| ЧАбд
ГжајМЏГЩЪЧМЋЯоБрГЬЪЎЖўЪЕМљжЎвЛЃЈ1999ФъKent BeckБраДЕФЁЖНтЮіМЋЯоБрГЬЁЗЃЉЃЌзюГѕБЛЪЙгУМЋЯоБрГЬЗНЗЈЕФПЊЗЂШЫдБЫљЭЦХѕЃЌВЂдкЙ§ШЅЕФМИФъжаЕУЕНЙуЗКгІгУЃЌГЩЮЊвЕНчЙуЮЊШЫжЊЕФШэМўПЊЗЂЪЕМљЁЃИУЪЕМљгУгкНтОіШэМўПЊЗЂЙ§ГЬжавЛИіОпЬхЧвживЊЕФЮЪЬтЃЌМДЁАШЗБЃЕБФГИіПЊЗЂШЫдБЭъГЩаТЕФЙІФмЛђаоИФДњТыКѓЃЌећИіШэМўШдОЩФме§ГЃЙЄзїЁЃЁБ
ШЛЖјЃЌГжајМЏГЩВЂЗЧЯёДѓЖрЪ§ШЫЯыЯёЕФФЧбљЃЌЪзДЮВПЪ№КУГжајМЏГЩЛЗОГКѓОЭДѓЙІИцГЩЃЌвЛРЭгРвнСЫЁЃЧЁЧЁЯрЗДЃЌЫќгыФуЯюФПжаЕФЦфЫќВњЦЗДњТывЛбљЃЌашвЊИФНјгыжиЙЙЃЌЗёдђЃЌОЭЛсЪЙФуНјШывЛжжЁАГжајФжаФЁБЕФзДЬЌЃЌЩѕжСПЩФмШУФуОѕЕУетМўЪТИљБОВЛгІИУзіЃЌШчКЮНтОіетвЛЮЪЬтФиЃПЖдЁАГжајМЏГЩЁБгІгУЁАRetrospectiveЁБКЭЁАжиЙЙЁБЁЃБОЮФНЋНсКЯCruiseЭХЖгвЛФъЖрЕФЪЕМЪРњГЬЃЌНВЪіГжајМЏГЩЪЕМљдкШэМўПЊЗЂЙ§ГЬжаЕФбнНјЁЃ
гбЧщЬсЪОЃКЧыЖСепдкдФЖСБОЮФЪБЃЌзЂжиЮФжаЫљЪіЕФЫМПМЙ§ГЬгыЁАГжајМЏГЩЁБЕФжиЙЙЗНЪНЃЌЖјЗЧВњЦЗБОЩэЁЃ
ЛљБОГжајМЏГЩЁЊЁЊЭђРяГЄеїЕквЛВН
ЪЕМЪЮЪЬтЃКЮвУЧашвЊвЛИіГжајМЏГЩЛЗОГ
ЮЊЪВУДвЊзіГжајМЏГЩВЛдкБОЮФЬжТлжЎФкЁЃ
РэТлЛљДЁ
ГжајМЏГЩЛљгкетбљвЛИіМйЩшЃКШчЙћСНДЮДњТыМЏГЩЕФМфИєЪБМфдНГЄЃЌзюжеМЏГЩЪБЭДПрЕФОРњОЭЛсдНЖрЁЃЖјЦфФПБъгаСНИіЃКвЛЪЧЁАЦЕЗБМЏГЩЁБЃЌЖўЪЧЁАЗДгГДњТыжЪСПЁБЁЃЮЊСЫзіЕНЁА
ЦЕЗБМЏГЩЁБЃЌОЭвЊЧѓШЮКЮПЊЗЂШЫдБдкУПДЮЯђжабыДњТыПтЬсНЛДњТыЪБЃЌОЭНЋЫљгаДњТыНјааБрвыЃЌДђАќЃЌВПЪ№ЃЌвдШЗБЃФмЙЛВњЩњНЛИЖЮяЁЃШЛЖјЃЌЁАЦЕЗБМЏГЩЁБНіНіжЄУїСЫУПДЮЬсНЛЪЧЗёПЩвдЕУЕННЛИЖЮяЃЌЖјЮвУЧеце§ашвЊжЊЕРЕФЪЧЁАетИіНЛИЖЮяЕФжЪСПШчКЮЁБЁЃШчЙћНЛИЖЮягаЮЪЬтЃЌв§Ц№ЮЪЬтЕФДњТыдђвЊУДБЛЛиЙіЃЌвЊУДБЛаое§ЁЃЕБШЛЃЌетбљЕФШЮЮёвВПЩвдЭЈЙ§ЪжЙЄРДЭъГЩЃЌЕЋЪжЙЄЙЄзїЕФЬиЕуОЭЪЧвзГіДэЧвКФЪБЃЌЫљвдашвЊНЋЦфздЖЏЛЏЁЃЮЊСЫзіКУЁАГжајМЏГЩЪЕМљЁБЃЌаДвЛИіздЖЏЛЏЙЙНЈНХБОРДздЖЏЙЙНЈВЂдЫаавЛаЉздЖЏЛЏВтЪдЬзМўЛЙЪЧБивЊЕФЁЃетжжДЋЭГЕФГжајМЏГЩЗНЪНГЃБЛЙЬЛЏгкПЊЗЂЛЗНкЃЌМДЃКПЊЗЂШЫдБАВзАвЛИізЈУХЕФГжајМЏГЩЗўЮёЦїРДздЖЏЛЏдЫааетаЉЕЅдЊВтЪдЃЌШЛКѓЭЈЙ§ИїжжИїбљздЖЏЩњГЩЕФВтЪдНсЙћЗжЮіДњТыЕФжЪСПЃЌетвВЪЧCruiseControlЕЎЩњЕФдвђЁЃ
НтОіЗНАИ
зюГѕЃЌЮвУЧЕФДњТыВЂВЛЖрЃЌздЖЏЛЏНХБОБШНЯМђЕЅЃЌдквЛЬЈЛњЦїЩЯдЫааЫљгаЕФВтЪдвВНіашвЊМИЗжжгЃЌИУЙЙНЈЬзМўЕФдЫааЫГађЪЧЃКCheckStyle
-> Compile -> UnitTest -> FunctionTest ->
ReportЁЃЪОвтШчЯТЃК
<project
name="Cruise" default="all"
basedir=".">
<target
name="all" depends="checkStyle,
Compile, UnitTest,FunctionTest, Report"/>
<target name="checkStyle">
....
</target>
<target name="Compile"
>
...
</target>
<target name="UnitTest" depends="Compile">
...
</target>
<target name="FunctionTest"
depends="Compile">
...
</target>
<target name="Report" depends="FunctionTest">
...
</target>
</project> |
етвВЪЧДѓВПЗжШэМўЭХЖгНјааГжајМЏГЩЕФЦ№ЕуЁЃ
ФПЧАЃЌгаКмЖржжГжајМЏГЩЙЄОпЃЌЦфжаВЛЗІПЊдДВњЦЗЃЌШчCruiseControlМвзхЁЃЯюФПвСЪМЃЌЮвУЧЪЙгУCruiseControlНЈСЂСЫздМКЕФГжајМЏГЩЗўЮёЦїЃЌећИіЯюФПЕФГжајМЏГЩЛљДЁНсЙЙШчЭМЫљЪОЃК
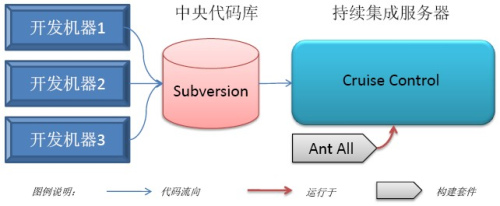
ЭМ1 ЛљДЁГжајМЏГЩФЃЪН
зЂЃКЕУЕНПьЫйЗДРЁЪЧПЊЗЂКУВњЦЗЕФЙиМќЁЃвђДЫЃЌЮвУЧздМКОЭзіСЫCruiseЕФЕквЛИігУЛЇЃЌЪзЯШНтОіздМКЕФГжајМЏГЩашЧѓЁЃЯюФППЊЪМКѓНіМИжмЃЌЮвУЧЕФВњЦЗCruiseвбОЛљБОТњзуздЩэЭХЖгГжајМЏГЩЕФашЧѓЃЌвђДЫЃЌЮвУЧОЭНЋCruiseControlЬцЛЛГЩCruiseЃЌЕЋГжајМЏГЩЛљБОНсЙЙВЂУЛгаБфЛЏЁЃ
НзЖЮЛЏГжајМЏГЩ ЁЊЁЊ ЦНКтЕФвеЪѕ
ЪЕМЪЮЪЬтЃКВтЪддНРДдНТ§ЃЌПЊЗЂШЫдБЕШЕУВЛФЭЗГЁЃ
ЫцзХЪБМфЕФЭЦвЦЃЌCruiseУПДЮзіГжајМЏГЩЕФдЫааЪБМфКмПьОЭГЌЙ§СЫ15ЗжжгЃЈПЊЗЂШЫдБФмЙЛШЬЪмЕФзюДѓЯоЖШЃЉЁЃШЛЖјЃЌЮЊСЫБЃжЄCruiseжЇГжДѓЖрЪ§фЏРРЦїЃЌЮвУЧЛЙДђЫудіМгCruiseдЫаагкВЛЭЌВйзїЯЕЭГМАВЛЭЌфЏРРЦїЕФЙІФмВтЪдЁЃ
РэТлЛљДЁ
вЛАуРДЫЕЃЌВтЪдДњТыдНЖрЃЌдНФмЙЛе§ШЗЗДгГДњТыЕФжЪСПЃлЧАЬсЃКФуаДЕФВтЪдЪЧгавтвхЕФ:)ЃнЁЃЫљвддкећИіЩњУќжмЦкжаЃЌДѓМвЖМЪдЭМдіМгИќЖрЕФВтЪдДњТыЁЃШЛЖјЃЌдНЖрЕФВтЪдДњТывВвтЮЖзХИќГЄЕФдЫааЪБМфЃЌИќТ§ЕФЗДРЁЫйЖШЁЃвђДЫЃЌЮвУЧВЛЕУВЛдкЁАЗДРЁЪБМфЁБгыЁАХаЖЯжЪСПзМШЗадЁБСНепжЎМфевЕНвЛжжЦНКтЃЌЖјЁАНзЖЮЛЏГжајМЏГЩЁБ
ОЭгаСЫгУЮфжЎЕиЁЃ
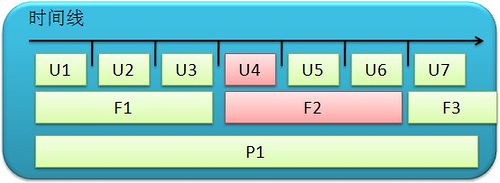
ЫљЮНЕФЁАНзЖЮЛЏГжајМЏГЩЁБЪЧжИЮЊВЛЭЌЕФЙЙНЈВтЪдЬзМўЃЈвдЯТГЦЙЙНЈМЦЛЎЃЉНЈСЂВЛЭЌЕФГжајМЏГЩбЛЗжмЦкЃЌгЩгкЕЅдЊВтЪддЫааЪБМфЖЬЃЌЗДРЁНЯПьЃЌЫљвдПЩвдЦЕЗБНјааЃЌЖјЙІФмВтЪдЁЂадФмВтЪдЕФЪБМфБШНЯГЄЃЌеМгУзЪдДБШНЯЖрЃЌБШНЯАКЙѓЃЌЫљвдЪЪЕБМѕЩйМЏГЩДЮЪ§ЃЌЕЋвЛЖЈвЊБЃжЄЦфжмЦкаддЫааЁЃвђДЫЃЌЮвУЧЕФГжајМЏГЩЗНАИКмздШЛЕиЗжГЩСЫЖрИіЙЙНЈМЦЛЎЃКПьЫйЙЙНЈМЦЛЎШУПЊЗЂШЫдБОЁПЩФмПьЕиЕУЕНЗДРЁЃЌДЫЪБЮвУЧЮўЩќСЫзМШЗадРДЛЛШЁЪБМфЁЃЕЋЕБФуЕУЕНСЫПьЫйЗДРЁвдКѓЃЌдйЛЈЖрвЛЕуЖљЪБМфДгЦфЫќЙЙНЈМЦЛЎжаЕУЕНИќЯъЯИЕФЗДРЁЁЃетбљвЛРДЃЌЖдгкЭЌвЛИіЯюФПЃЌФугаЖрИіЙЙНЈМЦЛЎЃЌУПИіЖдгІвЛжжЙЙНЈРраЭЃЈЕЅдЊВтЪдЃЌЙІФмВтЪдЁЂЙІФмВтЪдЕШЃЉЃЌдНППКѓЕФЙЙНЈМЦЛЎдкдЫааЪБашвЊЕФЪБМфОЭдНГЄЁЃШчЯТЭМЃЌ
ЕЅдЊВтЪдЙЙНЈМЦЛЎдЫааСЫЖрДЮЃЌ U1,U2...U7ЃЌЦфжаU4ЪЇАмСЫЁЃЙІФмВтЪдЙЙНЈМЦЛЎЪБМфНЯГЄЃЌдкИУЪБМфЖЮФкНідЫааСНДЮЃЌF1КЭF2(ЪЇАм)ЃЌЖјадФмВтЪдЙЙНЈМЦЛЎP1ЪБМфзюГЄЁЃећИіГжајМЏГЩЯЕЭГгЩЖрИіЛњЦїзщГЩЃЌАќРЈвЛИіжааФЗўЮёЦїЃЈServerЃЉКЭЖрЬЈЙЄзїеОЃЈAgentЃЉЃЌУПИіЙЙНЈМЦЛЎЖМдквЛЬЈЙЄзїеОЃЈagentЃЉЖРСЂжДааЃЌвдБуЮоЯрЛЅгАЯьЁЃ
ЭМ2 НзЖЮЪНВЂааЙЙНЈЭМНт
НтОіЗНАИ
гЩгкCruiseБОЩэвбОжЇГжетжжГжајМЏГЩФЃЪНЃЌЫљвдЮвУЧЕФГжајМЏГЩЛљБОПђМмвВбнБфГЩЯТЭМЃК
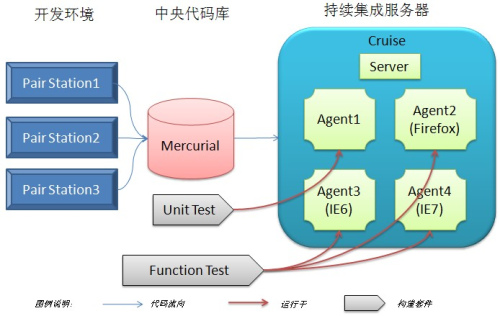
ЭМ3 НзЖЮЪНГжајМЏГЩФЃЪНЭМНт
жааФЗўЮёЦї(Server)ЕФд№ШЮЪЧЃЈ1ЃЉМьВщжабыДњТыПтЕФДњТыЪЧЗёЗЂЩњБфЛЏЃЌЃЈ2ЃЉШчЙћДњТыЗЂЩњСЫБфЛЏЃЌНЋЯргІЕФЙЙНЈРраЭЗжХфЕНИїздЕФЙЄзїеОЃЈAgentЃЉЩЯдЫааЃЛЃЈ3ЃЉжааФВжПтЃЌБЃДцЫљгааХЯЂЁЃЩЯЭМжаЃЌЕЅдЊВтЪд(Unit
Test)ЙЙНЈРраЭдЫаагкЙЄзїеОAgent1ЩЯЃЌУПДЮжДааашвЊ15ЗжжгзѓгвЃЌЖјЙІФмВтЪд(Function
Test)ЙЙНЈРраЭЗжБ№дЫаагкШ§ИіЙЄзїеОЃЈAgent2,Agent3КЭAgent4ЃЉЩЯЃЌУПДЮжДаадМ30ЗжжгЃЈЦфжаAgent1ЮЊDebianВйзїЯЕЭГЃЌAgent2ЪЧUbuntu8.04ВйзїЯЕЭГЃЌАВзАгаFirefox2.0ЃЌAgent3ЪЧWindowXPЃЋIE6ЃЌЖјAgent4ЪЧ
Windows 2003 + IE7ЃЉЁЃ
ЯИаФЕФЖСепЛсЗЂЯжЃЌжабыДњТыПтДгSubversionБфГЩСЫMercurialЃЌЮвЕФЭЌЪТКњПдкЁЖЮЊЪВУДЮвУЧвЊЗХЦњSubversionЁЗвЛЮФжаНВЪіСЫдЕгЩЃЌЦфИљБОЪевцОЭЪЧЬсИпСЫCruiseЩњВњаЇТЪЁЃЙЙНЈМЦЛЎЃКЪЧИљОнЙІФмЛЎЗжЕФздЖЏЙЙНЈбЛЗжмЦкЃЌгЩвЛЯЕСаЕФВНжшзщГЩЁЃЯТЭМЮЊШ§жжВЛЭЌЕФЙЙНЈМЦЛЎЃК

ЭМ4 ВЛЭЌРраЭЕФЙЙНЈМЦЛЎ
РћБзЗжЮі
вцДІЃКднЪБНтОіЗДРЁЪБМфГЄЕФЮЪЬтЁЃ
ШБЕуЃКШдДцдкРЫЗбЃЌЬсНЛЦЕЗБЪБЃЌЮЪЬтЖЈЮЛгаЪБНЯРЇФбЁЃ
дкжДааУПИіЙЙНЈМЦЛЎЧАЃЌЖМашвЊДгжабыЗўЮёЦїЩЯМьГіДњТыЁЃВЛЭЌЕФЙЙНЈМЦЛЎжаЃЌгаКмЖрВНжшЖМЪЧжиИДЕФЃЌР§ШчЭМ4ЫљЪОЕФБрвыгыДђАќЙЄзїЁЃЕБДњТыПтБШНЯаЁЪБЃЌетВЂВЛЪЧвЛИіДѓЮЪЬтЁЃШЛЖјЃЌЖдгкДЫЪБЕФCruiseРДЫЕЃЌОЭвбОЪЧЁАРЫЗбЁБСЫЁЃдкЭМ2жаЃЌЕЅдЊВтЪдU4вбОвдЪЇАмЖјИцжеЃЌПЩЙІФмВтЪдЛЙЪЧдкСэЭтШ§ЬЈЙЄзїеОЃЈAgentЃЉЩЯдЫаазХЃЌвЛжБеМгУзХЛњЦїЃЌжБжСНсЪјЁЃЯыЯёвЛЯТЃЌШчЙћЙЙНЈМЦЛЎЕФЪ§СПЖргкЙЄзїеОЃЈAgentЃЉЕФИіЪ§ЪБЃЌетжжзЪдДЕФРЫЗбгжЪЧЖрУДбЯжиФиЃП
СэЭтЃЌШчЭМ2ЫљЪОЃЌгЩгкЕЅдЊВтЪддЫааНЯПьЃЌЫљвдЙІФмВтЪдF2жаАќКЌЖрИіЕЅдЊВтЪдЃЈU2,U3,U4ЃЉЫљИВИЧЕФДњТыБфЛЏЁЃШчЙћF2ЪЇАмЃЌКмФбХаЖЯЪЧФФДЮCheckinЪЙF2ЪЇАмЕФЃЌвђЮЊЧАУцвбОГЩЙІНсЪјЕФU2КЭU3вВПЩФмЪЙF2ЪЇАмЁЃ
Й§ГЬЛЏГжајМЏГЩ ЁЊЁЊ ЯћГ§РЫЗб
ЪЕМЪЮЪЬт
ПЊЪМЪЙгУНзЖЮЪНГжајМЏГЩЪБЃЌгЩгкВЛгУИФЬЋЖрЕФЙЙНЈНХБОЃЌЖјЧввВГѕВНДяЕНСЫФПЕФЁЃПЩЪЧЫцзХЪБМфЕФЭЦвЦЃЌДњТыдНРДдНЖрЃЌТпМдНРДдНИДдгЃЌЮЪЬтЖЈЮЛСюЮвУЧЭЗЭДЃЌЖјЧвУПИіЙЙНЈМЦЛЎЖМвЊжиаТБрвыКЭДђАќЕШжиИДадЙЄзївВШУЭХЖгВЛЫЌЁЃ
РэТлЛљДЁ
Й§ГЬЛЏдђЪЧНЋУПвЛИіВНжшЕЅдЊЛЏЃЌВЂЫГађжДааЁЃШчЕквЛИіЕЅдЊЪЧCheckStyleЃЌБрвыМАЕЅдЊВтЪдЃЌЕкЖўИіЕЅдЊЪЧДђАќЩњГЩШэМўЃЌЕкШ§ИіЕЅдЊЪЧЁАВПЪ№ВЂНјааЙІФмВтЪдЁБЃЌЕкШ§ИіЕЅдЊЪЧЁАадФмВтЪдЁБЁЃетжжЙ§ГЬЛЏЗжНтвђШЅГ§СЫжиИДВНжшЃЌЫљвдИќгааЇТЪЃЌЖјЧвУПДЮжДааЪБЃЌДњТыПЩвдЫГађОРњвЛЯЕСаЕФВтЪдЁЃ
ЭМ5 Й§ГЬЛЏЙЙНЈЭМНт
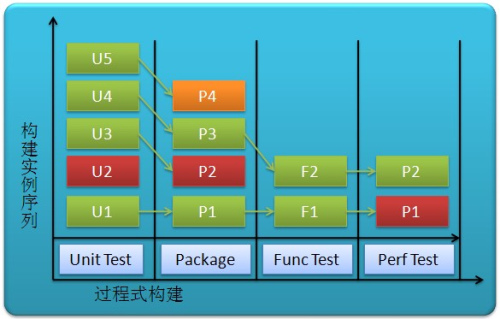
ИУРраЭМЏГЩЕФЙиМќдкгкШУЫљгаетаЉЗжРыЕФЕЅдЊПЩвдЫГађжДааЁЃЪзЯШЃЌБрвыЙ§ГЬБЛЕїгУЃЌвЛЕЉБрвыЕЅдЊГЩЙІНсЪјЃЌЯТвЛЕЅдЊЃЈПьЫйВтЪдЃЉМДПЊЪМЁЃе§ЪЧДЫПЬЃЌЮвУЧгіЕНСЫЕквЛИіИДдгадЁЃгЩгкЕкЖўИіЕЅдЊЃЈШчПьЫйВтЪдЃЉВЂВЛЪЧвЛИіЭъећЕФЙ§ГЬЃЌЫљвдВЂВЛФмгУЫќздМКВњЩњЕФВњЮяРДВтЪдЁЃЖјетвЛЕуЧЁЧЁЪЧЙ§ГЬЛЏГжајМЏГЩЕФЕФЙиМќЃКНЋЙЙНЈгыВтЪдЗжРывдНкЪЁЪБМфЃЌетвВЪЧЦфгыНзЖЮадМЏГЩЕФВЛЭЌжЎДІЁЃгЩгкКѓајЕЅдЊВЂВЛВњЩњВтЪдЫљашвЊЕФВњЮяЃЌОЭвЊДгЭтВПЛёШЁЃЌЖјетаЉВњЮяе§КУВњЩњгкЧАУцЕФЕЅдЊЁЃвђДЫЃЌдЫааЧАУцЕЅдЊЪБЃЌЫќвЊНЋетаЉВњЮяЗХдквЛИівбжЊЮЛжУЃЌЖјКѓајЕФЕЅдЊДгетИівбжЊЮЛжУФУЕНВњЮяЁЃЭМ5ЫљЪОЃЌU4ГЩЙІКѓЃЌP3ДгU4ДІФУЕНДњТыНјааДђАќЃЛP3
НсЪјКѓЃЌF2ДгP3ДІФУЕННЛИЖЮяНјааВПЪ№КЭЙІФмВтЪдЃЌF2ГЩЙІКѓЃЌP2дйПЊЪМдЫааЁЃ
РћБзЗжЮі
гХЕуЃКЯћГ§КЭжиИДЙЄзїЃЌЬсЙЉСЫГжајЕФаХЯЂЗДРЁЃЌЗДгГСЫећИіЕФЙ§ГЬЁЃ
ЧАвЛИіЙЙНЈМЦЛЎU2ЪЇАмКѓЃЌКѓајЕФЙЙНЈМЦЛЎP2вВВЛЛсДгU2жаФУШЁВњЮяРДдЫааЃЌЖјЪЧЕШД§ФУU3ЕФНсЙћРДдЫааЃЌДгЖјвВгааЇЕФРћгУЕФзЪдДЁЃ
ШБЕуЃКЭХЖгздМКЙмРэЕФФкШнЖрвЛаЉЃЌИДдгвЛаЉЁЃ
гЩгкИїИіЙЙНЈМЦЛЎжЎМфЪЧИїздЖРСЂЕФЃЌЫљвдЫќУЧжЎМфЕФвРРЕЙиЯЕгЩЫќУЧжЎМфДЋЕнЕФВЮЪ§БэЯжЁЃЕБФњЯызЗзйФГИіКѓајЙЙНЈМЦЛЎЮЊЪВУДЪЇАмЪБЃЌФуБиаыевЕНетИіВЮЪ§ЁЃПЩетжжЙ§ГЬЛЏГжајМЏГЩВЂУЛгаЬсЙЉвЛИіФкдкЙІФмРДЭъГЩЫќЃЌЫљвдФуБиаыздМКдйЖрзівЛЕуЖљЙЄзїЃЌЖјЧвЧАКѓЙЙНЈЕЅдЊжЎМфЕФВњЮяДЋЕнвВвЊздМКРДЭъГЩЁЃВњЮяДЋЕнПДЩЯШЅвЊИДдгвЛЕуЖљЁЃвђЮЊзюНќвЛДЮЙЙНЈЕФНсЙћКмШнвзНЋЧАвЛДЮЕФНсЙћИВИЧЕєЁЃНтОіетвЛЮЪЬтЕФвЛжжЗНЗЈЪЧНЋУПДЮЙЙНЈЕФНсЙћЗжПЊДцЗХЃЌЖјКѓајЕФЕЅдЊвЊжЊЕРдкФФРяПЩвдевЕНЫќУЧЫљашЕФЮФМўЁЃРћгУЙЙНЈБрКХзіЮЊФПТМУћРДБЃДцЙЙНЈНсЙћЪБЃЌКѓајЕФЕЅдЊОЭашвЊжЊЕРетИіЙЙНЈБрКХЃЌвдБуевЕНЫќЫљашвЊЕФЮФМўЁЃОЁЙметВЛФбзіЕНЃЌЕЋЛЙЪЧашвЊзівЛЕуЖљЙЄзїВХФмзіЕНЕФЁЃ
СэЭтЃЌгЩгкетжжЗНЪНашвЊзМБИВњЦЗЕФжабыДцДЂПеМфЃЌНЈСЂУќУћЙцдђЃЌаоИФЮвУЧЕФЙЙНЈДњТыЃЌвдБудкИїЙ§ГЬжЎМфДЋВЮЪ§ЁЃСэЭтЃЌетжжФЃЪНЛЙЪЧВЛФмДгИљБОНтОіЮЪЬтЖЈЮЛетИіФбЬтЁЃ
ЭХЖгНсТл
гЩгкВЩгУетжжЗНЪНЕФЙмРэИДдгадНЯИпЃЌдкЮвУЧЕФЛЗОГжаЃЌЧБдкЕФЪБМфЯћКФвВВЛЩйЃЌЫљвдЮвУЧЗХЦњСЫетжжМЏГЩЗНЪНЁЃ
ЙмЕРЪНГжајМЏГЩЁЊЁЊЦѓвЕМЖГжајМЏГЩЕФНтОіЗНАИ
ЪЕМЪЮЪЬт
НзЖЮЛЏГжајМЏГЩжиИДШЮЮёЖрЃЌЖјЙ§ГЬЛЏМЏГЩЕФЙмРэИДдгадЬЋИпСЫЃЌШЮКЮЙ§ГЬЛЏЩЯЕФБфЛЏЖМвЊаоИФвбОаДКУЕФНХБОЃЌЖјетаЉНХБОЮЌЛЄБШНЯРЇФбЁЃМШШЛвдЩЯСНжжФЃЪНЖМВЛСщСЫЃЌФЧОЭдйЯыБ№ЕФАьЗЈАЩЁЃ
РэТлЛљДЁ
ЙмЕРЪНГжајМЏГЩаЮЪНЩЯгыЙ§ГЬЛЏГжајМЏГЩЯрРрЫЦЃЌЕЋШДдкИХФюЩЯгаЯджјВЛЭЌЁЃдкЙмЕРЪНГжајМЏГЩжаЃЌЫљгаЕФЙ§ГЬЕЅдЊЖМдЫаадкЭЌвЛЙмЕРЕФЩЯЯТЮФжаЃЌМДИїЕЅдЊЫљЪЙгУЕФдВФСЯЖМЪЧЭъГЩЯрЭЌЕФЃЌМДДњТыЛљЯпЯрЭЌЁЃЕБГжајМЏГЩЗўЮёЦїЗЂЯжгааТЕФДњТыЪБЃЌЛсДДНЈаТЕФвЛИіЙмЕРЃЌЫљгаЕФЙ§ГЬЕЅдЊЖМдкетвЛИіЙмЕРжадЫааЁЃЖјУПИіЕЅдЊВњЩњЕФВњЮявВдкИУЙмЕРжагааЇЁЃШчЭМЫљЪОЃК

ЭМ6 ЙмЕРЛЏГжајМЏГЩ
РћБзЗжЮі
ЙмЕРЪНГжајМЏГЩзлКЯСЫНзЖЮЛЏгыЙ§ГЬЛЏЕФгХЕуЃЌЖјДјРДЕФИДдгадШДВЛгУФуВйаФЃЌвђЮЊCruiseЮЊФуЙмРэетвЛЧаЁЃ
вВОЭЪЧЫЕЃЌФуКмШнвзОЭеЦЮеЃЌФФаЉВњЦЗДњТыЪЧдкФФИіЙмЕРжаЩњГЩЕФЃЌЪЧгЩФФаЉдВФСЯЃЈдДДњТыЃЉЩњГЩЕФЃЌЖјгыЦфЫќЙмЕРВњЩњЕФВњЦЗДњТыгаЪВУДВЛЭЌЁЃдкЙмЕРЪНжаЃЌУПДЮЙЙНЈЖМЛсЪдЭМДгЙмЕРЕФвЛЖЫзпЕНСэвЛЖЫЁЃвђДЫЃЌФуВЛЛсвХТЉШЮКЮвЛИіАцБОЕФГЩЙІВњЦЗДњТыЁЃ
НтОіЗНАИ
CruiseГжајМЏГЩРрЫЦгкЯТУцЕФГжајМЏГЩЙЙНЈЙмЕРЃК
<pipeline
name="Cruise">
<stage name="UnitTest">
<job name = "windows">
<artifacts>
<artifact src="testreport"
dest="report"/>
<artifact src="pkg" dest="package"/>
</artifacts>
<tasks>
<ant />
</tasks>
</job>
<job name="linux"/>
</stage>
<stage
name="FuncTest">
<job name = "windows"/>
<job name="linux"/>
</stage>
<stage
name="TwistTest">
<job name = "windows"/>
<job name="linux"/>
</stage>
<stage
name="Package">
<job name = "Solaris"/>
<job name="linux"/>
</stage>
</pipeline> |
ШчЭМ7ЫљЪОЃЌзюКѓвЛДЮЙЙНЈАцБОЃЈ1.2.128ЃЉДгЙмЕРЕФвЛЭЗГЩЙІзпЕНСЫСэвЛЭЗЃЌе§дкНјаазюКѓвЛВНЃЈВПЪ№ЕНЩњВњЛЗОГЃЌЛЦЩЋЗНПщДњБэе§дкдЫааЃЉЃЌАцБО
1.2.127ЪЇАмгкДђАќНЛИЖЮяЃЌЫфШЛЮвУЧШУАцБО1.2.126зпЕНСЫЙмЕРЕФОЁЭЗЃЌЕЋФњПЩФмзЂвтЕНетЪЧвЛИігаЯОДУЕФАцБОЃЈPackageгаЕуЮЪЬтЃЉЃЌЖјЧвБЛКмПьдк1.2.128жааоИДСЫЁЃЖјЦфЫќАцБОЖМгаЮЪЬтЖјЮДФмзпЕНЙмЕРЕФОЁЭЗЁЃ

ЭМ7 ЙЙНЈЙмЕРЭМНт
ВЂЗЂжДааЁЊЁЊЪБМфОЭЪЧН№ЧЎЃЌзЪдДвВЪЧН№ЧЎ
ЪЕМЪЮЪЬт
ОЁЙмЮвУЧНЋећИіГжајМЏГЩЙ§ГЬжаЫљашЭъГЩЕФЙЄзїИљОнОпЬхШЮЮёЗжГЩСЫКмЖрЖРСЂЕФВНжшЃЌВЂЙмЕРЛЏдЫааЃЌЕЋЪЧВЂЮДФмНтОіеце§ЕФЁАЪБМфдЫааГЌГЄЁБЮЪЬтЁЃвђЮЊЃЌЮвУЧЕФВтЪдДњТывбОДяЕНЯрЕБЪ§СПЃЌдЫаавЛДЮЫљгаЕФЕЅдЊВтЪдвЊдк40ЗжжгвдЩЯЃЌЖјдквЛЬЈЛњЦїЩЯдЫааЫљгаЙІФмВтЪдДѓдМашвЊ2аЁЪБвдЩЯЁЃЖјЧвПЩвддЄМћЕНЃЌетвЛЪБМфСПЛсПьЫйдіМгЁЃФЧУДЃЌвЊШчКЮНтОіетИіЮЪЬтФиЃПЕБШЛВЛПЩФмвђЮЊЪБМфГЄЖјВЛдіМгВтЪдЁЃ
РэТлЛљДЁ
НЋЭЌвЛРраЭЕФВтЪдЗжГЩМИзщЃЌЭЌЪБдЫаадкХфжУЯрЭЌЕФAgentЩЯЁЃетбљЃЌЫфШЛВЛФмМѕЩйзмЪБМфЃЌЕЋЪЧЭъГЩЫљгаЭЌРраЭВтЪдЫљашвЊЕФЪБМфжмЦкЛсЫѕЖЬЁЃ
НтОіЗНАИ
CruiseЭХЖгГЩдБРћгУвЕгрЪБМфДДНЈСЫвЛИіПЊдДЯюФПЃЌУћЮЊTest-Load-BalanceЃЌРћгУCruiseЕФЬиадЃЌИљОнCruiseжаJobЕФХфжУЃЌздЖЏНЋВтЪдЗжГЩЖрзщЃЌдЫаагкВЛЭЌЕФAgentжаЁЃЕБВтЪддЫааЪБМфЕНСЫЮоЗЈНгЪмЕФЪБКђЃЌжЛашвЊдк
CruiseЕФХфжУЮФМўжадіМгвЛИіJobЃЌЫќОЭЛсздЖЏИажЊетвЛБфЛЏЃЌНЋВтЪддйЖрЗжвЛЗнГіРДЁЃжЛвЊгазуЙЛЕФAgentЃЌФЧУДФуЕФВтЪдЪБМфвЛЖЈЛсЫѕЖЬЕН15ЗжжгвдФкЁЃФПЧАЃЌCruiseЕФЕЅдЊВтЪдБЛTest-load-BalanceздЖЏЕШЗжГЩЫФзщдЫаагкWindowsЃЌвдМАЮхзщдЫаагкLinuxЃЌЖјЙІФмВтЪдвВвЛбљБЛздЖЏЗжГЩЫФзщЃЌЗжБ№дЫаагкWindowsКЭLinuxЁЃФПЧАгУгк
CruiseГжајМЏГЩЛЗОГжаЕФЙЄзїеОЙВМЦ11ЬЈащФтЛњЃЌЪЙCruiseЕФЫљгаЕЅдЊВтЪдПЩвддк15ЗжжгФкЭъГЩЃЌЫљгаЕФЙІФмВтЪдПЩвддк35ЗжжгФкЭъГЩЁЃ
ЮвУЧЕФГжајМЏГЩЛљБОНсЙЙБфЮЊЃК
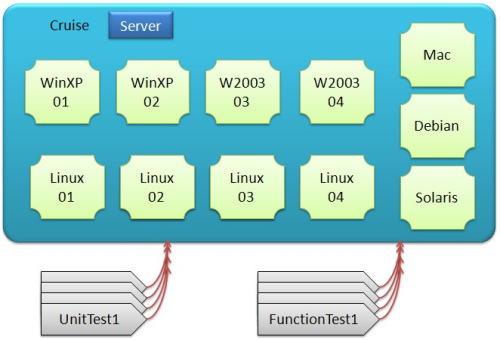
ЭМ8 Build Cloud
CruiseЭХЖгЕФГжајМЏГЩРрЫЦЯТУцЕФХфжУЮФМўЃК
<pipeline
name="Cruise">
<stage name="UnitTest">
<job name = "windows-01"/>
<job name = "windows-02"/>
<job name = "windows-03"/>
<job name = "windows-04"/>
<job name="linux-01"/>
<job name="linux-02"/>
<job name="linux-03"/>
<job name="linux-04"/>
</stage>
<stage
name="FuncTest">
<job name = "windows"/>
<job name="linux"/>
</stage>
<stage
name="TwistTest">
<job name = "windows-01"/>
<job name = "windows-02"/>
<job name = "windows-03"/>
<job name = "windows-04"/>
<job name="linux-01"/>
<job name="linux-02"/>
<job name="linux-03"/>
<job name="linux-04"/>
</stage>
<stage
name="Package">
<job name = "Solaris"/>
<job name="linux"/>
</stage>
<stage
name="UAT">
<job name = "deployUAT"/>
</stage>
<stage name="Production">
<job name = "deployProd"/>
</stage>
</pipeline>
|
РћБзЗжЮі
ЮвУЧвбЮоашЭЖШыЙ§ЖрЕФОЋСІдкГжајМЏГЩЛЗОГЩЯСЫЃЌГ§ЗЧЮвУЧЕФгВМўВЛзуЃЈПЩЯждкЕФгВМўГЩБОвЊБШШЫЙЄГЩБОЕЭЖрСЫЃЉЁЃвђЮЊCruise
ServerздЖЏЛсНЋЙЙНЈМЦЛЎЦНОљЗжГЩЖрзщЃЌВЂЗжХфЕНЯргІЕФЙЄзїеО(Agent)ЩЯдЫааЁЃШчЙћВтЪдДњТыНјвЛВНХђеЭЃЌЮвУЧжЛашвЊдкЯргІЕФВтЪдНзЖЮМгдіМг
JobЕФИіЪ§ЃЌдйПЫТЁГіМИЬЈащФтЛњШгЕНЮвУЧЕФAgent gridжаЁЃЖјетНіашКмЩйЕФШЫЙЄВйзїЃЌИљБОВЛБиаоИФЮвУЧЕФздЖЏЙЙНЈДњТыЁЃ
ИіШЫГжајМЏГЩЁЊЁЊзюДѓЛЏРћгУзЪдД
ЪЕМЪЮЪЬт
ВтЪддНРДдНЖрЃЌдЫааЪБМфдНРДдНГЄЁЃПЊЗЂШЫдБдкБОЕижДааЕЅдЊВтЪдЕФЪБКђЃЌПЊЗЂШЫдБОЭвЊПДзХЦСФЛЕШД§Т№ЃП
НтОіЗНАИ
дкPairStationЩЯАВзАвЛИіащФтЛњЃЌдкЦфЩЯНЈСЂздМКЕФДњТыВжПтЁЃашвЊдЫааВтЪдЪБЃЌАбPairStationЮяРэЛњЦїЕФДњТыЬсНЛЕНетИіащФтЛњЕФДњТыВжПтжаЃЌВЂШУЦфдЫааВтЪдЁЃШЛКѓЃЌМЬајдкPairStationЩЯаДДњТыЁЃШчЭМЫљЪОЃК

РћБзЗжЮі
вцДІЯдЖјвзМћЃЌНкЪЁЪБМфЃЌЬсИпПЊЗЂаЇТЪЁЃЭХЖгЃЈжСЩйИіШЫЃЉвЊЪЙгУЗжВМЪНАцБОПижЦЯЕЭГЁЃСэЭтЃЌгУгкПЊЗЂЕФЮяРэЛњадФмВЛФмЬЋВюЁЃЦфЪЕЃЌетвВЫуВЛЩЯДѓЮЪЬтЃЌвђЮЊдкФуПЊЗЂШэМўЪБЃЌЫМПМЕФЪБМфгІИУЖргкФуаДДњТыЕФЪБМфЁЃ
аЁНс
дкУєНнЭХЖгжаЃЌЮвУЧЫљвЊзіЕФжЛВЛЙ§ЪЧЃКВЛЖЯЕФЛиЙЫЁЂевГіЮЪЬтгыЦПОБЁЂВЛЖЯЕижиЙЙЁЃЭЈЙ§ВЛЖЯжиЙЙГжајМЏГЩЛљДЁНсЙЙвдМАздЖЏЛЏЙЙНЈНХБОЃЌЪЙЦфДяЕНЮвУЧЖдЁАЗДРЁЪБМфЁБКЭЁАХаЖЯжЪСПзМШЗадЁБЕФвЊЧѓЁЃ
СэЭтЃЌЮвУЧвбНЋЁАГжајМЏГЩЁБРЉеЙЕНећИіШэМўПЊЗЂжмЦкЃЌКИЧСЫГжајВПЪ№МАЗЂВМЁЃдкЩЯУцЕФХфжУЮФМўжаЃЌЯИаФЕФФуЛсЗЂЯжзюКѓЕФСНИіStageЗжБ№УћЮЊ
ЁАUATЁБКЭЁАProductionЁБЃЌЫќУЧвЛИігУгкВПЪ№аТАцБОЕНЮвУЧздМКЕФГжајМЏГЩЗўЮёЦїЃЌСэвЛИігУгкВПЪ№аТАцБОЕНвЛИіЙЋгУЕФГжајМЏГЩЗўЮёЦїЁЃВПЪ№
ЁЎUATЁЏЕФЦЕТЪЮЊСНЬьЕНвЛжмжЎМфЃЌЁЎProductionЁЏЕФЦЕТЪЮЊвЛжмЁЃетбљЃЌЮвУЧПЩвдЕУЕНПьЫйЗДРЁЃЌИФНјздМКЕФВњЦЗЃЌЭЌЪБЦфЫќЭХЖгПЩвдОЁдчЕиЪЙгУЮвУЧПЊЗЂЕФаТЙІФмЁЃ
ГжајМЏГЩВЂВЛЪЧвЛѕэЖјОЭЕФЙЄзїЃЌашвЊИљОнЭХЖгЕФЪЕМЪЧщПіРДЪЕЪЉЃЈЕЋетВЂВЛФмГЩЛсЁАЭЕРЕЁБЕФСэвЛИіЫЕЗЈЃЉЁЃНіЙмCruiseЭХЖгЕФГжајМЏГЩЩаЪєЁАМђЕЅЁБжЎСаЃЌЕЋВЂВЛФмЫЕУїИДдгЯюФПЮоЗЈзіГжајМЏГЩЁЃЫзгяЕРЃЌЁАУЛгазіВЛЕНЃЌжЛгаЯыВЛЕНЁБЁЃжЛвЊВЛЖЯЗДЫМгыжиЙЙЃЌвЛбљПЩвдЫЖЙћРлРлЁЃ
зЂЃКетаЉГжајМЏГЩЗНЪНдчгаГіДІЃЌР§Шч2004ФъЕФЁЖЭЈЙ§ЁАВњЮявРРЕЁБЪЕЯжЦѓвЕМЖГжајМЏГЩЁЗЃЌЖјCruiseЭХЖгНіЪЧгТгкЪЕМљепЃЌВЂНјаазХВЛЖЯЕФЫМПМКЭгХЛЏЁЃ
|








