| »ňņŗ––ő™ ∂ĪūĶńńŅĶń «Õ®Ļż“ĽŌĶŃ–ĶńĻŘ≤ž£¨∂‘»ňņŗĶń∂Į◊ųņŗ–Õ°Ę––ő™ń£ ĹĹÝ––∑÷őŲļÕ ∂Īū£¨≤Ę Ļ”√◊‘»Ľ”Ô—‘Ķ»∑Ĺ Ĺ∂‘∆šĹÝ––√Ť ŲĶńľ∆ň„Ľķľľ ű°£”…”ŕ»ňņŗ––ő™Ķńłī‘”–‘ļÕ∂ŗ—ý–‘£¨ÕýÕý ∂Īū≥ŲĶńĹŠĻŻ «∂ŗ—ý–‘Ķń£¨≤Ę«“ѨīÝ◊Ň––ő™ņŗ–ÕĶńłŇ¬ š≥ŲĶń°£ňś◊Ň–ŇŌĘľľ űĶń∑Ę’Ļ£¨łų÷÷“∆∂Į…ŤĪłļÕŅ…ī©īų…ŤĪł’ż‘ŕ“‘ľ”ňŔ∂»Ķń∑Ĺ Ĺ‘Ų≥§£¨∆š–‘ń‹ļÕ«∂»ŽĶńīęł–∆ų“≤ĪšĶń∂ŗ—ýĽĮ£¨ņż»Á£ļłŖ«ŚŌŗĽķ°ĘĻ‚īęł–∆ų°ĘÕ”¬›“«īęł–∆ų°Ęľ”ňŔ∂»īęł–∆ų°ĘGPS“‘ľįő¬∂»īęł–∆ųĶ»°£łų÷÷łų—ýĶńīęł–∆ų∂ľ‘ŕ ĪŅŐĶńľ«¬ľ◊Ň Ļ”√’ŖĶń–ŇŌĘ£¨’‚–©ľ«¬ľ–ŇŌĘ≤ĽĹŲŅ…“‘”√”ŕ”√ĽßőĽ÷√Ķń‘§≤‚£¨“≤Ņ…“‘ĹÝ––”√Ľß––ő™Ķń ∂ĪūĶ»°£
Īĺőń Ļ”√Ńň÷«ń‹…ŤĪłľ”ňŔ∂»īęł–∆ųĶń żĺ›£¨ĹŠļŌ÷ß≥÷ŌÚŃŅĽķĶńŐō–‘ĹÝ––»ňņŗ––ő™ ∂Īūń£–ÕĶń…Ťľ∆ļÕ”¶”√°£
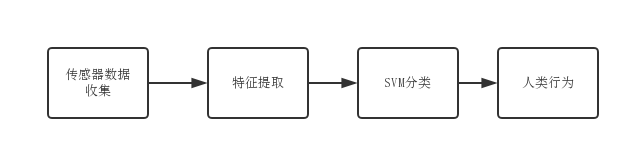
»Á…ŌÕľňý ĺ£¨–ŇļŇ żĺ›Ķń≤…ľĮņī◊‘”ŕ«∂»Ž‘ŕ÷«ń‹ ÷Ľķ÷–Ķńľ”ňŔ∂»īęł–∆ų£¨ Ķ—ť—°”√Ńň»ňņŗ»’≥£––ő™÷–ĶńŃýņŗ≥£ľŻ––ő™£¨∑÷Īūő™£ļ◊Ŗ¬∑°Ę¬żŇ‹°Ę…Ō¬•Ő›°ĘŌ¬¬•Ő›°Ę◊Ý°Ę’ĺŃĘ£¨ żĺ› ’ľĮļů£¨∂‘ żĺ›ĹÝ––Őō’ų≥ť»°£¨≥ť»°ļůĶńŐō’ų Ļ”√÷ß≥÷ŌÚŃŅĽķĶń∑÷ņŗĻ¶ń‹∂‘Őō’ųĹÝ––∑÷ņŗ£¨◊Óļů ∂Īū≥Ų»ňņŗĶńŃýņŗ––ő™°£
Ļō”ŕ÷ß≥÷ŌÚŃŅĽķ£®SVM£©
÷ß≥÷ŌÚŃŅĽķ(Support Vector Machine) «CortesļÕVapnik”ŕ1995ńÍ ◊Ō»ŐŠ≥ŲĶń£¨ňŁ‘ŕĹ‚ĺŲ–°—ýĪĺ°Ę∑«ŌŖ–‘ľįłŖő¨ń£ Ĺ ∂Īū÷–ĪŪŌ÷≥Ų–Ū∂ŗŐō”–Ķń”Ň ∆£¨≤Ęń‹ĻĽÕ∆Ļ„”¶”√ĶĹļĮ żń‚ļŌĶ»∆šňŻĽķ∆ų—ßŌįő Ő‚÷–°£SVMň„∑® «Ľý”ŕľšłŰ◊ÓīůĽĮĶń“Ľ÷÷ľŗ∂Ĺ—ßŌįň„∑®£¨įŁļ¨ŌŖ–‘ļÕ∑«ŌŖ–‘ŃĹ÷÷ń£–Õ£¨∂‘”ŕŌŖ–‘≤ĽŅ…∑÷ő Ő‚£¨Õ®≥£ĽŠľ”»ŽļňļĮ żĹÝ––ī¶ņŪ°£
÷ß≥÷ŌÚŃŅĽķĪĺ÷ …Ō «“ĽłŲ∂Ģņŗ∑÷ņŗ∑Ĺ∑®£¨ňŁĶńĽýĪĺń£–Õ «∂®“Ś‘ŕŐō’ųŅ’ľš…ŌĶńľšłŰ◊ÓīůĽĮĶńŌŖ–‘∑÷ņŗ∆ų£¨ľšłŰ◊ÓīůĽĮ ĻňŁ”–Īū”ŕł–÷™Ľķ°£∂‘”ŕŌŖ–‘Ņ…∑÷Ķń—ĶŃ∑ľĮ£¨ł–÷™ĽķĶń∑÷ņŽ≥¨∆Ĺ√ś «≤Ľő®“ĽĶń£¨ĽŠ”–őř«ÓłŲ£¨∂Ý÷ß≥÷ŌÚŃŅĽķĽŠ∂‘∑÷ņŽ≥¨∆Ĺ√ś‘Ųľ”‘ľ ÝŐűľĢ£¨ ĻĶ√∑÷ņŗ≥¨∆Ĺ√śő®“Ľ°£
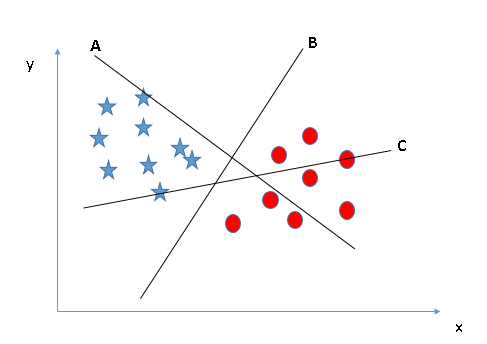
ľŔ…Ťő“√«”–“Ľ◊ť∑÷ Ű”ŕŃĹņŗĶń∂Ģő¨Ķ„£¨∑÷Īū”√–«ļÕ‘≤ĪŪ ĺ£¨’‚–©Ķ„Ņ…“‘Õ®Ļż÷ĪŌŖ∑÷łÓ£¨ő“√«–Ť“™’“ĶĹ“ĽŐű◊Ó”ŇĶń∑÷łÓŌŖ:
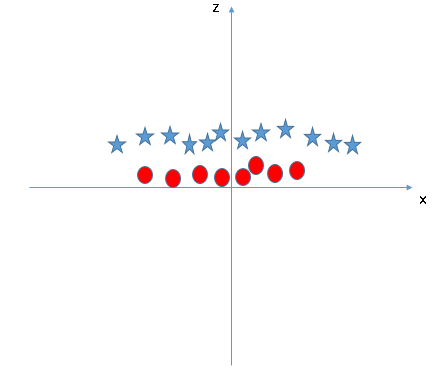
1.’“ĶĹ’ż»∑Ķń≥¨∆Ĺ√ś£®≥°ĺį1£©£ļ’‚ņÔ£¨ő“√«”–»żłŲ≥¨∆Ĺ√ś(A°ĘB°ĘC)£¨ő“√«–Ť“™’“ĶĹ’ż»∑Ķń≥¨∆Ĺ√śņī∑÷łÓ–«ļÕ‘≤£ļ
ő“√«ĶńńŅĶń «—°‘ŮłŁļ√Ķō∑÷łÓŃĹłŲņŗĶń≥¨∆Ĺ√ś£¨“Úīň…ŌÕľ÷–Ņ…“‘ŅīĶĹ≥¨∆Ĺ√ś B “—ĺ≠ń‹ĻĽÕÍ≥…∑÷łÓĶńĻ§◊ų°£
2.’“ĶĹ’ż»∑Ķń≥¨∆Ĺ√ś£®≥°ĺį2£©£ļÕ¨—ý”–»żłŲ≥¨∆Ĺ√ś(A°ĘB°ĘC)£¨ő“√«–Ť“™’“ĶĹ’ż»∑Ķń≥¨∆Ĺ√śņī∑÷łÓ–«ļÕ‘≤£ļ
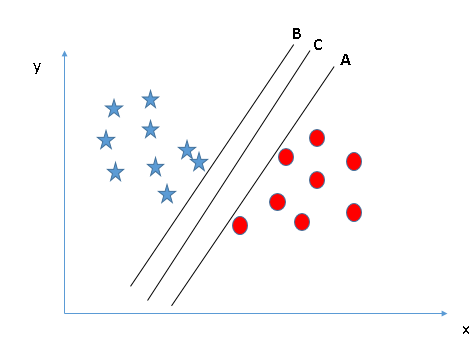
…ŌÕľ÷–£¨’Ž∂‘»ő“‚“ĽłŲņŗ£¨◊ÓīůĽĮ◊ÓĹŁĶń żĺ›Ķ„ļÕ≥¨∆Ĺ√ś÷ģľšĶńĺŗņŽĹę”–÷ķ”ŕő“√«—°‘Ů’ż»∑Ķń≥¨∆Ĺ√ś£¨’‚łŲĺŗņŽ≥∆ő™ĪŖĺŗ£¨»ÁŌ¬Õľ£ļ
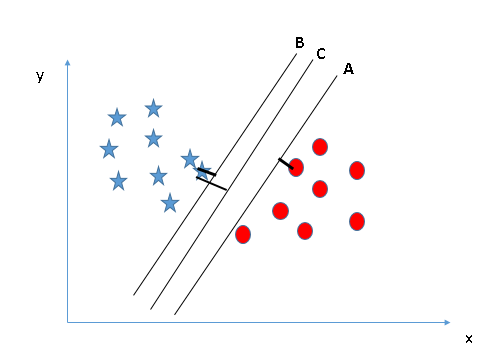
Ņ…“‘ŅīĶĹ£¨≥¨∆Ĺ√śCĺŗņŽŃĹłŲņŗĪūĶńĪŖ‘ĶĪ»AļÕB∂ľ“™łŖ£¨“Úīňő“√«Ĺę≥¨∆Ĺ√śC∂®ő™◊Ó”ŇĶń≥¨∆Ĺ√ś°£—°‘ŮĪŖĺŗ◊ÓłŖĶń≥¨∆Ĺ√śĶńŃŪ“ĽłŲ÷ō“™Ķń‘≠“Ú «¬≥įŰ–‘£¨ľŔ…Ťő“√«—°‘Ů◊ÓĶÕĪŖĺŗĶń≥¨∆Ĺ√ś£¨ń«√ī∑÷ņŗĹŠĻŻĶńīŪőů¬ Ĺ꼊ľęīůĶń…żłŖ°£
3.’“ĶĹ’ż»∑Ķń≥¨∆Ĺ√ś£®≥°ĺį3£©£ļÕ¨—ý”–»żłŲ≥¨∆Ĺ√ś(A°ĘB°ĘC)£¨ő“√« Ļ”√≥°ĺį2ĶńĻś‘Ú—į’“’ż»∑Ķń≥¨∆Ĺ√śņī∑÷łÓ–«ļÕ‘≤£ļ
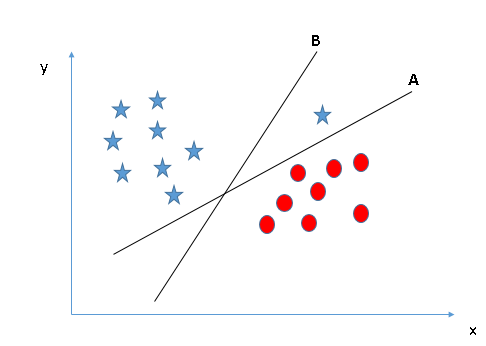
Ņ…ń‹ŅīĶĹ…ŌÕľ£¨Ķŕ“Ľ”°Ōů◊Ó”ŇĶń≥¨∆Ĺ√ś «B£¨“Úő™ňŁĪ»≥¨∆Ĺ√śA”–łŁłŖĶńĪŖĺŗ°£Ķę «£¨’‚ņÔ «“Ľ÷÷“‚Õ‚«ťŅŲ£¨÷ß≥÷ŌÚŃŅĽķĽŠ—°‘Ů‘ŕĹęĪŖĺŗ◊ÓīůĽĮ÷ģ«į∂‘ņŗĹÝ––ĺę»∑∑÷ņŗĶń≥¨∆Ĺ√ś°£’‚ņÔ£¨≥¨∆Ĺ√śBĺŖ”–∑÷ņŗőů≤Ó£¨≥¨∆Ĺ√śA“—ĺ≠’ż»∑Ķń∑÷ņŗ£¨“Úīňīň«ťŅŲŌ¬£¨◊Ó”Ň≥¨∆Ĺ√ś‘Ú «A°£
4.ń‹ĻĽ∑÷ņŗŃĹłŲņŗĪū£®≥°ĺį4£©£ļ’Ž∂‘ņŻ»ļĶ„«ťŅŲ£¨—į’“◊Ó”Ň≥¨∆Ĺ√ś£ļ
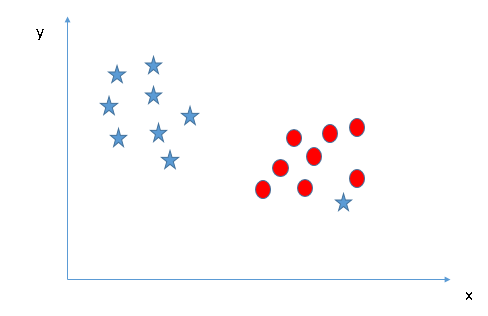
…ŌÕľ÷–£¨“ĽłŲ–«≥ŲŌ÷‘ŕŃň‘≤ňý‘ŕĶń«Ý”Úńŕ£¨īň–«Ņ…≥∆ő™ņŻ»ļĶ„°£Ķę «÷ß≥÷ŌÚŃŅĽķĺŖ”–ļŲ¬‘“ž≥£Ķ„≤Ę’“ĶĹĺŖ”–◊ÓīůĪŖĺŗĶń≥¨∆Ĺ√śĶńŐō’ų£¨“Úīň£¨Ņ…“‘ňĶ£¨÷ß≥÷ŌÚŃŅĽķ «¬≥įŰ–‘Ķń°£◊Ó÷’◊Ó”Ň≥¨∆Ĺ√ś»ÁŌ¬Õľňý ĺ£ļ
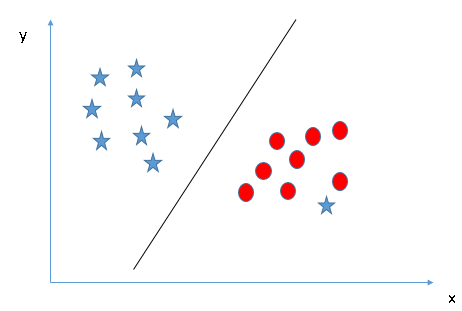
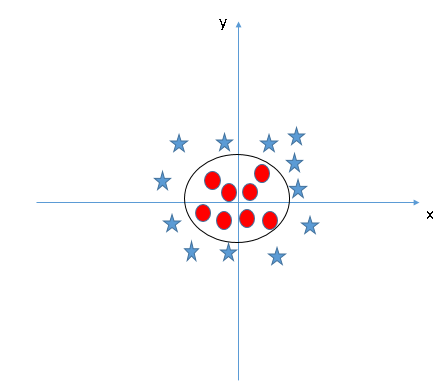
5.’“ĶĹ≥¨∆Ĺ√ś≤Ę∑÷ņŗ£®≥°ĺį5£©£ļ“‘…ŌĶń≥°ĺįĺý «ŌŖ–‘≥¨∆Ĺ√ś°£‘ŕŌ¬√śĶń≥°ĺį÷–£¨ő“√«őř∑®÷ĪĹ”‘ŕŃĹłŲņŗ÷ģľš’“ĶĹŌŖ–‘≥¨∆Ĺ√ś£¨ń«√ī÷ß≥÷ŌÚŃŅĽķ»Áļő∑÷ņŗ’‚ŃĹłŲņŗńō£Ņ
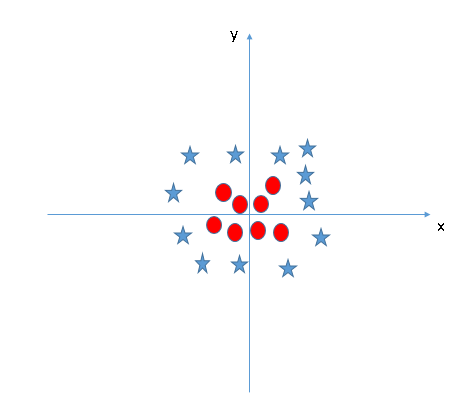
÷ß≥÷ŌÚŃŅĽķŅ…“‘«Šň…ĶńĹ‚ĺŲ£¨ňŁ“ż»ŽŃň“Ľ–©łĹľ”ĶńŐō–‘ņīĹ‚ĺŲīňņŗő Ő‚°£’‚ņÔ£¨ő“√«ŐŪľ”“ĽłŲ–¬ĶńŐō’ų°£÷ō–¬Ľś÷∆◊ÝĪÍ÷Š…ŌĶń żĺ›Ķ„»ÁŌ¬£ļ
‘ŕ÷ß≥÷ŌÚŃŅĽķ÷–£¨“—ĺ≠ļ‹»›“◊‘ŕ’‚ŃĹłŲņŗ÷ĪĹ”’“ĶĹŌŖ–‘≥¨∆Ĺ√śŃň£¨Ķę «£¨≥ŲŌ÷ĶńŃŪ“ĽłŲ÷ō“™Ķńő Ő‚ «£¨ő“√« «∑Ů“™ ÷∂Įī¶ņŪ’‚—ýĶńő Ő‚ńō£ŅĶĪ»Ľ≤Ľ–Ť“™£¨‘ŕ÷ß≥÷ŌÚŃŅĽķ÷–£¨”–“ĽłŲļňļĮ żĶńľľ ű£¨ňŁĽŠĹęĶÕő¨Ņ’ľšĶń š»Ž◊™ĽĽő™łŖő¨Ņ’ľš£¨–ő≥…”≥…š°£”…īňĽŠĹęń≥–©≤ĽŅ…∑÷Ķńő Ő‚◊™ĽĽő™Ņ…∑÷ő Ő‚£¨÷ų“™”√”ŕ“Ľ–©∑«ŌŖ–‘∑÷ņŗő Ő‚÷–°£
ĶĪő“√«≤ťŅī≥°ĺį5÷–Ķń≥¨∆Ĺ√ś «£¨Ņ…ń‹ĽŠ»ÁŌ¬Õľňý ĺ£ļ
“‘…ŌĹŲĹŲ «Ļō”ŕ÷ß≥÷ŌÚŃŅĽķĶń“ĽĶ„Ĺť…‹£¨÷ß≥÷ŌÚŃŅĽķ”–’‚łī‘”Ķńň„∑®“‘ľįÕÍĪłĶń÷§√ų£¨’‚ņÔ≤Ľ‘ŔņŘ Ų£¨Ņ…≤őŅľSupport_vector_machine≤ťŅī—ßŌį°£
∂‘”ŕ÷ß≥÷ŌÚŃŅĽķņīňĶ£¨Ī»ĹŌ”–√ŻĶńņŗŅ‚ĶĪ ŰŐ®ÕŚīů—ßŃ÷÷«» (LinChih-Jen)ĹŐ ŕňýĻĻĹ®ĶńLIBSVMņŗŅ‚£¨”…”ŕLIBSVM≥Ő–Ú–°£¨‘ň”√ŃťĽÓ£¨ š»Ž≤ő ż…Ŕ£¨≤Ę«“ «Ņ™‘īĶń£¨“◊”ŕņ©’Ļ£¨“Úīň≥…ő™ńŅ«į”¶”√◊Ó∂ŗĶń÷ß≥÷ŌÚŃŅĽķĶńŅ‚°£
ŃŪÕ‚ĽĻŐŠĻ©Ńň∂ŗ÷÷”Ô—‘ĶńĹ”Ņŕ£¨Ī„”ŕ‘ŕ≤ĽÕ¨Ķń∆ĹŐ®Ō¬ Ļ”√£¨Īĺőń÷– Ļ”√Ķń“≤ «’‚łŲņŗŅ‚°£ Ļō”ŕMacŌ¬īňņŗŅ‚ĶńĪŗ“Žį≤◊į£¨«Ž≤őŅľőńĶĶInstall
libsvm on Mac OSX£¨ĪĺőńĽŠ‘ŕMacŌ¬ĹÝ––—ĶŃ∑ żĺ›‘§ī¶ņŪ°Ęń£–Õ—ĶŃ∑°Ę≤ő żĶų”ŇĶ»£¨◊Ó÷’Ķ√ĶĹń£–ÕĽŠ Ļ”√‘ŕiOSŌÓńŅ÷–£¨ĶĪ»Ľł√ń£–Õ“≤Ņ…“‘ Ļ”√‘ŕAndroid“‘ľį∆šňŻ»őļőŅ…“‘ Ļ”√ĶńĶō∑Ĺ°£
’Ž∂‘÷ß≥÷ŌÚŃŅĽķ“‘ľįLIBSVMŌÍŌłĶńĹť…‹£¨Ņ…≤ťŅīĻŔ∑ĹłÝ≥ŲĶńőńĶĶ£ļPDF
īęł–∆ų żĺ›ľĮ
Īĺőń Ļ”√Ńň WISDM (Wireless Sensor Data Mining) Lab Ķ—ť “ĻęŅ™Ķń
Actitracker Ķń żĺ›ľĮ°£ WISDM ĻęŅ™ŃňŃĹłŲ żĺ›ľĮ£¨“ĽłŲ «‘ŕ Ķ—ť “Ľ∑ĺ≥≤…ľĮĶń£ĽŃŪ“ĽłŲ «‘ŕ’ś Ķ Ļ”√≥°ĺį÷–≤…ľĮĶń£¨’‚ņÔ Ļ”√Ķń « Ķ—ť “Ľ∑ĺ≥≤…ľĮĶń żĺ›°£
1.≤‚ ‘ľ«¬ľ£ļ1,098,207 Őű
2.≤‚ ‘»ň ż£ļ36 »ň
3.≤…—ý∆Ķ¬ £ļ20 Hz
4.––ő™ņŗ–Õ£ļ6 ÷÷
◊Ŗ¬∑
¬żŇ‹
…Ō¬•Ő›
Ō¬¬•Ő›
◊Ý
’ĺŃĘ
5.īęł–∆ųņŗ–Õ£ļľ”ňŔ∂»
6.≤‚ ‘≥°ĺį£ļ ÷Ľķ∑Ň‘ŕ“¬∂ĶņÔ√ś
żĺ›∑÷őŲ
ī” Ķ—ť “≤…ľĮ żĺ›Ō¬‘ōĶō÷∑Ō¬‘ō żĺ›ľĮ—ĻňűįŁ£¨Ĺ‚—ĻļůŅ…“‘ŅīĶĹŌ¬√ś’‚–©őńľĢ£ļ
readme.txt
WISDM_ar_v1.1_raw_about.txt
WISDM_ar_v1.1_trans_about.txt
WISDM_ar_v1.1_raw.txt
WISDM_ar_v1.1_transformed.arff |
ő“√«–Ť“™Ķń «įŁļ¨ RAW żĺ›ĶńWISDM_ar_v1.1_raw.txt őńľĢ£¨∆šňŻĶń «◊™ĽĽļůĶńĽÚ’ŖňĶ√ųőńľĢ°£Ō»ŅīŅī’‚–© żĺ›Ķń∑÷≤ľ«ťŅŲ£ļ
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import precision
_score, recall_score, f1_score, confusion
_matrix, roc_curve, auc
if __name__ == "__main__":
column_names = ['user-id', 'activity',
'timestamp', 'x-axis', 'y-axis', 'z-axis']
df = pd.read_csv("WISDM_ar_v1.1_raw.txt
", header=None, names=column_names)
n = 10
print df.head(n)
subject = pd.DataFrame(df["user-id"]
.value_counts(), columns=["Count"])
subject.index.names = ['Subject']
print subject.head(n)
activities = pd.DataFrame(df["activity"]
.value_counts(), columns=["Count"])
activities.index.names = ['Activity']
print activities.head(n)
activity_of_subjects = pd.DataFrame(df
.groupby("user-id")["activity"].
value_counts())
print activity_of_subjects.unstack()
.head(n)
activity_of_subjects.unstack().
plot(kind='bar', stacked=True,
colormap='Blues', title="Distribution")
plt.show() |
WISDM_ar_v1.1_raw.txt őńľĢ≤Ľ «ļŌ∑®Ķń CSV
őńľĢ£¨√Ņ––ļů√ś”–łŲ ; ļŇ£¨»ÁĻŻ Ļ”√ Pandas Ķń read_csv∑Ĺ∑®÷ĪĹ”ľ”‘ōĽŠ≥ŲīŪ£¨–Ť“™Ō»Ĺę’‚–©∑÷ļŇ»ę≤Ņ…ĺ≥ż°£
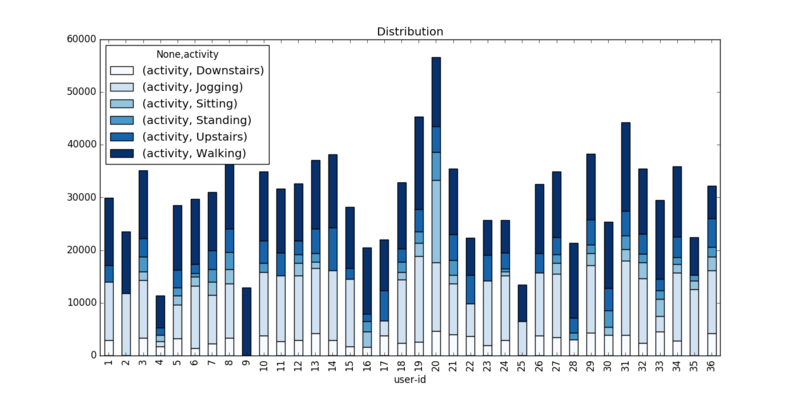
≤ťŅī żĺ›ľĮłųłŲ––ő™Ķń’ľĪ»«ťŅŲ£¨Ľś÷∆ĪżÕľ»ÁŌ¬£ļ
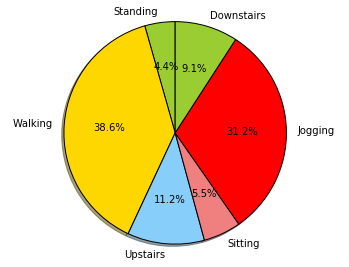
Ņ…“‘ŅīĶĹīň żĺ›ľĮ «“ĽłŲ≤Ľ∆Ĺļ‚Ķń żĺ›ľĮ£¨Ķę «’‚ņÔ‘› ĪļŲ¬‘∆š≤Ľ∆Ĺļ‚–‘°£
żĺ›‘§ī¶ņŪ
‘ŕLIBSVMĶńĻŔ∑ĹőńĶĶ÷–Ņ…“‘ŅīĶĹ£¨LIBSVMňý Ļ”√Ķń żĺ›ľĮ «”–—ŌłŮĶńłŮ ĹĻś∑∂£ļ
<label> <index1>:<value1>
<index2>:<value2> ... |
<label>£ļ∂‘”ŕ∑÷ņŗő Ő‚īķĪŪ—ýĪĺĶńņŗĪū£¨ Ļ”√’Ż żĪŪ ĺ£¨÷ß≥÷∂ŗłŲņŗĪū£Ľ∂‘”ŕĽōĻťő Ő‚īķĪŪńŅĪÍĪšŃŅ£¨Ņ…“‘ «»ő“‚ Ķ ż°£
<index1>:<value1>£ļĪŪ ĺŐō’ųŌÓ°£∆š÷– <index>
īķĪŪŐō’ųŌÓĶńĪŗļŇ£¨ Ļ”√ī” 1 Ņ™ ľĶń’Ż żĪŪ ĺ£¨Ņ…“‘≤ĽŃ¨–Ý£Ľ<value> īķĪŪł√Őō’ųŌÓ∂‘”¶ĶńŐō’ų÷Ķ£¨ Ļ”√ Ķ żĪŪ ĺ°£‘ŕ Ķľ Ķń≤Ŕ◊ų÷–£¨»ÁĻŻ—ýĪĺ»Ī…Ŕń≥łŲŐō’ųŌÓ£¨Ņ…“‘÷ĪĹ” °¬‘£¨LIBSVM
ĽŠ◊‘∂Įį—ł√ŌÓĶńŐō’ų÷Ķł≥ő™ 0°£
ĪÍ«©ļÕ√ŅŌÓŐō’ų÷ģľš Ļ”√Ņ’łŮ∑÷łÓ£¨√Ņ–– żĺ› Ļ”√\n∑÷łÓ°£
÷Ľ”–∑ŻļŌ’‚—ýłŮ ĹĶń żĺ›£¨≤Ňń‹ĻĽĪĽLIBSVM Ļ”√£¨∑Ů‘ÚĽŠ÷ĪĹ”Ī®īŪ°£’‚∂‘◊ľĪłļ√Ķń żĺ›£¨īňņŗŅ‚ĽĻŐŠĻ©Ńň“ĽłŲtools/checkdata.pyļň≤ťĻ§ĺŖ£¨“‘Ī„ļň≤ť żĺ›ľĮ «∑Ů∑ŻļŌ“™«ů°£’Ž∂‘Őō’ųĶńŐŠ»°£¨ő™ŃňľÚĶ•£¨’‚ņÔĹŲŐŠ»°őŚņŗŐō’ų£ļ
1.∆Ĺĺý÷Ķ
2.◊Óīů÷Ķ
3.◊Ó–°÷Ķ
4.∑Ĺ≤Ó
◊ťļŌ»ż÷ŠĶńľ”ňŔ∂»÷Ķ math.sqrt(math.pow(acc_x, 2)+math.pow(acc_y,
2)+math.pow(acc_z, 2))
ŃňĹ‚Ńňňý–Ť“™Ķń żĺ›łŮ Ĺļů£¨Ņ™ ľĹÝ–– żĺ›Ķń‘§ī¶ņŪ£¨≤Ę◊™ĽĽő™ňý–Ť“™ĶńłŮ ĹőńľĢ°£Ĺ”Ō¬ņī∑÷ĪūĹę—ĶŃ∑ļÕ≤‚ ‘ żĺ›ľĮĹÝ––Őō’ų≥ť»°≤Ęįī’’LIBSVMĶń żĺ›łŮ Ĺ÷ō◊ť£¨īķ¬Ž»ÁŌ¬£ļ
import ast
import math
import numpy as np
FEATURE = ("mean", "max",
"min",
"std")
STATUS = ("Sitting", "Walking",
"Upstairs", "Downstairs",
"Jogging", "Standing")
def preprocess(file_dir,
Seg_granularity):
gravity_data = []
with open(file_dir) as f:
index = 0
for line in f:
clear_line = line.strip().lstrip
().rstrip(';')
raw_list = clear_line.split(',')
index = index + 1
if len(raw_list) < 5:
continue
status = raw_list[1]
acc_x = float(raw_list[3])
acc_y = float(raw_list[4])
print index
acc_z = float(raw_list[5])
if acc_x == 0 or acc_y == 0
or acc_z == 0:
continue
gravity = math.sqrt(math.pow
(acc_x, 2)+math.pow(acc_y, 2)
+math.pow(acc_z, 2))
gravity_tuple = {"gravity":
gravity, "status": status}
gravity_data.append(gravity_tuple)
# split data sample of gravity
splited_data = []
cur_cluster = []
counter = 0
last_status = gravity_data[0]
["status"]
for gravity_tuple in gravity_data:
if not (counter < Seg_granularity
and gravity_tuple["status"] ==
last_status):
seg_data = {"status": last_status,
"values": cur_cluster}
# print seg_data
splited_data.append(seg_data)
cur_cluster = []
counter = 0
cur_cluster.append(gravity_tuple
["gravity"])
last_status = gravity_tuple["status"]
counter += 1
# compute statistics of gravity data
statistics_data = []
for seg_data in splited_data:
np_values = np.array(seg_data.pop
("values"))
seg_data["max"] = np.amax(np_values)
seg_data["min"] = np.amin(np_values)
seg_data["std"] = np.std(np_values)
seg_data["mean"] = np.mean(np_values)
statistics_data.append(seg_data)
# write statistics result into a
file in format of LibSVM
with open("WISDM_ar_v1.1_raw_svm.
txt", "a") as the_file:
for seg_data in statistics_data:
row = str(STATUS.index(seg_data
["status"])) + " " + \
str(FEATURE.index("mean")) + ":"
+
str(seg_data["mean"]) + " "
+ \
str(FEATURE.index("max")) + ":"
+
str(seg_data["max"]) + " "
+ \
str(FEATURE.index("min")) + ":"
+
str(seg_data["min"]) + " "
+ \
str(FEATURE.index("std")) + ":"
+
str(seg_data["std"]) + "\n"
# print row
the_file.write(row)
if __name__ == "__main__":
preprocess("WISDM_ar_v1.1_raw.txt",
100)
pass |
≥…Ļ¶◊™ĽĽļůĶń żĺ›łŮ Ĺ–ő»Á£ļ
.
.
.
5 0:9.73098373254 1:10.2899465499 2:9
.30995703535 3:0.129482033438
5 0:9.74517171235 1:10.449291842 2:9.
15706284788 3:0.161143714697
5 0:9.71565678822 1:10.4324206204 2:9.
41070666847 3:0.136704694206
5 0:9.70622803003 1:9.7882020821 2:9.
60614907234 3:0.0322246639852
5 0:9.74443440742 1:10.2915256401 2:9
.28356073929 3:0.165543789197
0 0:9.28177794859 1:9.47500395778 2:8
.92218583084 3:0.0700079500015
0 0:9.27218416165 1:9.40427562335 2:9.
14709243421 3:0.0433805537826
0 0:9.27867211792 1:9.39755287296 2:9
.1369415014 3:0.037533026091
0 0:9.27434585368 1:9.33462907672 2:9
.21453200114 3:0.0263815511773
.
.
. |
”…”ŕł√ żĺ›ľĮ≤Ęőī«Ý∑÷—ĶŃ∑ļÕ≤‚ ‘ żĺ›ľĮ£¨“Úīňő™Ńň◊Ó÷’Ķńń£–Õ—ť÷§£¨ ◊Ō»–Ť“™∑÷łÓł√ żĺ›ľĮő™ŃĹ∑›£¨∑÷ĪūĹÝ––—ĶŃ∑ļÕń£–Õ—ť÷§£¨∑÷łÓ∑Ĺ∑®ĺÕ Ļ”√◊ÓľÚĶ•Ķń2\8‘≠‘Ú£¨ Ļ”√LIBSVMŐŠĻ©ĶńĻ§ĺŖtools/subset.pyĹÝ–– żĺ›∑÷łÓ£ļ
Ļ§ĺŖ Ļ”√Ĺť…‹£ļ
Usage: subset.py [options] dataset
subset_size [output1] [output2]
This script randomly selects
a subset of the dataset.
options:
-s method : method of selection (default 0)
0 -- stratified selection
(classification only)
1 -- random selection
output1 : the subset (optional)
output2 : rest of the data (optional)
If output1 is omitted, the subset
will be printed on the screen. |
Ļ”√Ļ§ĺŖĹÝ–– żĺ›∑÷łÓ£ļ
python subset.py -s 0 WISDM_ar_v1.1_raw
_svm.txt 2190 raw_test.txt raw_train.txt |
!! ◊Ę“‚ !!
…Ō√śīķ¬Ž∂ő÷–Ķń2190ĺÕ «subset.pyĻ§ĺŖ◊” żĺ›ľĮĶńīů–°£¨ł√īů–°≤Ę≤Ľ «őńľĢĶńīů–°£¨∂Ý «łý囑≠ ľőńľĢ÷–Ķń–– żĹÝ––2\8∑÷ļůĶń–– ż°£subset.pyĽŠňśĽķ≥ť»°ňý…Ť÷√–– żĶń żĺ›ĶĹ÷ł∂®ĶńőńľĢ÷–°£
svm-train -b 1 raw_train.txt
raw_trained.model |
ÕÍ≥…ļů£¨ő“√«ĺÕĶ√ĶĹŃň—ĶŃ∑ żĺ›ľĮraw_train.txtļÕ≤‚ ‘ żĺ›ľĮraw_test.txt°£
ĶĹīň£¨ňý–Ť“™ Ļ”√Ķń żĺ›ľĮ“—ĺ≠ÕÍ»ę◊™ĽĽő™LIBSVMňý–Ť“™ĶńłŮ Ĺ£¨»ÁĻŻ≤Ľ∑Ň–ń żĺ›łŮ Ĺ£¨Ņ…“‘ Ļ”√tools/checkdata.pyĻ§ĺŖĹÝ––ľž≤ť°£
ń£–ÕīīĹ®”Ž—ĶŃ∑
‘ŕĻō”ŕ÷ß≥÷ŌÚŃŅĽķ≤Ņ∑÷£¨»ÁĻŻ“—ĺ≠‘ŕMac…Ōį≤◊įļ√Ńňlibsvm£¨ń«√ī‘ŕń„Ķń√ŁŃÓ––Ļ§ĺŖ÷– š»Žsvm-train£¨ľīŅ…ŅīĶĹīň√ŁŃÓĶń Ļ”√∑Ĺ ĹļÕ≤ő żňĶ√ų£¨ľŔ…Ťő“√« Ļ”√ń¨»ŌĶń≤ő żĹÝ––ń£–Õ—ĶŃ∑£ļ
svm-train -b 1 raw_train.txt
raw_trained.model |
∆š÷–-b Ķńļ¨“Ś «probability_estimates£¨ «∑Ů—ĶŃ∑“ĽłŲSVCĽÚ’ŖSVRń£–Õ”√”ŕłŇ¬ Õ≥ľ∆£¨…Ť÷√ő™1£¨“‘Ī„◊Ó÷’Ķńń£–Õ∆ņĻņ Ļ”√°£
—ĶŃ∑Ļż≥ŐĶńŅ…ń‹ĽŠŌŻļń“ĽĶ„ Īľš£¨÷ų“™‘ŕ”ŕňý Ļ”√Ķń—ĶŃ∑ żĺ›ľĮĶńīů–°£¨—ĶŃ∑ ĪĶń»’÷ĺ š≥Ų–ő»Á£ļ
.
.
.
optimization finished, #iter = 403
nu = 0.718897
obj = -478.778647, rho = -0.238736
nSV = 508, nBSV = 493
Total nSV = 508
*
optimization finished, #iter = 454
nu = 0.734417
obj = -491.057723, rho = -0.318206
nSV = 518, nBSV = 507
Total nSV = 518
*
optimization finished, #iter = 469
nu = 0.722888
obj = -604.608449, rho = -0.360926
nSV = 636, nBSV = 622
Total nSV = 4136
.
.
. |
∆š÷–£ļ#iter «ĶŁīķīő ż£¨nu «—°‘ŮĶńļňļĮ żņŗ–ÕĶń≤ő ż£¨obj ő™ SVM őńľĢ◊™ĽĽő™Ķń∂ĢīőĻśĽģ«ůĹ‚Ķ√ĶĹĶń◊Ó–°÷Ķ£¨rho
ő™Ň–ĺŲļĮ żĶń∆ę÷√ŌÓ b£¨nSV «ĪÍ◊ľ÷ß≥÷ŌÚŃŅłŲ ż£®0 < a[i] < c£©£¨nBSV
«ĪŖĹÁ…ŌĶń÷ß≥÷ŌÚŃŅłŲ ż£®a[i] = c£©£¨Total nSV «÷ß≥÷ŌÚŃŅ◊‹łŲ ż°£
’‚—ýő“√«ĺÕĶ√ĶĹŃňń£–ÕőńľĢraw_trained.model£¨ ◊Ō» Ļ”√ń„ňý žŌ§ĶńőńĪĺĪŗ“ŽĻ§ĺŖīÚŅ™īňőńľĢ£¨»√ő“√«≤ťŅī“ĽŌ¬īňőńľĢ÷–Ķńńŕ»›£ļ
svm_type c_svc //ňý—°‘ŮĶń svm
ņŗ–Õ£¨ń¨»Ōő™ c_svc
kernel_type rbf //—ĶŃ∑≤…”√Ķńļň
ļĮ żņŗ–Õ£¨īňī¶ő™ RBF ļň
gamma 0.333333 //RBF ļňĶń
gamma ŌĶ ż
nr_class 6 //ņŗĪū ż£¨
īňī¶ő™Ńý‘™∑÷ņŗő Ő‚
total_sv 4136 //÷ß≥÷
ŌÚŃŅ◊‹łŲ ż
rho -0.369589 -0.28443 -0.352834
-0.852275 -0.831555 0.267266 0.158289
-0.777357 -0.725441 -0.271317
-0.856933 -0.798849 -0.807448
-0.746674 -0.360926
//Ň–ĺŲļĮ żĶń∆ę÷√ŌÓ b
label 4 1 2 3 0 5 //ņŗĪūĪÍ ∂
probA -3.11379 -3.0647 -3.2177 -5.
78365 -5.55416 -2.30133 -2.26373
-6.05582 -5.99505 -1.07317 -4.50318
-4.51436 -4.48257 -4.71033 -1.18804
probB 0.099704 -0.00543388 -0.240146
-0.43331 -1.01639 0.230949 0.342831
-0.249265 -0.817104 -0.0249471
-0.209852 -0.691243 -0.0803133
-0.940074 0.272984
nr_sv 558 1224 880 825 325 324
//√ŅłŲņŗĶń÷ß≥÷ŌÚŃŅĽķĶńłŲ ż
SV
//“‘Ō¬ő™łųłŲņŗĶń»®ŌĶ ż
ľįŌŗ”¶Ķń÷ß≥÷ŌÚŃŅ
1 0 0 0 0 0:14.384883 1:24.
418964 2:2.5636304 3:5.7143112
1 1 1 0 0 0:11.867873 1:23.
548919 2:4.5479318 3:4.5074937
1 0 0 0 0 0:14.647238 1:24.
192184 2:4.0759445 3:5.367968
1 0 0 0 0 0:14.374831 1:24
.286867 2:2.0045062 3:5.5710882
1 0 0 0 0 0:14.099495 1:24
.03442 2:2.42664 3:5.7580063
1 0 0 0 0 0:14.313538 1:25.
393975 2:1.9496137 3:5.6174387
... |
Ķ√ĶĹń£–ÕőńľĢ÷ģļů£¨ ◊Ō»“™ĹÝ––ĶńĺÕ «ń£–ÕĶń≤‚ ‘—ť÷§£¨ĽĻľ«Ķ√Ņ™ ľĹÝ–– żĺ›◊ľĪłĶń ĪļÚ£¨ő“√«∑÷łÓŃň—ĶŃ∑ļÕ≤‚ ‘ żĺ›ľĮ¬ū£Ņ—ĶŃ∑ żĺ›ľĮĹÝ––Ńňń£–ÕĶń—ĶŃ∑£¨Ĺ”Ō¬ņīĺÕ «≤‚ ‘ żĺ›ľĮ∑ĘĽ”◊ų”√Ķń ĪļÚŃň°£
—ť÷§ń£–Õ£¨LIBSVMŐŠĻ©ŃňŃŪ“ĽłŲ√ŁŃÓ∑Ĺ∑®svm-predict£¨ Ļ”√Ĺť…‹»Á
Usage: svm-predict [options]
test_file model_file output_file
options:
-b probability_estimates: whether
to predict probability estimates,
0 or 1 (default 0);
for one-class SVM only 0 is supported
-q : quiet mode (no outputs) |
Ō¬£ļ
Ļ”√≤‚ ‘ żĺ›ľĮĹÝ––ń£–Õ—ť÷§£ļ
svm-predict -b 1 raw_test.txt
raw_trained.model predict.out |
÷ī––īň√ŁŃÓļů£¨LIBSVMĽŠĹÝ–– ∂Īū‘§≤‚£¨”…”ŕő“√« Ļ”√Ńň-b 1≤ő ż£¨“Úīň◊Ó÷’ĽŠ š≥ŲłųłŲņŗĪūĶń ∂ĪūłŇ¬ ĶĹpredict.outőńľĢ÷–£¨≤Ę«“ĽŠ š≥Ų“ĽłŲ◊‹ŐŚĶń’ż»∑¬ £ļ
Accuracy = 78.4932% (1719/2190)
(classification) |
Ņ…“‘ŅīĶĹīň Īő“√«—ĶŃ∑Ķńń£–ÕĶń ∂Īū’ż»∑¬ ő™78.4932%°£
predict.out őńľĢńŕ»›–ő»Á£ļ
labels 4 1 2 3 0 5
4 0.996517 0.000246958 0.00128824
0.00123075 0.000414204 0.000303014
4 0.993033 0.000643327 0.00456298
0.00103339 0.000427387 0.000299934
1 0.0117052 0.773946 0.128394
0.0848292 0.00065714 0.0004682
1 0.0135437 0.484226 0.343907
0.156548 0.00105013 0.0007251
1 0.0117977 0.885448 0.0256842
0.0761578 0.000513167 0.000399136
3 0.00581106 0.380545 0.120613
0.490377 0.00179286 0.000861917
1 0.0117571 0.91544 0.0145561
0.0573158 0.000524352 0.000406782
1 0.0122297 0.811546 0.0824789
0.0924932 0.000704449 0.000547972 |
∆š÷–£¨Ķŕ“Ľ––ő™ĪŪÕ∑£¨Ķŕ“ĽŃ– « ∂Īū≥ŲĶńņŗĪūĪÍ«©£¨ļů√ś“ņīőłķ◊ŇłųłŲĪÍ«©Ķń ∂ĪūłŇ¬ °£
ń«√īő Ő‚ņīŃň£¨ń—Ķņń£–ÕĶń ∂Īū’ż»∑¬ ĺÕ÷Ľń‹ĶĹ’‚łŲ≥Ő∂»Ńň¬ū£Ņő“√«‘ŔīőĽōĻňsvm-train√ŁŃÓ£¨∆š÷–”–ļ‹∂ŗĶń≤ő żő“√«∂ľ Ļ”√Ńňń¨»ŌĶń…Ť÷√£¨≤Ę√Ľ”–ĹÝ––Őō∂®Ķń…Ť÷√°£Õ®Ļż≤ťŅīLIBSVMĻŔ∑ĹĶńőńĶĶ£¨∑ĘŌ÷ĺĻ»ĽŐŠĻ©Ńň≤ő ż—į”ŇĶńĻ§ĺŖtools/grid.py£¨Õ®ĻżīňĻ§ĺŖŅ…“‘◊‘∂Į—į’“—ĶŃ∑ żĺ›ľĮ÷–Ķń◊Ó”Ň≤ő żCŌĶ żļÕgammaŌĶ ż£¨“‘‘ŕ—ĶŃ∑Ķń ĪļÚ Ļ”√°£ĺŖŐŚ”√∑®»ÁŌ¬£ļ
Usage: grid.py [grid_options]
[svm_options] dataset
grid_options :
-log2c {begin,end,step | "null"}
: set the range of c (default -5,15,2)
begin,end,step -- c_range = 2^{begin
,...,begin+k*step,...,end}
"null" -- do not grid with c
-log2g {begin,end,step | "null"} :
set the range of g (default 3,-15,-2)
begin,end,step -- g_range = 2^{begin,
...,begin+k*step,...,end}
"null" -- do not grid with g
-v n : n-fold cross validation (default 5)
-svmtrain pathname : set svm
executable path and name
-gnuplot {pathname | "null"} :
pathname -- set gnuplot executable
path and name
"null" -- do not plot
-out {pathname | "null"} :
(default dataset.out)
pathname -- set output file path
and name
"null" -- do not output file
-png pathname : set graphic output
file path and name (default
dataset.png)
-resume [pathname] : resume the grid
task using an existing output
file (default pathname is dataset.out)
This is experimental. Try this
option only if some parameters
have been checked for the SAME data.
svm_options : additional options
for svm-train |
”÷ «“Ľ∂—Ķń≤ő ż£¨Ķę «≤ĽĪōĶ£–ń£¨∂‘”ŕ≥ű—ß’ŖņīňĶ£¨’‚ņÔĶńīů≤Ņ∑÷≤ő ż∂ľŅ…“‘≤Ľ”√…Ť÷√£¨÷ĪĹ” Ļ”√ń¨»Ō÷ĶľīŅ…£¨»ÁĻŻń„–Ť“™≤ťŅī≤ő ż—į”ŇĶńĻż≥Ő£¨ĽĻ–Ť“™į≤◊įgnuplot≤Ęįī’’ĻŔ∑ĹňĶ√ųŇš÷√°£
python /tools/grid.py -b 1 raw_train.txt |
÷ī––īň√ŁŃÓļů£¨ĽŠ≤Ľ∂ŌĶń š≥Ų≤ĽÕ¨ĶńCŌĶ żļÕgammaŌĶ ż»°÷Ķ«ťŅŲŌ¬Ķń∑÷ņŗ◊ľ»∑¬ £¨≤Ę‘ŕ◊Óļů“Ľ–– š≥Ų◊Ó”ŇĶń≤ő ż—°‘Ů£ļ
...
[local] 13 -15 73.1217 (best c=8192
.0, g=0.03125, rate=79.3446)
[local] 13 3 72.8477 (best c=8192
.0, g=0.03125, rate=79.3446)
[local] 13 -9 77.8488 (best c=8192
.0, g=0.03125, rate=79.3446)
[local] 13 -3 78.3741 (best c=8192
.0, g=0.03125, rate=79.3446)
8192.0 0.03125 79.3446 |
≤Ę«“ĽŠ‘ŕĶĪ«įńŅ¬ľŌ¬…ķ≥… š≥ŲőńľĢraw_train.txt.outļÕ∂‘”¶ĶńÕľ–őőńľĢraw_train.txt.png£ļ
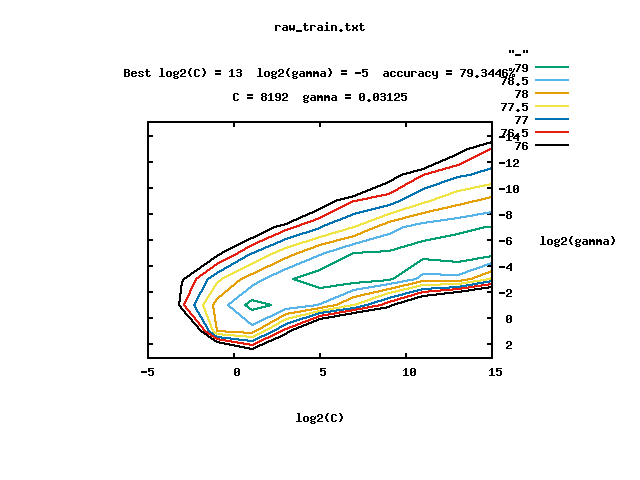
ĺ≠Ļż◊Ó”Ň≤ő żĶń—į’“£¨◊Ó÷’łÝ≥ŲŃňCŌĶ żő™8192.0£¨gammaŌĶ żő™0.03125Ķń«ťŅŲŌ¬£¨ń£–Õ∑÷ņŗĶń◊ľ»∑¬ ◊ÓłŖ£¨ő™79.3446°£
Ĺ”Ō¬ņīő“√«‘Ŕīő Ļ”√svm-train∑Ĺ∑®£¨≤Ę…Ť÷√ĶĪ«į◊Ó”ŇCŌĶ ż÷ĶļÕgammaŌĶ ż÷Ķ£¨÷ō–¬—ĶŃ∑ő“√«Ķńń£–Õ£ļ
svm-train -b 1 -c -g raw_train.
txt raw_bestP_trained.model |
—ĶŃ∑ÕÍ≥…ļů£¨Ķ√ĶĹ–¬Ķńń£–ÕőńľĢraw_bestP_trained.model£¨‘Ŕīő Ļ”√≤‚ ‘ żĺ›ľĮĹÝ––—ť÷§£ļ
svm-predict -b 1 raw_test.txt
raw_bestP_trained.model bestP_predict.out |
◊Ó÷’ š≥ŲĹŠĻŻ»ÁŌ¬£ļ
Accuracy = 79.1324% (1733/2190)
(classification) |
Ņ…“‘ŅīĶĹń£–ÕĶń‘§≤‚’ż»∑¬ √ųŌ‘ŐŠ…żŃň≤Ľ…Ŕ°£…Ō√śĶń≤ő ż—į”ŇĹŲĹŲ « Ļ”√Ńňń¨»ŌĶń≤ő żĹÝ––—į’“£¨ń„“≤Ņ…“‘ľŐ–Ý≥Ę ‘…Ť÷√łųłŲ≤ő żĹÝ––≤ő ż—į”Ň£¨“‘ĹÝ“Ľ≤ĹŐŠ…żń£–Õ ∂Īū’ż»∑¬ £¨’‚ņÔ≤Ľ‘ŕĹÝ––ĹÝ“Ľ≤ĹĶń≤ő ż—į”Ň°£
–°ĹŠ
Ņ…“‘ŅīĶĹSVMĹÝ––”√Ľß––ő™ ∂Īū£¨Ņ…“‘Ķ√ĶĹĹŌļ√Ķń–ßĻŻ£¨Īĺőń÷– Ļ”√Ķń żĺ› « Ķ—ť “ żĺ›£¨≤Ę«“Őō’ų“≤ĹŲĹŲŐŠ»°ŃňĽýĪĺĶńľłłŲ£¨◊ľ»∑¬ ľīŅ…īÔĶĹ79%“‘…Ō£¨īň∑ĹįłŅ…“‘ľŐ–ÝĹÝ––”ŇĽĮ£¨ Ļ”√’ś Ķ ņĹÁ≤…ľĮĶń żĺ›£¨ĹÝ––łŁľ”ŌÍŌłĶńŐō’ų◊ľĪł£¨ŐŠłŖ—ĶŃ∑ ĪĶńĶŁīķīő żĶ»£¨ĹÝ––ń£–Õ÷ō–¬—ĶŃ∑”ŇĽĮ£¨◊Ó÷’īÔĶĹłŁļ√Ķń∑÷ņŗ–ßĻŻ°£
Ō¬√ś£¨ő“√«Ĺę‘ŕiOS∆ĹŐ®Ō¬ĻĻĹ®”¶”√£¨≤Ę Ļ”√LIBSVMļÕĪĺőń÷–—ĶŃ∑ňýĶ√ĶĹĶńń£–Õ£¨ĹÝ––◊ľ Ķ Ī»ňņŗ––ő™ ∂Īū°£
«į√ś£¨ő“√«ľÚĶ•Ĺť…‹Ńň÷ß≥÷ŌÚŃŅĽķ“‘ľį»Áļő Ļ”√LIBSVMņŗŅ‚ļÕľ”ňŔ∂»īęł–∆ų żĺ›ĹÝ––Őō’ųĶń≥ť»°°Ęń£–ÕĶń—ĶŃ∑°Ę≤ő żĶńĶų”ŇļÕń£–ÕĶń≤‚ ‘Ķ»£¨‘ŕĪĺőń÷–£¨Ĺę Ļ”√…Ō∆™◊Ó÷’Ķ√ĶĹĶńń£–ÕőńľĢ£¨“‘ľįLIBSVMņŗŅ‚£¨‘ŕiOS∆ĹŐ®Ō¬ĻĻĹ®“ĽłŲń‹ĻĽ ∂ĪūĶĪ«įŅÕĽß∂ň”√ĽßĶń––ő™ņŗ–ÕĶń”¶”√°£
ňś◊Ň“∆∂Į÷’∂ň…ŤĪłĶń–‘ń‹‘Ĺņī‘ĹłŖ£¨∆šľĮ≥…Ķńīęł–∆ų…ŤĪł“≤‘Ĺņī‘Ĺ∂ŗ£¨’ž≤‚ĺę∂»‘Ĺņī‘ĹłŖĶń«ťŅŲ£¨”¶”√”ŕ“∆∂Į÷’∂ň…ŤĪł…ŌĶńĽķ∆ų—ßŌį”¶”√“≤∂ŗŃň∆ūņī°£‘ŕiOS∆ĹŐ®Ō¬£¨∆ĽĻŻĻŔ∑ĹĶńļ‹∂ŗ”¶”√÷–“≤≥ Ō÷≥ŲŃňĽķ∆ų—ßŌįĶń”į◊”°£ņż»ÁiOS
10 ŌĶÕ≥÷–ĶńŌŗ≤Š£¨ń‹ĻĽĹÝ––»ňŃ≥ ∂Īū≤ĘĹÝ––’’∆¨Ķń◊‘∂Į∑÷ņŗ°Ę” ľĢ÷–Ķń◊‘∂Įņ¨ĽÝ” ľĢĻťņŗ°ĘSiri÷«ń‹÷ķņŪ°ĘĹ°ŅĶ”¶”√÷–Ķń”√Ľß‘ň∂Įņŗ–Õ∑÷ņŗĶ»°£
”√ĽßĶń‘ň∂Įņŗ–Õ
‘ŕiOSŌĶÕ≥ĶńĹ°ŅĶ”¶”√÷–£¨Ņ…“‘ŅīĶĹń„Ķń‘ň––ņŗ–Õ£¨∆š÷–įŁļ¨Ńň––◊Ŗ°ĘŇ‹≤Ĺ°ĘŇņ¬•Ő›°Ę≤Ĺ ż°Ę∆Ô◊‘––≥ĶĶ»ņŗ–Õ°£

‘ŕiOS SDK÷–“≤ŐŠĻ©Ńň“ĽłŲ◊®”√”ŕ‘ň∂Įņŗ–ÕĽŮ»°ĶńņŗCMMotionActivityManager£¨∆š÷–įŁļ¨Ńň
stationary
walking
running
automotive
cycling
unknown |
ľł÷÷––ő™ņŗ–Õ£¨Ķę «‘ŕ Ļ”√ĶńĻż≥Ő÷–£¨Ņ…ń‹ĽŠ”ŲĶĹĶĪ«į––ő™ļÕīňņŗłÝ≥ŲĶńĹŠĻŻ≤ĽŌŗÕ¨ĽÚ’ŖÕ¨“Ľ ĪŅŐ”–∂ę÷–ņŗ–ÕĶń«ťŅŲ£¨’‚ņÔ“ż”√∆ĽĻŻłÝ≥ŲĶń“Ľ∂őĹŠ¬Ř£ļ
An estimate of the user's activity
based on the motion of the device.
The activity is exposed as a set
of properties, the properties are not
mutually exclusive.
For example, if you're in a car
stopped at a stop sign the state might
look like:
stationary = YES, walking = NO,
running = NO, automotive = YES
Or a moving vehicle,
stationary = NO, walking = NO,
running = NO, automotive = YES
Or the device could be in motion
but not walking or in a vehicle.
stationary = NO, walking = NO,
running = NO, automotive = NO.
Note in this case all of the
properties are NO. |
“Úīň”√Ľß––ő™Ķń ∂Īū≤Ę≤Ľ «—ŌłŮ“‚“Ś…ŌĶń◊ľ»∑Ķń£¨‘ŕĽķ∆ų—ßŌįŃž”Ú£¨‘§≤‚∂ľĽŠ”–“ĽłŲłŇ¬ Ķń š≥Ų£¨“ż…Í≥ŲĶńĺÕ «’ż»∑¬ £¨’ż»∑¬ “≤ «∆ņĻņ“ĽłŲĽķ∆ų—ßŌįń£–ÕĶńĪÍ◊ľ÷ģ“Ľ°£
Ļō”ŕľ”ňŔ∂»īęł–∆ų
∆ĽĻŻĶń“∆∂Į…ŤĪł÷–£¨ľĮ≥…Ńň∂ŗ÷÷īęł–∆ų£¨Īĺőńňý—› ĺĶńĹŲĹŲ Ļ”√ľ”ňŔ∂»īęł–∆ų£¨ń„“≤Ņ…“‘‘Ųľ”īęł–∆ųņŗ–Õ£¨ŐŠłŖ żĺ›Ķńő¨∂»Ķ»°£
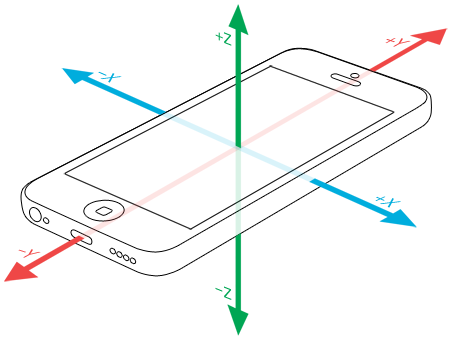
ľ”ňŔ∂»īęł–∆ų żĺ› CMAccelerometerData Ķńņŗ–Õő™CMAcceleration£¨ŐŠĻ©Ńň»ż÷Šľ”ňŔ∂»÷Ķ£¨»ÁŌ¬£ļ
typedef struct {
double x;
double y;
double z;
} CMAcceleration;
// A structure containing
3-axis acceleration data. |
īňľ”ňŔ∂»÷Ķ «ĶĪ«į…ŤĪł◊‹Ķńľ”ňŔ∂»÷Ķ£¨ŌŽ“™ĽŮ»°ľ”ňŔ∂»∑÷ŃŅĶń ĪļÚ£¨Ņ…“‘ Ļ”√CMDeviceMotionĹÝ––ĽŮ»°°£
ĻĻĹ®iOSŌÓńŅ£¨ ’ľĮīęł–∆ų żĺ›
‘ŕ…Ō∆™÷–£¨ő“√«“—ĺ≠÷™Ķņ£¨LIBSVMĺŖ”–∂ŗ÷÷”Ô—‘ĶńĹ”Ņŕ£¨’‚ņÔő“√«÷ĪĹ” Ļ”√∆šC”Ô—‘Ĺ”Ņŕ£¨‘ŕiOSŌÓńŅ÷–ĻĻĹ®SVM∑÷ņŗ∆ų°£
1. īęł–∆ų żĺ› ’ľĮ
◊Ō»–Ť“™ ’ľĮľ”ňŔ∂»īęł–∆ų żĺ›£¨≤ĘĹÝ–– żĺ›Őō’ų≥ť»°ļÕ żĺ›◊ľĪł£¨“‘Ī„SVMň„∑® ∂Īū Ļ”√°£‘ŕiOSĶńCoreMotionŅÚľ‹÷–£¨“—ĺ≠ŐŠĻ©ŃňĽŮ»°ľ”ňŔ∂»īęł–∆ųĶńAPI£¨Ņ™∑Ę’ŖŅ…“‘÷ĪĹ”Ķų”√Ĺ”ŅŕĽŮ»°ľ”ňŔ∂»īęł–∆ų żĺ›£ļ
CMMotionManager *motionManager
= [[CMMotionManager alloc] init];
if ([motionManager isAccele
rometerAvailable]) {
[motionManager setAccele
rometerUpdateInterval:0.02];
startTime = [[NSDate date]
timeIntervalSince1970];
[motionManager startAccelerometer
UpdatesToQueue:[NSOperationQueue
mainQueue] withHandler:^(CMAcce
lerometerData * _Nullable
accelerometerData, NSError
* _Nullable error) {
if (error) {
NSLog(@"%@", error.description);
}else{
[self handleDeviceAcc:accelerometerData];
}
}];
} |
2. żĺ›ŇķŃŅĽĮī¶ņŪ
ő“√«‘ŕĪĺőńŅ™ ľĹť…‹—ĶŃ∑ żĺ›ľĮĶń ĪļÚ£¨ŐŠĶĹŃň żĺ›Ķń≤…ľĮ∆Ķ¬ « 20 Hz£¨“Úīňő“√«‘ŕĹÝ–– żĺ›≤…ľĮĶń ĪļÚ“≤–Ť“™Õ¨—ýĶń∆Ķ¬ £¨≤Ę«“Ĺęīęł–∆ų żĺ›ĹÝ––ŇķŃŅĽĮī¶ņŪ£¨“‘Ī„”ŕń£–Õ ∂Īū ĪĺŖ”–ļŌ żŃŅĶń żĺ›°£
NSArray *valueArr = @[
@(accelerometerData.
acceleration.x * g_value),
@(accelerometerData
.acceleration.y * g_value),
@(accelerometerData
.acceleration.z * -g_value)];
NSMutableDictionary *sample =
[NSMutableDictionary dictionary];
[sample setValue:currenStatus
forKey:@"status"];
[sample setValue:@"acc" forKey
:@"sensorName"];
[sample setValue:@([self
getTimeStampByMiliSeconds])
forKey:@"timestamp"];
[sample setValue:valueArr
forKey:@"values"];
if (sampleDatas == nil) {
sampleDatas = [NSMutableArray
array];
}
if ([sampleDatas count]
== 256) {
NSArray *readySamples =
[NSArray arrayWithArray:sampleDatas];
sampleDatas = nil;
[self stopMotionAccelerometer];
[self recognitionData:
[readySamples copy]];
}else{
[sampleDatas addObject:sample];
} |
3. Őō’ų≥ť»°
‘ŕŅ™ ľīň≤Ĺ÷Ť÷ģ«į£¨ő“√«–Ť“™Ķľ»ŽLIBSVMĶńņŗŅ‚ĶĹŌÓńŅĻ§≥Ő÷–£¨’‚ņÔĹŲ–Ť“™Ķľ»Žsvm.hļÕsvm.cppŃĹłŲőńľĢľīŅ…°£
‘ŕ—ĶŃ∑ń£–ÕĶń ĪļÚ£¨ő“√« Ļ”√ŃňőŚ÷÷Őō’ų£¨◊Ó÷’…ķ≥…ňý–Ť“™Ķń żĺ›łŮ Ĺ£¨’‚ņÔÕ¨—ý£¨ő“√«“≤–Ť“™’Ž∂‘ żĺ›ĹÝ––Őō’ųŐŠ»°£¨≤Ę÷ō–¬◊ťļŌ żĺ›≥…ő™LIBSVMňý“™«ůĶń żĺ›łŮ Ĺ£ļ
for (NSUInteger index = 0;
index < [raw_datas count]; index++) {
NSDictionary *jsonObject
= raw_datas[index];
NSArray *valuesArray =
jsonObject[@"values"];
if (!valuesArray ||
valuesArray.count <= 0) {
break;
}
id acc_x_num = valuesArray[0];
id acc_y_num = valuesArray[1];
id acc_z_num = valuesArray[2];
acc_x_axis[index] = acc_x_num;
acc_y_axis[index] = acc_y_num;
acc_z_axis[index] = acc_z_num;
gravity[index] = @(sqrt(pow
([acc_x_num doubleValue], 2)
+ pow([acc_y_num doubleValue],
2) + pow([acc_z_num doubleValue], 2)));
}
NSMutableArray *values =
[NSMutableArray array];
/* mean Feature */{
struct svm_node node_x_mean = {0,
[StatisticFeature mean:acc_x_axis]};
NSValue *node_x_mean_value = [NSValue
valueWithBytes:&node_x_mean objCType:
@encode(struct svm_node)];
[values addObject:node_x_mean_value];
struct svm_node node_y_mean = {1,
[StatisticFeature mean:acc_y_axis]};
NSValue *node_y_mean_value = [NSValue
valueWithBytes:&node_y_mean objCType
:@encode(struct svm_node)];
[values addObject:node_y_mean_value];
struct svm_node node_z_mean = {2,
[StatisticFeature mean:acc_z_axis]};
NSValue *node_z_mean_value = [NSValue
valueWithBytes:&node_z_mean objCType
:@encode(struct svm_node)];
[values addObject:node_z_mean_value];
struct svm_node node0 = {3,
[StatisticFeature mean:gravity]};
NSValue *value0 = [NSValue valueWithBytes:&node0
objCType:@encode(struct svm_node)];
[values addObject:value0];
}
/* max Feature */{
struct svm_node node_x_max = {4,
[StatisticFeature max:acc_x_axis]};
NSValue *node_x_max_value = [NSValue
valueWithBytes:&node_x_max objCType
:@encode(struct svm_node)];
[values addObject:node_x_max_value];
struct svm_node node_y_max = {5,
[StatisticFeature max:acc_y_axis]};
NSValue *node_y_max_value = [NSValue
valueWithBytes:&node_y_max objCType
:@encode(struct svm_node)];
[values addObject:node_y_max_value];
struct svm_node node_z_max = {6,
[StatisticFeature max:acc_z_axis]};
NSValue *node_z_max_value = [NSValue
valueWithBytes:&node_z_max objCType
:@encode(struct svm_node)];
[values addObject:node_z_max_value];
struct svm_node node1 = {7, [Statis
ticFeature max:gravity]};
NSValue *value1 = [NSValue valueWithBytes:&node1
objCType:@encode(struct svm_node)];
[values addObject:value1];
}
/* min Feature */{
struct svm_node node_x_min = {8,
[StatisticFeature min:acc_x_axis]};
NSValue *node_x_min_value = [NSValue
valueWithBytes:&node_x_min objCTyp
e:@encode(struct svm_node)];
[values addObject:node_x_min_value];
struct svm_node node_y_min = {9,
[StatisticFeature min:acc_y_axis]};
NSValue *node_y_min_value = [NSValue
valueWithBytes:&node_y_min objCTyp
e:@encode(struct svm_node)];
[values addObject:node_y_min_value];
struct svm_node node_z_min = {10,
[StatisticFeature min:acc_z_axis]};
NSValue *node_z_min_value = [NSValue
valueWithBytes:&node_z_min objCType
:@encode(struct svm_node)];
[values addObject:node_z_min_value];
struct svm_node node2 = {11,
[StatisticFeature min:gravity]};
NSValue *value2 = [NSValue
valueWithBytes:&node2 objCType:
@encode(struct svm_node)];
[values addObject:value2];
}
/* stev Feature */{
struct svm_node node_x_stev = {12,
[StatisticFeature stev:acc_x_axis]};
NSValue *node_x_stev_value = [NSValue
valueWithBytes:&node_x_stev objCType
:@encode(struct svm_node)];
[values addObject:node_x_stev_value];
struct svm_node node_y_stev = {13,
[StatisticFeature stev:acc_y_axis]};
NSValue *node_y_stev_value = [NSValue
valueWithBytes:&node_y_stev objCType:
@encode(struct svm_node)];
[values addObject:node_y_stev_value];
struct svm_node node_z_stev = {14,
[StatisticFeature stev:acc_z_axis]};
NSValue *node_z_stev_value = [NSValue
valueWithBytes:&node_z_stev objCType
:@encode(struct svm_node)];
[values addObject:node_z_stev_value];
struct svm_node node3 = {15,
[StatisticFeature stev:gravity]};
NSValue *value3 = [NSValue
valueWithBytes:&node3 objCType
:@encode(struct svm_node)];
[values addObject:value3];
} |
’‚ņÔ–Ť“™◊Ę“‚Ķń «£¨Őō’ųĶńň≥–ÚĪō–ŽļÕń£–Õ—ĶŃ∑ Ī—ĶŃ∑ żĺ›ľĮ÷–ĶńŐō’ųň≥–Ú“Ľ÷¬£¨∑Ů‘Ú‘§≤‚ĶńĹŠĻŻĹę≥ŲŌ÷—Ō÷ōĶń∆ę≤Ó°£
4. Ķľ»Žń£–ÕőńľĢ≤Ęľ”‘ō
ÕÍ≥…Ńň żĺ›◊ľĪł÷ģļů£¨ő“√«Ķľ»Ž÷ģ«į—ĶŃ∑ļ√Ķńń£–ÕőńľĢraw_bestP_trained.modelĶĹŌÓńŅ÷–£¨»Ľļů Ļ”√LIBSVMŐŠĻ©Ķńń£–Õľ”‘ō∑Ĺ∑®£¨ľ”‘ōń£–ÕĶĹsvm_modelĹŠĻĻŐŚ∂‘Ōů£ļ
struct svm_model * model =
svm_load_model([model_dir UTF8String]);
if (model == NULL) {
NSLog(@"Can't open model file:
%@",model_dir);
return nil;
}
if (svm_check_probability_model
(model) == 0) {
NSLog(@"Model does not support
probabiliy estimates");
return nil;
} |
5. ––ő™ ∂Īū
LIBSVMŐŠĻ©Ńň∂ŗłŲ∑Ĺ∑®ĹÝ––‘§≤‚£¨ő™Ńň◊Ó÷’ŅīĶĹ‘§≤‚ĶńłŇ¬ £¨ő“√« Ļ”√
double svm_predict_probability
(const struct svm_model *model,
const struct svm_node *x,
double* prob_estimates); |
∑Ĺ∑®£¨‘ŕ š≥Ų‘§≤‚ĹŠĻŻĶń ĪļÚ£¨ĽŠīÝ”–∂‘”¶ĶńłŇ¬ £ļ
//Type of svm model
int svm_type = svm_get_
svm_type(model);
//Count of labels
int nr_class = svm_get
_nr_class(model);
//Label of svm model
int *labels = (int *)
malloc(nr_class*sizeof(int));
svm_get_labels(model, labels);
// Probability of each
possible label in result
double *prob_estimates =
(double *) malloc(nr_
class*sizeof(double));
// Predicting
// result of prediction including:
// - Most possible label
// - Probability of each
possible label
double label = 0.0;
if (svm_type == C_SVC ||
svm_type == NU_SVC) {
label = svm_predict_probability
(model, X, prob_estimates);
NSLog(@"svm_predict_probability
label: %f",label);
}else{
NSLog(@"svm_type is not support !!!");
return nil;
} |
Õ®Ļż“‘…ŌĶń‘§≤‚÷ģļů£¨◊Ó÷’Ķń‘§≤‚ĹŠĻŻĺÕ «label£¨≤ʑ༊‘ŕprob_estimates÷– š≥ŲłųłŲ∑÷ņŗĪÍ«©Ķń‘§≤‚łŇ¬ °£
£°£°◊Ę“‚ £°£°
** prob_estimates ÷–ĹŲĹŲĽŠ š≥ŲłŇ¬ £¨≤Ę≤ĽĽŠ š≥ŲłŇ¬ ļÕĪÍ«©Ķń∂‘”¶ĻōŌĶ°£prob_estimates÷–ĶńłŇ¬ ň≥–Ú «ļÕń£–Õ÷–Ķń š»ŽĪÍ«©ň≥–Ú“Ľ÷¬Ķń£¨–Ť“™◊Ę“‚£°
**
◊Ó÷’Ķń‘§≤‚ĹŠĻŻ»ÁŌ¬£ļ
label: 4 -- prob: 0.491513
label: 1 -- prob: 0.285421
label: 2 -- prob: 0.119973
label: 3 -- prob: 0.096848
label: 0 -- prob: 0.002580
label: 5 -- prob: 0.003665 |
Ļō”ŕń£–ÕĶń∆ņĻņ
∑÷ņŗń£–ÕĶń∂»ŃŅ”–ļ‹∂ŗ∑Ĺ Ĺ£¨ņż»ÁĽžŌżĺō’ů£®Confusion Matrix£©°ĘROC«ķŌŖ°ĘAUC√śĽż°ĘLift£®ŐŠ…ż£©ļÕGain£®‘Ų“ś£©°ĘK-SÕľ°ĘĽýńŠŌĶ żĶ»£¨’‚ņÔő“√« Ļ”√ROC«ķŌŖ∆ņĻņő“√«◊Ó÷’Ķ√ĶĹĶńń£–Õ£¨“‘≤ťŅīń£–ÕĶń÷ ŃŅ£¨◊Ó÷’ĶńROC«ķŌŖÕľ»ÁŌ¬£ļ
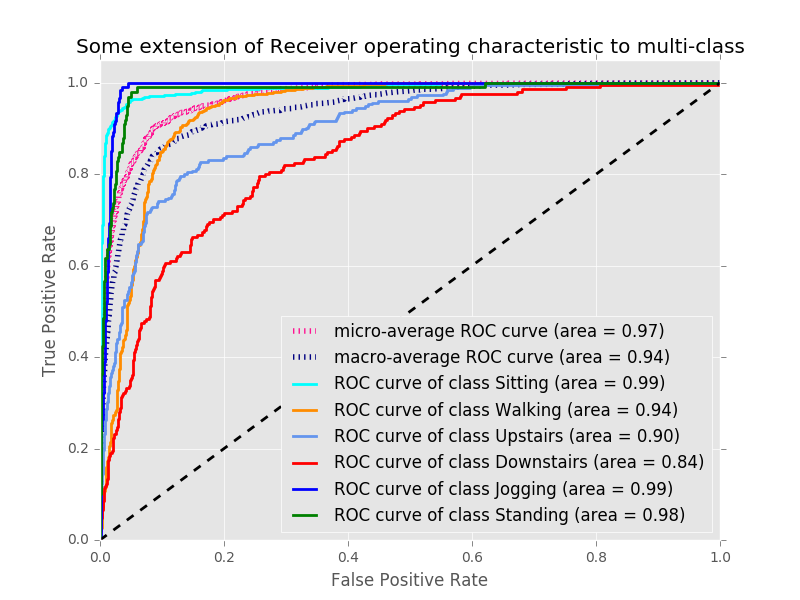
Ņ…“‘ŅīĶĹł√ń£–Õ’Ž∂‘ń≥–©––ő™Ķń ∂Īūń‹Ń¶ĹŌļ√£¨ņż»Á’ĺŃʰʬżŇ‹£¨Ķę «∂‘ŃŪ“Ľ–©––ő™Ķń ∂Īū»ī≤Ľ‘ű√īļ√Ńň£¨ņż»ÁŌ¬¬•Ő›°£
◊‹ĹŠ
Ņ…“‘ŅīĶĹSVM‘ŕ∑÷ņŗő Ő‚…Ōń‹ĻĽļ‹ļ√Ķń ∂ĪūŐō’ųĹÝ––ņŗĪū«Ý∑÷°£”…”ŕ∆™∑ý‘≠“Ú£¨Īĺőń÷–≤Ę√Ľ”–∂‘ żĺ›ĶńŐō’ųĹÝ––łŁľ”Ōł÷¬Ķń—°‘ŮļÕ≥ť»°£¨Ņ…ń‹ĽŠĶľ÷¬“Ľ–©––ő™ņŗ–ÕĶń ∂Īū≤Ľń‹īÔĶĹņŪŌŽĶń–ßĻŻ£¨Ķę «Ōŗ–Ň‘ŕ◊„ŃŅĶń żĺ›Ō¬£¨ĹÝ––łŁľ”Ōł÷¬ĶńŐō’ųĻ§≥Őļů£¨ņŻ”√SVM‘ŕ∑÷ņŗń‹Ń¶…ŌĶń”Ň ∆£¨ń‹ĻĽĻĻĹ®≥ŲłŁľ””Ň–„Ķń»ňņŗ––ő™ņŗ–Õ ∂ĪūĶń÷«ń‹”¶”√°£ |









