|
����
����������У����˻��� & �㷨 & ��Ŀ֮�⣬�������ʵ���Ҫ����ܺ��������Լ���֪���ļ��ַ��������㷨(��Ȼ������ȫ�������㽫���������л������������⣬ֻ����Ϊ�ҵļ�����д�˾䣺��Ϥ�����ľ���
& �����㷨����)������������һ������ֻ֪��Ƥë���������룬��дһ���й������ھ�ʮ���㷨��ϵ����������Ϊ�Լ�����֮�ã������Ա����������ع�˼�����������ң����������ܶԶ�����һ����������������ա�
���Ľ���Ͳο��������飬һ����Tom M.Mitchhell�����Ļ���ѧϰ��һ���������ھ��ۣ���������Էֱ��ǻ���ѧϰ
& �����ھ�����Ŀ�ɽ or �ܶ�֮���������м���������ȥ����Ȥ�Ļ����������Ķ�����֮�κ�ϸϸ�ж��������顣����֮�⣬���ο������ϲ���ţ�˵���Ʒ(��ĩ��ע���ο���������)���ڴˣ���һһ��ʾ��л(�ӱ��������������ĸ�����һƪ����
& �����ʼ�)��
˵���ˣ�һ�����ǰ�����ڱ�blog��д��һƪ���£������������ھ�����ʮ���㷨��̽(���⻰������и�����������ѱ���������ҵ����ң��������ڿ��������������������ңң����)�����ڣ��ҳ�ȡ���м�����ֵ��һд�ļ����㷨ÿһ����дһ�飬���ڶ����и�����ͨ���˽⡣
OK���ݳƱ�ϵ��ΪTop 10 Algorithms in Data Mining����ȫϵ���κ�һƪ���������κδ���©��������֮�������������һ��Ҫ��ʱ���ߴͽ�
& ָ����лл��λ��
��������࣬�ලѧϰ���ලѧϰ
�ڽ�����ķ���;����㷨֮ǰ���б�Ҫ��һ��ʲô�Ƿ��࣬ʲô�Ǿ��࣬�Լ���������Щ�����㷨�����⡣
Classification (����)������һ�� classifier ��ͨ����Ҫ��������������������Ϊijij�ࡱ����һЩ���ӣ���������£�һ��
classifier ������õ���ѵ�����н��С�ѧϰ�����Ӷ��߱���δ֪���ݽ��з���������������ṩѵ�����ݵĹ���ͨ������
supervised learning (�ලѧϰ)��
��Clustering(����)����˵���ǰ����ƵĶ����ֵ�һ�飬�����ʱ�����Dz�������ijһ����ʲô��������Ҫʵ�ֵ�Ŀ��ֻ�ǰ����ƵĶ����۵�һ����ˣ�һ�������㷨ͨ��ֻ��Ҫ֪����μ�������
�ȾͿ��Կ�ʼ�����ˣ���� clustering ͨ��������Ҫʹ��ѵ�����ݽ���ѧϰ������ Machine
Learning �б����� unsupervised learning (�ලѧϰ).
�����ķ���������㷨
��ν������࣬����˵�����Ǹ����ı������������ԣ����ֵ����е�����С�������Ȼ���Դ���NLP�У����Ǿ����ᵽ���ı���������һ���������⣬һ���ģʽ��������������ı������о������õķ����㷨���������������෨�����صı�Ҷ˹�����㷨(native
Bayesian classifier)������֧��������(SVM)�ķ������������編��k-����ڷ�(k-nearest
neighbor��kNN)��ģ�����෨�ȵ�(������Щ�����㷨�պ��ڱ�blog�ڶ���һһ½������)��
������Ϊһ�ּලѧϰ������Ҫ�����������ȷ֪������������Ϣ�����Ҷ������д��������һ�������֮��Ӧ�����Ǻܶ�ʱ�����������ò������㣬�������ڴ����������ݵ�ʱ�����ͨ��Ԥ����ʹ��������������㷨��Ҫ������۷dz�����ʱ����Կ���ʹ�þ����㷨��
��K��ֵ(K-means clustering)������������͵ľ����㷨(��Ȼ������֮�⣬���кܶ��������ڻ��ַ�K-MEDOIDS�㷨��CLARANS�㷨�����ڲ�η���BIRCH�㷨��CURE�㷨��CHAMELEON�㷨�ȣ������ܶȵķ�����DBSCAN�㷨��OPTICS�㷨��DENCLUE�㷨�ȣ���������ķ�����STING�㷨��CLIQUE�㷨��WAVE-CLUSTER�㷨������ģ�͵ķ�������ϵ�к�����������м���)��
�ලѧϰ���ලѧϰ
����ѧϰ��չ�����ڣ�һ�㻮��Ϊ �ලѧϰ(supervised learning)����ලѧϰ(semi-supervised
learning)�Լ��ලѧϰ(unsupervised learning)���ࡣ�ٸ�����Ķ�Ӧ���ӣ����DZ���˵����NLP��������У�Ҳ��Ϊ�ල����᪷��������ල����᪷��������мල����᪷����У�ѵ����������֪�ģ���ÿ���ʵ���������DZ���ע�˵ģ������ල����᪷����У�ѵ��������δ����ע�ġ�
���������ܵij����ķ����㷨���ڼලѧϰ�������������ලѧϰ(������˵���ලѧϰ���ڷ����㷨��ȷ����Ϊ�ලѧϰֻ��˵���Ǹ�����sampleͬʱ�����˱�ǩ��label����Ȼ��ͬʱ���������ͱ�ǩ������Ӧ��ѧϰ�������ǽ��������ڷ����������������ල���⣬����������ѧϰ������ѧϰ�ȵ�Ҳ�Ǽල�ģ����Dz��Ƿ���)��
�پٸ����ӣ���������ͨ����֪����ѧϰ��ϼ��������������Ҫͨ��ѧϰ���ܾ���ʶ�����������������������������ѧϰ�IJ��Ͼ����뱻ʶ���������ͬ������������������ලѧϰ���ڸ�������ѧϰ������ͬʱ����������������������������������ѧϰ���������������Ϣ,�����ලѧϰ(dz�Ե�˵��ͬ����ѧϰѵ�����ලѧϰ�У����������������Ѿ���ע�������ಡ�ģ����ģ����ලѧϰ�У����Ǹ���һ��ѵ�������û�б����Ǻ��ֲ�����)��
����֧������������һ����ලѧϰ�µĶ����ǣ�������������/����Ը���ʱ����Ϊ�ලѧϰ���й�����/���������ϵ��������Ϊѵ�����ݡ������ලѧϰ�У������ݲ��������ֵ��ѧϰ���������������ݲ����Ĺ��̡�
��һ���֡�������ѧϰ
1.1��ʲô�Ǿ�����
����ֱ���������⡣��ν������������˼�壬��һ������һ�������ڲ��Ծ������������������
����ѧϰ�У���������һ��Ԥ��ģ�ͣ����������Ƕ������������ֵ֮���һ��ӳ���ϵ������ÿ���ڵ��ʾij������ÿ���ֲ�·���������ij�����ܵ�����ֵ����ÿ��Ҷ������Ӧ�Ӹ��ڵ㵽��Ҷ�ڵ���������·������ʾ�Ķ����ֵ�����������е�һ����������и�����������Խ��������ľ������Դ�����ͬ�����
�����ݲ����������Ļ���ѧϰ��������������ѧϰ, ͨ��˵���Ǿ�������˵���ˣ�����һ�������ڷ��ࡢѵ���ϵ�Ԥ������������֪Ԥ�⡢����δ����
�����۵�̫���������������dz���������ӣ�
��һ������
������������������˼���������Ҷ���������һ��Ů����ĸ��Ҫ�����Ů�����������ѣ�������������ĶԻ���
Ů�����������ˣ�
ĸ�ף�26��
Ů��������˧��˧��
ĸ�ף�ͦ˧�ġ�
Ů��������߲���
ĸ�ף�����ܸߣ��е������
Ů�����ǹ���Ա����
ĸ�ף��ǣ���˰����ϰ��ء�
Ů�����Ǻã���ȥ������
���Ů���ľ��߹��̾��ǵ��͵ķ��������ߡ��൱��ͨ�����䡢���ࡢ������Ƿ���Ա�Խ����˷�Ϊ������𣺼��Ͳ������������Ů�������˵�Ҫ���ǣ�30�����¡������е����ϲ����Ǹ��������е���������Ĺ���Ա����ô�����������ͼ��ʾŮ���ľ�������
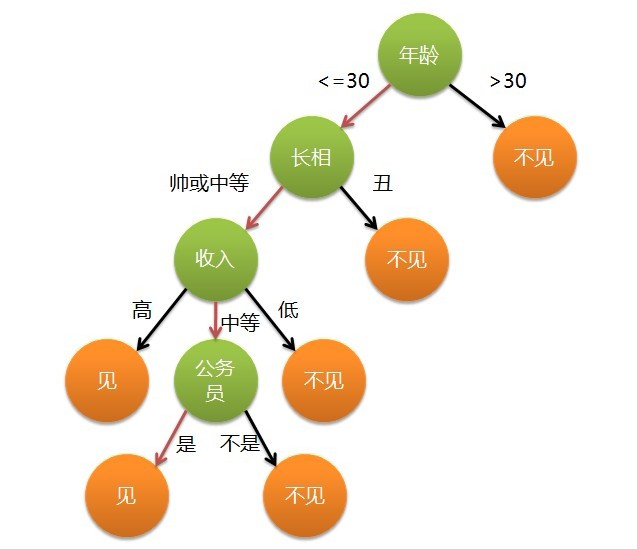
Ҳ����˵���������ļ��Ծ��ǣ��ñȹ�˾��Ƹ���Թ�����ɸѡһ���˵ļ����������������൱�ñ���˵ij985/211�ص��ѧ��ʿ��ҵ����ô������˵��ֱ�ӽй������ԣ�������ص��ѧ��ҵ����ʵ����Ŀ����ḻ����ôҲҪ���ǽй�������һ�£�����ν�������������������ߡ���ÿһ��δ֪��ѡ��ǿ��Թ��ൽ���еķ�������еġ�
�ڶ�������
����������Tom M.Mitchell���Ļ���ѧϰһ�飺
С����Ŀ����ͨ����������Ԥ��Ѱ��ʲôʱ�����ǻ��߶������˽���Ǿ����Ƿ�����ԭ������Ҫȡ�������������������״�����磬�ƺ��ꣻ�����û����¶ȱ�ʾ�����ʪ���ðٷֱȣ��������硣��ˣ����DZ���Թ���һ�þ����������£������������������������Ƿ���ʴ�����
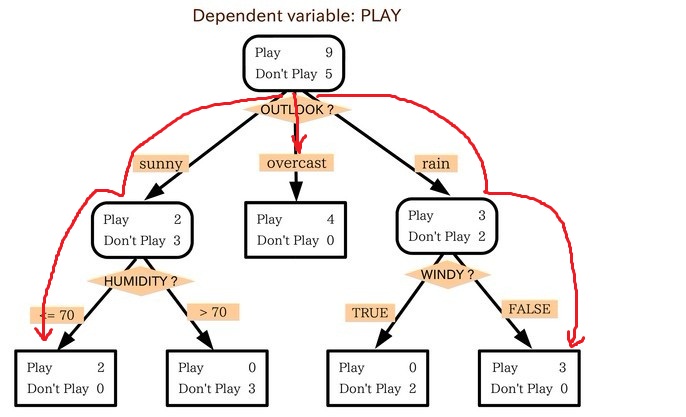
������������Ӧ�����±���ʽ��
��Outlook=Sunny ^Humidity<=70��V ��Outlook = Overcast��V
��Outlook=Rain ^ Wind=Weak��
1.2��ID3�㷨
1.2.1��������ѧϰ֮ID3�㷨
ID3�㷨�Ǿ������㷨��һ�֡����˽�ʲô��ID3�㷨֮ǰ�����ǵ�������һ������¿�ķ�굶��
�¿�ķ�굶��Occam's Razor, Ockham's Razor�����ֳơ��¿����굶��������14������ѧ�ҡ�ʥ���ø�����ʿ�¿�ķ��������William
of Occam��Լ1285����1349�꣩��������ڡ�������ע��2��15��˵�������˷ѽ϶ණ����ȥ�����ý��ٵĶ�����ͬ���������õ����顯����˵�����ǣ�be
simple��
ID3�㷨��Iterative Dichotomiser 3 ����������3������һ����Ross Quinlan���������ھ��������㷨������㷨���ǽ��������������ܵİ¿�ķ�굶�Ļ����ϣ�Խ��С�͵ľ�����Խ���ڴ�ľ�������be
simple�����ۣ���������ˣ����㷨Ҳ��������������С�����νṹ������һ������ʽ�㷨��
OK������Ϣ��֪ʶ������֪����������ϢԽС����Ϣ����Խ�Ӷ�����Խ�ߡ�ID3�㷨�ĺ���˼���������Ϣ�����������ѡ��ѡ����Ѻ���Ϣ����(�ܿ죬��������ͻ�֪����Ϣ����������ôһ����)�������Խ��з��ѡ����㷨�����Զ����µ�̰�������������ܵľ������ռ䡣
���ԣ�ID3��˼����ǣ�
�Զ����µ�̰�������������ܵľ������ռ乹�������(�˷�����ID3�㷨��C4.5�㷨�Ļ���)��
�ӡ���һ�����Խ������ĸ��ڵ㱻���ԡ���ʼ��
ʹ��ͳ�Ʋ�����ȷ��ÿһ��ʵ�����Ե�������ѵ������������������������õ�������Ϊ���ĸ�������(��ζ����������һ�������Ƿ���������õ��أ���������Ľ�Ҫ���ܵ���Ϣ���棬or
��Ϣ������)��
Ȼ��Ϊ��������Ե�ÿ������ֵ����һ����֧������ѵ���������е��ʵ��ķ�֧��Ҳ����˵�������ĸ�����ֵ��Ӧ�ķ�֧��֮�¡�
�ظ�������̣���ÿ����֧��������ѵ��������ѡȡ�ڸõ㱻���Ե�������ԡ�
���γ��˶Ժϸ��������̰��������Ҳ�����㷨�Ӳ��������¿�����ǰ��ѡ��
��ͼ��ʾ��������ѧϰ����������ID3�㷨��Ҫ��

1.2.2���ĸ���������ѵķ�������
1����Ϣ����Ķ���������
�����У������ᵽ����ID3�㷨�ĺ���˼���������Ϣ�����������ѡ��ѡ����Ѻ���Ϣ����(�ܿ죬��������ͻ�֪����Ϣ����������ôһ����)�������Խ��з��ѡ��������������Ǿ������������Ϣ�����Ǹ�ʲô����(��Ȼ�����˽���Ϣ����֮ǰ������������⣺��Ϣ����Ķ���������)��
������ID3�㷨�ĺ���������ѡȡ������ÿ�����Ҫ���Ե����ԡ�����ϣ��ѡ������������ڷ���ʵ�������ԣ���Ϣ����(Information
Gain)������������������������ѵ����������������ID3�㷨����������ÿһ��ʹ����Ϣ����Ӻ�ѡ������ѡ�����ԡ�
Ϊ�˾�ȷ�ض�����Ϣ���棬�����ȶ�����Ϣ���й㷺ʹ�õ�һ������������Ϊ�أ�entropy�������̻��������������Ĵ��ȣ�purity����������������ij��Ŀ����������������������S����ôS�����������ͷ������Ϊ��
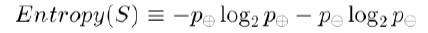
������ʽ�У�p+�����������������ڱ��Ŀ�ͷ�ڶ���������p+����ζ��ȥ����ë��p-���������������ȥ����(���й��ص����м��������Ƕ���0log0Ϊ0)��
���д����ʵ���صļ��㣬��������ʾ��
//���ݾ������Ժ�ֵ��������
double ComputeEntropy(vector <vector <string> >
remain_state, string attribute, string value,bool ifparent){
vector<int> count (2,0);
unsigned int i,j;
bool done_flag = false;//�ڱ�ֵ
for(j = 1; j < MAXLEN; j++){
if(done_flag) break;
if(!attribute_row[j].compare(attribute)){
for(i = 1; i < remain_state.size(); i++){
if((!ifparent&&!remain_state[i][j].compare(value))
|| ifparent){//ifparent��¼�Ƿ��㸸�ڵ�
if(!remain_state[i][MAXLEN - 1].compare(yes)){
count[0]++;
}
else count[1]++;
}
}
done_flag = true;
}
}
if(
//ȫ������ʵ�����߸�ʵ��
//��������� ����[+count[0],-count[1]],
log2Ϊ��ͨ������ʽ������Ȼ������
double sum = count[0] + count[1];
double entropy
= -count[0]/sum*log(count[0]/sum)/log(2.0)
- count[1]/sum*log(count[1]/sum)/log(2.0);
return entropy;
} |
������˵������S��һ�����ڲ����������14�������ļ��ϣ�������9��������5�����������Dz��üǺ�[9+��5-]��������������������������ôS��������������������Ϊ��
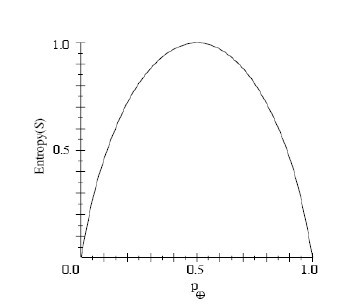
Entropy��[9+��5-]��=-��9/14��log2��9/14��-��5/14��log2��5/14��=0.940��
So���������������ʽ�����ǿ��Եõ���S�����г�Ա����ͬһ�࣬Entropy(S)=0�� S����������������ȣ�Entropy(S)=1��S�����������������ȣ��ؽ���0��1֮�䣬����ͼ��ʾ��
��Ϣ���ж��ص�һ�ֽ��ͣ���ȷ����Ҫ���뼯��S�������Ա�ķ�������Ҫ�����ٶ�����λ������һ��أ����Ŀ�����Ծ���c����ͬ��ֵ����ôS�����c��״̬�ķ�����ض���Ϊ��
PiΪ�Ӽ����в�ͬ��(����Ԫ���༴������������)�������ı�����
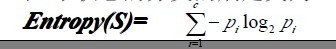
2����Ϣ��������������ؽ���
��Ϣ����Gain(S,A)����
�Ѿ���������Ϊ����ѵ���������ϴ��ȵı������ڿ��Զ������Է���ѵ�����ݵ�Ч���Ķ����������������Ϊ����Ϣ���棨information
gain��������˵��һ�����Ե���Ϣ�����������ʹ��������Էָ����������µ������ؽ���(����˵����������ij���Ի���ʱ����ؼ��ٵ�����)������ȷ�ؽ���һ������A�����������S����Ϣ����Gain(S,A)������Ϊ��

���� Values(A)������A���п���ֵ�ļ��ϣ���S������A��ֵΪv���Ӽ������仰������Gain(S,A)�����ڸ�������A��ֵ���õ��Ĺ���Ŀ�꺯��ֵ����Ϣ������S��һ�������Ա��Ŀ��ֵ����ʱ��Gain(S,A)��ֵ����֪������A��ֵ����Խ�ʡ�Ķ�����λ����
���������б�Ҫ���Ѷ���һ�£������������������� or ��ʽ��
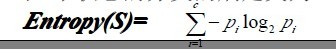
��һ��Entropy(S)���ض��壬�ڶ���������Ϣ����Gain(S,A)�Ķ��壬��Gain(S,A)�ɵ�һ��Entropy(S)���������ס�ˡ�
���棬�ٸ����ӣ��ٶ�S��һ���й�������ѵ���������������������������Ǿ���Weak��Strong����ֵ��Wind����ǰ��һ�����ٶ�S����14��������[9+��5-]������14�������У��ٶ������е�6���ͷ����е�2����Wind
=Weak����������Wind=Strong�����ڰ�������Wind����14�������õ�����Ϣ������Լ������¡�
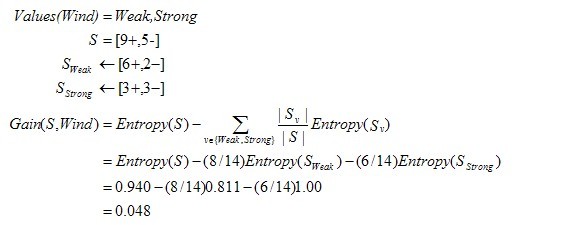
�����ڱ��Ŀ�ͷ�ٵõڶ���������������Ƿ��������ë��������ϣ��õ�����ѷ�����������ͼ��ʾ��
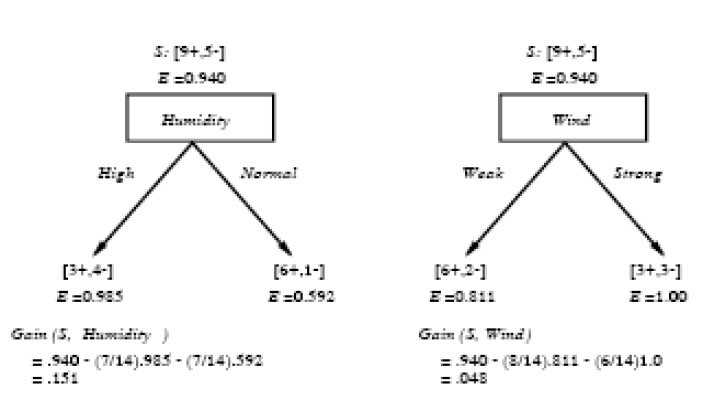
����ͼ�У�������������ͬ���ԣ�ʪ��(humidity)�ͷ���(wind)����Ϣ���棬����humidity���ַ������Ϣ����0.151>wind�����0.048��˵���ˣ������������������Ƿ��ʺϴ��������������У���ȡhumidity��wind��Ϊ�������Ը��ѣ��������ɴ˶�����
//������Ϣ���棬DFS����������
//current_nodeΪ��ǰ�Ľڵ�
//remain_stateΪʣ������������
//remian_attributeΪʣ�û�п��ǵ�����
//���ظ����ָ��
Node * BulidDecisionTreeDFS(Node * p, vector
<vector <string> > remain_state, vector <string> remain_attribute){
//if(remain_state.size() > 0){
//printv(remain_state);
//}
if (p == NULL)
p = new Node();
//�ȿ���������Ҷ�����
if (AllTheSameLabel(remain_state, yes)){
p->attribute = yes;
return p;
}
if (AllTheSameLabel(remain_state, no)){
p->attribute = no;
return p;
}
if(remain_attribute.size() == 0)
{//���е����Ծ��Ѿ���������,��û�з־�
string label = MostCommonLabel(remain_state);
p->attribute = label;
return p;
}
double max_gain = 0, temp_gain;
vector <string>::iterator max_it;
vector <string>::iterator it1;
for(it1 = remain_attribute.begin(); it1
< remain_attribute.end(); it1++){
temp_gain = ComputeGain(remain_state, (*it1));
if(temp_gain > max_gain) {
max_gain = temp_gain;
max_it = it1;
}
}
//�������max_itָ������������ֵ�ǰ������
���������������Լ�
vector <string> new_attribute;
vector <vector <string> > new_state;
for(vector <string>::iterator it2 =
remain_attribute.begin(); it2 < remain_attribute.end(); it2++){
if((*it2).compare(*max_it)) new_attribute.push_back(*it2);
}
//ȷ������ѻ������ԣ�ע�Ᵽ��
p->attribute = *max_it;
vector <string> values = map_attribute_values[*max_it];
int attribue_num = FindAttriNumByName(*max_it);
new_state.push_back(attribute_row);
for(vector <string>::iterator it3
= values.begin(); it3 < values.end(); it3++){
for(unsigned int i = 1; i < remain_state.size(); i++){
if(!remain_state[i][attribue_num].compare(*it3)){
new_state.push_back(remain_state[i]);
}
}
Node * new_node = new Node();
new_node->arrived_value = *it3;
if(new_state.size() == 0)
{//��ʾ��ǰû�������֧����������ǰ��new_nodeΪҶ�ӽڵ�
new_node->attribute = MostCommonLabel(remain_state);
}
else
BulidDecisionTreeDFS
(new_node, new_state, new_attribute);
//�ݹ麯������ʱ������ʱ��Ҫ
1 ���½����븸�ڵ㺢������ 2���new_state����
p->childs.push_back(new_node);
new_state.erase(new_state.begin()+1,new_state.end());
//ע�������new_state�е�ǰһ��ȡֵ������
����������һ��ȡֵ����
}
return p;
} |
1.2.3��ID3�㷨���������γ�
OK����ͼΪID3�㷨��һ�����γɵIJ��־������������ۺ���������������������ˡ�1��overcast������Ϊ��������ΪҶ�ӽ�㣬��Ϊyes��2��ID3���ݣ��ֲ����ţ�����ȫ�����ţ�������һ������������������ͼ��ID3�㷨��һ�����γɵIJ��־�������
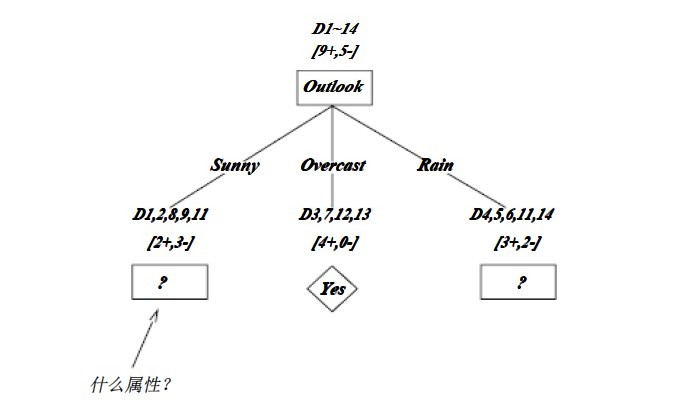
����ͼ��ѵ�����������е���Ӧ�ķ�֧��㡣��֧Overcast�����������������������Գ�ΪĿ�����ΪYes��Ҷ��㡣��������㽫����һ��չ���������ǰ����µ������Ӽ�ѡȡ��Ϣ������ߵ����ԡ�
1.3��C4.5�㷨
1.3.1��ID3�㷨�ĸĽ���C4.5�㷨
C4.5���ǻ���ѧϰ�㷨�е���һ������������㷨�����Ǿ�����(������Ҳ���������ߵĽڵ�����֯��ʽ��һ��������ʵ��һ������)�����㷨��Ҳ������1.2�������ܵ�ID3�ĸĽ��㷨�����Ի������˽���һ����������췽�����ܹ�������
���������췽����ʵ����ÿ��ѡ��һ���õ������Լ����ѵ���Ϊ��ǰ�ڵ�ķ���������
��Ȼ˵C4.5�㷨��ID3�ĸĽ��㷨����ôC4.5�����ID3�Ľ��ĵط�����Щ�أ���
����Ϣ��������ѡ�����ԡ�ID3ѡ�������õ�����������Ϣ���棬��������úܶ����������Ϣ��ID3ʹ�õ�����(entropy������һ�ֲ����ȶ�����),Ҳ�����صı仯ֵ����C4.5�õ�����Ϣ�����ʡ��ԣ����������һ������Ϣ���棬һ������Ϣ�����ʡ�
������������н��м�֦���ڹ����������ʱ����Щ���ż���Ԫ�صĽڵ㣬��������ã���Ȼ������overfitting��
�Է���ɢ����Ҳ�ܴ�����
�ܹ��Բ��������ݽ��д���
���������һ�㣬�����£�һ����˵�ʾ�������ȡƽ���õģ�����������ò�࣬�����������ܲ����ˣ�һ�������10m/s���ˡ���10s��Ϊ20m/s����һ����������1m/s����1s��Ϊ2m/s������������ֵ��ô�������ͺܴ��ˣ����ʹ���ٶ�������(���ٶȣ�������Ϊ1m/s^2)��������2���˾���һ���ļ��ٶȡ���ˣ�C4.5�˷���ID3����Ϣ����ѡ������ʱƫ��ѡ��ȡֵ������ԵIJ��㡣
C4.5�㷨֮��Ϣ������
OK����Ȼ�������ᵽC4.5�õ�����Ϣ�����ʣ��������ʵľ�������ζ�����أ���
�ǵģ������C4.5�㷨������ͨ����Ϣ������ѡ��������ԡ�һ������ѡ��Ķ��������������gain
ratio��Quinlan 1986����������ʶ�������ǰ����������Gain(S��A)�ͷ�����Ϣ����SplitInformation(S��A)����ͬ����ģ�������ʾ��
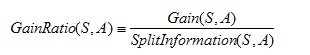
���У�������Ϣ����������Ϊ(������Ϣ�����������Է������ݵĹ�Ⱥ;���)��
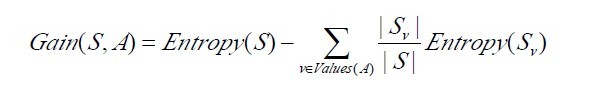
����S1��Sc��c��ֵ������A�ָ�S���γɵ�c�������Ӽ���ע�������Ϣʵ���Ͼ���S��������A�ĸ�ֵ���ء���������ǰ����ص�ʹ�ò�ͬ������������ֻ����S����ѧϰ������ҪԤ���Ŀ�����Ե�ֵ���ء�
��ע�⣬������Ϣ���谭ѡ��ֵΪ���ȷֲ������ԡ����磬����һ������n�������ļ��ϱ�����A���ָ��ע���ֳ�n�飬��һ������һ�飩����ʱ������Ϣ��ֵΪlog2n���෴��һ����������B�ָ�ͬ����n��ʵ�������ǡ��ƽ�����룬��ô������Ϣ��1���������A��B����ͬ������Ϣ���棬��ô����������ʶ���������B��÷ָ��ߡ�
ʹ��������ʴ���������ѡ�����Բ�����һ��ʵ�������ǣ���ij��Si�ӽ�S��|Si|?|S|��ʱ��ĸ����Ϊ0��dz�С�����ij�����Զ���S�����������м���ͬ����ֵ����ʱҪô�����������δ���壬Ҫô��������ʷdz���Ϊ�˱���ѡ���������ԣ����ǿ��Բ�������һЩ����ʽ�������ȼ���ÿ�����Ե����棬Ȼ�������Щ����߹�ƽ��ֵ������Ӧ��������ʲ��ԣ�Quinlan
1986����
������Ϣ���棬Lopez de Mantaras��1991����������һ��ֱ����������������ƵĶ��������ǻ��ھ���ģ�distance-based������������������������һ�����ݻ��ּ�ľ���߶ȡ����������ο���Tom
M.Mitchhell�����Ļ���ѧϰ֮3.7.3�ڡ�
1.3.2��C4.5�㷨����������Ĺ���
Function C4.5(R:�����������Ե���������Լ���,C:�������,S:ѵ����)
/*����һ�þ�����*/
Begin
If SΪ��,����һ��ֵΪFailure�ĵ����ڵ�;
If S������ͬ�������ֵ�ļ�¼���,
����һ�����и�ֵ�ĵ����ڵ�;
If RΪ��,��һ�����ڵ�,
��ֵΪ��S�ļ�¼���ҳ���Ƶ����ߵ��������ֵ;
[ע��δ���ִ�������ζ���Dz��ʺϷ���ļ�¼]��
For �������R(Ri) Do
If ����RiΪ�������ԣ���
Begin
��Ri����Сֵ����A1��
��Rm�����ֵ����Am��/*mֵ�ֹ�����*/
For j From 2 To m-1 Do Aj=A1+j*(A1Am)/m;
��Ri��Ļ���{< =Aj,>Aj}�������Ϣ��������(Ri,S)����A��
End��
��R������֮����������Ϣ���������(D,S)����D;
������D��ֵ����{dj/j=1,2...m}��
���ֱ��ɶ�Ӧ��D��ֵΪdj�ļ�¼��ɵ�S���Ӽ�����{sj/j=1,2...m};
����һ������������ΪD;��֦���Ϊd1,d2...dm;
�ٷֱ���������:
C4.5(R-{D},C,S1),C4.5(R-{D},C,S2)...C4.5(R-{D},C,Sm);
End C4.5 |
1.3.3��C4.5�㷨ʵ���еļ����ؼ�����
�������У������Ѿ�֪���˾�����ѧϰC4.5�㷨��4����Ҫ����ı�����£�
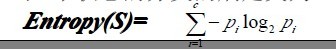

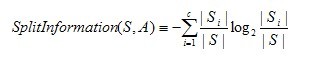

������������д�´���ʵ�֣�
1����Ϣ��
double C4_5::entropy(int *attrClassCount, int classNum, int allNum){
double iEntropy = 0.0;
for(int i = 0; i < classNum; i++){
double temp = ((double)attrClassCount[i]) / allNum;
if(temp != 0.0)
iEntropy -= temp * (log(temp) / log(2.0));
}
return iEntropy;
} |
2����Ϣ������
double C4_5::gainRatio(int classNum, vector<int *> attriCount, double pEntropy){
int* attriNum = new int[attriCount.size()];
int allNum = 0;
for(int i = 0; i < (int)attriCount.size(); i++){
attriNum[i] = 0;
for(int j = 0; j < classNum; j++){
attriNum[i] += attriCount[i][j];
allNum += attriCount[i][j];
}
}
double gain = 0.0;
double splitInfo = 0.0;
for(int i = 0; i < (int)attriCount.size(); i++){
gain -= ((double)attriNum[i]) / allNum * entropy
(attriCount[i], classNum, attriNum[i]);
splitInfo -= ((double)attriNum[i]) /
allNum * (log(((double)attriNum[i])/allNum) / log(2.0));
}
gain += pEntropy;
delete[] attriNum;
return (gain / splitInfo);
} |
3��ѡȡ�������������Ϊ��������
int C4_5::chooseAttribute(vector<int> attrIndex, vector<int *>* sampleCount){
int bestIndex = 0;
double maxGainRatio = 0.0;
int classNum = (int)(decisions[attrIndex[(int)attrIndex.size()-1]]).size();//number of class
//computer the class entropy
int* temp = new int[classNum];
int allNum = 0;
for(int i = 0; i < classNum; i++){
temp[i] = sampleCount[(int)attrIndex.size()-1][i][i];
allNum += temp[i];
}
double pEntropy = entropy(temp, classNum, allNum);
delete[] temp;
//computer gain ratio for every attribute
for(int i = 0; i < (int)attrIndex.size()-1; i++){
double gainR = gainRatio(classNum, sampleCount[i], pEntropy);
if(gainR > maxGainRatio){
bestIndex = i;
maxGainRatio = gainR;
}
}
return bestIndex;
} |
4������һϵ�н�������ӡ���IJ��裬�˴��Թ���
1.4�����ߵ���
form Wind��������ʹ��������ȡֵ��ɢ�����������������һ��ҲҪ��������ɢ��(���ܶ�����û�б�����������Ĺؼ�����or����)��ʵ��Ӧ���У�������overfitting�Ƚϵ����أ�һ��Ҫ��boosting���������������ϲ�ȥ������Ҫ��ԭ�����������ļ����Բ��㣬�����Ƿ������ĺû����õ��������кõķ���Ч����������ֻ������ء�
�������� �����ļ������أ�һ���������ʱ��������domain knowledge�����Ƕ���ȡ������������ѡ�任����ѧϰ����һ���ǻ���ѧϰ�㷨���ܵIJ���(��˵����Щ������Ծ������ģ���˲���˵�Ǿ��������ص㣬ֻ��һЩ����ѧϰ�㷨��Ӧ�ù����еľ������)��
�ڶ����֡���Ҷ˹����
�岥�����ڱ�Ҷ˹��������������������������ĵ�һ���֣��ӱ�Ҷ˹����̸����Ҷ˹���硣July��2014��11��14�ո��¡�
���ڱ�Ҷ˹����ƪ���½��ܵIJ�������ѧ֮������ƪ��ƽ����������ı�Ҷ˹���������ĵڶ�����֮�ֻ���������δ����֮��(���˲��ָĶ�)�������κβ���֮��������ԭ���ߺ��ڶ��ߺ�����лл����Ȼ���պ��һ�������±�Ҷ˹��PS�������Ѿ���д�������ĵ�һ���֣���
2.1��ʲô�DZ�Ҷ˹����
��ά���ٿ��ϵĽ��ܣ���Ҷ˹�����ǹ�������¼�A��B���������ʺͱ�Ե���ʵ�һ������
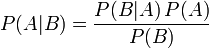
������ʾ������P(A|B)����B�����������A�����Ŀ����ԡ��ڱ�Ҷ˹�����У�ÿ�����ʶ���Լ���׳ɵ����ƣ�
P(A)��A��������ʻ��Ե���ʡ�֮���Գ�Ϊ"����"��������������κ�B��������ء�
P(A|B)����֪B������A���������ʣ�ֱ����������������B����=>����A����Ҳ���ڵ���B��ȡֵ��������A�ĺ�����ʡ�
P(B|A)����֪A������B���������ʣ�ֱ����������������A����=>����B����Ҳ���ڵ���A��ȡֵ��������B�ĺ�����ʡ�
P(B)��B��������ʻ��Ե���ʣ�Ҳ������������normalized constant����
����Щ���Bayes�����ɱ���Ϊ��������� = (���ƶ�*�������)/����������Ҳ�����f�����������������ʺ����ƶȵij˻������ȡ����⣬����P(B|A)/P(B)Ҳ��ʱ�����������ƶȣ�standardised
likelihood����Bayes�����ɱ���Ϊ��������� = �����ƶ�*������ʡ�
2.2 ��Ҷ˹��ʽ��ζ���
��Ҷ˹��ʽ����ô���ģ������پ�wikipedia �ϵ�һ�����ӣ�
һ��ѧУ������ 60% ��������40% ��Ů�����������Ǵ����㣬Ů����һ�봩����һ�봩ȹ�ӡ�������Щ��Ϣ֮�����ǿ������ؼ��㡰���ѡȡһ��ѧ������������������ĸ��ʺʹ�ȹ�ӵĸ����Ƕ���������ǰ��˵�ġ�������ʡ��ļ��㡣Ȼ��������������У�У�ӭ������һ���������ѧ�����ܲ��ҵ�����߶Ƚ��ƣ���ֻ���ü��������������Ƿ㣬����ȷ�������������Ա𣩣����ܹ��ƶϳ����������������ĸ����Ƕ����
һЩ��֪��ѧ���о����������������жϡ��Լ���Rationality for Mortals����12�£�С��Ҳ���Խ����Ҷ˹���⣩�����Ƕ���ʽ���ı�Ҷ˹���ⲻ�ó�����������Ƶ����ʽ���ֵĵȼ�����ȴ���ó�����������Dz������������������ɣ�����У����������ߣ�������
N ����������ˣ���Ȼ��������ֱ�ӹ۲쵽���ǵ��Ա𣩣����� N ���������ж��ٸ�Ů�����ٸ�������
��˵����������ѧУ�����ж��ٴ�����ģ�Ȼ������Щ������������ж���Ů�����������ˣ�
��������һ�㣺����ѧУ�����˵������� U ����60% �������������㣬�������ǵõ��� U * P(Boy)
* P(Pants|Boy) ��������ģ������������� P(Boy) �������ĸ��� = 60%��������Լ�����Ϊ�����ı�����P(Pants|Boy)
���������ʣ����� Boy ��������´�����ĸ����Ƕ�������� 100% ����Ϊ���������������㣩��40%
��Ů����������һ�루50%���Ǵ�����ģ����������ֵõ��� U * P(Girl) * P(Pants|Girl)
��������ģ�Ů������������һ���� U * P(Boy) * P(Pants|Boy) + U * P(Girl)
* P(Pants|Girl) ��������ģ������� U * P(Girl) * P(Pants|Girl)
��Ů��������һ�Ⱦ�����Ҫ��Ĵ𰸡�
�������ǰ��������ʽ��һ�£�����Ҫ����� P(Girl|Pants) ����������������ж���Ů���������Ǽ���Ľ����
U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy)
+ U * P(Girl) * P(Pants|Girl)] ������������У���˵��������صģ�����ͬʱ��ȥU�����ǵõ�
P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) *
P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
ע�⣬�������ʽ������������ĸ��ʵ���� P(Pants) ��������ʵ���� P(Pants, Girl)
���������������Ȼ�ؾͶ������ڴ�������ˣ� P(Pants) �������ж��٣������㣩��Ů���� P(Pants,
Girl) ����
��ʽ�е� Pants �� Boy/Girl ����ָ��һ�ж�����So����һ����ʽ���ǣ�
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) *
P(~B) ]
�����������ǣ�
P(B|A) = P(AB) / P(A)
��ʵ����͵��ڣ�
P(B|A) * P(A) = P(AB)
����һ��������P(B|A)����������A������£�B���ֵĸ����Ƕ��Ȼ������ôƽ���ı�Ҷ˹��ʽ������ȴ�����ŷdz���̵�ԭ����
2.3��ƴд����
�����������˹����ܣ��ִ�������������֮һ Peter Norvig ����д��һƪ�������дһ��ƴд���/�����������£������õ��ľ��DZ�Ҷ˹���������棬�������˼��������¡�
���ȣ�������Ҫѯ�ʵ��ǣ���������ʲô����
���������ǿ����û�������һ�������ֵ��еĵ��ʣ�������Ҫȥ�²⣺������һﵽ������������ĵ�����ʲô�أ����øղ�������ʽ�����������������ǣ�������Ҫ��
P(���Dz²���������ĵ��� | ��ʵ������ĵ���)
������ʡ����ҳ��Ǹ�ʹ������������IJ²ⵥ�ʡ���Ȼ�����ǵIJ²�δ����Ψһ�ģ�����ǰ��ٵ��Ǹ���Ȼ���Ե������Ե�����һ������������û����룺
thew ����ô�������������� the ������������ thaw �������ĸ��²�����Ը����أ����˵������ǿ����ñ�Ҷ˹��ʽ��ֱ�ӳ����Ǹ��Եĸ��ʣ����Dz��������ǵĶ���²��Ϊ
h1 h2 .. �� h ���� hypothesis�������Ƕ�����һ����������ɢ�IJ²�ռ� H �������ܹ�����ô����ѣ������û�ʵ������ĵ��ʼ�Ϊ
D �� D ���� Data �����۲����ݣ�������
P(���ǵIJ²�1 | ��ʵ������ĵ���)
���Գ���ؼ�Ϊ��
P(h1 | D)
���Ƶأ��������ǵIJ²�2������ P(h2 | D)������ͳһ��Ϊ��
P(h | D)
����һ�α�Ҷ˹��ʽ�����ǵõ���
P(h | D) = P(h) * P(D | h) / P(D)
���ڲ�ͬ�ľ���²� h1 h2 h3 .. ��P(D) ����һ���ģ������ڱȽ� P(h1 | D)
�� P(h2 | D) ��ʱ�����ǿ��Ժ������������������ֻ��Ҫ֪����
P(h | D) �� P(h) * P(D | h) ��ע���Ǹ����ŵ���˼�ǡ��������ڡ������������ע������Ҷ�����һ��Сȱ�ڵġ���
���ʽ�ӵij������ǣ����ڸ����۲����ݣ�һ���²��Ǻ��ǻ���ȡ���ڡ�����²Ȿ�������Ŀ����Դ�С��������ʣ�Prior
�����͡�����²��������ǹ۲�����ݵĿ����Դ�С������Ȼ��Likelihood ���ij˻������嵽���ǵ��Ǹ�
thew �����ϣ�������ǣ��û�ʵ���������� the �Ŀ����Դ�Сȡ���� the �����ڴʻ���б�ʹ�õĿ����ԣ�Ƶ���̶ȣ���С��������ʣ���
��� the ȴ��� thew �Ŀ����Դ�С����Ȼ���ij˻���
ʣ�µ�����ͺܼ��ˣ��������Dz²�Ϊ���ܵ�ÿ�����ʼ���һ�� P(h) * P(D | h) ���ֵ��Ȼ��ȡ���ģ��õ��ľ�����IJ²⡣����ϸ����ο�δ����֮ԭ�ġ�
2.4����Ҷ˹��Ӧ��
2.4.1�����ķִ�
��Ҷ˹�ǻ���ѧϰ�ĺ��ķ���֮һ���������ķִ�������õ��˱�Ҷ˹���˳�֮�۵���������ڡ���ѧ֮����ϵ���о���һƪ�ǽ������ķִʵġ��������һ�º��ĵ�˼�룬����������ϸ��ο������ԭ�ġ�
�ִ����������Ϊ������һ�����ӣ��ִ������磺
�Ͼ��г�������
��ζ�������ӽ��зִʣ��ʴ���������ġ����磺
1. �Ͼ���/��������
2. �Ͼ�/�г�/������
�������ִʣ������ĸ��������أ�
�����ñ�Ҷ˹��ʽ����ʽ��������������⣬�� X Ϊ�ִ������ӣ���Y Ϊ�ʴ���һ���ض��ķִʼ��裩�����Ǿ�����ҪѰ��ʹ��
P(Y|X) ���� Y ��ʹ��һ�α�Ҷ˹�ɵã�
P(Y|X) �� P(Y)*P(X|Y)
����Ȼ������˵���� ���ִַʷ�ʽ���ʴ����Ŀ����� ���� ����ʴ��������ǵľ��ӵĿ����ԡ����ǽ�һ�������������Խ��Ƶؽ�
P(X|Y) �����Ǻ���� 1 �ģ���Ϊ��������һ�ִַʷ�ʽ֮���������ǵľ������Ǿ������ɵģ�ֻ��ѷִ�֮��ķֽ�����ӵ����ɣ������ǣ����Ǿͱ����ȥ���
P(Y) ��Ҳ����Ѱ��һ�ִַ�ʹ������ʴ������ӣ��ĸ����������μ���һ���ʴ���
W1, W2, W3, W4 ..
�Ŀ������أ�����֪�����������ϸ��ʵĹ�ʽչ����P(W1, W2, W3, W4 ..) = P(W1)
* P(W2|W1) * P(W3|W2, W1) * P(W4|W1,W2,W3) * .. �������ǿ���ͨ��һϵ�е��������ʣ���ʽ���ij˻������������ϸ��ʡ�Ȼ�����ҵ�������������Ŀ�����ӣ�P(Wn|Wn-1,Wn-2,..,W1)
�������� n-1 ����������ϡ������Ҳ��Խ��Խ���أ��������Ͽ��ٴ�Ҳ��ͳ�Ƴ�һ������ P(Wn|Wn-1,Wn-2,..,W1)
����Ϊ�˻���������⣬�������ѧ����һ�������ʹ���ˡ����桱���裺���Ǽ��������һ���ʵij��ָ���ֻ��������ǰ�������
k ���ʣ�k һ�㲻���� 3�����ֻ������ǰ���һ���ʣ�����2Ԫ����ģ�ͣ�2-gram����ͬ���� 3-gram
�� 4-gram �ȣ������������ν�ġ�����ƽ�ߡ����衣
��Ȼ������������ɵ�����棬�����ȴ�������Ľ�������Ǻܺú�ǿ��ģ�����Ҫ�ᵽ�����ر�Ҷ˹����ʹ�õļ�����������������ȫһ�µģ����ǻ����Ϊʲô������һ������ļ����ܹ��õ�ǿ��Ľ����Ŀǰ����ֻҪ֪��������������裬�ղ��Ǹ��˻��Ϳ��Ը�д�ɣ�
P(W1) * P(W2|W1) * P(W3|W2) * P(W4|W3) .. ������ÿ����ֻ��������ǰ���һ���ʣ�����ͳ��
P(W2|W1) �Ͳ����ܵ�����ϡ������������ˡ��������������ᵽ�����ӡ��Ͼ��г������š���������������ҵ�̰�������ִʵĻ�������ͳ��ˡ��Ͼ��г�/�����š�����������ձ�Ҷ˹�ִʵĻ�������ʹ��
3-gram�������ڡ��Ͼ��г����͡������š������Ͽ���һ����ֵ�Ƶ��Ϊ 0 ���������ĸ��ʱ�ᱻ�ж�Ϊ
0 �� �Ӷ�ʹ�á��Ͼ���/�������š���һ�ִʷ�ʽʤ����
2.4.2����Ҷ˹ͼ��ʶ��Analysis by Synthesis
��Ҷ˹������һ���dz� general ��������ܡ������������������ɣ�Analysis by Synthesis
��ͨ���ϳ�����������06 �����֪��ѧ�½�չ����һƪ paper ���ǽ��ñ�Ҷ˹�����������Ӿ�ʶ��ģ�һͼʤǧ�ԣ���ͼ����ժ����ƪ
paper ��
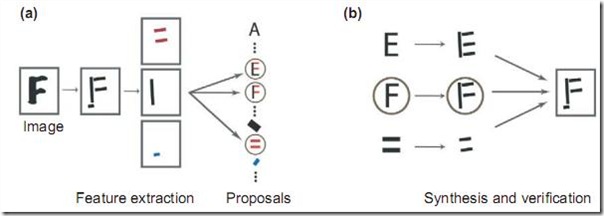
�������Ӿ�ϵͳ��ȡͼ�εı߽�������Ȼ��ʹ����Щ�����Ե����ϵؼ���߲�ij����������� E ���� F
���ǵȺţ���Ȼ��ʹ��һ���Զ����µ���֤���Ƚϵ����ĸ�������ѵؽ����˹۲쵽��ͼ��
2.4.3�������Ȼ����С����

ѧ�����Դ����Ĵ�Ŷ�֪���������С���˷����������Իع顣���������ǣ�����ƽ���� N ���㣬�����ﲻ��������������һ��ֱ���������Щ�㡪���ع���Կ�������ϵ�������������������ϣ����ҳ�һ�������������Щ���ֱ�ߡ�
һ�����������������ǣ�������ζ�����ѣ�������ÿ���������Ϊ (Xi, Yi) �����ֱ��Ϊ y
= f(x) ����ô (Xi, Yi) ��ֱ�߶������ġ�Ԥ�⡱��(Xi, f(Xi)) �������һ��
��Yi = |Yi �C f(Xi)| ����С���˾���˵Ѱ��ֱ��ʹ�� (��Y1)^2 + (��Y2)^2
+ .. ��������ƽ���ͣ���С������Ϊʲô������ƽ���Ͷ��������ľ���ֵ�ͣ�ͳ��ѧ��Ҳû��ʲô�õĽ��͡�Ȼ����Ҷ˹����ȴ�ܶԴ��ṩһ�������Ľ��͡�
���Ǽ���ֱ�߶������� Xi ������Ԥ�� f(Xi) �����Ԥ�⣬����������ƫ�� f(Xi) ����Щ���ݵ㶼����������������ʹ������ƫ����������һ��ֱ�ߣ�һ�������ļ������ƫ��·��ԽԶ�ĸ���ԽС������С���٣�������һ����̬�ֲ�������ģ�⣬����ֲ�������ֱ�߶�
Xi ������Ԥ�� f(Xi) Ϊ���ģ�ʵ��������Ϊ Yi �ĵ� (Xi, Yi) �����ĸ��ʾ������� EXP[-(��Yi)^2]����EXP(..)
�����Գ��� e Ϊ�Ķ��ٴη�����
�������ǻص�����ı�Ҷ˹���棬����Ҫ����ĺ�������ǣ�
P(h|D) �� P(h) * P(D|h)
�ּ���Ҷ˹������ h ����ָһ���ض���ֱ�ߣ�D ����ָ�� N �����ݵ㡣������ҪѰ��һ��ֱ�� h ʹ��
P(h) * P(D|h) �����Ȼ��P(h) �����������Ǿ��ȵģ���Ϊ����ֱ��Ҳ������һ������Խ����������ֻ��Ҫ��
P(D|h) ��һ���һ����ָ����ֱ��������Щ���ݵ�ĸ��ʣ��ղ�˵���ˣ��������ݵ� (Xi, Yi)
�ĸ���Ϊ EXP[-(��Yi)^2] ����һ���������� P(D|h) = P(d1|h) * P(d2|h)
* .. ������������ݵ��Ƕ������ɵģ����Կ���ÿ�����ʳ��������������� N �����ݵ�ĸ���Ϊ EXP[-(��Y1)^2]
* EXP[-(��Y2)^2] * EXP[-(��Y3)^2] * .. = EXP{-[(��Y1)^2
+ (��Y2)^2 + (��Y3)^2 + ..]} ���������ʾ���Ҫ��С�� (��Y1)^2 + (��Y2)^2
+ (��Y3)^2 + .. �� ��Ϥ���ʽ����
�������������ܵ�֮�⣬��Ҷ˹���ڴ�����᪣�����ģ�͵�ƽ�������ж���һ��Ӧ�á��½ڣ����������������ر�Ҷ˹������
2.5�����ر�Ҷ˹����
���ر�Ҷ˹������һ�����ر�ķ���������ֵ�ý���һ�¡����ڶ�ķ���ģ���У�Ӧ����Ϊ�㷺�����ַ���ģ���Ǿ�����ģ��(Decision
Tree Model)�����ر�Ҷ˹ģ�ͣ�Naive Bayesian Model��NBC���� ���ر�Ҷ˹ģ�ͷ�Դ�ڹŵ���ѧ���ۣ����ż�ʵ����ѧ�������Լ��ȶ��ķ���Ч�ʡ�
ͬʱ��NBCģ��������ƵIJ������٣���ȱʧ���ݲ�̫���У��㷨Ҳ�Ƚϼ������ϣ�NBCģ���������������Ⱦ�����С������ʡ�����ʵ���ϲ���������ˣ�������ΪNBCģ�ͼ�������֮������������������ʵ��Ӧ���������Dz������ģ����NBCģ�͵���ȷ���������һ��Ӱ�졣�����Ը����Ƚ϶��������֮������Խϴ�ʱ��NBCģ�͵ķ���Ч�ʱȲ��Ͼ�����ģ�͡�������������Խ�Сʱ��NBCģ�͵�������Ϊ���á�
�����������������ر�Ҷ˹�������ʼ������е�Ӧ��������˵����
2.5.1����Ҷ˹�����ʼ�������
������ʲô�������ǣ�����һ���ʼ����ж����Ƿ����������ʼ����������������ǻ����� D ����ʾ����ʼ���ע��
D �� N ��������ɡ������� h+ ����ʾ�����ʼ���h- ��ʾ�����ʼ������������ʽ��������Ϊ��
P(h+|D) = P(h+) * P(D|h+) / P(D)
P(h-|D) = P(h-) * P(D|h-) / P(D)
���� P(h+) �� P(h-) ������������ʶ��Ǻ�����������ģ�ֻ��Ҫ����һ���ʼ������������ʼ��������ʼ��ı��������ˡ�Ȼ��
P(D|h+) ȴ����������Ϊ D ���溬�� N ������ d1, d2, d3, .. ������P(D|h+)
= P(d1,d2,..,dn|h+) ��������һ������������ϡ���ԣ�Ϊʲô��ô˵�أ�P(d1,d2,..,dn|h+)
����˵�������ʼ����г��ָ�����Ŀǰ����ʼ�һģһ����һ���ʼ��ĸ����Ƕ����Ц��ÿ���ʼ����Dz�ͬ�ģ����������������ʼ����ƣ����������ϡ���ԣ���Ϊ���Կ϶���˵�����ռ���ѵ�����ݿⲻ�����溬�˶��ٷ��ʼ���Ҳ�������ҳ�һ���Ŀǰ���һģһ���ġ�����أ������ָ����������
P(d1,d2,..,dn|h+) �أ�
���ǽ� P(d1,d2,..,dn|h+) ��չΪ�� P(d1|h+) * P(d2|d1, h+)
* P(d3|d2,d1, h+) * .. ����Ϥ���ʽ�����������ǻ�ʹ��һ���������ļ��裬���Ǽ���
di �� di-1 ����ȫ�����صģ�����ʽ�Ӿͼ�Ϊ P(d1|h+) * P(d2|h+) * P(d3|h+)
* .. �����������ν�������������裬Ҳ�������ر�Ҷ˹����������֮���������� P(d1|h+) * P(d2|h+)
* P(d3|h+) * .. ��̫���ˣ�ֻҪͳ�� di ��������������ʼ��г��ֵ�Ƶ�ʼ��ɡ����ڱ�Ҷ˹�����ʼ����˸�������ݿ��Բο������Ŀ��ע�������ᵽ���������ϡ�
2.6���㼶��Ҷ˹ģ��
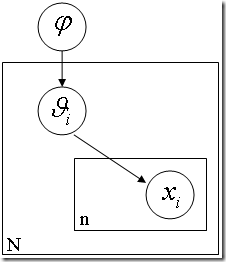
�㼶��Ҷ˹ģ�����ִ���Ҷ˹�����ı�־�Խ���֮һ��ǰ�潲�ı�Ҷ˹��������ͬһ���������ϵĸ�������֮�����ͳ��������Ȼ����α�Ҷ˹ģ������ѧ�ϸ�������һ�㣬����Щ���ر�������أ�ԭ���ԭ��ԭ���ԭ���Դ����ƣ�����������һ���̿��������ǣ��������ͷ��
N öӲ�ң�������ͬһ�������������ģ����ÿһöӲ������һ�������Ȼ������� N ��������� N ��Ӳ�ҵ�
�� ����������ı���������������������������Ȼ��ÿ��Ӳ�ҵ� �� ���� 1 ���� 0 �����ǰ���ᵽ���ģ���Ȼ��������֪��ÿ��Ӳ�ҵ�
p(��) ����һ��������ʵģ�Ҳ����һ�� beta �ֲ���Ҳ����˵��ÿ��Ӳ�ҵ�ʵ��Ͷ����� Xi ������
�� Ϊ���ĵ���̬�ֲ����� �� �ַ�����һ���� �� Ϊ���ĵ� beta �ֲ�����������ϵ�����ֳ����ˡ�����
�� ������������������ϸ��ϲ�����أ��Դ����ơ�
2.7������newsgroup�ĵ����ı�Ҷ˹�㷨ʵ��
2.7.1��newsgroup�ĵ���������Ԥ����
Newsgroups������Lang��1995�ռ�����[Lang 1995]��ʹ�á�������20000ƪ���ҵ�Usenet�ĵ�������ƽ������20����ͬ�������顣��������4.5%���ĵ������������������ϵ����������⣬�����ĵ�������һ�������飬�����ͨ������Ϊ����ע����������������Newsgroups�Ѿ���Ϊ�ı���������г��õ��ĵ���������MIT��ѧJason
Rennie��Newsgroups���˱�Ҫ�Ĵ�����ʹ��ÿ���ĵ�ֻ����һ�������飬�γ�Newsgroups-18828��
��ע����2.7��������ҪԮ���Բο�������Ŀ9�����ݣ����κβ���֮��������ԭ�����ڶ��ߺ�����лл)
Ҫ���ı��������ȵ�����ı���Ԥ������Ԥ��������Ҫ�������£�
Ӣ�Ĵʷ�������ȥ�����֡����ַ��������š����� �ַ������д�д��ĸת����Сд���������������ʽ��String
res[] = line.split("[^a-zA-Z]")��
ȥͣ�ôʣ����˶Է�����ֵ�Ĵʣ�
�ʸ���ԭstemming������Porter�㷨��
del> private static String lineProcess
(String line, ArrayList<String> stopWordsArray) throws IOException {
// TODO Auto-generated method stub
//step1 Ӣ�Ĵʷ�������ȥ�����֡����ַ���
�����š������ַ������д�д��ĸת����Сд�����Կ������������ʽ
String res[] = line.split("[^a-zA-Z]");
//����ҪС�ģ���ֹ���е����м������ֺ����ַ��ĵ��� �ض���
�����ǽض�Ҳû��
String resString = new String();
//step2ȥͣ�ô�
//step3stemming,���غ�һ����
for(int i = 0; i < res.length; i++){
if(!res[i].isEmpty() &
& !stopWordsArray.contains(res[i].toLowerCase())){
resString += " " + res[i].toLowerCase() + " ";
}
}
return resString;
} </del> |
2.7.2�������ʵ�ѡȡ
����ͳ�ƾ���Ԥ�������������ĵ��г��ֲ��ظ��ĵ���һ����87554��������Щ�ʽ���ͳ�Ʒ��֣�
���ִ������ڵ���1�εĴ���87554��
���ִ������ڵ���3�εĴ���36456��
���ִ������ڵ���4�εĴ���30095��
�����ʵ�ѡȡ���ԣ�
����һ���������д���Ϊ������ ����87554��
���Զ���ѡȡ���ִ������ڵ���4�εĴ���Ϊ�����ʹ���30095��
�����ʵ�ѡȡ���ԣ����ò���һ�����潫������������ѡȡ���Եļ���ʱ���ƽ��ȷ�����Ա�
2.7.3����Ҷ˹�㷨������ʵ��
�������ر�Ҷ˹��ʽ��ÿ��������������ij�����ĸ��� = ���в���������������������������P(tk|c)֮��
* �������P(c)
�ھ���������������ʺ��������ʱ�����ر�Ҷ˹������������ģ�ͣ�
(1) ����ʽģ��( multinomial model ) �C�Ե���Ϊ����
za����������P(tk|c)=(��c�µ���tk�ڸ����ĵ��г��ֹ��Ĵ���֮��+1)/����c�µ�������+ѵ�������в��ظ�������������
�������P(c)=��c�µĵ�������/����ѵ�������ĵ�������
(2) ��Ŭ��ģ�ͣ�Bernoulli model�� �C���ļ�Ϊ����
����������P(tk|c)=����c�°�������tk���ļ���+1��/(��c���ļ�����+2)
�������P(c)=��c���ļ�����/����ѵ���������ļ�����
��������ѡ�ö���ʽģ�ͼ��㣬����˹̹���ġ�Introduction to Information Retrieval
���μ�����˵������ʽģ�ͼ���ȷ�ʸ��ߡ�
��Ҷ˹�㷨��ʵ��������ע��㣺
��������õ���BigDecimal��ʵ�����⾫�ȼ��㣻
�ý�����֤����ʮ�η���ʵ�飬��ȷ��ȡƽ��ֵ��
������ȷ��Ŀ�ļ��ͷ������ļ�����������������
Map<String,Double> cateWordsProb keyΪ����Ŀ_���ʡ�,
valueΪ����Ŀ�¸õ��ʵij��ִ����������ظ����㡣
2.7.4�����ر�Ҷ˹�㷨��newsgroup�ĵ���������Ľ��
�ھ���һϵ��Newsgroup�ĵ�Ԥ�����������ʵ�ѡȡ����ʵ���˱�Ҷ˹�㷨֮�����������ر�Ҷ˹�㷨�Ƕ�newsgroup�ĵ��������࣬�����˱�Ҷ˹�㷨��Ч����
��Ҷ˹�㷨������-���������ʾ���Խ�����֤�ĵ�6��ʵ����Ϊ��������ȷ����ߴﵽ80.47%��

��������Ӳ��������Intel Core 2 Duo CPU T5750 2GHZ, 2G�ڴ棬ʵ�������£�
ȡ���дʹ�87554����Ϊ�����ʣ�10�ν�����֤ʵ��ƽ��ȷ��78.19%����ʱ23min,ȷ�ʷ�Χ75.65%-80.47%����6��ʵ��ȷ�ʳ���80%��ȡ���ִ������ڵ���4�εĴʹ���30095����Ϊ�����ʣ�
10�ν�����֤ʵ��ƽ��ȷ��77.91%����ʱ22min��ȷ�ʷ�Χ75.51%-80.26%����6��ʵ��ȷ�ʳ���80%������ͼ��ʾ��
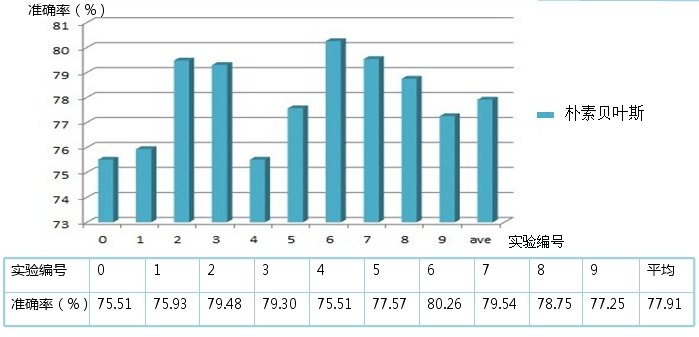
���ۣ����ر�Ҷ˹�㷨����ȥ�����ִ����ܵ͵Ĵʣ���Ϊ���ִ����ܵ͵Ĵʵ�IDF�Ƚ� ��ȥ�������ȷ���½���������ʱ�䲢û����������
2.7.5����Ҷ˹�㷨�ĸĽ�
Ϊ�˽�һ����߱�Ҷ˹�㷨�ķ���ȷ�ʣ����Կ���
�Ż������ʵ�ѡȡ���ԣ�
�Ľ�����ʽģ�͵����������ʵļ��㹫ʽ���Ľ�Ϊ ����������P(tk|c)=(��c�µ���tk�ڸ����ĵ��г��ֹ��Ĵ���֮��+0.001)/����c�µ�������+ѵ�������в��ظ������������������ӵ�tkû�г���ʱ��ֻ��0.001(֮ǰ����2.7.3����+1)���������Ӿ�ȷ�������Ĵʵ�ͳ�Ʒֲ����ɣ�
���˸Ľ���Ļ�����������

���Կ�����6�η���ʵ���ȷ����ߵ�84.79%����7�ʷ���ʵ���ȷ�ʴﵽ85.24%��ƽ��ȷ����77.91%��ߵ���82.23%,�Ż�Ч�����Ǻ����Եġ��������ݣ���ο�ԭ�ģ��ο�������Ŀ8��лл��
���������ڱ�Ҷ˹��������������������������ĵ�һ���֣��ӱ�Ҷ˹����̸����Ҷ˹���硣July��2014��11��14�ո��¡�
�������֡���EM�㷨�������ɷ�ģ�ͣ�HMM��
3.1��EM �㷨�����ģ�͵ľ���
��ͳ�Ƽ����У�������� ��EM��Expectation�CMaximization���㷨���ڸ��ʣ�probabilistic��ģ����Ѱ�Ҳ��������Ȼ���Ƶ��㷨�����и���ģ�����������۲�����ر�����Latent
Variabl������������������ڻ���ѧϰ�ͼ�����Ӿ������ݼ��ۣ�Data Clustering������
ͨ����˵��������һ����ָ���Ļ���ѧϰ���⣬�����������������һ�����ݵ㣬���㽫������طֳ�һ��һ�ѵġ������㷨�ܶ࣬��ͬ���㷨��Ӧ�ڲ�ͬ�����⣬���������һ������ģ�͵ľ��࣬�þ����㷨�����ݵ�ļ����ǣ���Щ���ݵ�ֱ���Χ��
K �����ĵ� K ����̬�ֲ�Դ��������ɵģ�ʹ�� Han JiaWei �ġ�Data Ming�� Concepts
and Techniques���е�ͼ��
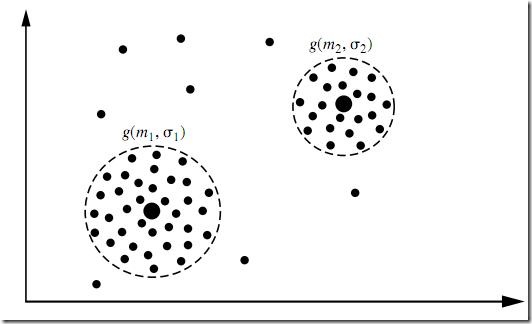
ͼ����������̬�ֲ����ģ������˴������ѵ㡣���ǵľ����㷨������Ҫ���ݸ���������Щ�㣬�����������̬�ֲ��ĺ�����ʲôλ�ã��Լ��ֲ��IJ����Ƕ��١������������һ����Ҷ˹���⣬����β�ͬ���ǣ���������������������ֿ����ԣ�������ǣ�ֻ�е�����֪������Щ������ͬһ����̬�ֲ�Ȧ��ʱ����ܹ�������ֲ��IJ�����������Ԥ�⣬�������ѵ����һ�������ֲ�֪����Щ�����ڵ�һ����̬�ֲ�����Щ���ڵڶ�������������ֻ�е����ǶԷֲ��IJ��������˿���Ԥ��ʱ����֪��������Щ�����ڵ�һ���ֲ�����Щ�����ڵڶ����ֲ�����ͳ���һ�����м��������е��������ˡ�Ϊ�˽�����ѭ������������һ��Ҫ�ȴ��ƽ��֣�˵�������ˣ����������һ��ֵ������������ô�䣬Ȼ�����ٸ�����ı仯�����ҵı仯��Ȼ����˵����Ų��ϻ����Ƶ�������������һ���⡣�����
EM �㷨��
EM ����˼�ǡ�Expectation-Maximazation��������������������棬������������һ����������̬�ֲ��IJ������������ʲô�ط��������Ƕ��١�Ȼ������ÿ�����ݵ���������ڵ�һ�����ǵڶ�����̬�ֲ�Ȧ�����������
Expectation һ��������ÿ�����ݵ�Ĺ��������ǾͿ��Ը������ڵ�һ���ֲ������ݵ�������������һ���ֲ��IJ������ӵ��ٻص������������
Maximazation �����������ֱ�������������ٷ����仯Ϊֹ������������������еı�Ҷ˹�����ڵڶ������������ݵ���ֲ��IJ������档
3.2�������ɷ�ģ�ͣ�HMM��
�����鼮�����Ķ����������������ɷ�ģ��(HMM)������δ����֮ԭ��Ҳ���ò����������ס����������Ҿ�����ֱ���������Բ������ģ�͡�Ȼ�ڽ��������ɷ�ģ��֮ǰ���б�Ҫ���н����µ��������ɷ�ģ��(������Ҫ���ã�ͳ����Ȼ���Դ������ڳ������һ���ϵ��������)��
3.2.1�����ɷ�ģ��
����֪������������ֳ��������������ʱ�������仯�Ĺ��̡����ɷ�ģ�ͱ���������һ����Ҫ��������̡����dz�����Ҫ����һ������������У���Щ��������������������(ע�⣺�������������������֮����ǧ˿���Ƶ���ϵ)��
�����ʱ����Ҳ��һ����״̬����ʽ��������Ҳ��������Խ��Խ���ӵĹ�Ȧ�ˡ����ԣ�ֱ�Ӿ����Ӱɣ��磬һ�����������ʡ����ʡ����ݴ�������Գ��ֵ������������״̬�������Ʒ�ģ���������£�
״̬s1������
״̬s2������
״̬s3�����ݴ�
����״̬֮���ת�ƾ������£�
s1 s2 s3
s1 0.3 0.5 0.2
A = [aij] = s2 0.5 0.3 0.2
s3 0.4 0.2 0.4
����ڸö�������ijһ�����ӵĵ�һ����Ϊ���ʣ���ô������һģ��M���ڸþ�����������ʳ���˳��ΪO="�����������ĸ���Ϊ��
P(O|M)=P(s1��s2��s3��s1 | M) = P(s1) ����P(s2 | s1) * P(s3
| s2)*P(s1 | s3)
=1* a12 * a23 * a31=0.5*0.2*0.4=0.004
�����ɷ�ģ���ֿ���Ϊ���������״̬���������·������Ա�ʾ��״̬ͼ��ת�ƻ����и��ʵķ�ȷ��������״̬�Զ�����������ͼ��ʾ��
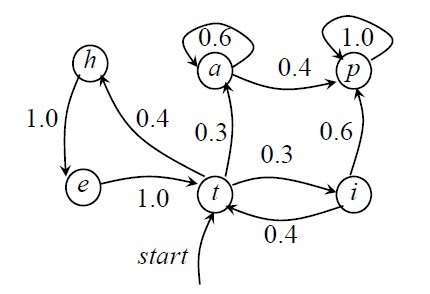
����ͼ�У�ԲȦ��ʾ״̬��״̬֮���ת���ô���ͷ�Ļ���ʾ�����ϵ�����Ϊ״̬ת�Ƶĸ��ʣ���ʼ״̬�ñ��Ϊstart�������ͷ��ʾ�������κ�״̬������Ϊ��ֹ״̬��ͼ������ʵ�ת�ƻ�ʡ�ԣ���ÿ���ڵ������з������ĸ���֮�͵���1������ͼ���Կ����������ɷ�ģ�Ϳ��Կ�����һ��ת�ƻ����и��ʵķ�ȷ��������״̬�Զ�����
3.2.2�������ɷ�ģ��(HMM)
�����Ľ��ܵ����ɷ�ģ���У�ÿ��״̬������һ���ɹ۲���¼������ԣ����ɷ�ģ����ʱ�ֳ��������ɷ�ģ��(VMM)������ij�̶ֳ���������ģ�͵���Ӧ�ԡ��������ǵ������ɷ�ģ��(HMM)�У����Dz�֪��ģ����������״̬���У�ֻ֪��״̬�ĸ��ʺ�����Ҳ����˵���۲쵽���¼���״̬�������������˸�ģ����һ��˫�ص�������̡����У�ģ�͵�״̬ת���Dz��ɹ۲�ģ������εģ��ɹ۲��¼���������������ε�״̬���̵����������
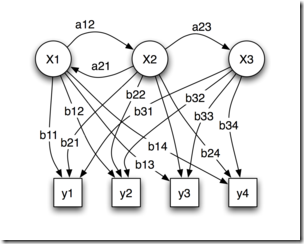
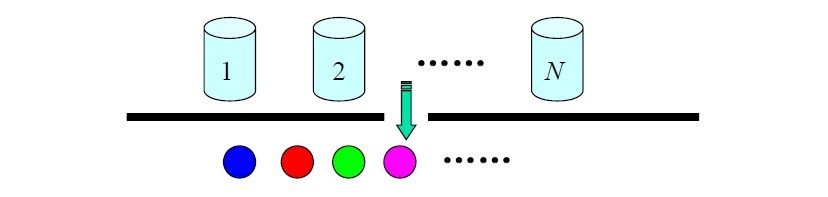
���۶�˵���棬���������پٸ����ӡ�N �����ӣ�ÿ����������M �ֲ�ͬ��ɫ����һʵ��Ա����ijһ���ʷֲ�ѡ��һ�����ӣ�Ȼ����ݴ����в�ͬ��ɫ��ĸ��ʷֲ����ȡ��һ��������������ɫ���Ծ����ˣ��ɹ۲�Ĺ����Dz�ͬ��ɫ������У������ӵ������Dz��ɹ۲�ġ�ÿֻ���Ӷ�ӦHMM�е�һ��״̬�������ɫ��Ӧ��HMM
��״̬�������
3.2.2��HMM�����ķִʡ���������ȷ���ľ���Ӧ��
�����ɷ�ģ���ںܶ�涼���ž����Ӧ�ã������������ɷ�ģ��HMM�ṩ��һ�������ۺ����ö���������Ϣ��ͳ�ƿ�ܣ���ˣ�������ȫ���Խ������Զ��ִ�����Ա�עͳһ���죬��������HMM�ķִ�����Ա�ע��һ�廯ϵͳ��
�������Ķ�HMM�Ľ��ܣ�һ��HMMͨ�����Կ�������������ɣ�һ����״̬ת��ģ�ͣ�һ����״̬���۲����е�����ģ�͡����嵽���ķִ���һ�����У����Ѻ��ִ������S��Ϊ���룬���ʴ�SwΪ״̬����������۲����У�Sw=w1w2w3...wN(N>=1)����������StΪ״̬���У�ÿ�����Ա��ct��ӦHMM�е�һ��״̬qi��Sc=c1c2c3...cn��
��ô������HMM������������ǡ�ö�Ӧ�ڽ��HMM�������������⣺
����ģ�͵IJ�����
����һ������������S������ܵ��������Sw��ģ��u=(A��B��*)�����ٵؼ���P(Sw|u)�����п��ܵ�Sw��ʹ����P(Sw|u)���Ľ����Ҫ�ҵķִ�Ч����
���ٵ�ѡ�����ŵ�״̬���л�������У�ʹ����õؽ��۲����С�
�����ķִʷ����Ӧ��֮�⣬HMM����ͳ�ƻ�����������Ӧ�ã������HMM�Ĵʶ�λģ�ͣ�������ο���ͳ����Ȼ���Դ������ڳ��������
| 





