| 一、hdfs介绍
hdfs设计原则
1.非常大的文件:
这里的非常大是指几百MB,GB,TB.雅虎的hadoop集群已经可以存储PB级别的数据
2.流式数据访问:
基于一次写,多次读。
3.商用硬件:
hdfs的高可用是用软件来解决,因此不需要昂贵的硬件来保障高可用性,各个生产商售卖的pc或者虚拟机即可。
hdfs不适用的场景
1.低延迟的数据访问
hdfs的强项在于大量的数据传输,递延迟不适合他,10毫秒以下的访问可以无视hdfs,不过hbase可以弥补这个缺陷。
2.太多小文件
namenode节点在内存中hold住了整个文件系统的元数据,因此文件的数量就会受到限制,每个文件的元数据大约150字节,1百万个文件,每个文件只占一个block,那么就需要300MB内存。你的服务器可以hold住多少呢,你可以自己算算
3.多处写和随机修改
目前还不支持多处写入以及通过偏移量随机修改
hdfs block
为了最小化查找时间比例,hdfs的块要比磁盘的块大很多。hdfs块的大小默认为64MB,和文件系统的块不同,hdfs的文件可以小于块大小,并且不会占满整个块大小。
查找时间在10ms左右,数据传输几率在100MB/s,为了使查找时间是传输时间的1%,块的大小必须在100MB左右,一般都会设置为128MB
有了块的抽象之后,hdfs有了三个优点:
1.可以存储比单个磁盘更大的文件
2.存储块比存储文件更加简单,每个块的大小都基本相同
3.使用块比文件更适合做容错性和高可用
namenodes和datanodes
hdfs集群有两种类型的节点,一种为master及namenode,另一种为worker及datanodes。
namenode节点管理文件系统的命名空间。它包含一个文件系统的树,所有文件和目录的原数据都在这个树上,这些信息被存储在本地磁盘的两个文件中,image文件和edit
log文件。文件相关的块存在哪个块中,块在哪个地方,这些信息都是在系统启动的时候加载到namenode的内存中,并不会存储在磁盘中。
datanode节点在文件系统中充当的角色就是苦力,按照namenode和client的指令进行存储或者检索block,并且周期性的向namenode节点报告它存了哪些文件的block。
namenode节点如果不能使用了,那么整个hdfs就玩完了。为了防止这种情况,有两种方式可供选择
1.namenode通过配置元数据可以写到多个磁盘中,最好是独立的磁盘,或者NFS.
2.使用第二namenode节点,第二namenode节点平时并不作为namenode节点工作,它的主要工作内容就是定期根据编辑日志(edit
log)合并命名空间的镜像(namespace image),防止编辑日志过大,合并后的image它自己也保留一份,等着namenode节点挂掉,然后它可以转正,由于不是实时的,有数据上的损失是很可能发生的。
hdfs Federation
namenode节点保持所有的文件和块的引用在内存中,这就意味着在一个拥有很多很多文件的很大的集群中,内存就成为了一个限制的条件,hdfs
federation在hadoop 2.x的被实现了,允许hdfs有多个namenode节点,每个管hdfs的一部分,比如一个管/usr,另一个管/home,每个namenode节点是相互隔离的,一个挂掉不会影响另外一个。
hdfs的高可用
不管namenode节点的备份还是第二namenode节点都只能保证数据的恢复,并不能保证hdfs的高可用性,一旦namenode节点挂掉就会产生单点故障,这时候要手动去数据备份恢复,或者启用第二节点,新的namenode节点在对外服务器要做三件事:
1.把命名空间的镜像加载到内存中
2.重新运行编辑日志
3.接受各个datanode节点的block报告
在一个大型一点的hdfs系统中,等这些做完需要30分钟左右。
2.x已经支持了高可用性(HA),通过一对namenode热备来实现,一台挂掉,备机马上提供无中断服务要实现HA,要做三点微调:
1.namenode节点必须使用高可用的共享存储。
2.datanode节点必须象两个namenode节点发送block报告
3.客户端做改动可以在故障时切换到可用的namenode节点上,而且要对用户是无感知的
failover和fencing
将备份namenode激活的过程就叫failover,管理激活备份namenode的系统叫做failover
controller,zookeeper就可以担当这样的角色,可以保证只有一个节点处于激活状态。
必须确认原来的namenode已经真的挂掉了,很多时候只是网络延迟,如果备份节点已经激活了,原来的节点又可以提供服务了,这样是不行的,防止原来namenode活过来的过程就叫fencing。
可以用STONITH实现, STONITH可以做到直接断电把原namenode节点fencing掉。
二、java访问hdfs
读数据
使用hadoop url读取
比较简单的读取hdfs数据的方法就是通过java.net.URL打开一个流,不过在这之前先要预先调用它的setURLStreamHandlerFactory方法设置为FsUrlStreamHandlerFactory(由此工厂取解析hdfs协议),这个方法只能调用一次,所以要写在静态块中。然后调用IOUtils类的copyBytes将hdfs数据流拷贝到标准输出流System.out中,copyBytes前两个参数好理解,一个输入,一个输出,第三个是缓存大小,第四个指定拷贝完毕后是否关闭流。我们这里要设置为false,标准输出流不关闭,我们要手动关闭输入流。
package com.sweetop.styhadoop;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
import java.net.URL;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-5-31
* Time: 上午10:16
* To change this template use File | Settings | File Templates.
*/
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
|
使用FileSystem API读取数据
首先是实例化FileSystem对象,通过FileSystem类的get方法,这里要传入一个java.net.URL和一个配置Configuration。然后FileSystem可以通过一个Path对象打开一个流,之后的操作和上面的例子一样
package com.sweetop.styhadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
import java.net.URI;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-5-31
* Time: 上午11:24
* To change this template use File | Settings | File Templates.
*/
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri=args[0];
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
InputStream in=null;
try {
in=fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
|
FSDataInputStream
通过FileSystem打开流返回的对象是个FSDataInputStream对象,该类实现了Seekable接口
public interface Seekable {
void seek(long l) throws java.io.IOException;
long getPos() throws java.io.IOException;
boolean seekToNewSource(long l) throws java.io.IOException;
} |
seek方法可跳到文件中的任意位置,我们这里跳到文件的初始位置再重新读一次
public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in=null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0);
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
} |
FSDataInputStream还实现了PositionedReadable接口
public interface PositionedReadable {
int read(long l, byte[] bytes, int i, int i1) throws java.io.IOException;
void readFully(long l, byte[] bytes, int i, int i1) throws java.io.IOException;
void readFully(long l, byte[] bytes) throws java.io.IOException;
}
|
可以在任意位置(第一个参数),偏移量(第三个参数),长度(第四个参数),到数组中(第二个参数)这里就不实现了,大家可以试下。
写数据
FileSystem类有很多种创建文件的方法,最简单的一种是public
FSDataOutputStream create(Path f) throws IOException
它还有很多重载方法,可以指定是否强制覆盖已存在的文件,文件的重复因子,写缓存的大小,文件的块大小,文件的权限等。还可以指定一个回调接口:
public interface Progressable {
void progress();
}
|
和普通文件系统一样,也支持apend操作,写日志时最常用public FSDataOutputStream
append(Path f) throws IOException,但并非所有hadoop文件系统都支持append,hdfs支持,s3就不支持。以下是个拷贝本地文件到hdfs的例子
package com.sweetop.styhadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-6-2
* Time: 下午4:54
* To change this template use File | Settings | File Templates.
*/
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() {
@Override
public void progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
|
目录
创建一个目录的方法:public boolean mkdirs(Path
f) throws IOException
mkdirs方法会自动创建所有不存在的父目录
检索
检索一个目录,查看目录和文件的信息在任何操作系统这些都是不可或缺的功能,hdfs也不例外,但也有一些特别的地方:
FileStatus
FileStatus 封装了hdfs文件和目录的元数据,包括文件的长度,块大小,重复数,修改时间,所有者,权限等信息,FileSystem的getFileStatus可以获得这些信息,
package com.sweetop.styhadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-6-2
* Time: 下午8:58
* To change this template use File | Settings | File Templates.
*/
public class ShowFileStatus {
public static void main(String[] args) throws IOException {
Path path = new Path(args[0]);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(args[0]), conf);
FileStatus status = fs.getFileStatus(path);
System.out.println("path = " + status.getPath());
System.out.println("owner = " + status.getOwner());
System.out.println("block size = " + status.getBlockSize());
System.out.println("permission = " + status.getPermission());
System.out.println("replication = " + status.getReplication());
}
}
|
Listing files
有时候你可能会需要找一组符合要求的文件,那么下面的示例就可以帮到你,通过FileSystem的listStatus方法可以获得符合条件的一组FileStatus对象,listStatus有几个重载的方法,可以传入多个路径,还可以使用PathFilter做过滤,我们下面就会讲到它。这里还有一个重要的方法,FileUtils.stat2Paths可以将一组FileStatus对象转换成一组Path对象,这是个非常便捷的方法。
package com.sweetop.styhadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-6-2
* Time: 下午10:09
* To change this template use File | Settings | File Templates.
*/
public class ListStatus {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length];
for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
} |
接着上面我们来讲PathFilter接口,该接口只需实现其中的一个方法即可,即accpet方法,方法返回true时表示被过滤掉,我们来实现一个正则过滤,并在下面的例子里起作用
package com.sweetop.styhadoop;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-6-3
* Time: 下午2:49
* To change this template use File | Settings | File Templates.
*/
public class RegexExludePathFilter implements PathFilter {
private final String regex;
public RegexExludePathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
} |
File patterns
当需要很多文件时,一个个列出路径是很不便捷的,hdfs提供了一个通配符列出文件的方法,通过FileSystem的globStatus方法提供了这个便捷,globStatus也有重载的方法,使用PathFilter过滤,那么我们结合两个来实现一下
package com.sweetop.styhadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
/**
* Created with IntelliJ IDEA.
* User: lastsweetop
* Date: 13-6-3
* Time: 下午2:37
* To change this template use File | Settings | File Templates.
*/
public class GlobStatus {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FileStatus[] status = fs.globStatus(new Path(uri),new RegexExludePathFilter("^.*/1901"));
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
}
|
删除数据
删除数据比较简单
public abstract boolean delete(Path f,
boolean recursive)
throws IOException
|
第一个参数很明确,第二个参数表示是否递归删除子目录或目录下的文件,在Path为目录但目录是空的或者Path为文件时可以忽略,但如果Path为目录且不为空的情况下,如果recursive为false,那么删除就会抛出io异常。
三、hdfs数据流
1、拓扑距离
这里简单讲下hadoop的网络拓扑距离的计算
在大数量的情景中,带宽是稀缺资源,如何充分利用带宽,完美的计算代价开销以及限制因素都太多。hadoop给出了这样的解决方案:
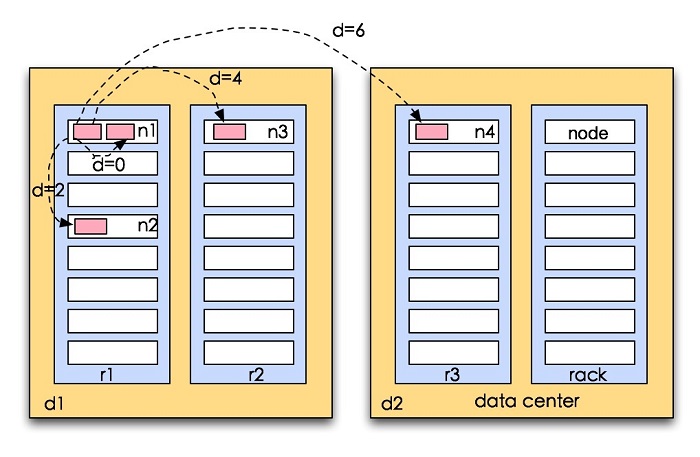
计算两个节点间的间距,采用最近距离的节点进行操作,如果你对数据结构比较熟悉的话,可以看出这里是距离测量算法的一个实例。
如果用数据结构表示的话,这里可以表示为tree,两个节点的距离计算就是寻找公共祖先的计算。
在现实情况下比较典型的情景如下,
tree结构的节点由数据中心data center,这里表示为d1,d2,机架rack,这里表示为r1,r2,r3,还有服务器节点node,这里表示为n1,n2,n3,n4
1.distance(d1/r1/n1,d1/r1/n1)=0 (相同节点)
2.distance(d1/r1/n1,d1/r1/n2)=2 (相同机架不同节点)
3.distance(d1/r1/n1,d1/r2/n3)=4 (相同数据中心不同机架)
4.distance(d1/r1/n1,d2/r3/n4)=6 (不同数据中心)
2、副本存放
先来定义一下,namenode节点选择一个datanode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。那么我们来看两个极端现象:
1.把所有的副本存放在同一个节点上,写带宽是保证了,但是这个可靠性是完全假的,一旦这个节点挂掉,数据就全没了,而且跨机架的读带宽也很低。
2.所有副本打散在不同的节点上,可靠性提高了,但是带宽有成了问题。
即使在同一个数据中心也有很多种副本存放方案,0.17.0版本中提供了一个相对较为均衡的方案,1.x之后副本存放方案已经是可选的了。
我们来讲下hadoop默认的方案:
1.把第一副本放在和客户端同一个节点上,如果客户端不在集群中,那么就会随即选一个节点存放。
2.第二个副本会在和第一个副本不同的机架上随机选一个
3.第三个副本会在第二个副本相同的机架上随机选一个不同的节点
4.剩余的副本就完全随机节点了。
如果重复因子是3的话,就会形成下图这样的网络拓扑:
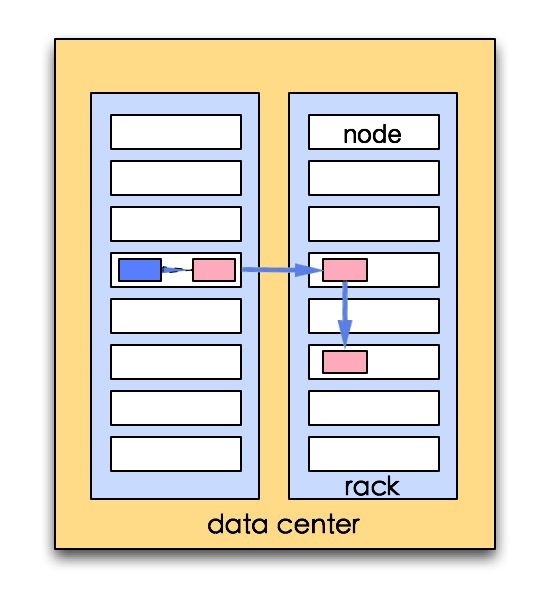
可以看出这个方案比较合理:
1.可靠性:block存储在两个机架上
2.写带宽:写操作仅仅穿过一个网络交换机
3.读操作:选择其中得一个机架去读
4.block分布在整个集群上。
3、读文件解析
图解读文件的数据流
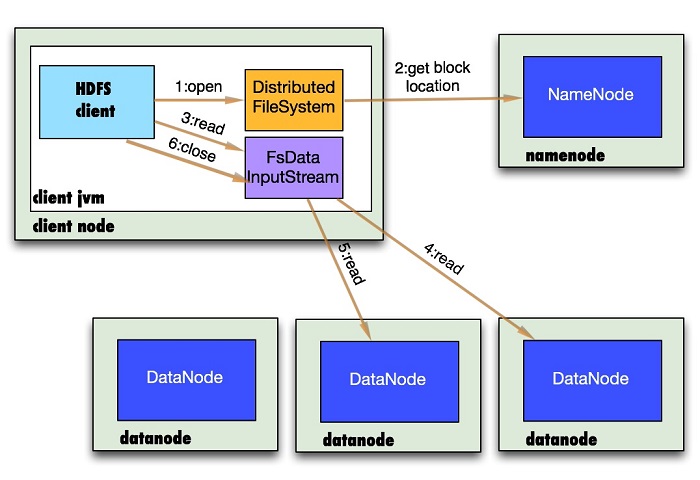
1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
2.DistributedFileSystem通过rpc获得文件的第一批个block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接(参考第一小节)。
4.数据从datanode源源不断的流向客户端。
5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像。
该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block
location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
4、写文件解析
图解写文件的数据流
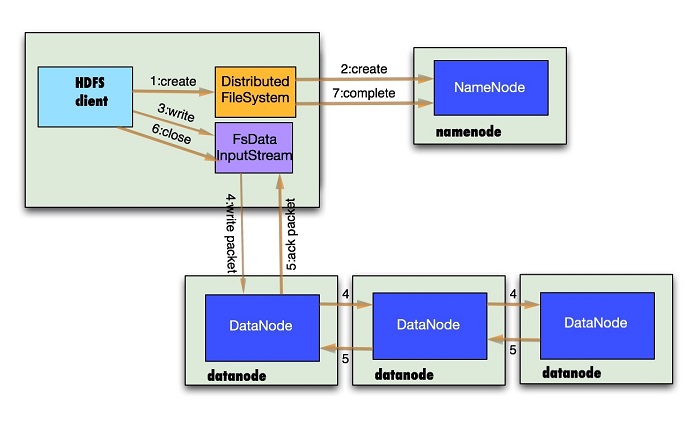
1.客户端通过调用DistributedFileSystem的create方法创建新文件
2.DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
3.前两步结束后会返回FSDataOutputStream的对象,象读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data
quene。
4.DataStreamer会去处理接受data quene,他先问询namenode这个新的block最适合存储的在哪几个datanode里(参考第二小节),比如重复数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
5.DFSOutputStream还有一个对列叫ack quene,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc
quene才会把对应的packet包移除掉。
如果在写的过程中某个datanode发生错误,会采取以下几步:1) pipeline被关闭掉;2)为了防止防止丢包ack
quene里的packet会同步到data quene里;3)把产生错误的datanode上当前在写但未完成的block删掉;4)block剩下的部分被写到剩下的两个正常的datanode中;5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.客户端完成写数据后调用close方法关闭写入流
7.DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
另外要注意得一点,客户端执行write操作后,写完得block才是可见的,正在写的block对客户端是不可见的,只有调用sync方法,客户端才确保该文件被写操作已经全部完成,当客户端调用close方法时会默认调用sync方法。是否需要手动调用取决你根据程序需要在数据健壮性和吞吐率之间的权衡。
四、distcp
我们前几篇文章讲的都是单线程的操作,如果要并行拷贝很多文件,hadoop提供了一个小工具distcp,最常见的用法就是在两个hadoop集群间拷贝文件,帮助文档很详尽,这里就不一一解释了,开发环境没有两个集群,用同一集群演示:
hadoop distcp hdfs://namenode:9000/user/hadoop/input
hdfs://namenode:9000/user/hadoop/input1
完整的options列表:
distcp [OPTIONS] *
OPTIONS:
-p[rbugp] Preserve status
r: replication number
b: block size
u: user
g: group
p: permission
-p alone is equivalent to -prbugp
-i Ignore failures
-log Write logs to
-m Maximum number of simultaneous copies
-overwrite Overwrite destination
-update Overwrite if src size different from dst size
-skipcrccheck Do not use CRC check to determine if src is
different from dest. Relevant only if -update
is specified
-f Use list at as src list
-filelimit Limit the total number of files to be <= n
-sizelimit Limit the total size to be <= n bytes
-delete Delete the files existing in the dst but not in src
-mapredSslConf Filename of SSL configuration for mapper task
|
看下distcp的执行结果你会发现,distcp是个MapReduce任务,但只有map没有reducer。
13/06/18 10:59:19 INFO tools.DistCp: srcPaths=[hftp://namenode:50070/user/hadoop/input]
13/06/18 10:59:19 INFO tools.DistCp: destPath=hdfs://namenode:9000/user/hadoop/input1
13/06/18 10:59:20 INFO tools.DistCp: hdfs://namenode:9000/user/hadoop/input1 does not exist.
13/06/18 10:59:20 INFO tools.DistCp: sourcePathsCount=3
13/06/18 10:59:20 INFO tools.DistCp: filesToCopyCount=2
13/06/18 10:59:20 INFO tools.DistCp: bytesToCopyCount=1.7m
13/06/18 10:59:20 INFO mapred.JobClient: Running job: job_201306131134_0009
13/06/18 10:59:21 INFO mapred.JobClient: map 0% reduce 0%
13/06/18 10:59:35 INFO mapred.JobClient: map 100% reduce 0% |
distcp把一大堆文件平均分摊开交给map去执行,每个文件单独一个map任务。那么默认会分成几个map合适呢?首先按256mb平均分,如果总大小低于256mb,distcp只会分配一个map。但如果平分得结果出现节点得map数大于20的情况,每个节点的map数就会按20算,看下流程图:
你可以通过-m手动设置,如果为了hdfs的均衡,最好是将maps设的多一些,将block分摊开来。
如果两个集群间的版本不一致,那么使用hdfs可能就会产生错误,因为rpc系统不兼容。那么这时候你可以使用基于http协议的hftp协议,但目标地址还必须是hdfs的,象这样:
hadoop distcp hftp://namenode:50070/user/hadoop/input
hdfs://namenode:9000/user/hadoop/input1
推荐用hftp的替代协议webhdfs,源地址和目标地址都可以使用webhdfs,可以完全兼容。
hadoop distcp webhdfs://namenode:50070/user/hadoop/input webhdfs://namenode:50070/user/hadoop/input1
|
|


