| БрМЭЦМі: |
БОЮФРДздInfoQЃЌБОЮФЭЈЙ§ЖдDDDЕФЬНЬж.вРРЕКЭВтЪдЃЌНщЩмСЫАЂРяКаТэСьгђЧ§ЖЏЩшМЦЪЕМљЁЃ
|
|
ЧАбд
ЩшМЦЪЧАбЫЋШаНЃЃЌУЛгазюКУЕФЃЌвВУЛгаИќКУЕФЃЌЖјЪЧЬѕЬѕДѓТЗЕНКМжнЁЃЭЌЪБВЛЩшМЦКЭЙ§ЖШЩшМЦЖМЪЧгаЮЪЬтЕФЃЌЧЁЕНКУДІЕФЩшМЦВХЪЧЮвУЧзЗЧѓЕФМЋжТЁЃ
DDDЃЈDomain-Driven DesignЃЌСьгђЧ§ЖЏЩшМЦЃЉжЛЪЧвЛИіСїХЩЃЌЬИВЛЩЯбЙЕЙадгХЪЦЃЌИќВЛЪЧЭъУРЮоШБЁЃ
ЮвИќЯыИњДѓМвЗжЯэЕФЪЧЮвУЧЪЧЗёЙизЂЩшМЦБОЩэЃЌВЛЙмЪВУДСїХЩЕФЩшМЦЃЌгаЩшМЦОЭЪЧКУЕФЁЃ
ДгЮвПДЕНЕФДњТыЩЯРДНВЃЌАЂРяМЏЭХФкВПДѓВПЗжДњТыЖМВЛЪєгк DDD РраЭЃЌгаЩшМЦЕФвВВЛЖрЃЌИќЖрЕФЯёЁАУцЬѕДњТыЁБЃЌДгЖЫЩЯвЛЬѕЯпЩБЕНЪ§ОнПтЭъГЩвЛИіВйзїЃЌНігаЕФвЛаЉЩшМЦМЏжадкЪ§ОнПтЩЯЁЃЮвУЧвРППЧПДѓЕФВтЪдБЃжЄСЫШэМўЕФЭтВПжЪСПЃЈЯђПрБЦЕФВтЪдУЧжТОДЃЉЃЌЖјФкВПжЪСПдкНєеХЕФЯюФПжмЦкжаТХТХЕУВЛЕНжиЪгЃЌЯнШыШеИДвЛШеЕФММЪѕИКеЎжаЁЃ
вЛжБЯыаДЕуЪВУДЛНЦ№ДѓМвЕФЩшМЦвтЪЖЃЌЕЋВЛжЊЕРаДЕуЪВУДКЯЪЪЁЃШЅФъзЊЕНКаТэЃЌгаСЫИќЖрЕФЛњЛсаДДњТыЃЌПЩвдДгЮоЕНгаШЅЙЙНЈвЛИіЯЕЭГЁЃКаТэИњМЏЭХДѓЖрЪ§вЕЮёВЛЭЌЃЌКаТэЕФвЕЮёИќУцЯђ
B ЖЫЃЌДгЙЉгІЕНХфЫЭСДЬѕЃЌећЬхадКмЧПЃЌЙиЯЕИДдгЃЌВЛећРэЧхГўЃЌЫвВИуВЛУїАзЗЂЩњЪВУДСЫЁЃЫљвдетРяЩшМЦКмживЊЃЌВЛЩшМЦЕФДњТыНёЬьВЛЫРвВЪЧЭЯЕНУїЬьШЅЫРЃЌВЛЙмЮвУЧдкКаТэД§ЖрОУЃЌВЛФмИјЮДРДЕФажЕмЭкПгАЁЁЃдкЮвИКд№ЕФФЃПщРяЃЌЮвУЧЭъећЕигІгУСЫ
DDD ЕФЗНЪНШЅЭъГЩећИіЯЕЭГЃЌЦфжагаЮвУЧздМКЕФЫМПМКЭИФБфЃЌдкетРяЮвЯыИјДѓМвЗжЯэвЛЯТЃЌЫћЩНжЎЪЏПЩвдЙЅгёЃЌДѓМвПЩвдНшМјЁЃ
СьгђФЃаЭЬНЬж
1. СьгђФЃаЭЩшМЦЃКЛљгкЪ§ОнПт vs ЛљгкЖдЯѓ
ЩшМЦЩЯЮвУЧЭЈГЃДгСНжжЮЌЖШШыЪжЃК
1.Data Modeling: ЭЈЙ§Ъ§ОнГщЯѓЯЕЭГЙиЯЕЃЌвВОЭЪЧЪ§ОнПтЩшМЦ
2.Object Modeling: ЭЈЙ§УцЯђЖдЯѓЗНЪНГщЯѓЯЕЭГЙиЯЕЃЌвВОЭЪЧУцЯђЖдЯѓЩшМЦДѓВПЗжМмЙЙЪІЖМЪЧДг
Data Modeling ПЊЪМЩшМЦШэМўЯЕЭГЃЌЩйВПЗжШЫЭЈЙ§ Object Modeling ЗНЪНПЊЪМЩшМЦШэМўЯЕЭГЁЃетСНжжНЈФЃЗНЪНВЂВЛЛЅЯрГхЭЛЃЌЖМКмживЊЃЌЕЋДгФФИіЗНЯђПЊЪМЩшМЦЃЌЖдЯЕЭГзюжеаЮЬЌгаКмДѓЕФЧјБ№ЁЃ
Data Model
СьгђФЃаЭЃЈдкетРяНаЪ§ОнФЃаЭЃЉЖдЫљгаШэМўДгвЕепРДНВЖМВЛЪЧвЛИіФАЩњЕФУћДЪЃЌвЛИіШэМўВњЦЗЕФФкдкжЪСПКУЛЕПЩФмБЛСьгђФЃаЭЧхЮњгыЗёЫљОіЖЈЃЌКУЕФСьгђФЃаЭПЩвдШУВњЦЗНсЙЙЧхГўЁЂаоИФИќЗНБуЁЂбнНјГЩБОИќЕЭЁЃ
дквЛИіПЊЗЂЭХЖгРяЃЌМмЙЙЪІКмживЊЃЌЫћОіЖЈСЫШэМўНсЙЙЃЌетИіНсЙЙОіЖЈСЫШэМўЮДРДЕФПЩЖСадЁЂПЩРЉеЙадКЭПЩбнНјадЁЃЭЈГЃРДЫЕМмЙЙЪІЩшМЦСьгђФЃаЭЃЌПЊЗЂШЫдБЛљгкетИіСьгђФЃаЭНјааПЊЗЂЁЃЁАСьгђФЃаЭЁБЪЧИіГБСїУћДЪЃЌШчЙћРЛиЕН
10 МИФъЧАЃЌетИіФЃаЭЮвУЧНаЁАЪ§ОнзжЕфЁБЃЌЫЕАзСЫЃЌСьгђФЃаЭОЭЪЧЪ§ОнПтЩшМЦЁЃ
МмЙЙЪІУЧдкашЧѓЬжТлЕФЙ§ГЬжаВЛЭЃЕибнНјИќаТетИіЪ§ОнзжЕфЃЌгааЉЩшМЦЪІЛсАбетаЉзжЕфаДГЩ SQL гяОфЃЌетаЉгяОфаЮГЩСЫВњЦЗ
/ ЯюФПЪ§ОнПтЕФЗЂг§ЪЗЃЌОЭЯёШЫРрХпЬЅЗЂг§ЃКвЛИіЯИАћЃЈвЛИіБэЃЉЃЌЖрИіЯИАћЃЈЖрИіБэЃЉЃЌГЄГіЮВАЭЃЈЩшМЦгаЮЪЬтЃЉЃЌгжАбЮВАЭЫѕЕєЃЈИќаТЩшМЦЃЉЃЌзюКѓЭлЭлТфЕиЃЈЩЯЯпЃЉЁЃ
ДЋЭГЯюФПжаЃЌМмЙЙЪІНЛИјПЊЗЂЕФвЛАуЪЧвЛБОКёКёЕФИХвЊЩшМЦЮФЕЕЃЌРяУцГ§СЫУмУмТщТщЕФЮФзжОЭЪЧЗжКУСЫгђЕФЪ§ОнПтБэЩшМЦЁЃбдЯТжЎвтЃКЪ§ОнПтЩшМЦЪЧИљБОЃЌвЛЧаПЊЗЂЮЇШЦзХетБОЪ§ОнзжЕфеЙПЊЃЌаЮГЩРрЫЦгкЯТБпЕФМмЙЙЭМЃК
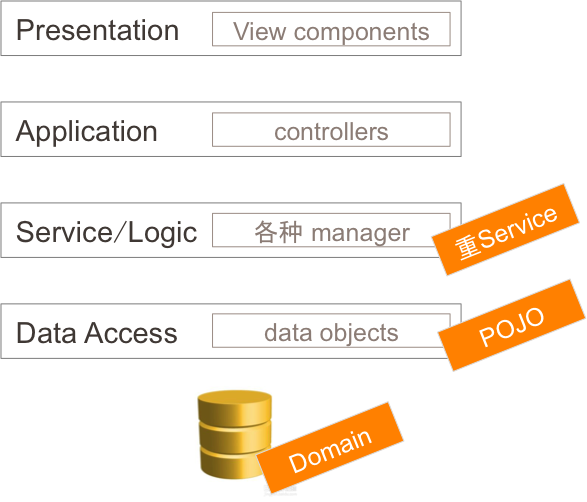
дк service ВуЭЈЙ§ЮвУЧЗЧГЃЯВЛЖЕФ manager ШЅ manage ДѓВПЗжЕФТпМЃЌPOJOЃЈКѓЮФЪЇбЊФЃаЭЛсНВЕНЃЉзїЮЊЪ§Ондк
manager ЪжЃЈЩЯЕлжЎЪжЃЉРяВЛЭЃЕиБфЛЛКЭзщКЯЃЌservice ВудкетРяЪЧвЛИіОоДѓЕФМгЙЄЙЄГЇЃЈКмжиЕФвЛВуЃЉЃЌЮЇШЦзХЪ§ОнПтетЗн
DNAЃЌЭъГЩвЕЮёТпМЁЃ
ОйИіВЛЧЁЕБЕФР§згЃКМйШчгаИИЧзКЭЖљзгетСНИіБэЃЌЩњГЩЕФ POJO гІИУЪЧЃК
| public
class Father{Ё}
public class Son{
private String fatherId;//son БэРяга fatherId зїЮЊ
Father Бэ id ЭтМќ
public String getFatherId(){
return fatherId;
}
ЁЁ
} |
етЪБКђЖљзгЗИСЫЕуЪВУДДэЃЌРЯАжЗЧГЃВЛЫЌЕиЩШСЫЖљзгвЛИіЖњЙтЃЌРЯАжЪжЬлЃЌЖљзгСГЬлЁЃManager ЭЈГЃетУДзіЃК
| public
class SomeManager{
public void fatherSlapSon(Father father, Son
son){
// ШчЙћТпМЩЯЫЕВЛЭЈЃЌДѓМвШЬШЬ
father.setPainOnHand();
son.setPainOnFace();// МйЩш painOnHand, painOnFace
ЖМЪЧЪ§ОнПтзжЖЮ
}
} |
етРяЃЌmanager ГфЕБСЫЩЯЕлЕФНЧЩЋЃЌЩШИіЖњЙтЖМЕУЫћРЯШЫМвАяУІЁЃ
Object Model
2004 ФъЃЌEric Evans ЗЂБэСЫЁЖDomain-Driven Design ЈCTackling
Complexity in the Heart of SoftwareЁЗЃЈСьгђЧ§ЖЏЩшМЦЃЉЃЌМђГЦ Evans
DDDЃЌЯШдкетРяИјДѓМвЭЦМіетБОЪщЃЌЪщРяЖдСьгђЧ§ЖЏзіСЫПЊДДадЕФРэТлВћЪіЁЃ
дкСФЕН DDD ЕФЪБКђЃЌЮвОГЃЛсзівЛИіМйЩшЃКМйЩшФуЕФЛњЦїФкДцЮоЯоДѓЃЌгРдЖВЛхДЛњЃЌдкетИіЧАЬсЯТЃЌЮвУЧЪЧВЛашвЊГжОУЛЏЪ§ОнЕФЃЌвВОЭЪЧЮвУЧПЩвдВЛашвЊЪ§ОнПтЃЌФЧУДФуНЋЛсдѕУДЩшМЦФуЕФШэМўЃПетОЭЪЧЮвУЧЫЕЕФ
Persistence IgnoranceЃКГжОУЛЏЮоЙиЩшМЦЁЃ
УЛСЫЪ§ОнПтЃЌСьгђФЃаЭОЭвЊЛљгкГЬађБОЩэРДЩшМЦСЫЃЌШШАЎЩшМЦФЃЪНЕФЭЌбЇУЧПЩвддкетРяДѓЯдЩэЪжЁЃдкУцЯђЙ§ГЬЁЂУцЯђКЏЪ§ЁЂУцЯђЖдЯѓЕФБрГЬгябджаЃЌУцЯђЖдЯѓЮовЩЪЧСьгђНЈФЃзюМбЗНЪНЁЃ
РргыБэгаЕуЯёЃЌЕЋВЛЩйШЫШЯЮЊБэКЭРрОЭЪЧЖдгІЕФЃЌаа row КЭЖдЯѓ object ОЭЪЧЖдгІЕФЃЌЮвИіШЫЧПСвВЛШЯЭЌетжжЕШЭЌЙиЯЕЃЌетжжШЯжЊжБНгЕМжТСЫШэМўЩшМЦБфЕУУЛгавтвхЁЃ
РрКЭБэгавдЯТМИИіЯджјЧјБ№ЃЌетаЉЧјБ№ЖдСьгђНЈФЃЕФБэДяЗсИЛЖШгаЯджјЕФВюБ№ЃЌгаСЫЗтзАЁЂМЬГаКЭЖрЬЌЃЌЮвУЧЖдСьгђФЃаЭЕФБэДявЊЩњЖЏЕУЖрЃЌЖд
SOLID ддђЕФзёЪивВЛсбЯНїКмЖрЃК
1.в§гУЃКЙиЯЕЪ§ОнПтБэБэЪОЖрЖдЖрЕФЙиЯЕЪЧгУЕкШ§еХБэРДЪЕЯжЃЌетИіСьгђФЃаЭБэЪОВЛОпЯѓЛЏЃЌ
вЕЮёЭЌбЇПДВЛЖЎЁЃ
2.ЗтзАЃКРрПЩвдЩшМЦЗНЗЈЃЌЪ§ОнВЂВЛФмЭъећЕиБэДяСьгђФЃаЭЃЌЪ§ОнБэПЩвджЊЕРвЛИіШЫЕФШ§ЮЌЃЌЕЋВЂВЛжЊЕРЁАвЛИіШЫЪЧПЩвдХмЕФЁБЁЃ
3.МЬГаЁЂЖрЬЌЃКРрПЩвдЖрЬЌЃЌЪ§ОнЩЯЮоЗЈЪЖБ№ШЫгыжэГ§СЫШ§ЮЌЪ§ОнЛЙгаааЮЊЕФЧјБ№ЃЌЪ§ОнБэВЛжЊЕРЁАвЛИіШЫХмЦ№РДКЭвЛЭЗжэХмЦ№РДЪЧВЛвЛбљЕФЁБЁЃ
дйПДПДРЯзгЩњЦјЩШЖљзгЕФР§згЃК
| public
class Father{
// НЬбЕЖљзгЪЧздМКЕФЪТЧщЃЌВЂВЛашвЊБ№ШЫАяУІЃЌЩЯЕлвВВЛаа
public void slapSon(Son son){
this.setPainOnHand();
son.setPainOnFace();
}
} |
ИљОнетИіЫМТЗЃЌТ§Т§ЕиЃЌЮвУЧдкУцЯђЖдЯѓЕФЪРНчРяЩшМЦСЫшђшђШчЩњЕФСьгђФЃаЭЃЌservice ВуОЭЪЧЛљгкетаЉФЃаЭзіЕФвЕЮёВйзїЃЈЫќБфБЁСЫЃЌКмЖрЖЏзїНЛИјСЫ
domain objects ШЅДІРэЃЉЃКСьгђФЃаЭВЂВЛЭъГЩвЕЮёЃЌУПИі domain object ЖМЪЧЭъГЩЪєгкздМКгІгаЕФааЮЊЃЈsingle
responsibilityЃЉЃЌОЭШчЭЌШЫХметИіЖЏзїЃЌperson.run ЪЧвЛИігывЕЮёЮоЙиЕФааЮЊЃЌЕЋетИіЪБКђ
manager Лђеп service дкЕїгУ some person.run ЕФЪБКђПЩвдЭъГЩ 100
УзБШШќетИівЕЮёЃЌвВПЩвдЭъГЩХмШЅЫЭЭтТєетИівЕЮёЁЃетбљЕФЛАаЮГЩСЫРрЫЦгкЯТБпЕФМмЙЙЭМЃК
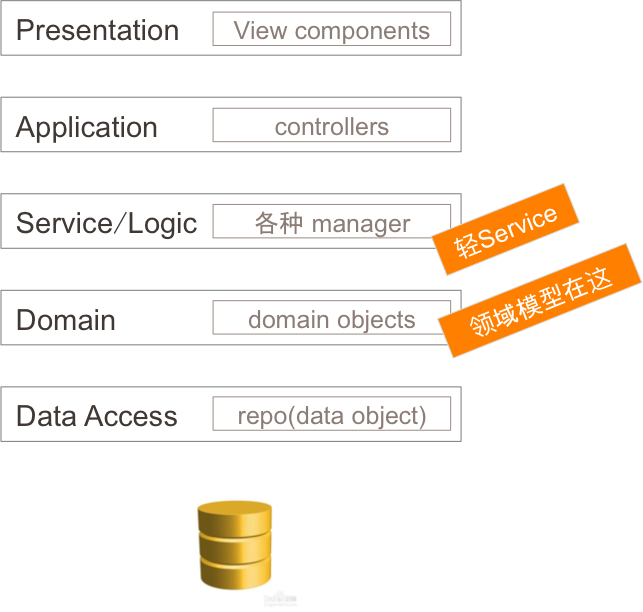
ЮвУЧЛиЕНИеВХЕФМйЩшЃЌЯждкАбМйЩшШЅЕєЃЌУЛгаЫЕФЛњЦїЪЧФкДцЮоЯоДѓЃЌгРдЖВЛхДЛњЕФЃЌФЧУДЮвУЧашвЊЪ§ОнПтЃЌЕЋЪ§ОнПтЕФжАд№ВЛдйГадиСьгђФЃаЭетИіГСжиЕФАќИЄСЫЃЌЪ§ОнПтЛиЙщ
persistence ЕФБОжЪЃЌЭъГЩвдЯТСНИіЪТЧщЃК
1.ДцЃКНЋЖдЯѓЪ§ОнГжОУЛЏЕНДцДЂНщжЪжаЁЃ
2.ШЁЃКИпаЇЕиАбЪ§ОнВщбЏЗЕЛиЕНФкДцжаЁЃ
гЩгкВЛдйГадиСьгђНЈФЃетИіЬиадЃЌЪ§ОнПтЕФЩшМЦПЩвдБфЕУЬьТэааПеЃЌШЮКЮПЩвдМгЫйДцДЂКЭЫбЫїЕФЪжЖЮЖМПЩвдгУЩЯЃЌЮвУЧПЩвдгУ
column Ъ§ОнПтЃЌПЩвдгУ document Ъ§ОнПтЃЌПЩвдЩшМЦЗЧГЃОЋЧЩЕФжаМфБэШЅЭъГЩДѓЪ§ОнЕФВщбЏЁЃзмжЎЪ§ОнПтЩшМЦвЊзіЕФЪТЧщОЭЪЧОЁПЩФмИпаЇДцШЁЃЌЖјВЛЪЧЭъУРБэДяСьгђФЃаЭЃЈДЫбдТлгаЕуЗДЖЏЃЌДѓМвПДПДОЭКУЃЉЃЌетбљЮвУЧдйПДПДМмЙЙЭМЃК
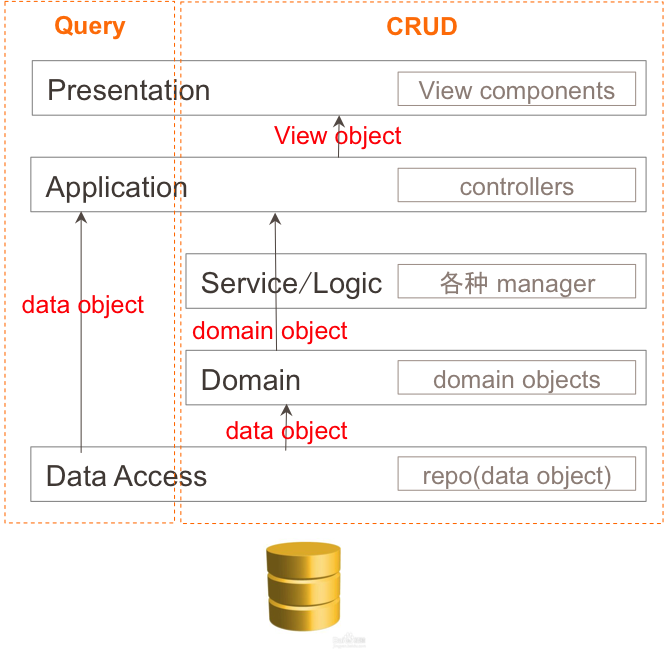
етРяЮвЯыИњДѓМвЧПЕїЕФЪЧЃК
1.СьгђФЃаЭЪЧгУгкСьгђВйзїЕФЃЌЕБШЛвВПЩвдгУгкВщбЏЃЈreadЃЉЃЌВЛЙ§етИіВщбЏЪЧгаДњМлЕФЁЃдкетИіЧАЬсЯТЃЌвЛИі
aggregate ПЩФмФкКЌСЫШєИЩЪ§ОнЃЌетаЉЪ§ОнГ§СЫРрЫЦгк getById етжжЗНЪНЃЌВЛЪЪгУЖрбљЛЏВщбЏЃЈqueryЃЉЃЌСьгђЧ§ЖЏЩшМЦвВВЛЪЧЮЊЖрбљЛЏВщбЏЩшМЦЕФЁЃ
2.ВщбЏЪЧЛљгкЪ§ОнПтЕФЃЌЫљгаЕФИДдгБфЬЌВщбЏЦфЪЕЖМгІИУШЦЙ§ Domain
ВуЃЌжБНггыЪ§ОнПтДђНЛЕРЁЃ
3.дйОЋМђвЛЯТЃКСьгђВйзї ->objectsЃЌЪ§ОнВщбЏ ->table
rows
2. СьгђФЃаЭЃКЪЇбЊЁЂЦЖбЊЁЂГфбЊ
ЪЇбЊЁЂЦЖбЊЁЂГфбЊКЭеЭбЊФЃаЭгІИУЪЧРЯТэЬсГіЕФЃЈДЫРЯТэЗЧТэРЯЪІЃЌЪЧ Martin FowlerЃЉЃЌНВЪіЕФЪЧЛљгкСьгђФЃаЭЕФЗсТњГЬЖШЯТШчКЮЖЈвхвЛИіФЃаЭЃЌгаЕуЯёЃКЪнЁЂжаЕШЁЂНЁзГКЭХжЁЃеЭбЊЃЈХжЃЉФЃаЭЬЋХжЃЌдкетРяЮвУЧВЛзіЬжТлЁЃ
ЪЇбЊФЃаЭЃКЛљгкЪ§ОнПтЕФСьгђЩшМЦЗНЪНЦфЪЕОЭЪЧЕфаЭЕФЪЇбЊФЃаЭЃЌвд Java ЮЊР§ЃЌPOJO жЛгаМђЕЅЕФЛљгк
field ЕФ setterЁЂgetter ЗНЗЈЃЌPOJO жЎМфЕФЙиЯЕвўВидкЖдЯѓЕФФГаЉ ID РяЃЌгЩЭтУцЕФ
manager НтЪЭЃЌБШШч son.fatherIdЃЌSon ВЂВЛжЊЕРЫћИњ Father гаЙиЯЕЃЌЕЋ
manager ЛсЭЈЙ§ son.fatherId ЕУЕНвЛИі FatherЁЃ
ЦЖбЊФЃаЭЃКЖљзгВЛжЊЕРздМКЕФИИЧзЪЧЫЪЧВЛЖдЕФЃЌВЛФмУПДЮЖМЭЈЙ§жаМфЛњЙЙЃЈManagerЃЉбщ DNA(son.fatherId)
РДевАжАжЃЌСьгђФЃаЭПЩвдИќЗсИЛвЛЕуЃЌИј son етИіРраоИФвЛЯТЃК
| public
class Son{
private Father father;
public Father getFather(){return this.father;}
} |
Son етИіРрБфЕУЗсИЛЦ№РДСЫЃЌЕЋЛЙгавЛИіаЁаЁЕФВЛЗНБуЃЌОЭЪЧЭЈЙ§ Father ЮоЗЈЛёЕУ SonЃЌАжАждѕУДПЩвдВЛжЊЕРЖљзгЪЧЫЃПетбљЮвУЧдйИј
Father ЬэМгетИіЪєадЃК
| public
class Father{
private Son son;
private Son getSon(){return this.son;}
} |
ЯждкПДзХСНИіРрОЭЗсТњЖрСЫЃЌетвВОЭЪЧЮвУЧвЊЫЕЕФЦЖбЊФЃаЭЃЌдкетИіФЃаЭЯТМвЭЅЛЙЫуЭъУРЃЌИИзгЯрШЯЁЃШЛЖјзаЯИбаОПетСНИіРрЮвУЧЛсЗЂЯжвЛЕуЮЪЬтЃКЭЈГЃвЛИі
object ЪЧЭЈЙ§вЛИі repositoryЃЈЪ§ОнПтВщбЏЃЉЃЌЛђеп factoryЃЈФкДцаТНЈЃЉЕУЕНЕФ:
| Son
someSon = sonRepo.getById(12345); |
етИіЗНЗЈПЩвдНЋвЛИі son object ДгЪ§ОнПтРяШЁГіРДЃЌЮЊСЫЙЙНЈЭъећЕФ son ЖдЯѓЃЌsonRepo
РяашвЊвЛИі fatherRepo РДЙЙНЈвЛИі father ШЅИГжЕ son.fatherЁЃЖј fatherRepo
дкЙЙНЈвЛИіЭъећ father ЕФЪБКђгжашвЊ sonRepo ШЅЙЙНЈвЛИі son РДИГжЕ father.sonЁЃетаЮГЩСЫвЛИіЮоЯђгаЛЗШІЃЌетИібЛЗЕїгУЮЪЬтЪЧПЩвдНтОіЕФЃЌЕЋЮЊСЫНтОіетИіЮЪЬтЃЌСьгђФЃаЭЛсБфЕУгааЉЖёаФКЭНЋОЭЁЃгаЯђЮоЛЗВХЪЧЮвУЧЕФЩшМЦФПБъЃЌЮЊСЫЗРжЙетИібЛЗЕїгУЃЌЮвУЧЪЧЗёПЩвддк
Father КЭ Son етСНИіРрРяЪЁТдЕєвЛИів§гУЃПаоИФвЛЯТ Father етИіРрЃК
| public
class Father{
//private Son son; ЩОГ§етИів§гУ
private SonRepository sonRepo;// ЬэМгвЛИі Son ЕФ
repo
private getSon(){return sonRepo.getByFatherId(this.id);}
} |
етбљдкЙЙдь Father ЕФЪБКђОЭВЛЛсдйЙЙдьвЛИі Son СЫЃЌЕЋДњМлЪЧЮвУЧдк Father етИіРрРяв§ШыСЫвЛИі
SonRepositoryЃЌвВОЭЪЧЮвУЧдквЛИі domain ЖдЯѓРяв§гУСЫвЛИіГжОУЛЏВйзїЃЌетОЭЪЧЮвУЧЫЕЕФГфбЊФЃаЭЁЃ
ГфбЊФЃаЭЃКГфбЊФЃаЭЕФДцдкШУ domain object ЪЇШЅСЫбЊЭГЕФДПе§адЃЌЫћВЛдйЪЧвЛИіДПЕФФкДцЖдЯѓЃЌетИіЖдЯѓРяТёВиСЫвЛИіЖдЪ§ОнПтЕФВйзїЃЌетЖдВтЪдЪЧВЛгбКУЕФЃЌЮвУЧВЛгІИУдкзіПьЫйЕЅдЊВтЪдЕФЪБКђСЌНгЪ§ОнПтЃЌетИіЮЪЬтЮвУЧЩдКѓРДНВЁЃЮЊБЃжЄФЃаЭЕФЭъећадЃЌГфбЊФЃаЭдкгааЉЧщПіЯТЪЧБиШЛДцдкЕФЃЌБШШчдквЛИіКаТэУХЕъРяПЩвдЪлТєКУМИЧЇИіЩЬЦЗЃЌУПИіЩЬЦЗгаКУМИАйИіЪєадЁЃШчЙћЮвдкЙЙНЈвЛИіЕъЕФЪБКђАбЫљгаЩЬЦЗЖМФУГіРДЃЌетИіаЇТЪОЭЬЋВюСЫЃК
| public
class Shop{
//private List<Product> products; етИіЩЬЦЗСаБэдкЙЙНЈЪБЬЋДѓСЫ
private ProductRepository productRepo;
public List<Product> getProducts(){
//return this.products;
return productRepo.getShopProducts(this.id);
}
} |
3. СьгђФЃаЭЃКвРРЕзЂШы
МђЕЅЫЕвЛЫЕвРРЕзЂШыЃК
вРРЕзЂШыдк runtime ЪЧвЛИі singleton ЖдЯѓЃЌжЛгадк spring ЩЈУшЗЖЮЇФкЕФЖдЯѓЃЈ@ComponentЃЉВХФмЭЈЙ§
annotationЃЈ@AutowiredЃЉгУЩЯвРРЕзЂШыЃЌЭЈЙ§ new ГіРДЕФЖдЯѓЪЧЮоЗЈЭЈЙ§ annotation
ЕУЕНзЂШыЕФЁЃ
ИіШЫЭЦМіЙЙдьЦївРРЕзЂШыЃЌетжжЧщПіЯТВтЪдгбКУЃЌЖдЯѓЙЙдьЭъећадКУЃЌЯдЪНЕиИцЫпФуБиаы mock/stub
ФФИіЖдЯѓЁЃ
ЫЕЭъвРРЕзЂШыЮвУЧдйПДИеВХЕФГфбЊФЃаЭЃК
| public
class Father{
private SonRepository sonRepo;
private Son getSon(){return sonRepo.getByFatherId(this.id);}
public Father(SonRepository sonRepo){this.sonRepo
= sonRepo;}
} |
аТНЈвЛИі Father ЕФЪБКђашвЊИГжЕвЛИі SonRepositoryЃЌетЯдШЛдкаДДњТыЕФЪБКђЪЧЗЧГЃШУШЫФеЛ№ЕФЃЌФЧУДЮвУЧЪЧЗёПЩвдЭЈЙ§вРРЕзЂШыЕФЗНЪНАб
SonRepository зЂШыНјШЅФиЃПFather дкетРяВЛПЩФмЪЧвЛИі singleton ЖдЯѓЃЌЫќПЩФмдкСНИіГЁОАЯТБЛ
new ГіРДЃКаТНЈЁЂВщбЏЃЌДг Father ЕФЙЙдьЙ§ГЬЃЌSonRepository ЪЧЮоЗЈзЂШыЕФЁЃетЪБЙЄГЇФЃЪНОЭЯдЪОГіЦфвтвхСЫЃЈКмЖрШЫШЯЮЊЙЄГЇФЃЪНОЭЪЧвЛИіАкЩшЃЉЃК
гЩгк FatheFactory ЪЧЯЕЭГЩњГЩЕФ singleton ЖдЯѓЃЌSonRepository
здШЛПЩвдзЂШыЕН Factory РяЃЌnewFather ЗНЗЈвўВиСЫетИізЂШыЕФ sonRepoЃЌетбљ
new вЛИі Father ЖдЯѓОЭБфИЩОЛСЫЁЃ
4. СьгђФЃаЭЃКВтЪдгбКУ
ЪЇбЊФЃаЭКЭЦЖбЊФЃаЭЪЧЬьШЛВтЪдгбКУЕФЃЈЦфЪЕЪЇбЊФЃаЭвВУЛЩЖКУВтЪдЕФЃЉЃЌвђЮЊЫћУЧЖМЪЧДПФкДцЖдЯѓЁЃЕЋЪЕМЪгІгУжаГфбЊФЃаЭЪЧДцдкЕФЃЌвЊВЛОЭЪЧАб
domain ЖдЯѓВ№ЩЂЃЌБфЕУЩдЮЂВЛФЧУДгХбХЃЈЕБШЛПЩвдЃЌЦЖбЊКЭГфбЊЕФеНељДгРДОЭУЛгаЖЯЙ§ЃЉЁЃФЧУДдкГфбЊФЃаЭЯТЃЌЖдЯѓРяДјЩЯСЫ
persisitence ЬиадЃЌетОЭЖдЪ§ОнПтгаСЫвРРЕЃЌmock/stub ЕєетаЉвРРЕЪЧИпаЇЕЅдЊЛЏВтЪдЕФЛљБОвЊЧѓЃЌЮвУЧдйПД
Father етИіР§згЃК
| @Component
public class FatherFactory{
private SonRepository sonRepo;
@Autowired
public FatherFactory(SonRepository sonRepo){}
public Father createFather(){
return new Father(sonRepo);
}
} |
Аб SonRepository ЗХЕНЙЙдьКЏЪ§ЕФвтвхОЭЪЧЮЊСЫВтЪдЕФгбКУадЃЌЭЈЙ§ mock/stub етИі
RepositoryЃЌЕЅдЊВтЪдОЭПЩвдЫГРћЭъГЩЁЃ
5. СьгђФЃаЭЃККаТэФЃЪНЯТ repository ЕФЪЕЯжЗНЪН
АДее object domain ЕФЫМТЗЃЌСьгђФЃаЭДцдкгкФкДцЖдЯѓРяЃЌетаЉЖдЯѓзюжеЖМвЊТфЕНЪ§ОнПтЃЌгЩгкАкЭбСЫСьгђФЃаЭЕФЪјИПЃЌЪ§ОнПтЩшМЦЪЧСщЛюЖрБфЕФЁЃдкКаТэЃЌdomain
object ЪЧдѕУДНјШыЕНЪ§ОнПтЕФФиЁЃ
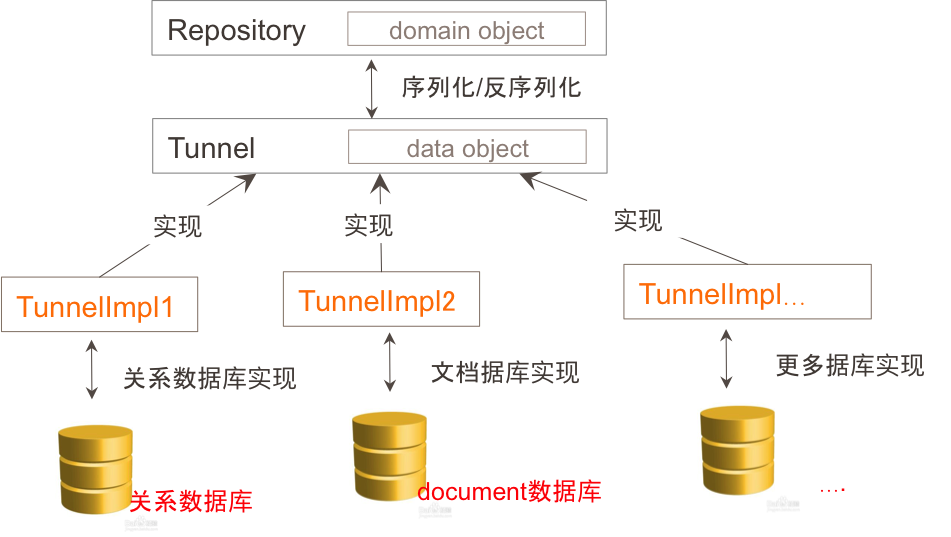
дкКаТэЃЌЮвУЧЩшМЦСЫ Tunnel етИіЖРЬиЕФНгПкЃЌЭЈЙ§етИіНгПкЮвУЧПЩвдЪЕЯжЖд domain ЖдЯѓдкВЛЭЌРраЭЪ§ОнПтЕФДцШЁЁЃRepository
ВЂУЛгажБНгНјааГжОУЛЏЙЄзїЃЌЖјЪЧНЋ domain ЖдЯѓзЊЛЛГЩ POJO НЛИј Tunnel ШЅзіГжОУЛЏЙЄзїЃЌTunnel
ОпЬхПЩвддкШЮКЮАќЪЕЯжЃЌетбљЃЌВПЪ№ЩЯЃЌdomain СьгђФЃаЭЃЈdomain objects+repositoriesЃЉКЭГжОУЛЏ
(Tunnels) ЭъШЋЕФЗжПЊЃЌdomain АќГЩЮЊСЫЕЅДПЕФФкДцЖдЯѓМЏЁЃ
6. СьгђФЃаЭЃКВПЪ№МмЙЙ
КаТэвЕЮёОпгаКмЧПЕФећЬхадЃКДгЙЉгІЩЬВЩЙКЃЌЕНЩЬЦЗПьЕнЕНгУЛЇЪжЩЯЃЌЖдЯѓжЎМфЙиЯЕЪЧБШНЯУїШЗЕФЃЌддђЩЯПЩвдВЩгУвЛИіДѓЖјШЋЕФСьгђФЃаЭЃЌвВПЩвддЫгУ
boundedContext ЗНЪНВ№ЗжзггђЃЌВЂдкНЛНгДІДІРэКУЪ§ОнДЋЫЭЃЌетРяв§гУРЯТэЕФвЛЗљЭМЃК
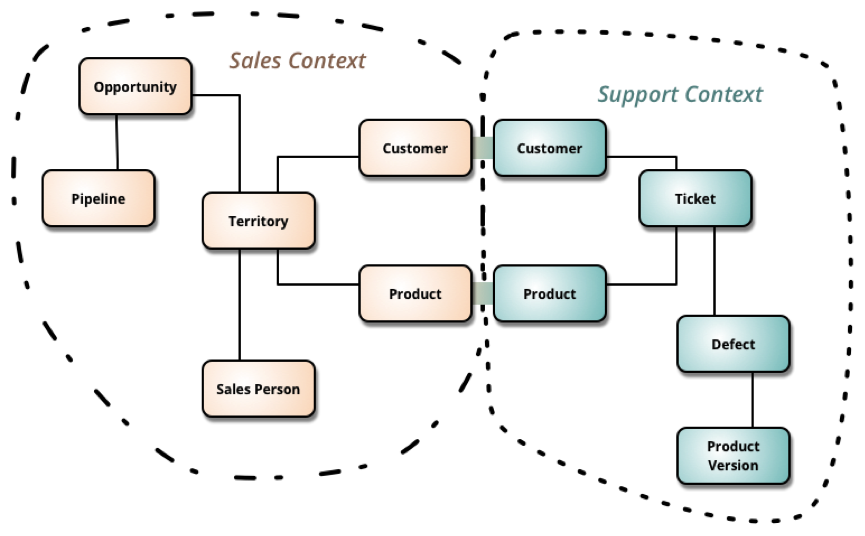
ЮвИіШЫЧуЯђгкДѓ domain ЕФзіЗЈЃЌЮвЧуЯђЃЈЫљвдЪЕМЪЧщПіВЛЪЧетбљЕФЃЉЕФВПЪ№НсЙЙЪЧ:
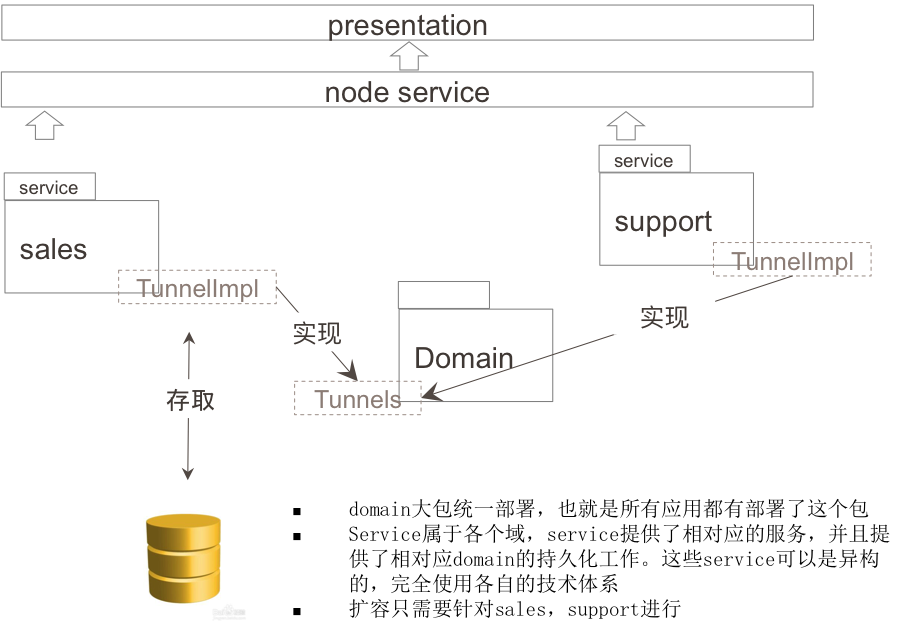
Нсгя
КаТэдкМмЙЙЩшМЦЩЯЛЙдкзіИќЖрЕФЬНЫїЃЌдк 2B+ ЛЅСЊЭјЕФеИаТвЕЮёФЃЪНЯТЃЌгаКмЖрПЩвдЩюШыЬНЬжЕФЯИНкЁЃDDD
дкКаТэвбОТѕГіСЫМсЪЕЕФЕквЛВНЃЌВЂЧвдквЕЮёРЉеЙадКЭЯЕЭГЮШЖЈадЩЯОЪмСЫЪЕеНЕФПМбщЁЃЛљгкЛЅСЊЭјЗжВМЪНЕФЙЄзїСїв§ЧцЃЈNobleЃЉЃЌЭъШЋЛЅСЊЭјЕФЭМаЮЛцжЦв§ЧцЃЈIvyЃЉЖМдкОЋаФДђФЅжаЃЌЦкД§дкЮДРДЕФОЭМИИідТРяЃЌКаТэЙЄГЬЪІУЧИјДѓМвЗюЯзИќЖрЕФЩшМЦзїЦЗЁЃ |









