|
�����ھ�Data mining��
�����ھ�Ӣ�Data mining��������Ϊ����̽�������ݲɿ��������ݿ�֪ʶ���֣�Ӣ�Knowledge-Discovery
in Databases����ƣ�KDD)�е�һ�����衣�����ھ�һ����ָ�Ӵ�����������ͨ���㷨����������������Ϣ�Ĺ��̡������ھ�ͨ����������ѧ�йأ���ͨ��ͳ�ơ����߷����������鱨����������ѧϰ��ר��ϵͳ��������ȥ�ľ��鷨��ģʽʶ���������ʵ������Ŀ�ꡣ


�����ھ�Data Mining��DM����Ŀǰ�˹����ܺ����ݿ������о����ȵ����⣬��ν�����ھ���ָ�����ݿ�Ĵ��������н�ʾ�������ġ���ǰδ֪�IJ���DZ�ڼ�ֵ����Ϣ�ķ�ƽ�����̡������ھ���һ�־���֧�ֹ��̣�����Ҫ�����˹����ܡ�����ѧϰ��ģʽʶ��ͳ��ѧ�����ݿ⡢���ӻ������ȣ��߶��Զ����ط�����ҵ�����ݣ����������Ե������������ھ��DZ�ڵ�ģʽ�����������ߵ����г����ԣ����ٷ��գ�������ȷ�ľ��ߡ�
֪ʶ���ֹ�����������������ɣ���1������������2�������ھ�3���������ͽ��͡������ھ�������û���֪ʶ�⽻����
�����ھ���ͨ������ÿ�����ݣ��Ӵ���������Ѱ������ɵļ�������Ҫ��������������Ѱ�Һ��ɱ�ʾ3�����衣�������Ǵ���ص�����Դ��ѡȡ��������ݲ����ϳ����������ھ�����ݼ�������Ѱ������ij�ַ��������ݼ������Ĺ����ҳ��������ɱ�ʾ�Ǿ��������û�������ķ�ʽ������ӻ������ҳ��Ĺ��ɱ�ʾ������
�����ھ�������й����������������������������쳣����������Ⱥ��������ݱ�������ȵȡ�
��Դ
��Ҫ�Ƿ���֮ĸ���������������ھ���������Ϣ��ҵ��ļ����ע������Ҫԭ���Ǵ��ڴ������ݣ����Թ㷺ʹ�ã�����������Ҫ����Щ����ת�������õ���Ϣ��֪ʶ����ȡ����Ϣ��֪ʶ���Թ㷺���ڸ���Ӧ�ã���������������������ƣ��г�������������ƺͿ�ѧ̽���ȡ�
�����ھ���������������һЩ�����˼�룺(1) ����ͳ��ѧ�ij��������ƺͼ�����飬(2)�˹����ܡ�ģʽʶ��ͻ���ѧϰ�������㷨����ģ������ѧϰ���ۡ������ھ�ҲѸ�ٵؽ������������������˼�룬��Щ����������Ż����������㡢��Ϣ�ۡ��źŴ��������ӻ�����Ϣ������һЩ��������Ҳ����Ҫ��֧�����á��ر�أ���Ҫ���ݿ�ϵͳ�ṩ��Ч�Ĵ洢�������Ͳ�ѯ����֧�֡�Դ�ڸ����ܣ����У�����ļ����ڴ����������ݼ����泣������Ҫ�ġ��ֲ�ʽ����Ҳ�ܰ��������������ݣ����ҵ����ݲ��ܼ��е�һ����ʱ����������Ҫ��
��չ��
��һ�Σ������ʼ���
����ο�����Ϊ�Ǵ�70�����ʼ��ƽ����ͨѶ����ÿ�꼸�����ٶ�������
�ڶ��Σ���Ϣ������
��1995������Web����Ϊ��������Ϣ����ϵͳ����ըʽ�سɳ���������ΪĿǰInternet����ҪӦ�á���С��ҵ��ΰ��պôӡ��ַ��͡��������͡�Ӫ��ʱ���ĵ�������
������ EC(Electronic Commerce���������������
EC������Ҳ�Ÿոտ�ʼ��֮����EC��Ϊһ����ʱ���Ķ���������ΪInternet��������Ҫ��ҵ��;�����ǵ�������ͬʱ������Ҳ����˵������������ҵ��Ϣ����Ҫ��ͨ��Internet���ݡ�Internet������Ϊ���������ҵ��Ϣ������ϵͳ��1997����ڼ��ô��¸绪���еĵ������̫������֯����ʽ���Ի��飨APEC����������ͳ���ֶ�����شٸ�����ͬ�ٽ���������չ���鰸����������ȫ�����ԵĹ�ע��IBM��HP��Sun�ȹ�����������Ϣ���������Ѿ�����1998��Ϊ���������ꡣ
���ĽΣ�ȫ�̵��������
����SaaS��Software as a service����������ģʽ�ij��֣�������½������[5]���ӳ��˵��������������γ��˵������µġ�ȫ�̵���������ģʽ��Ҳ����γ���һ�Ŷ�����ѧ�ơ��������ھ���ͻ���ϵ����˶ʿ��
����������
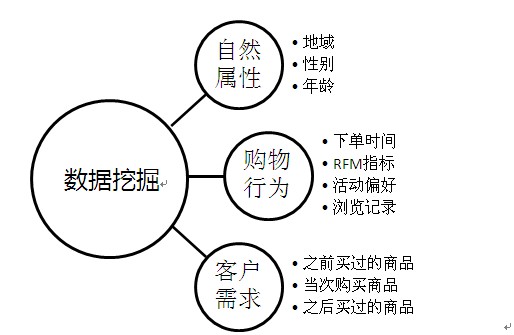
1.���� ��Classification��
2.���ƣ�Estimation��
3.Ԥ�⣨Prediction��
4.����Է�����������Affinity grouping or association
rules��
5.���ࣨClustering��
6.�������������ھ�(Text, Web ,ͼ��ͼ����Ƶ����Ƶ��)
������飺
1.���� ��Classification��
���ȴ�������ѡ���Ѿ��ֺ����ѵ�������ڸ�ѵ���������������ھ����ļ�������������ģ�ͣ�����û�з�������ݽ��з��ࡣ
���ӣ�
a. ���ÿ������ߣ�����Ϊ�͡��С��߷���
b. ������ϣ��й����ּ������Ϻ�������Ϣ��������˾���������������ھ����Ըֲ�������ȫ���̽���������غͷ������������ϵ�ͼ��ʵʱ������Ʒ����覴õ�ԭ����Ч����˲�Ʒ�������ʡ�
ע�⣺ ��ĸ�����ȷ���ģ�Ԥ�ȶ���õ�
2.���ƣ�Estimation��
������������ƣ���֮ͬ�����ڣ���������������ɢ�ͱ��������������ֵ��������ֵ�����������������ȷ����Ŀ�ģ���ֵ�����Dz�ȷ���ġ�
���ӣ�
a. ���ݹ���ģʽ������һ����ͥ�ĺ��Ӹ���
b. ���ݹ���ģʽ������һ����ͥ������
c. ����real estate�ļ�ֵ
һ����˵����ֵ������Ϊ�����ǰһ������������һЩ�������ݣ�ͨ����ֵ���õ�δ֪������������ֵ��Ȼ����Ԥ���趨����ֵ�����з��ࡣ���磺���жԼ�ͥ����ҵ�����ù�ֵ���������ͻ��Ƿ֣�Score
0~1����Ȼ������ֵ�����������ࡣ
3.Ԥ�⣨Prediction��
ͨ����Ԥ����ͨ��������ֵ�����õģ�Ҳ����˵��ͨ��������ֵ�ó�ģ�ͣ���ģ�����ڶ�δ֪������Ԥ�ԡ�������������˵��Ԥ����ʵû�б�Ҫ��Ϊһ���������ࡣԤ����Ŀ���Ƕ�δ��δ֪������Ԥ�⣬����Ԥ������Ҫʱ������֤�ģ������뾭��һ��ʱ���֪��Ԥ��ȷ���Ƕ��١�
4.����Է�����������Affinity grouping or association
rules��
������Щ���齫һ������
���ӣ�
a. �����пͻ��ڹ���A��ͬʱ�������Ṻ��B����A => B(��������)
b. �ͻ��ڹ���A��һ��ʱ�䣬�Ṻ��B �����з�����
5.���ࣨClustering��
�����ǶԼ�¼���飬�����Ƶļ�¼��һ���ۼ������ͷ���������Ǿۼ���������Ԥ�ȶ���õ��࣬����Ҫѵ������
���ӣ�
a. һЩ�ض�֢״�ľۼ�����Ԥʾ��һ���ض��ļ���
b. ��VCD���Ͳ����ƵĿͻ��ۼ������ܰ�ʾ��Ա���ڲ�ͬ�����Ļ�Ⱥ
�ۼ�ͨ����Ϊ�����ھ�ĵ�һ�������磬"��һ����Ĵ����Կͻ���Ӧ��ã�"��������һ
�����⣬���ȶ������ͻ����ۼ������ͻ������ڸ��Եľۼ��Ȼ���ÿ����ͬ�ľۼ����ش����⣬����Ч�����á�
6.�����Ϳ��ӻ���Description and Visualization��
�Ƕ������ھ����ı�ʾ��ʽ��һ��ֻ��ָ���ݿ��ӻ����ߣ������������ߺ���ҵ���ܷ�����Ʒ��BI����ͳ�ơ�Ʃ��ͨ��Yonghong
Z-Suite�ȹ��߽������ݵ�չ�֣���������ȡ���������ھ�ķ��������������̵�չ�ֳ�����
��һ��Ŀ���ɣ�ҵ��Ŀ�����������ݽ��������Դͷ��
�ڶ���֪ʶ�ɣ�ҵ��֪ʶ�������ھ����ÿһ���ĺ��ġ�
���������ɣ�����Ԥ�����������ھ������κ�һ�����̶���Ҫ��
���ģ�������(NFL�ɣ�No Free Lunch)�����������ھ�����˵������û����ѵ���ͣ�һ����ȷ��ģ��ֻ��ͨ��������ܱ����֡�
���壬ģʽ��(������)���������ܺ���ģʽ��
�����������ɣ������ھ������ҵ�����֪��
���ߣ�Ԥ���ɣ�Ԥ���������Ϣ����������
�ڰˣ���ֵ�ɣ������ھ�Ľ���ļ�ֵ��ȡ����ģ�͵��ȶ��Ի�Ԥ���ȷ�ԡ�
�ھţ��仯�ɣ����е�ģʽ��ҵ��仯���仯��

�����ھ����Credilogros C��a Financiera S.A.���ƿͻ���������
Credilogros C��a Financiera S.A. �ǰ���͢������Ŵ���˾���ʲ����Ƽ�ֵΪ9570����Ԫ������Credilogros���ԣ���Ҫ����ʶ����DZ��Ԥ�ȸ���ͻ���ص�DZ�ڷ��գ��Ա㽫�е��ķ�����С����
�ù�˾�ĵ�һ��Ŀ���Ǵ���һ���빫˾����ϵͳ���������ñ��湫˾ϵͳ�����ľ��������������Ŵ����롣ͬʱ��Credilogros����Ѱ�������������ĵ�����ͻ�Ⱥ����Զ���������ֹ��ߡ�����Щ֮�⣬�����������������������35����֧�칫�ص��200�����ص����۵��е��κ�һ��ʵʱ�������������ۼҵ���������ֻ����۹�˾��
����Credilogros ѡ����SPSS Inc.�������ھ�����PASWModeler����Ϊ���ܹ������ɵ����ϵ�
Credilogros �ĺ�����Ϣϵͳ�С�ͨ��ʵ��PASW Modeler��Credilogros�����ڴ����������ݺ��ṩ�����������ֵ�ʱ�����̵���8�����ڡ���ʹ����֯�ܹ�Ѹ������ܾ��Ŵ����þ������滹ʹ
Credilogros �ܹ���С��ÿ���ͻ������ṩ������֤���ĵ�����һЩ��������£�ֻ���ṩһ������֤���������Ŵ������⣬��ϵͳ���ṩ��ع��ܡ�CredilogrosĿǰƽ��ÿ��ʹ��PASW
Modeler����35000�����롣����ʵ�� 3 ���º�Ͱ���Credilogros ������֧��ʧְ������
20%.
�����ھ����DHLʵʱ���ٻ����¶�
DHL�ǹ��ʿ�ݺ�������ҵ��ȫ���г������ߣ����ṩ��ݡ�ˮ½����·���䡢��ͬ��������������Լ������ʼ�����DHL�Ĺ������罫����220�����Ҽ�������ϵ������Ա����������28.5���ˡ�������
FDA Ҫ��ȷ����������ҩƷװ�˵��¶ȴ����һѹ��֮�£�DHL��ҽҩ�ͻ�ǿ��Ҫ���ṩ���ɿ��Ҹ�ʵ�ݵ�ѡ�����Ҫ��DHL�ڵ��͵ĸ����ζ�Ҫʵʱ���ټ�װ����¶ȡ�
��Ȼ�ɼ�¼���������ɵ���Ϣȷ��������ʵʱ�������ݣ��ͻ���DHL�����ڷ����¶�ƫ��ʱ��ȡ�κ�Ԥ���;�����ʩ����ˣ�DHL��ĸ��˾�¹�������������DPWN��ͨ�������봴�¹�����TIM��������ȷ�ⶨ��һ���ƻ�����ʹ��RFID�����ڲ�ͬʱ���ȫ�̸���װ�˵��¶ȡ�ͨ��IBMȫ����ҵ��ѯ�����ƾ�������Ĺؼ����ܲ��������̿�ܡ�DHL���������������棺�������տͻ���˵���ܹ�ʹҽҩ�ͻ����������г��ֵ�װ��������ǰ������Ӧ����������עĿ�ĵͳɱ�ȫ����ʵ����ǿ�����Ϳɿ��ԡ�����DHL��˵������˿ͻ�����Ⱥ���ʵ�ȣ�Ϊ���־�������춨��ʵ�Ļ���������Ϊ��Ҫ���µ�����������Դ��
��ҵӦ��
�۸�����ǰ���ң�����ҵ�����������������������й��ƶ�ͨ���г���������ǰ��δ�е�����ѹ�����й�����ҵ�ĸ�ļ����ƽ��γ����µľ���̬�ƣ��ƶ���Ӫ�г��ľ�����Ⱥ�ǿ�Ƚ���һ���Ӵ����ر�����ڼ��ſͻ������ƶ���Ϣ���ͼ��ſͻ���Ȼ��Ϊδ������Ӫ��Ӧ�Ծ�������ȡ���������������档
���Ź������㶦��ȫҵ����̬�ƺ�3G���շ��ţ�����Ӫ��Ϊ���ſͻ��ṩ�ںϵ���Ϣ������������Ǵ������������ƶ���Ϣ������Ϊȫ�������Ϣ������������ȵ���������ͳ�ƶ���Ӫ����������ŴӴ�ͳ����ҵ��ת��ͬʱ��չ���ſͻ���Ϣ��ҵ���������ս�����Ӧ���������ⲿ����ս��Ѹ�����ƶ���Ϣ��ҵ����Ϊ�ں�ҵ��ľ�������֮һ��չ���ſͻ��г����������г������ڲ���֮�أ��Ǵ�ͳ�ƶ���Ӫ����Ҫ����Ľ������⡣
�����ھ�ʮ���㷨
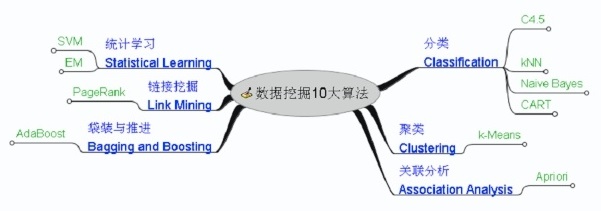
1. C4.5���ǻ���ѧϰ�㷨�е�һ�ַ���������㷨��������㷨��ID3�㷨��
2. K-means�㷨����һ�־����㷨��
3.SVM��һ�ּලʽѧϰ�ķ������㷺������ͳ�Ʒ����Լ��ع������
4.Apriori ����һ������Ӱ����ھ���������Ƶ������㷨��
5.EM���������ֵ����
6.pagerank����google�㷨����Ҫ���ݡ�
7. Adaboost:��һ�ֵ����㷨�������˼�������ͬһ��ѵ����ѵ����ͬ�ķ�����Ȼ�������������������������һ����ǿ�����շ�������
8.KNN:��һ�������ϱȽϳ���ĵķ�����Ҳ����Ļ���ѧϰ����֮һ��
9.Naive Bayes�����ڶ������У�Ӧ����㷺���о�����ģ�ͺ����ر�Ҷ˹��Naive
Bayes��
10.Cart��������ع������ڷ����������������ؼ���˼�룬��һ���ǹ��ڵݹ�ػ����Ա����ռ���뷨���ڶ���������֤���ݽ��м�֦��
����������
�������йع��������һЩϸ��֮ǰ������������һ����Ȥ�Ĺ��£� "����ơ��"�Ĺ��¡�
��һ�ҳ������һ����Ȥ��������ơ�ƺ�Ȼ����һ����ۡ����������ֵľٴ�ȴʹ��ơ�Ƶ�����˫˫�����ˡ��ⲻ��һ��Ц�������Ƿ����������ֶ��������곬�е���ʵ��������һֱΪ�̼�������ֵ����ֶ���ӵ���������������ݲֿ�ϵͳ��Ϊ���ܹ�ȷ�˽�˿������ŵ�Ĺ���ϰ�ߣ��ֶ������˿͵Ĺ�����Ϊ���й�������������֪���˿;���һ�������Ʒ����Щ���ֶ������ݲֿ��O��������ŵ����ϸԭʼ�������ݡ�����Щԭʼ�������ݵĻ����ϣ��ֶ������������ھ�����Щ���ݽ��з������ھ�һ������ķ����ǣ�"����һ����������Ʒ����ơ�ƣ���������ʵ�ʵ���ͷ�������ʾ��һ��������"����ơ��"����������˵�һ����Ϊģʽ����������һЩ����ĸ����°��Ҫ������ȥ��Ӥ��������������30%��40%����ͬʱҲΪ�Լ���һЩơ�ơ�������һ�����ԭ���ǣ�������̫̫�dz��������ǵ��ɷ��°��ΪС���������ɷ��������������ִ���������ϲ����ơ�ơ�
������˼ά������ơ�Ʒ���ţ���༰�������ǽ��������ھ����Դ����������ݽ����ھ�������ֶ����Dz����ܷ�������������һ�м�ֵ�Ĺ��ɵġ�
���ݹ��������ݿ��д��ڵ�һ����Ҫ�Ŀɱ����ֵ�֪ʶ������������������ȡֵ֮�����ij�ֹ����ԣ��ͳ�Ϊ�����������ɷ�Ϊ������ʱ��������������������������Ŀ�����ҳ����ݿ������صĹ���������ʱ����֪�����ݿ������ݵĹ�����������ʹ֪��Ҳ�Dz�ȷ���ģ���˹����������ɵĹ�����п��Ŷȡ����������ھ��ִ����������֮����Ȥ�Ĺ����������ϵ��Agrawal����1993������������ھ�˿ͽ������ݿ������Ĺ����������⣬�Ժ������о���Ա�Թ���������ھ���������˴������о������ǵĹ���������ԭ�е��㷨�����Ż���������������������е�˼��ȣ�������㷨�ھ�����Ч�ʣ��Թ��������Ӧ�ý����ƹ㡣���������ھ��������ھ�����һ����Ҫ�Ŀ��⣬��������ѱ�ҵ�����㷺�о���
���������ھ������Ҫ���������Σ���һ�α����ȴ����ϼ������ҳ����еĸ�Ƶ��Ŀ��(FrequentItemsets)���ڶ���������Щ��Ƶ��Ŀ���в�����������(Association
Rules)��
���������ھ�ĵ�һ�α����ԭʼ���ϼ����У��ҳ����и�Ƶ��Ŀ��(Large
Itemsets)����Ƶ����˼��ָijһ��Ŀ����ֵ�Ƶ����������м�¼���ԣ�����ﵽijһˮƽ��һ��Ŀ����ֵ�Ƶ�ʳ�Ϊ֧�ֶ�(Support)����һ������A��B������Ŀ��2-itemsetΪ�������ǿ��Ծ��ɹ�ʽ(1)��ð���{A,B}��Ŀ���֧�ֶȣ���֧�ֶȴ��ڵ������趨����С֧�ֶ�(Minimum
Support)�ż�ֵʱ����{A,B}��Ϊ��Ƶ��Ŀ�顣һ��������С֧�ֶȵ�k-itemset�����Ϊ��Ƶk-��Ŀ��(Frequent
k-itemset)��һ���ʾΪLarge k��Frequent k���㷨����Large k����Ŀ�����ٲ���Large
k+1��ֱ�������ҵ������ĸ�Ƶ��Ŀ��Ϊֹ��
���������ھ�ĵڶ�����Ҫ������������(Association Rules)���Ӹ�Ƶ��Ŀ�������������������ǰһ����ĸ�Ƶk-��Ŀ����������������С������(Minimum
Confidence)�������ż��£���һ��������õ�������������С�����ȣ��ƴ˹���Ϊ�����������磺���ɸ�Ƶk-��Ŀ��{A,B}�������Ĺ���AB���������ȿɾ��ɹ�ʽ(2)��ã��������ȴ��ڵ�����С�����ȣ����ABΪ��������
���ֶ��갸�����ԣ�ʹ�ù��������ھ������Խ������Ͽ��еļ�¼���������ھ����ȱ���Ҫ�趨��С֧�ֶ�����С�����������ż�ֵ���ڴ˼�����С֧�ֶ�min_support=5%
����С������min_confidence=70%����˷��ϴ˸ó�������Ĺ���������ͬʱ�������������������������ھ�������ҵ��Ĺ���������ơ�ơ��������������������ɽ��ܡ���ơ�ơ��Ĺ��������ù�ʽ��������Support(��ơ��)>=5%��Confidence(��ơ��)>=70%�����У�Support(��ơ��)>=5%�ڴ�Ӧ�÷����е�����Ϊ:�����еĽ���¼�����У�������5%�Ľ��׳�������ơ����������Ʒ��ͬʱ����Ľ�����Ϊ��Confidence(��ơ��)>=70%�ڴ�Ӧ�÷����е�����Ϊ:�����а����Ľ���¼�����У�������70%�Ľ���ͬʱ����ơ�ơ���ˣ��������ij�����߳��ֹ�������Ϊ�����н����Ƽ���������ͬʱ����ơ�ơ������Ʒ�Ƽ�����Ϊ���Ǹ��ݡ���ơ�ơ�����������Ϊ�ó��й�ȥ�Ľ���¼���ԣ�֧���ˡ��ݹ����Ľ��ף���ͬʱ����ơ�ơ���������Ϊ��
������Ľ��ܻ����Կ��������������ھ�ͨ���Ƚ��������¼�е�ָ��ȡ��ɢֵ����������ԭʼ���ݿ��е�ָ��ֵ��ȡ���������ݣ����ڹ��������ھ�֮ǰӦ�ý����ʵ���������ɢ����ʵ���Ͼ��ǽ�ij�������ֵ��Ӧ��ij��ֵ�������ݵ���ɢ���������ھ�ǰ����Ҫ���ڣ���ɢ���Ĺ����Ƿ������ֱ��Ӱ�����������ھ�����
����
���ղ�ͬ���������������Խ��з������£�
1.���ڹ����д����ı�������𣬹���������Է�Ϊ�����ͺ���ֵ�͡�
����������������ֵ������ɢ�ġ�����ģ�����ʾ����Щ����֮��Ĺ�ϵ������ֵ����������ԺͶ�ά���������������������������ֵ���ֶν��д�����������ж�̬�ķָ����ֱ�Ӷ�ԭʼ�����ݽ��д�������Ȼ��ֵ����������Ҳ������������������磺�Ա�=��Ů��=>ְҵ=�����顱
���Dz������������Ա�=��Ů��=>avg�����룩=2300���漰����������ֵ���ͣ�������һ����ֵ��������
2.���ڹ��������ݵij����Σ����Է�Ϊ�����������Ͷ���������
�ڵ���Ĺ��������У����еı�����û�п��ǵ���ʵ�������Ǿ��ж����ͬ�IJ�εģ����ڶ��Ĺ��������У������ݵĶ�����Ѿ������˳�ֵĿ��ǡ����磺IBM̨ʽ��=>Sony��ӡ������һ��ϸ�������ϵĵ����������̨ʽ��=>Sony��ӡ������һ���ϸ߲�κ�ϸ�ڲ��֮��Ķ���������
3.���ڹ������漰�������ݵ�ά��������������Է�Ϊ��ά�ĺͶ�ά�ġ�
�ڵ�ά�Ĺ��������У�����ֻ�漰�����ݵ�һ��ά�����û��������Ʒ�����ڶ�ά�Ĺ��������У�Ҫ���������ݽ����漰���ά��������һ�仰����ά���������Ǵ������������е�һЩ��ϵ����ά���������Ǵ�����������֮���ijЩ��ϵ�����磺ơ��=>����������ֻ�漰���û��Ĺ������Ʒ���Ա�=��Ů��=>ְҵ=�����顱������������漰�������ֶε���Ϣ��������ά�ϵ�һ����������
�㷨
1.Apriori�㷨��ʹ�ú�ѡ���Ƶ���
Apriori�㷨��һ������Ӱ����ھ���������Ƶ������㷨��������ǻ�������Ƶ��˼��ĵ����㷨���ù��������ڷ��������ڵ�ά�����㡢���������������������֧�ֶȴ�����С֧�ֶȵ����ΪƵ��������Ƶ����
���㷨�Ļ���˼���ǣ������ҳ����е�Ƶ������Щ����ֵ�Ƶ�������ٺ�Ԥ�������С֧�ֶ�һ����Ȼ����Ƶ������ǿ����������Щ�������������С֧�ֶȺ���С���Ŷȡ�Ȼ��ʹ�õ�1���ҵ���Ƶ�����������Ĺ�����ֻ�������ϵ�������й�������ÿһ��������Ҳ�ֻ��һ�������õ����й���Ķ��塣һ����Щ�������ɣ���ôֻ����Щ�����û���������С���ŶȵĹ���ű���������Ϊ����������Ƶ����ʹ���˵��Ƶķ�����
���ܲ��������ĺ�ѡ��,�Լ�������Ҫ�ظ�ɨ�����ݿ⣬��Apriori�㷨������ȱ�㡣
2.���ڻ��ֵ��㷨
Savasere�������һ�����ڻ��ֵ��㷨������㷨�Ȱ����ݿ�����Ϸֳɼ��������ཻ�Ŀ飬ÿ�ε�������һ���ֿ鲢�����������е�Ƶ����Ȼ��Ѳ�����Ƶ���ϲ��������������п��ܵ�Ƶ������������Щ���֧�ֶȡ�����ֿ�Ĵ�Сѡ��Ҫʹ��ÿ���ֿ���Ա��������棬ÿ����ֻ�豻ɨ��һ�Ρ����㷨����ȷ������ÿһ�����ܵ�Ƶ��������ijһ���ֿ�����Ƶ����֤�ġ����㷨�ǿ��Ը߶Ȳ��еģ�����ÿһ�ֿ�ֱ�����ijһ������������Ƶ��������Ƶ����ÿһ��ѭ������������֮�����ͨ��������ȫ�ֵĺ�ѡk-���ͨ�������ͨ�Ź������㷨ִ��ʱ�����Ҫƿ��������һ���棬ÿ�������Ĵ���������Ƶ����ʱ��Ҳ��һ��ƿ����
3.FP-��Ƶ���㷨
���Apriori�㷨�Ĺ���ȱ�ݣ�J. Han������˲�������ѡ�ھ�Ƶ����ķ�����FP-��Ƶ���㷨�����÷ֶ���֮�IJ��ԣ��ھ�����һ��ɨ��֮�����ݿ��е�Ƶ��ѹ����һ��Ƶ��ģʽ����FP-tree����ͬʱ��Ȼ�������еĹ�����Ϣ������ٽ�FP-tree�ֻ���һЩ�����⣬ÿ�����һ������Ϊ1��Ƶ����أ�Ȼ���ٶ���Щ������ֱ�����ھ�ԭʼ�������ܴ��ʱ��Ҳ���Խ�ϻ��ֵķ���,ʹ��һ��FP-tree���Է��������С�ʵ�������FP-growth�Բ�ͬ���ȵĹ����кܺõ���Ӧ�ԣ�ͬʱ��Ч���Ͻ�֮Apriori�㷨�о����ߡ�
Ӧ��
��Ŀǰ���ԣ����������ھ����Ѿ����㷺Ӧ��������������ҵ��ҵ�У������Գɹ�Ԥ�����пͻ�����һ���������Щ��Ϣ�����оͿ��Ը�������Ӫ���������������춼�ڿ����µĹ�ͨ�ͻ��ķ��������������Լ���ATM���Ͼ������˹˿Ϳ��ܸ���Ȥ�ı��в�Ʒ��Ϣ����ʹ�ñ���ATM�����û��˽⡣������ݿ�����ʾ��ij����������Ŀͻ������˵�ַ������ͻ����п����½�������һ�������סլ����˻��п�����Ҫ������������߶˵������ÿ���������Ҫһ��ס�����ƴ����Щ��Ʒ������ͨ�����ÿ��˵��ʼĸ��ͻ������ͻ���绰��ѯ��ʱ�����ݿ���������ذ����绰���۴��������۴����ĵ�����Ļ�Ͽ�����ʾ���ͻ����ص㣬ͬʱҲ������ʾ���˿ͻ��ʲô��Ʒ����Ȥ��
ͬʱ��һЩ֪���ĵ�������վ��Ҳ��ǿ��Ĺ��������ھ��е����档��Щ���ӹ�����վʹ�ù��������й�������ھ�Ȼ�������û�����Ҫһ������������Ҳ��һЩ������վʹ������������Ӧ�Ľ������ۣ�Ҳ���ǹ���ij����Ʒ�Ĺ˿ͻῴ����ص�����һ����Ʒ�Ĺ�档
����Ŀǰ���ҹ��������ݺ�������Ϣȱ��������ҵ���������ݴ���֮���ձ�����Ե����Ρ�Ŀǰ����ҵʵʩ�Ĵ�������ݿ�ֻ��ʵ�����ݵ�¼�롢��ѯ��ͳ�ƵȽϵͲ�εĹ��ܣ�ȴ�����������д��ڵĸ������õ���Ϣ��Ʃ�����Щ���ݽ��з���������������ģʽ��������Ȼ����ܷ���ij���ͻ�������Ⱥ�����֯�Ľ��ں���ҵ��Ȥ�����ɹ۲�����г��ı仯���ơ�����˵�����������ھ�ļ������ҹ����о���Ӧ�ò����Ǻܹ㷺���롣
��������Ӧ�����������ȳ��й�����������ӣ������о��Ӳ�ͬ�ĽǶȶԹ�������������չ������������ؼ��ɵ����������ھ�֮�У��Դ˷ḻ���������Ӧ�������ؿ�֧�ֹ������ߵķ�Χ���翼������֮�������ι�ϵ��ʱ̬��ϵ������ھ�ȡ�������Χ�ƹ���������о���Ҫ�������������棬����չ������������ܹ��������ķ�Χ�����ƾ�����������ھ��㷨Ч�ʺ�����Ȥ�ԡ�
1.��������
һ�������ʵ������ǣ������ھ��OLAP�����кβ�ͬ�����潫����ͣ���������ȫ��ͬ�Ĺ��ߣ����ڵļ���Ҳ���ྶͥ��
OLAP�Ǿ���֧�������һ���֡���ͳ�IJ�ѯ�ͱ��������Ǹ��������ݿ��ж���ʲô��what
happened����OLAP�����һ����������һ������ô����What next����������Ҳ�ȡ�����Ĵ�ʩ�ֻ���ô����What
if�����û����Ƚ���һ�����裬Ȼ����OLAP�������ݿ�����֤��������Ƿ���ȷ�����磬һ������ʦ���ҵ�ʲôԭ�����˴�����Ƿ������������һ����ʼ�ļٶ�����Ϊ������������ö�Ҳ�ͣ�Ȼ����OLAP����֤��������衣����������û�б�֤ʵ��������ȥ�쿴��Щ�߸�ծ���˻�����������У���Ҳ��Ҫ�������ծһ���ǣ�һֱ������ȥ��ֱ���ҵ�����Ҫ�Ľ���������
Ҳ����˵��OLAP����ʦ�ǽ���һϵ�еļ��裬Ȼ��ͨ��OLAP��֤ʵ���Ʒ���Щ���������յõ��Լ��Ľ��ۡ�OLAP���������ڱ�������һ�����������Ĺ��̡�������������ı����ﵽ��ʮ���ϰٸ�����ô����OLAP�ֶ�������֤��Щ���轫��һ���dz����Ѻ�ʹ������顣
�����ھ���OLAP��ͬ�ĵط��ǣ������ھ���������֤ij���ٶ���ģʽ��ģ�ͣ�����ȷ�ԣ����������ݿ����Լ�Ѱ��ģ�͡����ڱ�������һ�����ɵĹ��̡����磬һ���������ھߵķ���ʦ���ҵ����������Ƿ�ķ������ء������ھ߿��ܰ����ҵ��߸�ծ�͵����������������������أ����������ܷ���һЩ����ʦ����û��������Թ����������أ��������䡣
�����ھ��OLAP����һ���Ļ����ԡ������������ھ�����Ľ��۲�ȡ�ж�֮ǰ����Ҳ��Ҫ��֤һ�������ȡ�������ж������˾����ʲô����Ӱ�죬��ôOLAP�����ܻش������Щ���⡣
������֪ʶ���ֵ����ڽΣ�OLAP����������һЩ��;��������̽�����ݣ��ҵ���Щ�Ƕ�һ������Ƚ���Ҫ�ı����������쳣���ݺͻ���Ӱ��ı������ⶼ�ܰ�����õ�����������ݣ��ӿ�֪ʶ���ֵĹ��̡�
2.��ؼ���
�����ھ��������˹����ܣ�AI����ͳ�Ʒ����Ľ����������ĺô���������ѧ�ƶ�������ģʽ���ֺ�Ԥ�⡣
�����ھ���Ϊ�������ͳ��ͳ�Ʒ����������෴������ͳ�Ʒ�������ѧ���������չ���������ͳ�Ʒ����������������Ƶ���ѧ���ۺ߳��ļ��ɣ�Ԥ���ȷ�Ȼ�����������ģ�����ʹ���ߵ�Ҫ��ܸߡ������ż�������������IJ�����ǿ�������п������ü����ǿ��ļ�������ֻͨ����Լ̶��ķ������ͬ���Ĺ��ܡ�
һЩ���˵ļ���ͬ����֪ʶ��������ȡ���˺ܺõ�Ч��������Ԫ����;����������㹻������ݺͼ��������£����Ǽ��������˵Ĺ����Զ�������������м�ֵ�Ĺ��ܡ�
�����ھ����������ͳ�ƺ��˹����ܼ�����Ӧ�ó���������Щ����ӵļ�����װ������ʹ���Dz����Լ�������Щ����Ҳ�����ͬ���Ĺ��ܣ����Ҹ�רע���Լ���Ҫ��������⡣
3.���Ӱ��
ʹ�����ھ���������Ϊ���ܵĹؼ�һ���Ǽ�������ܼ۸�ȵľ�������ڹ�ȥ�ļ�������̴洢���ļ۸�������99%�����ںܴ�̶��ϸı�����ҵ��������ռ��ʹ洢��̬�ȡ����ÿ�ļ۸��ǣ�10���Ǵ��1TB�ļ۸��ǣ�10,000,000������ÿ�ļ۸�Ϊ1ëǮʱ���洢ͬ��������ֻ�У�100,000��
��������������۸�Ľ���ͬ���dz�������ÿһ��оƬ�ĵ��������CPU�ļ����������һ���ڴ�RAMҲͬ������Ѹ�٣�����֮��ÿ���ڴ�ļ۸��ɼ��ٿ�Ǯ��������ֻҪ����Ǯ��ͨ��PC����64M�ڴ棬����վ�ﵽ��256M��ӵ����G�ڴ�ķ������Ѿ�����ʲô�������ˡ�
�ڵ���CPU�����������������ͬʱ�����ڶ��CPU�IJ���ϵͳҲȡ���˺ܴ�Ľ�����Ŀǰ�������еķ�������֧�ֶ��CPU����ЩSMP���������������óɰ���ǧ��CPUͬʱ������
���ڲ���ϵͳ�����ݿ����ϵͳҲ�������ھ�����Ӧ�ô����˱������������һ���Ӵ�����ӵ������ھ�����Ҫ��ͨ���������ݿ�ȡ�����ݣ���ôЧ����ߵİ취��������һ�����صIJ������ݿ⡣
������Щ��Ϊ�����ھ��ʵʩɨ���˵�·������ʱ�����������������������·��Խ��Խƽ̹��
NO.1 Data Mining ��ͳ�Ʒ�����ʲô��ͬ��
ӲҪȥ����Data Mining��Statistics�IJ�����ʵ��û��̫������ġ�һ�㽫֮����ΪData
Mining������CART��CHAID��ģ������ȵ����۷�����Ҳ������ͳ��ѧ�߸���ͳ����������չ����������һ���Ƕȿ���Data
Mining���൱��ı������ɸߵ�ͳ��ѧ�еĶ����������֧�š�����ΪʲôData Mining�ij��ֻ�����������Ĺ㷺ע���أ���Ҫԭ��������ڴ�ͳͳ�Ʒ������ԣ�Data
Mining�����м������ԣ�
1.��������ʵ�����ݸ�ǿ�ƣ�������̫רҵ��ͳ�Ʊ���ȥʹ��Data Mining�Ĺ��ߣ�
2.���ݷ�������Ϊ�Ӵ������ݿ�ץȡ�������ݲ�ʹ��ר�����������������Data
Mining�Ĺ��߸�������ҵ����
3. �������۵Ļ�����������Data Mining��ͳ�Ʒ�����Ӧ���ϵIJ�𣬱Ͼ�Data
MiningĿ���Ƿ�����ҵ�ն��û�ʹ�ö��Ǹ�ͳ��ѧ�Ҽ���õġ�
NO.2 ���ݲֿ�������ھ�Ĺ�ϵΪ�Σ�
����Data Warehousing�����ݲֿ⣩��������ӣ�Data Mining���������Ӳ�
��Ĺ������Ͼ�Data Mining����һ���������е�ħ����Ҳ���ǵ�ʯ�ɽ������������û�й��ḻ���������ݣ��Ǻ����ڴ�Data
Mining���ھ��ʲô���������Ϣ�ġ�
Ҫ���Ӵ������ת����Ϊ���õ���Ϣ����������Ч�ʵ��ռ���Ϣ�����ſƼ��Ľ������������Ƶ����ݿ�ϵͳ�ͳ�����õ��ռ����ݵĹ��ߡ����ݲֿ⣬��˵�������Ѽ���������ϵͳ���������ݣ������һ���ϵĴ������ڡ�������ʵ����һ�������������ϣ��������ر��Ĺ�ϵ�����ݿ⣬���Դ������֧��ϵͳ��Decision
Support System����������ݣ�������֧�ֻ����ݷ���ʹ�á�����Ϣ�����ĽǶ����������ݲֿ��Ŀ��������֯�У�����ȷ��ʱ�䣬����ȷ�����ݽ�����ȷ���ˡ�
�����˶���Data Warehousing��Data Miningʱ����������֪��ηֱ档��ʵ�����ݲֿ������ݿ⼼����һ�������⣬���ü����ϵͳ�������Dz����������˼��������ҵ��ʽ�ı䣬���߷�ʽҲ���Ÿı䡣
���ݲֿⱾ����һ���dz�������ݿ⣬������������֯��ҵ���ݿ������϶��������ݣ��ر���ָ������ϵͳOLTP��On-Line
Transactional Processing�������������ݡ�����Щ���Ϲ��������÷������ݲֿ��У�����˾�ľ�������������Щ���������ߣ����ǣ����ת�����������ݵĹ��̣��ǽ���һ�����ݲֿ�������ս����Ϊ����ҵ�е�����ת�������õĵIJ�������Ϣ���������ݲֿ���ص㡣�������������ݲֿ�Ӧ�þ�����Щ���ݣ����������ݣ�integrated
data������ϸ�ͻ����Ե�����(detailed and summarized data)����ʷ���ݡ��������ݵ����ݡ������ݲֿ��ھ���Ծ������õ���Ϣ��֪ʶ���ǽ������ݲֿ���ʹ��Data
Mining�����Ŀ�ģ����ߵı���������������¡����仰˵�����ݲֿ�Ӧ���н�����ɣ�Data mining������Ч�ʵĽ��У���Ϊ���ݲֿⱾ�����������Ǹɾ�(�����д�������ݲ�������)���걸���Ҿ������ϵġ�������߹�ϵ�����ɽ��ΪData
Mining�ǴӾ����ݲֿ����ҳ�������Ϣ��һ�ֹ����뼼����
������£������ھ�Ҫ�Ȱ����ݴ����ݲֿ����õ������ھ������ݼ����У���ͼ1����
�����ݲֿ���ֱ�ӵõ����������ھ������������ô����������Ǻ���ὲ���ģ����ݲֿ�����������������ھ������������࣬��������ڵ������ݲֿ�ʱ�Ѿ����������Ǻܿ������������ھ�ʱ��û��Ҫ������һ���ˣ��������е����ݲ�һ�µ����ⶼ�Ѿ��������ˡ�
�����ھ�������������ݲֿ��һ�����ϵ��Ӽ�������һ���ǵ��������ϵ��������ݿ⡣�����������ݲֿ�ļ�����Դ�Ѿ��ܽ��ţ�������û��ǽ���һ�������������ھ�⡣
��ȻΪ�������ھ���Ҳ���طǵý���һ�����ݲֿ⣬���ݲֿⲻ�DZ���ġ�����һ��������ݲֿ⣬�Ѹ�����ͬԴ������ͳһ��һ�𣬽�����е����ݳ�ͻ���⣬Ȼ������е����ݵ���һ�����ݲֿ��ڣ���һ���Ĺ��̣�����Ҫ�ü����ʱ�仨�ϰ����Ǯ������ɡ�ֻ��Ϊ�������ھ������һ�����������ݿ��һ��ֻ�������ݿ��У��Ͱ����������ݼ��У�Ȼ������������������ھ�
NO.3 OLAP �ܲ��ܴ��� Data Mining��
��νOLAP��Online Analytical Process����ָ�����ݿ���������������߷�������������Щ�˻�˵�������Ѿ���OLAP�Ĺ����ˣ������Ҳ���ҪData
Mining������ʵ�������ǽ�Ȼ��ͬ�ģ���Ҫ��������Data Mining���ڲ������裬OLAP�����ڲ�֤���衣����˵��OLAP����ʹ������������ʹ��������һЩ���裬Ȼ������OLAP����֤�����Ƿ��������Data
Mining������������ʹ���߲������衣������ʹ��OLAP������Query�Ĺ���ʱ��ʹ�������Լ�����̽����Exploration������Data
Mining���ù����ڰ�����̽����
�ٸ�����������һ�г�����ʦ��Ϊ���й滮��Ʒ�ܹ����ʱ�����ܻ��ȼ���Ӥ����Ӥ���̷ۻ��dz���һ����IJ�Ʒ�����ű������OLAP�Ĺ���ȥ��֤�˼����Ƿ�Ϊ�棬�ֳ�����֤���ж����ԣ���Data
Mining��Ȼ��ִ��Data Mining���˽��Ӵ�Ľ�����������������Ҫ������ڴ����ܵĽ������Mining�������ҳ������������е�DZ�ڹ����������ǿ��ܵõ�������ơ�Ƴ���ͬʱ�����������֮���֣�����OLAP���������ġ�
Data Mining�����ھ����Խ���ɷ�Χ�Ĺ�ϵ����OLAP���������˹���ѯ�����ӻ��ı�����ȷ��ijЩ��ϵ������Data
Mining�����Զ��ҳ��������ᱻ���ɹ�������ģ�����ϵ�����ԣ���ʵ���ѳ�Խ�����Ǿ��顢�����������������ƣ�OLAP���Ժ�Data
Mining������������������Data Mining����OLAPȡ���ġ�
NO.4 ������Data Mining ������Щ���裿
1�������ھ�
�����ھ���ָһ�������Ĺ���,�ù��̴Ӵ������ݿ����ھ���ǰδ֪��,��Ч��,��ʵ�õ���Ϣ,��ʹ����Щ��Ϣ��������ḻ֪ʶ.
�������ھ���ʾ������ͼ:
�����ھ���ͼ.gif
2�������ھ����ͼ
��ͼ�����������ھ�Ļ������̺���Ҫ����
�����ھ�Ļ������̺���Ҫ����
3�������ھ���̹�����
�������ھ��б��о���ҵ��������������̵Ļ���,�����������������ھ����,Ҳ�Ǽ����������ָ��������Ա��������ھ�����ݺ���.ͼ2�������ǰ�һ��˳����ɵ�,��Ȼ���������л�����ڲ����ķ���.�����ھ�Ĺ��̲������Զ���,��������Ĺ�����Ҫ�˹����.ͼ3�����˸����������������еĹ�����֮��.���Կ���,60%��ʱ��������������,��˵���������ھ�����ݵ��ϸ�Ҫ��,�����ھ�����ռ�ܹ�������10%.
4�������ھ���̼��
�����и�����Ĵ�����������:
(1). ȷ��ҵ�����
�����ض����ҵ������,���������ھ��Ŀ���������ھ����Ҫһ��.�ھ�����ṹ�Dz���Ԥ���,��Ҫ̽��������Ӧ����Ԥ����,Ϊ�������ھ�������ھ������äĿ��,�Dz���ɹ���.
(2). ������
1)�����ݵ�ѡ��
����������ҵ������йص��ڲ����ⲿ������Ϣ,������ѡ��������������ھ�Ӧ�õ�����.
2)�����ݵ�Ԥ����
�о����ݵ�����,Ϊ��һ���ķ�������.��ȷ����Ҫ���е��ھ����������.
3)�����ݵ�ת��
������ת����һ������ģ��.�������ģ��������ھ��㷨������.����һ�������ʺ��ھ��㷨�ķ���ģ���������ھ�ɹ��Ĺؼ�.
(3). �����ھ�
�����õ��ľ���ת�������ݽ����ھ�.�������ƴ�ѡ����ʵ��ھ��㷨��,����һ�й��������Զ������.
(4). �������
���Ͳ��������.��ʹ�õķ�������һ��Ӧ�������ھ��������,ͨ�����õ����ӻ�����.
(5). ֪ʶ��ͬ��
���������õ���֪ʶ���ɵ�ҵ����Ϣϵͳ����֯�ṹ��ȥ.
5�������ھ���Ҫ����Ա
�����ھ���̵ķֲ�ʵ��,��ͬ�IJ�����Ҫ���в�ͬר������Ա,���Ǵ�����Է�Ϊ����.
ҵ�������Ա:Ҫ��ͨҵ��,�ܹ�����ҵ�����,�����ݸ�ҵ�����ȷ�����������ݶ�����ھ��㷨��ҵ������.
���ݷ�����Ա:��ͨ���ݷ�������,����ͳ��ѧ�н�����������,��������ҵ������ת��Ϊ�����ھ�ĸ�������,��Ϊÿ������ѡ����ʵļ���.
���ݹ�����Ա:��ͨ���ݹ�������,�������ݿ�����ݲֿ����ռ�����.
���Ͽɼ�,�����ھ���һ������ר�Һ����Ĺ���,Ҳ��һ�����ʽ��Ϻͼ����ϸ�Ͷ��Ĺ���.��һ����Ҫ�������Р��ڷ��������У����ϵ���������ı��ʣ����ϵ���������Ľ�����������������ϸ�����ӺͲ�ּ�¼ѡȡ�����������ӻ�����̽��������������硢����������ͳ�ơ�ʱ�����н����ۺϽ�����������֪ʶ����ȡ������̽�����ݵ���ģ�ͻ����ۡ�
NO.5 Data Mining ��������Щ�����뼼����
Data Mining�ǽ��������ݿ�Ӧ�ü������൱���ŵ����⣬�������桢����ʱ�֣�ʵ����ȴҲ����ʲô�¶�������������֮����Ԥ��ģ�͡����ݷָ���������Link
Analysis����ƫ����⣨Deviation Detection���ȣ��������ڶ��������սǰ����Ӧ���������˿��ղ鼰���µȷ��档
������Ϣ�Ƽ���������Ľ�չ�������µļ�����������������������ϵ�����ݿ⡢ģ���������ۡ������㷨���Լ���������ȣ�ʹ�ô������з��س�Ϊһ��ϵͳ���ҿ�ʵ�еij���
һ����ԣ�Data Mining�����ۼ����ɷ�Ϊ��ͳ���������������֧����ͳ������ͳ�Ʒ���Ϊ������ͳ��ѧ����������ͳ�ơ������ۡ��ع������������ݷ����ȶ����ڴ�ͳ�����ھ���������
Data Mining �����Ϊ�����������������Ӵ�����ݣ����Ըߵ�ͳ��ѧ��������֮���������������������������ط�����Factor
Analysis��������������б������Discriminant Analysis�����Լ���������Ⱥ��ķ�Ⱥ������Cluster
Analysis���ȣ���Data Mining�������ر��á�
�ڸ����������棬Ӧ�ý��ձ���о��������ۣ�Decision Trees�����������磨Neural
Network���Լ�������ɷ���Rules Induction���ȡ���������һ������֦״չ�������ܸ�������Ӱ������֮Ԥ��ģ�ͣ����ݶ�Ŀ���������֮ЧӦ�IJ�ͬ����������Ĺ���һ��������ڶԿͻ����ݵķ����ϣ���������лغ���δ�غ����ʼĶ����ҳ�Ӱ����������ı�����ϣ����÷����ΪCART��Classification
and Regression Trees����CHAID��Chi-Square Automatic Interaction
Detector�����֡�
����������һ�ַ�������˼���ṹ�����ݷ���ģʽ��������֮��������ֵ������ѧϰ������ѧϰ��������֪֮ʶ���ϵ����������ڽ������ݵ�����(patterns)����������Ϊ�����Ե���ƣ��봫ͳ�ع������ȣ��ô����ڽ��з���ʱ������ģʽ���ر����ݱ�������н���ЧӦʱ���Զ�������ȱ�����������������Ϊһ�ں��ӣ��ʳ����Կɶ�֮ģ��ʽչ�֣�ÿ�εļ�Ȩ��ת�����ȷ���ǹ�����������������������ڸ߶ȷ������Ҵ����൱�̶ȵı�������ЧӦʱ��
������ɷ���֪ʶ�������������õĸ�ʽ������һ����һ�����ġ������/��If
/ Then����֮����������ݽ���ϸ�ֵļ�������ʵ������ʱ��ν綨����Ϊ��Ч���������⣬ͨ�����Ƚ������з�����̫�ٵ���Ŀ�������Ա�������������������
NO.6 Data Mining������Щ��Ҫ���ܣ�
Data Miningʵ��Ӧ�ù��ܿɷ�Ϊ��������������˵����Classification��Clustering���ڷ��������ࣻRegression��Time-series��������Ԥ���ࣻAssociation��Sequence���������й����ࡣ
Classification�Ǹ���һЩ��������ֵ�����㣬�����ս�������ࡣ������Ľ�����ᱻ����Ϊ������������ɢ��ֵ�����罫һ�����ݷ�Ϊ
"���ܻ���Ӧ" ���� "���ܲ�����Ӧ" ���ࣩ��Classification��������������ǰ����֮�ʼĶ���ɸѡ�����⡣���ǻ���һЩ������ʷ�����Ѿ�����õ��������о����ǵ�������Ȼ���ٸ�����Щ����������δ����������µ�������Ԥ�⡣��Щ��������Ѱ���������ѷ������ݿ������������ǵ����еĿͻ����ݣ����ǽ�һ���������ݿ�������ȡ�����پ���ʵ�ʵ����������ԣ�Ʃ������һ�������ʼĶ������ݿ�IJ���ȡ��������һ��Classification
Model�����������Model�������ݿ���������ݻ����µ�����������Ԥ�⡣
Clustering���ڽ����ݷ�Ⱥ����Ŀ�����ڽ�Ⱥ��IJ����ҳ�����ͬʱҲ��Ⱥ�ڳ�Ա���������ҳ�����Clustering��Classification��ͬ���ǣ��ڷ���ǰ����֪�����Ժ��ַ�ʽ����������ࡣ���Ա���Ҫ���רҵ����֪ʶ�������Щ��Ⱥ�����塣
Regression��ʹ��һϵ�е�������ֵ��Ԥ��һ��������ֵ�Ŀ���ֵ��������Χ�����������Logistic
Regression��Ԥ�����������ر��ڹ㷺�����ִ����������������������������۵ȷ������ߣ��ƹ�Ԥ���ģʽ�Ѳ���ֹ�ڴ�ͳ���Եľ��ޣ���Ԥ��Ĺ����ϴ��������ѡ�ߵĵ�����Ӧ�÷�Χ�Ĺ�ȡ�
Time-Series Forecasting��Regression�������ƣ�ֻ�����������е���ֵ��Ԥ��δ������ֵ����������������Time-Series����������ֵ����ʱ���йء�Time-Series
Forecasting�Ĺ��߿��Դ����й�ʱ���һЩ���ԣ�Ʃ��ʱ��������ԡ��ײ��ԡ��������Լ�������һЩ�ر����أ����ȥ��δ���Ĺ����ԣ���
Association��Ҫ�ҳ���ijһ�¼����������л�ͬʱ���ֵĶ������������ԣ����A��ijһ�¼���һ��ѡ����BҲ�����ڸ��¼��еĻ����ж��١������磺����˿����˻��Ⱥ�����֭����ô����˿�ͬʱҲ����ţ�̵Ļ�����85%����
Sequence Discovery��Association��ϵ�����У�����ͬ����Sequence
Discovery���¼����������ʱ�������������������磺���A��Ʊ��ijһ������12%�����ҵ�����м�Ȩָ���½�����B��Ʊ������֮�����ǵĻ�����
68%����
NO.7 Data Mining�ڸ������Ӧ������Ϊ�Σ�
Data Mining�ڸ������Ӧ�÷dz��㷺��ֻҪ�ò�ҵӵ�о߷�����ֵ����������ݲִ������ݿ⣬�Կ�����Mining���߽�����Ŀ�ĵ��ھ������һ��ϳ�����Ӧ�ð������������ҵ��ֱЧ�����硢����ҵ��������ڱ��ա�ͨѶҵ�Լ�ҽ�Ʒ���ȡ�
�����������з���˿͵�����ϰ�ԣ����ɽ��ɽ���¼�ҳ��˿�ƫ�õIJ�Ʒ��ϣ����������ҳ���ʧ�˿͵��������Ƴ��²�Ʒ��ʱ����ȵȶ�������ҵ������ʵ����ֱЧ����ǿ���ķ��ڸ��������ݿ�������ʽ�ڵ���Data
Mining�ļ�����ʹֱЧ�����ķ�չ�Ը�Ϊǿ����������Data Mining�����˿�Ⱥ֮������Ϊ�뽻��¼����ϻ������ݣ��������Ʒ�Ƽ�ֵ�ȼ��ĸߵ��������˿ͣ������ﵽ���컯������Ŀ�ģ�����ҵ��Data
Mining�������������Ʒ�ʿعܷ��棬������������ҳ�Ӱ���ƷƷ������Ҫ�����أ����������ҵ���̵�Ч�ʡ�
�����绰��˾�����ÿ���˾�����չ�˾�Լ���Ʊ�����̶���թ����Ϊ����⣨Fraud
Detection����������Ȥ����Щ��ҵÿ����Ϊթ����Ϊ����ɵ���ʧ���dz��ɹۣ�Data Mining���Դ�һЩ���ò����Ŀͻ��������ҳ�����������Ԥ����ܵ�թ�۽��ף��ﵽ������ʧ��Ŀ�ġ��������ҵ��������
Data Mining�������г�����Ԥ�����˾��Ӫ���Լ��ɼ�����Data Mining����һ�����ص��÷�����ҽ��ҵ������Ԥ����������ҩ����ϡ��������̿��Ƶ�Ч�ʡ�
NO.8 Web Mining �������ھ���ʲô��ͬ��
�����Web��ΪCRM��һ���µ�Channel����Web Mining��ɵ�������Data
MiningӦ�����������ݵķ��ơ�
����β���һ����վ�Ƿ�ɹ�����Щ���ݡ��Żݡ���������������ģ���Ҫ�ÿ�����Щ�ˣ�ʲôԭ����������ǰ������δӶѻ���ɽ֮���������������������ҳ�����վ��������Ч�ʵIJ������أ��������ֽ���Web
Mining ����֮���롣Web Mining ����ֻ����һ���Ϊ����֪��log file���������˼�����ҳ������Լ��ÿ��˴��⣬�ٷ������ϵ����ۡ��������ͨѶ�����������ء�ҽ����ѯ��Զ���ѧ�ȵȣ�ֻҪ����������������ݿ������������Off-Line�ɽ��еķ�����Web
Mining���������������������Off-Line��On-Line�����ݿ⣬ʵʩ�����ģ��ģ��Ԥ�����ƹ����Ͼ�ƾ����������ı����������������������Ϊ�Ŀ�������������ʣ�һ��һ���������������л�����������������ȫ��ʵ�ġ�
������ԣ�Web Mining�����������ԣ�1.�����ռ������Ҳ�����ע�⣬��ν���߹������ºۼ������ÿͽ�����վ���һ�������Ϊ�����̶��ǿ�����������¼�ģ�2.
�Խ���ʽ���˻�����Ϊ�ռ�Ŀ�꣬������Ӧ��ͬ�ÿͳ���ר����Ƶ���ҳ֮�⣬��ͬ�ķÿ�Ҳ���в�ͬ�ķ���3.
�������ⲿ��Դ�����÷������ܷ��ӵظ�����㣬����log file��cookies����Ա������ݡ����ϵ������ݡ����Ͻ������ݵ�������ֱ��ȡ�õ���Դ�⣬���ʵ�������ۻ�ʱ����á���Χ�������Դ����ʹ�����Ľ����ȷҲ�����롣
����Data Mining��������������ķÿ����������������Լܹ�����Ԥ��ģʽ�����ڳ��������������˻������������Web
MiningŬ���ķ���
NO.9 �����ھ��� CRM �а��ݵĽ�ɫΪ�Σ�
CRM��Customer Relationship Management���ǽ�����������������߶ȹ��е����⣬������ֱЧ����������������Ŀ��ٷ�չ�����£�������CRM�ĽŲ���ͬ������ʱ������ʵ��CRM�������·���������ֱЧ�����ƶ�ʮ�����CO��Customer
Ownership���������ڴ��̸��CRM���ͻ���ϵ������
Data MiningӦ����CRM����Ҫ��ʽ�ɶ�Ӧ��Gap Analysis֮�������֣�
���Acquisition Gap��������Customer Profiling�ҳ��ͻ���һЩ��ͬ��������ϣ���ܽ�������˽�ͻ�������Cluster
Analysis�Կͻ����з�Ⱥ����ͨ��Pattern AnalysisԤ����Щ�˿��ܳ�Ϊ���ǵĿͻ�������������Ա�ҵ���ȷ���������������ͳɱ���Ҳ��������ijɹ��ʡ�
���Sales Gap��������Basket Analysis�����˽�ͻ��IJ�Ʒ����ģʽ���ҳ���Щ��Ʒ�ͻ�������һ����������Sequence
DiscoveryԤ��ͻ�������ijһ����Ʒ֮���ڶ��֮�ڻ�����һ����Ʒ�ȵȡ����� Data Mining���Ը���Ч�ľ�����Ʒ��ϡ���Ʒ�Ƽ������������������������ڵ���Ҫ��ΰ����Ʒ�ȣ�ͬʱҲ������������������ij�Ч��
���Retention Gap��������ԭ�ͻ�����ȴת�ɾ������ֵĿͻ�Ⱥ�У��������������ٸ��ݷ�����������пͻ��������ҳ�����ת��Ŀͻ���Ȼ�����һЩ����Ԥ���ͻ���ʧ������ϵͳ�������ǽ���Neural
Network���ݿͻ���������Ϊ�뽻��¼�Կͻ��ҳ϶Ƚ���Scoring������������������ʧ�ʵĵȼ�������ϲ�ͬ�IJ��ԡ�
CRM������һ����800���ͷ�ר�߾����ˣ�������ֻ�ǰ�һ�ѿͻ���������������������������CRM������������ص�Ӳ����ϵͳ�ܽ�ȫ��֧��֮ǰ����̫��������������������Ҫ�ƶ�����ҵ��Data
Mining���Էֱ���Բ��ԡ�Ŀ�궨λ������Ч��������������ĸ�����֮������⣬��Ч�ʵش��г���˿����Ѽ��ۻ�֮�����������ھ���������߶�����ؼ�������Ҫ�Ĵ𰸣������Խ��������ɿͻ����������Ŀͻ���ϵ������
| 




