| ����Ϊʵ���˹����ܵ��Ѷ������ڽ���������Ҫ��һ��ǿ������棬���д�����ȼ�ϡ��������ǿ������浫ȱ��ȼ�ϣ�����϶���������ġ����ֻ��һ�����������棬���ٶ�ȼ��Ҳ����ɡ����Ҫ������ǿ�������ʹ���ȼ���DZز����ٵġ�
�Դ���������ѧϰ�Ļ������ѧϰ������Կ���������棬������Ϊ�㷨�ṩ�ĺ������ݿ��Կ�����ȼ�ϡ�?��?Andrew
Ng
������ѧϰ����ͻȻ��ʼ�������У��������Է��롢�������Ϸ���Լ����˼�ʻ�������漰��������������������ȡ������Ŀ�ijɹ���ʹ�����ѧϰ�����������Ĺ����У�������ϰ�����ѵ��ģ����������ĺ������ݡ���Ҫ��˶�����ݣ�ԭ�����ڻ�����ѧϰ�Ĺ����л���ģ������������������
������Щģ���г����IJ���������Χ������
���ѧϰģ�͵�ϸ��
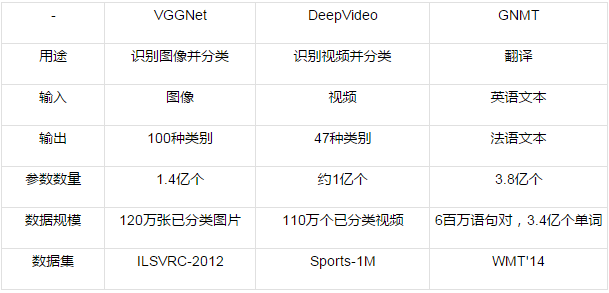
�����磨�����ѧϰ����һ�ֲַ�ʽ�ṹ�������ܶѵ���һ�𣨾����ָ�ľ��
���ѧϰ������ʵ����һ�ִ��ģ�����磬���ǿ��Խ��������翴��һ������ͼ�����ݴ�һ�˽��룬�����/�˽�����һ����������ǻ����Խ��������ֳɶ�����֣����κ�һ�����еõ��Լ���Ҫ�����������Ҳ�����õ�������Ľ��������Ȼ����������������Google
DeepDream�����������ġ�
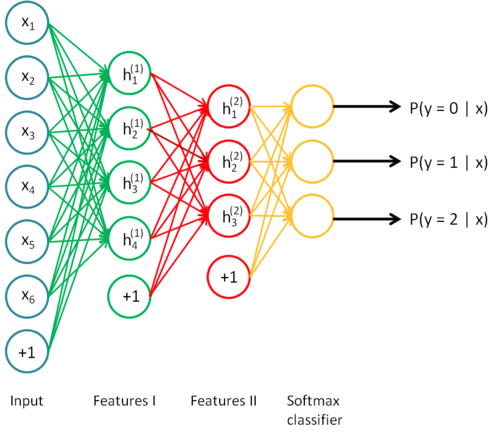
��ģ��ģ�ͣ� �� ��ģ�����ݣ� �� ���Ӷȣ����⣩
��ģ�͵Ĺ�ģ�������������Ĺ�ģ֮�����һ����Ȥ�Ľ��������ԵĹ�ϵ�������������ڣ������ض������⣨����������������ģ�ͱ����㹻���Ա�õ�����֮��Ĺ�ϵ������ͼƬ�еIJ��ʺ���״���ı��е�����Լ������е����أ���ģ���е�ǰ������ʶ�������������в�ͬ���֮��ĸ����ϵ�������Ե��ģʽ�������������ʶ�������������������������Ϣ����Щ��Ϣͨ�����������ֲ�ͬ�Ľ��������������ĸ��ӶȽϸߣ�����ͼ����ࣩ������IJ����������������ͻ�dz���
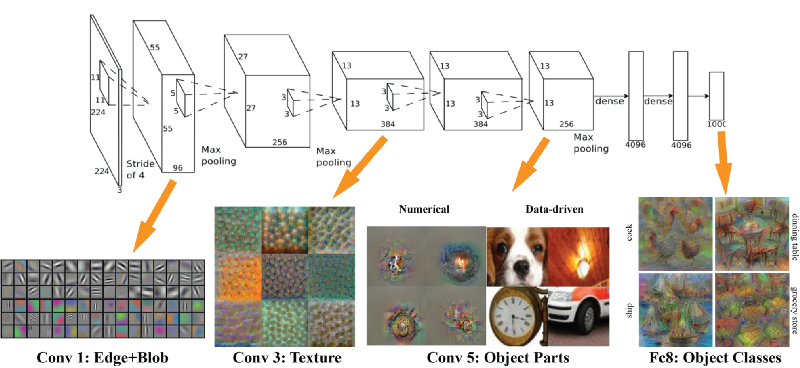
AlexNet��ÿ�����ڡ�������������
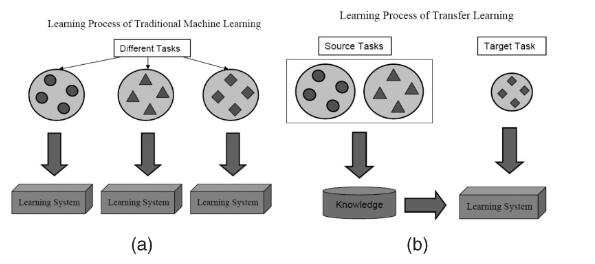
Ǩ��ѧϰ����ȣ�
�����ijһ����ľ�������ʱ��ͨ���������õ�����ģ�������ģ�����ݡ�Ȼ����һ��ģ��ѵ�����������ij���������ݻ�õĹ�ϵҲ�������ɵ�Ӧ����ͬһ����IJ�ͬ���⡣���ּ���Ҳ����Ǩ��ѧϰ��Transfer
Learning����
|
Qiang Yang��Sinno Jialin Pan����A
Survey on Transfer Learning����IEEE Transactions
on Knowledge & Data Engineering��vol. 22, no.
, pp. 1345�C1359, October 2010, doi:10.1109/TKDE.2009.191
|
| Ǩ��ѧϰ������һ��û��Ը�Ᵽ�ص�����ܡ�����ҵ�����˽�֪����������֪�顣
|
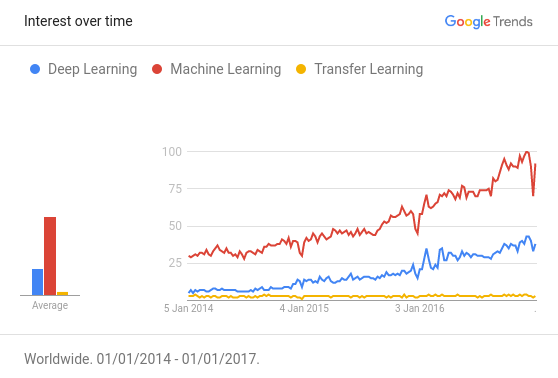
�ȸ������У�����ѧϰ�����ѧϰ���Լ�Ǩ��ѧϰ�����ؼ��ֵ��������Ʊ仯
����Awesome?��?Most Cited Deep Learning Papers�����������ѧϰ��������Ҫ������ͳ�ƣ�����50%������ʹ����ij����ʽ��Ǩ��ѧϰ��Ԥѵ����������Դ�����ݺͼ��������������ˣ�Ǩ��ѧϰ��������Ҫ�����վ�����Ȼ����һ������δ�õ�Ӧ�г̶ȵ����Ӱ�졣����Ҫ���ּ���������������֪�����ּ����Ĵ��ڡ�
| ������ѧϰ��ʥ���������������ˣ���ôǨ��ѧϰ���Ǵ���Կ�ס�
|
����Ǩ��ѧϰ���������ǿ���ֱ��ʹ��Ԥѵ������ģ�ͣ�����ģ���Ѿ�ͨ����������õ����ݼ����й�ѵ������Ȼ�������ȫ��ͬ���������ѵ���ģ��������������ȫ��ͬ��ֻ��������Ľ����ͬ�����������ҳ������������õIJ㡣���ǿ���ʹ����Щ����������䵱���룬����ѵ����һ������������������٣���ģҲ��С�����硣���С��ģ����ֻ��Ҫ�˽��ض�������ڲ���ϵ��ͬʱ�Ѿ�ͨ��Ԥ��ѵģ��ѧϰ���������̺���ģʽ��ͨ�����ַ�ʽ�����ɽ�����ѵ�����è���ģ����������������ߵĻ�����
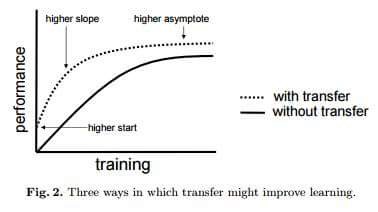
Ǩ��ѧϰ��������һ���ش��������ڿ��Զ�ģ�ͽ������Ƶġ�ͨ�û���������ģ�������������ݹ�����ϣ�Overfit�������罨ģ����������ԶԶ���������������������ڴ���δ������������ʱЧ�����ܲ������ʱ��ô�á�����Ǩ��ѧϰ������ģ�Ϳ�����ͬ���͵����ݣ���˿���ϰ�ø���ɫ�ĵײ����
| ������ϣ�������ѧϰ�����е�����Ӳ����?��?James Faghmous
|
Ǩ��ѧϰ�ɼ�С������
������Ҫ�ս�ȹ�ӵ���������ɫ���ǰ�ɫ�����飬������Ҫ�ռ������ѻ�֤ʵ������ɫ�Ͱ�ɫ��ȹ��ͼƬ�����Ҫʹ�����������ᵽ�ķ�ʽ������1.4�ڸ������������й���һ��ȷ��ģ�Ͳ��������ѵ����������Ҫ��120����ͼƬ�������������ʵ�ֵġ���ʱ���������Ǩ��ѧϰ��
���ʹ��Ǩ��ѧϰ������ѵ������IJ����������㷽ʽ���£�
���������� = [��ģ(����) + 1] * [��ģ(���) + 1]
= [2048+1]*[1+1]~ 4098 ������
�������������1.4*10?��������4*103���������������������ֻҪ�ռ�����100��ͼƬ���ˡ����˿�����
���ʵ��û���ļ����Ķ���ϣ������֪��ȹ�ӵ���ɫ������ֱ����������ĩβ����������й���һ��������ģ�͡�
Ǩ��ѧϰѭ��ָ��?��?ʹ��ʾ��������������
�����ʾ���й���72ƪӰ����
1.62ƪ��������ȷ�������������ڶ�ģ�ͽ���Ԥѵ��
2.8ƪ������ȷ�������������ڶ�ģ�ͽ���ѵ��
3.2ƪ������ȷ�������������ڶ�ģ�ͽ��в���
����ֻ��8��������ǩ�ľ��ӣ�������ȷ�����ľ��ӣ���������ȿ���Ԥѵ��ģ�ͽ���������Ԥ�⡣���ֻʹ����8������ѵ��ģ�ͣ�ȷ�ȿɴ�50%��������ȷ�Ⱥ���Ӳ�Ҳ�ࣩ��
���ǽ�ʹ��Ǩ��ѧϰ�������������⣬����ʹ��62������ѵ��ģ�ͣ����ʹ�õ�һ��ģ�͵IJ������ݣ��Դ�Ϊ����ѵ����һ��������������ʹ�����8�����ӽ���ѵ���������2�����Ӳ��Եõ���100%�ľ�ȷ�ȡ�
��1��
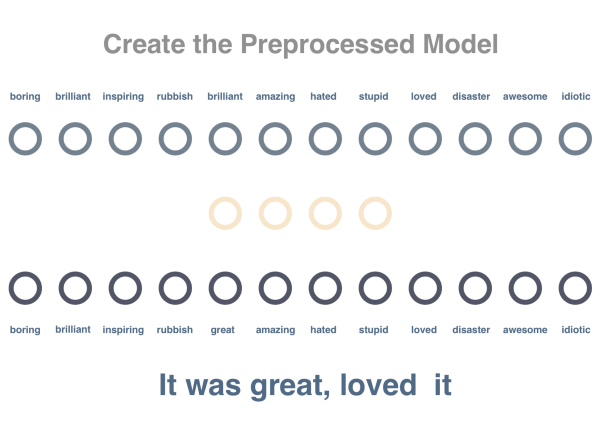
���ǽ�ѵ��һ���Դ���֮��Ĺ�ϵ���н�ģ�����硣�������а�����һ�����ﴫ�ݽ�ȥ��������Ԥ��ô��������ͬһ�������С������д�����Ƕ��ľ������СΪvocabulary
x embedding_size�����д洢�˴���ÿ�����������������Ĵ�СΪ��4������
| graph = tf.Graph() with graph.as_default(): train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) valid_dataset = tf.constant(valid_examples, dtype=tf.int32) with tf.device('/cpu:0'): embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) embed = tf.nn.embedding_lookup(embeddings, train_inputs) nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) loss = tf.reduce_mean(tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels, num_sampled, vocabulary_size)) optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True) init = tf.global_variables_initializer()
|
pretraining_model.py�й���GitHub���鿴Դ�ļ�
��2��
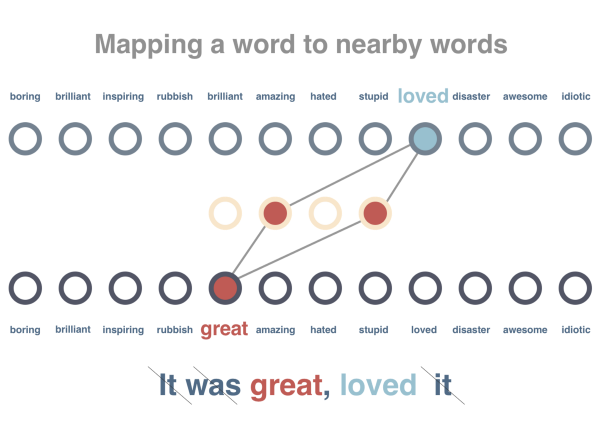
���Ǽ��������ͼ������ѵ��������ͬ�������г��ֵĴ�����Ի�����Ƶ��������������ǻ����Щ���ӽ���Ԥ�������Ƴ�����ͣ�ôʣ�Stop
word����ʵ�ֱ�ǻ���Tokenizing�������һ�δ���һ������������̸ô����������ܱߴ���֮��ľ��룬�������������IJ��������������֮��ľ��롣
| with tf.Session(graph=graph) as session: init.run() average_loss = 0 for step in range(10001): batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} _, loss_val, normalized_embeddings_np = session.run([optimizer, loss, normalized_embeddings], feed_dict=feed_dict) average_loss += loss_val final_embeddings = normalized_embeddings.eval()
|
training_the_pretrained_model.py�й���GitHub���鿴Դ�ļ�
��3��
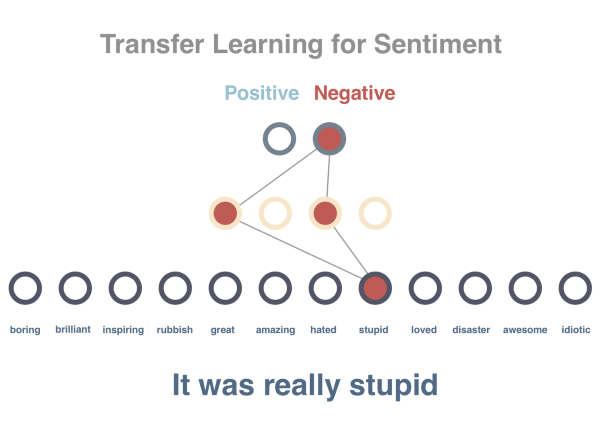
������ǻ�����Ԥ����ӵ�������Ŀǰ�Ѿ���10����8��ѵ���ã�2�������ã����Ӵ����������ı�ǩ��������һ���õ���ģ���Ѿ����������д�����ϰ�õ�������������Щ��������ֵ���Կ��Դ�������������ģ���˿ɽ�һ����������Ԥ�⡣
��ʱ���Dz���ֱ��ʹ�þ��ӣ����ǽ����ӵ���������Ϊ����ȫ�������ƽ��ֵ����һ����ʵ������ͨ������LSTM�ļ���ʵ�ֵģ���������������Ϊ���봫�ݵ������У�������Ϊ����Ϊ�������ķ����������õ���һ�����ص��м�㣬��ͨ�����б�ǩ�ľ��Ӷ�ģ�ͽ���ѵ����������������Ȼÿ��ֻ������10�������������ģ��ʵ����100%��ȷ�ȡ�
| input = tf.placeholder("float", shape=[None, x_size]) y = tf.placeholder("float", shape=[None, y_size]) w_1 = tf.Variable(tf.random_normal((x_size, h_size), stddev=0.1)) w_2 = tf.Variable(tf.random_normal((h_size, y_size), stddev=0.1)) h = tf.nn.sigmoid(tf.matmul(X, w_1)) yhat = tf.matmul(h, w_2) predict = tf.argmax(yhat, dimension=1) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(yhat, y)) updates = tf.train.GradientDescentOptimizer(0.01).minimize(cost) sess = tf.InteractiveSession() init = tf.initialize_all_variables() sess.run(init)
for epoch in range(1000):
for i in range(len(train_X)):
sess.run(updates, feed_dict={X: train_X[i: i +
1], y: train_y[i: i + 1]})
train_accuracy = numpy.mean(numpy.argmax(train_y,
axis=1) == sess.run(predict, feed_dict={X: train_X,
y: train_y}))
test_accuracy = numpy.mean(numpy.argmax(test_y,
axis=1) == sess.run(predict, feed_dict={X: test_X,
y: test_y}))
print("Epoch = %d, train accuracy=%.2f%%,
test accuracy=%.2f%%" % (epoch+1,100.*train_accuracy,100.*
test_accuracy)) |
training_the_sentiment_model.py�й���GitHub���鿴Դ�ļ�
��Ȼ��ֻ�Ǹ�ʾ���������Է�����Ǩ��ѧϰ�����İ����£���ȷ�ȴ�50%����������100%����Ҫ�鿴���������ʹ�����������е�ַ��
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
Ǩ��ѧϰ��һЩ��ʵ����
ͼ��ʶ��ͼ����ǿ�����ת�ơ������⡢Ƥ������⡣
����ʶ��Zero Shot���롢�������ࡣ
Ǩ��ѧϰʵ�ֹ����е��ѵ�
��Ȼ�����ø�����������ѵ��ģ�ͣ����ü������������Ÿ��ߵļ���Ҫ��ֻ��Ҫ��������������Ӳ���������������������һ��Ҫ��ģ��ѵ�����ǰ���ϵ�����Щ������Ǩ��ѧϰ����ʹ�õ��Ѷ�֮������֪��
Ǩ��ѧϰ����Ŀǰ���ٵ����������
1.�ҵ�Ԥѵ������Ĵ��ģ���ݼ�
2.��������Ԥѵ����ģ��
3.����ģ�����κ�һ��������Ԥ�ڹ��������Ƚ����Ե���
4.��ȷ��Ϊ��ѵ��ģ�ͻ���Ҫ��������������
5.ʹ��Ԥѵ��ģ��ʱ���Ծ���������ֹͣ
6.��Ԥѵ��ģ�͵Ļ����ϣ�ȷ��ģ�������Ͳ���������
7.�йܲ��ṩ��Ϻ��ģ��
8.�����ָ������ݻ���õļ�����Ԥѵ��ģ�ͽ��и���
| ���ݿ�ѧ�����١��ҵ��ܷ������ݿ�ѧ�ҵ�����ʵһ�����ѡ�?��?Krzysztof
Zawadzki
|
NanoNets��Ǩ��ѧϰ��ø���
������������Щ��������ǿ�ʼ����ͨ������֧��Ǩ��ѧϰ�������ƶ����ѧϰ��������ͨ�����ּ����õķ�������Щ���⡣�÷����а���һϵ��Ԥѵ����ģ�ͣ������������������������й�ѵ������ֻ��Ҫ�ϴ��Լ������ݣ������������������ݣ����÷��������ľ�������ѡ�����ʺϵ�ģ�ͣ�������Ԥѵ��ģ�͵Ļ����Ͻ����µ�NanoNet��������������뵽NanoNet�н��д�����
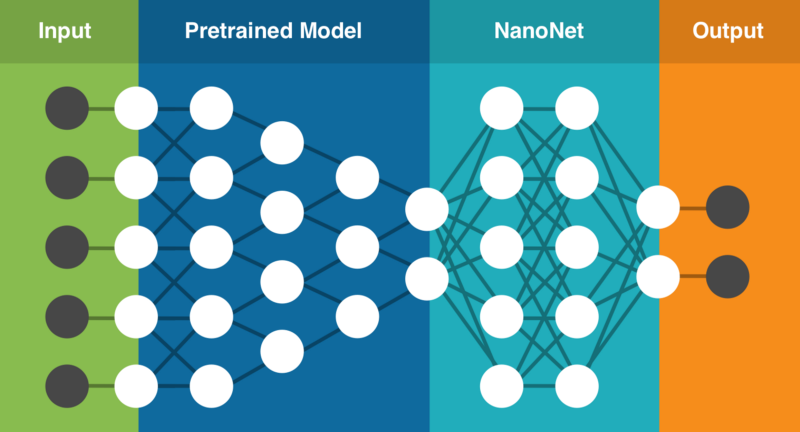
NanoNets��Ǩ��ѧϰ�������üܹ���Ϊ�������֣�
���������NanoNet��ͼ����ࣩ
1.������ѡ����Ҫ�����ķ��ࡣ
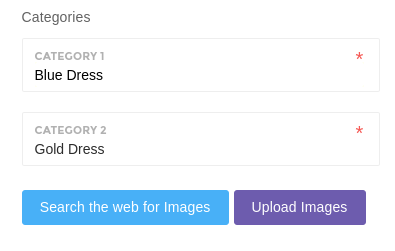
2.һ�������ʼ�������粢����ģ�ͣ���Ҳ�����ϴ��Լ���ͼƬ����

3.�������ȹ�ӵ����飨ģ�;��������ǻ�ͨ�������õ�Web���������ϴ�����ͼƬ��ͬʱ���ṩ�˲������ض����Ե�API����

|






