|
ժҪ: ����ͨ�� IBM SPSS Statistics �е� Python
���ģ���ԭʼ AT&T �������ݽ���Ԥ������Ȼ��������ģ�ͺ����ؿ�����������������ԭʼ�������ݵĻ����ϴ�������ģ����ҵ����ʵ�������ʹ��������Ӷ�Ϊ��ҵ�Ĵ�
...
��״������
Խ��Խ�����ҵ����ʼ��ע�������������ʹ��״�����Թ�����������ʹ�÷�������������ȷ����ҵ�ؼ�ҵ��õ���ֵĴ������ϣ�����Ҳ���Է��ִ���ʹ����������в����������ڴֵ���ҵ���Ѿ������˻���
SNMP ���� Netflow ������ƽ̨����˶���ҵ���ԣ�������ǰ��ʹ��״�����˽�ġ�Ȼ����Ϊ�˽��ҵ��չ�Դ���������������Ҫ��ʱԤ��δ������������״�����Ӷ�Ϊ���������ṩ���ݡ�
���ڹ����������dz�������ˣ�����ҵ������������������ʱ����������Ĵ��������ϸ��Ҫ��Ҫ��֤��ҵҵ��Դ��������������ֲ����������࣬����Ͷ���˷ѵ������
��������
Ŀǰ���Դ�����Ԥ����Ҫ�����¼��ַ�������һ�ַ�����ͨ������õ����÷���ͨ���ۼӹؼ�ҵ����ռ�ô�����Ȼ�����ͬʱ���ߵĸ��ʡ��ڶ��ַ�����ͨ����ҵ�������������������ݡ������ַ�����ͨ����ҵ�����������ݽ�����ѧģ�ͣ��Ӷ�Ԥ��δ����������
����ǰ���ַ������ϴ���������ҵ��������ʱ����ȷ�Ե�Ҫ��������Ҫ���۵ģ����Ǵ���ҵ�����������ֽ�����ѧģ�ͣ�ȷ��Ԥ��δ����������
������������
�������ɷ���
��ҵ���ܹ��߽���
Ŀǰ�������������ҵ�����ܲ�Ʒ��Ҫ�ǻ��� SNMP Э�����˼�Ƶ� Netflow ���������� SNMP
Э������ܲ�Ʒ���������ڲ�����·�������ʣ��������������ʻ����Լ����������豸�����ܲ��������� CUP��MEM
�ȡ��dz������� Orion NPM �����������ܲ�Ʒ������һ���ǻ��� Netflow �����ܲ�Ʒ�������������ڶ�
IP ��ַ������Э��ķ������� Orion NTA�������������ܲ�ƷҲ���ֶ����ּ����ںϵ����ơ�
ʵ����AT&T ����ȡ����
������ʹ�õ�����ƽ̨�����Ի��� Netflow �����ܲ�Ʒ Application Traffic Analyzer������ͼ
1 ��ʾ�����ɱ���ʱ�����Զ������Ҫ�ֶ���Ҫ�У�
Function�����ֶ��������屨���Ĺ��ܣ����磬����������Э�顢�Ự��Ŀ�� IP���������Ϊ��Ҫ���ݵı�����
Report Type�����ֶ������������ɱ��������ͣ�����ͼ������״ͼ����״ͼ�ȣ�
Granularity�����ֶ������������ɱ����Ŀ����ȣ����� 5 ���ӡ�10 ���ӡ�1 Сʱ��1 �졢1
���ڵȣ�
Traffic Direction�����ֶζ��������ķ��������������dz�������
Statistic�����ֶζ�����ͳ�Ʒ��������磺��͡���ƽ��ֵ�������ֵ���� 95% �ȣ�
Scaling�����ֶζ�����������λ�����磺Mbps��Megabytes��Kilobytes �ȡ�
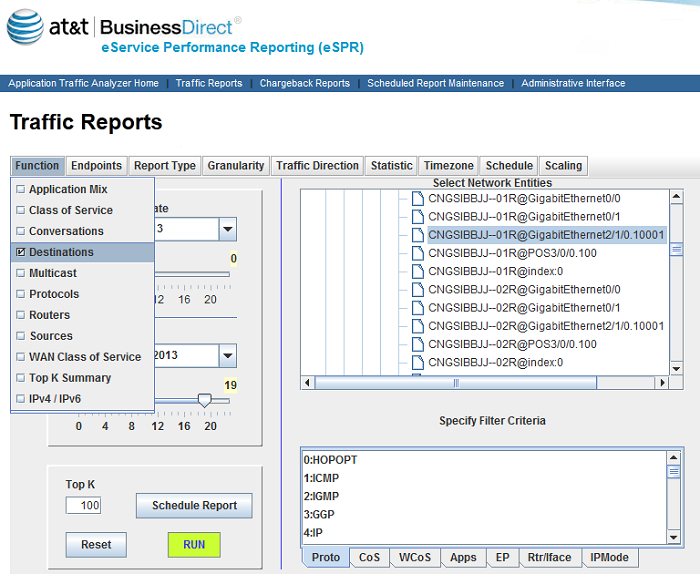
ͼ 1. Application Traffic Analyzer
������ʹ�õı������� 5 ����Ϊ������λ��ÿ������һ�ŵ����ı������������Ҫ�ֶ����£�
Time range��9:00 am �C 19:00 pm
Scaling��Mbps
Statistic��Sum
Traffic direction��inbound������ Inbound ����Զ���� Outbound ��������������������ѡȡ�ϴ����������
Function��destinations�������������Ŀ�ĵ� IP ���������е� inbound ������ |
����Ԥ����
���������е�ԭʼ���ݶ���ֱ����������Ԥ��ģ�͡�ͨ���Դ�������������һ����ȷ�����Ķ��壬��ȷ��ԭʼ�����Ƿ���ֱ��֧�ֽ�������Ĺ�����������ܣ�����Ҫ��һЩ�ֶν��д��������ɼ�����ݽ�ģ�������ȿ����ṩ�㹻����Ϣ֧�֣�Ҳ�ܱ�֤Ԥ�����ǿɺ�����������ģ��Ӷ�����������������Ľ����
���ݷ����Ͷ���
�� IT �����õ���ԭʼ���ݣ���Ԥ����ǰ����Ҫ�������ݷ��������ݽ��������Ŀ�궨���֮��Ĺ�ϵ�����Ľṹ��Ŀ����������������
�����У�IT �����ṩ�˴� 2012 �� 11 �µ� 2013 �� 1 �µ������������ݡ���Щ���ݰ���ÿ����������������Ʊ������깲��
92 �ű���EXCEL ��ʽ����ÿ�ű���ʽͳһ�������� 2012 �� 11 �� 17 ��Ϊ��������ԭʼ���Ľṹ��
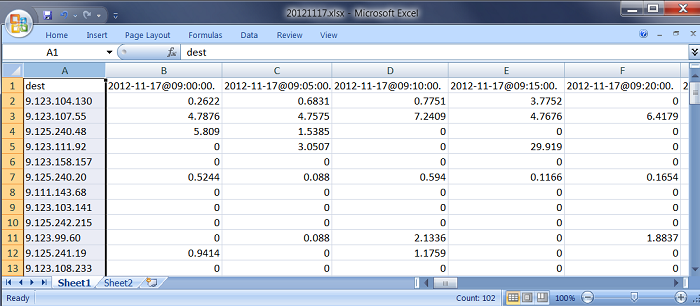
ͼ 2. ԭʼ���ṹ
��ͼ 2 ��ʾ��ԭʼ�����б�������������������ǰ 100 ���� IP ���ϣ����а������绷���µķ�������Server����
PC �ն˻�����Client���������б�����ÿ�� IP ÿ�� 5 ���ӣ�ʱ��㣩��¼����������ֵ������
9 �㵽�� 7 �㹲�� 119 �С�
���ĵ�Ŀ����Ҫ�ҵ�Ӱ��ij��ҵ���������������ء�ԭʼ�����ṩ����Ϣ�м�¼ʱ�䡢Server ������ Client
�������������ݷ�����������Ƕ��������ڽ�ģ���ձ��ṹ����ͼ 3 ��ʾ��

ͼ 3. �ձ��ṹ
���Ƕ����Ŀ����������������� COS_Total��������м�¼���� Date��ǰ 10~70 �����������������ܺʹ�
Top10Server_sum �� Top70Server_sum��ǰ 10~70 ���ն˻������������ܺʹ�
Top10Client_sum �� Top70Client_sum��ÿһ��ԭʼ������Ϣ��Ϊ�ձ���һ���м�¼���ڡ�
Python ��̽ӿڣ�����Ԥ�����Զ���
���ձ���ԭʼ���Ľṹ���Կ�����ԭʼ���ı�������ֱ����Ϊ�ձ��ı����������Ҫ��ÿ��ԭʼ����ʱ���������Ϣת��Ϊ��������Ϣ��������Ϊ�ܹ���
95%�û������������������ֵ������Ϊ��ҵ��������������ܺ�ֵ��
ת����˼·�ǣ�1��ÿ�� IP ÿ�����������ֵ total_per_IP�������������и� IP ��������ʱ�����������ֵ��ȡ��
95%��ֵ������ total_per_IP ֵѡȡ����ǰ 10~70 �ķ��������նˡ�2��ÿ��ǰ 10~70
��������/�ն˲��������������� topNClient/Server_sum��ȡǰ 10~70 ��������/�ն˲���������������ֵ��3������������ֵ
COS_Total�����ڽ����� IP ��ÿ��ʱ�����������������ܺ��������к�ȡ�� 95%��ֵ���������£�
total_per_IP=Percentage(Sort(Time1,Time2,Time3,��,Time119)ascending)95%
topNClient/Server_sum=Mean(SumTime1,SumTime2,SumTime3,��,SumTime119)
COS_Total= Percentage(Sort(SumTime1,SumTime2,SumTime3,��,SumTime119)ascending)95% |
ͳ�Ʒ������� IBM SPSS Statistics ��ӵ�е�ǿ������ݴ���������ͬʱ��Ҳ�ṩ�˷ḻ�ı�̽ӿڣ�Python��R��.Net������������
Statistics �� Compute��Aggregate��Transpose��OMS��Merge �ȹ��ܶ�ԭʼ���ݽ��в��������ϣ����ͨ����д
Python �ű��������������ݱ���ʵ������Ԥ�����Զ�������������� Statistics ������ Python
�ű�����μ� Statistics ��Ʒ�����ĵ���
������Ҫ�ᵽ���ǣ�ԭʼ���е�û�����ַ������� PC �ն˵� IP ��ַ��Python ��װ�� Netaddr
���ܹ����ݿͻ��趨�Ĺ���� IP ���ࡣ������������ͼ 4 ��ʾ��
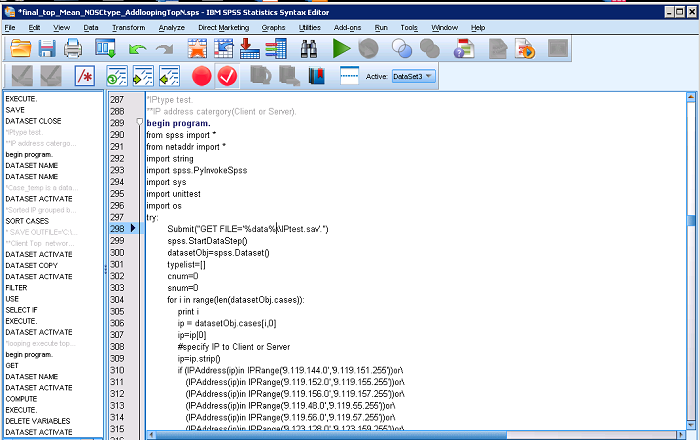
ͼ 4. IP ����ű�
��ģ������
����ģ�͵Ľ���
ͨ�� IBM SPSS Statistics �ṩ�����Իع����ģ�飬���ý�������ͼ 5 ��ʾ���������
3 ���µ����ݣ�Ѱ�� COS_Total ������������֮��Ĺ�ϵ��
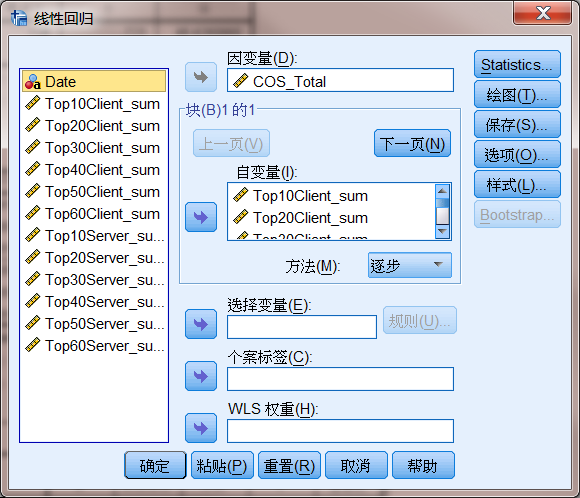
ͼ 5. ���Իع����
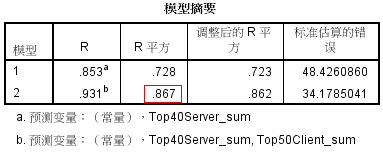
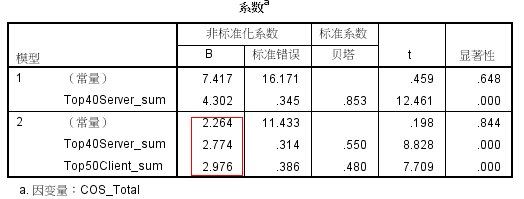
ͨ���� 1 �ͱ� 2 ���Կ����������� Top40Server_sum��Top50Client_sum
��������ģ����Ԥ�� COS_Total��Ԥ��ȷ�ȴﵽ 86.2%��˵�� COS_Total �� Top40Server_sum��Top50Client_sum
�Ĺ�ϵ��Ϊ���ܣ������Խ�������ģ�͵ķ�����Ԥ�� COS_Total��
COS_Total = 2.264+ 2.774 * Top40Server_sum + 2.976
* Top50Client_sum
�� 1. ģ��Ҫ
�� 2. ϵ��
���ؿ���������
���ؿ����������� IBM SPSS Statistics 21 �汾�������ӵĹ��ܣ���ԭ���ǵ��������������и�������ʱ�������ü����ģ��ķ�������������������ݳ�������ͳ�������߲�����ֵ������ģ����������࣬����ͨ���Ը���ͳ����������Ĺ���ֵ��ƽ���ķ����õ��ȶ����ۣ����ؿ�������ڽ��ڡ�ҽҩ�ȶ����ҵ���Ź㷺��Ӧ�á�
��Ϊ������ֻ�� 3 ���µ������������ݣ�������Ԥ�� COS_Total ����ģ�ͷ��̣�������ǿ��Ը��������������ݵķֲ���������ģ������ɴ���ģ�����ݣ�������ģ�����ݷ�����
COS_Total �ķֲ��������Ӷ��Թ�˾�ĺ�������ʹ���ṩ���ݡ�
�� IBM SPSS Statistics 22 ��ѡ������˵��µ�ģ��ģ�飬������ͼ 6 ���棬ѡ�����뷽�̡���
ͼ 6. ģ��ģ��
�ڡ����̱༭�����Ի����У�ͼ 7������ǰ������Ԥ�� COS_Total �����Է������뵽����ġ����ֱ���ʽ���У���������������ťȷ�ϡ�
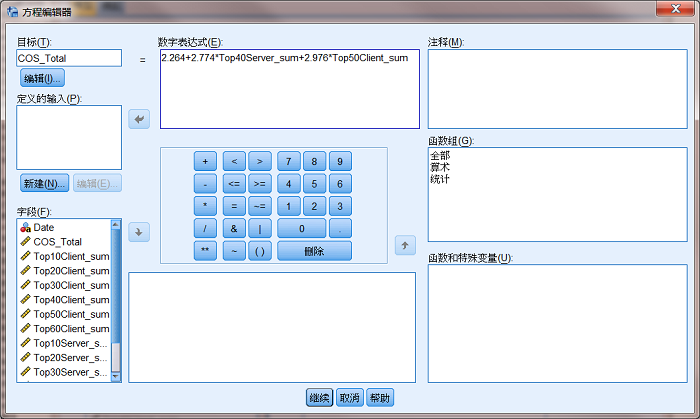
ͼ 7. ���̱༭��
�ڡ�ģ�⡱ҳ�棬���������ȫ������ť��Statistics �����ͻ�������е� 3 ���������е� Top40Server_sum
�� Top50Client_sum �����Զ��ļ�������Ӧ�ķֲ������Է��� Top40Server_sum
���� Weibull �ֲ����� Top50Client_sum ������̬�ֲ������������С���ť���ͻ����������������ķֲ������е����Է��̣���
COS_Total �ĸ��ʷֲ����з�����㡣
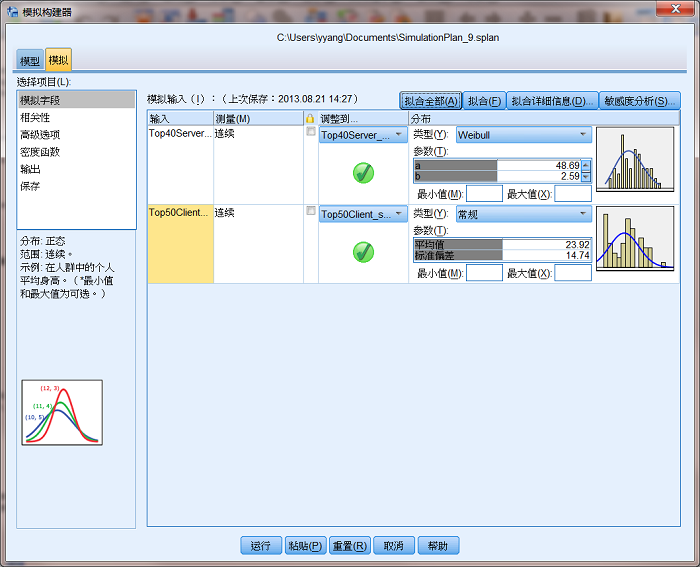
ͼ 8. ģ�����
���ؿ����������õ��� COS_Total �ĸ��ʷֲ�����ͼ 9 ��ʾ��ͼ�еĺ����ʾ COS_Total
��ȡֵ��Χ��-100M �� 500M�������ʾ����ÿһ�� COS_Total ֵ�ϵĸ����ܶȣ���Ӧ�ı��зֱ�����˸���
5% �� COS_Total ֵ��5%-95% �� COS_Total ֵ�� 95% �� COS_Total
ֵ�����˵������˾�ɹ���������趨Ϊ 332.95M ʱ���������� 95% ������µ�ʹ�ã�����ɹ������趨Ϊ
54.52%����ֻ������ 5% �����ʹ�á�
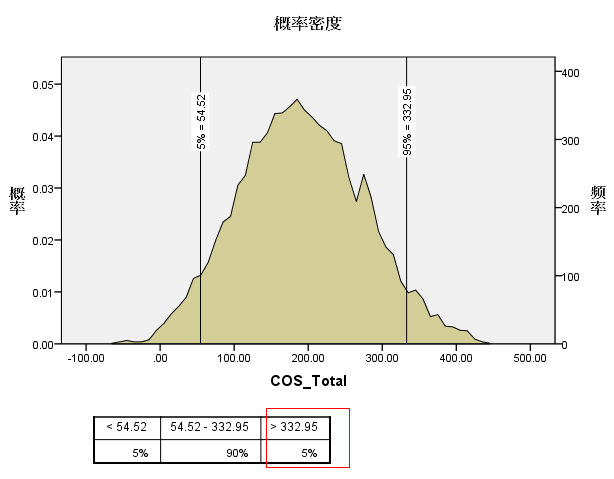
ͼ 9. �����ܶ�
ҵ�����
��ҵ������״����

ͼ 10. ���ܱ���
���������ܱ��棨ͼ 10�����Կ�������ҵ������ʵ��ʹ��������ò�ͬ��ɫ���֡���ɫ��ʾ��·ռ����С�� 50%��˵����·���ڽ���״̬����ɫ��ʾ��·ռ���ʴ���
50%-70%������������״̬ʱ��˵�����紦��ӵ��״̬������ʱ�з�������Ҫ���������������ˡ���ɫ��ʾ��·ռ���ʴ���
70%������������״̬ʱ��ҵ�����ܻ������½���������ҵ�������ʹ�á����ǿ��Եó����ۣ���ҵ��Ҫ�������������ˡ���ô�����������ٺ����أ�
��ҵ������������
��������ǰ��Ԥ������Ľ������ 95%������£���ҵ����λ�� 332.95Mbps ���ڣ�������ܱ����еĴ���ʵ��ʹ�������һ�µġ������Ĵ���������ʽ���Ǽ�Ҫ��֤���õ��û����飨����ʹ����<70%�������ܹ�������ʡ�ɱ���������ǽ������������������Χ��
475.6Mbps��332.95/0.7��~665.9Mbps��332.95/0.5���������������� 475.6Mbps
��һ�������ķ�����������������ҵ�����������¶������ʹ��Ҫ����ɫ������ʹȫ����Դ��ռ��Ҳ����������������½�����ɫ�������⡣��Ȼ�������ҵ����������Ҫ��ܸ߲���Ը��Ͷ��ɱ���ѡ��������
665.9Mbps ����ҵ�����紦�ڻ᳤�ڴ��ڽ���״̬����ɫ�����Ӷ��Թؼ�ҵ�������и��ɿ��ı�֤�� | 





