| 这个题目有点怪怪的,意思就是一提到ArcSDE的性能问题,都会提到重建空间索引,本文就以Oracle的索引例子,来类比ArcSDE
for Oracle的空间索引,如果能把oracle索引示例弄明白,那么对ArcSDE的索引问题应该非常好理解了。
在数据库系统中,索引是非常重要的一个对象,尤其是面对大型数据表时,索引能大大提高数据检索的速度。本节将介绍索引的原理及索引的使用。
索引在现实世界中最典型的例子莫过于字典检索了。用户在使用字典时,可以使用两种方式,一是逐页翻查,以获得需要查找的目标;二是根据字典的检索目录来获得目标所在的页数,然后直接在该页获得查找目标。毫无疑问,利用检索目录(索引)检索目标是更为高效的方式。
现有的主流数据库都提供了索引这一概念,Oracle也不例外。一旦在数据表的某列上建立了索引,Oracle将另辟新的空间,以存储该列上所有值与其记录的rowid的对应关系。当用户试图以索引列作为搜索条件时,Oracle将利用索引来获得相应的rowid,并捕获该记录。
select * from people where name = 'David';
当Oracle处理该查询语句时,将执行全表扫描。当搜索到第6条记录时,会发现该条记录符合搜索条件,并将该记录纳入结果集合。但是搜索并不会停止,因
为Oracle并不知道在后面的记录中是否仍然存在符合条件的记录。直至搜索完整个表,Oracle才会返回最终的结果集合。
但是,如果预先在表people的name列上创建了一个索引,那么,搜索的顺序将完全不同。创建索引的语法如下所示:
create index idx_people_name on people(name)
一旦索引创建,那么表中所有数据将按照字母表顺序进行分块处理,例如,以每5条记录作为一个数据块(当然,实际数据块将大得多)。分块后的数据结构如下图所示。
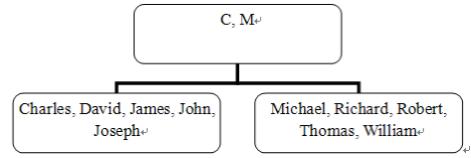
说明:文中的Oracle索引是以字符串字段创建的索引,那么字符串字段是以字母表顺序进行分类的,当然了也可以使用数字、日期等,那么对ArcSDE
for Oracle也是一样的,空间索引是格网,与该例子比较,无非是他们将按字母排序,五个五个的,那么ArcGIS是按照格网的范围,在该范围的包含相关的
要素。
此时执行搜索语句select * from people where name
= 'David';时,Oracle只会在第一个数据块中进行搜索,因为数据库知道,第二个数据库都是M以后的数据。当搜索到David之后,如果下一条记
录的name列的值不是David,Oracle也将停止搜索,因为列中所有值都是按照字母表顺序进行排列的,所有的"David"位置肯定是相邻的。一
旦搜索到"David",Oracle会马上获得其对应的rowid,并根据rowid快速定位该记录。
对于如下SQL语句,索引的作用会反映的更加清晰。
select * from people where name = 'Michael';
因为要搜索的条件为name列的值为"Michael",所以,将会直接跳转到第二个数据块进行搜索,因为第二个数据块才是以M开头的数据。而且,当获得Michael的下一条记录为"Richard"时,将停止搜索,返回结果集合。
说明:ArcSDE数据在oracle中进行查询会执行下面的步骤:
1)首先比较grid和查询范围,找出在查询范围内的所有grid.
2)找出在这些grid内的所有要素。
3)将这些要素的外包络矩形和查询范围比较,找出所有在查询范围内以及和查询范围相交的要素。
基本上可以类比。
索引应用于大数据量的数据表时,将很大程度上提高查询速度。为了演示这种情况,首先来创建一个大的数据表。视图dba_objects可以获得数据库中所有对象的基本信息
createtable test_objects as select *
from dba_objects;
利用PL/SQLDeveloper的执行计划查看:
select* from test_objects where object_name
= 'PEOPLE'
创建索引:
createindex idx_test_object on test_objects(object_name);
再次查看执行计划。
这里需要注意的是,搜索条件中包含索引列才能真正使用到索引所带来的好处。
select* from test_objects where owner
= 'SCOTT'
1.添加数据对索引的影响
以表people为例,一旦在其上创建了索引,向其中插入数据时,数据库将会重新组织索引。
insert into people (ID, NAME, STATUS)
values (11, 'Zoey', 'ACT');
在以上SQL语句中,向表people中插入名为"Zoey"的用户信息。此时数据库除了正常的插入操作开销之外,还需要将为该记录添加索引项,而索引已有数据块无法满足存储要求,因此,数据库将为其分配新的存储空间,如图所示:
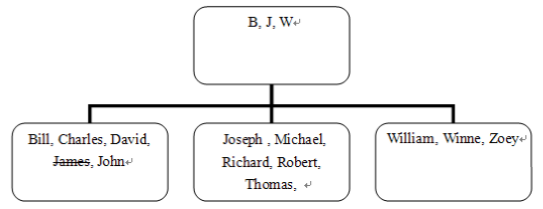
2.修改数据对索引的影响
从图中可以看出,"James"被添加了删除标记,而在最后一个数据块中添加了索引项"Winne".Oracle采取该策略是为了最大程度上减小数据库
操作的开销。但这同时带来了空间上的浪费,因为索引项"James"仍然占用索引空间。新的索引项仍然不能够插入第一个数据块中。
3. 删除数据对索引的影响
删除数据对索引的影响相对简单,因为数据删除之后,相应的索引项只是被打上了删除标记,表征该索引项不可用。例如,利用如下SQL语句删除一条记录。
delete from people where name = 'Robert'
此时的索引项被修改为:
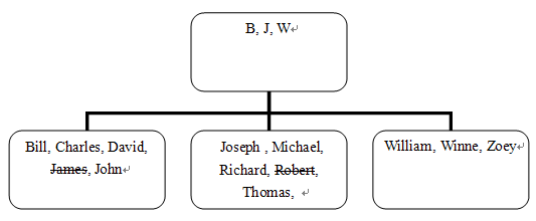
分析此时的索引结构可知,删除操作是DML操作中针对索引的开销最小的一种。但是,仍然不可避免地形成了对存储空间的浪费。
说明:从上面对Oracle的增删改操作对索引的影响可以类比一下ArcSDE增删改对索引的影响是一样的。所以说,频繁的进行编辑操作,不仅仅是对表进行操作,相关的索引信息也会发生很多变化。
那么由上面所示,可以看出,其实索引最大的功劳还是针对只读数据(不是绝对的),那么可以得到以下的总结:
1.小数据量的表不宜使用索引
小数据量的表,首先要创建索引,并寻找数据块,然后才进行数据的实际搜索,因此,对于小数据量的表,使用全表搜索往往会快于使用索引。
2.频繁使用插入、修改、删除等DML操作的数据表不宜使用索引。
针对表的插入、修改、删除等操作非常频繁时,将会降低数据库性能。因为每次的动作都可能会触发两倍甚至两倍以上的成本来完成索引操作。
说明:对ArcSDE也是一样,如果你的数据现在是频繁的进行编辑,可以将空间索引进行删除,这样编辑的数据就不会耗费资源来维护索引对象,这样效率也会有一定的提高。不过上面的这些话还在于灵活掌握索引再实施。
这就是为什么说,每次感觉速度慢,esri工程师就会简单的给用户说,重建索引即可,其实这句话背后经历了这么多复杂的过程,但是软件不就是这样么,尽管
有多么复杂的原理,公式等,暴露给用户的就是一个简单的操作!理解这些知识,对感兴趣的用户或者对性能优化比较注重的用户有所帮助吧!
可以通过如下的方法创建空间索引:
对于格网索引,可在 ArcCatalog 的要素类属性 对话框的"索引"选项卡上单击添加。请参阅设置空间索引。
使用 sdelayer 管理命令实用工具。请参阅《ArcSDE 管理命令参考》。
使用 SQL.请参阅为包含 ST_Geometry 列的表创建空间索引。
使用 ArcSDE C 或 Java 应用程序编程接口 (API)。请参阅地理数据库资源中心。
使用 sdelayer 命令的 load_only_io 和 normal_io
操作,将要素类从只加载 I/O 模式切换回正常 I/O 模式。每次将要素类从 LOAD_ONLY_IO
模式切换为 NORMAL_IO 模式时,ArcSDE 都会自动删除并重新创建由 ArcSDE 创建的所有空间索引。
关于索取的其他知识,不是说建立索引可以加快查询速度,就让所有字段都建立索引,建立索引也是有一定的代价的,以下只针对属性索引的创建:
创建索引和维护索引要耗费时间,这种时间随着数据 量的增加而增加。
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
对于那些在查询中很少使用或者参考的列不应该创建索引。这是因 为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
对于那 些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比
例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因
此,当修改性能远远大于检索性能时,不应该创建索引。 |


