| вЊЕу
дкГЃМћЕФЛњЦїбЇЯА/ЩюЖШбЇЯАЯюФПРяЃЌЪ§ОнзМБИеМШЅећИіЗжЮіЙмЕРЕФ60ЃЅЕН80ЃЅЁЃ
ЪаГЁЩЯгаИїжжгУгкЪ§ОнЧхЯДКЭЬиеїЙЄГЬЕФБрГЬгябдЁЂПђМмКЭЙЄОпЁЃЫќУЧжЎМфЕФЙІФмгажиЕўЃЌвВИїгаШЈКтЁЃ
Ъ§ОнећРэЪЧЪ§ОндЄДІРэЕФживЊРЉеЙЁЃЫќзюЪЪКЯдкПЩЪгЛЏЗжЮіЙЄОпжаЪЙгУЃЌетФмЙЛБмУтЗжЮіСїГЬБЛДђЖЯЁЃ
ПЩЪгЛЏЗжЮіЙЄОпгыПЊдДЪ§ОнПЦбЇзщМўжЎМфЃЌШчRЁЂPythonЁЂKNIMEЁЂRapidMinerЛЅЮЊВЙГфЁЃ
БмУтЙ§ЖрЕиЪЙгУзщМўФмЙЛМгЫйЪ§ОнПЦбЇЯюФПЁЃвђДЫЃЌдкЪ§ОнзМБИВНжшжаРћгУСїЪНЛёШЁПђМмЛђСїЪНЗжЮіВњЦЗЛсЪЧвЛИіВЛДэЕФбЁдёЁЃ
ЛњЦїбЇЯАКЭЩюЖШбЇЯАЯюФПдкДѓЖрЪ§ЦѓвЕжаБфЕУдНРДдНживЊЁЃвЛИіЭъећЕФЯюФПСїГЬАќРЈЪ§ОнзМБИЃЈdata preparationЃЉЁЂЙЙНЈЗжЮіФЃаЭвдМАВПЪ№жСЩњВњЛЗОГЁЃИУСїГЬЪЧвЛИіЖДВь-ааЖЏ-бЛЗЃЈinsights-action-loopЃЉЃЌДЫбЛЗФмВЛЖЯЕиИФНјЗжЮіФЃаЭЁЃForresterАбетИіЭъећЕФСїГЬКЭЦфБГКѓЕФЦНЬЈГЦЮЊЖДВьЦНЬЈЃЈInsights
PlatformЃЉЁЃ
ЕБФуДђЫуЪЙгУЛњЦїбЇЯАЛђЩюЖШбЇЯАММЪѕРДЙЙНЈЗжЮіФЃаЭЪБЃЌвЛИіживЊЕФШЮЮёЪЧМЏГЩВЂЭЈЙ§ИїжжЪ§ОндДРДзМБИЪ§ОнМЏЃЌетаЉЪ§ОндДАќРЈБШШчЮФМўЁЂЪ§ОнПтЁЂДѓЪ§ОнДцДЂЁЂДЋИаЦїЛђЩчНЛЭјТчЕШЕШЁЃДЫВНжшПЩеМећИіЗжЮіЯюФПЕФ80ЃЅЁЃ
БОЮФБШНЯСЫгУгкЪ§ОнзМБИЕФМИжжЗНЗЈЃЌЫќУЧЗжБ№ЪЧЬсШЁ-БфЛЛ-МгдиЃЈextract-transform-loadЃЌETLЃЉХњДІРэЁЂСїЪНЛёШЁЃЈstreaming
ingestionЃЉКЭЪ§ОнећРэЃЈdata wranglingЃЉЁЃЭЌЪБНшжњгкЯШНјЕФЗжЮіММЪѕКЭПЊдДПђМмЃЈШчRЁЂApache
SparkЁЂKNIMEЁЂRapidMinerЃЉЃЌЬжТлСЫИїжжВЛЭЌЕФбЁдёМАЦфелжаЁЃБОЮФЛЙЬжТлСЫЪ§ОнзМБИШчКЮгыПЩЪгЛЏЗжЮіЯрЙиСЊЃЌвдМАВЛЭЌгУЛЇНЧЩЋЃЈШчЪ§ОнПЦбЇМвЛђвЕЮёЗжЮіШЫдБЃЉгІШчКЮЙВЭЌЙЙНЈЗжЮіФЃаЭЕФзюМбЪЕМљЁЃ
Ъ§ОнзМБИ=Ъ§ОнЧхЯДЃЈData CleansingЃЉ+ЬиеїЙЄГЬЃЈFeature EngineeringЃЉ
Ъ§ОнзМБИЪЧЪ§ОнПЦбЇЕФКЫаФЁЃЫќАќРЈЪ§ОнЧхЯДКЭЬиеїЙЄГЬЁЃСэЭтСьгђжЊЪЖЃЈdomain knowledgeЃЉвВЗЧГЃживЊЃЌЫќгажњгкЛёЕУКУЕФНсЙћЁЃЪ§ОнзМБИВЛФмЭъШЋздЖЏЛЏЃЌжСЩйдкГѕЪМНзЖЮВЛФмЁЃЭЈГЃЃЌЪ§ОнзМБИеМШЅећИіЗжЮіЙмЕРЃЈСїГЬЃЉЕФ60ЃЅЕН80ЃЅЁЃЕЋЪЧЃЌЮЊСЫЪЙЛњЦїбЇЯАЫуЗЈдкЪ§ОнМЏЩЯЛёЕУзюгХЕФОЋШЗадЃЌЪ§ОнзМБИБиВЛПЩЩйЁЃ
Ъ§ОнЧхЯДПЩЪЙЪ§ОнЛёЕУгУгкЗжЮіЕФе§ШЗаЮзДЃЈshapeЃЉКЭжЪСПЃЈqualityЃЉЁЃЫќАќРЈСЫаэЖрВЛЭЌЕФЙІФмЃЌР§ШчЃК
ЛљБОЙІФмЃЈбЁдёЁЂЙ§ТЫЁЂШЅжиЁЂ...ЃЉ
ВЩбљЃЈЦНКтЃЈbalancedЃЉЁЂЗжВуЃЈstratifiedЃЉЁЂ...ЃЉ
Ъ§ОнЗжХфЃЈДДНЈбЕСЗ+бщжЄ+ВтЪдЪ§ОнМЏЁЂ...ЃЉ
БфЛЛЃЈЙщвЛЛЏЁЂБъзМЛЏЁЂЫѕЗХЁЂpivotingЁЂ...ЃЉ
ЗжЯфЃЈBinningЃЉЃЈЛљгкМЦЪ§ЁЂНЋШБЪЇжЕзїЮЊЦфздМКЕФзщДІРэЁЂ...ЃЉ
Ъ§ОнЬцЛЛЃЈМєЧаЃЈcuttingЃЉЁЂЗжИюЃЈsplittingЃЉЁЂКЯВЂЁЂ...ЃЉЃЉ
МгШЈгыбЁдёЃЈЪєадМгШЈЁЂздЖЏгХЛЏЁЂ...ЃЉ
ЪєадЩњГЩЃЈIDЩњГЩЁЂ...ЃЉ
Ъ§ОнЬюВЙЃЈimputationЃЉЃЈЪЙгУЭГМЦЫуЗЈЬцЛЛШБЪЇЕФЙлВьжЕЃЉ
ЬиеїЙЄГЬЛсЮЊЗжЮібЁШЁе§ШЗЕФЪєадЁЃЮвУЧашвЊНшжњЪ§ОнЕФСьгђжЊЪЖРДбЁШЁЛђДДНЈЪєадЃЌетаЉЪєадФмЪЙЛњЦїбЇЯАЫуЗЈе§ШЗЕиЙЄзїЁЃЬиеїЙЄГЬЙ§ГЬАќРЈЃК
ЭЗФдЗчБЉЛђЬиеїВтЪд
ЬиеїбЁдё
бщжЄетаЉЬиеїШчКЮгыФЃаЭХфКЯЪЙгУ
ШчЙћашвЊЃЌИФНјЬиеї
ЛиЕНЭЗФдЗчБЉ/ДДНЈИќЖрЕФЬиеїЃЌжБЕНЙЄзїЭъГЩ
ЧызЂвтЃЌЬиеїЙЄГЬвбЪЧНЈФЃЃЈЙЙНЈЗжЮіФЃаЭЃЉВНжшРяЕФвЛВПЗжЃЌЕЋЫќвВРћгУЪ§ОнзМБИетвЛЙІФмЃЈР§ШчЬсШЁзжЗћДЎЕФФГаЉВПЗжЃЉЁЃ
Ъ§ОнЧхЯДКЭЬиеїЙЄГЬЪЧЪ§ОнзМБИЕФвЛВПЗжЃЌвВЪЧЛњЦїбЇЯАКЭЩюЖШбЇЯАгІгУЕФЛљДЁЁЃетЖўепВЂВЛЪЧФЧУДШнвзЃЌЖМашвЊЛЈЗбЙІЗђЁЃ
Ъ§ОнзМБИЛсГіЯждкЗжЮіЯюФПЕФВЛЭЌНзЖЮЃК
Ъ§ОндЄДІРэЃКДгЪ§ОндДЛёШЁЪ§ОнжЎКѓжБНгДІРэЪ§ОнЁЃЭЈГЃгЩПЊЗЂШЫдБЛђЪ§ОнПЦбЇМвЪЕЯжЃЌЫќАќРЈГѕЪМзЊЛЛЁЂОлКЯЃЈaggregationЃЉКЭЪ§ОнЧхЯДЁЃДЫВНжшдкЪ§ОнЕФНЛЛЅЪНЗжЮіПЊЪМжЎЧАЭъГЩЁЃЫќжЛжДаавЛДЮЁЃ
Ъ§ОнећРэЃКдкНЛЛЅЪНЪ§ОнЗжЮіКЭНЈФЃЦкМфзМБИЪ§ОнЁЃЭЈГЃгЩЪ§ОнПЦбЇМвЛђвЕЮёЗжЮіЪІЭъГЩЃЌвдБуИќИФЪ§ОнМЏКЭЬиеїЙЄГЬЕФЪгЭМЁЃДЫВНжшЛсЕќДњИќИФЪ§ОнМЏЕФаЮзДЃЌжБЕНЫќФмКмКУЕиВщевЖДВьЛђЙЙНЈСМКУЕФЗжЮіФЃаЭЁЃ
ВЛПЩЛђШБЕФЪ§ОндЄДІРэКЭЪ§ОнећРэ
ШУЮвУЧПДвЛПДЕфаЭЕФгУгкФЃаЭЙЙНЈЕФЗжЮіСїГЬЃК
Ъ§ОнЗУЮЪ
Ъ§ОндЄДІРэ
ЬНЫїадЪ§ОнЗжЮіЃЈExploratory Data AnalysisЃЉЃЈEDAЃЉ
ФЃаЭЙЙНЈ
ФЃаЭбщжЄ
ФЃаЭжДаа
ВПЪ№
ВНжш2ЕФжиЕуЪЧдкЙЙНЈЗжЮіФЃаЭжЎЧАНјааЕФЪ§ОндЄДІРэЃЌЖјЪ§ОнећРэдђгУгкВНжш3КЭВНжш4ЃЈдкЗжЮіЪ§ОнКЭЙЙНЈФЃаЭЪБЃЌЪ§ОнећРэдЪаэНЛЛЅЪНЕїећЪ§ОнМЏЃЉЁЃзЂвтЃЌетШ§ИіВНжшЃЈ2ЁЂ3ЁЂ4ЃЉЖМПЩвдАќРЈЪ§ОнЧхЯДКЭЬиеїЙЄГЬЁЃ
вдЯТНиЭМЪЧЁАЪ§ОнзМБИЁБЁЂЁАЪ§ОндЄДІРэЁБКЭЁАЪ§ОнећРэЁБетМИИіЪѕгяЕФGoogleЫбЫїЧїЪЦЁЃПЩвдПДГіЃЌЪ§ОнећРэЪмЕНСЫдНРДдНЖрЕФЙизЂЃК
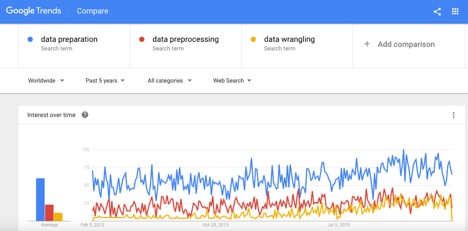
ЭМ1ЃКЁАЪ§ОнзМБИЁБЁЂЁАЪ§ОндЄДІРэЁБКЭЁАЪ§ОнећРэЁБЕФGoogleЫбЫїЧїЪЦ
ЁАinlineЪ§ОнећРэЁБЃЈinline data wranglingЃЉЪЧЁАЪ§ОнећРэЁБЕФвЛжжЬиЪтаЮЪНЁЃдкinlineЪ§ОнећРэРяЃЌФуПЩвдРћгУПЩЪгЛЏЗжЮіЙЄОпЁЃетаЉЙЄОпВЛНіФмгУгкПЩЪгЛЏКЭФЃаЭЙЙНЈЃЌЖјЧвЛЙФмгУгкжБНгНЛЛЅЪНећРэЁЃinlineЪ§ОнећРэгаОоДѓЕФгХЪЦЃЌШчЯТЭМЫљЪОЃК
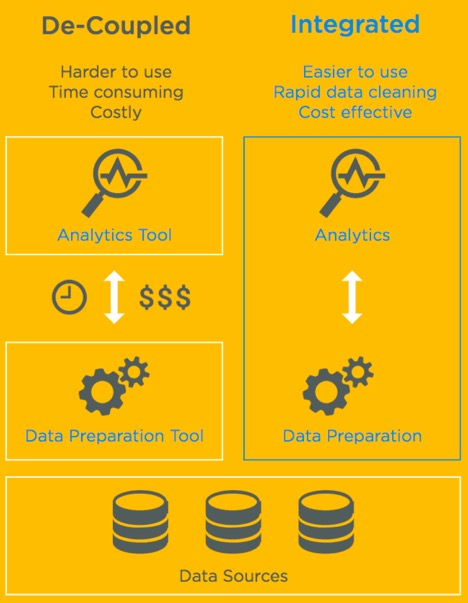
ЭМ2ЃКНтёюЪ§ОндЄДІРэЃЈdecoupled
data preprocessingЃЉгыinlineЪ§ОнећРэЕФБШНЯ
ЗжЮіЙмЕРжаЕФЪ§ОндЄДІРэКЭЪ§ОнећРэВНжшЭЈГЃгЩВЛЭЌРраЭЕФгУЛЇЭъГЩЁЃвдЯТЪЧВЮгыЗжЮіЯюФПЕФИїжжгУЛЇНЧЩЋЃК
вЕЮёЗжЮіЪІЃКОпгаЬиЖЈСьгђжЊЪЖЕФЩЬвЕ/аавЕзЈМв
Ъ§ОнПЦбЇМвЃКЪ§бЇЁЂЭГМЦгыБрГЬЃЈЪ§ОнПЦбЇ/НХБОБраДЃЉзЈМвЃЛФмЙЛБраДЕзВуДњТыЛђЪЙгУИќЩЯВуЕФЙЄОп
ЦНУёЪ§ОнПЦбЇМвЃЈCitizen Data ScientistЃЉЃКРрЫЦгкЪ§ОнПЦбЇМвЃЌЕЋДІгкИќЩЯВуЃЛашвЊЪЙгУИќЩЯВуЕФЙЄОпЖјЗЧБраДДњТыЃЛШЁОігкЙЄОпЕФвзгУадЃЌЯрЙиЙЄзїЩѕжСПЩвдгЩвЕЮёЗжЮіЪІРДЭъГЩ
ПЊЗЂепЃКШэМўПЊЗЂзЈМвЃЈЦѓвЕгІгУГЬађЃЉ
етаЉгУЛЇБиаыУмЧаКЯзїЃЌвдБудкЪ§ОнПЦбЇЯюФПжаШЁЕУГЩЙІЃЈСэМћЁАШчКЮБмУтЗжЮіжаЕФЗДФЃЪНЃКЛњЦїбЇЯАЕФШ§ИівЊЕуЁБЃЌетЦЊЮФеТФмАяФуИќКУЕиСЫНтетаЉгУЛЇНЧЩЋЃЉЁЃ
ЫфШЛБОЮФжиЕуЪЧНщЩмЪ§ОнзМБИЃЌЕЋвЛЭМЪЄЧЇбдЃЌВЂЧвШЫРржЛФмНтЪЭжБЙлПЩМћЕФЖЋЮїЖјЗЧФЧаЉИДдгЕФЗЧНсЙЙЛЏЪ§ОнМЏЃЌвђДЫСЫНтЪ§ОнзМБИгыПЩЪгЛЏЗжЮіЕФЙиЯЕвВЗЧГЃживЊЁЃгаЙиИќЖрЯИНкЃЌЧыВЮдФЮФеТЮЊЪВУДгІИУЪЙгУПЩЪгЛЏЗжЮіРДзіГіИќКУЕФОіВпЁЃФПЧАжївЊЕФПЩЪгЛЏЗжЮіЙЄОпгаQlikЁЂTableauКЭTIBCO
SpotfireЁЃ
ФЧУДПЩЪгЛЏЗжЮіЪЧШчКЮгыЪ§ОнећРэЯрЙиСЊЕФФиЃПRITOбаОПЙЋЫОЕФЪзЯЏЗжЮіЪІЫЕЃЌЁАШУЗжЮіЪІЭЃЯТЫћУЧЪжРяе§дкНјааЕФЙЄзїЃЌЖјШЅЧаЛЛЕНСэвЛИіЙЄОпЪЧСюШЫЗЂПёЕФЁЃетЦЦЛЕСЫЫћУЧЕФЙЄзїСїГЬЁЃ
ЫћУЧВЛЕУВЛЗЕЛижиЪАЫМТЗЃЌжиаТПЊЪМЁЃетбЯжигАЯьСЫЫћУЧЕФЩњВњСІКЭДДдьСІЁБЁЃ
KaggleЕФTitanicЪ§ОнМЏ
вдЯТеТНкИјГіСЫЪ§ОнзМБИЕФМИжжБИбЁЗНАИЁЃЮвУЧНЋгУЗЧГЃжјУћЕФTitanicЪ§ОнМЏЃЈРДздгкKaggleЃЉРДбнЪОвЛаЉЪЕгУЕФР§згЁЃTitanicЪ§ОнМЏБЛЗжЮЊбЕСЗМЏКЭВтЪдМЏЃЌЫќНЋгУгкЙЙНЈЗжЮіФЃаЭЃЌетаЉФЃаЭгУРДдЄВтФФИіГЫПЭПЩФмЛсДцЛюЛђЫРЭіЃК

ЭМ3ЃКKaggle TitanicЪ§ОнМЏЕФдЊЪ§Он
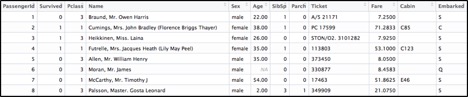
ЭМ4ЃКKaggle TitanicЪ§ОнМЏЕФЪ§ОнааЪОР§
дЪМЪ§ОнМЏВЛФмжБНггУгкЙЙНЈЗжЮіФЃаЭЁЃЫќКЌгажиИДЁЂШБЪЇжЕвдМААќКЌИїжжВЛЭЌаХЯЂЕФЕЅдЊИёЁЃвђДЫЃЌдкгІгУЛњЦїбЇЯАЫуЗЈЪБЃЌашвЊЯШНЋдЪМЪ§ОнМЏДІРэКУЃЌвдБуЛёЕУзюМбНсЙћЁЃвдЯТЪЧвЛаЉЪ§ОнЧхЯДКЭЬиеїЙЄГЬЕФР§згЃК
ЭЈЙ§ЬиеїЬсШЁЃЈfeature extractionЃЉДДНЈаТСаЃКЛёШЁУПЮЛГЫПЭЕФаеУћЧАзКЃЌДгЖјЭЦЖЯГіЦфадБ№ЃЌР§ШчЃЌЯШЩњЁЂЗђШЫЁЂаЁНуЁЂДѓЪІ
ЭЈЙ§ОлКЯДДНЈаТСаЃЌвдВщПДУПЮЛГЫПЭЕФТУааЭХжагаЖрЩйШЫЃКЁАМвЭЅДѓаЁ= 1 + SibSp + ParchЁБ
ЭЈЙ§ЬсШЁЕквЛИізжЗћРДДДНЈаТСаЃЌвдБуХХађКЭЗжЮіВеЪвЃКЬсШЁЁАВеЪвЁБСаЕФЕквЛИізжЗћ
ЩОГ§Ъ§ОнМЏжаЕФжиИДЯюЃЌР§ШчЃЌГЫПЭМШдкбЕСЗМЏжагждкВтЪдМЏжа
ЭЈЙ§ЬюВЙНЋЪ§ОнЬэМгЕНПеЕЅдЊИёЃЌвдБуФмЙЛДІРэЪ§ОнШБЪЇЕФааЃЌР§ШчЃЌФъСфЃКНЋЁАВЛПЩгУЁБЬцЛЛЮЊЫљгаГЫПЭЕФЦНОљФъСфЛђНЋЦфРыЩЂЕНЖдгІЕФЯфЃЈbinЃЉжаЃЛВеЪвЃКгУЁАUЁБЃЈЮДжЊЃЉЬцЛЛПежЕЃЛЛђгІгУИпМЖЬюВЙЗНЗЈЃЌР§ШчЃЌЭЈЙ§СДЪНЗНГЬЕФЖржиЬюВЙЃЈmultiple
imputation by chained equationsЃЉЃЈMICEЃЉ
РћгУЪ§ОнПЦбЇЙІФмЃЌР§ШчЃЌЫѕЗХЁЂЙщвЛЛЏЁЂжїГЩЗжЗжЮіЃЈPCAЃЉЛђBox-CoxЃЌЪЙЫљгаЪ§ОнДІгкЁАЯрЫЦаЮзДЁБЃЌвдБуФмЙЛНјааКЯРэЕФЗжЮі
вдЯТеТНкВћЪіСЫИїжжБрГЬгябдЁЂПђМмКЭЪ§ОнзМБИЙЄОпЁЃЧызЂвтЃЌУЛгаФФжжЗНАИЪЪгУгкЫљгаЮЪЬтЁЃДЫЭтЃЌетаЉЗНАИжЎМфвВгаКмЖржиЕўЃЈoverlappingЃЉЁЃвђДЫЃЌИљОнгУЛЇНЧЩЋКЭгУР§ЃЌаэЖрЮЪЬтПЩвдЪЙгУВЛЭЌЕФЗНАИРДНтОіЁЃ
Ъ§ОнПЦбЇЕФЪ§ОндЄДІРэ
вЛаЉБрГЬгябдЪЧзЈЮЊЪ§ОнПЦбЇЯюФПЖјЩшМЦЃЌЛђепЪЧЖдЫќгаЗЧГЃКУЕФжЇГжЃЌЬиБ№ЪЧRКЭPythonЁЃЫќУЧАќКЌСЫЛњЦїбЇЯАЫуЗЈЕФИїжжЪЕЯжЃЌжюШчЙ§ТЫЛђЬсШЁЕФдЄДІРэЙІФмЃЌвдМАжюШчЫѕЗХЁЂЙщвЛЛЏЛђЛьЯДЃЈshuffleЃЉЕФЪ§ОнПЦбЇЙІФмЁЃЪ§ОнПЦбЇМвашвЊБраДЯрЖдЕзВуЕФДњТыРДНјааЬНЫїадЪ§ОнЗжЮігызМБИЁЃгыЪЙгУJavaЛђCЃЃЕФДЋЭГБрГЬЯрЗДЃЌЪЙгУRЛђPythonНјааЪ§ОндЄДІРэЪБЃЌФуВЛашвЊБраДЬЋЖрЕФДњТыЃЛЫќИќЖрЕиЪЧШУФуСЫНтЭГМЦИХФювдМАЫуЗЈЕФЪ§ОнКЭОбщЃЌетаЉЪ§ОнКЭОбщПЩгУгкЪ§ОндЄДІРэКЭФЃаЭЙЙНЈЁЃ
етаЉБрГЬгябдЪЧЮЊЪ§ОнПЦбЇМвзМБИЪ§ОнКЭЙЙНЈЗжЮіФЃаЭЖјНЈСЂЃЌЫќУЧВЂВЛЪЪгУгкЦѓвЕВПЪ№ЃЈНЋЗжЮіФЃаЭВПЪ№ЕНОпгаИпЙцФЃКЭИпПЩППадЕФаТЪ§ОнжаЃЉЁЃвђДЫЃЌЪаГЁЩЯЬсЙЉСЫЩЬвЕЕФenterprise
runtimeАяжњФуЪЕЯжЦѓвЕВПЪ№ЁЃЭЈГЃЃЌЫќУЧжЇГжЯрЭЌЕФдДДњТыЃЌвђДЫФуВЛашвЊЮЊЦѓвЕВПЪ№жиаДШЮКЮЖЋЮїЁЃЖдгкRЃЌФуПЩвдЪЙгУПЊдДЕФMicrosoft
R OpenЃЈжЎЧАЕФRevolution RЃЉЃЌЛђTIBCO Enterprise Runtime
for RЁЃКѓепОпгаВЛЪмGPLПЊдДаэПЩжЄЯожЦЕФгХЪЦЃЌвђДЫФуПЩвдЪЙгУдкШЮКЮЧЖШыЪНЛђЭтВПЛЗОГРяЁЃ
ЯТУцЕФДњТыеЊТМгквЛИіВЛДэЕФRНЬГЬЃЌЫќбнЪОСЫШчКЮЪЙгУЛљБОЕФRгябдРДдЄДІРэКЭЗжЮіTitanicЪ§ОнМЏЃК
| ### ЪЙгУЛљБОЕФRгябдНјааЪ§ОндЄДІРэЃК
# ДцЛюЪЧЁАЪЧ/ЗёЁБ
# =>РраЭзЊЛЛЃКУЛгаnumericжЕКЭЖдгІЕФЪ§ОнДІРэ/ЗжЮі
data.combined$Survived <- as.factor(data.combined$Survived)
# ДгШЋГЦРяНтЮіГіаеКЭЭЗЯЮ
data.combined[1:25, "Name"]
name.splits <- str_split(data.combined$Name,
",")
name.splits[1]
last.names <- sapply(name.splits, "[",
1)
last.names[1:10]
# ЬиеїЙЄГЬЃКДДНЈМвЭЅДѓаЁЬиеї
#ЃЈажЕмНуУУ/ХфХМ+ИИФИ/КЂзг+1ЃЉ
temp.SibSp <- c(train$SibSp, test$SibSp)
temp.Parch <- c(train$Parch, test$Parch)
data.combined$FamilySize <- as.factor(temp.SibSp
+ temp.Parch + 1) |
Г§СЫЖддЄДІРэЕФЛљБОжЇГжЭтЃЌетаЉБрГЬгябдЛЙЬсЙЉСЫаэЖрЖюЭтЕФЪ§ОнПЦбЇШэМўАќЁЃР§ШчЃЌаэЖрЪ§ОнПЦбЇМвРћгУRжаЗЧГЃЧПДѓЕФcaretАќРДМђЛЏЪ§ОнзМБИКЭМѕЩйДњТыСПЁЃИУШэМўАќМђЛЏСЫИДдгЛиЙщКЭЗжРрЮЪЬтЕФФЃаЭзМБИгыбЕСЗЙ§ГЬЁЃЫќЮЊЪ§АйИіЯжгаЕФRФЃаЭЪЕЯжЃЈдкЕзВуЪЙгУСЫИїжжИїбљЕФAPIЃЉЬсЙЉСЫвЛИіЭЈгУНгПкЁЃвдЯТДњТыЖЮЪЙгУСЫcaretЕФЭЈгУAPIЖдTitanicЪ§ОнМЏНјаадЄДІРэЃК
| ### ЪЙгУR caretАќНјааЪ§ОндЄДІРэЃК
# РћгУcaretЕФpreProcessКЏЪ§ЖдЪ§ОнзіЙщвЛЛЏ
preproc.data.combined <- data.combined[,
c("ticket.party.size", "avg.fare")]
preProc < - preProcess (preproc.data.combined,
method = c("center", "scale"))
# ->ФуПДЕНЕФЪЧЯрЖджЕЖјЗЧОјЖджЕЃЈМДБЫДЫжЎМфЕФЙиЯЕЃЉЃК
postproc.data.combined <- predict(preProc,
preproc.data.combined) |
СэвЛИігУгкЪ§ОндЄДІРэЕФRАќЪЧdplyrАќЁЃЫќВЛЯёcaretАќФЧбљЧПДѓЃЌВЂЧвжЛзЈзЂгкВйзїЁЂЧхЯДКЭЛузмЃЈsummarizeЃЉЗЧНсЙЙЛЏЪ§ОнЁЃ
DplyrжМдкЮЊЪ§ОнВйзїЕФУПИіЛљБОЖЏзїЖМЬсЙЉвЛИіКЏЪ§ЃК
filterЃЈЃЉЃЈКЭsliceЃЈЃЉЃЉ
arrangeЃЈЃЉ
selectЃЈЃЉЃЈКЭrenameЃЈЃЉЃЉ
distinctЃЈЃЉ
mutateЃЈ)ЃЈКЭtransmuteЃЈЃЉЃЉ
summariseЃЈЃЉ
sample_n (КЭsample_fracЃЈЃЉЃЉ |
вђДЫЃЌбЇЯАКЭРэНтаэЖрЪ§ОнВйзїШЮЮёБфЕУШнвзЁЃЖдгкdata.tableАќвВЪЧетбљЁЃе§ШчФуЫљМћЕФЃЌдкRгябдРяФугааэЖрЗНЗЈРДдЄДІРэЪ§ОнМЏЁЃ
Ъ§ОнПЦбЇМвЛђПЊЗЂепЕФДѓЪ§ОнМЏдЄДІРэ
жюШчRЛђPythonетбљЕФБрГЬгябдПЩгУгкДІРэаЁЪ§ОнМЏЁЃЕЋЪЧЃЌЫќУЧВЂВЛЪЧЮЊДІРэеце§ЕФДѓЪ§ОнМЏЖјДДНЈЃЛгыДЫЭЌЪБЃЌЮвУЧОГЃашвЊЗжЮіМИИіGBЁЂTBЩѕжСPBМЖБ№ЕФЪ§ОнЁЃРрЫЦгкApache
HadoopЛђApache SparkЕФДѓЪ§ОнПђМмдђЪЧЮЊДІгкБпдЕЕФЃЈМДЪ§ОнЫљдкЮЛжУЃЉЕЏадРЉеЙЃЈelastic
scalabilityЃЉКЭЪ§ОндЄДІРэЖјДДНЈЁЃ
етаЉДѓЪ§ОнПђМмВржигкЁАЕзВуЁББрТыЃЌВЂЧвХфжУЦ№РДБШRЛђPythonЛЗОГвЊИДдгЕУЖрЁЃЩЬвЕШэМўЃЌШчHortonworksЁЂClouderaЁЂMapRЛђDatabricksПЩвдАяжњНтОіДЫЮЪЬтЁЃЭЈГЃЃЌЪ§ОнПЦбЇМвгыПЊЗЂШЫдБЯрЛЅКЯзїРДЭъГЩДѓЪ§ОнЯюФПЁЃКѓепИКд№МЏШКХфжУЁЂВПЪ№КЭМрПиЃЌЖјЪ§ОнПЦбЇМвдђРћгУRЛђPython
APIБраДгУгкЪ§ОндЄДІРэКЭЙЙНЈЗжЮіФЃаЭЕФДњТыЁЃ
дДДњТыЭЈГЃПДЦ№РДгыНіЪЙгУRЛђPythonЕФДњТыЗЧГЃЯрЫЦЃЌЕЋЪ§ОндЄДІРэЪЧдкећИіМЏШКЩЯВЂааЭъГЩЕФЁЃЯТУцЕФЪОР§бнЪОСЫШчКЮЪЙгУSparkЕФScala
APIЖдTitanicЪ§ОнМЏНјаадЄДІРэКЭЬиеїЙЄГЬЃК
| ### ЪЙгУScalaКЭApache
Spark APIНјааЪ§ОндЄДІРэЃК
# ЬиеїЙЄГЬЃКДДНЈМвЭЅДѓаЁЬиеї
# ЃЈажЕмНуУУ/ХфХМ+ИИФИ/КЂзг+1ЃЉ
val familySize: ((Int, Int) => Int) = (sibSp:
Int, parCh: Int) => sibSp + parCh + 1
val familySizeUDF = udf(familySize)
val dfWithFamilySize = df.withColumn("FamilySize",
familySizeUDF(col("SibSp"), col("Parch")))
// ЮЊФъСфСаЬюГфПежЕ
val avgAge = trainDF.select("Age").union(testDF.select("Age"))
.agg(avg("Age"))
.collect() match {
case Array(Row(avg: Double)) => avg
case _ => 0
} |
ЕБШЛЃЌФуПЩвдЪЙгУSparkЕФJavaЛђPython APIзіЭЌбљЕФЪТЧщЁЃ
ЦНУёЪ§ОнПЦбЇМвЕФЪ§ОндЄДІРэ
ЭЈГЃЃЌФуЯывЊУєНнВЂЧвПьЫйЕУЕННсЙћЁЃетГЃГЃашвЊдкзМБИКЭЗжЮіЪ§ОнМЏЪБДѓСПЕиЪдДэЁЃФуПЩвдРћгУЯжДцЕФИїжжПьНнвзгУЕФЪ§ОнПЦбЇЙЄОпЁЃетаЉЙЄОпЬсЙЉСЫЃК
ПЊЗЂЛЗОГКЭдЫаа/жДааЗўЮёЦї
ЪЙгУЭЯЗХгыДњТыЩњГЩЕФПЩЪгЛЏЁАБрТыЁБ
МЏГЩИїжжЪ§ОнПЦбЇПђМмЃЌШчRЁЂPythonЛђИќЧПДѓЕФЃЈжюШчApache HadoopЁЂApache SparkЛђЕзВуЕФH2O.aiЃЉДѓЪ§ОнПђМм
Ъ§ОнПЦбЇМвПЩвдЪЙгУетаЉЙЄОпРДМгЫйЪ§ОндЄДІРэКЭФЃаЭНЈСЂЁЃДЫЭтЃЌИУРрЙЄОпЛЙАяжњНтОіСЫЪ§ОндЄДІРэКЭЛњЦїбЇЯАЫуЗЈЕФЪЕЯжЃЌвђДЫУЛгаЬЋЖрЯюФПОбщЕФЦНУёЪ§ОнПЦбЇМввВПЩвдЪЙгУЫќУЧЁЃвЛаЉЙЄОпЩѕжСФмЙЛЬсГіНЈвщЃЌетаЉНЈвщгажњгкгУЛЇдЄДІРэЁЂЯдЪОКЭЗжЮіЪ§ОнМЏЁЃетаЉЙЄОпдкЕзВуШЫЙЄжЧФмЕФЧ§ЖЏЯТБфЕУдНРДдНжЧФмЁЃ
ЯТУцЕФР§згеЙЪОСЫШчКЮЪЙгУСНИіПЊдДЪ§ОнПЦбЇЙЄОпKNIMEКЭRapidMinerРДдЄДІРэTitanicЪ§ОнМЏЃК
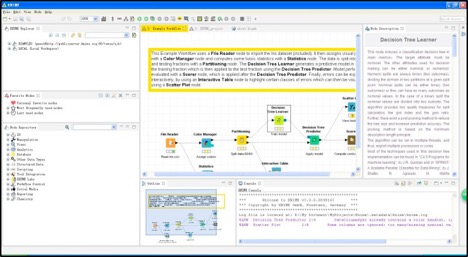
ЪЙгУKNIMEРДдЄДІРэTitanicЪ§ОнМЏ
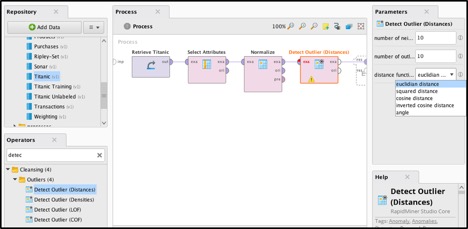
ЪЙгУRapidMinerРДдЄДІРэTitanicЪ§ОнМЏ
ФуПЩвдЪЙгУПЩЪгЛЏIDEРДХфжУдЄДІРэЃЌЖјЗЧШчЧАЫљЪіЕФгУRЛђScalaБраДдДДњТыЁЃЖдДѓЖрЪ§гУЛЇРДЫЕЃЌетЪЙЕУЪ§ОнзМБИКЭЗжЮіБфЕУИќШнвзЃЌВЂЧвЪ§ОнЕФЮЌЛЄКЭвЦНЛвВБфЕУИќШнвзЁЃ
вЕЮёЗжЮіЪІЛђЦНУёЪ§ОнПЦбЇМвЕФЪ§ОнећРэ
Ъ§ОнећРэЃЈгаЪБвВГЦЮЊdata mungingЃЉЪЧвЛжжЪЙгУЭМаЮЙЄОпЕФЪ§ОнзМБИЗНЗЈЃЌИУЗНЗЈМђЕЅжБЙлЁЃетаЉЙЄОпВржигквзгУадКЭУєНнЕФЪ§ОнзМБИЁЃвђДЫЃЌЫќВЛвЛЖЈгЩПЊЗЂШЫдБЛђЪ§ОнПЦбЇМвЭъГЩЃЌЖјЪЧЫљгаЕФгУЛЇЖМПЩвдЃЈАќРЈвЕЮёЗжЮіЪІЛђЦНУёЪ§ОнПЦбЇМвЃЉЁЃDataWranglerКЭTrifacta
WranglerЪЧЪ§ОнећРэЕФСНИіЪОР§ЁЃ
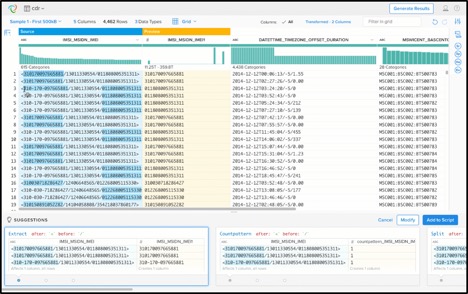
гУгкЪ§ОнећРэЕФTrifacta
ЧызЂвтЃЌетаЉЙЄОпУЛгаЪ§ОндЄДІРэПђМмФЧУДЧПДѓЃЌвђДЫЫќУЧОГЃгУгкЪ§ОнзМБИЕФзюКѓвЛЙЋРяЁЃЫќУЧВЛЛсЬцЛЛЦфЫќЕФМЏГЩбЁЯюЃЌШчETLЃЈЬсШЁ-БфЛЛ-МгдиЃЉЙЄОпЃЌЛђЪЙгУRЁЂPythonЁЂKNIMEЁЂRapidMinerЕШНјааЕФЪ§ОндЄДІРэЁЃ
Шчв§бджаЫљЬжТлЃЌвђЮЊЪ§ОнећРэгыЪЕМЪЪ§ОнЗжЮіЯрЛЅНтёюЃЌЫљвдЪ§ОнећРэздЩэЕФЙЄОпПЩФмЛсДцдквЛаЉВЛзужЎДІЁЃПЩЪгЛЏЗжЮіЙЄОпжаЕФЪ§ОнећРэдЪаэдкЪ§ОнЕФЬНЫїадЗжЮіЦкМфНјааinlineЪ§ОнећРэЁЃЕЅИіЕФгУЛЇЪЙгУЕЅвЛЕФЙЄОпОЭФмЙЛЭъГЩЫќЁЃР§ШчЃЌЧыВЮдФTIBCO
SpotfireЪОР§ЃЌЫќНсКЯСЫПЩЪгЛЏЗжЮігыinlineЪ§ОнећРэЃЈвдМАЦфЫќЕФЪ§ОнПЦбЇЙІФмРДЙЙНЈЗжЮіФЃаЭЃЉЃК
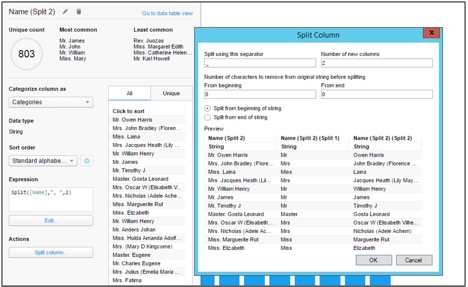
ПЩЪгЛЏЗжЮіЙЄОпTIBCO SpotfireжаЕФinlineЪ§ОнећРэ
Ъ§ОнећРэЙЄОпКЭДјгаinlineЪ§ОнећРэЕФПЩЪгЛЏЗжЮіЙЄОпПЩвдБЛУПжжгУЛЇНЧЩЋЪЙгУЃКвЕЮёЗжЮіЪІЁЂЃЈЦНУёЃЉЪ§ОнПЦбЇМвЛђПЊЗЂШЫдБЃЌетаЉЙЄОпФмЙЛМгЫйЪ§ОнзМБИКЭЪ§ОнЗжЮіЁЃ
БОЮФжиЕуНщЩмСЫгУгкНЈСЂЛњЦїбЇЯАФЃаЭЕФЪ§ОнзМБИЁЃФуПЩвдЪЙгУБрГЬгябдЃЈШчRЛђPythonЃЉЁЂЪ§ОнПЦбЇЙЄОпЃЈШчKNIMEЛђRapidMinerЃЉЁЂЪ§ОнећРэЃЈЪЙгУDataWranglerЛђTrificataЃЉЛђinlineЪ§ОнећРэЃЈЭЈЙ§TIBCO
SpotfireЃЉЁЃЭЈГЃЃЌдкПЊЪМетвЛЧажЎЧАЃЌФуашвЊФмЙЛЗУЮЪФугЕгаЕФЫљгаЪ§ОнЃЌетаЉЪ§ОнДцДЂгкИїжжЛђЖрЛђЩйећРэЙ§ЕФЪ§ОндДжаЃЈШчЙиЯЕЪ§ОнПтЁЂЪ§ОнВжПтЁЂДѓЪ§ОнМЏШКЃЉЁЃвђДЫЃЌдквдЯТСНВПЗжЃЌЮвУЧНЋМђвЊНщЩмгУгкЪ§ОнЛёШЁЃЈdata
ingestionЃЉЕФETLКЭСїЪНЗжЮіЙЄОпЃЌЭЈГЃЪ§ОнЛёШЁЛЙАќРЈЪ§ОнзМБИЕФФГаЉВПЗжЃЌЬиБ№ЪЧЪ§ОнОлКЯКЭЪ§ОнЧхЯДЁЃ
ПЊЗЂепЕФETLЃЈЬсШЁ-БфЛЛ-МгдиЃЉКЭDQЃЈЪ§ОнжЪСПЃЌData QualityЃЉ
ETLЙЄОпЪЧЮЊПЊЗЂепМЏГЩИїжжЪ§ОндДЖјЩшМЦЕФЃЌЫќАќРЈСЫаэЖрвХСєКЭзЈгаЃЈproprietaryЃЉНгПкЃЈШчMainframeЛђEDIFACTНгПкЃЉЃЌетаЉНгПкОпгаЪЎЗжИДдгЕФЪ§ОнНсЙЙЁЃЫќЛЙАќРЈСЫЪ§ОнЧхЯДЃЈдкЩЯЯТЮФжаЭЈГЃБЛГЦЮЊЁАЪ§ОнжЪСПЁБЙЄОпЃЉЃЌВЂНЋжиЕуЗХдквзгУадКЭЪЙгУПЩЪгЛЏБрТыЕФЦѓвЕВПЪ№ЩЯЃЈРрЫЦгкШчKNIMEЛђRapidMinerЕФЪ§ОнПЦбЇЙЄОпЃЌЕЋЪЧзЈзЂгкETLКЭЪ§ОнжЪСПЃЉЁЃЫќУЧЛЙжЇГжДѓЪ§ОнПђМмЃЌШчApache
HadoopКЭApache SparkЁЃДЫЭтЃЌЫќУЧЛЙЮЊжЪСПИФНјЬсЙЉСЫПЊЯфМДгУЃЈout-of-the-box
ЃЉЕФжЇГжЃЌР§ШчЃЌЕижЗбщжЄЁЃETLКЭDQЭЈГЃдкГЄЪБМфдЫааЕФХњДІРэНјГЬжаЪЕЯжЃЌвђДЫШчЙћФуашвЊЪЙгУЪЕЪБЪ§ОнЙЙНЈФЃаЭЃЌФЧУДетгаЪБПЩФмЛсВњЩњИКУцгАЯьЁЃ
ETLКЭDQЙЄОпЕФР§згЪЧвЛаЉПЊдДЙЄОпЃЌШчPentahoЛђTalendЃЌЛђзЈгаЙЉгІЩЬInformaticaЁЃЪаГЁе§дкЯђИќМђЕЅвзгУЕФWebгУЛЇНчУцзЊвЦЃЌетаЉМђЕЅвзгУЕФНчУцФмЙЛШУЦфЫћгУЛЇНЧЩЋвВжДаавЛаЉЛљБОЕФШЮЮёЁЃ
ПЊЗЂепЕФЪ§ОнЛёШЁгыСїЪНЗжЮі
Ъ§ОнЛёШЁгыСїЪНЗжЮіЙЄОпПЩгУгкдкСїЃЈstreamЃЉжаЬэМгКЭдЄДІРэЪ§ОнЁЃетаЉПђМмдЪаэХњСПЕиЛђЪЕЪБЕидЄДІРэЪ§ОнЁЃЯТЭМеЙЪОСЫвЛИіЕфаЭЕФСїЪНЗжЮіСїГЬЃЌЫќАќРЈЪ§ОнЛёШЁЁЂдЄДІРэЁЂЗжЮіЁЂДІРэКЭЪфГіЃК
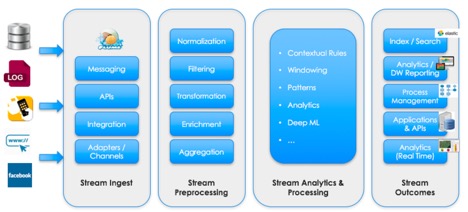
СїЪНЗжЮіСїГЬЕФВНжш
ФПЧАЪаГЁЩЯгаИїжжИїбљЕФПђМмКЭЙЄОпЁЃЫќУЧЖМвдетжжЛђФЧжжЗНЪНжЇГжРрЫЦHadoopЛђSparkЕФДѓЪ§ОнПђМмЁЃОйМИИіР§згЃК
Ъ§ОнЛёШЁПЊдДПђМмЃЈНіЙизЂЪ§ОнЛёШЁКЭдЄДІРэВНжшЃЉЃКApache NiFiЁЂStreamSetsЁЂCask
Hydrator
СїЪНДІРэПЊдДПђМмЃЈЭъећЕФСїЪНЗжЮіСїГЬЃЉЃКApache StormЁЂApache FlinkЁЂApache
Apex
СїЪНДІРэЩЬвЕШэМўЃЈЭъећЕФСїЪНЗжЮіСїГЬЃЉЃКSoftware AG ApamaЁЂIBM StreamsЁЂTIBCO
StreamBase
гаЙиИќЖраХЯЂЃЌЧыВЮдФСїЪНЗжЮіПђМмЁЂВњЦЗКЭдЦЗўЮёЕФБШНЯЁЃ
ЪЙгУетаЉЙЄОпЃЈАќРЈETLЃЉЕФОоДѓгХЪЦЪЧЃЌФуПЩвдЪЙгУЭЌвЛЬзЙЄОпЛђПђМмЃЈЖдРњЪЗЪ§ОнЃЉНјааЪ§ОндЄДІРэЃЌвдМАЃЈЖдаТЪ§ОнЃЉНјааЪЕЪБДІРэЃЈвдБудкБфЛЏЕФЪ§ОнРяЪЙгУЗжЮіФЃаЭЃЉЁЃетНЋЛсЪЧвЛИіВЛДэЕФбЁдёЃЌгУЛЇВЛНіПЩвдБЃГжаЁЖјОЋЕФЙЄОпМЏЃЌЖјЧвЛЙФмЭЈЙ§вЛЬзЙЄОпЭЌЪБЛёЕУETL/ЛёШЁКЭЪЕЪБДІРэЁЃЯТЭМЪЧвЛИіЪЙгУTIBCO
StreamBaseЖдTitanicЪ§ОнМЏНјаадЄДІРэЕФР§згЃК
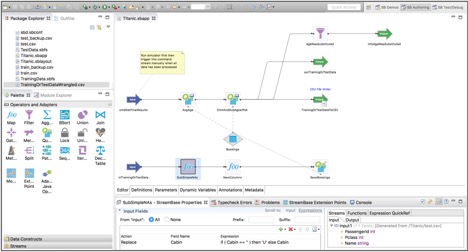
TitanicЪ§ОнМЏЕФСїЪНдЄДІРэ
ЖдгкЪ§ОнЛёШЁКЭETLЙЄОпЃЌСїЪНЗжЮіЕФЪаГЁе§дкзЊЯђИќМђЕЅЕФWebгУЛЇНчУцЃЌетаЉМђЕЅЕФгУЛЇНчУцШУЦфЫћгУЛЇНЧЩЋвВФмжДаавЛаЉЛљБОЕФШЮЮёЁЃЕЋетВЛЛсШЁДњЯжгаЕФЙЄОпдкИќИпМЖБ№гУР§РяЕФЪЙгУЃЌЖјЪЧЮЊЗжЮіЪІЛђЪ§ОнПЦбЇМвЬсЙЉСЫаТЕФбЁдёЁЃдкУЛгаПЊЗЂШЫдБЕФАяжњЯТЃЌЫћУЧФмЙЛИќШнвзКЭИќжБНгЕиВПЪ№вЛаЉЙцдђЁЂЙиСЊЛђЗжЮіФЃаЭЁЃ
Ъ§ОнзМБИЪЧЛњЦїбЇЯАЯюФПГЩЙІЕФЙиМќ
ЪЙгУЛњЦїбЇЯАЛђЩюЖШбЇЯАММЪѕЙЙНЈЗжЮіФЃаЭВЂВЛШнвзЁЃЪ§ОнзМБИеМШЅећИіЗжЮіЙмЕРЕФ60ЃЅЕН80ЃЅЁЃЪаГЁЩЯгаИїжжгУгкЪ§ОнЧхЯДКЭЬиеїЙЄГЬЕФБрГЬгябдЁЂПђМмКЭЙЄОпЁЃЫќУЧжЎМфЕФЙІФмгажиЕўЃЌвВИїгаШЈКтЁЃ
Ъ§ОнећРэЪЧЪ§ОндЄДІРэЕФживЊРЉеЙЃЈadd-onЃЉЁЃЫќзюЪЪКЯдкПЩЪгЛЏЗжЮіЙЄОпжаЪЙгУЃЌетФмЙЛБмУтЗжЮіСїГЬБЛДђЖЯЁЃПЩЪгЛЏЗжЮіЙЄОпгыПЊдДЪ§ОнПЦбЇзщМўЃЈcomponentЃЉжЎМфЃЌШчRЁЂPythonЁЂKNIMEЁЂRapidMinerЛЅЮЊВЙГфЁЃ
БмУтЙ§ЖрЕиЪЙгУзщМўФмЙЛМгЫйЪ§ОнПЦбЇЯюФПЁЃвђДЫЃЌдкЪ§ОнзМБИВНжшжаРћгУСїЪНЛёШЁПђМмЛђСїЪНЗжЮіВњЦЗЛсЪЧвЛИіВЛДэЕФбЁдёЁЃЮвУЧжЛашвЊБраДвЛДЮдЄДІРэЕФВНжшЃЌШЛКѓНЋЦфгУгкРњЪЗЪ§ОнЕФХњДІРэжаЃЌДгЖјНјааЗжЮіФЃаЭЕФЙЙНЈЃЌЭЌЪБЃЌЛЙПЩвдНЋЦфгУгкЪЕЪБДІРэЃЌетбљОЭФмНЋЮвУЧЙЙНЈЕФЗжЮіФЃаЭгУЕНаТЕФЪТМўжаЁЃ
етаЉЛУЕЦЦЌКЭЪгЦЕЬсЙЉСЫИќЖрЙигкЪ§ОнзМБИЕФаХЯЂЃЌЭЈЙ§етаЉзЪСЯФуФмИќЯъЯИЕиСЫНтБОЮФЕФФкШнЁЃ |









