本文主要通过实例介绍
IBM SPSS Statistics 的直销工具。直销工具是 IBM SPSS Statistics
18 的一个新特性,它简化了统计算法的使用,使市场或销售人员可以更加高效的分析客户群体,并给出参考信息以利于决策。通过阅读本文,读者可以对直销工具的使用有全面的了解,并能将其应用到工作中。
IBM SPSS Statistics 给用户提供了丰富的统计算法,用以构建针对不同问题的预测分析方案。这给用户带来了很大的便利,但是也要求用户具有一定的数学统计知识,特别是在使用一些比较复杂算法或将不同算法结合起来使用的时候。
对于市场或销售人员,他们更专长于数据的收集,更关心分析的结果,而不擅长算法的综合使用、参数的设置等。针对这些问题,IBM
SPSS Statistics 提供了直销工具。该工具针对常见的市场销售问题,将不同的统计算法结合起来,提供了比较好的解决方案。这些方案包括:识别最佳客户(RFM
分析)、客户分组、生成潜在客户概要文件、邮政编码响应率、购买倾向分析以及比较活动效果。
基本概念与统计算法
本章节主要介绍与直销工具相关的统计算法。这些算法协同工作,给直销工具提供支持,以实现相关的功能。
AGGREGATE 算法:该算法也叫分类汇总算法,主要用来对数据文件中的实例按一定标准(例如:年龄、性别、住址等)进行分组,并可以生成一些属性变量来反应每一组的特性。在识别最佳客户的过程中,如果数据文件是由交易实例组成,那么需要使用
AGGREGATE 算法,将同一客户的交易汇总,并生成基于客户的数据文件。这些操作不需要用户去执行,IBM
SPSS Statistics 会自动做好数据处理,这也是直销工具的优势所在。
DMGGRAPH 算法:这是一个绘图算法。通过计算输入的统计变量,DMGGRAPH
算法可以绘制出不同的图形,形象的反应统计结果。在 RFM 分析中,使用该算法绘制块计数图表,可以直观显示不同客户的购买情况,如频率、最近购买日期以及购买额等。
DMCLUSTER 算法:DMCLUSTER 算法源于聚类算法。它可以根据实例的自然属性,将其分类。在使用过程中,通过对一个或多个属性变量的计算,得到不同实例之间的距离,然后按照距离的远近,可以分成不同种类。直销工具中的客户分组,就是使用该算法实现的。
DMTREE 算法:DMTREE 算法用来构建一个树形模型。它可以根据预测变量的值,将实例划分成不同的组。当有多个预测变量时,首先浏览所有变量以确定最佳的分组方法,然后按照预测变量的次序递归划分。比如,有两个预测变量性别、年龄。那么,先按性别分两组,然后在各组内继续按年龄划分。IBM
SPSS Statistics 将该算法应用到生成潜在客户概要文件中。根据客户对测试活动的响应,对客户进行划分。
DMLOGISTIC 算法:DMLOGISTIC 算法是一种建模方法。它根据已有数据集的特征建立模型,并将该模型用于对其它数据的预测分析。例如,银行可以基于已有贷款客户的信息建立模型,来预测潜在客户贷款的可能性或者风险大小。在直销工具中,将该算法用于对客户购买趋势的预测。
DMROC 算法:该算法主要用于模型测评。在预测客户购买趋势时,先使用
DMLOGISTIC 算法建立模型,然后使用 DMROC 算法评价模型的有效性。
识别最佳客户
识别最佳各户又称为 RFM(Recency, Frequency, Monetary)分析。它是一种通过分析客户的最近消费日期、消费频率以及总消费总额来识别最佳各户的统计算法。该算法的实现基于以下理论:1)最近购买的客户比过去购买的客户更可能再次购买。2)过去购买次数较多的客户比购买次数少的客户更可能做出反应。3)过去消费金额较多(所有购买的总和)的客户比消费金额较少的客户更可能做出反应。
根据每一个客户最近消费日期、消费频率以及消费总额的大小,分别分配一个数值。比如,指定一个从
1 到 5 的分数,最低的是 1 分,最高的是 5 分。那么,对每一个客户就可以算出最近消费分数(Recency
Score)、消费频率分数(Frequency Score)和消费总额分数(Monetary Score)。然后,将三个分数连到一起,可以得到客户的合并分数(RFM
Score)。合并分数代表客户购买新产品的可能性,分数越高,可能性越大,反之越小。
根据分析数据的不同,识别最佳客户方法分为基于客户的 RFM 分析和基于交易的
RFM 分析。如果数据文件中的每一个实例代表一位客户,则使用基于客户的 RFM 分析;如果每一个实例代表客户的一次交易记录,则使用基于交易的
RFM 分析。下面,通过实例分别对这两种方法进行演示。
基于客户的 RFM 分析
首先,打开数据文件。在本例中,使用某厂商 2005 年度的客户购买记录。在该文件中,每个实例代表一位客户,包括客户
ID、最近购买日期、购买频率、购买总额等。通过使用 RFM 分析,为该厂商找出最佳客户,即最有可能再次购买的客户。
从 IBM SPSS Statistics 的“直销”菜单中,点击“选择方法”菜单项,弹出直销工具选择对话框。
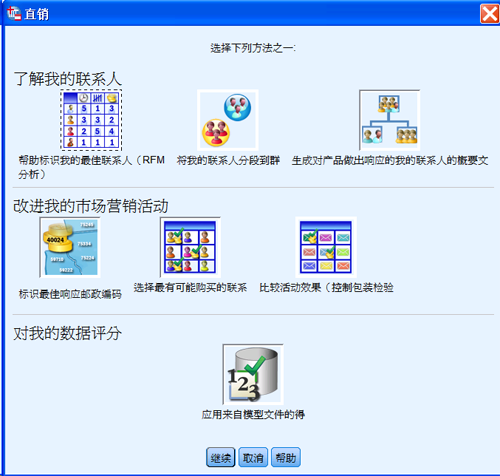
图 1. 图片示例直销工具选择对话框
在图的左上角,点击“帮助标识我的最佳联系人(RFM 分析)”。点击“继续”,弹出选择数据格式的对话框。
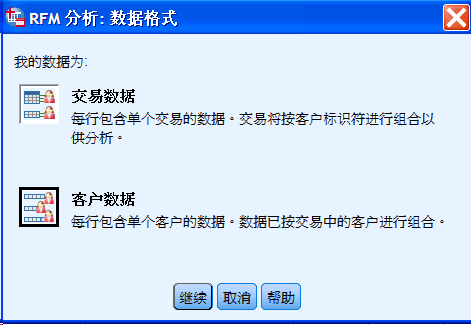
图 2. RFM 分析数据格式选择对话框
根据使用的数据格式,选择“客户数据”;点击“继续”,进入到 RMF 分析的参数设置界面。
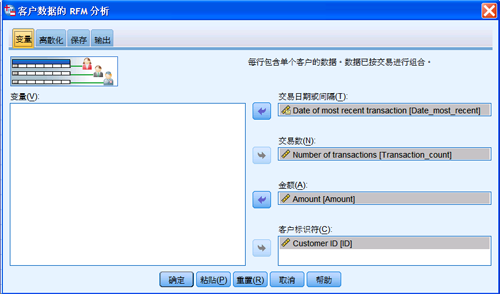
图 3. 基于客户数据的 RMF 分析
如图所示,将相应的变量拖到交易日期或间隔、交易数、金额、客户标示符文本框中。点击“确定”,就可以进行
RMF 分析。另外,用户也可以在“离散化”页面中,对 RFM 之间的关系(一是嵌套,最近交易日期、交易频率和交易总额三个变量相关,依次对客户进行区分;二是独立,对三个变量分别计算)和块数(从高到低的级别数,比如常用的从
1 到 5。)进行设置。通过 RFM 分析,生成包含 RFM 分数的数据集。
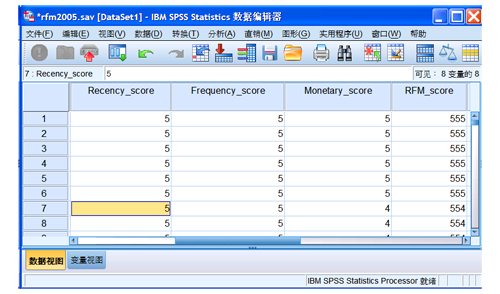
图 4. 具有 RFM 分数的数据
该数据文件在原数据基础上,添加了 4 个分数变量,来衡量客户再次购买的可能性。从图中可以看出,分数为“555”的客户,即为最佳客户。
在默认情况下,生成 RMF 分数的同时,输出窗口输出 RFM 分析的块计数图表(Bin
Counts)。块计数图表显示选定离散化方法的块分布。每个蓝条代表不同 RFM 得分的客户数。
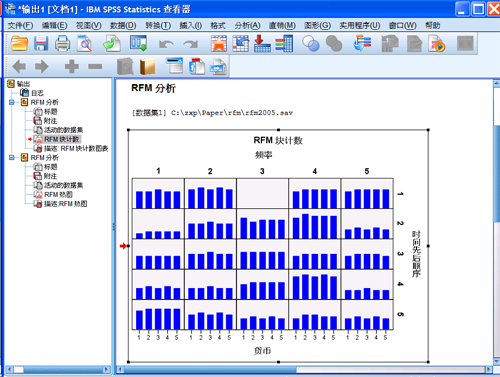
图 5. RFM 分析的块计数图表
从图中可以看出,RFM 分数在 441-445、241-245 之间的客户最多,而分数在
131-135 之间则没有客户。这样就完成了一个最基本的 RFM 分析。另外,也可以对不同年份的数据做最佳客户分析,然后比较分析结果,以此判断客户的购买趋势或者忠诚度。这样就可以采取相应的措施,和客户保持良好的关系,防止客户流失,提高客户满意度。
基于交易的 RFM 分析
对于按交易组织的数据文件,需要采用基于交易的 RFM 分析。与基于客户的
RFM 分析不同的是,在分析之前,需要使用 AGGREGATE 算法对数据进行分类汇总,生成基于客户的数据文件。在本例中,使用的原数据如下图所示。
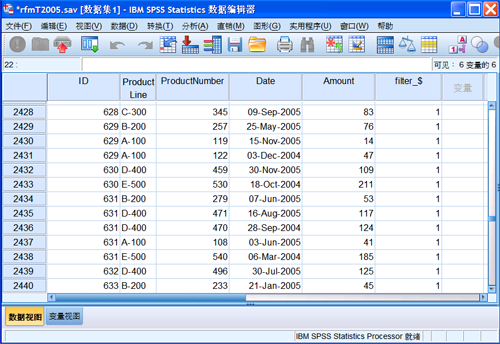
图 6. 基于交易的数据格式
在文件中,每一笔交易是一条实例,每一个客户对应一条或者多条实例。实例的属性包含客户
ID、产品类型、产品号、购买日期、购买数量等。在“RFM 分析数据格式选择对话框”(图 2)中,选择“交易数据”,进入“交易数据
RFM 分析”对话框。
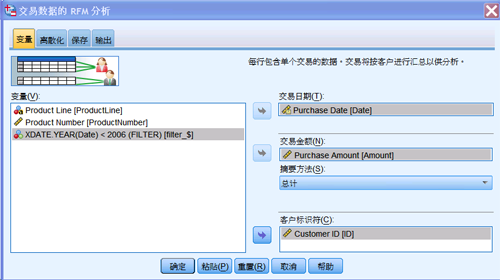
图 7. 交易数据 RFM 分析对话框
点击“确定”,执行 RFM 分析。在分析过程中,会生成新的数据文件。
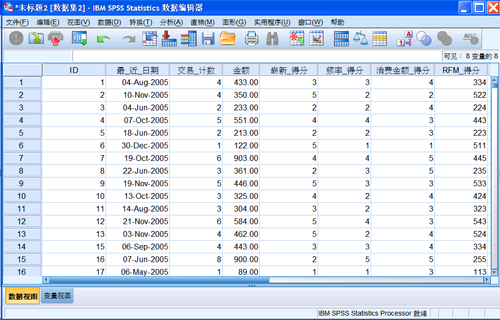
图 8. 生成的基于客户的数据格式
新的数据中,将实例按不同客户进行了分类,并计算出最近交易日期、交易频率以及总额。在此基础上,通过
RFM 分析得到了相应的分数。输出的结果,基于交易的 RFM 分析和基于客户的 RFM 分析完全一样,这里不再赘述。
从以上的实例可以看出,RFM 分析可以有效识别最佳客户,厂商可以据此制定更加有效的销售策略,从而提高效率,节省费用。
客户分组
客户分组使用聚类算法,根据客户个体的特征,将客户分成不同类别。这是一个探索,发掘新知识的过程。在分组前,客户所属的类别是未知的。选择的分析变量及数据的排序都会影响分组结果。
从 IBM SPSS Statistics 自带的实例文件中,选择德国客户信贷记录集(genman_credit.sav)。它详细记录了信贷客户的个人及财产信息。选择直销工具中的“客户分组(将我的联系人分段到群)”,打开聚类分析对话框,并选择变量
Account Status、 # of existing credits、Other installment
debts、Housing、 Age in Years, Duration in months 作为分析变量。
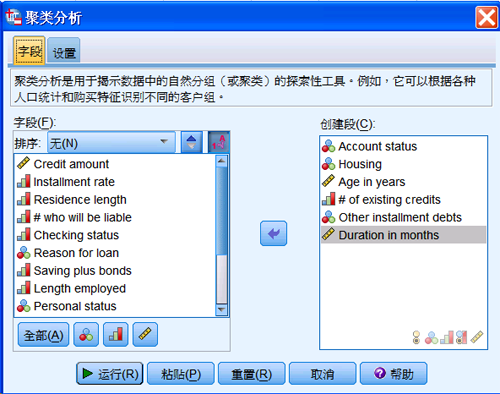
图 9. 聚类分析对话框
点击“运行”按钮,执行聚类分析。分析完成后,默认情况下会在原数据集中添加一个字段,用来指出针对每个客户的分组结果。根据这个变量值,可以很容易把客户分到新的数据集中或者作为过滤条件,对目标客户做进一步的分析。
下面,主要对聚类分析的输出结果,做进一步的研究。在输出窗口中,默认显示客户分组的模型概要图(Model
Summary),如下图所示。
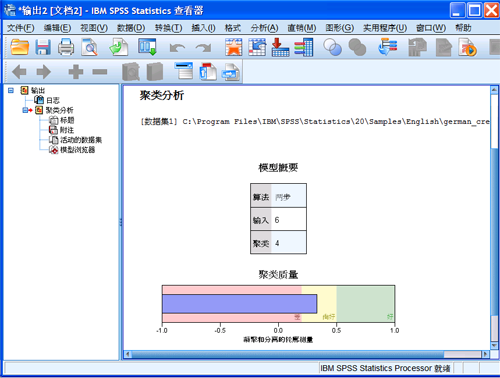
图 10. 聚类分析模型概要
从上面的表格看出,根据 6 个分析变量的值,使用两步聚类算法,得到 4
个分组;下面的模型质量图说明模型的质量在可接受的范围内。如果想查看分组的详细信息,可以双击模型概要图。从打开的模型浏览器中,选择“聚类”视图,就可以看到每个组分析变量信息。
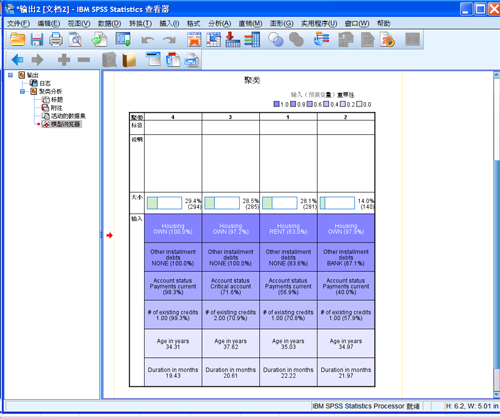
图 11. 聚类变量信息图
上面的结果显示了各个分组的特征信息。对于连续变量,显示组内的平均值;对于离散变量,显示出现最频繁的数值。例如,在分组
4 中,所有的人都拥有住房,没有其它债务,绝大多数的人都拥有信用卡。确定了分组的信息,就可以有针对性的对数据进行过滤,做进一步分析。
生成潜在客户概要文件
该工具根据测试活动的结果,生成客户的概要文件。在将来的产品推广中,可以根据该文件,决定投递对象,以提高成功率。本例使用
IBM SPSS Statistics 自带的 dmdata.sav 作为数据文件。从“直销”菜单中打开“生成潜在客户概要文件”的设置界面。
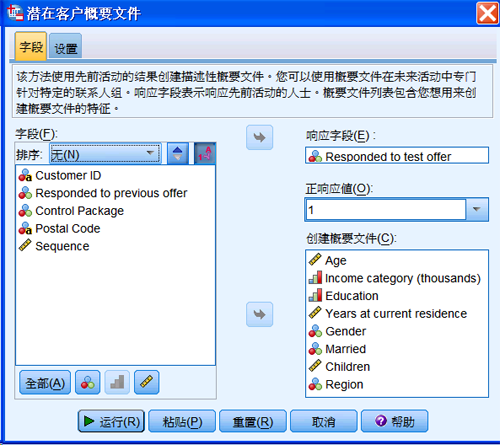
图 12. 潜在客户概要文件对话框
在上图中,“响应字段”表示客户对先前活动响应与否,“创建概要文件”变量列表是用来创建概要文件的特征变量。另外,在“设置”页面中,可以对最小响应率进行设置。点击“运行”,生成概要文件。
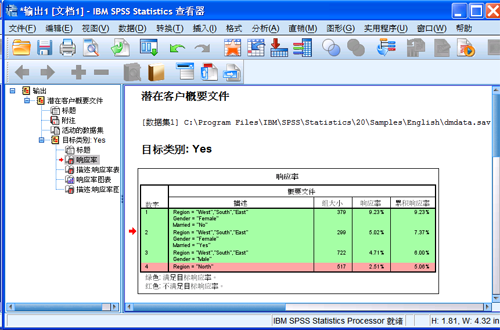
图 13. 潜在客户概要文件的响应率表格
表格中,绿色区域表示满足最小响应率,红色区域表示不满足。本例中最小响应率为
6%,则绿色区域累积响应率大于等于 6%,红色区域则小于 6%。
响应率表格显示每个概要文件组的信息。概要文件描述只包括为模型提供显著贡献的那些变量的特征,不包括那些对模型没有显著贡献的变量。响应率是做出正面响应(购买产品)的客户的百分比。累积响应率是当前和所有前面概要文件组的平均响应率。根据分析结果,厂商想要获得比较好的产品推广效果,可以选择第一组(东、南、西三个区域的未婚女性)作为对象。
识别最佳响应的邮政编码
邮政编码采用分级编码制,将全国的邮寄地址按地域层层划分。不同国家的邮政编码长度和编码规则也不完全一样,比如美国采用的三级五位编码,而我国使用的是四级六位编码。在分析过程中,可以指定分析的位数,以针对不同的地域层级。
识别最佳响应的邮政编码,根据历史邮寄数据统计出邮政编码响应率高的客户群,也即客户响应率高的地区,这样可针对该地区做营销活动。这个工具和前面提到的“生成潜在客户的概要文件”实现方法类似,因此这里主要关注设置和输出结果的分析。
打开软件自带的数据文件 dmdata.sav,从直销对话框中选择“标识最佳响应邮政编码”,完成字段的选择后,转换到“设置”页面。

图 14. 邮政编码响应率设置对话框
在“邮政编码分组方式”栏中,选择“前 3 个数字或者字符”。这样,邮政编码前三个数字相同的实例,就会被放到一起来计算响应率。按照美国邮政编码的规则,前三位可能代表某一个大城市。在“输出”栏中,选择“响应率和容量分析”,并设置最低可接受响应率及最大联系人数量。在本例中,使用默认值。最后,可以在“导出到
Excel”中,选择是否将编码响应率保存到一个 Excel 文件中。
在完成设置后,点击“运行”。在默认情况下,会输出响应率表格及相关图形。这和“生成潜在客户的概要文件”中的结果基本一样,不再赘述。这里,主要关注新生成的数据集。
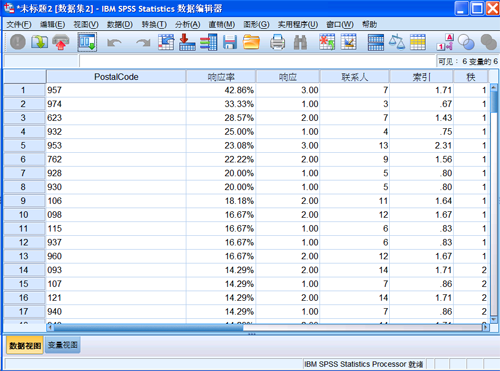
图 15. 生成的数据集
新数据集合并了前 3 位编码相同的实例。它的主要变量有邮政编码、响应率、响应数量、联系人数量、索引、秩。响应率变量是同一邮政编码下的响应比率;响应变量是对测试做出正面响应的客户数量;联系人变量是具有同一邮政编码总的客户数量;索引变量可以看作是加权的响应率,用来区分具有相同响应率的邮政编码。在这种情况下,客户数量多的邮政编码,将被赋予更大的权重,也就是索引值更大。最后一个变量是秩,表示实例在整个数据集中的级别。例如,数值
1 表示前 10% 的邮政编码。
基于新的数据信息以及输出的图表信息,就可以筛选出符合条件的邮政编码,从而针对某些地区推广产品,做到有的放矢。
购买倾向分析
购买倾向分析通过建立模型来预测客户购买产品的可能性。本例中,主要关注使用二元
LOGISTIC 算法构建预测模型、ROC 模型测试,以及应用模型到其它数据集。我们使用两个 IBM SPSS
Statistics 自带的数据集(dmdata2.sav、dmdata3.sav)来完成整个分析。 数据文件
dmdata2.sav 用来创建模型,而数据文件 dmdata3.sav 用来使用模型。
创建模型
首先打开数据 dmdata2.sav,从直销工具中选择“最有可能购买的联系人”。
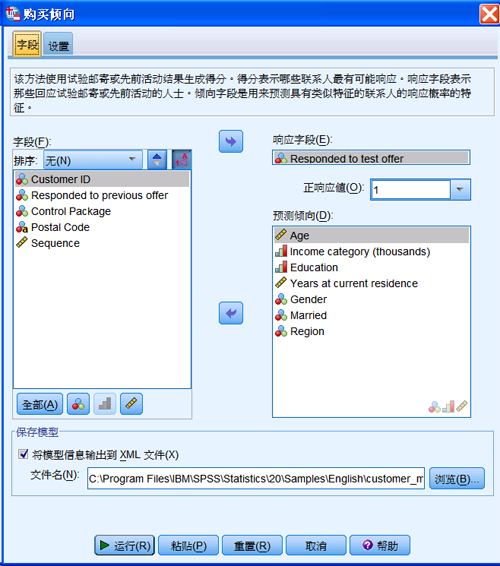
图 16. 购买倾向字段设置对话框
在图中,特别注意将模型信息保存到一个 XML 文件中,其它设置和前面提到的工具相同。在“设置”页面中,可以添加模型测试信息。
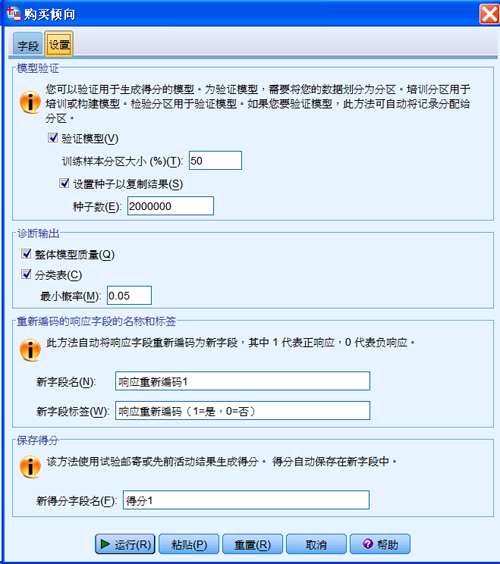
图 17. 购买倾向测试设置对话框
在“模型验证”区域,设置 50% 的数据用于训练,50% 用于验证;在“诊断输出”区域,选择整体模型质量图及分类表,同时将最小概率设置为最小的目标响应率。其它设置使用默认值,点击“运行”,就可以得到详细的模型评价信息。
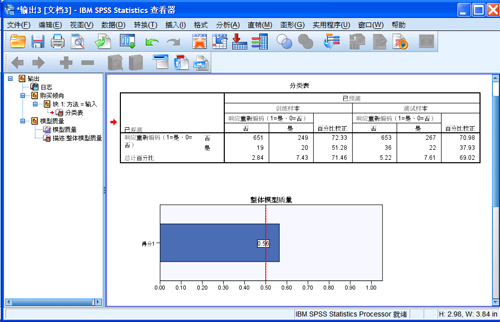
图 18. 模型测试信息
从下面的整体模型质量图可以看出,模型质量系数超过 0.5,满足一个良好模型的标准。不过,它只反映了总体模型的大概质量,更多详细的信息,还需要从上面的分类表中获取。
分类表对预测值和实际值做比较,整体的准确率可以反映出一个模型的优劣。在这里,我们更关心对正响应的预测准确率。从数据上划分,包含训练样本和测试样本。对于那些预测为具有正响应的训练样本,实际正响应的正确分类率为
7.43%; 对于那些预测为具有正响应的检验样本,实际正响应的正确分类率为 7.61%。它大于指定的最小可能性
5%。这表明此模型可以用于确定满足指定的最小可能性的一组联系人。
应用模型
下面,将上面建立的模型应用到对 dmdata3.sav 的分析中。打开数据文件,从菜单“实用程序”选择“评分向导”,选择创建的模型文件
customer_model.xml,并匹配模型变量和数据集变量。
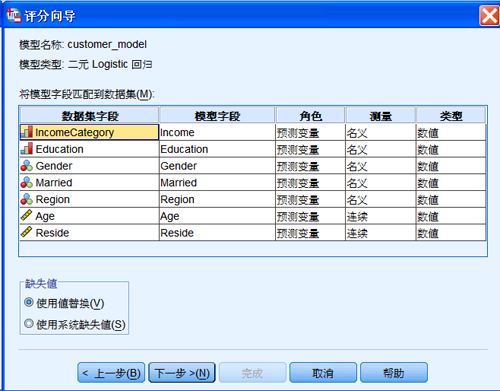
图 19. 评分向导对话框
上图中列出的变量,都是模型中的预测变量。模型将根据数据集中这些变量的值,预测客户购买产品的可能性。点击“下一步”,进入选择评分函数对话框。
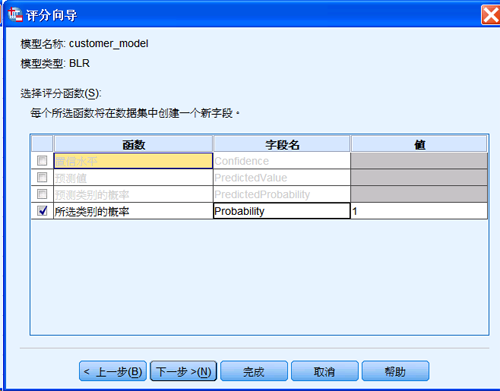
图 20. 选择评分函数对话框
勾选“所选类别的概率”,并设置值为 1。这样,该函数就会在数据集中创建一个
Probability 变量,来表示客户购买产品的可能性。
到目前为止,已经完成建立模型,评估模型及数据分析。用户就可以利用这些信息,制定出合理的营销策略。
小结
文章从应用的角度,介绍了 IBM SPSS Statistics 中的直销工具的使用方法。在讲解算法使用的基础上,简单介绍了各个工具的实现方法。文章在很大篇幅上描述了识别最佳客户、客户分组、生成潜在客户概要文件、邮政编码响应率、购买倾向分析五个实例,有助于读者快速掌握这些工具的使用。前面几个工具的知识点,基本上覆盖了“比较活动效果”,这里没有多加阐述。
| 

