������ǽ�����¡�NoSQL Data Modeling Techniques������ò��ã�������¡���ƪ���¿���֮������ܻ��NoSQL�����ݽṹ����Щ�о����ҵĸо��ǣ���ϵ�����ݿ����һ���ԣ������ԣ�������CRUD���ɺã�NoSQLֻ��ijһ���£����������˺ܶ��Ķ�����������˵���Ҿ���NoSQL���ʺ���Cache�����������ġ���
NoSQL ���ݿ⾭���������ܶ�ǹ����Եĵط����磬��չ�ԣ����ܺ�һ���Եĵط�����ЩNoSQL�����������ۺ�ʵ���ж����ڱ����ڹ㷺���о��ţ��о����ȵ�������Щ�����ֲܷ�ʽ��صķǹ����ԵĶ��������Ƕ�֪��
CAP ���۱��ܺõ�Ӧ������ NoSQL ϵͳ�У����ע��CAP����һ����(Consistency)��
������(Availability)�� ����������(Partition tolerance)���ڷֲ�ʽϵͳ�У�������Ҫ�����ֻ��ͬʱʵ����������NoSQLһ���������һ���ԣ���������һ���棬NoSQL�����ݽ�ģ����ȴ��Ϊȱ�����ϵ�����ݿ������Ļ�������û�б����˺ܺõ��о�����ƪ���´����ݽ�ģ�����NoSQL��������˱Ƚϣ������ۼ������������ݽ�ģ������
Ҫ��ʼ�������ݽ�ģ���������Dz��ò������ٵ���ϵͳ�ؿ�һ��NoSQL����ģ�͵ijɳ������ƣ��Դ����ǿ����˽�һЩ�������ڵ���ϵ����ͼ��NoSQL����Ľ���ͼ�����ǿ��Կ��������Ľ�����Key-Valueʱ����BigTableʱ����Documentʱ����ȫ������ʱ������Graph���ݿ�ʱ���������ע��ע��ͼ��SQL˵���Ǿ仰��NoSQL��������չ��ȥ����SQL�ˣ���������
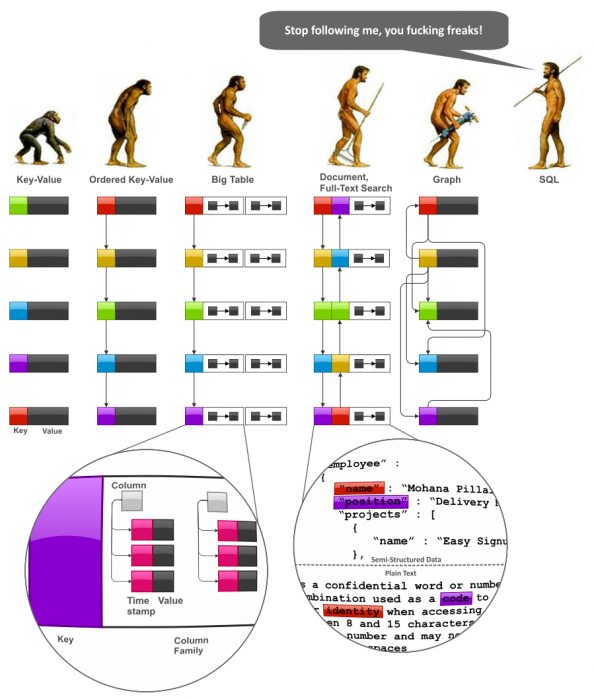
NoSQL Data Models
���ȣ�������Ҫע�����SQL��ϵ������ģ���Ѵ����˺ܳ���ʱ�䣬���������û�����Ȼ����ζ�ţ�
- �����û�һ�������Ȥ�����ݵľۺ���ʾ�������Ƿ�������ݣ�����Ҫͨ��SQL����ɡ�
- ������ͨ�����ֹ��������ݵIJ����ԣ������ԣ�һ���ԣ�������������У����Щ�����ġ������ΪʲôSQL��Ҫ������ά���ṹ��schema����������������ܶ��¡�
��һ���棬SQL����������Ӧ�ó����ںܶ�����²���Ҫ�������ݿ�����ݾۺϣ������������Ժ���Ч�Խ��п��ơ����������ȥ��������һ���ԣ���������Щ������������ܺͷֲ��洢�����صİ���������Ϊ��ˣ����Dz�������ģ�͵Ľ�����
- Key-Value ��ֵ�Դ洢�Ƿdz���ǿ��ġ�����ĺܶ༼�������϶��ǻ������������ʼ��չ�ġ����ǣ�Key-Value��һ���dz����������⣬�Ǿ������������Ҫ����һ�η�Χ�ڵ�key�������ע��ѧ��hash-table���ݽṹ���˶�Ӧ��֪����hash-table�Ƿ������������䲢�������飬���ӣ�������Щ�������������ǿ��Կ������ݴ洢��˳�����ǣ������ֵ
��Ordered Key-Value�� ����ģ�ͱ���Ƴ��������һ���ƣ����Ӹ�����������ݼ������⡣
- Ordered Key-Value �����ֵģ��Ҳ�dz�ǿ���ǣ���Ҳû�ж�Value�ṩij������ģ�͡�ͨ����˵��Value��ģ�Ϳ�����Ӧ�ø�������ʹ�ȡ�����ֺܲ����㣬���dz�����
BigTable���͵����ݿ⣬�������ģ����ʵ����map����map��map������map��һ��һ������ȥ��Ҳ���Dz��Ƕ��key-value��value������һ��key-value�����������ݿ��Value��Ҫͨ�������塱��column
families�����У���ʱ��������ư汾�������ע������ʱ����������ݵİ汾������Ҫ�ǽ�����ݴ洢�������⣬Ҳ������ν���ֹ������������汾��������(MVCC)�ڷֲ�ʽϵͳ�е�Ӧ�á���
- Document databases �ĵ����ݿ� �Ľ��� BigTable ģ�ͣ����ṩ������������ĸ��ơ���һ��������Value�������۵�ģʽ��scheme����������map��map���ڶ�����������
Full Text Search Engines ȫ������������Ա��������ĵ����ݿ��һ�����֣����ǿ����ṩ���Ŀɱ������ģʽ��scheme���Լ��Զ�����������֮��IJ�ͬ����Ҫ�ǣ��ĵ����ݿ����ֶ�������������ȫ�������������ֶ�ֵ��������
- Graph data models ͼʽ���ݿ� ���Ա���Ϊ��������������д� Ordered Key-Value
���ݿⷢչ������һ����֧��ͼʽ���ݿ�����������ͼ�ṹ������ģ�͡������ĵ����ݿ��й�ϵ��ԭ���ǣ����ĺܶ�ʵ������value������һ��map����һ��document��
NoSQL ����ģ��ժҪ
����ʣ�µ��½ڽ�����������ݽ�ģ�ļ���ʵ�ֺ����ģʽ�����ǣ��ڽ�����Щ����֮ǰ������һ�����ԣ�
NoSQL ����ģ�����һ���ҵ��Ӧ�õľ������ݲ�ѯ���֣����������ݼ�Ĺ�ϵ��
��ϵ�͵�����ģ�ͻ������Ƿ������ݼ�Ľṹ��ϵ������������ǣ� ��What
answers do I have?��
NoSQL ����ģ�ͻ������Ǵ�Ӧ�ö����ݵĴ�ȡ��ʽ���֣��磺����Ҫ֧��ij�����ݲ�ѯ�������������
��What questions do I have?��
NoSQL ����ģ����Ʊȹ�ϵ�����ݿ���Ҫ�����ݽṹ���㷨�ĸ�����˽⡣����ƪ�������һ�ʹ��˵��Щ���˽�֪�����ݽṹ����Щ���ݽṹ����ֻ�DZ�NoSQLʹ�ã����Ƕ���NoSQL������ģ��ȴ�dz��а�����
��������ͷ������һ�ȹ���
��ϵ�����ݿ���ڴ����㼶���ݺ�ͼʽ���ݷdz��IJ����㡣NoSQL�������ͼʽ����������һ���dz��õĽ���������������е�NoSQL���ݿ���Ժ�ǿ�ؽ���������⡣�����Ϊʲô��ƪ����ר���ó�һ����˵���㼶����ģ�͡�
������NoSQL�ķ������Ҳ��������д��ƪ����ʱ��ʵ���IJ�Ʒ��
- Key-Value �洢: Oracle Coherence, Redis, Kyoto Cabinet
- ��BigTable�洢: Apache HBase, Apache Cassandra
- �ĵ����ݿ�: MongoDB, CouchDB
- ȫ������: Apache Lucene, Apache Solr
- ͼ���ݿ�: neo4j, FlockDB
����� Conceptual Techniques
��һ����Ҫ����NoSQL����ģ�͵Ļ���ԭ��
(1) ����� Denormalization
����� Denormalization ���Ա���Ϊ�ǰ���ͬ�����ݿ�������ͬ���ĵ����DZ��У������Ϳ��Լ��Ż���ѯ�����������ʺ��û���ij���ر������ģ�͡���ƪ��������˵�ľ�����������������ٵص�������һ������
������˵���������ҪȨ��������Щ������
��ѯ������ /��ѯIO VS ����������ʹ�÷����һ�������һ����ѯ�������Ҫ������������������ŵ�һ���ط��洢������ζ�ţ�������ͬ��ͬ��ѯ����Ҫ����ͬ�����ݣ���Ҫ���ڱ�ͬ�ĵط�����ˣ�������˺ܶ���������ݣ��Ӷ�������������������
�������Ӷ� VS ��������. �ڷ��Ϸ�ʽ������ģʽ�Ͻ��б����ӵIJ�ѯ������Ȼ�������˲�ѯ�����ĸ��Ӷȣ�������ڷֲ�ʽϵͳ��˵���ǡ����������ģ�����������Է����ѯ�ķ�ʽ���湹�����ݽṹ�Լ�ѯ���Ӷȡ�
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⡣
(2) �ۺ� Aggregates
�������͵�NoSQL���ݿⶼ���ṩ����Schema�����ݽṹ�������ݸ�ʽ�����ƣ���
Key-Value Stores �� Graph Databases ��������˵����Value����ʽ������Value�����������ʽ������һ������ʹ�����ǿ����������һ��ҵ��ʵ���keys�����磬������һ���û��ʺŵ�ҵ��ʵ�壬����Ա�������Щkey���������
UserID_name, UserID_email, UserID_messages �ȵȡ����һ���û�û��email��message����ô��ӦҲ�����������ļ�¼��
BigTable ģ��ͨ���м�����֧������Schema�����dz�֮Ϊ���壨column
family����BigTable��������ͬһ��¼�ϳ��ֲ�ͬ�İ汾��ͨ��ʱ�������
Document databases �ĵ����ݿ���һ�ֲ㼶ʽ�ġ�ȥSchema���Ĵ洢����Ȼ��Щ���������ݿ�����������Ҫ����������Ƿ�����ij��Schema��
����Schema�����������һ��Ƕ��ʽ���ڲ����ݷ�ʽ���洢һ���й�����ҵ��ʵ�壨���ע��������JSON���������ݷ�װ��ʽ������������Ϊ���Ǵ��������ô���
��С����һ�Զࡱ��ϵ��������ͨ��Ƕ��ʽ�ķ�ʽ���洢ʵ�壬����������һЩ�����ᡣ
�������ڲ������ϵ����ݴ洢���ӽ���ҵ��ʵ�壬�ر������ֻ��ʽ��ҵ��ʵ�塣���ܴ���һ���ĵ�������һ�ű��С�
��ͼʾ���������ֺô���ͼ������˵��������е���Ʒģ�ͣ����ע���Ҽǵ����ڡ���ս�����ڡ�һ����˵���������в�Ʒ�������ݿ���Ƶ���ս��
���ȣ����е���ƷProduct������һ��ID��Price �� Description��
Ȼ�����ǿ���֪����ͬ�����͵���Ʒ���в�ͬ�����ԡ����磬������������ԣ�������ţ�п�����ԡ���Щ���Կ����ǡ�һ�Զࡱ���ǡ���Զࡱ�Ĺ�ϵ���磺��Ƭ�е���Ŀ��
������������֪����ijЩҵ��ʵ�岻����ʹ�ù̶������͡��磺ţ�п�����Բ��������е����Ӷ��еģ����ң���Щ���ƻ����dz��ر�����ԡ�
���ڹ�ϵ�����ݿ���˵��Ҫ�������������ģ�Ͳ�����������Ƴ����ľ��������ź�Զ��Զ��������NoSQL������Schema������ʹ��һ���ۺ�
Aggregate (product) ���Խ������в�ͬ�������Ʒ�����ǵIJ�ͬ�����ԣ�

Entity Aggregation
��ͼ�����ǿ��ԱȽϹ�ϵ�����ݿ��NoSQL�IJ�𡣵������ǿ��Կ��������ݸ����ϣ��ǹ�����ݴ洢�����ܺ�һ�����ϻ��кܴ��Ӱ�죬�����������Ҫ�ص�ע��Ͳ��ò������ĵط���
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⡣
(3) Ӧ�ò����� Application Side Joins
����������ϲ���NoSQL֧�֡���������ǰ����˵�ģ�NoSQL�ǡ��������⡱�����ǡ�����𰸡��ģ���֧�ֱ�������ǡ��������⡱�ĺ�������������������ʱ����������ģ���������ִ��ʱ��������ġ����ԣ�������������ʱ���кܴ����ģ����ע�����SQL������Ķ�֪���ѿ�������ʲô������������ڲο���ǰ��ǵġ�ͼ�����ݿ��Joins������������ʹ����
Denormalization �� Aggregates ���������ǻ������ý��б����ᣬ�磺����ʹ��Ƕ��ʽ������ʵ�塣��Ȼ���������Ҫ�������ݣ�����Ҫ��Ӧ�ò��������¡������Ǽ�����Ҫ��Use
Case��
��Զ������ʵ���ϵ����������Ҫ�����ӻ����ᡣ
�ۺ� Aggregates ���������������ֶξ������ı��������Դˣ�������Ҫ����Щ�������ı���ֶηֵ�����ı��У����ڲ�ѯʱ������Ҫ�������ݡ����磬�����и�Messageϵͳ������һ��Userʵ�壬�������һ����Ƕ��Messageʵ�塣���ǣ�����û������ڸ���
message����ô����ð�message��ֵ���һ��������ʵ�壬���ڲ�ѯʱ������User��Message������ʵ�塣����ͼ��
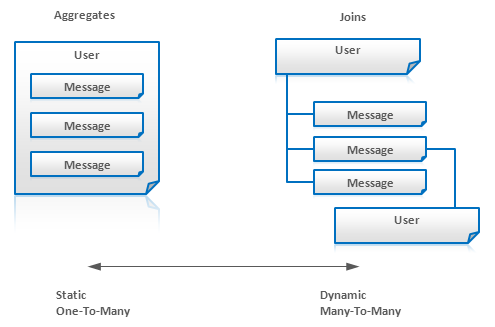
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⣬ Graph Databases ͼ���ݿ⡣
ͨ�ý�ģ���� General Modeling Techniques
�ڱ����У����ǽ�����NoSQL�и��ֲ�ͬ��ͨ�õ����ݽ�ģ������
(4) ԭ�Ӿۺ� Atomic Aggregates
�ܶ�NoSQL�����ݿ⣨���������У����������϶��Ƕ̰塣��ijЩ����£����ǿ���ͨ���ֲ�ʽ����������Ӧ�ò������MVCC������ʵ���������ԣ����ע���ɲο���վ�ġ���汾��������(MVCC)�ڷֲ�ʽϵͳ�е�Ӧ�á������ǣ�ͨ����˵ֻ��ʹ�þۺ�Aggregates��������֤һЩACIDԭ��
�����Ϊʲô���ǵĹ�ϵ�����ݿ���Ҫ��ǿ������������ơ�����Ϊ��ϵ�����ݿ�������DZ��������˲�ͬ�ĵط������ԣ�Aggregates�ۺ��������ǰ�һ��ҵ��ʵ����һ���ĵ������һ�У����һ��key-value�������Ϳ���ԭ��ʽ�ĸ����ˣ�

Atomic Aggregates
��Ȼ��ԭ�Ӿۺ� Atomic Aggregates ��������ģ�Ͳ�����ʵ����ȫ�����ϵ����������������֧��ԭ���ԣ�������
test-and-set ָ���ô�� Atomic Aggregates �ǿ������õġ�
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⡣
(5) ��ö�ټ� Enumerable Keys
Ҳ����������˳���Key-Value���ĺô���ҵ��ʵ����Ա�����hash�Է����ڶ���������ϡ��������˵�key�������㸴�ӣ�������Щʱ��һ��Ӧ���ܴ�����key�л�úܶ�ô������������ݿⱾ�����ṩ������ܡ���������˼����email��Ϣ������ģ�ͣ�
һЩNoSQL�����ݿ��ṩԭ�Ӽ�������������һЩ������ID������������£����ǿ���ʹ��
userID_messageID ����Ϊһ�����key���������֪�����µ�message ID���Ϳ���֪��ǰһ��message��Ҳ����֪����ǰ��ͺ����Message��
Messages���Ա���������磬ÿ����ʼ��������������ǾͿ��Զ��ʼ���ָ����ʱ�����������
������: Key-Value Store ��ֵ�����ݿ⡣
(6) ��ά Dimensionality Reduction
Dimensionality Reduction ��ά��һ�ּ�������������һ����ά������ӳ���һ��Key-Value���������Ƕ��������ģ�͡�
��ͳ�ĵ���λ����Ϣϵͳʹ��һЩ�硰�ķ���QuadTree�� �� ��R-Tree��
��������λ����������Щ���ݽṹ��������Ҫ�����ʵ���λ�ø��£����ң�����������ܴ�Ļ��������ɱ���ܸߡ���һ�����������ǿ��Ա���һ����ά�����ݽṹ�������ƽ����һ���б���һ��������֪��������Geohash��������ϣ����һ��Geohashʹ�á�֮���Ρ���·��ɨ��һ��2ά�Ŀռ䣬���ұ����е��ƶ����Ա�����0��1����ʾ�䷽��Ȼ�����ƶ��Ĺ����в���0/1������ͼչʾ����һ�㷨�������ע���Ȱѵ�ͼ�ֳ��ķݣ�����Ϊ��һλ��γ��Ϊ�ڶ�λ��������ߵľ�����0���ұߵ���1��γ��Ҳһ����������Ϊ1�������Ϊ0����������γ�ȾͿ�����ϳ�01��11��00��10���ĸ�ֵ�����ʶ���Ŀ��������ǿ�����˲��ϵĵݹ�ض�ÿ����������ķ֣�Ȼ����Եõ�һ��1��0��ɵ��ִ���Ȼ��ʹ��0-9��b-z
ȥ����ȥ��a, i, l, o����32����ĸ����base32����õ�һ��8�����ȵı��룬�����Geohash���㷨��
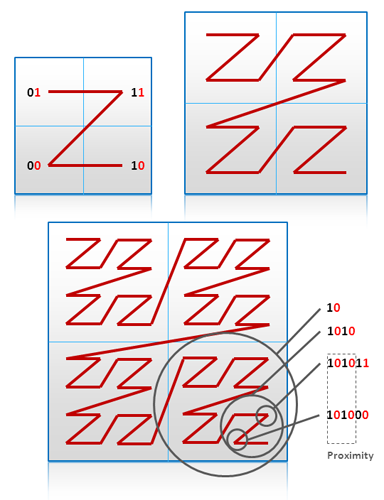
Geohash Index
Geohash����ǿ��Ĺ�����ʹ�ü�λ�����Ϳ���֪�����������ľ��룬����ͼ����ʾ����𩣺proximity���ŵ����������������IP��ַ�ˣ���Geohash��һ����ά�����������ر����һ��һά������ģ�ͣ�����ǽ�ά������BigTable�Ľ�ά�����ο������º����
[6.1]������Ĺ���Geohash�������������Բο� [6.2] �� [6.3]��
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⡣
(7) ������ Index Table
Index Table ��������һ���dz�ֱ�ļ�������������ڲ�֧�����������ݿ��еõ������ĺô���BigTable����������Ҫ�����ݿ⡣����Ҫ����ά��һ������Ӧ��ȡģʽ���ر�������磬������һ�����������û��ʺţ�����Ա�UserID��ȡ��ij��ѯ��Ҫ���ij�����������е��û����������ǿ��Լ���һ�ű������ű��ó��������������к����������ص�UserID����Value��������ʾ��
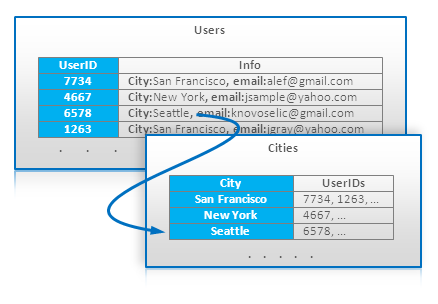
Index Table Example
�ɼ�����������������Ҫ�Ͷ������û�������һ���ԣ���ˣ�������ÿһ�����¿�����Ҫ�����������и��£���Ȼ����һ�����������¡������ĸ���ʽ���ⶼ������һЩ���ܣ���Ϊ��Ҫ����һ���ԡ�
Index Table ���������Ա���Ϊ�ǹ�ϵ�����ݿ��е���ͼ�ĵȼ��
������: BigTable ���ݿ⡣
(8) ��������� Composite Key Index
Composite key �������һ���ܳ��õļ������Դˣ������ǵ����ݿ�֧�ּ�����ʱ�ܵõ�����ĺô���Composite
key��ϼ���ƴ�ӳ�Ϊ�ڶ������ֶο������㹹����һ�ֶ�ά���������������֮ǰ˵���� Dimensionality
Reduction ��ά���������磬������Ҫ��ȡ�û�ͳ�ơ����������Ҫ���ݲ�ͬ�ĵ�����ͳ���û��ķֲ���������ǿ���Key��Ƴ������ĸ�ʽ
(State:City:UserID)������һ������ʹ�����ǿ���ͨ��State��City����������û����ر������ǵ�NoSQL���ݿ�֧����key�ϰ�����ѯ���磺BigTable���ϵͳ����
SELECT Values WHERE state="CA:*"
SELECT Values WHERE city="CA:San
Francisco*"
������: BigTable ���ݿ⡣
(9) ����Ͼۺ� Aggregation with Composite
Keys
Composite keys ����ϼ���������������������������ͬ�������������ֲ��õ����͵�������֧�����ݷ��顣����һ�����ӣ�������һ����������־���飬�����־��¼�˻������ϵ��û��ķ�����Դ��������Ҫ�����ijһ��վ�����Ķ����ÿ͵��������ڹ�ϵ�����ݿ��У����ǿ�����Ҫ����������SQL��ѯ��䣺
SELECT count(distinct(user_id)) FROM
clicks GROUP BY site���ǿ�����NoSQL�н������µ�����ģ�ͣ�

Counting Unique Users
using Composite Keys
���������ǾͿ������ݰ�UserID���������ǾͿ��Ժ����װ�ͬһ���û������ݣ�һ���û����������̫���event�����д�����ȥ����Щ�ظ���վ�㣨ʹ��hash
table���DZ��ʲô������һ����ѡ�ļ����ǣ����ǿ��Զ�ÿһ���û�����һ������ʵ�壬Ȼ�����վ����Դ�ӵ��������ʵ���У���Ȼ������һ�������ݵĸ������������֮�»���һ����ʧ��
������: Ordered Key-Value Store �����ֵ�����ݿ⣬
BigTable�������ݿ⡣
(10) ��ת���� Inverted Search �C ֱ�Ӿۺ� Direct
Aggregation
�����������������ݴ������������������ݽ�ģ������������ˣ�����������ǻ�Ӱ������ģ�͡������������Ҫ���뷨��ʹ��һ���������ҵ�����ij���������ݣ����ǰ����ݾۺ�����Ҫʹ��ȫ��������������������˵һ��ʾ���������������Ǹ����ӣ������кܶ����־�����а����������û������ǵķ�����Դ�������Ǽٶ�ÿ����¼����һ��UserID�������û�������
(Men, Women, Bloggers, ��)���Լ��û����ڵij��У��ͷ��ʹ���վ�㡣����Ҫ�ɵ����ǣ�Ϊÿ���û������ҵ�����ijЩ����������Դ�����ڳ��У��ȣ��ĵĶ����û���
�����ԣ�������Ҫ������Щ�����������û����������ʹ�÷�ת��������������ǰ����¸ɵú����ף��磺
{Category -> [user IDs]} �� {Site -> [user IDs]}��ʹ��������������
���ǿ���ȡ��������UserIDҪ�Ľ�����������º����ɣ����ҿ��Ըɵúܿ죬�����ЩUserID���ź���ģ������ǣ�����Ҫ���û����������ɱ��������е��鷳����Ϊ�����������ܻ�����������
SELECT count(distinct(user_id)) ...
GROUP BY category��������SQL��û��Ч�ʣ���Ϊcategory����̫���ˡ�Ϊ��Ӧ��������⣬���ǿ��Խ���һ��ֱ������
{UserID -> [Categories]} Ȼ���������������ɱ�����

Counting Unique Users
using Inverse and Direct Indexes
���������Ҫ���ף���ÿ��UserID�������ѯ�Ǻ�û��Ч�ʵġ����ǿ���ͨ������ѯ���������������⡣����ζ�ţ�����һЩ�û��������ǿ��Խ���Ԥ��������ͬ�IJ�ѯ��������
������: Key-Value Store ��ֵ�����ݿ⣬ Document
Databases�ĵ����ݿ⣬ BigTable�������ݿ⡣
�㼶ʽģ�� Hierarchy Modeling Techniques
(11) ���ξۺ�Tree Aggregation
���λ��������ͼ���跴������Ա�ֱ�Ӵ��һ����¼���ĵ���š�
�����νṹ��һ����ȡ��ʱ���dz���Ч�ʣ��磺������Ҫչʾһ��blog���������ۣ�
�������κδ�ȡ���ʵ�嶼��������⡣
���ڴ����NoSQL��ʵ����˵���������ݶ��Ǻܲ����õģ��������������˵��
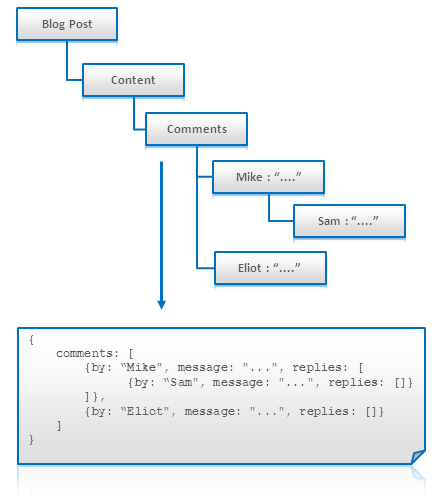
Tree Aggregation
������: Key-Value ��ֵ�����ݿ�, Document Databases
�ĵ����ݿ�
(12) �ڽ��б� Adjacency Lists
Adjacency Lists �ڽ��б���һ��ͼ �C ÿһ����㶼��һ�������ļ�¼���������
���еĸ������ӽ�㡣���������ǾͿ���ͨ�������ĸ����ӽ����������������Ȼ��������Ҫͨ��hop��ѯ����ͼ����������ڹ�Ⱥ���Ȳ�ѯ���Լ��õ�ij������������û��Ч�ʡ�
������: Key-Value ��ֵ�����ݿ�, Document Databases
�ĵ����ݿ�
(13) Materialized Paths
Materialized Paths ����������ݹ�������磺���νṹ�����������Ҳ���Ա���Ϊ�Ƿ����һ�ֱ��֡����뷨��Ϊÿ�������ϸ������ӽ��ı�ʶ���ԣ������Ϳ��Բ���Ҫ������֪�����еĺ���������Ƚ���ˣ�
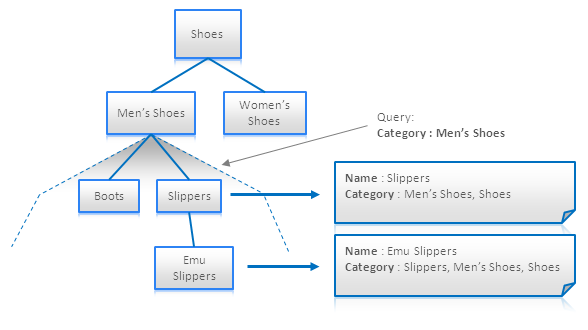
Materialized Paths for
eShop Category Hierarchy
�����������ȫ������������˵�dz��а�������Ϊ�����������һ���㼶�ṹת��һ���ĵ��������ʾͼ�����ǿ��Կ������е���Ʒ��Men��s
Shoes�µ��ӷ�����Ա�һ���̵ܶIJ�ѯ��䴦������ֻ��Ҫ��������������
Materialized Paths ���Դ洢һ��ID�ļ��ϣ�����һ��IDƴ�����ַ���������������ͨ��һ���������ʽ������һ���ض��ķ�֧·������ͼչʾ�������������֧��·�������˽�㱾������
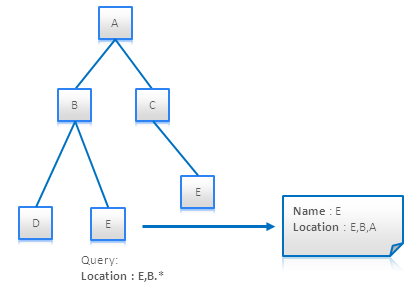
Query Materialized Paths
using RegExp
������: Key-Value ��ֵ�����ݿ�, Document Databases
�ĵ�����, Search Engines ��������
(14) Ƕ�� Nested Sets
Nested sets Ƕ�������νṹ�ı������������㷺�������˹�ϵ�����ݿ��У�����ȫ�������� Key-Value
��ֵ�����ݿ� �� Document Databases �ĵ����ݿ⡣����������뷨�ǰ�Ҷ�ӽ��洢��һ�����飬��ͨ��ʹ�������Ŀ�ʼ�ͽ�����ӳ��ÿһ����Ҷ�ӽ�㵽һ��Ҷ�ӽ�㼯��������ͼ��ʾһ����
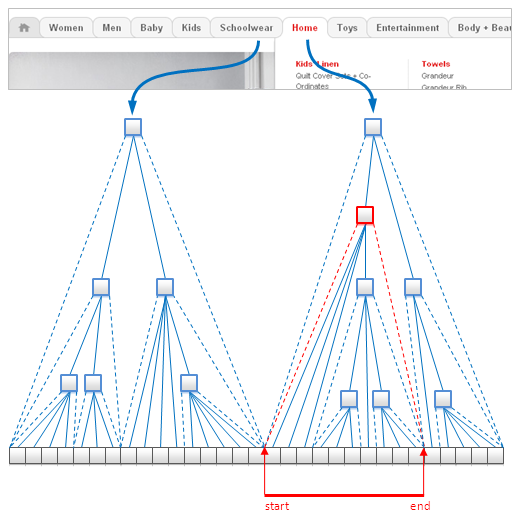
Modeling of eCommerce
Catalog using Nested Sets
���������ݽṹ����immutable data��������� �зdz�������Ч�ʣ���Ϊ����ڴ�ռ�С�����ҿ��Ժܿ���ҳ����е�Ҷ�ӽ�������Ҫ���ı�����������ˣ��ڲ����������Ҫ�ܸߵ����ܳɱ�����Ϊ�µ�Ҷ�ӽ����Ҫ���ģ�ظ���������
������: Key-Value Stores ��ֵ���ݿ�, Document
Databases �ĵ����ݿ�
(15) Ƕ���ĵ���ƽ���������ֶ��� Nested Documents
Flattening: Numbered Field Names
���������������˵�ͱ�ƽ�ĵ�һͬ�������磺ÿһ���ĵ���һ����ƽ���ֶκ�ֵ����������������ģ�͵�������ҵ��ʵ��ӳ�䵽һ���ı��ĵ��ϣ�������ҵ��ʵ���кܸ��ӵ��ڲ��ṹ������ܻ��ú�����ս��һ�����͵���ս�ǰ�һ���в㼶���ĵ�ӳӳ����������磬�ĵ���Ƕ����һ���ĵ��������ǿ��������ʾ����

Nested Documents Problem
�����ÿһ��ҵ��ʵ�����һ�ּ������������������һ�������б����Ұ�����㼶�ĵ�ӳ���һ���ı��ĵ���һ�ַ����Ǵ���
Skill �� Level �ֶΡ����ģ�Ϳ���ͨ���������ǵȼ�������һ���ˣ�����ͼ��ע����������ϲ�ѯ���ʧ�ܡ������ע����Ϊ�ֲ���Excellent�Ƿ���Math����Poetry�ϵģ�
�������е� [4.6] ������һ�ֽ����������Ϊÿ���ֶζ��������� Skill_i
�� Level_i�������Ϳ��Էֿ�����ÿһ���ԣ���ͼ��ʹ����OR�������������п��ܵ��ֶΣ�:
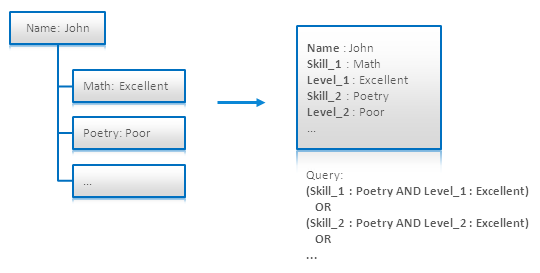
Nested Document Modeling
using Numbered Field Names
�����ķ�ʽ����û����չ�ԣ�����һЩ���ӵ�������˵ֻ���ô��븴�ӶȺ�ά���������
������: Search Engines ȫ������
(16)Ƕ���ĵ���ƽ�����ڽ���ѯ Nested Documents Flattening:
Proximity Queries
�ڸ�¼ [4.6]�и���������������������ƽ����ĵ��������ڽ��IJ�ѯ�����ƿɱ���ѯ�ĵ��ʵķ�Χ����ͼ�У����еļ��ܺ͵ȼ�������һ���ֶ��У���
SkillAndLevel����ѯ�г��ֵ� ��Excellent�� �� ��Poetry�� ����һ��������һ����
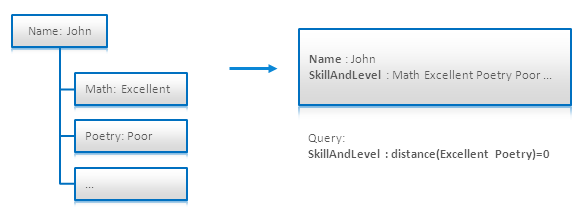
Nested Document Modeling
using Proximity Queries
��¼ [4.3] �н������������������Solr�е�һ���ɹ�������
������: Search Engines ȫ������
(17) ͼ�ṹ������ Batch Graph Processing
Graph databases ͼ���ݿ⣬�� neo4j ��һ�����ڵ�ͼ���ݿ⣬������ʹ��һ�������̽���ھӽ�㣬����̽���������������ǰ�Ĺ�ϵ�����Ǵ���������ͼ�����Ǻ�û��Ч�ʵģ���Ϊͼ���ݿ�����ܺ���չ�Բ�������Ŀ�ġ��ֲ�ʽ��ͼ���ݴ������Ա�
MapReduce �� Message Passing pattern ���������磺 ����ǰһƪ�������е��Ǹ�ʾ�����������������
Key-Value stores, Document databases, �� BigTable-style
databases �ʺ��ڴ�����ͼ��
Applicability: Key-Value Stores, Document
Databases, BigTable-style Databases |


