АйЖШIDLбаОПдБаьЮАЁЂгръЛФаЁЂеХКЃГЌЬсГіСЫвЛИіаТЕФПђМмЃЌЭЈЙ§ЖрШЮЮёЧПЛЏбЇЯАКЭСуЪ§ОнбЇЯАЃЌШУжЧФмЬхдкУЛгаЯШбщжЊЪЖЕФЧщПіЯТЃЌздМКбЇЛсСЫНсКЯгябдКЭЪгОѕСНжжаХКХдкУдЙЌжаЕМКНВЂЖЈЮЛЮяЬхЁЃетЯюбаОПЪЧАйЖШдкЭЈгУAIбаОПжаНЛЛЅЪНбЇЯАЩЯЕФЭЛЦЦЃЌгажњгкбаЗЂдкЯжЪЕЪРНчжаЭъГЩШЮЮёЕФЛњЦїШЫЁЃ
АйЖШетДЮПЊЗЂЕФAIашвЊЭъГЩЕФШЮЮёЪЧдкЖўЮЌУдЙЌРяевЖЋЮїЃЌЕЋгывдЭљДѓЖрЪ§баОПШУAIздМКШЅЬНЫїаТЛЗОГВЛЭЌЃЌАйЖШбаОПШЫдБЪЙгУСЫвЛИіЁАНЬСЗЁБЫуЗЈЃЌЪЙгУгябдУќСюAIШЅЕНВЛЭЌЕФЕиЗНзіЪТЧщЁЃ
дкетРяЃЌAIвЊЭъГЩШЮЮёЃЌГ§СЫздМКДІРэЪгОѕаХКХЕМКНЃЌЛЙашвЊбЇЛсРэНтгябдаХКХВЂНЋетаЉгябдаХКХгыЪгОѕаХЯЂЖдгІЦ№РДЁЃетжжНсКЯСЫЭМЯёЗжЮіЁЂздШЛгябдДІРэвдМАЯжЪЕЪРНчааЖЏЕФФмСІЃЌе§ЪЧШЫРрЪЙгУгябдУќСюЛњЦїШЫШЅЭъГЩШЮЮёЫљВЛПЩЛђШБЕФЁЃгЩДЫЃЌетЯюбаОПЖдгкЛњЦїШЫгІгУгаКмДѓЕФЧБСІЁЃ
ТлЮФзїепЁЂАйЖШЩюЖШбЇЯАбаОПдКНмГіПЦбЇМваьЮАдкНгЪмЭтУНВЩЗУЪББэЪОЃЌЫћУЧЯЃЭћНЬЛсЛњЦїШЫгУШЫЕФЗНЪНзіЪТЧщЃЌетбљЖдШЫРргУЛЇЖјбдИќМгЗНБуЃЌЖјЁАгябддђЪЧжЊЪЖНЛСїКмживЊЕФВПЗжЁБЁЃ
АйЖШЕФетИіAIОпЬхдѕУДЙЄзїФиЃПдквЛИі7ЁС7ЕФУдЙЌжаЃЌAIашвЊевЕНЫЎЙћЃЌевЕНСЫвдКѓгаНБРјЃЌХіБкЛђепзпДэЗНЯђдђЛсЪмДІЗЃЁЃТлЮФРяЕФAIЫуЗЈгЩЫФИіВПЗжзщГЩЃКвЛИігябдФЃПщЃЌгУгкРэНтУќСюКЭЩњГЩД№АИЃЛвЛИіЪЖБ№ФЃПщЃЌгУгкУїШЗЙиМќДЪЃЈБШШчЦЛЙћЃЉЃЛвЛИіЪгОѕФЃаЭЃЌгУгкЁАПДЁБУдЙЌЃЛЛЙгавЛИіОіВпФЃаЭЃЌгУгкОіВпЁЃ
ЩЯЮФЬсЕНЕФФЧИіЁАНЬСЗЁБЫуЗЈЛсЗЂГіжИСюЃЈгЂгяЃЉЃЌБШШчЁАЭљЦЛЙћЕФЖЋБпвЦЖЏЁБЃЌОРњЪ§АйЭђДЮЕФЕќДњвдКѓЃЌAIОЭФмбЇЛсЪВУДЪЧЁАЖЋЁБЁЂЪВУДЪЧЁАЦЛЙћЁБЃЌвдМАетСНИіИХФюШчКЮЙиСЊЁЃ
ВЛНіШчДЫЃЌбаОПШЫдБЛЙЗЂЯжЃЌЪЕбщжаAIЭЈЙ§ЧПЛЏбЇЯАЃЌдкНгЪеЕНвдЧАУЛгаНгДЅЙ§ЕФгябдУќСюКѓЃЌвВФме§ШЗжДааШЮЮёЁЃ
ЫфШЛФПЧАТлЮФРяAIФмЙЛЭъГЩЕФШЮЮёЛЙЪЎЗжМђЕЅЃЌЫуЗЈвВВЛФмЩњГЩЭъећЕФОфзгЯьгІЃЌЕЋаьЮАБэЪОЃЌетЯюбаОПЪЧвЛЯюЁАИХФюжЄУїЁБЃЈproof
of conceptЃЉЃЌгУгкЬНЫїЫуЗЈФмЗёЭЌЪБбЇЛсгябдКЭдкУдЙЌжаЕМКНЁЃ
баОПШЫдБдкТлЮФжаБэЪОЃЌЫћУЧНгЯТРДМЦЛЎНЋЪЕбщЭиеЙЕНШ§ЮЌЛЗОГЁЃ
жЕЕУвЛЬсЃЌЯЕЭГЪЧЪЙгУАйЖШPaddlePaddleПђМмаДЕФЁЃ
етИіЪЕбщгыаьЮАЕФбаОПФПБъЪЎЗжКєгІЁЃ3дТ2ШеЃЌЩюЖШбЇЯАММЪѕМАгІгУЙњМвЙЄГЬЪЕбщЪвбЇЪѕбаЬжЛсдкОЉейПЊЃЈРюбхКъГЦАйЖШвЊзіХЎХХФЧбљЕФШЫЙЄжЧФмЙњМвЖгЃЉЃЌаьЮАдкЯжГЁБэЪОЃКЁАЯждкЮвУЧЕФЛњЦїКЭШЫЛЙЪЧгазХЗЧГЃДѓЕФВюОрЃЌЮвУЧгІИУДгвЛИіЗЧГЃМђЕЅЕФбЇЯАГЁОАПЊЪМЃЌШУЛњЦїЯёЖљЭЏвЛбљЃЌЭЈЙ§дкЛЗОГжаЕФЛЅЖЏШЅбЇЯАИажЊЁЂааЖЏЁЂгябдетбљвЛаЉЛљБОЕФФмСІЁЃЁБ
ЕБЬьЃЌаьЮАЗЂБэСЫЙигкЭЈгУAIЕФбнНВЃЌЬИТлСЫШчКЮДђдьЭЈгУШЫЙЄжЧФмЕФбаОПЦНЬЈЁЃаьЮАдкбнНВжаЫЕЃКЁАЮвдкетРяКЭДѓМвЗжЯэЕФЪЧЮвУЧЖдгквдКѓШЫЙЄжЧФмЗЂеЙЕФЯЃЭћКЭЮвУЧЯждкзіЕФвЛаЉЙЄзїЁЃЮвЬиБ№вЊЧПЕїЕФЪЧЃЌЮвУЧЯждкПМТЧЕФЪЧЭЈгУШЫЙЄжЧФмЕФММЪѕЗЂеЙЁЃЁБ
ЯТУцЃЌЮвУЧОпЬхРДПДПДетЯюбаОПЁЃ
ащФтЛЗОГжаРрЫЦШЫРргябдЯАЕУЕФЩюЖШзщКЯадПђМмЃЈA Deep Compositional Framework
for Human-like Language Acquisition in Virtual EnvironmentЃЉ

еЊвЊ
ЮвУЧШУвЛИіжЧФмЬхдквЛИіБЛГЦЮЊ XWORLD ЕФ 2D УдЙЌЛЗОГжабЇЯАЕМКНШЮЮёЁЃдкУПИіЛиКЯЃЌжЧФмЬхЕУЕНвЛИідЪМЯёЫижЁЕФађСаЃЌвЛИігЩжИЕМепЃЈteacherЃЉЗЂГіЕФУќСюЃЌвдМАвЛзщНБРјЁЃжЧФмЬхашвЊДгСуПЊЪМбЇЯА
teacher ЕФгябдЃЌвддкОЙ§бЕСЗКѓФмЙЛе§ШЗжДаа zero-shot ЕФУќСюЃК1ЃЉУќСюгяОфжаГіЯжЕФДЪзщДгЮДдкЯШЧАГіЯжЙ§ЃЛКЭ/Лђ
2ЃЉУќСюгяОфАќКЌДгСэвЛИіШЮЮёжабЇЯАЕНЕФаТЕФЖдЯѓИХФюЃЈnew object conceptsЃЉЃЌЕЋетаЉИХФюДгЮДдкЕМКНЃЈnavigationЃЉШЮЮёжабЇЙ§ЁЃ
ЮвУЧЖджЧФмЬхЕФЩюВуПђМмЕФбЕСЗЪЧЖЫЕНЖЫЕФЃКЫќЭЌЪБбЇЯАЛЗОГЕФЪгОѕБэЪОЃЌгябдЕФОфЗЈКЭгявхЃЌвдМАгУгкЪфГіааЖЏЕФЖЏзїФЃПщЃЈaction
moduleЃЉЁЃИУПђМмЕФ zero-shot бЇЯАФмСІРДздЦфОпгаВЮЪ§дМЪјЃЈparameter tyingЃЉЕФзщКЯадЃЈcompositionalityЃЉКЭФЃПщЛЏЃЈmodularityЃЉЁЃЮвУЧЖдИУПђМмЕФжаМфЪфГіНјааСЫПЩЪгЛЏЃЌжЄУїжЧФмЬхеце§РэНтШчКЮНтОіЮЪЬтЁЃЮвУЧЯраХЃЌЮвУЧЕФНсЙћЬсЙЉСЫЖддк3DЛЗОГжабЕСЗОпгаРрЫЦФмСІЕФжЧФмЬхЕФГѕВНЦєЗЂЁЃ
в§бд
ИДдггябдЯЕЭГЕФЗЂеЙЪЧЪЕЯжШЫРрЫЎЦНЕФЛњЦїжЧФмЕФЙиМќЁЃгябдЕФгявхРДдДгкИажЊОбщЃЌПЩвдБрТыгаЙиИажЊЪРНчЕФжЊЪЖЁЃетжжжЊЪЖФмЙЛДгвЛИіШЮЮёЧЈвЦЕНСэвЛИіШЮЮёЃЌИГгшЛњЦїЗКЛЏЕФФмСІЃЈgeneralization
abilityЃЉЁЃгабаОПШЯЮЊЃЌЛњЦїБиаыОРњЮяРэЕФЬхбщЃЌВХФмбЇЯАШЫРрЫЎЦНЕФгявх[Kiela et al.,
2016]ЃЌМДЃЌБиаыОРњРрЫЦШЫРрЕФгябдЯАЕУЙ§ГЬЁЃШЛЖјЃЌФПЧАЕФЛњЦїбЇЯАММЪѕЛЙУЛгаФмвдИпаЇТЪЪЕЯжетвЛЕуЕФЗНЗЈЁЃвђДЫЃЌЮвУЧбЁдёдкащФтЛЗОГжаЖдетИіЮЪЬтНјааНЈФЃЃЌзїЮЊбЕСЗЮяРэжЧФмЛњЦїЕФЕквЛВНЁЃ
дкЭЈЙ§здШЛгябдЕФжИЕМбЇЯАаТЕФИХФюКЭММФмЪБЃЌШЫРрЪЧФмЙЛЗЧГЃКУЕиОйвЛЗДШ§ЁЂЭЦЙуЗКЛЏЕФЁЃЮвУЧФмЙЛНЋвбгаЕФММФмгІгУЕНаТбЇЛсЕФИХФюЩЯЃЌЖјЧвКСВЛЗбОЂЁЃР§ШчЃЌЕБвЛИіШЫдкбЇЛсШчКЮжДааЁАгУЕЖЧа
XЁБЃЌX ЕШгкЦЛЙћетИіУќСюКѓЃЌЕБ X ЪЧЦфЫћетИіШЫжЊЕРЕФЖЋЮїЃЌР§ШчРцЛђГШЃЌЛђепЩѕжСXЪЧЦфЫћЫћДгЮДБЛЮЪЙ§ЕФЖЋЮїЪБЃЌЫћЖМФмЙЛе§ШЗжДааетИіУќСюЁЃ
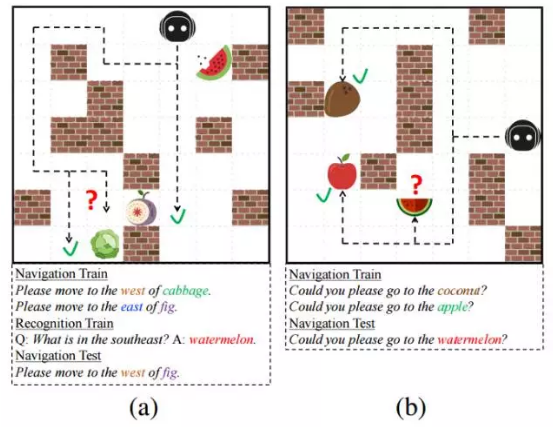
ЭМ1ЃКXWORLD ЛЗОГКЭ zero-shot ЕМКНШЮЮёЕФЭМЪОЁЃЃЈaЃЉВтЪдУќСюАќКЌвЛИіДгЮДгіЙ§ЕФЕЅДЪзщКЯЃЛЃЈbЃЉВтЪдУќСюАќКЌШЋаТЕФЮяЬхИХФюЃЌетаЉИХФюдкЧАУцЕФЛиКЯЃЈaЃЉЕФЮяЬхЪЖБ№ШЮЮёжабЇЙ§ЁЃ
етЦЊТлЮФНщЩмСЫвЛИіПђМмЃЌИУПђМмбнЪОСЫвЛИіжЧФмЬхдкЬиЖЈШЮЮёжаЕФ zero-shot бЇЯАФмСІЃЌМДЃЌдкУћЮЊ
XWORLD ЕФРрЫЦУдЙЌЕФЛЗОГжабЇЯАЕМКНЃЈЭМ1ЃЉЁЃЮвУЧЪдЭМНтОіЕФЮЪЬтгыгЄЖљбРбРбЇгяЪБдкбЇЯАзпТЗКЭЕМКНжаЫљгіЕНЕФЮЪЬтРрЫЦЁЃИИФИПЩФмЛсИјГівЛаЉМђЕЅЕФжИЕМадЕФУќСюЃЌЦфжазюГѕжЛАќКЌСНШ§ИіЕЅДЪЃЌШЛКѓЫцзХЪБМфЕФЭЦвЦУќСюж№НЅБфЕУИДдгЁЃЭЌЪБЃЌИИФИвВЛсдкЦфЫћвЛаЉШЮЮёжаНЬКЂзггябдЃЌР§ШчЪЖБ№ЮяЬхЕФШЮЮёЁЃдкгЄЖљРэНтСЫгябдВЂеЦЮеСЫЕМКНЕФММЧЩКѓЃЌЫћФмЙЛТэЩЯАбдкЮяЬхЪЖБ№жабЇЕНЕФаТИХФюгІгУЕНЕМКНШЮЮёжаЃЌМДЪЙетаЉИХФюДгЮДГіЯждкИИФИЕФЕМКНУќСюжаЁЃ
ЮвУЧдк XWORLD жагУЖрИібЇЯАЛиКЯбЕСЗЮвУЧЕФгЄЖљжЧФмЬхЁЃдкУПИіЛиКЯЃЌжЧФмЬхЕУЕНвЛЯЕСаЕФдЪМЯёЫиЭМЯёгУвдИажЊЛЗОГЃЌвЛИігЩ
teacher ЗЂГіЕФздШЛгябдаЮЪНЕФУќСюЃЌвдМАвЛзщНБРјЁЃЕБФГаЉЬѕМўБЛДЅЗЂЪБЃЌжЧФмЬхвВХМЖћЛсНгЕНРДзд
teacher ЕФгаЙиЖдЯѓЪЖБ№ЕФЮЪЬтЁЃЭЈЙ§ЬНЫїЛЗОГЃЌжЧФмЬхЭЌЪБбЇЯАЛЗОГЕФЪгОѕБэЪОЃЌгябдЕФОфЗЈКЭгявхЃЌвдМАШчКЮдкЛЗОГжаИјздМКЕМКНЁЃжЧФмЬхЕФећИіПђМмЪЙгУЬнЖШЯТНЕЖЫЕНЖЫЕиДгСуПЊЪМбЕСЗЁЃЮвУЧдкШ§ИіВЛЭЌЕФУќСюЬѕМўЯТВтЪджЧФмЬхБэЯжЃЌЦфжаСНИівЊЧѓжЧФмЬхФмЙЛЭЦЙуШЅНтЪЭДгЮДМћЙ§ЕФУќСюКЭДЪЛуЃЌЖјЧвПђМмЕФНсЙЙЪЧФЃПщЛЏЕФЃЌвдБуЦфЫћФЃПщЃЈШчЪгОѕИажЊФЃПщКЭЖЏзїФЃПщЃЉдкетжжЧщПіЯТШдШЛПЩвде§ГЃЙЄзїЁЃЮвУЧЕФЪЕбщБэУїЃЌИУжЧФмЬхдкЫљгаЬѕМўЯТБэЯжЕУВюВЛЖрКУЃЈЦНОљГЩЙІТЪдМ
90%ЃЉЁЃДЫЭтЃЌМђЕЅбЇЯАЭМЯёКЭгябдЕФСЊКЯЧЖШыЕФМИИіЛљЯпПђМмЕФНсЙћКмВюЁЃ
ИХПіЖјбдЃЌЮвУЧЕФбаОПЕФжївЊЙБЯзЪЧЃК
вЛжжНЋЪгОѕКЭгябдећКЯЕНвЛЦ№ЕФаТЕФЕМКНШЮЮёЃЌЪЙгУЩюЖШЧПЛЏбЇЯАЃЈRLЃЉЁЃДЫЭтЃЌИУгябдУЛгаБЛдЄНтЮіЃЈpre-parsedЃЉ[Sukhbaatar
et al., 2016]ЛђБЛСДНгЕНЛЗОГжа [Mikolov et al., 2015, Sukhbaatar
et al., 2016]ЁЃЯрЗДЃЌжЧФмЬхБиаыДгСуПЊЪМбЇЯАЫљгаФкШнЃЌВЂНЋгябджУгкЪгОѕЕФЛљДЁЩЯЁЃ
гябдЕФЖрШЮЮёЧЈвЦбЇЯАМгЫйСЫ RLЁЃИЈжњШЮЮёжаЕФгябдЯАЕУПЩвдАяжњжЧФмЬхИќПьЕиРэНтЕМКНУќСюЃЌДгЖјИќПьЕиеЦЮеЕМКНММЧЩЁЃ
ЭЈЙ§РћгУгябдКЭФЃаЭМмЙЙЕФзщКЯадЃЈcompositionalityЃЉЕУЕН zero-shot бЇЯАФмСІЁЃЮвУЧШЯЮЊетжжФмСІЪЧШЫРрЫЎЦНЕФжЧФмЕФЙиМќвЊЫиЁЃ
XWORLD ЛЗОГ
ЪзЯШЃЌШУЮвУЧМђЕЅНщЩмвЛЯТ XWORLD ЕФЛЗОГЁЃИќЖрЯИНкЧыВЮМћТлЮФИНТМ 8.3ЁЃXWORLD ЪЧвЛИі
2D ЕФеЄИёЃЈgridЃЉЪРНчЃЈЭМ1ЃЉЁЃвЛИіжЧФмЬхдкЖрИіЪБМфВНГЄ T жагыЛЗОГНјааНЛЛЅЃЌЦфжага4ИіЖЏзїЃКЩЯЃЌЯТЃЌзѓЃЌгвЁЃбЕСЗЙ§ГЬгааэЖрИіЛиКЯЁЃУПИіЛиКЯПЊЪМЪБЃЌжИЕМепЃЈteacherЃЉЦєЖЏМЦЪБЦїВЂЗЂГівЛИіздШЛгябдаЮЪНЕФУќСюЃЌвЊЧѓжЧФмЬхЕНДяЛЗОГжаЬиЖЈЖдЯѓЕФЮЛжУЁЃЦфжаПЩФмЛсгаЦфЫћЮяЬхзїЮЊИЩШХЮяГіЯжЁЃвђДЫЃЌжЧФмЬхашвЊЧјЗжВЛЭЌЕФЖдЯѓЃЌВЂЕМКНЕНе§ШЗЕФЮЛжУЁЃжЧФмЬхЭЈЙ§ОпгаздЮвжааФЪгЭМЕФ
RGB ЯёЫиИажЊећИіЛЗОГЃЈЭМ2cЃЉЁЃШчЙћжЧФмЬхдкЪБМфНсЪјЧАе§ШЗжДааСЫУќСюЃЌдђЛсЕУЕНЛ§МЋЕФМЄРјR +ЃЛУПЕБЫќХіЕНЧНБкЃЌЛђепЕНДяЕФЮЛжУВЛЪЧФПБъЖдЯѓЪБЃЌЗжБ№ЛсЕУЕНЯћМЋЕФМЄРјR-
wЛђR- oЃЛМйШчжЧФмЬхдкХЧЛВВЛЧАЃЌЛсЕУЕНЯћМЋНБРј R ? tЁЃдкУПИіЛиКЯНсЪјКѓЃЌЛЗОГКЭжЧФмЬхЖМЛсБЛжижУЁЃ
ЯТУцЪЧвЛаЉЪОР§УќСюЃЈРЈКХРяАќКЌДгжЧФмЬхжаБЃСєЕФЛЗОГХфжУЃЌЯТЭЌЃЉ
ЧыЕМКНЕНЦЛЙћЁЃЃЈгавЛИіЦЛЙћЃЌвЛИіЯуНЖЃЌвЛИіГШзгКЭвЛИіЦЯЬбЁЃЃЉ
ФуФмвЦЖЏЕНЦЛЙћКЭЯуНЖжЎМфЕФЭјИёТ№ЃПЃЈгавЛИіЦЛЙћКЭвЛИіЯуНЖЃЌЦЛЙћКЭЯуНЖМфгавЛИіПеИёИєПЊЁЃЃЉ
ФуФмвЦЖЏЕНКьЦЛЙћФЧЖљТ№ЃПЃЈгавЛИіЧрЦЛЙћЃЌвЛИіКьЦЛЙћКЭвЛИіКьгЃЬвЁЃЃЉ
етИіЕМКНШЮЮёЕФФбЕудкгкЃЌвЛПЊЪМЃЌжЧФмЬхЖдетжжгябдЪЧвЛЮоЫљжЊЕФЃКУПИізжЫЦКѕЖМУЛгавтвхЁЃОЙ§ЪдбщКЭЗИДэКѓЃЌжЧФмЬхБиаыХЊЧхгябдЕФОфЗЈКЭгявхЃЌвде§ШЗЕижДааУќСюЁЃ
ЮвУЧЬэМгвЛИіИЈжњЕФЖдЯѓЪЖБ№ШЮЮёРДАяжњжЧФмЬхбЇЯАгябдЁЃдкЬНЫїЛЗОГЕФЭЌЪБЃЌЕБФГаЉЬѕМўБЛДЅЗЂЪБЃЌteacher
ЛсбЏЮЪвЛаЉгыЖдЯѓгаЙиЕФЮЪЬтЃЌЮЪЬтЕФД№АИЖМЪЧвЛИіДЪЛуЃЌВЂЧвД№АИвВгЩ teacher ЬсЙЉЁЃЯТУцЪЧвЛаЉ
QA ЪОР§ЃК
QЃКБББпЕФЮяЬхЪЧЪВУДЃП AЃКЯуНЖЁЃЃЈжЧФмЬхдкЯуНЖФЯБпЃЌЦЛЙћБББпЃЌЛЦЙЯЮїБпЁЃЃЉ
QЃКЯуНЖдкФФРяЃПAЃКББЁЃЃЈжЧФмЬхдкЯуНЖФЯБпЃЌЦЛЙћЖЋБпЁЃЃЉ
QЃКЦЛЙћЮїБпЕФЮяЬхЕФбеЩЋЪЧЪВУДЃПAЃКЛЦЩЋЃЈЦЛЙћЕФЮїБпгавЛИіЯуНЖЃЌЖЋБпгавЛИіЛЦЙЯЁЃЃЉ
ЮвУЧЯЃЭћжЧФмЬхдкетИіИЈжњШЮЮёЕФАяжњЯТЃЌФмЙЛИќПьЕибЇЯАгябдЁЃ
Zero-shot ЕМКНЕФзщКЯадПђМм
ЮвУЧЕФПђМмАќКЌЫФИіжївЊФЃПщЃКгябдФЃПщЃЌЪЖБ№ФЃПщЃЌЪгОѕИажЊФЃПщКЭЖЏзїФЃПщЁЃПђМмЕФЩшМЦжївЊЪмашвЊЕМКНЕНаТЕФЮяЬхЕФгАЯьЃЈЭМ1bЃЉЃЌетаЉаТЕФЮяЬхИХФюВЛЛсГіЯждкУќСюгяОфжаЃЈНіГіЯждкЪЖБ№ФЃПщжазїЮЊД№АИЯдЪОЃЌЖјВЛЛсГіЯждкЭМ2aЕФгябдФЃПщЃЉЁЃ
етИіПђМмгаШ§ИіЙиМќЪєадЃК
гябдФЃПщБиаыЪЧзщКЯадЕФЃЈcompositionalЃЉЁЃИУФЃПщашвЊДІРэОфзгЃЌЭЌЪББЃСєЃЈжївЊЕФЃЉОфзгНсЙЙЁЃР§згжЎвЛЪЧЪфГігяЗЈЗжЮіЪїЃЈparse
treeЃЉЕФгяЗЈЗжЮіЦїЃЈparserЃЉЁЃ
ЙщФЩЦЋЯђЃЈinductive biasЃЉ[Lake et al., 2016]БиаыДгЯжгаЕФОфзгжабЇЯАЁЃгябдФЃПщжЊЕРШчЙћгУЭъШЋаТЕФЕЅДЪЬюГфЕНвбжЊНсЙЙРяЕФЕЅДЪЮЛжУЪБЃЌгІИУШчКЮНтЮіОфзгЁЃ
гябдНгЕиЃЈlanguage groundingЃЉЃЈЭМ2aЃЉКЭЪЖБ№ЃЈЭМ2bЃЉБиаыЫѕМѕГЩЃЈДѓдМЃЉЯрЭЌЕФЮЪЬтЁЃетбљПЩвдШЗБЃгУn-1ИіЕЅДЪбЕСЗЕФгябдНгЕидкДгЪЖБ№ШЮЮёжабЕСЗЕФЕк
n ИіЕЅДЪЩЯШдШЛФме§ГЃЙЄзїЁЃ
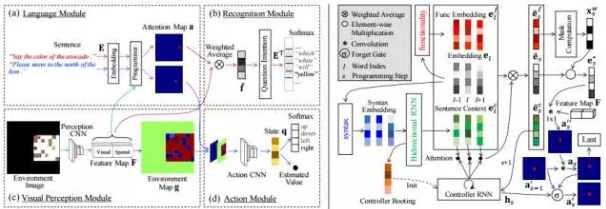
ЭМ2ЃКзѓЃКПђМмЕФЪОР§ЁЃЪфШыЪЧЛЗОГЭМЯёКЭОфзгЃЈвЛИіЕМКНУќСюЛђвЛИіЮЪЬтЃЉЁЃЪфГіЗжБ№ЪЧЕМКНЖЏзїЛђЮЪЬтЕФД№АИЁЃЃЈaЃЉжаЕФКьЩЋКЭРЖЩЋЯпБэЪОЭъШЋЯрЭЌЙ§ГЬЕФВЛЭЌШЮЮёЁЃгвЃКгябдФЃПщЁЃЪфШыЪЧзжЧЖШыађСаЁЃЪфГіЪЧзюКѓвЛВНЕФзЂвтСІЕиЭМЁЃ
ЪЕбщ
ЮвУЧЪЙгУСЫAdagradЃЌШУЫцЛњЬнЖШЯТНЕЃЈSGDЃЉЕФбЇЯАТЪДяЕН10-5ЁЃдкЫљгаЕФЪЕбщжаЃЌЮвУЧАбBatch
ЕФДѓаЁЩшЖЈдк16ЃЌВЂЧвбЕСЗ200k ЕФ batchesЁЃФПБъВЮЪ§ІШ - дкУПвЛИіJ=2k batches
жаЖМЛсБЛИќаТЁЃЫљгаЕФВЮЪ§ЖМгавЛИіФЌШЯШЈжиЫЅЭЫЃЌЯрЕБгк10-4x Bath ДѓаЁЁЃЖдгкЩёОЭјТчжаЕФУПвЛВуЃЌЭЈЙ§ФЌШЯЦфВЮЪ§ЮЊ0ЃЌвдМАвЛИіБъзМЕФХЩЩњ1/
ЁЬ NЃЌЦфжаNЪЧУПвЛВуЕФВЮЪ§Ъ§СПЁЃжЧФмЬхзмЙВгЕга500kИіЬНЫїВНжшЃЌЬНЫїТЪЃЈexploration
rateЃЉІС ЕФНЕЕЭЪЧЯпадЕФЃЌДг1ЕН0ЁЃЮвУЧаое§СЫБрГЬВНжшЕФЪ§СПSзїЮЊ3ЁЃЮвУЧЪЙгУСЫ4ИіЫцЛњЕФГѕЪМЛЏРДбЕСЗУПвЛИіФЃаЭЁЃећИіПђМмЖМЪЙгУPaddlePaddle
4РДЖЫЕНЖЫЕФВПЪ№КЭбЕСЗЁЃИќЖрЕФВПЪ№ЯИНкЛсдкИНТМ8.1жаНјааУшЪіЁЃ
ЭМ3ЃКбЕСЗМЄРјЧњЯпЁЃЭМжаЯдЪОЕФМЄРјЪЧУПИіЛиКЯРлЛ§ЕФелПлМЄРјЃЌгЩУП8kИібЕСЗЪОР§ЦНОљЕУРДЁЃУПЬѕЧњЯпЕФвѕгАЧјгђБэЪО4ИіЫцЛњГѕЪМЛЏжЎМфЕФЗНВюЁЃЃЈaЃЉЮвУЧЕФПђМмдкВЛЭЌЕФУќСюЬѕМўЯТЕФМЄРјЧњЯпЁЃЃЈbЃЉБъзМУќСюЬѕМўЯТЫФИіЛљЯпЕФЧњЯпЁЃ
zero-shot ЕМКН
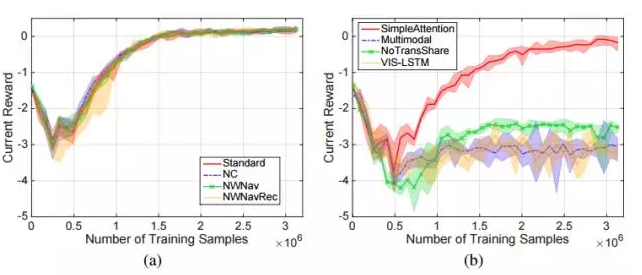
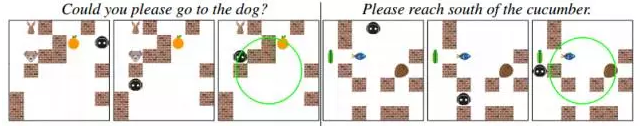
ЮвУЧЕФжївЊЮЪЬтЪЧжЧФмЬхЪЧЗёОпгажДаавдЧАДгЮДгіЙ§ЕФУќСюЕФЁАСубљБОЁБЃЈzero-shotЃЉЕМКНФмСІЁЃЮвУЧЩшМЦСЫ4ИіУќСюЬѕМўРДбЕСЗжЧФмЬхЃК
БъзМЃЈStandardЃЉЁЃбЕСЗЕФУќСюМЏгыВтЪдЕФУќСюМЏОпгаЯрЭЌЕФЗжВМЁЃ
NCЁЃдкбЕСЗЕФУќСюМЏжаЩОГ§ФГаЉДЪЛузщКЯЃЌЫфШЛбЕСЗУќСюМЏжаШдАќКЌЫљгаЕЅДЪЁЃОпЬхРДЫЕЃЌЮвУЧПМТЧСЫШ§жжРраЭЕФДЪЛузщКЯЃКЃЈobjectЃЌlocationЃЉЃЌЃЈobjectЃЌcolorЃЉКЭЃЈobjectЃЌobjectЃЉЁЃЮвУЧСаОйСЫУРжаРраЭЕФЫљгазщКЯЃЌВЂЫцЛњдк
teacher ЕФЕМКНУќСюМЏжаЩОГ§СЫ10%ЕФзщКЯЁЃ
NWNav КЭ NWNavRecЁЃвЛаЉЮяЬхДЪЃЈobject wordsЃЉБЛХХГ§дкЕМКНбЕСЗжЎЭтЃЌЖјЧвНіГіЯждкЪЖБ№ШЮЮёЕФбЕСЗжаЃЌзїЮЊаТЕФИХФюЁЃNWNavRec
БЃжЄаТДЪВЛЛсГіЯждкЮЪЬтжаЃЌЖјжЛФмГіЯждкД№АИжаЃЛNWNav дђВЛГіЯждкД№АИжаЁЃЮвУЧЫцЛњХХГ§СЫ10%ЕФЮяЬхДЪЁЃ
ЮвУЧЕФПђМмдкВЛШнЕФбЕСЗЛЗОГЯТЖМгаЯрЭЌЕФГЌВЮЪ§ЁЃдкВтЪджаЃЌЮвУЧАбСєДцЃЈ held-outЃЉзлКЯЮя/ДЪгя
РЛиЕНУќСюжаЃЈР§ШчЃЌБъзМЕФЬѕМўЃЉЃЌВЂЧвВтЪдСЫ10k ЕФsessionЃЌгУгкЫФИіЕМКНЕФДЮМЖШЮЮёЃК nav_obj,
nav_col_obj, nav_nr_obj, and nav_bw_obj (Appendix
8.3).
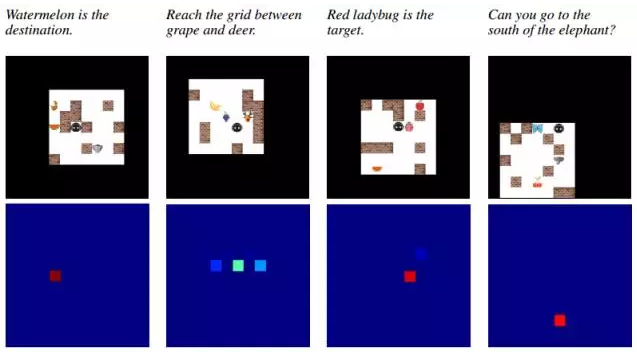
ЭМ4.ВЛЭЌsession жаattention ЕиЭМЕФР§згЁЃЖЅВПЃКЕМКНУќСюЁЃжаМфЃКЕБЯТЕФЛЗОГЭМЯёЁЃЕзВПЃКЯргІЕФattention
ЕиЭМЃЌгЩгябдФЃПщЪфГіЁЃашвЊжИГіЕФЪЧЃЌattention ЕиЭМЖМЪЧздЮвЮЊжааФЕФЃЌЕиЭМЕФжааФОЭЪЧжЧФмЬхЕФЖЈЮЛЁЃ

ЭМ5. гУСНИіР§згРДУшЪігябдЕФБрГЬЙ§ГЬЁЃПМТЧЕНЕБЯТЕФЛЗОГЭМЯёКЭЕМКНУќСюЃЌГЬађЭЈЙ§Ш§ИіВНжшЩњГЩвЛИіattention
mapЁЃ
дкУПвЛИіВНжшжаЃЌГЬађЛсЙизЂВЛЭЌЕФОфзгжаЕФВЛЭЌВПЗжЁЃДЪгяЕФattention ЭЈЙ§ВЪЩЋЯпЬѕНјааПЩЪгЛЏЃЌЦфжаЃЌдНССЕФВПЗжДњБэИќЖрЕФattentionЁЃдкзѓБпЃЌУПвЛИіВЪЩЋЯпЬѕДњБэЕФЯргІЕФattention
ЕиЭМКЭЕБЯТЕФЛЗОГЃЌвдМАДЫЧАДЂДцЕФвЛИіЃЈЭМ2 гвЃЉЁЃзюКѓЕФattentionЕиЭМБЛгУзїГЬађЕФЪфГіЁЃ
ЭМ6ЃКbypassing long wallsЕФР§згЁЃдкУПвЛИіЭЈЕРжаЃЌжЛгаШ§ИіЙиМќЕФВНжшЕУЕНСЫеЙЪОЁЃ
ЮвУЧМЦЫуСЫГЩЙІТЪЃЌЦфжаГЩЙІжИЕФЪЧжЧФмЬхвЊдкУПвЛИіsessionЙцЖЈЕФЪБМфФкЕжДяФПБъЖЈЮЛЁЃЭМ3a еЙЪОСЫбЕСЗЕФЛиБЈЧњЯпЃЌБэ1a
АќКЌСЫГЩЙІТЪЁЃЧњЯпжЎМфБЫДЫКмНгНќЃЌетКЭЦкД§ЕФвЛжТЃЌвђЮЊжИСюЃЈcommandsЃЉ10%ЕФМѕЩйМИКѕВЛЛсИФБфбЇЯАЕФФбЖШЁЃЮвУЧдкЫљгаЕФЛЗОГЯТЖМЛёЕУСЫМИКѕЯрЭЌЕФГЩЙІТЪЃЌВЂЧвЛёЕУСЫИпЕФzero-shot
ГЩЙІТЪЁЃNWNavRec ЕФНсЙћЯдЪОЃЌЫфШЛвЛаЉаТЕФЖдЯѓИХФюЪЧДгвЛИіЭъШЋВЛЭЌЕФЮЪЬтжаНјаабЇЯАЕФЃЌЕЋЪЧЫќУЧвВФмЙЛдкВЛашвЊШЮКЮФЃаЭбЕСЗКЭЕїВЮЕФЧуЯђЯТЃЌдкЕМКНетвЛЗНУцНјааВтЪдЁЃ
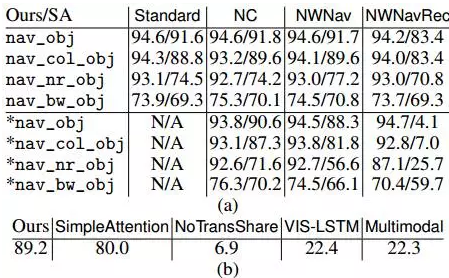
Бэ1ЃКГЩЙІТЪЃЈ%ЃЉЃЌЃЈaЃЉЮвУЧЕФПђМмКЭSimpleAttentionЃЈSAЃЉдкВЛЭЌбЕСЗУќСюЬѕМўЃЈСаЃЉЯТЕФЫФИізгШЮЮёЕФЗжНтТЪЁЃзюКѓЫФааЯдЪОАќКЌВтЪдsessionЃЌАќКЌбЕСЗжаУЛгаПДЕНЕФУќСюЁЃ
ЃЈbЃЉБъзМУќСюЬѕМўЯТЫљгаЗНЗЈЕФзмЬхГЩЙІТЪЁЃ
НсТл
БОЮФеЙЪОСЫащФтжЧФмЬхЕФвЛИіЖЫЕНЖЫЕФзщКЯПђМмЃЌФмЙЛНЋвббЇЛсЕФММФмЭЦЙуЕНаТЕФИХФюЃЌЖјЮоашНЈФЃдйбЕСЗЛђЮЂЕїЁЃетжжЭЦЙуФмСІЪЧЭЈЙ§жиаТРћгУдкЦфЫћШЮЮёжабЇЕНЕФЃЌВЂгЩздШЛгябдБрТыЕФжЊЪЖЪЕЯжЕФЁЃЭЈЙ§вдВЛЭЌЕФЗНЪНзщКЯДЪЛуЃЌжЧФмЬхФмЙЛгІЖдаТЕФШЮЮёЃЌЭЌЪБРћгУЯжгаЕФжЊЪЖЁЃетжжФмСІЖдгкПьЫйбЇЯАКЭИќКУЕиЗКЛЏжСЙиживЊЁЃЮвУЧдкПђМмЪЕМЪжаЗДгГСЫетаЉживЊЙлЕуЃЌВЂНЋЦфгІгУгкОпЬхЕФР§згЃКдк
XWORLD жажДаа zero-shot ЕМКНЁЃ
ЮвУЧЕФПђМмжЛЪЧвЛИіПЩФмЕФЪЕЯжЁЃПђМмЕФвЛаЉзщМўШдДцдкИФНјЕФПеМфЁЃЮвУЧЕФжїеХВЂВЛЪЧвЛИіжЧФмЬхБиаыЯёТлЮФжаеЙЯжЕФФЧбљОпгааФжЧФЃаЭЃЈmental
modelЃЉЃЌЕЋЪЧБиаыОпгадкЕк1НкКЭЕк4НкЫљЬжТлЕФМИИіЙиМќЪєадЁЃФПЧАЃЌжЧФмЬхЛЙжЛЪЧдк 2D ЛЗОГжаНјааСЫЬНЫїЁЃЮДРДЃЌЮвУЧМЦЛЎНЋИУжЧФмЬхЗХЕНР§Шч
Malmo [Johnson et alЁЃЃЌ2016]ФЧбљЕФ 3D ЛЗОГжаЁЃетНЋЛсЬсГівЛаЉаТЕФЬєеНЃЌР§ШчЃЌЪгОѕИажЊКЭМИКЮБфЛЛНЋИќМгФбвдФЃФтЁЃЮвУЧЯЃЭћФПЧАЕФПђМмЮЊШчКЮдк
3D ЛЗОГжабЕСЗРрЫЦЕФжЧФмЬхЬсЙЉвЛаЉГѕВНЕФЫМПМЁЃ |









