|

�ռ�web��־��Ŀ��
Web��־�ھ���ָ���������ھ�������վ���û�����Web�����������в�������־���ݽ��з����������Ӷ�����Web�û��ķ���ģʽ����Ȥ���õȣ���Щ��Ϣ��վ�㽨��DZ�����õĿ������δ֪��Ϣ��֪ʶ�����ڷ���վ��ı��������������վ������;���֧�ֵȡ�
1���ԸĽ�webվ�����ΪĿ�꣬ͨ���ھ��û�������û���Ƶ������·������վ���ҳ��֮������ӹ�ϵ������Ӧ�û��ķ���ϰ�ߣ�����ͬʱΪ�û��ṩ������Եĵ����������Ի�����Ϣ����Ӧ����Ϣ���������������ܻ�Webվ�㡣
2���Է���Webվ������ΪĿ�꣬��Ҫ��ͳ��ѧ�ĽǶȣ�����־��������д��Ե�ͳ�Ʒ������õ��û�Ƶ������ҳ����λʱ��ķ�����������������ʱ��ֲ�ͼ�ȡ����еľ��������Web��־�������߶����ڴ��ࡣ
3���������û���ͼΪĿ�꣬��Ҫ��ͨ�����û������Ĺ����ռ��û�����Ϣ��Web������������Щ��Ϣ���û������ҳ����вü���Ϊ�û����ض��Ƶ�ҳ�棬��Ŀ�ľ�������û�������Ⱥ��ṩ���Ի��ķ���
�ռ���ʽ
��վ����������Ҫ�������ռ���ʽ��Web��־��JavaScript��ǺͰ���̽����
1. Web��־
web��־�������̣�
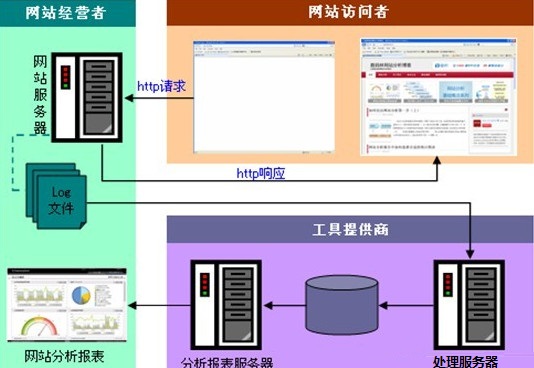
����ͼ���Կ�����վ�������ݵ��ռ�����վ����������URL����վ����������http����Ϳ�ʼ�ˡ���վ���������յ����������Լ���Log�ļ�����һ����¼����¼���ݰ�����Զ��������(������IP��ַ)����¼������¼ȫ��������������ڡ��������ʱ�䡢�������ϸ(��������ķ�������ַ��Э��)�����ص�״̬�������ĵ��Ĵ�С�������վ��������ҳ�淵�ص������ߵ�������ڵ���չ�֡�
2. JavaScript���
JavaScript��Ǵ������̣�
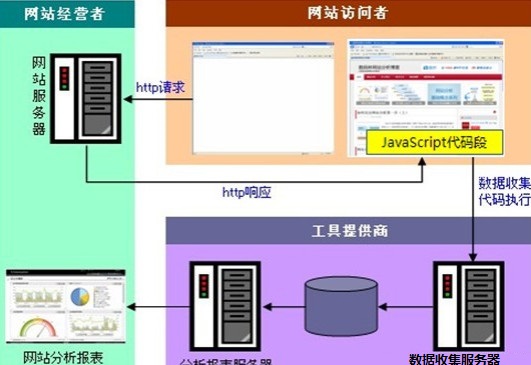
��ͼ��ʾJavaScript���ͬWeb��־�ռ�����һ��������վ�����߷���http����ʼ����ͬ���ǣ�JavaScript��Ƿ��ظ������ߵ���ҳ�����л����һ�������JavaScript���룬��ҳ��չʾ��ͬʱ��δ���Ҳ����ִ�С���δ����ӷ����ߵ�Cookie��ȡ����ϸ��Ϣ(����ʱ�䡢�������Ϣ�����߳��̸��赱ǰ�����ߵ�userID��)�����͵������̵������ռ��������������ռ����������ռ��������ݴ�����������ݿ��С���վ��Ӫ��Աͨ�����ʷ�������ϵͳ�鿴��Щ���ݡ�
3. ����̽��
ͨ������̽���ռ����������̣�
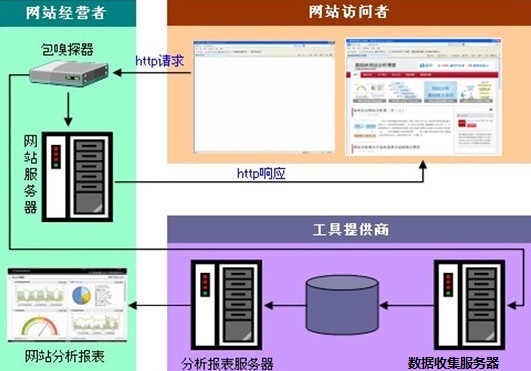
��ͼ���Կ�����վ�����߷�����������վ������֮ǰ�����Ⱦ�������̽����Ȼ�����̽���ŻὫ�����͵���վ������������̽���ռ��������ݾ������߳��̵Ĵ�����������������ݿ⡣�����վ��Ӫ��Ա�Ϳ���ͨ����������ϵͳ������Щ���ݡ�
web��־�ھ����
�������̲ο���ͼ��
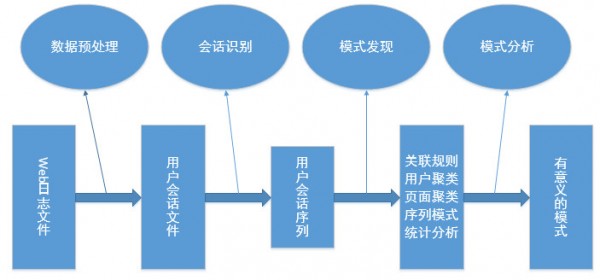
1������Ԥ�����θ����ھ��Ŀ�ģ� ��ԭʼWeb��־�ļ��е����ݽ�����ȡ���ֽ⡢�ϲ������ת��Ϊ�û��Ự�ļ�
���ý���Web������Ϣ�ھ���ؼ��ĽΣ�����Ԥ��������:�����û�������Ϣ��Ԥ�������������ݺͽṹ��Ԥ������
2���Ựʶ��θýα�����������Ԥ�������е�һ���֣����ォ�仮�ֳɵ�����һ���Σ�����Ϊ���û��Ự�ļ����ֳɵ�һ�����û��Ự���н�ֱ�������ھ��㷨�����ľ���ֱ�Ӿ������ھ����ĺû������ھ����������Ҫ�ĽΡ�
3��ģʽ���ֽ�ģʽ���������ø��ַ����ͼ�����Web��־�������ھ�ͷ����û�ʹ��Web�ĸ���DZ�ڵĹ��ɺ�ģʽ��ģʽ����ʹ�õ��㷨�ͷ������������������ھ�������������ѧϰ��ͳ��ѧ��ģʽʶ�������רҵ����
ģʽ���ֵ���Ҫ�����У�ͳ�Ʒ�����statistical analysis������������association
rules�������ࣨclustering�������ࣨclassification��������ģʽ��sequential
patterns����������ϵ��dependency����
��1��ͳ�Ʒ�����statistical analysis�������õ�ͳ�Ƽ����У���Ҷ˹������Ԥ��ع顢�����ع顢����-���Իع�ȡ�������������ҳ�ķ���Ƶ�ʣ���ҳ�ķ���ʱ�䡢����·����������ϵͳ���ܷ��������ְ�ȫ©����Ϊ��վ�ġ��г������ṩ֧�֡�
��2����������association rules����������������������ھ�����ͬʱҲ��WUM��õķ�������WUM�г������ڱ����ʵ���ҳ�У����������Ż���վ��֯����վ����ߡ���վ���ݹ����ߺ��г�������ͨ���г���������֪����Щ��Ʒ��Ƶ��������Щ�˿���DZ�ڹ˿͡�
��3�����ࣨclustering�������༼�����ں���������Ѱ�ұ˴����ƶ����飬��Щ���ݻ��ھ��뺯�����������֮������ƶȡ���WUM�п��Ѿ�������ģʽ���û��ֳ��飬�������ڵ����������г���Ƭ��Ϊ�û��ṩ���Ի�����
��4�����ࣨclassification�������༼����Ҫ��;�ǽ��û����Ϲ���ijһ�ض����У��������ѧϰ��ϵ�ܽ��ܡ������õļ����У���������decision
tree����K-����ھӡ�Na?ve Bayesian classifiers��֧����������support
vector machines����
��5������ģʽ��sequential patterns��������һ���ɲ�ͬ������ɵļ��ϣ����У�ÿ�������ɲ�ͬ��Ԫ�ذ�˳���������У�ÿ��Ԫ���ɲ�ͬ��Ŀ��ɣ�ͬʱ����һ���û�ָ������С֧�ֶ���ֵ������ģʽ�ھ�����ҳ����е�Ƶ�������У��������������м��еij���Ƶ�ʲ������û�ָ������С֧�ֶ���ֵ��
��6��������ϵ��dependency����һ��������ϵ����������Ԫ��֮�䣬���һ��Ԫ��A��ֵ�����Ƴ���һ��Ԫ��B��ֵ����B������A��
4��ģʽ������ģʽ������Webʹ���ھ����һ������ҪĿ���ǹ���ģʽ���ֽβ����Ĺ����ģʽ��ȥ����Щ���õ�ģʽ�����ѷ��ֵ�ģʽͨ��һ���ķ���ֱ�۵ı��ֳ���������Webʹ���ھ��ڴ���������������ƫ��ѧϰ���п����ھ�����е�ģʽ�������Բ����ų�������Щģʽ�dz�ʶ�Եģ���ͨ�Ļ������û�������Ȥ�ģ��ʱ������ģʽ�����ķ���ʹ���ھ�����Ĺ����֪ʶ���пɶ��Ժ����տ������ԡ�������ģʽ����������ͼ�κͿ��ӻ����������ݿ��ѯ���ơ�����ͳ�ƺͿ����Է����ȡ�
�ռ����ݰ���
�ռ���������Ҫ������
ȫ��UUID���������ڡ�����ʱ�䡢������־��ķ�������IP��ַ���ͻ�����ͼִ�еIJ������ͻ��˷��ʵķ�������Դ���ͻ��˳���ִ�еIJ�ѯ���ͻ������ӵ��Ķ˿ںš����ʷ�����������֤�û����ơ����ͷ�������Դ����Ŀͻ���IP��ַ���ͻ���ʹ�õIJ���ϵͳ�����������Ϣ��������״̬�루200�ȣ�����״̬����Windows@ʹ�õ������ʾ�IJ�����״̬�����������
�û�ʶ��
������վ����Ӫ����˵������ܹ���Ч��ȷ��ʶ���û��dz��ؼ���������վ��Ӫ��������İ������綨���Ƽ��ȡ�
�û�ʶ�����£�
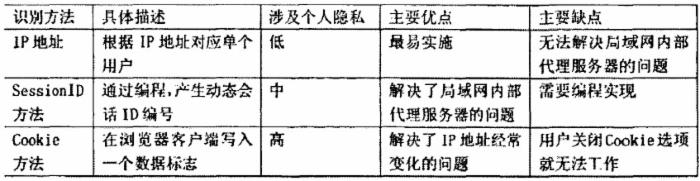
ʹ��HDFS�洢
�����ռ���������֮�������������Կ��ǽ����ݴ洢��hadoop��HDFS�С�
�����ڵ���ҵ�У�һ������¶��Ƕ�̨������������־����־����nginx���ɵģ�Ҳ�����ڳ�����ʹ��log4j���ɵ��Զ����ʽ�ġ�
ͨ���ļܹ�����ͼ��
ʹ��mapreduce����nginx��־
nginxĬ�ϵ���־��ʽ���£�
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939
"http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36" |
remote_addr: ��¼�ͻ��˵�ip��ַ, 222.68.172.190
remote_user: ��¼�ͻ����û�����, �C
time_local: ��¼����ʱ����ʱ��, [18/Sep/2013:06:49:57
+0000]
request: ��¼�����url��httpЭ��, ��GET /images/my.jpg
HTTP/1.1��
status: ��¼����״̬,�ɹ���200, 200
body_bytes_sent: ��¼�����ͻ����ļ��������ݴ�С, 19939
http_referer: ������¼���Ǹ�ҳ�����ӷ��ʹ�����, ��http://www.angularjs.cn/A00n��
http_user_agent: ��¼�ͻ�������������Ϣ, ��Mozilla/5.0
(Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/29.0.1547.66 Safari/537.36��
����ֱ��ʹ��mapreduce��������־���� ��
��hadoop�м����ʱ���뵽��ϵ�����ݿ��н���չ�֡�
Ҳ����ʹ��hive������mapreduce���з�����
�ܽ�
web��־�ռ���ÿ����������ҵ����Ҫ�����Ĺ��̣����ռ��������ݣ�����ͨ���ʵ��������ھ�֮���������վ����Ӫ��������վ���Ż������ʵ��������������������ݻ����������ݻ���Ӫ�� | 





