| ±ајНЖјц: |
±ѕОДЦчТЄЅйЙЬКІГґКЗБмУтЗэ¶ЇЈ¬єЛРДёЕДоЈ¬HaloїтјЬёЕКцµИПа№ШДЪИЭЎЈ
±ѕОДАґЧФУЪІШґфСтЈ¬УЙ»рБъ№ыИнјюAnna±ајЎўНЖјцЎЈ
|
|
1ЎўБмУтЗэ¶ЇёЕКц
Оў·юОсПµНіµДЙијЖЧФИ»АлІ»їЄDDDЈЁDomain-Driven DesignЈ¬БмУтЗэ¶ЇЙијЖЈ©Ј¬ЛьУЙEric
EvansМбіцЈ¬КЗТ»ЦЦИ«РВµДПµНіЙијЖєНЅЁДЈ·Ѕ·ЁЎЈDDDКВКµЙПКЗХл¶ФГжПт¶ФПу·ЦОцєНЙијЖµДТ»ёцА©Х№єНСУЙмЈ¬¶ФјјКхјЬ№№ЅшРРБЛ·ЦІг№ж»®Ј¬Н¬К±¶ФГїёцАаЅшРРБЛІЯВФєНАаРНµД»®·ЦЎЈБмУтДЈРНКЗБмУтЗэ¶ЇµДєЛРДЎЈБмУтДЈРННЁ№эѕЫєПЈЁAggregateЈ©ЧйЦЇФЪТ»ЖрЈ¬ѕЫєПјдУРГчПФµДТµОс±ЯЅзЈ¬ХвР©±ЯЅзЅ«БмУт»®·ЦОЄТ»ёцёцПЮЅзЙППВОДЈЁBounded
ContextЈ©ЎЈІЙУГDDDµДЙијЖЛјПлЈ¬ТµОсВЯјІ»ФЩјЇЦРФЪјёёцґуРНµДАаЙПЈ¬¶шКЗУЙґуБїПа¶ФРЎµДБмУт¶ФПуЈЁАаЈ©ЧйіЙЈ¬ХвР©АаѕЯ±ёЧФјєµДЧґМ¬єНРРОЄЈ¬ГїёцАаКЗПа¶ФНкХыµД¶АБўМеЈ¬ІўУлПЦКµБмУтµДТµОс¶ФПуУіЙдЎЈБмУтДЈРНѕНКЗУЙРн¶аХвСщµДПёБЈ¶ИµДАаЧйіЙµДЎЈ»щУЪБмУтЗэ¶ЇµДЙијЖЈ¬±ЈЦ¤БЛПµНіµДїЙО¬»¤РФЎўїЙА©Х№РФєНїЙёґУГРФЈ¬ФЪґ¦АнёґФУТµОсВЯј·ЅГжУРЧЕПИМмµДУЕКЖЎЈ1.1ЎўSpring
CloudУлБмУтЗэ¶Ї
ФЪОў·юОсЈЁMicroServicesЈ©јЬ№№КµјщЦРЈ¬ґуБїЅиУГБЛDDDЦРµДёЕДоєНјјКхЈ¬±ИИзТ»ёцОў·юОсУ¦ёГ¶ФУ¦DDDЦРµДТ»ёцПЮЅзЙППВОДЈЁBounded
ContextЈ©Ј»ФЪОў·юОсЙијЖЦРУ¦ёГКЧПИК¶±ріцDDDЦРµДѕЫєПёщЈЁAggregate RootЈ©Ј»»№УРФЪОў·юОсЦ®јдјЇіЙК±У¦ёГІЙУГDDDЦРµД·АёЇІгЈЁAnti-Corruption
Layer, ACLЈ©ЎЈОТГЗЙхЦБїЙТФЛµDDDєНОў·юОсУРЧЕМмЙъµДД¬ЖхЎЈ
ЧўЈєѕЫєПёщµДЙијЖУИОЄЦШТЄЈ¬Из№ыѕЫєПёщЙијЖјЇЦР»ЇЈ¬»бЛжЧЕєуАґµДТµОсА©Х№ДЈРНФЅАґФЅЕӴ󣬻ᵼЦВТ»ПµБРµДДЪґжЎўРФДЬµИОКМвЈ¬¶шЗТјёєхІ»їЙДЬЅвѕцЈ¬іэ·ЗЦШ№№ѕЫєПёщЙијЖЎЈ1.2ЎўОЄКІГґРиТЄБмУтЅЁДЈ
БмУтДЈРНУРЦъУЪНЕ¶УґґЅЁТ»ёцТµОсІїГЕУлITІїГЕ¶јДЬАнЅвµДНЁУГДЈРНЈ¬ІўУГёГДЈРНАґ№µНЁТµОсРиЗуЎўКэѕЭКµМеЎў№эіМДЈРНЎЈДЈРНКЗДЈїй»ЇЎўїЙА©Х№ЎўТЧУЪО¬»¤µДЈ¬Н¬К±ЙијЖ»№·ґУіБЛТµОсДЈРНЈ¬МбёЯБЛТµОсБмУт¶ФПуµДїЙЦШУГРФєНїЙІвРФЎЈ·ґ№эАґЈ¬Из№ыITНЕ¶УФЪїЄ·ўґуЦРРНЖуТµИнјюУ¦УГК±І»ЧсСБмУтДЈРН·Ѕ·ЁЈ¬І»Н¶·ЕЧКФґИҐЅЁБўєНїЄ·ўБмУтДЈРНЈ¬»бµјЦВУ¦УГјЬ№№іцПЦЎ°·К·юОсІгЎ±єНЎ°Ж¶СЄµДБмУтДЈРНЎ±Ј¬ФЪХвСщµДјЬ№№ЦРЈ¬»б»эѕЫФЅАґФЅ¶аµДТµОсВЯјЎЈОТГЗПЈНыБмУт¶ФПуДЬ№»ЧјИ·µШ±нґпіцТµОсТвНјЈ¬µ«КЗ¶аКэК±єтЈ¬ОТГЗїґµЅµДИґКЗідВъgetterєНsetterµДБмУт¶ФПуЎЈґЛК±µДБмУт¶ФПуТСѕІ»КЗБмУт¶ФПуБЛЈ¬ЛьГЗЦ»КЗёцКэѕЭФШМеЈ¬ТІѕНКЗMartin
FowlerЛщЛµµДЖ¶СЄ¶ФПуЎЈХвЦЦЧц·Ё»бµјЦВБмУтМШ¶ЁТµОсВЯј·ЦЙўФЪТ»¶СserviceІгЦРЈ¬ИнјюјЬ№№ЛжТµОсїЄ·ўіЈДкАЫ»эТ°ВщЙъі¤Ј¬ґУ¶шёЇ°ЬЈ¬ОЮ·ЁО¬»¤ЎЈБмУтЗэ¶ЇЙијЖёжЛЯОТГЗЈ¬ФЪНЁ№эИнјюКµПЦТ»ёцТµОсПµНіК±Ј¬ЅЁБўТ»ёцБмУтДЈРНКЗ·ЗіЈЦШТЄєН±ШТЄµДЈ¬ТтОЄБмУтДЈРНѕЯУРТФПВМШµгЈє
БмУтДЈРНКЗ¶ФѕЯУРДіёц±ЯЅзµДБмУтµДТ»ёційПуЈ¬·ґУіБЛБмУтДЪУГ»§ТµОсРиЗуµД±ѕЦКЈ»БмУтДЈРНКЗУР±ЯЅзµДЈ¬Ц»·ґУіБЛОТГЗФЪБмУтДЪЛщ№ШЧўµДІї·ЦЎЈ
БмУтДЈРНЦ»·ґУіТµОсЈ¬єНИОєОјјКхКµПЦОЮ№ШЈ»БмУтДЈРНІ»ЅцДЬ·ґУіБмУтЦРµДТ»Р©КµМеёЕДоЈ¬Из»хОпЎўКй±ѕЎўУ¦ЖёјЗВјЎўµШЦ·µИЈ»»№ДЬ·ґУіБмУтЦРµДТ»Р©№эіМёЕДоЈ¬ИзЧКЅрЧЄХЛµИЎЈ
БмУтДЈРНИ·±ЈБЛОТГЗµДИнјюТµОсВЯј¶јФЪТ»ёцДЈРНЦРЈ¬ХвСщ¶ФМбёЯИнјюµДїЙО¬»¤РФЈ¬ТµОсїЙАнЅвРФТФј°їЙЦШУГРФ¶јУР°пЦъЎЈ
БмУтДЈРНДЬ№»°пЦъїЄ·ўИЛФ±Па¶ФЖЅ»¬µШЅ«БмУтЦЄК¶ЧЄ»ЇОЄИнјю№№ФмЎЈ
БмУтДЈРН№бґ©Инјю·ЦОцЎўЙијЖј°їЄ·ўµДХыёц№эіМЈ»БмУтЧЁјТЎўЙијЖИЛФ±ЎўїЄ·ўИЛФ±НЁ№эБмУтДЈРНЅшРРЅ»БчЈ¬±ЛґЛ№ІПнЦЄК¶УлРЕПўЈ»ТтОЄґујТГжПтµД¶јКЗН¬Т»ёцДЈРНЈ¬ЛщТФїЙТФ·АЦ№РиЗуЧЯСщЈ¬їЙТФИГИнјюЙијЖїЄ·ўИЛФ±ЧціцАґµДИнјюХжХэВъЧгРиЗуЎЈ
ТЄЅЁБўХэИ·µДБмУтДЈРНІўІ»јтµҐЈ¬РиТЄБмУтЧЁјТЎўЙијЖИЛФ±ЎўїЄ·ўИЛФ±»эј«№µНЁ№ІН¬Е¬Б¦Ј¬И»єуІЕДЬК№ґујТ¶ФБмУтµДИПК¶І»¶ПЙоИлЈ¬ґУ¶шІ»¶ППё»ЇєННкЙЖБмУтДЈРНЎЈ
ОЄБЛИГБмУтДЈРНїґµГјыЈ¬ОТГЗРиТЄУГТ»Р©·Ѕ·ЁАґ±нКѕЛьЈ»НјКЗ±нґпБмУтДЈРНЧоіЈУГµД·ЅКЅЈ¬µ«І»КЗОЁТ»µД·ЅКЅЈ¬ґъВл»тОДЧЦГиКцТІДЬ±нґпБмУтДЈРНЎЈ
БмУтДЈРНКЗХыёцИнјюµДєЛРДЈ¬КЗИнјюЦРЧоУРјЫЦµєНЧоѕЯѕєХщБ¦µДІї·ЦЈ»ЙијЖЧг№»ѕ«БјЗТ·ыєПТµОсРиЗуµДБмУтДЈРНДЬ№»ёьїмЛЩµШПмУ¦РиЗуµД±д»ЇЎЈ
2ЎўБмУтЗэ¶ЇєЛРДёЕДо
2.1Ўў КµМеёЕКц
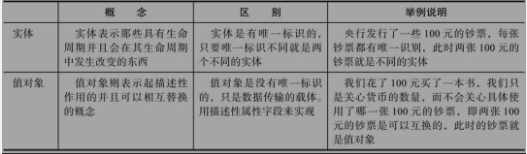
КµМеЈЁEntityЈ©КЗБмУтЦРРиТЄОЁТ»±кК¶µДБмУтёЕДоЈ¬ТтОЄОТГЗУРК±РиТЄЗш·ЦКЗДДёцКµМеЎЈИз№ыУРБЅёцКµМеЈ¬ЗТОЁТ»±кК¶І»Т»СщЈ¬ДЗГґјґ±гКµМеµДЖдЛыЛщУРКфРФ¶јТ»СщЈ¬ОТГЗТІИПОЄЛьГЗКЗІ»Н¬µДКµМеЈ»ТтОЄКµМеУРЙъГьЦЬЖЪЈ¬КµМе±»ґґЅЁєуїЙДЬ»б±»іЦѕГ»ЇµЅКэѕЭївЈ¬И»єуДіёцК±єтУЦ»б±»ИЎіцАґЎЈЛщТФЈ¬Из№ыОТГЗІ»ОЄКµМе¶ЁТеТ»ЦЦїЙТФОЁТ»Зш·ЦµД±кК¶Ј¬ДЗОТГЗѕНОЮ·ЁЗш·ЦµЅµЧКЗХвёцКµМе»№КЗДЗёцКµМеЎЈ
БнНвЈ¬І»У¦ёГёшКµМе¶ЁТеМ«¶аµДКфРФ»тРРОЄЈ¬¶шУ¦ёГС°ХТ№ШБЄЈ¬·ўПЦЖдЛыТ»Р©КµМе»тЦµ¶ФПуЈ¬Ѕ«КфРФ»тРРОЄЧЄТЖµЅЖдЛы№ШБЄµДКµМе»тЦµ¶ФПуЙПЎЈ±ИИзCustomerКµМеЈ¬ЛьУРТ»Р©µШЦ·РЕПўЈ¬УЙУЪµШЦ·РЕПўКЗТ»ёцНкХыµДУРТµОсє¬ТеµДёЕДоЈ¬ЛщТФОТГЗїЙТФ¶ЁТеТ»ёцAddress¶ФПуЈ¬И»єу°СCustomerЦРУлµШЦ·Па№ШµДРЕПўЧЄТЖµЅAddress¶ФПуЙПЎЈИз№ыГ»УРAddress¶ФП󣬶ш°СХвР©µШЦ·РЕПўЦ±ЅУ·ЕФЪCustomer¶ФПуЙПЈ¬ІўЗТ°СЖдЛыАаЛЖAddressµДРЕПўТІ¶јЦ±ЅУ·ЕФЪCustomerЙПЈ¬»бµјЦВCustomer¶ФПуєЬ»мВТЈ¬Ѕб№№І»ЗеОъЈ¬ЧоЦХµјЦВЛьДСТФО¬»¤єНАнЅвЎЈ
2.2ЎўЦµ¶ФПуёЕКц
ФЪБмУтЦРЈ¬ІўІ»КЗГїТ»ёцКВОп¶ј±ШРлУРТ»ёцОЁТ»±кК¶Ј¬ТІѕНКЗЛµОТГЗІ»№ШРД¶ФПуКЗДДёцЈ¬Ц»№ШРД¶ФПуКЗКІГґЎЈѕНТФЙПГжµДµШЦ·¶ФПуAddressОЄАэЈ¬Из№ыУРБЅёцCustomerµДµШЦ·РЕПўКЗТ»СщµДЈ¬ОТГЗѕН»бИПОЄХвБЅёцCustomerµДµШЦ·КЗН¬Т»ёцЎЈТІѕНКЗЛµЦ»ТЄµШЦ·РЕПўТ»СщЈ¬ОТГЗѕНИПОЄКЗН¬Т»ёцµШЦ·ЎЈ
УГіМРтµД·ЅКЅАґ±нґпѕНКЗЈ¬Из№ыБЅёц¶ФПуµДЛщУРКфРФµДЦµ¶јПаН¬Ј¬ОТГЗ»бИПОЄЛьГЗКЗН¬Т»ёц¶ФПуЈ¬ДЗГґОТГЗѕНїЙТФ°СХвЦЦ¶ФПуЙијЖОЄЦµ¶ФПуЈЁValue
ObjectЈ©ЎЈТтґЛЈ¬Цµ¶ФПуГ»УРОЁТ»±кК¶Ј¬ХвКЗЛьєНКµМеµДЧоґуІ»Н¬ЎЈБнНвЦµ¶ФПуФЪЕР¶ПКЗ·сКЗН¬Т»ёц¶ФПуК±КЗНЁ№эЛьГЗµДЛщУРКфРФКЗ·сПаН¬КµПЦµДЈ¬Из№ыПаН¬ФтИПОЄКЗН¬Т»ёцЦµ¶ФП󣻶шОТГЗФЪЗш·ЦКЗ·сКЗН¬Т»ёцКµМеК±Ј¬Ц»їґКµМеµДОЁТ»±кК¶КЗ·сПаН¬Ј¬І»№ЬКµМеµДКфРФКЗ·сПаН¬ЎЈЦµ¶ФПуБнНвТ»ёцГчПФµДМШХчКЗІ»їЙ±дЈ¬јґЛщУРКфРФ¶јКЗЦ»¶БµДЎЈТтОЄКфРФКЗЦ»¶БµДЈ¬ЛщТФїЙТФ±»°ІИ«№ІПнЎЈµ±№ІПнЦµ¶ФПуК±Ј¬Т»°гУРёґЦЖєН№ІПнБЅЦЦЧц·ЁЈ¬ѕЯМеІЙУГДДЦЦЧц·Ё»№ТЄёщѕЭКµјКЗйїц¶ш¶ЁЎЈБнНвЈ¬ОТГЗУ¦ёГЅ«Цµ¶ФПуЙијЖµГѕЎБїјтµҐЈ¬І»ТЄИГЛьТэУГєЬ¶аЖдЛы¶ФПуЈ¬ТтОЄЛьЦ»КЗТ»ёцЦµЎЈКµМеєНЦµ¶ФПуµД¶Ф±ИЈ¬ИзПВ±нЛщКѕЈє
2.3ЎўБмУт·юОс
БмУтЦРµДТ»Р©ёЕДоІ»ККєПЅЁДЈОЄ¶ФПуЈ¬јґІ»ККєП№йАаµЅКµМе¶ФПу»тЦµ¶ФПуЈ¬ТтОЄЛьГЗ±ѕЦКЙПѕНКЗТ»Р©ІЩЧч»т¶ЇЧчЈ¬¶шІ»КЗКµОпЎЈХвР©ІЩЧч»т¶ЇЧчНщНщ»бЙжј°¶аёцБмУтµД¶ФПуЈ¬ІўЗТРиТЄРµчХвР©БмУт¶ФПу№ІН¬НкіЙХвёцІЩЧч»т¶ЇЧчЎЈИз№ыЗїРРЅ«ХвР©ІЩЧчЦ°Фр·ЦЕдёшИОєОТ»ёц¶ФПуЈ¬Фт±»·ЦЕдµД¶ФПуѕН»біРµЈТ»Р©І»ёГіРµЈµДЦ°Ф𣬴Ӷш»бµјЦВ¶ФПуµДЦ°ФрІ»ГчИ·ЎЈµ«КЗ»щУЪАаµДГжПт¶ФПуµДУпСФ№ж¶ЁЈ¬ИОєОКфРФ»тРРОЄ¶ј±ШРл·ЕФЪ¶ФПуАпГжЎЈЛщТФОТГЗРиТЄС°ХТТ»ЦЦРВµДДЈКЅАґ±нКѕХвЦЦїз¶аёц¶ФПуµДІЩЧчЈ¬DDDИПОЄ·юОсКЗТ»ёцєЬЧФИ»µД·¶КЅЈ¬їЙУГАґ¶ФУ¦ХвЦЦїз¶аёц¶ФПуµДІЩЧчЈ¬ЛщТФѕНУРБЛБмУт·юОсЈЁDomain
ServiceЈ©ХвёцДЈКЅЎЈБмУт·юОс±ѕАґѕНКЗАґґ¦АнХвЦЦіЎѕ°µДЎЈ±ИИзТЄ¶ФГЬВлЅшРРЅвГЬЈ¬їЙТФґґЅЁТ»ёцPasswordServiceАґЧЁГЕґ¦АнјУЅвГЬµДОКМвЎЈ
БмУт·юОс»№УРТ»ёцєЬЦШТЄµД№¦ДЬЈ¬ѕНКЗїЙТФ±ЬГвБмУтВЯјР№В¶µЅУ¦УГІгЎЈТтОЄИз№ыГ»УРБмУт·юОсЈ¬ДЗГґУ¦УГІг»бЦ±ЅУµчУГБмУт¶ФПуНкіЙ±ѕёГКфУЪБмУт·юОсЧцµДІЩЧчЈ¬ХвСщТ»АґЈ¬БмУтІгїЙДЬ»б°СТ»Ії·ЦБмУтР№В¶µЅУ¦УГІгЎЈТтґЛЈ¬ТэИлБмУт·юОсїЙТФУРР§·АЦ№БмУтІгµДВЯјР№В¶µЅУ¦УГІгЎЈ¶ФУЪУ¦УГІгЈ¬ґУїЙАнЅвµДЅЗ¶ИАґЅІЈ¬НЁ№эµчУГБмУт·юОсМṩµДјтµҐЎўТЧ¶®ЎўГчИ·µДЅУїЪїП¶ЁТЄ±ИЦ±ЅУІЩЧЭБмУт¶ФПуИЭТЧµГ¶аЎЈ
ДЗИзєОИҐК¶±рБмУт·юОсДШЈїЦчТЄїґЛьКЗ·сВъЧгТФПВИэёцМШХчЈє
·юОсЦґРРµДІЩЧчґъ±нБЛТ»ёцБмУтёЕДоЈ¬ХвёцБмУтёЕДоОЮ·ЁЧФИ»БҐКфУЪТ»ёцКµМе»тХЯЦµ¶ФПуЎЈ
±»ЦґРРµДІЩЧчЙжј°БмУтЦРµДЖдЛыµД¶ФПуЎЈ
ІЩЧчКЗОЮЧґМ¬µДЎЈ
2.4ЎўѕЫєПј°ѕЫєПёщ
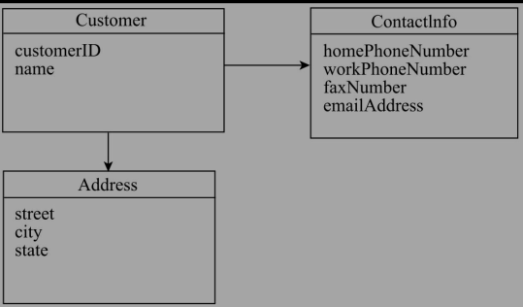
ѕЫєПНЁ№э¶ЁТе¶ФПуЦ®јдЗеОъµДЛщКф№ШПµєН±ЯЅзАґКµПЦБмУтДЈРНµДДЪѕЫЈ¬Іў±ЬГвБЛґнЧЫёґФУµДЎўДСТФО¬»¤µД¶ФПу№ШПµНшµДРОіЙЎЈѕЫєП¶ЁТеБЛТ»ЧйѕЯУРДЪѕЫ№ШПµµДПа№Ш¶ФПуµДјЇєПЈ¬ОТГЗ°СѕЫєПїґЧчТ»ёцРЮёДКэѕЭµДµҐФЄЎЈѕЫєПЦРЛщ°ьє¬µД¶ФПуЦ®јдѕЯУРГЬІ»їЙ·ЦµДБЄПµЈ¬ЛьГЗКЗДЪѕЫФЪТ»ЖрµДЎЈ±ИИзТ»БѕЖыіµЈЁCarЈ©°ьє¬БЛТэЗжЈЁEngineЈ©ЎўіµВЦЈЁWheelЈ©єНУНПдЈЁTankЈ©µИЧйјюЈ¬И±Т»І»їЙЎЈТ»ёцѕЫєПЦРїЙТФ°ьє¬¶аёцКµМеєНЦµ¶ФПуЈ¬ТтґЛѕЫєПТІ±»іЖОЄёщКµМеЎЈИзПВНјЛщКѕѕНКЗТ»ёцѕЫєПЈ¬CustomerКЗѕЫєПёщТІКЗКµМеЈ¬addressКЗЦµ¶ФПуЈ¬ContactInfoТІКЗЦµ¶ФПуЎЈ
ѕЫєПёщЈЁAggregate RootЈ©КЗDDDЦРµДТ»ёцёЕДоЈ¬КЗТ»ЦЦёьґу·¶О§µД·вЧ°Ј¬Жд°СТ»ЧйУРПаН¬ЙъГьЦЬЖЪЎўФЪТµОсЙПІ»їЙ·ЦёфµДКµМеєНЦµ¶ФПу·ЕФЪТ»ЖрїјВЗЈ¬Ц»УРёщКµМеїЙТФ¶ФНⱩ¶ТэУГЈ¬ТІКЗТ»ЦЦДЪѕЫРФµД±нПЦЎЈµ«КЗТЄИ·¶ЁѕЫєП±ЯЅзТЄВъЧг№М¶Ё№жФтЈЁInvariantЈ©Ј¬ТІѕНКЗФЪКэѕЭ±д»ЇК±±ШРл±ЈіЦТ»ЦВРФ№жФтЈ¬ѕЯМе№жФтИзПВЈє
ёщКµМеѕЯУРИ«ѕЦ±кК¶Ј¬ЧоЦХёєФрјмІй№ж¶Ё№жФтЎЈ
ѕЫєПДЪµДКµМеѕЯУР±ѕµШ±кК¶Ј¬ХвР©±кК¶ФЪAggregateДЪІїІЕКЗОЁТ»µДЎЈ
НвІї¶ФПуІ»ДЬТэУГіэёщEntityЦ®НвµДИОєОДЪІї¶ФПуЎЈ
Ц»УРAggregateµДёщEntityІЕДЬЦ±ЅУНЁ№эКэѕЭївІйСЇ»сИЎЈ¬ЖдЛы¶ФПу±ШРлНЁ№э±йАъ№ШБЄАґ·ўПЦЎЈ
AggegateДЪІїµД¶ФПуїЙТФ±ЈіЦ¶ФЖдЛыAggregateёщµДТэУГЎЈ
¶ФAggregate±ЯЅзДЪµДИОєО¶ФПуЅшРРРЮёДК±Ј¬ХыёцAggregateµДЛщУР№М¶Ё№жФт¶ј±ШРлВъЧгЎЈ
2.5Ўў±ЯЅзЙППВОД
БмУтКµМеКЗУР±ЯЅзЙППВОДµДЈ¬ПµНі»сИЎµДКэѕЭКЗУРЅзЙППВОДЈЁBounded ContextЈ©ПВµДКэѕЭЎЈ±ЯЅзЙППВОДЈЁBounded
ContextЈ©ФЪDDDАпГжКЗТ»ёц·ЗіЈЦШТЄµДёЕДоЈ¬Bounded ContextГчИ·ПЮ¶ЁБЛДЈРНµДУ¦УГ·¶О§ЎЈФЪContextЦРЈ¬ТЄ±ЈЦ¤ДЈРНФЪВЯјЙПНіТ»Ј¬¶шІ»УГїјВЗЛьКЗІ»КЗККУГУЪ±ЯЅзЦ®НвµДЗйїцЎЈФЪЖдЛыContextЦРЈ¬»бК№УГЖдЛыДЈРНЈ¬ХвР©ДЈРНѕЯУРІ»Н¬µДКхУпЎўёЕДоЎў№жФтєНUbiquitous
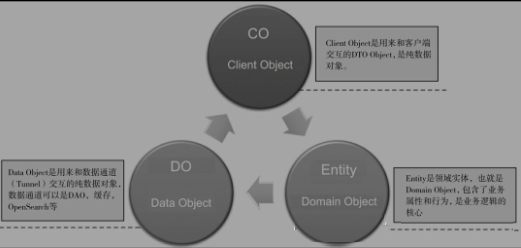
LanguageЎЈДЗГґІ»Н¬ContextПВµДТµОсТЄ»ҐПаНЁРЕФхГґ°мЈїХвѕНЙжј°їз±ЯЅзµДјЇіЙБЛЈ¬јЇіЙІ»ДЬКЗјтµҐµДRPC·юОсµчУГЈ¬¶шРиТЄТ»ёцЧЁГЕµД·АёЇІгЈЁAnti-CorruptionЈ©ЧцЧЄ»ЇЎЈ·АёЇІгЦчТЄКЗ¶ФНвІїТААµЅвсоЈ¬ТФј°±ЬГвНвІїБмУтёЕДоОЫИѕContextДЪІїКµМеУпТеЎЈТФОТГЗХжКµµДТµОсіЎѕ°ѕЩёцАэЧУЈ¬±ИИз»бФ±ХвёцёЕДоФЪICBUНшХѕЙПЦёНшХѕЙПµДВтЦчЈ¬µ«КЗФЪCRMБмУтЦРЦёїН»§Ј¬ЛдИ»єЬ¶аµДКфРФ¶јКЗТ»СщµДЈ¬µ«КЗ¶юХЯФЪІ»Н¬µДContextПВЖдУпТеєНёЕДоКЗУРІо±рµДЈ¬ОТГЗРиТЄУГ·АёЇІгЧцТ»ПВЧЄ»»Ј¬ИзНјЛщКѕЈє
2.6Ўў№¤і§
DDDЦРµД№¤і§ЈЁFactoryЈ©ТІКЗТ»ЦЦМеПЦ·вЧ°ЛјПлµДДЈКЅЎЈDDDЦРТэИ빤і§ДЈКЅµДФТтКЗЈєУРК±ґґЅЁТ»ёцБмУт¶ФПуКЗТ»јю±ИЅПёґФУµДКВЗйЈ¬¶шІ»КЗЅцЅцЅшРРјтµҐµДnewІЩЧчѕНїЙТФЎЈХэИз¶ФПу·вЧ°БЛДЪІїКµПЦТ»СщЈЁОТГЗОЮРлЦЄµА¶ФПуµДДЪІїКµПЦѕНїЙТФК№УГ¶ФПуµДРРОЄЈ©Ј¬№¤і§ФтУГАґ·вЧ°ґґЅЁТ»ёцёґФУ¶ФПуµДІЩЧчЎЈ№¤і§µДЧчУГКЗЅ«ґґЅЁ¶ФПуµДПёЅЪТюІШЖрАґЎЈ
№¤і§ФЪґґЅЁТ»ёцёґФУµДБмУт¶ФПуК±Ј¬НЁіЈ»бЦЄµАёГВъЧгКІГґТµОс№жФтЈЁЛьЦЄµАПИФхСщКµАэ»ЇТ»ёц¶ФПуЈ¬И»єу¶ФХвёц¶ФПуЧцДДР©іхКј»ЇІЩЧчЈ¬ХвР©№жФтѕНКЗґґЅЁ¶ФПуµДПёЅЪЈ©Ј¬Из№ыґ«µЭЅшАґµДІОКэ·ыєПґґЅЁ¶ФПуµДТµОс№жФтЈ¬ФтїЙТФЛіАыґґЅЁПаУ¦µД¶ФПуЈ»µ«КЗИз№ыУЙУЪІОКэОЮР§µИІ»ДЬґґЅЁіцЖЪНыµД¶ФПуЈ¬ФтУ¦ёГЕЧіцТ»ёцТміЈЈ¬ТФИ·±ЈІ»»бґґЅЁіцТ»ёцґнОуµД¶ФПуЎЈ
µ±И»ТІІ»КЗЛщУР¶јРиТЄНЁ№э№¤і§АґґґЅЁ¶ФП󣬵±№№ФмЖчєЬјтµҐ»тХЯ№№Фм¶ФПуІ»ТААµУЪЖдЛы¶ФПуАґґґЅЁК±Ј¬ОТГЗЦ»РиТЄјтµҐµШК№УГ№№ФмєЇКэґґЅЁ¶ФПуѕНїЙТФЎЈТюІШґґЅЁ¶ФПуµДєГґ¦КЗПФ¶шТЧјыµДЈ¬ХвСщїЙТФІ»ИГБмУтІгµДТµОсВЯјР№В¶µЅУ¦УГІгЈ¬Н¬К±ТІјхЗбБЛУ¦УГІгµДёєµЈЈ¬ЛьЦ»РиТЄјтµҐµШµчУГБмУт№¤і§ґґЅЁ·ыєПЖЪНыµД¶ФПујґїЙЎЈ
2.7ЎўІЦґў/ЧКФґїв
БмУтДЈРНЦРµД¶ФПуЧФґУ±»ґґЅЁіцАґєуІ»»бТ»Ц±ФЪДЪґжЦР»о¶ЇЈ¬µ±ЛьІ»»о¶ЇК±»б±»іЦѕГ»ЇµЅКэѕЭївЦРЈ¬И»єуµ±РиТЄµДК±єтОТГЗ»бЦШЅЁёГ¶ФПуЎЈЦШЅЁ¶ФПуѕНКЗёщѕЭКэѕЭївЦРТСґжґўµД¶ФПуµДЧґМ¬ЦШРВґґЅЁ¶ФПуЎЈЛщТФЦШЅЁ¶ФПуКЗТ»ёцєНКэѕЭївґтЅ»µАµД№эіМЎЈґУёь№гТеµДЅЗ¶ИАґАнЅвЈ¬ОТГЗѕіЈ»бПсјЇєПТ»СщґУДіёцАаЛЖјЇєПµДµШ·ЅёщѕЭДіёцМхјю»сИЎТ»ёц»тТ»Р©¶ФПуЈ¬НщјЇєПЦРМнјУ¶ФПу»тТЖіэ¶ФПуЎЈТІѕНКЗЛµЈ¬ОТГЗРиТЄМṩһЦЦ»ъЦЖЈ¬їЙТФМṩАаЛЖјЇєПµДЅУїЪАґ°пЦъОТГЗ№ЬАн¶ФПуЎЈІЦґўЈЁRepositoryЈ©ѕНКЗ»щУЪХвСщµДЛјПл±»ЙијЖіцАґµДЎЈ
ІЦґўАпГжґж·ЕµД¶ФПуТ»¶ЁКЗѕЫєПЈ¬ФТтКЗБмУтДЈРНЦРКЗТФѕЫєПµДёЕДоИҐ»®·Ц±ЯЅзµДЎЈѕЫєПКЗОТГЗёьРВ¶ФПуµДТ»ёц±ЯЅзЈ¬КВКµЙПОТГЗ°СХыёцѕЫєПїґіЙТ»ёцХыМеёЕДоЈ¬ТЄГґТ»Жр±»ИЎіцАґЈ¬ТЄГґТ»Жр±»ЙѕіэЎЈОТГЗУАФ¶І»»бµҐ¶А¶ФДіёцѕЫєПДЪµДЧУ¶ФПуЅшРРµҐ¶АІйСЇ»тЧцёьРВІЩЧчЎЈТтґЛЈ¬ОТГЗЦ»ОЄѕЫєПЙијЖІЦґўЎЈ
ІЦґў»№УРТ»ёцЦШТЄµДМШХчѕНКЗ·ЦОЄІЦґў¶ЁТеІї·ЦєНІЦґўКµПЦІї·ЦЈ¬ФЪБмУтДЈРНЦРОТГЗ¶ЁТеІЦґўµДЅУїЪЈ¬¶шФЪ»щґЎЙиК©ІгКµПЦѕЯМеµДІЦґўЎЈХвСщЙијЖµДФТтКЗЈєІЦґў±ієуµДКµПЦ¶јКЗФЪєНКэѕЭївґтЅ»µАЈ¬µ«КЗОТГЗУЦІ»ПЈНыµчУГ·ЅЈЁИзУ¦УГІгЈ©°СЦШµг·ЕФЪИзєОґУКэѕЭїв»сИЎКэѕЭµДОКМвЙПЈ¬ТтОЄХвСщЧц»бµјЦВµчУГ·ЅЈЁУ¦УГІгЈ©ґъВл»мВТЈ¬єЬїЙДЬ»бТтґЛ¶шєцВФБЛБмУтДЈРНµДґжФЪЎЈЛщТФОТГЗРиТЄМṩһёцјтµҐГчБЛµДЅУїЪ№©µчУГ·ЅК№УГЈ¬И·±ЈїН»§ДЬТФЧојтµҐµД·ЅКЅ»сИЎБмУт¶ФП󣬴ӶшїЙТФИГЛьФЪІ»±»КэѕЭ·ГОКґъВлґтИЕµДЗйїцПВРµчБмУт¶ФПуТФНкіЙТµОсВЯјЎЈХвЦЦНЁ№эЅУїЪАґёфАл·вЧ°±д»ЇµДЧц·ЁЖдКµєЬіЈјыЎЈУЙУЪ¶ФНⱩ¶µДКЗійПуµДЅУїЪІўІ»КЗѕЯМеµДКµПЦЈ¬ЛщТФїЙТФЛжК±Мж»»ІЦґўµДХжКµКµПЦЎЈ
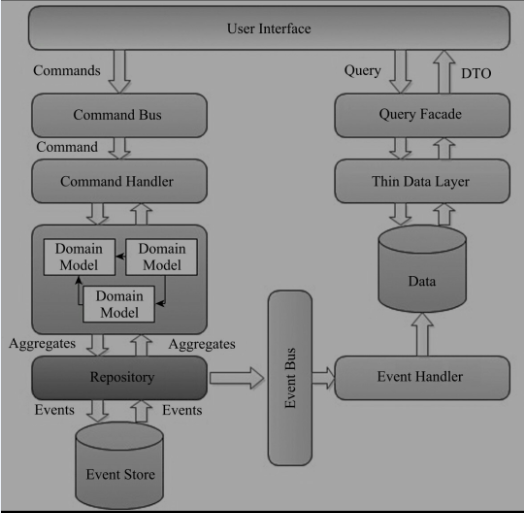
2.8ЎўCQRSјЬ№№
CQRSµДєЛРДЛјПлКЗЅ«У¦УГіМРтµДІйСЇІї·ЦєНГьБоІї·ЦНкИ«·ЦАлЈ¬ХвБЅІї·ЦїЙТФУГНкИ«І»Н¬µДДЈРНєНјјКхИҐКµПЦЎЈ±ИИзГьБоІї·ЦїЙТФНЁ№эБмУтЗэ¶ЇЙијЖАґКµПЦЈ»ІйСЇІї·ЦїЙТФЦ±ЅУУГЧоїмµД·ЗГжПт¶ФПуµД·ЅКЅАґКµПЦЈ¬±ИИзУГSQLЎЈХвСщµДЛјПлУРєЬ¶аєГґ¦Јє
КµПЦГьБоІї·ЦµДБмУтДЈРНЈ¬І»УГѕіЈОЄБЛїјВЗБмУт¶ФПуїЙДЬ»б±»ИзєОІйСЇ¶шЧцТ»Р©ХЫЦРґ¦АнЎЈ
УЙУЪГьБоєНІйСЇКЗНкИ«·ЦАлµДЈ¬ЛщТФХвБЅІї·ЦїЙТФУГІ»Н¬µДјјКхјЬ№№КµПЦЈ¬°ьАЁКэѕЭївЙијЖАнВЫЙП¶јїЙТФ·ЦїЄЙијЖЈ¬ГїТ»Ії·ЦїЙТФід·Ц·ў»УЖді¤ґ¦ЎЈ
ТтОЄГьБо¶ЛГ»УР·µ»ШЦµЈ¬ЛщТФїЙТФПсПыПў¶УБРТ»СщЅУКЬГьБоЈ¬·ЕФЪ¶УБРЦРЈ¬ВэВэґ¦АнЈ»ґ¦АнНкєуЈ¬їЙТФНЁ№эТмІЅµД·ЅКЅНЁЦЄІйСЇ¶ЛЈ¬ХвСщІйСЇ¶ЛїЙТФЧцКэѕЭН¬ІЅµДґ¦АнЎЈ
CQRSјЬ№№µДУЕИ±µгИзПВ±нЛщКѕЈє

2.9ЎўБмУтКВјю
БмУтКВјюЈЁDomain EventЈ©КЗЧоЅьјёДкІЕјУИлDDDЙъМ¬ПµНіµДЈ¬НЁ№эБмУтКВјюµД·ЅКЅґпµЅёчёцЧйјюЦ®јдµДКэѕЭТ»ЦВРФЎЈБмУтКВјюµД¶оНвєГґ¦ФЪУЪЛьїЙТФјЗВј·ўЙъФЪИнјюПµНіЦРµДЛщУРЦШТЄРЮёДЈ¬ХвСщїЙТФєЬєГµШЦ§іЦіМРтµчКФєНЙМТµЦЗДЬ»ЇЎЈФЪCQRSјЬ№№µДИнјюПµНіЦРЈ¬БмУтКВјю»№УГУЪРґДЈРНєН¶БДЈРНЦ®јдµДКэѕЭН¬ІЅЎЈФЩЅшТ»ІЅ·ўХ№Ј¬КВјюЗэ¶ЇјЬ№№їЙТФСЭ±діЙКВјюФґЈЁEvent
SourcingЈ©Ј¬јґ¶ФѕЫєПµД»сИЎІўІ»КЗНЁ№эјУФШКэѕЭївЦРµДЛІК±ЧґМ¬КµПЦµДЈ¬¶шКЗНЁ№эЦШ·Е·ўЙъФЪѕЫєПЙъГьЦЬЖЪЦРµДЛщУРБмУтКВјюНкіЙµДЎЈ
КВјюЛЭФґЈЁEvent SourcingЈ©КЗ»щУЪDDDЙијЖµДЈ¬¶ФУЪѕЫєПЈ¬І»±ЈґжѕЫєПµДµ±З°ЧґМ¬Ј¬¶шКЗ±Јґж¶ФПуЙПЛщ·ўЙъµДГїёцКВјюЎЈµ±ТЄЦШЅЁТ»ёцѕЫєП¶ФПуК±Ј¬їЙТФНЁ№э»ШЛЭХвР©КВјюЈЁјґИГХвР©КВјюЦШРВ·ўЙъЈ©АґИГ¶ФПу»ЦёґµЅДіёцМШ¶ЁµДЧґМ¬Ј»ТтОЄУРК±Т»ёцѕЫєПїЙДЬ»б·ўЙъєЬ¶аКВјюЈ¬ЛщТФИз№ыГїґОТЄФЪЦШЅЁ¶ФПуК±¶јґУН·»ШЛЭКВјюЈ¬»бµјЦВРФДЬµНПВЈ¬ЛщТФОТГЗ»бФЪТ»¶ЁК±єтОЄѕЫєПґґЅЁТ»ёцїмХХЎЈХвСщЈ¬ОТГЗѕНїЙТФ»щУЪДіёцїмХХїЄКјґґЅЁѕЫєП¶ФПуБЛЎЈ
2.10Ўў БмУтЗэ¶ЇДЈРНµДЙијЖІЅЦи
БмУтЗэ¶ЇДЈРНµДЙијЖІЅЦиИзПВЈє
ЈЁ1Ј©ёщѕЭРиЗуЅЁБўТ»ёціхІЅµДБмУтДЈРНЈ¬К¶±ріцТ»Р©ГчПФµДБмУтёЕДој°ЛьГЗЦ®јдµД№ШБЄЈ¬№ШБЄїЙТФФЭК±Г»УР·ЅПтµ«РиТЄУРТ»¶ФТ»ЎўТ»¶Ф¶аЎў¶а¶Ф¶аХвР©№ШПµЎЈїЙТФУГОДЧЦѕ«И·ЗТГ»УРЖзТеµШГиКціцГїёцБмУтёЕДоµДєТеј°°ьє¬µДЦчТЄРЕПўЎЈ
ЈЁ2Ј©·ЦОцЦчТЄµДИнјюУ¦УГіМРт№¦ДЬЈ¬К¶±ріцЦчТЄµДУ¦УГІгµДАаЈ¬ХвСщУРЦъУЪј°Фз·ўПЦДДР©КЗУ¦УГІгµДЦ°ФрЈ¬ДДР©КЗБмУтІгµДЦ°ФрЎЈ
ЈЁ3Ј©ЅшТ»ІЅ·ЦОцБмУтДЈРНЈ¬К¶±ріцДДР©КЗКµМеЈ¬ДДР©КЗЦµ¶ФПуЈ¬ДДР©КЗБмУт·юОсЎЈ
ЈЁ4Ј©·ЦОц№ШБЄЈ¬НЁ№э¶ФТµОсЅшРРёьЙоИл·ЦОцј°ёчЦЦИнјюЙијЖФФтЎўРФДЬ·ЅГжµДИЁєвЈ¬ГчИ·№ШБЄµД·ЅПт»тХЯИҐµфТ»Р©І»РиТЄµД№ШБЄЎЈ
ЈЁ5Ј©ХТіцѕЫєП±ЯЅзј°ѕЫєПёщЈ¬ХвКЗТ»јюєЬУРДС¶ИµДКВЗйЈ¬ТтОЄФЪ·ЦОцµД№эіМЦРНщНщ»бЕцµЅєЬ¶аДСТФЗеОъЕР¶ПµДОКМвЈ¬ґЛК±РиТЄОТГЗЖѕЅиѕСйХТіцХэИ·µДѕЫєПёщЎЈ
ЈЁ6Ј©ОЄѕЫєПёщЕд±ёІЦґўЈ¬Т»°гЗйїцПВКЗОЄТ»ёцѕЫєП·ЦЕдТ»ёцІЦґўЈ¬ґЛК±Ц»ТЄЙијЖєГІЦґўµДЅУїЪјґїЙЎЈ
ЈЁ7Ј©ЮЫЛіКµјКТµОсУ¦УГіЎѕ°Ј¬И·¶ЁОТГЗЙијЖµДБмУтДЈРНДЬ№»УРР§ЅвѕцТµОсРиЗуЎЈ
ЈЁ8Ј©їјВЗИзєОґґЅЁБмУтКµМе»тЦµ¶ФПуЈ¬ГчИ·КЗНЁ№э№¤і§»№КЗЦ±ЅУНЁ№э№№ФмєЇКэКµПЦЎЈ
ЛдИ»ЙПГжЅйЙЬБЛЙијЖБмУтДЈРНµДІЅЦиЈ¬µ«КЗБмУтЅЁДЈКЗТ»ёцІ»¶ПЦШ№№ЎўіЦРшНкЙЖДЈРНµД№эіМЎЈґујТ»бФЪМЦВЫЦРЅ«±д»ЇµДІї·Ц·ґУіµЅДЈРНЦРЈ¬ґУ¶шК№ДЈРНІ»¶ППё»ЇІўіЇХэИ·µД·ЅПтЧЯЎЈБмУтЅЁДЈКЗБмУтЧЁјТЎўЙијЖИЛФ±ЎўїЄ·ўИЛФ±Ц®јд№µНЁЅ»БчµД№эіМЈ¬КЗґујТ№¤ЧчєНЛјїјОКМвµД»щґЎЎЈ
2.11ЎўБмУтЗэ¶ЇїтјЬПЦЧґ
ЧФґУEric EvanМбіцDDDБмУтЗэ¶ЇЙијЖТФАґТСѕ№эБЛєЬ¶аДкБЛЈ¬ПЦФЪТСѕУРєЬ¶аИЛФЪС§П°»тКµјщDDDЎЈµ«КЗДїЗ°АґїґДЬ№»Ц§іЦDDDїЄ·ўµДїтјЬІўІ»¶аЈ¬ЦБЙЩФЪ№ъДЪ±ИЅПє±јыЎЈФЪJavaЖЅМЁЙПЈ¬№ъНв±ИЅПКЬ»¶УµДБмУтЗэ¶ЇїтјЬКЗAxon
FrameworkЈ¬ёГїтјЬ·ўХ№ЦБЅсПа¶ФАґЛµ±ИЅП»оФѕЈ¬ДїЗ°GithubЙПРЗ±кТСѕі¬№э1000ЎЈ»№УРѕНКЗbanqµДJdon
frameworkЈ¬ХвКЗ»щУЪDDD+CQRS+EventSourcingµДїЄ·ўЈ¬ТІКЗ»щУЪJavaЖЅМЁµДЎЈ
ЙП±нЦРБРѕЩµДБмУтЗэ¶ЇїтјЬёчУРУЕµгєНИ±µгЎЈИз№ыѕНJavaЖЅМЁАґЅІЈ¬їЙТФіўКФК№УГAxon
FrameworkЈ¬ДїЗ°ТСѕЦ§іЦSpring CloudЎЈµ«КЗЛьІ»КЗДїЗ°ЧоєГµДБмУтЗэ¶ЇїтјЬЈ¬ПВГжЅ«ЅйЙЬµДHaloїтјЬ»бёьУРУЕКЖЎЈ
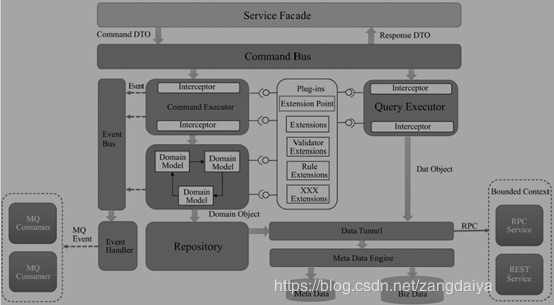
3ЎўHaloїтјЬёЕКц
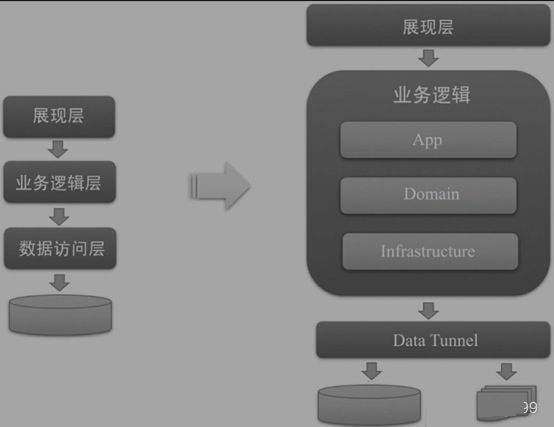
HaloїтјЬКЗ»щУЪБмУтЗэ¶Ї+CQRS+А©Х№µг+БчіМ±аЕЕµДУ¦УГїтјЬЈ¬ЦВБ¦УЪІЙУГБмУтЗэ¶ЇµДЙијЖЛјПлЈ¬№ж·¶їШЦЖіМРтФ±µДЛжРДЛщУыЈ¬ґУ¶шЅвѕцИнјюµДёґФУРФОКМвЎЈјЬ№№ЙијЖФФт·ЗіЈјтµҐЈ¬јґФЪёЯДЪѕЫЎўµНсоєПЎўїЙА©Х№ЎўТЧАнЅвµДґуµДЦёµјЛјПлПВЈ¬ѕЎїЙДЬ№бі№ГжПт¶ФПуµДЙијЖЛјПлєНФФтЎЈ
HaloїтјЬјЬ№№НјИзПВЈє
·ЦІгЙијЖИзПВЈє
CQRSјЬ№№ИзПВЈє
|









