| 数据库该如何设计,一直以来都是一个仁者见仁智者见智的问题。
对于某一种数据库设计,并不能简单的用好与不好来区分。或许真的应了那句话,没有最好,只有最适合。讨论某种数据库设计的时候,应该在某种特定的需求环境下讨论。
下面来讨论一下在项目中经常碰到的用户的联系方式储存的问题。
我在这里套用之前网络上流行“普通――文艺――二逼”的分类方式来描述我下文中提及的三种数据库设计思路,并且通过查询数据(对数据增删改,三种设计要付出的代码成本都差不多)和数据库面临需求变动两个方面来思考这三种设计各有怎样的优劣。
普通青年:
或许我们都这样设计过数据库
学生表 tb_Student:
| Name |
varchar(100) |
名字 |
| Telphone |
varchar(200) |
联系电话 |
| Email |
varchar(200) |
你懂的 |
| Fax |
varchar(200) |
传真 |
这应该是最容易想到的一种思路,简单、明了。
比如说我要查询某个人的联系方式,那么我只用一条语句就能实现:
select Name,Telphone,Email,Fax from
表 where 条件
在查询的时候,这种数据库设计十分清晰,没有任何思维的难度,没有任何逻辑的挑战。但是当面临需求变动的时候,那将会是一场灾难。
比如现在要新增一类用户:校长。那么我们要如何处理?
答案是:再加一张表 tb_Headmaster。
事实上,再加一张表其实修改并不大,因为我们完全不需要修改学生表的存储逻辑,换句话说,这种设计是遵循了开闭原则的
但如果学生要添加一种联系方式HomePhone的时候,灾难发生了
怎么办?
在tb_Student中加一列HomePhone?这意味着至少要修改整个Model层(或者说DAL层),这种改动是十分巨大的,而且容易造成错误。
或者再建一张表tb_Student2,来储存HomePhone,然后以ID来关联两张表?按改动规模来说,这种改动相对简单而且不容易出错,但是在今后的维护中会增加逻辑成本。当你一而再再而三的以这样的方式来应对需求变动的时候,你的程序将变得不可理解。
文艺青年:
| UserRole |
int |
对应用户类型(None = 0, Student = 1, Teacher
= 2, Headmaster = 4) |
| OwnerID |
int |
对应用户ID |
| ContactMethod |
int |
联系方式(None = 0, Email = 1, HomePhone = 8, WorkPhone
= 16,MobilePhone = 32,Fax=64) |
| ContactInfo |
varchar(255) |
联系信息 |
这种是一个一对多关系。当我们要查询某个用户对应的联系方式的时候,那是一场逻辑上的浩劫:
select ContactInfo from 表 where UserRole=某种用户类型
and OwnerID=某用户ID
这种写法是一次性取出某个用户所有的联系方式,包括Email,HomePhone,WorkPhone等,之后我们可以在程序中判断ContactMethod的类型,将具体的联系方式加以区分。你可以简单的想到用switch-case的写法,类似这样:
var contact = 上面的SQL语句取出来的用户所有的联系方式;
foreach (var item in contact)
{
switch (item.ContactMethod)
{
case ContactMethod.WorkPhone:
txtWorkPhone.Text = item.ContactInfo;break;
case ContactMethod.Email:
txtEmail.Text = item.ContactInfo;
break;
case ContactMethod.Fax:
txtFax.Text = item.ContactInfo;
break;
case ContactMethod.OtherPhone:
txtOtherPhone.Text = item.ContactInfo;
break;
case ContactMethod.MobilePhone:
txtMobilePhone.Text = item.ContactInfo;
break;
}
} |
当然你也可以尝试下面这种写法,我个人认为这种写法更优雅
var contact = 上面的SQL语句取出来的用户所有的联系方式;
txtWorkPhone.Text = (from a in contact
where a.ContactMethod == ContactMethod.Work_Phone
select a.ContactInfo).ToString();//后面以此类推,你懂的 |
注意,请不要试图使用类似下面这类语句来查询某用户的联系方式:
select ContactInfo from 表 where UserRole=某种用户类型 and OwnerID=某用户ID and ContactMethod=1
//取出某用户的Email
select ContactInfo from 表 where UserRole=某种用户类型 and OwnerID=某用户ID and ContactMethod=8
//取出某用户的HomePhone |
相信我,这种做法非常愚蠢:每当你要取出这个用户的一种联系方式,就要和数据库建立一次连接,打开/关闭一次数据库;这种做法代价是十分巨大的,即使有数据库连接池,即使有数据库缓存,都应该避免这种愚蠢的做法
唔,用了那么多的代码,终于查出了某个用户的联系信息了。反正我个人觉得这种设计方式在查询的时候,是逻辑上的浩劫。什么?你说你很享受?好吧,看来是我脑容量不够…
不过当我们面临需求变动的时候,那就非常愉快了
什么,要加一类用户?简单,UserRole加一个枚举就好了。
什么,要加一种联系方式?ContactMethod加一个枚举就OK。
使用了这种表设计的时候,相信你会微笑着面对需求变动的
二逼青年
昨天和同事也探讨了下这个问题,按他的说法就是:哪个表要联系方式,我就扔个字段进去,存json
| Contact |
varchar(8000) |
用于储存json |
举例来说,有这么一个用户:
| ID:1 |
Name:张三 |
Telphone:1234 |
Email:123@123.com |
Fax:5678 |
那么数据库中就这样存:
[{"ID":1,"Name":"张三","Telphone":"1234","Email":"123@123.com","Fax":"5678"}]
当我听到这种设计思路的时候,虎躯微微一震:靠,这都行。按这种设计,我整张表都放进一个json里面一股脑的存进去就算了。不过震惊之后仔细想一想,其实这种设计也是有可取之处
首先,从查询来说,和普通青年一样,只需一句SQL:
select Contact from 表 where 条件
查询之后,就可以通过json处理函数将想要的数据取出来,在此就不赘述了
那么当面临需求变动的时候会发生什么:
加一类用户的时候,要添加一张表。也是符合开闭原则,原有代码没有改动
加一种联系方式,只用存json的时候多存一点东西
不过这种设计如果要更新某条数据的话要稍微麻烦一点:先查询一条数据,重组json之后再Update
最近公司要开发新系统,基本决定使用ORM(高层还在犹豫,担心效率问题)。既然使用了ORM,那么自然而然的就想到了用面向对象的思想来设计数据库
本篇文章旨在讨论如何抽象(以用户作为抽象的例子),并提出一些解耦的思路
我也是第一次在实际项目中使用面向对象的思想来设计数据库,写下这篇博客,也是希望与大家多多交流
正文开始
首先来需求分析
我们的系统有前台和后台,前台用户有:Man,Woman,SuperMan,SpiderMan与IronMan。后台用户为Administrator
前台用户都要填写联系方式与地址,然后SuperMan,SpiderMan与IronMan都有Ability
需求很简单。那么按照这个需求,我们来随手画一个继承关系图。其中V代表抽象类(应该是abstract,画图的时候脑抽想着是virtual就用V开头了,懒得改图了大家凑合着看吧),I代表Interface。如下图:
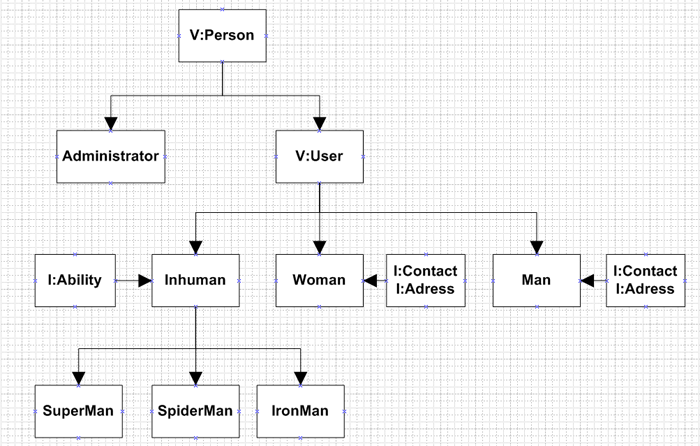
从图中可以看出,由抽象类Person派生出Administration与抽象类User。类Man与类Womam实现了接口Address与接口Contact,Inhumans则实现了Ability接口
然后抽象类代码:
View Code
public abstract class Person
{
public string Username { get; set; }
public string Password { get; set; }
}
public abstract class User : Person
{
public string Name { get; set; }
} |
接口代码:
View Code
public interface IAddress
{
string Address { get; set; }
}
public interface IContact
{
string Email{get;set;}
string WorkPhone { get; set; }
string MobilePhone { get; set; }
string Fax { get; set; }
} |
最后是Man类和Woman类:
View Code
public class Man : User, IContact, IAddress
{
public string Address { get; set; }
public string Email { get; set; }
public string WorkPhone { get; set; }
public string MobilePhone { get; set; }
public string Fax { get; set; }
public bool HasCar { get; set; } //如果这三项都为false的话
public bool HasHouse { get; set; } //这辈子就甭想结婚了
public bool HasMoney { get; set; } //T T我泪涌
} |
View Code
class Woman : User, IAddress, IContact
{
public string Address { get; set; }
public string Email { get; set; }
public string WorkPhone { get; set; }
public string MobilePhone { get; set; }
public string Fax { get; set; }
public bool IsBeauty { get; set; } //这个为true,一辈子不愁吃喝
} |
代码非常简单。其他几个类限于篇幅就不说那么细了
那么按照这个model,使用EF Model First来建立数据库,得到的Woman表如下:
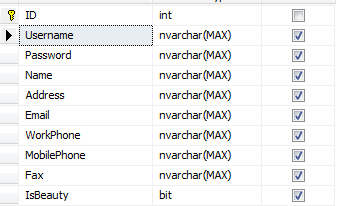
那么接下来就是重点了:为什么不把Contact和Address分表储存。这样与Man表、Woman表写在一起的话,出现改动(如新增一种联系方式),会不会非常痛苦
如果不是使用ORM,那么这个改动的确是很痛苦;但是如果使用了(这里默认使用的ORM可以从Model生成/改动数据库),那么这个改动是没什么大不了的了,只需要修改一下接口定义,然后根据报错去改就好了。至于数据库的变动,就交给ORM去做就OK了
这样有一个好处,可以在有限的范围内实现解耦,部分减少了关系――若将Contact和Address分表的话,取Woman要Join两次,这看起来没什么大不了的,但是如果放大了看,如果是join十次呢?这样弄出来的东西很难去维护(现在公司老系统就是这样,动不动就join十次二十次的,改动起来十分费力)
具体怎么去解耦,这个问题相当相当的深奥,就不敢在这班门弄斧了
在上面,园友Jacklondon Chen提出了一些问题,大致如下:
“man/woman应该设计在同一张表中。 用户表大多都设计成一个表。连分
administrator 和 user 都不应该。”
我想还是因为我举例太随意,因为博文中Man和Woman只有4个差异属性:HasCar\HasHouse\HasMoney,以及IsBeauty
其实对于这个问题我无力吐槽什么,简单的说说吧:假设为Man用户实现的是一个征婚系统,而Woman用户实现的是一个选美系统。这么说应该能理解Man和Woman的不能并同一张表的原因了吧
废话说完,正文开始
/*=============================================================*/
现在有一个系统,我们暂时假设为学校选课系统。有两类用户Teacher和Student,还有一张Curriculum表是课程总表,来储存学校一共有哪些课程,每门课的学分什么的。然后一个老师,一门课程和多名学生,就可以开始上课了
表结构如下图:
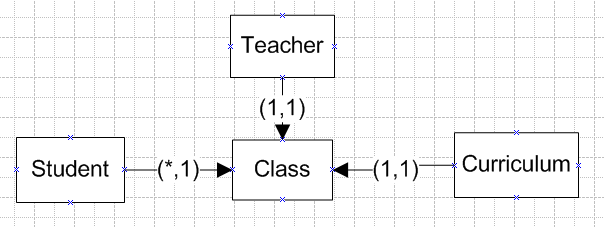
逻辑很简单,一目了然
但是问题在于,我们的系统要按学校来卖。每个学校的选课逻辑都是一样的,而表中的数据有共性,但是也有差异性。比如说基本的Teacher表结构是这样的:

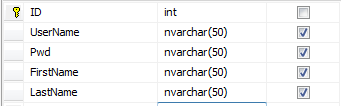
现在把系统卖给A学校。A学校除了的Teacher表除了用户名和密码之外,还要储存老师的FirstName和LastName,那么表结构变化如下:
现在B学校也买了我们的系统。他们的Teacher表不要FirstName和LastName,但是要储存教师的工号“Number”,表结构如下:

好,现在我们的问题出来了:怎么去解决这种差异性
最简单的思路莫过于表中加冗余字段。比如说将表设计成这样:
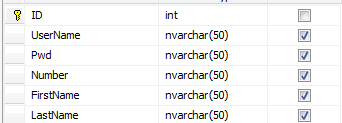
如果我们的系统只卖两三个学校,这样是可行的。但是打个比方,我们的系统卖了30所学校,每个学校有一个自己的差异字段,那么这个表就要有30个冗余字段来应对这种差异性。且不说每次加冗余都要改动系统,且不说冗余多了浪费空间降低传输效率,光说怎么维护这些冗余,我就已经觉得是灾难了:Teacher表有差异字段,其他表也会有。假设一个中型系统,60张表,其中30张实体表30张关系表不算过分吧。那么总共要维护
30(表数量)*30(冗余数量) = 900 个差异字段
第二个想法是建立一张冗余表来储存差异。这种其实和表中加冗余异曲同工,就不多加分析了,留给大家自己思考
第三个想法是建立不同的数据库。其实本来每个学校的数据库就是不同的,唔……怎么说呢,A学校自己的数据库中的表,存的是A学校自己的特有字段,B学校存B学校的特有字段。两者之间并无关系,然后Model用l继承的思路来设计(详见上一篇文章),通过配置文件来选择恰当的数据库和其对应的Model
是的,这种方法挺好的,唯一的不足可能就是比较依赖于ORM――使用ORM来生成数据库,以及T-SQL语句
如果您是一个关系型数据库的重度爱好者,那么这篇文章到这就结束了,下面的东西不会对您胃口的
/*=============================================================*/
众所周知,因为大量使用了反射,ORM的效率不是那么的高,而且本身关系型数据库的可拓展性也不是那么的好
作为一个激进的开发者,我一直希望在项目中尝试NoSql |


