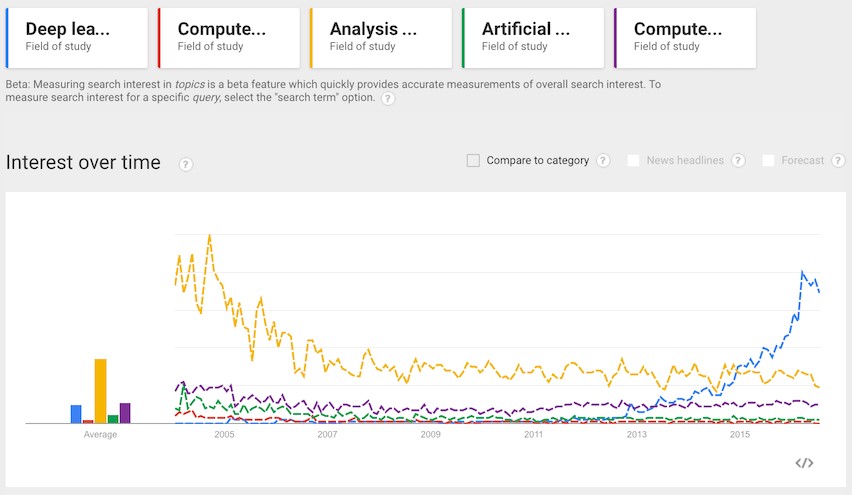
| дк2015Фъ11дТ9КХGoogleЗЂВМСЫШЫЙЄжЧФмЯЕЭГTensorFlowВЂаћВМПЊдДЃЌДЫОйдкЩюЖШбЇЯАСьгђгАЯьОоДѓЃЌвВЪмЕНДѓСПЕФЩюЖШбЇЯАПЊЗЂепМЋДѓЕФЙизЂЁЃЕБШЛЃЌЖдгкШЫЙЄжЧФметИіСьгђЃЌвРШЛгаВЛЩйжЪвЩЕФЩљвєЃЌЕЋВЛПЩЗёШЯЕФЪЧШЫЙЄжЧФмШдШЛЪЧЮДРДЗЂеЙЕФЧїЪЦЁЃ
ЖјTensorFlowФмЙЛдкЕЧТНGitHubЕФЕБЬьОЭГЩЮЊзюЪмЙизЂЕФЯюФПЃЌзїЮЊЙЙНЈЩюЖШбЇЯАФЃаЭЕФзюМбЗНЪНЁЂЩюЖШбЇЯАПђМмЕФСьЭЗепЃЌдкЗЂВМЕБжмЧсЫЩЛёЕУГЌЙ§1ЭђИіаЧЪ§ЦРМЖЃЌетжївЊЪЧвђЮЊGoogleдкШЫЙЄжЧФмСьгђЕФбаЗЂГЩМЈьГШЛКЭЩёМЖЕФММЪѕШЫВХДЂБИЁЃЕБШЛЛЙгавЛЕуЪЧдкЮЇЦхЩЯЕквЛДЮДђАмШЫРрЃЌШЛКѓЩ§МЖАцMasterБЃГжСЌај60ХЬВЛАмЕФAlphaGoЃЌЦфЧПЛЏбЇЯАЕФПђМмвВЪЧЛљгкTensorFlowЕФИпМЖAPIЪЕЯжЕФЁЃ
TensorFlow: ЮЊЪВУДЪЧЫќ?
зїЮЊGoolgeЖўДњDLПђМмЃЌЪЙгУЪ§ОнСїЭМЕФаЮЪННјааМЦЫуЕФTensorFlowвбОГЩЮЊСЫЛњЦїбЇЯАЁЂЩюЖШбЇЯАСьгђжазюЪмЛЖгЕФПђМмжЎвЛЁЃздДгЗЂВМвдРДЃЌTensorFlowВЛЖЯдкЭъЩЦВЂдіМгаТЙІФмЃЌВЂдкНёФъЕФ2дТ26КХдкMountain
ViewОйАьЕФЪзНьФъЖШTensorFlowПЊЗЂепЗхЛсЩЯе§ЪНЗЂВМСЫTensorFlow 1.0АцБОЃЌЦфзюДѓЕФССЕуОЭЪЧЭЈЙ§гХЛЏФЃаЭДяЕНзюПьЕФЫйЖШЃЌЧвПьЕНСюШЫФбвджУаХЃЌИќШУШЫЯыВЛЕНЕФЪЧКмЖргЕЛЄепгУTensorFlow
1.0ЕФЗЂВМРДЖЈвхAIЕФдЊФъЁЃ
ЭЈЙ§вдЩЯGoogleжИЪ§ЃЌЩюЖШбЇЯАеМОнФПЧАСїГЬММЪѕЕФЕквЛЮЛ
TensorFlowдкЙ§ШЅЛёЕУГЩМЈжївЊгавдЯТМИЕуЃК
1.TensorFlowБЛгІгУдкGoogleКмЖрЕФгІгУАќРЈЃКGmail,
Google Play Recommendation, Search, Translate, MapЕШЕШЃЛ
2.дквНСЦЗНУцЃЌTensorFlowБЛПЦбЇМвгУРДДюНЈИљОнЪгЭјФЄРДдЄЗРЬЧФђВЁжТУЄЃЈКѓУцвВЬсЕНStanfordЕФPHDЪЙгУTensorFlowРДдЄВтЦЄЗєАЉЃЌЯрЙиЙЄзїЩЯСЫNatureЗтУцЃЉЃЛ
3.ЭЈЙ§дквєРжЁЂЛцЛетПщЕФСьгђЪЙгУTensorFlowЙЙНЈЩюЖШбЇЯАФЃаЭРДАяжњШЫРрИќКУЕиРэНтвеЪѕЃЛ
4.ЪЙгУTensorFlowПђМмКЭИпПЦММЩшБИЃЌЙЙНЈздЖЏЛЏЕФКЃбѓЩњЮяМьВтЯЕЭГЃЌгУРДАяжњПЦбЇМвСЫНтКЃбѓЩњЮяЕФЧщПіЃЛ
5.TensorFlowдквЦЖЏПЭЛЇЖЫЗЂСІЃЌгаЖрПюдквЦЖЏЩшБИЩЯЪЙгУTensorFlowзіЗвыЁЂЗчИёЛЏЕШЙЄзїЃЛ
6.TensorFlowдквЦЖЏЩшБИCPUЃЈИпЭЈ820ЃЉЩЯЃЌФмЙЛДяЕНИќИпЕФадФмКЭИќЕЭЕФЙІКФЃЛ
7.TensorFlow ecosystemНсКЯЦфЫћПЊдДЯюФПФмЙЛПьЫйЕиДюНЈИпадФмЕФЩњВњЛЗОГЃЛ
8.TensorBoard Embedded vectorПЩЪгЛЏЙЄзї
9.ФмЙЛАяжњPHD/ПЦбаЙЄзїепПьЫйПЊеЙprojectбаОПЙЄзїЁЃ
GoogleЕквЛДњЗжВМЪНЛњЦїбЇЯАПђМмDistBeliefВЛдйТњзуGoogleФкВПЕФашЧѓЃЌGoogleЕФаЁЛяАщУЧдкDistBeliefЛљДЁЩЯзіСЫжиаТЩшМЦЃЌв§ШыИїжжМЦЫуЩшБИЕФжЇГжАќРЈCPU/GPU/TPUЃЌвдМАФмЙЛКмКУЕидЫаадквЦЖЏЖЫЃЌШчАВзПЩшБИЁЂiosЁЂЪїнЎХЩ
ЕШЕШЃЌжЇГжЖржжВЛЭЌЕФгябдЃЈвђЮЊИїжжhigh-levelЕФapiЃЌбЕСЗНіжЇГжPythonЃЌinferenceжЇГжАќРЈC++ЃЌGoЃЌJavaЕШЕШЃЉЃЌСэЭтАќРЈЯёTensorBoardетРрКмАєЕФЙЄОпЃЌФмЙЛгааЇЕиЬсИпЩюЖШбЇЯАбаОПЙЄзїепЕФаЇТЪЁЃ
TensorFlowдкGoogleФкВПЯюФПгІгУЕФдіГЄвВЪЎЗжбИЫйЃКдкGoogleЖрИіВњЦЗЖМгагІгУШчЃКGmailЃЌGoogle
Play RecommendationЃЌ SearchЃЌ TranslateЃЌ MapЕШЕШЃЛгаНЋНќ100ЖрprojectКЭpaperЪЙгУTensorFlowзіЯрЙиЙЄзїЁЃ

TensorFlowдке§ЪНАцЗЂВМЧАЕФЙ§ШЅ14ИідТЕФЪБМфФквВЛёЕУСЫКмЖрЕФГЩМЈЃЌАќРЈ475+ЗЧGoogleЕФContributorsЃЌ14000+ДЮcommitЃЌГЌЙ§5500БъЬтжаГіЯжЙ§TensorFlowЕФgithub
projectвдМАдкStack OverflowЩЯгаАќРЈ5000+ИівбБЛЛиД№ ЕФЮЪЬтЃЌЦНОљУПжм80+ЕФissueЬсНЛЃЌЧвБЛвЛаЉЖЅМтЕФбЇЪѕбаОПЯюФПЪЙгУЃК
ЈC Neural Machine Translation ЈC Neural Architecture
Search ЈC Show and Tell.
ЕБШЛСЫЃЌЫЕЕНЕзЩюЖШбЇЯАОЭЪЧгУЗЧМрЖНЪНЛђепАыМрЖНЪНЕФЬиеїбЇЯАЃЌЗжВуЬиеїЬсШЁИпаЃЫуЗЈРДЬцДњЪжЙЄЛёШЁЬиеїЁЃФПЧАбаОПШЫдБКЭДгЪТЩюЖШбЇЯАЕФПЊЗЂепЪЙгУЩюЖШбЇЯАПђМмвВВЂЗЧжЛгаTensorFlowвЛИіЃЌЭЌбљвВгаКмЖрдкЪгОѕЁЂгябдЁЂздШЛгябдДІРэКЭЩњЮяаХЯЂЕШСьгђНЯЮЊгХауЕФПђМмЃЌБШШчTorchЁЂCaffeЁЂTheanoЁЂDeeplearning4jЕШЁЃ
ЯТУцЃЌБрепећРэЖЮЪЏЪЏВЉЮФжаЕФвЛаЉЖдЭјТчЩёОФЃаЭЁЂЫуЗЈЩюЖШЗжЮіЕФФкШнЃЌСЫНтTensorFlowетИіПЊдДЩюЖШбЇЯАПђМмЕФЧПДѓжЎДІЁЃ
ЩюШыРэНтNeural Style
етЦЊЮФеТжївЊеыЖдTensorflowРћгУCNNЕФЗНЗЈЖдвеЪѕееЦЌзіЯТNeural
StyleЕФЯрЙиЙЄзїЁЃЪзЯШЃЌзїепЛсЯъЯИНтЪЭЯТA Neural Algorithm of Artistic
StyleетЦЊpaperЪЧдѕУДзіЕФЃЌШЛКѓЛсНсКЯвЛИіПЊдДЕФTensorflowЕФNeural StyleАцБОРДСьТдЯТДѓЩёЕФЗчВЩЁЃ
A Neural Algorithm of Artistic Style
дквеЪѕСьгђЃЌгШЦфЪЧЛцЛЃЌвеЪѕМвУЧЭЈЙ§ДДдьВЛЭЌЕФФкШнгыЗчИёЃЌВЂЯрЛЅНЛШкгАЯьРДДДСЂЖРСЂЕФЪгОѕЬхбщЁЃШчЙћИјЖЈСНеХЭМЯёЃЌЯждкЕФММЪѕЪжЖЮЃЌЭъШЋгаФмСІШУМЦЫуЛњЪЖБ№ГіЭМЯёОпЬхФкШнЁЃЖјЗчИёЪЧвЛжжКмГщЯѓЕФЖЋЮїЃЌдкМЦЫуЛњЕФблжаЃЌЕБШЛОЭЪЧвЛаЉpixelЃЌЕЋШЫблОЭФмКмгааЇЕиЕФБцБ№ГіВЛЭЌЛМвВЛЭЌЕФstyleЃЌЪЧЗёгавЛаЉИќИДдгЕФfeatureРДЙЙГЩЃЌзюПЊЪМбЇЯАDeepLearningЕФpaperЪБЃЌЖрВуЭјТчЕФЪЕжЪЦфЪЕОЭЪЧевГіИќИДдгЁЂИќФкдкЕФfeaturesЃЌЫљвдЭМЯёЕФstyleРэТлЩЯПЩвдЭЈЙ§ЖрВуЭјТчРДЬсШЁРяУцПЩФмвЛаЉгавтЫМЕФЖЋЮїЁЃЖјетЦЊЮФеТОЭЪЧРћгУОэЛ§ЩёОЭјТчЃЈРћгУpretrainЕФPre-trained
VGG network modelЃЉРДЗжБ№зіContentЁЂStyleЕФreconstructionЃЌдкКЯГЩЪБПМТЧcontent
loss гыstyle lossЕФзюаЁЛЏЃЈЦфЪЕЛЙАќРЈШЅдыБфЛЏЕФЕФlossЃЉЃЌетбљКЯГЩГіРДЕФЭМЯёЛсБЃжЄдкcontent
КЭstyleЕФжиЙЙЩЯИќзМШЗЁЃ

етРяЪЧећИіpaperдкneural styleЕФЙЄзїСїЃЌРэНтетЗљЭМЖдРэНтећЦЊpaperЕФТпМКмЙиМќЃЌжївЊЗжЮЊСНВПЗжЃК
1.Content Reconstruction: ЩЯЭМжаЯТУцВПЗжЪЧContent
ReconstructionЖдгІгкCNNжаЕФaЃЌbЃЌcЃЌdЃЌeВуЃЌзЂвтзюПЊЪМБъСЫContent RepresentationsЕФВПЗжВЛЪЧдЪМЭМЦЌЃЈПЩвдРэНтЪЧИјМЦЫуЛњБШШчЗжРрЦїПДЕФЭМЦЌЃЌвђДЫШчЙћПЩЪгЛЏЫќЃЌПЩФмЭъШЋОЭВЛжЊЕРЪЧЪВУДФкШнЃЉЃЌЖјЪЧОЙ§СЫPre-trainedжЎКѓЕФVGG
network modelЕФЭМЯёЪ§ОнЃЌ ИУmodelжївЊгУРДзіobject recognitionЃЌ
етРяжївЊгУРДЩњГЩЭМЯёЕФContent RepresentationsЁЃРэНтСЫетРяЃЌКѓУцОЭБШНЯШнвзСЫЃЌОЙ§ЮхВуОэЛ§ЭјТчРДзіContentЕФжиЙЙЃЌЮФеТзїепЪЕбщЗЂЯждкЧА3ВуЕФContent
ReconstructionаЇЙћБШНЯКУЃЌdЃЌeСНВуЖЊЪЇСЫВПЗжЯИНкаХЯЂЃЌБЃСєСЫБШНЯhigh-levelЕФаХЯЂЁЃ
2.Style ReconstructionЃК StyleЕФжиЙЙБШНЯИДдгЃЌКмФбШЅФЃаЭЛЏStyleетИіЖЋЮїЃЌStyle
RepresentionЕФЩњГЩвВЪЧКЭContent RepresentationЕФЩњГЩРрЫЦЃЌвВЪЧгЩVGG
network modelШЅзіЕФЃЌВЛЭЌЕудкгкa,b,c,d,eЕФДІРэЗНЪНВЛЭЌЃЌStyle RepresentionЕФReconstructionЪЧдкCNNЕФВЛЭЌЕФзгМЏЩЯРДМЦЫуЕФЃЌдѕУДЫЕФиЃЌЫќЛсЗжБ№ЙЙдьconv1_1(a),[conv1_1,
conv2_1](b),[conv1_1, conv2_1, conv3_1],[conv1_1,
conv2_1, conv3_1,conv4_1],[conv1_1, conv2_1, conv3_1,
conv4_1, conv5_1]ЁЃетбљжиЙЙЕФStyle ЛсдкИїИіВЛЭЌЕФГпЖШЩЯИќМгЦЅХфЭМЯёБОЩэЕФstyleЃЌКіТдГЁОАЕФШЋОжаХЯЂЁЃ
methods
РэНтСЫвдЩЯСНЕуЃЌЪЃЯТЕФОЭЪЧНЈФЃЕФЪ§ОнЮЪЬтСЫЃЌетРяАДContentКЭStyleРДЗжБ№МЦЫуlossЃЌContent
lossЕФmethodБШНЯМђЕЅЃК
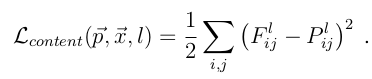
ЦфжаF^lЪЧВњЩњЕФContent RepresentationдкЕкlВуЕФЪ§ОнБэЪОЃЌP^lЪЧдЪМЭМЦЌдкЕкlВуЕФЪ§ОнБэЪОЃЌЖЈвхsquared-error
lossЮЊСНжжЬиеїБэЪОЕФerrorЁЃ
StyleЕФlossЛљБОвВКЭContent lossвЛбљЃЌжЛВЛЙ§вЊАќКЌУПвЛВуЪфГіЕФerrorsжЎКЭ
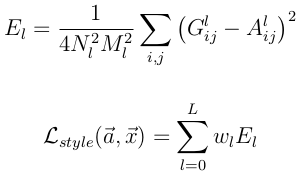
ЦфжаA^l ЪЧдЪМstyleЭМЦЌдкЕкlЕФЪ§ОнБэЪОЃЌЖјG^lЪЧВњЩњЕФStyle
RepresentationдкЕкlВуЕФБэЪО
ЖЈвхКУlossжЎКѓОЭЪЧВЩгУгХЛЏЗНЗЈРДзюаЁЛЏФЃаЭloss(зЂвтpaperЕБжажЛгаcontent
lossКЭstyle loss)ЃЌдДТыЕБжаЛЙЩцМАЕННЕдыЕФlossЃК
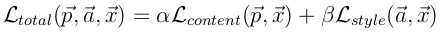
гХЛЏЗНЗЈетРяОЭВЛНВСЫЃЌtensorflowгаФкжУЕФШчAdamетбљЕФЗНЗЈРДДІРэЁЃ
ЩюШыРэНтAlexNet
ЧАУцПДСЫвЛаЉTensorflowЕФЮФЕЕКЭвЛаЉБШНЯгавтЫМЕФЯюФПЃЌЗЂЯжетРяУцЫЎКмЩюЕФЃЌашвЊЖрЛЈЪБМфКУКУДгЭЗСЫНтЯТЃЌгШЦфЪЧcvетПщЕФЖЋЮїЃЌЬиБ№ИааЫШЄЃЌНгЯТРДвЛЖЮЪБМфЛсПЊЪМЩюШыСЫНтImageNetБШШќжажаЛёЕУКУГЩМЈЕФФЧаЉФЃаЭЃК
AlexNetЁЂGoogLeNetЁЂVGGЃЈЖдОЭЪЧжЎЧАдкnerual networkгУЕФpretrainedЕФmodelЃЉЁЂdeep
residual networksЁЃ
ImageNet Classification with Deep
Convolutional Neural Networks
ImageNet Classification with Deep
Convolutional Neural Networks ЪЧHintonКЭЫћЕФбЇЩњAlex Krizhevskyдк12ФъImageNet
ChallengeЪЙгУЕФФЃаЭНсЙЙЃЌЫЂаТСЫImage ClassificationЕФМИТЪЃЌДгДЫdeep
learningдкImageетПщПЊЪМвЛДЮДЮГЌЙ§state-of-artЃЌЩѕжСгкДюЕНДђАмШЫРрЕФЕиВНЃЌПДетБпЮФеТЕФЙ§ГЬжаЃЌЗЂЯжСЫКмЖрвдЧАСуСуЩЂЩЂПДЕНЕФвЛаЉгХЛЏММЪѕЃЌЕЋЪЧКмЖрУЛгаЩюШыСЫНтЃЌетЦЊЮФеТНВНтСЫЫћУЧalexnetШчКЮзіЕНФмДяЕНФЧУДКУЕФГЩМЈЃЌКУЕФЗЯЛАВЛЖрЫЕЃЌРДПЊЪМПДЮФеТЃК
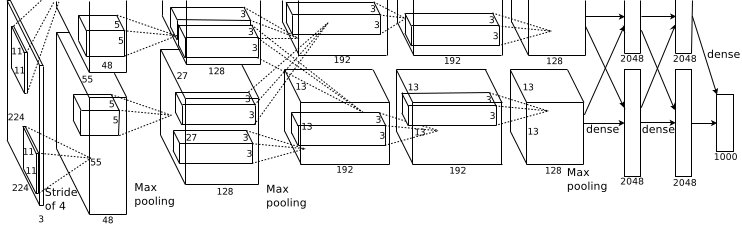
етеХЭМЪЧЛљБОЕФcaffeжаalexnetЕФЭјТчНсЙЙЃЌетРяБШНЯГщЯѓЃЌзїепгУcaffeЕФdraw_netАбalexnetЕФЭјТчНсЙЙЛГіРДСЫЃК
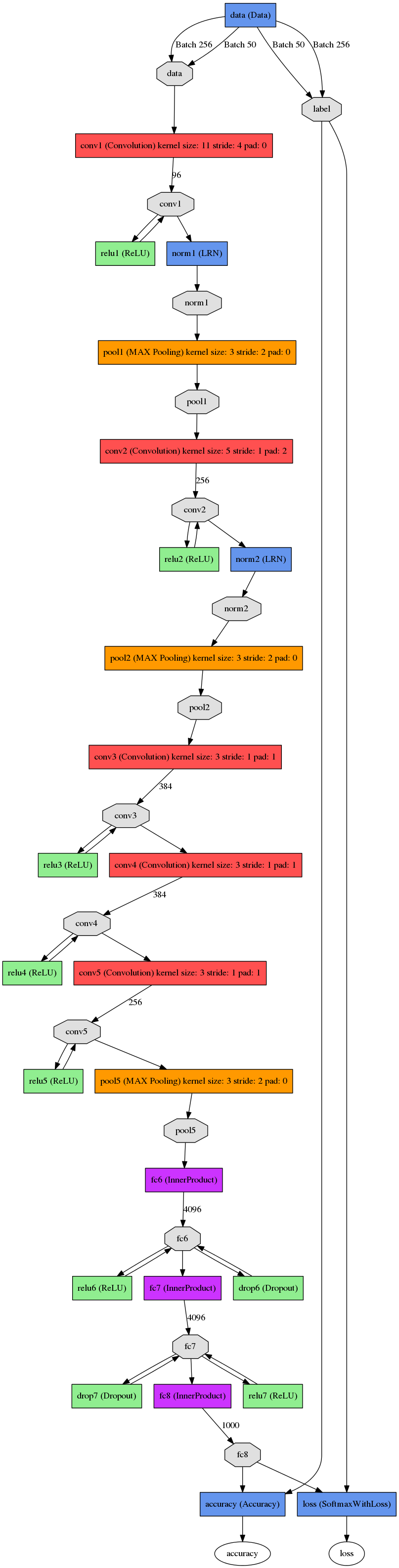
AlexNetЕФЛљБОНсЙЙ
alexnetзмЙВАќРЈ8ВуЃЌЦфжаЧА5ВуconvolutionalЃЌКѓУц3ВуЪЧfull-connectedЃЌЮФеТРяУцЫЕЕФЪЧМѕЩйШЮКЮвЛИіОэЛ§НсЙћЛсБфЕУКмВюЃЌЯТУцОпЬхНВНВУПвЛВуЕФЙЙГЩЃК
1.ЕквЛВуОэЛ§Ву ЪфШыЭМЯёЮЊ227*227*3(paperЩЯУВЫЦгаЕуЮЪЬт224*224*3)ЕФЭМЯёЃЌЪЙгУСЫ96ИіkernelsЃЈ96,11,11,3ЃЉЃЌвд4ИіpixelЮЊвЛИіЕЅЮЛРДгввЦЛђепЯТвЦЃЌФмЙЛВњЩњ5555ИіОэЛ§КѓЕФОиаЮПђжЕЃЌШЛКѓНјааresponse-normalizedЃЈЦфЪЕЪЧLocal
Response NormalizedЃЌКѓУцЮвЛсНВЯТетРяЃЉКЭpooledжЎКѓЃЌpoolетвЛВуКУЯёcaffeРяУцЕФalexnetКЭpaperРяУцВЛЬЋвЛбљЃЌalexnetРяУцВЩбљСЫСНИіGPUЃЌЫљвдДгЭМЩЯУцПДЕквЛВуОэЛ§ВуКёЖШгаСНВПЗжЃЌГиЛЏpool_size=(3,3),ЛЌЖЏВНГЄЮЊ2ИіpixelsЃЌЕУЕН96Иі2727ИіfeatureЁЃ
2.ЕкЖўВуОэЛ§ВуЪЙгУ256ИіЃЈЭЌбљЃЌЗжВМдкСНИіGPUЩЯЃЌУПИі128kernelsЃЈ5*5*48ЃЉЃЉЃЌзіpad_size(2,2)ЕФДІРэЃЌвд1ИіpixelЮЊЕЅЮЛвЦЖЏЃЈИааЛЭјгбжИГіЃЉЃЌФмЙЛВњЩњ27*27ИіОэЛ§КѓЕФОиеѓПђЃЌзіLRNДІРэЃЌШЛКѓpooledЃЌГиЛЏвд3*3ОиаЮПђЃЌ2ИіpixelЮЊВНГЄЃЌЕУЕН256Иі13*13ИіfeaturesЁЃ
3.ЕкШ§ВуЁЂЕкЫФВуЖМУЛгаLRNКЭpoolЃЌЕкЮхВужЛгаpoolЃЌЦфжаЕкШ§ВуЪЙгУ384ИіkernelsЃЈ3*3*384ЃЌpad_size=(1,1),ЕУЕН384*15*15ЃЌkernel_sizeЮЊЃЈ3ЃЌ3),вд1ИіpixelЮЊВНГЄЃЌЕУЕН384*13*13ЃЉЃЛЕкЫФВуЪЙгУ384ИіkernelsЃЈpad_size(1,1)ЕУЕН384*15*15ЃЌКЫДѓаЁЮЊЃЈ3ЃЌ3ЃЉВНГЄЮЊ1ИіpixelЃЌЕУЕН384*13*13ЃЉЃЛЕкЮхВуЪЙгУ256ИіkernelsЃЈpad_size(1,1)ЕУЕН384*15*15ЃЌkernel_size(3,3)ЃЌЕУЕН256*13*13ЃЌpool_size(3ЃЌ3ЃЉВНГЄ2ИіpixelsЃЌЕУЕН256*6*6ЃЉЁЃ
4.ШЋСЌНгВуЃК ЧАСНВуЗжБ№га4096ИіЩёОдЊЃЌзюКѓЪфГіsoftmaxЮЊ1000ИіЃЈImageNetЃЉЃЌзЂвтcaffeЭМжаШЋСЌНгВужагаreluЁЂdropoutЁЂinnerProductЁЃ
paperРяУцвВжИГіСЫетеХЭМЪЧдкСНИіGPUЯТзіЕФЃЌЦфжаКЭcaffeРяУцЕФalexnetПЩФмЛЙецгаЕуВювьЃЌЕЋетПЩФмВЛЪЧжиЕуЃЌИїЮЛдкЪЙгУЕФЪБКђЃЌжБНгВЮПМcaffeжаЕФalexnetЕФЭјТчНсЙћЃЌУПвЛВуЖМЪЎЗжЯъЯИЃЌЛљБОЕФНсЙЙРэНтКЭЩЯУцЪЧвЛжТЕФЁЃ
AlexNetЮЊЩЖШЁЕУБШНЯКУЕФНсЙћ
ЧАУцНВСЫЯТAlexNetЕФЛљБОЭјТчНсЙЙЃЌДѓМвПЯЖЈЛсЖдЦфжаЕФвЛаЉЕуВњЩњвЩЮЪЃЌБШШчLRNЁЂReluЁЂdropoutЃЌ
ЯраХНгДЅЙ§dlЕФаЁЛяАщУЧЖМгаЬ§ЫЕЛђепСЫНтЙ§етаЉЁЃетРяАДpaperжаЕФУшЪіЯъЯИНВЪіетаЉЖЋЮїЮЊЪВУДФмЬсИпзюжеЭјТчЕФадФмЁЃ
ReLU Nonlinearity
вЛАуРДЫЕЃЌИеНгДЅЩёОЭјТчЛЙУЛгаЩюШыСЫНтЩюЖШбЇЯАЕФаЁЛяАщУЧЖдетИіЖМВЛЛсЬЋЪьЃЌвЛАуЖМЛсИќСЫНтСэЭтСНИіМЄЛюКЏЪ§ЃЈеце§ЭљЩёОЭјТчжав§ШыЗЧЯпадЙиЯЕЃЌЪЙЩёОЭјТчФмЙЛгааЇФтКЯЗЧЯпадКЏЪ§ЃЉtanh(x)КЭ(1+e^(-x))^(-1),ЖјReLU(Rectified
Linear Units) f(x)=max(0,x)ЁЃЛљгкReLUЕФЩюЖШОэЛ§ЭјТчБШЛљгкtanhЕФЭјТчбЕСЗПщЪ§БЖЃЌЯТЭМЪЧвЛИіЛљгкCIFAR-10ЕФЫФВуОэЛ§ЭјТчдкtanhКЭReLUДяЕН25%ЕФtraining
errorЕФЕќДњДЮЪ§ЃК
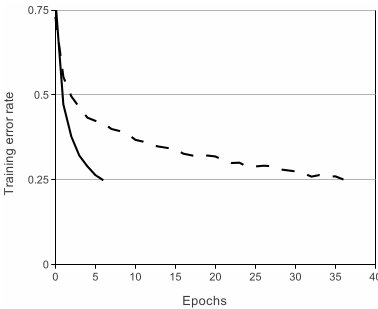
ЪЕЯпЁЂМфЖЯЯпЗжБ№ДњБэЕФЪЧReLUЁЂtanhЕФtraining errorЃЌПЩМћReLUБШtanhФмЙЛИќПьЕФЪеСВ
Local Response Normalization
ЪЙгУReLU f(x)=max(0,x)КѓЃЌФуЛсЗЂЯжМЄЛюКЏЪ§жЎКѓЕФжЕУЛгаСЫtanhЁЂsigmoidКЏЪ§ФЧбљгавЛИіжЕгђЧјМфЃЌЫљвдвЛАудкReLUжЎКѓЛсзівЛИіnormalizationЃЌLRUОЭЪЧЮФжаЬсГіЃЈетРяВЛШЗЖЈЃЌгІИУЪЧЬсГіЃПЃЉвЛжжЗНЗЈЃЌдкЩёОПЦбЇжагаИіИХФюНаЁАLateral
inhibitionЁБЃЌНВЕФЪЧЛюдОЕФЩёОдЊЖдЫќжмБпЩёОдЊЕФгАЯьЁЃ
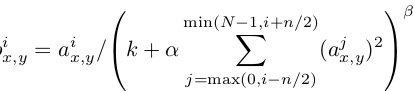
Dropout
DropoutвВЪЧОГЃЭІЫЕЕФвЛИіИХФюЃЌФмЙЛБШНЯгааЇЕиЗРжЙЩёОЭјТчЕФЙ§ФтКЯЁЃ
ЯрЖдгквЛАуШчЯпадФЃаЭЪЙгУе§дђЕФЗНЗЈРДЗРжЙФЃаЭЙ§ФтКЯЃЌЖјдкЩёОЭјТчжаDropoutЭЈЙ§аоИФЩёОЭјТчБОЩэНсЙЙРДЪЕЯжЁЃЖдгкФГвЛВуЩёОдЊЃЌЭЈЙ§ЖЈвхЕФИХТЪРДЫцЛњЩОГ§вЛаЉЩёОдЊЃЌЭЌЪББЃГжЪфШыВугыЪфГіВуЩёОдЊЕФИіШЫВЛБфЃЌШЛКѓАДееЩёОЭјТчЕФбЇЯАЗНЗЈНјааВЮЪ§ИќаТЃЌЯТвЛДЮЕќДњжаЃЌжиаТЫцЛњЩОГ§вЛаЉЩёОдЊЃЌжБжСбЕСЗНсЪј
Data Augmentation
ЦфЪЕЃЌзюМђЕЅЕФдіЧПФЃаЭадФмЃЌЗРжЙФЃаЭЙ§ФтКЯЕФЗНЗЈЪЧдіМгЪ§ОнЃЌЕЋЪЧЦфЪЕдіМгЪ§ОнвВЪЧгаВпТдЕФЃЌpaperЕБжаДг256*256жаЫцЛњЬсГі227*227ЕФpatches(paperРяУцЪЧ224*224)ЃЌЛЙгаОЭЪЧЭЈЙ§PCAРДРЉеЙЪ§ОнМЏЁЃетбљОЭКмгааЇЕиРЉеЙСЫЪ§ОнМЏЃЌЦфЪЕЛЙгаИќЖрЕФЗНЗЈЪгФуЕФвЕЮёГЁОАШЅЪЙгУЃЌБШШчзіЛљБОЕФЭМЯёзЊЛЛШчдіМгМѕЩйССЖШЃЌвЛаЉТЫЙтЫуЗЈЕШЕШжЎРрЕФЃЌетЪЧвЛжжЬиБ№гааЇЕиЪжЖЮЃЌгШЦфЪЧЕБЪ§ОнСПВЛЙЛДѓЕФЪБКђЁЃ
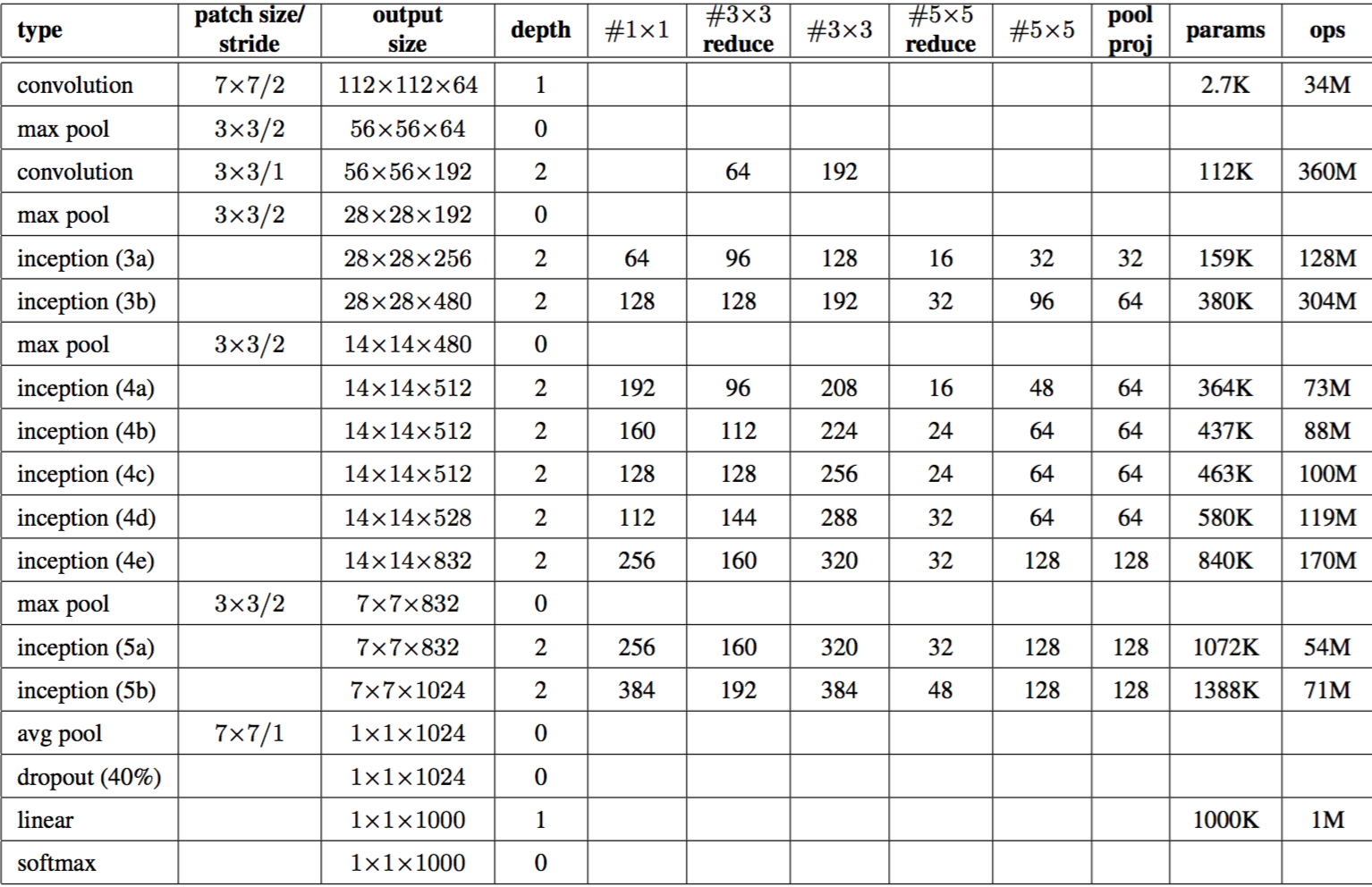
ЩюЖШРэНтGoogLeNet
GoogLeNetЪЧILSVRC 2014ЕФЙкОќЃЌжївЊЪЧжТОДОЕфЕФLeNet-5ЫуЗЈЃЌжївЊЪЧGoogleЕФteamГЩдБЭъГЩЃЌpaperМћGoing
Deeper with Convolutions.ЯрЙиЙЄзїжївЊАќРЈLeNet-5ЁЂGabor filtersЁЂNetwork-in-Network.Network-in-NetworkИФНјСЫДЋЭГЕФCNNЭјТчЃЌВЩгУЩйСПЕФВЮЪ§ОЭЧсЫЩЕиЛїАмСЫAlexNetЭјТчЃЌЪЙгУNetwork-in-NetworkЕФФЃаЭзюКѓДѓаЁдМЮЊ29MNetwork-in-Network
caffe model.GoogLeNetНшМјСЫNetwork-in-NetworkЕФЫМЯыЃЌЯТУцЛсЯъЯИНВЪіЯТЁЃ
1ЃЉNetwork-in-Network
зѓБпЪЧCNNЕФЯпадОэЛ§ВуЃЌвЛАуРДЫЕЯпадОэЛ§ВугУРДЬсШЁЯпадПЩЗжЕФЬиеїЃЌЕЋЫљЬсШЁЕФЬиеїИпЖШЗЧЯпадЪБЃЌашвЊИќМгЖрЕФfiltersРДЬсШЁИїжжЧБдкЕФЬиеїЃЌетбљОЭДцдквЛИіЮЪЬтЃЌfiltersЬЋЖрЃЌЕМжТЭјТчВЮЪ§ЬЋЖрЃЌЭјТчЙ§гкИДдгЖдгкМЦЫубЙСІЬЋДѓЁЃ
ЮФеТжївЊДгСНИіЗНЗЈРДзіСЫвЛаЉИФСМЃК
1ЃЌОэЛ§ВуЕФИФНјЃКMLPconvЃЌдкУПИіlocalВПЗжНјааБШДЋЭГОэЛ§ВуИДдгЕФМЦЫуЃЌШчЩЯЭМгвЃЌЬсИпУПвЛВуОэЛ§ВуЖдгкИДдгЬиеїЕФЪЖБ№ФмСІЃЌетРяОйИіВЛЧЁЕБЕФР§згЃЌДЋЭГЕФCNNЭјТчЃЌУПвЛВуЕФОэЛ§ВуЯрЕБгквЛИіжЛЛсзіЕЅвЛШЮЮёЃЌФуБиаывЊдіМгКЃСПЕФfiltersРДДяЕНЭъГЩЬиЖЈСПРраЭЕФШЮЮёЃЌЖјMLPconvЕФУПВуconvгаИќМгДѓЕФФмСІЃЌУПвЛВуФмЙЛзіЖржжВЛЭЌРраЭЕФШЮЮёЃЌдкбЁдёfiltersЪБжЛашвЊКмЩйСПЕФВПЗжЃЛ
2ЃЌВЩгУШЋОжОљжЕГиЛЏРДНтОіДЋЭГCNNЭјТчжазюКѓШЋСЌНгВуВЮЪ§Й§гкИДдгЕФЬиЕуЃЌЖјЧвШЋСЌНгЛсдьГЩЭјТчЕФЗКЛЏФмСІВюЃЌAlexnetжагаЬсИпЪЙгУdropoutРДЬсИпЭјТчЕФЗКЛЏФмСІЁЃ
зюКѓзїепЩшМЦСЫвЛИі4ВуЕФNetwork-in-network+ШЋОжОљжЕГиЛЏВуРДзіimagenetЕФЗжРрЮЪЬтЁЃ
class NiN(Network):
def setup(self):
(self.feed('data')
.conv(11, 11, 96, 4, 4, padding='VALID',
name='conv1')
.conv(1, 1, 96, 1, 1, name='cccp1')
.conv(1, 1, 96, 1, 1, name='cccp2')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(5, 5, 256, 1, 1, name='conv2')
.conv(1, 1, 256, 1, 1, name='cccp3')
.conv(1, 1, 256, 1, 1, name='cccp4')
.max_pool(3, 3, 2, 2, padding='VALID',
name='pool2')
.conv(3, 3, 384, 1, 1, name='conv3')
.conv(1, 1, 384, 1, 1, name='cccp5')
.conv(1, 1, 384, 1, 1, name='cccp6')
.max_pool(3, 3, 2, 2, padding='VALID',
name='pool3')
.conv(3, 3, 1024, 1, 1, name='conv4-1024')
.conv(1, 1, 1024, 1, 1, name='cccp7-1024')
.conv(1, 1, 1000, 1, 1, name='cccp8-1024')
.avg_pool(6, 6, 1, 1, padding='VALID',
name='pool4')
.softmax(name='prob')) |
ЭјТчЛљБОНсЙћШчЩЯЃЌДњТыМћhttps://github.com/ethereon/caffe-tensorflow.
етРявђЮЊзїепзюНќЙЄзїБфЖЏЕФЮЪЬтЃЌУЛгаСЫЛњЦїРДХмвЛЦЊЃЌвВЮоЗЈЛЯТЛљБОЕФЭјТчНсЙЙЭМЃЌжЎКѓЛсВЙЩЯЁЃетРяжИЕФЬсГіЕФЪЧжаМфcccp1КЭccp2ЃЈcross
channel poolingЃЉЕШМлгк1*1kernelДѓаЁЕФОэЛ§ВуЁЃcaffeжаNINЕФЪЕЯжЃЈТдЃЌЧыЧАЭљдЮФдФЖСЃЉ
NINЕФЬсГіЦфЪЕвВПЩвдШЯЮЊЮвУЧМгЩюСЫЭјТчЕФЩюЖШЃЌЭЈЙ§МгЩюЭјТчЩюЖШЃЈдіМгЕЅИіNINЕФЬиеїБэЪОФмСІЃЉвдМАНЋдЯШШЋСЌНгВуБфЮЊaver_poolВуЃЌДѓДѓМѕЩйСЫдЯШашвЊЕФfiltersЪ§ЃЌМѕЩйСЫmodelЕФВЮЪ§ЁЃpaperжаЪЕбщжЄУїДяЕНAlexnetЯрЭЌЕФадФмЃЌзюжеmodelДѓаЁНіЮЊ29MЁЃ
РэНтNINжЎКѓЃЌдйРДПДGoogLeNetОЭВЛЛсгаВЛУїЫљРэЕФИаОѕЁЃ
ЭДЕуЃК
1.дНДѓЕФCNNЭјТчЃЌгаИќДѓЕФmodelВЮЪ§ЃЌвВашвЊИќЖрЕФМЦЫуСІжЇГжЃЌВЂЧвгЩгкФЃаЭЙ§гкИДдгЛсЙ§ФтКЯЃЛ
2.дкCNNжаЃЌЭјТчЕФВуЪ§ЕФдіМгЛсАщЫцзХашЧѓМЦЫузЪдДЕФдіМгЃЛ
3.ЯЁЪшЕФnetworkЪЧПЩвдНгЪмЃЌЕЋЪЧЯЁЪшЕФЪ§ОнНсЙЙЭЈГЃдкМЦЫуЪБаЇТЪКмЕЭ
Inception module
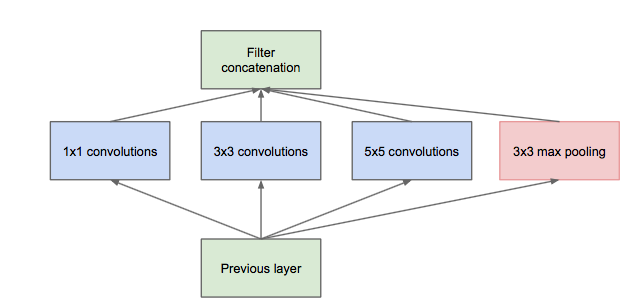
Inception moduleЕФЬсГіжївЊПМТЧЖрИіВЛЭЌsizeЕФОэЛ§КЫФмЙЛholdЭМЯёЕБжаВЛЭЌclusterЕФаХЯЂЃЌЮЊЗНБуМЦЫуЃЌpaperжаЗжБ№ЪЙгУ1*1ЃЌ3*3ЃЌ5*5ЃЌЭЌЪБМгШы3*3
max poolingФЃПщЁЃ ШЛЖјетРяДцдквЛИіКмДѓЕФМЦЫувўЛМЃЌУПвЛВуInception moduleЕФЪфГіЕФfiltersНЋЪЧЗжжЇЫљгаfiltersЪ§СПЕФзлКЯЃЌОЙ§ЖрВужЎКѓЃЌзюжеmodelЕФЪ§СПНЋЛсБфЕУОоДѓЃЌnaiveЕФinceptionЛсЖдМЦЫузЪдДгаИќДѓЕФвРРЕЁЃ
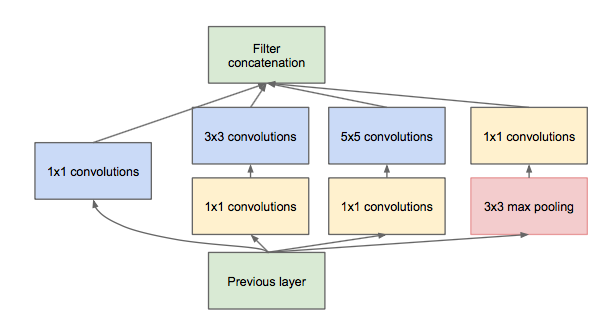
ЧАУцгаЬсЕНNetwork-in-NetworkФЃаЭЃЌ1*1ЕФФЃаЭФмЙЛгааЇНјааНЕЮЌЃЈЪЙгУИќЩйЕФРДБэДяОЁПЩФмЖрЕФаХЯЂЃЉЃЌЫљвдЮФеТЬсГіСЫЁБInception
module with dimension reductionЁБ,дкВЛЫ№ЪЇФЃаЭЬиеїБэЪОФмСІЕФЧАЬсЯТЃЌОЁСПМѕЩйfiltersЕФЪ§СПЃЌДяЕНМѕЩйmodelИДдгЖШЕФФПЕФЁЃ
Overall of GoogLeNet
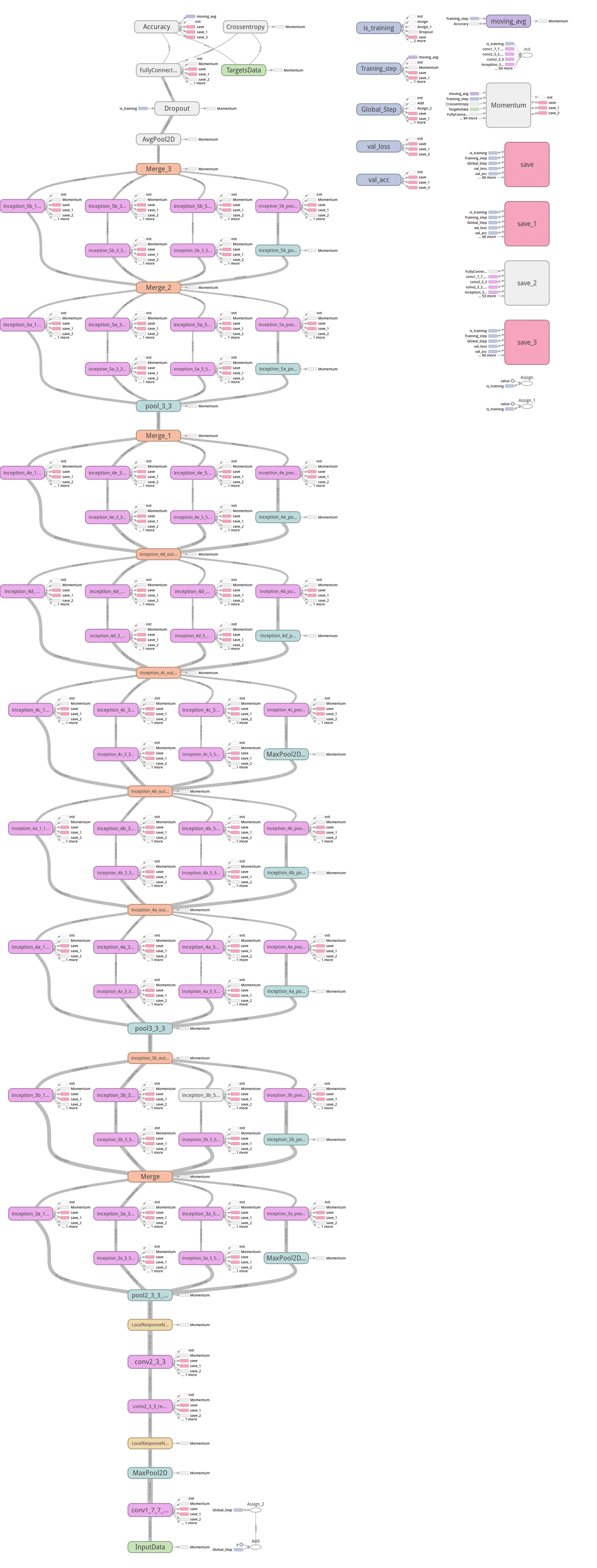
дкtensorflowЙЙдьGoogLeNetЛљБОЕФДњТыдкhttps://github.com/ethereon/caffe-tensorflowжаЃЈШчЙћРСЕУевЃЌдЮФгаеЙЪОЃЉЃЌзїепЗтзАСЫвЛаЉЛљБОЕФВйзїЃЌСЫНтЭјТчНсЙЙжЎКѓЃЌЙЙдьGoogLeNetКмШнвзЁЃжЎКѓЕШЕНаТЙЋЫОжЎКѓЃЌзїепЛсЪдзХдкtflearnЕФЛљДЁЩЯаДЯТGoogLeNetЕФЭјТчДњТыЁЃ
GoogLeNet on Tensorflow
GoogLeNetЮЊСЫЪЕЯжЗНБуЃЌзїепгУtflearnРДжиаДСЫЯТЃЌДњТыжаКЭcaffe
modelРяУцВЛвЛбљЕФОЭЪЧвЛаЉpaddingЕФЮЛжУЃЌвђЮЊИФЕФБШНЯТщЗГЃЌБиаыБЃГжinceptionВПЗжЕФconcatЪБвЊвЛжТЃЌетРявВВЛжЊЕРдѕУДаоИФpadЕФжЕЃЈcaffe
prototxtЃЉЃЌЫљвдЭГвЛpaddingЩшЖЈЮЊsameЃЌОпЬхДњТыЃЈТдЃЌдЮФгаеЙЪОЃЉ
ДѓМвШчЙћИааЫШЄЃЌПЩвдПДПДетВПЗжЕФcaffe model prototxtЃЌ
АяУІМьВщЯТЪЧЗёгаЮЪЬтЃЌДњТызїепвбОЬсНЛЕНtflearnЕФЙйЗНПтСЫЃЌadd GoogLeNet(Inception)
in ExampleЃЌИїЮЛгаtensorflowЕФжБНгАВзАЯТtflearnЃЌПДПДЪЧЗёФмАяУІМьВщЯТЪЧЗёгаЮЪЬтЃЌетРявђЮЊУЛгаGPUЕФЛњЦїЃЌХмЕФБШНЯТ§ЃЌTensorBoardЕФЭМШчЯТЃЌВЛЯёжЎЧАAlexnetФЧУДУїЯдЃЈжївЊЛЙЪЧУЛгаХмФЧУДЖрepoch,етРядкаДШыЕФЪБКђЗЂЯжжїЛњЩЯУЛгаДХХЬПеМфСЫЃЌоЯоЮЃЌШЛКѓДгаТаДСЫrestoreРДХмЕФЃЌTensorBoardЕФЭМвВУВЫЦГ§СЫЕуЮЪЬтЃЌ
КУЯёУПДЮдиШыЖМВЛЬЋвЛбљЃЌЕЋЪЧДгЛљБОЕФlogРяУцЕФЖЋЮїРДПДЃЌЪЧж№ВНдкЪеСВЕФЃЌетРяЭМвВЬљЯТПДПДАЩЃЉ
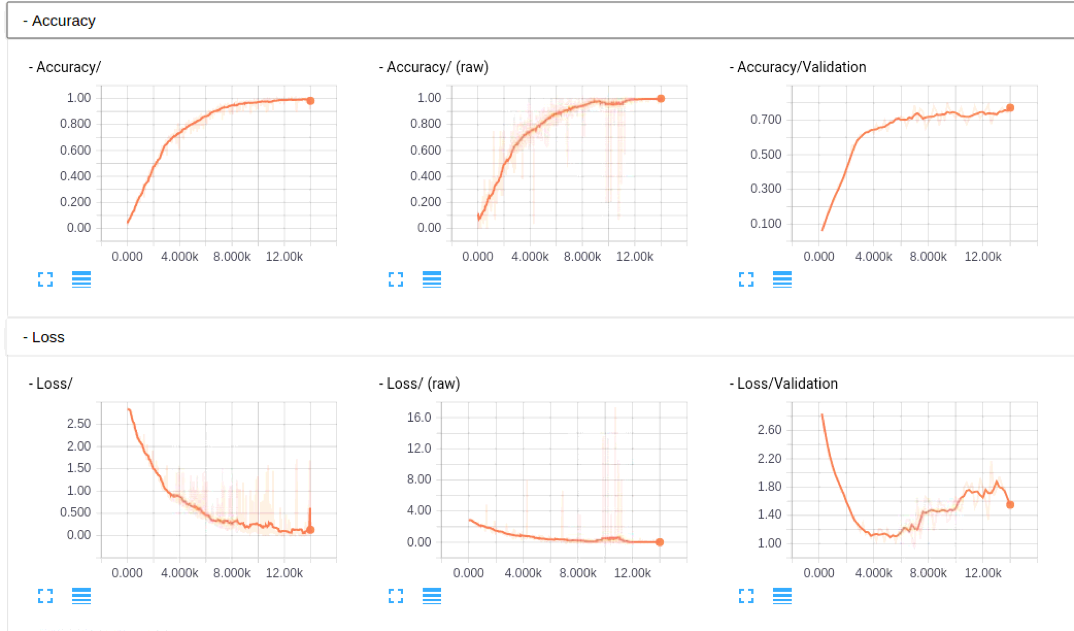
ЭјТчНсЙЙЃЌетРягаИіbugЃЌПЩФмЪЧTensorBoardЕФЃЌgooglenetЕФgraphПЩФмЪЧЬЋДѓЃЌДѓИХЪЧ1.3mЃЌдкchromeЩЯЮоЗЈЯТдиЃЌЪдСЫЛ№КќУВЫЦПЩвдСЫЃК
ЩюШыРэНтVGG\Residual Network
етЖЮЪБМфЕНСЫаТЙЋЫОЃЌЙЄзїЩЯПЊЪМбаОПDeepLearningвдМАTensorFlowЃЌЭІУІСЫЃЌЧАЖЮЪБМфПДСЫVGGКЭdeep
residualЕФpaperЃЌвЛжБУЛгаЪБМфаДЃЌНёЬьзМБИКУКУАбетСНЦЊЯрЙиЕФpaperжиЖСЯТЁЃ
VGGnet
VGGnetЪЧOxfordЕФVisual Geometry GroupЕФteamЃЌдкILSVRC
2014ЩЯЕФЯрЙиЙЄзїЃЌжївЊЙЄзїЪЧжЄУїСЫдіМгЭјТчЕФЩюЖШФмЙЛдквЛЖЈГЬЖШЩЯгАЯьЭјТчзюжеЕФадФмЃЌШчЯТЭМЃЌЮФеТЭЈЙ§ж№ВНдіМгЭјТчЩюЖШРДЬсИпадФмЃЌЫфШЛПДЦ№РДгавЛЕуаЁБЉСІЃЌУЛгаЬиБ№ЖрШЁЧЩЕФЃЌЕЋЪЧШЗЪЕгааЇЃЌКмЖрpretrainedЕФЗНЗЈОЭЪЧЪЙгУVGGЕФmodelЃЈжївЊЪЧ16КЭ19ЃЉЃЌVGGЯрЖдЦфЫћЕФЗНЗЈЃЌВЮЪ§ПеМфКмДѓЃЌзюжеЕФmodelга500ЖрmЃЌalnextжЛга200mЃЌgooglenetИќЩйЃЌЫљвдtrainвЛИіvggФЃаЭЭЈГЃвЊЛЈЗбИќГЄЕФЪБМфЃЌЫљавгаЙЋПЊЕФpretrained
modelШУЮвУЧКмЗНБуЕФЪЙгУЃЌЧАУцneural styleетЦЊЮФеТОЭЪЙгУЕФpretrainedЕФmodelЃЌpaperжаЕФМИжжФЃаЭШчЯТЃК
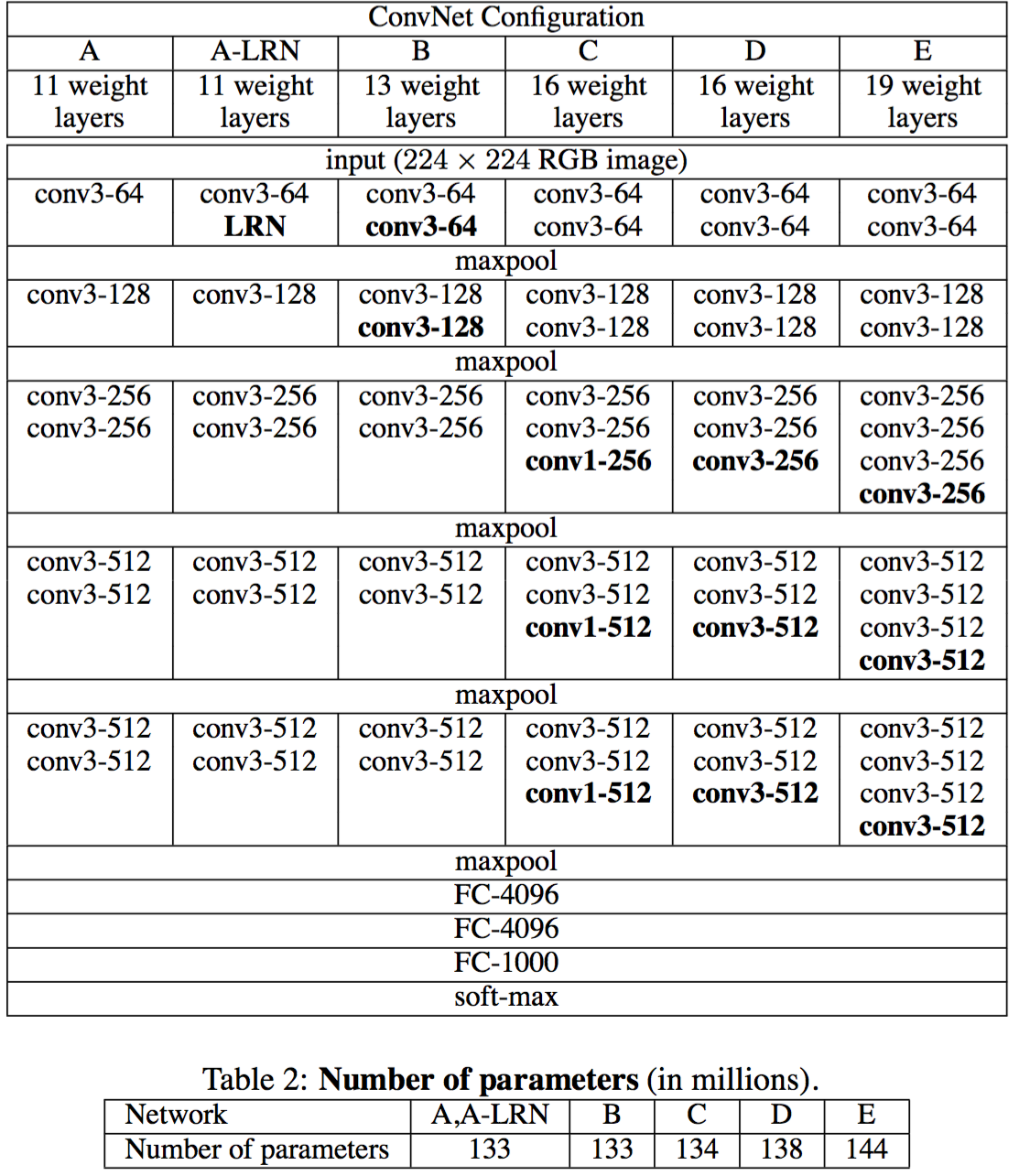
ПЩвдДгЭМжаПДГіЃЌДгAЕНзюКѓЕФEЃЌЫћУЧдіМгЕФЪЧУПвЛИіОэЛ§зщжаЕФОэЛ§ВуЪ§ЃЌзюКѓDЃЌEЪЧЮвУЧГЃМћЕФVGG-16ЃЌVGG-19ФЃаЭЃЌCжазїепЫЕУїЃЌдкв§Шы1*1ЪЧПМТЧзіЯпадБфЛЛЃЈетРяchannelвЛжТЃЌ
ВЛзіНЕЮЌЃЉЃЌКѓУцдкзюжеЪ§ОнЕФЗжЮіЩЯРДПДCЯрЖдгкBШЗЪЕгавЛЖЈГЬЖШЕФЬсЩ§ЃЌЕЋВЛШчDЁЂVGGжївЊЕУгХЪЦдкгк
1.МѕЩйВЮЪ§ЕФДыЪЉЃЌЖдгквЛзщЃЈМйЖЈ3ИіЃЌpaperРяУцжЛstack
of three 3*3ЃЉОэЛ§ЯрЖдгк7*7дкЪЙгУ3ВуЕФЗЧЯпадЙиЯЕЃЈ3ВуRELUЃЉЕФЭЌЪББЃжЄВЮЪ§Ъ§СПЮЊ3*ЃЈ3^2C^2ЃЉ=27C^2ЕФЃЌЖј7*7ЮЊ49C^2ЃЌВЮЪ§дМЮЊ7*7ЕФ81%
2.ШЅЕєСЫLRNЃЌМѕЩйСЫФкДцЕФаЁЯћКФКЭМЦЫуЪБМф
VGG-16 tflearnЪЕЯж
tflearn ЙйЗНgithubЩЯгаИјГіЛљгкtflearnЯТЕФVGG-16ЕФЪЕЯж
from future import division, print_function, absolute_import
import tflearn
from tflearn.layers.core import input_data,
dropout, fully_connected
from tflearn.layers.conv import conv_2d,
max_pool_2d
from tflearn.layers.estimator import
regression
# Data loading and preprocessing
import tflearn.datasets.oxflower17
as oxflower17
X, Y = oxflower17.load_data(one_hot=True)
# Building 'VGG Network'
network = input_data(shape=[None,
224, 224, 3])
network = conv_2d(network, 64, 3,
activation='relu')
network = conv_2d(network, 64, 3,
activation='relu')
network = max_pool_2d(network, 2,
strides=2)
network = conv_2d(network, 128, 3,
activation='relu')
network = conv_2d(network, 128, 3,
activation='relu')
network = max_pool_2d(network, 2,
strides=2)
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = fully_connected(network,
4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network,
4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network,
17, activation='softmax')
network = regression(network, optimizer='
rmsprop',
loss='categorical_
crossentropy',
learning_rate=0.001)
# Training
model = tflearn.DNN(network, checkpoint_path
='model_vgg',
max_checkpoints=1,
tensorboard_verbose=0)
model.fit(X, Y, n_epoch=500, shuffle=True,
show_metric=True, batch_size=32,
snapshot_step=500,
snapshot_epoch=False, run_id=
|
VGG-16 graphШчЯТЃК
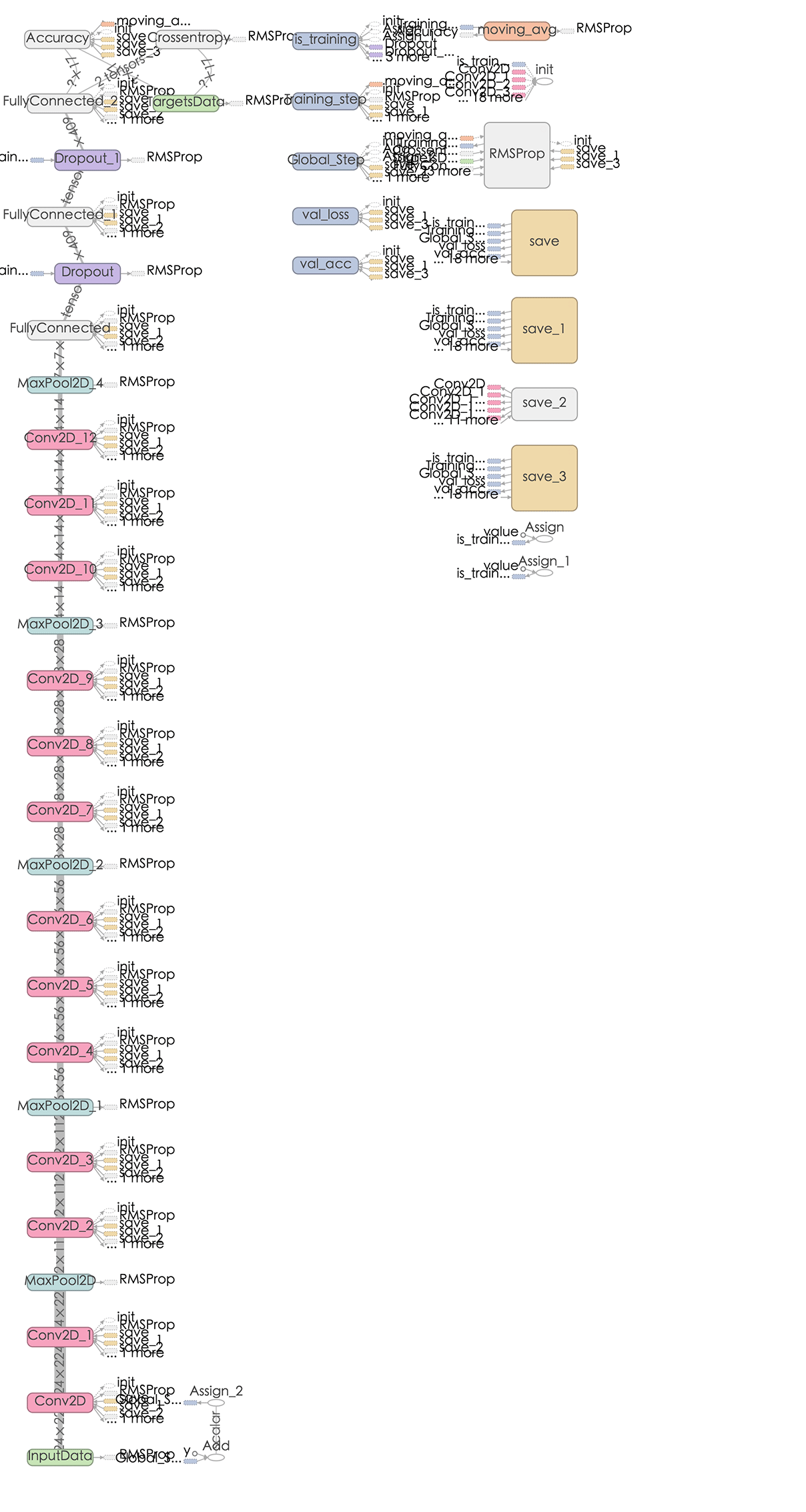
ЖдVGGЃЌзїепИіШЫОѕЕУЫћЕФССЕуВЛЖрЃЌpre-trainedЕФmodelЮвУЧПЩвдКмКУЕФЪЙгУЃЌЕЋЪЧВЛШчGoogLeNetФЧбљШУШЫгаблЧАвЛССЕФИаОѕЁЃ
Deep Residual Network
вЛАуРДЫЕдНЩюЕФЭјТчЃЌдНФбБЛбЕСЗЃЌDeep Residual Learning
for Image RecognitionжаЬсГівЛжжresidual learningЕФПђМмЃЌФмЙЛДѓДѓМђЛЏФЃаЭЭјТчЕФбЕСЗЪБМфЃЌЪЙЕУдкПЩНгЪмЪБМфФкЃЌФЃаЭФмЙЛИќЩю(152ЩѕжСГЂЪдСЫ1000)ЃЌИУЗНЗЈдкILSVRC2015ЩЯШЁЕУзюКУЕФГЩМЈЁЃ
ЫцзХФЃаЭЩюЖШЕФдіМгЃЌЛсВњЩњвдЯТЮЪЬтЃК
1.vanishing/exploding gradientЃЌЕМжТСЫбЕСЗЪЎЗжФбЪеСВЃЌетРрЮЪЬтФмЙЛЭЈЙ§norimalized
initialization КЭintermediate normalization layersНтОіЃЛ
2.ЖдКЯЪЪЕФЖюЩюЖШФЃаЭдйДЮдіМгВуЪ§ЃЌФЃаЭзМШЗТЪЛсбИЫйЯТЛЌЃЈВЛЪЧoverfitдьГЩЃЉЃЌtraining
errorКЭtest errorЖМЛсКмИпЃЌЯргІЕФЯжЯѓдкCIFAR-10КЭImageNetЖМгаЬсМА
ЮЊСЫНтОівђЩюЖШдіМгЖјВњЩњЕФадФмЯТНЕЮЪЬтЃЌзїепЬсГіЯТУцвЛжжНсЙЙРДзіresidual
learningЃК
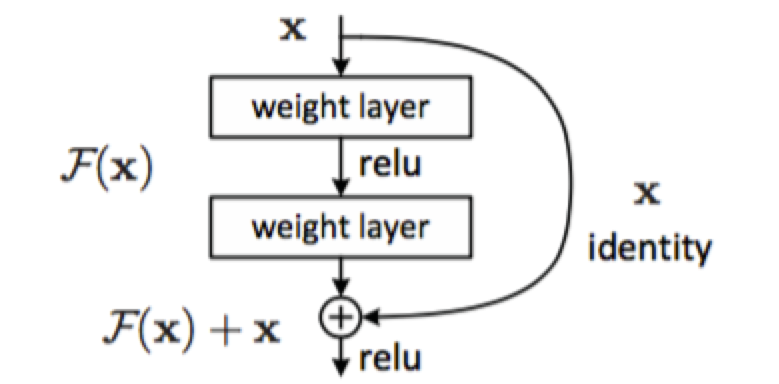
МйЩшЧБдкгГЩфЮЊH(x)ЃЌЪЙstacked nonlinear layersШЅФтКЯF(x):=H(x)-xЃЌВаВюгХЛЏБШгХЛЏH(x)ИќШнвзЁЃ
F(x)+xФмЙЛКмШнвзЭЈЙ§ЁБshortcut connectionsЁБРДЪЕЯжЁЃ
етЦЊЮФеТжївЊЕУИФЩЦОЭЪЧЖдДЋЭГЕФОэЛ§ФЃаЭдіМгresidual learningЃЌЭЈЙ§ВаВюгХЛЏРДевЕННќЫЦзюгХidentity
mappingsЁЃ
paperЕБжаЕФвЛИіЭјТчНсЙЙЃК
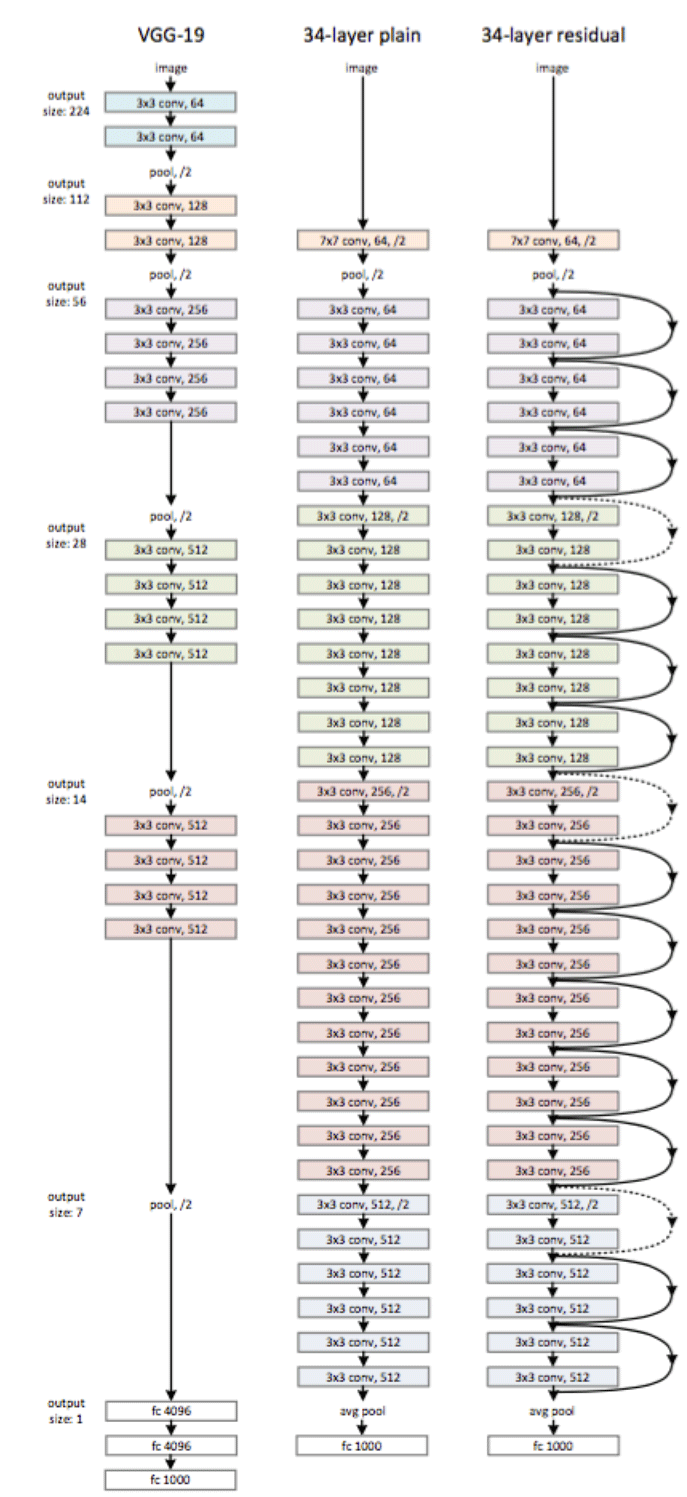
Deep Residual Network tflearnЪЕЯждЮФРяУцгаЯъЯИЕФНщЩмЁЃ
РэНтFast Neural Style
ЧАУцМИЦЊЮФеТНВЪіСЫдкComputer VisionСьгђРяУцГЃгУЕФФЃаЭЃЌНгЯТРДвЛЖЮЪБМфЃЌзїепЛсЛЈОЋСІРДбЇЯАвЛаЉTensorFlowдкComputer
VisionСьгђЕФгІгУЃЌжївЊЪЧЗжЮіЯрЙиpapeКЭдДТыЃЌНёЬьЛсРДЯъЯИСЫНтЯТfast neural styleЕФЯрЙиЙЄзїЃЌЧАУцвВгаЮФеТЗжЮіneural
styleЕФФкШнЃЌФЧЦЊЫуЪЧneural styleЕФЦ№дДЃЌЕЋЪЧЮоЗЈгІгУЕНЪЕМЪЙЄзїЩЯЃЌЮЊЩЖФиЃПЫќУПДЮЖМашвЊжИЖЈКУcontent
imageКЭstyle imageЃЌШЛКѓзюаЁЛЏcontent loss КЭstyle lossШЅЩњГЩЭМЯёЃЌЪБМфЛЈЯњКмДѓЃЌЖјЧвЮоЗЈБЃДцФГжжЗчИёЕФmodelЃЌЫљвдУПДЮЩњГЩЭМЯёЖМЪЧбЕСЗвЛИіmodelЕФЙ§ГЬЃЌЖјfast
neural styleжаФмЙЛНЋбЕСЗКУЕФФГжжstyleЕФimageЕФФЃаЭБЃДцЯТРДЃЌШЛКѓЖдcontent
image НјааtransformЃЌЕБШЛЮФжаЛЙЬсЕНСЫimage transformЕФСэвЛИігІгУЗНЯђЃКSuper-ResolutionЃЌРћгУЩюЖШбЇЯАЕФММЪѕНЋЕЭЗжБцТЪЕФЭМЯёзЊЛЛЮЊИпЗжБцТЪЭМЯёЃЌЯждкдкКмЖрДѓаЭЕФЛЅСЊЭјЙЋЫОЃЌгШЦфЪЧЪгЦЕЭјеОЩЯвВгагІгУЁЃ
PaperдРэ
МИИідТЧАЃЌОЭПДСЫNeural StyleЯрЙиЕФЮФеТTensorFlowжЎЩюШыРэНтNeural
Style,A Neural Algorithm of Aritistic StyleжаЙЙдьСЫвЛИіЖрВуЕФОэЛ§ЭјТчЃЌЭЈЙ§зюаЁЛЏЖЈвхЕФcontent
lossКЭstyle lossзюКѓЩњГЩвЛИіНсКЯСЫcontentКЭstyleЕФЭМЯёЃЌКмгавтЫМЃЌЖјPerceptual
Losses for Real-Time Style Transfer and Super-ResolutionЃЌЭЈЙ§ЪЙгУperceptual
lossРДЬцДњper-pixels lossЪЙгУpre-trainedЕФvgg modelРДМђЛЏдЯШЕФlossМЦЫуЃЌдіМгвЛИіtransform
NetworkЃЌжБНгЩњГЩContent imageЕФstyleАцБОЃЌ ШчКЮЪЕЯжЕФФиЃЌЧыПДЯТЭМЃК
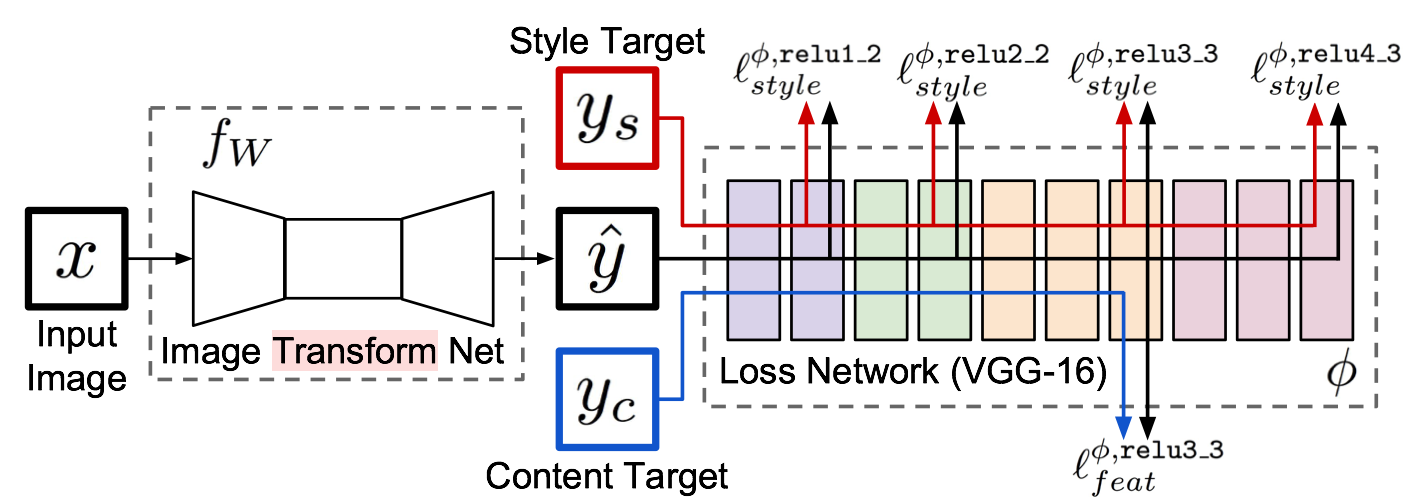
ећИіЭјТчЪЧгЩВПЗжзщГЩЃКimage transformation networkЁЂ
loss netwrokЃЛImage Transformation networkЪЧвЛИіdeep residual
conv netwrokЃЌгУРДНЋЪфШыЭМЯёЃЈcontent imageЃЉжБНгtransformЮЊДјгаstyleЕФЭМЯёЃЛЖјloss
networkВЮЪ§ЪЧfixedЕФЃЌетРяЕФloss networkКЭA Neural Algorithm
of Aritistic StyleжаЕФЭјТчНсЙЙвЛжТЃЌжЛЪЧВЮЪ§ВЛзіИќаТЃЌжЛгУРДзіcontent loss
КЭstyle lossЕФМЦЫуЃЌетИіОЭЪЧЫљЮНЕФperceptual lossЃЌзїепЪЧетбљНтЪЭЕФЮЊImage
ClassificationЕФpretrainedЕФОэЛ§ФЃаЭвбОКмКУЕФбЇЯАСЫperceptualКЭsemantic
informationЃЈГЁОАКЭгявхаХЯЂЃЉЃЌЫљвдКѓУцЕФећИіloss networkНіНіЪЧЮЊСЫМЦЫуcontent
lossКЭstyle lossЃЌЖјВЛЯёA Neural Algorithm of Aritistic
StyleзіИќаТетВПЗжЭјТчЕФВЮЪ§ЃЌетРяИќаТЕФЪЧЧАУцЕФtransform networkЕФВЮЪ§ЃЌЫљвдДгећИіЭјТчНсЙЙЩЯРДПДЪфШыЭМЯёЭЈЙ§transform
networkЕУЕНзЊЛЛЕФЭМЯёЃЌШЛКѓМЦЫуЖдгІЕФlossЃЌећИіЭјТчЭЈЙ§зюаЁЛЏетИіlossШЅupdateЧАУцЕФtransform
networkЃЌЪЧВЛЪЧКмМђЕЅЃП
lossЕФМЦЫувВКЭжЎЧАЕФЖМКмРрЫЦЃЌcontent lossЃК
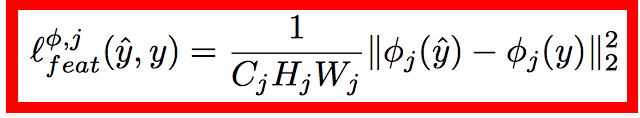
style loss:
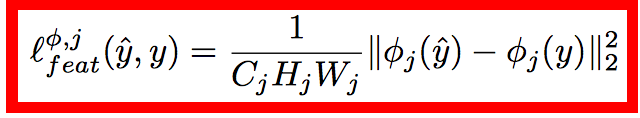
style lossжаЕФgram matrix:
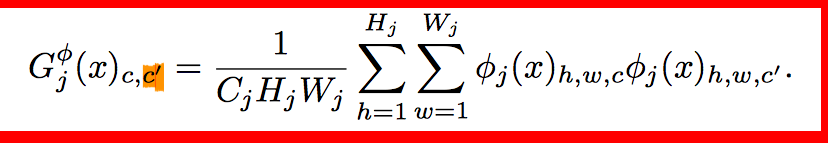
Gram MatrixЪЧвЛИіКмживЊЕФЖЋЮїЃЌЫћПЩвдБЃжЄy^hatКЭyжЎМфгаЭЌбљЕФshapeЁЃ
GramЕФЫЕУїОпЬхМћpaperетВПЗжЃЌзїепетвВНтЪЭВЛЧхГўЃЌЯраХЖСепвЛПДОЭУїАзЃК

ЯраХПДЕНетРяОЭЛљБОЩЯУїАзСЫетЦЊpaperдкfast neural styleЪЧШчКЮзіЕФЃЌзмНсвЛЯТЃК
1.transform network ЭјТчНсЙЙЮЊdeep residual
networkЃЌНЋЪфШыimageзЊЛЛЮЊДјгаЬижжЗчИёЕФЭМЯёЃЌЭјТчВЮЪ§ПЩИќаТЁЃ
2.loss network ЭјТчНсЙЙЭЌжЎЧАpaperРрЫЦЃЌетРяжївЊЪЧМЦЫуcontent
lossКЭstyle lossЃЌ зЂвтВЮЪ§ВЛзіИќаТЁЃ
3.Gram matrixЕФЬсГіЃЌШУtransformжЎКѓЕФЭМЯёгызюКѓОЙ§loss
networkжЎКѓЕФЭМЯёВЛЭЌshapeЪБМЦЫуlossвВКмЗНБуЁЃ |









