm…Ő∆∑ ∂Īūń£–ÕĶń∑Ĺįł£ļ÷™ ∂Õľ∆◊Ķń ∂Īū∑ĹįłĶń”Ň ∆ «‘ŕ”ŕ◊ľ»∑¬ łŖ£¨Ķę «≤Ľń‹ł≤ł«ňý”–Ķńcase°£“Úīň£¨ő“√«ŐŠ≥ŲŃň“Ľ÷÷Ľý”ŕ”Ô“Śňų“żļÕdssmĹŠļŌĶń…Ő∆∑ ∂Īū∑Ĺįł∂ĶĶ◊°£
Õľ8 Ľý”ŕ”Ô“Śňų“żļÕdssmĶń…Ő∆∑ ∂Īū∑Ĺįł
4.”Ô“Śňų“żĶńĻĻ‘ž
Õ®≥£”Ô“Śňų“żĶńĻĻ‘ž”–Ľý”ŕĪĺŐŚĶń∑Ĺ Ĺ£¨Ľý”ŕLSIĶń∑Ĺ Ĺ°£ő“√«”√Ńň“Ľ÷÷ĹŠļŌň—ňųĶ„Ľų żĺ›ļÕī ŌÚŃŅĶń∑Ĺ ĹĻĻ‘žĶń”Ô“Śňų“ż°£÷ų“™įŁņ®Ō¬√śľł≤Ĺ£ļ
Ķŕ“Ľ≤Ĺ£ļņŻ”√ň—ňųĶ„Ľų––ő™£¨ŐŠ»°∑÷ī ĶĹņŗńŅĶńļÚ—°£Ľ
Ķŕ∂Ģ≤Ĺ£ļĽý”ŕī ŌÚŃŅ£¨ľ∆ň„∑÷ī ļÕļÚ—°ņŗńŅĶńŌŗň∆–‘£¨∂‘ňų“ż÷ōŇŇ–Ú°£
5.Ľý”ŕdssmĶń…Ő∆∑ ∂Īū
dssm «őĘ»ŪŐŠ≥ŲĶń“Ľ÷÷”√”ŕqueryļÕdoc∆•ŇšĶń”–ľŗ∂ĹĶń…Ó∂»”Ô“Ś∆•ŇšÕݬÁ£¨ń‹ĻĽĹŌļ√ĶōĹ‚ĺŲī Ľ„ļŤĻĶĶńő Ő‚£¨≤∂◊Ĺĺš◊”Ķńńŕ‘ŕ”Ô“Ś°£Īĺőń“‘dssm◊ųő™Ľýī°£¨ĻĻĹ®ŃňqueryļÕļÚ—°ņŗńŅĶńŌŗň∆∂»ľ∆ň„ń£–Õ°£»°Ķ√ŃňĹŌļ√Ķń–ßĻŻ£¨ń£–ÕĶńacc‘ŕ≤‚ ‘ľĮ…Ō”–92%◊ů”“°£
Õľ9 dssmń£–ÕĶńÕݬÁĹŠĻĻÕľ
—ýĪĺĶńĻĻ‘ž£ļ—ĶŃ∑Ķń’ż—ýĪĺ «Õ®Ļżň—ňų»’÷ĺ÷–Ķńň—ňųqueryļÕĶ„ĽųņŗńŅĻĻ‘žĶń°£łļ—ýĪĺ‘Ú «Õ®ĻżņŻ”√queryļÕĶ„ĽųĶńņŗńŅ◊ųő™÷÷◊”£¨ľžňų≥Ųņī“Ľ–©Ōŗň∆ĶńņŗńŅ£¨Ĺę≤Ľ‘ŕ’ż—ýĪĺ÷–ĶńņŗńŅ◊ųő™łļ—ýĪĺ£¨’żłļ—ýĪĺĶńĪ»ņż1:1°£
6.∆∑ņŗĻōŌĶľ∆ň„
∆∑ņŗĻōŌĶĶńľ∆ň„÷ų“™”√”ŕ÷«ń‹ĶľĻļĶń“‚ÕľĻ‹ņŪ÷–£¨’‚ņÔ÷ų“™Ņľ¬«Ķńľł÷÷ĻōŌĶ «…ŌŌ¬őĽĻōŌĶļÕŌŗň∆ĻōŌĶ°£ĺŔłŲņż◊”£¨”√ĽßĶńĶŕ“ĽłŲ“‚Õľ «“™¬Ú“¬∑Ģ£¨ĶĪļů√śĶń“‚ÕľňĶ“™¬ÚňģĪ≠Ķń ĪļÚ£¨÷ģ«į“¬∑ĢňýīÝ”–Ķń Ű–‘ĺÕ≤Ľ”¶ł√ĪĽľŐ≥–łÝňģĪ≠°£Ōŗ∑ī£¨»ÁĻŻ’‚łŲ ĪļÚ”√ĽßňĶĶń «“™Ņ„◊”£¨”…”ŕŅ„◊” «“¬∑ĢĶńŌ¬őĽī £¨‘Ú÷ģ«į‘ŕ“¬∑Ģ…ŌĶń Ű–‘ĺÕ”¶ł√ĪĽľŐ≥–Ō¬ņī°£
…ŌŌ¬őĽĻōŌĶĶńľ∆ň„ŃĹ÷÷∑Ĺįł£ļ
≤…”√Ľý”ŕ÷™ ∂Õľ∆◊ĶńĻōŌĶ‘ňň„°£
Õ®Ļż”√ĽßĶńň—ňųqueryĶńŐŠ»°°£
Ōŗň∆–‘ľ∆ň„ĶńŃĹ÷÷∑Ĺįł£ļ
1.Ľý”ŕŌŗÕ¨Ķń…ŌőĽī °£Ī»∑ĹňĶ–°√◊£¨Ľ™ő™Ķń…ŌőĽī ∂ľ « ÷Ľķ£¨‘ÚňŻ√«Ōŗň∆°£
2.Ľý”ŕfast-textĶń∆∑ņŗī ĶńembeddingĶń”Ô“ŚŌŗň∆∂»°£
7.Ľý”ŕ÷™ ∂Õľ∆◊ļÕŌŗň∆∂»ľ∆ň„Ķń Ű–‘Ļ‹ņŪ
Õľ10 Ű–‘Ļ‹ņŪľ‹ĻĻÕľ
’ŻŐŚ…Ō Ű–‘Ļ‹ņŪįŁņ® Ű–‘ ∂ĪūļÕ Ű–‘ĻōŌĶľ∆ň„ŃĹłŲļň–ńń£Ņť£¨ňľ¬∑ļÕ∆∑ņŗĻ‹ņŪĹŌő™Ōŗň∆°£’‚ņÔĺÕ≤Ľ‘ŔŌÍŌłĹť…‹Ńň°£
…Ó∂»«ŅĽĮ—ßŌįĶńŐĹňųľį≥Ę ‘
«ŅĽĮ—ßŌį «agentī”Ľ∑ĺ≥ĶĹ––ő™Ķń”≥…š—ßŌį£¨ńŅĪÍ «ĹĪņÝ–ŇļŇ£®«ŅĽĮ–ŇļŇ£©ļĮ ż÷Ķ◊Óīů£¨”…Ľ∑ĺ≥ŐŠĻ©«ŅĽĮ–ŇļŇ∆ņľŘ≤ķ…ķ∂Į◊ųĶńļ√ĽĶ°£agentÕ®Ļż≤Ľ∂ŌĶńŐĹňųÕ‚≤ŅĶńĽ∑ĺ≥£¨ņīĶ√ĶĹ“ĽłŲ◊Ó”ŇĶńĺŲ≤Ŗ≤Ŗ¬‘£¨ ļŌ”ŕ–ÚŃ–ĺŲ≤Ŗő Ő‚°£Õľ11 «“ĽłŲ«ŅĽĮ—ßŌįĶńModelļÕĽ∑ĺ≥ĹĽĽ•Ķń’Ļ ĺ°£
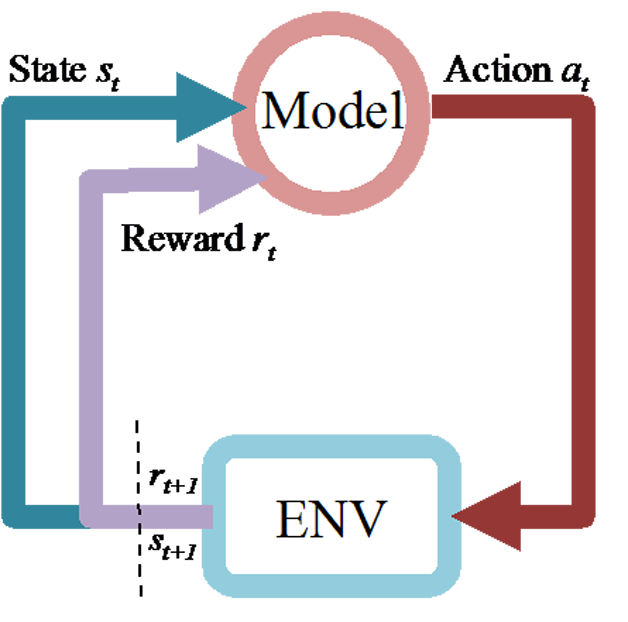
Õľ11 ENV-ModelĶńĹĽĽ•Õľ
…Ó∂»«ŅĽĮ—ßŌį «ĹŠļŌŃň…Ó∂»—ßŌįĶń«ŅĽĮ—ßŌį£¨÷ų“™ņŻ”√…Ó∂»—ßŌį«ŅīůĶń∑«ŌŖ–‘ĪŪīÔń‹Ń¶£¨ņīĪŪ ĺagent√ś∂‘ĶństateļÕstate…ŌĺŲ≤Ŗ¬Ŗľ≠°£
ńŅ«įő“√«”√DRL÷ų“™ņī”ŇĽĮő“√«ĶńĹĽĽ•≤Ŗ¬‘°£“Úīň£¨ő“√«Ķń…Ť∂® «£¨”√Ľß ««ŅĽĮ—ßŌį÷–ĶńENV£¨∂ÝĽķ∆ų «Model°£action «Īĺ¬÷ «∑Ů≥Ų÷ų∂Į∑īő ĶńĹĽĽ•£¨ĽĻ «÷ĪĹ”≥Ųň—ňųĹŠĻŻ°£
1.◊īŐ¨£®state£©Ķń…Ťľ∆£ļ
’‚ņÔ◊īŐ¨Ķń…Ťľ∆÷ų“™Ņľ¬«£¨”√ĽßĶń∂ŗ¬÷“‚Õľ°Ę”√ĽßĶń»ň»ļĽģ∑÷°Ę“‘ľį√Ņ“Ľ¬÷ĹĽĽ•Ķń≤ķ∆∑Ķń–ŇŌĘ◊ųő™ĶĪ«įĶńĽķ∆ųł–÷™ĶĹĶń◊īŐ¨°£
state = ( intent1, query1, price1, is_click, query_item_sim,
°≠, power, user_inter, age)
∆š÷–intent1ĪŪ√ųĶń «”√ĽßĶĪ«įĶń“‚Õľ£¨query1ĪŪ ĺĶń”√ĽßĶń‘≠ ľquery°£price1ĪŪ ĺĶĪ«į’ĻŌ÷łÝ”√ĽßĶń…Ő∆∑ĶńĺýľŘ£¨is_clickĪŪ ĺĪĺ¬÷ĹĽĽ• «∑Ů∑Ę…ķĶ„Ľų£¨query_item_simĪŪ ĺqueryļÕitemĶńŌŗň∆∂»°£powerĪŪ ĺ «”√ĽßĶńĻļ¬ÚѶ£¨user_interĪŪ ĺ”√ĽßĶń–ň»§£¨age
ĪŪ ĺ”√ĽßĶńńÍŃš°£
2.rewardĶń…Ťľ∆£ļ
”…”ŕ◊Ó÷’ļ‚ŃŅĶń «”√ĽßĶń≥…ĹĽļÕĶ„Ľų¬ ļÕ∂‘ĽįĶń¬÷ ż°£“ÚīňrewardĶń…Ťľ∆÷ų“™įŁņ®Ō¬√ś»żłŲ∑Ĺ√ś£ļ
1.”√ĽßĶńĶ„ĽųĶńreward…Ť÷√≥…1
2.≥…ĹĽ…Ť÷√≥…[ 1 + math.log(price + 1.0) ]
3.∆š”ŗĶń…Ť÷√≥…0.1
3.DRLĶń∑ĹįłĶń—°–Õ£ļ
’‚ņÔĺŖŐŚĶń∑Ĺįł£¨÷ų“™≤…”√ŃňDQN£¨policy-gradientļÕA3CĶń»ż÷÷∑Ĺįł°£
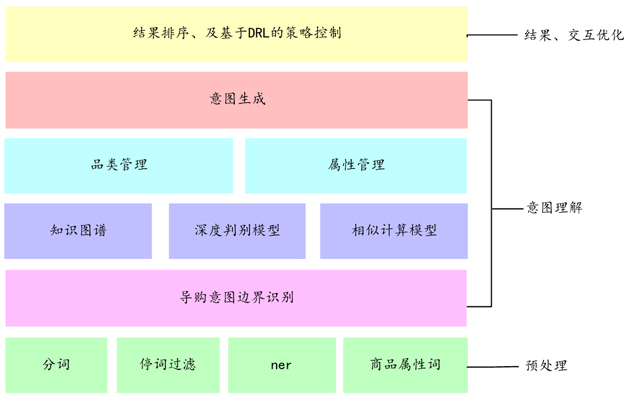
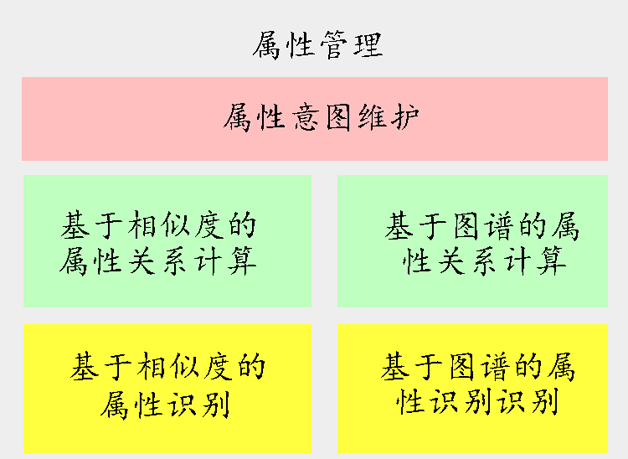
÷«ń‹∑ĢőŮ£ļĽý”ŕ÷™ ∂Õľ∆◊ĻĻĹ®”Žľžňųń£–ÕĶńľľ ű Ķľý
÷«ń‹∑ĢőŮĶńŐōĶ„£ļ”–Ńž”Ú÷™ ∂ĶńłŇńÓ£¨«“÷™ ∂÷ģľšĶńĻōŃ™–‘łŖ£¨≤Ę«“∂‘ĺę◊ľ∂»“™«ůĪ»ĹŌłŖ°£
Ľý”ŕő īū–Õ≥°ĺįĶńŐōĶ„£¨ő“√«‘ŕľľ ű—°–Õ…Ō≤…”√Ńň÷™ ∂Õľ∆◊ĻĻĹ®+ľžňųń£–ÕŌŗĹŠļŌĶń∑Ĺ ĹņīĹÝ––ļň–ń∆•Ňšń£–ÕĶń…Ťľ∆°£
÷™ ∂Õľ∆◊ĶńĻĻĹ®ī”ŃĹłŲĹ«∂»ņīĹÝ––≥ťŌů£¨“ĽłŲ « ĶŐŚő¨∂»ĶńÕŕĺÚ£¨“ĽłŲ «∂Őĺšő¨∂»ĹÝ––ÕŕĺÚ£¨Õ®Ļż‘ŕŐ‘Ī¶∆ĹŐ®…ŌĽżņŘĶńīůŃŅ żĺ›“‘ľįĽ•Ń™ÕÝ żĺ›£¨“‘÷ųŐ‚ń£–ÕĶń∑Ĺ ĹĹÝ––ÕŕĺÚ°ĘĪÍ◊Ę”Ž«ŚŌī£¨‘ŔÕ®Ļż‘§…Ť∂®ļ√ĶńĻōŌĶĹÝ–– ĶŐŚ÷ģľšĻōŌĶĶń∂®“Ś◊Ó÷’–ő≥…÷™ ∂Õľ∆◊°£ĽýĪĺĶńÕŕĺÚŅÚľ‹Ńų≥Ő»ÁÕľ12°£ÕŕĺÚĻĻĹ®Ķń÷™ ∂Õľ∆◊ ĺņż»ÁÕľ13°£
Õľ12 ÷™ ∂Õľ∆◊Ķń ĶŐŚļÕ∂Ő”ÔÕŕĺÚŃų≥Ő
Õľ13 ĺŖŐŚĶń÷™ ∂Õľ∆◊Ķń ĺņż
Ľý”ŕ÷™ ∂Õľ∆◊Ķń∆•Ňšń£ ĹĺŖĪł“‘Ō¬ŃĹłŲ”ŇĶ„£ļ
1.‘ŕ∂‘ĽįĹŠĻĻļÕŃų≥ŐĶń…Ťľ∆÷–÷ß≥÷ ĶŐŚľšĶń…ŌŌ¬őńĽŠĽį ∂Īū”ŽÕ∆ņŪ£Ľ
2.Õ®≥£‘ŕ“Ľį„–Õő īūĶń◊ľ»∑¬ Ōŗ∂‘Ī»ĹŌłŖ£®ĶĪ»Ľ£¨ĺŖĪłÕ∆ņŪ–Õ≥°ĺįĶń–Ť“™Őō ‚Ķń…Ťľ∆£¨ĽŠ”––©łī‘”£©°£
Õ¨—ý“≤”–√ųŌ‘Ķń»ĪĶ„£ļ
1.ń£–ÕĻĻĹ®≥ű∆ŕŅ…ń‹ĽŠīś‘ŕ żĺ›ň……ĘļÕł≤ł«¬ ő Ő‚£¨Ķľ÷¬∆•ŇšĶńł≤ł«¬ »Ī ߣĽ
2.∂‘”ŕ÷™ ∂Õľ∆◊‘ŲŃŅő¨Ľ§ŌŗĪ»īęÕ≥ĶńQA Pair∂‘÷™ ∂ő¨Ľ§…ŌĶń≥…Ī弊łŁīů“Ľ–©£Ľ
“ÚīňÕŇ∂”‘ŕįĘņÔ–°√ŘĶńő īū–Õ…Ťľ∆÷–£¨ĽĻ «»ŕ»ŽŃňīęÕ≥ĶńĽý”ŕľžňųń£–ÕĶń∂‘Ľį∆•Ňš°£
∆š‘ŕŌŖĽýĪĺŃų≥Ő∑÷ő™£ļ
1.ŐŠő ‘§ī¶ņŪ£ļ∑÷ī °Ę÷łīķŌŻĹ‚°ĘĺņīŪĶ»ĽýĪĺőńĪĺī¶ņŪŃų≥Ő£Ľ
2.ľ∆ň„£ļÕ®ĻżQueryĹŠļŌ…ŌŌ¬őńń£–Õ”ŽļÚ—° żĺ›ĹÝ––ľ∆ň„£¨ő“√«≤…”√őńĪĺ÷ģľšĶńĺŗņŽľ∆ň„∑Ĺ Ĺ£®”ŗŌ“Ōŗň∆∂»°ĘĪŗľ≠ĺŗņŽ£©“‘ľį∑÷ņŗń£–ÕŌŗĹŠļŌĶń∑Ĺ ĹĹÝ––ľ∆ň„£Ľ
3.◊Ó÷’łýĺ›∑ĶĽōĶńļÚ—°ľĮīÚ∑÷„–÷ĶĹÝ––◊Ó÷’Ķń≤ķ∆∑Ńų≥Ő…Ťľ∆°£
ņŽŌŖŃų≥Ő∑÷ő™£ļ
1.÷™ ∂ żĺ›Ķńňų“żĽĮ£Ľ
2.ņŽŌŖőńĪĺń£–ÕĶńĻĻĹ®£ļņż»ÁTerm-Weightľ∆ň„Ķ»°£
ľžňųń£–Õ’ŻŐŚŃų≥Ő»ÁÕľ14°£
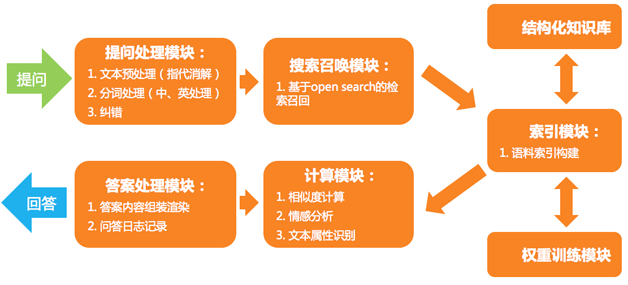
Õľ14 ľžňųń£–ÕĶńŃų≥ŐÕľ
÷«ń‹ŃńŐž£ļĽý”ŕľžňųń£–ÕļÕ…Ó∂»—ßŌįń£–ÕŌŗĹŠļŌĶńŃńŐž”¶”√
÷«ń‹ŃńŐžĶńŐōĶ„£ļ∑«√śŌÚńŅĪÍ£¨”Ô“Ś“‚Õľ≤Ľ√ų»∑£¨Õ®≥£∆ŕīżĶń «”Ô“ŚŌŗĻō–‘ļÕĹ•ĹÝ–‘£¨∂‘◊ľ»∑¬ “™«ůŌŗ∂‘ĹŌĶÕ°£
√śŌÚopen domainĶńŃńŐžĽķ∆ų»ňńŅ«įőř¬Ř‘ŕ—ß űĹÁĽĻ «‘ŕĻ§“ĶĹÁ∂ľ «“Ľīůń—Ő‚£¨Õ®≥£‘ŕńŅ«į’‚łŲĹ◊∂ő”–ŃĹ÷÷∑Ĺ Ĺņī◊Ų∂‘Ľį…Ťľ∆£ļ
“Ľ÷÷ «—ß űĹÁ∑«≥£ĽūĪ¨ĶńDeep Learning…ķ≥…ń£–Õ∑Ĺ Ĺ£¨Õ®ĻżEncoder-Decoderń£–ÕÕ®ĻżLSTMĶń∑Ĺ ĹĹÝ––Sequence
to Sequence…ķ≥…£¨»ÁÕľ15°£
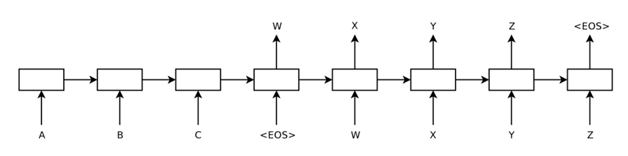
Õľ15 Seq2SeqÕݬÁĹŠĻĻÕľ
1.Generation Model£®…ķ≥…ń£–Õ£©£ļ
”ŇĶ„£ļÕ®Ļż…Ó≤„”Ô“Ś∑Ĺ ĹĹÝ––īūįł…ķ≥…£¨īūįł≤Ľ ‹”ÔŃŌŅ‚Ļśń£Ōř÷∆£Ľ
»ĪĶ„£ļń£–ÕĶńŅ…Ĺ‚ Õ–‘≤Ľ«Ņ£¨«“ń—“‘Ī£÷§“Ľ÷¬–‘ļÕļŌņŪ–‘Ľōīū°£
ŃŪÕ‚“Ľ÷÷∑Ĺ Ĺ «Õ®ĻżīęÕ≥Ķńľžňųń£–ÕĶń∑Ĺ ĹņīĻĻĹ®”ÔŃńĶńő īū∆•Ňš°£
2.Retrieval Model£®ľžňųń£–Õ£©£ļ
”ŇĶ„£ļīūįł‘ŕ‘§…ŤĶń”ÔŃŌŅ‚÷–£¨Ņ…Ņō£¨∆•Ňšń£–ÕŌŗ∂‘ľÚĶ•£¨Ņ…Ĺ‚ Õ–‘«Ņ£Ľ
»ĪĶ„£ļ‘ŕ“Ľ∂®≥Ő∂»…Ō»Ī∑¶“Ľ–©”Ô“Ś–‘£¨«“”–ĻŐ∂®”ÔŃŌŅ‚Ķńĺ÷Ōř–‘°£
“Úīň‘ŕįĘņÔ–°√ŘĶńŃńŐž“ż«ś÷–£¨ĹŠļŌŃĹ’Ŗłų◊‘Ķń”Ň ∆£¨ĹęŃĹłŲń£–ÕĹÝ––Ńň»ŕļŌ–ő≥…ŃňįĘņÔ–°√ŘŃńŐž“ż«śĶńļň–ń°£Ō»Õ®ĻżīęÕ≥Ķńľžňųń£–Õľžňų≥ŲļÚ—°ľĮ żĺ›£¨»ĽļůÕ®ĻżSeq2Seq
Model∂‘ļÚ—°ľĮĹÝ––Rerank£¨÷ōŇŇ–Úļů≥¨Ļż÷∆∂®Ķń„–÷ĶĺÕĹÝ–– š≥Ų£¨≤ĽĶĹ„–÷ĶĺÕÕ®ĻżSeq2Seq
ModelĹÝ––īūįł…ķ≥…£¨’ŻŐŚŃų≥Ő»ÁÕľ16°£
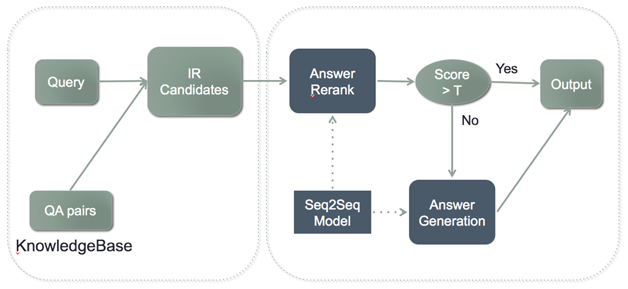
Õľ16 –°√ŘĶńŌ–Ńńń£Ņť
őīņīľľ űĶń∑Ę’Ļ”Ž’ĻÕŻ
ńŅ«įĶń»ňĻ§÷«ń‹Ńž”Ú»‘»Ľī¶‘ŕ»ű»ňĻ§÷«ń‹Ĺ◊∂ő£¨ŐōĪū «ī”ł–÷™ĶĹ»Ō÷™Ńž”Ú–Ť“™ŐŠ…żĶńŅ’ľšĽĻ∑«≥£īů°£÷«ń‹»ňĽķĹĽĽ•‘ŕ√śŌÚńŅĪÍĶńŃž”Ú“—ĺ≠Ņ…“‘”Ž Ķľ Ļ§“Ķ≥°ĺįĹŰ√‹ĹŠļŌ≤Ę≤ķ…ķĺřīůľŘ÷Ķ£¨ňś◊Ň»ňĻ§÷«ń‹ľľ űĶń≤Ľ∂Ō∑Ę’Ļ£¨őīņī÷«ń‹»ňĽķĹĽĽ•Ńž”ÚĶń∑Ę’ĻĽĻĹ꼊”–≤Ľ∂ŌĶńŐŠ…ż£¨∂‘”ŕőīņīľľ űĶń∑Ę’Ļő“√«÷ĶĶ√∆ŕīżļÕ’ĻÕŻ°£
1. żĺ›Ķń≤Ľ∂ŌĽżņŘ£¨“‘ľįŃž”Ú÷™ ∂Õľ∆◊Ķń≤Ľ∂ŌÕÍ…∆”ŽĻĻĹ®Ĺę≤Ľ∂Ō÷ķÕ∆÷«ń‹»ňĽķĹĽĽ•Ķń≤Ľ∂ŌŐŠ…ż°£
2.√śŌÚ»őőŮĶńīĻ÷ĪŌł∑÷Ńž”Ú£¨Ľķ∆ų»ňĶńĻĻĹ®Ĺę «÷ģļůĽķ∆ų»ň≤Ľ∂ŌĪ¨∑ĘĶń‘Ų≥§Ķ„£¨open
domainĶńĽ•∂ĮĽķ∆ų»ň‘ŕőīņī“Ľ∂ő ĪľšĽĻ–Ť“™≤Ľ∂ŌŐŠ…ż”Ž√Ģňų°£
3.ňś◊Ň∑÷≤ľ Ĺľ∆ň„ń‹Ń¶Ķń≤Ľ∂ŌŐŠ…ż£¨…Ó∂»—ßŌį‘ŕŌĮĺŪŃňÕľŌٰʔԓŰĶ»Ńž”Úļů£¨‘ŕNLP£®◊‘»Ľ”Ô—‘ī¶ņŪ£©Ńž”ÚĹ꼊ľŐ–Ý∑Ę’Ļ£¨‘ŕ∂‘Ľį°ĘQAŃž”ÚĶń—ß ű—–ĺŅĹ꼊≥÷–ÝĽÓ‘ĺ°£ |









