| ����������Դ��һ�β����ڲ��ķ�������Ҫ���AI��ѧ�ߣ����ܰ���CNN��Deep
Q Network�Լ�TensorFlowƽ̨�����ݡ����ڱ��߲������ѧϰ�㷨�о��ߣ�������¸����Ӧ�õĽǶȶ�����ϵͳ���н��ܣ������������ϸ�Ĺ�ʽ�Ƶ���
������Ҫ�������ͨ��AI���˹����ܣ��ķ�ʽ��Flappy Bird��Ϸ����Ϊ�����ĸ��������ݣ�
1.Flappy Bird ��Ϸչʾ
2.ģ�ͣ�����������
3.�㷨��Deep Q Network
4.���룺TensorFlowʵ��
һ��Flappy Bird ��Ϸչʾ
�ڽ���ģ�͡��㷨ǰ����ֱ�ӿ���Ч������ͼ�Ǹտ�ʼѵ����ʱ�����е�С�������ͷ��Ӭһ���ҷɣ���ͼչʾ�����ڱ����������������ã�ѵ������10Сʱ��ѵ����������2000000�������������óɼ��Ѿ�����200�֣���������ѻ��������ܳ�Խ��

ѵ����С��10000�����տ�ʼѵ����

ѵ����������2000000����10Сʱ��
���ڱ���������CUDA�Լ�cuDNN��������NVIDIA���Կ����в��м��㣬����������ǰ��һ������ʱ����־�����
| ����CUDA�Լ�cuDNN�����ã�������һЩ�Ӱ�������װCUDA֮��ѭ����¼����Ļ�ֱ������������ڵȵȣ���
������NVIDIA������װ�����⣬�ⲻ�DZ���Ҫ���۵���Ҫ���ݣ����߿�����Google��
|
����CUDA�����

TensorFlow�����豸 /gpu:0

/gpu:0 ����TensorFlowƽ̨Ĭ�ϵ����÷�������ʾʹ��ϵͳ�еĵ�һ���Կ���
| ������Ӳ�����ã�
ϵͳ��Ubuntu 16.04
�Կ���NVIDIA GeForce GTX 745 4G
�汾��TensorFlow 1.0
��������OpenCV 3.2.0��Pygame��Numpy����
ϸ�ĵ����ѿ��ܷ��֣����ߵ��Կ����ò����ߣ�GeForce GTX 745���Դ�3.94G������3.77G������ռ����һ���֣������������е����š�����רҵ�����ѧϰ�㷨�����ѣ�����Կ���Ȼ�Dz����ġ�֪���������ӽ̴����ô���ø�רҵ���Կ�������Ȥ�Ŀ����Ʋ���
|
����ģ�ͣ�����������
�������㷨�����ڶ����Ԫ�ɵ�������Ȩֵ���Ӷ��ɣ����д��ģ���д������ֲ�ʽ��Ϣ�洢�����õ�����֯��ѧϰ�������ص㡣�˹���Ԫ��������Ԫ�ṹ���ƣ���ṹ�Ա�����ͼ��ʾ��
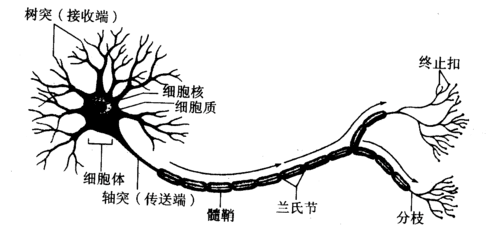
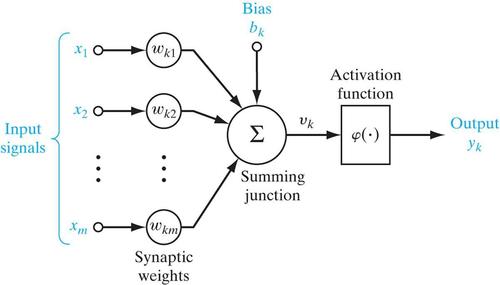
�˹���Ԫ�����루x1,x2��xm��������������Ԫ����ͻ�����뾭����ͬ��Ȩֵ��wk1,
wk2, ��.wkn��������ƫ�ã�����������õ���������������䵽��һ����Ԫ���д�����
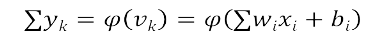
�����Ϊ�������������˷��������ԣ���Ҳ������������ڻع���㷨���������ǿ��ԭ���õļ��������sigmoid��tanh�ȣ����ǵĺ�������ʽ���£�
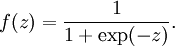
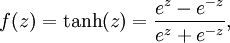
������Կ�����sigmoid������ֵ���ǣ�0,1����tanh������ֵ���ǣ�-1,1����
������������Դ�ڶ�����Ӿ�ϵͳ����Ҫ�����ļ����ǣ�
1.�ֲ���֪��ϡ�����ӣ���
2.����������
3.������ˣ�
4.�ػ���
1. �ֲ���֪��ϡ�����ӣ�
ȫ����������������ڣ�
��Ҫѵ���IJ������࣬�������½�����������ݶ���ʧ������ѵ���Ѷȼ���
ʵ���϶���ij���ֲ�����Ԫ���������������е���С��Χ�ڵ����룬���仰˵�����ڽ�Զ�����룬������Ժܵͣ�ȨֵҲ�ͷdz�С��
������Ӿ�ϵͳ���������ڹ۲�����ʱ�����ǴӾֲ���ȫ�֡�
| ���磬���ǿ���һ����Ů���������ȹ۲쵽������Ů���ϵ�ijЩ��λ���Լ���ᣩ��
|
��ˣ�������������������Ӿ����ƣ����þֲ���֪���Ͳ����Ԫֻ�����֪�ֲ�����Ϣ���������Ĺ����У��߲����Ԫ���ֲ���Ϣ�ۺ������õ�ȫ����Ϣ��
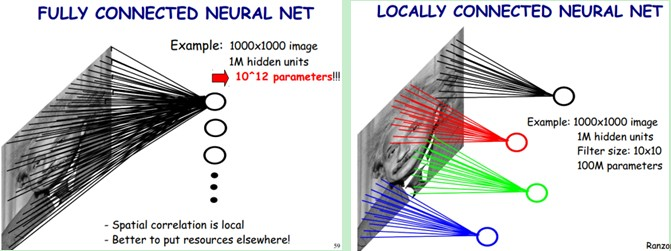
ȫ������ֲ����ӵĶԱȣ�ͼƬ���Ի�������
����ͼ�п��Կ��������þֲ�����֮���Դ��Ľ���ѵ��������������
2. ��������
��Ȼͨ���ֲ���֪������ѵ��������������������������Ҫѵ���IJ�����Ȼ�ܶࡣ
�����������ǽ����������ͬͳ�������IJ�������Ϊ��ͬ����������ͼ����һ���ֵ�ͳ������������������һ���ġ���ʵ����ͨ����ͼ����о�����������������������Դ����
��������Ϊ�������һ��ͼ���е�ij���ֲ��������˴�С����ȡ��ij��������Ȼ������������Ϊ̽������Ӧ�õ�����ͼ���У�������ͼ��˳����о������õ���ͬ��������
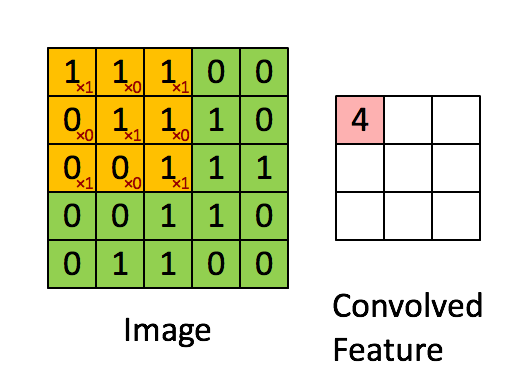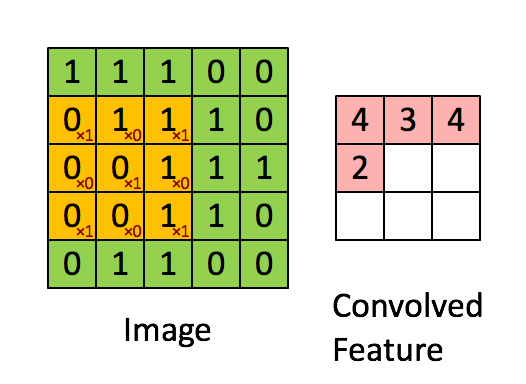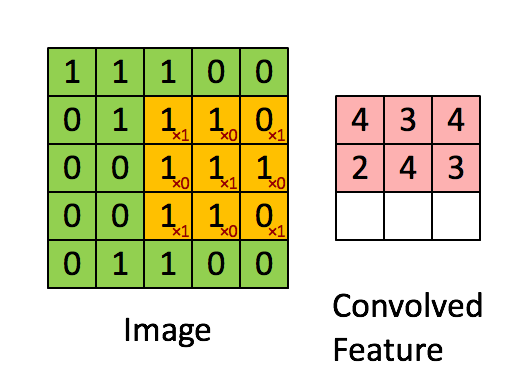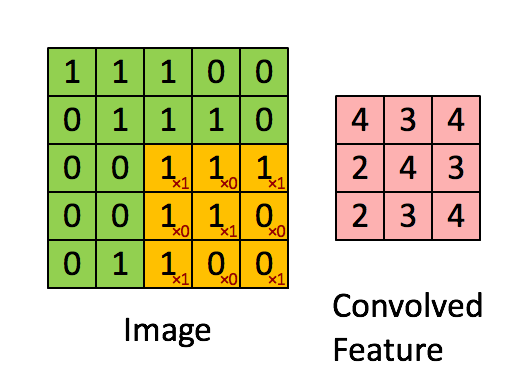
�������̣�ͼƬ���Ի�������
ÿ����������һ��������ȡ��ʽ������һ��ɸ�ӣ���ͼ���з�������������ֵԽ��Խ�����������IJ���ɸѡ������ͨ�����־����ͽ�һ������ѵ��������������
3. �������
���ϣ�ÿ����������һ��������ȡ��ʽ����ô��������ͼ��������������������ȡ�������϶��Dz����ģ���ô��ͬһ��ͼ��ʹ�ö��־����˽���������ȡ�����ܵõ��������ͼ��feature
map����
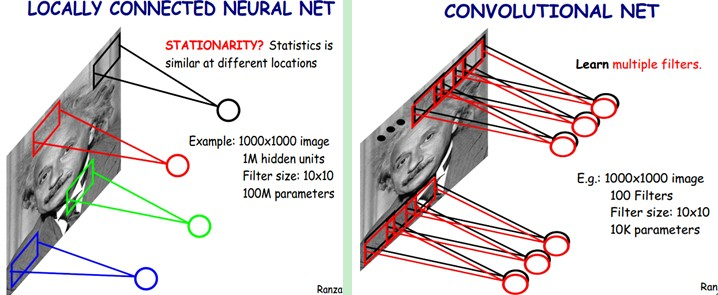
��ͬ�ľ�������ȡ��ͬ��������ͼƬ���Ի�������
�������ͼ���Կ�����ͬһ��ͼ��IJ�ͬͨ������������ں������ʵ�ֵ�ʱ���õ��ϡ�
4. �ػ�
�õ�����ͼ֮����ʹ����ȡ��������ȥѵ��������������Ȼ����������ά�ȹ��࣬���Լ��㣬���ҿ��ܹ���ϵ����⡣��ͼ��ʶ��ĽǶ�������ͼ����ܴ���ƫ�ơ���ת�ȣ���ͼ�������ȴ��ͬ�������Ҳ���Dz�ͬ�������������ܶ�Ӧ����ͬ�Ľ������ô�ػ����ǽ���������ġ�
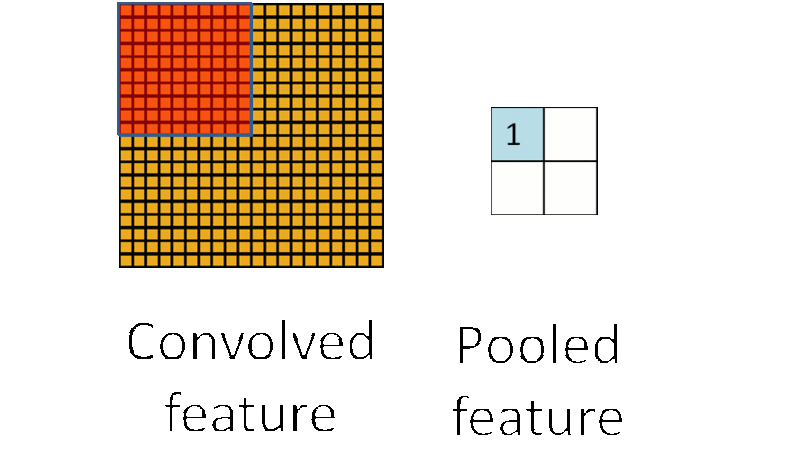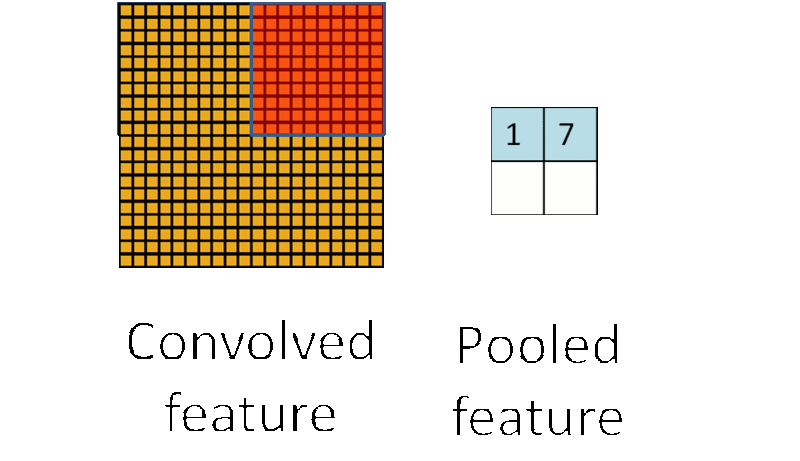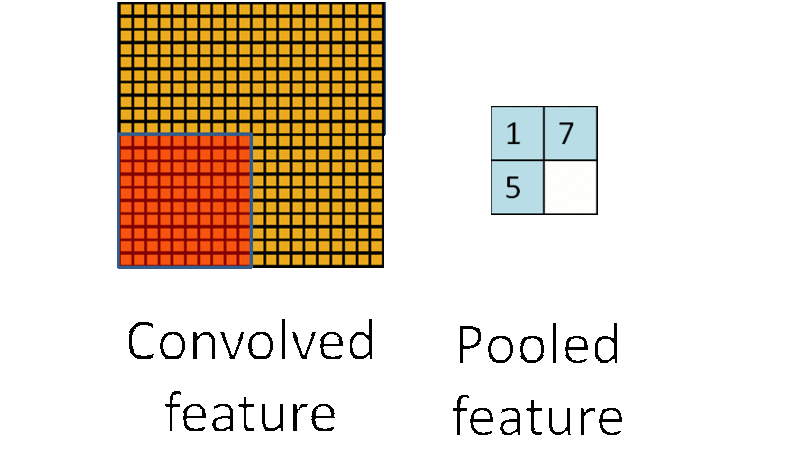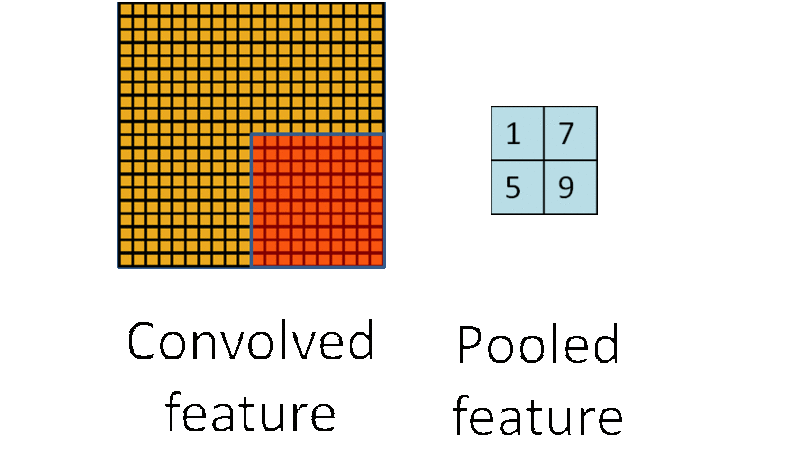
�ػ����̣�ͼƬ���Ի�������
�ػ����ǽ��ػ��˷�Χ�ڣ�����2*2��Χ����ѵ����������ƽ��ֵ��ƽ��ֵ�ػ��������ֵ�����ֵ�ػ��������������
���ڵ���չʾģ�͵�ʱ���������ͼ�DZ����ֻ��ģ��õ��Ի�̫��ʱ�����Ϳ��ɣ������ͼչʾ�˱���������ѵ����Ϸ���õľ���������ģ�͡�
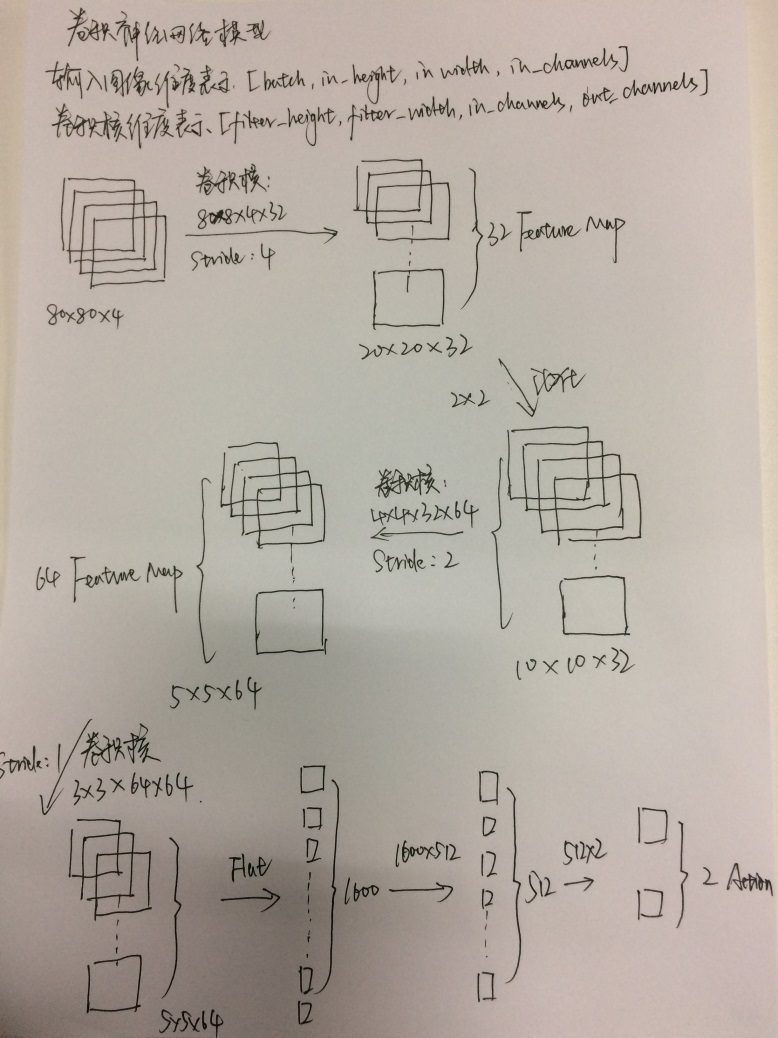
����������ģ��
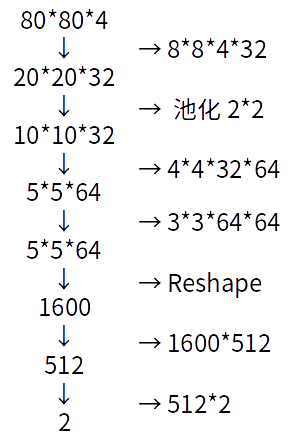
ͼ��Ĵ�������
1.��ʼ�����ķ�ͼ��80��80��4��4��������ͨ������ʼʱ�ķ�ͼ������ȫһ�µģ�������������8��8��4��32������ͨ��4�����ͨ��32��������Ϊ4��ÿ��������4�����ص㣩���õ�32������ͼ��feature
map������СΪ20��20��
2.��20��20��ͼ����гػ����ػ���Ϊ2��2���õ�ͼ���СΪ10��10��
3.�ٴξ�����������Ϊ4��4��32��64������Ϊ2���õ�ͼ��5��5��64��
4.�ٴξ�����������Ϊ3��3��64*64������Ϊ2���õ�ͼ��5��5��64����Ȼ����һ���õ���ͼ���ģһ�£����ٴξ���֮���ͼ����Ϣ��Ϊ����Ҳ���ӽ�ȫ����Ϣ��
5.Reshape��������ά����ͼת��Ϊ�����������õ�1600ά������������
6.����ȫ����1600��512���õ�512ά����������
7.�ٴ�ȫ����512��2���õ����յ�2ά����[0,1]��[1,0]���ֱ������Ϸ��Ļ�ϵ��Ƿ����¼���
���Կ�������ģ��ʵ���˶˵��˵�ѧϰ�����������Ϸ��Ļ�Ľ�ͼ��Ϣ�������о���opencv�����������������Ϸ�Ķ��������Ƿ�����Ļ�����ѧϰ��ǿ�������������������������Ҫ��ͳ����ѧϰ�и��ӵ�������ȡ���̣���������ģ�ͷ��������ڲ��Ĺ�ϵ��
| ������Ҳ������һ��������⣬�Ǿ������ѧϰ�߶����������ı�ǩ���ݣ�����Щ���ݻ�ȡ�ɱ����ߡ�
|
�����㷨��Deep Q Network
���˾���������ģ�ͣ���ô����ѵ��ģ�ͣ�ʹ��ģ���������Ӷ��ܹ�ָ����Ϸ�����أ�����ѧϰ��Ϊ�ලѧϰ���Ǽලѧϰ��ǿ��ѧϰ������Ҫ���ܵ�Q
Network����ǿ��ѧϰ��Reinforcement Learning���ķ��롣����ʽ����Q Network֮ǰ���ȼ�˵�����Ĺ�����ʷ��
2014��Google 4�������չ�DeepMind���ŶΣ���ҿ�����˵������ô��DeepMind����α�Google�����ϵ��أ�����ԭ����Թ��Ϊ��ƪ���ģ�
| Playing Atari
with Deep Reinforcement Learning
|
DeepMind�Ŷ�ͨ��ǿ��ѧϰ�������20������Ϸ��ʵ���˶˵��˵�ѧϰ�����õ����㷨����Q Network��2015�꣬DeepMind�Ŷ��ڡ�Nature���Ϸ�����һƪ�����棺
| Human-level
control through deep reinforcement learning
|
�Դˣ���������Ϸ�������Ѿ������������ˡ�����������AlphaGo���Լ�Master����Ȼ���ⶼ�Ǻ��ˡ���ʵ����Ҳ�����������ĵķ��룬ֻ��������TensorFlowƽ̨������ʵ�֣�������һЩ�����Լ���������ѡ�
�ص����⣬Q Network����ǿ��ѧϰ����ô�Ƚ�����ǿ��ѧϰ��
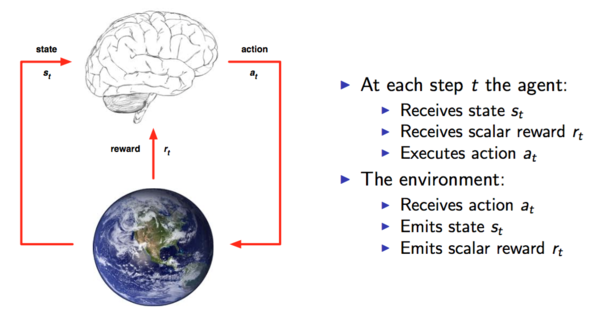
ǿ��ѧϰģ��
����ͼ�Ǵ�UCL�Ŀγ��п������ģ��γ����ӵ�ַ��YouTube����
| ����ͼ�Ǵ�UCL�Ŀγ��п������ģ��γ����ӵ�ַ��YouTube����
https://www.youtube.com/watch?v=2pWv7GOvuf0
|
ǿ��ѧϰ������������ɲ��֣�
1.���ܴ�����ѧϰϵͳ��
2.����
��ͼ��ʾ����ÿ�����������У��������ܴ�����ѧϰϵͳ�����ջ�����״̬st��Ȼ���������at�����ڻ������������ն���at�����Ҷ���������ۣ����������ܴ���rt�����ϵ�ѭ��������̣��ͻ����һ��״̬/����/���������У���s1,
a1, r1, s2, a2, r2��..,sn, an, rn������������������Ǻ���Ȼ��������:
�����Ʒ���߹���
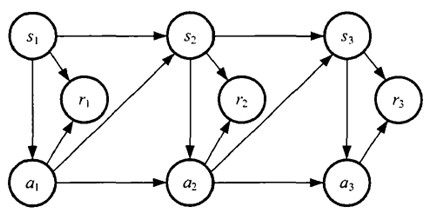
MDP�������Ʒ���߹���
�����Ʒ���߹�����������HMM���������Ʒ�ģ�ͣ���ͬ���ǣ����Ƕ����������Ʒ����ԡ���ôʲô�������Ʒ������أ�����˵������δ����״ֻ̬ȡ���ڵ�ǰ��״̬�����ȥ��״̬�ء�
| HMM�������Ʒ�ģ�ͣ�������ʶ����Ϊʶ��Ȼ���ѧϰ�����н�Ϊ�㷺��Ӧ�á����������ģ�ͣ�Conditional
Random Field����������Ȼ���Դ���������ģ��������ʶ����Ȼ���Դ�������Ļ�ʯ��
|
��ͼ������һ���������������˵�����������ҵ������һ����˾����ij�ʼְ����T1����Ӧͼ�е� s1�������ڹ����Ͽ̿�Ŭ�������Ͻ�����Ӧͼ�е�a1����Ȼ���쵼�����㲻������������ְ����Ӧͼ�е�r1�������ǣ���������T2��������̿�Ŭ�������Ͻ��������ϵ�Ŭ�������ϵ���ְ�����������sn����Ȼ����Ҳ�п��ܲ�Ŭ���Ͻ�����Ҳ��һ�ֶ��������仰˵���ö���aҲ���ڶ�������A��Ȼ��õ��ķ���r����û����ְ��н�Ļ��ᡣ
����ע���£����ǵ�Ȼϣ����ȡ������ְ����ô����ת��Ϊ����θ��ݵ�ǰ״̬s��s����״̬��S������A��ѡȡ����aִ���ڻ������Ӷ���ȡ����r����r1
+ r2 ����+rn�ĺ���� ���������Ҫ����һ����ѧ��ʽ��״ֵ̬������
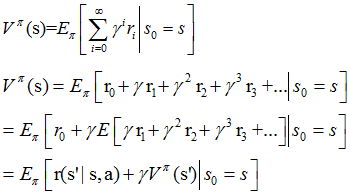
״ֵ̬����ģ��
��ʽ���и��ۺ����Ӧã���ȡֵ��ΧΪ[0,1]������Ϊ0ʱ����ʾֻ���ǵ�ǰ�����Ե�ǰ��Ӱ�죬�����ǶԺ��������Ӱ�죬����Ϊ1ʱ����ʾ��ǰ�����Ժ���ÿ�����о��ȵ�Ӱ�졣��Ȼ��ʵ�����ͨ���ǵ�ǰ�����Ժ����÷���һ����Ӱ�죬�����Ų������ӣ���Ӱ���С��
�ӹ�ʽ�п��Կ�����״ֵ̬��������ͨ�������ķ�ʽ����⡣��ǿѧϰ��Ŀ�ľ�����������ɷ���߹��̣�MDP�������Ų��ԡ�
| ���Ծ�����θ��ݻ���ѡȡ������ִ�е����ݡ����Է�Ϊ�ȶ��IJ��ԺͲ��ȶ��IJ��ԣ��ȶ��IJ�������ͬ�Ļ�����
���ǻ������ͬ�Ķ��������ȶ��IJ�����֮������������Ҫ�����ȶ��IJ��ԡ�
|
�������״̬������Ҫ���ö�̬�滮�ķ����������嵽��ʽ�����ò��
����������
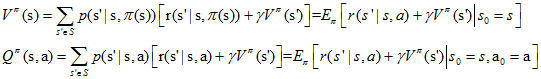
���У��д��������ᵽ�IJ��ԣ�Q �� (s, a)�����V �� (s)�������˶���������������ֵ�������Ա��������������Ž⣬�͵õ��˱����������Է��̡�
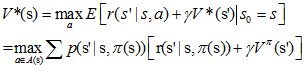
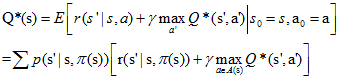
���÷��������ַ��������Ե�����ֵ������
���Ե���
���Ե�����Ϊ�������裺���������Ͳ��ԸĽ����������������ԣ��õ�״ֵ̬��������Σ��Ľ����ԣ�����µIJ��Ա�֮ǰ�ã�������ϵIJ��ԡ�

ֵ����
���������ǿ��Կ��������Ե����㷨������һ�����Թ��ƵĹ��̣������Թ�������Ҫɨ��(sweep)���е�״̬���ɴΣ����о�ļ�����ֱ��Ӱ���˲��Ե����㷨��Ч�ʡ���ֵ����ÿ��ֻɨ��һ�Σ����¹������£�

����ֵ�����ĵ�k+1�ε���ʱ��ֱ�ӽ��ܻ�õ�����V��(s)ֵ����Vk+1��
Q-Learning
Q-Learning�Ǹ���ֵ������˼·������ѧϰ�ġ����㷨�У�Qֵ���µķ������£�
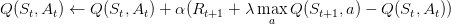
��Ȼ����ֵ���������Ŀ��Qֵ���������ﲢû��ֱ�ӽ����Qֵ���ǹ���ֵ��ֱ�Ӹ����µ�Q�����Dz��ý����ķ�ʽ�����ݶ��½�����Ŀ������һС����ȡ���ڦ�������ܹ����ٹ��������ɵ�Ӱ�졣��������ݶ��½������������������ŵ�Qֵ�������㷨���£�

���û�нӴ�����̬�滮��ͯЬ��������ʽ�����е�ͷ������ͨ����������ʾ��Qֵ���µĹ��̣���Ҿ������ˡ�
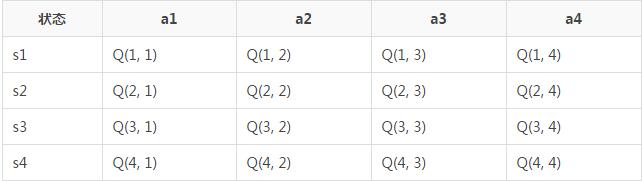
Q-Learning�㷨�Ĺ��̾��Ǵ洢Qֵ�Ĺ��̡��ϱ��У�����Ϊ״̬s������ΪAction a��s��a�����˱��е�Qֵ��
��һ������ʼ���������е�Qֵȫ����0��
�ڶ��������ݲ��Լ�״̬s��ѡ��aִ�С��ٶ���ǰ״̬Ϊs1�����ڳ�ʼֵ��Ϊ0����������ѡȡaִ�У��ٶ�����ѡȡ��a2ִ�У��õ���rewardΪ1�����ҽ�����״̬s3������Qֵ���¹�ʽ��
������Qֵ���������Ǽ������1����Ҳ����1��Ҳ����ÿһ�ζ���Ŀ��Qֵ����Q����ô���﹫ʽ��ɣ�
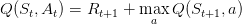
�������������
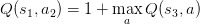
��ô��Ӧ��s3״̬�����ֵ��0������
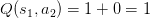
Q����ͱ�ɣ�
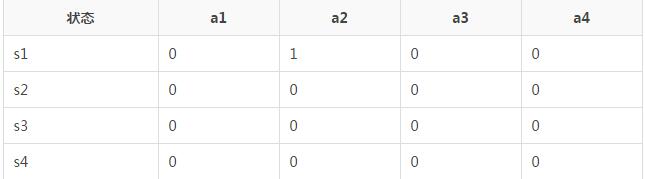
Ȼ����λ��ǰ״̬sΪs3��
������������ѭ��������������һ�ζ�������ǰ״̬��s3������ѡ����a3��Ȼ��õ�rewardΪ2��״̬���s1����ô����ͬ�����и��£�
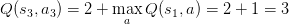
����Q�ı���ͱ�ɣ�
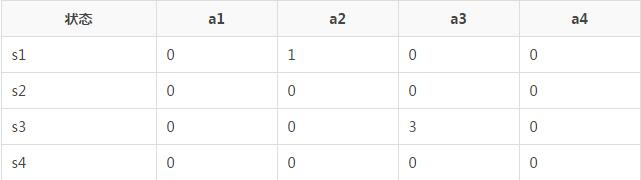
���IJ��� ����ѭ����Qֵ�������ͬʱ�������£�ֱ��������
����������ʾ�˾���4��״̬/4����Ϊ��ϵͳ��Ȼ����ʵ��Ӧ���У��Ա��Ľ�����Flappy Bird��ϷΪ��������Ϊ80*80�����ص㣬ÿ�����ص��ɫֵ��256�ֿ��ܡ���ôʵ�ʵ�״̬����Ϊ256��80*80�η�������һ���ܴ�����֣�ֱ�ӵ�����ͨ�������˼·���м��㡣
��ˣ�Ϊ��ʵ�ֽ�ά������������һ����ֵ�������Ƶķ�����ͨ��һ�����������Ʊ����ֵ������
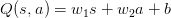
���У��� �� b �ֱ�Ϊ����������������ڿ�����ϵ��ǰ���ᵽ���������ˣ�����ı���ʽ��������Ԫ�ĺ�����
Q-network
��������ͼ�������ġ�Human-level Control through
Deep Reinforcement Learning����������ϸ������������Qֵ�����绯�Ĺ��̡�������Ȥ�Ŀ��Ե�֮ǰ�������˽�ԭ�ġ���
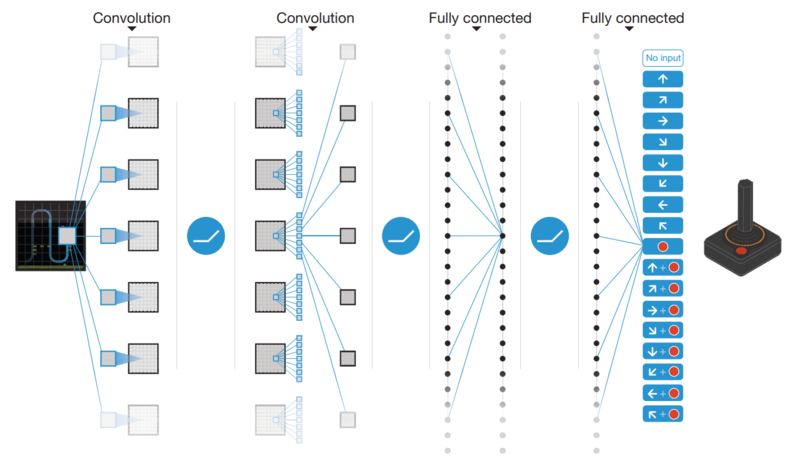
�Ա���Ϊ���������Ǿ���������4��������80��80ͼ��Ȼ�����������㣬һ���ػ��㣬����ȫ���Ӳ㣬����������ÿһ������Qֵ��������
�����Ѿ���Q-learning�����绯ΪQ-network�ˣ������������������ѵ����������硣������ѵ���Ĺ�����ʵ����һ�����Ż��������Ĺ��̣�����ϵͳ����ʧ������Ȼ������ʧ������С���Ĺ��̡�
ѵ�����������������ᵽ��DQN�㷨����Ŀ��Qֵ��Ϊ��ǩ����ˣ���ʧ�������Զ���Ϊ��
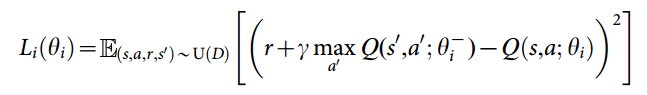
���湫ʽ��s'��a'����һ��״̬�Ͷ�����ȷ������ʧ������ȷ���˻�ȡ�����ķ�ʽ��DQN�������㷨Ҳ�ͳ����ˣ�

ֵ��ע����������D��Experience Replay��Ҳ���Ǿ���أ�������δ洢���������������⡣
������Flappy Bird��Ϸ���ɼ���������һ��ʱ�����У�����֮����������ԣ����ÿ�εõ���������Qֵ���������ֲ�Ӱ�죬Ч����á���ˣ�һ����ֱ�ӵ��뷨���ǰ������ȴ�������Ȼ�����������Σ������Experience
Replay��˼�롣
�㷨ʵ���ϣ��ȷ���ʵ�飬���ҽ�ʵ�����ݴ洢��D�У��洢��һ���̶ȣ��ʹ��������ȡ���ݣ�����ʧ���������ݶ��½���
�ġ����룺TensorFlowʵ��
���ڵ��˿������ʱ�����������£������ߴ�Deep Mind���������֣���ͼ��TensorFlowʵ�ֶ�Flappy
Bird��Ϸ����ʵ��ʱ������github���д������demo��˼·��ͬ������ֱ���Թ�������Ϊ�����з���˵���ˡ�
����Դ����Ҫ�����Ʋ�github��Using Deep Q-Network to Learn How
To Play Flappy Bird��
����ӽṹ����������Ҫ��Ϊ���¼����֣�
1.GameState��Ϸ�࣬frame_step���������ƶ�
2.CNNģ����
3.OpenCV-Pythonͼ��Ԥ��������
4.ģ��ѵ������
1. GameState��Ϸ�༰frame_step����
ͨ��Pythonʵ����Ϸ��ȻҪ��pygame�⣬�����ʱ�ӡ���������ʾ���ơ�������Ϸ�ؼ��������¼��ȣ��Դ�����Ȥ�ģ�������ϸ�˽�pygame��frame_step���������ΪshapeΪ
(2,) ��ndarray��ֵ�� [1,0]��ʲô�������� [0,1]������Bird�������´���ʵ�֣�
| if input_actions[1]
== 1:
if self.playery > -2 * PLAYER_HEIGHT:
self.playerVelY = self.playerFlapAcc
self.playerFlapped = True
# SOUNDS['wing'].play()
|
���������������÷֡����ý��桢����Ƿ���ײ�ȣ����ﲻ����ϸչ����
frame_step�����ķ���ֵ�ǣ�
| return image_data,
reward, terminal
|
�ֱ��ʾ����ͼ�����ݣ��÷��Լ��Ƿ������Ϸ����Ӧǰ��ǿ��ѧϰģ�ͣ�����ͼ�����ݱ�ʾ����״̬ s���÷ֱ�ʾ��������ѧϰϵͳ�ķ���
r��
2. CNNģ����
��Demo�а������������㣬һ���ػ��㣬����ȫ���Ӳ㣬����������ÿһ������Qֵ����������ˣ����ȶ���Ȩ�ء�ƫ�á������ͳػ�������
| # Ȩ��
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
# ƫ��
def bias_variable(shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
# ����
def conv2d(x, W, stride):
return tf.nn.conv2d(x, W, strides=[1, stride,
stride, 1], padding="SAME")
# �ػ�
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1,
2, 2, 1], padding="SAME") |
Ȼ��ͨ������������������������ģ�ͣ��Դ����в�������ģ���ֱ����ǰ���������������ֻ���ͼ����
| def createNetwork():
# ��һ�����
W_conv1 = weight_variable([8, 8, 4, 32])
b_conv1 = bias_variable([32])
# �ڶ������
W_conv2 = weight_variable([4, 4, 32, 64])
b_conv2 = bias_variable([64])
# ���������
W_conv3 = weight_variable([3, 3, 64, 64])
b_conv3 = bias_variable([64])
# ��һ��ȫ����
W_fc1 = weight_variable([1600, 512])
b_fc1 = bias_variable([512])
# �ڶ���ȫ����
W_fc2 = weight_variable([512, ACTIONS])
b_fc2 = bias_variable([ACTIONS])
# �����
s = tf.placeholder("float", [None, 80,
80, 4])
# ��һ�����ز�+�ػ���
h_conv1 = tf.nn.relu(conv2d(s, W_conv1, 4) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# �ڶ������ز㣨����ֻ����һ��ػ��㣩
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2,
2) + b_conv2)
# h_pool2 = max_pool_2x2(h_conv2)
# ���������ز�
h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3,
1) + b_conv3)
# h_pool3 = max_pool_2x2(h_conv3)
# Reshape
# h_pool3_flat = tf.reshape(h_pool3, [-1, 256])
h_conv3_flat = tf.reshape(h_conv3, [-1, 1600])
# ȫ���Ӳ�
h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat, W_fc1)
+ b_fc1)
# �����
# readout layer
readout = tf.matmul(h_fc1, W_fc2) + b_fc2
return s, readout, h_fc1 |
3. OpenCV-Pythonͼ��Ԥ��������
| ��Ubuntu�а�װopencv�IJ���Ƚ��鷳����ʱҲ���˲��ٿӣ�����Google��������鰲װopencv3��
|
�ⲿ����Ҫ��frame_step�������ص����ݽ����˻ҶȻ��Ͷ�ֵ����Ҳ�����������ͼ��Ԥ����������
| x_t, r_0,
terminal = game_state.frame_step(do_nothing)
# ���Ƚ�ͼ��ת��Ϊ80*80��Ȼ����лҶȻ�
x_t = cv2.cvtColor(cv2.resize(x_t, (80, 80)),
cv2.COLOR_BGR2GRAY)
# �ԻҶ�ͼ���ֵ��
ret, x_t = cv2.threshold(x_t, 1, 255, cv2.THRESH_BINARY)
# ��ͨ������ͼ��
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2)
|
4. DQNѵ������
���Ǵ��벿��Ҫ�����ص㣬Ҳ������Q-learning�㷨�Ĵ��뻯��
i. �ڽ���ѵ��֮ǰ�����ȴ���һЩ������
| # define
the cost function
a = tf.placeholder("float", [None, ACTIONS])
y = tf.placeholder("float", [None])
readout_action = tf.reduce_sum(tf.multiply(readout,
a), axis=1)
cost = tf.reduce_mean(tf.square(y - readout_action))
train_step = tf.train.AdamOptimizer(1e-6).minimize(cost)
# open up a game state to communicate with emulator
game_state = game.GameState()
# store the previous observations in replay memory
D = deque() |
��TensorFlow�У�ͨ�������ֶ�ȡ���ݵķ�ʽ��Feeding��Reading from files��Preloaded
data��Feeding�����Ҳ����Ч�ķ���������ģ�ͣ�Graph������֮ǰ����ʹ��placeholder����ռλ������ʱ��û��ѵ�����ݣ�ѵ����ͨ��feed_dict�������ݡ�
�����a��ʾ����Ķ�������ǿ��ѧϰģ���е�Action��y��ʾ��ǩֵ��readout_action��ʾģ�������a��˺���һά��ͣ���ʧ�����Ա�ǩֵ�����ֵ�IJ����ƽ����train_step��ʾ����ʧ��������Adam�Ż���
��ֵ�Ĺ���Ϊ��
| # perform
gradient step
train_step.run(feed_dict={
y: y_batch,
a: a_batch,
s: s_j_batch}
)
|
ii. ������Ϸ������� D
| # open up
a game state to communicate with emulator
game_state = game.GameState()
# store the previous observations in replay memory
D = deque() |
����� D�����˶��е����ݽṹ����TensorFlow������������ݽṹ������ͨ��dequeue()��enqueue([y])��������ȡ����ѹ�����ݡ������
D�����洢ʵ������е����ݣ������ѵ�����̻�������ȡ��һ������batch����ѵ����
�����������֮����Ҫ����TensorFlowϵͳ����tf.global_variables_initializer()����һ������ʵ�ֱ�����ʼ��������ʱ������ģ������ɣ�Session����֮�������磺
| # Create
two variables.
weights = tf.Variable(tf.random_normal([784, 200],
stddev=0.35),
name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
...
# Add an op to initialize the variables.
init_op = tf.global_variables_initializer()
# Later, when launching the model
with tf.Session() as sess:
# Run the init operation.
sess.run(init_op)
...
# Use the model
... |
iii. �������漰����
����TensorFlowѵ��ģ�ͣ���Ҫ��ѵ���õ��IJ������б��棬��Ȼһ�ػ�����һҹ�ص����ǰ�ˡ�TensorFlow����Saver������һ����Session()����֮ǰ��ͨ��tf.train.Saver()��ȡSaverʵ����
�����Ļָ�ʹ��saver��restore������
| # Create
some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore
variables from disk, and
# do some work with the model.
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, "/tmp/model.ckpt")
print("Model restored.")
# Do some work with the model
... |
�ڸ�Demoѵ��ʱ��Ҳ������Saver���в������档
| # saving
and loading networks
saver = tf.train.Saver()
checkpoint = tf.train.get_checkpoint_state("saved_networks")
if checkpoint and checkpoint.model_checkpoint_path:
saver.restore(sess, checkpoint.model_checkpoint_path)
print("Successfully loaded:", checkpoint.model_checkpoint_path)
else:
print("Could not find old network weights")
|
���ȼ���CheckPointState�ļ���Ȼ�����saver.restore���Ѵ��ڲ������лָ���
�ڸ�Demo�У�ÿ��10000�����ͶԲ������б��棺
| # save progress
every 10000 iterations
if t % 10000 == 0:
saver.save(sess, 'saved_networks/' + GAME + '-dqn',
global_step=t)
|
iv. ʵ�鼰�����洢
���ȣ����ݦ� ����ѡ��һ��Action��
| # choose
an action epsilon greedily
readout_t = readout.eval(feed_dict={s: [s_t]})[0]
a_t = np.zeros([ACTIONS])
action_index = 0
if t % FRAME_PER_ACTION == 0:
if random.random() <= epsilon:
print("----------Random Action----------")
action_index = random.randrange(ACTIONS)
a_t[random.randrange(ACTIONS)] = 1
else:
action_index = np.argmax(readout_t)
a_t[action_index] = 1
else:
a_t[0] = 1 # do nothing
|
���readout_t��ѵ������Ϊ֮ǰ�ᵽ����ͨ��ͼ���ģ�������a_t�Ǹ��ݦ� ����ѡ���Action��
��Σ�ִ��ѡ��Ķ����������淵�ص�״̬���÷֡�
| # run the
selected action and observe next state and reward
x_t1_colored, r_t, terminal = game_state.frame_step(a_t)
x_t1 = cv2.cvtColor(cv2.resize(x_t1_colored, (80,
80)), cv2.COLOR_BGR2GRAY)
ret, x_t1 = cv2.threshold(x_t1, 1, 255, cv2.THRESH_BINARY)
x_t1 = np.reshape(x_t1, (80, 80, 1))
# s_t1 = np.append(x_t1, s_t[:,:,1:], axis = 2)
s_t1 = np.append(x_t1, s_t[:, :, :3], axis=2)
# store the transition in D
D.append((s_t, a_t, r_t, s_t1, terminal)) |
�����D�������һ�������Ʒ����С�(s_t, a_t, r_t, s_t1, terminal)�ֱ��ʾtʱ��״̬s_t��ִ�еĶ���a_t���õ��ķ���r_t���Լ��õ�����һ����״̬s_t1����Ϸ�Ƿ�����ı�־terminal��
����һѵ�������У����µ�ǰ״̬��������
| # update
the old values
s_t = s_t1
t += 1
|
�ظ��������̣�ʵ�ַ���ʵ�鼰�����洢��
v. ͨ���ݶ��½�����ģ��ѵ��
��ʵ��һ��ʱ������D���Ѿ�������һЩ�������ݺͿ��Դ���Щ�����������������������ģ��ѵ���ˡ���������������ΪOBSERVE
= 100000.�����������������ΪBATCH = 32��
| if t >
OBSERVE:
# sample a minibatch to train on
minibatch = random.sample(D, BATCH)
# get the batch variables
s_j_batch = [d[0] for d in minibatch]
a_batch = [d[1] for d in minibatch]
r_batch = [d[2] for d in minibatch]
s_j1_batch = [d[3] for d in minibatch]
y_batch = []
readout_j1_batch = readout.eval(feed_dict={s:
s_j1_batch})
for i in range(0, len(minibatch)):
terminal = minibatch[i][4]
# if terminal, only equals reward
if terminal:
y_batch.append(r_batch[i])
else:
y_batch.append(r_batch[i] + GAMMA * np.max(readout_j1_batch[i]))
# perform gradient step
train_step.run(feed_dict={
y: y_batch,
a: a_batch,
s: s_j_batch}
) |
s_j_batch��a_batch��r_batch��s_j1_batch�ǴӾ����D����ȡ���������Ʒ����У�JavaͯЬ��ĽPython���б��Ƶ�ʽ������y_batchΪ��ǩֵ������Ϸ������������һ����״̬��Ӧ��Qֵ������Qֵ���¹��̣���ֱ������r_batch����δ�����������ۺ����ӣ�0.99������һ����״̬�����Qֵ�ij˻���������y_batch��
���ִ���ݶ��½�ѵ����train_step�������s_j_batch��a_batch��y_batch����ྭ��2000000�����ڱ����ϴ��10��Сʱ��ѵ��֮���ܴﵽ���Ŀ�ͷ��ͼ�е�Ч������ |






