| һ���ֲ�ʽ���㿪Դ���Hadoopʵ��
��SIP��Ŀ��ƵĹ����У��������Ӵ����־�ڿ�ʼʱ�Ϳ���ʹ������ֽ�Ķ��̴߳���ģʽ������ͳ�ƣ����Ҵ�ǰд�����¡�Tiger
Concurrent Practice --��־�������зֽ������ʵ�֡��������ᵽ����������ͳ�Ƶ�������ʱ����ʮ�ּ����ԾͲ���Memcache��Ϊ�����������MySQL������˷��ʿ����Լ�ͳ�ƵĹ�����Ȼ��δ�������ں�����־�����Ĺ�����������Ҫ���������������ļ����ʻ�Ī���ڡ��Ƽ��㡱����Open
API����ʢ�еĽ��죬������Ӧ�õ����ݽ���Խ��Խ�м�ֵ�����ȥ������Щ���ݣ��ھ������ڼ�ֵ������Ҫ�ֲ�ʽ������֧�ź������ݵķ���������
�ع�ͷ�������������ֶ��̣߳�������ֽ����־������ƣ���ʵ�Ƿֲ�ʽ�����һ�����������ԣ���ν����ֵ����Ĺ������зֲ𣬱��Эͬ�����ļ�Ⱥ����ʵ���Ƿֲ�ʽ������������漰�ġ���ȥ��μ�BEA����ʱ��BEA��VMWare���������������������Ⱥ���Ǿ���ϣ��ʹ�ü����Ӳ���ܹ�������Ӧ�ó�������Դ�ص���Դ��ʹ�������������Դ�ķ���������Ӷ������Ӳ����Դ��ʹ�ü�ֵ���ֲ�ʽ����Ҳ����ˣ�����ļ�����������һ̨����ִ�У�ִ�к���˭�����ܣ��ⶼ�ɷֲ�ʽ��ܵ�Master������ʹ����ֻ��ؽ������������ṩ���ֲ�ʽ����ϵͳ��Ϊ���룬�Ϳ��Եõ��ֲ�ʽ�����Ľ����
Hadoop��Apache��Դ��֯��һ���ֲ�ʽ���㿪Դ��ܣ��ںܶ������վ�϶��Ѿ��õ���Ӧ�ã�������ѷ��Facebook��Yahoo�ȵȡ�
��������˵�������һ��ʹ�õ���Ƿ���ƽ̨����־����������ƽ̨����־������ܴ���Ҳ���÷����˷ֲ�ʽ��������ó�������־����������������
������Ӧ�ó�������
��ǰû����ʽȷ��ʹ�ã�����Ҳ���Լ�ҵ��������������д��������ݣ�����һ�����ֵ�ѧϰ���̣��������һЩ����ֻ��ϣ����¼�������Է���������־ͬ���ϵ����ѡ�
ʲô��Hadoop��
��ʲô����֮ǰ����һ����Ҫ֪��What����ʲô����Ȼ����Why��Ϊʲô����������How����ô���������ܶ�������������˶�����Ŀ�Ժ�ϰ������How��Ȼ��What��������Why������ֻ�����Լ���ø��꣬ͬʱ�����Ὣ���������ڲ��ʺϵij�����
Hadoop���������ĵ���ƾ��ǣ�MapReduce��HDFS��MapReduce��˼������Google��һƪ�������ἰ������Ϊ�����ģ�
��һ�仰����MapReduce���ǡ�����ķֽ������Ļ��ܡ���HDFS��Hadoop�ֲ�ʽ�ļ�ϵͳ��Hadoop
Distributed File System������д��Ϊ�ֲ�ʽ����洢�ṩ�˵ײ�֧�֡�
MapReduce���������������ʹ��¿��Կ�����Ե�ɣ���������Map��Reduce����Map��չ���������ǽ�һ������ֽ��Ϊ�����
��Reduce�����ǽ��ֽ����������Ľ�������������ó����ķ���������ⲻ��ʲô��˼�룬��ʵ��ǰ���ᵽ�Ķ��̣߳����������ƾͿ����ҵ���
��˼���Ӱ�ӡ���������ʵ��ᣬ�����ڳ�������У�һ����������Ա���ֳ�Ϊ�����������֮��Ĺ�ϵ���Է�Ϊ���֣�һ���Dz���ص������Բ���ִ
�У���һ��������֮��������������Ⱥ�˳���ܹ��ߵ������������������д����ġ��ص���ѧʱ�ڣ������Ͽ�ʱ�ô��ȥ�����ؼ�·�����Ǿ�������ʡʱ��
����ֽ�ִ�з�ʽ���ڷֲ�ʽϵͳ�У�������Ⱥ�Ϳ��Կ���Ӳ����Դ�أ������е������֣�Ȼ����ÿһ�����л�����Դȥ�������ܹ�����������Ч�ʣ�ͬʱ
������Դ���ԣ����ڼ��㼯Ⱥ����չ�����ṩ����õ���Ʊ�֤������ʵ��һֱ��ΪHadoop�Ŀ�ͨͼ�겻Ӧ����һ��С��Ӧ�������ϣ��ֲ�ʽ����ͺñ�
���ϳԴ������۵Ļ���Ⱥ����ƥ���κθ����ܵļ������������չ������ʼ�յв���������չ��б�ߣ�������ֽ���Ժ��Ǿ���Ҫ�������Ժ�Ľ���ٻ�����
���������ReduceҪ���Ĺ�����
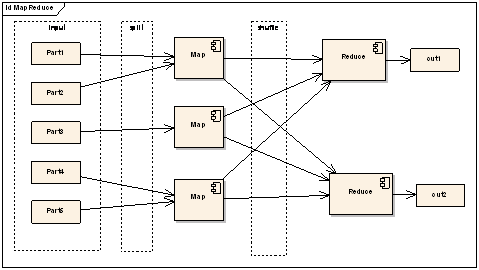
ͼ1��MapReduce�ṹʾ��ͼ
��ͼ����MapReduce���µĽṹͼ����Mapǰ�����ܻ�������������Split���ָ�Ĺ��̣���֤������Ч�ʣ���Map֮����Shuffle����ϣ��Ĺ��̣��������Reduce��Ч���Լ���С���ݴ����ѹ���кܴ�İ��������������ἰ��Щ���ֵ�ϸ�ڡ�
HDFS�Ƿֲ�ʽ����Ĵ洢��ʯ��Hadoop�ķֲ�ʽ�ļ�ϵͳ�������ֲ�ʽ�ļ�ϵͳ�кܶ����Ƶ����ʡ��ֲ�ʽ�ļ�ϵͳ�����ļ����ص㣺
- ����������Ⱥ�е�һ�������ռ䡣
- ����һ���ԡ��ʺ�һ��д���ζ�ȡ��ģ�ͣ��ͻ������ļ�û�б��ɹ�����֮ǰ�������ļ����ڡ�
- �ļ��ᱻ�ָ�ɶ���ļ��飬ÿ���ļ��鱻����洢�����ݽڵ��ϣ����Ҹ������û��ɸ����ļ�������֤���ݵİ�ȫ�ԡ�
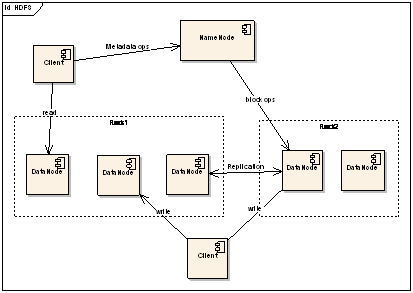
ͼ2��HDFS�ṹʾ��ͼ
��ͼ��չ��������HDFS������Ҫ��ɫ��NameNode��DataNode��Client��NameNode���Կ����Ƿֲ�ʽ�ļ�ϵͳ�еĹ���
�ߣ���Ҫ��������ļ�ϵͳ�������ռ䡢��Ⱥ������Ϣ�ʹ洢��ĸ��Ƶȡ�NameNode�Ὣ�ļ�ϵͳ��Meta-data�洢���ڴ��У���Щ��Ϣ��Ҫ����
���ļ���Ϣ��ÿһ���ļ���Ӧ���ļ������Ϣ��ÿһ���ļ�����DataNode����Ϣ�ȡ�DataNode���ļ��洢�Ļ�����Ԫ������Block�洢�ڱ���
�ļ�ϵͳ�У�������Block��Meta-data��ͬʱ�����Եؽ����д��ڵ�Block��Ϣ����NameNode��Client������Ҫ��ȡ�ֲ�ʽ��
��ϵͳ�ļ���Ӧ�ó�������ͨ������������˵������֮��Ľ�����ϵ��
�ļ�д�룺
- Client��NameNode�����ļ�д�������
- NameNode�����ļ���С���ļ���������������ظ�Client������������DataNode����Ϣ��
- Client���ļ�����Ϊ���Block������DataNode�ĵ�ַ��Ϣ����˳��д�뵽ÿһ��DataNode���С�
�ļ���ȡ��
- Client��NameNode�����ļ���ȡ������
- NameNode�����ļ��洢��DataNode����Ϣ��
- Client��ȡ�ļ���Ϣ��
�ļ�Block���ƣ�
- NameNode���ֲ����ļ���Block��������С���������߲���DataNodeʧЧ��
- ֪ͨDataNode�����Block��
- DataNode��ʼֱ������ơ�
�����˵һ��HDFS�ļ�������ص㣨���ڿ�����ֵ�ý������
- Block�ķ��ã�Ĭ�ϲ����á�һ��Block�������ݱ��ݣ�һ�ݷ���NameNodeָ����DataNode����һ�ݷ���
��ָ��DataNode��ͬһRack�ϵ�DataNode�����һ�ݷ�����ָ��DataNodeͬһRack�ϵ�DataNode�ϡ������Ǿ���Ϊ��
���ݰ�ȫ������ͬһRack��ʧ������Լ���ͬRack֮�����ݿ�����������Ͳ����������÷�ʽ��
- �������DataNode�Ľ���״���������������Ͳ�ȡ���ݱ��ݵķ�ʽ����֤���ݵİ�ȫ�ԡ�
- �� �ݸ��ƣ�����ΪDataNodeʧ�ܡ���Ҫƽ��DataNode�Ĵ洢�����ʺ���Ҫƽ��DataNode���ݽ���ѹ�����������������˵һ�£�ʹ��
HDFS��balancer�����������һ��Threshold��ƽ��ÿһ��DataNode���������ʡ�����������ThresholdΪ10%����ô
ִ��balancer�����ʱ������ͳ������DataNode�Ĵ��������ʵľ�ֵ��Ȼ���ж����ijһ��DataNode�Ĵ��������ʳ��������ֵ
Threshold���ϣ���ô��������DataNode��blockת�Ƶ����������ʵ͵�DataNode��������½ڵ�ļ�����˵ʮ�����á�
- ���ݽ��飺����CRC32�����ݽ��顣���ļ�Blockд���ʱ�����д�����ݻ���д�뽻����Ϣ���ڶ�ȡ��ʱ����Ҫ������ٶ��롣
- NameNode�ǵ��㣺���ʧ�ܵĻ�����������Ϣ�����¼�ڱ����ļ�ϵͳ��Զ�˵��ļ�ϵͳ�С�
- �� �ݹܵ��Ե�д�룺���ͻ���Ҫд���ļ���DataNode�ϣ����ȿͻ��˶�ȡһ��BlockȻ��д����һ��DataNode�ϣ�Ȼ���ɵ�һ��
DataNode���ݵ����ݵ�DataNode�ϣ�һֱ��������Ҫд�����Block��NataNode���ɹ�д�룬�ͻ��˲Ż������ʼд��һ��
Block��
- ��ȫģʽ���ڷֲ�ʽ�ļ�ϵͳ������ʱ��ʼ��ʱ����а�ȫģʽ�����ֲ�ʽ�ļ�ϵͳ���ڰ�ȫģʽ������£���
��ϵͳ�е����ݲ�������Ҳ������ɾ����ֱ����ȫģʽ��������ȫģʽ��Ҫ��Ϊ��ϵͳ������ʱ�������DataNode�����ݿ����Ч�ԣ�ͬʱ���ݲ��Ա�
Ҫ�ĸ��ƻ���ɾ���������ݿ顣������ͨ������Ҳ���Խ��밲ȫģʽ����ʵ�������У�ϵͳ������ʱ��ȥ�ĺ�ɾ���ļ�Ҳ���а�ȫģʽ�������ĵij�����ʾ��ֻ��Ҫ�ȴ�һ������ɡ�
�����ۺ�MapReduce��HDFS����Hadoop�Ľṹ��
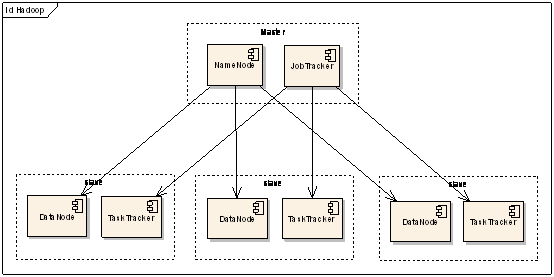
ͼ3��Hadoop�ṹʾ��ͼ
��Hadoop��ϵͳ�У�����һ̨Master����Ҫ����NameNode�Ĺ����Լ�JobTracker�Ĺ�����JobTracker����Ҫְ��
�������������ٺ͵��ȸ���Slave������ִ�С������ж�̨Slave��ÿһ̨Slaveͨ������DataNode�Ĺ��ܲ�����TaskTracker��
������TaskTracker����Ӧ��Ҫ������ϱ�������ִ��Map�����Լ�Reduce����
˵�������Ҫ�ᵽ�ֲ�ʽ��������Ҫ��һ����Ƶ㣺Moving Computation
is Cheaper than Moving Data�������ڷֲ�ʽ�����У��ƶ����ݵĴ������Ǹ���ת�Ƽ���Ĵ��ۡ�����˵���Ƿֶ���֮�Ĺ�������Ҫ������Ҳ�ֶ��洢��������������������Ȼ���
�ܣ������Żᱣ֤�ֲ�ʽ����ĸ�Ч�ԡ�
ΪʲôҪѡ��Hadoop��
˵����What����˵һ��Why���ٷ���վ�Ѿ����˺ܶ��˵��������ʹ���˵һ�����ŵ㼰ʹ�õij�����û�в��õĹ��ߣ�ֻ�ò����õĹ��ߣ����ѡ��ó������ܹ��������ӷֲ�ʽ��������ã���
- ����չ�������Ǵ洢�Ŀ���չ���Ǽ���Ŀ���չ����Hadoop����Ƹ�����
- ���ã���ܿ����������κ���ͨ��PC�ϡ�
- �ɿ����ֲ�ʽ�ļ�ϵͳ�ı��ݻָ������Լ�MapReduce�������ر�֤�˷ֲ�ʽ�����Ŀɿ��ԡ�
- ��Ч���ֲ�ʽ�ļ�ϵͳ�ĸ�Ч���ݽ���ʵ���Լ�MapReduce���Local
Data������ģʽ��Ϊ��Ч������������Ϣ���˻�������
ʹ�ó��������˾������ʺϵľ��Ǻ������ݵķ�������ʵGoogle�������MapReduceҲ����Ϊ�˺������ݷ�����ͬʱHDFS������Ϊ����������ʵ�ֶ������ģ������ű����ڷֲ�ʽ�������С��������ݱ��ָ��ڶ���ڵ㣬Ȼ����ÿһ���ڵ㲢�м��㣬���ó��Ľ�
���鲢�������ͬʱ��һ�ε�����ֿ�����Ϊ��һ�μ�������룬��˿�������һ����״�ṹ�ķֲ�ʽ����ͼ���ڲ�ͬ�ζ��в�ͬ������ͬʱ���кʹ��н�
�ϵļ���Ҳ���Ժܺõ��ڷֲ�ʽ��Ⱥ����Դ�µ��Ը�Ч�Ĵ�����
����Hadoop�еļ�Ⱥ���ú�ʹ�ü���
��ʵ�ο�Hadoop�ٷ��ĵ��Ѿ��ܹ����������÷ֲ�ʽ������л����ˣ����������Ȼд�˾��ٶ�дһ�㣬ͬʱ��һЩϸ����Ҫע���Ҳ˵��һ�£���ʵ
Ҳ������Щϸ�ڻ������������졣Hadoop���Ե����ܣ�Ҳ�������ü�Ⱥ�ܣ������ܾͲ���Ҫ��˵�ˣ�ֻ��Ҫ����Demo������˵��ֱ��ִ������ɡ�����
��Ҫ�ص�˵һ�¼�Ⱥ�������еĹ��̡�
����
7̨��ͨ�Ļ���������ϵͳ����Linux���ڴ��CPU�Ͳ�˵�ˣ�����Hadoopһ���ص���ǻ����ڶ�ھ���JDK������1.5���ϵģ�����мǡ�7̨�����Ļ�������ز�ͬ��������̸������������MapReduce�кܴ��Ӱ�졣
������
���������������ģ�����Hadoop�ļ�Ⱥ��˵�����Էֳ��������ɫ��Master��Slave��ǰ����Ҫ����NameNode��
JobTracker�Ľ�ɫ�������ֲܹܷ�ʽ���ݺͷֽ������ִ�У���������DataNode��TaskTracker�Ľ�ɫ������ֲ�ʽ���ݴ洢�Լ���
���ִ�С������Ҵ��㿴��һ̨�����Ƿ�������ó�Master��ͬʱҲ��ΪSlaveʹ�ã�����������NameNode��ʼ���Ĺ������Լ�
TaskTrackerִ�й����л��������ú����г�ͻ��NameNode��TaskTracker����Hosts��������Щ��ͻ�������ǰѻ�������Ӧ
IP��������ǰ�滹�ǰ�Localhost��ӦIP����ǰ���е����⣬��������Ҳ�����Լ�������ɣ������ҿ��Ը���ʵʩ������ҷ����������������һ
̨Master����̨Slave���������ӵ�Ӧ�ÿ����Ͳ��Խ���ıȶԻ����ӻ������á�
ʵʩ����
- �����еĻ����϶�������ͬ��Ŀ¼��Ҳ���Ծͽ�����ͬ���û����Ը��û���home·������hadoop�İ�װ·���������������еĻ����϶�������
/home/wenchu��
- ����Hadoop���Ƚ�ѹ��Master�ϡ������������ص�0.17.1�İ汾����ʱHadoop�İ�װ·������
/home/wenchu/hadoop-0.17.1��
- ��ѹ�����confĿ¼����Ҫ��Ҫ�������ļ���
hadoop-env.sh��hadoop-site.xml��masters��slaves��
Hadoop�Ļ��������ļ���hadoop-default.xml����Hadoop�Ĵ������֪����Ĭ�Ͻ���һ��Job��ʱ��Ὠ��Job��Config��Config���ȶ���hadoop-default.xml�����ã�Ȼ���ٶ���hadoop-site.xml�����ã�����ļ���ʼ��ʱ������Ϊ�գ���hadoop-site.xml����Ҫ��������Ҫ���ǵ�hadoop-default.xml��ϵͳ�����ã��Լ�����Ҫ�����MapReduce������ʹ�õ��Զ������ã������һЩʹ������final�Ȳο��ĵ�����
������һ����hadoop-site.xml�����ã�
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>//���namenode�����ã��������Ӷ˿�
<value>hdfs://10.2.224.46:54310/</value>
</property>
<property>
<name>mapred.job.tracker</name>//���JobTracker�����ã��������Ӷ˿�
<value>hdfs://10.2.224.46:54311/</value>
</property>
<property>
<name>dfs.replication</name>//������Ҫ���ݵ�������Ĭ������
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>//Hadoop��Ĭ����ʱ·�������������ã��������
���ڵ�������������Ī�������DataNode�������ˣ���ɾ�����ļ��е�tmpĿ¼���ɡ�
�������ɾ����NameNode�����Ĵ�Ŀ¼����ô����Ҫ����ִ��NameNode��ʽ�������
<value>/home/wenchu/hadoop/tmp/</value>
</property>
<property>
<name>mapred.child.java.opts</name>//java�������һЩ�������Բ�������
<value>-Xmx512m</value>
</property>
<property>
<name>dfs.block.size</name>//block�Ĵ�С����λ�ֽڣ�������ᵽ�ô���������
512�ı�������Ϊ����crc���ļ�������У�飬Ĭ������512��checksum����С��Ԫ��
<value>5120000</value>
<description>The default block size for new files.</description>
</property>
</configuration>
hadoop-env.sh�ļ�ֻ��Ҫ��һ��������
# The java implementation to use. Required.
export JAVA_HOME=/usr/ali/jdk1.5.0_10
�������Java·������סһ��Ҫ1.5�汾���ϣ����Ī������������⡣
Masters������Masters��IP��������������ǻ�������ô��Ҫ��/etc/hosts���������á�Slaves�����õ���Slaves��IP����������ͬ������ǻ�������Ҫ��/etc/hosts���������á��������£����������õĶ���IP��
Masters:
10.2.224.46
Slaves:
10.2.226.40
10.2.226.39
10.2.226.38
10.2.226.37
10.2.226.41
10.2.224.36
- ����Master��ÿһ̨Slave��SSH����֤�顣����Master����ͨ��SSH��������Slave��Hadoop��������Ҫ�����������˫��֤�鱣֤����ִ��ʱ����Ҫ���������롣��Master�����е�Slave������ִ�У�
ssh-keygen
-t rsa��ִ�д������ʱ������ʾֻ��Ҫ�س���Ȼ��ͻ���/root/.ssh/�������id_rsa.pub��֤���ļ���ͨ��scp��Master�����ϵ�����ļ�������Slave�ϣ��ǵ������ƣ������磺scp
root@masterIP:/root/.ssh/id_rsa.pub /root/.ssh/46_rsa.pub��Ȼ��ִ��cat
/root/.ssh/46_rsa.pub >>/root/.ssh/authorized_keys������authorized_keys��
�����ɣ����Դ�����ļ�������Ҳ����rsa�Ĺ�Կ��Ϊkey��user@IP��Ϊvalue����ʱ��������һ�£���master
ssh��slave�Ѿ�����Ҫ�����ˡ���slave������Ҳ��ͬ����ΪʲôҪ�����أ���ʵ���һֱ����Master�����رյĻ���ôû�б�Ҫ������
��ֻ���������SlaveҲ���Թر�Hadoop����Ҫ��������
- ��Master�ϵ�Hadoopͨ��scp������ÿһ��Slave��ͬ��Ŀ¼�£�����ÿһ��Slave��
Java_HOME�IJ�ͬ����hadoop-env.sh��
- ��Master��
/etc/profile��
�����������ݣ�����������ݸ�����İ�װ·���ģ��ⲽֻ��Ϊ�˷���ʹ�ã�
��
export HADOOP_HOME=/home/wenchu/hadoop-0.17.1
export PATH=$PATH:$HADOOP_HOME/bin
����Ϻ�ִ��source /etc/profile��ʹ����Ч��
- ��Master��ִ��
Hadoop namenode
�Cformat�����ǵ�һ��Ҫ���ij�ʼ�������Կ�����ʽ���ɣ��Ժ�������������ᵽ��ɾ����Master�ϵ�hadoop.tmp.dirĿ¼�������Dz���Ҫ�ٴ�ִ�еġ�
- Ȼ��ִ��Master�ϵ�
start-all.sh������������ֱ��ִ�У���Ϊ��6���Ѿ����ӵ���path·�����������������hdfs��mapreduce�����֣���Ȼ��Ҳ���Էֿ���������hdfs��mapreduce���ֱ���binĿ¼�µ�start-dfs.sh��start-mapred.sh��
- ���Master��logsĿ¼������Namenode��־�Լ�JobTracker��־�Ƿ�����������
- ���Slave��logsĿ¼����Datanode��־�Լ�TaskTracker��־�Ƿ�������
- �����Ҫ�رգ���ô��ֱ��ִ��
stop-all.sh���ɡ�
���ϲ���Ϳ�������Hadoop�ķֲ�ʽ������Ȼ����Master�Ļ�������Master�İ�װĿ¼��ִ��hadoop
jar hadoop-0.17.1-examples.jar wordcount����·�������·�����Ϳ��Կ�������ͳ�Ƶ�Ч���ˡ��˴�������·�������·����ָ����HDFS�е�·����������������ͨ�����������ļ�ϵͳ�е�Ŀ¼��HDFS�еķ�ʽ������HDFS�е�����·����
hadoop dfs -copyFromLocal /home/wenchu/test-in
test-in������/home/wenchu/test-in�DZ���·����test-in�ǽ��Ὠ����HDFS�е�·����ִ������Ժ����ͨ��hadoop
dfs �Cls����test-inĿ¼�Ѿ����ڣ�ͬʱ����ͨ��hadoop dfs
�Cls test-in�鿴��������ݡ����·��Ҫ������HDFS�в����ڵģ���ִ�����Ǹ�demo�ԺͿ���ͨ��hadoop
dfs �Cls ���·���������е����ݣ������ļ������ݿ���ͨ��hadoop
dfs �Ccat�ļ��������鿴��
�����ܽ��ע������ⲿ��������ʹ�ù����л���һЩʱ���ߵ���·����
- Master��Slave�ϵļ���conf�����ļ�����Ҫȫ��ͬ�������ȷ������ͨ��Masterȥ�����رգ���ôSlave�����ϵ����ò���Ҫȥά���������ϣ��������һ̨���������������ر�Hadoop����ô����Ҫȫ������һ���ˡ�
- Master��Slave�����ϵ�
/etc/hosts��
����Ѽ�Ⱥ�л�����������ȥ�������ڸ��������ļ���ʹ�õ���IP������Թ����ٿ�ͷ��ԭ����Ϊ������IP�Ͳ���Ҫȥ����Host�����������ִ��
Reduce��ʱ�����ǿ�ס���ڿ�����ʱ�����������ȥ���������ԡ����������Ⱥ���������̨�����Ļ���������ظ�Ҳ��������⡣
- ����������˽ڵ����ɾ���ڵ��ʱ����������⣬���Ⱦ�ȥɾ��Slave��
hadoop.tmp.dir��Ȼ�������������Կ���������Dz����Ǿɴ��Master��hadoop.tmp.dirɾ������ζ��dfs�ϵ�����Ҳ�ᶪʧ�������ɾ����Master��hadoop.tmp.dir����ô����Ҫ����namenode
�Cformat��
- Map��������Լ�Reduce����������á�ǰ��ֲ�ʽ�ļ�ϵͳ����ᵽһ���ļ������뵽�ֲ�ʽ�ļ�ϵͳ�У��ᱻ�ָ�ɶ��block���õ�ÿһ����DataNode�ϣ�Ĭ��
dfs.block.sizeӦ����64M��Ҳ����˵�������õ�HDFS�ϵ�����С��64����ô��ֻ��һ��Block����ʱ�ᱻ���õ�ijһ��DataNode�У��������ͨ��ʹ�����hadoop
dfsadmin �Creport�Ϳ��Կ��������ڵ�洢�������Ҳ����ֱ��ȥijһ��DataNode�鿴Ŀ¼��hadoop.tmp.dir/dfs/data/current��
���Կ�����Щblock�ˡ�Block����������ֱ��Ӱ�쵽Map�ĸ�������Ȼ����ͨ���������趨Map��Reduce�����������Map�ĸ���ͨ��Ĭ��
��HDFS��Ҫ������blocks��ͬ��Ҳ����ͨ������Map��������������minimum split
size���趨��ʵ�ʵĸ���Ϊ��max(min(block_size,data/#maps),min_split_size)��Reduce����ͨ�������ʽ���㣺0.95*num_nodes*mapred.tasktracker.tasks.maximum��
�ܵ���˵�����������������ʱ�����ȥ������־�����������еס�
Hadoop�е����Command���ܽ�
�ⲿ��������ʵ����ͨ�������Help�Լ������˽⣬����Ҫ�����ڽ���һ�����õıȽ϶�ļ������Hadoop
dfs ����������Ӳ������Ƕ���HDFS�IJ�������Linux����ϵͳ����������ƣ����磺
Hadoop dfs �Cls���Dz鿴/usr/rootĿ¼�µ����ݣ�Ĭ���������·������ǵ�ǰ�û�·����
Hadoop dfs �Crmr xxx����ɾ��Ŀ¼�����кܶ�������ͺ��������֣�
Hadoop dfsadmin �Creport����������ȫ�ֵIJ鿴DataNode�������
Hadoop job�������Ӳ����Ƕ��ڵ�ǰ���е�Job�IJ���������list,kill�ȣ�
Hadoop balancer����ǰ���ᵽ�ľ�����̸��ص����
�����Ͳ���ϸ�����ˡ�
����Hadoop����������Ӧ�ÿ���
Hadoop��������
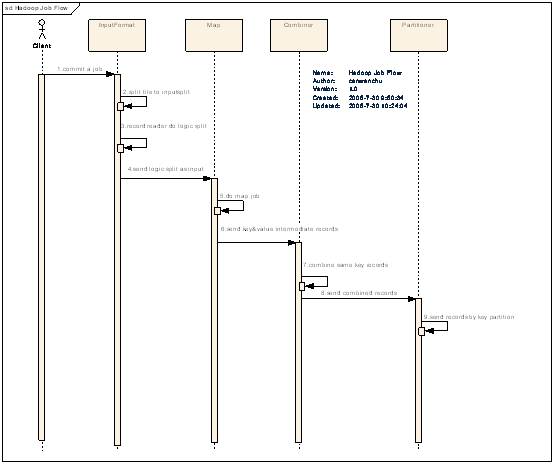
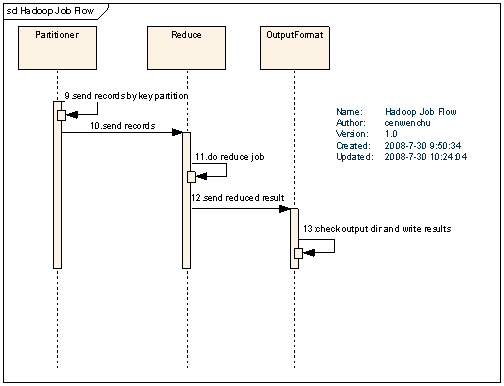
һ��ͼƬ̫���ˣ�ֻ�÷ָ��Ϊ�����֡���������ͼ��˵һ�¾���һ������ִ�е������
- �ڷֲ�ʽ�����пͻ��˴��������ύ��
- InputFormat��Mapǰ��Ԥ��������Ҫ�������¹�����
��
- ��֤����ĸ�ʽ�Ƿ����JobConfig�����붨�壬�����ʵ��Map����Conf��ʱ��ͻ�֪���������������Writable���������ࡣ
- ��input���ļ��з�Ϊ���ϵ�����InputSplit����ʵ������������ᵽ���ڷֲ�ʽ�ļ�ϵͳ��blocksize���д�С���Ƶģ���˴��ļ��ᱻ����Ϊ���block��
- ͨ��RecordReader���ٴδ���inputsplitΪһ��records�������Map����inputsplitֻ�����зֵĵ�һ����������θ����ļ��е���Ϣ���зֻ���ҪRecordReader��ʵ�֣��������Ĭ�Ϸ�ʽ���ǻس����е��з֣�
- RecordReader������Ľ����ΪMap�����룬Mapִ�ж����Map��������������key��value��Ӧ����ʱ�м��ļ���
- Combiner��ѡ�����ã���Ҫ��������ÿһ��Mapִ��������Ժ��ڱ���������Reduce�Ĺ�����������Reduce�����е����ݴ�������
- Partitioner��ѡ�����ã���Ҫ�������ڶ��Reduce������£�ָ��Map�Ľ����ijһ��Reduce������ÿһ��Reduce�����е���������ļ���������Ĵ���ʵ�����н���ʹ�ó�����
- Reduceִ�о����ҵ���������ҽ�������������OutputFormat��
- OutputFormat��ְ���ǣ���֤���Ŀ¼�Ƿ��Ѿ����ڣ�ͬʱ��֤�����������Ƿ���Config�����ã�������Reduce���ܺ�Ľ����
ҵ���ʹ��뷶��
ҵ�����������趨��������·��������ϵͳ��·����HDFS·���������ݷ�����־����ijһ��Ӧ�÷���ijһ��API���ܴ�������������ͳ�ƺ�ֱ�����������ļ��С��������Ϊ�˲��ԣ�û��ȥϸ�ֺܶ��࣬�����е���鲢��һ�������˵�����⡣
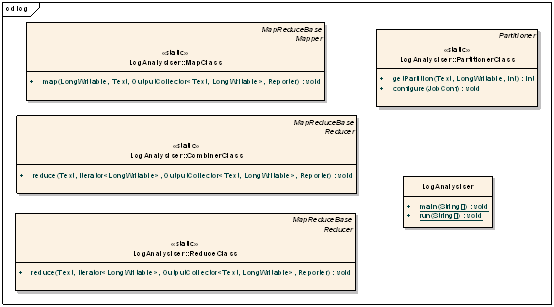
���Դ�����ͼ
LogAnalysiser�������࣬��Ҫ�������ύ���������������Ϣ���ڲ��ļ���������;���Բο��������ᵽ�Ľ�ɫְ�𡣾���ؿ���������ͷ����Ĵ���Ƭ�ϣ�
LogAnalysiser::MapClass
public static class MapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, LongWritable>
{
public void map(LongWritable key, Text value, OutputCollector<Text,
LongWritable> output, Reporter reporter)
throws IOException
{
String line = value.toString();//û������RecordReader������Ĭ�ϲ���line
��ʵ�֣�key�����кţ�value����������
if (line == null || line.equals(""))
return;
String[] words = line.split(",");
if (words == null || words.length < 8)
return;
String appid = words[1];
String apiName = words[2];
LongWritable recbytes = new LongWritable(Long.parseLong(words[7]));
Text record = new Text();
record.set(new StringBuffer("flow::").append(appid)
.append("::").append(apiName).toString());
reporter.progress();
//���������ͳ�ƽ����ͨ��flow::��Ϊǰ����ʾ��output.collect(record, recbytes);
record.clear();
record.set(new StringBuffer("count::").append(appid).append("::")
.append(apiName).toString());
//���������ͳ�ƽ����ͨ��count::��Ϊǰ����ʾ
output.collect(record, new LongWritable(1));
}
}
LogAnalysiser:: PartitionerClass
public static class PartitionerClass implements Partitioner<Text, LongWritable>
{
public int getPartition(Text key, LongWritable value, int numPartitions)
{
if (numPartitions >= 2)//Reduce �������ж��������Ǵ�����ͳ�Ʒ��䵽��ͬ��Reduce
if (key.toString().startsWith("flow::"))
return 0;
else
return 1;
else
return 0;
}
public void configure(JobConf job){}
}
LogAnalysiser:: CombinerClass
�ο�ReduceClass��ͨ�����߿���ʹ��һ��������������Щ��ͬ�Ĵ����ͷֳ�����������ReduceClass����ɫ���б�ʾ��CombinerClass�в����ڡ�
LogAnalysiser:: ReduceClass
public static class ReduceClass extends MapReduceBase
implements Reducer<Text, LongWritable,Text, LongWritable>
{
public void reduce(Text key, Iterator<LongWritable> values,
OutputCollector<Text, LongWritable> output, Reporter reporter)throws IOException
{
Text newkey = new Text();
newkey.set(key.toString().substring(key.toString().indexOf("::")+2));
LongWritable result = new LongWritable();
long tmp = 0;
int counter = 0;
while(values.hasNext())//�ۼ�ͬһ��key��ͳ�ƽ��
{
tmp = tmp + values.next().get();
counter = counter +1;//���Ĵ���̫�ã�JobTracker��ʱ��û���յ��������ΪTaskTracker�Ѿ�ʧЧ����˶�ʱ����һ��
if (counter == 1000)
{
counter = 0;
reporter.progress();
}
}
result.set(tmp);
output.collect(newkey, result);//������Ļ��ܽ��
}
}
LogAnalysiser
public static void main(String[] args)
{
try
{
run(args);
} catch (Exception e)
{
e.printStackTrace();
}
}
public static void run(String[] args) throws Exception
{
if (args == null || args.length <2)
{
System.out.println("need inputpath and outputpath");
return;
}
String inputpath = args[0];
String outputpath = args[1];
String shortin = args[0];
String shortout = args[1];
if (shortin.indexOf(File.separator) >= 0)
shortin = shortin.substring(shortin.lastIndexOf(File.separator));
if (shortout.indexOf(File.separator) >= 0)
shortout = shortout.substring(shortout.lastIndexOf(File.separator));
SimpleDateFormat formater = new SimpleDateFormat("yyyy.MM.dd");
shortout = new StringBuffer(shortout).append("-")
.append(formater.format(new Date())).toString();
if (!shortin.startsWith("/"))
shortin = "/" + shortin;
if (!shortout.startsWith("/"))
shortout = "/" + shortout;
shortin = "/user/root" + shortin;
shortout = "/user/root" + shortout;
File inputdir = new File(inputpath);
File outputdir = new File(outputpath);
if (!inputdir.exists() || !inputdir.isDirectory())
{
System.out.println("inputpath not exist or isn��t dir!");
return;
}
if (!outputdir.exists())
{
new File(outputpath).mkdirs();
}
JobConf conf = new JobConf(new Configuration(),LogAnalysiser.class);//����Config
FileSystem fileSys = FileSystem.get(conf);
fileSys.copyFromLocalFile(new Path(inputpath), new Path(shortin));//�������ļ�ϵͳ���ļ�������HDFS��
conf.setJobName("analysisjob");
conf.setOutputKeyClass(Text.class);//�����key���ͣ���OutputFormat����
conf.setOutputValueClass(LongWritable.class); //�����value���ͣ���OutputFormat����
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(CombinerClass.class);
conf.setReducerClass(ReduceClass.class);
conf.setPartitionerClass(PartitionerClass.class);
conf.set("mapred.reduce.tasks", "2");//ǿ����Ҫ������Reduce���ֱ��������ʹ�����ͳ��
FileInputFormat.setInputPaths(conf, shortin);//hdfs�е�����·��
FileOutputFormat.setOutputPath(conf, new Path(shortout));//hdfs�����·��
Date startTime = new Date();
System.out.println("Job started: " + startTime);
JobClient.runJob(conf);
Date end_time = new Date();
System.out.println("Job ended: " + end_time);
System.out.println("The job took " + (end_time.getTime() - startTime.getTime()) /1000 + " seconds.");
//ɾ��������������ʱ�ļ�
fileSys.copyToLocalFile(new Path(shortout),new Path(outputpath));
fileSys.delete(new Path(shortin),true);
fileSys.delete(new Path(shortout),true);
}
���ϵĴ������������е����Դ��룬Ȼ����Ҫһ��ע����������ע��ҵ��ClassΪһ���ɱ�ʾ�������hadoop
jar����ִ�С�
public class ExampleDriver {
public static void main(String argv[]){
ProgramDriver pgd = new ProgramDriver();
try {
pgd.addClass("analysislog", LogAnalysiser.class, "A map/reduce program that analysis log .");
pgd.driver(argv);
}
catch(Throwable e){
e.printStackTrace();
}
}
}
��������jar����������jar��mainClassΪExampleDriver����ࡣ�ڷֲ�ʽ���������Ժ�ִ��������䣺
hadoop jar analysiser.jar analysislog /home/wenchu/test-in /home/wenchu/test-out
��/home/wenchu/test-in������Ҫ��������־�ļ���ִ�к�ͻῴ������ִ�й��̣�������Map��Reduce�Ľ��ȡ�ִ����ϻ�
��/home/wenchu/test-out�¿�����������ݡ��������ļ���part-00000��part-00001�ֱ��¼��ͳ�ƺ�Ľ����
�����Ҫ��ִ�еľ�����������Կ������Ŀ¼�µ�_logs/history/xxxx_analysisjob���������������е�Map��Reduce
�Ĵ�������Լ�ִ���������������Ҳ����ͨ����������鿴Map,Reduce�������http://MasterIP:50030
/jobtracker.jsp
Hadoop��Ⱥ����
��������ʹ������ķ�����Ϊ���ԣ�Ҳû����̫����Ż����ã�������Խ��ֻ��Ϊ�˿�����Ⱥ��Ч�����Լ�һЩ�������õ�Ӱ�졣
�ļ�������Ϊ1��blocksize 5M
| Slave�� |
������¼��(����) |
ִ��ʱ�䣨�룩 |
| 2 |
95 |
38 |
| 2 |
950 |
337 |
| 4 |
95 |
24 |
| 4 |
950 |
178 |
| 6 |
95 |
21 |
| 6 |
950 |
114 |
Blocksize 5M
| Slave�� |
������¼��(����) |
ִ��ʱ�䣨�룩 |
| 2���ļ�������Ϊ1�� |
950 |
337 |
| 2���ļ�������Ϊ3�� |
950 |
339 |
| 6���ļ�������Ϊ1�� |
950 |
114 |
| 6���ļ�������Ϊ3�� |
950 |
117 |
�ļ�������Ϊ1
| Slave�� |
������¼��(����) |
ִ��ʱ�䣨�룩 |
| 6(blocksize 5M) |
95 |
21 |
| 6(blocksize 77M) |
95 |
26 |
| 4(blocksize 5M) |
950 |
178 |
| 4(blocksize 50M) |
950 |
54 |
| 6(blocksize 5M) |
950 |
114 |
| 6(blocksize 50M) |
950 |
44 |
| 6(blocksize 77M) |
950 |
74 |
���Ե����ݽ�����ȶ��������⼸��ͬ�������¶���һ����ͨ�����Խ�����Կ������¼��㣺
- �������������ܻ����а����ģ�����û˵^_^����
- �ļ�������������ֻ��ȫ���а��������Ƕ�������û��̫��������������ڲ�ȡ���ǽ�����ϵͳ�ļ�������HDFS�У����Ա��ݶ��ˣ�����ʱ��ܳ���
- blocksize��������Ӱ��ܴ����������block���ֵ�̫С����ô��������job��������ͬʱҲ������Э���Ĵ��ۣ����������ܣ��������õ�̫��Ҳ����job��������д������������ֵ��������Ҫ�������ݴ������������ǡ�
- �����dz�������������г����Ľ����Ӧ��ȥ��ϸ�����Ŀ¼�е�_logs/history�е�xxx_analysisjob����ļ��������¼��ȫ����ִ�й����Լ���д�����������Ը���������˽�������ܻ���Ӻ�ʱ��
����
���Ƽ��㡱�ȵ����֣��ͺ�SAAS��Web2��SNS��һ�������������ڸ���ֻ������̤̤ʵʵ�Ĵ��ͻ�������˾���Ż�Ͷ����������ȥ�о�������
���ķֲ�ʽ���㡣��ʵ�����������û����ô���ʱ�����ֲַ�ʽ����Ҳ�ͽ���ֻ��һ����߶��ѣ�ֻ���������������Ĺ����У������ε�����Żᱻ�ھ��
����
����ƪ���£��ֲ�ʽ���㿪Դ���Hadoop���ܣ�Hadoop�еļ�Ⱥ���ú�ʹ�ü��ɣ�������Ϊ�˸��Էֲ�ʽ��������Ȥ��������ש��Ҫ����ľ�
�ӣ���ô��̤̤ʵʵ��ȥ�á�ȥ�롢ȥ�����������Լ�Ҳ�����һ����ȥ�о�����е�ʵ�ֻ��ƣ��ڽ���Լ������ͬʱ��Ҳ�ܹ�����һЩʲô��
ǰ���տ������˹����Ϊ�ܹ�ʦ�ķ�ʽ��������Щ�ɱ�����Щ��Ц����ʵ�ж��ټܹ�ʦ֪��ʲô�����ܹ����ܹ�ʦ��ְ����ʲô����������ôһ�����ţ�������̤̤ʵʵ������ʯͷ����ˮ�ס�Ҫ֪�������ۺͳ����Ĺ��̾���һ�ֳɳ���
| 