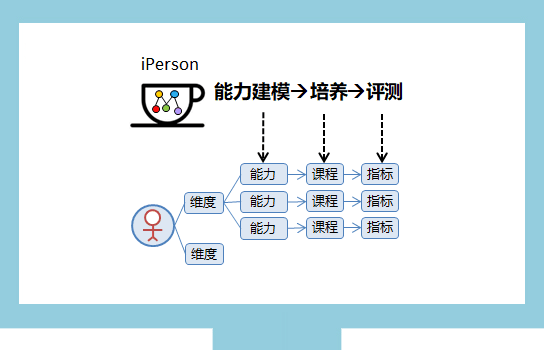
| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”Ύinfoq.comΘ§±ΨΈΡΒΡ÷ς“ΣΡΩΒΡ ««ΩΒς‘ΎΟφœρΖΰΈώΒΡΧεœΒΫαΙΙ÷–ΖΰΈώ…ηΦΤΒΡ÷Ί“Σ–‘ΓΘ |
|
“ΐ―‘
ΟφœρΖΰΈώΒΡΧεœΒΫαΙΙΘ®Service-Oriented ArchitectureΘ§SOAΘ©ΧαΙ©ΝΥ÷ß≥÷“ΒΈώΝιΜν–‘ΒΡ
IT ΝιΜν–‘‘ΕΨΑΓΘ‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«ΫΪ÷ΊΒψΧ÷¬έ IT ΝιΜν–‘ΒΡΝΫΗωΧΊΕ®ΖΫΟφΘΚΝς≥Χ Βœ÷ΒΡΖ÷άκΚΆΦρΜ·ΓΘ»γΚΈΥΒΟςΚΆ Βœ÷ΗςΗωΖΰΈώΕ‘
IT ΝιΜν–‘ΒΡ’β–©ΖΫΟφ”–Κή¥σΒΡ”ΑœλΘ§“ρ¥Υ“≤Ε‘“ΒΈώΝιΜν–‘”–Κή¥σΒΡ”ΑœλΓΘΈ“Ο«¥Υ¥ΠΒΡΡΩ±ξ «ΧαΙ©÷ß≥÷ SOA
‘ΕΨΑΒΡΖΰΈώΥΒΟςΚΆ Βœ÷÷ΗΡœΓΘ±ΨΈΡΒΡ¬έ ωΫαΙΙ»γœ¬ΘΚ
1. Ήœ»Θ§Έ“Ο«ΫΪΟη ωΫΪ‘ΎΤδ÷–ΥΒΟςΚΆ Βœ÷ΖΰΈώΚΆΖΰΈώ≤ΌΉςΒΡ…œœ¬ΈΡΜΖΨ≥ΓΘΈ“Ο«ΫΪΩΦ¬«
SOA Μυ¥ΓΫαΙΙΒΡ÷Α‘πΚΆΖΰΈώΒΡ÷Α‘πΓΘ
2.Ϋ”œ¬ά¥Θ§Έ“Ο«ΫΪΧ÷¬έ ”Ο”Ύ’ϊΗωΖΰΈώΘ®Εχ≤Μ «ΗςΗω≤ΌΉςΘ©ΙφΖΕΒΡ…ηΦΤ‘≠‘ρΓΘ
3.ΉνΚσΘ§Έ“Ο«ΫΪΥΒΟς ”Ο”ΎΗςΗωΖΰΈώ≤ΌΉςΒΡ…ηΦΤ‘≠‘ρΓΘ
Έ“Ο«‘ΎΈΡ÷–ΥυΗχ≥ωΒΡ…ηΦΤ‘≠‘ρ÷Φ‘ΎΆ®ΙΐΗΡ…ΤΝς≥Χ Βœ÷ΒΡΖ÷άκΚΆΦρΜ·ά¥ΧαΗΏ IT ΝιΜν–‘Θ§“ρ¥ΥΘ§Έ“Ο«ΫΪΆ®ΙΐΕ‘’β–©άμΡνΫχ––ΗϋΈΣ…ν»κΒΡΖ÷Έωά¥Άξ≥…Έ“Ο«ΒΡΫι…ήΓΘ
Ζ÷άκ
SOA ‘≠‘ρΖ«≥Θ«ΩΒςΫΪΖΰΈώ Ι”Ο’ΏΚΆΖΰΈώΧαΙ©’ΏΖ÷άκΩΣά¥Θ§ΙΊ”Ύ¥ΥάύΖ÷άκ ΒΦ ΒΡΚ§“εΘ§”–ΚήΕύ≤Μ’ΐ ΫΒΪΖ«≥Θ”–”ΟΒΡ‘ΦΕ®ΓΘΖ÷άκ±≥ΚσΒΡ“ΜΗωΜυ¥ΓΗ≈ΡνΨΆ «Θ§Ε‘ΖΰΈώΧαΙ©’ΏΒΡ–όΗΡ≤Μ”Π“Σ«σ‘ΎΖΰΈώ Ι”Ο’Ώ÷–Ϋχ––œύ”ΠΒΡ–όΗΡΓΘάΐ»γΘ§ΫΪΒ±«Α‘ΎΧΊΕ®≤ΌΉςœΒΆ≥…œ‘Υ––ΒΡΖΰΈώ÷Ί–¬≤Ω πΒΫΝμ“ΜΗωΤΫΧ®ΒΡΨωΕ®Άξ»ΪΩ…Ρή≤Μ“Σ«σΕ‘ΖΰΈώ Ι”Ο’ΏΫχ––ΗϋΗΡΓΘ“ΜΗω÷ς“ΣΒΡ
SOA ÷ΗΒΦ‘≠‘ρΨΆ «Θ§“ΣΦθ…Ό Ι”Ο’ΏΚΆΧαΙ©’Ώ÷°ΦδΒΡ“άάΒΙΊœΒΓΘ
Ζ÷άκ”Π”Ο”ΎΦΦ θ≤ψΟφΘ§«ΩΒς Web ΖΰΈώΚΆ“λ≤ΫœϊœΔΫΜΗΕ÷°άύΒΡΦΦ θΘ§“‘‘ –μ Ι”Ο’ΏΕάΝΔ”ΎΖΰΈώΧαΙ©’Ώ―Γ‘ώ Βœ÷ΚΆΩ…”Ο–‘―ΓœνΓΘΈ“Ο«ΜΙΩ…“‘Ά®ΙΐΗς÷÷ΖΫ Ϋ»Ο
SOA Μυ¥ΓΫαΙΙ Βœ÷ΦΦ θΖ÷άκΘ§»γΘΚ
ΖΰΈώ”ΠΗΟ…ηΦΤΈΣ”κ“Σ≤Ω πΒΫΤδ÷–ΒΡ SOA Μυ¥ΓΫαΙΙΦφ»ίΘ§ΧΊ±π «Θ§ΖΰΈώ”Π»Ζ±Θ±ήΟβ≤Μ±Ί“ΣΒΡώνΚœΓΘΨΌΗωœύΖ¥ΒΡάΐΉ”Θ§”–Ή¥Χ§ΖΰΈώΫ”ΩΎΫΪ«ψœρ”ΎΆ®ΙΐΫΪ Ι”Ο’Ώ”κΧΊΕ®ΧαΙ©’Ώ ΒάΐΙΊΝΣά¥‘ωΦ” Ι”Ο’ΏΚΆΧαΙ©’ΏΦδΒΡώνΚœΓΘ
Ζ÷άκΒΡΗ≈Ρν“≤Ά§―υ ”Ο”ΎΖ«ΦΦ θΒΡ“ΒΈώ≤ψ¥ΈΓΘΖΰΈώ Ι”Ο’Ώ”ΠΗΟΨΓΩ…Ρή”κΖΰΈώΧαΙ©’Ώ Βœ÷ΒΡ“ΒΈώ¬ΏΦ≠œΗΫΎΖ÷άκΓΘΈΣΝΥ Βœ÷¥ΥάύΖ÷άκΘ§Ά§―υ“≤–η“ΣΫχ––œΗ–ΡΒΡ…ηΦΤΓΘ‘Ύœ¬ΟφΒΡΖΰΈώ…ηΦΤ‘≠‘ρ≤ΩΖ÷Θ§Έ“Ο«ΫΪΧ÷¬έΫΪΖΰΈώΫ”ΩΎ±μ ωΈΣ”–“β“εΒΡ“ΒΈώ≤ΌΉςΘ®Εχ≤Μ «œΗΝΘΕ»ΒΡ‘≠”οΖΫΖ®Θ©ΒΡΚΟ¥ΠΓΘ
Νς≥Χ Βœ÷
‘Ύ SOA ÷–Θ§Έ“Ο«Ά®ΙΐΕ‘ΗςΗωΖΰΈώΫχ––±ύ≈≈Θ®Ά®Ιΐ±ύ≥ΧΖΫ ΫΜρ Ι”ΟΜυ”Ύ“ΒΈώΝς≥Χ÷¥––”ο―‘ΓΣΓΣBusiness
Process Execution LanguageΘ§BPELΓΣΓΣΒΡΙΛΨΏΘ©ά¥ Βœ÷“ΒΈώΝς≥ΧΓΘ»γΙϊ“Σ Βœ÷
SOA ‘ΕΨΑΘ§‘ρ±Ί–κΦρΜ·¥¥Ϋ®ΚΆ–όΗΡΝς≥ΧΒΡ»ΈΈώΓΣΓΣΦ¥Θ§ΖΰΈώ±ύ≈≈»ΈΈώΓΘ
“ΒΈώΝς≥Χ±ύ≈≈ΒΡΡΩ±ξ‘Ύ”Ύ ΒΦ Εχ”––ßΒΊ Βœ÷Υυ–ηΒΡ“ΒΈώ¬ΏΦ≠ΓΘΝς≥Χ Βœ÷»Υ‘±ΥυΟφΝΌΒΡΈ ΧβΑϋά®ΘΚ
―Γ‘ώ«ΓΒ±ΒΡΖΰΈώ≤ΌΉς
»ΖΕ® Ι”Ο’ΐ»Ζ≤Έ ΐΒς”ΟΖΰΈώΒΡΥ≥–ρ
¥ΠάμΗς÷÷Ω…ΡήΒΡœλ”ΠΘ§Αϋά®¥μΈσœλ”Π
”ΠΒ±«ε≥ΰΘ§ΖΰΈώ…ηΦΤΒΡ÷ ΝΩΕ‘±ύ≈≈ΦρΜ·”–Κή¥σΒΡ”ΑœλΓΘ”–ΙΊΖΰΈώΓΔ≤ΌΉςΚΆ≤Έ ΐΒΡΟϊ≥ΤΚΆ ΐΝΩ“‘ΦΑΈΡΒΒ÷ ΝΩΚΆΖΰΈώ≤ΌΉς÷°ΦδΒΡœύΜΞ“άάΒ≥ΧΕ»ΓΣΓΣΥυ”–…ηΦΤΈ ΧβΓΣΓΣΒΡΨω≤ΏΕΦΩ…ΡήΗχ±ύ≈≈¥χά¥Κή¥σΒΡ”ΑœλΓΘ
SOA …ηΦΤ‘≠‘ρ
’β“Μ≤ΩΖ÷ «”–ΙΊ’ϊΗω SOA œΒΆ≥ΒΡ÷ΗΡœΘ§¥ζ±μΝΥ‘ΎΫ®ΝΔœΒΆ≥ ±–η“ΣΫχ––Ψω≤ΏΒΡΗςΗωΖΫΟφΓΘΡζΫΪœρ…ηΦΤ»Υ‘±ΚΆ Βœ÷»Υ‘±ΧαΙ©ΡΡ–©Ιφ‘ρΚΆ÷ΗΒΦΖΫ’κΘΩΡζΒΡ
SOA Μυ¥ΓΫαΙΙΫΪΧαΙ©ΚΈ÷÷ΙΠΡήΘΩΈ“Ο«ΫΪΗχ≥ω“ΜœΒΝ–Ϋ®“ι…ηΦΤ‘≠‘ρΘ§ΒΪΟΩΗωΕΦ «…ηΦΤΙΐ≥Χ÷–ΒΡ“Μ÷÷’έ÷‘ΉωΖ®ΓΘΡζΒΡΤσ“ΒΩ…Ρή”–ΨΏΧεΒΡ“Σ«σΘ§Εχ–η“Σ―Γ‘ώ”κΈ“Ο«ΧαΙ©ΒΡ≥ΘΙφΫ®“ι≤ΜΆ§ΒΡ―ΓœνΓΘΈ“Ο«Χα≥ω…ηΦΤ‘≠‘ρΒΡΡΩΒΡ‘Ύ”Ύ±ξ Ε–η“ΣΫχ––Ψω≤ΏΒΡΖΫΟφΘΜΕχ¥ΥάύΨω≤Ώ‘ρ «ΦήΙΙ…ηΦΤ»Υ‘±ΒΡ‘π»ΈΓΘΈ“Ο«≤Δ≤Μ»œΈΣΥυΧα≥ωΒΡ…ηΦΤ‘≠‘ρΖ«≥Θ»ΪΟφΘΜ‘ΎΡζΒΡΤσ“Β÷– Βœ÷
SOA ±Θ§Κή”–Ω…ΡήΜα≤…”ΟΤδΥϊ‘≠‘ρΘ§Έ“Ο«Ζ«≥ΘœΘΆϊΡζΡήΫΪ’β–©…ηΦΤ‘≠‘ρΖ¥άΓΗχΈ“Ο«ΓΘ
SOA “Σ«σ“Μ÷¬–‘
”–ΚήΕύΩ…”Ο”Ύ¥¥Ϋ®ΓΔΖΔ≤ΦΓΔΖΔœ÷ΚΆΒς”ΟΖΰΈώΒΡΚρ―ΓΦΦ θΓΘSOA ”ΠΧαΙ©“ΜΗω≤ΈΩΦΧεœΒΫαΙΙΘ§“‘÷ΗΕ®ΖΰΈώΧαΙ©’ΏΚΆ Ι”Ο’ΏΫΪ Ι”ΟΒΡΧΊΕ®Μζ÷ΤΘΜΈ“Ο«”Π“‘‘Ύ
SAO Υυ”–≤Έ”κ’ΏΦδ Βœ÷“Μ÷¬–‘ΈΣΡΩ±ξΓΘ¥Υάύ“Μ÷¬–‘Ω…“‘Φθ…ΌΩΣΖΔΓΔΦ·≥…ΚΆΈ§ΜΛΙΛΉςΓΘ
»γΙϊ–η“Σ Ι”Ο≤ΈΩΦΧεœΒΫαΙΙ÷°ΆβΒΡ‘ΣΥΊΘ§Έ“Ο«ΆΤΦω Ι”Ο≤Ι≥δ–‘ΖΫΖ®ΓΘάΐ»γΘ§ΦΌ»γΈ“Ο«ΈΣΖΰΈώΖΔ≤ΦΚΆΖΔœ÷―Γ‘ώΒΡΜζ÷Τ «
UDDIΘ§ΒΪΡ≥ΗωΧΊΕ®ΒΡΩΣΖΔΆ≈Ε”“―‘Ύ Ι”Ο“ΜΗωΜυ”ΎΤδΥϊ¥φ¥ΔΩβΦΦ θΒΡΩΣΖΔΝς≥ΧΘ§¥Υ ±ΗΟ»γΚΈ¥ΠάμΡΊΘΩΈ“Ο«ΫΪ―Γ‘ώΆΕ»κΨΪΝΠΫΪΗΟΆ≈Ε”ΒΡΖΰΈώΆ§ ±ΖΔ≤ΦΒΫΝΫΗω¥φ¥ΔΩβΓΘ’β―υΘ§œ÷”–ΒΡΖΰΈώ Ι”Ο’ΏΨΆΩ…“‘ Ι”ΟΤδ λœΛΘ®ΒΪΩ…Ρή≤Δ≤Μ±ξΉΦΘ©ΒΡ¥φ¥ΔΩβΝΥΓΘΕχ‘Υ––”ΎΙΪΙ≤
SOA Μυ¥ΓΫαΙΙ…œΒΡ Ι”Ο’Ώ‘ρΩ…“‘ΈΣΥυ”–ΖΰΈώ Ι”Ο±ξΉΦ¥φ¥ΔΩβΓΣΓΣάΐ»γ UDDIΓΘ
SOA ΦρΜ·ΩΣΖΔ
Έ“Ο«œΘΆϊ»ΈΚΈΤσ“ΒΦΕΒΡ SOA Μυ¥ΓΫαΙΙΕΦΨΏ”–Ω……λΥθ–‘ΚΆΒ·–‘ΘΜΜΙ”ΠΑϋΚ§––“ΒΦΕΒΡΤσ“ΒΖΰΈώΉήœΏΘ®Enterprise
Service BusΘ§ESBΘ©ΚΆΑ≤»ΪΦΦ θΓΘΜρ’ΏΘ§ΜΜ÷÷ΥΒΖ®Θ§“‘ SOA ΈΣΡΩ±ξΒΡΖΰΈώΚΆΝς≥ΧΒΡΩΣΖΔ»Υ‘±Ω…άϊ”Ο≥… λΒΡ÷–ΦδΦΰΘ§“άάΒ
SOA Μυ¥ΓΫαΙΙΧαΙ©Έ ΧβΒΡΫβΨωΖΫΑΗΘ§»γ…μΖί―ι÷ΛΓΔœϊœΔΉΣΜΜΚΆΩ…ΩΩœϊœΔΫΜΗΕΓΘ
’β–©÷–ΦδΦΰΙΠΡήΒΡΧαΙ©”Π“‘“ΜΗω÷Ί“ΣΒΡ‘≠‘ρΈΣΜυ¥ΓΘΚΖΰΈώΚΆΝς≥ΧΩΣΖΔ»Υ‘±”Π‘Εάκ÷–ΦδΦΰ Βœ÷ΒΡΗ¥‘”œΗΫΎΓΘΈ“Ο«ΒΡάμœκΡΩ±ξ «Θ§‘ΎΈ“Ο«ΒΡ
SOA ΜΖΨ≥÷–ΙΛΉςΒΡΩΣΖΔ»Υ‘±”Π÷Μ–η“Σ“ΒΈώΝλ”ρΒΡœύΙΊ÷Σ ΕΚΆΜυ±ΨΒΡ±ύ≥ΧΦΦ«…ΓΘ
Έ“Ο«Ω…“‘Ά®ΙΐΗς÷÷ΖΫ Ϋ Βœ÷¥ΥΡΩ±ξΘ§»γœ¬Υυ ωΘΚ
…υΟςΦΦ θΘΚ J2EE ±ύ≥ΧΡΘ–ΆΨΆ « Ι”Ο…υΟςΦΦ θΧαΙ©”Π”Ο≥Χ–ρ¬ΏΦ≠ΚΆ÷–ΦδΦΰ≈δ÷ΟΖ÷άκΒΡ“ΜΗωάΐΉ”ΓΘάΐ»γΘ§”Π”Ο≥Χ–ρΉιΉΑ»Υ‘±Ά®Ιΐ‘Ύ≤Ω πΟη ωΖϊΘ®Εχ≤Μ «¥ζ¬κΘ©÷–ΧμΦ”œύ”ΠΧθΡΩά¥”Π”Ο
EJB ΖΫΖ®Ϋ«…ΪΒΡΑ≤»Ϊ Ύ»®ΘΜ»ΜΚσ≤Ω π»Υ‘±ΜαΫΪ’β–©Ϋ«…Ϊ”≥…δΒΫ”ΟΜßΚΆΉιΓΘ«κΉΔ“βΘ§≤Ω π»Υ‘±Έό–η±ύ–¥»ΈΚΈ Ύ»®¥ζ¬κΓΘ
≥ιœσΘΚ ‘ΎΡ≥–©«ιΩωœ¬Θ§SOA Μυ¥ΓΫαΙΙ÷–Ω…“‘ΧαΙ© APIΘ§“‘”Ο”ΎΧΊΕ®ΒΡ”ΟΆΨΓΘάΐ»γΘ§SOA Μυ¥ΓΫαΙΙΩ…“‘ΧαΙ©¥μΈσ±®ΗφΚΆ…σΚΥΜζ÷ΤΓΘ‘Ύ…ηΦΤ¥Υάύ
API ±”ΠΖ«≥Θ–Γ–ΡΘ§“ΣΉΔ“βΤδ“Ή”Ο–‘ΓΘΈ“Ο«”Π”≈œ»ΩΦ¬«…υΟςΦΦ θΘ§Εχ≤Μ «Ε‘’β–©Μζ÷ΤΫχ––±ύ≥Χ≈δ÷ΟΓΘΆ§―υΘ§‘Ύ±ξΉΦ
API Ω…”Ο ±Θ®άΐ»γ Java »’÷Ψ APIΘ©Θ§Έ“Ο«”ΠΆ®Ιΐ’β–©±ξΉΦ API ΙΪΩΣ SOA Μυ¥ΓΫαΙΙΙΠΡήΘ§Εχ≤Μ «≤…”ΟΉ‘ΦΚΩΣΖΔ±ύ–¥ΒΡΖΫ ΫΓΘ
¥ζ¬κ…ζ≥…ΘΚ ‘ΎΈόΖ®±ήΟβ¥ζ¬κΗ¥‘”–‘ΒΡΒΊΖΫΘ§Ω…“‘ Ι”Ο¥ζ¬κ…ζ≥…ΦΦ θΓΘάΐ»γΘ§Web ΖΰΈώΟη ω”ο―‘Θ®Web Services
Definition LanguageΘ§WSDLΘ©ΨΆΩ…“‘ΈΣΩΣΖΔ»Υ‘±“ΰ≤Ί SOAPΓΔHTTP ΚΆ JMS
ΒΡΗ¥‘”œΗΫΎΓΘ’β «Ά®ΙΐΉιΚœ”Ο WSDL ±μ ΨΒΡΩ…”…ΦΤΥψΜζ¥ΠάμΒΡΫ”ΩΎΕ®“εΚΆΩ…¥” WSDL …ζ≥…œύΙΊΒς”Ο¥ζ¬κΒΡ”ο―‘ΧΊΕ® Βœ÷ΒΡΙΛΨΏά¥ Βœ÷ΒΡΓΘ
ΙΛΨΏΘΚ‘Ύ≤ΜΩ…±ήΟβ SOA Μυ¥ΓΫαΙΙΒΡœΗΫΎΫχ»κΩΣΖΔ»Υ‘±¥ζ¬κΒΡ«ιΩωœ¬Θ§Έ“Ο«Ω…“‘Ά®Ιΐ Ι”ΟΚœ ΒΡΙΛΨΏά©’ΙΩΣΖΔΜΖΨ≥ά¥Φθ…ΌΩΣΖΔ»Υ‘±ΙΛΉςΒΡΗ¥‘”–‘ΓΘIBM
Rational? Software Development Platform ≤ζΤΖΥυΧαΙ©ΒΡΜυ”Ύ Eclipse
ΒΡΜΖΨ≥Ω… Ι”ΟΉ‘Ε®“ε≤εΦΰΓΔ¥ζ¬κΤ§ΕΈΚΆ”ΟΜß÷ΗΡœ«αΥ…ΒΊΫχ––ά©’ΙΓΘ
ΡΘ–Ά«ΐΕ·ΒΡΩΣΖΔΘΚΡΘ–Ά«ΐΕ·ΒΡΩΣΖΔΦΦ θΩ…“‘±Μ ”ΈΣ«ΑΟφΝΫ÷÷ΖΫΖ®ΒΡΧΊΕ®Η¥‘”ΉιΚœΘ§Ά§ ±άϊ”ΟΝΥΙΛΨΏΚΆ¥ζ¬κ…ζ≥…ΙΠΡήά¥ΦρΜ·ΩΣΖΔΧε―ιΓΘΩΣΖΔ»Υ‘±…ζ≥…Ά≥“ΜΫ®ΡΘ”ο―‘Θ®Unified
Modeling LanguageΘ§UMLΘ©ΡΘ–ΆΘ§¥ΥάύΡΘ–ΆΩ…ΉΣΜΜΈΣœύ”ΠΒΡ¥ζ¬κΘ§Τδ÷–ΑϋΚ§άϊ”Ο SOA
Μυ¥ΓΫαΙΙΥυ±Ί–ηΒΡ¥ζ¬κΓΘ
Ήή÷°Θ§‘ΎΕ®“εΟφœρΖΰΈώΒΡΧεœΒΫαΙΙΦΑΤδΜυ¥ΓΫαΙΙ ±Θ§Έ“Ο«±Ί–κΧΊ±πΉΔ“βΩΣΖΔ»Υ‘±ΒΡ–η«σΓΘΒ±ΈΣΩΣΖΔ»Υ‘±ΧαΙ©÷ΗΡœΘ§“‘Ηφ÷ΣΥϊΟ«”Π»γΚΈΩΣΖΔΜρ Ι”ΟΖΰΈώ ±Θ§Έ“Ο«”ΠΗΟ―Α’“Ω…¥ΌΫχ’β–©÷ΗΒΦΖΫ’κΉώ―≠ΒΡΜζ÷ΤΓΘ“ΜΗωΉήΒΡ‘≠‘ρ «ΓΑ÷Μ“ΣΩ…ΖΫ±ψΆξ≥…Υυ–ηΒΡΙΛΉςΘ§ΨΆΥΒΟςΖΫΖ® «’ΐ»ΖΒΡΓΘΓ±ΜΜΨδΜΑΥΒΘ§Ήώ―≠œύΙΊ÷ΗΡœ”ΠΒ±ΈΣΉηΝΠΉν–ΓΒΡΖΫΖ®ΓΘSOA
ΡΎΒΡΩΊ÷ΤΕ‘Τδ≥…ΙΠ…θΈΣΙΊΦϋΓΘ
¥”ΩΣΖΔ»Υ‘±ΒΡΫ«Ε»Εχ―‘Θ§ΥϊΟ«”–‘π»ΈΝΥΫβ SOA Μυ¥ΓΫαΙΙΚΆ÷ΗΡœΘ§≤ΔΜΐΦΪ Ι”Ο÷ΗΡœΘ§Εχ≤Μ“Σ≥Δ ‘Ϋχ––Ιφ±ήΓΘ
ΖΰΈώΨΏ”–±ξΉΦΒΡΓΔΨ≠Ιΐ’ΐ ΫΕ®“εΒΡΩ…”…ΦΤΥψΜζ¥ΠάμΒΡΫ”ΩΎ
ΝΥΫβΝΥΙΛΨΏΚΆ¥ζ¬κ…ζ≥…‘Ύ SOA Βœ÷÷–Ω…Αγ―ί÷Ί“ΣΫ«…Ϊ÷°ΚσΘ§Έ“Ο«œ÷‘Ύ“Σ«ΩΒς Ι”ΟΩ…”…ΦΤΥψΜζ¥ΠάμΒΡΫ”ΩΎΒΡ÷Ί“Σ–‘ΓΘΒ± Ι”ΟΕ®“εΝΦΚΟΒΡΩ…”…ΦΤΥψΜζ¥ΠάμΒΡ”ο―‘Οη ωΝΥΫ”ΩΎ ±Θ§ ΒΦ …œΨΆΈΣΗς÷÷ΙΛΨΏ÷ß≥÷ΙΠΡήΧαΙ©ΝΥ÷ß≥÷ΓΘΈ“Ο«œΘΆϊΗΡ…ΤΖ÷άκΉ¥ΩωΘ§“ρ¥ΥΈ“Ο««ΩΝ“Ϋ®“ι Ι”Ο
WSDL ÷°άύ’ΐ ΫΕ®“εΒΡΩΣΖ≈±ξΉΦ”ο―‘Θ§Εχ≤Μ“Σ Ι”ΟΉ®”ΟΗώ ΫΓΘ
Ω…”…ΦΤΥψΜζ¥ΠάμΒΡΖΫΖ®ΒΡΗ≈Ρν”ΠΗΟ¥”ΖΰΈώΫ”ΩΎΟη ωΘ®»γ WSDLΘ©ά©’ΙΒΫΥυ”–ΤδΥϊ–Έ ΫΒΡ…υΟς–≈œΔΜρ‘Σ ΐΨίΓΘ÷Μ”–Ά§ ±«ΩΒς…υΟςΦΦ θΚΆΩ…”…ΦΤΥψΜζ¥ΠάμΒΡ‘Σ ΐΨίΘ§≤≈ΡήΫΪΤδœύΙΊΒΡΗ¥‘”–‘¥”“ΒΈώ”Π”Ο≥Χ–ρΩΣΖΔ»Υ‘±ΉΣ“ΤΒΫΜυ”Ύ±ξΉΦΒΡ÷–ΦδΦΰ÷–ΓΘ–¬–ΥΒΡ
WS-Policy ÷°άύΒΡΦΦ θ‘Ύ÷ß≥÷¥ΥΖΫΖ®ΖΫΟφ≥δΒ±Ή≈÷Ί“ΣΒΡΫ«…ΪΓΘ
ΖΰΈώ”Π…ηΦΤΈΣΩ…÷Ί”Ο
ΖΰΈώ…ηΦΤ»Υ‘±”ΠΗΟΦ«ΉΓΘ§ΥϊΟ«ΥυΩΣΖΔΒΡ»ΈΚΈΖΰΈώΕΦΩ…Ρή≥…ΈΣΩ…÷Ί”ΟΉ ≤ζΓΘ…ηΦΤ»Υ‘±≤Μ”Π÷ΜΙΊΉΔΖΰΈώΒΡΉν≥θ Ι”Ο’ΏΒΡ–η«σΘ§Εχ”ΠΗΟΫχ––ΗϋΈΣΙψΖΚΒΡ“ΒΈώΖ÷ΈωΘ§“‘»ΖΕ®Ηϋ»ΪΟφΒΡ–η«σΓΘΈ“Ο«Ϋ®“ιΘ§…ηΦΤ»Υ‘±”ΠΩΦ¬«ΖΰΈώΩ…ΡήΒΡΖΔ’ΙΖΫœρΘΚ
1.…ηΦΤ±Ί–κΡή ”Π≤ΜΕœ‘ωΦ”ΒΡΆΧΆ¬ΝΩΘΜ»γΙϊΖΰΈώ‘Ύ Ι”ΟΖΰΈώΒΡ ΐΝΩ‘ωΦ”ΒΡ«ιΩωœ¬»‘Ω…≥…ΙΠ‘Υ––Θ§Ρ«Ο¥ Ι”Ο¬ “≤Μα≥…ΦΕ ΐΒί‘ωΓΘ
2.»γΙϊ Ι”ΟΖΰΈώΒΡ ΐΝΩ‘ωΦ”Θ§‘ρ ΐΨίΝΩΚΆ≤ΔΖΔ ΐΨίΖΟΈ ΡΘ ΫΩ…ΡήΜα”κΉν≥θΆΕ»κ Ι”Ο ±ΒΡ«ιΩω¥σΈΣ≤ΜΆ§ΓΘ
3.Έ“Ο«±Ί–κΕ‘ΖΰΈώ«κ«σΒΡΈ¥ά¥‘ω≥ΛΫχ––‘ΛΦΤΘΜ–¬ Ι”Ο’ΏΩ…Ρή–η“ΣΤδΥϊΒΡΙΠΡήΘ§Μρ’Ώ–η“ΣΕ‘œ÷”–ΙΠΡήΫχ––ΗϋΗΡ
ΈΡ±ΨΤδ”ύ≤ΩΖ÷ΥυΧ÷¬έΒΡΚήΕύ…ηΦΤ‘≠‘ρΕΦ”κ»Ζ±ΘΖΰΈώΒΡΩ……λΥθ–‘ΚΆΩ…Έ§ΜΛ–‘Οή«–œύΙΊΓΘ–η“ΣΧα–―“Μœ¬ΘΚΩ…ΡήΜα”…”ΎΩΦ¬«ΝΥ«±‘ΎΒΡ÷Ί”ΟΕχ≤…”Ο≤Μ«ΓΒ±ΒΡ…ηΦΤΖΫΖ®Ε‘ΖΰΈώΫχ––…ηΦΤΘ§¥”ΕχΒΦ÷¬ Βœ÷ΓΑΙΐΒ±Γ±ΓΘΈ“Ο«ΙΡάχΫΪΉν≥θΒΡ÷ΊΒψΖ≈‘ΎΖΰΈώΫ”ΩΎ…ηΦΤ…œΘ§“‘»Ζ±ΘΤδ÷ß≥÷Ω……λΥθ–‘ΘΜΈ“Ο«ΒΡ…ηΦΤ‘≠‘ρΩ…Αο÷ζΉωΒΫ’β“ΜΒψΓΘ»ΜΚσ…ζ≥…“ΜΗωΗΟΫ”ΩΎΒΡ’Ϋ θ–Ά Βœ÷Θ§“Σ«σΉψ“‘¬ζΉψΡΩ«Α“―÷ΣΒΡ–η«σΓΘΦΌ»γΗΟΫ”ΩΎ…ηΦΤΝΦΚΟΘ§”ΠΗΟΩ…“‘‘Ύ≥ωœ÷œύΙΊ–η«σ ±Χφ¥ζ…λΥθ–‘ΗϋΚΟΒΡ Βœ÷ΓΘ
ΖΰΈώ…ηΦΤ‘≠‘ρ
Έ“Ο«‘χΥΒΙΐΘ§ΖΰΈώ «ΤδΫ”ΩΎ≤…”ΟΡ≥÷÷“Μ÷¬»œΩ…ΒΡΗώ ΫΖΔ≤ΦΒΡΖΰΈώ≤ΌΉςΒΡ¬ΏΦ≠Ζ÷ΉιΘ§Ρ«Ο¥Έ“Ο«Ϋ”œ¬ά¥ΫΪΧ÷¬έ ”Ο”Ύ’ϊΗωΖΰΈώΒΡ…ηΦΤ‘≠‘ρΓΘ‘Ύœ¬ΟφΒΡΖΰΈώ≤ΌΉς…ηΦΤ‘≠‘ρ÷–Θ§Έ“Ο«ΫΪΧ÷¬έΗςΗω≤ΌΉςΒΡ…ηΦΤΓΘ
ΟϋΟϊΖΰΈώ ±”Π“‘Ήν¥σΜ·“Ή”Ο–‘ΈΣΡΩ±ξ
Έ“Ο«‘Ύ―Γ‘ώΖΰΈώΓΔ≤ΌΉςΓΔ ΐΨίάύ–ΆΚΆ≤Έ ΐΒΡΟϊ≥Τ ±”–“ΜΗω÷ΗΒΦ‘≠‘ρΘΚœΘΆϊΉν¥σΜ·ΖΰΈώΒΡ“Ή”Ο–‘ΓΘΈ“Ο«œΘΆϊΑο÷ζΝς≥ΧΩΣΖΔ»Υ‘±±ξ Ε Βœ÷“ΒΈώΝς≥ΧΥυ–ηΒΡΖΰΈώΚΆ≤ΌΉςΓΘ“ρ¥ΥΘ§Έ“Ο««ΩΝ“Ϋ®“ι Ι”ΟΖΰΈώ Ι”Ο’ΏΉ®“ΒΝλ”ρΡΎ”–“β“εΒΡΟϊ≥ΤΘ§”≈œ»―Ôϓ¸ώΗ≈ΡνΕχ≤Μ «ΦΦ θΗ≈ΡνΓΘ
Έ“Ο«ΒΡΫ®“ιΨΆ «ΘΚ”Π Ι”ΟΟϊ¥ Ε‘ΖΰΈώΫχ––ΟϋΟϊΘΜΕχ”Π Ι”ΟΕ·¥ Ε‘≤ΌΉςΫχ––ΟϋΟϊΓΘ
±»Ϋœ«εΒΞ 1 ΚΆ«εΒΞ 2 ÷–Υυ ΨΒΡΝΫΗωΖΰΈώΕ®“εΓΘΈ“Ο« Ι”ΟΦρΜ·ΒΡΈ±¥ζ¬κά¥Φθ…Ό±ύ≥Χ”ο―‘ΓΑ¥ΊΓ±ΓΘ
«εΒΞ 1. Ι”ΟΕ·¥ ΕΧ”οΚΆ IT ΙΙ‘λΒΡΖΰΈώΕ®“ε
| ManageCustomerData
{
InsertCustomerRecord()
UpdateCustomerRecord()
// etc ...
} |
«εΒΞ 2. Ι”ΟΟϊ¥ ΚΆΕ·¥ ΕΧ”οΦΑ“ΒΈώΗ≈ΡνΒΡΖΰΈώΕ®“ε
|
CustomerService {
CreateNewCustomer()
ChangeCustomerAddress()
CorrectCustomerAddress()
EnableOverdraftFacilityForCustomer()
// etc ...
} |
«κΉΔ“β«εΒΞ 1 ÷–ΒΡΕ®“ε «»γΚΈ Ι”Ο IT Η≈ΡνΫχ––±μ ω≤ΔΆ§ ±ΈΣΖΰΈώΚΆ≤ΌΉς Ι”ΟΕ·¥ ΕΧ”οΒΡΓΘ‘Ύ«εΒΞ 2
÷–Θ§ΖΰΈώ±μ ωΈΣΟϊ¥ Θ§Εχ≤ΌΉς‘ρ Ι”ΟΨΏ”–«ε≥ΰΒΡ“ΒΈώΚ§“εΒΡΕ·¥ ΕΧ”οΫχ––ΟϋΟϊΓΘΈ“Ο«»œΈΣΒΎΕΰΗω ΨάΐΒΡ“Ή”Ο–‘ΗϋΚΟ“Μ–©ΓΘ¥ΥΆβΘ§‘ΎΒΎΕΰΗω Ψάΐ÷–Θ§ΖΰΈώΒΡ“ΒΈώ”ΟΆΨΖ«≥Θ«ε≥ΰΘ§Εχ≤ΜΒΞ «ΫωΫω÷Η ΨΤδ δ≥ωΓΘ“ρ¥ΥΘ§Έ“Ο«≤Μ Ι”ΟΓΑupdate
customer recordΓ±Θ®Ω…“‘ΈΣ≥ω”Ύ»ΈΚΈ‘≠“ρΫχ––ΒΡ»ΈΚΈΗϋ–¬Θ©Θ§Εχ Ι”ΟΓΑenable overdraft
facilityΓ±ΓΘ”κ¥ΥάύΥΤΘ§‘ΎΩΆΜßΑα«® ±Θ§Έ“Ο« Ι”ΟΓΑchange customer addressΓ±ΖΫΖ®ΗϋΗΡΩΆΜßΒΊ÷ΖΘΜΕχ‘ΎœΘΆϊΗϋ’ΐΈό–ß ΐΨί ± Ι”ΟΓΑcorrect
customer addressΓ±Ηϋ’ΐΩΆΜßΒΊ÷ΖΘ§“ρΈΣ’β―υΚή»ί“ΉΩ¥≥ω’βΝΫΗω≤ΌΉς≤…”ΟΝΥ≤ΜΆ§ΒΡΖΰΈώ¬ΏΦ≠ΓΘ
»γΙϊ≤…”ϓ¸ώΗ≈Ρν±μ ωΖΰΈώΚΆ≤ΌΉςΟϊ≥ΤΘ§‘ρ±Ί–κΟή«–ΉΔ“β»γΚΈ»ΖΕ®’β–©Οϊ≥ΤΓΘ’βΨΆΖ«≥Θ–η“Σ”–“ΜΗω’ΐ ΫΒΡ θ”ο¥ Μψ±μΘ§Ω…“‘Ά®Ιΐ“ΒΈώΖ÷ΈωΜνΕ·ΒΟΒΫ’βΗω¥ Μψ±μΓΘ¥ Μψ±μ”ΠΗΟ”–“ΜΗω’ΐ ΫΒΡΥυ”–’ΏΓΘ
ΖΰΈώ”ΠΨΏ”–ΨΪ–Ρ―Γ‘ώΒΡΝΘΕ»
ΝΘΕ» “Μ¥ ‘Ύ SOA œύΙΊΧ÷¬έ÷–”–Εύ÷÷≤ΜΆ§ΒΡ”ΟΖ®ΓΘ‘Ύ±ΨΈΡΒΡΖΰΈώ…ηΦΤΧ÷¬έ÷–Θ§Έ“Ο«ΩΦ¬«ΒΡ «ΖΰΈώ±Ψ…μΒΡΝΘΕ»Θ§Φ¥ΖΰΈώ”ΠΗΟΑϋΚ§ΒΡ≤ΌΉς ΐΝΩΓΘ
ΟΜ”–Ω…”Ο”Ύ»ΖΕ®ΖΰΈώΝΘΕ»ΒΡΦρΒΞΤτΖΔ ΫΖΫΖ®ΓΘΈ“Ο«ΫΪΧαΙ©ΝΫΗω‘Ύ…ηΦΤΖΰΈώ ±”ΠΗΟΩΦ¬«ΒΡ“ρΥΊΒΡ ΨάΐΦ”“‘ΥΒΟςΘΚ
1.ΖΰΈώΫΪΆ®≥ΘΉςΈΣ≤β ‘ΚΆΖΔ≤ΦΒΡΒΞΈΜΓΘ»γΙϊΝΘΕ»Ιΐ¥÷Θ§ΕχΫΪ¥σΝΩ≤ΌΉςΖ÷ΉιΒΫΒΞΗωΖΰΈώ÷–Θ§‘ρΩ…ΡήΫΪ‘ωΦ”ΖΰΈώΒΡ Ι”Ο’ΏΓΘ“ρ¥ΥΘ§»γΙϊΈ“Ο«Ε‘ΖΰΈώΒΡΡ≥–©ΖΫΟφΫχ––ΗϋΗΡΘ®Ω…ΡήΫωΈΣΝΥΤδ÷–“Μ–© Ι”Ο’ΏΒΡάϊ“φΘ©Θ§‘ρ±Ί–κ÷Ί–¬ΖΔ≤Φ’ϊΗωΖΰΈώΘ§¥”ΕχΩ…Ρή”ΑœλΥυ”– Ι”Ο’ΏΓΘ
2.ΖΰΈώ Ι”Ο’ΏΥυΟφΝΌΒΡ“ΜΗωΧτ’ΫΨΆ «’“ΒΫ’ΐ»ΖΒΡ≤ΌΉςΓΘΆ®≥ΘΘ§ Ι”Ο’Ώ–η“Σδ·άάΖΰΈώΝ–±μΘ§»ΜΚσ‘Ύ±ξ ΕΝΥΚœ ΒΡΖΰΈώΚσδ·άάΖΰΈώ≤ΌΉςΝ–±μΓΘΈ“Ο«»œΈΣΘ§ΖΰΈώΝΘΕ»ΒΡΝΫΗωΦΪΕΥΓΣΓΣΧαΙ©Ϋω”–ΦΗΗωΖΫΖ®ΒΡΚήΕύΖΰΈώΘ§Μρ ΐ °Μρ ΐΑΌΗω≤ΌΉςΨυΦ·÷–‘ΎΦΗΗωΖΰΈώ÷–ΓΣΓΣΕΦΫΪΕ‘“Ή”Ο–‘‘λ≥…”ΑœλΓΘ
’β±μΟςΘ§‘Ύ―Γ‘ώΖΰΈώΝΘΕ» ±Θ§Έ“Ο«Ω…Ρή–η“Σ‘ΎΕύΗω“ρΥΊΦδΫχ––’έ÷‘Θ§»γΩ…Έ§ΜΛ–‘ΓΔΩ…≤ΌΉς–‘ΚΆ“Ή”Ο–‘ΓΘ»ΈΚΈΗχΕ®ΒΡ
SOA ΕΦ”ΠœρΖΰΈώ…ηΦΤ»Υ‘±ΧαΙ©÷ΗΡœΘ§“‘±ψ»ΖΕ®¥Υάύ’έ÷‘ΖΫΑΗΓΘ
ΖΰΈώ”Π «ΡΎΨέΕχΆξ’ϊΒΡ
Φ»»Μ»œ ΕΒΫΝΥ‘Ύ»ΖΕ®ΖΰΈώΝΘΕ» ±–η“ΣΩΦ¬«÷ή»ΪΘ§Ρ«Ο¥‘Ύ»ΖΕ®ΡΡ–©≤ΌΉς”ΠΉι≥…ΖΰΈώ ±”– ≤Ο¥ΉΔ“β ¬œνΡΊΘΩΈ“Ο«»œΈΣ”–ΝΫΗωΕ‘œσ…ηΦΤΗ≈ΡνΚή”–”ΟΘΚΡΎΨέ–‘ΚΆΆξ’ϊ–‘ΓΘΈ“Ο«Ω…ΫΪ’β–©Η≈Ρν”Π”Ο”ΎΖΰΈώΫ”ΩΎΓΘ
Έ“Ο«œΘΆϊ¥¥Ϋ®ΙΠΡήΡΎΨέΒΡΫ”ΩΎΘ§“ΜΉι≤ΌΉς”…”ΎΤδΙΠΡήœύΙΊΕχΨέΚœΒΫ“ΜΤπΓΘΈ“Ο«ΖΔœ÷Θ§Β±ΤάΙάΡΎΨέ≥ΧΕ» ±Θ§¥”ΖΰΈώ Ι”Ο’ΏΫ«Ε»Ω¥¥ΐΖΰΈώΚή”–”ΟΓΘΆ®Ιΐ Ι”Ο’ΏΒΡ ”Ϋ«Θ§Έ“Ο«ΜαΫΪ÷ΊΒψΖ≈‘ΎΖΰΈώΒΡΙΠΡή…œΓΘΫΪ¥ΥΖΫΖ®”κ Ι”Ο“‘œ¬ΡΎΨέ±ξΉΦΫχ––Ε‘±»ΘΚ
Έ“Ο«Ω…“‘ΩΦ¬«Μυ”ΎΙΠΡή Βœ÷ΒΡΡΎΨέ–‘Ϋχ––Ψω≤ΏΓΘ «Ζώ”Π”…”Ύ≤ΌΉς Ι”ΟœύΆ§ΒΡΥψΖ®Ζ÷ΉιΒΫ“ΜΤπΘ§Μρ’Ώ”…”ΎΨυ « Ι”ΟœύΆ§÷ςΜζ…œΒΡ
CICS ¬Έώ Βœ÷ΒΡΕχΫΪΤδΖ÷ΉιΒΫ“ΜΤπΘΩ’β–© « Βœ÷œΗΫΎΘ§≤Μ”Π”ΑœλΫ”ΩΎ…ηΦΤΓΘ
Ω…“‘ Ι”Ο ±ΦδΡΎΨέ–‘‘≠‘ρΘ§Φ¥Θ§ΫΪ‘ΎΕΧ ±ΦδΡΎ“ΜΤπ Ι”ΟΒΡ≤ΌΉςΖ÷ΉιΒΫ“ΜΤπΘ§άΐ»γΘ§RetrieveCustomerDetailsΓΔCheckCreditRatingΓΔCreateLoanFacility
ΚΆ TransferFunds ≤ΌΉςΕΦΩ…Ρή‘ΎΫπ»Ύ“ΒΈώΝς≥Χ÷–“ά¥Έ≥ωœ÷ΓΘ≤ΜΙΐΘ§ ±ΦδΡΎΨέ–‘≤Δ≤Μ“βΈΕΉ≈’β–©≤ΌΉς”ΠΗΟ”…Ά§“ΜΗωΖΰΈώΧαΙ©Θ§CheckCreditRating
ΚΆ TransferFunds ΨΆ»±ΖΠΙΠΡήΡΎΨέ–‘ΓΘ
Ι”ΟΟϊ¥ -Ε·¥ Ε‘ΖΰΈώΚΆ≤ΌΉςΫχ––ΟϋΟϊΒΡΙφ‘ρΩ…“‘Αο÷ζΈ“Ο«ΫΪ÷ΊΒψΖ≈‘ΎΖΰΈώΫ”ΩΎΒΡΙΠΡήΡΎΨέ–‘…œΓΘΈ“Ο«Ω…“‘Έ ’β―υ“ΜΗωΈ ΧβΓΑ’βΗωΕ·¥ «Ζώ «ΗΟΟϊ¥ ΥυΫχ––ΒΡ≤ΌΉςΘΩΓ±
Έ“Ο«ΒΡΒΎΕΰΗωΕ‘œσ…ηΦΤΗ≈Ρν «Άξ’ϊ–‘Η≈ΡνΓΘ‘ΎΈΣ“―÷Σ Ι”Ο’Ώ¥¥Ϋ®ΖΰΈώ ±Θ§Άξ’ϊ–‘ΒΡΈ Χβ”»ΈΣ÷ΒΒΟΉΔ“βΓΘ‘Ύ’β÷÷«ιΩωœ¬Θ§Έ“Ο«Ά®≥ΘΜαΫΪ÷ΊΒψΖ≈‘Ύ¬ζΉψΥυ÷ΣΒΡ Ι”Ο’Ώ–η«σ…œΓΘ«κΈώ±ΊΦ«ΉΓΘ§ΖΰΈώ”ΠΗΟΈΣΩ…÷Ί”ΟΒΡΘ§“ρ¥Υ–η“ΣΩΦ¬«ΫΪά¥ΒΡ Ι”Ο’ΏΒΡΩ…Ρή–η«σΓΘΨΌΗωΦρΒΞΒΡάΐΉ”Θ§ΦΌ»γ”–ΗωΟϊΈΣ
CellPhone ΒΡΖΰΈώΧαΙ© CreateΓΔUpdateΓΔQueryΓΔDelete ΚΆ Deactivate
Β»≤ΌΉςΓΘΈ“Ο«Άξ»ΪΩ…“‘œκœσΜα–η“ΣΕ‘Τζ”ΟΒΡ ÷ΜζΫχ––÷Ί–¬ΦΛΜνΘ§“ρ¥Υ”ΠΨωΕ® «Ζώ“≤”ΠΧαΙ©Ε‘≥ΤΒΡ Activate
ΖΫΖ®ΓΘ
Ά®Ιΐ≈–ΕœΘ§Έ“Ο«”ΠΗΟ”Π”ΟΆξ’ϊ–‘Ιφ‘ρΓΘ»γΙϊ≤Μ÷ΣΒά Ι”Ο’Ώ–η«σΘ§‘ρΩ…ΡήΚήΡ―ΧαΙ©’ΐ»ΖΒΡΙΠΡήΘ§“ρ¥ΥΨΆ”–Ω…Ρή¥φ‘ΎΫΪΩΣΖΔΚΆ≤β ‘ΙΛΉςάΥΖ―‘ΎΧαΙ©ΫΪ≤ΜΜα Ι”ΟΒΡ≤ΌΉς…œΒΡΖγœ’ΓΘ
ΖΰΈώ”ΠΕ‘ Βœ÷œΗΫΎΫχ––ΖβΉΑ
Νμ“ΜΗωΕ‘œσ…ηΦΤ‘≠‘ρΘ®ΖβΉΑΘ©“≤ ”Ο”Ύ…ηΦΤΖΰΈώΫ”ΩΎΓΘΈ“Ο«ΖβΉΑΖΰΈώ Βœ÷ΒΡœΗΫΎΓΣΓΣΥυ”ΟΒΡΥψΖ®ΚΆΉ ‘¥ΓΣΓΣΒΡΕ·Μζ‘Ύ”Ύ‘ωΦ”ΖΰΈώ Ι”Ο’ΏΚΆΧαΙ©’Ώ÷°ΦδΒΡΖ÷άκΘ§¥”ΕχΈΣΫΪά¥ά©’ΙΧαΙ©ΝιΜν–‘ΓΘ
ΖΰΈώ ”ΠΕύ÷÷Βς”ΟΡΘ Ϋ
WebSphere? Β»ΧαΙ©ΒΡ Web ΖΰΈώΦΦ θ‘ –μΫχ––ΗϋΗΏ≤ψ¥ΈΒΡΖβΉΑΓΘΖΰΈώ Ι”Ο’ΏΆ®Ιΐ Ι”ΟΗς÷÷Βς”ΟΡΘ ΫΘ§Ω…“‘ Ι”ΟΆξ»ΪœύΆ§ΒΡ¥ζ¬κΦΦ θά¥Βς”Ο
Web ΖΰΈώΘ§»γ“‘œ¬’β–©ΡΘ ΫΘΚ
1. Ι”Ο SOAP over HTTP ΒΡ¥ΪΆ≥Ά§≤ΫΒς”Ο
2. Ι”Ο SOAP over JMS ΒΡΜυ”ΎœϊœΔΒΡ“λ≤ΫΒς”Ο
3. Ι”Ο Java Ιΐ≥ΧΒς”ΟΒΡ±ΨΒΊΒς”Ο
≤ΜΙΐΘ§Υδ»Μ Web ΖΰΈώΜυ¥ΓΫαΙΙΩ…“‘ΖβΉΑΒς”ΟΒΡœΗΫΎΘ§¥”ΕχΦρΜ·¥ζ¬κΘ§ΒΪΖΰΈώ…ηΦΤ“≤”ΠΕ‘Βς”ΟΖΫ ΫΦ”“‘ΩΦ¬«ΓΘΕ‘±»“Μœ¬±ΨΒΊΒς”ΟΚΆ‘Ε≥ΧΒς”ΟΓΘ”κ«εΒΞ
3 Υυ ΨΡΎ»ίάύΥΤΒΡΖΰΈώ…ηΦΤΩ…“‘ΧαΙ©”–Φέ÷ΒΒΡ“ΒΈώΙΠΡήΘ§ΒΪ»¥≤Μ Κœ‘ΎΚήΕύ SOA ΜΖΨ≥÷–≤Ω πΓΘ
«εΒΞ 3. Ζ±ΟΠ–ΆΖΰΈώΫ”ΩΎ
|
LibraryCatalogService {
// search operations elided
String getBookTitle(String isbn)
String getBookAuthor(String isbn)
Date getBookPublicationDate(String isbn)
// further operations elided
} |
‘Ύ±ΨΒΊΒς”Ο ±Θ§«εΒΞ 3 Υυ ΨΒΡΖΰΈώΫ”ΩΎΩ…ΡήΡήΙΜ’ΐ≥ΘΙΛΉςΓΘ≤ΜΙΐΘ§»γΙϊΖΰΈώ «‘Ύ‘Ε≥ΧΈΜ÷Οœρ Ι”Ο’ΏΧαΙ©ΒΡΘ§‘ρΗΟΖΰΈώ‘Ύ≥ΘΦϊ Ι”Ο≥ΓΨΑ÷–ΒΡ–‘ΡήΩ…ΡήΜαΚή≤νΓΘάΐ»γΘ§‘Ύ Ι”ΟΖΰΈώΦλΥς ΐΨίά¥Χν≥δœ‘ Ψ ιΒΡΡΩ¬ΦœνΒΡΤΝΡΜ ±Θ§ΫΪ”–±Ί“ΣΫχ––ΕύΗωΕάΝΔΒΡ‘Ε≥ΧΒς”ΟΘ§“‘ΦλΥς ιΟϊΓΔΉς’ΏΚΆ≥ωΑφ»’ΤΎΓΘΫχ––’β–©Βς”ΟΩ…ΡήΜα”–Κή¥σΒΡ–‘ΡήΥπ ßΓΘ‘Ε≥ΧΖΰΈώ”ΠΧαΙ©¥÷ΝΘΕ»ΒΡ≤ΌΉςΘ§“‘‘ΎΒΞΗωΒς”Ο÷–ΦλΥςΙΊ”ΎΡ≥±Ψ ιΒΡΥυ”––≈œΔΓΘ
Ω…‘Ε≥ΧΒς”ΟΒΡΖΰΈώΒΡ’βΗω…ηΦΤ‘≠‘ρΒΟΒΫΝΥΙψΖΚΒΡ»œΩ…ΘΜΈ“Ο«‘Ύ¥Υ¥Π«ΩΒς¥Υ‘≠‘ρΒΡΡΩΒΡ‘Ύ”ΎΥΒΟς±ΜΖβΉΑΒΡΖΰΈώΒς”ΟœΗΫΎΩ…ΡήΗχΈ“Ο«»γΚΈ―Γ‘ώ…ηΦΤΖΫΖ®¥χά¥Κή¥σΒΡ”ΑœλΓΘΈ“Ο«»œΈΣΘ§Ά§≤ΫΒς”ΟΚΆ“λ≤ΫΒς”Ο÷°ΦδΒΡ―Γ‘ώ“≤Ω…ΡήΕ‘ΖΰΈώΫ”ΩΎ…ηΦΤ”–άύΥΤΒΡ”ΑœλΓΘ
’βΨΆ“ΐ»κΝΥ“ΜΗω÷Ί“ΣΒΡΈ ΧβΘΚ…ηΦΤΖΰΈώ ±Θ§ ≤Ο¥ΨωΕ®ΝΥΥυ Ι”ΟΒΡΒς”ΟΖΫ ΫΘΩΖΰΈώ…ηΦΤ»Υ‘± «ΖώΩ…“‘Ή‘”…―Γ‘ώ±ΨΒΊΒς”ΟΚΆ‘Ε≥ΧΒς”ΟΓΔΆ§≤ΫΒς”ΟΚΆ“λ≤ΫΒς”ΟΘΩΈ“Ο«Ϋ®“ι
SOA ”ΠΕ‘’βΖΫΟφΫχ––ΥΒΟςΓΘΈ“Ο«Χα≥ω¥ΥΫ®“ι”–ΝΫΗω‘≠“ρΓΘ Ήœ»Θ§Έ“Ο«œΘΆϊΆ®Ιΐ»Ζ±Θ“Μ÷¬–‘ΧαΗΏ“Ή”Ο–‘ΘΜ±ύ≈≈Νς≥Χ ±Θ§ΖΰΈώΉνΚΟΨΏ”–Ω…‘Λ≤βΒΡΧΊ’ςΓΘΤδ¥ΈΘ§Έ“Ο«œΘΆϊΆ®ΙΐΫΪ Ι”Ο’Ώ”κΧαΙ©’ΏΖ÷άκά¥ΧαΗΏΝιΜν–‘ΓΘΆ®ΙΐΙΡάχΫχ––‘Ε≥ΧΒς”ΟΘ§Έ“Ο«Ω…“‘Ϋχ––ΈΜ÷ΟΓΔΤΫΧ®ΚΆ±ύ≥Χ”ο―‘Ζ÷άκΓΘΆ®ΙΐΙΡάχΫχ––“λ≤ΫΒς”ΟΘ§Έ“Ο«Ω…“‘Ζ÷άκ Ι”Ο’ΏΚΆΧαΙ©’ΏΒΡΩ…”Ο–‘ΧΊ’ςΓΘ
»γΙϊ SOA “ΣΨΏ”–Οη ω–‘Θ§ «Ζώ”Π…υΟςΥυ”–ΖΰΈώΕΦ”Π…ηΦΤΈΣ‘ –μ‘Ε≥ΧΓΔ“λ≤ΫΒς”ΟΘΩΈ“Ο«Ϋ®“ιΕ‘¥ΥΟη ω–‘≤…”ΟΗϋΈΣœΗΝΘΕ»ΒΡΖΫΖ®ΓΘΩ…ΡήΒΡΖΰΈώάύ–ΆΑϋά®ΧαΙ©“ΒΈώœύΙΊΫœΕύΒΡ≤ΌΉςΘ§»γ
PlaceOrderΘ§“≤Αϋά®ΦΦ θ–‘≤ύ÷ΊΫœΕύΒΡ≤ΌΉςΘ§»γ CheckUserInRoleΓΘSOA Άξ»Ϊ”ΠΗΟΕ‘≤ΜΆ§ΒΡΖΰΈώάύ±πΫχ––≤ΜΆ§ΒΡΟη ωΓΘΈ“Ο«‘ΛΤΎΫΪΗϋΕύΒΊΒς”Ο”κ“ΒΈώœύΙΊΒΡ≤ΌΉςΘ§ΕχΦΦ θ≤ΌΉςΆξ»ΪΩ…Ρή≤…”Ο±ΨΒΊΒς”ΟΒΡΖΫ ΫΓΘ
ΖΰΈώΨΏ”–ΈόΉ¥Χ§Ϋ”ΩΎ
Έ“Ο«‘ΎΖΰΈώ”Π…ηΦΤΈΣΩ…÷Ί”Ο÷–ΧαΒΫΘ§”ΠΗΟΫΪΖΰΈώ…ηΦΤΈΣΩ……λΥθ«“Ω…≤Ω πΒΫΗΏΩ…”Ο–‘Μυ¥ΓΫαΙΙ÷–ΓΘ¥ΥΉήΧε‘≠‘ρΒΡ“ΜΗωΆΤ¬έΨΆ «Θ§ΖΰΈώ≤Μ”ΠΈΣ”–Ή¥Χ§–ΆΒΡΓΘΦ¥Θ§ΥϋΟ«≤Μ”Π“άάΒ”Ύ Ι”Ο’ΏΚΆΧαΙ©’ΏΦδ≥ΛΤΎ¥φ‘ΎΒΡΙΊœΒΘ§≤ΌΉςΒς”Ο“≤≤Μ”Π“ΰ ΫΒΊ“άάΒ”Ύ«Α“ΜΗωΒς”ΟΓΘΈΣΝΥΥΒΟς’β“ΜΒψΘ§Έ“Ο«“‘œ¬ΟφΒΡΒγΜΑΉΣΜΜΈΣάΐΘΚ
«εΒΞ 4. ”–Ή¥Χ§ΉΣΜΜ
|
Q:What is Dave's account balance?
A: It's Γξ320
Q:What's his credit limit?
A:It's Γξ2,000 |
¥Υ Ψάΐ―ί ΨΝΥΉΣΜΜΒΡΝΫΗω”–Ή¥Χ§ΖΫΟφΓΘΒΎΕΰΗωΈ ΧβΆ®Ιΐ Ι”ΟΓΑhisΓ±“ΐ”ΟΒΎ“ΜΗωΈ ΧβΓΘ’βΗω Ψάΐ÷–ΒΡ≤ΌΉς“άάΒ”ΎΉΣΜΜ…œœ¬ΈΡΓΘœ÷‘Ύ»ΟΈ“Ο«ΩΦ¬«“Μœ¬ΥυΧαΙ©ΒΡ”Π¥πΓΘ«κΉΔ“βΘ§œλ”Π÷–ΟΜ”–…œœ¬ΈΡ–≈œΔΓΘ”ΠΒ±÷Μ”–‘Ύ―·Έ ’Ώ÷ΣΒάΥυ―·Έ ΒΡΈ Χβ ±Θ§’βΗω”Π¥π≤≈”–“β“εΓΘ‘Ύ¥Υ Ψάΐ÷–Θ§“Σ«σ Ι”Ο’ΏΈ§ΜΛΕ‘ΜΑΉ¥Χ§Θ§“‘±ψΫβ ΆΥυΒΟΒΫΒΡ”Π¥πΓΘ’βΝΫΗω”–Ή¥Χ§ΙΊœΒΘ®Ν§–χΒΡΒς”Ο÷°ΦδΚΆ«κ«σ”κœλ”Π÷°ΦδΒΡΙΊœΒΘ©ΕΦ”κ
SOA ΖΰΈώ…ηΦΤ”–ΙΊΓΘ
Ήœ»Θ§Έ“Ο«ΩΦ¬«“Μœ¬“άάΒ”Ύ«Α“Μ≤ΌΉςΫ®ΝΔΒΡ…œœ¬ΈΡΒΡ≤ΌΉςΓΘΦΌ»γ’β «“ΜΗω”κΚτΫ–÷––ΡΒΡΫΜΜΞΓΘ÷Μ“Σ”κΆ§“ΜΗω≤ΌΉς»Υ‘±Ε‘ΜΑΘ§Ε‘ΜΑΨΆΩ…“‘”––ßΒΊΫα χΓΘΒΪΈ“Ο«ΦΌ…ηΚτΫ–±Μ÷–ΕœΝΥΘ§»γœ¬Υυ ΨΘΚ
«εΒΞ 5. ±Μ÷–ΕœΒΡ”–Ή¥Χ§ΉΣΜΜ
|
Q:What is Dave's account balance?
Operator 1: It's Γξ320
An interruption occurs, and the caller talks
to a different operator.
Q:What's his credit limit?
Operator 2: Who? |
÷–ΕœΒΦ÷¬…œœ¬ΈΡΕΣ ßΘ§“ρ¥ΥΒΎΕΰΗωΈ Χβ «ΟΜ”–“β“εΒΡΓΘΨΆ’βΗωΒγΜΑΕ‘ΜΑΕχ―‘Θ§Έ“Ο«Ω…“‘Ά®Ιΐ÷Ί–¬Ϋ®ΝΔ…œœ¬ΈΡΕχΒ÷œϊ÷–Εœ¥χά¥ΒΡΚσΙϊΘΚΓΑΈ“‘ΎΈ
Dave ΒΡ“χ––’ ΜßΒΡ–≈œΔΘ§ΡζΡήΗφΥΏΈ“ΥϊΒΡ–≈”ΟΕνΕ»¬πΘΩΓ±≤ΜΙΐΘ§‘ΎΩ…ά©’ΙΖΰΈώΒς”ΟΝλ”ρΘ§”–Ή¥Χ§Ε‘ΜΑΆ®≥ΘΗϋΈΣ¬ιΖ≥Θ§‘Ύ¥ΥΝλ”ρ÷–Θ§÷Ί–¬Ϋ®ΝΔ…œœ¬ΈΡΩ…Ρή‘ΎΦΦ θ…œ≤ΜΩ…––Θ§Μρ’ΏΩ…Ρή¥χά¥Κή¥σΒΡ–‘ΡήΩΣœζΓΘ
Ά®≥ΘΘ§ΙΙΫ®Ω……λΥθΒΡΩ…ΩΩΜυ¥ΓΫαΙΙ”κ‘ –μ”–Ή¥Χ§ΫΜΜΞ÷°Φδ”–ΫτΟήΒΡΙΊœΒΓΘ¥¥Ϋ®÷ß≥÷”–Ή¥Χ§ΒΡΖΰΈώΒς”ΟΒΡ SOA
Μυ¥ΓΫαΙΙ‘ΎΦΦ θ…œΩ…––ΓΘΩ…“‘ Ι”ΟΒΡΦΦ θΑϋά®ΘΚ
1. Ι”Ο Http Cookie Έ§ΜΛΜαΜΑ…œœ¬ΈΡ
2. Ι”Ο”–Ή¥Χ§ΜαΜΑ EJBΘΜBean ΒΡΨδ±ζ‘Ύ SOAP Header
÷–¥ΪΒί
≤ΜΙΐΘ§Έ“Ο«±Ί–κΉ–œΗΩΦ¬«Ήν÷’Μυ¥ΓΫαΙΙΒΡΩ……λΥθ–‘ΚΆΩ…ΩΩ–‘ΓΘ «Ζώ“Σ«σ Ι”ΟΙΊΝΣ–‘ΘΩΦ¥Θ§œύΆ§ΒΡ Ι”Ο’ΏΖΔ≥ωΒΡΝ§–χ«κ«σ «Ζώ±Ί–κΫΜΗΕΒΫœύΆ§ΒΡΧαΙ©’Ώ ΒάΐΘΩ“Σ«σ Ι”ΟΙΊΝΣ–‘ «“Μ÷÷”–Ή¥Χ§–‘”κΩ……λΥθ–‘ΦΑΩ…ΩΩ–‘≥εΆΜΒΡ«ιΩωΓΘ»γΙϊΜυ¥ΓΫαΙΙΩ…“‘Υφ“βΫΪ«κ«σΧαΫΜΒΫΕύΗωΧαΙ©’Ώ Βάΐ÷–ΒΡ“ΜΗωΘ§ΨΆΩ…ΦρΜ·ΗΚ‘ΊΤΫΚβΘ§ΕχΗςΗωΧαΙ©’Ώ ΒάΐΒΡΩ…ΩΩ–‘“Σ«σΨΆΩ…ΜΚΚΆΓΘ
»γΙϊΟΜ”–ΙΊΝΣ–‘–η«σΘ§«“‘ –μΜυ¥ΓΫαΙΙΫΪ“ΜΗω Ι”Ο’ΏΒΡΝ§–χ«κ«σΫΜΗΕΒΫ≤ΜΆ§ΒΡΧαΙ©’Ώ ΒάΐΘ§‘ρ»ΈΚΈΜαΜΑΉ¥Χ§±Ί–κΕ‘Υυ”–ΧαΙ©’Ώ ΒάΐΩ…”ΟΓΘ”Π”ΟΖΰΈώΤςΜυ¥ΓΫαΙΙΧαΙ©ΜαΜΑΗ¥÷ΤΜζ÷ΤΓΘ¥ΥάύΜζ÷ΤΩ…“‘”Ο”ΎΧαΙ©ΜαΜΑΉ¥Χ§Θ§ΒΪ Ι”ΟΥϋΟ«Μα”––‘ΡήΥπ ßΓΘΕχ«“Θ§Έ“Ο«ΒΡ
Web ΩΣΖΔΨ≠―ι±μΟςΘ§»γΙϊΟΜ”–Ω…ΩΩΒΡ÷ΗΡœΘ§ΩΣΖΔ»Υ‘±ΫΪΩ…“‘Υφ“β Ι”ΟΜαΜΑΉ¥Χ§ΘΜΙΐΕ» Ι”Ο HTTP ΜαΜΑΆ®≥Θ «ΒΦ÷¬–‘ΡήΒΆœ¬ΒΡ≥ΘΦϊ‘≠“ρΓΘ«κ≤Έ‘ΡΓΑPerformance
Analysis for Java Web SitesΓ±Θ®Ής’ΏΘΚJoinesΓΔWillenborg
ΚΆ HyghΘ§ΒΎ 59 “≥ΓΣ60 “≥Θ§Addison-Wesley ISBN 0201844540Θ©ΓΘ
Έ“Ο««ΩΝ“Ϋ®“ιΘ§ΖΰΈώ”Π…ηΦΤΈΣΩ…±ήΟβΈ§ΜΛΜαΜΑ…œœ¬ΈΡΒΡ–η«σΓΘ
œ÷‘ΎΘ§»ΟΈ“Ο«ΩΦ¬«“Μœ¬Ε‘ΜΑΒΡΤδΥϊ”–Ή¥Χ§ΖΫΟφ“‘ΦΑ«κ«σΚΆœλ”ΠΦδΒΡΙΊœΒΓΘΈ“Ο« «Ζώ“Σ≤…”Ο…œΟφΒΡΒγΜΑΕ‘ΜΑΖΫ ΫΫχ––ΖΰΈώ…ηΦΤΘ§“άάΒΜαΜΑ…œœ¬ΈΡά¥Ϋβ Άœλ”ΠΓΑWhat
is Dave's credit limit?Γ±ΓΣΓΣΓΑΓξ320Γ±ΓΣΓΣ»ΜΚσΈ“Ο«ΫΪΕ‘ SOA Μυ¥ΓΫαΙΙ‘Ό¥ΈΫχ––‘Φ χΓΘ
Μυ¥ΓΫαΙΙ±Ί–κ ”ΠΗς÷÷Ω…Ρή–‘Θ§»γΡ≥–© Ι”Ο’ΏΈόΖ®‘ΎΝΌ ±ΆΘΜζΒΡ«ιΩωœ¬±ΘΝτΤδΜαΜΑΉ¥Χ§ΓΘ
Έ“Ο«Ω…“‘Ά®ΙΐΫΪΖΰΈώ…ηΦΤΈΣ‘Ύœλ”Π÷–ΑϋΚ§Κœ ΒΡΙΊΝΣ–≈œΔΘ§¥”Εχ±ήΟβΜαΜΑΉ¥Χ§ΒΡ–η«σΘ§άΐ»γ“‘œ¬ΒΡœλ”ΠΘΚ
«εΒΞ 6. ΑϋΚ§ΙΊΝΣ–≈œΔΒΡΕ‘ΜΑ
|
Q: What is Dave's credit limit?
A: Dave's credit limit is Γξ2000 |
ΗΟœλ”ΠΦ»±ξ Ε»Υ‘±”÷ΧαΙ©ΨΏΧεΒΡ ΐΨίΓΘΒ±ΑϋΉΑ“≈ΝτœΒΆ≥ ±Θ§Ά®≥Θ”… ≈δΤςΗΚ‘πΧαΙ©¥ΥάύΙΊΝΣ–≈œΔΓΘœ÷”–Ά§≤Ϋ API
Άξ»Ϊ”–Ω…Ρή≤ΜΧαΙ©ΙΊΝΣ ΐΨίΓΘ‘Ύœλ”Π÷–ΑϋΚ§ΙΊΝΣ–≈œΔ÷°Υυ“‘ «ΚήΚΟΒΡΉωΖ®Θ§”–ΚήΕύ‘≠“ρΓΘ Ήœ»Θ§ΥϋΦρΜ·ΝΥΒ·–‘Ω……λΥθΫβΨωΖΫΑΗΒΡΙΙ‘λΘ§ΜΙΡήΧαΙ©Κή¥σΒΡ’οΕœΑο÷ζΘ§«“‘Ύ≤ΜΩ…Ρήœρ‘≠ Φ«κ«σ≥Χ–ρΫΜΗΕ¥μΈσœλ”Π ±Ζ«≥Θ÷Ί“ΣΓΘΈ¥ΫΜΗΕΒΡœϊœΔΩ…ΡήΖ≈÷Ο‘Ύ¥μΈσΕ”Ν–…œΘ§ΟΩΗω¥ΥάύœϊœΔΒΡΫβ ΆΕΦ“Σ«σ Ι”Ο…œœ¬ΈΡ–≈œΔΓΘ
Ήή÷°Θ§Ή–œΗΒΊΫχ––ΖΰΈώ…ηΦΤΩ…“‘±ήΟβΕ‘Ή¥Χ§Ε‘ΜΑΒΡ–η«σΘ§¥”ΕχΦρΜ·Ω…ΩΩΒΡΩ……λΥθ SOA Μυ¥ΓΫαΙΙΒΡ Βœ÷ΓΘ
ΖΰΈώ”Π Ι”ΟΉ¥Χ§ ¬ΈώΫ®ΡΘ
«ΑΟφΗχ≥ωΝΥ“ΜΗωΉήΒΡΫ®“ιΘ§“‘±ήΟβ“άάΒΕ‘ΜΑΉ¥Χ§Θ§ΒΪΈ“Ο«”ΠΒ±Φ«ΉΓΘ§”–”ΟΒΡΦΤΥψΜζœΒΆ≥Ά®≥ΘΫΪΈΣ”–Ή¥Χ§ΒΡΘΜΆ®≥ΘΖ¥”≥ΝΥ“ΒΈώΕ‘œσΒΡ…ζΟϋ÷ήΤΎΓΘ
άΐ»γΘ§ΩΦ¬«ΙΚΈο÷–ΒΡ“ΜΗωΕ©ΒΞΒΡ…ζΟϋ÷ήΤΎΘΚ¥¥Ϋ®Ε©ΒΞΓΘ¥””ΟΜßΒΡΫ«Ε»ά¥Ω¥Θ§¥¥Ϋ®ΝΥ“ΜΗωΩ’ΒΡΙΚΈο≥ΒΓΘ”ΟΜßΫΪΥφΚσœρΕ©ΒΞΧμΦ”ΈοΤΖΘ§Φ¥ΫΪΤδΖ≈»κΙΚΈο≥Β÷–ΓΘΉνΚσΧαΫΜΕ©ΒΞΘ§»ΜΚσΕ©ΒΞΫΪ±Μ¥ΪΥΆΗχ≈δΥΆ≤ΩΟ≈ΓΘΆΦ
1 œ‘ ΨΝΥΕ‘¥Υ…ζΟϋ÷ήΤΎΫ®ΡΘΒΡΦρΜ·Ή¥Χ§ΉΣΜΜΆΦΓΘ
ΆΦ 1. Ε©ΒΞ…ζΟϋ÷ήΤΎΉ¥Χ§ΉΣΜΜ
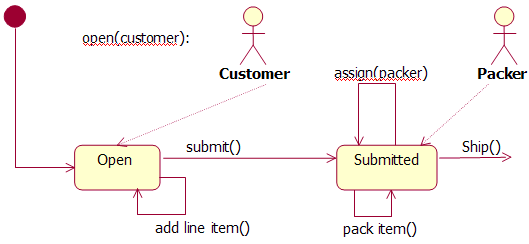
ΗΟΡΘ–ΆΥΒΟςΝΥ“Μ–©”–Ή¥Χ§ΒΡ––ΈΣΓΘάΐ»γΘ§Έ“Ο«Ω¥ΒΫΘ§‘Ύ¥Π”Ύ Open Ή¥Χ§ ±Ω…“‘œρΕ©ΒΞΧμΦ”–– ΫœνΡΩΘ§ΒΪ‘ΎΧαΫΜΚσΨΆ≤ΜΡήΝΥΓΘ
»ΟΈ“Ο«ΩΦ¬«“‘œ¬ Order ΖΰΈώΒΡ…ηΦΤΓΘΈ“Ο«Ω…“‘≤…”Ο»γ«εΒΞ 7 Υυ ΨΒΡΫ”ΩΎΓΘ
«εΒΞ 7. Order ΖΰΈώ…ηΦΤ
|
OrderService {
void addLineItemToOrder(int orderId, int productId,
int quantity)
void assignOrderToPacker(int packerId)
int createOrder(int customerId) // returns id
of new order
int packItemForOrder(int orderId, int quantity)
// returns quantity left to ship
boolean shipOrder(int orderId) // returns whether
all order is now shipped
void submitOrder(int orderId)
// ... query operations elided ... |
Έ“Ο«“ΣΩΦ¬«¥ΥΫ”ΩΎΒΡ“Ή”Ο–‘ΓΘΘ®Ηϋœ÷ Β“Μ–©Θ§Έ“Ο«”ΠΗΟΩΦ¬«Ρ«–©ΨΏ”–ΗϋΕύΖΫΖ®ΒΡΆξ’ϊΫ”ΩΎΘ§»γ”Ο”ΎΝ–≥ωΚΆ…Ψ≥ΐ–– ΫœνΡΩΒΡΖΫΖ®ΓΘΘ©»γΙϊΟΜ”–Ή¥Χ§ΆΦΙ©≤ΈΩΦΘ§Φ¥ Ι≤ιΩ¥Έ“Ο«ΒΡ’βΗω–Γ ΨάΐΘ§“≤Ζ«≥ΘΡ―”ΎΖ÷«εΖΫΖ®”ΠΗΟΑ¥’’ΚΈ÷÷Υ≥–ρΫχ––Βς”ΟΓΘ“ρ¥ΥΈ“Ο«»œΈΣΘ§ΖΰΈώ…ηΦΤ»Υ‘±±Ί–κΫχ––“ΜΕ®ΒΡΙΛΉςΘ§“‘ΦρΜ· Ι”Ο’ΏΒΡ»ΈΈώΓΘΈ“Ο«ΧαΙ©ΝΥ“Μ–©Ω…ΡήΒΡΦΦ θΓΘ
Ήœ»Θ§ΩΦ¬«≤ΌΉςΚΆ≤Έ ΐΒΡΟϊ≥ΤΓΘΈ“Ο«…œΟφΒΡ Ψάΐ÷–ΒΡΟϊ≥Τ «Ψ≠ΙΐœΗ–Ρ―Γ‘ώΒΡΘ§≤ΔΫχ––“ΜΕ®ΒΡ≈§ΝΠΘ§“‘ΆΤΒΦ≥ωΖΫΖ®ΒΡΩ…ΡήΒς”ΟΥ≥–ρΓΘ«κ±»Ϋœ«εΒΞ
8 ΚΆ«εΒΞ 9 ÷–ΒΡ ΨάΐΘ§’βΝΫΗω¥ζ¬κΤ§ΕΈΦΗΚθΆξ»Ϊ“Μ―υΘ§÷Μ «≤ΌΉςΚΆ≤Έ ΐΒΡΟϊ≥Τ≤ΜΆ§ΓΘ
«εΒΞ 8. ≤ΜΚœάμ―Γ‘ώΒΡ≤ΌΉςΚΆ≤Έ ΐΟϊ≥Τ
|
ZettuylService {
int wibble(int wibId, int wobId, String which);
int wobble(int quibId);
boolean wrubble(int wibId);
void quibble(int widId)
void quash(int wibId)
Stuff[] getStuff(int wibId );
void quite(int wibId);
Things[] getThings(int wibId);
void hinge(int wibId, intwobId);
int henge(int wibId , Stuff someStuff)
} |
«εΒΞ 9. Κœάμ―Γ‘ώΒΡ≤ΌΉςΚΆ≤Έ ΐΟϊ≥Τ
|
ExpenseService {
int approveClaimItem(int claimId, int itemId,
String comment);
int createClaim(String userId);
boolean auditClaim(int claimId);
void approveClaim(claimId)
void returnClaim(claimId)
ClaimItemDetails[] getClaimItems(int claimId
);
void payClaim(int claimId);
ClaimErrors[] validateClaim(int claimId);
void removeClaimItem(int claimId, int itemId);
int addClaimItem(int claimId, ClaimItemDetails
details)
} |
«εΒΞ 8 ÷–ΒΡΟϊ≥ΤΕΦ «Ρ―“‘άμΫβΒΡΓΘΕχ«εΒΞ 9 ÷–―Γ‘ώΒΡΟϊ≥ΤΥΒΟςΝΥΖΰΈώΒΡΡΩΒΡΘ§≤ΔΩ…“‘Φθ…ΌΚήΕύ≤ΌΉς”ΠΑ¥ΧΊΕ®Υ≥–ρΒς”ΟΒΡ«ιΩωΓΘάΐ»γΘ§createClaim()
ΫΪ‘Ύ approveClaim() «Α Ι”ΟΘ§ΕχΚσ’Ώ”÷ΫΪ‘Ύ payClaim() «Α Ι”ΟΓΘ“ρ¥ΥΘ§’ΐ»γΈ“Ο«‘Ύ«ΑΟφΒΡΟϋΟϊΖΰΈώ ±”Π“‘Ήν¥σΜ·“Ή”Ο–‘ΈΣΡΩ±ξΥυ÷Η≥ωΒΡΘ§Οϊ≥ΤΒΡ―Γ‘ώΕ‘“Ή”Ο–‘”ΑœλΖ«≥Θ¥σΓΘ
Τδ¥ΈΘ§«ΑΟφΒΡ Order ΒΡΉ¥Χ§ΉΣΜΜΆΦΩ…«ε≥ΰΥΒΟςΕ©ΒΞΒΡ”–Ή¥Χ§––ΈΣΓΘΗΟΆΦΧαΙ©ΝΥ”–”ΟΒΡΥΒΟς–≈œΔΘ§œ‘ ΨΝΥΕ©ΒΞΒΡΉ¥Χ§“‘ΦΑΟΩΗωΉ¥Χ§÷–œύ”ΠΒΡ≤ΌΉςΓΘ
‘ωΦ”“Ή”Ο–‘ΒΡΒΎΕΰœνΦΦ θ «Θ§“ΣΦ«ΉΓ≤ΔΖ«Υυ”–Φ«¬ΦΒΡ÷ΒΕΦΩ…“‘Ά®ΙΐΖΰΈώΫ”ΩΎΕ®“ε Βœ÷ΉνΦ―ΒΡΫΜΗΕΓΘΦ«¬ΦΝΦΚΟΒΡ
WSDL ΈΡΦΰΚή”–Φέ÷ΒΘ§ΒΪ“ΜΤπΧαΙ©ΒΡΙΊœΒΆΦΚΆ Ψάΐ“≤”–Κή¥σΒΡΦέ÷ΒΓΘ
‘ωΦ”“Ή”Ο–‘ΒΡΝμ“ΜœνΦΦ θ «Θ§¥¥Ϋ®Ζ¥”≥“ΒΈώΕ‘œσ…ζΟϋ÷ήΤΎΒΡΉ¥Χ§ΒΡΖΰΈώΫ”ΩΎΓΘ‘ΎΈ“Ο«Ζ―”Ο…ξΝλ Ψάΐ÷–Θ§ΟΩ± Ζ―”Ο…ξΝλΒΡ…ζΟϋ÷ήΤΎΕΦΑϋΚ§ΥΡΗωΉ¥Χ§Θ§»γΆΦ
2 ÷–Υυ ΨΓΘ
ΆΦ 2. expense Ε‘œσΒΡΥΡΗωΉ¥Χ§
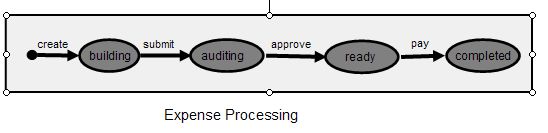
’β–©Ή¥Χ§÷°Υυ“‘÷Ί“ΣΘ§”–ΝΫΗω‘≠“ρΓΘΒΎ“ΜΘ§ΟΩΗωΉ¥Χ§Μυ±Ψ…œΕΦ”κ≤ΜΆ§ΒΡœΒΆ≥”ΟΜßœύΙΊΓΘάΐ»γΘ§Β±Ζ―”Ο…ξΝλ¥Π”ΎΙΙΫ®
(building) Ή¥Χ§ ±Θ§÷ς“ΣœΒΆ≥”ΟΜß « δ»κΖ―”Ο…ξΝλœξœΗ–≈œΔΒΡ…ξΝλ»ΥΘ§Εχ‘Ύ…σΚΥ (auditing)
Ή¥Χ§÷–Θ§‘ρ «”…ΨΏ”–≈ζΉΦ»®άϊΒΡ»ΥΕ‘Ζ―”Ο…ξΝλΫχ––Φλ≤ιΓΘ
ΒΎΕΰΘ§÷ς“ΣΉ¥Χ§÷°ΦδΒΡΉΣΜΜΆ®≥ΘΖ¥”≥ΝΥ≤ΜΆ§ IT œΒΆ≥÷°ΦδΒΡ ΐΨίΝςΓΘάΐ»γΘ§‘ΎΙΙΫ® (building)
Ή¥Χ§ΤΎΦδΘ§Ω…“‘‘Ύ”ΟΜßΒΡΙΛΉς’Ψ…œ Ι”Ο“ΜΗω ίΩΆΜßΕΥ”Π”Ο≥Χ–ρά¥≤ΕΜώΖ―”Ο…ξΝλΓΘΧαΫΜΚσΘ§Ζ―”Ο…ξΝλΫΪ¥ΪΒίΗχΖ―”Ο…ξΝλ¥ΠάμœΒΆ≥Θ§ΕχΒ±ΒΟΒΫ≈ζΉΦΚσΘ§Ζ―”Ο…ξΝλΫΪ¥ΪΒίΗχΝμΆβ“ΜΗωœΒΆ≥Θ§Φ¥÷ßΗΕœΒΆ≥ΓΘ‘Ύ¥ΪΒίΙΐ≥Χ÷–Θ§Έ“Ο«–η“ΣΧαΒΫΒΡ «Θ§»γΙϊ Βœ÷ΒΡ»Ζ“ΣΫΪ ΐΨί¥”“ΜΗωœΒΆ≥¥ΪΒίΒΫΝμ“ΜΗωœΒΆ≥Θ§‘ρ–η“Σ”»ΈΣΉΔ“βΗΚ‘π‘ΎœΒΆ≥÷°ΦδΫχ––¥Ϊ δΒΡ≤ΌΉςΘ®‘ΎΈ“Ο«ΒΡ Ψάΐ÷–ΈΣ
submitClaim() ΚΆ approveClaim()Θ©ΓΘΥϋΟ«ΒΡ Βœ÷ΫΪ–η“ΣΕ‘ΝΫΗωœΒΆ≥Ϋχ––Ηϋ–¬Θ§Εχ’β―υΚή»ί“Ή…Ξ ßΝΫΗωœΒΆ≥÷–»Έ“β“ΜΗωΒΡΩ…”Ο–‘ΓΘ’β–©ΖΫΖ®ΒΡ Βœ÷ΫΪΩ…“‘Ά®Ιΐ Ι”Ο“λ≤Ϋ≈≈Ε”Μζ÷ΤΒΟΒΫΗΡ…ΤΓΘ
”…”Ύ“ΒΈώΕ‘œσΉ¥Χ§≥Θ≥ΘΡήΆ§ ±Ζ¥”≥“ΒΈώΚΆΦΦ θΝΫΖΫΟφΒΡΡΎ»ίΘ§“ρ¥ΥΆξ»ΪΩ…“‘ΫΪ‘≠ Φ ExpenseClaimService
≤πΖ÷ΈΣ ”ΠΟΩΗωΉ¥Χ§ΒΡΕύΗωΖΰΈώΓΘΈ“Ο«Ω…“‘ΒΟΒΫ»γ«εΒΞ 10 ÷–Υυ ΨΒΡΖΰΈώΓΘ
«εΒΞ 10. ΗυΨίΉ¥Χ§Μ°Ζ÷ΖΰΈώ
|
ClaimEntryService {
createClaim(String userId);
ClaimItemDetails[] getClaimItems(int );.
ClaimErrors[] validateClaim(int claimId);
void removeClaimItem(int claimId, int itemId);
int addClaimItem(int claimId, ClaimItemDetails
details)
int submitClaim(int claimId);
}
ClaimApprovalService {
int approveClaimItem(int claimId, int itemId,
String comment);
void approveClaim(claimId)
void returnClaim(claimId)
ClaimItemDetails[] getClaimItems(int );.
ClaimErrors[] validateClaim(int claimId);
}
ClaimPaymentService {
void payClaim(int claimId);
} |
Ά®Ιΐ’β÷÷ΖΫ ΫΘ§ΡήΗϋΖΫ±ψΒΊάμΫβΟΩΗωΖΰΈώΓΘΕχ«“Θ§ΫΪΫ”ΩΎ’β―υΜ°Ζ÷ΫΪΩ…ΡήΖ«≥Θ ΚœΖΰΈώΘ®ΜρΖΰΈώΦ·Θ©ΒΡΩΣΖΔΓΔ≤Ω πΓΔΈ§ΜΛΚΆ Ι”ΟΖΫ ΫΓΘ’β–©ΖΰΈώΚήΩ…Ρή’κΕ‘≤ΜΆ§ΒΡ Ι”Ο’ΏΘ§Ω…“‘”…ΕάΝΔΒΡΩΣΖΔΆ≈Ε”Ϋχ––ΩΣΖΔΘ§Ω…“‘Ζ÷ΩΣ≤Ω πΘ§“ρΕχΨΏ”–Ζ÷άκΒΡΑφ±Ψ÷ήΤΎΓΘΜΜΨδΜΑΥΒΘ§Ά®ΙΐΫΪ÷ΊΒψΖ≈‘ΎΕ‘œσ…ζΟϋ÷ήΤΎ…œΘ§Έ“Ο«ΨΆΩ…“‘Ϋ®ΝΔΨΏ”–«ΓΒ±ΝΘΕ»ΒΡΖΰΈώΓΘ
ΖΰΈώ≤ΌΉς…ηΦΤ‘≠‘ρ
«ΑΟφΈ“Ο«Χ÷¬έΝΥΖΰΈώΒΡΉήΧε…ηΦΤΖΫΟφΒΡΈ ΧβΘ§Ϋ”œ¬ά¥ΨΆ“ΣΧ÷¬έ“Μœ¬ΗςΗωΖΰΈώ≤ΌΉςΒΡ…ηΦΤΝΥΓΘ
≤ΌΉς±μ Ψ“ΒΈώΕ·ΉςΓΘ
Έ“Ο«“―Ψ≠÷Η≥ωΘ§ΉήΒΡ‘≠‘ρ «Θ§Έ“Ο«”ΠΗΟ”≈œ»Ε‘ΖΰΈώΚΆ≤ΌΉς ɔϓ¸ώΝλ”ρΒΡΟϊ≥ΤΘ§ Ι”ΟΕ·¥ ΉςΈΣ≤ΌΉςΟϊ≥ΤΓΘΕ‘”Ύ≤ΌΉςΘ§Έ“Ο«ΫΪ’βΗωΫ®“ιΫχ“Μ≤Ϋ…νΜ·ΘΚ”ΠΒ± Ι”ΟΨΏΧεΒΡ“ΒΈώΚ§“εΕχ≤Μ «ΖΚ–Ά≤ΌΉςΕ‘≤ΌΉςΫχ––Ε®“εΓΘάΐ»γΘ§≤Μ“Σ Ι”ΟΖΚΖΚΒΡ
UpdateCustomerDetails ≤ΌΉςΘ§Εχ“Σ¥¥Ϋ® ChangeCustomerAddressΓΔRecordCustomerMarriage
ΚΆ AddAlternativeCustomerContactNumber ÷°άύΒΡ≤ΌΉςΓΘ¥ΥΖΫΖ®ΨΏ”–“‘œ¬ΚΟ¥ΠΘΚ
≤ΌΉς”κΨΏΧε“ΒΈώ≥ΓΨΑΕ‘”ΠΓΘ¥Υάύ≥ΓΨΑΩ…Ρή≤ΜΫω «ΦρΒΞΒΡΗϋ–¬ ΐΨίΩβ÷–ΒΡΦ«¬ΦΓΘάΐ»γΘ§ΗϋΗΡΒΊ÷ΖΜρΜι“ωΉ¥ΩωΩ…“‘“Σ«σ…ζ≥…’ΐ ΫΒΡΈΡΒΒΘ§ΕχΫΪ“Σ«σœΒΆ≥Φ«¬ΦΗΟΈΡΒΒΒΡœξœΗ–≈œΔΓΣΓΣΜρ…®ΟηΑφ±ΨΓΘ»γΙϊ Ι”Ο≤ΜΧΪΨΏΧεΒΡ≤ΌΉςΘ®»γ
UpdateCustomerDetailsΘ©Θ§‘ρΫœΡ― Βœ÷¥Υάύ“ΒΈώ≥ΓΨΑΓΘ
ΗςΗω≤ΌΉςΫ”ΩΎΫΪΖ«≥ΘΦρΒΞΘ§«““Ή”ΎάμΫβΘ§¥”ΕχΧαΗΏΝΥ“Ή”Ο–‘ΓΘ
ΟΩΗω≤ΌΉςΒΡΗϋ–¬ΒΞ‘ΣΒΟΒΫΝΥ«ε≥ΰΒΡΕ®“εΘ®‘ΎΈ“Ο«ΒΡ Ψάΐ÷–ΈΣΒΊ÷ΖΓΔΜι“ωΉ¥ΩωΚΆΒγΜΑΚ≈¬κΘ©ΓΘ‘Ύ Βœ÷ΨΏ”–ΗΏ≤ΔΖΔ–‘“Σ«σΒΡœΒΆ≥ ±Θ§Έ“Ο«Ω…“‘Μυ”Ύ≤ΌΉςΒΡ“Σ«σ≤…”ΟΗϋœΗΝΘΕ»ΒΡΥχΕ®≤Ώ¬‘Θ§¥”ΕχΦθ…ΌΉ ‘¥’υ”ΟΓΘ
≤ΌΉς”Π≤…”Ο¥÷ΝΘΕ»≤Έ ΐ
‘ΎΧ÷¬έ≤ΌΉς≤Έ ΐ ±Θ§Ά§―υ“ΣΟφΕ‘ΝΘΕ»ΒΡΈ ΧβΓΘ«κ±»Ϋœ«εΒΞ 11 ΚΆ«εΒΞ 12 ÷–Υυ ΨΒΡ CreateNewCustomer
≤ΌΉςΒΡΝΫΗωΫ”ΩΎΓΘ
«εΒΞ 11. ≤…”ΟœΗΝΘΕ»≤Έ ΐΒΡ CreateNewCustomer ≤ΌΉςΫ”ΩΎ
|
int CreateNewCustomer(String familyName,
String givenName,
String initials,
int age
String address1
String address2
String postcode
// ...
) |
«εΒΞ 12. ≤…”ΟΒΞΗω¥÷ΝΘΕ»≤Έ ΐΒΡ CreateNewCustomer ≤ΌΉςΫ”ΩΎ
| int
CreateNewCustomer( CustomerDetails newDetails) |
«εΒΞ 11 œ‘ ΨΝΥ“ΜΗωΨΏ”–ΚήΕύœΗΝΘΕ»≤Έ ΐΒΡ≤ΌΉςΓΘΕχ‘Ύ«εΒΞ 12 ÷–ΒΡ≤ΌΉς‘ρ≤…”ΟΫαΙΙΜ·άύ–ΆΉςΈΣΒΞΗω¥÷ΝΘΕ»≤Έ ΐΓΘΈ“Ο«÷°Υυ“‘Ϋ®“ι Ι”Ο¥÷ΝΘΕ»≤Έ ΐΘ§”–ΝΫΗω‘≠“ρΓΘ Ήœ»Θ§ΥϋΟ«ΧαΙ©ΝΥ¥¥Ϋ®ΝιΜν≤ΌΉςΒΡΜζΜαΘ§÷ß≥÷‘Ύ≤ΜΗ…»≈œ÷”– Ι”Ο’ΏΒΡ«ιΩωœ¬ΧαΙ©–¬Αφ±ΨΒΡ≤ΌΉςΓΘΤδ¥ΈΘ§ΨΏ”–¥σΝΩάύ–ΆœύΥΤΒΡ≤Έ ΐΒΡ≤ΌΉς“Ή”Ύ‘Ύ¥”ΒΎ»ΐ¥ζ”ο―‘¥ζ¬κΫχ––Βς”Ο ±≥ωœ÷ΉΣΜΜ¥μΈσΓΘœύΖ¥Θ§Β± ΐΨίΖ≈÷Ο‘ΎΥυ Ι”ΟΒΡΫαΙΙΜ·άύ–ΆΒΡœ‘ ΫΖΫΖ®Θ®»γ
setGivenName() ΚΆ setInitials()Θ©÷– ±Θ§¥ΥΖΫΖ®≥ω¥μΒΡΦΗ¬ Ηϋ–ΓΓΘ
≤ΌΉς…ηΦΤ”ΠΩΦ¬«≤ΔΖΔ–‘
¥ΪΆ≥ΒΡ ¬Έώ–Ά±ύ≥ΧΡΘ–ΆΘ®»γ Entity Enterprise Java Bean (Entity Bean)
Υυ÷ß≥÷ΒΡ±ύ≥ΧΡΘ–ΆΘ©‘ –μ Βœ÷ ΐΨίΩβΗϋ–¬Θ§“ρ¥ΥΤδ ΐΨίΩβΥχΕ®ΖΫ Ϋ»γ«εΒΞ 13 ÷–Υυ ΨΓΘ
«εΒΞ 13. ¬Έώ–Ά±ύ≥ΧΡΘ–Ά
|
Begin Transaction
Retrieve data from database - locking record
Modify values
Update database record with modified values
Commit Transaction - unlocking record |
«κΉΔ“βΘ§ ΐΨίΩβΥχΕ®¥”ΒΎ 1 ––ΦλΥς ±“Μ÷±±Θ≥÷ΒΫΒΎ 5 ––ΒΡΧαΫΜ≤ΌΉςΓΘ’β―υ“‘“ΜΕ®ΒΡ―”≥Ό»Ζ±ΘΝΥ’ΐ»ΖΒΡ≤ΔΖΔ––ΈΣΓΘ»γΙϊΈ“Ο«œΘΆϊ…ηΦΤ“ΜΗωΧαΙ© ΐΨίΩβΗϋ–¬ΙΠΡήΒΡΖΰΈώΘ§‘ρΩ…“‘ΧαΙ©”κ«εΒΞ
8 ÷–ΒΡΒΎ 2 ––ΚΆΒΎ 4 ––ΒΡΦλΥςΚΆ–¥»κ≤ΌΉςΕ‘”ΠΒΡ≤ΌΉςΓΘ≤ΜΙΐΘ§Έ“Ο««ΩΝ“Ϋ®“ιΘ§≤Μ“Σ‘ΎΗΏΕ»Ζ÷άκ«“Ω…Ρή“λ≤ΫΒΡ
SOA Μυ¥ΓΫαΙΙ÷–ΒΡΝ§–χΒς”ΟΦδ±Θ≥÷ΥχΕ®ΓΘΈ“Ο«Ϋ®“ι≤…”Οά÷ΙέΥχΕ®≤Ώ¬‘Θ§ΫΪ≤ΔΖΔΩΊ÷ΤΒΡ‘π»ΈΈ·≈…Ηχœύ”ΠΒΡ”Π”Ο≥Χ–ρ¬ΏΦ≠ΓΘ
ά÷ΙέΥχΕ®≤Ώ¬‘÷–ΒΡΗϋ–¬«κ«σΩ…“‘Ϋβ ΆΈΣΓΑ“‘œ¬ «Μυ”ΎΦ«¬Φ XYZ ΒΡ V Αφ±ΨΒΡ“Μ–©Φ«¬ΦΗϋ–¬ΓΘ«κΫω‘Ύ¥”Έ“ΕΝ»ΓΗΟΦ«¬ΦΚσΟΜ”–»ΥΫχ–––όΗΡΒΡ«ιΩωœ¬Ϋχ––ΗϋΗΡΓΘΓ±
“‘œ¬ «ΈΣ«εΒΞ 12 Υυ ΨΒΡΆ§“ΜΗωΡΘ–Ά Ι”ΟΝΥ ΐΨίΩβ¥ΞΖΔΤςΚΆ–όΕ©ΦΤ ΐΤςΒΡά÷ΙέΥχΕ® Βœ÷ΓΘΗΟ Βœ÷“Σ«σ÷¥––“‘œ¬≤Ϋ÷ηΘΚ
1.œρ“Σ Ι”Οά÷ΙέΥχΕ®ΒΡ±μ÷–ΧμΦ”“ΜΗωΕνΆβΒΡ’ϊ ΐΝ–ΘΜΗΟΝ–±Θ¥φ–όΕ©ΦΤ ΐΤςΓΘ
2.œρ ΐΨίΩβΧμΦ”¥ΞΖΔΤςΘ§“‘±ψΕ‘ΗΟ±μ÷–ΒΡΦ«¬ΦΒΡΟΩΗωΗϋ–¬ΕΦΜαΒΦ÷¬–όΕ©ΦΤ ΐΤςΒί‘ωΓΘ
3.Υυ”–ΦλΥς≤ΌΉςΨυΜαΖΒΜΊΑϋΚ§–όΕ©ΦΤ ΐΤςΒΡ ΐΨίœνΓΘ
4.Υυ”–Ηϋ–¬≤ΌΉςΕΦ±Ί–κΑϋΚ§¥”ΦλΥςΜώΒΟΒΡ–όΕ©ΦΤ ΐΤςΓΘ
Ηϋ–¬≤ΌΉς Βœ÷±Ί–κΕ‘ ΐΨίΩβΦ«¬ΦΫχ––œόΕ®ΒΡΗϋ–¬≤ΌΉςΘ§»γΓΑ»γΙϊ–όΕ©ΦΤ ΐΤςΒ»”Ύ...‘ρΗϋ–¬Φ«¬Φ...Γ±»γΙϊΤδΦδΕ‘Φ«¬ΦΫχ––ΝΥ»ΈΚΈ–όΗΡΘ§¥ΥΗϋ–¬≤ΌΉςΫΪ ßΑήΓΣΓΣ‘ΎΤδΦδΘ§»γΙϊ≥ωœ÷ΝΥΗϋ–¬Θ§‘ρΜα¥ΞΖΔΗϋ–¬¥ΞΖΔΤςΘ§“ρ¥ΥΜα–όΗΡ–όΕ©ΦΤ ΐΤςΓΘ
»γΙϊ”…”ΎΤδΥϊ Ι”Ο’Ώ‘ΎΤδΦδΫχ––ΝΥΗϋ–¬ΕχΒΦ÷¬Ηϋ–¬ ßΑήΘ§‘ρΫΪœρ Ι”Ο’Ώ±®Ηφ“ΜΗωΧΊΕ®ΒΡ¥μΈσΓΘ
«κΉΔ“βΘ§¥Υ Βœ÷‘ΎΗϋ–¬ ±“Σ«σ Ι”Ο’ΏΧαΙ©’ΐ»ΖΒΡ–όΕ©ΦΤ ΐΤςΘΜΫχ––Ψά’ΐΒΡ‘π»ΈΖ÷…ΔΒΫ ΐΨίΩβΓΔΧαΙ©’ΏΚΆ Ι”Ο’Ώ»ΐ’Ώ…μ…œΓΘΝμΆβΘ§ΜΙ«κΉΔ“βΘ§¥Υ Βœ÷…ηΦΤ’φΒΡΖ«≥Θά÷ΙέΘΜ»γΙϊ’υ”ΟΒΡΗ≈¬ ΚήΒΆΘ§ΨΆΡήΚήΚΟΒΊΙΛΉςΓΘ»γΙϊΩ…Ρή≥ωœ÷Ηϋ–¬≥εΆΜΘ§‘ρ÷Ί ‘ΒΡ–‘ΡήΩΣœζΫΪΖ«≥Θ¥σΓΘΝμΆβΘ§ΜΙ–η“Σ“Μ–©ΤδΥϊΩ…ΡήΒΡά÷ΙέΥχΕ®≤Ώ¬‘ΚΆœξœΗ…ηΦΤΘ§“‘÷ΤΕ®Κœ ΒΡ≤ΔΖΔΖΫΑΗΓΘ
ΩΦ¬«ΒΫΙήάμ≤ΔΖΔΗϋ–¬ΒΡœύΕ‘Η¥‘”–‘Θ§Έ“Ο«Χα≥ω“ΜΗωœύΙΊΒΡΫ®“ιΘΚΨΓΩ…Ρή Ι”ΟΈόΉ¥Χ§”ο“εΓΘάΐ»γΘ§”κ Βœ÷Β»–ßΒΡΓΑRetrieve
recordΓ±-ΓΑWrite recordΓ±ΝΫΗω≤ΌΉςΘ® Ι”Ο’ΏΜα‘ΎΦλΥςΚΆ–¥»κ≤ΌΉςΦδ Ι÷ΒΒί‘ωΘ©œύ±»Θ§Ω…Ρή Βœ÷ΨΏ”–ΝΦΚΟ≤ΔΖΔ––ΈΣΒΡΒΞΗω≤ΌΉςΓΑIncrement
balance by XΓ±ΗϋΈΣ»ί“ΉΓΘ
Ϋα χ”ο
Έ“Ο«≤Δ≤Μ»œΈΣΈΡ÷–ΑϋΚ§ΝΥ»Ϊ≤Ω…ηΦΤ‘≠‘ρΓΘΕχ «œΘΆϊΆ®Ιΐ’β–©‘≠‘ρΡήΙΜΥΒΟςΘ§ΟΩΗω
SOA ΕΦ–η“Σ…ς÷ΊΒΊΈΣΤδΤσ“Β»ΖΕ®“ΜΉι«ΓΒ±ΒΡ‘≠‘ρΘ§≤ΔΥφΚσ»ΖΕ®ΟΩΗωΖΰΈώ¥¥Ϋ®»Υ‘±ΕΦΡήΉώ―≠’β–©‘≠‘ρΓΘ
|