| БрМЭЦМі: |
БОЮФРДздгкзїепеХНЈЗЩЃЌЮФеТжївЊНщЩмСЫШчКЮНјааСьгђНЈФЃЁЂСьгђЗўЮёвдМАФЃаЭжиЙЙЕШЯрЙиФкШнЁЃ
|
|
ЮЊЪВУДвЊСьгђНЈФЃ
ЮЌЛЄЙ§ЦѓвЕМЖвЕЮёЯЕЭГЕФЭЌбЇЃЌЛљБОЩЯУЛгавЛИіВЛБЇдЙвЕЮёДњТыРУЕФЃЌЙ§ГЬЪНЕФУцЬѕДњТыГфГтзХЦСФЛЃЌГЬађдБЕФаФСІКЭЬхСІЖМОЪмзХМЋДѓЕФПМбщЃЌдѕУДЦЦЃП
DDDИяУќ
DDDИяУќаддкгкЃЌСьгђФЃаЭзМШЗЗДгГСЫвЕЮёгябдЃЌЖјДЋЭГJ2EEЛђSpring+HibernateЕШЪТЮёадБрГЬФЃаЭжЛЙиаФЪ§ОнЃЌетаЉЪ§ОнЖдЯѓГ§СЫМђЕЅsetter/getterЗНЗЈЭтЃЌУЛгаШЮКЮвЕЮёЗНЗЈЃЌБЛБШгїГЩЦЖбЊФЃЪНЁЃ
вдвјааеЫКХAccountЮЊАИР§ЃЌAccountгаЁАДцПюЁБЃЌЁАМЦЫуРћЯЂЁБКЭЁАШЁПюЁБЕШвЕЮёааЮЊЃЌЕЋЪЧДЋЭГОЕфЕФЗНЪНЪЧНЋЁАДцПюЁБЃЌЁАМЦЫуРћЯЂЁБКЭЁАШЁПюЁБааЮЊЗХдкеЫКХЕФЗўЮёAccountServiceжаЃЌЖјВЛЪЧЗХдкAccountЖдЯѓБОЩэжЎжаЁЃЮвУЧВЛФмвђЮЊгУСЫМЦЫуЛњЃЌгУСЫЪ§ОнПтЃЌгУСЫПђМмЃЌвЕЮёФЃаЭЗДЖјБЛММЪѕПђМмИјАѓМмСЫЃЌОЭЯёШЫЫфШЛЪЧгЩФИЧзЩњЕФЃЌЕЋЪЧШЫЕФГдКШРШіФИЧзВЛФмЬцДњЃЌИќВЛФмвдФИАЎУћвхАўЖсШЫЕФе§ГЃжАд№ааЮЊЃЌШчЙћЪЧетбљЃЌетИіШЫОЭЪЧБЛФИАЎАѓМмСЫЁЃ
DDDВЛЪЧвјЕЏ
ШэМўЕФЪРНчРяУЛгавјЕЏЃЌЪЧгУЪТЮёНХБОЛЙЪЧСьгђФЃаЭУЛгаЖдДэжЎЗжЃЌЙиМќПДЪЧЗёКЯЪЪЁЃОЭЯёздгЊКЭЦНЬЈФФИіФЃЪНИќКУЃПД№АИЪЧЖМКмКУЃЌЫљвдбЧТэбЗПЩвдгаШ§ЗНШызЁЃЌАЂРявВПЩвдгаздНЈВжТяЁЃ
ЪЕМЪЩЯЃЌCQRSОЭЪЧЖдЪТЮёНХБОКЭСьгђФЃаЭСНжжФЃЪНЕФзлКЯЃЌвђЮЊЖдгкQueryКЭБЈБэЕФГЁОАЃЌЪЙгУСьгђФЃаЭЭљЭљЛсАбМђЕЅЕФЪТЧщХЊИДдгЃЌДЫЪБЭъШЋПЩвдгУАТПЈФЗЬъЕЖАбСьгђВуЬъЕєЃЌжБНгЗУЮЪInfrastructureЁЃ
ЮвИіШЫвВЪЧМсОіЗДЖдЙ§ЖШЩшМЦЕФЃЌвђДЫЖдгкМђЕЅвЕЮёГЁОАЃЌЮвЧПСІНЈвщЛЙЪЧЪЙгУЪТЮёНХБОЃЌЦфгХЕуЪЧМђЕЅЁЂжБЙлЁЂвзЩЯЪжЁЃЕЋЖдгкИДдгЕФвЕЮёГЁОАЃЌФудйетУДЭцОЭВЛааСЫЃЌвђЮЊвЛЕЉвЕЮёБфЕУИДдгЃЌЪТЮёНХБООЭКмФбгІЖдЃЌШнвздьГЩДњТыЕФЁАвЛЙјжрЁБЃЌЯЕЭГЕФИЏЛЏЫйЖШКЭИДдгадГЪжИЪ§МЖЩЯЩ§ЁЃФПЧАБШНЯгааЇЕФжЮРэАьЗЈОЭЪЧСьгђНЈФЃЃЌвђЮЊСьгђФЃаЭЪЧУцЯђЖдЯѓЕФЃЌдкЗтзАвЕЮёТпМЕФЭЌЪБЃЌЬсЩ§СЫЖдЯѓЕФФкОладКЭжигУадЃЌвђЮЊЪЙгУСЫЭЈгУгябдЃЈUbiquitous
LanguageЃЉЃЌЪЙЕУвўВиЕФвЕЮёТпМЕУЕНЯдадЛЏБэДяЃЌЪЙЕУИДдгаджЮРэГЩЮЊПЩФмЁЃ
НгЯТРДЃЌШУЮвУЧПДвЛИівјаазЊеЫЕФЪЕР§ЃЌЖдБШЯТЪТЮёНХБОКЭСьгђФЃаЭСНепБрГЬФЃаЭЕФВЛЭЌЁЃ
DDDГѕЬхбщ
вјаазЊеЫЪТЮёНХБОЪЕЯж
дкЪТЮёНХБОЕФЪЕЯжжаЃЌЙигкдкСНИіеЫКХжЎМфзЊеЫЕФСьгђвЕЮёТпМЖМБЛаДдкСЫMoneyTransferServiceЕФЪЕЯжРяУцСЫЃЌЖјAccountНіНіЪЧgettersКЭsettersЕФЪ§ОнНсЙЙЃЌвВОЭЪЧЮвУЧЫЕЕФЦЖбЊФЃаЭЃК
public class
MoneyTransferServiceTransactionScriptImpl
implements MoneyTransferService {
private AccountDao accountDao;
private BankingTransactionRepository
bankingTransactionRepository;
. . .
@Override
public BankingTransaction transfer(
String fromAccountId, String toAccountId, double
amount) {
Account fromAccount = accountDao.findById(fromAccountId);
Account toAccount = accountDao.findById(toAccountId);
. . .
double newBalance = fromAccount.getBalance() -
amount;
switch (fromAccount.getOverdraftPolicy()) {
case NEVER:
if (newBalance < 0) {
throw new DebitException("Insufficient funds");
}
break;
case ALLOWED:
if (newBalance < -limit) {
throw new DebitException(
"Overdraft
limit (of " + limit + ") exceeded: "
+ newBalance);
}
break;
}
fromAccount.setBalance(newBalance);
toAccount.setBalance(toAccount.getBalance() +
amount);
BankingTransaction moneyTransferTransaction =
new MoneyTranferTransaction(fromAccountId,
toAccountId,
amount);
bankingTransactionRepository.addTransaction
(moneyTransferTransaction);
return moneyTransferTransaction;
}
} |
ЩЯУцЕФДњТыДѓМвПДЦ№РДгІИУБШНЯблЪьЃЌвђЮЊФПЧАДѓВПЗжЯЕЭГЖМЪЧетУДаДЕФЁЃашЧѓЦРЩѓЭъЃЌЙЄГЬЪІЛМИеХUMLЭМЭъГЩЩшМЦЃЌОЭПЊЪМЯђЩЯУцетбљэЁвЕЮёДњТыСЫЃЌетбљаДЛљБОВЛгУЬЋЗбФдЃЌЭъШЋЪЧУцЯђЙ§ГЬЕФДњТыЗчИёЁЃгааЉЭЌбЇПЩФмЛсЫЕЃЌЮветбљаДвВПЩвдЪЕЯжЯЕЭГЙІФмАЁЃЌЛЙЪЧФЧОфЛАЁАjust
because you can, doesnЁЏt mean you shouldЁБЁЃЫЕОфВЛКУЬ§ЕФЃЌе§ЪЧгаетУДЖрЁАУЛгазЗЧѓЁБЁЂЁАВЛЧѓЩЯНјЁБЕФТыХЉВХдьГЩСЫгІгУЯЕЭГЕФЛьТвЁЂАмЛЕСЫгІгУПЊЗЂЕФУћЩљЁЃетвВЪЧЮЊЪВУДКмЖргІгУПЊЗЂЙЄГЬЪІОѕЕУЙЄзїУЛвтЫМЃЌММЪѕКЌСПЕЭЃЌОѕЕУећЬьОЭЪЧаДif-elseЕФвЕЮёТпМДњТыЃЌЯЕЭГгжРУЃЌЙЄзїЗБЫіЁЂЮоСФЁЂУЛгаГЩГЄЁЂУЛгаГЩОЭИаЃЌЫљвдзЊЯђШЅзіжаМфМўАЁЃЌШЅаДJDKАЁЃЌОѕЕУФЧИіNBЁЃЪЕМЪЩЯЃЌгІгУПЊЗЂвЛЕуЖМВЛМђЕЅвВВЛЮоСФЃЌвЕЮёЕФБфЛЏБШЕзВуInfrastructureЕФБфЛЏвЊЖрЕУЖрЃЌНтОіЕФФбЖШвВЫПКСВЛБШаДЕзВуДњТыШнвзЃЌжЛЪЧКмЖрШЫбЁдёСЫгУЮоСФЕФЗНЪНШЅзіЁЃЦфЪЕЮвУЧЪЧгаАьЗЈзіЕФИќгХбХЕФЃЌетжжгХбХЕФЗНЪНОЭЪЧСьгђНЈФЃЃЌЮЈгаеЦЮеСЫетжжгХбХФуВХФмЪЕЯжДгЙЄГЬЪІЯђгІгУМмЙЙЕФзЊаЭЁЃЭЌбљЕФвЕЮёТпМЃЌНгЯТРДОЭШУЮвУЧПДвЛЯТгУDDDЪЧдѕУДзіЕФЁЃ
вјаазЊеЫСьгђФЃаЭЪЕЯж
ШчЙћгУDDDЕФЗНЪНЪЕЯжЃЌAccountЪЕЬхГ§СЫеЫКХЪєаджЎЭтЃЌЛЙАќКЌСЫааЮЊКЭвЕЮёТпМЃЌБШШчdebit(
)КЭcredit( )ЗНЗЈЁЃ
/ @Entity
public class Account {
// @Id
private String id;
private double balance;
private OverdraftPolicy overdraftPolicy;
. . .
public double balance() { return balance; }
public void debit(double amount) {
this.overdraftPolicy.preDebit(this, amount);
this.balance = this.balance - amount;
this.overdraftPolicy.postDebit(this, amount);
}
public void credit(double amount) {
this.balance = this.balance + amount;
}
} |
ЖјЧвЭИжЇВпТдOverdraftPolicyвВВЛНіНіЪЧвЛИіEnumСЫЃЌЖјЪЧБЛГщЯѓГЩАќКЌСЫвЕЮёЙцдђВЂВЩгУСЫВпТдФЃЪНЕФЖдЯѓЁЃ
public interface
OverdraftPolicy {
void preDebit(Account account, double amount);
void postDebit(Account account, double amount);
}
public class NoOverdraftAllowed implements OverdraftPolicy
{
public void preDebit(Account account, double amount)
{
double newBalance = account.balance() - amount;
if (newBalance < 0) {
throw new DebitException("Insufficient funds");
}
}
public void postDebit(Account account, double
amount) {
}
}
public class LimitedOverdraft implements OverdraftPolicy
{
private double limit;
. . .
public void preDebit(Account account, double amount)
{
double newBalance = account.balance() - amount;
if (newBalance < -limit) {
throw new DebitException(
"Overdraft
limit (of " + limit + ") exceeded: "
+ newBalance);
}
}
public void postDebit(Account account, double
amount) {
}
} |
ЖјDomain ServiceжЛашвЊЕїгУDomain EntityЖдЯѓЭъГЩвЕЮёТпММДПЩЁЃ
public class
MoneyTransferServiceDomainModelImpl
implements MoneyTransferService {
private AccountRepository accountRepository;
private BankingTransactionRepository
bankingTransactionRepository;
. . .
@Override
public BankingTransaction transfer(
String fromAccountId, String toAccountId, double
amount) {
Account fromAccount = accountRepository.findById
(fromAccountId);
Account toAccount = accountRepository.findById(toAccountId);
. . .
fromAccount.debit(amount);
toAccount.credit(amount);
BankingTransaction moneyTransferTransaction =
new MoneyTranferTransaction(fromAccountId,
toAccountId,
amount);
bankingTransactionRepository.addTransaction
(moneyTransferTransaction);
return moneyTransferTransaction;
}
} |
ЭЈЙ§ЩЯУцЕФDDDжиЙЙКѓЃЌдРДдкЪТЮёНХБОжаЕФТпМЃЌБЛЗжЩЂЕНDomain ServiceЃЌDomain
EntityКЭOverdraftPolicyШ§ИіТњзуSOLIDЕФЖдЯѓжаЃЌдкМЬајдФЖСжЎЧАЃЌЮвНЈвщПЩвдздМКЯШЬхЛсвЛЯТDDDЕФКУДІЁЃ
СьгђНЈФЃЕФКУДІ
DDDзюДѓЕФКУДІЪЧЃКНгДЅЕНашЧѓЕквЛВНОЭЪЧПМТЧСьгђФЃаЭЃЌЖјВЛЪЧНЋЦфЧаИюГЩЪ§ОнКЭааЮЊЃЌШЛКѓЪ§ОнгУЪ§ОнПтЪЕЯжЃЌааЮЊЪЙгУЗўЮёЪЕЯжЃЌзюКѓдьГЩашЧѓЕФЪзжЋЗжРыЁЃDDDШУФуЪзЯШПМТЧЕФЪЧвЕЮёгябдЃЌЖјВЛЪЧЪ§ОнЁЃDDDЧПЕївЕЮёГщЯѓКЭУцЯђЖдЯѓБрГЬЃЌЖјВЛЪЧЙ§ГЬЪНвЕЮёТпМЪЕЯжЁЃжиЕуВЛЭЌЕМжТБрГЬЪРНчЙлВЛЭЌЁЃ
УцЯђЖдЯѓ
ЗтзАЃКAccountЕФЯрЙиВйзїЖМЗтзАдкAccount EntityЩЯЃЌЬсИпСЫФкОладКЭПЩжигУадЁЃ
ЖрЬЌЃКВЩгУВпТдФЃЪНЕФOverdraftPolicyЃЈЖрЬЌЕФЕфаЭгІгУЃЉЬсИпСЫДњТыЕФПЩРЉеЙадЁЃ
вЕЮёгявхЯдадЛЏ
ЭЈгУгябдЃКЁАвЛИіЭХЖгЃЌвЛжжгябдЁБЃЌНЋФЃаЭзїЮЊгябдЕФжЇжљЁЃШЗБЃЭХЖгдкФкВПЕФЫљгаНЛСїжаЃЌДњТыжаЃЌЛЭМЃЌаДЖЋЮїЃЌЬиБ№ЪЧНВЛАЕФЪБКђЖМвЊЪЙгУетжжгябдЁЃР§ШчеЫКХЃЌзЊеЫЃЌЭИжЇВпТдЃЌетаЉЖМЪЧЗЧГЃживЊЕФСьгђИХФюЃЌШчЙћетаЉУќУћЖМКЭЮвУЧШеГЃЬжТлвдМАPRDжаЕФУшЪіБЃГжвЛжТЃЌНЋЛсМЋДѓЬсЩ§ДњТыЕФПЩЖСадЃЌМѕЩйШЯжЊГЩБОЁЃЫЕЕНетЃЌЩдЮЂЭТВлвЛЯТЮвУЧгааЉЙЄГЬЪІЕФгЂгяЫЎЦНЃЌгааЉЩёЗвыШУвЛаЉКЫаФСьгђИХФюБфЕУУцФПШЋЗЧЁЃ
ЯдадЛЏЃКОЭЪЧНЋвўЪНЕФвЕЮёТпМДгвЛЭЦif-elseРяУцГщШЁГіРДЃЌгУЭЈгУгябдШЅУќУћЁЂШЅаДДњТыЁЂШЅРЉеЙЃЌШУЦфБфГЩЯдЪОИХФюЃЌБШШчЁАЭИжЇВпТдЁБетИіживЊЕФвЕЮёИХФюЃЌАДееЪТЮёНХБОЕФаДЗЈЃЌЦфКЌвхЭъШЋбЭУЛдкДњТыТпМжаУЛгаЭЛЯдГіРДЃЌПДДњТыЕФШЫздШЛвВЪЧвЛСГуТБЦЃЌЖјСьгђФЃаЭРяУцНЋЦфгУВпТдФЃЪНГщЯѓГіРДЃЌВЛНіЬсИпСЫДњТыЕФПЩЖСадЃЌПЩРЉеЙадвВКУСЫКмЖрЁЃ
ШчКЮНјааСьгђНЈФЃ
ГѕВННЈФЃ
КУЕФФЃаЭгІИУЪЧНЈСЂдкЖдвЕЮёЩюШыРэНтЕФЛљДЁЩЯЁЃОЭЮвздМКЕФОбщЖјбдЃЌНЈФЃЪЧвЛИіВЛЖЯЕќДњЕФЙ§ГЬЃЌвЛПЊЪМПЩвдМђЕЅЕуРДЁЃ
ЪзЯШзЅзЁвЛаЉКЫаФИХФюЃЌетаЉвЕЮёжЊЪЖКЭКЫаФИХФюПЩвдЭЈЙ§КЭвЕЮёзЈМвЙЕЭЈЃЌвВПЩвдЭЈЙ§ЭЗФдЗчБЉЕФаЮЪНДгUser
StoryЛђепEvent StormingШЅПлЁЃ
ШЛКѓМйЩшвЛаЉвЕЮёГЁОАзпВщвЛЯТЃЌдйаДвЛаЉЮБДњТыбщжЄвЛЯТrunвЛЯТЃЌПДПДЫГВЛЫГЃЌШчЙћКмЫГЛЌЃЌЫЕУїУЛУЋВЁЃЌЗёдђОЭвЊПДПДЪЧВЛЪЧашвЊЕїећвЛЯТФЃаЭЃЌЫцзХЯюФПЕФНјааКЭЖдвЕЮёРэНтЕФВЛЖЯЩюШыЃЌетжжЕќДњНЋГжајНјааЁЃ
ОйИіРѕзгЃЌБШШчШУФуЩшМЦвЛИіжаНщЯЕЭГЃЌвЛИіЕфаЭЕФUser StoryПЩФмЪЧЁАаЁУїШЅевЙЄзїЃЌжаНщЫЕФуСєИіЕчЛАЃЌгаЙЄзїЛњЛсЮвЛсЭЈжЊФуЁБЃЌетРяУцЕФЙиМќУћДЪКмПЩФмОЭЪЧЮвУЧашвЊЕФСьгђЖдЯѓЃК
- аЁУїЪЧЧѓжАепЁЃ
- ЕчЛАЪЧЧѓжАепЕФЪєадЁЃ
- жаНщАќКЌСЫжаНщЙЋЫОЃЌжаНщдБЙЄСНИіЙиМќЖдЯѓЁЃ
- ЙЄзїЛњЛсПЯЖЈвВЪЧЙиМќСьгђЖдЯѓЃЛ
- ЭЈжЊетИіЖЏДЪАЕЪОЮвУЧетРягУЙлВьепФЃЪНЛсБШНЯКЯЪЪЁЃ
ШЛКѓдйЪсРэвЛЯТСьгђЖдЯѓжЎМфЕФЙиЯЕЃЌвЛИіЧѓжАепПЩвдгІЦИЖрИіЙЄзїЛњЛсЃЌвЛИіЙЄзїЛњЛсвВПЩвдБЛЖрИіЧѓжАепгІЦИЃЌM2MЕФЙиЯЕЃЌжаНщЙЋЫОПЩвдАќКЌЖрИідБЙЄЃЌO2MЕФЙиЯЕЁЃЖдгкетбљМђЕЅЕФГЁОАЃЌетИіНЈФЃОЭВюВЛЖрСЫЁЃ
ЕБШЛЮвУЧЕФвЕЮёГЁОАЭљЭљБШетИівЊИДдгЃЌЖјЧвВЛЪЧЫљгаЕФУћДЪЖМЪЧСьгђЖдЯѓвВПЩФмЪЧЪєадЃЌвВВЛЪЧЫљгаЕФЖЏДЪЖМЪЧЗНЗЈвВПЩФмЪЧСьгђЖдЯѓЃЌдйепЃЌПДЕФМћЪЕЬхКУевЃЌПДВЛМћЕФЁЂвўВиЕФЃЌашвЊЩюШыРэНтвЕЮёЃЌашвЊЁАЮожаЩњгаЁБВХФмЕУЕНЕФГщЯѓОЭУЛФЧУДШнвзЗЂЯжСЫЃЌЫљвдвЊОпЬхЮЪЬтОпЬхЖдД§ЃЌетИіНјЛЏЕФЙ§ГЬашвЊЮвУЧгаКмКУЕФвЕЮёРэНтСІЃЌГщЯѓФмСІвдМАНЈФЃЕФОбщЃЈжЊЕРЮЊЪВУДЙЋЫОЕФjob
modelРяФЧУДЧПЕїММЪѕШЫдБЕФвЕЮёРэНтСІКЭГщЯѓФмСІСЫАЩЁЃ
БШШчЭЈГЃЧщПіЯТЃЌМлИёКЭПтДцжЛЪЧЖЉЕЅКЭЩЬЦЗЕФвЛИіЪєадЃЌЕЋЪЧдкАЂРяЯЕЕчЩЬвЕЮёГЁОАЯТЃЌМлИёМЦЫуКЭПтДцПлМѕЕФИДдгГЬЖШПЩвдШУФуЛГвЩШЫЩњЃЌвђДЫзїЮЊЕчЩЬжаЬЈЃЌАбМлИёКЭПтДцЕЅЖРЕБГЩвЛИігђЃЈDomainЃЉШЅЖдД§ЪЧКмБивЊЕФЁЃ
ЕБШЛетИіжЛЪЧзюГѕМЖЕФФЃаЭЃЌНгЯТРДЮвЛсЭЈЙ§DDDжаЕФвЛаЉКЫаФИХФюЕФНщЩмЃЌШУДѓМвИќЧхГўЕФСЫНтНЈФЃЕФЙ§ГЬЁЃ
СьгђЪТМў(Domain Event)
An event is something that has happened in the past.
A domain event is, logically, something that happened
in a particular domain, and something you want other
parts of the same domain (in-process) or domain in
aonther bounded context to be aware of and potentially
react to.
Domain EventЪЧгЩвЛИіЬиЖЈСьгђДЅвђЮЊвЛИігУЛЇCommandДЅЗЂЕФЗЂЩњдкЙ§ШЅЕФааЮЊВњЩњЕФЪТМўЃЌЖјетИіЪТМўЪЧЯЕЭГжаЦфЫќВПЗжИааЫШЄЕФЁЃ
ЮЊЪВУДDomain EventШчДЫживЊЃП вђЮЊдкЯждкЕФЗжВМЪНЛЗОГЯТЃЌУЛгавЛИівЕЮёЯЕЭГЪЧИюСбЕФЃЌЖјMessagingОјЖдЪЧЯЕЭГжЎМфёюКЯЖШзюЕЭЃЌзюНЁзГЃЌзюШнвзРЉеЙЕФвЛжжЭЈаХЛњжЦЁЃвђДЫРэТлЩЯЫќЪЧЗжВМЪНЯЕЭГЕФБибЁЯюЁЃ
ЕЋЪЧФПЧАДѓВПЗжЯЕЭГЕФEventЖМЩшМЦЕФКмЫцадЃЌУЛгаЭГвЛЕФжИЕМКЭЙцЗЖЃЌЕМжТEventРФгУКЭЮогУЕФЧщПіЪБгаЗЂЩњЃЌЖјDomain
EventИјЮвУЧвЛИіКмКУЕФЗНЯђЃЌжИв§ЮвУЧИУШчКЮЩшМЦЮвУЧЯЕЭГЕФEventЁЃ
EventУќУћ
Your Domain Event type names should be a statement
of a past occurrence, that is, a verb in the past
tense.
вђЮЊБэЪОЕФЪЧЙ§ШЅЪТМўЃЌЫљвдЭЦМіУќУћЮЊDomain Name + ЖЏДЪЕФЙ§ШЅЪН + EventЁЃетбљБШНЯПЩвдШЗЧаЕФБэДявЕЮёгявхЁЃ
ЯТУцЪЧМИИіОйР§ЃК
1. CustomerCreatedEvent,БэЪОПЭЛЇДДНЈКѓЗЂГіЕФСьгђЪТМўЁЃ
2. OpportunityTransferedEventЃЌБэЪОЛњЛсзЊвЦКѓЗЂГіЕФСьгђЪТМўЁЃ
3. LeadsCreatedEventЃЌБэЪОЯпЫїДДНЈКѓЗЂГіЕФСьгђЪТМўЁЃ
EventФкШн
EventЕФФкШнгаСНжжаЮЪНЃК
EnrichmentЃКвВОЭЪЧдкEventЕФpayloadжаОЁСПЖрЖрЗХdataЃЌетбљconsumerОЭПЩвдздЧЁЃЈAutonomyЃЉЕФДІРэЯћЯЂСЫЁЃ
Query-BackЃКетжжЪЧдкEventжаЭЈЙ§ЛиЕїФУЕНИќЖрЕФdataЃЌетжжаЮЪНЛсМгжиЯЕЭГЕФИКдиЃЌperformanceвВЛсВювЛаЉЁЃ
ЫљвдШчЙћвЊдкEnrichmentКЭQuery-BackжЎМфзібЁдёЕФЛАЃЌЪзЯШЭЦМіЪЙгУEnrichmentЁЃ
Event Sourcing
Event SourcingЪЧдкDomain EventЩЯУцЕФвЛИіРЉеЙЃЌЪЧвЛИіПЩбЁЯюЁЃвВОЭЪЧвЊгавЛИіEvent
StoreБЃДцЫљгаЕФEventsЃЌЦфЪЕШчЙћФуЪЧгУMetaQзїЮЊEventЛњжЦЕФЛАЃЌетаЉEventsЖМЪЧДцДЂдкMetaQЕБжаЕФЃЌжЛЪЧMetaQВЂУЛгаЬсЙЉКмКУЕФEventВщбЏКЭЛиЫнЃЌЫљвдШчЙћОіЖЈЪЙгУEvent
SourcingЕФЛАЃЌзюКУЛЙЪЧздМКЕЅЖРНЈСЂвЛИіEvent StoreЁЃ
ЪЙгУEvent SourcingжївЊгавдЯТКУДІЃЌШчЙћгУВЛЕНЕФЛАЃЌЭъШЋПЩвдВЛгУЃЌЕЋЪЧDomain EventЛЙЪЧЧПСвНЈвщвЊЪЙгУЁЃ
Event SourcingДцДЂСЫЫљгаЗЂЩњдкCore DomainЩЯУцЕФЪТМўЁЃ
ЛљгкетаЉЪТМўЃЌЮвУЧПЩвдзіЯЕЭГЛиЗХЃЌЯЕЭГDebugЃЌвдМАзігУЛЇааЮЊЕФЗжЮіЃЈРрЫЦгкДђЕуЃЉ
Event Storming
ЪТМўЗчБЉЪЧЁЖDDD DistilledЁЗЪщжаЬсГіЕФвЛИівЕЮёЗжЮіЕФЗНЗЈТлЃЌЦфжївЊзїгУЪЧДгDomianЪТМўГіЗЂЃЌРДЗжЮігУЛЇCommandЃЌРДевЕНUbiquitous
LanguangeЃЌРДГщЯѓDomain EntityвдМАBounded ContextЁЃ
ПЩвдКЭUser StoryЕФЗНЗЈТлНсКЯЦ№РДЪЙгУЃЌЦфзюДѓЕФгХЕуЪЧЃЌетжжЗжЮіЗНЪНМДЪЙЪЧnon-techЕФШЫЃЌБШШчВњЦЗЃЌвЕЮёзЈМвЕШвВФмЬ§ЕУЖЎЃЌвВФмВЮгыНјРДЁЃЯрБШНЯвЛЩЯРДОЭЪЙгУUMLЛСьгђФЃаЭЭМЖјбдЁЃ
ОлКЯИљ(Aggreagte)
ОлКЯИљЃЈAggregate RootЃЉЪЧDDDжаЕФвЛИіИХФюЃЌЪЧвЛжжИќДѓЗЖЮЇЕФЗтзАЃЌАбвЛзщгаЯрЭЌЩњУќжмЦкЁЂдквЕЮёЩЯВЛПЩЗжИєЕФЪЕЬхКЭжЕЖдЯѓЗХдквЛЦ№ПМТЧЃЌжЛгаИљЪЕЬхПЩвдЖдЭтБЉТЖв§гУЃЌвВЪЧвЛжжФкОладЕФБэЯжЁЃ
ШЗЖЈОлКЯБпНчвЊТњзуЙЬЖЈЙцдђЃЈInvariantЃЉЃЌЪЧжИдкЪ§ОнБфЛЏЪББиаыБЃГжЕФвЛжТадЙцдђЃЌОпЬхЙцдђШчЯТ
- ИљЪЕЬхОпгаШЋОжБъЪЖЃЌзюжеИКд№МьВщЙцЖЈЙцдђ
- ОлКЯФкЕФЪЕЬхОпгаБОЕиБъЪЖЃЌетаЉБъЪЖдкAggregateФкВПВХЪЧЮЈвЛЕФ
- ЭтВПЖдЯѓВЛФмв§гУГ§ИљEntityжЎЭтЕФШЮКЮФкВПЖдЯѓ
- жЛгаAggregateЕФИљEntityВХФмжБНгЭЈЙ§Ъ§ОнПтВщбЏЛёШЁЃЌЦфЫћЖдЯѓБиаыЭЈЙ§БщРњЙиСЊРДЗЂЯж
- AggegateФкВПЕФЖдЯѓПЩвдБЃГжЖдЦфЫћAggregateИљЕФв§гУ
- AggregateБпНчФкЕФШЮКЮЖдЯѓаоИФЪБЃЌећИіAggregateЕФЫљгаЙЬЖЈЙцдђЖМБиаыТњзу
ЛЙЪЧПДвјааЕФР§згЃЌAccountЃЈеЫКХЃЉЪЧCustomerInfoЃЈПЭЛЇаХЯЂЃЉEntityКЭAddressЃЈжЕЖдЯѓЃЉЕФОлКЯИљЃЌTansactionЃЈНЛвзЃЉЪЧСїЫЎЃЈJournalЃЉЕФОлКЯИљЃЌвђЮЊСїЫЎЪЧвђЮЊНЛвзВХВњЩњЕФЃЌОпгаЯрЭЌЕФЩњУќжмЦкЁЃ
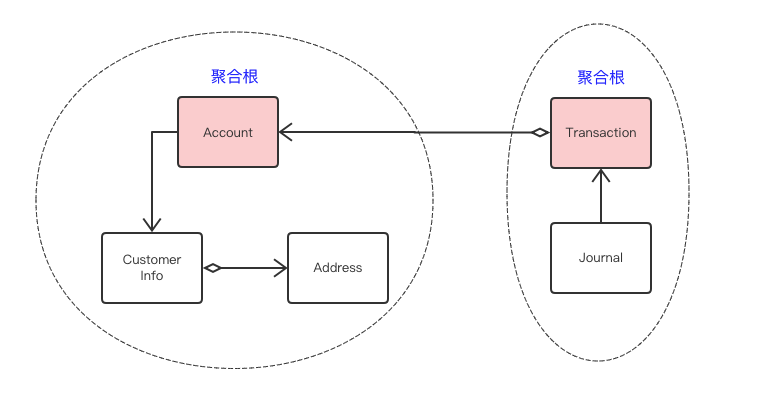
зюКѓЬсабвЛЯТЃЌОлКЯИљЪЧвЛИіТпМИХФюЃЌжїЙладКмЧПЃЌЫљвддкНЈФЃЙ§ГЬжаКмШнвзВњЩњЗжЦчЃЌвђДЫдкШеГЃЙЄзїжаЧЇЭђВЛвЊНЬЬѕЃЌАбЮезЁвЛЬѕжївЊддђЃЌЮвУЧЕФзюжеФПЕФЪЧЮЊСЫвЕЮёгявхЯдЯжЛЏЃЌШчЙћвђЮЊОлКЯИљАбФЃаЭХЊЕФЛоЩЌФбЖЎФЧОЭЕУВЛГЅЪЇСЫ
СьгђЗўЮё(Domain Service)
ЪВУДЪЧСьгђЗўЮё
гааЉСьгђжаЕФЖЏзїЃЌЫќУЧЪЧвЛаЉЖЏДЪЃЌПДЩЯШЅШДВЛЪєгкШЮКЮЖдЯѓЁЃЫќУЧДњБэСЫСьгђжаЕФвЛИіживЊЕФааЮЊЃЌЫљвдВЛФмКіТдЫќУЧЛђепМђЕЅЕиАбЫќУЧКЯВЂЕНФГИіЪЕЬхЛђепжЕЖдЯѓжаЁЃЕБетбљЕФааЮЊДгСьгђжаБЛЪЖБ№ГіРДЪБЃЌзюМбЪЕМљЪЧНЋЫќЩљУїГЩвЛИіЗўЮёЁЃетбљЕФЖдЯѓВЛдйгЕгаФкжУЕФзДЬЌЁЃЫќЕФзїгУНіНіЪЧЮЊСьгђЬсЙЉЯргІЕФЙІФмЁЃServiceЭљЭљЪЧвдвЛИіЛюЖЏРДУќУћЃЌЖјВЛЪЧEntityРДУќУћЁЃР§ШчПЊЦЊзЊеЫЕФР§згЃЌзЊеЫЃЈtransferЃЉетИіааЮЊЪЧвЛИіЗЧГЃживЊЕФСьгђИХФюЃЌЕЋЪЧЫќЪЧЗЂЩњдкСНИіеЫКХжЎМфЕФЃЌЙщЪєгкеЫКХEntityВЂВЛКЯЪЪЃЌвђЮЊвЛИіеЫКХEntityУЛгаБивЊШЅЙиСЊЫћашвЊзЊеЫЕФеЫКХEntityЃЌетжжЧщПіЯТЃЌЪЙгУMoneyTransferDomainServiceОЭБШНЯКЯЪЪСЫЁЃ
ЪЖБ№СьгђЗўЮёЃЌжївЊПДЫќЪЧЗёТњзувдЯТШ§ИіЬиеїЃК
1. ЗўЮёжДааЕФВйзїДњБэСЫвЛИіСьгђИХФюЃЌетИіСьгђИХФюЮоЗЈздШЛЕиСЅЪєгквЛИіЪЕЬхЛђепжЕЖдЯѓЁЃ
2. БЛжДааЕФВйзїЩцМАЕНСьгђжаЕФЦфЫћЕФЖдЯѓЁЃ
3. ВйзїЪЧЮозДЬЌЕФЁЃ
СьгђЗўЮёЯнкх
дкЪЙгУСьгђЗўЮёЪБвЊЬиБ№ЕБаФЃЌвЛИіБШНЯГЃМћЕФДэЮѓЪЧУЛгаХЌСІЮЊааЮЊевЕНвЛИіЪЪЕБЕФЖдЯѓЃЌОЭжБНгГщЯѓГЩСьгђЗўЮёЃЌетЛсЪЙЮвУЧЕФДњТыж№НЅзЊЛЏЮЊЙ§ГЬЪНЕФБрГЬЃЌвЛИіМЋЖЫЕФР§згЪЧАбЫљгаЕФааЮЊЖМЗХЕНСьгђЗўЮёжаЃЌЖјСьгђФЃаЭЭЫЛЏГЩжЛгаЪєадЕФЦЖбЊDOЃЌФЧDDDОЭУЛгаШЮКЮвтвхСЫЁЃЫљвдвЛЖЈвЊЩюШыЫМПМЃЌМШВЛФмУуЧПНЋааЮЊЗХЕНВЛЗћКЯЖдЯѓЖЈвхЕФЖдЯѓжаЃЌЦЦЛЕЖдЯѓЕФФкОладЃЌЪЙЦфгявхБфЕУФЃК§ЁЃвВВЛФмВЛМгЫМПМЕФЖМЗХЕНСьгђЗўЮёжаЃЌДгЖјЭЫЛЏГЩУцЯђЙ§ГЬЕФБрГЬЁЃ
гІгУЗўЮёКЭСьгђЗўЮёШчКЮЛЎЗж
дкСьгђНЈФЃжаЃЌЮвУЧвЛАуНЋЯЕЭГЛЎЗжШ§ИіДѓЕФВуДЮЃЌМДгІгУВуЃЈApplication LayerЃЉЃЌСьгђВуЃЈDomain
LayerЃЉКЭЛљДЁЪЕЪЉВуЃЈInfrastructure LayerЃЉЃЌЙигкетШ§ИіВуДЮЕФЯъЯИФкШнПЩвдВЮПМЮвЕФСэвЛЦЊSOFAПђМмЕФЗжВуЩшМЦЁЃПЩвдПДЕНдкAppВуКЭDomainВуЖМгаЗўЮёЃЈServiceЃЉЃЌетСНИіServiceШчКЮЛЎЗжФиЃЌЪВУДбљЕФЙІФмгІИУЗХдкгІгУВуЃЌЪВУДбљЕФЙІФмгІИУЗХдкСьгђВуФиЃП
ОіЖЈвЛИіЗўЮёЃЈServiceЃЉгІИУЙщЪєгкФФвЛВуЪЧКмРЇФбЕФЁЃШчЙћЫљжДааЕФВйзїИХФюЩЯЪєгкгІгУВуЃЌФЧУДЗўЮёОЭгІИУЗХЕНетИіВуЁЃШчЙћВйзїЪЧЙигкСьгђЖдЯѓЕФЃЌЖјЧвШЗЪЕЪЧгыСьгђгаЙиЕФЁЂЮЊСьгђЕФашвЊЗўЮёЃЌФЧУДЫќОЭгІИУЪєгкСьгђВуЁЃзмЕФРДЫЕЃЌЩцМАЕНживЊСьгђИХФюЕФааЮЊгІИУЗХдкDomainВуЃЌЖјЦфЫќЗЧСьгђТпМЕФММЪѕДњТыЗХдкAppВуЃЌР§ШчВЮЪ§ЕФНтЮіЃЌЩЯЯТЮФЕФзщзАЃЌЕїгУСьгђЗўЮёЃЌЯћЯЂЗЂЫЭЕШЁЃЛЙЪЧвјаазЊеЫЕФcaseЮЊР§ЃЌЯТЭМИјГіСЫЛЎЗжЕФНЈвщЃК

БпНчЩЯЯТЮФ(Bounded Context)
СьгђЪЕЬхЪЧгаБпНчЩЯЯТЮФЕФЃЌБШШчAppleетИіЪЕЬхВЛЭЌЕФЩЯЯТЮФЃЌБэДяЕФКЌвхОЭЭъШЋВЛвЛбљЃЌдкЫЎЙћЕъЫќОЭЪЧЫЎЙћЃЌдкЦЛЙћзЈТєЕъЫќОЭЪЧЪжЛњЁЃ
ЫљвдБпНчЩЯЯТЮФЃЈBounded ContextЃЉдкDDDРяУцЪЧвЛИіЗЧГЃживЊЕФИХФюЃЌBounded ContextУїШЗЕиЯоЖЈСЫФЃаЭЕФгІгУЗЖЮЇЃЌдкContextжаЃЌвЊБЃжЄФЃаЭдкТпМЩЯЭГвЛЃЌЖјВЛгУПМТЧЫќЪЧВЛЪЧЪЪгУгкБпНчжЎЭтЕФЧщПіЁЃдкЦфЫћContextжаЃЌЛсЪЙгУЦфЫћФЃаЭЃЌетаЉФЃаЭОпгаВЛЭЌЕФЪѕгяЁЂИХФюЁЂЙцдђКЭUbiquitous
LanguageЕФааЛАЁЃ
ЩЯЯТЮФгГЩф(Context Mapping)
ФЧУДВЛЭЌContextЯТЕФвЕЮёвЊЛЅЯрЭЈаХдѕУДАьФиЃПетОЭЩцМАПчБпНчЕФContext MappingЃЈЩЯЯТЮФгГЩфЃЉЃЌЪзЯШВЛЭЌЩЯЯТЮФжЎМфЕФЭЈаХПЩвдЪЧЭЌВНЕФЃЌвВПЩвдЪЧвьВНЕФЃЌЭЌВНЕФЛАвЛАуЪЧRPCЛђепRESTFulЃЌвьВНЕФЛАЛсЭЦМіЩЯЮФЬсЕНЕФDomain
Event.
MappingЕФЗНЪНгаКмЖржжЃЌгаShared KernalЃЈЙВЯэФкКЫЃЉЃЌConformistЃЈзЗЫцепЃЉЃЌвдМАAnti-CorruptionЃЈЗРИЏВуЃЉЕШЕШЁЃ
ЮвИіШЫБШНЯЭЦГчDomain Event + ACЃЌетбљПЩвдНЋЯЕЭГжЎМфЕФёюКЯНЕЕНзюЕЭЁЃ
вдЮвУЧецЪЕЕФвЕЮёГЁОАОйИіР§згЃЌБШШчЛсдБетИіИХФюдкICBUЭјеОЪЧжИЭјеОЩЯЕФBuyerЃЌЕЋЪЧдкCRMСьгђЪЧжИCustomerЃЌЫфШЛКмЖрЕФЪєадЖМЪЧвЛбљЕФЃЌЕЋЪЧЖўепдкВЛЭЌЕФContextЯТЦфгявхКЭИХФюЪЧгаВюБ№ЕФЃЌЮвУЧашвЊгУACзівЛЯТзЊЛЛЃК
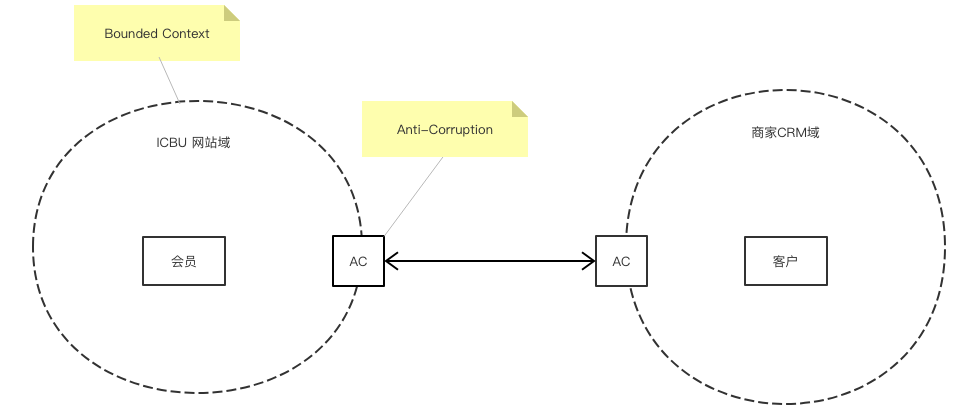
БпНчЩЯЯТЮФКЭЮЂЗўЮё
ЯШРДЫЕвЛЯТЮЂЗўЮёЃЌХзПЊвдDockerЮЊДњБэЕФЕзВуШнЦїЛЏММЪѕВЛПДЃЌЮЂЗўЮёКЭЮвУЧжЎЧАЕФSOAУДгаБОжЪЧјБ№ЁЃ
етВЛЪЧЮввЛИіШЫЕФЙлЕуЃЌЙигкетИіЯыЗЈЮвЛЙзЈУХЧѓжЄСЫвЕНчДѓХЃRandy
ShoupЃЌЮЪЫћЮЂЗўЮёКЭSOAЕФЧјБ№ЃЌЯТУцЪЧЫћИјЮвЕФЛиД№

ФЧУДШчКЮЛЎЗжЯЕЭГЃЌВХФмЕУЕНвЛИіБШНЯКЯЪЪЕФСЃЖШЃЌВЛЛсЬЋДжЃЌвВВЛЛсЬЋЯИФиЁЃДЫЪБЮвУЧПЩвдПМТЧDDDЕФеНТдЩшМЦЃЌМДДгеНТдНЧЖШећЬхУшЪівЕЮёСьгђШЋУВЃЌШЛКѓЭЈЙ§БпНчЩЯЯТЮФНЋВЛЭЌЕФЪЕЬхЙщРрЕНЯрЖдгІЕФгђРяУцЁЃ
БШШчдкCRMСьгђЃЌЮвУЧАДееЯТУцЕФеНТдЩшМЦЭМЃЌЮвЛсздШЛЕФАбCRMЯЕЭГЛЎЗжГЩЯњЪлЗўЮёЃЌзщжЏШЈЯоЗўЮёЃЌгЊЯњЗўЮёЃЌЪлТєЗўЮёЁЃ
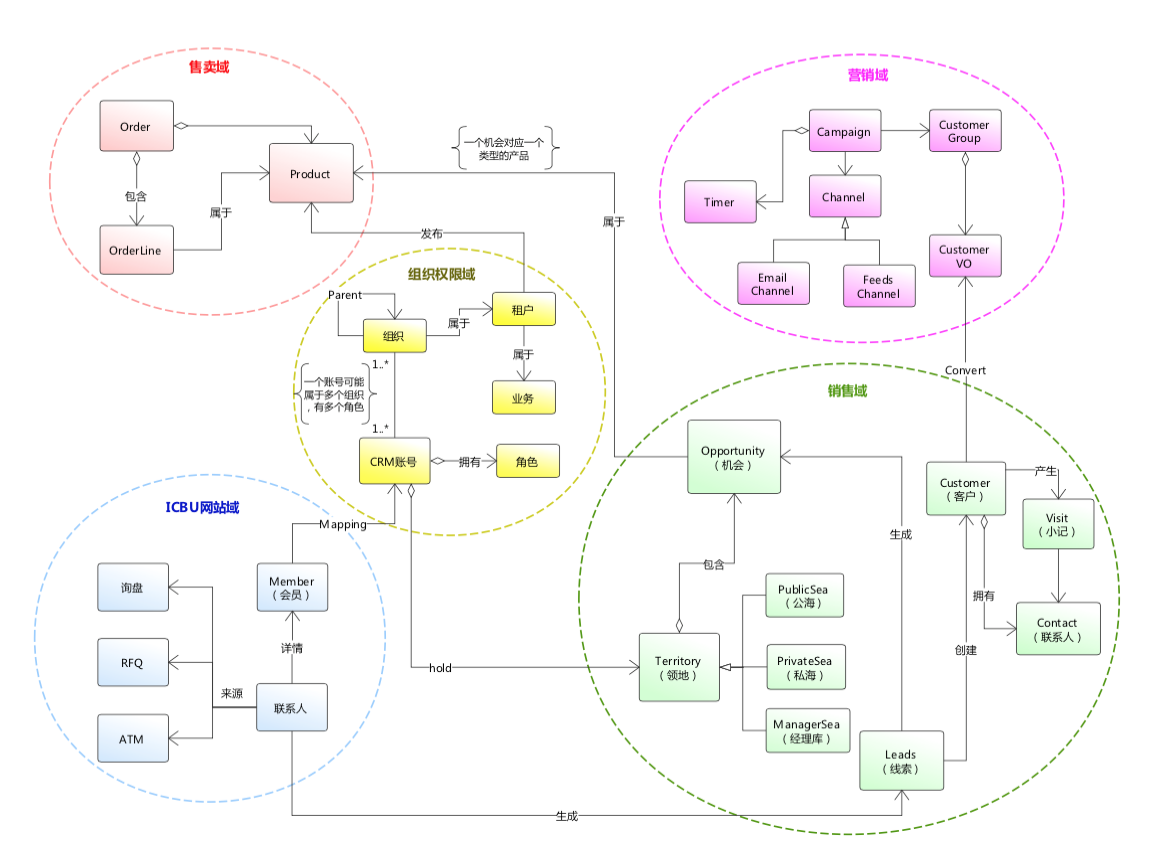
ФЃаЭжиЙЙ
зюКѓЮвЯыЧПЕїЕФЪЧЃЌНЈФЃВЛЪЧвЛДЮадЕФЙЄзїЃЌвВВЛПЩФмЪЧвЛДЮадЕФЙЄзїЃЌвЕЮёдкбнЛЏЃЌЫцжЎЖјРДЕФФЃаЭвВашвЊбнЛЏКЭжиЙЙЃЌЕБФЃаЭКЭвЕЮёВПЦЅХфЕФЪБКђЃЌФуЛЙЪЧвЊАдЭѕгВЩЯЙЕФЭљРяУцШћЃЌЦфНсЙћПЩЯыЖјжЊЁЃ
ФЃаЭЭГвЛ
НЈФЃЕФЙ§ГЬКмЯёУЄШЫУўЯѓЃЌВЛЭЌБГОАШЫгУВЛЭЌЕФЪгНЧПДЭЌвЛИіЖЋЮїЃЌЦфРэНтвВЪЧВЛвЛбљЕФЁЃБШШчСНИіУЄШЫЖМУўЕНДѓЯѓБЧзгЃЌвЛИіШЫШЯЮЊЪЧЯёЩпЃЈЛюЕФФмЖЏЃЉЃЌЖјСэвЛИіШЫШЯЮЊЯёЯћЗРЫЎЙмЃЈПЩвдХчЫЎЃЉЃЌФЧУДЫћУЧНЋКмФбМЏГЩЁЃЫЋЗНЖМЮоЗЈНгЪмЖдЗНЕФФЃаЭЃЌвђЮЊФЧВЛЗћКЯздМКЕФЬхбщЁЃЪТЪЕЩЯЃЌЫћУЧашвЊвЛИіаТЕФГщЯѓЃЌетИіГщЯѓашвЊАбЩпЕФЁАЛюзХЕФЬиадЁБгыЯћЗРЫЎЙмЕФЁАХчЫЎЙІФмЁБКЯВЂЕНвЛЦ№ЃЌЖјетИіГщЯѓЛЙгІИУХХГ§ЯШЧАСНИіФЃаЭжавЛаЉВЛШЗЧаЕФКЌвхКЭЪєадЃЌБШШчЖОбРЃЌЛђепОэЦ№РДЗХЕНЯћЗРГЕЩЯШЅЕФааЮЊЃЌетОЭЪЧФЃаЭЕФЭГвЛЁЃЭГвЛЭъЕФФЃаЭвВаэЛЙВЛНаДѓЯѓБЧзгЃЌЕЋЪЧвбОКмНгНќДѓЯѓБЧзгЕФЪєадКЭЙІФмСЫЃЌЫцзХЮвУЧЖдФЃаЭЖдЯѓЁЂЖдвЕЮёРэНтЕФдНРДдНЩюШыЁЂдНРДдНЭИГЙЃЌЮвУЧЛсВЛЖЯЕФЕїећбнЛЏЮвУЧЕФФЃаЭЃЌЫљвдНЈФЃВЛЪЧвЛИіone-time
offЕФЙЄзїЃЌЖјЪЧвЛИіГжајВЛЖЯбнЛЏжиЙЙЕФЙ§ГЬЁЃ
ФЃаЭбнЛЏ
ЪРНчЩЯЮЈвЛВЛБфЕФОЭЪЧБфЛЏЃЌФЃаЭКЭДњТывЛбљвВашвЊВЛЖЯЕФжиЙЙКЭОЋЛЏЃЌУПвЛДЮЕФОЋЛЏжЎКѓЃЌПЊЗЂШЫдБгІИУЖдСьгђжЊЪЖгаСЫИќМгЧхЮњЕФШЯЪЖЁЃетЪЙЕУРэНтЩЯЕФЭЛЦЦГЩЮЊПЩФмЃЌжЎКѓЃЌвЛЯЕСаПьЫйЕФИФБфЕУЕНСЫИќЗћКЯгУЛЇашвЊВЂИќМгЧаКЯЪЕМЪЕФФЃаЭЁЃЦфЙІФмадМАЫЕУїадМБЫйдіЧПЃЌЖјИДдгадШДЫцжЎЯћЪЇЁЃетжжЭЛЦЦашвЊЮвУЧЖдвЕЮёгаИќМгЩюПЬЕФСьЮђКЭЫМПМЃЌШЛКѓдйМгЩЯжиЙЙЕФгТЦјКЭФмСІЃЌгТЦјЪЧЯюФПЙЄЦкКмНєФуИвВЛИвжиЙЙЃЌФмСІЪЧФугаУЛгаЭъБИЕФCIБЃжЄФуЕФжиЙЙВЛЦЦЛЕЯжгаЕФвЕЮёТпМЁЃ
ЪЕЬхдкбнБф
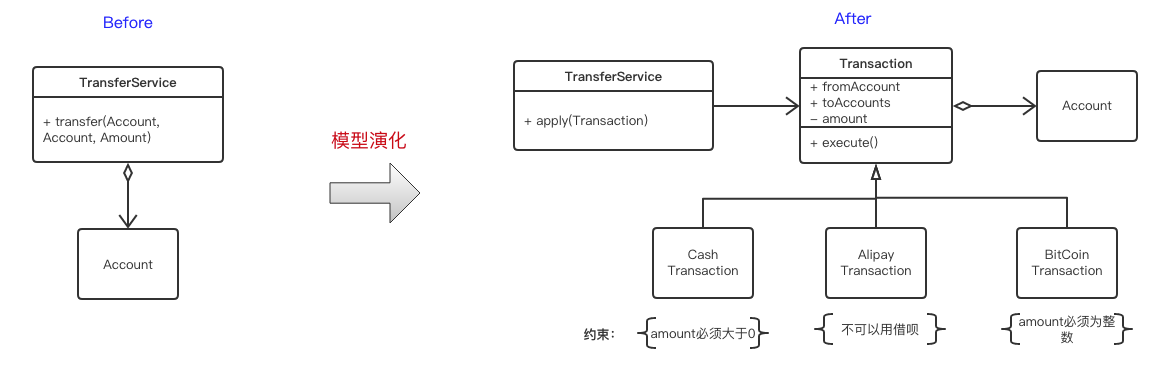
вдПЊЦЊЕФвјааеЫКХЮЊР§ЃЌМйШчвЛПЊЪМеЫКХЖМгаwithdrawЃЈШЁЧЎЃЉЕФааЮЊЃЌДЫЪБжЛашвЊдкAccountЩЯМгЩЯwithdrawЗНЗЈОЭКУСЫЁЃ
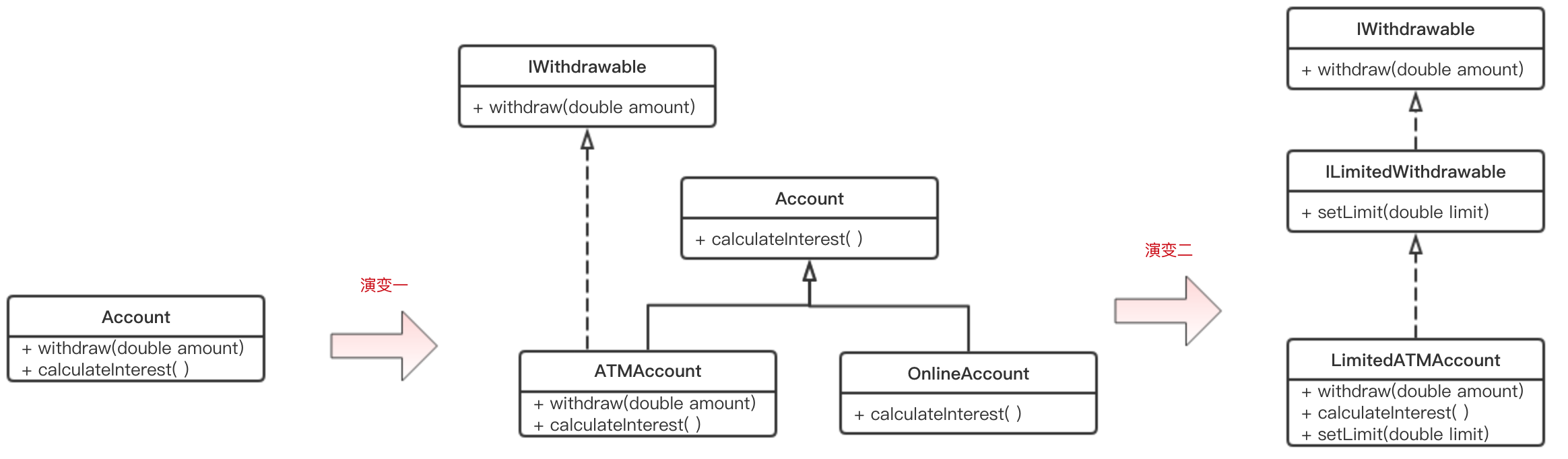
- бнБфвЛЃК
ЫцзХвЕЮёЕФЗЂеЙЃЌЮвУЧашвЊжЇГжATMеЫКХКЭOnlineеЫКХЃЌЖјOnlineеЫКХЪЧВЛФмwithdrawЕФЃЌДЫЪБзюВюЕФзіЗЈЪЧБЃГжФЃаЭВЛБфЃЌЖјЪЧдкwithdrawЗНЗЈжаХаЖЯШчЙћЪЧOnlineAccountдђХзГівьГЃЁЃетжжМђЕЅЕФДњТыЖбЦіПЩвдТњзувЕЮёЙІФмЃЌЕЋЪЧЦфвЕЮёгявхЭъШЋБЛбкИЧЁЃИќКУЕФжиЙЙЗНЗЈгІИУЪЧНЋwithdrawГщГЩвЛИіНгПкIWithdrawableЁЃ
- бнБфЖўЃК
КУЕФЃЌУЛгаЪВУДПЩвдзшЕВвЕЮёЖдБфЛЏЕФЯђЭљЁЃЯждкЙЋЫОГігкАВШЋадЕФПМТЧЃЌЮЊаТПЊЭЈЕФATMAccountЩшжУСЫШЁПюЩЯЯпЃЌГЌЙ§дђВЛФмжЇШЁЁЃМђЕЅзіЗЈЪЧдкIWithdrawableжадйМгШывЛИіsetLimitааЮЊЃЌПЩЪЧЮвУЧВЂВЛЯыИФЖЏгАЯьЕНРЯЕФеЫКХвЕЮёЃЌЫљвдИќКУЕФжиЙЙгІИУЪЧжиаТаДвЛИіILimitedWithdrawableНгПкЃЌШУЦфМЬГаРЯНгПкЃЌетбљРЯЕФДњТыОЭПЩвдБЃГжВЛБфСЫЁЃ
ЭЈЙ§ЩЯУцЕФР§згЃЌЮвУЧПЩвдПДЕНСьгђФЃаЭКЭУцЯђЖдЯѓЪЧвЛЖдТЯЩњажЕмЃЌЮвУЧЛсгУЕНДѓСПЕФOOддђЃЌБШШчЩЯУцЕФжиЙЙОЭгУЕНСЫSOLIDЕФSRPЃЈЕЅвЛжАд№ЃЉКЭOCPЃЈПЊБеддђЃЉЁЃдкЪЕМЪЙЄзїжаЃЌЮвЕФШЗвВгаетбљЕФЬхЛсЃЌздДгМљааDDDвдКѓЃЌЮвУЧВЩгУOOAКЭOODЕФЪБКђБШвдЧАУїЯдЖрСЫКмЖрЃЌOOЕФФмСІвВдкВЛЖЯЕФЬсЩ§ЁЃ
в§ШыаТГщЯѓ
ЛЙЪЧвдПЊЦЊЕФзЊеЫРДОйИіР§згЃЌМйШчзЊеЫвЕЮёПЊЪМБфЕФИДдгЃЌвЊжЇГжЯжН№ЃЌаХгУПЈЃЌжЇИЖБІЃЌБШЬиБвЕШЖржжЭЈЕРЃЌЧвУЛжжЭЈЕРЕФдМЪјВЛвЛбљЃЌЛЙвЊжЇГжвЛЖдЖрЕФзЊеЫЁЃФЧУДФуЛЙЪЧгУвЛИіtransfer(fromAccount,
toAccount)ОЭВЛКЯЪЪСЫЃЌПЩФмашвЊГщЯѓГівЛИізЈУХЕФСьгђЖдЯѓTransactionЃЌетбљВХФмИќКУЕФБэДявЕЮёЃЌЦфбнЛЏЙ§ГЬШчЯТЃК
вЕЮёПЩЪгЛЏКЭПЩХфжУЛЏ
КУЕФСьгђНЈФЃПЩвдНЕЕЭгІгУЕФИДдгадЃЌЖјПЩЪгЛЏКЭПЩХфжУЛЏжївЊЪЧАяжњДѓМвЃЈжївЊЪЧЗЧММЪѕШЫдБЃЌБШШчВњЦЗЃЌвЕЮёКЭПЭЛЇЃЉжБЙлЕиСЫНтЯЕЭГКЭХфжУЯЕЭГЃЌЬсЙЉСЫвЛжжЁАcode
freeЁБЕФНтОіЗНАИЃЌвВЪЧSaaSШэМўЕФжївЊТєЕуЁЃвЊзЂвтЕФЪЧПЩЪгЛЏКЭПЩХфжУЛЏФбУтЛсИјЯЕЭГдіМгЖюЭтЕФИДдгЖШЃЌБиаыЩїжЎгжЩїЃЌзюКУЪЧФмЪЙПЩЪгЛЏКЭХфжУЛЏЕФТпМгывЕЮёТпМОЁСПЩйЕФёюКЯЃЌЗёдђЦЦЛЕСЫдгаЕФМмЙЙЃЌАбЪТЧщИуЕФИќИДдгОЭЕУВЛГЅЪЇСЫЁЃ
дкПЩРЉеЙЩшМЦжаЃЌЮввбОНщЩмСЫЮвУЧSOFAМмЙЙЪЧШчКЮЭЈЙ§РЉеЙЕуЕФЩшМЦРДжЇГХВЛЭЌвЕЮёВювьЛЏЕФашЧѓЕФЃЌФЧУДПЩЗёИќНјвЛВНЃЌЮвУЧНЋСьгђЕФааЮЊЃЈвВНаФмСІЃЉКЭРЉеЙЕугУПЩЪгЛЏЕФЗНЪНГЪЯжГіРДЃЌВЂЖдгквЛаЉВЛашвЊБрТыЪЕЯжЕФРЉеЙЕугУХфжУЕФЗНЪНШЅЭъГЩФиЁЃЕБШЛЪЧПЩвдЕФЃЌБШШчЛЙЪЧПЊЦЊзЊеЫЕФР§згЃЌЖдгкЭИжЇВпТдOverdraftPolicyетИівЕЮёРЉеЙЕуЃЌаТРДвЛИівЕЮёЫЕЭИжЇЖюЖШВЛФмГЌЙ§1000ЃЌЮвУЧПЩвдЭъШЋНсКЯЙцдђв§ЧцНјааХфжУЛЏЭъГЩЃЌЖјВЛашвЊБрТыЁЃ
ЫљвдЮвФмЯыЕНЕФвЛжжЛЙБШНЯгХбХЕФЗНЪНЃЌЪЧЭЈЙ§AnnotationзЂНтЕФЗНЪНЖдСьгђФмСІКЭРЉеЙЕуНјааБъзЂЃЌШЛКѓдкЯЕЭГbootstrapНзЖЮЃЌЭЈЙ§ДњТыЩЈУшЕФЗНЪНЃЌНЋетаЉФмСІЕуКЭРЉеЙЕуЪеМЏЦ№РДЩЯДЋЕНжааФЗўЮёЦїЃЌШЛКѓдйЭЈЙ§GUIЕФЗНЪНГЪЯжГіРДЃЌДгЖјзіЕНвЕЮёЕФПЩЪгЛЏКЭПЩХфжУЛЏЁЃДѓИХЕФЪОвтЭМШчЯТЃК
гаЭЌбЇПЩФмЛсЮЪСїГЬвЊВЛвЊПЩЪгЛЏЃЌетРявЊЗжЧхГўСНИіИХФюЃЌвЕЮёТпМСїКЭЙЄзїСїЃЌКмЖрЭЌбЇЛьЯ§СЫетСНИіИХФюЁЃвЕЮёТпМСїЪЧЯьгІвЛДЮгУЛЇЧыЧѓЕФвЕЮёДІРэЙ§ГЬЃЌЦфБОЩэОЭЪЧвЕЮёТпМЃЌЖдЦфБрХХКЭПЩЪгЛЏЕФвтвхВЂВЛЪЧКмДѓЃЌЮоЭтКѕжЛЪЧАбДњТыТпМПЩЪгЛЏСЫЃЌдкЮвУЧЕФSOFAПђМмжаЃЌЪЧЭЈЙ§РЉеЙЕуКЭВпТдФЃЪНРДДІРэвЕЮёЕФЗжжЇЧщПіЃЌЖјЮвПДЕНЮвУЧАЂРяКмЖрЕФФкВПЯЕЭГНЋетжжЯьгІвЛДЮгУЛЇЧыЧѓЕФвЕЮёТпМгУКмжиЕФЙЄзїСїв§ЧцРДзіЃЌУРЦфУћдЛСїГЬПЩБрХХЃЌЪЕжЪЩЯЭљЭљЪЧАбМђЕЅЕФЪТЧщИДдгЛЏСЫЁЃЖјЙЄзїСїЪЧжИЭъГЩвЛЯюШЮЮёЫљашвЊВЛЭЌНкЕуЕФСЌНгЃЌНкЕужївЊЗжЮЊздЖЏНкЕуКЭШЫЙЄНкЕуЃЌЦфжаУПИіШЫЙЄНкЕуЖМашвЊгУЛЇЕФВЮгыЃЌвВОЭЪЧЯьгІвЛДЮгУЛЇЕФЧыЧѓЃЌБШШчЩѓХњСїГЬжаЕФОРэЩѓХњНкЕуЃЌCRMЯњЪлЙ§ГЬЕФвЕЮёдБЕФДІРэНкЕуЕШЕШЁЃДЫЪБПЩвдПМТЧЪЙгУЙЄзїСїв§ЧцЃЌЬиБ№ЪЧЕБФуЕФЯЕЭГашвЊШУгУЛЇздЖЈвхСїГЬЕФЪБКђЃЌФЧОЭВЛЕУВЛЪЙгУПЩЪгЛЏКЭПЩХфжУЕФЙЄзїСїв§ЧцСЫЃЌГ§ДЫжЎЭтЃЌзюКУВЛвЊздевТщЗГЁЃЮвдјдквјааЙЄзїЙ§ЃЌЧзблПДМћЙ§IBMЪЧдѕУДКігЦвјааЪЙгУЫќУЧЕФBPMЯЕЭГЃЌШЛКѓАбЯЕЭГХЊЕФОоИДдгЮоБШЃЌЫљвдЮвЖдЙЄзїСїв§ЧцЕФгЁЯѓВЂВЛКУЃЌЕБШЛвВВЛХХГ§гагУЕФЬиБ№КЯЪЪЕФАИР§ЃЌжЛЪЧЮвЛЙУЛПДМћЃЌШчЙћгаПДМћЕФЭЌбЇТщЗГИцЫпЮввЛЩљЃЌбЇЯАвЛЯТЁЃвђЮЊЮвУЧЯждкЛЙУЛгаШУгУЛЇздЖЈвхСїГЬЕФЫпЧѓЃЌЫљвдЪЙгУЙЄзїСїв§ЧцВЂВЛдкЮвУЧЯжНзЖЮЕФПМТЧЗЖЮЇжЎФкЁЃ |









