| БрМЭЦМі: |
БОЮФРДздiteye.comЃЌНщЩмСЫСьгђЁЂзггђЁЂЯоНчЩЯЯТЮФЃЌЩЯЯТЮФгГЩфЃЌDDDМмЙЙЕШжЊЪЖЁЃ
|
|
СьгђЁЂзггђЁЂЯоНчЩЯЯТЮФ
DDDЃЈDomain-Drive DesignЃЉЕФИХФюЛђепЫЕвЕНчЕФЩљвєЦфЪЕПЩвдзЗЫнЕНМИЪЎФъЧАСЫЁЃзюНќПЊЪМЯывЊЯЕЭГЕУећРэвЛЯТDDDЕФвЛаЉЖЋЮїЁЃетвЛЦЊЪЧвЛИіМђЕЅЕФв§згЃЌвВЪЧmarkвЛЯТздМКНгДЅЕНЕФИХФюКЭРэНтЁЃ
ЖдгкСьгђЕФИХФюЦфЪЕКмКУРэНтЃЌОЭШчзжУцвтЫМвЛбљЃЌБШШчГіАцЪщМЎСьгђЃЌЙуИцЩшМЦСьгђЁЃШІЖЈСЫвЛЖЈЕФЗЖГыЃЌВЂЧвдкетИіЗЖГыФкЃЌЫљгаЭХЖгГЩдБЖдгкФГвЛИХФюЕФРэНтЪЧвЛжТЕФЁЃБШШчЪщМЎОЭЪЧЮвУЧашвЊГіАцЕФЪщМЎЃЌЖјВЛЪЧБШШчГіАцЩчИјдБЙЄЬсЙЉЕФЪВУДМОЖШНБРјЪщМЎЁЃвВаэетРяЕФР§згЛЙЪЧгаЕуЦЋВюЃЌЕЋЪЧЕБОпЬхЩшМЦЯЕЭГЕФЪБКђОЭЛсШЅЫМПМеце§ЕФвЕЮёБпНчЁЃ
ЮвРэНтЕФСьгђЧ§ЖЏЩшМЦВЛЪЧвЛжжЩшМЦЗчИёЃЌвВВЛЪЧвЛжжМмЙЙФЃаЭЁЃЖјЪЧвЛжжЫМПМЗНЪНЁЃдкПМТЧвЛИіЯюФПЁЂашЧѓЕФЪБКђВЛЛсЯШШЅЫМПМашвЊдѕбљЕФЪ§ОнДцДЂНсЙЙвдМАЛсгаФФаЉааЮЊКЭВйзїашвЊЪЕЯжЁЃЖјЪЧШЅЫМПМвЕЮёжавЛаЉживЊЕФКЫаФНчЯовдМАИХФюЁЃзюживЊЕФОЭЪЧЖЈвхЭЈгУгябдЁЃШчКЮЖЈвхвЛИіЯоНчЩЯЯТЮФЕФЭЈгУгябдЃЌРДБЃжЄдкОпЬхЕФЯЕЭГЩшМЦжаЃЌвВМДвЛИіЯоНчЩЯЯТЮФжаЪЧвЛИіЮЈвЛИХФюЪЧЗЧГЃживЊЕФЁЃЯоНчЩЯЯТЮФАќКЌСЫФЃПщЃЈСьгђФЃаЭЃЉвдМАЩЯЯТЮФЃЌЫљвдЫќвВЪЧвЛИіЯдЪОБпНчЁЃ
ЯоНчЩЯЯТЮФжаЕФЪѕгявЛЖЈзМШЗЗДгГЭЈгУгябдЯоНчЩЯЯТЮФПЩвдЪЧЮвУЧЕФвЛИіЯЕЭГЁЃБШШчзюГѕЃЌЮвУЧвЊИјвЛИіЭМЪщЙнПЭЛЇзівЛИіЯЕЭГЃЌАќКЌСЫЭМЪщЙнЕФЪщМЎЙмРэЃЌШыПтЁЂНшГіЁЃШЛКѓЭМЪщЙнгжЬсГіЃЌБШШчФГаЉЪщМЎЪЧзЈУХТєЕФЃЌШЛКѓФГаЉЪщМЎЪЧзЈУХТђНјРДНБРјвЛаЉЛсдБЕФНБЦЗЁЃШЛКѓЮвУЧашвЊШЗЖЈЃЌЁАЪщЁБетИіИХФюЃЌЪЧВЛЪЧвбОв§Ц№СЫЦчвхЁЃЕБЮвУЧЕФПЊЗЂШЫдБЫЕГіЪщетИіДЪЕФЪБКђЃЌПЩФмгаЕФШЫРэНтЪЧашвЊНшЕФЪщЃЌгаЕФШЫРэНтЪЧЛиРЁПЭЛЇЕФНБЦЗЁЃетИіЪБКђОЭГіЯжСЫЖдгкЁАЪщЁБЕФРэНтВЛвЛжТЃЌвВОЭЮЅЗДСЫСьгђФЃаЭЕФЭЈгУадЁЃЮвУЧЕФЯЕЭГБпНчЃЌгІИУЪЧЭъећЕФБэДявЛИіСьгђФЃаЭЃЌЛђепЫЕЪЧЭЈгУгябдЁЃетОЭЯёвєРжМвДДзїЕФНЛЯьРжЦзвЛбљЃЌЖрвЛИівєЗћВЛЖрЃЌЩйвЛИівєЗћВЛЩйЃЌИеИеКУКУЃЌЭъећЖјгХУРЕУПЩвдбнзрГіРДвЛЦЊЛЊРіЕФзїЦЗЁЃЫљвдЯЕЭГЩшМЦвВЪЧвЛбљЃЌЮвУЧЫљЫЕЕФСьгђзЈМвЦфЪЕОЭЪЧОпБИФмЯИжТЕУЛЎЗжСьгђБпНчЃЌвдМАДгИДдгЕФвЕЮёжаГщЯѓГіРДЭЈгУгябдЕФШЫЁЃЫљвдИеВХЕФЭМЪщЙнЕФР§згЃЌдкТфЕиЕНЯЕЭГжаЕФЪБКђЃЌОЭашвЊПМТЧЯЕЭГЛЎЗжСЫЁЃГіЪлЪщЕФЯЕЭГжаЕФЪщЃЌВЛЛсЪЙгУзтЪщЯЕЭГжаЕФЪщЕФЪЕЬхРДДІРэздМКЕФСьгђЪТМўЁЃ
дкЯоНчЩЯЯТЮФЖЈвхКУжЎКѓЃЌОЭПЩвдЛЎЖЈКЫаФгђСЫЁЃБШШчетРяЃЌЭМЪщЙнЕФКЫаФвЕЮёЪЧзтЪщРДЪеШЁЖЈЦкЕФдФЖСЗбгУЁЃФЧУДзтЪщЩЯЯТЮФжаЕФзтЪщЗўЮёОЭЪЧЮвУЧЕФКЫаФгђСЫЁЃЭМЪщЙнЕФГЁОАжаЃЌЛЙашвЊгавЛИіЖРСЂЕФгУЛЇЯЕЭГЃЌРДЙмРэгУЛЇЕЧТМКЭгУЛЇЛљБОаХЯЂЁЃзтЪщЩЯЯТЮФЃЌЪлЪщЩЯЯТЮФЖМЛсашвЊЕїгУгУЛЇЙмРэЩЯЯТЮФЁЃгУЛЇЙмРэЩЯЯТЮФОЭЪЧвЛИіЭЈгУзггђЁЃЕБШЛЛЙгаЦфЫћзггђЃЌгааЉзггђПЩФмЙВЯэвЛаЉзДЬЌЃЌЪЧвЛжжазїЩЯЯТЮФЁЃ
ЩЯЯТЮФгГЩф
ЕБЮвУЧашвЊЩшМЦЖрИіЩЯЯТЮФРДЭъГЩашЧѓЕФЪБКђЃЌОЭЛсвЊПМТЧЩЯЯТЮФжЎМфЪЧЗёДцдкзХвЛаЉСЊЯЕЁЃОЭШчЩЯЪіЃЌгУЛЇЙмРэЩЯЯТЮФОЭЪЧвЛИіЩЯгЮЯЕЭГЃЌГЩЮЊЦфЫћЯЕЭГЕФжЇГХзггђЁЃЕБЮвУЧашвЊдкзтЪщЯЕЭГжаашвЊгУЛЇаХЯЂЕФЪБКђПЩвдгаМИжжзіЗЈЃК
1.ЙВЯэФкКЫЗНЪНЃКЖдгкФЃаЭКЭДњТыЕФЙВЯэЃЌЕЋЪЧеташвЊЭХЖгжЎМфазїНєУмЃЌЪМжеБЃГжЭЈгУгябдЕФвЛжТад
2.ПЭЛЇ-ЙЉгІЙиЯЕЃКЩЯгЮЭХЖгЕФПЊЗЂашЖРСЂгкЯТгЮЃЌВЂЧввВвЊОЁСПЙРМЦЯТгЮЭХЖгЪЧашЧѓКЭЪБМфЁЃ
3.ЗРИЏВуЃЈAnticorruption LayerЃЉ: ЯТгЮЯЕЭГЖдЩЯгЮФЃаЭНјааЗвыЁЃЗРИЏВуЕФНгПкгУРДКЭЦфЫћЯЕЭГНЛЛЅЃЌдкЗРИЏВуФкВПЃЌРДЪЕЯжФЃаЭИХФюЕФзЊЛЛЁЃ
4.ПЊЗХжїЛњЗўЮёЃЈOpen Host ServiceЃЉ:ЖЈвхавщЃЌШУЦфЫћЯЕЭГЭЈЙ§авщЗУЮЪЯЕЭГЗўЮёЁЃ
5.ЗЂВМгябдЃЈPublished LanguageЃЉ:дкСНИіЯоНчЩЯЯТЮФжЎМфЗЂВМвЛИіЙЋгУгябдгІгУгкЗвыФЃаЭжаЁЃ
дкЪЕМЪЕФМЏГЩжаЮвУЧПЩФиЙ§ашвЊНсКЯЖржжгГЩфЗНЪНЁЃБШШчЃЌШчЙћЪЙгУЗжРыФкКЫЃЈКЭЙВЯэФкКЫЯрЖдЕФЃЉЃЌПЩвддкЩЯгЮгУЛЇЙмРэЩЯЯТЮФжаЪЙгУПЊЗХжїЛњЗўЮёКЭЗЂВМгябдЃЌШЛКѓЯТгЮЕФНшЪщЩЯЯТЮФЭЈЙ§ЗРИЏВуРДНјааФЃаЭЕФзЊЛЛЁЃетжжЩЯЯТЮФЕФгГЩфБЃжЄСЫЭЈгУгябддкЫљгаФЃПщЕФДПНрадЁЃУПИіЩЯЯТЮФЕФПЊЗЂЭХЖгОЭжЛашвЊзЈзЂгкздМКЩЯЯТЮФЕФСьгђКЭЭГвЛЕФгябдЛЗОГжаОЭПЩвдСЫЁЃ
дкЪЕМЪЕФЪЕЯжЪжЖЮЩЯПЩвдгаЖржжЗНЪНЃЌБШШчПЊЗХжїЛњЗўЮёЃЌПЩвдЪЙгУRestЕФЗНЪНЃЌЛђепRPC ЛњжЦЃЌЛђепЯћЯЂЛњжЦЁЃЗЂВМгябдПЩвдЪЙгУXMLЁЂJsonЁЂprotocal
bufferЕШЛђепЯћЯЂЕФаЮЪНЁЃЗРИЏВуОЭЪЧАбЭтНчЕФИХФюЗвыГЩБОЩЯЯТЮФЕФЖдЯѓЁЃдкПЊЗЂЙ§ГЬжавВПЩвдгУвЛаЉИХФюгГЩфЙиЯЕРДБэДяЭЈгУгябдЁЃЭХЖгГЩдБЙВЯэетаЉИХФюЃЌВЂЧвЪБПЬЬсабздМКЫљЙизЂЕФСьгђЗЖЮЇЁЃЩЯгЮЩЯЯТЮФашвЊАбзЪдДВЛПЩгУЯдЪОБЉТЖГіРДЃЌЯТгЮЩЯЯТЮФашвЊФме§ШЗДІРэЩЯгЮЕФФЃаЭзДЬЌЁЃдкЪЕЪЉжаПЩвдгУЯћЯЂЛњжЦЃЌЛђепзівЛаЉвьВНЕФЬНВтвРРЕЕФЩЯЯТЮФЕФПЩгУзДЬЌЕШЁЃ
DDDМмЙЙ
жегкЕНСЫе§ЮФЁЃКѓУцАДееМИжжБШНЯЦеБщЕФЗжРрГТЪіЁЃ
вРРЕЕЙжУ
ЯждкжїСїЕФПђМмжаЃЌвРРЕЕЙжУМђбджЎОЭЪЧвРРЕНгПкЁЂГщЯѓЃЌЖјВЛЪЧвРРЕОпЬхЕФЪЕЯжЁЃетжжЗжВуЕФаЮЪНЃЌдкЯждкЕФЯЕЭГМмЙЙжаЖМЦеБщСїааЁЃJavaгябдЕФSpringОЭЪЧвЛИіЕфаЭЕФМљаавРРЕЕЙжУЕФПђМмЁЃетжжЛљгкГщЯѓЕФЗжВуЃЌФмШУгІгУЗўЮёКЭСьгђЗўЮёКмКУЕФНтёюЁЃЕЋЪЧгаЪБКђЙ§ЖШЕУЩшМЦЗжВувВЛсЕЙжУЦЖбЊФЃаЭЁЃЦЖбЊФЃаЭКЭЗДФЃЪНетжжЛАЬтвВЪЧШєИЩФъУЛгаЬжТлГівЛИіЫЪЧЫЗЧЕФЛАЬтЃЌетРяОЭВЛеЙПЊСЫЁЃЦфЪЕЃЌжЛвЊЪЧЖдСьгђФЃаЭгае§ШЗЕФГщЯѓЃЌФмЗДгІГівЛЬзЭГвЛЕФЭЈгУгябдЃЌдйИљОнОпЬхЕФвЕЮёЪБМфШЅбЁдёздМКЕФМмЙЙЗНЪНОЭзуЙЛСЫЁЃ
ЫљвдетРяЯЃЭћдкЪЕМљЕФЙ§ГЬжаЃЌашвЊМсГжВЛвЊЙ§ЖШвРРЕгІгУЗўЮёЃЌШУгІгУЗўЮёЕФГщЯѓГаЕЃСЫЬЋЖрЕФСьгђЗўЮёжАд№ОЭПЩвдСЫЁЃСэЭтЃЌгІгУЗўЮёКЭСьгђЗўЮёЪЧСНИіЭъШЋВЛЭЌЕФИХФюЁЃгІгУЗўЮёПЩвдКЭЦфЫћЩЯЯТЮФНјааЗўЮёЪфГіЁЂЪфШыЁЂПЩвдДІРэЪТЮёКЭИДдгЕФвЕЮёТпМЁЃЕЋЪЧСьгђЗўЮёЪЧИќМгЧсСПМЖЕФЃЌЮЊгІгУЗўЮёЬсЙЉСьгђВйзїЕФЁЃШчЙћНЋМЦЫуКЭбщжЄНсКЯдкЪЕЬхжаОЭЪЧГфбЊФЃЪНЃЌШчЙћЪЧашвЊЖрИіСьгђОлКЯЕФОЭПЩвддйГщЯѓГіРДвЛВуЕЅЖРЕФСьгђЗўЮёВуЁЃЕБШЛСьгђЗўЮёвВВЛвЛЖЈвЊгУвРРЕЕЙжУЃЌЛђепЫЕЃЌвЕЮёСьгђЗўЮёИљБОВЛашвЊНгПкЃЌвђЮЊСьгђзЈЪєЕФЖЋЮїЃЌВЛЯЃЭћЯђПЭЛЇЖЫаЙТЖРЉеЙЗНЪНЁЃ
СљБпаЮ
СљБпаЮЕФМмЙЙЪЧКмЪЪКЯКЭСьгђЧ§ЖЏНсКЯЕФМмЙЙЗНЪНЁЃСљБпаЮМмЙЙЕФМђЕЅМмЙЙЭМШчЯТЃК
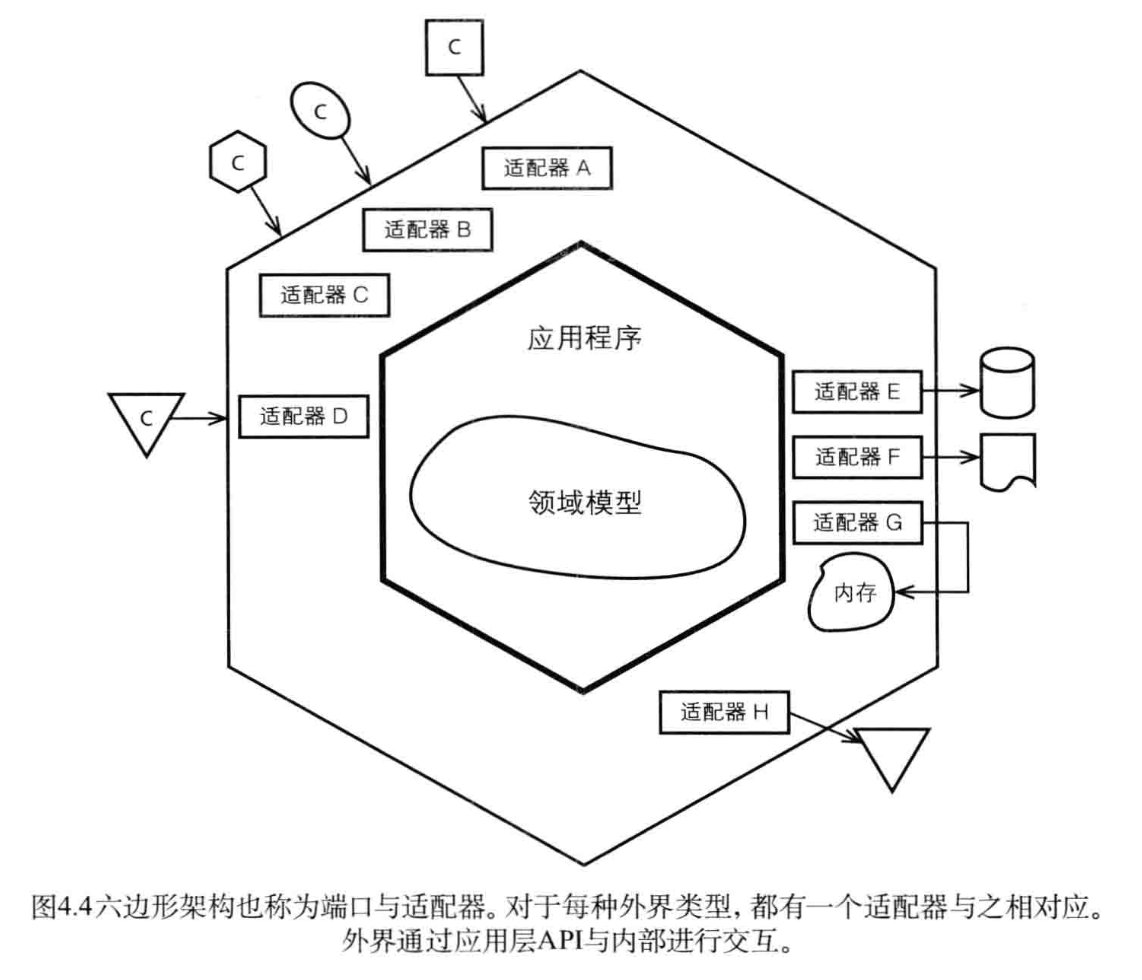
ЭМЦЌРДздЁЖЪЕМљСьгђЧ§ЖЏЩшМЦЁЗЁЃЮоТлЪЧSOA ЛђепЪЧRESTful ЖМКмЪЪгУСљБпаЮЕФМмЙЙЁЃЮвОѕЕУетРяЕФСљБпаЮЬхЯжСЫвЛжжЦНЕШадЃЌОЭЯёЗфГВвЛбљЁЃУПвЛИіЮбЖМЪЧЦНЕШЕФЃЌВЂЧвПЩвдКмКУЕиНЛЛЅЁЃаТдівЛИіРЉеЙЕФClientжЛвЊаТдівЛИіЪЪХфЦїОЭПЩвдНЋclientЕФЪфШызЊЛЏГЩЯЕЭГФкВПЕФAPIЕФВЮЪ§ФЃаЭЁЃЯЕЭГЪфГіЗўЮёвВЪЧвЛбљЕФЁЃЫљвдСљБуЯАЙпЕФЙиМќОЭЪЧУПИіЪЪХфЦїЁЃУПИіЭтНчЕФРраЭЖМгавЛИіЪЪХфЦїЯыЖдгІЁЃЭтНчЭЈЙ§APIКЭЯЕЭГНЛЛЅЃЌПЩвдЪЙвЛИіHttpЧыЧѓЃЌвВПЩвдЪЧЯћЯЂЛњжЦЁЃЪЪХфЦїНЋЭтНчЕФЧыЧѓЛђепФкВПЕФЪфГіЖМЭЈЙ§APIВЮЪ§ЕФаЮЪНРДЩшМЦКЭНЛЛЅЁЃЖдгкВЮЪ§гГЩфПЩвдВЩгУКмЖрПђМмРДАяжњЭъГЩЁЃСљБпаЮЕФФкВПОЭЪЧСьгђФЃаЭЕФгІгУЁЃЭЈЙ§ЪЪХфЦїЃЌФмНјааКмКУЕФЯЕЭГМфЗРИЏЃЌзіЕНЭтНчВЮЪ§КЭСьгђФЃаЭЕФЛЅЯрзЊЛЛЁЃSpring
ПђМмЖдгкRestfulЕФВЮЪ§гГЩфКЭзЪдДгГЩфвВгаКмКУЕФжЇГжЁЃЭЈЙ§зЂНтЕФЗНЪНЃЌОЭПЩвдЭъГЩЪЪХфЦїгІИУзіЕФЙЄзїЁЃОпЬхЕФР§згПЩвдВЮПДЯТSpring
Annotation Based ControllersЁЃ
SOA
SOA МмЙЙЭМШчЯТЃК
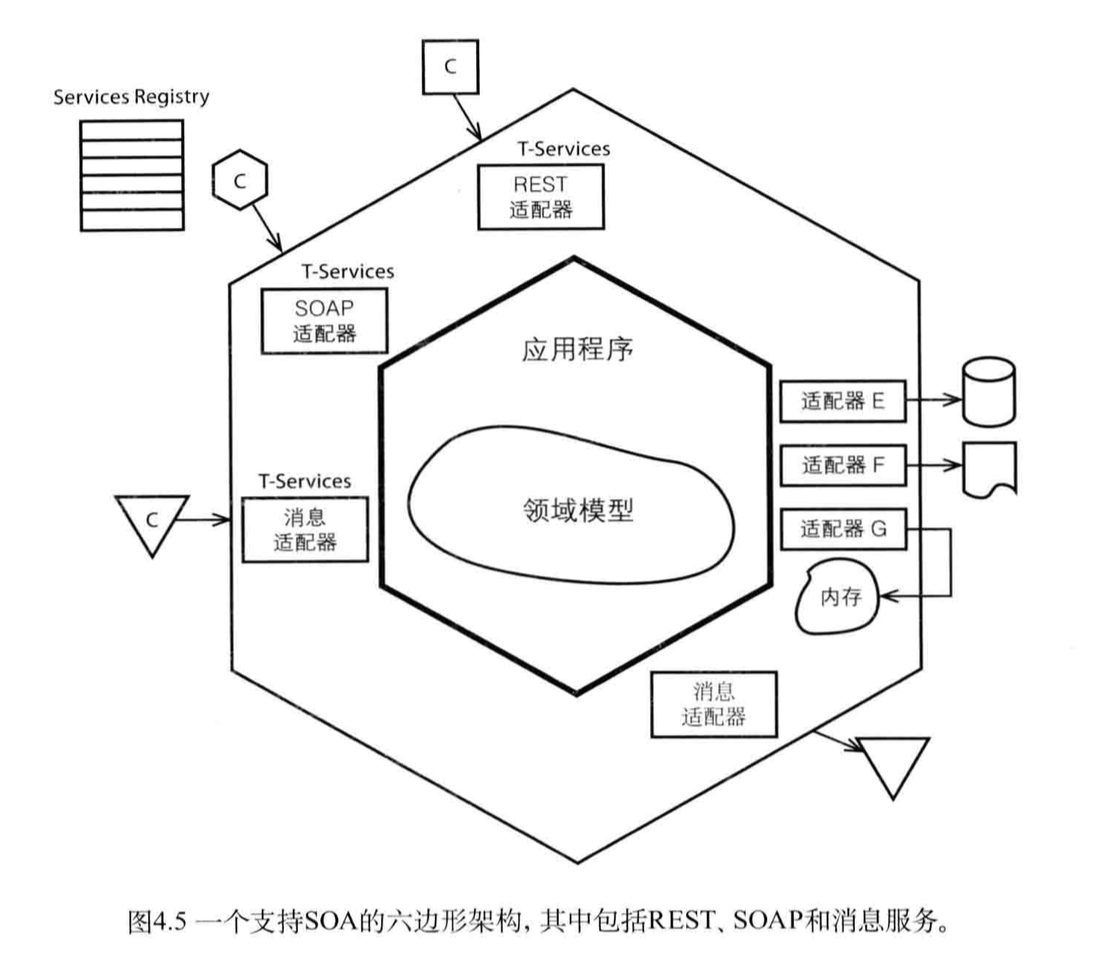
SOAСљБпаЮ SOAНсЙЙжаЃЌЗўЮёЕФБпНчЪЧдкСљБпаЮЕФЭтВуЃЈетРяЕФСљБпаЮвРШЛЪЧУшЪіСЫЕЅИіЩЯЯТЮФЕФНсЙЙЃЉЁЃдкЩшМЦSOA
МмЙЙЕФЪБКђЃЌВЛгІИУвдREST ЛђепSOAP ЛђЯћЯЂРраЭРДОіЖЈЩЯЯТЮФЕФДѓаЁЁЃетбљЛсЕМжТЖрИіаЁЕФЯоНчЩЯЯТЮФКЭСьгђФЃаЭЁЃЫљвддкЩшМЦЗўЮёЕМЯђЕФЩЯЯТЮФЕФЪБКђашвЊзЂвтБЃжЄЩЯЯТЮФЫљвЊБэДяЕФЭЈгУгябдЕФСьгђФЃаЭЁЃ
RESTFul Http
RESTFul ЕФМмЙЙжаЃЌУПИізЪдДЖМгавЛИіURI,ЭЈЙ§зЪдДЕФЗНЪНРДЯђЭтНчЬсЙЉВйзїКЭЗУЮЪШыПкЁЃRestfulЪЧОпгаЁБPresentationЁБКЭЁБStateЁБЕФЁЃ
- еЙЯжЕФИёЪНПЩвдЪЧxmlЁЂjsonЛђепhtmlЃЌЛђепЖўНјжЦЕФЪ§ОнЁЃ
- ЮозДЬЌБэЪОЕФЪЧвЛжжЧыЧѓЕФЖРСЂадЃЌЬсИпПЩЩЯЯТЮФЕФПЩЩьЫѕадЁЃ
ЖдгкзЪдДШЗЖЈжЎКѓОЭПЩвдШЗЖЈВйзїНгПкЃЈШчHttpЕФgetЁЂpostЁЂputЁЂdeleteЕШЃЉЁЃЕЋЪЧдкЩшМЦНгПкжаВЛгІИУНЋСьгђФЃаЭБЉТЖИјЭтНчЃЌВЛФмвђЮЊСьгђФЃаЭЕФИФБфЕМжТЯЕЭГНгПкЕФБфЛЏЁЃЫљвдRestful
ПЩвдНсКЯСљБпаЮМмЙЙЁЃгУSpringЕФweb.bindЗўЮёОЭПЩвдКмКУЕиЪЕЯжетИіЩЯЯТЮФБпНчЕФЩшМЦЁЃ
ЮЊСЫКЭСьгђЧ§ЖЏКмКУЕФНсКЯЃЌЛЙПЩвдКЭЮЂЗўЕФМмЙЙЫМЯывЛЦ№ПМТЧЃЌШчЙћУПИіЩЯЯТЮФЖМЪЧвЛИіЮЂЗўЃЌПЩвдЖРСЂВПЪ№ЁЃФЧУДдкУПИіСьгђЕФЯоНчЩЯЯТЮФжЎМфПЩвдНЈСЂвЛИіЭГвЛЕФЯЕЭГНгПкВуЁЃЫљгаашвЊЖрИіСьгђЩЯЯТЮФЕФЧыЧѓЖМПЩвдЭЈЙ§етИіЯЕЭГНгПкВуЁЃНЋКЫаФСьгђКЭИїИіазїЩЯЯТЮФЕФСьгђНтёюЁЃетжжЪЧЖдгкИїИіЩЯЯТЮФУЛгаЛЅЯрвРРЕЕФЧщПіЯТРДЫЕЪЧвЛжжКмКУЕФЗўЮёЪфГіЗНЪНЃЌВЂЧвЛЙПЩвдгУКмЖрвьВНЁЂВЂЗЂПижЦПђМмРДЬсИпЧыЧѓДІРэЕФадФмЁЃ
ЖдгкЩЯЯТЮФжЎМфвРРЕЃЌЦфЪЕГ§СЫRPC,вВПЩвдЭЈЙ§ЪТМўЧ§ЖЏЛђепЛЙЪЧгУRestfulЕФЗНЪННјааМЏГЩЁЃЕЋЪЧЮоТлвдЪВУДЗНЪНЛђепММЪѕЪжЖЮРДЪЕЯжЃЌЖМвЊзЂвтВЛвЊНЋЭтВПЕФСьгђФЃаЭБЉТЖИјБОЕиЯЕЭГЃЌЛђепАбБОЕиЯоНчЩЯЯТЮФЕФСьгђФЃаЭБЉТЖИјЭтВПЁЃОпЬхЕФДІРэЗНЪНЃЌвРОнВЛЭЌЕФМмЙЙЛсгаВЛЭЌЕФЪЕЯжЁЃШчЙћЪЧRestful
ЕФЗНЪНЃЌПЩвдЭЈЙ§вЛИіЪЪХфЦїЃЈAdapterЃЉРДЪЕЯжhttp ЧыЧѓЕФзЊЗЂЃЌКЭЖдБОЕиФЃаЭЃЈDTOЃЉгГЩфЕФДІРэЁЃШЛКѓНЋФЃаЭзЊЛЏНјвЛВННЛИјЗвыЦї(Translator)ЃЌЗвыЦїИКд№НЋдЖГЬЖдЯѓЃЈЦфЫћЯоНчЩЯЯТЮФЕФDTO,ЖјЗЧСьгђФЃаЭЃЉзЊЛЏЮЊБОЕиDTOЃЌетИіЙ§ГЬПЩвдгУSpringЕФRestTemplateЃЈвВПЩвдНјвЛВНЖдгкtemplateЗтзАвЛВуБОЕиЗўЮёЕФFacadeЃЉРДАяжњЖдHttpClient
ЕФЗтзАКЭJSONЪ§ОнНјааДІРэЁЃ
CQRS
CQRS ЪЧУќСюВщбЏЕФд№ШЮЗжРыCommand Query Responsibility SegregationЕФМђГЦЁЃЦфЪЕПЩвдМђЕЅРэНтЮЊЖСЃЈQuery
ЧыЧѓЃЉаДЃЈCommendЧыЧѓЃЉЗўЮёЕФЗжРыЁЃCQRSПЩвдКмКУЕФНтОіИДдгЕФНчУцЯдЪОЕФЮЪЬтЁЃвЛИіНгПкЛђепЪЧЛёШЁВЮЪ§ДІРэУќСюЕФЃЌЛђепЪЧЗЕЛиЪ§ОнЕФЁЃетбљЕФЗжРыПЩвддкЖСаДСНИіВуДЮЩЯЗжБ№ГщШЁГіВЛЭЌЕФЯЕЭГЗўЮёЁЃCКЭQЕФЪ§ОнПЩвдЭЈЙ§СьгђЪТМўЕФЗНЪННјааЭЌВНЁЃCQRSвЛЦЊКмКУЕФзмНсПЩвдВЮПМвЛЯТCQRSМмЙЙМђНщ
ЪТМўЧ§ЖЏ
Event-Driven Architecture(EDA) ЭЈЙ§ЯћЯЂЛњжЦПЩвдКмКУЕиЭъГЩЩЯЯТЮФжЎМфЕФНтёюЁЃЕБШЛдкбЁдёгУЯћЯЂМЏГЩЕФЪБКђЃЌЖдгкПЩППадКЭЪЕЪБадЩЯЕФвЊЧѓашвЊзіКУШЈКтЁЃЪТМўЧ§ЖЏПЩвдНсКЯдкСљБпаЮЕФМмЙЙКЭRestfulМмЙЙжаЁЃзїЮЊвЛжжИЈжњЕФНтёюЗНЪНЁЃБОЕиЕФЯћЯЂПЩвдЭЈЙ§guavaЕФEventbusЃЌМЏШКЕФПЩвдЭЈЙ§RabbitMQРДЪЕЯжЁЃ
ЖдгкЪТМўдДРДЫЕЃЌЪТМўЗЂВМашвЊЖдгкСьгђЖдЯѓЕФаоИФНјааИњзйЃЌОлКЯЩЯЕФУПвЛДЮВйзїЖМгавЛИіСьгђЪТМўЗЂВМГіШЅЃЌУПвЛИіСьгђЪТМўЖМашвЊБЛБЃДцЕНвЛИіЪБМфДцДЂжаЃЌетбљПЩвдБЃжЄЖдгкЪТМўЗЂВМЧАКѓЕФИїИізДЬЌЖМФмЛиЫнЁЃдкЪЕЯжзюжевЛжТадЩЯЃЌЯћЯЂЛњжЦЭљЭљашвЊИќМгИДдгЕФДІРэЁЃЖЉдФЗНвВМДObserverжаЕФЙлВьепашвЊЖдЪБМфНјааДцДЂЁЃЕБПЭЛЇЖЫашвЊВщевОлКЯЪЕР§ЕФЪБКђЃЌЭЈЙ§зЪдДПтдйЯђЪТМўДцДЂжаВщевзюжеашвЊЕФОлКЯЪЕР§ЁЃЕБОлКЯЪЕР§ЗЂЩњБфЛЏЕФЪБКђдйжДааЪЕМљЕФЗЂВМЁЃЮЇШЦвЛИіОлКЯЕФЪЕР§ОЭаЮГЩСЫвЛИіЩњВњКЭЯћЗбЕФБеЛЗЁЃећИіЪТМўЛњжЦжаЛЙвЊПМТЧжиЗЂЛњжЦвдМАГЌЪБЪБМфЁЃЖЉдФЗНашвЊУнЕШЕУДІРэЪТМўЃЌВЂЧвдйзДЬЌВЛвЛжТЕФЪБКђЃЌПЩвдНјааЪЇАмВЙГЅЁЃШчЙћдЪаэЪЇАмЃЌФЧОЭПЩвджБНгВЩгУЙЄзїСїЕФЗНЪНЁЃдкОпЬхЕФЪЕЪЉжаПЩвдгаКмЖрЗНЪНЃЌЖМашвЊИљОнЪЕМЪЕФГЁОАКЭЭЖШыВњГізіОпЬхЕФКтСПЁЃ
Ъ§ОнЭјжЏ
DataFabric жївЊЪЧдкДѓЪ§ОнДІРэЩЯЕФвЛжжМмЙЙЗНАИЃЌДІРэDB адФмЦПОБЕФЪБКђПЩвдНЋСьгђФЃаЭвдађСаЛЏЕФЗНЪНЗХЕНЛКДцжаЃЌОпЬхЕФБЃДцЗНЪНПЩвдЪЧЮФБОЁЂjsonИёЪНЃЌвВПЩвдЪЧЖўНјжЦЪ§ОнЁЃПЩвдЭЈЙ§КмЖрNosqlММЪѕРДЪЕЯжЃЌGemFireЁЂCoherenceЁЂredisЁЂMongoЕШЁЃ
Нсгя
вдЩЯЕФЫљгаМмЙЙЖМПЩвдЭЈЙ§DDDЕФЫМЯыНјааЪЕЯжЃЌдкЪЕМЪЕФЯЕЭГМмЙЙЩЯЃЌПЯЖЈвВВЛжЙЪЧжЛгІгУЦфжаЕФвЛжжЁЃСљБпаЮвЛАуЖМПЩвдНсКЯRestfulЛђепЪТМўЧ§ЖЏЁЃЕБШЛЮоТлВЩгУЪВУДМмЙЙЛђепММЪѕЪжЖЮЃЌЛиЙщЕНСьгђЧ§ЖЏЕФКЫаФОЭЪЧЖдгкЭЈгУгябдЕФЖЈвхЁЃЯоНчЩЯЯТЮФвЊБЃжЄздМКЕФДПДтадЃЌОЁСПМѕЩйЩЯЯТЮФМфЕФзёЗюЙиЯЕЛђепЙВЯэФкКЫЁЃОЁСПБЃжЄЯЕЭГЕФзджЮадЃЌЖдЦфЫћЯЕЭГЕФЮоИажЊадЃЌВЛвЊНЋЯЕЭГФкВПЕФСьгђФЃаЭБЉТЖИјПЭЛЇЖЫЁЃКѓУцЛсМЬајГщПеЖдDDDЕФЪЕЪЉНјааЯъЯИЕФзмНсКЭећРэЁЃ
|









