我们在实验机器学习算法时,常常遇到一种情况:相同的算法,相同的数据,但每次计算得到的结果都不同。这是因为算法中存在随机的因素,导致最终的结果不稳定。因此,为了比较随机算法的优劣或是检验参数的最优解,我们需要多次重复实验,取平均值来衡量算法。
那么问题来了,假设场景不变,随机算法实验需要重复多少次才足以客观公正地反映模型的效果呢?
有些朋友建议至少重复30次,甚至100次,更有甚者重复上千次的实验。
在本文中,我们将会用统计学的方法来教你如何正确地估计随机算法实验的重复次数。本文所有代码的执行环境可以是Python
2或者3,并且安装了NumPy、Pandas和Matplotlib。
准备数据
假设我们在一组训练数据上重复训练了1000次结构相同的神经网络模型或是其它随机算法,并且记录模型在测试集的RMSE。另外,我们假设数据是正态分布的,这是开展后续分析的必要条件。
记得每次查看预测结果的分布,往往也是呈正态分布。这里我们随机生成一组均值为60、标准差为10的正态分布数据。生成数据的代码如下图所示,并将结果保存为CSV格式的文件,命名为results.csv。
我们用seed函数作为随机数生成器,以保证每次运行这段代码时得到的数据都一致。用normal()函数生成正态分布随机数,savetxt()函数保存结果。
from numpy.random import seed
from numpy.random import normal
from numpy import savetxt
# define underlying distribution of results
mean = 60
stev = 10
# generate samples from ideal distribution
seed(1)
results = normal(mean, stev, 1000)
# save to ASCII file
savetxt('results.csv', results) |
运行这段代码,我们会得到包含1000个随机数的文件,模拟随机算法重复运行的结果。下图是该文件最后十行。
...
6.160564991742511864e+01
5.879850024371251038e+01
6.385602292344325548e+01
6.718290735754342791e+01
7.291188902850875309e+01
5.883555851728335995e+01
3.722702003339634302e+01
5.930375460544870947e+01
6.353870426882840405e+01
5.813044983467250404e+01 |
基本分析
首先,我们对上一步得到的结果简单地做一个统计分析。
基本的统计分析有三种常用方法:
计算统计信息,比如均值、标准差、百分位等等;
对数据绘制箱形图或者;
绘制数据的直方图分布。
下面的代码用来实现基本分析的功能。首先加载results.csv文件,然后计算统计信息和绘制图形。
from
pandas import DataFrame
from pandas import read_csv
from numpy import mean
from numpy import std
from matplotlib import pyplot
# load results file
results = read_csv('results.csv', header=None)
# descriptive stats
print(results.describe())
# box and whisker plot
results.boxplot()
pyplot.show()
# histogram
results.hist()
pyplot.show() |
上述样本的统计量如下图所示,算法的平均性能为60.3,标准差为9.8。如果我们假设这个分值表示的是某种误差,例如RMSE,那么最差的性能会达到99.5,而最好的情况是29.4。
count
1000.000000
mean 60.388125
std 9.814950
min 29.462356
25% 53.998396
50% 60.412926
75% 67.039989
max 99.586027 |
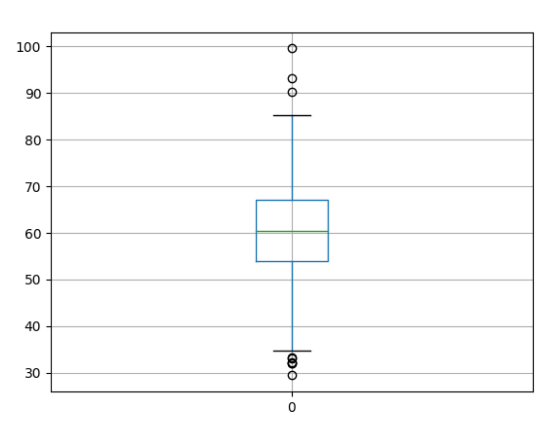
下图所示的箱形图展示了数据的分布,其中箱子部分是中段50%的样本,原点表示异常值,绿线表示中位数的值。
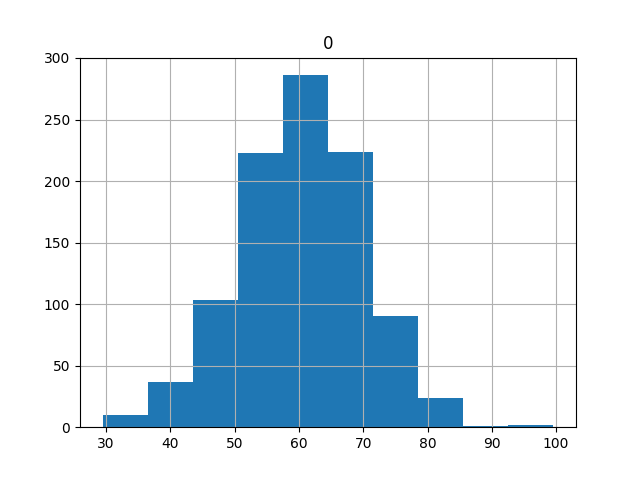
下图是数据的直方图分布,整体趋势符合正态分布,均值落在60附近。
重复次数的影响
我们总共伪造了1000个数据。那么1000次究竟是已经足够我们做出准确的决策呢,还是远不足所需的实验重复次数?我们该怎么判断?
首先,我们可以绘制实验重复次数与分值均值的函数。期初,均值的波动幅度预计较大。随着重复次数增长,我们预期均值也将很快收敛到期望值附近。
from
pandas import DataFrame
from pandas import read_csv
from numpy import mean
from matplotlib import pyplot
import numpy
# load results file
results = read_csv('results.csv', header=None)
values = results.values
# collect cumulative stats
means = list()
for i in range(1,len(values)+1):
data = values[0:i, 0]
mean_rmse = mean(data)
means.append(mean_rmse)
# line plot of cumulative values
pyplot.plot(means)
pyplot.show() |
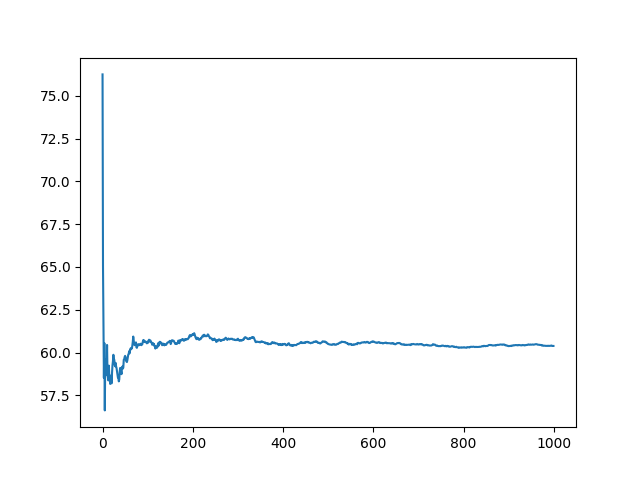
执行上面这段代码,可以得到下图。如图所示,重复次数在200次以内时,曲线波动较大;当实验超过600次之后,均值几乎趋于稳定。
接下来,我们只取前500次实验结果绘制图形,并将最终的平均结果也用橙色线绘制到同一张图上。下面是代码和展示图形。
from
pandas import DataFrame
from pandas import read_csv
from numpy import mean
from matplotlib import pyplot
import numpy
# load results file
results = read_csv('results.csv', header=None)
values = results.values
final_mean = mean(values)
# collect cumulative stats
means = list()
for i in range(1,501):
data = values[0:i, 0]
mean_rmse = mean(data)
means.append(mean_rmse)
# line plot of cumulative values
pyplot.plot(means)
pyplot.plot([final_mean for x in range(len(means))])
pyplot.show() |
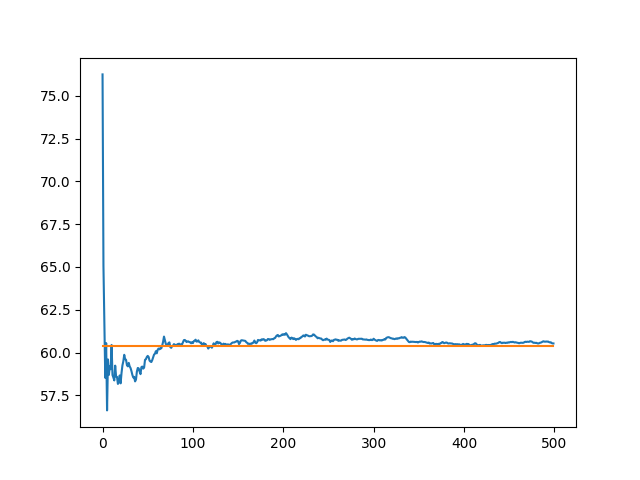
可见,当重复到100次时,结果已经接近期望值。当重复400次时,结果更加接近期望值,但是提升的比例不多。
以上只是定性分析了实验重复次数对决策判断的影响,是否有更合理的方法呢?
计算标准误差
标准误差( standard error )是样本统计量的标准差,体现样本均值与总体均值的偏差范围。标准误差与标准差不同。标准差是离均差平方的算术平均数的平方根,反映一个数据集的离散程度。
标准误差一般用来判定该组测量数据的可靠性,在数学上它的值等于测量值误差的平方和的平均值的平方根。由于在测量中的待测物体的真值很难得到。因此我们在实际的计算中,用标准误差估算值代替实际误差。
我们期望随着实验次数的增加,标准误差逐渐减小。
下面的代码计算了每次重复实验之后的标准误差。
from
pandas import read_csv
from numpy import std
from numpy import mean
from matplotlib import pyplot
from math import sqrt
# load results file
results = read_csv('results.csv', header=None)
values = results.values
# collect cumulative stats
std_errors = list()
for i in range(1,len(values)+1):
data = values[0:i, 0]
stderr = std(data) / sqrt(len(data))
std_errors.append(stderr)
# line plot of cumulative values
pyplot.plot(std_errors)
pyplot.show() |
横坐标是实验重复次数,纵坐标表示标准误差。如我们预期,随着实验重复次数增加,标准误差逐渐减小。我们还能发现,标准误差下降到一定程度之后,下降趋势变得非常缓慢,这称作可接受误差,大约在1~2个单位量。
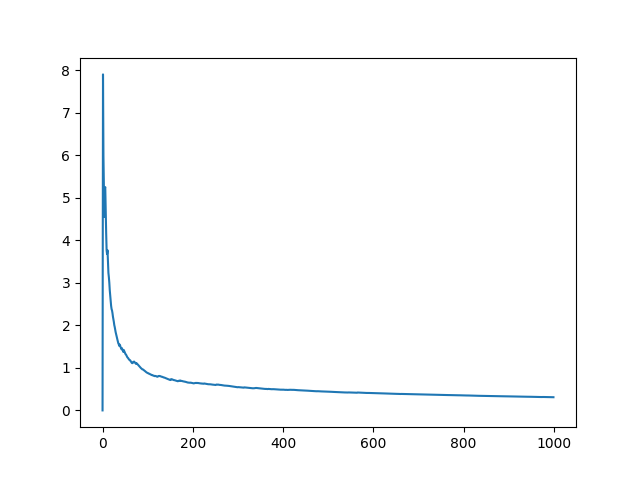
我们在上图中在添加两条辅助线,分别标识标准误差在0.5和1的情况。代码如下图所示。
from
pandas import read_csv
from numpy import std
from numpy import mean
from matplotlib import pyplot
from math import sqrt
# load results file
results = read_csv('results.csv', header=None)
values = results.values
# collect cumulative stats
std_errors = list()
for i in range(1,len(values)+1):
data = values[0:i, 0]
stderr = std(data) / sqrt(len(data))
std_errors.append(stderr)
# line plot of cumulative values
pyplot.plot(std_errors)
pyplot.plot([0.5 for x in range(len(std_errors))],
color='red')
pyplot.plot([1 for x in range(len(std_errors))],
color='red')
pyplot.show() |
若标准误差低于1在可接受的范围,那么大约重复100次实验就够了。若标准误差低于0.5才能接受,那么大约需要重复300~350次实验。
再强调一遍,标准误差是衡量在模型配置参数和随机初始条件不变的前提下,模型效果的样本均值与整体均值的偏差范围。
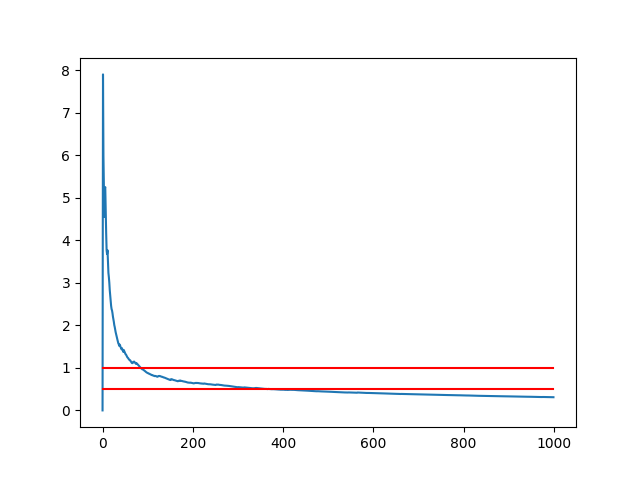
我们也可以把标准误差当做模型平均效果的置信区间。比如,若置信度为95%,置信区间的上下界可以表示为:
样本均值 +/- ( 标准误差 * 1.96 )
用下面这段代码重新绘制带有置信区间的样本均值。
from
pandas import read_csv
from numpy import std
from numpy import mean
from matplotlib import pyplot
from math import sqrt
# load results file
results = read_csv('results.csv', header=None)
values = results.values
# collect cumulative stats
means, confidence = list(), list()
n = len(values) + 1
for i in range(20,n):
data = values[0:i, 0]
mean_rmse = mean(data)
stderr = std(data) / sqrt(len(data))
conf = stderr * 1.96
means.append(mean_rmse)
confidence.append(conf)
# line plot of cumulative values
pyplot.errorbar(range(20, n), means, yerr=confidence)
pyplot.plot(range(20, n), [60 for x in range(len(means))],
color='red')
pyplot.show() |
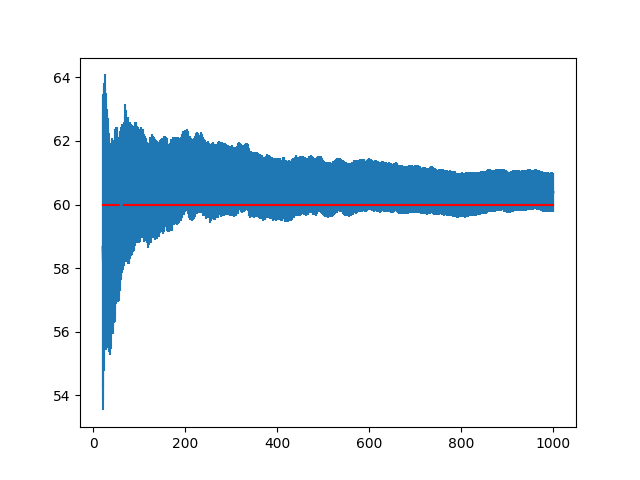
结果如下图所示。其中红线表示总体的均值。通过观察可以发现,尽管样本均值高估了总体均值,但是总体均值还是落在了置信度为95%的置信区间之内。95%置信度的含义是若样本数目不变的情况下,做100次实验,有95个置信区间包含了总体均值的真值,剩余5个置信区间没有包括。
如图所示,随着实验的重复次数增多,置信区间的范围逐渐缩小,当重复次数超过500次之后,继续重复实验对效果的提升并不明显。
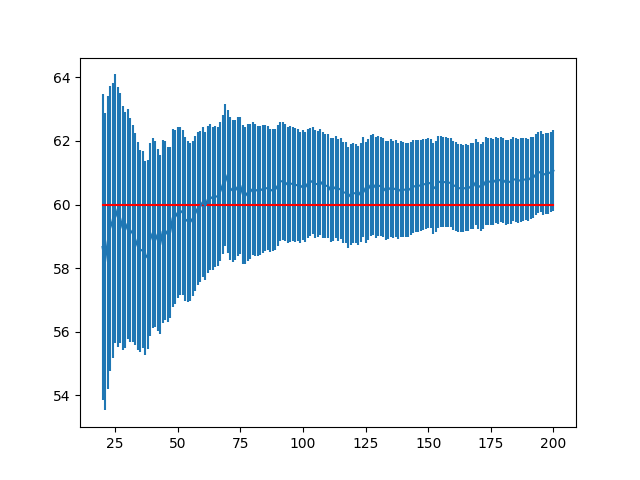
若把20~200次的区间放大绘制,趋势会看的更加明显。
from
pandas import read_csv
from numpy import std
from numpy import mean
from matplotlib import pyplot
from math import sqrt
# load results file
results = read_csv('results.csv', header=None)
values = results.values
# collect cumulative stats
means, confidence = list(), list()
n = 200 + 1
for i in range(20,n):
data = values[0:i, 0]
mean_rmse = mean(data)
stderr = std(data) / sqrt(len(data))
conf = stderr * 1.96
means.append(mean_rmse)
confidence.append(conf)
# line plot of cumulative values
pyplot.errorbar(range(20, n), means, yerr=confidence)
pyplot.plot(range(20, n), [60 for x in range(len(means))],
color='red')
pyplot.show() |
小结
通过阅读本文,我们列举了几种选择随机算法实验重复次数的方法。
简单地尝试重复30次、100次或者1000次等等;
绘制样本均值与重复次数的关系图,并根据拐点选择;
绘制标准误差与重复次数的关系图,并根据误差阈值选择;
绘制置信区间与重复次数的关系图,并根据误差的分布选择。 |









