| ЭМЯёЗжРрЃЌЙЫУћЫМвхЃЌЪЧвЛИіЪфШыЭМЯёЃЌЪфГіЖдИУЭМЯёФкШнЗжРрЕФУшЪіЕФЮЪЬтЁЃЫќЪЧМЦЫуЛњЪгОѕЕФКЫаФЃЌЪЕМЪгІгУЙуЗКЁЃ
ЭМЯёЗжРрЕФДЋЭГЗНЗЈЪЧЬиеїУшЪіМАМьВтЃЌетРрДЋЭГЗНЗЈПЩФмЖдгквЛаЉМђЕЅЕФЭМЯёЗжРрЪЧгааЇЕФЃЌЕЋгЩгкЪЕМЪЧщПіЗЧГЃИДдгЃЌДЋЭГЕФЗжРрЗНЗЈВЛПАжиИКЁЃЯждкЃЌЮвУЧВЛдйЪдЭМгУДњТыРДУшЪіУПвЛИіЭМЯёРрБ№ЃЌОіЖЈзЊЖјЪЙгУЛњЦїбЇЯАЕФЗНЗЈДІРэЭМЯёЗжРрЮЪЬтЁЃ
ЁЁЁЁ
ФПЧАЃЌаэЖрбаОПепЪЙгУCNNЕШЩюЖШбЇЯАФЃаЭНјааЭМЯёЗжРр;СэЭтЃЌОЕфЕФKNNКЭSVMЫуЗЈвВШЁЕУВЛДэЕФНсЙћЁЃШЛЖјЃЌЮвУЧЫЦКѕЮоЗЈЖЯбдЃЌФФжжЗНЗЈЖдгкЭМЯёЗжРДЮЪЬтаЇЙћзюМбЁЃ
ЁЁЁЁ
БОЯюФПжаЃЌЮвУЧзіСЫвЛаЉгавтЫМЕФЪТЧщЃК
НЋвЕФкЦеБщгУгкЭМЯёЗжРрЕФCNNКЭЧЈвЦбЇЯАЫуЗЈгыKNNЃЌ SVM ЃЌ BP ЩёОЭјТчНјааБШНЯЁЃ
ЛёШЁЩюЖШбЇЯАОбщЁЃ
ЬНЫїЙШИшЛњЦїбЇЯАПђМмTensorFlowЁЃ
ЯТУцЪЧОпЬхЪЕЪЉЯИНкЁЃ
ЯЕЭГЩшМЦ
дкБОЯюФПжаЃЌгУгкЪЕбщЕФ5жжЫуЗЈЮЊKNNЁЂSVMЁЂBPЩёОЭјТчЁЂCNNвдМАЧЈвЦбЇЯАЁЃЮвУЧВЩгУШчЯТШ§жжЗНЪННјааЪЕбщ
KNNЁЂSVMЁЂBPЩёОЭјТчЪЧЮвУЧдкбЇаЃФмЙЛбЇЕНЕФЁЃЙІФмЧПДѓЖјЧввзВПЪ№ЁЃЫљвдЕквЛВНЃЌЮвУЧжївЊЪЙгУ
sklearn ЪЕЯжKNNЃЌSVMЃЌКЭBPЩёОЭјТчЁЃ
гЩгкДЋЭГЕФЖрВуИажЊЛњФЃаЭдкЭМЯёЪЖБ№ЗНУцаЇЙћЩѕМбЃЌЕЋгЩгкЦфНкЕуМфЕФШЋСЌНгФЃЪНЖдгкЦфбгеЙаддьГЩСЫзшАЃЌвђДЫЖдгкИпЗжБцТЪЕФЭМЯёЃЌЪЖБ№ТЪВЛЪЧКмРэЯыЁЃЫљвдетвЛВНЃЌЮвУЧгУ
Google TensorFlow ПђМмЙЙНЈ CNN ЁЃ
ЖдгквбОдЄбЕСЗЙ§ЕФЩюЖШЩёОЭјТчInception V3НјаажибЕСЗЁЃInception V3гЩ
TensorFlow ЬсЙЉЃЌЪЙгУImageNetзд2012ФъвдРДЕФЪ§ОнНјаабЕСЗЁЃImageNetЪЧМЦЫуЛњЪгОѕСьгђвЛИіОЕфЬєеНЃЌВЮШќепЪдЭМгУФЃаЭНЋШЋВПЭМЯёЗХжС1000ИіЗжРржаЁЃЮЊСЫвЊжиаТбЕСЗвбОдЄбЕСЗКУЕФФЃаЭЃЌЮвУЧБиаыБЃжЄЮвУЧздМКЕФЪ§ОнМЏУЛгаБЛдЄбЕСЗЙ§ЁЃ
ЪЕЪЉ
ЕквЛжжЗНЗЈЃКЪЙгУsklearnдЄДІРэЪ§ОнвдМАЪЕЯжKNNЃЌSVMКЭBPЩёОЭјТчЁЃ
ВНжш1ЃЌЪЙгУopenCVАќЃЌЖЈвх2ИідЄДІРэКЏЪ§ЃЌЗжБ№ЪЧЭМЯёЬиеїЯђСП(гУРДЕїећЭМЯёДѓаЁВЂНЋЭМЯёБтЦНЛЏГЩвЛЯЕСаааЯёЫи)КЭЬсШЁбеЩЋжБЗНЭМ(ЪЙгУcv2.normalizeДгHSVЩЋгђжаЬсШЁвЛИі3DбеЩЋжБЗНЭМВЂзіЦНЛЌДІРэ)ЁЃ
ВНжш2ЃЌЙЙдьВЮЪ§ЁЃгЩгкЮвУЧЪдЭМдкећИіЪ§ОнМЏвдМАОпгаВЛЭЌРрБ№Ъ§ФПЕФзгЪ§ОнМЏЩЯНјааадФмВтЪдЃЌЫљвдЮвУЧАбИїИіЪ§ОнМЏПДзїЮЊВЮЪ§ЃЌвдБуНјааЪЕбщЗжЮіЁЃСэЭтЃЌЮвУЧЛЙЩшжУСЫKNNжаЕФСкОгЪ§ФПзїЮЊВЮЪ§ЁЃ
ВНжш3ЃЌЬсШЁЭМЯёЬиеїВЂаДШыЪ§зщЁЃЮвУЧЪЙгУcv2.imreadКЏЪ§ЖСШЁЭМЯёЃЌИљОнЙцЗЖЛЏЕФЭМЯёУћГЦНјааЗжРрЁЃШЛКѓдЫааЕкВНжш1жаЬсЕНЕФ2ИіКЏЪ§ЃЌЗжБ№ЕУЕН2жжЭМЯёЬиеїВЂаДШыЪ§зщЁЃ
ВНжш4ЃЌЪЙгУКЏЪ§train_test_splitЗжИюЪ§ОнМЏЁЃ85%ЕФЪ§ОнзїЮЊбЕСЗМЏЃЌ15%ЕФЪ§ОнзїЮЊВтЪдМЏЁЃ
ВНжш5ЃЌЪЙгУKNNЃЌSVMКЭBPЩёОЭјТчЗНЗЈШЅЦРЙРЪ§ОнЁЃЖдгкKNNЃЌЪЙгУ KNeighborsClassifier
ЃЌЖдгкSVMЃЌЪЙгУSVCЃЌЖдгкBPЩёОЭјТчЃЌЪЙгУMLPClassifierЁЃ
ЕкЖўжжЗНЗЈЃКЛљгкTensorFlowЙЙНЈCNNЁЃЪЙгУTensorFlowЕУЕНМЦЫуЭМВЂдкC++жаЪЕЯжЃЌБШPythonИќИпаЇЁЃ
TensorFlowжаЪЙгУЕНЕФЕФМИИіИХФюЃКеМЮЛЗћЃЌБфСПЃЌЪ§бЇЙЋЪНЃЌГЩБОМЦСПЃЌзюгХЗНЗЈЃЌCNNЬхЯЕНсЙЙЁЃ
ВНжш1ЃЌЕквЛВуЗХжУЭМЯёЁЃ
ВНжш2ЃЌЙЙНЈ3ВуОэЛ§Ву(3 Convolutional layers)ЃЌ2X2ЕФmax-poolingКЭReLUЁЃЪфШыЪЧ4ЮЌеХСПЃКЁОЭМЯёБрКХЃЌYзјБъЃЌXзјБъЃЌЭЈЕРЁПЁЃЪфГіЪЧСэвЛИіОДІРэЕУЕНЕФ4ЮЌеХСПЃКЁОЭМЯёБрКХ(ВЛБф)ЃЌYзјБъЃЌXзјБъЃЌЭЈЕРЁПЁЃ
ВНжш3ЃЌЙЙНЈ2ВуШЋСЌНгВу(2 Fully-Connected Layers)ЁЃЪфШыЪЧ2ЮЌеХСПЃКЁОЭМЯёБрКХЃЌЪфШыБрКХЁПЁЃЪфГіЪЧ2ЮЌеХСПЁОЭМЯёБрКХЃЌЪфГіБрКХЁПЁЃЪЙгУ
ВНжш4ЃЌЪЙгУКЯВЂВу(Flatten Layer)СДНгОэЛ§ВуКЭШЋСЌНгВуЁЃ
ВНжш5ЃЌЪЙгУsoftmax layerБъзМЛЏЪфГіЁЃ
ВНжш6ЃЌгХЛЏбЕСЗНсЙћЁЃЮвУЧЪЙгУНЛВцьи (cross entropy) зїЮЊГЩБОМЦСПКЏЪ§ЃЌШЁЦфОљжЕЁЃзюгХЗНЗЈЪЙгУ
tf. train. AdamOptimizer() ЁЃ
ЕкШ§жжЗНЗЈЃКRetrain Inception V3ЁЃЪЙгУ Retrain Inception
V3 ЃЌВЂРћгУЧЈвЦбЇЯАМѕЩйЙЄзїСПЁЃ
ЮвУЧЕУЕНpre-trainedФЃаЭЃЌвЦГ§дгаЖЅВуЃЌбЕСЗаТФЃаЭЁЃШЛКѓЗжЮідкДХХЬЩЯЕФЫљгаЭМЯёВЂМЦЫуЫќУЧЕФ
bottleneckжЕЁЃНХБОЛсдЫаа4000ДЮЁЃУПДЮдЫааЖМЛсДгбЕСЗМЏжаЫцЛњбЁШЁ10ИіЭМЯёЃЌевЕНЫќУЧЕФ
bottleneck жЕВЂзЂШызюКѓвЛВуЕУЕНдЄВтНсЙћЁЃШЛКѓдкЗДЯђДЋВЅЙ§ГЬжаЃЌИљОндЄВтНсЙћКЭЪЕМЪБъЧЉЕФБШНЯНсЙћШЅИќаТУПВуЕФШЈжиЁЃ
ЪЕбщ
ЪЕбщжаЪЙгУЕНЕФЪ§ОнМЏЪЧOxford-IIIT Pet Ъ§ОнМЏЁЃЦфжагаШЎРр25РрЃЌУЈРр12РрЁЃУПРрга200ИіЭМЯёЁЃЮвУЧЪЙгУЕНИУЪ§ОнМЏжаЕФ10ИіРрБ№ЕФУЈЕФЪ§ОнЃЌЗжБ№ЪЧ[ЁЎSphynxЁЏ,ЁЏSiameseЁЏ,ЁЏRagdollЁЏ,ЁЏPersianЁЏ,
ЁЏMaine-CoonЁЏ, ЁЏ British-shorthairЁЏ , ЁЏBombayЁЏ ,ЁЏBirmanЁЏ,ЁЏ
BengalЁЏ , ЁЏAbyssinianЁЏ] ЁЃМДЃЌЙВга2000ИіЭМЯёЃЌгЩгкЭМЯёДѓаЁВЛвЛЃЌЮвУЧЕїећДѓаЁЭГвЛЮЊЙЬЖЈГпДч64X64Лђ128X128ЁЃ
ЁЁ
БОЯюФПжаЃЌЮвУЧжївЊЪЙгУOpenCVдЄДІРэЭМЯёЁЃвЛАуЭЈЙ§БфаЮЁЂМєВУЛђССЛЏЫцЛњДІРэбЕСЗМЏЁЃ github
ИГжЕ
ЕквЛжжЗНЗЈЃКKNNЃЌSVMЃЌКЭBPЩёОЭјТч
ЕквЛВПЗжЃКЪЙгУsklearnдЄДІРэЪ§ОнвдМАЪЕЯжKNNЃЌSVMКЭBPЩёОЭјТчЁЃдк image_
to_ feature _vector КЏЪ§жаЃЌЮвУЧЩшЖЈГпДч128X128ЁЃОЪдбщБэУїЃЌЭМЯёГпДчдНДѓЃЌНсЙћдНОЋШЗЃЌдЫааИКЕЃдНДѓЁЃзюжеЮвУЧОіЖЈЪЙгУ128X128ЕФГпДчЁЃдкextract_color_histogramКЏЪ§жаЃЌЩшЖЈУПИіЭЈЕРЕФШнЦїЪ§СПЮЊ32,32,32ЁЃЖдгкЪ§ОнМЏЃЌЪЙгУ3жжЪ§ОнМЏЁЃЕквЛИіЪЧОпга400ИіЭМЯёЃЌ2ИіБъЧЉЕФзгЪ§ОнМЏЁЃЕкЖўИіЪЧОпга1000ИіЭМЯёЃЌ5ИіБъЧЉЕФзгЪ§ОнМЏЁЃЕкШ§ИіЪЧећИіЪ§ОнМЏЃЌ1997ИіЭМЯёЃЌ10ИіБъЧЉЁЃ
дкKNeighborsClassifierжаЃЌЮвУЧжЛИФБфСкОгЪ§СПЧвДцДЂНсЙћзїЮЊУПИіЪ§ОнМЏЕФзюМбKжЕЃЌЦфЫћВЮЪ§ФЌШЯЁЃ
дкMLPClassifierжаЃЌЮвУЧЩшЖЈУПВуга50ИіЩёОдЊЁЃ
дкSVCжаЃЌзюДѓЕќДњДЮЪ§ЪЧ1000ЃЌРрШЈжиЪЧЁАbalancedЁБЁЃ
вРОнЪ§ОнМЏЃЌ2ИіБъЧЉЕН10ИіБъЧЉВЛЭЌЃЌдЫааЪБМфДѓдМЮЊ3ЕН5ЗжжгВЛЕШЁЃ
ЕкЖўжжЗНЗЈЃКЛљгкTensorFlowЙЙНЈCNN
гЩгкдкећИіЪ§ОнМЏжадЫааЪБМфЙ§ГЄЃЌЮвУЧдкУПИіЕќДњжаЗжХњДЮДІРэЁЃУПХњДЮвЛАуга32ИіЛђ64ИіЭМЯёЁЃЪ§ОнМЏЗжЮЊ1600ИіЭМЯёЕФбЕСЗМЏЃЌ400ИіЭМЯёЕФбщжЄМЏЃЌ300ИіЭМЯёЕФВтЪдМЏЁЃ
БОЗНЗЈжагаДѓСПЕФВЮЪ§ПЩЕїећЁЃбЇЯАЫйТЪЩшЖЈЮЊ1x10^-4;ЭМЯёДѓаЁЩшЖЈЮЊ64x64КЭ128x128;ШЛКѓЪЧВуКЭаЮзДЃЌШЛЖјгаЬЋЖрЕФВЮЪ§ПЩЕїећЃЌЮвУЧвРОнОбщВЂНјааЪЕбщШЅЕУЕНзюМбНсЙћЁЃ
ЮЊСЫЕУЕНзюМбЕФlayersЃЌЮвУЧНјааЪЕбщЁЃЪзЯШЃЌВЮЪ§ШчЯТЃК
# Convolutional Layer 1. filter_size1
= 5 num_filters1 = 6
# Convolutional Layer 2. filter_size2
= 5 num_filters2 = 64 # Convolutional
Layer 3. filter_size3
= 5 num_filters3 = 128
# Fully-connected layer 1. fc1_size = 256
# Fully-connected layer 2. fc1_size = 256 |
ЮвУЧЪЙгУСЫ3ИіОэЛ§ВуКЭ2ИіШЋСЌНгВуЃЌШЛЖјБЏОчЕФЪЧЙ§ЖШФтКЯЁЃОЙ§баОПЗЂЯжЃЌЖдгкИУЙЙдьЃЌЮвУЧЕФЪ§ОнМЏЙ§аЁЃЌЭјТчЙ§гкИДдгЁЃ
зюжеЃЌЮвУЧЪЙгУШчЯТВЮЪ§ЃК
# Convolutional Layer 1. filter_size1
= 5 num_filters1 = 64
# Convolutional Layer 2. filter_size2
= 3 num_filters2 = 64
# Fully-connected layer 1. fc1_size = 128
# Number of neurons in fully-connected layer.
# Fully-connected layer 2. fc2_size = 128
# Number of neurons in fully-connected layer.
# Number of color channels for the images:
1 channel for gray-scale. num_channels = 3
|
ЮвУЧжЛЪЙгУСЫ2ИіОэЛ§ВуКЭ2ИіШЋСЌНгВуЁЃвРШЛВЛОЁШЫвтЃЌОЙ§4000ДЮЕќДњЃЌНсЙћШдОЩЙ§ФтКЯЃЌВЛЙ§КУдкВтЪдНсЙћ10%гХгкЧАепЁЃзюжеЃЌОЙ§5000ДЮЕќДњЃЌЮвУЧЕУЕН43%ЕФОЋШЗЖШЃЌдЫааЪБМфЪЧАыаЁЪБвдЩЯЁЃ
PSЃКЮвУЧЪЙгУСэвЛИіЪ§ОнМЏCIFAR-10НјааСЫЪЕбщЁЃ
ЁЁЁЁ
ИУЪ§ОнМЏАќКЌ60000Иі32x32ЕФВЪЩЋЭМЯёЃЌЗжЮЊ10ИіРрБ№ЃЌУПИіРрБ№6000ИіЭМЯёЁЃбЕСЗМЏ50000ИіЭМЯёЃЌВтЪдМЏ10000ИіЭМЯёЁЃЪЙгУЭЌбљЕФЭјТчНсЙЙЃЌОЙ§10ИіаЁЪБЕФбЕСЗЃЌзюжеЕУЕН78%ЕФОЋШЗЖШЁЃ
ЕкШ§жжЗНЗЈЃКRetrain Inception V3
гывдЩЯЗНЗЈЯрЫЦЃЌбЕСЗДЮЪ§ЮЊ4000ЃЌвРОнНсЙћНјааЕїећЁЃбЇЯАЫйТЪвРОнУПХњДЮЕФЭМЯёЪ§СПНјааЕїећЁЃ80%ЕФЪ§ОнгУРДбЕСЗЃЌ10%гУРДбщжЄЃЌ10%гУРДВтЪдЁЃ
ЪЕбщНсЙћ
ЕквЛжжЗНЗЈЃКKNNЃЌSVMЃЌКЭBPЩёОЭјТч
ЁЁЁЁ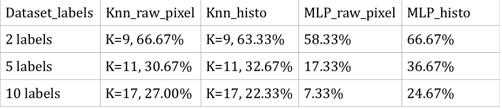
дкKNNжаЃЌKnn_raw_pixelКЭKnn_histoЕФОЋШЗЖШЕФжЕБШНЯНгНќЁЃдк5РрБъЧЉЧщПіЯТЃЌЧАепБШКѓепвЊЕЭЃЌећЬхРДЫЕЃЌдЪМЯёЫиБэЯжИќКУЁЃ
дкMLPЗжРрЦїжаЃЌдЪМЯёЫиОЋШЗЕивЊЕЭгкжљзДЭМОЋШЗЖШЁЃЖдгкећИіЪ§ОнМЏ(10ИіБъЧЉ)РДНВЃЌдЪМЯёЫиОЋШЗЖШОЙШЛЕЭгкЫцЛњВТЯыЕФОЋШЗЖШЁЃ
ЩЯУцСНжжsklearnЗНЗЈЖМУЛгаЕУЕНЗЧГЃКУЕФадФмЁЃЖдгкећИіЪ§ОнМЏЃЌжЛга24%ЕФОЋШЗЖШЁЃЪЕбщНсЙћжЄУїЃЌ
sklearn ЗНЗЈВЛФмЙЛгааЇНјааЭМЯёЗжРрЁЃЮЊСЫгааЇНјааЭМЯёЗжРрВЂЧвЬсИпОЋШЗЖШЃЌгаБивЊЪЙгУЩюЖШбЇЯАЕФЗНЗЈЁЃ
ЕкЖўжжЗНЗЈЃКЛљгкTensorFlowЙЙНЈCNN
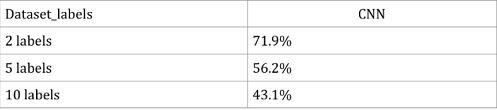
гЩгкЙ§ФтКЯЃЌЮвУЧЮоЗЈЕУЕНКУЕФЪЕбщНсЙћЁЃдЫааЪБМфвЛАуЮЊАыИіаЁЪБЃЌгЩгкЙ§ФтКЯЃЌЮвУЧШЯЮЊЃЌдЫааЪБМфЮоЗЈдЄЙРЁЃЭЈЙ§гыЗНЗЈ1БШНЯЃЌПЩвдЕУГіЃКМДЪЙCNNЙ§ФтКЯбЕСЗМЏЃЌЪЕбщНсЙћвРОЩгХгкЗНЗЈ1ЁЃ
ЕкШ§жжЗНЗЈЃКRetrain Inception V3
ЁЁЁЁ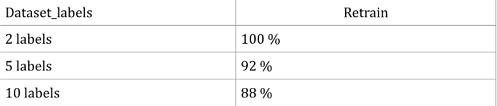
ећИібЕСЗЙ§ГЬВЛГЌЙ§10ЗжжгЃЌЧвЮвУЧЕУЕНСЫЗЧГЃКУЕФНсЙћЁЃЪТЪЕжЄУїЃЌЩюЖШбЇЯАКЭЧЈвЦбЇЯАЪЎЗжЧПДѓЁЃ
DemoЃК
ЁЁЁЁ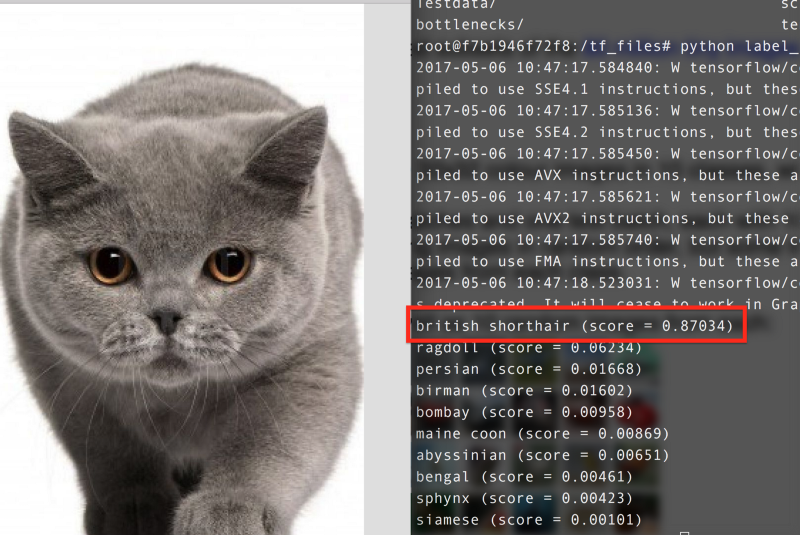
НсТл
ЛљгквдЩЯЪЕбщБШНЯЃЌЮвУЧЕУГіЃК
KNNЃЌSVMЃЌКЭBPЩёОЭјТчдкЭМЯёЗжРржаВЛЙЛгааЇЁЃ
МДЪЙдкCNNжаЙ§ФтКЯЃЌCNNЕФЪЕбщНсЙћвРОЩБШДЋЭГЗжРрЫуЗЈКУЁЃ
ЧЈвЦбЇЯАдкЭМЯёЗжРрЮЪЬтЩЯЗЧГЃгааЇЁЃдЫааЪБМфЖЬЧвНсЙћОЋзМЃЌФмЙЛСМКУЕиНтОіЙ§ФтКЯКЭЪ§ОнМЏЙ§аЁЕФЮЪЬтЁЃ
ЭЈЙ§БОДЮЯюФПЃЌЮвУЧЕУЕНСЫаэЖрБІЙѓЕФОбщЃЌШчЯТЫљЪОЃК
ЕїећЭМЯёЪЙЦфИќаЁЁЃ
ЖдгкбЕСЗЕФУПДЮЕќДњЃЌЫцЛњбЁШЁаЁХњДЮЪ§ОнЁЃ
ЫцЛњбЁШЁаЁХњДЮЪ§ОнзїЮЊбщжЄМЏНјаабщжЄЃЌВЂЧвдкбЕСЗЦкМфЗДРЁбщжЄЦРЗжЁЃ
РћгУImage AugmentationАбЪфШыЭМЯёМЏзЊБфЮЊПЩЕїећЕФИќДѓЕФаТЪ§ОнМЏЁЃ
ЭМЯёЪ§ОнМЏвЊДѓгк200x10ЁЃ
ИДдгЭјТчНсЙЙашвЊИќЖрЕФбЕСЗМЏЁЃ
аЁаФЙ§ФтКЯЁЃ |









