HBase中的所有数据文件都存储在Hadoop
HDFS文件系统上,主要包括两种文件类型:
1. HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2. HLog File,HBase中WAL(Write Ahead Log)
的存储格式,物理上是Hadoop的Sequence File
下面主要通过代码理解一下HFile的存储格式。
HFile
下图是HFile的存储格式:
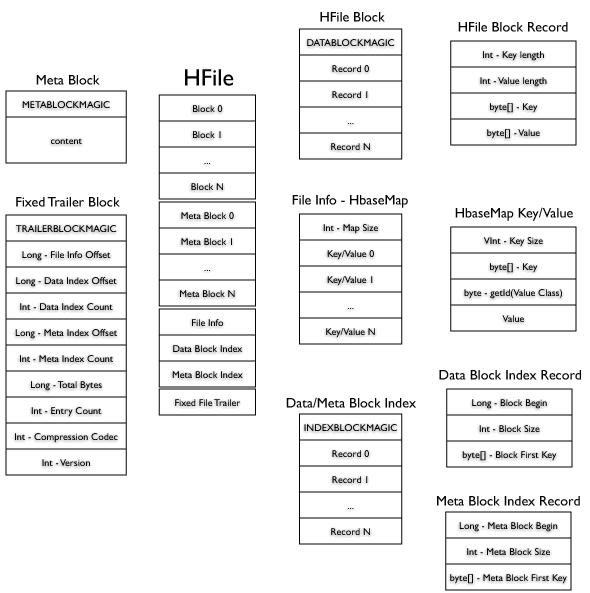
HFile由6部分组成的,其中数据KeyValue保存在Block 0
… N中,其他部分的功能有:确定Block Index的起始位置;确定某个key所在的Block位置(如block
index);判断一个key是否在这个HFile中(如Meta Block保存了Bloom Filter信息)。具体代码是在HFile.java中实现的,HFile内容是按照从上到下的顺序写入的(Data
Block、Meta Block、File Info、Data Block Index、Meta Block
Index、Fixed File Trailer)。
KeyValue: HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是
RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time
Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
Data Block:由DATABLOCKMAGIC和若干个record组成,其中record就是一个KeyValue(key
length, value length, key, value),默认大小是64k,小的数据块有利于随机读操作,而大的数据块则有利于scan操作,这是因为读KeyValue的时候,HBase会将查询到的data
block全部读到Lru Block Cache中去,而不是仅仅将这个record读到cache中去。
private void append(final byte [] key, final int koffset, final int klength, final
byte [] value, final int voffset, final int vlength) throws IOException {
this.out.writeInt(klength);
this.keylength += klength;
this.out.writeInt(vlength);
this.valuelength += vlength;
this.out.write(key, koffset, klength);
this.out.write(value, voffset, vlength);
}
|
Meta Block:由METABLOCKMAGIC和Bloom Filter信息组成。
public void close() throws IOException {
if (metaNames.size() > 0) {
for (int i = 0 ; i < metaNames.size() ; ++ i ) {
dos.write(METABLOCKMAGIC);
metaData.get(i).write(dos);
}
}
}
|
File Info: 由MapSize和若干个key/value,这里保存的是HFile的一些基本信息,如hfile.LASTKEY,
hfile.AVG_KEY_LEN, hfile.AVG_VALUE_LEN, hfile.COMPARATOR。
private long writeFileInfo(FSDataOutputStream o) throws IOException {
if (this.lastKeyBuffer != null) {
// Make a copy. The copy is stuffed into HMapWritable. Needs a clean
// byte buffer. Won’t take a tuple.
byte [] b = new byte[this.lastKeyLength];
System.arraycopy(this.lastKeyBuffer, this.lastKeyOffset, b, 0, this.lastKeyLength);
appendFileInfo(this.fileinfo, FileInfo.LASTKEY, b, false);
}
int avgKeyLen = this.entryCount == 0? 0: (int)(this.keylength/this.entryCount);
appendFileInfo(this.fileinfo, FileInfo.AVG_KEY_LEN, Bytes.toBytes(avgKeyLen), false);
int avgValueLen = this.entryCount == 0? 0: (int)(this.valuelength/this.entryCount);
appendFileInfo(this.fileinfo, FileInfo.AVG_VALUE_LEN,
Bytes.toBytes(avgValueLen), false);
appendFileInfo(this.fileinfo, FileInfo.COMPARATOR, Bytes.toBytes(this.comparator.getClass().getName()), false);
long pos = o.getPos();
this.fileinfo.write(o);
return pos;
}
|
Data/Meta Block Index: 由INDEXBLOCKMAGIC和若干个record组成,而每一个record由3个部分组成
― block的起始位置,block的大小,block中的第一个key。
static long writeIndex(final FSDataOutputStream o, final List keys, final List offsets, final List sizes) throws IOException {
long pos = o.getPos();
// Don’t write an index if nothing in the index.
if (keys.size() > 0) {
o.write(INDEXBLOCKMAGIC);
// Write the index.
for (int i = 0; i < keys.size(); ++i) {
o.writeLong(offsets.get(i).longValue());
o.writeInt(sizes.get(i).intValue());
byte [] key = keys.get(i);
Bytes.writeByteArray(o, key);
}
}
return pos;
}
|
Fixed file trailer: 大小固定,主要是可以根据它查找到File Info, Block
Index的起始位置。
public void close() throws IOException {
trailer.fileinfoOffset = writeFileInfo(this.outputStream);
trailer.dataIndexOffset = BlockIndex.writeIndex(this.outputStream,
this.blockKeys, this.blockOffsets, this.blockDataSizes);
if (metaNames.size() > 0) {
trailer.metaIndexOffset = BlockIndex.writeIndex(this.outputStream,
this.metaNames, metaOffsets, metaDataSizes);
}
trailer.dataIndexCount = blockKeys.size();
trailer.metaIndexCount = metaNames.size();
trailer.totalUncompressedBytes = totalBytes;
trailer.entryCount = entryCount;
trailer.compressionCodec = this.compressAlgo.ordinal();
trailer.serialize(outputStream);
}
|
注:上面的代码剪切自HFile.java中的代码,更多信息可以查看Hbase源代码。 |


