| ±ύΦ≠ΆΤΦω: |
±ΨΈΡά¥Ή‘cnblogsΘ§Ϋι…ήΝΥΩΣΖΔ÷–”ωΒΫ¥ΪΆ≥––“Β»μΦΰΟφΝΌΒΡΈ ΧβΘ§»ΜΚσ‘Ό≥Δ ‘‘Ύ ΒΦυ÷–”ΟDDDΒΡΥΦœκά¥ΫβΨω’β–©Έ ΧβΓΘ
|
|
«Α―‘
÷Ν…Ό30Ρξ“‘«ΑΘ§“Μ–©»μΦΰ…ηΦΤ»Υ‘±ΨΆ“―Ψ≠“β ΕΒΫΝλ”ρΫ®ΡΘΚΆ…ηΦΤΒΡ÷Ί“Σ–‘Θ§≤Δ–Έ≥…“Μ÷÷ΥΦ≥±Θ§Eric
EvansΫΪΤδΕ®“εΈΣΝλ”ρ«ΐΕ·…ηΦΤΘ®Domain-Driven DesignΘ§Φρ≥ΤDDDΘ©ΓΘ‘ΎΜΞΝΣΆχΩΣΖΔΓΑ–Γ≤ΫΩλ≈ήΘ§Βϋ¥ζ ‘¥μΓ±ΒΡ¥σΜΖΨ≥œ¬Θ§DDDΥΤΚθ «“Μ÷÷±»ΫœΓΑΙ≈άœΕχΜΚ¬ΐΓ±ΒΡΥΦœκΓΘ»ΜΕχΘ§”…”ΎΜΞΝΣΆχΙΪΥΨ“≤÷πΫΞ…ν»κ ΒΧεΨ≠ΦΟΘ§“ΒΈώ»’“φΗ¥‘”Θ§Έ“Ο«‘ΎΩΣΖΔ÷–“≤‘Ϋά¥‘ΫΕύΒΊ”ωΒΫ¥ΪΆ≥––“Β»μΦΰΩΣΖΔ÷–ΥυΟφΝΌΒΡΈ ΧβΓΘ±ΨΈΡΨΆœ»ά¥Ϋ≤“Μœ¬’β–©Έ ΧβΘ§»ΜΚσ‘Ό≥Δ ‘‘Ύ ΒΦυ÷–”ΟDDDΒΡΥΦœκά¥ΫβΨω’β–©Έ ΧβΓΘ
Έ Χβ
ΙΐΕ»ώνΚœ
“ΒΈώ≥θΤΎΘ§Έ“Ο«ΒΡΙΠΡή¥σΕΦΖ«≥ΘΦρΒΞΘ§Τ’Ά®ΒΡCRUDΨΆΡή¬ζΉψΘ§¥Υ ±œΒΆ≥ ««εΈζΒΡΓΘΥφΉ≈Βϋ¥ζΒΡ≤ΜΕœ―ίΜ·Θ§“ΒΈώ¬ΏΦ≠±δΒΟ‘Ϋά¥‘ΫΗ¥‘”Θ§Έ“Ο«ΒΡœΒΆ≥“≤‘Ϋά¥‘Ϋ»Ώ‘”ΓΘΡΘΩι±Υ¥ΥΙΊΝΣΘ§Υ≠ΕΦΚήΡ―ΥΒ«εΡΘΩιΒΡΨΏΧεΙΠΡή“βΆΦ «…ΕΓΘ–όΗΡ“ΜΗωΙΠΡή ±Θ§ΆυΆυΙβΜΊΥίΗΟΙΠΡή–η“ΣΒΡ–όΗΡΒψΨΆ–η“ΣΚή≥Λ ±ΦδΘ§Ηϋ±πΧα–όΗΡ¥χά¥ΒΡ≤ΜΩ…‘Λ÷ΣΒΡ”ΑœλΟφΓΘ
œ¬ΆΦ «“ΜΗω≥ΘΦϊΒΡœΒΆ≥ώνΚœ≤ΓάΐΓΘ
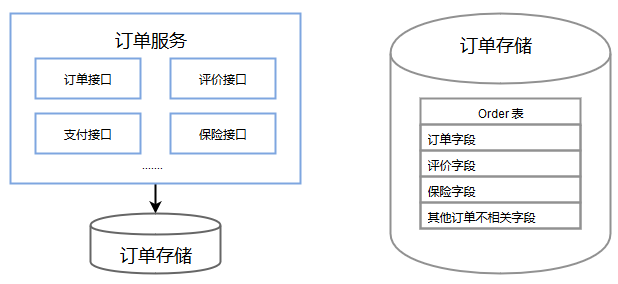
Ε©ΒΞΖΰΈώΫ”ΩΎ÷–ΧαΙ©ΝΥ≤ι―·ΓΔ¥¥Ϋ®Ε©ΒΞœύΙΊΒΡΫ”ΩΎΘ§“≤ΧαΙ©ΝΥΕ©ΒΞΤάΦέΓΔ÷ßΗΕΓΔ±Θœ’ΒΡΫ”ΩΎΓΘΆ§ ±Έ“Ο«ΒΡ±μ“≤ «“ΜΗωΕ©ΒΞ¥σ±μΘ§ΑϋΚ§ΝΥΖ«≥ΘΕύΉ÷ΕΈΓΘ‘ΎΈ“Ο«Έ§ΜΛ¥ζ¬κ ±Θ§«Θ“ΜΖΔΕχΕ·»Ϊ…μΘ§ΚήΩ…Ρή÷Μ «œκΗΡœ¬ΤάΦέœύΙΊΒΡΙΠΡήΘ§»¥”ΑœλΒΫΝΥ¥¥ΒΞΚΥ–Ρ¬ΖΨΕΓΘΥδ»ΜΈ“Ο«Ω…“‘Ά®Ιΐ≤β ‘±Θ÷ΛΙΠΡήΆξ±Η–‘Θ§ΒΪΒ±Έ“Ο«‘ΎΕ©ΒΞΝλ”ρ”–¥σΝΩ–η«σΆ§ ±≤Δ––ΩΣΖΔ ±Θ§ΗΡΕ·÷ΊΒΰΓΔΕώ–‘―≠ΜΖΓΔΤΘ”Ύ±ΦΟϋ–όΗΡΗς÷÷Έ ΧβΓΘ
…œ ωΈ ΧβΘ§ΙιΗυΒΫΒΉ‘Ύ”ΎœΒΆ≥ΦήΙΙ≤Μ«εΈζΘ§Μ°Ζ÷≥ωά¥ΒΡΡΘΩιΡΎΨέΕ»ΒΆΓΔΗΏώνΚœΓΘ
”–“Μ÷÷ΫβΨωΖΫΑΗΘ§Α¥’’―ίΫχ Ϋ…ηΦΤΒΡάμ¬έΘ§»ΟœΒΆ≥ΒΡ…ηΦΤΥφΉ≈œΒΆ≥ Βœ÷ΒΡ‘ω≥ΛΕχ‘ω≥ΛΓΘΈ“Ο«≤Μ–η“ΣΉςΧα«Α…ηΦΤΘ§ΨΆ»ΟœΒΆ≥ΑιΥφ“ΒΈώ≥…≥ΛΕχ―ίΫχΓΘ’βΒ±»Μ «Ω…––ΒΡΘ§ΟτΫί ΒΦυ÷–ΒΡ÷ΊΙΙΓΔ≤β ‘«ΐΕ·…ηΦΤΦΑ≥÷–χΦ·≥…Ω…“‘Ε‘ΗΕΗς÷÷Μ묓Έ ΧβΓΘ÷ΊΙΙΓΣΓΣ±Θ≥÷––ΈΣ≤Μ±δΒΡ¥ζ¬κΗΡ…Τ«ε≥ΐΝΥ≤Μ–≠ΒςΒΡΨ÷≤Ω…ηΦΤΘ§≤β ‘«ΐΕ·…ηΦΤ»Ζ±ΘΕ‘œΒΆ≥ΒΡΗϋΗΡ≤ΜΜαΒΦ÷¬œΒΆ≥ΕΣ ßΜρΤΤΜΒœ÷”–ΙΠΡήΘ§≥÷–χΦ·≥…‘ρΈΣΆ≈Ε”ΧαΙ©ΝΥΆ§“Μ¥ζ¬κΩβΓΘ
‘Ύ’β»ΐ÷÷ ΒΦυ÷–Θ§÷ΊΙΙ «ΩΥΖΰ―ίΫχ Ϋ…ηΦΤ÷–¥σ‘”ΜβΈ ΧβΒΡ÷ςΝΠΘ§Ά®Ιΐ‘ΎΒΞΕάΒΡάύΦΑΖΫΖ®ΦΕ±π…œΉω“ΜœΒΝ––Γ≤Ϋ÷ΊΙΙά¥Άξ≥…ΓΘΈ“Ο«Ω…“‘Κή»ί“Ή÷ΊΙΙ≥ω“ΜΗωΕάΝΔΒΡάύά¥Ζ≈Ρ≥–©Ά®”ΟΒΡ¬ΏΦ≠Θ§ΒΪ «ΡψΜαΖΔœ÷ΡψΚήΡ―ΗχΥϋ“ΜΗω“ΒΈώ…œΒΡΚ§“εΘ§÷ΜΡήΗχ”η“ΜΗωΦΦ θΈ§Ε»ΟηΜφΒΡΚ§“εΓΘ’βΜα¥χά¥ ≤Ο¥Έ ΧβΡΊΘΩ–¬Ά§―ß≤Δ≤ΜΉή «÷ΣΒάΕ‘Ά®”Ο¬ΏΦ≠ΒΡΗΡΕ·ΜρΜώ»Γά¥Ή‘ΗΟάύΓΘœ‘»ΜΘ§÷ΤΕ®œνΡΩΙφΖΕ≤Δ≤Μ «ΚΟΒΡideaΓΘΈ“Ο«”÷Έ≈ΒΫΝΥ¥ζ¬κΦ¥ΫΪΗ·ΑήΒΡΈΕΒάΓΘ
¬ Β…œΘ§ΡψΩ…Ρή“β ΕΒΫΈ Χβ÷°Υυ‘ΎΓΘ‘ΎΫβΨωœ÷ ΒΈ Χβ ±Θ§Έ“Ο«ΜαΫΪΈ Χβ”≥…δΒΫΡ‘ΚΘ÷–ΒΡΗ≈ΡνΡΘ–ΆΘ§‘ΎΡΘ–Ά÷–ΫβΨωΈ ΧβΘ§‘ΌΫΪΫβΨωΖΫΑΗΉΣΜΜΈΣ ΒΦ ΒΡ¥ζ¬κΓΘ…œ ωΈ Χβ‘Ύ”ΎΈ“Ο«ΫβΨωΝΥ…ηΦΤΒΫ¥ζ¬κ÷°ΦδΒΡ÷ΊΙΙΘ§ΒΪΧαΝΕ≥ωά¥ΒΡ…ηΦΤΡΘ–ΆΘ§≤Δ≤ΜΨΏ”– ΒΦ ΒΡ“ΒΈώΚ§“εΘ§’βΨΆΒΦ÷¬‘ΎΩΣΖΔ–¬–η«σ ±Θ§ΤδΥϊΆ§―ß≤Δ≤ΜΡήΚήΉ‘»ΜΒΊΫΪ“ΒΈώΈ Χβ”≥…δΒΫΗΟ…ηΦΤΡΘ–ΆΓΘ…ηΦΤΥΤΚθ±δ≥…ΝΥ÷ΊΙΙ’ΏΒΡΉ‘”ιΉ‘ά÷Θ§¥ζ¬κΦΧ–χΗ·ΑήΘ§÷Ί–¬÷ΊΙΙΓ≠Γ≠Έό–ί÷ΙΒΡ―≠ΜΖΓΘ
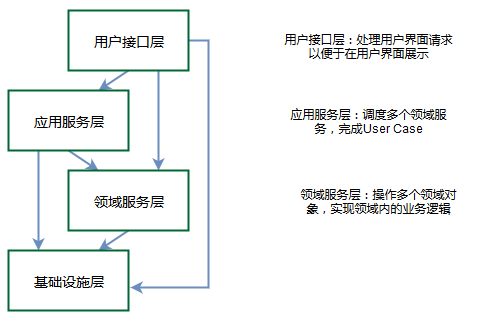
”ΟDDD‘ρΩ…“‘ΚήΚΟΒΊΫβΨωΝλ”ρΡΘ–ΆΒΫ…ηΦΤΡΘ–ΆΒΡΆ§≤ΫΓΔ―ίΜ·Θ§ΉνΚσ‘ΌΫΪΖ¥”≥ΝΥΝλ”ρΒΡ…ηΦΤΡΘ–ΆΉΣΈΣ ΒΦ ΒΡ¥ζ¬κΓΘ
ΉΔΘΚΡΘ–Ά «Έ“Ο«ΫβΨω ΒΦ Έ ΧβΥυ≥ιœσ≥ωά¥ΒΡΗ≈ΡνΡΘ–ΆΘ§Νλ”ρΡΘ–Ά‘ρ±μ¥ο”κ“ΒΈώœύΙΊΒΡ ¬ ΒΘΜ…ηΦΤΡΘ–Ά‘ρΟη ωΝΥΥυ“ΣΙΙΫ®ΒΡœΒΆ≥ΓΘ
ΤΕ―Σ÷ΔΚΆ ß“δ÷Δ
ΤΕ―ΣΝλ”ρΕ‘œσ
ΤΕ―ΣΝλ”ρΕ‘œσΘ®Anemic Domain ObjectΘ© «÷ΗΫω”ΟΉς ΐΨί‘ΊΧεΘ§ΕχΟΜ”–––ΈΣΚΆΕ·ΉςΒΡΝλ”ρΕ‘œσΓΘ
‘ΎΈ“Ο«œΑΙΏΝΥJ2EEΒΡΩΣΖΔΡΘ ΫΚσΘ§Action/Service/DAO’β÷÷Ζ÷≤ψΡΘ ΫΘ§ΜαΚήΉ‘»ΜΒΊ–¥≥ωΙΐ≥Χ Ϋ¥ζ¬κΘ§Εχ―ßΒΫΒΡΚήΕύΙΊ”ΎOOάμ¬έΒΡ“≤ΚΝΈό”ΟΈδ÷°ΒΊΓΘ Ι”Ο’β÷÷ΩΣΖΔΖΫ ΫΘ§Ε‘œσ÷Μ « ΐΨίΒΡ‘ΊΧεΘ§ΟΜ”–––ΈΣΓΘ“‘ ΐΨίΈΣ÷––ΡΘ§“‘ ΐΨίΩβER…ηΦΤΉς«ΐΕ·ΓΘΖ÷≤ψΦήΙΙ‘Ύ’β÷÷ΩΣΖΔΡΘ Ϋœ¬Θ§Ω…“‘άμΫβΈΣ «Ε‘ ΐΨί“ΤΕ·ΓΔ¥ΠάμΚΆ Βœ÷ΒΡΙΐ≥ΧΓΘ
“‘± ’ΏΉνΫϋΩΣΖΔΒΡœΒΆ≥≥ιΫ±ΤΫΧ®ΈΣάΐΘΚ
≥ΓΨΑ–η«σ
Ϋ±≥Ίάο≈δ÷ΟΝΥΚήΕύΫ±œνΘ§Έ“Ο«–η“ΣΑ¥‘Υ”Σ‘Λœ»≈δ÷ΟΒΡΗ≈¬ ≥ι÷–“ΜΗωΫ±œνΓΘ
Βœ÷Ζ«≥ΘΦρΒΞΘ§…ζ≥…“ΜΗωΥφΜζ ΐΘ§ΤΞ≈δΖϊΚœΗΟΥφΜζ ΐ…ζ≥…Η≈¬ ΒΡΫ±œνΦ¥Ω…ΓΘ
ΤΕ―ΣΡΘ–Ά Βœ÷ΖΫΑΗ
œ»…ηΦΤΫ±≥ΊΚΆΫ±œνΒΡΩβ±μ≈δ÷ΟΓΘ
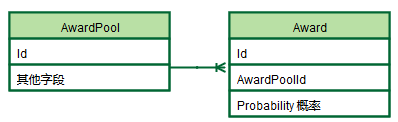
…ηΦΤAwardPoolΚΆAwardΝΫΗωΕ‘œσΘ§÷Μ”–ΦρΒΞΒΡgetΚΆset τ–‘ΒΡΖΫΖ®
class AwardPool
{
int awardPoolId;
List<Award> awards;
public List <Award> getAwards() {
return awards;
}
public void setAwards (List<Award> awards)
{
this.awards = awards;
}
......
}
class Award {
int awardId;
int probability;//Η≈¬
......
}
|
Service¥ζ¬κ Βœ÷
…ηΦΤ“ΜΗωLotteryServiceΘ§‘ΎΤδ÷–ΒΡdrawLottery()ΖΫΖ®–¥ΖΰΈώ¬ΏΦ≠
AwardPool awardPool
= awardPoolDao .getAwardPool (poolId); //sql≤ι―·Θ§ΫΪ ΐΨί”≥…δΒΫAwardPoolΕ‘œσ
for (Award award : awardPool.getAwards()) {
// ―Α’“ΒΫΖϊΚœaward.getProbability( )Η≈¬ ΒΡ award
} |
Α¥’’Έ“Ο«Ά®≥ΘΥΦ¬Ζ Βœ÷Θ§Ω…“‘ΖΔœ÷ΘΚ‘Ύ“ΒΈώΝλ”ράοΖ«≥Θ÷Ί“ΣΒΡ≥ιΫ±Θ§Έ“ΒΡ“ΒΈώ¬ΏΦ≠ΕΦ «–¥‘ΎService÷–ΒΡΘ§Award≥δΤδΝΩ÷Μ «Ηω ΐΨί‘ΊΧεΘ§ΟΜ”–»ΈΚΈ––ΈΣΓΘΦρΒΞΒΡ“ΒΈώœΒΆ≥≤…”Ο’β÷÷ΤΕ―ΣΡΘ–ΆΚΆΙΐ≥ΧΜ·…ηΦΤ «ΟΜ”–Έ ΧβΒΡΘ§ΒΪ‘Ύ“ΒΈώ¬ΏΦ≠Η¥‘”ΝΥΘ§“ΒΈώ¬ΏΦ≠ΓΔΉ¥Χ§Μα…Δ¬δΒΫ‘Ύ¥σΝΩΖΫΖ®÷–Θ§‘≠±ΨΒΡ¥ζ¬κ“βΆΦΜαΫΞΫΞ≤ΜΟς»ΖΘ§Έ“Ο«ΫΪ’β÷÷«ιΩω≥ΤΈΣ”…ΤΕ―Σ÷Δ“ΐΤπΒΡ ß“δ÷ΔΓΘ
ΗϋΚΟΒΡ «≤…”ΟΝλ”ρΡΘ–ΆΒΡΩΣΖΔΖΫ ΫΘ§ΫΪ ΐΨίΚΆ––ΈΣΖβΉΑ‘Ύ“ΜΤπΘ§≤Δ”κœ÷ Β άΫγ÷–ΒΡ“ΒΈώΕ‘œσœύ”≥…δΓΘΗςάύΨΏ±ΗΟς»ΖΒΡ÷Α‘πΜ°Ζ÷Θ§ΫΪΝλ”ρ¬ΏΦ≠Ζ÷…ΔΒΫΝλ”ρΕ‘œσ÷–ΓΘΦΧ–χΨΌΈ“Ο«…œ ω≥ιΫ±ΒΡάΐΉ”Θ§ Ι”ΟΗ≈¬ ―Γ‘ώΕ‘”ΠΒΡΫ±ΤΖΨΆ”ΠΒ±Ζ≈ΒΫAwardPoolάύ÷–ΓΘ
ΈΣ ≤Ο¥―Γ‘ώDDD
»μΦΰœΒΆ≥Η¥‘”–‘”ΠΕ‘
ΫβΨωΗ¥‘”ΚΆ¥σΙφΡΘ»μΦΰΒΡΈδΤςΩ…“‘±Μ¥÷¬‘ΒΊΙιΈΣ»ΐάύΘΚ≥ιœσΓΔΖ÷÷ΈΚΆ÷Σ ΕΓΘ
Ζ÷÷Έ Α―Έ ΧβΩ’ΦδΖ÷ΗνΈΣΙφΡΘΗϋ–Γ«““Ή”Ύ¥ΠάμΒΡ»τΗ…Ή”Έ ΧβΓΘΖ÷ΗνΚσΒΡΈ Χβ–η“ΣΉψΙΜ–ΓΘ§“‘±ψ“ΜΗω»ΥΒΞ«ΙΤΞ¬μΨΆΡήΙΜΫβΨωΥϊΟ«ΘΜΤδ¥ΈΘ§±Ί–κΩΦ¬«»γΚΈΫΪΖ÷ΗνΚσΒΡΗςΗω≤ΩΖ÷ΉΑ≈δΈΣ’ϊΧεΓΘΖ÷ΗνΒΟ‘ΫΚœάμ‘Ϋ“Ή”ΎάμΫβΘ§‘ΎΉΑ≈δ≥…’ϊΧε ±Θ§Υυ–ηΗζΉΌΒΡœΗΫΎ“≤ΨΆ‘Ϋ…ΌΓΘΦ¥Ηϋ»ί“Ή…ηΦΤΗς≤ΩΖ÷ΒΡ–≠ΉςΖΫ ΫΓΘΤά≈– ≤Ο¥ «Ζ÷÷ΈΒΟΚΟΘ§Φ¥ΗΏΡΎΨέΒΆώνΚœΓΘ
≥ιœσ Ι”Ο≥ιœσΡήΙΜΨΪΦρΈ ΧβΩ’ΦδΘ§Εχ«“Έ Χβ‘Ϋ–Γ‘Ϋ»ί“ΉάμΫβΓΘΨΌΗωάΐΉ”Θ§¥”±±Ψ©ΒΫ…œΚΘ≥ω≤νΘ§Ω…“‘œ»άμΫβΈΣ Ι”ΟΫΜΆ®ΙΛΨΏ«ΑΆυΘ§ΒΪ≤Μ–η“Σ“ΜΩΣ ΦΨΆœκ«ε≥ΰΒΫΒΉ «ΗΏΧζΜΙ «Ζ…ΜζΘ§“‘ΦΑ≥ΥΉχΥϋΟ«–η“ΣΉΔ“β ≤Ο¥ΓΘ
÷Σ Ε ΙΥΟϊΥΦ“εΘ§DDDΩ…“‘»œΈΣ «÷Σ ΕΒΡ“Μ÷÷ΓΘ
DDDΧαΙ©ΝΥ’β―υΒΡ÷Σ Ε ÷ΕΈΘ§»ΟΈ“Ο«÷ΣΒά»γΚΈ≥ιœσ≥ωœόΫγ…œœ¬ΈΡ“‘ΦΑ»γΚΈ»ΞΖ÷÷ΈΓΘ
”κΈΔΖΰΈώΦήΙΙœύΒΟ“φ’Ο
ΈΔΖΰΈώΦήΙΙ÷ΎΥυ÷ή÷ΣΘ§¥Υ¥Π≤ΜΉωΉΗ ωΓΘΈ“Ο«¥¥Ϋ®ΈΔΖΰΈώ ±Θ§–η“Σ¥¥Ϋ®“ΜΗωΗΏΡΎΨέΓΔΒΆώνΚœΒΡΈΔΖΰΈώΓΘΕχDDD÷–ΒΡœόΫγ…œœ¬ΈΡ‘ρΆξΟάΤΞ≈δΈΔΖΰΈώ“Σ«σΘ§Ω…“‘ΫΪΗΟœόΫγ…œœ¬ΈΡάμΫβΈΣ“ΜΗωΈΔΖΰΈώΫχ≥ΧΓΘ
…œ ω «¥”Ηϋ÷±ΙέΒΡΫ«Ε»ά¥Οη ωΝΫ’ΏΒΡœύΥΤ¥ΠΓΘ
‘ΎœΒΆ≥Η¥‘”÷°ΚσΘ§Έ“Ο«ΕΦ–η“Σ”ΟΖ÷÷Έά¥≤πΫβΈ ΧβΓΘ“ΜΑψ”–ΝΫ÷÷ΖΫ ΫΘ§ΦΦ θΈ§Ε»ΚΆ“ΒΈώΈ§Ε»ΓΘΦΦ θΈ§Ε» «άύΥΤMVC’β―υΘ§“ΒΈώΈ§Ε»‘ρ «÷ΗΑ¥“ΒΈώΝλ”ρά¥Μ°Ζ÷œΒΆ≥ΓΘ
ΈΔΖΰΈώΦήΙΙΗϋ«ΩΒς¥”“ΒΈώΈ§Ε»»ΞΉωΖ÷÷Έά¥”ΠΕ‘œΒΆ≥Η¥‘”Ε»Θ§ΕχDDD“≤ «Ά§―υΒΡΉ≈÷Ί“ΒΈώ ”Ϋ«ΓΘ
»γΙϊΝΫ’Ώ‘ΎΉΖ«σΒΡΡΩ±ξΘ®“ΒΈώΈ§Ε»Θ©¥οΒΫΝΥ…œœ¬ΈΡΒΡΆ≥“ΜΘ§Ρ«Ο¥‘ΎΨΏΧεΉωΖ®…œ”– ≤Ο¥ΝΣœΒΚΆ≤ΜΆ§ΡΊΘΩ
Έ“Ο«ΫΪΦήΙΙ…ηΦΤΜνΕ·ΨΪΦρΈΣ“‘œ¬»ΐΗω≤ψΟφΘΚ
“ΒΈώΦήΙΙΓΣΓΣΗυΨί“ΒΈώ–η«σ…ηΦΤ“ΒΈώΡΘΩιΦΑΤδΙΊœΒ
œΒΆ≥ΦήΙΙΓΣΓΣ…ηΦΤœΒΆ≥ΚΆΉ”œΒΆ≥ΒΡΡΘΩι
ΦΦ θΦήΙΙΓΣΓΣΨωΕ®≤…”ΟΒΡΦΦ θΦΑΩρΦή
“‘…œ»ΐ÷÷ΜνΕ·‘Ύ ΒΦ ΩΣΖΔ÷– «”–œ»ΚσΥ≥–ρΒΡΘ§ΒΪ≤Μ“ΜΕ® κœ» κΚσΓΘ‘ΎΈ“Ο«ΫβΨω≥ΘΙφΧΉ¬ΖΈ Χβ ±Θ§Έ“Ο«ΜαΚήΉ‘»ΜΒΊΆυ λœΛΒΡΖ÷≤ψΦήΙΙΧΉΘ®œ»»ΖΕ®œΒΆ≥ΦήΙΙΘ©Θ§Μρ’Ώ”ΟPHPΩΣΖΔΚήΩλΘ®œ»»ΖΕ®ΦΦ θΦήΙΙΘ©Θ§‘Ύ“ΒΈώ≤ΜΗ¥‘” ±Θ§’β―υ «ΚœάμΒΡΓΘ
ΧχΙΐ“ΒΈώΦήΙΙ…ηΦΤ≥ωά¥ΒΡΦήΙΙΙΊΉΔΒψ≤Μ‘Ύ“ΒΈώœλ”Π…œΘ§Ω…ΡήΨΆ «Ηω¥σΡύ«ρΘ§‘ΎΟφΝΌ–η«σΒϋ¥ζΜρœλ”Π –≥Γ±δΜ· ±ΨΆΚήΆ¥ΩύΓΘ
DDDΒΡΚΥ–ΡΥΏ«σΨΆ «ΫΪ“ΒΈώΦήΙΙ”≥…δΒΫœΒΆ≥ΦήΙΙ…œΘ§‘Ύœλ”Π“ΒΈώ±δΜ·Βς’ϊ“ΒΈώΦήΙΙ ±Θ§“≤Υφ÷°±δΜ·œΒΆ≥ΦήΙΙΓΘΕχΈΔΖΰΈώΉΖ«σ“ΒΈώ≤ψΟφΒΡΗ¥”ΟΘ§…ηΦΤ≥ωά¥ΒΡœΒΆ≥ΦήΙΙΚΆ“ΒΈώ“Μ÷¬ΘΜ‘ΎΦΦ θΦήΙΙ…œ‘ρœΒΆ≥ΡΘΩι÷°Φδ≥δΖ÷ΫβώνΘ§Ω…“‘Ή‘”…ΒΊ―Γ‘ώΚœ ΒΡΦΦ θΦήΙΙΘ§»Ξ÷––ΡΜ·ΒΊ÷ΈάμΦΦ θΚΆ ΐΨίΓΘ
Ω…“‘≤ΈΦϊœ¬ΆΦά¥ΗϋΚΟΒΊάμΫβΥΪΖΫ÷°ΦδΒΡ–≠ΉςΙΊœΒΘΚ
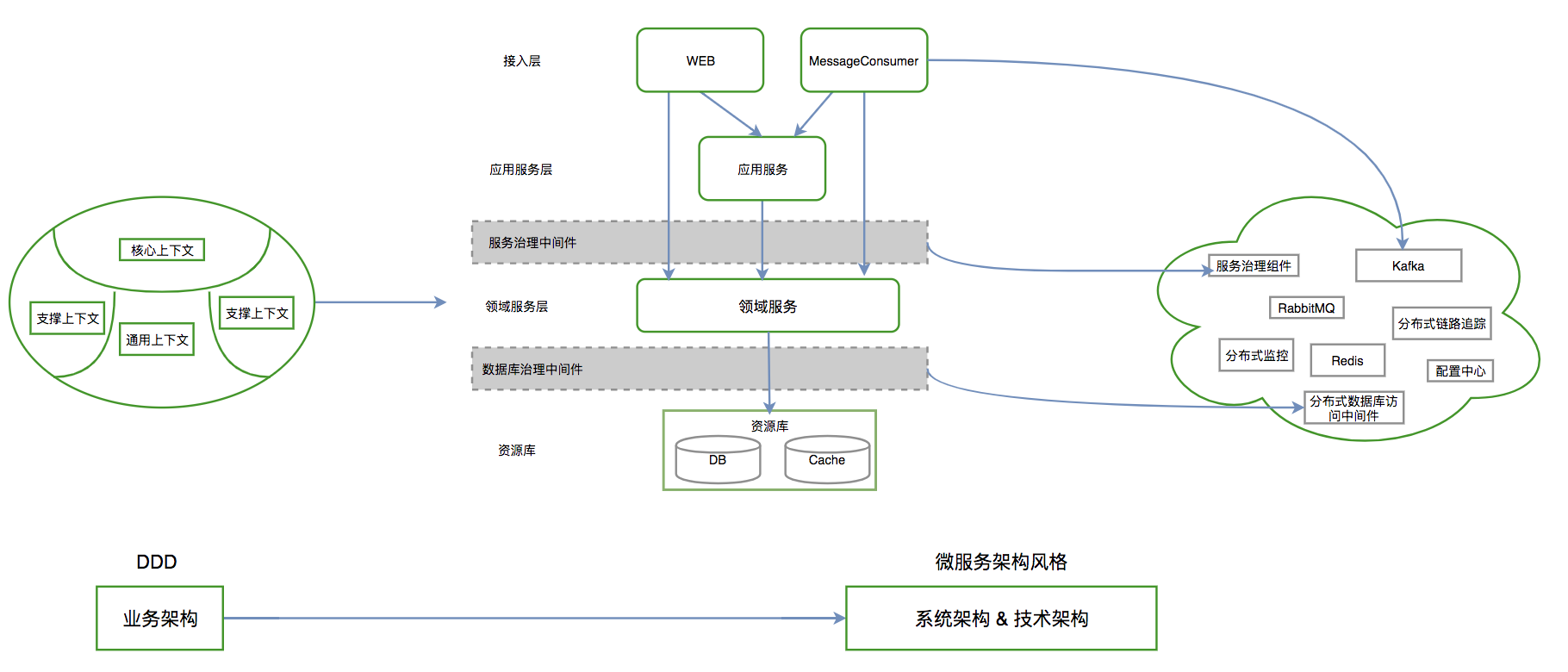
»γΚΈ ΒΦυDDD
Έ“Ο«ΫΪΆ®Ιΐ…œΈΡΧαΒΫΒΡ≥ιΫ±ΤΫΧ®Θ§ά¥œξœΗΫι…ήΈ“Ο«»γΚΈΆ®ΙΐDDDά¥ΫβΙΙ“ΜΗω÷––ΆΒΡΜυ”ΎΈΔΖΰΈώΦήΙΙΒΡœΒΆ≥Θ§¥”ΕχΉωΒΫœΒΆ≥ΒΡΗΏΡΎΨέΓΔΒΆώνΚœΓΘ
Ήœ»Ω¥œ¬≥ιΫ±œΒΆ≥ΒΡ¥σ÷¬–η«σΘΚ
‘Υ”ΣΓΣΓΣΩ…“‘≈δ÷Ο“ΜΗω≥ιΫ±ΜνΕ·Θ§ΗΟΜνΕ·Οφœρ“ΜΗωΧΊΕ®ΒΡ”ΟΜß»ΚΧεΘ§≤Δ’κΕ‘“ΜΗω”ΟΜß»ΚΧεΖΔΖ≈“Μ≈ζ≤ΜΆ§άύ–ΆΒΡΫ±ΤΖΘ®”≈Μί»·Θ§ΦΛΜν¬κΘ§ ΒΈοΫ±ΤΖΒ»Θ©ΓΘ
”ΟΜßΓΣΓΣΆ®ΙΐΜνΕ·“≥Οφ≤Έ”κ≤ΜΆ§άύ–ΆΒΡ≥ιΫ±ΜνΕ·ΓΘ
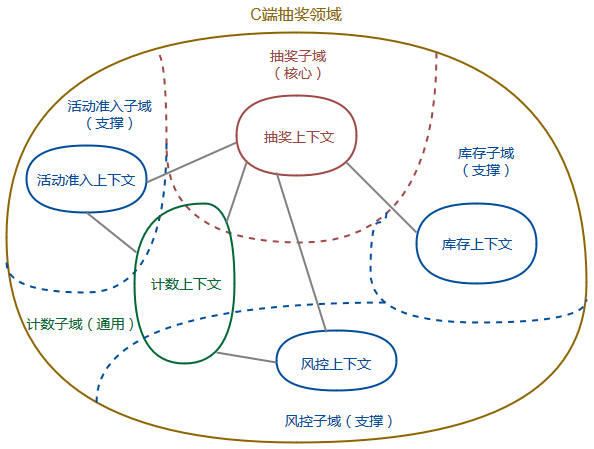
…ηΦΤΝλ”ρΡΘ–ΆΒΡ“ΜΑψ≤Ϋ÷η»γœ¬ΘΚ
1.ΗυΨί–η«σΜ°Ζ÷≥ω≥θ≤ΫΒΡΝλ”ρΚΆœόΫγ…œœ¬ΈΡΘ§“‘ΦΑ…œœ¬ΈΡ÷°ΦδΒΡΙΊœΒΘΜ
2.Ϋχ“Μ≤ΫΖ÷ΈωΟΩΗω…œœ¬ΈΡΡΎ≤ΩΘ§ Ε±π≥ωΡΡ–© « ΒΧεΘ§ΡΡ–© «÷ΒΕ‘œσΘΜ
3.Ε‘ ΒΧεΓΔ÷ΒΕ‘œσΫχ––ΙΊΝΣΚΆΨέΚœΘ§Μ°Ζ÷≥ωΨέΚœΒΡΖΕ≥κΚΆΨέΚœΗυΘΜ
4.ΈΣΨέΚœΗυ…ηΦΤ≤÷¥ΔΘ§≤ΔΥΦΩΦ ΒΧεΜρ÷ΒΕ‘œσΒΡ¥¥Ϋ®ΖΫ ΫΘΜ
5.‘ΎΙΛ≥Χ÷– ΒΦυΝλ”ρΡΘ–ΆΘ§≤Δ‘Ύ ΒΦυ÷–Φλ―ιΡΘ–ΆΒΡΚœάμ–‘Θ§ΒΙΆΤΡΘ–Ά÷–≤ΜΉψΒΡΒΊΖΫ≤Δ÷ΊΙΙΓΘ
’Ϋ¬‘Ϋ®ΡΘ
’Ϋ¬‘ΚΆ’Ϋ θ…ηΦΤ «’Ψ‘ΎDDDΒΡΫ«Ε»Ϋχ––Μ°Ζ÷ΓΘ’Ϋ¬‘…ηΦΤ≤ύ÷Ί”ΎΗΏ≤ψ¥ΈΓΔΚξΙέ…œ»ΞΜ°Ζ÷ΚΆΦ·≥…œόΫγ…œœ¬ΈΡΘ§Εχ’Ϋ θ…ηΦΤ‘ρΙΊΉΔΗϋΨΏΧε Ι”ΟΫ®ΡΘΙΛΨΏά¥œΗΜ·…œœ¬ΈΡΓΘ
Νλ”ρ
œ÷ Β άΫγ÷–Θ§Νλ”ρΑϋΚ§ΝΥΈ Χβ”ρΚΆΫβœΒΆ≥ΓΘ“ΜΑψ»œΈΣ»μΦΰ «Ε‘œ÷ Β άΫγΒΡ≤ΩΖ÷ΡΘΡβΓΘ‘ΎDDD÷–Θ§ΫβœΒΆ≥Ω…“‘”≥…δΈΣ“ΜΗωΗωœόΫγ…œœ¬ΈΡΘ§œόΫγ…œœ¬ΈΡΨΆ «»μΦΰΕ‘”ΎΈ Χβ”ρΒΡ“ΜΗωΧΊΕ®ΒΡΓΔ”–œόΒΡΫβΨωΖΫΑΗΓΘ
œόΫγ…œœ¬ΈΡ
“ΜΗω”…œ‘ Ϋ±ΏΫγœόΕ®ΒΡΧΊΕ®÷Α‘πΓΘΝλ”ρΡΘ–Ά±ψ¥φ‘Ύ”Ύ’βΗω±ΏΫγ÷°ΡΎΓΘ‘Ύ±ΏΫγΡΎΘ§ΟΩ“ΜΗωΡΘ–ΆΗ≈ΡνΘ§Αϋά®ΥϋΒΡ τ–‘ΚΆ≤ΌΉςΘ§ΕΦΨΏ”–ΧΊ βΒΡΚ§“εΓΘ
“ΜΗωΗχΕ®ΒΡ“ΒΈώΝλ”ρΜαΑϋΚ§ΕύΗωœόΫγ…œœ¬ΈΡΘ§œκ”κ“ΜΗωœόΫγ…œœ¬ΈΡΙΒΆ®Θ§‘ρ–η“ΣΆ®Ιΐœ‘ Ϋ±ΏΫγΫχ––Ά®–≈ΓΘœΒΆ≥Ά®Ιΐ»ΖΕ®ΒΡœόΫγ…œœ¬ΈΡά¥Ϋχ––ΫβώνΘ§ΕχΟΩ“ΜΗω…œœ¬ΈΡΡΎ≤ΩΫτΟήΉι÷·Θ§÷Α‘πΟς»ΖΘ§ΨΏ”–ΫœΗΏΒΡΡΎΨέ–‘ΓΘ
“ΜΗωΚή–ΈœσΒΡ“ΰ”ςΘΚœΗΑϊ÷ Υυ“‘ΡήΙΜ¥φ‘ΎΘ§ «“ρΈΣœΗΑϊΡΛœόΕ®ΝΥ ≤Ο¥‘ΎœΗΑϊΡΎΘ§ ≤Ο¥‘ΎœΗΑϊΆβΘ§≤Δ«“»ΖΕ®ΝΥ ≤Ο¥Έο÷ Ω…“‘Ά®ΙΐœΗΑϊΡΛΓΘ
Μ°Ζ÷œόΫγ…œœ¬ΈΡ
Μ°Ζ÷œόΫγ…œœ¬ΈΡΘ§≤ΜΙή «Eric EvansΜΙ «Vaughn VernonΘ§‘ΎΥϊΟ«ΒΡ¥σΉςάοΕΦΟΜ”–‘θΟ¥ΧαΦΑΓΘ
œ‘»ΜΈ“Ο«≤Μ”ΠΗΟΑ¥ΦΦ θΦήΙΙΜρ’ΏΩΣΖΔ»ΈΈώά¥¥¥Ϋ®œόΫγ…œœ¬ΈΡΘ§”ΠΗΟΑ¥’’”ο“εΒΡ±ΏΫγά¥ΩΦ¬«ΓΘ
Έ“Ο«ΒΡ ΒΦυ «Θ§ΩΦ¬«≤ζΤΖΥυΫ≤ΒΡΆ®”Ο”ο―‘Θ§¥”÷–Χα»Γ“Μ–© θ”ο≥Τ÷°ΈΣΗ≈ΡνΕ‘œσΘ§―Α’“Ε‘œσ÷°ΦδΒΡΝΣœΒΘΜΜρ’Ώ¥”–η«σάοΧα»Γ“Μ–©Ε·¥ Θ§Ιέ≤λΕ·¥ ΚΆΕ‘œσ÷°ΦδΒΡΙΊœΒΘΜΈ“Ο«ΫΪΫτώνΚœΒΡΗςΉ‘»Π‘Ύ“ΜΤπΘ§Ιέ≤λΥϊΟ«ΡΎ‘ΎΒΡΝΣœΒΘ§¥”Εχ–Έ≥…Ε‘”ΠΒΡœόΫγ…œœ¬ΈΡΓΘ–Έ≥…÷°ΚσΘ§Έ“Ο«Ω…“‘≥Δ ‘”Ο”ο―‘ά¥Οη ωœ¬œόΫγ…œœ¬ΈΡΒΡ÷Α‘πΘ§Ω¥Υϋ «Ζώ«εΈζΓΔΉΦ»ΖΓΔΦρΫύΚΆΆξ’ϊΓΘΦρ―‘÷°Θ§œόΫγ…œœ¬ΈΡ”ΠΗΟ¥”–η«σ≥ωΖΔΘ§Α¥Νλ”ρΜ°Ζ÷ΓΘ
«ΑΈΡΧαΒΫΘ§Έ“Ο«ΒΡ”ΟΜßΜ°Ζ÷ΈΣ‘Υ”ΣΚΆ”ΟΜßΓΘΤδ÷–Θ§‘Υ”ΣΕ‘≥ιΫ±ΜνΕ·ΒΡ≈δ÷Ο °Ζ÷Η¥‘”ΒΪœύΕ‘ΒΆΤΒΓΘ”ΟΜßΕ‘’β–©≥ιΫ±ΜνΕ·≈δ÷ΟΒΡ Ι”Ο «ΗΏΤΒ¥Έ«“ΈόΗ–÷ΣΒΡΓΘΗυΨί’β―υΒΡ“ΒΈώΧΊΒψΘ§Έ“Ο« Ήœ»ΫΪ≥ιΫ±ΤΫΧ®Μ°Ζ÷ΈΣCΕΥ≥ιΫ±ΚΆMΕΥ≥ιΫ±ΙήάμΤΫΧ®ΝΫΗωΉ””ρΘ§»ΟΝΫ’ΏΆξ»ΪΫβώνΓΘ
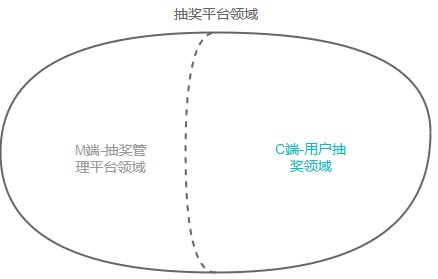
‘Ύ»Ζ»œΝΥMΕΥΝλ”ρΚΆCΕΥΒΡœόΫγ…œœ¬ΈΡΚσΘ§Έ“Ο«‘ΌΕ‘ΗςΉ‘…œœ¬ΈΡΡΎ≤ΩΫχ––œόΫγ…œœ¬ΈΡΒΡΜ°Ζ÷ΓΘœ¬ΟφΈ“Ο«”ΟCΕΥΫχ––ΨΌάΐΓΘ
≤ζΤΖΒΡ–η«σΗ≈ ω»γœ¬ΘΚ
1. ≥ιΫ±ΜνΕ·”–ΜνΕ·œό÷ΤΘ§άΐ»γ”ΟΜßΒΡ≥ιΫ±¥Έ ΐœό÷ΤΘ§≥ιΫ±ΒΡΩΣ ΦΚΆΫα χΒΡ ±ΦδΒ»ΘΜ
2. “ΜΗω≥ιΫ±ΜνΕ·ΑϋΚ§ΕύΗωΫ±ΤΖΘ§Ω…“‘’κΕ‘“ΜΗωΜρΕύΗω”ΟΜß»ΚΧεΘΜ
3. Ϋ±ΤΖ”–Ή‘…μΒΡΫ±ΤΖ≈δ÷ΟΘ§άΐ»γΩβ¥φΝΩΘ§±Μ≥ι÷–ΒΡΗ≈¬ Β»Θ§ΉνΕύ±Μ“ΜΗω”ΟΜß≥ι÷–ΒΡ¥Έ ΐ»»ΘΜ
4. ”ΟΜß»ΚΧε”–Εύ÷÷«χ±πΖΫ ΫΘ§»γΑ¥’’”ΟΜßΥυ‘Ύ≥« –«χΖ÷Θ§Α¥’’–¬άœΩΆ«χΖ÷Β»ΘΜ
5. ΜνΕ·ΨΏ”–ΖγΩΊ≈δ÷ΟΘ§ΡήΙΜœό÷Τ”ΟΜß≤Έ”κ≥ιΫ±ΒΡΤΒ¬ ΓΘ
ΗυΨί≤ζΤΖΒΡ–η«σΘ§Έ“Ο«Χα»ΓΝΥ“Μ–©ΙΊΦϋ–‘ΒΡΗ≈ΡνΉςΈΣΉ””ρΘ§–Έ≥…Έ“Ο«ΒΡœόΫγ…œœ¬ΈΡΓΘ
Ήœ»Θ§≥ιΫ±…œœ¬ΈΡΉςΈΣ’ϊΗωΝλ”ρΒΡΚΥ–ΡΘ§≥–ΒΘΉ≈”ΟΜß≥ιΫ±ΒΡΚΥ–Ρ“ΒΈώΘ§≥ιΫ±÷–ΑϋΚ§ΝΥΫ±ΤΖΚΆ”ΟΜß»ΚΧεΒΡΗ≈ΡνΓΘ
‘Ύ…ηΦΤ≥θΤΎΘ§Έ“Ο«‘χΨ≠ΩΦ¬«Μ°Ζ÷≥ω≥ιΫ±ΚΆΖΔΫ±ΝΫΗωΝλ”ρΘ§«Α’ΏΗΚ‘π―ΓΫ±Θ§Κσ’ΏΗΚ‘πΫΪ―Γ÷–ΒΡΫ±ΤΖΖΔΖ≈≥ω»ΞΓΘΒΪ‘Ύ ΒΦ ΩΣΖΔΙΐ≥Χ÷–Θ§Έ“Ο«ΖΔœ÷’βΝΫ≤ΩΖ÷ΒΡ¬ΏΦ≠ΫτΟήΝ§Ϋ”Θ§Ρ―“‘≤πΖ÷ΓΘ≤Δ«“ΒΞ¥ΩΒΡΖΔΫ±¬ΏΦ≠ΉψΙΜΦρΒΞΘ§ΫωΫω «Βς”ΟΒΎ»ΐΖΫΖΰΈώΫχ––ΖΔΫ±Θ§≤ΜΉψ“‘ΕάΝΔ≥ωά¥≥…ΈΣ“ΜΗωΝλ”ρΓΘ
Ε‘”ΎΜνΕ·ΒΡœό÷ΤΘ§Έ“Ο«Ε®“εΝΥΜνΕ·ΉΦ»κΒΡΆ®”Ο”ο―‘Θ§ΫΪΜνΕ·ΩΣ Φ/Ϋα χ ±ΦδΘ§ΜνΕ·Ω…≤Έ”κ¥Έ ΐΒ»œό÷ΤΧθΦΰΕΦ ’¬ΘΒΫΜνΕ·ΉΦ»κ…œœ¬ΈΡ÷–ΓΘ
Ε‘”Ύ≥ιΫ±ΒΡΫ±ΤΖΩβ¥φΝΩΘ§”…”ΎΩβ¥φΒΡ––ΈΣ”κΫ±ΤΖ±Ψ…μœύΕ‘ΫβώνΘ§Ωβ¥φΙΊΉΔΒψΗϋΕύ «Ωβ¥φΡΎ»ίΒΡΚΥœζΘ§«“Ωβ¥φ±Ψ…μΨΏ±ΗΆ®”Ο–‘Θ§Ω…“‘±ΜΫ±ΤΖ÷°ΆβΒΡΡΎ»ί Ι”ΟΘ§“ρ¥ΥΈ“Ο«Ε®“εΝΥΕάΝΔΒΡΩβ¥φ…œœ¬ΈΡΓΘ
”…”ΎCΕΥ¥φ‘Ύ“Μ–©ΥΔΒΞ––ΈΣΘ§Έ“Ο«ΗυΨί≤ζΤΖ–η«σΕ®“εΝΥΖγΩΊ…œœ¬ΈΡΘ§”Ο”ΎΕ‘ΜνΕ·Ϋχ––ΖγΩΊΓΘ
ΉνΚσΘ§ΜνΕ·ΉΦ»κΓΔΖγΩΊΓΔ≥ιΫ±Β»Νλ”ρΕΦ…φΦΑΒΫ“Μ–©¥Έ ΐΒΡœό÷ΤΘ§“ρ¥ΥΈ“Ο«Ε®“εΝΥΦΤ ΐ…œœ¬ΈΡΓΘ
Ω…“‘Ω¥ΒΫΘ§Ά®ΙΐDDDΒΡœόΫγ…œœ¬ΈΡΜ°Ζ÷Θ§Έ“Ο«ΫγΕ®≥ω≥ιΫ±ΓΔΜνΕ·ΉΦ»κΓΔΖγΩΊΓΔΦΤ ΐΓΔΩβ¥φΒ»ΈεΗω…œœ¬ΈΡΘ§ΟΩΗω…œœ¬ΈΡ‘ΎœΒΆ≥÷–ΕΦΗΏΕ»ΡΎΨέΓΘ
…œœ¬ΈΡ”≥…δΆΦ
‘ΎΫχ––…œœ¬ΈΡΜ°Ζ÷÷°ΚσΘ§Έ“Ο«ΜΙ–η“ΣΫχ“Μ≤Ϋ αάμ…œœ¬ΈΡ÷°ΦδΒΡΙΊœΒΓΘ
ΩΒΆΰΘ®ΟΖΕϊΓΛΩΒΆΰΘ©Ε®¬…
»ΈΚΈΉι÷·‘Ύ…ηΦΤ“ΜΧΉœΒΆ≥Θ®Ιψ“εΗ≈Ρν…œΒΡœΒΆ≥Θ© ±Θ§ΥυΫΜΗΕΒΡ…ηΦΤΖΫΑΗ‘ΎΫαΙΙ…œΕΦ”κΗΟΉι÷·ΒΡΙΒΆ®ΫαΙΙ±Θ≥÷“Μ÷¬ΓΘ
ΩΒΆΰΕ®¬…ΗφΥΏΈ“Ο«Θ§œΒΆ≥ΫαΙΙ”ΠΨΓΝΩΒΡ”κΉι÷·ΫαΙΙ±Θ≥÷“Μ÷¬ΓΘ’βάοΘ§Έ“Ο«»œΈΣΆ≈Ε”ΫαΙΙΘ®Έό¬έ «ΡΎ≤ΩΉι÷·ΜΙ «Ά≈Ε”ΦδΉι÷·Θ©ΨΆ «Ήι÷·ΫαΙΙΘ§œόΫγ…œœ¬ΈΡΨΆ «œΒΆ≥ΒΡ“ΒΈώΫαΙΙΓΘ“ρ¥ΥΘ§Ά≈Ε”ΫαΙΙ”ΠΗΟΚΆœόΫγ…œœ¬ΈΡ±Θ≥÷“Μ÷¬ΓΘ
αάμ«ε≥ΰ…œœ¬ΈΡ÷°ΦδΒΡΙΊœΒΘ§¥”Ά≈Ε”ΡΎ≤ΩΒΡΙΊœΒά¥Ω¥Θ§”–»γœ¬ΚΟ¥ΠΘΚ
1.»ΈΈώΗϋΚΟ≤πΖ÷Θ§“ΜΗωΩΣΖΔ»Υ‘±Ω…“‘»Ϊ…μ–ΡΒΡΆΕ»κΒΫœύΙΊΒΡ“ΜΗωΒΞΕάΒΡ…œœ¬ΈΡ÷–ΘΜ
2.ΙΒΆ®ΗϋΦ”Υ≥≥©Θ§“ΜΗω…œœ¬ΈΡΩ…“‘Ος»ΖΉ‘ΦΚΕ‘ΤδΥϊ…œœ¬ΈΡΒΡ“άάΒΙΊœΒΘ§¥”Εχ ΙΒΟΆ≈Ε”ΡΎΩΣΖΔ÷±Ϋ”ΗϋΚΟΒΡΕ‘Ϋ”ΓΘ
¥”Ά≈Ε”ΦδΒΡΙΊœΒά¥Ω¥Θ§Ος»ΖΒΡ…œœ¬ΈΡΙΊœΒΡήΙΜ¥χά¥»γœ¬Αο÷ζΘΚ
1.ΟΩΗωΆ≈Ε”‘ΎΥϋΒΡ…œœ¬ΈΡ÷–ΡήΙΜΗϋΦ”Ος»ΖΉ‘ΦΚΝλ”ρΡΎΒΡΗ≈ΡνΘ§“ρΈΣ…œœ¬ΈΡ «Νλ”ρΒΡΫβœΒΆ≥ΘΜ
2.Ε‘”ΎœόΫγ…œœ¬ΈΡ÷°ΦδΖΔ…ζΫΜΜΞΘ§Ά≈Ε””κ…œœ¬ΈΡΒΡ“Μ÷¬–‘Θ§ΡήΙΜ±Θ÷ΛΈ“Ο«Ος»ΖΕ‘Ϋ”ΒΡΆ≈Ε”ΚΆ“άάΒΒΡ…œœ¬”ΈΓΘ
œόΫγ…œœ¬ΈΡ÷°ΦδΒΡ”≥…δΙΊœΒ
ΚœΉςΙΊœΒΘ®PartnershipΘ©ΘΚΝΫΗω…œœ¬ΈΡΫτΟήΚœΉςΒΡΙΊœΒΘ§“Μ»ΌΨψ»ΌΘ§“ΜΥπΨψΥπΓΘ
Ι≤œμΡΎΚΥΘ®Shared KernelΘ©ΘΚΝΫΗω…œœ¬ΈΡ“άάΒ≤ΩΖ÷Ι≤œμΒΡΡΘ–ΆΓΘ
ΩΆΜßΖΫ-Ι©”ΠΖΫΩΣΖΔΘ®Customer-Supplier DevelopmentΘ©ΘΚ…œœ¬ΈΡ÷°Φδ”–Ήι÷·ΒΡ…œœ¬”Έ“άάΒΓΘ
ΉώΖν’ΏΘ®ConformistΘ©ΘΚœ¬”Έ…œœ¬ΈΡ÷ΜΡήΟΛΡΩ“άάΒ…œ”Έ…œœ¬ΈΡΓΘ
ΖάΗ·≤ψΘ®Anticorruption LayerΘ©ΘΚ“ΜΗω…œœ¬ΈΡΆ®Ιΐ“Μ–© ≈δΚΆΉΣΜΜ”κΝμ“ΜΗω…œœ¬ΈΡΫΜΜΞΓΘ
ΩΣΖ≈÷ςΜζΖΰΈώΘ®Open Host ServiceΘ©ΘΚΕ®“ε“Μ÷÷–≠“ιά¥»ΟΤδΥϊ…œœ¬ΈΡά¥Ε‘±Ψ…œœ¬ΈΡΫχ––ΖΟΈ ΓΘ
ΖΔ≤Φ”ο―‘Θ®Published LanguageΘ©ΘΚΆ®≥Θ”κOHS“ΜΤπ Ι”ΟΘ§”Ο”ΎΕ®“εΩΣΖ≈÷ςΜζΒΡ–≠“ιΓΘ
¥σΡύ«ρΘ®Big Ball of MudΘ©ΘΚΜλ‘”‘Ύ“ΜΤπΒΡ…œœ¬ΈΡΙΊœΒΘ§±ΏΫγ≤Μ«εΈζΓΘ
ΝμΡ±Υϊ¬ΖΘ®Separate WayΘ©ΘΚΝΫΗωΆξ»ΪΟΜ”–»ΈΚΈΝΣœΒΒΡ…œœ¬ΈΡΓΘ
…œΈΡΕ®“εΝΥ…œœ¬ΈΡ”≥…δΦδΒΡΙΊœΒΘ§Ψ≠ΙΐΈ“Ο«ΒΡΖ¥Η¥’εΉΟΘ§≥ιΫ±ΤΫΧ®…œœ¬ΈΡΒΡ”≥…δΙΊœΒΆΦ»γœ¬ΘΚ
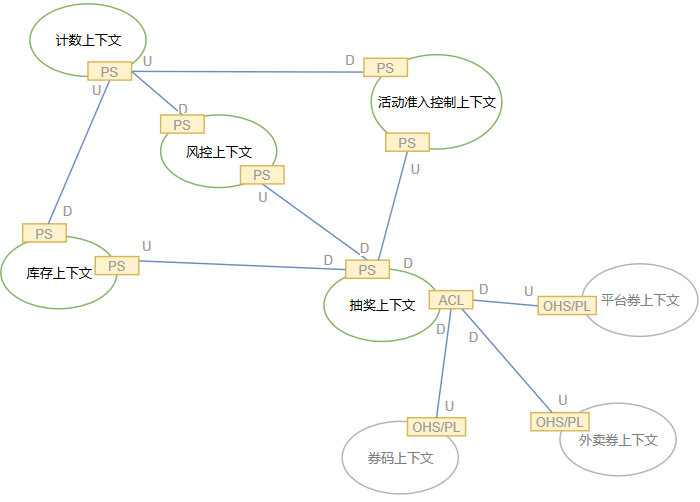
”…”Ύ≥ιΫ±Θ§ΖγΩΊΘ§ΜνΕ·ΉΦ»κΘ§Ωβ¥φΘ§ΦΤ ΐΈεΗω…œœ¬ΈΡΕΦ¥Π‘Ύ≥ιΫ±Νλ”ρΒΡΡΎ≤ΩΘ§Υυ“‘ΥϋΟ«÷°ΦδΖϊΚœΓΑ“Μ»ΌΨψ»ΌΘ§“ΜΥπΨψΥπΓ±ΒΡΚœΉςΙΊœΒΘ®PartnerShipΘ§Φρ≥ΤPSΘ©ΓΘ
Ά§ ±Θ§≥ιΫ±…œœ¬ΈΡ‘ΎΫχ––ΖΔ»·Ε·Ής ±Θ§Μα“άάΒ»·¬κΓΔΤΫΧ®»·ΓΔΆβ¬τ»·»ΐΗω…œœ¬ΈΡΓΘ≥ιΫ±…œœ¬ΈΡΆ®ΙΐΖάΗ·≤ψΘ®Anticorruption
LayerΘ§ACLΘ©Ε‘»ΐΗω…œœ¬ΈΡΫχ––ΝΥΗτάκΘ§Εχ»ΐΗω»·…œœ¬ΈΡΆ®ΙΐΩΣΖ≈÷ςΜζΖΰΈώΘ®Open Host ServiceΘ©ΉςΈΣΖΔ≤Φ”ο―‘Θ®Published
LanguageΘ©Ε‘≥ιΫ±…œœ¬ΈΡΧαΙ©ΖΟΈ Μζ÷ΤΓΘ
Ά®Ιΐ…œœ¬ΈΡ”≥…δΙΊœΒΘ§Έ“Ο«Ος»ΖΒΡœό÷ΤΝΥœόΫγ…œœ¬ΈΡΒΡώνΚœ–‘Θ§Φ¥‘Ύ≥ιΫ±ΤΫΧ®÷–Θ§Έό¬έ «…œœ¬ΈΡΡΎ≤ΩΫΜΜΞΘ®ΚœΉςΙΊœΒΘ©ΜΙ «”κΆβ≤Ω…œœ¬ΈΡΫΜΜΞΘ®ΖάΗ·≤ψΘ©Θ§ώνΚœΕ»ΕΦœόΕ®‘Ύ ΐΨίώνΚœΘ®Data
CouplingΘ©ΒΡ≤ψΦΕΓΘ
’Ϋ θΫ®ΡΘΓΣΓΣœΗΜ·…œœ¬ΈΡ
αάμ«ε≥ΰ…œœ¬ΈΡ÷°ΦδΒΡΙΊœΒΚσΘ§Έ“Ο«–η“Σ¥”’Ϋ θ≤ψΟφ…œΤ Έω…œœ¬ΈΡΡΎ≤ΩΒΡΉι÷·ΙΊœΒΓΘ Ήœ»Ω¥œ¬DDD÷–ΒΡ“Μ–©Ε®“εΓΘ
ΒΧε
Β±“ΜΗωΕ‘œσ”…Τδ±ξ ΕΘ®Εχ≤Μ « τ–‘Θ©«χΖ÷ ±Θ§’β÷÷Ε‘œσ≥ΤΈΣ ΒΧεΘ®EntityΘ©ΓΘ
άΐΘΚΉνΦρΒΞΒΡΘ§ΙΪΑ≤œΒΆ≥ΒΡ…μΖί–≈œΔ¬Φ»κΘ§Ε‘”Ύ»ΥΒΡΡΘΡβΘ§Φ¥»œΈΣ « ΒΧεΘ§“ρΈΣΟΩΗω»Υ «Εά“ΜΈόΕΰΒΡΘ§«“ΤδΨΏ”–Έ®“Μ±ξ ΕΘ®»γΙΪΑ≤œΒΆ≥Ζ÷ΖΔΒΡ…μΖί÷ΛΚ≈¬κΘ©ΓΘ
‘Ύ ΒΦυ…œΫ®“ιΫΪ τ–‘ΒΡ―ι÷ΛΖ≈ΒΫ ΒΧε÷–ΓΘ
÷ΒΕ‘œσ
Β±“ΜΗωΕ‘œσ”Ο”ΎΕ‘ ¬ΈώΫχ––Οη ωΕχΟΜ”–Έ®“Μ±ξ Ε ±Θ§Υϋ±Μ≥ΤΉς÷ΒΕ‘œσΘ®Value ObjectΘ©ΓΘ
άΐΘΚ±»»γ―’…Ϊ–≈œΔΘ§Έ“Ο«÷Μ–η“Σ÷ΣΒά{"name":"ΚΎ…Ϊ"Θ§"css":"#000000"}’β―υΒΡ÷Β–≈œΔΨΆΡήΙΜ¬ζΉψ“Σ«σΝΥΘ§’β±ήΟβΝΥΈ“Ο«Ε‘±ξ ΕΉΖΉΌ¥χά¥ΒΡœΒΆ≥Η¥‘”–‘ΓΘ
÷ΒΕ‘œσΚή÷Ί“ΣΘ§‘ΎœΑΙΏΝΥ Ι”Ο ΐΨίΩβΒΡ ΐΨίΫ®ΡΘΚσΘ§Κή»ί“ΉΫΪΥυ”–Ε‘œσΩ¥Ής ΒΧεΓΘ Ι”Ο÷ΒΕ‘œσΘ§Ω…“‘ΗϋΚΟΒΊΉωœΒΆ≥”≈Μ·ΓΔΨΪΦρ…ηΦΤΓΘ
ΥϋΨΏ”–≤Μ±δ–‘ΓΔœύΒ»–‘ΚΆΩ…ΧφΜΜ–‘ΓΘ
‘Ύ ΒΦυ÷–Θ§–η“Σ±Θ÷Λ÷ΒΕ‘œσ¥¥Ϋ®ΚσΨΆ≤ΜΡή±Μ–όΗΡΘ§Φ¥≤Μ‘ –μΆβ≤Ω‘Ό–όΗΡΤδ τ–‘ΓΘ‘Ύ≤ΜΆ§…œœ¬ΈΡΦ·≥… ±Θ§Μα≥ωœ÷ΡΘ–ΆΗ≈ΡνΒΡΙΪ”ΟΘ§»γ…ΧΤΖΡΘ–ΆΜα¥φ‘Ύ”ΎΒγ…ΧΒΡΗςΗω…œœ¬ΈΡ÷–ΓΘ‘ΎΕ©ΒΞ…œœ¬ΈΡ÷–»γΙϊΡψ÷ΜΙΊΉΔœ¬ΒΞ ±…ΧΤΖ–≈œΔΩλ’’Θ§Ρ«Ο¥ΫΪ…ΧΤΖΕ‘œσ ”ΈΣ÷ΒΕ‘œσ «ΚήΚΟΒΡ―Γ‘ώΓΘ
ΨέΚœΗυ
Aggregate(ΨέΚœΘ© «“ΜΉιœύΙΊΕ‘œσΒΡΦ·ΚœΘ§ΉςΈΣ“ΜΗω’ϊΧε±ΜΆβΫγΖΟΈ Θ§ΨέΚœΗυΘ®Aggregate
RootΘ© «’βΗωΨέΚœΒΡΗυΫΎΒψΓΘ
ΨέΚœ «“ΜΗωΖ«≥Θ÷Ί“ΣΒΡΗ≈ΡνΘ§ΚΥ–ΡΝλ”ρΆυΆυΕΦ–η“Σ”ΟΨέΚœά¥±μ¥οΓΘΤδ¥ΈΘ§ΨέΚœ‘ΎΦΦ θ…œ”–Ζ«≥ΘΗΏΒΡΦέ÷ΒΘ§Ω…“‘÷ΗΒΦœξœΗ…ηΦΤΓΘ
ΨέΚœ”…Ηυ ΒΧεΘ§÷ΒΕ‘œσΚΆ ΒΧεΉι≥…ΓΘ
»γΚΈ¥¥Ϋ®ΚΟΒΡΨέΚœΘΩ
±ΏΫγΡΎΒΡΡΎ»ίΨΏ”–“Μ÷¬–‘ΘΚ‘Ύ“ΜΗω ¬Έώ÷–÷Μ–όΗΡ“ΜΗωΨέΚœ ΒάΐΓΘ»γΙϊΡψΖΔœ÷±ΏΫγΡΎΚήΡ―Ϋ” ή«Ω“Μ÷¬Θ§≤ΜΙή «≥ω”Ύ–‘ΡήΜρ≤ζΤΖ–η«σΒΡΩΦ¬«Θ§”ΠΗΟΩΦ¬«Αΰάκ≥ωΕάΝΔΒΡΨέΚœΘ§≤…”ΟΉν÷’“Μ÷¬ΒΡΖΫ ΫΓΘ
…ηΦΤ–ΓΨέΚœΘΚ¥σ≤ΩΖ÷ΒΡΨέΚœΕΦΩ…“‘÷ΜΑϋΚ§Ηυ ΒΧεΘ§ΕχΈό–ηΑϋΚ§ΤδΥϊ ΒΧεΓΘΦ¥ Ι“ΜΕ®“ΣΑϋΚ§Θ§Ω…“‘ΩΦ¬«ΫΪΤδ¥¥Ϋ®ΈΣ÷ΒΕ‘œσΓΘ
Ά®ΙΐΈ®“Μ±ξ Εά¥“ΐ”ΟΤδΥϊΨέΚœΜρ ΒΧεΘΚΒ±¥φ‘ΎΕ‘œσ÷°ΦδΒΡΙΊΝΣ ±Θ§Ϋ®“ι“ΐ”ΟΤδΈ®“Μ±ξ ΕΕχΖ«“ΐ”ΟΤδ’ϊΧεΕ‘œσΓΘ»γΙϊ «Άβ≤Ω…œœ¬ΈΡ÷–ΒΡ ΒΧεΘ§“ΐ”ΟΤδΈ®“Μ±ξ ΕΜρΫΪ–η“ΣΒΡ τ–‘ΙΙ‘λ÷ΒΕ‘œσΓΘ
»γΙϊΨέΚœ¥¥Ϋ®Η¥‘”Θ§ΆΤΦω Ι”ΟΙΛ≥ßΖΫΖ®ά¥ΤΝ±ΈΡΎ≤ΩΗ¥‘”ΒΡ¥¥Ϋ®¬ΏΦ≠ΓΘ
ΨέΚœΡΎ≤ΩΕύΗωΉι≥…Ε‘œσΒΡΙΊœΒΩ…“‘”Οά¥÷ΗΒΦ ΐΨίΩβ¥¥Ϋ®Θ§ΒΪ≤ΜΩ…±ήΟβ¥φ‘Ύ“ΜΕ®ΒΡΩΙΉηΓΘ»γΨέΚœ÷–¥φ‘ΎList<÷ΒΕ‘œσ>Θ§Ρ«Ο¥‘Ύ ΐΨίΩβ÷–Ϋ®ΝΔ1:NΒΡΙΊΝΣ–η“ΣΫΪ÷ΒΕ‘œσΒΞΕάΫ®±μΘ§¥Υ ± «”–idΒΡΘ§Ϋ®“ι≤Μ“ΣΫΪΗΟid±©¬ΕΒΫΉ ‘¥ΩβΆβ≤ΩΘ§Ε‘Άβ“ΰ±ΈΓΘ
Νλ”ρΖΰΈώ
“Μ–©÷Ί“ΣΒΡΝλ”ρ––ΈΣΜρ≤ΌΉςΘ§Ω…“‘ΙιάύΈΣΝλ”ρΖΰΈώΓΘΥϋΦ»≤Μ « ΒΧεΘ§“≤≤Μ «÷ΒΕ‘œσΒΡΖΕ≥κΓΘ
Β±Έ“Ο«≤…”ΟΝΥΈΔΖΰΈώΦήΙΙΖγΗώΘ§“Μ«–Νλ”ρ¬ΏΦ≠ΒΡΕ‘Άβ±©¬ΕΨυ–η“ΣΆ®ΙΐΝλ”ρΖΰΈώά¥Ϋχ––ΓΘ»γ‘≠±Ψ”…ΨέΚœΗυ±©¬ΕΒΡ“ΒΈώ¬ΏΦ≠“≤–η“Σ“άΆ–”ΎΝλ”ρΖΰΈώΓΘ
Νλ”ρ ¬Φΰ
Νλ”ρ ¬Φΰ «Ε‘Νλ”ρΡΎΖΔ…ζΒΡΜνΕ·Ϋχ––ΒΡΫ®ΡΘΓΘ
≥ιΫ±ΤΫΧ®ΒΡΚΥ–Ρ…œœ¬ΈΡ «≥ιΫ±…œœ¬ΈΡΘ§Ϋ”œ¬ά¥Ϋι…ήœ¬Έ“Ο«Ε‘≥ιΫ±…œœ¬ΈΡΒΡΫ®ΡΘΓΘ
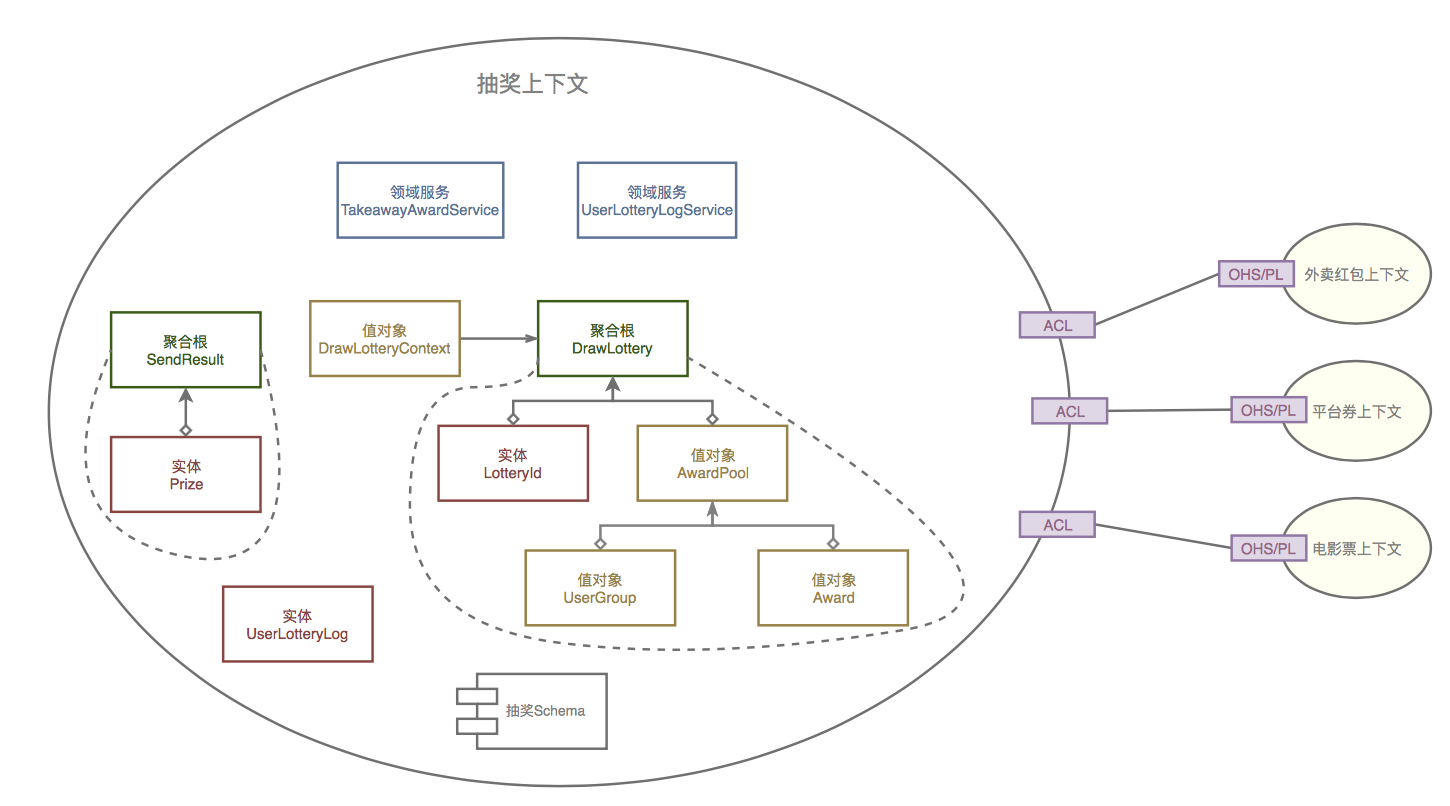
‘Ύ≥ιΫ±…œœ¬ΈΡ÷–Θ§Έ“Ο«Ά®Ιΐ≥ιΫ±Θ®DrawLotteryΘ©’βΗωΨέΚœΗυά¥ΩΊ÷Τ≥ιΫ±––ΈΣΘ§Ω…“‘Ω¥ΒΫΘ§“ΜΗω≥ιΫ±Αϋά®ΝΥ≥ιΫ±IDΘ®LotteryIdΘ©“‘ΦΑΕύΗωΫ±≥ΊΘ®AwardPoolΘ©Θ§Εχ“ΜΗωΫ±≥Ί’κΕ‘“ΜΗωΧΊΕ®ΒΡ”ΟΜß»ΚΧεΘ®UserGroupΘ©…η÷ΟΝΥΕύΗωΫ±ΤΖΘ®AwardΘ©ΓΘ
ΝμΆβΘ§‘Ύ≥ιΫ±Νλ”ρ÷–Θ§Έ“Ο«ΜΙΜα Ι”Ο≥ιΫ±ΫαΙϊΘ®SendResultΘ©ΉςΈΣ δ≥ω–≈œΔΘ§ Ι”Ο”ΟΜßΝλΫ±Φ«¬ΦΘ®UserLotteryLogΘ©ΉςΈΣΝλΫ±ΤΨΨίΚΆ¥φΗυΓΘ
Ϋς…ς Ι”Ο÷ΒΕ‘œσ
‘Ύ ΒΦυ÷–Θ§Έ“Ο«ΖΔœ÷Υδ»Μ“Μ–©Νλ”ρΕ‘œσΖϊΚœ÷ΒΕ‘œσΒΡΗ≈ΡνΘ§ΒΪ «ΥφΉ≈“ΒΈώΒΡ±δΕ·Θ§ΚήΕύ‘≠”–ΒΡΕ®“εΜαΖΔ…ζ±δΗϋΘ§÷ΒΕ‘œσΩ…Ρή–η“Σ‘Ύ“ΒΈώ“β“εΨΏ”–Έ®“Μ±ξ ΕΘ§ΕχΕ‘’βάύ÷ΒΕ‘œσΒΡ÷ΊΙΙΆυΆυ–η“ΣΫœΗΏ≥…±ΨΓΘ“ρ¥Υ‘ΎΧΊΕ®ΒΡ«ιΩωœ¬Θ§Έ“Ο«“≤“ΣΗυΨί ΒΦ «ιΩωά¥»®ΚβΝλ”ρΕ‘œσΒΡ―Γ–ΆΓΘ
DDDΙΛ≥Χ Βœ÷
‘ΎΕ‘…œœ¬ΈΡΫχ––œΗΜ·ΚσΘ§Έ“Ο«ΩΣ Φ‘ΎΙΛ≥Χ÷–’φ’ΐ¬δΒΊDDDΓΘ
ΡΘΩι
ΡΘΩιΘ®ModuleΘ© «DDD÷–Ος»ΖΧαΒΫΒΡ“Μ÷÷ΩΊ÷ΤœόΫγ…œœ¬ΈΡΒΡ ÷ΕΈΘ§‘ΎΈ“Ο«ΒΡΙΛ≥Χ÷–Θ§“ΜΑψΨΓΝΩ”Ο“ΜΗωΡΘΩιά¥±μ Ψ“ΜΗωΝλ”ρΒΡœόΫγ…œœ¬ΈΡΓΘ
»γ¥ζ¬κ÷–Υυ ΨΘ§“ΜΑψΒΡΙΛ≥Χ÷–ΑϋΒΡΉι÷·ΖΫ ΫΈΣ{com.ΙΪΥΨΟϊ.Ήι÷·ΦήΙΙ.“ΒΈώ.…œœ¬ΈΡ.*}Θ§’β―υΒΡΉι÷·ΫαΙΙΡήΙΜΟς»ΖΒΡΫΪ“ΜΗω…œœ¬ΈΡœόΕ®‘ΎΑϋΒΡΡΎ≤ΩΓΘ
import com
.company. team. bussiness. lottery.*;//≥ιΫ±…œœ¬ΈΡ
import com. company. team. bussiness. riskcontrol.*;
// ΖγΩΊ…œœ¬ΈΡ
import com. company. team. bussiness. counter.*;//ΦΤ ΐ…œœ¬ΈΡ
import com. company. team. bussiness. condition.*;//ΜνΕ·ΉΦ»κ…œœ¬ΈΡ
import com.company.team.bussiness.stock.*;//Ωβ¥φ…œœ¬ΈΡ
|
¥ζ¬κ―ί Ψ1 ΡΘΩιΒΡΉι÷·
Ε‘”ΎΡΘΩιΡΎΒΡΉι÷·ΫαΙΙΘ§“ΜΑψ«ιΩωœ¬Έ“Ο« «Α¥’’Νλ”ρΕ‘œσΓΔΝλ”ρΖΰΈώΓΔΝλ”ρΉ ‘¥ΩβΓΔΖάΗ·≤ψΒ»Ήι÷·ΖΫ ΫΕ®“εΒΡΓΘ
import com.company.
team.bussiness. lottery.domain. valobj. * ;//Νλ”ρΕ‘œσ-÷ΒΕ‘œσ
import com.company. team.bussiness. lottery.domain
.entity.* ;//Νλ”ρΕ‘œσ- ΒΧε
import com.company. team.bussiness. lottery.domain.
aggregate .* ;//Νλ”ρΕ‘œσ-ΨέΚœΗυ
import com.company.team.bussiness.lottery.service.*;//Νλ”ρΖΰΈώ
import com.company .team.bussiness.lottery.repo.*;//Νλ”ρΉ ‘¥Ωβ
import com.company .team.bussiness.lottery.facade.*;//Νλ”ρΖάΗ·≤ψ
|
¥ζ¬κ―ί Ψ2 ΡΘΩιΒΡΉι÷·
ΟΩΗωΡΘΩιΒΡΨΏΧε Βœ÷Θ§Έ“Ο«ΫΪ‘Ύœ¬ΈΡ÷–’ΙΩΣΓΘ
Νλ”ρΕ‘œσ
«ΑΈΡΧαΒΫΘ§Νλ”ρ«ΐΕ·“ΣΫβΨωΒΡ“ΜΗω÷Ί“ΣΒΡΈ ΧβΘ§ΨΆ «ΫβΨωΕ‘œσΒΡΤΕ―ΣΈ ΧβΓΘ’βάοΈ“Ο«”Ο÷°«ΑΕ®“εΒΡ≥ιΫ±Θ®DrawLotteryΘ©ΨέΚœΗυΚΆΫ±≥ΊΘ®AwardPoolΘ©÷ΒΕ‘œσά¥ΨΏΧεΥΒΟςΓΘ
≥ιΫ±ΨέΚœΗυ≥÷”–ΝΥ≥ιΫ±ΜνΕ·ΒΡidΚΆΗΟΜνΕ·œ¬ΒΡΥυ”–Ω…”ΟΫ±≥ΊΝ–±μΘ§ΥϋΒΡ“ΜΗωΉν÷ς“ΣΒΡΝλ”ρΙΠΡήΨΆ «ΗυΨί“ΜΗω≥ιΫ±ΖΔ…ζ≥ΓΨΑΘ®DrawLotteryContextΘ©Θ§―Γ‘ώ≥ω“ΜΗω ≈δΒΡΫ±≥ΊΘ§Φ¥chooseAwardPoolΖΫΖ®ΓΘ
chooseAwardPoolΒΡ¬ΏΦ≠ «’β―υΒΡΘΚDrawLotteryContextΜα¥χ”–”ΟΜß≥ιΫ± ±ΒΡ≥ΓΨΑ–≈œΔΘ®≥ιΫ±ΒΟΖ÷Μρ≥ιΫ± ±Υυ‘ΎΒΡ≥« –Θ©Θ§DrawLotteryΜαΗυΨί’βΗω≥ΓΨΑ–≈œΔΘ§ΤΞ≈δ“ΜΗωΩ…“‘Ηχ”ΟΜßΖΔΫ±ΒΡAwardPoolΓΘ
package com.company.
team.bussiness. lottery.domain . aggregate ;
import ...;
public class DrawLottery {
private int lotteryId; //≥ιΫ±id
private List <AwardPool> awardPools; //Ϋ±≥ΊΝ–±μ
//getter & setter
public void setLotteryId(int lotteryId) {
if (id<=0){
throw new IllegalArgumentException ("Ζ«Ζ®ΒΡ≥ιΫ±id");
}
this.lotteryId = lotteryId;
}
// ΗυΨί≥ιΫ±»κ≤Έcontext―Γ‘ώΫ±≥Ί
public AwardPool chooseAwardPool(DrawLotteryContext
context ) {
if (context.getMtCityInfo()!=null) {
return chooseAwardPoolByCityInfo (awardPools,
context .getMtCityInfo ());
} else {
return chooseAwardPoolByScore (awardPools, context.
getGameScore ());
}
}
//ΗυΨί≥ιΫ±Υυ‘Ύ≥« –―Γ‘ώΫ±≥Ί
private AwardPool chooseAwardPoolByCityInfo (List
<AwardPool> awardPools, MtCifyInfo cityInfo)
{
for (AwardPool awardPool: awardPools) {
if (awardPool.matchedCity (cityInfo.getCityId()))
{
return awardPool;
}
}
return null;
}
//ΗυΨί≥ιΫ±ΜνΕ·ΒΟΖ÷―Γ‘ώΫ±≥Ί
private AwardPool chooseAwardPoolByScore (List
<AwardPool> awardPools, int gameScore) {...}
}
|
¥ζ¬κ―ί Ψ3 DrawLottery
‘ΎΤΞ≈δΒΫ“ΜΗωΨΏΧεΒΡΫ±≥Ί÷°ΚσΘ§–η“Σ»ΖΕ®ΉνΚσΗχ”ΟΜßΒΡΫ±ΤΖ « ≤Ο¥ΓΘ’β≤ΩΖ÷ΒΡΝλ”ρΙΠΡή‘ΎAwardPoolΡΎΓΘ
package com.company.team.bussiness.lottery.domain.valobj;
import ...;
public class AwardPool {
private String cityIds;//Ϋ±≥Ί÷ß≥÷ΒΡ≥« –
private String scores;//Ϋ±≥Ί÷ß≥÷ΒΡΒΟΖ÷
private int userGroupType;//Ϋ±≥ΊΤΞ≈δΒΡ”ΟΜßάύ–Ά
private List <Awrad> awards;//Ϋ±≥Ί÷–ΑϋΚ§ΒΡΫ±ΤΖ
//Β±«ΑΫ±≥Ί «Ζώ”κ≥« –ΤΞ≈δ
public boolean matchedCity (int cityId) {...}
//Β±«ΑΫ±≥Ί «Ζώ”κ”ΟΜßΒΟΖ÷ΤΞ≈δ
public boolean matchedScore (int score) {...}
//ΗυΨίΗ≈¬ ―Γ‘ώΫ±≥Ί
public Award randomGetAward() {
int sumOfProbablity = 0;
for (Award award: awards) {
sumOfProbability + = award.getAwardProbablity();
}
int randomNumber = ThreadLocalRandom .current()
. nextInt (sumOfProbablity);
range = 0;
for (Award award: awards) {
range += award.getProbablity();
if (randomNumber<range) {
return award;
}
}
return null;
}
}
|
¥ζ¬κ―ί Ψ4 AwardPool
”κ“‘ΆυΒΡΫω”–getterΓΔsetterΒΡ“ΒΈώΕ‘œσ≤ΜΆ§Θ§Νλ”ρΕ‘œσΨΏ”–ΝΥ––ΈΣΘ§Ε‘œσΗϋΦ”Ζα¬ζΓΘΆ§ ±Θ§±»ΤπΫΪ’β–©¬ΏΦ≠–¥‘ΎΖΰΈώΡΎΘ®άΐ»γ**ServiceΘ©Θ§Νλ”ρΙΠΡήΒΡΡΎΨέ–‘Ηϋ«ΩΘ§÷Α‘πΗϋΦ”Ος»ΖΓΘ
Ή ‘¥Ωβ
Νλ”ρΕ‘œσ–η“ΣΉ ‘¥¥φ¥ΔΘ§¥φ¥ΔΒΡ ÷ΕΈΩ…“‘ «Εύ―υΜ·ΒΡΘ§≥ΘΦϊΒΡΈόΖ« « ΐΨίΩβΘ§Ζ÷≤Φ ΫΜΚ¥φΘ§±ΨΒΊΜΚ¥φΒ»ΓΘΉ ‘¥ΩβΘ®RepositoryΘ©ΒΡΉς”ΟΘ§ΨΆ «Ε‘Νλ”ρΒΡ¥φ¥ΔΚΆΖΟΈ Ϋχ––Ά≥“ΜΙήάμΒΡΕ‘œσΓΘ‘Ύ≥ιΫ±ΤΫΧ®÷–Θ§Έ“Ο« «Ά®Ιΐ»γœ¬ΒΡΖΫ ΫΉι÷·Ή ‘¥ΩβΒΡΓΘ
// ΐΨίΩβΉ ‘¥
import com. company. team. bussiness. lottery.
repo. dao. AwardPoolDao;// ΐΨίΩβΖΟΈ Ε‘œσ-Ϋ±≥Ί
import com. company. team. bussiness. lottery.
repo. dao. AwardDao;// ΐΨίΩβΖΟΈ Ε‘œσ-Ϋ±ΤΖ
import com. company. team. bussiness. lottery
.repo. dao .po. AwardPO;// ΐΨίΩβ≥÷ΨΟΜ·Ε‘œσ-Ϋ±ΤΖ
import com.company. team. bussiness. lottery.
repo. dao . po. AwardPoolPO;// ΐΨίΩβ≥÷ΨΟΜ·Ε‘œσ-Ϋ±≥Ί
import com.company. team. bussiness. lottery.repo
. cache . DrawLottery CacheAccessObj ; //Ζ÷≤Φ ΫΜΚ¥φΖΟΈ Ε‘œσ-≥ιΫ±ΜΚ¥φΖΟΈ
import com.company. team.bussiness .lottery.repo.
repository . DrawLottery Repository ; //Ή ‘¥ΩβΖΟΈ Ε‘œσ-≥ιΫ±Ή ‘¥Ωβ
|
¥ζ¬κ―ί Ψ5 RepositoryΉι÷·ΫαΙΙ
Ή ‘¥ΩβΕ‘ΆβΒΡ’ϊΧεΖΟΈ ”…RepositoryΧαΙ©Θ§ΥϋΨέΚœΝΥΗςΗωΉ ‘¥ΩβΒΡ ΐΨί–≈œΔΘ§Ά§ ±“≤≥–ΒΘΝΥΉ ‘¥¥φ¥ΔΒΡ¬ΏΦ≠Θ®άΐ»γΜΚ¥φΗϋ–¬Μζ÷ΤΒ»Θ©ΓΘ
‘Ύ≥ιΫ±Ή ‘¥Ωβ÷–Θ§Έ“Ο«ΤΝ±ΈΝΥΕ‘ΒΉ≤ψΫ±≥ΊΚΆΫ±ΤΖΒΡ÷±Ϋ”ΖΟΈ Θ§Εχ «ΫωΕ‘≥ιΫ±ΒΡΨέΚœΗυΫχ––Ή ‘¥ΙήάμΓΘ¥ζ¬κ Ψάΐ÷–’Ι ΨΝΥ≥ιΫ±Ή ‘¥Μώ»ΓΒΡΖΫΖ®Θ®Ήν≥ΘΦϊΒΡCache
Aside PatternΘ©ΓΘ
±»Τπ“‘ΆυΫΪΉ ‘¥ΙήάμΖ≈‘ΎΖΰΈώ÷–ΒΡΉωΖ®Θ§”…Ή ‘¥ΩβΕ‘Ή ‘¥Ϋχ––ΙήάμΘ§÷Α‘πΗϋΦ”Ος»ΖΘ§¥ζ¬κΒΡΩ…ΕΝ–‘ΚΆΩ…Έ§ΜΛ–‘“≤Ηϋ«ΩΓΘ
package com.company.team.bussiness.lottery.repo;
import ...;
@Repository
public class DrawLotteryRepository {
@ Autowired
private AwardDao awardDao;
@ Autowired
private AwardPoolDao awardPoolDao;
@ AutoWired
private DrawLotteryCacheAccessObj drawLotteryCacheAccessObj;
public DrawLottery getDrawLotteryById(int
lotteryId) {
DrawLottery drawLottery = drawLotteryCacheAccessObj
.get (lotteryId);
if (drawLottery!=null){
return drawLottery;
}
drawLottery = getDrawLotteyFromDB(lotteryId);
drawLotteryCacheAccessObj .add(lotteryId, drawLottery
);
return drawLottery;
}
private DrawLottery getDrawLotteryFromDB (int
lotteryId ) {...}
}
|
¥ζ¬κ―ί Ψ6 DrawLotteryRepository
ΖάΗ·≤ψ
“ύ≥Τ ≈δ≤ψΓΘ‘Ύ“ΜΗω…œœ¬ΈΡ÷–Θ§”– ±–η“ΣΕ‘Άβ≤Ω…œœ¬ΈΡΫχ––ΖΟΈ Θ§Ά®≥ΘΜα“ΐ»κΖάΗ·≤ψΒΡΗ≈Ρνά¥Ε‘Άβ≤Ω…œœ¬ΈΡΒΡΖΟΈ Ϋχ––“Μ¥ΈΉΣ“εΓΘ
”–“‘œ¬ΦΗ÷÷«ιΩωΜαΩΦ¬«“ΐ»κΖάΗ·≤ψΘΚ
–η“ΣΫΪΆβ≤Ω…œœ¬ΈΡ÷–ΒΡΡΘ–ΆΖ≠“κ≥…±Ψ…œœ¬ΈΡάμΫβΒΡΡΘ–ΆΓΘ
≤ΜΆ§…œœ¬ΈΡ÷°ΦδΒΡΆ≈Ε”–≠ΉςΙΊœΒΘ§»γΙϊ «Ι©Ζν’ΏΙΊœΒΘ§Ϋ®“ι“ΐ»κΖάΗ·≤ψΘ§±ήΟβΆβ≤Ω…œœ¬ΈΡ±δΜ·Ε‘±Ψ…œœ¬ΈΡΒΡ«÷ ¥ΓΘ
ΗΟΖΟΈ ±Ψ…œœ¬ΈΡ Ι”ΟΙψΖΚΘ§ΈΣΝΥ±ήΟβΗΡΕ·”ΑœλΖΕΈßΙΐ¥σΓΘ
»γΙϊΡΎ≤ΩΕύΗω…œœ¬ΈΡΕ‘Άβ≤Ω…œœ¬ΈΡ–η“ΣΖΟΈ Θ§Ρ«Ο¥Ω…“‘ΩΦ¬«ΫΪΤδΖ≈ΒΫΆ®”Ο…œœ¬ΈΡ÷–ΓΘ
‘Ύ≥ιΫ±ΤΫΧ®÷–Θ§Έ“Ο«Ε®“εΝΥ”ΟΜß≥« ––≈œΔΖάΗ·≤ψ(UserCityInfoFacade)Θ§”Ο”ΎΆβ≤ΩΒΡ”ΟΜß≥« ––≈œΔ…œœ¬ΈΡΘ®ΈΔΖΰΈώΦήΙΙœ¬±μœ÷ΈΣ”ΟΜß≥« ––≈œΔΖΰΈώΘ©ΓΘ
“‘”ΟΜß–≈œΔΖάΗ·≤ψΨΌάΐΘ§Υϋ“‘≥ιΫ±«κ«σ≤Έ ΐ(LotteryContext)ΈΣ»κ≤ΈΘ§“‘≥« ––≈œΔ(MtCityInfo)ΈΣ δ≥ωΓΘ
package com.company.team.bussiness.lottery.facade;
import ...;
@Component
public class UserCityInfoFacade {
@Autowired
private LbsService lbsService; //Άβ≤Ω”ΟΜß≥« ––≈œΔRPCΖΰΈώ
public MtCityInfo getMtCityInfo(LotteryContext
context ) {
LbsReq lbsReq = new LbsReq();
lbsReq.setLat(context.getLat());
lbsReq.setLng(context.getLng());
LbsResponse resp = lbsService .getLbsCityInfo
(lbsReq);
return buildMtCifyInfo (resp);
}
private MtCityInfo buildMtCityInfo (LbsResponse
resp) {...}
}
|
¥ζ¬κ―ί Ψ7 UserCityInfoFacade
Νλ”ρΖΰΈώ
…œΈΡ÷–Θ§Έ“Ο«ΫΪΝλ”ρ––ΈΣΖβΉΑΒΫΝλ”ρΕ‘œσ÷–Θ§ΫΪΉ ‘¥Ιήάμ––ΈΣΖβΉΑΒΫΉ ‘¥Ωβ÷–Θ§ΫΪΆβ≤Ω…œœ¬ΈΡΒΡΫΜΜΞ––ΈΣΖβΉΑΒΫΖάΗ·≤ψ÷–ΓΘ¥Υ ±Θ§Έ“Ο«‘ΌΜΊΙΐΆΖά¥Ω¥Νλ”ρΖΰΈώ ±Θ§ΡήΙΜΖΔœ÷Νλ”ρΖΰΈώ±Ψ…μΥυ≥–‘ΊΒΡ÷Α‘π“≤ΨΆΗϋΦ”«εΈζΝΥΘ§Φ¥ΨΆ «Ά®Ιΐ¥°ΝΣΝλ”ρΕ‘œσΓΔΉ ‘¥ΩβΚΆΖάΗ·≤ψΒ»“ΜœΒΝ–Νλ”ρΡΎΒΡΕ‘œσΒΡ––ΈΣΘ§Ε‘ΤδΥϊ…œœ¬ΈΡΧαΙ©ΫΜΜΞΒΡΫ”ΩΎΓΘ
Έ“Ο«“‘≥ιΫ±ΖΰΈώΈΣάΐΘ®issueLotteryΘ©Θ§Ω…“‘Ω¥ΒΫ‘Ύ Γ¬‘ΝΥ“Μ–©Ζά”υ–‘¬ΏΦ≠Θ®“λ≥Θ¥ΠάμΘ§Ω’÷Β≈–ΕœΒ»Θ©ΚσΘ§Νλ”ρΖΰΈώΒΡ¬ΏΦ≠“―Ψ≠ΉψΙΜ«εΈζΟςΝΥΓΘ
package com.company
.team.bussiness. lottery.service .impl
import ...;
@Service
public class LotteryServiceImpl implements LotteryService
{
@Autowired
private DrawLotteryRepository drawLotteryRepo;
@Autowired
private UserCityInfoFacade UserCityInfoFacade;
@Autowired
private AwardSendService awardSendService;
@Autowired
private AwardCounterFacade awardCounterFacade;
@Override
public IssueResponse issueLottery (LotteryContext
lotteryContext ) {
DrawLottery drawLottery = drawLotteryRepo .getDrawLotteryById
(lotteryContext .getLotteryId()) ;//Μώ»Γ≥ιΫ±≈δ÷ΟΨέΚœΗυ
awardCounterFacade. incrTryCount (lotteryContext);//‘ωΦ”≥ιΫ±ΦΤ ΐ–≈œΔ
AwardPool awardPool = lotteryConfig .chooseAwardPool
(bulidDrawLottery Context ( drawLottery , lotteryContext));//―Γ÷–Ϋ±≥Ί
Award award = awardPool.randomChooseAward();//―Γ÷–Ϋ±ΤΖ
return buildIssueResponse (awardSendService.sendAward(award,
lotteryContext )) ;//ΖΔ≥ωΫ±ΤΖ ΒΧε
}
private IssueResponse buildIssueResponse ( AwardSend
Response awardSendResponse ) {...}
} |
¥ζ¬κ―ί Ψ8 LotteryService
ΐΨίΝςΉΣ
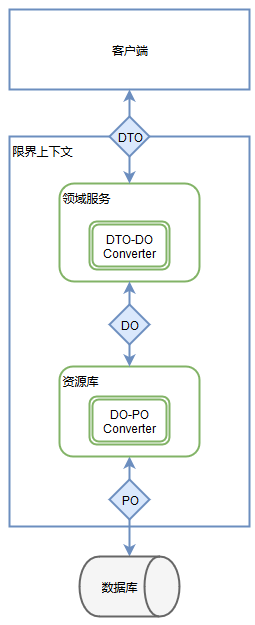
‘Ύ≥ιΫ±ΤΫΧ®ΒΡ ΒΦυ÷–Θ§Έ“Ο«ΒΡ ΐΨίΝςΉΣ»γ…œΆΦΥυ ΨΓΘ
Ήœ»Νλ”ρΒΡΩΣΖ≈ΖΰΈώΆ®Ιΐ–≈œΔ¥Ϊ δΕ‘œσΘ®DTOΘ©ά¥Άξ≥…”κΆβΫγΒΡ ΐΨίΫΜΜΞΘΜ‘ΎΝλ”ρΡΎ≤ΩΘ§Έ“Ο«Ά®ΙΐΝλ”ρΕ‘œσΘ®DOΘ©ΉςΈΣΝλ”ρΡΎ≤ΩΒΡ ΐΨίΚΆ––ΈΣ‘ΊΧεΘΜ‘ΎΉ ‘¥ΩβΡΎ≤ΩΘ§Έ“Ο«―Ίœ°ΝΥ‘≠”–ΒΡ ΐΨίΩβ≥÷ΨΟΜ·Ε‘œσΘ®POΘ©Ϋχ–– ΐΨίΩβΉ ‘¥ΒΡΫΜΜΞΓΘΆ§ ±Θ§DTO”κDOΒΡΉΣΜΜΖΔ…ζ‘ΎΝλ”ρΖΰΈώΡΎΘ§DO”κPOΒΡΉΣΜΜΖΔ…ζ‘ΎΉ ‘¥ΩβΡΎΓΘ
”κ“‘ΆυΒΡ“ΒΈώΖΰΈώœύ±»Θ§Β±«ΑΒΡ±ύ¬κΙφΖΕΩ…ΡήΕύ‘λ≥…ΝΥ“Μ¥Έ ΐΨίΉΣΜΜΘ§ΒΪΟΩ÷÷ ΐΨίΕ‘œσ÷Α‘πΟς»ΖΘ§ ΐΨίΝςΉΣΗϋΦ”«εΈζΓΘ
…œœ¬ΈΡΦ·≥…
Ά®≥ΘΦ·≥……œœ¬ΈΡΒΡ ÷ΕΈ”–Εύ÷÷Θ§≥ΘΦϊΒΡ ÷ΕΈΑϋά®ΩΣΖ≈Νλ”ρΖΰΈώΫ”ΩΎΓΔΩΣΖ≈HTTPΖΰΈώ“‘ΦΑœϊœΔΖΔ≤Φ-Ε©‘ΡΜζ÷ΤΓΘ
‘Ύ≥ιΫ±œΒΆ≥÷–Θ§Έ“Ο« Ι”ΟΒΡ «ΩΣΖ≈ΖΰΈώΫ”ΩΎΫχ––ΫΜΜΞΒΡΓΘΉνΟςœ‘ΒΡΧεœ÷ «ΦΤ ΐ…œœ¬ΈΡΘ§ΥϋΉςΈΣ“ΜΗωΆ®”Ο…œœ¬ΈΡΘ§Ε‘≥ιΫ±ΓΔΖγΩΊΓΔΜνΕ·ΉΦ»κΒ»…œœ¬ΈΡΕΦΧαΙ©ΝΥΖΟΈ Ϋ”ΩΎΓΘ
Ά§ ±Θ§»γΙϊ‘Ύ“ΜΗω…œœ¬ΈΡΕ‘Νμ“ΜΗω…œœ¬ΈΡΫχ––Φ·≥… ±Θ§»τ–η“Σ“ΜΕ®ΒΡΗτάκΚΆ ≈δΘ§Ω…“‘“ΐ»κΖάΗ·≤ψΒΡΗ≈ΡνΓΘ’β“Μ≤ΩΖ÷ΒΡ ΨάΐΩ…“‘≤ΈΩΦ«ΑΈΡΒΡΖάΗ·≤ψ¥ζ¬κ ΨάΐΓΘ
Ζ÷άκΝλ”ρ
Ϋ”œ¬ά¥Ϋ≤Ϋβ‘Ύ Β ©Νλ”ρΡΘ–ΆΒΡΙΐ≥Χ÷–Θ§»γΚΈ”Π”ΟΒΫœΒΆ≥ΦήΙΙ÷–ΓΘ
Έ“Ο«≤…”ΟΒΡΈΔΖΰΈώΦήΙΙΖγΗώΘ§”κVernon‘ΎΓΕ Βœ÷Νλ”ρ«ΐΕ·…ηΦΤΓΖ≤Δ≤ΜΧΪ“Μ÷¬Θ§ΗϋΨΏΧε≤ν“λΩ…‘ΡΕΝΥϊΒΡ ιΧεΜαΓΘ
»γΙϊΈ“Ο«Έ§ΜΛ“ΜΗω¥”«ΑΒΫΚσΒΡ”Π”ΟœΒΆ≥ΘΚ
œ¬ΆΦ÷–Νλ”ρΖΰΈώ « Ι”ΟΈΔΖΰΈώΦΦ θΑΰάκΩΣά¥Θ§ΕάΝΔ≤Ω πΘ§Ε‘Άβ±©¬ΕΒΡ÷ΜΡή «ΖΰΈώΫ”ΩΎΘ§Νλ”ρΕ‘Άβ±©¬ΕΒΡ“ΒΈώ¬ΏΦ≠÷ΜΡή“άΆ–”ΎΝλ”ρΖΰΈώΓΘΕχ‘ΎVernon÷χΉς÷–Θ§≤ΔΈ¥ΦΌΕ®ΈΔΖΰΈώΦήΙΙΖγΗώΘ§“ρ¥ΥΝλ”ρ≤ψ±©¬ΕΒΡ≥ΐΝΥΝλ”ρΖΰΈώΆβΘ§ΜΙ”–ΨέΚœΓΔ ΒΧεΚΆ÷ΒΕ‘œσΒ»ΓΘ¥Υ ±ΒΡ”Π”ΟΖΰΈώ≤ψ «±»ΫœΦρΒΞΒΡΘ§Μώ»Γά¥Ή‘Ϋ”ΩΎ≤ψΒΡ«κ«σ≤Έ ΐΘ§ΒςΕ»ΕύΗωΝλ”ρΖΰΈώ“‘ Βœ÷ΫγΟφ≤ψΙΠΡήΓΘ
ΥφΉ≈“ΒΈώΖΔ’ΙΘ§“ΒΈώœΒΆ≥ΩλΥΌ≈ρ’ΆΘ§Έ“Ο«ΒΡœΒΆ≥ τ”ΎΚΥ–Ρ ±ΘΚ
”Π”ΟΖΰΈώΥδ»ΜΟΜ”–Νλ”ρ¬ΏΦ≠Θ§ΒΪ…φΦΑΒΫΝΥΕ‘ΕύΗωΝλ”ρΖΰΈώΒΡ±ύ≈≈ΓΘΒ±“ΒΈώΙφΡΘ≈”¥σΒΫ“ΜΕ®≥ΧΕ»Θ§±ύ≈≈±Ψ…μΨΆΗΜΚ§ΝΥ“ΒΈώ¬ΏΦ≠Θ®≥ΐ¥Υ÷°ΆβΘ§”Π”ΟΖΰΈώ‘ΎΈ»Ε®–‘ΓΔ–‘Ρή…œΥυΉωΒΡ¥κ ©“≤œΘΆϊΆ≥“ΜΤπά¥Θ§ΕχΖ«…Δ¬δΗς¥ΠΘ©Θ§Ρ«Ο¥¥Υ ±”Π”ΟΖΰΈώΕ‘”ΎΆβ≤Ωά¥ΥΒ «“ΜΗωΝλ”ρΖΰΈώΘ§’ϊΧεΩ¥Τπά¥‘ρ «“ΜΗωΕάΝΔΒΡœόΫγ…œœ¬ΈΡΓΘ
¥Υ ±”Π”ΟΖΰΈώΕ‘ΡΎΜΙ τ”Ύ”Π”ΟΖΰΈώΘ§Ε‘Άβ“― «Νλ”ρΖΰΈώΒΡΗ≈ΡνΘ§–η“ΣΫΪΤ䱩¬ΕΈΣΈΔΖΰΈώΓΘ
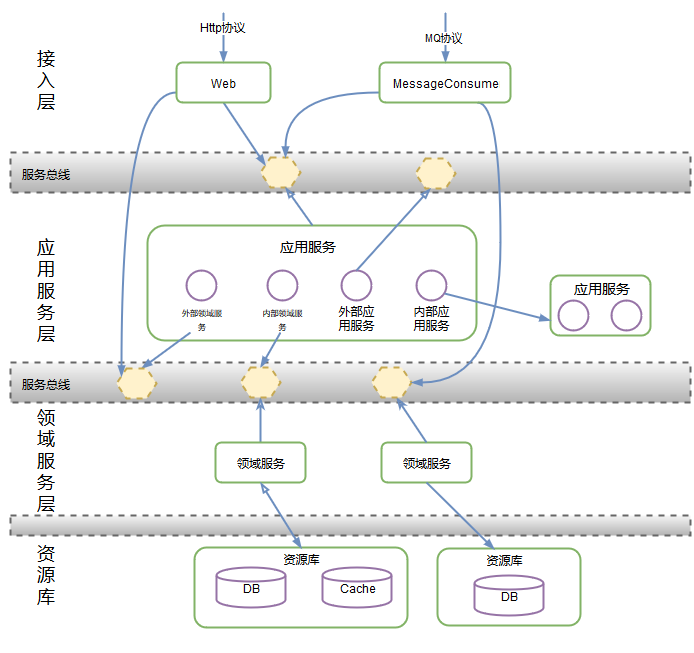
ΉΔΘΚΨΏΧεΒΡΦήΙΙ ΒΦυΩ…Α¥’’Ά≈Ε”ΚΆ“ΒΈώΒΡ ΒΦ «ιΩωά¥Θ§¥Υ¥ΠΫωΈΣΉς’ΏΉ‘…μΒΡ“ΒΈώ ΒΦυΓΘ≥ΐΖ÷≤ψΦήΙΙΆβΘ§»γCQRSΦήΙΙ“≤ «≤Μ¥μΒΡ―Γ‘ώ
“‘œ¬ «“ΜΗω ΨάΐΓΘΈ“Ο«Ε®“εΝΥ≥ιΫ±ΓΔΜνΕ·ΉΦ»κΓΔΖγœ’ΩΊ÷ΤΒ»ΕύΗωΝλ”ρΖΰΈώΓΘ‘Ύ±ΨœΒΆ≥÷–Θ§Έ“Ο«–η“ΣΦ·≥…ΕύΗωΝλ”ρΖΰΈώΘ§ΈΣΩΆΜßΕΥΧαΙ©“ΜΧΉΙΠΡήΆξ±ΗΒΡ≥ιΫ±”Π”ΟΖΰΈώΓΘ’βΗω”Π”ΟΖΰΈώΒΡΉι÷·»γœ¬ΘΚ
package ...;
import ...;
@Service
public class LotteryApplicationService {
@Autowired
private LotteryRiskService riskService;
@Autowired
private LotteryConditionService conditionService;
@Autowired
private LotteryService lotteryService;
//”ΟΜß≤Έ”κ≥ιΫ±ΜνΕ·
public Response <PrizeInfo, ErrorData> participateLottery
(LotteryContext lotteryContext) {
//–Θ―ι”ΟΜßΒ«¬Φ–≈œΔ
validateLoginInfo (lotteryContext);
//–Θ―ιΖγΩΊ
RiskAccessToken riskToken = riskService.accquire
(buildRiskReq (lotteryContext));
...
//ΜνΕ·ΉΦ»κΦλ≤ι
LotteryConditionResult conditionResult = condition
Service .checkLotteryCondition (otteryContext
. getLotteryId (), lotteryContext .getUserId());
...
//≥ιΫ±≤ΔΖΒΜΊΫαΙϊ
IssueResponse issueResponse = lotteryService .issurLottery
(lotteryContext);
if (issueResponse! =null && issueResponse
.getCode()== IssueResponse .OK) {
return buildSuccessResponse (issueResponse .getPrizeInfo
( ));
} else {
return buildErrorResponse (ResponseCode.ISSUE_
LOTTERY_ FAIL , ResponseMsg .ISSUE_ LOTTERY_ FAIL)
}
}
private void validateLoginInfo (LotteryContext
lottery Context ){...}
private Response <PrizeInfo, ErrorData>
buildErrorResponse (int code , String msg){...}
private Response <PrizeInfo, ErrorData>
buildSuccessResponse (PrizeInfo prizeInfo){...}
} |
¥ζ¬κ―ί Ψ9 LotteryApplicationService
Ϋα”ο
‘Ύ±ΨΈΡ÷–Θ§Έ“Ο«≤…”ΟΝΥΖ÷÷ΈΒΡΥΦœκΘ§¥”≥ιœσΒΫΨΏΧε≤ϊ ωΝΥDDD‘ΎΜΞΝΣΆχ’φ “¸ώœΒΆ≥÷–ΒΡ ΒΦυΓΘΆ®ΙΐΝλ”ρ«ΐΕ·…ηΦΤ’βΗω«Ω¥σΒΡΈδΤςΘ§Έ“Ο«ΫΪœΒΆ≥ΫβΙΙΒΡΗϋΦ”ΚœάμΓΘ
ΒΪ÷ΒΒΟΉΔ“βΒΡ «Θ§»γΙϊΡψΟφΝΌΒΡœΒΆ≥ΚήΦρΒΞΜρ’ΏΉω“Μ–©SmartUI÷°άύΘ§Ρ«Ο¥Ρψ≤Μ“ΜΕ®–η“ΣDDDΓΘΨΓΙή±ΨΈΡΕ‘ΤΕ―ΣΡΘ–ΆΓΔ―ίΫχ Ϋ…ηΦΤΧα≥ωΝΥ–©–μΩ¥Ζ®Θ§ΒΪΥϋΟ«‘ΎΧΊΕ®ΖΕΈßΚΆΨΏΧε≥ΓΨΑœ¬ΜαΗϋΗΏ–ßΓΘΕΝ’Ώ–η“Σ’κΕ‘Ή‘ΦΚΒΡ ΒΦ «ιΩωΘ§Ήω“ΜΕ®»Γ…αΘ§ ΚœΉ‘ΦΚΒΡ≤≈ «ΉνΚΟΒΡΓΘ
±ΨΤΣΆ®ΙΐDDDά¥Ϋ≤ ω»μΦΰ…ηΦΤΒΡ θ”κΤςΘ§±Ψ÷ «ΈΣΝΥΗΏΡΎΨέΒΆώνΚœΘ§ΫτΩΩ±Ψ÷ Θ§Α¥Ή‘ΦΚΒΡάμΫβΚΆΆ≈Ε”«ιΩωά¥ ΒΦυDDDΦ¥Ω…ΓΘ
|









