| БрМЭЦМі: |
| БОЮФРДздгкЪзЯЏМмЙЙЪІжЧПт,БОЮФНЋНщЩмDDDЕФвЛаЉжївЊФЃЪНЃЌСЫНтвЛаЉаТЪжЫЦКѕКмФбНтОіЕФЮЪЬтЃЌВЂжиЕуНщЩмвЛаЉЙЄОпКЭзЪдДЃЈЬиБ№ЪЧвЛИіЃЉЃЌвдАяжњФњдкЙЄзїжагІгУDDDЁЃ |
|
НёЬьЕФЦѓвЕгІгУГЬађЮовЩЪЧИДдгЕФЃЌВЂвРРЕвЛаЉзЈУХММЪѕЃЈГжОУадЃЌAJAXЃЌWebЗўЮёЕШЃЉРДЭъГЩЫќУЧЕФЙЄзїЁЃзїЮЊПЊЗЂШЫдБЃЌЮвУЧЧуЯђгкЙизЂетаЉММЪѕЯИНкЪЧПЩвдРэНтЕФЁЃЕЋЪТЪЕЪЧЃЌвЛИіВЛФмНтОівЕЮёашЧѓЕФЯЕЭГЖдШЮКЮШЫЖМУЛгагУЃЌЮоТлЫќПДЦ№РДЖрУДЦЏССЛђепШчКЮКмКУЕиЙЙНЈЦфЛљДЁЩшЪЉЁЃ
СьгђЧ§ЖЏЩшМЦЃЈDDDЃЉЕФРэФю - ЪзЯШгЩEric EvansдкЫћЕФЭЌУћЪщ[1]жаУшЪі - ЪЧЙигкНЋЮвУЧЕФзЂвтСІЗХдкгІгУГЬађЕФКЫаФЃЌЙизЂвЕЮёСьгђЙЬгаЕФИДдгадБОЩэЁЃЮвУЧЛЙНЋКЫаФгђЃЈвЕЮёЖРгаЃЉгыжЇГжзггђЃЈЭЈГЃЪЧЭЈгУЕФЃЌШчН№ЧЎЛђЪБМфЃЉЧјЗжПЊРДЃЌВЂНЋИќЖрЕФЩшМЦЙЄзїЗХдкКЫаФЩЯЁЃ
гђЧ§ЖЏЩшМЦАќКЌвЛзщгУгкДггђФЃаЭЙЙНЈЦѓвЕгІгУГЬађЕФФЃЪНЁЃдкФњЕФШэМўЩњбФжаЃЌФњПЩФмвбОгіЕНЙ§аэЖретбљЕФЯыЗЈЃЌЬиБ№ЪЧШчЙћФњЪЧOOгябдЕФОбщЗсИЛЕФПЊЗЂШЫдБЁЃЕЋНЋЫќУЧвЛЦ№гІгУНЋдЪаэФњЙЙНЈеце§ТњзувЕЮёашЧѓЕФЯЕЭГЁЃ
ДњТыКЭФЃаЭ......
ЪЙгУDDDЃЌЮвУЧЯЃЭћДДНЈЮЪЬтгђЕФФЃаЭЁЃГжОУадЃЌгУЛЇНчУцКЭЯћЯЂДЋЕнЕФЖЋЮїПЩвддквдКѓГіЯжЃЌетЪЧашвЊРэНтЕФСьгђЃЌвђЮЊе§дкЙЙНЈЕФЯЕЭГжаЃЌПЩвдЧјЗжЙЋЫОЕФвЕЮёгыОКељЖдЪжЁЃ
ЃЈШчЙћВЛЪЧетбљЃЌФЧУДПМТЧЙКТђАќзАВњЦЗЃЉЁЃ
АДФЃаЭЃЌЮвУЧВЛЪЧжИЭМБэЛђвЛзщЭМБэ;ШЗЖЈЃЌЭМБэКмгагУЃЌЕЋЫќУЧВЛЪЧФЃаЭЃЌжЛЪЧФЃаЭЕФВЛЭЌЪгЭМЃЈВЮМћЭМЃЉЁЃВЛЃЌФЃаЭЪЧЮвУЧбЁдёдкШэМўжаЪЕЯжЕФИХФюМЏЃЌвдДњТыКЭгУгкЙЙНЈНЛИЖЯЕЭГЕФШЮКЮЦфЫћШэМўЙЄМўБэЪОЁЃЛЛОфЛАЫЕЃЌДњТыОЭЪЧФЃаЭЁЃЮФБОБрМЦїЬсЙЉСЫвЛжжЪЙгУДЫФЃаЭЕФЗНЗЈЃЌОЁЙмЯжДњЙЄОпвВЬсЙЉСЫДѓСПЦфЫћПЩЪгЛЏЃЈUMLРрЭМЃЌЪЕЬхЙиЯЕЭМЃЌSpring
beandocs [2]ЃЌStruts / JSFСїЕШЃЉЁЃ
Figure 1: Model vs Views of the Model
етЪЧDDDФЃЪНЕФЕквЛИіЃКФЃаЭЧ§ЖЏЩшМЦЃЈmodel-driven designЃЉЁЃетвтЮЖзХФмЙЛНЋФЃаЭжаЕФИХФюгГЩфЕНЩшМЦ/ДњТыЕФИХФюЃЈРэЯыЧщПіЯТЃЉЁЃФЃаЭЕФБфЛЏвтЮЖзХДњТыЕФБфЛЏ;ИќИФДњТывтЮЖзХФЃаЭвбИќИФЁЃ
DDDВЂУЛгаЧПжЦвЊЧѓФњЪЙгУУцЯђЖдЯѓРДЙЙНЈгђ - Р§ШчЃЌЮвУЧПЩвдЪЙгУЙцдђв§ЧцЙЙНЈФЃаЭ - ЕЋМјгкжїСїЦѓвЕБрГЬгябдЪЧЛљгкOOЕФЃЌДѓЖрЪ§ФЃаЭБОжЪЩЯЖМЪЧOOЁЃБЯОЙЃЌOOЛљгкНЈФЃЗЖР§ЁЃФЃаЭЕФИХФюНЋБэЪОЮЊРрКЭНгПкЃЌзїЮЊРрГЩдБЕФжАд№ЁЃ
гябд
ЯждкШУЮвУЧПДвЛЯТгђЧ§ЖЏЩшМЦЕФСэвЛИіЛљБОддђЁЃЛиЙЫвЛЯТЃКЮвУЧЯывЊЙЙНЈвЛИіВЖЛёе§дкЙЙНЈЕФЯЕЭГЕФЮЪЬтгђЕФгђФЃаЭЃЌВЂЧвЮвУЧНЋдкДњТы/ШэМўЙЄМўжаБэДяетжжРэНтЁЃЮЊСЫАяжњЮвУЧзіЕНетвЛЕуЃЌDDDЬсГЋСьгђзЈМвКЭПЊЗЂШЫдБгавтЪЖЕиЪЙгУФЃаЭжаЕФИХФюНјааЙЕЭЈЁЃвђДЫЃЌгђзЈМвВЛЛсИљОнЦСФЛЛђВЫЕЅЯюЩЯЕФзжЖЮУшЪіаТЕФгУЛЇЙЪЪТЃЌЖјЪЧЬжТлгђЖдЯѓЫљашЕФЛљДЁЪєадЛђааЮЊЁЃРрЫЦЕиЃЌПЊЗЂШЫдБВЛЛсЬжТлЪ§ОнПтБэжаЕФРрЛђСаЕФаТЪЕР§БфСПЁЃ
бЯИёвЊЧѓЮвУЧПЊЗЂвЛжжЦеЪРЕФгябдЃЈubiquitous languageЃЉЁЃШчЙћвЛИіЯыЗЈВЛФмЧсвзБэДяЃЌФЧУДЫќБэУїСЫвЛИіИХФюЃЌетИіИХФюдкСьгђФЃаЭжаШБЪЇЃЌВЂЧвЭХЖгЙВЭЌХЌСІевГіШБЪЇЕФИХФюЪЧЪВУДЁЃвЛЕЉНЈСЂСЫетИіЃЌФЧУДЪ§ОнПтБэжаЕФЦСФЛЛђСаЩЯЕФаТзжЖЮОЭЛсМЬајЯдЪОЁЃ
ЯёDDDвЛбљЃЌетжжПЊЗЂЮоДІВЛдкЕФгябдЕФЯыЗЈВЂВЛЪЧвЛИіаТЯыЗЈЃКXPersГЦжЎЮЊЁАУћГЦЯЕЭГЁБЃЌЖрФъРДDBAНЋЪ§ОнзжЕфзщКЯдквЛЦ№ЁЃЕЋЮоДІВЛдкЕФгябдЪЧвЛИіСюШЫЛиЮЖЕФЪѕгяЃЌПЩвдГіЪлИјЩЬвЕКЭММЪѕШЫдБЁЃЯждкЃЌЁАећИіЭХЖгЁБУєНнЪЕМље§дкГЩЮЊжїСїЃЌетвВКмгавтвхЁЃ
ФЃаЭКЭЩЯЯТЮФ......
УПЕБЮвУЧЬжТлФЃаЭЪБЃЌЫќзмЪЧдкФГжжЧщПіЯТЁЃЭЈГЃПЩвдДгЪЙгУИУЯЕЭГЕФзюжегУЛЇМЏЭЦЖЯГіИУЩЯЯТЮФЁЃвђДЫЃЌЮвУЧгавЛИіВПЪ№ЕННЛвздБЕФЧАЬЈНЛвзЯЕЭГЃЌЛђГЌЪаЪевјдБЪЙгУЕФЯњЪлЕуЯЕЭГЁЃетаЉгУЛЇвдЬиЖЈЗНЪНгыФЃаЭЕФИХФюЯрЙиЃЌВЂЧвФЃаЭЕФЪѕгяЖдетаЉгУЛЇгавтвхЃЌЕЋВЛвЛЖЈЖдИУЩЯЯТЮФжЎЭтЕФШЮКЮЦфЫћШЫгавтвхЁЃ
DDDГЦжЎЮЊгаНчЩЯЯТЮФЃЈBCЃЉЁЃУПИігђФЃаЭЖМжЛДцдкгквЛИіBCжаЃЌЖјBCжЛАќКЌвЛИігђФЃаЭЁЃ
ЮвБиаыГаШЯЃЌЕБЮвЕквЛДЮЖСЕНЙигкBCЪБЃЌЮвПДВЛГіетвЛЕуЃКШчЙћBCгыгђФЃаЭЭЌЙЙЃЌЮЊЪВУДвЊв§ШывЛИіаТЪѕгяЃПШчЙћжЛгагыBCЯрЛЅзїгУЕФзюжегУЛЇЃЌдђПЩФмВЛашвЊетИіЪѕгяЁЃШЛЖјЃЌВЛЭЌЕФЯЕЭГЃЈBCЃЉвВЯрЛЅНЛЛЅЃЌЗЂЫЭЮФМўЃЌДЋЕнЯћЯЂЃЌЕїгУAPIЕШЁЃШчЙћЮвУЧжЊЕРгаСНИіBCЯрЛЅНЛЛЅЃЌФЧУДЮвУЧжЊЕРЮвУЧБиаызЂвтдквЛИіИХФюжЎМфНјаазЊЛЛЁЃСьгђКЭЦфЫћСьгђЁЃ
дкФЃаЭжмЮЇЩшжУУїШЗЕФБпНчвВвтЮЖзХЮвУЧПЩвдПЊЪМЬжТлетаЉBCжЎМфЕФЙиЯЕЁЃЪЕМЪЩЯЃЌDDDШЗЖЈСЫBCжЎМфЕФвЛећЬзЙиЯЕЃЌвђДЫЕБЮвУЧашвЊНЋВЛЭЌЕФBCСДНгдквЛЦ№ЪБЃЌЮвУЧПЩвдКЯРэЕиШЗЖЈгІИУзіЪВУДЃК
вбЗЂВМЕФгябдЃКНЛЛЅЪНBCsОЭЙВЭЌЕФгябдЃЈР§ШчЦѓвЕЗўЮёзмЯпЩЯЕФвЛЖбXMLФЃЪНЃЉДяГЩвЛжТЃЌЭЈЙ§ЫќУЧПЩвдЯрЛЅНЛЛЅ;
ПЊЗХжїЛњЗўЮёЃКBCжИЖЈШЮКЮЦфЫћBCПЩвдЪЙгУЦфЗўЮёЕФавщЃЈР§ШчRESTful WebЗўЮёЃЉ;
ЙВЯэФкКЫЃКСНИіBCЪЙгУвЛИіЙВЭЌЕФДњТыФкКЫЃЈР§ШчвЛИіПтЃЉзїЮЊвЛИіЭЈгУЕФЭЈгУгябдЃЌЕЋЪЧЗёдђвдЫћУЧздМКЕФЬиЖЈЗНЪНжДааЦфЫћЕФЖЋЮї;
ПЭЛЇ/ЙЉгІЩЬЃКвЛИіBCЪЙгУСэвЛИіBCЕФЗўЮёЃЌВЂЧвЪЧСэвЛИіBCЕФРћвцЯрЙиепЃЈПЭЛЇЃЉЁЃвђДЫЃЌЫќПЩвдгАЯьИУBCЬсЙЉЕФЗўЮё;
ЫГДгепЃКвЛИіBCЪЙгУСэвЛИіBCЕФЗўЮёЃЌЕЋВЛЪЧЦфЫћBCЕФРћвцЯрЙиепЁЃвђДЫЃЌЫќЪЙгУЁАдбљЁБЃЈЗћКЯЃЉBCЬсЙЉЕФавщЛђAPI;
ЗДИЏЪДВуЃКвЛИіBCЪЙгУСэвЛИіЗўЮёЖјВЛЪЧРћвцЯрЙиепЃЌЕЋжМдкЭЈЙ§в§ШывЛзщЪЪХфЦї - вЛИіЗДИЏАмВуРДзюаЁЛЏЫќЫљвРРЕЕФBCБфЛЏЕФгАЯьЁЃ
ФуПЩвдПДЕНЃЌдкетИіСаБэжаЃЌСНИіBCжЎМфЕФКЯзїЫЎЦНж№НЅНЕЕЭЃЈМћЭМ2ЃЉЁЃЪЙгУвбЗЂВМЕФгябдЃЈpublished
languageЃЉЃЌЮвУЧДгBCНЈСЂвЛИіЫћУЧПЩвдЛЅЖЏЕФЙВЭЌБъзМПЊЪМ;МШВЛгЕгаетжжгябдЃЌЖјЪЧгЩЫћУЧЫљОгзЁЕФЦѓвЕЫљгЕгаЃЈЩѕжСПЩФмЪЧаавЕБъзМЃЉЁЃгаСЫПЊЗХжїЛњЗўЮёЃЈopen
hostЃЉЃЌЮвУЧШдШЛзіЕУКмКУ; BCЬсЙЉЦфзїЮЊШЮКЮЦфЫћBCЕїгУЕФдЫааЪБЗўЮёЕФЙІФмЃЌЕЋЪЧЃЈПЩФмЃЉЫцзХЗўЮёЕФЗЂеЙНЋБЃГжЯђКѓМцШнадЁЃ
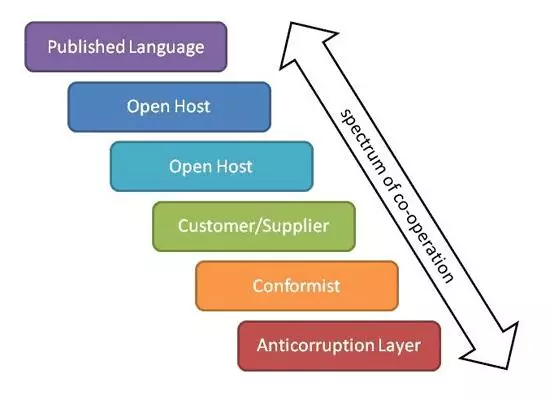
Figure 2: Spectrum of Bounded Context Relationship
ШЛЖјЃЌЕБЮвУЧзпЯђЫГДгЪБЃЌЮвУЧжЛЪЧКЭЮвУЧвЛЦ№ЩњЛю; вЛИіBCУїЯдЧќЗўгкСэвЛИіЁЃ ШчЙћЮвУЧБиаыгыЙКТђmegabucksЕФзмЗжРреЪЯЕЭГМЏГЩЃЌФЧПЩФмОЭЪЧЮвУЧЫљДІЕФЧщПіЁЃШчЙћЮвУЧЪЙгУЗДИЏАмВуЃЌФЧУДЮвУЧЭЈГЃЛсгывХСєЯЕЭГМЏГЩЃЌЕЋЪЧ
ЖюЭтЕФВуНЋЮвУЧОЁПЩФмЕиИєРыПЊРДЁЃ ЕБШЛЃЌеташвЊЛЈЧЎРДЪЕЪЉЃЌЕЋЫќНЕЕЭСЫвРРЕЗчЯеЁЃ ЗДИЏАмВувВБШжиаТЪЕЯжвХСєЯЕЭГБувЫКмЖрЃЌетзюЖрЛсЗжЩЂЮвУЧЖдКЫаФгђЕФзЂвтСІЃЌзюЛЕЕФЧщПіЪЧвдЪЇАмИцжеЁЃ
DDDНЈвщЮвУЧжЦЖЈвЛИіЩЯЯТЮФЭМЃЈcontext map tЃЉРДЪЖБ№ЮвУЧЕФBCвдМАЮвУЧвРРЕЛђвРРЕЕФBCЃЌвдШЗЖЈетаЉвРРЕЙиЯЕЕФаджЪЁЃ
ЭМ3ЯдЪОСЫЮвЙ§ШЅ5ФъзѓгввЛжБдкбаОПЕФЯЕЭГЕФЩЯЯТЮФгГЩфЁЃ
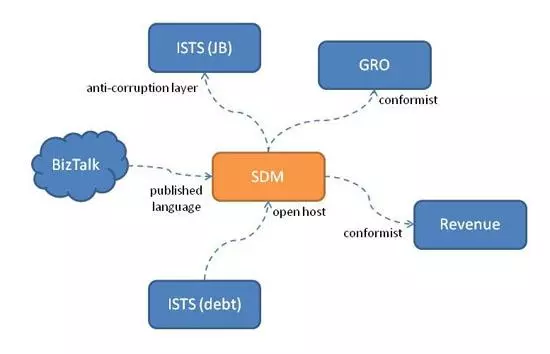
Figure 3: Context Mapping Example
ЫљгаетаЉЙигкБГОАЭМКЭBCЕФЬжТлгаЪББЛГЦЮЊеНТдадDDDЃЈ strategic DDDЃЉЃЌВЂЧвгаГфЗжЕФРэгЩЁЃ
БЯОЙЃЌЕБФуЯыЕНЫќЪБЃЌХЊЧхГўBCжЎМфЕФЙиЯЕЪЧЗЧГЃеўжЮЕФЃКЮвЕФЯЕЭГНЋвРРЕФФаЉЩЯгЮЯЕЭГЃЌЮвЪЧЗёШнвзгыЫќУЧМЏГЩЃЌЮвЪЧЗёФмЙЛРћгУЫќУЧЃЌЮвЯраХЫќУЧТ№ЃП
ЯТгЮвВЪЧШчДЫЃКФФаЉЯЕЭГНЋЪЙгУЮвЕФЗўЮёЃЌЮвШчКЮНЋЮвЕФЙІФмзїЮЊЗўЮёЙЋПЊЃЌЫћУЧЛсЖдЮвгаРћТ№ЃП ЮѓНтСЫетвЛЕуЃЌФњЕФгІгУГЬађПЩФмКмШнвзЪЇАмЁЃ
ВуКЭСљБпаЮ
ЯждкШУЮвУЧзЊЯђФкВПВЂПМТЧЮвУЧздМКЕФBCЃЈЯЕЭГЃЉЕФМмЙЙЁЃ ДгИљБОЩЯЫЕЃЌDDDжЛЙиаФгђВуЃЌЪЕМЪЩЯЃЌЫќЖдЦфЫћВугаКмЖрЛАвЊЫЕЃКБэЪОЃЌгІгУГЬађЛђЛљДЁМмЙЙЃЈЛђГжОУВуЃЉЁЃ
ЕЋЫќШЗЪЕЦкЭћЫќУЧДцдкЁЃ етЪЧЗжВуМмЙЙФЃЪНЃЈЭМ4ЃЉЁЃ
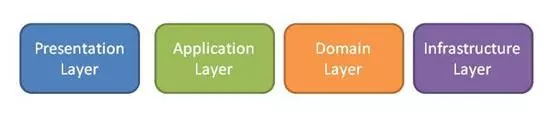
Figure 4: Layered Architecture
ЕБШЛЃЌЮвУЧЖрФъРДвЛжБдкЙЙНЈЖрВуЯЕЭГЃЌЕЋетВЂВЛвтЮЖзХЮвУЧБиаыЩУГЄЫќЁЃШЗЪЕЃЌЙ§ШЅЕФвЛаЉжїСїММЪѕ - ЪЧЕФЃЌEJB
2ЃЌЮве§дкПДзХФуЃЁ - ЖдгђФЃаЭПЩвдзїЮЊгавтвхЕФВуДцдкЕФЯыЗЈВњЩњСЫЛ§МЋЕФгАЯьЁЃЫљгаЕФвЕЮёТпМЫЦКѕЩјЭИЕНгІгУВуЛђЃЈИќдуИтЕФЃЉБэЪОВуЃЌСєЯТвЛзщЦЖбЊЕФгђРр[3]зїЮЊЪ§ОнГжгаепЕФПеПЧЁЃетВЛЪЧDDDЕФвтЫМЁЃ
вђДЫЃЌвЊОјЖдЧхГўЃЌгІгУГЬађВужаВЛгІДцдкШЮКЮгђТпМЁЃЯрЗДЃЌгІгУГЬађВуИКд№ЪТЮёЙмРэКЭАВШЋадЕШЪТЮёЁЃдкФГаЉЬхЯЕНсЙЙжаЃЌЫќЛЙПЩФмИКд№ШЗБЃДгЛљДЁНсЙЙ/ГжОУВужаМьЫїЕФгђЖдЯѓдкгыжЎНЛЛЅжЎЧАвбе§ШЗГѕЪМЛЏЃЈОЁЙмЮвИќЯВЛЖЛљДЁНсЙЙВужДааДЫВйзїЃЉЁЃ
дкБэЪОВудкЕЅЖРЕФДцДЂПеМфжадЫааЕФЧщПіЯТЃЌгІгУВувВГфЕББэЪОВуКЭгђВужЎМфЕФжаНщЁЃБэЪОВуЭЈГЃДІРэгђЖдЯѓЛђгђЖдЯѓЃЈЪ§ОнДЋЪфЖдЯѓЛђDTOЃЉЕФПЩађСаЛЏБэЪОЃЌЭЈГЃУПИіЁАЪгЭМЁБвЛИіЁЃШчЙћетаЉБЛаоИФЃЌФЧУДБэЪОВуЛсНЋШЮКЮИќИФЗЂЫЭЛигІгУГЬађВуЃЌЖјгІгУГЬађВугжШЗЖЈвбаоИФЕФгђЖдЯѓЃЌДгГжОУВуМгдиЫќУЧЃЌШЛКѓзЊЗЂЖдетаЉгђЖдЯѓЕФИќИФЁЃ
ЗжВуЬхЯЕНсЙЙЕФвЛИіШБЕуЪЧЫќНЈвщДгБэЪОВувЛжБЕНЛљДЁНсЙЙВуЕФвРРЕадЕФЯпадЖбЕўЁЃЕЋЪЧЃЌЮвУЧПЩФмЯЃЭћдкБэЪОВуКЭЛљДЁНсЙЙВужажЇГжВЛЭЌЕФЪЕЯжЁЃШчЙћЃЈе§ШчЮвШЯЮЊЕФФЧбљЃЁЃЉЮвУЧЯывЊВтЪдЮвУЧЕФгІгУГЬађОЭЪЧетжжЧщПіЃК
Р§ШчЃЌFitNesse [4]ЕШЙЄОпдЪаэЮвУЧДгзюжегУЛЇЕФНЧЖШбщжЄЮвУЧЯЕЭГЕФааЮЊЁЃЕЋЪЧетаЉЙЄОпЭЈГЃВЛЛсЭЈЙ§БэЪОВуЃЌЖјЪЧжБНгНјШыЯТвЛВуЃЌМДгІгУВуЁЃЫљвдДгФГжжвтвхЩЯЫЕЃЌFitNesseОЭЪЧСэвЛжжЙлВьепЁЃ
ЭЌбљЃЌЮвУЧПЩФмгаЖрИіГжОУадЪЕЯжЁЃЮвУЧЕФЩњВњЪЕЯжПЩФмЪЙгУRDBMSЛђРрЫЦММЪѕЃЌЕЋЪЧЖдгкВтЪдКЭдаЭЩшМЦЃЌЮвУЧПЩФмгавЛИіЧсСПМЖЪЕЯжЃЈЩѕжСПЩФмдкФкДцжаЃЉЃЌвђДЫЮвУЧПЩвдФЃФтГжОУадЁЃ
ЮвУЧПЩФмЛЙЯыЧјЗжЁАФкВПЁБКЭЁАЭтВПЁБВужЎМфЕФНЛЛЅЃЌЦфжаФкВПЮвжИЕФЪЧСНИіВуЭъШЋдкЮвУЧЕФЯЕЭГЃЈЛђBCЃЉФкЕФНЛЛЅЃЌЖјЭтВПНЛЛЅПчдНBCЁЃ
вђДЫЃЌВЛвЊНЋЮвУЧЕФгІгУГЬађЪгЮЊвЛзщЭМВуЃЌСэвЛжжЗНЗЈЪЧНЋЦфЪгЮЊСљБпаЮ[5]ЃЌШчЭМ5ЫљЪОЁЃЮвУЧЕФзюжегУЛЇЪЙгУЕФВщПДЦївдМАFitNesseВтЪдЪЙгУФкВППЭЛЇЖЫAPIЃЈЛђЖЫПкЃЉЃЌЖјРДздЦфЫћBCЕФЕїгУЃЈР§ШчЃЌRESTfulгУгкПЊЗХжїЛњНЛЛЅЃЌЛђРДздESBЪЪХфЦїЕФЕїгУгУгквбЗЂВМЕФгябдНЛЛЅЃЉУќжаЭтВППЭЛЇЖЫЖЫПкЁЃЖдгкКѓЖЫЛљДЁМмЙЙВуЃЌЮвУЧПЩвдПДЕНгУгкЬцДњЖдЯѓДцДЂЪЕЯжЕФГжОУадЖЫПкЃЌДЫЭтЃЌгђВужаЕФЖдЯѓПЩвдЭЈЙ§ЭтВПЗўЮёЖЫПкЕїгУЦфЫћBCЁЃ
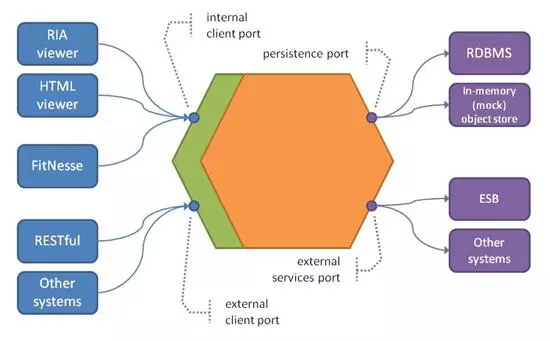
Figure 5: Hexagonal Architecture
ЕЋетзуЙЛДѓЕФЖЋЮї; ШУЮвУЧРДПДПДDDDдкУКЬПУцАхЩЯЕФбљзгЁЃ
ЙЙНЈФЃПщ
е§ШчЮвУЧвбОзЂвтЕНЕФЃЌДѓЖрЪ§DDDЯЕЭГПЩФмЛсЪЙгУOOЗЖР§ЁЃвђДЫЃЌЮвУЧЕФгђЖдЯѓЕФаэЖрЙЙНЈПщПЩФмКмЪьЯЄЃЌР§ШчЪЕЬхЃЌжЕЖдЯѓКЭФЃПщЃЈentities,
value objects and modules. ЃЉЁЃР§ШчЃЌШчЙћФњЪЧJavaГЬађдБЃЌФЧУДНЋDDDЪЕЬхЪгЮЊгыJPAЪЕЬхЛљБОЯрЭЌЃЈЪЙгУ@EntityзЂЪЭЃЉОЭзуЙЛАВШЋСЫ;жЕЖдЯѓЪЧзжЗћДЎЃЌЪ§зжКЭШеЦкжЎРрЕФЖЋЮї;вЛИіФЃПщОЭЪЧвЛИіАќЁЃ
ЕЋЪЧЃЌDDDЧуЯђгкИќЖрЕиЧПЕїжЕЖдЯѓЃЈvalue objects ЃЉЃЌЖјВЛЪЧЙ§ШЅЯАЙпЁЃЫљвдЃЌЪЧЕФЃЌФњПЩвдЪЙгУStringРДБЃДцCustomerЕФgivenNameЪєадЕФжЕЃЌР§ШчЃЌетПЩФмЪЧКЯРэЕФЁЃЕЋЪЧвЛБЪЧЎЃЌР§ШчВњЦЗЕФМлИёФиЃПЮвУЧПЩвдЪЙгУintЛђdoubleЃЌЕЋЪЧЃЈЩѕжСКіТдПЩФмЕФЩсШыДэЮѓЃЉ1Лђ1.0ЪЧЪВУДвтЫМЃП
$ 1Т№ЃП 1ЃП ЃЄ1ЃП 1ЗжЃЌЩѕжСЃПЯрЗДЃЌЮвУЧгІИУв§ШывЛИіMoneyжЕРраЭЃЌЫќЗтзАСЫCurrencyКЭШЮКЮЩсШыЙцдђЃЈНЋЬиЖЈгкCurrencyЃЉЁЃ
ЖјЧвЃЌжЕЖдЯѓгІИУЪЧВЛПЩБфЕФЃЌВЂЧвгІИУЬсЙЉвЛзщЮоИБзїгУЕФКЏЪ§РДВйзїЫќУЧЁЃЮвУЧгІИУаДЃК
Money m1 = new
Money("GBP", 10);
Money m2 = new Money("GBP", 20);
Money m3 = m1.add(m2); |
НЋm2ЬэМгЕНm1ВЛЛсИФБфm1ЃЌЖјЪЧЗЕЛивЛИіаТЕФMoneyЖдЯѓЃЈгЩm3в§гУЃЉЃЌЫќБэЪОвЛЦ№ЬэМгЕФСНИіMoneyЁЃ
жЕвВгІИУОпгажЕгявхЃЌетвтЮЖзХЃЈР§ШчдкJavaКЭCЃЃжаЃЉЫќУЧЪЕЯжequalsЃЈЃЉКЭhashCodeЃЈЃЉЁЃЫќУЧЭЈГЃвВПЩвдађСаЛЏЃЌПЩвдЪЧзжНкСїЃЌвВПЩвдЪЧStringИёЪНЁЃЕБЮвУЧашвЊМсГжЫќУЧЪБЃЌетКмгагУЁЃ
жЕЖдЯѓГЃМћЕФСэвЛжжЧщПіЪЧБъЪЖЗћЁЃвђДЫЃЌЃЈUSЃЉSocialSecurityNumberНЋЪЧвЛИіКмКУЕФР§згЃЌГЕСОЕФRegistrationNumberвВЪЧШчДЫЁЃ
URLвВЪЧШчДЫЁЃвђЮЊЮвУЧвбОжиаДСЫequalsЃЈЃЉКЭhashCodeЃЈЃЉЃЌЫљвдетаЉЖМПЩвдАВШЋЕигУзїЙўЯЃгГЩфжаЕФМќЁЃ
в§ШыМлжЕЖдЯѓВЛНіРЉеЙСЫЮвУЧЮоДІВЛдкЕФгябдЃЌЛЙвтЮЖзХЮвУЧПЩвдНЋааЮЊЭЦЯђМлжЕЙлБОЩэЁЃвђДЫЃЌШчЙћЮвУЧШЗЖЈMoneyгРдЖВЛЛсАќКЌИКжЕЃЌЮвУЧПЩвддкMoneyФкВПЪЕЯжДЫМьВщЃЌЖјВЛЪЧдкЪЙгУMoneyЕФШЮКЮЕиЗНЁЃШчЙћSocialSecurityNumberОпгааЃбщКЭЪ§зжЃЈдкФГаЉЙњМв/ЕиЧјОЭЪЧетжжЧщПіЃЉЃЌдђИУаЃбщКЭЕФбщжЄПЩвддкжЕЖдЯѓжаЁЃЮвУЧПЩвдвЊЧѓURLбщжЄЦфИёЪНЃЌЗЕЛиЦфЗНАИЃЈР§ШчhttpЃЉЃЌЛђепШЗЖЈЯрЖдгкЦфЫћURLЕФзЪдДЮЛжУЁЃ
ЮвУЧЕФСэЭтСНИіЙЙНЈПщПЩФмашвЊИќЩйЕФНтЪЭЁЃЪЕЬхЭЈГЃЪЧГжОУЕФЃЌЭЈГЃЪЧПЩБфЕФВЂЧвЃЈвђДЫЃЉЧуЯђгкОпгавЛЩњЕФзДЬЌБфЛЏЁЃдкаэЖрЬхЯЕНсЙЙжаЃЌЪЕЬхНЋзїЮЊааБЃДцдкЪ§ОнПтБэжаЁЃЭЌЪБЃЌФЃПщЃЈАќЛђУќУћПеМфЃЉЪЧШЗБЃгђФЃаЭБЃГжНтёюЕФЙиМќЃЌВЂЧвВЛЛсГЩЮЊФрНЌжаЕФвЛДѓПщ[6]ЁЃдкЫћЕФЪщжаЃЌАЃЮФЫЙЬИЕНИХФюТжРЊЃЌетЪЧвЛИігХбХЕФЖЬгяЃЌгУгкУшЪіШчКЮЧјЗжгђЕФжївЊЙизЂСьгђЁЃФЃПщЪЧЪЕЯжетжжЗжРыЕФжївЊЗНЪНЃЌвдМАШЗБЃФЃПщвРРЕадбЯИёЗЧбЛЗЕФНгПкЁЃЮвУЧЪЙгУжюШчUncleЁАBobЁБMartinЕФвРРЕЕЙжУддђ[7]жЎРрЕФММЪѕРДШЗБЃвРРЕЙиЯЕЪЧбЯИёЕЅЯђЕФЁЃ
ЪЕЬхЃЌжЕКЭФЃПщЪЧКЫаФЙЙНЈПщЃЌЕЋDDDЛЙгавЛаЉВЛЬЋЪьЯЄЕФЙЙНЈПщЁЃЮвУЧЯждкРДПДПДетаЉЁЃ
ОлКЯКЭОлКЯИљ
ШчЙћФњОЋЭЈUMLЃЌФЧУДФњНЋМЧзЁЃЌЫќдЪаэЮвУЧНЋСНИіЖдЯѓжЎМфЕФЙиСЊНЈФЃЮЊМђЕЅЙиСЊЃЌОлКЯЛђЪЙгУзщКЯЁЃОлКЯИљЃЈгаЪБЫѕаДЮЊARЃЉЪЧЭЈЙ§зщКЯзщГЩЦфЫћЪЕЬхЃЈвдМАЫќздМКЕФжЕЃЉЕФЪЕЬхЁЃвВОЭЪЧЫЕЃЌОлКЯЪЕЬхНігЩИљв§гУЃЈПЩФмЪЧПЩДЋЕнЕФЃЉЃЌВЂЧвПЩФмВЛЛсБЛОлКЯЭтЕФШЮКЮЖдЯѓЃЈгРОУЕиЃЉв§гУЁЃЛЛОфЛАЫЕЃЌШчЙћЪЕЬхОпгаЖдСэвЛИіЪЕЬхЕФв§гУЃЌдђв§гУЕФЪЕЬхБиаыЮЛгкЭЌвЛОлКЯФкЃЌЛђепЪЧФГИіЦфЫћОлКЯЕФИљЁЃ
аэЖрЪЕЬхЪЧОлКЯИљЃЌВЛАќКЌЦфЫћЪЕЬхЁЃЖдгкВЛПЩБфЕФЪЕЬхЃЈЯрЕБгкЪ§ОнПтжаЕФв§гУЛђОВЬЌЪ§ОнЃЉгШЦфШчДЫЁЃЪОР§ПЩФмАќРЈCountryЃЌVehicleModelЃЌTaxRateЃЌCategoryЃЌBookTitleЕШЁЃ
ЕЋЪЧЃЌИќИДдгЕФПЩБфЃЈЪТЮёЃЉЪЕЬхдкНЈФЃЮЊОлКЯЪБШЗЪЕЛсЪмвцЃЌжївЊЪЧЭЈЙ§МѕЩйИХФюПЊЯњЁЃЮвУЧВЛБиПМТЧУПИіЪЕЬхЃЌЖјжЛПМТЧОлКЯИљ;ОлКЯЪЕЬхНіНіЪЧОлКЯЕФЁАФкВПдЫзїЁБЁЃЫќУЧЛЙМђЛЏСЫЪЕЬхжЎМфЕФЯрЛЅзїгУ;ЮвУЧзёбвдЯТЙцдђЃКЃЈГжОУЛЏЃЉв§гУПЩФмжЛЪЧОлКЯЕФИљЃЌЖјВЛЪЧОлКЯжаЕФШЮКЮЦфЫћЪЕЬхЁЃ
СэвЛИіDDDддђЪЧОлКЯИљИКд№ШЗБЃОлКЯЪЕЬхЪМжеДІгкгааЇзДЬЌЁЃР§ШчЃЌOrderЃЈrootЃЉПЩФмАќКЌOrderItemsЕФМЏКЯЃЈОлКЯЃЉЁЃПЩФмДцдквдЯТЙцдђЃКЖЉЕЅЗЂЛѕКѓЃЌШЮКЮOrderItemЖМЮоЗЈИќаТЁЃЛђепЃЌШчЙћСНИіOrderItemв§гУЯрЭЌЕФВњЦЗВЂОпгаЯрЭЌЕФдЫЪфвЊЧѓЃЌдђЫќУЧНЋКЯВЂЕНЭЌвЛИіOrderItemжаЁЃЛђепЃЌOrderЕФХЩЩњtotalPriceЪєадгІИУЪЧOrderItemsЕФМлИёзмКЭЁЃЮЌЛЄетаЉВЛБфСПЪЧrootЕФд№ШЮЁЃ
ЕЋЪЧ......жЛгаОлКЯИљВХФмЭъШЋдкОлКЯжаЮЌЛЄЖдЯѓжЎМфЕФВЛБфСПЁЃ OrderItemв§гУЕФВњЦЗМИКѕПЯЖЈВЛЛсдкARжаЃЌвђЮЊЛЙгаЦфЫћгУР§ашвЊгыProductНјааНЛЛЅЃЌЖјВЛЙмЪЧЗёгаЖЉЕЅЁЃвђДЫЃЌШчЙћгавЛЬѕЙцдђВЛФмЖдвбЭЃВњЕФВњЦЗЯТДяЖЉЕЅЃЌФЧУДЖЉЕЅНЋашвЊвдФГжжЗНЪНДІРэЁЃЪЕМЪЩЯЃЌетЭЈГЃвтЮЖзХдкЖЉЕЅНЛвзИќаТЪБЪЙгУИєРыМЖБ№2Лђ3РДЁАЫјЖЈЁБВњЦЗЁЃЛђепЃЌПЩвдЪЙгУДјЭтЙ§ГЬРДаЕїНЛВцОлКЯВЛБфСПЕФШЮКЮЦЦЛЕЁЃ
дкЮвУЧМЬајЧАНјжЎЧАЭЫвЛВНЃЌЮвУЧПЩвдПДЕНЮвУЧгавЛЯЕСаСЃЖШЃК
| value < entity
< aggregate < module < bounded context
|
ЯждкШУЮвУЧМЬајбаОПвЛаЉDDDЙЙНЈПщЁЃ
ДцДЂПтЃЌЙЄГЇКЭЗўЮёЃЈRepositories, Factories and ServicesЃЉ
дкЦѓвЕгІгУГЬађжаЃЌЪЕЬхЭЈГЃЪЧГжОУЕФЃЌЦфжЕБэЪОетаЉЪЕЬхЕФзДЬЌЁЃЕЋЪЧЃЌЮвУЧШчКЮДгГжОУадДцДЂжаЛёШЁЪЕЬхФиЃП
ДцДЂПтЪЧГжОУадДцДЂЕФГщЯѓЃЌЗЕЛиЪЕЬх - ЛђепИќШЗЧаЕиЫЕЪЧОлКЯИљ - ТњзуФГаЉБъзМЁЃР§ШчЃЌПЭЛЇДцДЂПтНЋЗЕЛиCustomerОлКЯИљЪЕЬхЃЌЖЉЕЅДцДЂПтНЋЗЕЛиOrdersЃЈМАЦфOrderItemsЃЉЁЃЭЈГЃЃЌУПИіОлКЯИљгавЛИіДцДЂПтЁЃ
вђЮЊЮвУЧЭЈГЃЯЃЭћжЇГжГжОУадДцДЂЕФЖрИіЪЕЯжЃЌЫљвдДцДЂПтЭЈГЃгЩОпгаВЛЭЌГжОУадДцДЂЪЕЯжЕФВЛЭЌЪЕЯжЕФНгПкЃЈР§ШчЃЌCustomerRepositoryЃЉзщГЩЃЈР§ШчЃЌCustomerRepositoryHibernateЛђCustomerRepositoryInMemoryЃЉЁЃгЩгкДЫНгПкЗЕЛиЪЕЬхЃЈгђВуЕФвЛВПЗжЃЉЃЌвђДЫНгПкБОЩэвВЪЧгђВуЕФвЛВПЗжЁЃНгПкЕФЪЕЯжЃЈгывЛаЉЬиЖЈЕФГжОУадЪЕЯжёюКЯЃЉЪЧЛљДЁНсЙЙВуЕФвЛВПЗжЁЃ
ЮвУЧЫбЫїЕФБъзМЭЈГЃвўКЌдкУћЮЊЕФЗНЗЈУћГЦжаЁЃвђДЫЃЌCustomerRepositoryПЩФмЛсЬсЙЉfindByLastNameЃЈStringЃЉЗНЗЈРДЗЕЛиОпгажИЖЈаеЪЯЕФCustomerЪЕЬхЁЃЛђепЮвУЧПЩвдШУOrderRepositoryЗЕЛиOrdersЃЌfindByOrderNumЃЈOrderNumЃЉЗЕЛигыOrderNumЦЅХфЕФOrderЃЈЧызЂвтЃЌетРяЪЙгУжЕРраЭЃЁЃЉЁЃ
ИќИДдгЕФЩшМЦНЋБъзМАќзАЕНВщбЏЛђЙцЗЖжаЃЌРрЫЦгкfindByЃЈQuery <T>ЃЉЃЌЦфжаQueryАќКЌУшЪіБъзМЕФГщЯѓгяЗЈЪїЁЃШЛКѓЃЌВЛЭЌЕФЪЕЯжНтАќВщбЏвдШЗЖЈШчКЮвдЫћУЧздМКЕФЬиЖЈЗНЪНЖЈЮЛТњзуЬѕМўЕФЪЕЬхЁЃ
вВОЭЪЧЫЕЃЌШчЙћФуЪЧ.NETПЊЗЂШЫдБЃЌФЧУДжЕЕУвЛЬсЕФЪЧLINQ [8]ЁЃвђЮЊLINQБОЩэЪЧПЩВхАЮЕФЃЌЫљвдЮвУЧЭЈГЃПЩвдЪЙгУLINQБраДДцДЂПтЕФЕЅИіЪЕЯжЁЃШЛКѓБфЛЏЕФВЛЪЧДцДЂПтЪЕЯжЃЌЖјЪЧЮвУЧХфжУLINQвдЛёШЁЦфЪ§ОндДЕФЗНЪНЃЈР§ШчЃЌеыЖдEntity
FrameworkЛђеыЖдФкДцжаЕФЖдЯѓПтЃЉЁЃ
УПИіОлКЯИљЪЙгУЬиЖЈДцДЂПтНгПкЕФБфЬхЪЧЪЙгУЭЈгУДцДЂПтЃЌР§ШчRepository <Customer>ЁЃетЬсЙЉСЫвЛзщЭЈгУЗНЗЈЃЌР§ШчУПИіЪЕЬхЕФfindByIdЃЈintЃЉЁЃЕБЪЙгУQuery
<T>ЃЈР§ШчQuery <Customer>ЃЉЖдЯѓжИЖЈЬѕМўЪБЃЌетКмгааЇЁЃЖдгкJavaЦНЬЈЃЌЛЙгавЛаЉПђМмЃЌР§ШчHades
[9]ЃЌдЪаэЛьКЯКЭЦЅХфЗНЗЈЃЈДгЭЈгУЪЕЯжПЊЪМЃЌШЛКѓдкашвЊЪБЬэМгздЖЈвхНгПкЃЉЁЃ
ДцДЂПтВЛЪЧДгГжОУВув§ШыЖдЯѓЕФЮЈвЛЗНЗЈЁЃШчЙћЪЙгУЖдЯѓЙиЯЕгГЩфЃЈORMЃЉЙЄОпЃЈШчHibernateЃЉЃЌЮвУЧПЩвддкЪЕЬхжЎМфЕМКНв§гУЃЌдЪаэЮвУЧЭИУїЕиБщРњЭМаЮЁЃИљОнОбщЃЌЖдЦфЫћЪЕЬхЕФОлКЯИљЕФв§гУгІИУЪЧбгГйМгдиЕФЃЌЖјОлКЯжаЕФОлКЯЪЕЬхгІИУБЛМБЧаМгдиЁЃЕЋгыORMвЛбљЃЌЦкЭћНјаавЛаЉЕїећЃЌвдБуЮЊзюЙиМќЕФгУР§ЛёЕУКЯЪЪЕФадФмЬиеїЁЃ
дкДѓЖрЪ§ЩшМЦжаЃЌДцДЂПтЛЙгУгкБЃДцаТЪЕР§ЃЌвдМАИќаТЛђЩОГ§ЯжгаЪЕР§ЁЃШчЙћЕзВуГжОУадММЪѕжЇГжЫќЃЌФЧУДЫќУЧКмПЩФмДцдкгкЭЈгУДцДЂПтжаЃЌЕЋЪЧДгЗНЗЈЧЉУћЕФНЧЖШРДПДЃЌУЛгаЪВУДПЩвдЧјЗжБЃДцаТПЭЛЇКЭБЃДцаТЖЉЕЅЁЃ
зюКѓвЛЕу......жБНгДДНЈаТЕФОлКЯИљКмЩйМћЁЃЯрЗДЃЌЫќУЧЧуЯђгкгЩЦфЫћОлКЯИљДДНЈЁЃЖЉЕЅОЭЪЧвЛИіКмКУЕФР§згЃКЫќПЩФмЪЧЭЈЙ§ПЭЛЇЕїгУвЛИіЖЏзїРДДДНЈЕФЁЃ
етећЦыЕиДјИјЮвУЧЃК
ЙЄГЇ
ШчЙћЮвУЧвЊЧѓOrderДДНЈвЛИіOrderItemЃЌФЧУДЃЈвђЮЊБЯОЙOrderItemЪЧЦфОлКЯЕФвЛВПЗжЃЉЃЌOrderжЊЕРвЊЪЕР§ЛЏЕФОпЬхOrderItemРрЪЧКЯРэЕФЁЃЪЕМЪЩЯЃЌЪЕЬхжЊЕРЫќашвЊЪЕР§ЛЏЕФЭЌвЛФЃПщЃЈУќУћПеМфЛђАќЃЉжаЕФШЮКЮЪЕЬхЕФОпЬхРрЪЧКЯРэЕФЁЃ
МйЩшПЭЛЇЪЙгУCustomerЕФplaceOrderВйзїДДНЈЖЉЕЅЃЈВЮМћЭМ6ЃЉЁЃШчЙћПЭЛЇжЊЕРОпЬхЕФЖЉЕЅРрЃЌдђвтЮЖзХПЭЛЇФЃПщвРРЕгкЖЉЕЅФЃПщЁЃШчЙћЖЉЕЅОпгаЖдПЭЛЇЕФЗДЯђв§гУЃЌФЧУДЮвУЧНЋдкСНИіФЃПщжЎМфЛёЕУбЛЗвРРЕЁЃ
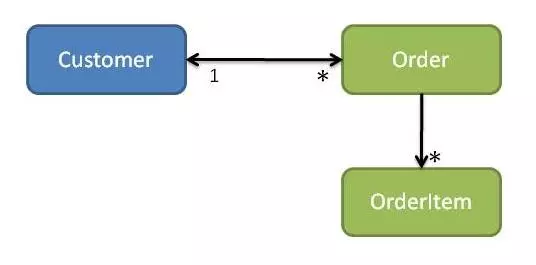
Figure 6: Customers and Orders (cyclic dependencie
ШчЧАЫљЪіЃЌЮвУЧПЩвдЪЙгУвРРЕадЗДзЊддђРДНтОіетРрЮЪЬтЃКДгЖЉЕЅжаЩОГ§вРРЕЙиЯЕ - >ПЭЛЇФЃПщЮвУЧНЋв§ШыOrderOwnerНгПкЃЌЪЙOrderв§гУЮЊOrderOwnerЃЌВЂЪЙCustomerЪЕЯжOrderOwnerЃЈВЮМћЭМ7ЃЉЃЉЁЃ
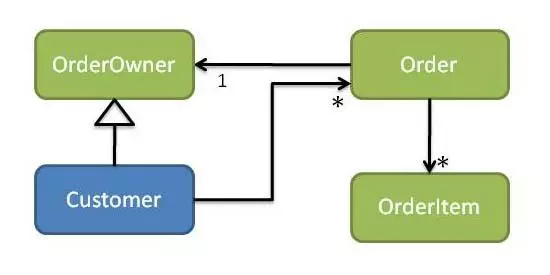
Figure 7: Customers and Orders (customer depends
o
ФЧУДСэвЛжжЗНЪНФиЃКШчЙћЮвУЧЯывЊЖЉЕЅ - >ПЭЛЇЃП дкетжжЧщПіЯТЃЌашвЊдкПЭЛЇФЃПщжагавЛИіБэЪОOrderЕФНгПкЃЈетЪЧCustomerЕФplaceOrderВйзїЕФЗЕЛиРраЭЃЉЁЃ
ШЛКѓЃЌЖЉЕЅФЃПщНЋЬсЙЉЖЉЕЅЕФЪЕЯжЁЃ гЩгкПЭЛЇВЛФмвРРЕЖЉЕЅЃЌвђДЫБиаыЖЈвхOrderFactoryНгПкЁЃ
ШЛКѓЃЌЖЉЕЅФЃПщвРДЮЬсЙЉOrderFactoryЕФЪЕЯжЃЈВЮМћЭМ8ЃЉЁЃ
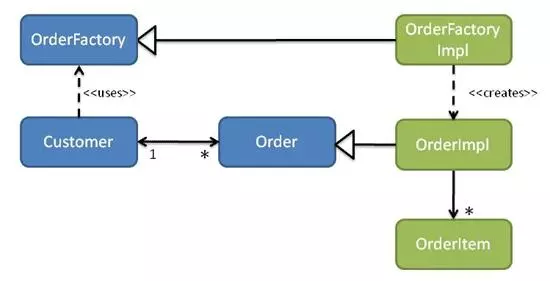
ПЩФмЛЙгаЯргІЕФДцДЂПтНгПкЁЃР§ШчЃЌШчЙћПЭЛЇПЩФмгаЪ§ЧЇИіЖЉЕЅЃЌФЧУДЮвУЧПЩФмЛсЩОГ§ЦфЖЉЕЅМЏКЯЁЃЯрЗДЃЌПЭЛЇНЋЪЙгУOrderRepositoryИљОнашвЊЖЈЮЛЦфЖЉЕЅЃЈЕФвЛВПЗжЃЉЁЃЛђепЃЈШчФГаЉШЫЫљдИЃЉЃЌФњПЩвдЭЈЙ§НЋЖдДцДЂПтЕФЕїгУвЦЖЏЕНгІгУГЬађЬхЯЕНсЙЙЕФИќИпВуЃЈР§ШчгђЗўЮёЛђгІгУГЬађЗўЮёЃЉРДБмУтДгЪЕЬхЕНДцДЂПтЕФЯдЪНвРРЕадЁЃ
ЪЕМЪЩЯЃЌЗўЮёЪЧЮвУЧашвЊЬНЫїЕФЯТвЛИіЛАЬтЁЃ
гђЗўЮёЃЌЛљДЁНсЙЙЗўЮёКЭгІгУГЬађЗўЮёЃЈDomain services, Infrastructure
services and Application servicesЃЉ
гђЗўЮёЃЈdomain serviceЃЉЪЧдкгђВуФкЖЈвхЕФгђЗўЮёЃЌЕЋЪЕЯжПЩвдЪЧЛљДЁНсЙЙВуЕФвЛВПЗжЁЃДцДЂПтЪЧгђЗўЮёЃЌЦфЪЕЯжШЗЪЕдкЛљДЁНсЙЙВужаЃЌЖјЙЄГЇвВЪЧгђЗўЮёЃЌЦфЪЕЯжЭЈГЃдкгђВуФкЁЃЬиБ№ЪЧдкЪЪЕБЕФФЃПщжаЖЈвхСЫДцДЂПтКЭЙЄГЇЃКCustomerRepositoryЮЛгкПЭЛЇФЃПщжаЃЌвРДЫРрЭЦЁЃ
ИќвЛАуЕиЫЕЃЌгђЗўЮёЪЧШЮКЮВЛШнвздкЪЕЬхжаЩњДцЕФвЕЮёТпМЁЃАЃЮФЫЙНЈвщдкСНИівјааеЫЛЇжЎМфНјаазЊеЫЗўЮёЃЌЕЋЮвВЛШЗЖЈетЪЧзюКУЕФР§згЃЈЮвЛсНЋзЊеЫБОЩэНЈФЃЮЊвЛИіЪЕЬхЃЉЁЃЕЋСэвЛжжгђЗўЮёЪЧвЛжжГфЕБЦфЫћгаНчЩЯЯТЮФЕФДњРэЁЃР§ШчЃЌЮвУЧПЩФмЯЃЭћгыБЉТЖПЊЗХжїЛњЗўЮёЕФGeneral
LedgerЯЕЭГМЏГЩЁЃЮвУЧПЩвдЖЈвхвЛИіЙЋПЊЮвУЧашвЊЕФЙІФмЕФЗўЮёЃЌвдБуЮвУЧЕФгІгУГЬађПЩвдНЋЬѕФПЗЂВМЕНзмеЪЁЃетаЉЗўЮёгаЪБЛсЖЈвхздМКЕФЪЕЬхЃЌетаЉЪЕЬхПЩФмЛсГжОУЛЏ;етаЉЪЕЬхЪЕМЪЩЯгАЯьСЫдкСэвЛИіBCжадЖГЬБЃДцЕФЯдзХаХЯЂЁЃ
ЮвУЧЛЙПЩвдЛёЕУММЪѕадИќЧПЕФЗўЮёЃЌР§ШчЗЂЫЭЕчзггЪМўЛђSMSЮФБОЯћЯЂЃЌЛђНЋCorrespondenceЪЕЬхзЊЛЛЮЊPDFЃЌЛђЪЙгУЬѕаЮТыБъМЧЩњГЩЕФPDFЁЃНгПкдкгђВужаЖЈвхЃЌЕЋЪЕЯждкЛљДЁМмЙЙВужаЗЧГЃУїШЗЁЃвђЮЊетаЉЗЧГЃММЪѕадЗўЮёЕФНгПкЭЈГЃЪЧИљОнМђЕЅЕФжЕРраЭЃЈЖјВЛЪЧЪЕЬхЃЉРДЖЈвхЕФЃЌЫљвдЮвЧуЯђгкЪЙгУЪѕгяЛљДЁНсЙЙЗўЮёЃЈinfrastructure
serviceЃЉЖјВЛЪЧгђЗўЮёЁЃЕЋЪЧШчЙћФуЯыГЩЮЊвЛИіЁАЕчзггЪМўЁБBCЛђЁАSMSЁБBCЕФЧХСКЃЌФуПЩвдЯыЕНЫќУЧЁЃ
ЫфШЛгђЗўЮёМШПЩвдЕїгУгђЪЕЬхвВПЩвдЕїгУгђЪЕЬхЃЌЕЋгІгУЗўЮёЃЈapplication serviceЃЉЮЛгкгђВужЎЩЯЃЌвђДЫгђВуФкЕФЪЕЬхВЛФмЕїгУЃЌжЛФмЗДЙ§РДЕїгУЁЃЛЛОфЛАЫЕЃЌгІгУВуЃЈЮвУЧЕФЗжВуМмЙЙЃЉПЩвдБЛШЯЮЊЪЧвЛзщЃЈЮозДЬЌЃЉгІгУЗўЮёЁЃ
ШчЧАЫљЪіЃЌгІгУГЬађЗўЮёЭЈГЃДІРэНЛВцКЭАВШЋЕШНЛВцЮЪЬтЁЃЫћУЧЛЙПЩвдЭЈЙ§вдЯТЗНЪНгыБэЪОВуНјааЕїНтЃКНтзщШыеОЧыЧѓ;ЪЙгУгђЗўЮёЃЈДцДЂПтЛђЙЄГЇЃЉЛёШЁЖдгыжЎНЛЛЅЕФОлКЯИљЕФв§гУ;дкИУОлКЯИљЩЯЕїгУЪЪЕБЕФВйзї;ВЂНЋНсЙћБрзщЛиБэЪОВуЁЃ
ЮвЛЙгІИУжИГіЃЌдкФГаЉЬхЯЕНсЙЙжаЃЌгІгУГЬађЗўЮёЕїгУЛљДЁНсЙЙЗўЮёЁЃвђДЫЃЌгІгУЗўЮёПЩвджБНгЕїгУPdfGenerationServiceЃЌДЋЕнДгЪЕЬхжаЬсШЁЕФаХЯЂЃЌЖјВЛЪЧЪЕЬхЕїгУPdfGenerationServiceНЋЦфздЩэзЊЛЛЮЊPDFЁЃетВЛЪЧЮвЕФЬиБ№ЦЋКУЃЌЕЋЫќЪЧвЛжжГЃМћЕФЩшМЦЁЃЮвКмПьОЭЛсЬИЕНетвЛЕуЁЃ
КУЕФЃЌетЭъГЩСЫЮвУЧЖджївЊDDDФЃЪНЕФИХЪіЁЃдкEvans 500 +вГУцЪщжаЛЙгаИќЖрФкШн - жЕЕУвЛЖС
- ЕЋЮвНгЯТРДвЊзіЕФЪЧЭЛГіЯдЪОШЫУЧЫЦКѕКмФбгІгУDDDЕФвЛаЉСьгђЁЃ
ЮЪЬтКЭеЯА
ЪЕЪЉЗжВуМмЙЙ
етЪЧЕквЛМўЪТЃКбЯИёжДааМмЙЙЗжВуПЩФмКмРЇФбЁЃЬиБ№ЪЧЃЌДггђВуЕНгІгУВуЕФвЕЮёТпМЩјЭИПЩФмЬиБ№вўБЮЁЃ
ЮввбОдкетРяЬєГіСЫJavaЕФEJB2зїЮЊзяП§ЛіЪзЃЌЕЋЪЧФЃаЭ - ЪгЭМ - ПижЦЦїФЃЪНЕФВЛСМЪЕЯжвВПЩФмЕМжТетжжЧщПіЗЂЩњЁЃПижЦЦїЃЈ=гІгУВуЃЉЛсЗЂЩњЪВУДЃЌГаЕЃЬЋЖрд№ШЮЃЌШУФЃаЭЃЈ=гђВуЃЉБфЕУЦЖбЊЁЃЪТЪЕЩЯЃЌгаИќаТЕФWebПђМмЃЈдкJavaЪРНчжаЃЌWicket
[10]ЪЧвЛИіеИТЖЭЗНЧЕФР§згЃЉЃЌГігкетжждвђУїШЗЕиБмУтСЫMVCФЃЪНЁЃ
БэЪОВуФЃК§СЫгђВу
СэвЛИіЮЪЬтЪЧГЂЪдПЊЗЂЮоДІВЛдкЕФгябдЁЃСьгђзЈМвдкЦСФЛЗНУцЬИЛАЪЧКмздШЛЕФЃЌвђЮЊБЯОЙЃЌетОЭЪЧЫћУЧПЩвдПДЕНЕФЯЕЭГЁЃвЊЧѓЫћУЧдкЦСФЛКѓУцВщПДВЂдкгђИХФюЗНУцБэДяЫћУЧЕФЮЪЬтПЩФмЗЧГЃРЇФбЁЃ
БэЪОВуБОЩэвВПЩФмДцдкЮЪЬтЃЌвђЮЊздЖЈвхБэЪОВуПЩФмЮоЗЈзМШЗЗДгГЃЈПЩФмЛсХЄЧњЃЉЕзВугђИХФюЃЌДгЖјЦЦЛЕЮвУЧЮоДІВЛдкЕФгябдЁЃМДЪЙВЛЪЧетжжЧщПіЃЌвВжЛашвЊНЋгУЛЇНчУцзщКЯдквЛЦ№ЫљашЕФЪБМфЁЃЪЙгУУєНнЪѕгяЃЌЫйЖШНЕЕЭвтЮЖзХУПДЮЕќДњЕФНјЖШНЯЩйЃЌвђДЫЖдећИігђЕФЩюШыСЫНтНЯЩйЁЃ
ДцДЂПтФЃЪНЕФЪЕЯж
ДгИќММЪѕадЕФНЧЖШРДПДЃЌаТЪжгаЪБЫЦКѕвВЛсЛьЯ§НЋДцДЂПтЃЈдкгђВужаЃЉгыЦфЪЕЯжЃЈдкЛљДЁМмЙЙВужаЃЉЕФНгПкЗжРыГіРДЁЃЮвВЛШЗЖЈЮЊЪВУДЛсетбљЃКБЯОЙЃЌетЪЧвЛИіЗЧГЃМђЕЅЕФOOФЃЪНЁЃЮвЯыетПЩФмЪЧвђЮЊАЃЮФЫЙЕФЪщВЂУЛгаДяЕНетИіЯИНкЫЎЦНЃЌетШУвЛаЉШЫБфЕУИпИпдкЩЯЁЃЕЋетвВПЩФмЪЧвђЮЊЬцЛЛГжОУадЪЕЯжЃЈИљОнСљБпаЮЬхЯЕНсЙЙЃЉЕФЯыЗЈВЂВЛЦеБщЃЌЕМжТГжОУадЪЕЯжЩјЭИЕНгђВуЕФЯЕЭГЁЃ
ЗўЮёвРРЕЯюЕФЪЕЯж
СэвЛИіММЪѕЮЪЬт - дкDDDДгвЕепжЎМфПЩФмДцдкЗжЦч - ОЭЪЕЬхгыгђ/ЛљДЁЩшЪЉЗўЮёЃЈАќРЈДцДЂПтКЭЙЄГЇЃЉжЎМфЕФЙиЯЕЖјбдЁЃгааЉШЫШЯЮЊЪЕЬхИљБОВЛгІИУвРРЕгђЗўЮёЃЌЕЋШчЙћЪЧетжжЧщПіЃЌдђЭтВПгІгУГЬађЗўЮёгыгђЗўЮёНЛЛЅВЂНЋНсЙћДЋЕнИјгђЪЕЬхЁЃИљОнЮвЕФЫМЮЌЗНЪНЃЌетЪЙЮвУЧзпЯђСЫвЛИіЦЖбЊЕФСьгђФЃаЭЁЃ
ЩдЮЂШсКЭЕФЙлЕуЪЧЪЕЬхПЩвдвРРЕгкгђЗўЮёЃЌЕЋгІгУГЬађЗўЮёгІИУИљОнашвЊДЋЕнЫќУЧЃЌР§ШчзїЮЊВйзїЕФВЮЪ§ЁЃЮввВВЛЯВЛЖетИіЃКЖдЮвЖјбдЃЌЫќНЋЪЕЯжЯИНкБЉТЖИјгІгУВуЃЈЁАетИіЪЕЬхашвЊетбљвЛИіЗўЮёВХФмЭъГЩетИіВйзїЁБЃЉЁЃЕЋЪЧаэЖрДгвЕепЖдетжжЗНЗЈИаЕНТњвтЁЃ
ЮвздМКЕФЪзбЁЗНАИЪЧЪЙгУвРРЕзЂШыНЋЗўЮёзЂШыЪЕЬхЁЃЪЕЬхПЩвдЩљУїЫќУЧЕФвРРЕЙиЯЕЃЌШЛКѓЛљДЁНсЙЙВуЃЈР§ШчHibernateЃЌSpringЛђЦфЫћвЛаЉПђМмЃЉПЩвдНЋЗўЮёзЂШыЪЕЬхЃК
public class
Customer {
Ё
private OrderFactory orderFactory;
public void setOrderFactory(OrderFactory orderFactory)
{
this.orderFactory = orderFactory;
}
Ё
public Order placeOrder( Ё ) {
Order order = orderFactory.createOrder();
Ё
return order;
}
} |
вЛжжЬцДњЗНЗЈЪЧЪЙгУЗўЮёЖЈЮЛЦїФЃЪНЁЃР§ШчЃЌНЋЫљгаЗўЮёзЂВсЕНJNDIжаЃЌШЛКѓУПИігђЖдЯѓВщевЫќЫљашЕФЗўЮёЁЃдкЮвПДРДЃЌетв§ШыСЫЖддЫааЪБЛЗОГЕФвРРЕЁЃЕЋЪЧЃЌгывРРЕзЂШыЯрБШЃЌЫќЖдЪЕЬхЕФФкДцашЧѓНЯЕЭЃЌетПЩФмЪЧвЛИіОіЖЈадвђЫиЁЃ
ВЛКЯЪЪЕФФЃПщЛЏ
е§ШчЮвУЧвбОШЗЖЈЕФФЧбљЃЌDDDдкЪЕЬхжЎЩЯЧјЗжСЫМИжжВЛЭЌЕФСЃЖШМЖБ№ЃЌМДОлКЯЃЌФЃПщКЭBCЁЃЛёЕУе§ШЗЕФФЃПщЛЏЫЎЦНашвЊвЛаЉСЗЯАЁЃе§ШчRDBMSФЃЪНПЩФмБЛЗЧЙцЗЖЛЏвЛбљЃЌЯЕЭГвВУЛгаФЃПщЛЏЃЈГЩЮЊФрНЌЕФДѓЧђЃЉЁЃЕЋЪЧЃЌЙ§ЖШЙцЗЖЛЏЕФRDBMSФЃЪНЃЈЦфжаЕЅИіЪЕЬхдкЖрИіБэЩЯБЛЗжНтЃЉвВПЩФмЪЧгаКІЕФЃЌЙ§ФЃПщЛЏЯЕЭГвВЪЧШчДЫЃЌвђЮЊЫќБфЕУФбвдРэНтЯЕЭГШчКЮзїЮЊећЬхЙЄзїЁЃ
ЮвУЧЪзЯШПМТЧФЃПщКЭBCЁЃМЧзЁЃЌФЃПщРрЫЦгкJavaАќЛђ.NETУќУћПеМфЁЃЮвУЧЯЃЭћСНИіФЃПщжЎМфЕФвРРЕЙиЯЕЪЧЗЧбЛЗЕФЃЌЕЋЪЧШчЙћЮвУЧШЗЖЈЃЈБШШчЫЕЃЉПЭЛЇвРРЕгкЖЉЕЅЃЌФЧУДЮвУЧВЛашвЊзіШЮКЮЖюЭтЕФЪТЧщЃКПЭЛЇПЩвдМђЕЅЕиЕМШыOrderАќ/УќУћПеМфВЂЪЙгУЫќНгПкКЭРрИљОнашвЊЁЃ
ЕЋЪЧЃЌШчЙћЮвУЧНЋПЭЛЇКЭЖЉЕЅЗХШыЕЅЖРЕФBCжаЃЌФЧУДЮвУЧЛЙгаИќЖрЕФЙЄзївЊзіЃЌвђЮЊЮвУЧБиаыНЋПЭЛЇBCжаЕФИХФюгГЩфЕНBCЖЉЕЅЕФИХФюЁЃдкЪЕМљжаЃЌетЛЙвтЮЖзХдкПЭЛЇBCжаОпгаЖЉЕЅЪЕЬхЕФБэЪОЃЈИљОнЧАУцИјГіЕФзмЗжРреЪЪОР§ЃЉЃЌвдМАЭЈЙ§ЯћЯЂзмЯпЛђЦфЫћЖЋЮїЪЕМЪазїЕФЛњжЦЁЃЧыМЧзЁЃКгЕгаСНИіBCЕФдвђЪЧЕБгаВЛЭЌЕФзюжегУЛЇКЭ/ЛђРћвцЯрЙиепЪБЃЌЮвУЧЮоЗЈБЃжЄВЛЭЌBCжаЕФЯрЙиИХФюНЋГЏзХЯрЭЌЕФЗНЯђЗЂеЙЁЃ
СэвЛИіПЩФмДцдкЛьЯ§ЕФСьгђЪЧНЋЪЕЬхгыОлКЯЧјЗжПЊРДЁЃУПИіОлКЯЖМгавЛИіЪЕЬхзїЮЊЦфОлКЯИљЃЌЖдгкКмЖрКмЖрЪЕЬхЃЌОлКЯНЋжЛАќКЌетИіЪЕЬхЃЈЁАЫіЫщЁБЕФЧщПіЃЌе§ШчЪ§бЇМвЫљЫЕЕФФЧбљЃЉЁЃЕЋЮвПДЕНПЊЗЂШЫдБШЯЮЊећИіЪРНчБиаыДцдкгквЛИіОлКЯжаЁЃвђДЫЃЌР§ШчЃЌЖЉЕЅАќКЌв§гУВњЦЗЕФOrderItemsЃЈЕНФПЧАЮЊжЙвЛжБКмКУЃЉЃЌвђДЫПЊЗЂШЫдБЕУГіНсТлЃЌВњЦЗвВдкОлКЯжаЃЈВЛЃЁЃЉИќдуИтЕФЪЧЃЌПЊЗЂШЫдБЛсЙлВьЕНПЭЛЇгаЖЉЕЅЃЌЫљвдЯыЯыетИівтЮЖзХЮвУЧБиаыгЕгаCustomer
/ Order / OrderItem / ProductЕФОоаЭОлКЯЃЈВЛЃЌВЛЃЌВЛЃЁЃЉЁЃЙиМќЪЧЁАПЭЛЇгаЖЉЕЅЁБВЂВЛвтЮЖзХАЕЪОЛузм;ПЭЛЇЃЌЖЉЕЅКЭВњЦЗЖМЪЧМЏКЯЕФИљдДЁЃ
ЪЕМЪЩЯЃЌвЛИіЕфаЭЕФФЃПщЃЈетЪЧЗЧГЃДжВкКЭзМБИКУЕФЃЉПЩФмАќКЌСљИіОлКЯЃЌУПИіОлКЯПЩФмАќКЌвЛИіЪЕЬхКЭМИИіЪЕЬхжЎМфЁЃдкетСљИіжаЃЌвЛИіКУЕФЪ§зжПЩФмЪЧВЛПЩБфЕФЁАВЮПМЪ§ОнЁБРрЁЃЛЙвЊМЧзЁЃЌЮвУЧФЃПщЛЏЕФдвђЪЧЮвУЧПЩвдРэНтвЛМўЪТЃЈдквЛЖЈЕФСЃЖШМЖБ№ЃЉЁЃЫљвдвЊМЧзЁЃЌЕфаЭЕФШЫвЛДЮжЛФмБЃГждк5ЕН9ИіжЎМф[11]ЁЃ
ШыУХ
е§ШчЮвдкПЊЪМЪБЫљЫЕЃЌФуПЩФмдкDDDжЎЧАгіЕНЙ§КмЖрЯыЗЈЁЃЪТЪЕЩЯЃЌЮвЫљЫЕЙ§ЕФУПвЛИіSmalltalkerЃЈЮвВЛЪЧвЛИіЃЌЮвВЛИвЫЕЃЉЫЦКѕКмИпаЫФмЙЛдкEJB2ЕШШЫЕФЛФвАЫъдТжЎКѓЛиЙщгђЧ§ЖЏЕФЗНЗЈЁЃ
СэвЛЗНУцЃЌШчЙћетаЉЖЋЮїЪЧаТЕФдѕУДАьЃПгаетУДЖрВЛЭЌЕФЗНЪНРДАэЕЙЃЌгаУЛгаАьЗЈПЩППЕиПЊЪМЪЙгУDDDЃП
ШчЙћФуЛЗЙЫвЛЯТJavaСьгђЃЈЖд.NETРДЫЕВЂВЛФЧУДдуИтЃЉЃЌЪЕМЪЩЯгаЪ§АйИігУгкЙЙНЈWebгІгУГЬађЕФПђМмЃЈJSPЃЌStrutsЃЌJSFЃЌSpring
MVCЃЌSeamЃЌWicketЃЌTapestryЕШЃЉЁЃДгГжОУадНЧЖШЃЈJDOЃЌJPAЃЌHibernateЃЌiBatisЃЌTopLinkЃЌJCloudЕШЃЉЛђЦфЫћЮЪЬтЃЈRestEasyЃЌCamelЃЌServiceMixЃЌMuleЕШЃЉЃЌгаКмЖреыЖдЛљДЁМмЙЙВуЕФПђМмЁЃЕЋЪЧКмЩйгаПђМмЛђЙЄОпРДАяжњDDDЫљЫЕЕФзюживЊЕФВуЃЌМДгђВуЁЃ
зд2002ФъвдРДЃЌЮввЛжБВЮгыЃЈЯждкЪЧвЛИіЬсНЛепЃЉвЛИіУћЮЊNaked ObjectsЕФЯюФПЃЌJavaЩЯЕФПЊдД[12]КЭ.NETЩЯЕФЩЬвЕ[13]ЁЃЫфШЛNaked
ObjectsУЛгаУїШЗЕиПЊЪМПМТЧСьгђЧ§ЖЏЕФЩшМЦ - ЪТЪЕЩЯЫќдчгкEvansЕФЪщ - ЫќгыDDDЕФдРэЗЧГЃЯрЫЦЁЃЫќЛЙПЩвдЧсЫЩПЫЗўЧАУцЬсЕНЕФеЯАЁЃ
ФњПЩвдНЋNaked ObjectsЪгЮЊгыHibernateЕШORMРрЫЦЁЃ ORMЙЙНЈгђЖдЯѓЕФдЊФЃаЭВЂЪЙгУЫќРДздЖЏНЋгђЖдЯѓГжОУБЃДцЕНRDBMSЃЌЖјNaked
ObjectsЙЙНЈдЊФЃаЭВЂЪЙгУЫќдкУцЯђЖдЯѓЕФгУЛЇНчУцжаздЖЏГЪЯжетаЉгђЖдЯѓЁЃ
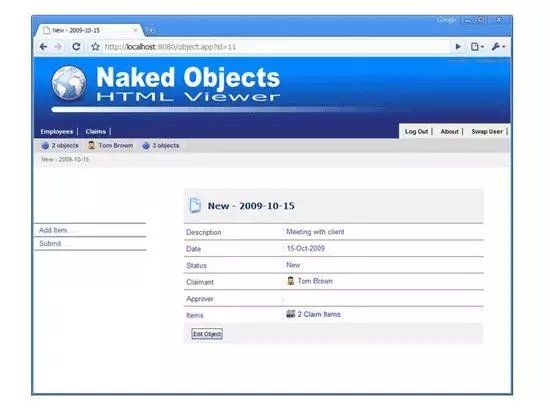
ПЊЯфМДгУЕФNaked ObjectsжЇГжСНИігУЛЇНчУцЃЌвЛИіИЛПЭЛЇЖЫВщПДЦїЃЈВЮМћЭМ9ЃЉКЭвЛИіHTMLВщПДЦїЃЈВЮМћЭМ10ЃЉЁЃетаЉЖМЪЧЙІФмЭъБИЕФгІгУГЬађЃЌашвЊПЊЗЂШЫдБжЛБраДвЊдЫааЕФгђВуЃЈЪЕЬхЃЌжЕЃЌДцДЂПтЃЌЙЄГЇЃЌЗўЮёЃЉЁЃ
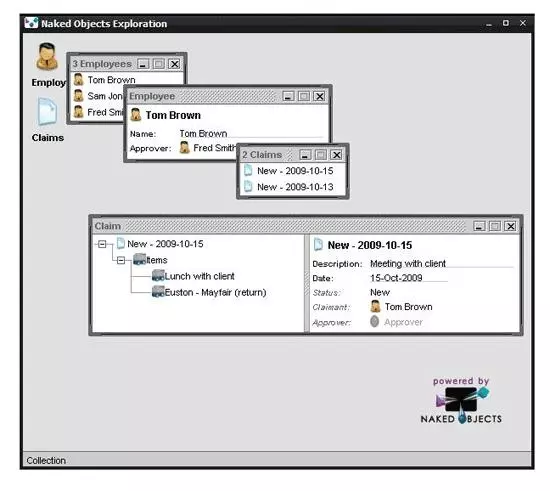
Figure 9: Naked Objects Drag-n-Drop Viewer
ЮвУЧРДПДПДClaimРрЕФЃЈJavaЃЉДњТыЃЈШчЦСФЛНиЭМЫљЪОЃЉЁЃЪзЯШЃЌетаЉРрЛљБОЩЯЪЧpojosЃЌОЁЙмЮвУЧЭЈГЃДгБуНнРрAbstractDomainObjectМЬГаЃЌжЛЪЧЮЊСЫЗжНтзЂШыЭЈгУДцДЂПтВЂЬсЙЉвЛаЉАяжњЗНЗЈЃК
public class
Claim extends AbstractDomainObject {
...
}
Next, we have some value properties:
// {{ Description
private String description;
@MemberOrder(sequence = "1")
public String getDescription() { return description;
}
public void setDescription(String d) { description
= d; }
// }}
// {{ Date
private Date date;
@MemberOrder(sequence="2")
public Date getDate() { return date; }
public void setDate(Date d) { date = d; }
// }}
// {{ Status
private String status;
@Disabled
@MemberOrder(sequence = "3")
public String getStatus() { return status; }
public void setStatus(String s) { status = s;
}
// }} |
етаЉЪЧМђЕЅЕФgetter / setterЃЌЗЕЛиРраЭЮЊStringЃЌШеЦкЃЌећЪ§ЕШЃЈОЁЙмNaked ObjectsвВжЇГжздЖЈвхжЕРраЭЃЉЁЃНгЯТРДЃЌЮвУЧгавЛаЉВЮПМЪєадЃК
// {{ Claimant
private Claimant claimant;
@Disabled
@MemberOrder(sequence = "4")
public Claimant getClaimant() { return claimant;
}
public void setClaimant(Claimant c) { claimant
= c; }
// }}
// {{ Approver
private Approver approver;
@Disabled
@MemberOrder(sequence = "5")
public Approver getApprover() { return approver;
}
public void setApprover(Approver a) { approver
= a; }
// }} |
етРяЮвУЧЕФClaimЪЕЬхв§гУЦфЫћЪЕЬхЁЃЪЕМЪЩЯЃЌClaimantКЭApproverЪЧНгПкЃЌвђДЫетдЪаэЮвУЧНЋгђФЃаЭЗжНтЮЊФЃПщЃЌШчЧАЫљЪіЁЃ
ЪЕЬхвВПЩвдгЕгаЪЕЬхМЏКЯЁЃдкЮвУЧЕФАИР§жаЃЌClaimгавЛИіClaimItemsЕФМЏКЯЃК
// {{ Items
private List<ClaimItem> items = new
ArrayList<ClaimItem>();
@MemberOrder(sequence = "6")
public List<ClaimItem> getItems() { return
items; }
public void addToItems(ClaimItem item) {
items.add(item);
}
// }} |
ЮвУЧЛЙгаЃЈNaked ObjectsЕїгУЕФЃЉЖЏзїЃЌМДsubmitКЭaddItemЃКетаЉЖМЪЧВЛДњБэЪєадКЭМЏКЯЕФЙЋЙВЗНЗЈЃК
// {{ action:
addItem
public void addItem(
@Named("Days since")
int days,
@Named("Amount")
double amount,
@Named("Description")
String description) {
ClaimItem claimItem = newTransientInstance(ClaimItem.class);
Date date = new Date();
date = date.add(0,0, days);
claimItem.setDateIncurred(date);
claimItem.setDescription(description);
claimItem.setAmount(new Money(amount, "USD"));
persist(claimItem);
addToItems(claimItem);
}
public String disableAddItem() {
return "Submitted".equals(getStatus())
? "Already
submitted" : null;
}
// }}
// {{ action: Submit
public void submit(Approver approver) {
setStatus("Submitted");
setApprover(approver);
}
public String disableSubmit() {
return getStatus().equals("New")?
null : "Claim has already been submitted";
}
public Object[] defaultSubmit() {
return new Object[] { getClaimant().getApprover()
};
}
// }} |
етаЉВйзїЛсдкNaked ObjectsВщПДЦїжаздЖЏГЪЯжЮЊВЫЕЅЯюЛђСДНгЁЃЖјетаЉааЖЏЕФДцдквтЮЖзХNaked
ObjectsгІгУГЬађВЛНіНіЪЧCRUDЗчИёЕФгІгУГЬађЁЃ
зюКѓЃЌгавЛаЉжЇГжЗНЗЈПЩвдЯдЪОБъЧЉЃЈЛђБъЬтЃЉВЂЙвЙГГжОУадЩњУќжмЦкЃК
// {{ Title
public String title() {
return getStatus() + " - " + getDate();
}
// }}
// {{ Lifecycle
public void created() {
status = "New";
date = new Date();
}
// }} |
жЎЧАЮвНЋNaked ObjectsгђЖдЯѓУшЪіЮЊpojosЃЌЕЋФњЛсзЂвтЕНЮвУЧЪЙгУзЂЪЭЃЈР§Шч@DisabledЃЉвдМАУќСюЪНАяжњЦїЗНЗЈЃЈР§ШчdisableSubmitЃЈЃЉЃЉРДЧПжЦжДаавЕЮёдМЪјЁЃ
Naked ObjectsВщПДЦїЭЈЙ§ВщбЏЦєЖЏЪБЙЙНЈЕФдЊФЃаЭРДз№жиетаЉгявхЁЃШчЙћФњВЛЯВЛЖетаЉБрГЬдМЖЈЃЌдђПЩвдИќИФЫќУЧЁЃ
ЕфаЭЕФNaked ObjectsгІгУГЬађгЩвЛзщгђРрзщГЩЃЌР§ШчЩЯУцЕФClaimРрЃЌвдМАДцДЂПтЃЌЙЄГЇКЭгђ/ЛљДЁНсЙЙЗўЮёЕФНгПкКЭЪЕЯжЁЃЬиБ№ЪЧЃЌУЛгаБэЪОВуЛђгІгУВуДњТыЁЃФЧУДNaked
ObjectsШчКЮАяжњНтОіЮвУЧвбОШЗЖЈЕФвЛаЉеЯАЃП
ЪЕЪЉЗжВуМмЙЙЃКвђЮЊЮвУЧБраДЕФЮЈвЛДњТыЪЧгђЖдЯѓЃЌгђТпМЮоЗЈЩјЭИЕНЦфЫћВуЁЃЪЕМЪЩЯЃЌNaked ObjectsзюГѕЕФЖЏЛњжЎвЛОЭЪЧАяжњПЊЗЂааЮЊЭъећЕФЖдЯѓ
БэЪОВуФЃК§СЫгђВуЃКвђЮЊБэЪОВуЪЧгђЖдЯѓЕФжБНгЗДгГЃЌећИіЭХЖгПЩвдбИЫйМгЩюЖдгђФЃаЭЕФРэНтЁЃФЌШЯЧщПіЯТЃЌNaked
ObjectsжБНгДгДњТыжаЛёШЁРрУћКЭЗНЗЈУћЃЌвђДЫЧПСввЊЧѓдкЮоДІВЛдкЕФгябджаЛёЕУУќУћШЈЁЃЭЈЙ§етжжЗНЪНЃЌNaked
ObjectsвВжЇГжDDDЕФФЃаЭЧ§ЖЏЩшМЦдРэ
ДцДЂПтФЃЪНЕФЪЕЯжЃКФњПЩвддкЦСФЛНиЭМжаПДЕНЕФЭМБъ/СДНгЪЕМЪЩЯЪЧДцДЂПтЃКEmployeeRepositoryКЭClaimRepositoryЁЃ
Naked ObjectsжЇГжПЩВхШыЖдЯѓДцДЂЃЌЭЈГЃдкдаЭЩшМЦжаЃЌЮвУЧЪЙгУеыЖдФкДцжаЖдЯѓДцДЂЕФЪЕЯжЁЃЕБЮвУЧзЊЯђЩњВњЪБЃЌЮвУЧЛсБраДвЛИіЪЕЯжЪ§ОнПтЕФЪЕЯжЁЃ
ЗўЮёвРРЕЯюЕФЪЕЯжЃКNaked ObjectsЛсздЖЏНЋЗўЮёвРРЕЯюзЂШыУПИігђЖдЯѓЁЃетЪЧдкДгЖдЯѓПтжаМьЫїЖдЯѓЪБЃЌЛђепЪзДЮДДНЈЖдЯѓЪБЭъГЩЕФЃЈЧыВЮдФЩЯУцЕФnewTransientInstanceЃЈЃЉЃЉЁЃЪТЪЕЩЯЃЌетаЉИЈжњЗНЗЈЫљзіЕФОЭЪЧЮЏЭаNaked
ObjectsЬсЙЉЕФУћЮЊDomainObjectContainerЕФЭЈгУДцДЂПт/ЙЄГЇЁЃ
ВЛКЯЪЪЕФФЃПщЛЏЃКЮвУЧПЩвдЭЈЙ§е§ГЃЗНЪНЪЙгУJavaАќЃЈЛђ.NETУќУћПеМфЃЉФЃПщЛЏЮЊФЃПщЃЌВЂЪЙгУStructure101
[14]КЭNDepend [15]ЕШПЩЪгЛЏЙЄОпРДШЗБЃЮвУЧЕФДњТыПтжаУЛгабЛЗвРРЕЁЃЮвУЧПЩвдЭЈЙ§зЂЪЭ@HiddenРДФЃПщЛЏЮЊОлКЯЃЌШЮКЮОлКЯЖдЯѓДњБэЮвУЧПЩМћОлКЯИљЕФФкВПЙЄзї;етаЉНЋВЛЛсГіЯждкNaked
ObjectsВщПДЦїжаЁЃЮвУЧПЩвдБраДгђКЭЛљДЁЩшЪЉЗўЮёЃЌвдБуИљОнашвЊЧХНгЕНЦфЫћBCЁЃ
Naked ObjectsЬсЙЉСЫаэЖрЦфЫћЙІФмЃКЫќОпгаПЩРЉеЙЕФЬхЯЕНсЙЙ - ЬиБ№ЪЧ - дЪаэЪЕЯжЦфЫћВщПДЦїКЭЖдЯѓДцДЂЁЃе§дкПЊЗЂЕФЯТвЛДњЙлжкЃЈР§ШчScimpi
[16]ЃЉЬсЙЉИќИДдгЕФЖЈжЦЙІФмЁЃДЫЭтЃЌЫќЛЙЬсЙЉЖржжВПЪ№бЁЯюЃКР§ШчЃЌФњПЩвдЪЙгУNaked ObjectsНјаадаЭЩшМЦЃЌШЛКѓдкНјааЩњВњЪБПЊЗЂздМКЕФЖЈжЦБэЪОВуЁЃЫќЛЙгыFitNesse
[17]ЕШЙЄОпМЏГЩЃЌПЩвдздЖЏЮЊгђЖдЯѓЬсЙЉRESTfulНгПк[18]ЁЃ
ЯТвЛВН
СьгђЧ§ЖЏЕФЩшМЦЛуМЏСЫвЛзщгУгкПЊЗЂИДдгЦѓвЕгІгУГЬађЕФзюМбЪЕМљФЃЪНЁЃвЛаЉПЊЗЂШЫдБЖрФъРДвЛжБдкгІгУетаЉФЃЪНЃЌЖдгкетаЉШЫРДЫЕЃЌDDDПЩФмжЛЪЧЖдЫћУЧЯжгаЪЕМљЕФПЯЖЈЁЃЕЋЖдгкЦфЫћШЫРДЫЕЃЌгІгУетаЉФЃЪНПЩФмЪЧвЛИіеце§ЕФЬєеНЁЃ
Naked ObjectsЮЊJavaКЭ.NETЬсЙЉСЫвЛИіПђМмЃЌЭЈЙ§ДІРэЦфЫћВуЃЌЭХЖгПЩвдзЈзЂгкживЊЕФВПЗжЃЌМДгђФЃаЭЁЃЭЈЙ§жБНгдкUIжаЙЋПЊгђЖдЯѓЃЌNaked
ObjectsдЪаэЭХЖгЗЧГЃздШЛЕиЙЙНЈвЛИіУїШЗЮоДІВЛдкЕФгябдЁЃЫцзХгђВуЕФНЈСЂЃЌЭХЖгПЩвдИљОнашвЊПЊЗЂИќМгСПЩэЖЈжЦЕФБэЪОВуЁЃ
|









