| 简介
在过去二十年中,计算能力的稳步增强催生了铺天盖地的数据量,这反过来引起计算架构和大型数据处理机制的范式转换。例如,天文学中的强大望远镜、物理学中的粒子加速器、生物学中的基因组测序系统都将海量数据交到了科学家手中。Facebook
每天会收集 15TB 的数据到 PB 级的数据仓库中。在业界(例如,Web 数据分析、点击流分析和网络监控日志分析)和科学界(例如,大规模模拟产生的数据的分析、传感器部署以及高吞吐量实验室设备),对大型数据挖掘和数据分析应用的需求都在增加。尽管并行数据库系统适用于这些数据分析应用中的其中一些,但是它们太过昂贵,难以管理,并缺乏对长期运行查询的容错性。
MapReduce 是 Google 引入的一个框架,用于编程商品计算机集群,以便在单个传递中执行大型数据处理。该框架被设计为:一个
MapReduce 集群可以通过容错的方式扩展到上千个节点。但是 MapReduce 编程模型有其自身的限制。它的单输入、两阶段数据流过于严格,而且层次过低。例如,即使最常见的运算您都得编写自定义代码。因此,许多程序员感觉
MapReduce 框架使用起来不自在,而更倾向于使用 SQL 作为一种高级声明式语言。已经开发了很多项目(Apache
Pig、Apache Hive 和 HadoopDB)来简化程序员的任务,并在 MapReduce 框架之上提供高级声明式接口。
首先了解一下 MapReduce 框架,然后查看向 MapReduce
框架提供高级接口的不同系统的功能。
MapReduce 框架
MapReduce 框架方法的一个主要优势在于,它将应用程序与运行分布式程序的细节分离开来,比如数据分布、调度和容错问题。在该模型中,计算功能利用一组输入键/值对,并产生一组输出键/值对。MapReduce
框架的用户使用两个函数来表达计算:Map 和 Reduce。Map 函数利用输入对,并生成一组中间键/值对。MapReduce
框架将与同一中间键 I (shuffling) 相关的所有中间值组合起来,将它们传递给 Reduce 函数。reduce
函数收到一个中间键 I 及其一组值,并将它们合并起来。通常,每个 reduce 调用只产生 0 或 1
个输出值。该模型的主要优势是,支持轻松并行化和重新执行大型计算以用作主要容错机制。
Apache Hadoop 项目是一个开源 Java? 软件,它通过实现
MapReduce 框架来支持数据密集型分布式应用程序。它最初由 Yahoo! 开发,作为 Google
MapReduce 基础架构的一个翻版,不过随后它变得具有开源性。Hadoop 负责跨计算机集群运行代码。一般而言,当一个数据集增长到超出单个物理机的存储容量时,就有必要跨大量不同的计算机对其进行分区。跨计算机集群管理存储的文件系统称为分布式文件系统。Hadoop
随附有一个名为 HDFS (Hadoop Distributed Filesystem) 的分布式文件系统。特别地,HDFS
是跨 Hadoop 集群的所有节点存储文件的一个分布式文件系统。它将文件分为大数据块并将它们分布到不同的计算机上,为每个数据块制作多个副本,这样一来,如果有任何一台计算机发生故障,数据也不会丢失。
清单 1 中的 MapReduce 程序使用伪代码表达,用于计算每个单词在文本行序列中出现的次数。在
清单 1 中,map 函数发出每个单词以及一个相关的发生标记,而 reduce 函数对特定单词发出的所有标记进行汇总。
清单 1. MapReduce 程序
map(String key, String value):
//key: line number, value: line text
for each word w in value:
EmitIntermediate(w, ?1?);
reduce(String key, Iterator values):
//key: a word, values: a list of counts
int wordCount = 0;
for each v in values:
wordCount += ParseInt(v);
Emit(AsString(wordCount)); |
现在采用 清单 2 中文本行的输入序列。
清单 2. 输入序列
1, This is Code Example
2, Example Color is Red
3, Car Color is Green |
清单 3 显示该输入的 map 函数的输出。
清单 3. map 函数的输出
('This', 1), ('is', 1). ('Code', 1), ('Example', 1)
('Example', 1), ('Color', 1), ('is', 1), ('Red', 1)
('Car', 1), ('Color', 1), ('is', 1), ('Green', 1) |
清单 4 显示 reduce 函数的输出(结果)。
清单 4. reduce 函数的输出
('Car', 1), ('Code', 1), ('Color', 2), ('Example', 2), ('Green', 1), ('Red', 1)
, ('This', 1), ('is', 3) |
对于程序员来说,MapReduce 框架的一个主要特性是,只有两个高级声明原语(map
和 reduce)可以使用选择的任何编程语言编写,而无需担心其并行执行的细节。另一方面,MapReduce
编程模型具有其自身的局限:
- 它的单输入、两阶段数据流过于严格。要执行具有不同数据流的任务(例如,联接或 n 阶段),您必须得想出粗略的解决方法。
- 即使最常见的运算(例如,projection 和 filter)都得编写自定义代码,这导致代码通常难以重用和维护。
- map 和 reduce 函数的不透明性限制了系统执行优化的能力。
而且,许多程序员不熟悉 MapReduce 框架,倾向于使用 SQL(因为他们对此更精通)作为高级声明式语言来表达其任务,同时将所有执行优化细节留给后台引擎。此外,不可否认的是,高级语言抽象能够让底层系统更好地执行自动优化。
我们来看一下旨在应对这些问题的语言和系统,并且在 MapReduce
框架之上添加 SQL 类语言。
Pig
Apache Pig 项目旨在作为 Hadoop 上并行执行数据的一个引擎。它使用一种名为
Pig Latin 的语言来表达这些数据流。使用 Pig Latin,您可以描述应当如何并行读取和处理来自一个或多个输入的数据,然后将其存储到一个或多个输出中。该语言在本着
SQL 精神使用高级声明式查询模式的表达任务和使用 MapReduce 的低级过程式编程中取得良好的折衷。Pig
Latin 数据流可以是简单的线性流,也可以是复杂的工作流,包括联接多个输入的流程和将数据分成将由不同运算子处理的流程。
一个 Pig Latin 程序包括一系列运算或转换,它们可以应用到输入数据中以生成输出。从整体看来,运算描述了
Pig 执行环境转换成一个可执行表示然后被执行的一个数据流。在内部,Pig 将转换变成一系列 MapReduce
作业。
有了 Pig,数据结构会变得更加丰富,通常具有多个值且是嵌套的;可以应用于数据的转换集更加强大。尤其是,Pig
Latin 数据模型包含以下四个类型:
- Atom 是一个简单的原子值,比如一个字符串或数字,例如 “John”。
- Tuple 是一连串字段,每一个字段都可能是任何数据类型,例如 ("John","Melbourne")。
- Bag 是具有可行副本的元组集合。所构成元组的架构很灵活,并非一个 Bag 中的所有元组都需要有同样数量和类型的字段。图
1 中的 Bag 列出两个元组:("John","Melbourne")
和 "Alice" ("UNSW" "Sydney")。
图 1. 一个 Bag

4.Map 是数据项集合,其中每个项目都有一个相关的键,可以通过该键查询项目。与
Bag 一样,所构成数据项的架构很灵活,但是键必须是图 2列表数据项的数据原子:K1-->("John","Melbourne")
和 K2-->30。
图 2. 一个 Map

Pig Latin 包含许多传统数据运算的算子(join、sort、filter、group
by、union 等),并且能够让用户开发其自己的函数来读取、处理和写入数据。
MapReduce 直接提供 group by 运算(实际上就是 shuffle
和 reduce 阶段),而且通过实现分组的方式直接提供 order by 运算。Filter 和 projection
可以在 map 阶段简单实现。不过不提供其他算子,尤其是 join,这些算子必须由用户编写。Pig 提供这些标准数据运算的一些复杂、非平凡的实现。例如,由于一个数据集中每个键的记录数很少均匀分布,发送给
reducer 的数据常常是斜式分布的。也就是说,一个 reducer 会比其他 reducer 获得
10 倍或更多的数据。Pig 拥有 join 和 order by 算子会处理这种情况并且(在某些情况下)重新平衡
reducer。 表 1 描述 Pig Latin 语言的主要算子。
在 MapReduce 中,map 和 reduce 阶段内的数据处理对系统并是不透明。这意味着
MapReduce 没有机会优化或检查用户代码。而 Pig 可以分析一个 Pig Latin 脚本并理解用户正描述的数据流。MapReduce
没有一个类型系统。这是有意的,而且它允许用户灵活地使用其自己的数据类型和序列化框架。不过缺点是,这进一步限制了系统在运行时之前和期间检查用户代码是否有错误。所有这些要点表明,编写和维护
Pig Latin 比编写和维护 MapReduce 的 Java 代码成本更低。
表 1. 表 1 Pig Latin 语言的主要算子
| 算子 |
描述 |
| LOAD |
将数据从文件系统或其他存储加载到一个关系表中 |
| DUMP |
打印关系表到系统控制台 FILTER |
| DISTINCT |
从关系表中删除重复的行 |
| FOREACH ... GENERATE |
添加或删除关系表中的字段 |
| JOIN |
联接两个或多个关系表 |
| ORDER |
根据一个或多个字段对关系表进行排序 |
| LIMIT |
将一个关系表的大小限制为最多的元组数 |
| STORE |
将一个关系表保存到文件系统或其他存储 |
| FILTER |
从关系表中删除不想要的行 |
| GROUP |
分组一个关系表中的数据 |
| CROSS |
创建两个或多个关系表的叉积 |
| UNION |
将两个或多个关系表结合为一个关系表 |
| SPLIT |
将一个关系表分成两个或多个关系表 |
清单 5显示一个查找所有高薪员工的简单 Pig Latin 程序。
清单 5. 查找所有高薪员工
employees = LOAD 'employee.txt' AS (id, name, salary);
highSalary = FILTER employees BY salary > 100000;
sortedList = ORDER highSalary BY salary DESC;
STORE sortedList INTO ' highSalary _Emp';
DUMP sortedList; |
在本例中,首先将输入文件加载到一个名为 employees 的 bag
中。然后创建一个名为 highSalary 的新 bag,其中仅包含 salary 字段大于 100000
的那些记录。sortedList bag 基于 salary 值降序排列过滤的记录。最后,将 sortedList
bag 的内容写到 HDFS 并打印屏幕上的 bag 内容。
清单 6显示如何使用 Pig Latin 轻松描述 join 运算。
清单 6. join 可使用 Pig Latin 轻松描述的运算
employees = LOAD 'employee.txt' AS (id, name, salary, dept);
departments = LOAD 'dept.txt' AS (deptID, deptName);
joinList = JOIN employees BY dept, departments BY deptID;
STORE joinList INTO ' joinFile'; |
传统上,即席报表是用 SQL 这样的语言完成的,便于快速形成供数据回答的问题。对于有关原生数据的研究,有些用户更喜欢
Pig Latin。由于 Pig 可在架构未知、不完整或不一致的情况下操作,而且因为它可以轻松管理嵌套的数据,希望在清理并将数据加载到仓库之前处理数据的研究人员通常倾向于使用
Pig。处理大数据集的研究人员通常使用 Perl 或 Python 等脚本语言来执行其处理。跟 SQL
的声明式查询范式比较,具有这些背景的用户通常更倾向于使用 Pig 的数据流范式。
Hive
Apache Hive 项目是 Facebook Data Infrastructure
Team 在 Hadoop 环境之上构建的一个开源数据仓库解决方案。该项目的主要目标是将熟悉的关系数据库概念(例如,表、列、分区)和
SQL 的子集引入非结构化的 Hadoop 世界,同时维持 Hadoop 享有的可扩展性和灵活性。因此,它支持所有主要原语类型(例如,整数、浮点数、字符串)以及复杂类型(例如,映射、列表、结构)。Hive
支持用 SQL 类声明语言 HiveQL (Hive Query Language) 表达的查询,因此任何熟悉
SQL 的人都可以轻松理解它。这些查询自动编译到使用 Hadoop 执行的 MapReduce 作业中。此外,HiveQL
允许用户将自定义 MapReduce 脚本插入到查询中。
HiveQL 支持 Data Definition Language
(DDL) 语句,您可以在数据库中使用该语句创建、删除和修改表。它允许用户分别通过加载和插入 Data
Manipulation Language (DML) 语句来加载外部来源的数据和将查询结果插入 Hive
表。但是,HiveQL 目前不支持更新和删除现有表中的行(特别是,INSERT INTO、UPDATE
和 DELETE 语句),这支持使用非常简单的机制来处理并行读写操作,而无需实施复杂的锁协议。元存储组件是
Hive 的系统目录,存储有关底层表的元数据。该元数据在表创建期间指定,且在每次 HiveQL 中引用表时被重用。与构建于
Pig Latin 这样的 MapReduce 类架构之上的类似数据处理系统相比,元存储将 Hive 区分为一种传统的仓储解决方案。
清单 7展示了 HiveQL 语句示例,描述了创建表、加载数据和查询表内容的操作。
清单 7. 描述创建表、加载数据和查询表内容的操作的 HiveQL 语句
CREATE TABLE employee (empID INT, name STRING, salary BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
LOAD DATA INPATH "employee_data" INTO TABLE employee;
SELECT * FROM employee WHERE salary > 100000 SORT BY salary DESC; |
Hive 还通过用户创建的函数支持数据操作(参见清单 8)。
清单 8. Hive 通过用户创建的函数支持数据操作
INSERT OVERWRITE TABLE employee
SELECT
TRANSFORM (empID, name, salary, address, department)
USING 'python employee_mapper.py'
AS (empID, name, salary, city)
FROM employee_data; |
一般而言,Hive 对于来自关系数据库世界的任何人来说都是一个不错的接口,不过底层实现的细节没有完全隐藏。您仍然需要担心一些差别,比如指定联接以实现最高性能的最佳方式,一些缺少的语言功能。Hive
确实支持为不适合 SQL 的情况插入自定义代码,并且提供大量工具来处理输入和输出。Hive 存在一些局限,比如它缺少对
UPDATE 或 DELETE 语句的支持,且不能对单个行、日期或时间类型执行 INSERT 操作,因为它们被看作是字符串。
HadoopDB
被 Hadapt 公司商业化的 HadoopDB 项目是一个混合系统,旨在结合
MapReduce 的可扩展性优势和并行数据库的性能和效率优势。HadoopDB 背后的基本思想是,连接多个单节点数据库系统
(PostgreSQL),使用 Hadoop 作为任务协调者和网络通信层。查询用 SQL 表达,但是其执行是使用
MapReduce 框架跨节点并行化的,以便将单一查询工作尽可能推送到相应的节点数据库中。
总之,并行数据库系统已经出现在商业市场上有将近 20 年了,现在市场上有许多不同的实现(例如,Teradata、Aster
Data 和 Greenplum)。这些系统的主要目标是通过各种操作,比如加载数据、创建索引、评估查询,来改进性能。一般而言,使
MapReduce 在某些场景下较并行 RDBM 更胜一筹的一些主要原因是:
- 及时地将大量数据格式化并加载到并行 RDBM 中是一项极具挑战且耗时的任务。
- 输入数据记录不总是遵循同样的架构。开发人员通常想要灵活地添加和删除属性,且对输入数据记录的解译也会随着时间而变化。
- 大规模数据处理会很耗时,因此即使在发生故障时仍然保持分析作业运行很重要。虽然大多数并行 RDBM
有容错支持,但是集群中即使只有一个节点发生故障,通常都要从头重新启动一个查询。相比之下,MapReduce
更优雅地处理故障,可以仅重做由于故障丢失的那部分计算。
MapReduce 框架与并行数据库系统的比较是一项长久以来未能平息的争论。在性能和开发复杂度方面对
MapReduce 框架的 Hadoop 实现与并行 SQL 数据库管理系统进行了大规模比较。该比较的结果表明,并行数据库系统在执行各种数据密集型分析任务时较
MapReduce 具有显著性能优势。另一方面,与并行数据库系统相比,Hadoop 实现更易于设置和使用。另外在最大限度减少硬件故障发生时丢失的工作量时,MapReduce
表现出卓越的性能。此外,与非常昂贵的并行 DBMS 解决方案相比,MapReduce(及其开源实现)是一种非常廉价的解决方案。
最初,MapReduce 框架的主要应用侧重于分析非常大型的非结构化数据集,比如
Web 索引编制、文本分析和图形数据挖掘。最近,随着 MapReduce 稳步发展为事实数据分析标准,它被重复用来查询结构化数据。长期以来,关系数据库一直支配着数据仓库系统的部署和对结构化数据的分析作业执行。人们越来越对结合
MapReduce 和传统数据库系统来维护两者的优势感兴趣。特别是,HadoopDB 尝试通过继承 Hadoop
的调度和作业跟踪来实现容错和在异构环境中进行操作的能力。它尝试通过在数据库引擎内执行大部分查询处理来实现并行数据库的性能优势。
图 3展示了 HadoopDB 的架构,其中包括两层:1) 一个数据存储层或
HDFS,2) 一个数据处理层或 MapReduce 框架。
图 3. HadoopDB 的架构
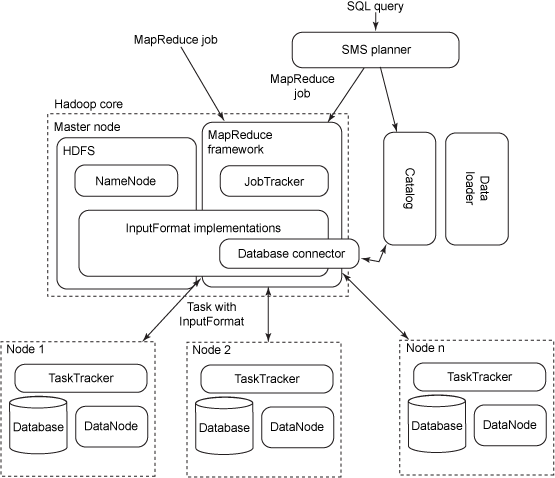
在该架构中,HDFS 是由中央 Name Node 管理的一个块结构文件系统。单个文件分为固定大小的数据块,且分布到集群中的多个
Data Node 中。Name Node 维护有关数据块大小和位置以及元数据的副本。MapReduce
框架遵循一个简单的主-从架构。主节点是一个 Job Tracker,从节点或工作节点是 Task Tracker。Job
Tracker 处理 MapReduce 作业的运行时调度,并维护每个 Task Tracker 的负载和可用资源相关信息。Database
Connector 是位于集群内节点上的独立数据库系统与 Task Trackers 之间的接口。Connector
连接到数据库,执行 SQL 查询并将结果作为键-值对返回。Catalog 组件维护有关数据库、其位置、副本位置和数据分区属性的元数据。在加载并将单一节点分成多个较小的分区或块之后,Data
Loader 组件负责在给定的分区键上全局重新分配数据。SMS Planner 扩展 HiveQL 转换器并将
SQL 转化为 MapReduce 作业,该作业连接 HDFS 中作为文件存储的表。
Jaql
Jaql 是专为 JavaScript Object Notation
(JSON) 设计的一种查询语言,JSON 是因其简单性和建模灵活性而很受欢迎的一种数据格式。JSON
是表示数据(从平面数据到半结构化 XML 数据)的一种简单而灵活的方式。Jaql 主要用于分析大型半结构化数据。它是一种函数式声明查询语言,适当时将高级查询重写为低级查询,该低级查询由使用
Apache Hadoop 项目评估的 Map-Reduce 作业组成。核心特性包括用户可扩展性和并行性。Jaql
包含一个脚本语言和编译器,以及一个运行时组件。它能够处理没有架构或只有部分架构的数据。但是,Jaql 还可以利用可用的刚性架构信息,用于类型检查和改进性能。清单
9 中的以下代码段展示了一个 JSON 文档样例。
清单 9. 一个 JSON 文档样例
[
{ id: 10,
name: "Joe Smith",
email: "JSmith@email.com",
zip: 85150
},
{ id: 20,
name: "Alice Jones",
email: "AJones@email.com",
zip: 82116
}
] |
Jaql 使用一种非常简单的数据模型,JDM (Jaql Data Model)
值可以是原子、数组或记录。大多数原子类型受支持,包括字符串、数字、零和日期。数组和记录是可任意嵌套的复合类型。更详细地讲,一个数组是一个有序的值集合,可用于建模数据结构,比如矢量、列表、集合或包
(bag)。一条记录是一个无序的名称-值对集合,可建模结构、字典和映射。JDM 虽然简单,但很灵活。它允许
Jaql 操作各种用于输入和输出的数据表示法,包括带分隔符的文本文件、JSON 文件、二进制文件、Hardtop
的序列文件、关系数据库、键值存储或 XML 文档。函数在 Jaql 中是一等值。可以将它们分配给一个变量,而且它们是高阶的,因为可以将其作为参数传递,或用作返回值。函数是主要的可重用因素,因为任何
Jaql 表达式都可封装在一个函数中,且可以通过强有力的方式参数化一个函数。清单 10 是一个包含一串函数的
Jaql 脚本示例。
清单 10. 包含一串函数的 Jaql 脚本
import myrecord;
countFields = fn(records) (
records
-> transform myrecord::names($)
-> expand
-> group by fName = $ as occurrences
into { name: fName, num: count(occurrences) }
);
read(hdfs("docs.dat"))
-> countFields()
-> write(hdfs("fields.dat")); |
在本例中 read 算子从 Hadoop Distributed File
System (HDFS) 加载原始数据,并将其转换为 Jaql 值。这些值由 countFields
子流程处理,提取字段名并计算其频率。最后 write 算子将结果存储回 HDFS。表 2描述 Jaql
脚本语言的核心表达式。
表 2. Jaql 脚本语言的核心表达式
表达式 |
描述 |
| transform |
transform 表达式在一个数组的每个元素上应用一个函数(或投影)以生成一个新数组。 |
| expand |
expand 表达式常用于解除其输入数组的嵌套。 |
| group by |
类似于 SQL 中的 GROUP BY,Jaql 中的 group by 表达式在一个分组表达式上分割其输入,并向每个组应用一个聚合表达式。 |
| Filter |
filter 表达式保留特定谓词为真的输入值。 |
| Join |
join 表达式支持两个或更多输入的同等联接。用于内部和外部联接的所有选项也受支持。 |
| Union |
union 表达式是一个将多个输入数组合并为一个输出数组的 Jaql 函数。 |
| Control-flow |
Jaql 中最常用的两个 control-flow 表达式是 if-then-else 和
block 表达式。if-then-else 表达式类似于在大部分脚本和编程语言中找到的条件表达式。一个
block 建立一个本地范围,其中可以声明零个或更多本地变量,且最后一个语句提供 block 的返回值。 |
在较高级别,图 4 中描述的 Jaql 架构类似于大部分数据库系统。
图 4. Jaql 系统架构
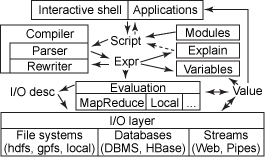
脚本被从解释器或一个应用程序传递到系统中,由分析器和重写引擎编译,然后通过
I/O 层的数据进一步解释或评估。存储层类似于一个联合数据库。它提供一个 API 来访问数据,这些数据来自不同的操作系统,包括本地或分布式文件系统(比如
Hadoop 的 HDFS)、数据库系统(比如 DB2、Netezza 和 HBase),或来自 Web
等流式处理源。但是与联合数据库不同的是,多数访问的数据存储在同一集群内,且 I/O API 描述数据分区,这在评估期间实现与数据关联的并行性。Jaql
的这种灵活性多数来自 Hadoop 的 I/O API。它读写许多常见的文件格式(比如逗号分隔的文件、JSON
文本和 Hadoop 序列文件)。可以轻松编写自定义适配器来实现数据集与 Jaql 数据模型之间的映射。输入甚至可以是脚本本身中构造的值。Jaql
解释器在编译了脚本的计算机本地评估脚本,不过使用 MapReduce 在远程节点上生成解释器。Jaql
编译器自动检测一个 Jaql 脚本中的并行化机会,并将其转换为一组 MapReduce 作业。
结束语
MapReduce 已成为驾驭计算机大型集群功能的一种流行方式。目前
MapReduce 作为一个用于海量数据分析的平台。它允许程序员以一种以数据为中心的方式进行思考,其中他们可以专注于向数据记录集应用转换,同时分布式执行和容错性的细节由
MapReduce 框架透明地管理。在实践中,许多程序员喜欢使用高级声明(或 SQL 类)语言来实现其并行化的大型数据分析作业,同时将所有执行优化细节留给后端引擎。在本文中,您了解了对
MapReduce 框架最新的高级声明式接口的概述。使用高级语言抽象能够让底层系统执行自动优化并改进用户任务的性能,从而最大限度减少您的编程负担。 |


