| БрМЭЦМі: |
НгЩЯЮФЃЌЯЕСаЮФеТЕФзюКѓвЛЦЊСЫЃЌБОЮФжївЊНщЩмСЫЗжВМЪНЪТЮёЕФЛљДЁЃЌГЁОАЃЌвдМАЗжВМЪНЪТЮяЕФНтОіЗНАИЃЌзюКѓЖдSeataНјааСЫНщЩмЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
ЕквЛеТ
ЃКЮЂЗўЮёЕФМмЙЙНщЩмЗЂеЙ
ЕкЖўеТ : ЮЂЗўЮёЛЗОГДюНЈ
ЕкШ§еТ Nacos Discovery--ЗўЮёжЮРэ
ЕкЫФеТ
Sentinel--ЗўЮёШнДэ
ЕкЮхеТ
Gateway--ЗўЮёЭјЙи
ЕкСљеТ
Sleuth--СДТЗзЗзй
ЕкЦпеТ
Rocketmq--ЯћЯЂЧ§ЖЏ
ЕкАЫеТ SMS--ЖЬаХЗўЮё
ЕкОХеТ Nacos Config--ЗўЮёХфжУ
ЕкЪЎеТ Seata--ЗжВМЪНЪТЮё
10.1 ЗжВМЪНЪТЮёЛљДЁ
10.1.1 ЪТЮё
ЪТЮёжИЕФОЭЪЧвЛИіВйзїЕЅдЊЃЌдкетИіВйзїЕЅдЊжаЕФЫљгаВйзїзюжевЊБЃГжвЛжТЕФааЮЊЃЌвЊУДЫљгаВйзїЖМГЩЙІЃЌвЊУДЫљгаЕФВйзїЖМБЛГЗЯњЁЃМђЕЅЕиЫЕЃЌЪТЮёЬсЙЉвЛжжЁАвЊУДЪВУДЖМВЛзіЃЌвЊУДзіШЋЬзЁБЛњжЦЁЃ
10.1.2 БОЕиЪТЮя
БОЕиЪТЮяЦфЪЕПЩвдШЯЮЊЪЧЪ§ОнПтЬсЙЉЕФЪТЮёЛњжЦЁЃЫЕЕНЪ§ОнПтЪТЮёОЭВЛЕУВЛЫЕЃЌЪ§ОнПтЪТЮёжаЕФ
ЫФДѓЬиад:
AЃКдзгад(Atomicity)ЃЌвЛИіЪТЮёжаЕФЫљгаВйзїЃЌвЊУДШЋВПЭъГЩЃЌвЊУДШЋВПВЛЭъГЩ
CЃКвЛжТад(Consistency)ЃЌдквЛИіЪТЮёжДаажЎЧАКЭжДаажЎКѓЪ§ОнПтЖМБиаыДІгквЛжТадзДЬЌ
IЃКИєРыад(Isolation)ЃЌдкВЂЗЂЛЗОГжаЃЌЕБВЛЭЌЕФЪТЮёЭЌЪБВйзїЯрЭЌЕФЪ§ОнЪБЃЌЪТЮёжЎМфЛЅВЛгАЯь
DЃКГжОУад(Durability)ЃЌжИЕФЪЧжЛвЊЪТЮёГЩЙІНсЪјЃЌЫќЖдЪ§ОнПтЫљзіЕФИќаТОЭБиаыгРОУЕФБЃДцЯТРД
ШЁДѓаДЪз зжФИ вВОЭЪЧ МђГЦ ACID
Ъ§ОнПтЪТЮёдкЪЕЯжЪБЛсНЋвЛДЮЪТЮёЩцМАЕФЫљгаВйзїШЋВПФЩШыЕНвЛИіВЛПЩЗжИюЕФжДааЕЅдЊЃЌИУжДааЕЅдЊжаЕФЫљгаВйзївЊУДЖМГЩЙІЃЌвЊУДЖМЪЇАмЃЌжЛвЊЦфжаШЮвЛВйзїжДааЪЇАмЃЌЖМНЋЕМжТећИіЪТЮёЕФЛиЙі
10.1.3 ЗжВМЪНЪТЮё
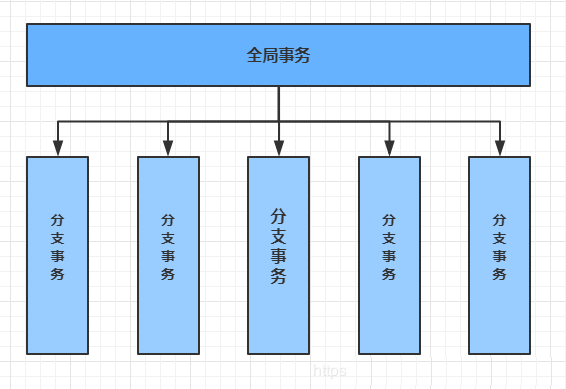
ЗжВМЪНЪТЮёжИЪТЮёЕФВЮгыепЁЂжЇГжЪТЮёЕФЗўЮёЦїЁЂзЪдДЗўЮёЦївдМАЪТЮёЙмРэЦїЗжБ№ЮЛгкВЛЭЌЕФЗжВМЪНЯЕЭГЕФВЛЭЌНкЕужЎЩЯЁЃ
МђЕЅЕФЫЕЃЌОЭЪЧвЛДЮДѓЕФВйзїгЩВЛЭЌЕФаЁВйзїзщГЩЃЌетаЉаЁЕФВйзїЗжВМдкВЛЭЌЕФЗўЮёЦїЩЯЃЌЧвЪєгкВЛЭЌЕФ,гІгУЃЌЗжВМЪНЪТЮёашвЊБЃжЄетаЉаЁВйзївЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЁЃ
БОжЪЩЯРДЫЕЃЌЗжВМЪНЪТЮёОЭЪЧЮЊСЫБЃжЄВЛЭЌЪ§ОнПтЕФЪ§ОнвЛжТадЁЃ
10.1.4 ЗжВМЪНЪТЮёЕФГЁОА
ЕЅЬхЯЕЭГЗУЮЪЖрИіЪ§ОнПт
вЛИіЗўЮёашвЊЕїгУЖрИіЪ§ОнПтЪЕР§ЭъГЩЪ§ОнЕФдіЩОИФВйзї
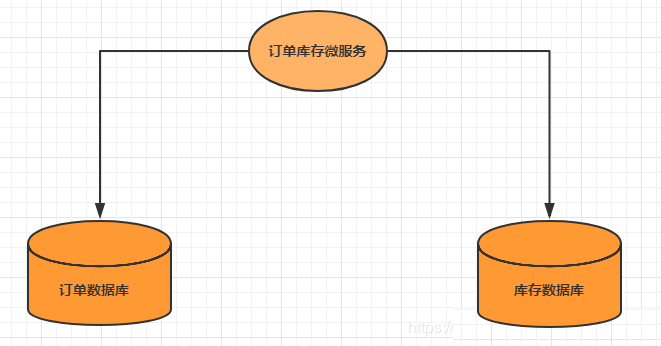
ЖрИіЮЂЗўЮёЗУЮЪЭЌвЛИіЪ§ОнПт
ЖрИіЗўЮёашвЊЕїгУвЛИіЪ§ОнПтЪЕР§ЭъГЩЪ§ОнЕФдіЩОИФВйзї
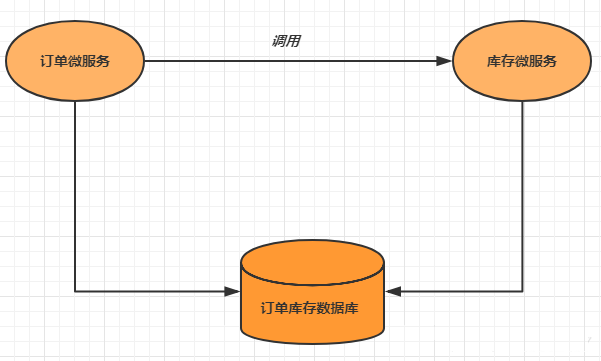
ЖрИіЮЂЗўЮёЗУЮЪЖрИіЪ§ОнПт
ЖрИіЗўЮёашвЊЕїгУвЛИіЪ§ОнПтЪЕР§ЭъГЩЪ§ОнЕФдіЩОИФВйзї
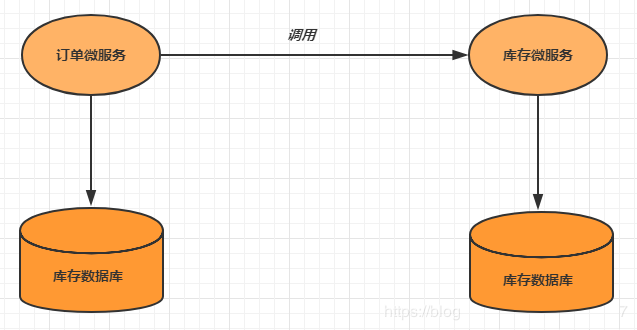
10.2 ЗжВМЪНЪТЮёНтОіЗНАИ
10.2.1 ШЋОжЪТЮё
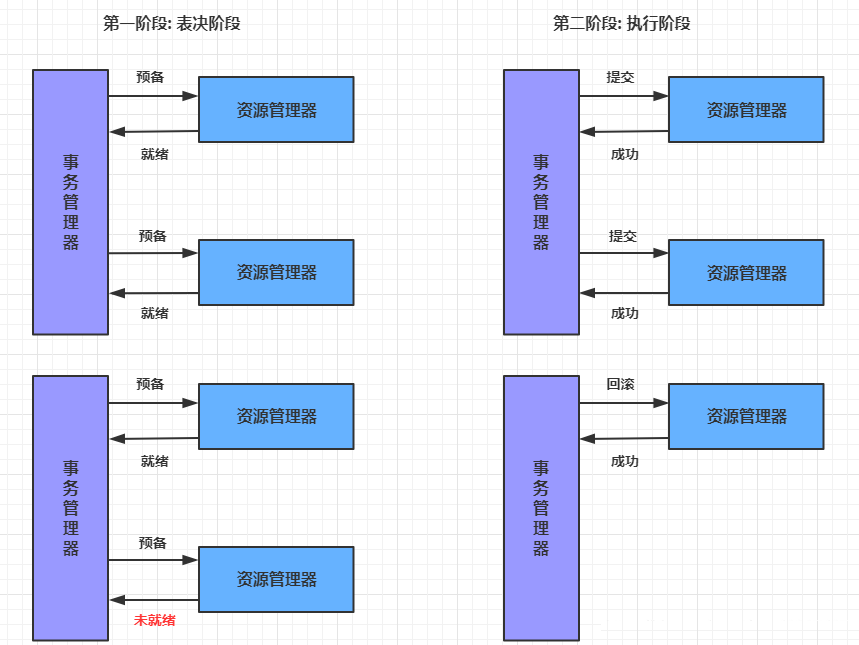
ШЋОжЪТЮёЛљгкDTPФЃаЭЪЕЯжЁЃDTPЪЧгЩX/OpenзщжЏЬсГіЕФвЛжжЗжВМЪНЪТЮёФЃаЭЁЊЁЊX/Open
Distributed Transaction Processing Reference ModelЁЃЫќЙцЖЈСЫвЊЪЕЯжЗжВМЪНЪТЮёЃЌашвЊШ§жжНЧЩЋЃК
AP: Application гІгУЯЕЭГ (ЮЂЗўЮё)
TM: Transaction Manager ЪТЮёЙмРэЦї (ШЋОжЪТЮёЙмРэ)
RM: Resource Manager зЪдДЙмРэЦї (Ъ§ОнПт)
ећИіЪТЮёЗжГЩСНИіНзЖЮ:
НзЖЮвЛ: БэОіНзЖЮЃЌЫљгаВЮгыепЖМНЋБОЪТЮёжДаадЄЬсНЛЃЌВЂНЋФмЗёГЩЙІЕФаХЯЂЗДРЁЗЂИјаЕїеп
НзЖЮЖў: жДааНзЖЮЃЌаЕїепИљОнЫљгаВЮгыепЕФЗДРЁЃЌЭЈжЊЫљгаВЮгыепЃЌВНЕївЛжТЕижДааЬсНЛЛђЛиЙіЁЃ
гХЕу
ЬсИпСЫЪ§ОнвЛжТадЕФИХТЪЃЌЪЕЯжГЩБОНЯЕЭ
ШБЕу
ЕЅЕуЮЪЬт: ЪТЮёаЕїепхДЛњ
ЭЌВНзшШћ: бгГйСЫЬсНЛЪБМфЃЌМгГЄСЫзЪдДзшШћЪБМф
Ъ§ОнВЛвЛжТ: ЬсНЛЕкЖўНзЖЮЃЌвРШЛДцдкcommitНсЙћЮДжЊЕФЧщПіЃЌгаПЩФмЕМжТЪ§ОнВЛвЛжТ
10.2.2 ПЩППЯћЯЂЗўЮё
ЛљгкПЩППЯћЯЂЗўЮёЕФЗНАИЪЧЭЈЙ§ЯћЯЂжаМфМўБЃжЄЩЯЁЂЯТгЮгІгУЪ§ОнВйзїЕФвЛжТадЁЃМйЩшгаAКЭBСНИіЯЕЭГЃЌЗжБ№ПЩвдДІРэШЮЮёAКЭШЮЮёBЁЃДЫЪБДцдквЛИівЕЮёСїГЬЃЌашвЊНЋШЮЮёAКЭШЮЮёBдкЭЌвЛИіЪТЮёжаДІРэЁЃОЭПЩвдЪЙгУЯћЯЂжаМфМўРДЪЕЯжетжжЗжВМЪНЪТЮёЁЃ
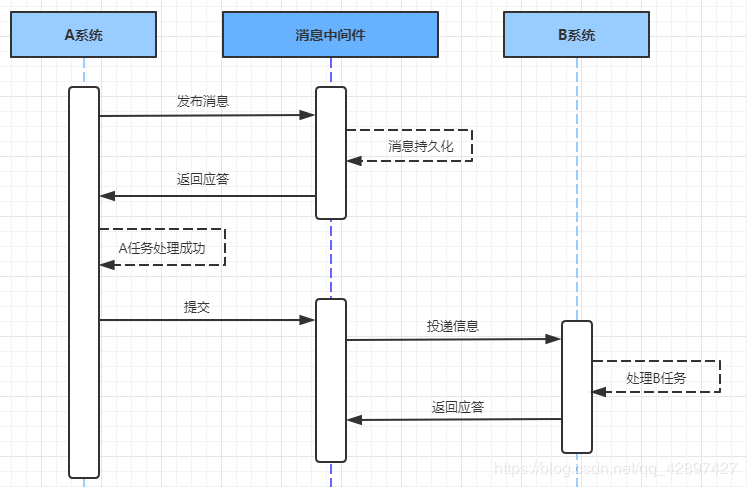
ЕквЛВН: ЯћЯЂгЩЯЕЭГAЭЖЕнЕНжаМфМў
дкЯЕЭГAДІРэШЮЮёAЧАЃЌЪзЯШЯђЯћЯЂжаМфМўЗЂЫЭвЛЬѕЯћЯЂ
ЯћЯЂжаМфМўЪеЕНКѓНЋИУЬѕЯћЯЂГжОУЛЏЃЌЕЋВЂВЛЭЖЕнЁЃГжОУЛЏГЩЙІКѓЃЌЯђAЛиИДвЛИіШЗШЯгІД№
ЯЕЭГAЪеЕНШЗШЯгІД№КѓЃЌдђПЩвдПЊЪМДІРэШЮЮёA
ШЮЮёAДІРэЭъГЩКѓЃЌЯђЯћЯЂжаМфМўЗЂЫЭCommitЛђепRollbackЧыЧѓЁЃИУЧыЧѓЗЂЫЭЭъГЩКѓЃЌЖдЯЕЭГAЖјбдЃЌИУЪТЮёЕФДІРэЙ§ГЬОЭНсЪјСЫ
ШчЙћЯћЯЂжаМфМўЪеЕНCommitЃЌдђЯђBЯЕЭГЭЖЕнЯћЯЂЃЛШчЙћЪеЕНRollbackЃЌдђжБНгЖЊЦњЯћЯЂЁЃЕЋЪЧ
ШчЙћЯћЯЂжаМфМўЪеВЛЕНCommitКЭRollbackжИСюЃЌФЧУДОЭвЊвРПП"ГЌЪБбЏЮЪЛњжЦ"ЁЃ
ГЌЪБбЏЮЪЛњжЦ
ЯЕЭГAГ§СЫЪЕЯже§ГЃЕФвЕЮёСїГЬЭтЃЌЛЙашЬсЙЉвЛИіЪТЮёбЏЮЪЕФНгПкЃЌЙЉЯћЯЂжаМфМўЕї
гУЁЃЕБЯћЯЂжаМфМўЪеЕНЗЂВМЯћЯЂБуПЊЪММЦЪБЃЌШчЙћЕНСЫГЌЪБУЛЪеЕНШЗШЯжИСюЃЌОЭЛсжїЖЏЕїгУ
ЯЕЭГAЬсЙЉЕФЪТЮёбЏЮЪНгПкбЏЮЪИУЯЕЭГФПЧАЕФзДЬЌЁЃИУНгПкЛсЗЕЛиШ§жжНсЙћЃЌжаМфМўИљОнШ§
жжНсЙћзіГіВЛЭЌЗДгІЃК
ЬсНЛ:НЋИУЯћЯЂЭЖЕнИјЯЕЭГB
ЛиЙі:жБНгНЋЬѕЯћЯЂЖЊЦњ
ДІРэжа:МЬајЕШД§
ЕкЖўВН: ЯћЯЂгЩжаМфМўЭЖЕнЕНЯЕЭГB
ЯћЯЂжаМфМўЯђЯТгЮЯЕЭГЭЖЕнЭъЯћЯЂКѓБуНјШызшШћЕШД§зДЬЌЃЌЯТгЮЯЕЭГБуСЂМДНјааШЮЮёЕФДІРэЃЌШЮЮёДІРэЭъГЩКѓБуЯђЯћЯЂжаМфМўЗЕЛигІД№ЁЃ
ШчЙћЯћЯЂжаМфМўЪеЕНШЗШЯгІД№КѓБуШЯЮЊИУЪТЮёДІРэЭъБЯ
ШчЙћЯћЯЂжаМфМўдкЕШД§ШЗШЯгІД№ГЌЪБжЎКѓОЭЛсжиаТЭЖЕнЃЌжБЕНЯТгЮЯћЗбепЗЕЛиЯћЗбГЩЙІЯьгІЮЊжЙЁЃ
вЛАуЯћЯЂжаМфМўПЩвдЩшжУЯћЯЂжиЪдЕФДЮЪ§КЭЪБМфМфИєЃЌШчЙћзюжеЛЙЪЧВЛФмГЩЙІЭЖЕнЃЌдђашвЊЪжЙЄИЩдЄЁЃетРяжЎЫљвдЪЙгУШЫЙЄИЩдЄЃЌЖјВЛЪЧЪЙгУШУЃСЯЕЭГЛиЙіЃЌжївЊЪЧПМТЧЕНећИіЯЕЭГЩшМЦЕФИДдгЖШЮЪЬтЁЃ
ЛљгкПЩППЯћЯЂЗўЮёЕФЗжВМЪНЪТЮёЃЌЧААыВПЗжЪЙгУвьВНЃЌзЂжиадФмЃЛКѓАыВПЗжЪЙгУЭЌВНЃЌзЂжиПЊЗЂГЩБОЁЃ
10.2.3 зюДѓХЌСІЭЈжЊ
зюДѓХЌСІЭЈжЊвВБЛГЦЮЊЖЈЦкаЃЖдЃЌЦфЪЕЪЧЖдЕкЖўжжНтОіЗНАИЕФНјвЛВНгХЛЏЁЃЫќв§ШыСЫБОЕиЯћЯЂБэРДМЧТМДэЮѓЯћЯЂЃЌШЛКѓМгШыЪЇАмЯћЯЂЕФЖЈЦкаЃЖдЙІФмЃЌРДНјвЛВНБЃжЄЯћЯЂЛсБЛЯТгЮЯЕЭГЯћЗбЁЃ
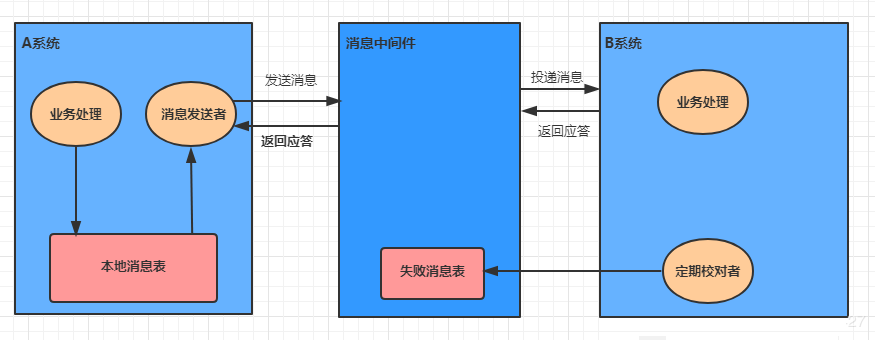
ЕквЛВН: ЯћЯЂгЩЯЕЭГAЭЖЕнЕНжаМфМў
ДІРэвЕЮёЕФЭЌвЛЪТЮёжаЃЌЯђБОЕиЯћЯЂБэжааДШывЛЬѕМЧТМ
зМБИзЈУХЕФЯћЯЂЗЂЫЭепВЛЖЯЕиЗЂЫЭБОЕиЯћЯЂБэжаЕФЯћЯЂЕНЯћЯЂжаМфМўЃЌШчЙћЗЂЫЭЪЇАмдђжиЪд
ЕкЖўВН: ЯћЯЂгЩжаМфМўЭЖЕнЕНЯЕЭГB
ЯћЯЂжаМфМўЪеЕНЯћЯЂКѓИКд№НЋИУЯћЯЂЭЌВНЭЖЕнИјЯргІЕФЯТгЮЯЕЭГЃЌВЂДЅЗЂЯТгЮЯЕЭГЕФШЮЮёжДаа
ЕБЯТгЮЯЕЭГДІРэГЩЙІКѓЃЌЯђЯћЯЂжаМфМўЗДРЁШЗШЯгІД№ЃЌЯћЯЂжаМфМўБуПЩвдНЋИУЬѕЯћЯЂЩОГ§ЃЌДгЖјИУЪТЮёЭъГЩ
ЖдгкЭЖЕнЪЇАмЕФЯћЯЂЃЌРћгУжиЪдЛњжЦНјаажиЪдЃЌЖдгкжиЪдЪЇАмЕФЃЌаДШыДэЮѓЯћЯЂБэ
ЯћЯЂжаМфМўашвЊЬсЙЉЪЇАмЯћЯЂЕФВщбЏНгПкЃЌЯТгЮЯЕЭГЛсЖЈЦкВщбЏЪЇАмЯћЯЂЃЌВЂНЋЦфЯћЗб
етжжЗНЪНЕФгХШБЕуЃК
гХЕуЃК вЛжжЗЧГЃОЕфЕФЪЕЯжЃЌЪЕЯжСЫзюжевЛжТадЁЃ
ШБЕуЃК ЯћЯЂБэЛсёюКЯЕНвЕЮёЯЕЭГжаЃЌШчЙћУЛгаЗтзАКУЕФНтОіЗНАИЃЌЛсгаКмЖрдгЛюашвЊДІРэЁЃ
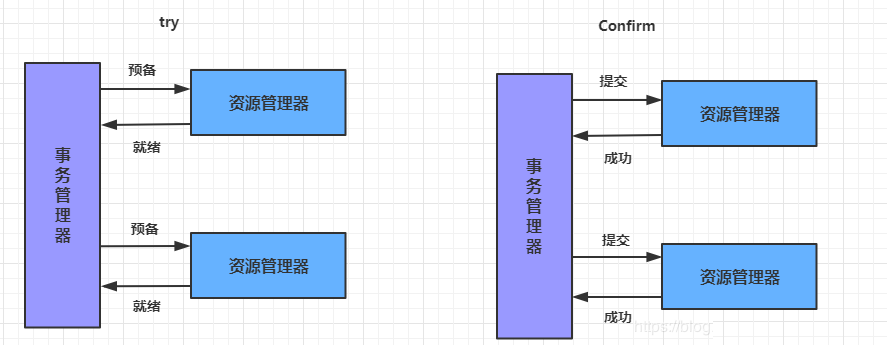
10.2.4 TCCЪТЮё
TCCМДЮЊTry Confirm CancelЃЌЫќЪєгкВЙГЅаЭЗжВМЪНЪТЮёЁЃTCCЪЕЯжЗжВМЪНЪТЮёвЛЙВгаШ§ИіВНжшЃК
TryЃКГЂЪдД§жДааЕФвЕЮё
етИіЙ§ГЬВЂЮДжДаавЕЮёЃЌжЛЪЧЭъГЩЫљгавЕЮёЕФвЛжТадМьВщЃЌВЂдЄСєКУжДааЫљашЕФШЋВПзЪдД
ConfirmЃКШЗШЯжДаавЕЮё
ШЗШЯжДаавЕЮёВйзїЃЌВЛзіШЮКЮвЕЮёМьВщЃЌ жЛЪЙгУTryНзЖЮдЄСєЕФвЕЮёзЪдДЁЃЭЈГЃЧщПіЯТЃЌВЩгУTCC
дђШЯЮЊ ConfirmНзЖЮЪЧВЛЛсГіДэЕФЁЃМДЃКжЛвЊTryГЩЙІЃЌConfirmвЛЖЈГЩЙІЁЃШєConfirmНзЖЮецЕФ
ГіДэСЫЃЌашв§ШыжиЪдЛњжЦЛђШЫЙЄДІРэЁЃ
CancelЃКШЁЯћД§жДааЕФвЕЮё
ШЁЯћTryНзЖЮдЄСєЕФвЕЮёзЪдДЁЃЭЈГЃЧщПіЯТЃЌВЩгУTCCдђШЯЮЊCancelНзЖЮвВЪЧвЛЖЈГЩЙІЕФЁЃШєCancelНзЖЮецЕФГіДэСЫЃЌашв§ШыжиЪдЛњжЦЛђШЫЙЄДІРэЁЃ
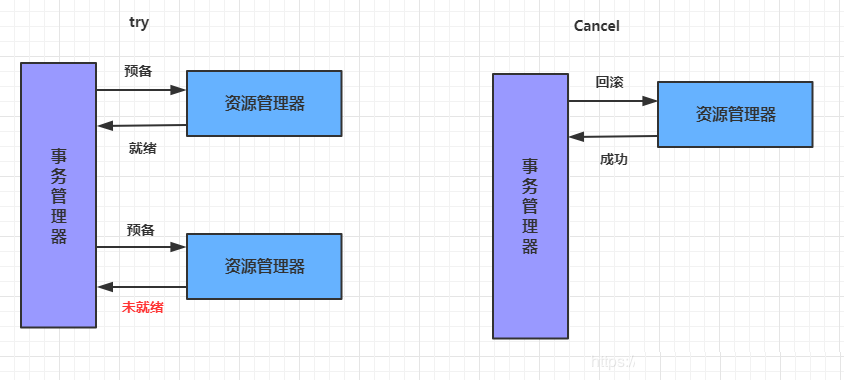
TCCСННзЖЮЬсНЛгыXAСННзЖЮЬсНЛЕФЧјБ№ЪЧЃК
XAЪЧзЪдДВуУцЕФЗжВМЪНЪТЮёЃЌЧПвЛжТадЃЌдкСННзЖЮЬсНЛЕФећИіЙ§ГЬжаЃЌвЛжБЛсГжгазЪдДЕФЫјЁЃ
TCCЪЧвЕЮёВуУцЕФЗжВМЪНЪТЮёЃЌзюжевЛжТадЃЌВЛЛсвЛжБГжгазЪдДЕФЫјЁЃ
TCCЪТЮёЕФгХШБЕуЃК
гХЕуЃКАбЪ§ОнПтВуЕФЖўНзЖЮЬсНЛЩЯЬсЕНСЫгІгУВуРДЪЕЯжЃЌЙцБмСЫЪ§ОнПтВуЕФ2PCадФмЕЭЯТЮЪЬтЁЃ
ШБЕуЃКTCCЕФTryЁЂConfirmКЭCancelВйзїЙІФмашвЕЮёЬсЙЉЃЌПЊЗЂГЩБОИпЁЃ
10.3 SeataНщЩм
2019 Фъ 1 дТЃЌАЂРяАЭАЭжаМфМўЭХЖгЗЂЦ№СЫПЊдДЯюФП FescarЃЈFast & EaSy
Commit And
RollbackЃЉЃЌЦфдИОАЪЧШУЗжВМЪНЪТЮёЕФЪЙгУЯёБОЕиЪТЮёЕФЪЙгУвЛбљЃЌМђЕЅКЭИпаЇЃЌВЂж№ВННтОіПЊЗЂепУЧ
гіЕНЕФЗжВМЪНЪТЮёЗНУцЕФЫљгаФбЬтЁЃКѓРДИќУћЮЊ SeataЃЌвтЮЊЃКSimple Extensible Autonomous
Transaction ArchitectureЃЌЪЧвЛЬзЗжВМЪНЪТЮёНтОіЗНАИЁЃ
SeataЕФЩшМЦФПБъЪЧЖдвЕЮёЮоЧжШыЃЌвђДЫДгвЕЮёЮоЧжШыЕФ2PCЗНАИзХЪжЃЌдкДЋЭГ2PCЕФЛљДЁЩЯбнНјЁЃЫќАбвЛИіЗжВМЪНЪТЮёРэНтГЩвЛИіАќКЌСЫШєИЩЗжжЇЪТЮёЕФШЋОжЪТЮёЁЃШЋОжЪТЮёЕФжАд№ЪЧаЕїЦфЯТЙмЯНЕФЗжжЇЪТЮёДяГЩвЛжТЃЌвЊУДвЛЦ№ГЩЙІЬсНЛЃЌвЊУДвЛЦ№ЪЇАмЛиЙіЁЃДЫЭтЃЌЭЈГЃЗжжЇЪТЮёБОЩэОЭЪЧвЛИіЙиЯЕЪ§ОнПтЕФБОЕиЪТЮёЁЃ
SeataжївЊгЩШ§ИіживЊзщМўзщГЩЃК
TCЃКTransaction Coordinator ЪТЮёаЕїЦїЃЌЙмРэШЋОжЕФЗжжЇЪТЮёЕФзДЬЌЃЌгУгкШЋОжадЪТЮёЕФЬсНЛКЭЛиЙіЁЃ
TMЃКTransaction Manager ЪТЮёЙмРэЦїЃЌгУгкПЊЦєЁЂЬсНЛЛђепЛиЙіШЋОжЪТЮёЁЃ
RMЃКResource Manager зЪдДЙмРэЦїЃЌгУгкЗжжЇЪТЮёЩЯЕФзЪдДЙмРэЃЌЯђTCзЂВсЗжжЇЪТЮёЃЌЩЯБЈЗжжЇЪТЮёЕФзДЬЌЃЌНгЪмTCЕФУќСюРДЬсНЛЛђепЛиЙіЗжжЇЪТЮёЁЃ
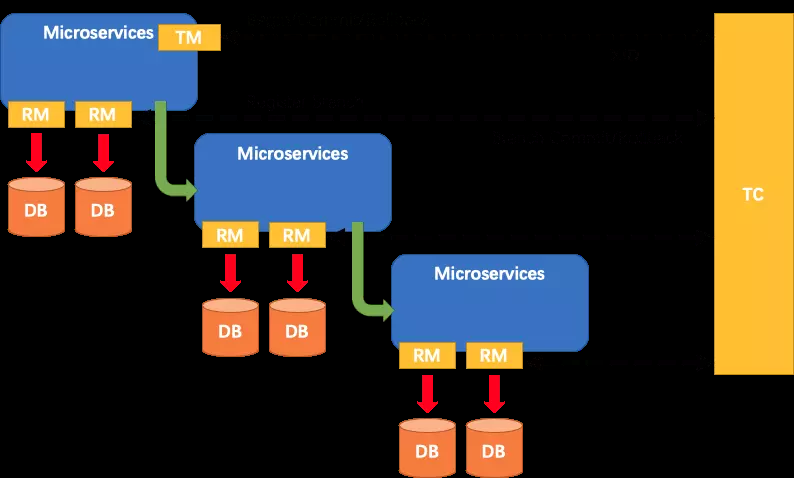
SeataЕФжДааСїГЬШчЯТ:
AЗўЮёЕФTMЯђTCЩъЧыПЊЦєвЛИіШЋОжЪТЮёЃЌTCОЭЛсДДНЈвЛИіШЋОжЪТЮёВЂЗЕЛивЛИіЮЈвЛЕФXID
AЗўЮёЕФRMЯђTCзЂВсЗжжЇЪТЮёЃЌВЂМАЦфФЩШыXIDЖдгІШЋОжЪТЮёЕФЙмЯН
AЗўЮёжДааЗжжЇЪТЮёЃЌЯђЪ§ОнПтзіВйзї
AЗўЮёПЊЪМдЖГЬЕїгУBЗўЮёЃЌДЫЪБXIDЛсдкЮЂЗўЮёЕФЕїгУСДЩЯДЋВЅ
BЗўЮёЕФRMЯђTCзЂВсЗжжЇЪТЮёЃЌВЂНЋЦфФЩШыXIDЖдгІЕФШЋОжЪТЮёЕФЙмЯН
BЗўЮёжДааЗжжЇЪТЮёЃЌЯђЪ§ОнПтзіВйзї
ШЋОжЪТЮёЕїгУСДДІРэЭъБЯЃЌTMИљОнгаЮовьГЃЯђTCЗЂЦ№ШЋОжЪТЮёЕФЬсНЛЛђепЛиЙі
TCаЕїЦфЙмЯНжЎЯТЕФЫљгаЗжжЇЪТЮёЃЌ ОіЖЈЪЧЗёЛиЙі
SeataЪЕЯж2PCгыДЋЭГ2PCЕФВюБ№ЃК
МмЙЙВуДЮЗНУцЃЌДЋЭГ2PCЗНАИЕФ RM ЪЕМЪЩЯЪЧдкЪ§ОнПтВуЃЌRMБОжЪЩЯОЭЪЧЪ§ОнПтздЩэЃЌЭЈЙ§XAавщЪЕЯжЃЌЖј
SeataЕФRMЪЧвдjarАќЕФаЮЪНзїЮЊжаМфМўВуВПЪ№дкгІгУГЬађетвЛВрЕФЁЃ
СННзЖЮЬсНЛЗНУцЃЌДЋЭГ2PCЮоТлЕкЖўНзЖЮЕФОівщЪЧcommitЛЙЪЧrollbackЃЌЪТЮёадзЪдДЕФЫјЖМвЊБЃГжЕНPhase2ЭъГЩВХЪЭЗХЁЃЖјSeataЕФзіЗЈЪЧдкPhase1
ОЭНЋБОЕиЪТЮёЬсНЛЃЌетбљОЭПЩвдЪЁШЅPhase2ГжЫјЕФЪБМфЃЌећЬхЬсИпаЇТЪЁЃ
10.4 SeataЪЕЯжЗжВМЪНЪТЮёПижЦ
БОЪОР§ЭЈЙ§SeataжаМфМўЪЕЯжЗжВМЪНЪТЮёЃЌФЃФтЕчЩЬжаЕФЯТЕЅКЭПлПтДцЕФЙ§ГЬ
ЮвУЧЭЈЙ§ЖЉЕЅЮЂЗўЮёжДааЯТЕЅВйзїЃЌШЛКѓгЩЖЉЕЅЮЂЗўЮёЕїгУЩЬЦЗЮЂЗўЮёПлГ§ПтДц
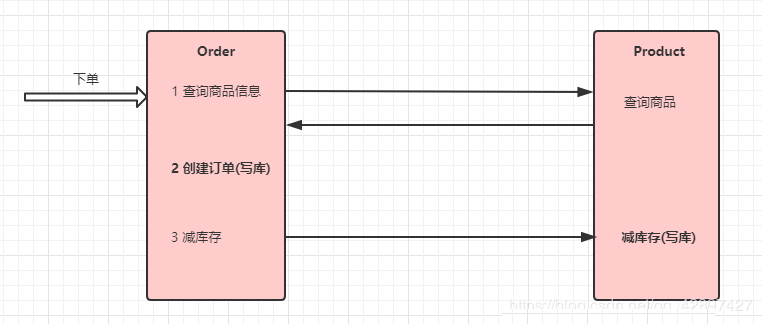
10.4.1 АИР§ЛљБОДњТы
10.4.1.1 аоИФorderЮЂЗўЮё
controller
OrderService

ProductService
@FeignClient(value
= "service-product")
public interface ProductService {
//МѕПтДц
@RequestMapping("/product/reduceInventory")
void reduceInventory(@RequestParam("pid")
Integer pid, @RequestParam("num")
int num);
}
|
10.4.1.2 аоИФProductЮЂЗўЮё
controller
//МѕЩйПтДц
@RequestMapping("/product/reduceInventory")
public void reduceInventory(Integer pid, int num)
{
productService.reduceInventory(pid, num);
}
|
service
@Override
public void reduceInventory(Integer pid, int num)
{
Product product = productDao.findById(pid).get();
product.setStock(product.getStock() - num);//МѕПтДц
productDao.save(product);
}
|
10.4.1.3 вьГЃФЃФт
дкProductServiceImplЕФДњТыжаФЃФтвЛИівьГЃ, ШЛКѓЕїгУЯТЕЅНгПк
@Override
public void reduceInventory(Integer pid, Integer
number) {
Product product = productDao.findById(pid).get();
if (product.getStock() < number) {
throw new RuntimeException("ПтДцВЛзу");
}
int i = 1 / 0;
product.setStock(product.getStock() - number);
productDao.save(product);
}
|
10.4.2 ЦєЖЏSeata
10.4.2.1 ЯТдиseata
10.4.2.2 аоИФХфжУЮФМў
НЋЯТдиЕУЕНЕФбЙЫѕАќНјааНтбЙЃЌНјШыconfФПТМЃЌЕїећЯТУцЕФХфжУЮФМўЃК
registry.conf
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
|
nacos-config.txt
service.vgroup_mapping.service
-product=default
service.vgroup_mapping.service -order=default |
етРяЕФгяЗЈЮЊЃК service.vgroup_mapping.${your-service-gruop}=default
ЃЌжаМфЕФ
${your-service-gruop} ЮЊздМКЖЈвхЕФЗўЮёзщУћГЦЃЌ етРяашвЊЮвУЧдкГЬађЕФХфжУЮФМўжаХфжУЁЃ
10.4.2.3 ГѕЪМЛЏseataдкnacosЕФХфжУ
# ГѕЪМЛЏseata ЕФnacosХфжУ
# зЂвт: етРявЊБЃжЄnacosЪЧвбОе§ГЃдЫааЕФ
cd conf
nacos-config.sh 127.0.0.1 |
жДааГЩЙІКѓПЩвдДђПЊNacosЕФПижЦЬЈЃЌдкХфжУСаБэжаЃЌПЩвдПДЕНГѕЪМЛЏСЫКмЖрGroupЮЊSEATA_GROUPЕФХфжУЁЃ
10.4.2.4 ЦєЖЏseataЗўЮё
cd bin
seata-server.bat -p 9000 -m file |
ЦєЖЏКѓдк Nacos ЕФЗўЮёСаБэЯТУцПЩвдПДЕНвЛИіУћЮЊ serverAddr ЕФЗўЮёЁЃ
10.4.3 ЪЙгУSeataЪЕЯжЪТЮёПижЦ
10.4.3.1 ГѕЪМЛЏЪ§ОнБэ
дкЮвУЧЕФЪ§ОнПтжаМгШывЛеХundo_logБэ,етЪЧSeataМЧТМЪТЮёШежОвЊгУЕНЕФБэ
CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
|
10.4.3.2 ЬэМгХфжУ
дкашвЊНјааЗжВМЪНПижЦЕФЮЂЗўЮёжаНјааЯТУцМИЯюХфжУ:
ЬэМгвРРЕ
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
|
DataSourceProxyConfig
Seata ЪЧЭЈЙ§ДњРэЪ§ОндДЪЕЯжЪТЮёЗжжЇЕФЃЌЫљвдашвЊХфжУ
io.seata.rm.datasource.DataSourceProxy ЕФ
BeanЃЌЧвЪЧ @PrimaryФЌШЯЕФЪ§ОндДЃЌЗёдђЪТЮёВЛЛсЛиЙіЃЌЮоЗЈЪЕЯжЗжВМЪНЪТЮё
|
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties (prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Primary
@Bean
public DataSourceProxy dataSource (DruidDataSource
druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
|
registry.conf
дкresourcesЯТЬэМгSeataЕФХфжУЮФМў registry.conf
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
}
|
bootstrap.yaml
spring:
application:
name: service-product
cloud:
nacos:
config:
server-addr: localhost:8848 # nacosЕФЗўЮёЖЫЕижЗ
namespace: public
group: SEATA_GROUP
alibaba:
seata:
tx-service-group: ${spring.application.name}
|
10.4.3.3 дкorderЮЂЗўЮёПЊЦєШЋОжЪТЮё
@GlobalTransactional//ШЋОжЪТЮёПижЦ
public Order createOrder(Integer pid) {}
|
10.4.3.4 ВтЪд
дйДЮЯТЕЅВтЪд
10.4.4 seataдЫааСїГЬЗжЮі
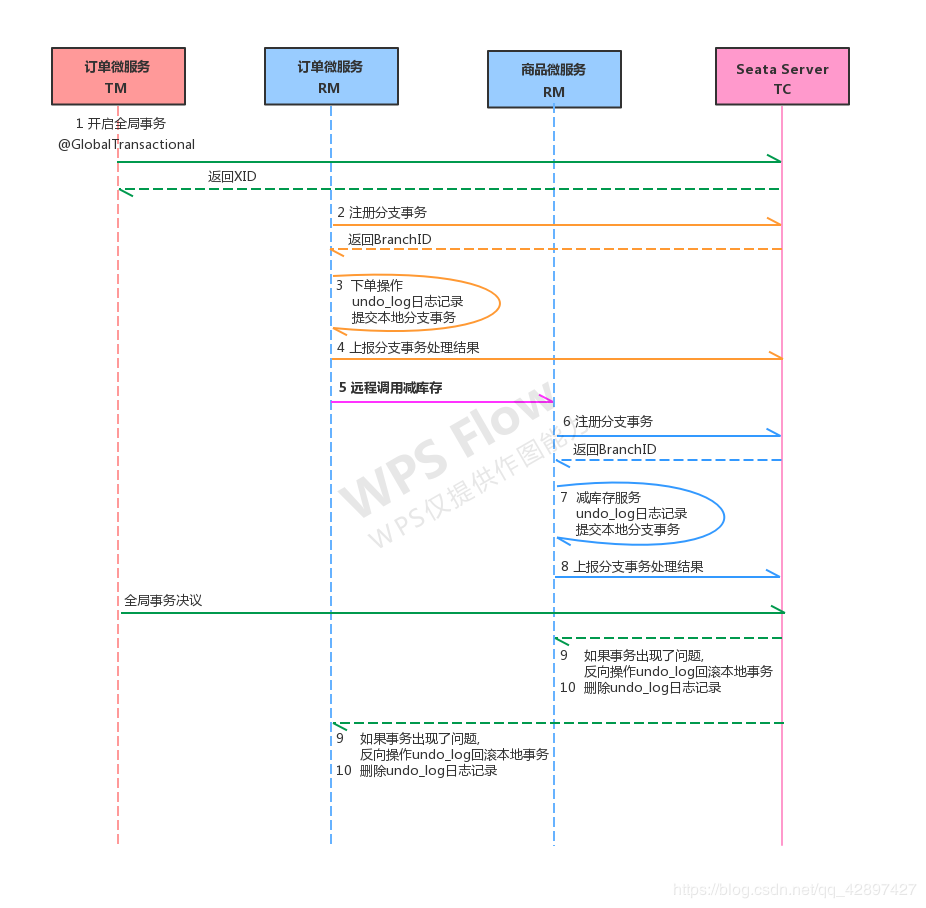
вЊЕуЫЕУїЃК
1ЁЂУПИіRMЪЙгУDataSourceProxyСЌНгЪ§ОнПтЃЌЦфФПЕФЪЧЪЙгУConnectionProxyЃЌЪЙгУЪ§ОндДКЭЪ§ОнСЌНгДњРэЕФФПЕФОЭЪЧдкЕквЛНзЖЮНЋundo_logКЭвЕЮёЪ§ОнЗХдквЛИіБОЕиЪТЮёЬсНЛЃЌетбљОЭБЃДцСЫжЛвЊгавЕЮёВйзїОЭвЛЖЈгаundo_logЁЃ
2ЁЂдкЕквЛНзЖЮundo_logжаДцЗХСЫЪ§ОнаоИФЧАКЭаоИФКѓЕФжЕЃЌЮЊЪТЮёЛиЙізїКУзМБИЃЌЫљвдЕквЛНзЖЮЭъГЩОЭвбОНЋЗжжЇЪТЮёЬсНЛЃЌвВОЭЪЭЗХСЫЫјзЪдДЁЃ
3ЁЂTMПЊЦєШЋОжЪТЮёПЊЪМЃЌНЋXIDШЋОжЪТЮёidЗХдкЪТЮёЩЯЯТЮФжаЃЌЭЈЙ§feignЕїгУвВНЋXIDДЋШыЯТгЮЗжжЇЪТЮёЃЌУПИіЗжжЇЪТЮёНЋздМКЕФBranch
IDЗжжЇЪТЮёIDгыXIDЙиСЊЁЃ
4ЁЂЕкЖўНзЖЮШЋОжЪТЮёЬсНЛЃЌTCЛсЭЈжЊИїИїЗжжЇВЮгыепЬсНЛЗжжЇЪТЮёЃЌдкЕквЛНзЖЮОЭвбОЬсНЛСЫЗжжЇЪТЮёЃЌетРяИїИїВЮгыепжЛашвЊЩОГ§undo_logМДПЩЃЌВЂЧвПЩвдвьВНжДааЃЌЕкЖўНзЖЮКмПьПЩвдЭъГЩЁЃ
5ЁЂЕкЖўНзЖЮШЋОжЪТЮёЛиЙіЃЌTCЛсЭЈжЊИїИїЗжжЇВЮгыепЛиЙіЗжжЇЪТЮёЃЌЭЈЙ§ XID КЭ Branch ID
евЕНЯргІЕФЛиЙіШежОЃЌЭЈЙ§ЛиЙіШежОЩњГЩЗДЯђЕФ SQL ВЂжДааЃЌвдЭъГЩЗжжЇЪТЮёЛиЙіЕНжЎЧАЕФзДЬЌЃЌШчЙћЛиЙіЪЇАмдђЛсжиЪдЛиЙіВйзїЁЃ
|









