|
����ʹ��Эͬ�����㷨������Ƽ�ϵͳ�����ɼ��������Ա��������������ȵ�����վ����������վ�Ϲ�����������ijЩ��Ʒ�Ӷ������ռ������Ӧ�����ݣ��´����ڴ��������վ��ʱ��ͻᷢ�֣����������֮ǰ�Ĺ���/�����¼Ϊ���Ƽ�һЩ��Ʒ������Щ��Ʒ���Ƽ�������ʮ�־��ģ���Ϊ���ǽ����ڴ����ݵĻ���֮�ϼ�������ġ�
����Эͬ���˵��Ƽ����Ƽ��㷨�е�һ��˼�룬Эͬ���˵�˼���������ģ�һ�����ں������û��з����һС���ֺ���Ʒλ�Ƚ����Ƶģ���Эͬ�����У���Щ�û���Ϊ�ھӣ�Ȼ���������ϲ��������������֯��һ�������Ŀ����Ϊ�Ƽ����㡣
Эͬ���˵ĺ������⣺
���ȷ��һ���û��Dz��Ǻ��������Ƶ�Ʒλ?
��ν��ھ��ǵ�ϲ����֯��һ�������Ŀ��?
ʵ��Эͬ���˵IJ��裺
���Ѿ����û���Ϊ���з����õ��û�ϲ�ú����ǿ��Ը����û�ϲ�ü��������û�����Ʒ��Ȼ����������û�������Ʒމ���Ƽ������������͵�
CF ��������֧��
1.�����û��� CF
2.������Ʒ�� CF
�����������CF�ֱ��������
�����û���Эͬ�����㷨UserCF
�����û���Эͬ���ˣ�ͨ����ͬ�û�����Ʒ�������������û�֮��������ԣ������û�֮��������������Ƽ���
���������ǣ����û��Ƽ�������Ȥ���Ƶ������û�ϲ������Ʒ��
����ͼ��ʾ��
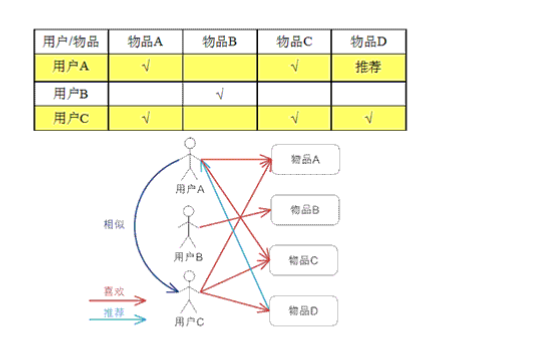
�û�A��������ƷA��C
�û�C��������ƷA,C,D
��ʱ�����ǿ��Խ�A,C�����û����������Ƶģ���Ϊ�����к����ƵĹ�����Ϊ����ʱ�����ǾͿ��Խ���ƷD�Ƽ����û�A
������Ʒ��Эͬ�����㷨ItemCF
����item��Эͬ���ˣ�ͨ���û��Բ�ͬitem������������item֮��������ԣ�����item֮��������������Ƽ���
���������ǣ����û��Ƽ�����֮ǰϲ������Ʒ���Ƶ���Ʒ��
����ͼ��ʾ��
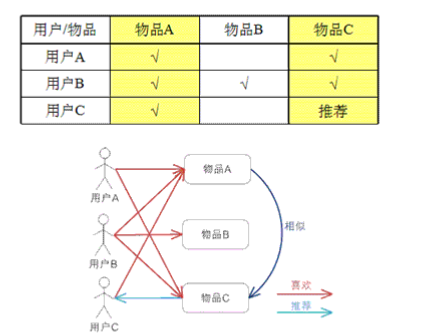
����ͼ���Կ���
�û�A��������ƷA��ͬʱ����������ƷC
�û�B��������ƷA��ͬʱ����������ƷB,C
���û�Cֻ��������ƷA
����������ӿ�����ƷA����ƷC�Ǿ�����һ����ģ���ô���ǿ��Խ�A,C���������Ƶģ����û�C������ƷA��ͬʱ����Ϊ���Ƽ���ƷC
UserCF vs. ItemCF
���ڵ��������û�����һ������Ʒ��������ʱItemCF�ļ��㸴�ӶȽϵ͡�
�ڷ��罻�������վ�У��������ڵ���ϵ�Ǻ���Ҫ���Ƽ�ԭ�����Ȼ��������û����Ƽ�ԭ�������Ч�������ڹ�����վ�ϣ����㿴һ�����ʱ���Ƽ�����
������Ƽ���ص��鼮������Ƽ�����Ҫ�Խ�����������վ��ҳ�Ը��û����ۺ��Ƽ������Կ���������������£�Item
CF ���Ƽ���Ϊ�������û��������Ҫ�ֶΡ�������Ʒ��Эͬ�����㷨����Ŀǰ�������������㷺���Ƽ��㷨��
�����罻����վ���У�User CF ��һ����������ѡ��UserCF �������������Ϣ�����������û����Ƽ����͵��ŷ��̶ȡ�
������Ʒ��Эͬ�����㷨ʵ��
������������UserCF��ItemCF�Ļ���˼�룬��������һ��ʵ����ʵ��ItemCF
�㷨ʵ�ֵIJ���Ϊ��
1. ������Ʒ֮������ƶ�
2. ������Ʒ�����ƶȺ��û�����ʷ��Ϊ���û������Ƽ��б�
����ͨ��һ����ӰԺ���ݷ���������ItemCF��ʵ�ֹ���
������������Ѿ������ֻ����������͵�����ת������������Ҫ�����ݸ�ʽ

����ͼ��������ÿ��3���ֶΣ��������û�ID,��ӰID,�û��Ե�Ӱ������(0-5�֣�ÿ0.5��Ϊһ�����ֵ�)
��֮ǰ���㷨˼������������֪��������Ҫ������Ӱ�͵�Ӱ֮������ƶȣ������������Dz�����ʹ��֮ǰ����ͨ�����ۻ����˹��ķ�ʽ���ó���Ʒ֮������ƶ��ˣ���Ϊ�ڴ����ݵ�ǰ���£��ֹ�������һ�ж���ͽ�͵�
��ô����Ҫ��ô�õ���Ӱ�͵�Ӱ֮������ƶ���?
������Ҫ��������ѧ�ϵļ���
�������£�
1. ������Ʒ��ͬ�־���
2. �����û�����Ʒ�����־���
3. ��������Ƽ����
1.������Ʒ��ͬ�־���
����ͼ��ʾ��
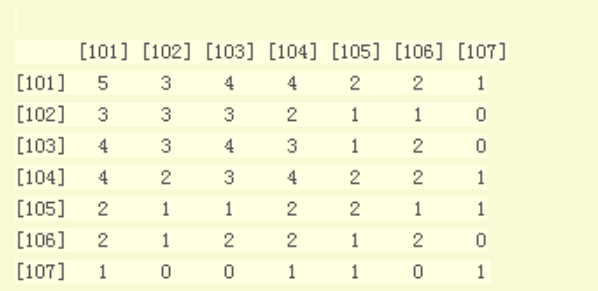
��������������ܹ�ֻ��7�����������������7*7
�������������?
�����������еı�Ŷ��Ƕ�Ӧ�ĵ�Ӱ���
�����ȿ�����ĶԽ��ߣ��Խ�������=�У���ʾ�����Ӱ�����ݼ��г����˼���(�����˿���)
�������һ�еڶ��е�����3��������ִ�������101��102��������Ӱһ��ͬһ���û������Ĵ�����Ҳ����ͬ�ֶ�
���������ϵ����ֱַ����ij������Ӱ֮���ͬ�ֶ�
��������������С���γɵ�ͬ�־����ģҲ�Ƚ�С����������һ���������������ʮ�־�ģ���Ҳ��ΪʲôItemCFһ����UserCF����(��Ϊ�û���һ����ԶԶ������Ʒ����)
��֮ǰ���㷨�����У��ж�������Ʒ�Ƿ������Ƶ��Ǹ�����������Ʒ�Dz��Ǿ�����һ�����ڱ����еĽ��;ͱ�ɣ���Щ��Ӱ�Ƿ���ͬһ���û��ۿ���������У���Щ��Ӱ�������Ƶ�
���ֻ����һ���Ͽ��Ļ�����ͬ�ֶȾ��������ǾͿ��Եó����Ƶĵ�Ӱ�������Ϊͬ�ֶȱ������Ǵ���������Ӱ֮��ͬʱ��һ���û��ۿ��Ĵ������������ڱ����к컹��һ��Ӱ���Ƽ���������أ��û�����
��������Ҫ�����������ݷ���
2.�����û�����Ʒ�����־���
���־�������ͼ��ʾ��

��ʾU3����û���ÿ����Ӱ������
3.��������Ƽ����
���ڸ��ݵõ���ͬ�־�������־����������Ƽ����
���㹫ʽ��ͬ�־���*���־���=�Ƽ����
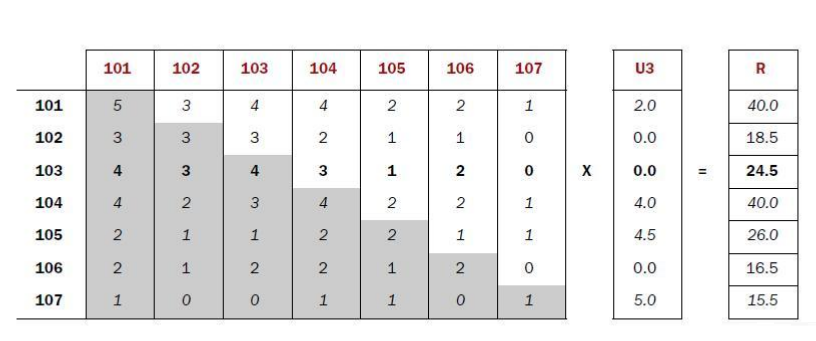
�Ƽ����
7* 7�ľ������7*1�ľ���ļ�����=һ��7 *1�ľ���
���е�һ�����������Ҫ=�ڶ������������������������
�ڽ������R�п��Կ����Ը��û�ÿ����Ӱ���Ƽ��֣���������ֻ���Ƽ���Щ�û�û�п����ĵ�Ӱ��Ҳ����ԭ������Ϊ0.0�ģ����Եõ���Ҫ�Ƽ��ĵ�ӰΪ103���Ƽ���Ϊ24.5��Ȼ���ڸ����Ƽ����������еõ��Ƽ��б�
��ôΪʲôͬ�־�������־�����˻�õ�����Ƽ��Ľ����?
�����������Ϊ��ͬ�ֶȵ�һ�ּ�Ȩ���㣬�����ֿ�����һ��Ȩֵ�����յõ���ȨֵԽ��Ȼ��Խ��Ҫ
�����㷨������ʽ
Mahout�ṩ��2�������Ƽ�����ָ�꣬���ʺ��ٻ���(��ȫ��)��������ָ�������������о���Ķ���������
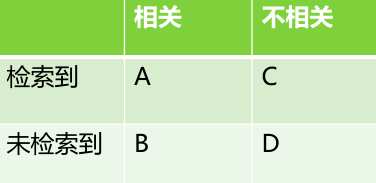
A���������ģ���ص� (�ѵ���Ҳ��Ҫ��)
B��δ�������ģ�������ص� (û�ѵ���Ȼ��ʵ������Ҫ��)
C���������ģ�����آ��ص� (�ѵ��ĵ�û�õ�)
D��δ�������ģ�Ҳآ��ص� (û�ѵ�Ҳû�õ�)
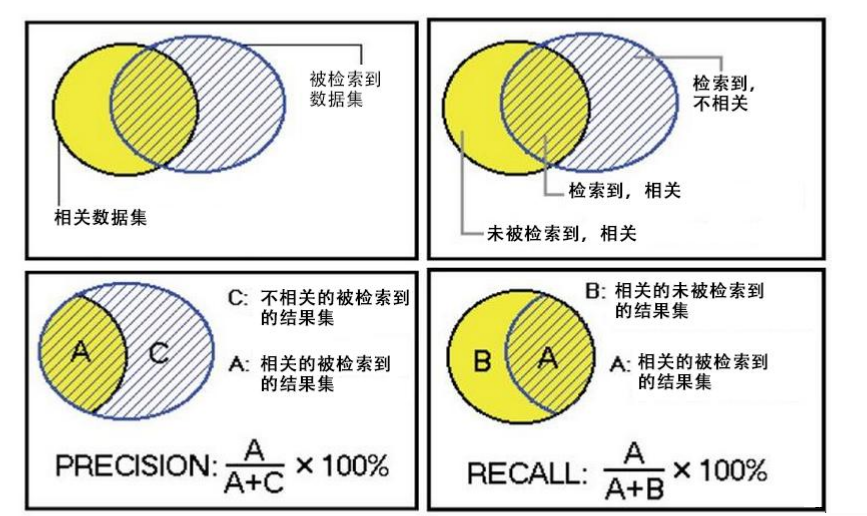
����������Խ��Խ�ã�������ȫ�ʡ�����A/(A+B)��Խ��Խ�á�
���������ģ�Խ��ص�Խ��Խ�ã�����ص�Խ��Խ�ã��������ʡ�����A/(A+C)��Խ��Խ�á�
�ڴ��ģ���ݼ����У�������ָ�������Լ�ġ���ϣ����������������ݵ�ʱ���ʾͻ��½�����ϣ��������ȷ��ʱ���������ٵ����ݡ� | 





