| ��飺
DB2? �߿��������ѻָ� (HADR) �� IBM? DB2 for Linux, UNIX, and
Windows��һ������ʹ�õ����ݸ��ƹ��ܣ�Ϊ���ֺ�����վ������ṩ�߿����� (HA) ����������� DB2
V9.5 Fix Pack 8 �� DB2 V9.7 Fix Pack 5 ��ʼ��������һ����Ϊ SUPERASYNC
��ȫ�� HADR ͬ��ģʽ�����Ľ����� SUPERASYNC ģʽ����;��ʹ�ø�ģʽ��һ�� HADR �ԵIJ����Լ���ģʽ�µı���״̬ת�������⣬���Ļ����ṩһЩ���������������������ѻָ���
SUPERASYNC ģʽ��ʵ�֡����Ľ��鿴��Ҫ���ݿ���ο˷���ѹ������ھ��е����������ݿ�����������ݿ��������ṩ���ñ��֣��Լ�ʹ�ô�ģʽ����ȱ�㡣
���ͱ���
HADR ��һ��ͨ�����ݸ����ṩ�߿����Ժ����ѻָ��� DB2 ���ܡ������øù���ʱ�����Խ���Ҫ���ݿ�������־ʵʱ���͵�
�������ݿ⡣�������ݿ�����ط����յ�����־���Ա�����Ҫ���ݿⱣ��ͬ����
�� DB2 V9.5 Fix Pack 8 �� DB2 V9.7 Fix Pack 5 ��ʼ��SUPERASYNC
��ָ��Ϊ hadr_syncmode��������Ҫ���ݿ����κ�����¶��������衣
���Ľ����� SUPERASYNC ģʽ����;������ڸ�ģʽ������ HADR���Լ���ģʽ�²�ͬ�ı������ݿ��ת��״̬�������ṩ��ʵ��
SUPERASYNC ģʽ����������������ʹ��������ȱ�㡣
SUPERASYNC ģʽ����;
�����ܻ������Ҫ���ݿ������������⣬������Ϊ���ö���־�ز����������µģ������ö���־�ز���������Ϊ����ϵͳȱ����Դ�Լ�����������ͣ������
SUPERASYNC ģʽ����Ԥ��������Ϊ������ͣ����ִ�д��������µ���Ҫ���ݿⱳѹ������/�谭����������
HADR ����� SUPERASYNC ģʽ�¹���
�� SUPERASYNC ģʽ�£�HADR EDU �ں�̨������־���ͣ����Ҳ�������������Ĵ���·��������ζ����־���Ͳ����ύ����ķ�Χ�ڡ���ˣ���������ֹ��Ҫ���ݿ�������������
HADR ����Զ������� Peer ״̬�� Disconnected Peer
״̬��HADR ״̬���� local catch up ��Ϊ remote catch up��Ȼ��ͣ����remote
catch up��HADR ���ǴӴ��̻�鵵��־����Ҫ���ݿⷢ����־��������Ҫ���� Peer ״̬��������־�Ǵ���Ҫ���ݿ���־���������͵ģ�������Ҫ���ݿ���־��д�����仺��
����ͼ 1 ��ʾ������ͬ��ģʽ���бȽ�ʱ����ģʽ�ṩ��������ܡ�
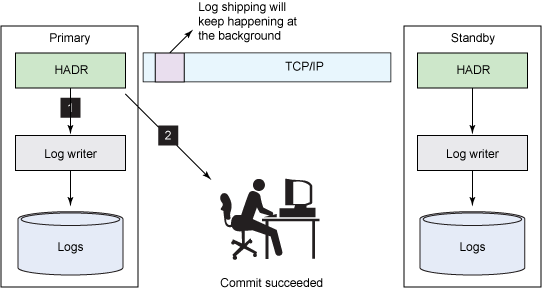
ͼ 1. SUPERASYNC �е� HADR
�Ĺ���ԭ��
��Ҫ���ݿ⽫��־��¼д����Ҫ���ݿ����־�ļ���
Ȼ���ύ��������ȴ�����־���Ƶ��������ݿ⡣
�� SUPERASYNC ģʽ������ HADR ��
Ҫ�� SUPERASYNC ģʽ������ HADR �ԣ�����ʹ���嵥 1
���嵥 3 ��ʾ�� SUPERASYNC �������� HADR_SYNCMODE db cfg ������
�嵥 1. ���� HADR_SYNCMODE
$ db2 update db cfg for hadrdb using HADR_SYNCMODE SUPERASYNC
DB20000I The UPDATE DATABASE CONFIGURATION command completed successfully.
SQL1363W One or more of the parameters submitted for immediate modification
were not changed dynamically. For these configuration parameters, the database
must be shutdown and reactivated before the configuration parameter changes
become effective. |
�嵥 2. ͣ�����ݿ�
$ db2 deactivate db hadrdb
DB20000I The DEACTIVATE DATABASE command completed successfully.
|
�嵥 3. �������ݿ�
$ db2 activate db hadrdb
DB20000I The ACTIVATE DATABASE command completed successfully.
|
ʹ�� MON_GET_HADR��V9.7 �п���û���ṩ������������
-hadr ѡ��� db2pd ��������Ҫ���ݿ�������ݿ��״̬��
���磬
SUPERASYNC ģʽ�µ� HADR ״̬ת��
��ͼ 2 ��ʾ�������ñ������ݿ�ʱ�����ݿ⽫����� Local catchup
״̬����ȡ������־·���Ͽ��õ���־�ļ����ڶ�ȡ������־�ļ�֮�������ݿ⽫���� Remote catchup
����״̬�����ȴ���Ҫ���ݿ�����ӡ�һ����Ҫ���ݿ����ӵ��������ݿ⣬���ǽ����� Remote catchup
״̬���Ҳ��ٽ��� Peer ״̬���Ա��������Ҫ���ݿⱳѹ��
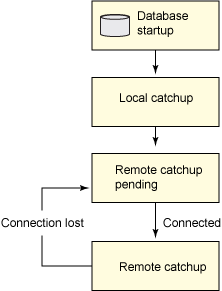
ͼ 2. SUPERASYNC ģʽ�µı������ݿ�״̬
����Ҫ���ݿ�ͱ������ݿ��� SUPERASYNC ģʽ�½�������ʱ���������ݿ��״̬����ͼ
3 ��ʾ�� RemoteCatchup��
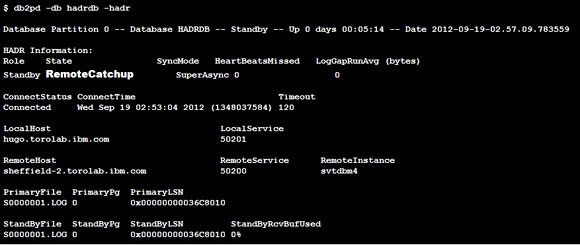
ͼ 3. �������ݿ��״̬�� Remote
catchup
�������ݿⲻ����ʱ����Ҫ���ݿ��״̬��Ϊ Disconnected����ͼ
4 ��ʾ��
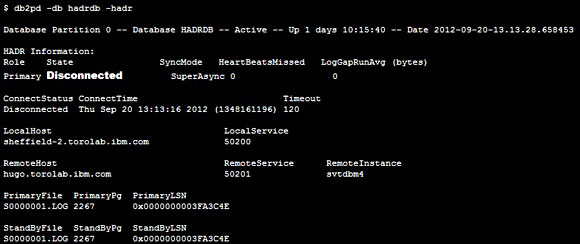
ͼ 4. �������ݿⲻ����ʱ����Ҫ���ݿ��״̬�ǶϿ�����
���������ݿ�����Ҫ���ݿ�Ͽ�����ʱ���������ݿ��״̬���� RemoteCatchupPending����ͼ
5 ��ʾ��
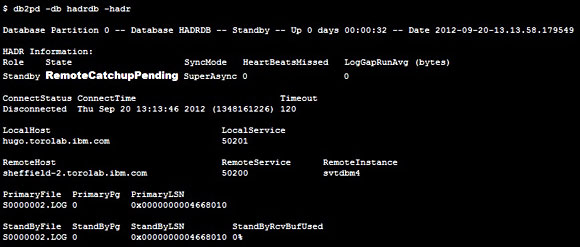
ͼ 5. �������ݿ��״̬�� RemoteCatchupPending
SUPERASYNC �� DB2 ���ѻָ������н�������
����С�������˿��Խ� SUPERASYNC ����Ϊ hadr_syncmode
�������������Լ�����ΰ������ѻָ�ʵ�ָ��õ���Ҫ���ݿ����ܡ�
ʹ�� HADR �� HA ͨ����Ⱥ����ʵ�� DB2 ���ѻָ�
����������� DB2 V9.7��
���磬�� Location 1 �н�����Ҫ���ݿ������ʹ�� TSA ��
HACMP ��Ⱥ�������̨������M1 �� M2��֮��ʵ�ָ߿����ԡ��� Location 2 �н����������ݿ⣬�Ա���
SUPERASYNC ģʽ��ʹ�� HADR ���ƹ���ʵ�����ѻָ�����ͼ 6 ��ʾ��
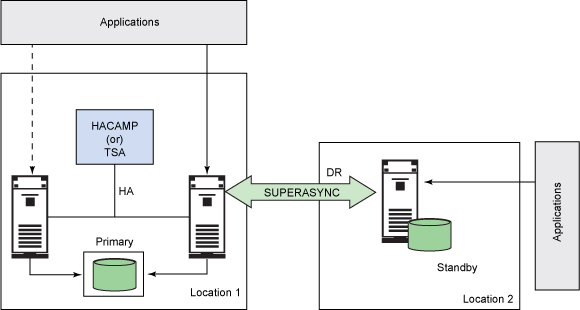
ͼ 6. ʹ�� SUPERASYNC �����ѻָ�
�û�Ӧ�ó�������Ҫ���ݿ⣨�� M1�������Ӳ�ִ��������־���� M1
���͵��������ݿ⡣���ڱ������ݿ����� SUPERASYNC ģʽ�½����ģ����Բ�����Ϊ��Զ����Ҫ���ݿ⣨�������ӳ٣���������ͣ��������Ҫ���ݿⱳѹ����ˣ���Ҫ���ݿ����ܱȽϺá�
�����Ҫ���ݿ⣨Location 1 �У��ϵ� M1 �ٶ��½�����ô��Ⱥ��������������һ������Ϊ�߿����ԵĽڵ㣨��
Location 1 �е� Machine M2����
����� HA ����ת��֮��ͨ�� HADR ���ƹ��̽���־�� M2 ���͵��������ݿ⡣���
Location 1 �ٶ��½���M1 �� M2 ���½������������ݿ⽫����Ϊ��Ҫ���ݿ����á�ͨ���������ã������Ի�����ݿ�߿�����������ܺ����ݿ�ָ����Ӷ���ֹ���ѷ�����
�� SUPERASYNC ģʽ��ʹ�� HADR ��������������ݿ���ʵ�����ѻ�
����������� DB2 V10.1
���ж���������ݿ�� HADR �У���ӵ�ж�������������ݿ⣬���� DB2
V10.1 �е�һ���¹��ܡ�����һ�����ݿ�����Ϊ ��Ҫ�������ݿ⣨֧������ HADR ͬ��ģʽ���������������������������ݿ⣨ֻ֧��
SUPERASYNC ģʽ������Ҫ�������ݿ�����ͬλ�ÿɲ���Ϊ��Ҫ���ݿ⡣�����������ݿ���Զ�̽��в���ģ�����Ϊ��Ҫ���ݿ����Ҫ�������ݿ��ṩ��������ֹ���ѷ�����
�������� SUPERASYNC ģʽ��ʹ�� HADR ��������������ݿ���ʵ�����ѻָ����������ܳ�����
1������ 1��ʹ�� HADR ʵ�� DB2 �߿��������ѻָ�
2������ 2��ʹ�� HADR ʵ�� DB2 �߿����ԺͶ�����ѻָ�
���� 1��ʹ�� HADR ʵ�� DB2 �߿����Ժ����ѻָ�
�ڸó����У��� Location 1 ��ʹ���� TSA ��Ⱥ��������Ҫ���ݿ����Ҫ�������ݿ�֮�����ø߿����ԡ������������ݿⱻ����Ϊʵ��
Location 2 �ϵ����ѻָ�����ͼ 7 ��ʾ��
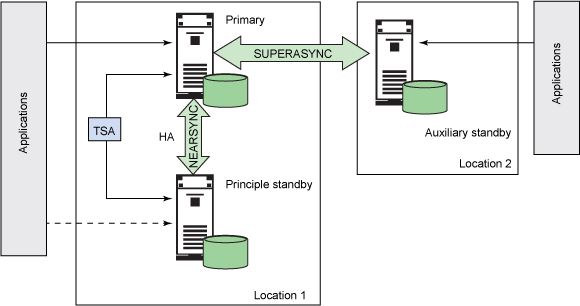
ͼ 7. ʹ�ö���������ݿ�ʵ�ָ߿����Ժ����ѻָ�
�û�Ӧ�ó�������Ҫ�����������Ӳ�ִ������������־������Ҫ���������͵���Ҫ���÷������������÷���������Ϊ�������÷���������
SUPERASYNC ģʽ�½����ģ����Բ�����Ϊ��Զ����Ҫ���������������ӳ٣���������ͣ������Ҫ�������ϲ����κα�ѹ��
���������Ҫ�������жϣ���ô��Ҫ���÷�����������Ϊ��Ҫ��������ʹ�ü�Ⱥ����
(TSA) �Զ����ã������µ���Ҫ�������Ὣ��־���͵� Location 2 �ı��÷������ϡ�
��� Location 1 �Ϸ������ѣ���Ҫ����������Ҫ���÷�����ͬʱͣ��������ô
Location 2 �ϵı��÷���������Ϊ��Ҫ���������á���Ϊ�������ѻָ�վ����ʹ���� SUPERASYNC
ģʽ����������Ҫ�������Ͽ���ͨ��������Զ����������ӳٶ������ı�ѹ��ʵ��������ܡ�
���� 2��ʹ�� HADR ʵ�� DB2 �߿����ԺͶ�����ѻָ�
�ó����У������� Location 1 ��ʹ�� TSA ��Ⱥ��������Ҫ����������Ҫ���÷�����֮�佨���߿����ԡ��������ѻָ�������
Location 2 �Ͻ����������÷����� 1���� Location 3 �Ͻ����������÷����� 2����ͼ
8 ��ʾ��
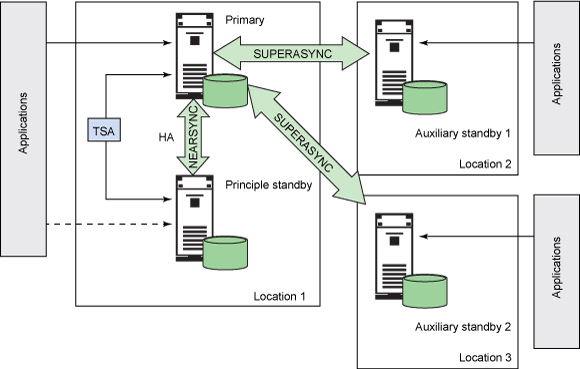
ͼ 8. ʹ�ö�����÷�����ʵ�ָ߿����ԺͶ�����ѻָ�
�û�Ӧ�ó�������Ҫ�������Ͻ������Ӳ�ִ������������־����Ҫ���������͵���Ҫ���÷�������ͬʱҲ���͵������������÷������ϡ���Ϊ�������÷���������
SUPERASYNC ģʽ�½����ģ����Բ�����Ϊ����������ӳٶ�Ӱ����Ҫ�������ϵĻ��
�����Ҫ�������������ϣ���ô��ͨ��ʹ�ü�Ⱥ���� (TSA) �Զ�������Ҫ���÷�������Ϊ��Ҫ�����������ҽ���־���µ���Ҫ���������͵��������÷�������
����� Location 1 �Ϸ������ѣ�����һ���������÷���������Ϊ��Ҫ���������ã�ͬʱӦ�ó�������ӵ�����µ���Ҫ��������������־���µ���Ҫ���������͵����౸�÷���������Ϊ�������ѻָ�վ����ʹ����
SUPERASYNC ģʽ����������Ҫ�������Ͽ���ͨ��������Զ����������ӳٲ����ı�ѹ��ʵ��������ܡ�
������
�ڱ����У����Ѿ��˽���ʹ�� SUPERASYNC ģʽ���ŵ��ȱ�㣬�ֱ��ǣ�
�� SUPERASYNC ģʽ�£�������Ӧʱ�����������ͬ��ģʽ��ʱ�䶼�̡����ǣ������Ҫϵͳ�������ϣ���ô���������ʧ�Ŀ���������������������Ҫϵͳ�ϵ���������������������������������Ӧʱ�䣬��ô��ģʽ�dz����á�
��Ҫ���ݿ��ϵ������ύ���� HADR ������÷�������Ӱ�졣����ܵ�����Ҫ���ݿ�ͱ������ݿ�����־�հ�
(log gap) �������ӡ��ϴ����־�հᵼ�������Ļָ�ʱ�䡣������ѷ�������Ҫϵͳ�ϣ���ô��־�հ��е��������ݶ�����ʧ����ˣ�ʹ��
hadr_log_gap ���Ԫ�ػ� db2pd �Chadr ��������־�հ�ʮ����Ҫ��������۲쵽�����ܵ���־�հף���ôӦ�õ����������ܻ������ݿ������ٶȣ�����ȡ������ʩ��������־�հס�
|


