|
Leveled Compaction策略是1.0版本提出的,主要为了在某些场合克服SizeTiered
Compaction策略的缺点。不过很不幸,什么时机选择适用Leveled Compaction策略,并不是那么明朗。下面的内容会给出一些选择Compaction策略的指导建议。
SizeTiered Compaction策略与Leveled Compaction策略的不同
Leveled Compaction有一个基本的特征,可以帮助开发人员确定它是否适合:为了保障,一行数据不会分布在更多的sstable中,在Compaction过程进行的时候,Leveled
Compaction策略需要更多的I/O操作。但是SizeTiered Compaction无法提供这个保障,尽管一行数据可能分布的最多sstable数量为10左右。【Leveled
Compaction能够保证一行数据不会出现在太多的sstable中,这个大家都是知道的,具体,如果单机有10T数据,最多只会出现在7个sstable中。SizeTiered
Compaction没有这个保证,原文中说的10个左右,也是有单机数据量的限制的,如果数据量再多,比如达到单机1T左右,可能会有三分之一的数据是重复的】。
当使用SizeTiered Compaction的时候,频繁的更新某一行,会出现如下的分布情况。
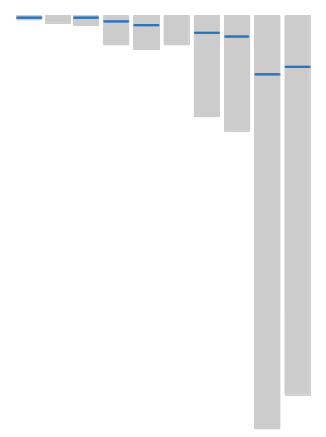
上图中,灰色的块代表sstable文件,蓝色的线代表统一行数据。
当要读取这一行被频繁更新的数据,代价是非常大的,几乎要读每一个sstable文件。seek磁盘次数太多,性能严重下降。
但是,当使用LeveledCompaction的时候,情况就完全不一样了。

使用Leveled Compaction,当你需要读取一行数据,90%的时间是只需要读一个sstable文件。我们假设N是要读取完整一行数据所必须读的sstable数量,读取N个不同文件的概率会随着N的增大,指数级的降低。概率分布如下:
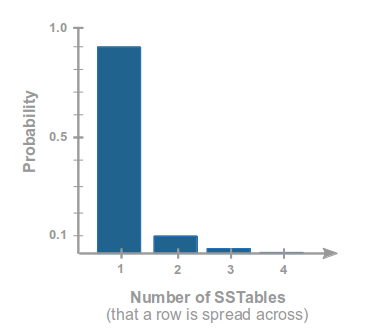
如果你熟悉一点数学,会算出,当读取某一随机行的时候,期望平均的sstable数量是1.111.这个和使用SizeTiered的情况相比,要小很多。当然,如果你停止更新这一行数据,SizeTiered
Compaction会最终把多份合并到一个sstable文件中。但是如果你持续更新,那同一行数据,还是会分布在多个sstable中的。但是使用Leveled
Compaction,即使持续更新某一行,也能够保证,要读取的sstable数量,远少于SizeTiered
Compaction。
什么时候Leveled Compaction是一个好的选择
对读延迟高度敏感
除了在通常意义下,Leveled Compaction会降低读延迟之外,Leveled
Compaction也会降低读过程中的变数【让读延迟更加可控】。如果你的应用在99%的时间里,对读延迟都有严格的要求,那么Leveled
Compaction必须是唯一满足这些要求的选择,因为它保证了读取sstable数量的上限,使得事情可控。
高读写比例
如果你的应用中,读写比例为至少2:1,Leveled Compaction可以节省磁盘I/O,尽管Compaction操作会消耗多一些I/O。尤其是当读非常随机的时候,而不是集中在某一部分热数据的时候,更会节省磁盘I/O。
数据频繁更新
无论是处理行数据不断被覆盖重写的情况,还是新的column不断的加入的情况,使用SizeTiered
Compaction都会使得数据分布在多个sstable文件中。但是Leveled Compaction可以保证sstable文件数量的上线,即使非常频繁的更新。
如果,你更新的一行数据具有很多列,定期的将所有列都切换到新的一行,会再一定程度上降低SizeTiered
Compaction的影响,但是还是远不如Leveled Compaction。如果,你的数据中,只有很少的column,Cassandra1.1以后,提供了一个新的优化,使得SizeTiered
Compaction可以更多的进行合并(但是并没有回收磁盘空间)。
在多列的数据中删除某一column或者某一column数据过期
如果你在具有很多column的行数据中,设置了TTLs(过期时间),当过期时间来到的时候,会有很多过期的数据。同样,如果采用column来实现队列机制,当不断删除column的时候,也会在每一行产生很多过期数据。
过期的column和普通的column是一样的,会让读操作seek更多的sstable。如果一行中非过期数据很好,那么读的时候,就会浪费很多字段在读没有用的column上。
值得注意的是,Cassandra1.2将会在SizeTiered Compaction下改进这个,尝试频繁的移除过期数据,这个会在一定程度上,减少读取sstable的数量。
什么时候Leveled Compaction可能不是一个好的选择
磁盘不能够承受如此多的Compaction I/O操作
如果你的集群,I/O压力已经很大,这时再切换到Leveled Compaction,只会使得问题更加糟糕。Compaction操作需要更多的I/O操作是Leveled
Compaction的最主要的缺点。所以在使用之前,要检查是否I/O已经压力非常大。
写压力大的场景
Leveled Compaction操作很难处理写多,读少的场景,Compaction的速度远远更不上写的速度的时候,Leveled
Compaction就不是一个好的选择。因为这个时候,读带来的好处,已经不明显,不需要了。
没有更新
如果所有的数据都是只写一次,没有更新,不会存在多个sstable中,那么使用SizeTiered
Compaction即可。因为已经不需要从多个文件中读取。
关于Leveled Compaction的其他建议
写采样(Write Sampling)
很难提前知道,在将Compaction策略切换到Leveled Compaction策略的时候,你的节点的Compaction操作是否能否跟得上。最好的办法,是采用live
traffic sampling机制(后文会进行详解!)。如果是在生产环境中适用个,强烈建议使用这种机制。
SSD和可以载入内存的数据
SizeTiered Compaction和Leveled Compaction在SSD下,都有良好的表现。但是Leveled
Compaction还是要突出一些,这不仅仅体现在Leveled Compaction可以减少读次数。而且Leveled
Compaction可以降低CPU和内存的使用,在Compaction的过程中。
需要更少的磁盘空间
在Compaction的过程中个,SizeTiered Compaction需要最大的Column
Family的大小的一倍空闲空间,而Leveled Compaction只需要10*sstable_size_in_mb的空闲空间。但是即便如此,也要流出更多的磁盘空间给其他操作,如:accommodate
streaming, repair和snapshots等,这些操作可能很容易的就用到10G以上的空间。更进一步,磁盘会在空间使用80-90%之后,性能下降。所以,不要把磁盘写得满满的。
除了在Compaction过程中,Leveled Compaction会需要很少的空闲空间,整体上而言,Leveled
Compaction需要的空间也比SizeTiered Compaction要少。 |


