| 简介:
在 Web 2.0 时代,NoSQL 数据存储(比如 Bigtable 和 CouchDB)从边缘进入主流,因为它们能够解决伸缩性问题,而且能够大规模解决该问题。Google
和 Facebook 只是已经开始使用 NoSQL 数据存储的两家知名公司,我们仍然处于使用 NoSQL
数据存储的早期阶段。无模式数据存储与传统的关系数据库存在根本区别,但是利用它们比您想象的要简单得多,尤其是当您从一个域模型而不是一个关系模型开始时。
关系数据库已经统治数据存储 30 多年了,但是无模式(或 NoSQL)数据库的逐渐流行表明变化正在发生。尽管
RDBMS 为在传统的客户端 - 服务器架构中存储数据提供了一个坚实的基础,但它不能轻松地(或便宜地)扩展到多个节点。在高度可伸缩的
Web 应用程序(比如 Facebook 和 Twitter)的时代,这是一个非常不幸的弱点。
尽管关系数据库的早期替代方案(还记得面向对象的数据库吗?)不能解决真正紧急的问题,NoSQL
数据库(比如 Google 的 Bigtable 和 Amazon 的 SimpleDB)却作为对 Web
的高可伸缩性需求的直接响应而崛起。本质上,NoSQL 可能是一个杀手问题的杀手应用程序 ―随着 Web
2.0 的演变,Web 应用程序开发人员可能会遇到更多,而不是更少这样的应用程序。
在这期 Java 开发 2.0 中,我将向您介绍无模式数据建模,这是经过关系思维模式训练的许多开发人员使用
NoSQL 的主要障碍。您将了解到,从一个域模型(而不是关系模型)入手是简化您的改变的关键。如果您使用
Bigtable(如我的示例所示),您可以借助 Gaelyk:Google App Engine 的一个轻量级框架扩展。
NoSQL:一种新的思维方式?
当开发人员谈论非关系或 NoSQL 数据库时,经常提到的第一件事是他们需要改变思维方式。我认为,那实际上取决于您的初始数据建模方法。如果您习惯通过首先建模数据库结构(即首先确定表及其关联关系)来设计应用程序,那么使用一个无模式数据存储(比如
Bigtable)来进行数据建模则需要您重新思考您的做事方式。但是,如果您从域模型开始设计您的应用程序,那么
Bigtable 的无模式结构将看起来更自然。
为实现伸缩性而构建
伴随高度可伸缩的 Web 应用程序面临的新问题而来的是一些新的解决方案。Facebook
并不依赖于一个关系数据库来解决其存储需求;相反,它使用一个 “键 / 值” 存储 ―主要是一个高性能 HashMap。称为
Cassandra 的内部解决方案也被 Twitter 和 Digg 使用,并在最近捐献给了 Apache
Software Foundation。Google 是另一个 Web 实体,它的爆炸式增长要求它寻求一个非关系数据存储
―Bigtable 就是寻求的结果。
非关系数据存储没有联接表或主键,甚至没有外键这个概念(尽管这两种类型的键以一种更松散的形式出现)。因此,如果您尝试将关系建模作为一个
NoSQL 数据库中的数据建模的基础,那么您可能最后以失败告终。从域模型开始将使事情变得简单;实际上,我已经发现,域模型下的无模式结构的灵活性正在重新焕发生机。
从关系数据模型迁移到无模式数据模型的相对复杂程度取决于您的方法:即您从基于关系的设计开始还是从基于域的设计开始。当您迁移到
CouchDB 或 Bigtable 这样的数据库时,您 的确会丧失 Hibernate(至少现在)这样的成熟的持久存储平台的顺畅感觉。另一方面,您却拥有能够亲自构建它的
“绿地效果”。在此过程中,您将深入了解无模式数据存储。
实体和关系
无模式数据存储赋予您首先使用对象来设计域模型的灵活性(Grails 这样的较新的框架自动支持这种灵活性)。您的下一步工作是将您的域映射到底层数据存储,这在使用
Google App Engine 时再简单不过了。
在文章 “Java 开发 2.0:针对 Google App Engine
的 Gaelyk” 中,我介绍了 Gaelyk ―― 一个基于 Groovy 的框架,该框架有利于使用
Google 的底层数据存储。那篇文章的主要部分关注如何利用 Google 的 Entity对象。下面的示例(来自那篇文章)将展示对象实体如何在
Gaelyk 中工作。
清单 1. 使用 Entity
的对象持久存储
def ticket = new Entity("ticket")
ticket.officer = params.officer
ticket.license = params.plate
ticket.issuseDate = offensedate
ticket.location = params.location
ticket.notes = params.notes
ticket.offense = params.offense
|
通过对象设计
倾向于对象模型而不是数据库的设计的模式在 Grails 和 Ruby on
Rails 这样的现代 Web 应用程序框架中展现出来,这些现代 Web 应用程序框架强调对象模型的设计,并为您处理底层数据库架构创建。
这种对象持久存储方法很有效,但容易看出,如果您频繁使用票据实体 ―例如,如果您正在各种
servlet 中创建(或查找)它们,那么这种方法将变得令人厌烦。使用一个公共 servlet(或 Groovlet)来为您处理这些任务将消除其中一些负担。一种更自然的选择
―我将稍后展示 ―将是建模一个 Ticket对象。
返回比赛
我不会重复 Gaelyk 简介中的那个票据示例,相反,为保持新鲜感,我将在本文中使用一个赛跑主题,并构建一个应用程序来展示即将讨论的技术。
如图 1 中的 “多对多” 图表所示,一个 Race拥有多个 Runner,一个
Runner可以属于多个 Race。

图 1. 比赛和参赛者
如果我要使用一个关系表结构来设计这个关系,至少需要 3 个表:第 3
表将是链接一个 “多对多” 关系的联接表。所幸我不必局限于关系数据模型。相反,我将使用 Gaelyk(和
Groovy 代码)将这个 “多对多” 关系映射到 Google 针对 Google App Engine
的 Bigtable 抽象。事实上,Gaelyk 允许将 Entity当作 Map,这使得映射过程相当简单。
通过 Shards 伸缩
Sharding是一种分区形式,它将一个表结构复制到多个节点,但逻辑上在各节点之间划分数据。例如,一个节点可以拥有驻留在美国的帐户的所有相关数据,而另一个节点则针对驻留在欧洲的所有帐户。但如果节点拥有关系
―即跨 Shard 联接,Shards 就会出现问题。这是一个棘手的问题,在很多情况下都无法解决。(参见
参考资料中的链接,参考我和 Google 的 Max Ross 关于 sharding 和使用关系数据库的可伸缩性挑战的讨论。)
无模式数据存储的好处之一是无须事先知道所有事情,也就是说,与使用关系数据库架构相比,可以更轻松地适应变化。(注意,我并非暗示不能更改架构;我只是说,可以更轻松地适应变化。)我不打算定义我的域对象上的属性
―我将其推迟到 Groovy 的动态特性(实际上,这个特性允许创建针对 Google 的 Entity对象的域对象代理)。相反,我将把我的时间花费在确定如何查找对象并处理关系上。这是
NoSQL 和各种利用无模式数据存储的框架还没有内置的功能。
Model 基类
我将首先创建一个基类,用于容纳 Entity对象的一个实例。然后,我将允许一些子类拥有一些动态属性,这些动态属性将通过
Groovy 的方便的 setProperty方法添加到对应的 Entity实例。setProperty针对对象中实际上不存在的任何属性设置程序调用。(如果这听起来耸人听闻,不用担心,您看到它的实际运行后就会明白。)
清单 2 展示了位于我的示例应用程序的一个 Model实例的第一个 stab:
清单 2. 一个简单的 Model
基类
package com.b50.nosql
import com.google.appengine.api.datastore.DatastoreServiceFactory
import com.google.appengine.api.datastore.Entity
abstract class Model {
def entity
static def datastore = DatastoreServiceFactory.datastoreService
public Model(){
super()
}
public Model(params){
this.@entity = new Entity(this.getClass().simpleName)
params.each{ key, val ->
this.setProperty key, val
}
}
def getProperty(String name) {
if(name.equals("id")){
return entity.key.id
}else{
return entity."${name}"
}
}
void setProperty(String name, value) {
entity."${name}" = value
}
def save(){
this.entity.save()
}
}
|
注意抽象类如何定义一个构造函数,该函数接收属性的一个 Map ―我总是可以稍后添加更多构造函数,稍后我就会这么做。这个设置对于
Web 框架十分方便,这些框架通常采用从表单提交的参数。Gaelyk 和 Grails 将这样的参数巧妙地封装到一个称为
params的对象中。这个构造函数迭代这个 Map并针对每个 “键 / 值” 对调用 setProperty方法。
检查一下 setProperty方法就会发现 “键” 设置为底层 entity的属性名称,而对应的
“值” 是该 entity的值。
Groovy 技巧
如前所述,Groovy 的动态特性允许我通过 get和 set Property方法捕获对不存在的属性的方法调用。这样,清单
2 中的 Model的子类不必定义它们自己的属性 ―它们只是将对一个属性的所有调用委托给这个底层 entity对象。
清单 2 中的代码执行了一些特定于 Groovy 的操作,值得一提。首先,可以通过在一个属性前面附加一个
@来绕过该属性的访问器方法。我必须对构造函数中的 entity对象引用执行上述操作,否则我将调用 setProperty方法。很明显,在这个关头调用
setProperty将打破这种模式,因为 setProperty方法中的 entity变量将是 null。
其次,构造函数中的调用 this.getClass().simpleName将设置
entity的 “种类” ― simpleName属性将生成一个不带包前缀的子类名称(注意,simpleName的确是对
getSimpleName的调用,但 Groovy 允许我不通过对应的 JavaBeans 式的方法调用来尝试访问一个属性)。
最后,如果对 id属性(即,对象的键)进行一个调用,getProperty方法很智能,能够询问底层
key以获取它的 id。在 Google App Engine 中,entities的 key属性将自动生成。
Race 子类
定义 Race子类很简单,如清单 3 所示:
清单 3. 一个 Race
子类
package com.b50.nosql
class Race extends Model {
public Race(params){
super(params)
}
}
|
当一个子类使用一列参数(即一个包含多个 “键 / 值” 对的 Map)实例化时,一个对应的
entity将在内存中创建。要持久存储它,只需调用 save方法。
清单 4. 创建一个 Race
实例并将其保存到 GAE 的数据存储
import com.b50.nosql.Runner
def iparams = [:]
def formatter = new SimpleDateFormat("MM/dd/yyyy")
def rdate = formatter.parse("04/17/2010")
iparams["name"] = "Charlottesville Marathon"
iparams["date"] = rdate
iparams["distance"] = 26.2 as double
def race = new Race(iparams)
race.save()
|
清单 4 是一个 Groovlet,其中,一个 Map(称为 iparams)创建为带有
3 个属性 ―一次比赛的名称、日期和距离。(注意,在 Groovy 中,一个空白 Map通过 [:]创建。)Race的一个新实例被创建,然后通过
save方法存储到底层数据存储。
可以通过 Google App Engine 控制台来查看底层数据存储,确保我的数据的确在那里,如图
2 所示:
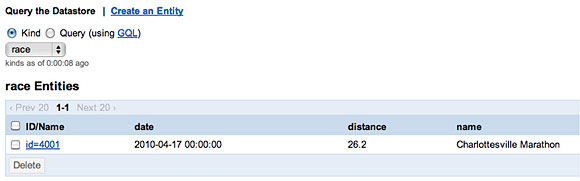
图 2. 查看新创建的 Race
查找程序方法生成持久存储的实体
现在我已经存储了一个 Entity,拥有查找它的能力将有所帮助。接下来,我可以添加一个
“查找程序” 方法。在本例中,我将把这个 “查找程序” 方法创建为一个类方法(static)并且允许通过名称查找这些
Race(即基于 name属性搜索)。稍后,总是可以通过其他属性添加其他查找程序。
我还打算对我的查找程序采用一个惯例,即指定:任何名称中不带单词 all的查找程序都企图找到
一个实例。名称中包含单词 all的查找程序(如 findAllByName)能够返回一个实例 Collection或
List。清单 5 展示了 findByName查找程序:
清单 5. 一个基于 Entity
名称搜索的简单查找程序
static def findByName(name){
def query = new Query(Race.class.simpleName)
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
if(preparedQuery.countEntities() > 1){
return new Race(preparedQuery.asList(withLimit(1))[0])
}else{
return new Race(preparedQuery.asSingleEntity())
}
}
|
这个简单的查找程序使用 Google App Engine 的 Query和
PreparedQuery类型来查找一个类型为 “Race” 的实体,其名称(完全)等同于传入的名称。如果有超过一个
Race符合这个标准,查找程序将返回一个列表的第一项,这是分页限制 1(withLimit(1))所指定的。
对应的 findAllByName与上述方法类似,但添加了一个参数,指定
您想要的实体个数,如清单 6 所示:
清单 6. 通过名称找到全部实体
static def findAllByName(name, pagination=10){
def query = new Query(Race.class.getSimpleName())
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
def entities = preparedQuery.asList(withLimit(pagination as int))
return entities.collect { new Race(it as Entity) }
}
|
与前面定义的查找程序类似,findAllByName通过名称找到 Race实例,但是它返回
所有 Race。顺便说一下,Groovy 的 collect方法非常灵活:它允许删除创建 Race实例的对应的循环。注意,Groovy
还支持方法参数的默认值;这样,如果我没有传入第 2 个值,pagination将拥有值 10。
清单 7. 查找程序的实际运行
def nrace = Race.findByName("Charlottesville Marathon")
assert nrace.distance == 26.2
def races = Race.findAllByName("Charlottesville Marathon")
assert races.class == ArrayList.class
|
清单 7中的查找程序按照既定的方式运行:findByName返回一个实例,而
findAllByName返回一个 Collection(假定有多个 “Charlottesville
Marathon”)。
“参赛者” 对象没有太多不同
现在我已能够创建并找到 Race的实例,现在可以创建一个快速的 Runner对象了。这个过程与创建初始的
Race实例一样简单,只需如清单 8 所示扩展 Model:
清单 8. 创建一个参赛者很简单
package com.b50.nosql
class Runner extends Model{
public Runner(params){
super(params)
}
}
|
看看 清单 8,我感觉自己几乎完成工作了。但是,我还需创建参赛者和比赛之间的链接。当然,我将把它建模为一个
“多对多” 关系,因为我希望我的参赛者可以参加多项比赛。
没有架构的域建模
Google App Engine 在 Bigtable 上面的抽象不是一个面向对象的抽象;即,我不能原样存储关系,但可以共享键。因此,为建模多个
Race和多个 Runner之间的关系,我将在每个 Race实例中存储一列 Runner键,并在每个 Runner实例中存储一列
Race键。
我必须对我的键共享机制添加一点逻辑,但是,因为我希望生成的 API 比较自然
―我不想询问一个 Race以获取一列 Runner键,因此我想要一列 Runner。幸运的是,这并不难实现。
在清单 9 中,我已经添加了两个方法到 Race实例。但一个 Runner实例被传递到
addRunner方法时,它的对应 id被添加到底层 entity的 runners属性中驻留的 id的
Collection。如果有一个现成的 runners的 collection,则新的 Runner实例键将添加到它;否则,将创建一个新的
Collection,且这个 Runner的键(实体上的 id属性)将添加到它。
清单 9. 添加并检索参赛者
def addRunner(runner){
if(this.@entity.runners){
this.@entity.runners << runner.id
}else{
this.@entity.runners = [runner.id]
}
}
def getRunners(){
return this.@entity.runners.collect {
new Runner( this.getEntity(Runner.class.simpleName, it) )
}
}
|
当清单 9 中的 getRunners方法调用时,一个 Runner实例集合将从底层的
id集合创建。这样,一个新方法(getEntity)将在 Model类中创建,如清单 10 所示:
清单 10. 从一个 id
创建一个实体
def getEntity(entityType, id){
def key = KeyFactory.createKey(entityType, id)
return this.@datastore.get(key)
}
|
getEntity方法使用 Google 的 KeyFactory类来创建底层键,它可以用于查找数据存储中的一个单独实体。
最后,定义一个新的构造函数来接受一个实体类型,如清单 11 所示:
清单 11. 一个新添加的构造函数
public Model(Entity entity){
this.@entity = entity
}
|
如清单 9、10和 11、以及 图 1的对象模型所示,我可以将一个 Runner添加到任一
Race,也可以从任一 Race获取一列 Runner实例。在清单 12 中,我在这个等式的 Runner方上创建了一个类似的联系。清单
12 展示了 Runner类的新方法。
清单 12. 参赛者及其比赛
def addRace(race){
if(this.@entity.races){
this.@entity.races << race.id
}else{
this.@entity.races = [race.id]
}
}
def getRaces(){
return this.@entity.races.collect {
new Race( this.getEntity(Race.class.simpleName, it) )
}
}
|
这样,我就使用一个无模式数据存储创建了两个域对象。
通过一些参赛者完成这个比赛
此前我所做的是创建一个 Runner实例并将其添加到一个 Race。如果我希望这个关系是双向的,如
图 1中我的对象模型所示,那么我也可以添加一些 Race实例到一些 Runner,如清单 13 所示:
清单 13. 参加多个比赛的多个参赛者
def runner = new Runner([fname:"Chris", lname:"Smith", date:34])
runner.save()
race.addRunner(runner)
race.save()
runner.addRace(race)
runner.save()
|
将一个新的 Runner添加到 race并添加对 Race的 save的调用后,这个数据存储已使用一列
ID 更新,如图 3 中的屏幕快照所示:
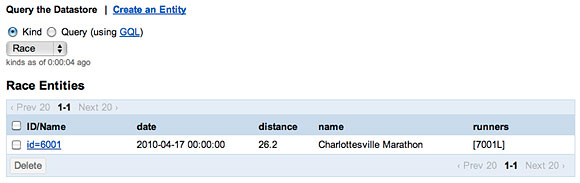
图 3. 查看一项比赛中的多个参赛者的新属性
通过仔细检查 Google App Engine 中的数据,可以看到,一个
Race实体现在拥有了一个 Runners 的 list,如图 4 所示。
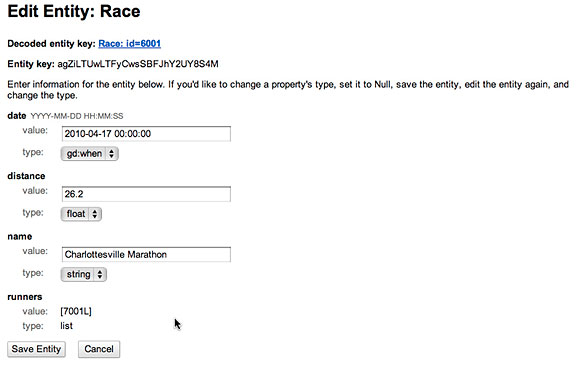
图 4. 查看新的参赛者列表
同样,在将一个 Race添加到一个新创建的 Runner实例之前,这个属性并不存在,如图
5 所示。
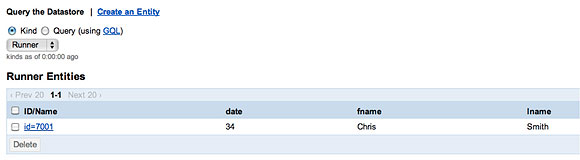
图 5. 一个没有比赛的参赛者
但是,将一个 Race关联到一个 Runner后,数据存储将添加新的
races ids 的 list。
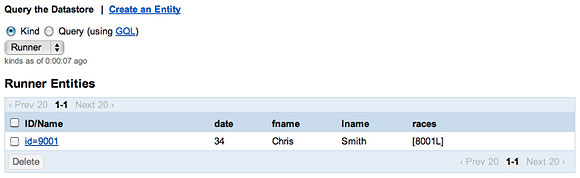
图 6. 一个参加比赛的参赛者
无模式数据存储的灵活性正在刷新 ―属性按照需要自动添加到底层存储。作为开发人员,我无须更新或更改架构,更谈不上部署架构了!
NoSQL 的利弊
当然,无模式数据建模也有利有弊。回顾上面的比赛应用程序,它的一个优势是非常灵活。如果我决定将一个新属性(比如
SSN)添加到一个 Runner,我不必进行大幅更改 ―事实上,如果我将该属性包含在构造函数的参数中,那么它就会自动添加。对那些没有使用一个
SSN 创建的旧实例而言,发生了什么事情?什么也没发生!它们拥有一个值为 null的字段。
快速阅读器
在 “NoSQL 与关系模型孰优孰劣” 的争论中,速度是一个重要因素。对于一个为潜在的数百万用户传输数据的现代
Web 站点(想想 Facebook 的 4 亿用户和计数)来说,关系模型的速度太慢了,更不用说其高昂的成本。相比之下,NoSQL
的数据存储的读取速度非常快。
另一方面,我已经明确表明要牺牲一致性和完整性来换取效率。这个应用程序的当前数据架构没有向我施加任何限制
―理论上我可以为同一个对象创建无限个实例。在 Google App Engine 引擎的键处理机制下,它们都有惟一的键,但其他属性都是一致的。更糟糕的是,级联删除不存在,因此如果我使用相同的技术来建模一个
“一对多” 关系并删除父节点,那么我得到一些无效的子节点。当然,我可以实现自己的完整性检查 ―但关键是,我必须亲自动手(就像完成其他任务一样)。
使用无模式数据存储需要严明的纪律。如果我创建各种类型的 Races ―有些有名称,有些没有,有些有
date属性,而另一些有 race_date属性 ―那么我只是在搬起石头砸自己(或使用我的代码的人)的脚。
当然,也有可能联合使用 JDO、JPA 和 Google App Engine。在多个项目上使用过关系模型和无模式模型后,我可以说
Gaelyk 的低级 API 最灵活,使用最方便。使用 Gaelyk 的另一个好处是能够深入了解 Bigtable
和一般的无模式数据存储。
结束语
流行时尚来了又去,有时无需理会它们(明智的建议来自一个衣橱里满是休闲服的家伙)。但
NoSQL 看起来不太像一种时尚,更像是高度可伸缩的 Web 应用程序开发的一个新兴基础。NoSQL 数据库不会替代
RDBMS,但是,它们将补充它。无数成功的工具和框架基于关系数据库,RDBMSs 本身似乎没有面临过时的危险。
总之,NoSQL 数据库的作用是向对象 - 关系数据模型提供一个及时的替代方案。它们向我们展示,有些事情是可行的,并且
―对于一些特定的、高度强制的用例 ―甚至更好。无模式数据库最适用于需要高速数据检索和可伸缩性的多节点 Web
应用程序。它们还有一个极好的副作用,即允许开发人员从一个面向域的视角、而不是关系视角进行数据建模。
参考资料
- Java 开发 2.0 :这个 developerWorks 系列探讨正在重新定义 Java
开发面貌的技术和工具,包括 Gaelyk(2009 年 12 月)、Google App Engine(2009
年 8 月)和 CouchDB(2009 年 12 月)。
- “NoSQL Patterns”(Ricky Ho,Pragmatic Programming
Techniques,2009 年 11 月):一个 NoSQL 数据库列表和概览,以及对 NoSQL
数据存储的公共架构的深入检查。
- “Saying Yes to NoSQL; Going Steady with Cassandra”(John
Quinn,Digg Blogs,2010 年 3 月):Digg 的工程副总裁解释从 MySQL
转到 Cassandra 的决策。
- “Sharding with Max Ross”(JavaWorld 播客,2008 年 7 月):Andrew
Glover 和 Google 的 Max Ross 谈论 Hibernate Shards 的 sharding
和开发技术。
- “Is the Relational Database Doomed?”(Tony Bain,ReadWriteEnterprise,2009
年 2 月):随着非关系数据库在云内外不断涌现,一条清晰的信息出现了:“如果您想要巨大的、按需提供的可伸缩性,您就需要一个非关系数据库。”
- “Google App Engine for Java:第 3 部分:持久性和关系”(Richard
Hightower,developerWorks,2009 年 8 月):Rick Hightower
解释 Google App Engine 当前的基于 Java 的持久存储框架的缺点,并讨论一些解决方案。
- “用 Amazon Web Services 进行云计算,第 5 部分:用 SimpleDB 在云中处理数据集”(Prabhakar
Chaganti,developerWorks,2009 年 2 月):了解 Amazon 的 SimpleDB
的概念,并探索用于与 SimpleDB 交互的一个开源 Python 库(boto)的一些函数。
- “Bigtable: A Distributed Storage System for Structured
Data”(Fay Chang 等,Google,2006 年 11 月):Bigtable 是一个用于管理结构化数据的分布式存储系统,设计用于伸缩到非常大的规模:跨数千个商品服务器的数
P 字节数据。
- “The Vietnam of Computer Science”(Ted Neward,2006
年 6 月):应对将对象映射到关系模型的相关挑战。
- 浏览 技术书店,阅读关于这些和其他技术主题的图书。
- developerWorks Java 技术专区:这里有数百篇关于 Java 编程各个方面的文章。
|


