| Νλ”ρ≤÷¥ΔΘ®Domain
RepositoryΘ©”κ ¬Φΰ¥φ¥ΔΘ®Event StoreΘ© «CQRSΧεœΒΫαΙΙ”Π”ΟœΒΆ≥÷–C≤ΩΖ÷Θ®Command≤ΩΖ÷Θ©ΒΡ÷Ί“ΣΉιΦΰΓΘΥδ»ΜΕΦ «¥φ¥ΔΜζ÷ΤΘ§ΒΪΝΫ’Ώ”–Ή≈±Ψ÷ ΒΡ«χ±πΘΚΝλ”ρ≤÷¥Δ « τ”ΎΝλ”ρ≤ψΒΡΘ§Εχ ¬Φΰ≤÷¥Δ‘ρ « τ”ΎΜυ¥ΓΫαΙΙ≤ψΒΡΓΘΝλ”ρΡΘ–Ά≤ζ…ζ ¬ΦΰΘ§Νλ”ρ≤÷¥ΔΗΚ‘π±Θ¥φΓΔΖΔ≤Φ ¬ΦΰΘ§≤ΔΆ®Ιΐ ¬Φΰ–ρΝ–÷ΊΥήΝλ”ρΡΘ–ΆΓΘ”…”ΎΝλ”ρ≤÷¥ΔΒΡ¥φ‘ΎΘ§ ΙΒΟΓΑΡΎ¥φΝλ”ρΡΘ–ΆΘ®In-memory
DomainΘ©Γ±≥…ΈΣΩ…ΡήΓΘ
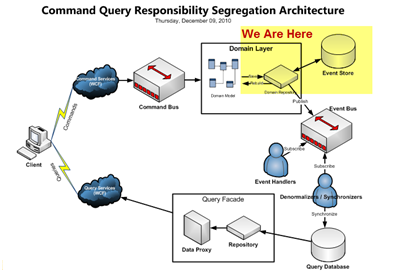
‘Ύ…œΈΡ÷–Έ““―Ψ≠Ε‘Ε‘œσΒΡΉ¥Χ§ΉωΝΥ“Μ–©Ϋι…ήΘ§Ά®Ιΐ’β–©Ϋι…ήΈ“Ο«ΡήΙΜΝΥΫβΒΫΘ§‘Ύ”Π”ΟœΒΆ≥÷–Θ§ «Νλ”ρ ¬ΦΰΒΦ÷¬ΝΥΕ‘œσΉ¥Χ§ΒΡ±δΜ·Θ§”Ύ «Θ§Έ“Ο«÷Μ–η“ΣΑ―’β–©Νλ”ρ ¬ΦΰΑ¥Υ≥–ρΦ«¬Φœ¬ά¥Θ§Έ“Ο«ΨΆ”–ΡήΝΠΫΪΝλ”ρΡΘ–ΆΜΙ‘≠ΒΫ»ΈΚΈ“ΜΗω ±ΦδΒψ…œΓΘΨΆ“‘Tiny
Library÷–ΒΡReaderΨέΚœΈΣάΐΘ§Β±ReaderΗ’Η’±Μ¥¥Ϋ®ΒΡ ±ΚρΘ§ΥϋΒΡNameΉ¥Χ§ «Ω’ΒΡΘ§ΩΆΜß≥Χ–ρΩ…“‘Ά®ΙΐReader ΒΧεΒΡChangeNameΖΫΖ®ά¥ΗΡ±δNameΒΡΉ¥Χ§ΓΘChangeNameΖΫΖ®Μα÷±Ϋ”≤ζ…ζ“ΜΗωReaderNameChangedEventΒΡΝλ”ρ ¬ΦΰΘ§Ηφ÷ΣœΒΆ≥Θ§œ÷‘ΎΖΔ…ζΝΥ“ΜΦΰ ¬«ιΘ§’βΦΰ ¬«ιΫΪΜαΗΡ±δReader ΒΧεΒΡΉ¥Χ§ΓΘReader ΒΧεΜώΒΟΝΥ’βΗω ¬ΦΰΆ®÷ΣΘ§ΨΆΫΪNameΉ¥Χ§…η÷ΟΈΣ ¬Φΰ ΐΨί÷–ΒΡΗχΕ®Οϊ≥ΤΘ§Ά§ ±Θ§’βΗωReaderNameChangedEvent ¬Φΰ“≤±ΜΝΌ ±±Θ¥φ‘ΎΝΥReader ΒΧε÷–ΓΘ
Νμ“ΜΖΫΟφΘ§Β±ΩΆΜß≥Χ–ρΒς”ΟΝλ”ρ≤÷¥Δά¥±Θ¥φReader ±Θ§≤÷¥ΔΜαΫΪReader÷–Υυ”–ΒΡΝλ”ρ ¬ΦΰΕΝ»Γ≥ωά¥Θ§Α¥’’Υ≥–ρ÷πΗω±Θ¥φΒΫ ¬Φΰ¥φ¥Δ÷–Θ§”κ¥ΥΆ§ ±Θ§ΫΪ’β–© ¬ΦΰΖΔ≤ΦΒΫ ¬ΦΰΉήœΏΘ®Event
BusΘ©…œΘ§“‘±ψΆ§“ΜœΒΆ≥ΒΡΤδΥϋΉιΦΰΘ®±»»γQuery DatabaseΘ©Μρ’ΏΤδΥϋΒΡœΒΆ≥ΡήΙΜΫ” ’ΒΫ ¬ΦΰΒΫ¥οΆ®÷ΣΕχΉωΫχ“Μ≤ΫΒΡ¥ΠάμΓΘ
Β±ΩΆΜß≥Χ–ρ–η“ΣΆ®ΙΐΝλ”ρ≤÷¥ΔΕΝ»ΓΨέΚœ ±Θ§Νλ”ρ≤÷¥ΔΨΆΜα–¬Ϋ®ΨέΚœΘ§»ΜΚσ¥” ¬Φΰ¥φ¥Δ÷–Θ§“‘ΗΟΨέΚœΒΡΨέΚœΗυΒΡάύ–ΆΉςΈΣΥ―ΥςΧθΦΰΘ§ΫΪΝλ”ρ ¬ΦΰΑ¥Υ≥–ρΕΝ»Γ≥ωά¥≤Δ“ΜΗωΗωΒΊ”Π”Ο‘Ύ’βΗω–¬Ϋ®ΒΡΨέΚœ…œΘ§ΨέΚœΗυ ΒΧε“ΜΒ©≤ΕΜώΒΫ ¬ΦΰΘ§ΨΆΜαΑ¥’’ ¬ΦΰΒΡ ΐΨίΡΎ»ίΗϋ–¬Ε‘”ΠΒΡΉ¥Χ§Θ§”Ύ «Θ§ΨέΚœ“≤ΨΆ±ΜΜ÷Η¥ΒΫΝΥΉνΚσ“Μ¥Έ ¬ΦΰΖΔ…ζΚσΒΡΉ¥Χ§ΝΥΓΘ
’βΗωΙΐ≥ΧΚήΦρΒΞΘ§Ά®Ιΐ…œΟφΒΡΖ÷Έω≤ΜΡ―ΖΔœ÷ΘΚ
1.”…”Ύ≤ι―·≤ΩΖ÷ΒΡΖ÷άκΘ§Νλ”ρ≤÷¥ΔΫω¥φΝΫ÷÷≤ΌΉςΘΚΫΪΨέΚœ±Θ¥φΒΫ ¬Φΰ¥φ¥Δ“‘ΦΑ¥” ¬Φΰ¥φ¥ΔΜΙ‘≠Ε‘œσΓΘ”κ÷°Ε‘”ΠΒΡ≤ΌΉς¥σ÷¬Ω…“‘±μ Ψ≥…œ¬ΟφΒΡΫ”ΩΎΘ®ΗΟ≤ΩΖ÷¥ζ¬κ’Σ¬ΦΉ‘Apworks
Application Development FrameworkΘ©ΘΚ
|
1: public interface IDomainRepository : IUnitOfWork,
IDisposable
2: {
3: TAggregateRoot Get<TAggregateRoot>(long
id)
4: where TAggregateRoot : class, ISourcedAggregateRoot,
new();
5:
6: void Save<TAggregateRoot>(TAggregateRoot
aggregateRoot)
7: where TAggregateRoot : class, ISourcedAggregateRoot,
new();
8: } |
2.’ϊΗωDomain Model÷Μ”–“ΜΗω ΐΨί‘¥ΘΚ ¬Φΰ¥φ¥ΔΘ®Event
StoreΘ©Θ§”Οά¥±Θ¥φΥυ”–ΖΔ…ζ‘ΎΨέΚœ…œΒΡΝλ”ρ ¬ΦΰΓΘ’βΗωEvent StoreΨΏΧε»γΚΈ…ηΦΤΘ§Ω…“‘ΗυΨί”Π”ΟœΒΆ≥ΒΡ–η«σά¥ΨωΕ®Θ§ΒΪΉήΙι «Ζ«≥ΘΒΡΦρΒΞΘ§…θ÷Ν”ΎΫω”Ο“Μ’≈ΙΊœΒ–Ά ΐΨίΩβΒΡ ΐΨί±μΨΆΩ…“‘ Βœ÷ΓΘΕ‘”Ύ≤…”ΟΙΊœΒ–Ά ΐΨίΩβ Βœ÷ΒΡ ¬Φΰ¥φ¥ΔΘ§”…”Ύ ΐΨί±μ ΐΝΩΚή…ΌΘ§Εχ«“÷°ΦδΒΡΙΊœΒ±δΒΟΖ«≥ΘΦρΒΞΘ§”Ύ «ORMΨΆΩ…“‘ Γ¬‘Θ§÷±Ϋ”≤…”ΟDirect
SQL Βœ÷ΘΜ»γΙϊ≤Μ≤…”ΟΙΊœΒ–Ά ΐΨίΩβΉςΈΣ ¬Φΰ¥φ¥ΔΘ§Ρ«Ω…“‘―Γ‘ώΒΡΖΕΈßΨΆΗϋ¥σΝΥΘΚΗς÷÷NoSQL ΐΨίΩβΓΔΕ‘œσ ΐΨίΩβΓΔΡΎ¥φ ΐΨίΩβ»»ΓΘΨΆΙΊœΒ–Ά ΐΨίΩβΕχ―‘Θ§Έ“Ο«Ω…“‘Ε‘ ¬Φΰ¥φ¥ΔΥυ Ι”ΟΒΡ ΐΨί±μΉω»γœ¬ΒΡ…ηΦΤΘΚ
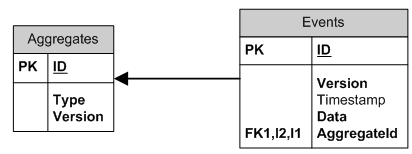
ΡΩ«ΑΘ§Tiny Library CQRSάΒ“‘…ζ¥φΒΡΩΣΖΔΩρΦήApworksΘ§ΫωΧαΙ©÷ß≥÷SQL
ServerΒΡEvent Store…ηΦΤΘ®ApworksΒ±«ΑΑφ±ΨΘΚAlphaΘ§v1.0.4016.23016Θ©
3.»γΙϊ ¬Φΰ¥φ¥Δ≤…”ΟΒΡ «ΙΊœΒ–Ά ΐΨίΩβΘ§Νλ”ρ≤÷¥ΔΕ‘ ¬Φΰ¥φ¥ΔΘ§‘≠‘ρ…œ“≤÷Μ”–άύΥΤ»γœ¬ΝΫ÷÷≤ΌΉςΘΚ
|
1: // ≤ι―· ¬Φΰ¥φ¥Δ
2: SELECT * FROM [Events] WHERE AggregateId=xxx
ORDER BY Version
3:
4: // œρ ¬Φΰ¥φ¥Δ±Θ¥φ ¬Φΰ
5: INSERT INTO [Events] ([AggregateId], [Timestamp],
[Version], [Data]) VALUES (...) |
Β±»ΜΘ§‘Ύ ΒΦ ”Π”Ο÷–Θ§Νλ”ρ≤÷¥Δ”κ ¬Φΰ¥φ¥ΔΒΡ Βœ÷≤ΔΟΜ”–Ρ«Ο¥ΦρΒΞΓΘ‘≠“ρΩ…“‘Ά®Ιΐ»γœ¬ΦΗΗω“…Έ Ϋχ––ΝΥΫβΘΚ
Νλ”ρ≤÷¥ΔΒΡ…ηΦΤ÷–Θ§ΟΜ”–ΧαΒΫ¥” ¬Φΰ¥φ¥Δ÷–…Ψ≥ΐ ¬Φΰ ΐΨίΘ§ ±Φδ“Μ≥ΛΘ§Τώ≤Μ « ¬Φΰ¥φ¥ΔΜα±δΒΟΚή¥σΘΩ
ΟΜ¥μΘΓΝλ”ρ≤÷¥Δ¥”ά¥≤ΜΜα¥” ¬Φΰ¥φ¥Δ÷–…Ψ≥ΐ ΐΨίΘ§Φ¥ Ι «ΩΆΜß≥Χ–ρ«κ«σ…Ψ≥ΐΡ≥ΗωΝλ”ρΕ‘œσΘ§’β“Μ≤ΌΉς“≤Ά§―υΜα≤ζ…ζ“ΜΗω ¬ΦΰΘ®±»»γΘΚReaderDeletedEventΘ©≤Δ±Θ¥φ‘Ύ ¬Φΰ¥φ¥Δ÷–ΓΘ’β―υΉωΒΡάμ”…ά¥Ή‘”ΎEvent
SourcingΥυ¥χά¥ΒΡ“Μ÷÷ ΐΨίΖ÷Έω”κΗζΉΌΒΡΩ…Ρή–‘ΘΚEvent AuditΓΘΥϋ‘ –μΡψΫΪΡψΒΡΝλ”ρΡΘ–ΆΜΙ‘≠ΒΫ»ΈΚΈ ±ΦδΒψΘ§»ΜΚσΆ®Ιΐ ¬Φΰ÷ΊΖ≈Θ®replayΘ©ά¥’οΕœΡψΒΡΡΘ–Ά ΐΨίΓΘ≤ΜΫω»γ¥ΥΘ§ΡψΜΙΩ…“‘άϊ”Ο’β–©±Θ¥φΒΡ ΐΨί÷Ί–¬¥νΫ®ΡψΒΡ≤β ‘ΜΖΨ≥Θ§”Οά¥Ε‘Ε‘œσ ΐΨίΫχ––≤β ‘ΓΘΒ±»ΜΘ§ΡΩ«Α¥σ≤ΩΖ÷œΒΆ≥Ω…Ρή”Ο≤ΜΒΫ’β―υΒΡEvent
AuditΒΡΙΠΡήΘ§Ρ«Ο¥Θ§‘Ύ“ΐ»κΓΑΩλ’’Γ±ΒΡ«ιΩωœ¬Θ§ΡψΩ…“‘¥” ¬Φΰ¥φ¥Δ ΐΨίΩβ÷–Ε®ΤΎΒΊ…Ψ≥ΐ ΐΨίΓΘ»ΜΕχΘ§’β «ΝμΆβ“Μ÷÷ΓΑΆΥΜ·Γ±ΒΡCQRS…ηΦΤΘ§“≤Ά§―υ «ΚœάμΒΡΘ§≤ΜΙΐ’β≤Μ «Έ“Ο«Χ÷¬έΒΡΖΕΈßΓΘΈ“Ο«“ΣΧ÷¬έΒΡ «Θ§ ±Φδ“Μ≥ΛΘ§ ¬Φΰ¥φ¥Δ±δΒΟΨό¥σ‘θΟ¥ΑλΘΩ
CQRSΦήΙΙ…γ«χ÷–”–“ΜΨδΖ«≥Θ”–“βΥΦΒΡΜΑΘ§ΨΆ «ΘΚStorage is cheapΘ§data is valuableΘ®¥φ¥Δ «Ν°ΦέΒΡΘ§Εχ ΐΨί «”–Φέ÷ΒΒΡΘ©ΓΘΆ®≥ΘΘ§ΕΦ «Ά®Ιΐ¥σ»ίΝΩ¥φ¥Δ±ΗΖί“‘ΦΑ ΐΨίΙιΒΒά¥ΫβΨω’β―υΒΡΈ ΧβΘΚΕ‘”ΎΫœ‘γΒΡ ¬Φΰ ΐΨίΘ§Έ“Ο«―Γ”ΟΗΏΥΌΕχΑΚΙσΒΡ¥φ¥ΔΫι÷ Ϋχ––±ΗΖίΘ§ΕχΕ‘”ΎΗϋ‘γΒΡ ¬Φΰ ΐΨίΘ§‘ρΩ…“‘≤…”ΟΒΆΥΌΕχ±ψ“ΥΒΡ¥φ¥ΔΫι÷ Ϋχ––ΙιΒΒΘ§ΉέΚœ≤…”ΟΝΫ÷÷≤ΜΆ§ΒΡΖΫΑΗ“‘ ΙΒΟ ¬Φΰ¥φ¥ΔΕΥΓΑ–‘Φέ±»Γ±¥οΒΫΉνΗΏΓΘΒ±»ΜΘ§’β―υΒΡ≤Ώ¬‘Ά§―υ–η“ΣΓΑΩλ’’Γ±ΒΡ÷ß≥÷
Ρ≥–©ΨέΚœΒΡ…ζΟϋ÷ήΤΎΩ…ΡήΚή≥ΛΘ§”Ύ «ΨΆΜα‘ΎΥϋΟ«…μ…œ≤ζ…ζ¥σΝΩΒΡ ¬Φΰ ΐΨίΘ§Β±Νλ”ρ≤÷¥Δ÷ΊΫ®’β–©ΨέΚœΒΡ ±ΚρΘ§–η“ΣΑ―¥σΝΩΒΡ ¬Φΰ“ά¥ΈΒΊΓΑ”Π”ΟΓ±‘Ύ’β–©ΨέΚœ…œΘ§Τώ≤Μ «ΜαΜ®ΚήΕύ ±ΦδΘΩ
‘Ύ¥ΥΘ§Έ“Ο«Ά®Ιΐ“ΐ»κΓΑΩλ’’Γ±ΒΡΗ≈Ρνά¥ΫβΨω’βΗωΈ ΧβΓΘ‘ΎœΒΆ≥÷–Θ§Ω…“‘ΗυΨί“ΜΕ®ΒΡΓΑΩλ’’≤Ώ¬‘Γ±ά¥»ΖΕ®ΚΈ ±”ΠΗΟΕ‘ΨέΚœΫχ––ΓΑΩλ’’Γ±ΓΘΟΩΒ±’βΗωΩλ’’≤Ώ¬‘ΒΡΧθΦΰΖϊΚœΘ§œΒΆ≥ΨΆΜαΕ‘ΨέΚœΉω“Μ¥ΈΩλ’’Θ§≤ΔΫΪΩλ’’ ΐΨίΦ«¬Φ‘Ύ ¬Φΰ¥φ¥Δ÷–ΓΘ±»»γΘΚΈ“Ο«Ω…“‘÷ΗΕ®Θ§ΟΩnΗω ¬ΦΰΖΔ…ζ ±Θ§ΨΆΕ‘ΨέΚœΉω“Μ¥ΈΩλ’’Θ§”Ύ «Θ§Β±Έ“Ο«–η“ΣΜώΒΟΒΎn+3Ηω ¬ΦΰΖΔ…ζ ±Θ§ΗΟΨέΚœΒΡΉ¥Χ§ΒΡ ±ΚρΘ§ΨΆ÷Μ–η“Σ÷±Ϋ”¥” ¬Φΰ¥φ¥Δ÷–ΕΝ»ΓΒΎnΗω ¬ΦΰΖΔ…ζ ±Θ§ΨέΚœΒΡΩλ’’Θ§»ΜΚσ‘Ό“ά¥ΈΫΪn+1ΓΔn+2ΓΔn+3Ηω ¬Φΰ”Π”ΟΒΫΨέΚœΦ¥Ω…ΓΘ’β―υΨΆ¥σ¥σΥθΕΧΝΥ÷ΊΫ®ΨέΚœΥυ–ηΒΡ ±ΦδΘ§“≤ ΙΒΟ…œΟφΒΎ“ΜΗωΈ Χβ÷–ΙιΒΒΒΡ Βœ÷≥…ΈΣΩ…Ρή
‘ΎApworks”Π”ΟΩΣΖΔΩρΦή÷–Θ§ΡΩ«ΑΑφ±ΨΘ®AlphaΘ§v1.0.4016.23016Θ©Ε‘Ωλ’’ΒΡ÷ß≥÷ «≤…”ΟΒΡGoFΒΡmementoΡΘ ΫΘ§ΕχΕ‘Ωλ’’≤Ώ¬‘ΒΡ÷ß≥÷ΨΆœ‘ΒΟΖ«≥ΘΦρΒΞΘΚΫωΫω «Ά®ΙΐApworks . Events . Storage . IDomainEventStorage . CreateOrUpdateSnapshot ΖΫΖ®Ϋχ––Ε®“εΒΡΓΘ‘Ύ Apworks . Events . Storage . SqlDomainEventStorage άύ÷–Θ§ Βœ÷ΝΥ’βΗωΖΫΖ®Θ§≤Δ÷ΗΕ®ΟΩΒ±ΒΎ1000ΗωΝλ”ρ ¬ΦΰΖΔ…ζ ±Θ§Ε‘ΨέΚœΉω“Μ¥ΈΩλ’’ΓΘ»γΙϊΡψ¥ρΥψΦΧ–χ≤…”ΟSQL
ServerΉςΈΣ ¬Φΰ¥φ¥ΔΘ§≤Δ¥ρΥψ÷Ί–¬Ε®÷ΤΩλ’’≤Ώ¬‘Θ§«κ–¬Ϋ®“ΜΗωάύ≤ΔΦΧ≥–Apworks . Events . Storage . SqlDomainEventStorage άύΘ§»ΜΚσ÷Ί–¥ CreateOrUpdateSnapshot ΖΫΖ®ΘΜ»γΙϊΡψ¥ρΥψ≤…”ΟΤδΥϋΒΡΫι÷ ΉςΈΣ ¬Φΰ¥φ¥ΔΘ§‘ρ«κΉ‘–– Βœ÷Apworks . Events . Storage . IDomainEventStorage Ϋ”ΩΎ
‘Ύ±Θ¥φΨέΚœΒΡ ±ΚρΘ§Νλ”ρ≤÷¥Δ≤ΜΫω–η“ΣΫΪ ¬Φΰ±Θ¥φΒΫ ¬Φΰ¥φ¥ΔΘ§Εχ«“ΜΙ–η“ΣΫΪ ¬ΦΰΆΤΥΆΒΫ ¬ΦΰΉήœΏ…œΘ§’β―υΉω¥”ΦΦ θ…œΚήΡ―±Θ÷Λ≤ΌΉςΒΡ‘≠Ή”–‘Θ§ΜΜΨδΜΑΥΒΘ§Μα≤ΜΜα‘λ≥… ΐΨίΒΡ≤Μ“Μ÷¬–‘ΘΩ
«ΒΡΘ§’βΨΆ «ΥυΈΫΒΡΓΑΝΫ¥ΈΧαΫΜΓ±Θ®Two-Phase Commit, TPCΘ©≤ΌΉςΓΘ‘Ύ…ηΦΤ÷–”ΠΗΟ±ήΟβTPCΒΡ≥ωœ÷Θ§“ρΈΣ‘ΎΝΫ¥ΈΧαΫΜ÷°ΦδΜαΖΔ…ζΚήΕύ ¬«ιΘ§»γΙϊ≤ΜΡή±Θ÷Λ≤ΌΉςΒΡ‘≠Ή”–‘Θ§“≤ΨΆΈόΖ®±Θ÷Λ ΐΨίΒΡ“Μ÷¬–‘ΓΘΕ‘”ΎCQRSΧεœΒΫαΙΙΒΡ”Π”ΟœΒΆ≥Εχ―‘Θ§’β «÷¬ΟϋΒΡΓΘΡΩ«Α‘Ύ ¬Φΰ¥φ¥Δ≤ΩΖ÷Θ§±ήΟβTPC”–ΝΫ÷÷ΖΫΑΗΘΚA.ΫΪ ¬Φΰ¥φ¥Δ’ϊΚœΒΫ ¬ΦΰΉήœΏΘΜB.ΫΪ ¬ΦΰΉήœΏ’ϊΚœΒΫ ¬Φΰ¥φ¥ΔΓΘΉή÷°Θ§ΥΦœκ÷Μ”–“ΜΗωΘΚΨΆ «≤…”ΟΆ§“ΜΗω≥÷ΨΟΜ·Μζ÷Τά¥’ϊΚœ¥φ¥Δ≤ΩΖ÷”κΉήœΏ≤ΩΖ÷ΓΘ”–ΙΊTPCΒΡ…ν»κ―–ΨΩΘ§Έ“Μα‘ΎΚσ–χΒΡά©’ΙΜΑΧβ÷–Χ÷¬έΓΘΡΩ«ΑΑφ±ΨΒΡApworksΘ®AlphaΘ§v1.0.4016.23016Θ©≤ΜΧαΙ©Ε‘TPCΒΡ÷ß≥÷
œ÷‘ΎΘ§Έ“Ο«‘Όά¥Ω¥Ω¥Tiny Library CQRSœνΡΩ÷–Θ§ ¬Φΰ¥φ¥ΔΒΡ Βœ÷ΖΫ ΫΓΘ ΒΦ …œΘ§Tiny Library
CQRS≤…”ΟΒΡ «Apworks”Π”ΟΩΣΖΔΩρΦήΥυΧαΙ©ΒΡΡ§»œΒΡ ¬Φΰ¥φ¥ΔΜζ÷ΤΘΚΜυ”ΎSQL ServerΒΡΒΞ±μ ¬Φΰ¥φ¥ΔΓΘ±μΫαΙΙ»γœ¬ΘΚ

Ήœ»Θ§Νλ”ρ≤÷¥Δ¥”ΨέΚœΜώΒΟΈ¥±Θ¥φΘ®Φ¥Έ¥ΧαΫΜΘ© ¬ΦΰΘ§»ΜΚσΘ§ Ι”Ο÷ΗΕ®ΒΡ–ρΝ–Μ·ΖΫ ΫΘ§ΫΪ ¬Φΰ–ρΝ–Μ·ΈΣΕΰΫχ÷ΤΝςΘ§≤Δ±Θ¥φΒΫApworks.Events.Storage.DomainEventDataObjectΕ‘œσ÷–Θ§’βΗωΕ‘œσΤδ Β «“ΜΗωDTOΘ§ΥϋΩ…“‘±Μ–ρΝ–Μ·/Ζ¥–ρΝ–Μ·Θ§“≤Ω…“‘±Μ–ρΝ–Μ·ΈΣData
ContractΕχΆ®ΙΐWCF‘ΎΆχ¬γ…œΉ‘”…¥Ϊ δΓΘApworksΒΡΜυ¥ΓΫαΙΙ≤ψΜαΆ®ΙΐDomainEventDataObjectΒΡ τ–‘Ε®“εΘ§≤ΔΫαΚœ“ΜΗωΗχΕ®ΒΡStorage
Mapping SchemaΘ®“≤ΨΆ «TinyLibrary.Services.DomainEventStorageMappings.xmlΈΡΦΰΘ©Θ§ΫΪDomainEventDataObjectΒΡ ΐΨί±Θ¥φΒΫ…œΟφΒΡ ΐΨί±μάοΓΘ
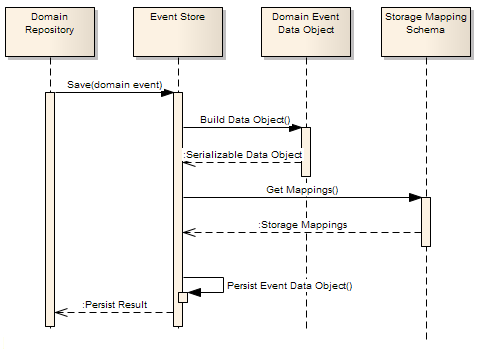
‘Ύ¥ΥΦρΒΞΫι…ή“Μœ¬’βΗωStorage Mapping SchemaΓΘ”…”ΎΈ“Ο« Ι”ΟΒΡ «ΙΊœΒ–Ά ΐΨίΩβΘ§ΈΣΝΥΫβώνΓΑ ΐΨίΕ‘œσ/ τ–‘Γ±”κΓΑ ΐΨί±μ/Ή÷ΕΈΓ±ΒΡΤΞ≈δΘ§Apworks“ΐ»κΝΥStorage
Mapping SchemaΘ§’βΗωΈΡΦΰ”–ΒψœώNHibernate÷–ΒΡMapping XMLΘ§ΒΪ±»NHibernateΒΡMapping
XMLΦρΒΞΚήΕύΘΚΥϋ≤Μ÷ß≥÷Ε‘ ΐΨίΕ‘œσΙΊœΒ”κ±μΙΊœΒΒΡ”≥…δΘ§Υϋ≤Μ «“ΜΗωORMΓΘ‘ΎStorage Mapping
Schema÷–Θ§ΫωΫωΦρΒΞΒΊΕ®“εΝΥ ΐΨίΕ‘œσ/ ΐΨί±μΘ§“‘ΦΑΕ‘œσ τ–‘/Ή÷ΕΈΒΡ”≥…δΙΊœΒΘ§’β «”…”ΎΘ§CQRSΧεœΒΫαΙΙ¥” Βœ÷…œΫΒΒΆΝΥΙΊœΒ–Ά ΐΨίΩβΒΡΒΊΈΜΘ§Ε®“ε ΐΨί±μΦΑΤδ÷°ΦδΒΡΙΊœΒ“―Ψ≠≤ΜΡ«Ο¥÷Ί“ΣΝΥΓΘ’βάοΈ“”÷Ω…“‘Ηχ≥ωΝΫ÷÷ΖΫΑΗΘΚ»γΙϊΡψ»‘»ΜœΘΆϊ‘Ύ ¬Φΰ¥φ¥Δ≤ΩΖ÷≤…”ΟΙΊœΒ–Ά ΐΨίΩβΘ§≤Δ¥ρΥψ»ΞΈ§ΜΛΗ¥‘”ΒΡ ΐΨί±μΙΊœΒΘ§Ρ«Ο¥Θ§ΡψΩ…“‘≤Μ―Γ”ΟStorage
Mapping SchemaΘ§Εχ≤…”ΟORMΘ®±»»γNHibernateΘ©Θ§¥Υ ±Θ§DomainEventDataObjectΨΆ «ORM…œΒΡΓΑ ΒΧεΓ±ΘΜ»γΙϊΡψ≤Μ¥ρΥψ≤…”ΟΙΊœΒ–Ά ΐΨίΩβΘ§Εχ―Γ‘ώΕ‘œσ ΐΨίΩβΘ®±»»γΘΚDb4OΘ©Θ§Ρ«Ο¥Θ§Ρψ“≤≤Μ–η“Σ»ΞΈ§ΜΛ»ΈΚΈΒΡMapping
XMLΘ§Ε‘œσ ΐΨίΩβΜαΑοΡψ¥ράμΚΟ“Μ«–Θ§’βΫΪ¥σ¥σΧαΗΏœΒΆ≥–‘ΡήΓΘ“‘œ¬ «Storage Mapping SchemaΒΡXSDΫαΙΙΘ§“‘Ι©≤ΈΩΦΓΘΗΟXSDΈΡΦΰ“―±ΜΑϋΚ§‘ΎApworks”Π”ΟΩΣΖΔΩρΦήΒΡΑ≤ΉΑΑϋάοΘ§”ΟΜßΩ…“‘‘ΎApworksΑ≤ΉΑΡΩ¬ΦΒΡscriptsΉ”ΡΩ¬Φ÷–’“ΒΫ’βΗωΈΡΦΰΓΘ
|
<?xml version="1.0" encoding="UTF-8"?>
2: <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
3: elementFormDefault="qualified"
4: attributeFormDefault="unqualified">
5: <xs:element name="StorageMappingSchema">
6: <xs:annotation>
7: <xs:documentation/>
8: </xs:annotation>
9: <xs:complexType>
10: <xs:sequence minOccurs="0">
11: <xs:element ref="DataTypes"/>
12: </xs:sequence>
13: </xs:complexType>
14: </xs:element>
15: <xs:element name="DataTypes">
16: <xs:complexType>
17: <xs:sequence minOccurs="0"
maxOccurs="unbounded">
18: <xs:element ref="DataType"/>
19: </xs:sequence>
20: </xs:complexType>
21: </xs:element>
22: <xs:element name="DataType">
23: <xs:complexType>
24: <xs:sequence minOccurs="0">
25: <xs:element ref="Properties"/>
26: </xs:sequence>
27: <xs:attribute name="FullName"
type="xs:string"
use="required"/>
28: <xs:attribute name="MapTo"
type="xs:string"
use="required"/>
29: </xs:complexType>
30: </xs:element>
31: <xs:element name="Properties">
32: <xs:complexType>
33: <xs:sequence minOccurs="0"
maxOccurs="unbounded">
34: <xs:element ref="Property"/>
35: </xs:sequence>
36: </xs:complexType>
37: </xs:element>
38: <xs:element name="Property">
39: <xs:complexType>
40: <xs:attribute name="Name" type="xs:string"
use="required"/>
41: <xs:attribute name="MapTo"
type="xs:string"
use="required"/>
42: <xs:attribute name="Identity"
type="xs:boolean"
use="optional"/>
43: <xs:attribute name="AutoGenerate"
type="xs:boolean" use="optional"/>
44: </xs:complexType>
45: </xs:element>
46: </xs:schema> |
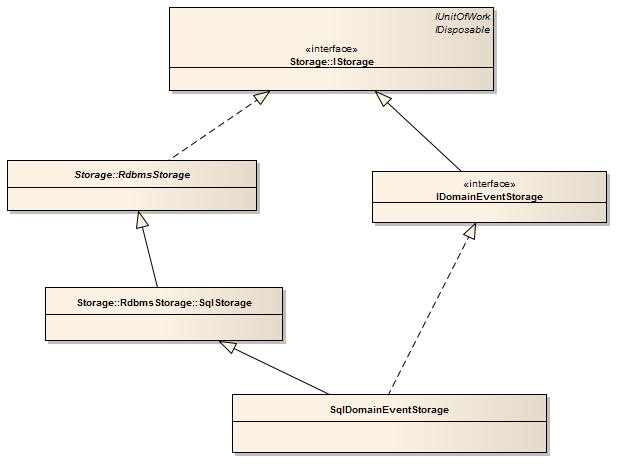
ΉνΚσΘ§‘Ύ¥ΥΗχ≥ωApworks”Π”ΟΩΣΖΔΩρΦή÷–Μυ”ΎSQL ServerΒΡEvent StoreΒΡάύΙΊœΒΆΦΘ§Ι©¥σΦ“≤ΈΩΦΓΘΈΣΝΥΫΎ ΓΑφΟφΩ’ΦδΘ§¥ΥΆΦ÷–“ΰ≤ΊΝΥάύ÷–ΒΡ τ–‘”κΖΫΖ®Ε®“εΘ§”––Υ»ΛΒΡ≈σ”―Ω…“‘ΒΫApworksΒΡ’ΨΒψhttp://apworks.codeplex.com…œ≤ιΩ¥ΨΏΧεΒΡ¥ζ¬κ Βœ÷ΓΘ
|








