|
最近正好刚帮某电信行业完成一个数据挖掘工作,其中的RFM模型还是有一定代表性,就再把数据挖掘RFM模型的建模思路细节与大家分享一下吧!手机充值业务是一项主要电信业务形式,客户的充值行为记录正好满足RFM模型的交易数据要求。
根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有三个神奇的要素,这三个要素构成了数据分析最好的指标:最近一次消费(Recency)、消费频率(Frequency)、消费金额(Monetary)。
我早期两篇博文已详述了RFM思想和IBM Modeler操作过程,有兴趣的朋友可以阅读!
RFM模型:R(Recency)表示客户最近一次购买的时间有多远,F(Frequency)表示客户在最近一段时间内购买的次数,M (Monetary)表示客户在最近一段时间内购买的金额。一般原始数据为3个字段:客户ID、购买时间(日期格式)、购买金额,用数据挖掘软件处理,加权(考虑权重)得到RFM得分,进而可以进行客户细分,客户等级分类,Customer Level Value得分排序等,实现数据库营销!
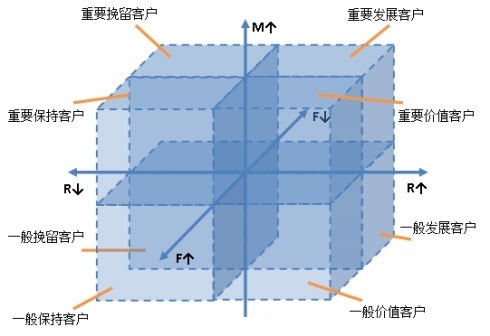
这里再次借用@数据挖掘与数据分析的RFM客户RFM分类图。
本次分析用的的软件工具:IBM SPSS Statistics 19,IBM SPSS Modeler14.1,Tableau7.0,EXCEL和PPT
因为RFM分析仅是项目的一个小部分分析,但也面临海量数据的处理能力,这一点对计算机的内存和硬盘容量都有要求。
先说说对海量数据挖掘和数据处理的一点体会:(仅指个人电脑操作平台而言)
一般我们拿到的数据都是压缩格式的文本文件,需要解压缩,都在G字节以上存储单位,一般最好在外置电源移动硬盘存储;如果客户不告知,你大概是不知道有多少记录和字段的;
Modeler挖掘软件默认安装一般都需要与C盘进行数据交换,至少需要100G空间预留,否则读取数据过程中将造成空间不足
海量数据处理要有耐心,等待30分钟以上运行出结果是常有的现象,特别是在进行抽样、合并数据、数据重构、神经网络建模过程中,要有韧性,否则差一分钟中断就悲剧了,呵呵;
数据挖掘的准备阶段和数据预处理时间占整个项目的70%,我这里说如果是超大数据集可能时间要占到90%以上。一方面是处理费时,一方面可能就只能这台电脑处理,不能几台电脑同时操作;
多带来不同,这是我一直强调的体验。所以海量数据需要用到抽样技术,用来查看数据和预操作,记住:有时候即使样本数据正常,也可能全部数据有问题。建议数据分隔符采用“|”存储;
如何强调一个数据挖掘项目和挖掘工程师对行业的理解和业务的洞察都不为过,好的数据挖掘一定是市场导向的,当然也需要IT人员与市场人员有好的沟通机制;
数据挖掘会面临数据字典和语义层含义理解,在MetaData元数据管理和理解上下功夫会事半功倍,否则等数据重构完成发现问题又要推倒重来,悲剧;
每次海量大数据挖掘工作时都是我上微博最多的时侯,它真的没我算的快,只好上微博等它,哈哈!
传统RFM分析转换为电信业务RFM分析主要思考:
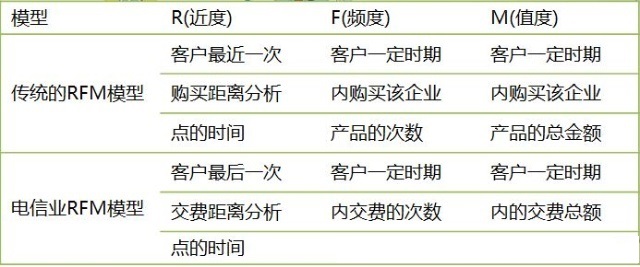
这里的RFM模型和进而细分客户仅是数据挖掘项目的一个小部分,假定我们拿到一个月的客户充值行为数据集(实际上有六个月的数据),我们们先用IBM Modeler软件构建一个分析流:
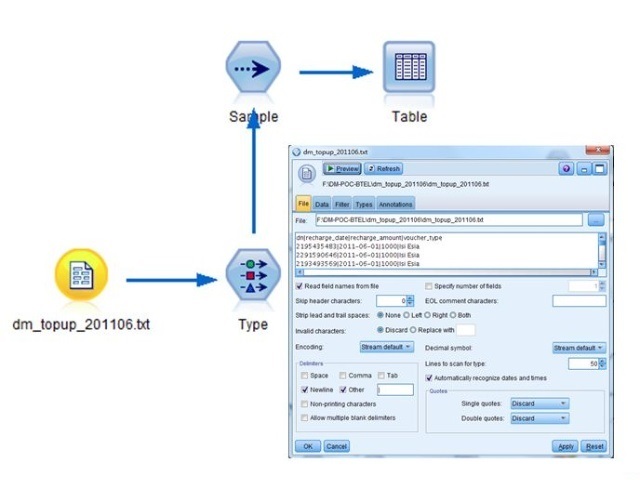
数据结构完全满足RFM分析要求,一个月的数据就有3千万条交易记录!
我们先用挖掘工具的RFM模型的RFM汇总节点和RFM分析节点产生R(Recency)、F(Frequency)、M (Monetary);
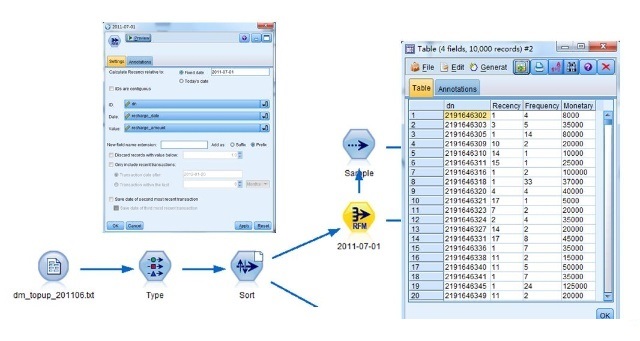
接着我们采用RFM分析节点就完成了RFM模型基础数据重构和整理;
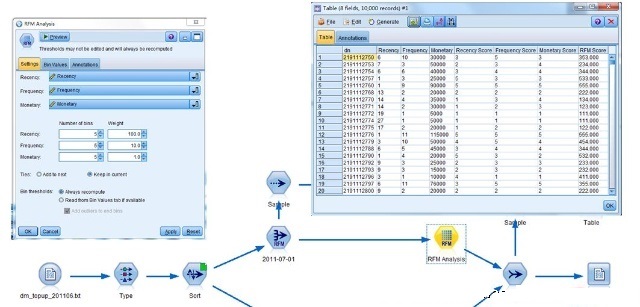
现在我们得到了RFM模型的Recency_Score、Frequency_Score、Monetary_Score和RFM_Score;这里对RFM得分进行了五等分切割,采用100、10、1加权得到RFM得分表明了125个RFM魔方块。
传统的RFM模型到此也就完成了,但125个细分市场太多啦无法针对性营销也需要识别客户特征和行为,有必要进一步细分客户群;
另外:RFM模型其实仅仅是一种数据处理方法,采用数据重构技术同样可以完成,只是这里固化了RFM模块更简单直接,但我们可以采用RFM构建数据的方式不为RFM也可用该模块进行数据重构。
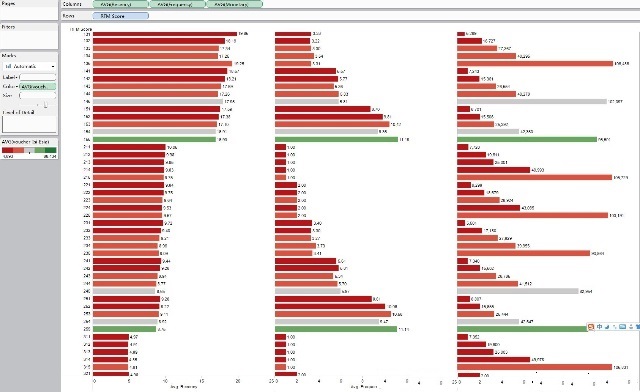
我们可以将得到的数据导入到Tableau软件进行描述性分析:(数据挖掘软件在描述性和制表输出方面非常弱智,哈哈)
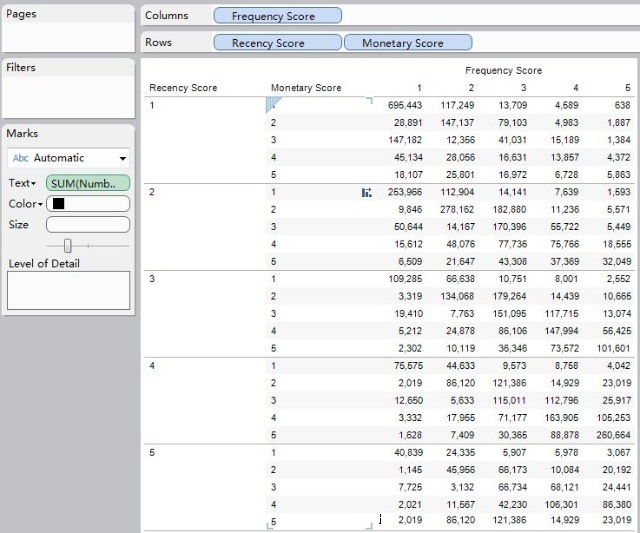
我们也可以进行不同块的对比分析:均值分析、块类别分析等等
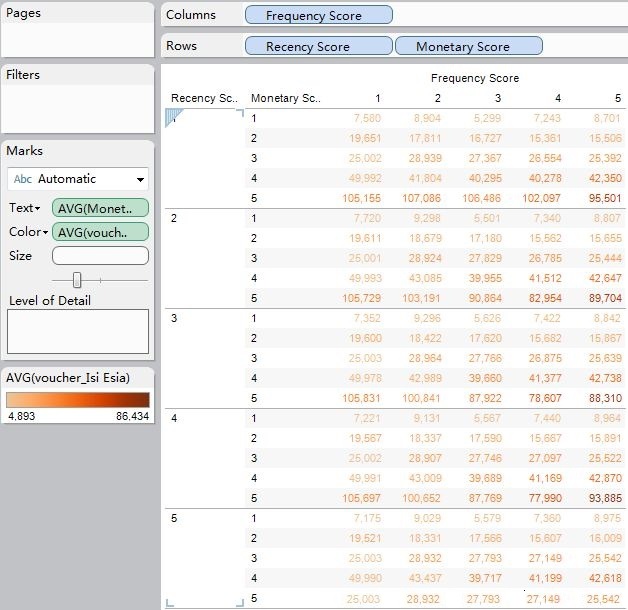
这时候我们就可以看出Tableau可视化工具的方便性
接下来,我们继续采用挖掘工具对R、F、M三个字段进行聚类分析,聚类分析主要采用:Kohonen、K-means和Two-step算法:
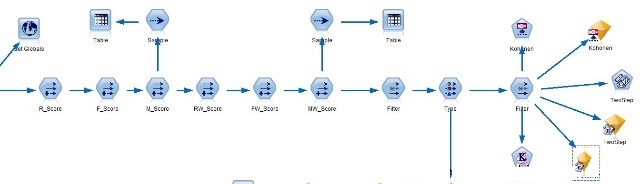
这时候我们要考虑是直接用R(Recency)、F(Frequency)、M (Monetary)三个变量还是要进行变换,因为R、F、M三个字段的测量尺度不同最好对三个变量进行标准化,例如:Z得分(实际情况可以选择线性插值法,比较法,对标法等标准化)!另外一个考虑:就是R、F、M三个指标的权重该如何考虑,在现实营销中这三个指标重要性显然不同!
有资料研究表明:对RFM各变量的指标权重问题,Hughes,Arthur认为RFM在衡量一个问题上的权重是一致的,因而并没有给予不同的划分。而Stone,Bob通过对信用卡的实证分析,认为各个指标的权重并不相同,应该给予频度最高,近度次之,值度最低的权重;
这里我们采用加权方法:WR=2 WF=3 WM=5的简单加权法(实际情况需要专家或营销人员测定);具体选择哪种聚类方法和聚类数需要反复测试和评估,同时也要比较三种方法哪种方式更理想!
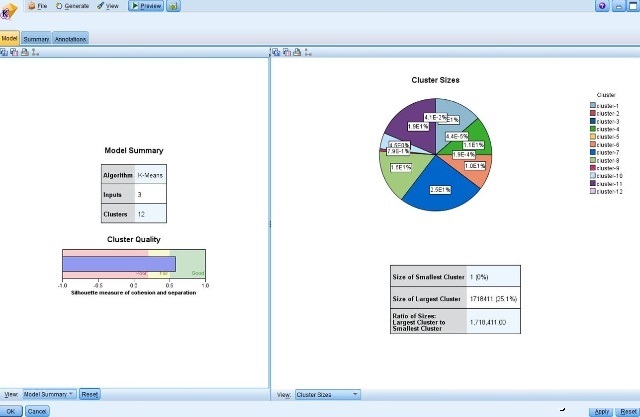
下图是采用快速聚类的结果:
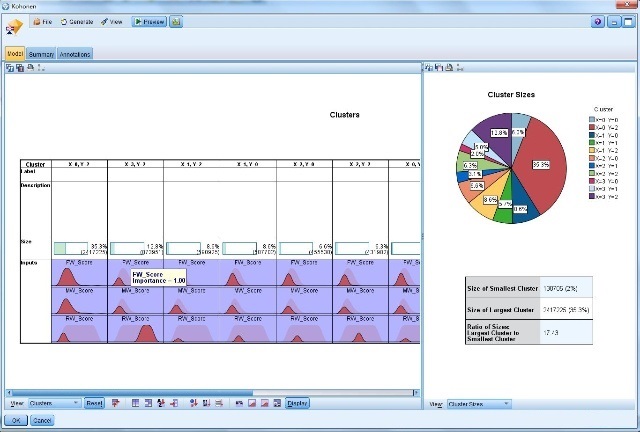
以及kohonen神经算法的聚类结果:
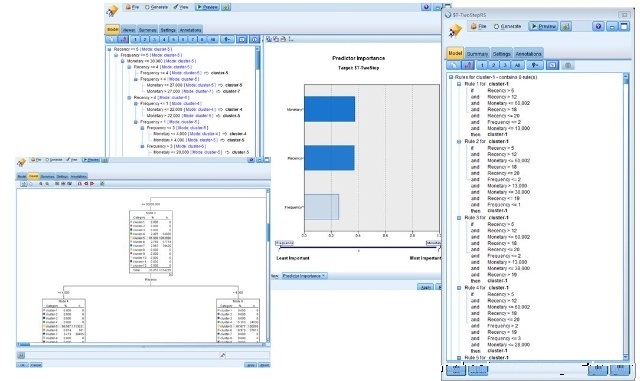
接下来我们要识别聚类结果的意义和类分析:这里我们可以采用C5.0规则来识别不同聚类的特征:
其中Two-step两阶段聚类特征图:
采用评估分析节点对C5.0规则的模型识别能力进行判断:
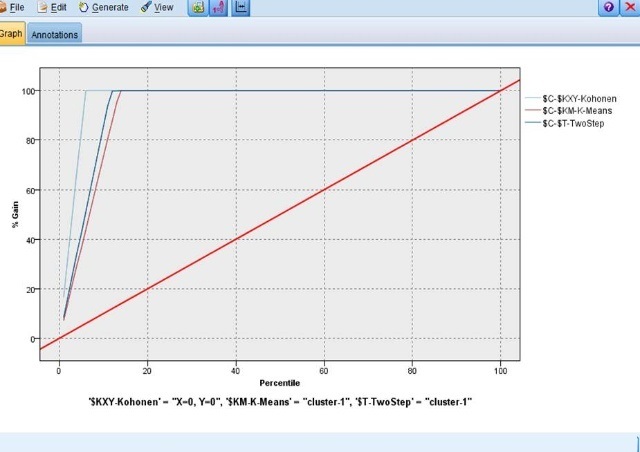
结果还不错,我们可以分别选择三种聚类方法,或者选择一种更易解释的聚类结果,这里选择Kohonen的聚类结果将聚类字段写入数据集后,为方便我们将数据导入SPSS软件进行均值分析和输出到Excel软件!
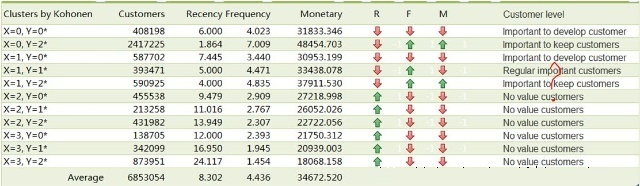
输出结果后将数据导入Excel,将R、F、M三个字段分类与该字段的均值进行比较,利用Excel软件的条件格式给出与均值比较的趋势!结合RFM模型魔方块的分类识别客户类型:通过RFM分析将客户群体划分成重要保持客户、重要发展客户、重要挽留客户、一般重要客户、一般客户、无价值客户等六个级别;(有可能某个级别不存在);
另外一个考虑是针对R、F、M三个指标的标准化得分按聚类结果进行加权计算,然后进行综合得分排名,识别各个类别的客户价值水平;
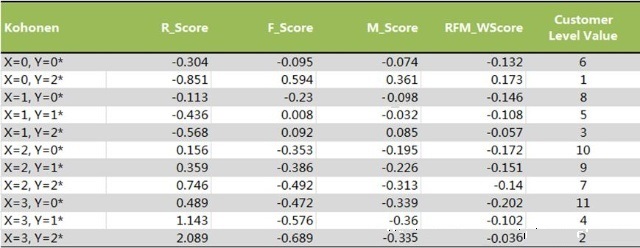
至此如果我们通过对RFM模型分析和进行的客户细分满意的话,可能分析就此结束!如果我们还有客户背景资料信息库,可以将聚类结果和RFM得分作为自变量进行其他数据挖掘建模工作!
| 





