论坛上总看到有人说某某数据库几百万的数据量怎么提高查询速度等等,最近正好做了一个关于这方面的表结构优化,分享给大家,希望对大家有帮助。本人也不是什么大牛,只希望互相交流学习。仅为分享,不喜勿喷,谢谢。
言归正传,下面说一下具体的实现及效果。
应用场景:
一张日志表,记录每天150w左右的数据量,应用要求存储6个月以上,则共计27000w左右的数据规模,表从设计初期就考虑到数据增长会很快,所以采用的是日志表的形似记录的内容,前端应用不需和任何表关联,只需从这张表中读取数据即可。应用主要是根据不同的条件进行日志数据的检索和统计功能(时间条件,条件1,条件2),数据检索分页显示。
原始处理方式,单表双TOP语句的方式。但是随着数据量的增长,检索速度越来越慢,老是出现查询超时的问题,同时由于双TOP方式分页的限制,导致页数越接近尾页越缓慢的现象。
为了解决以上的问题,对原始数据表的结构进行了如下的调整。
数据库对于百万级别的数据量,响应速度还是很快的,但是对于上亿级别的数据量而言,由于存在着大量的磁盘IO,所以速度的降低不是线性的,而是呈现指数级的下降,所以,优化方法的中心思想就是减少结果集的数量,提高数据库本身的响应时间。
针对以上的想法,分4个步骤对数据库的存储结构及数据的选取方式进行以下的优化。
1.分而治之
对于几千万甚至亿级的数据,想在如此庞大的基础数据中做到快速响应的读取数据,比较可行的方法就是大而化小的思想。
大而化小的思想对于算法来说,怎样选取“小”这一概念的界定就很关键了,对于如此庞大的表,发现每天产生的数据量相对较稳定,基本维持在150w左右每天,这个数据量对于数据库来说是个可以快速进行响应的数据规模。而选择的太小,比如说按小时计算的方式,虽然单位的数据量减少了24倍,但是相对于数据量从150w到6w的时间提升远比1张表到24张表的维护性提高付出的代价多,所以最后决定采用按日分表的方式进行分表,这样以3个月的数据来说,从13500w的一张大表转化为150w的90张小表。这样可以改善最终结果的选取速度大大提升。
2.合而击之
经过以上的步骤,将大表划分为多个小表,虽然对于最终选取来说,只是从某一个小表中选取最终的数据,但是还是无法避免第一次进行所有涉及表的轮循计算行数的过程,这样与以前的方式相比数据量没有减少反而增加了算法的复杂度,所以单单分而治之的方法无法解决计算行数及页数的轮循产生的时间开销。
针对选取首页时的行数计算,可以反其道而行之,采用合而击之的方式,在数据初始化的时候进行以日为单位的选取条件统计,将统计结果分类存放于月表中,这样在选取时对于整日的区间只要直接从月表中读取响应日期的数据条目就可以了。
目前日志的查询条件有3组,分别是日期,条件1(固定),条件2(固定)。这样以日期为划分依据,就将检索条件由3组缩小为2组,减少了排列组合的数量,同时条件1和条件2的月表存储采用了“鸡兔同笼问题”的逆运算,通过选取条件确定某一类别的方式计算某一条件组合的信息条数。这样,实际的实验数据表明,可以讲150w的数据量缩小的4千左右的数据行数。对于表的数目来说每个月产生一张,代价很小。
CREATE TABLE monthtable
(
条件1,
条件2,
数量,
日期
)
这样就有效地避免了在计算总行数时轮循所有日表的大量读取工作,节省了时间。
3.折半计算
以上的2部,可以解决大表,及轮循时耗费大量时间的问题,但是对于起始日期来说,如果是完整的一天可以直接从月表中读取数据,若不是完整的一天,则还是需要读取日表,虽然最多只需要读取两张日表,但是还是会浪费一些时间。
对于表的顺序选取来说,由于数据库本身的机制限制,所以无法避免的需要进行正逆两次数据的选取,所以现在可以做的就是减少首次选取的行数及减少排序操作的次数。
出于以上的目的,现将日表的数据选取方式修改为折半计算的方式。即选取行之前,先计算所选取的行是否超过表选取数据行数的一半,若未超过仍采用原始的数据选取方式,若超过,则通过倒序选取的方式从数据尾部提取数据,这样当选去的尾行<总行数一半时,选取时间与原是相同,当选取的尾行>总行数的一半时,由于少了一次排序,并且选取的行数也减少了,所以速度优于原始的选取方式,而且越接近数据尾部选取的速度越快,尾页的速度和首页相同,这要比原始的方式速度提升很多倍。
这样,扫描的结果集最大值仅为原始的一半,而且少了一次大结果集的排序过程,时间大大提高。
原始方式流程图:

折中计算流程图:

4.创建统计表
在数据库的数据选取过程中创中间统计表存储结果,用于存取在每个日表中选取的数据行数,只要传入的参数不是选择首页,那么数据库都直接从统计表中读取行数,这样就不用每一页都计算总行数,节省大量时间。
信息查询流程图:
优化前:

优化后:
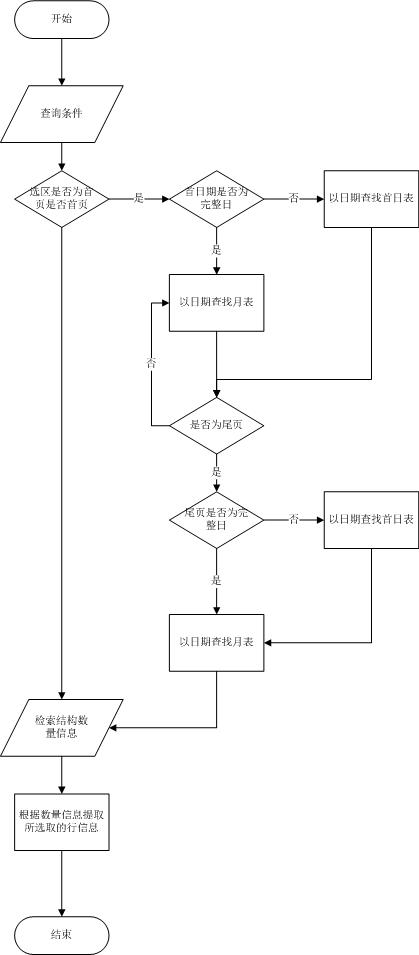
以上数据选取过程封装在存储过程中统一进行。
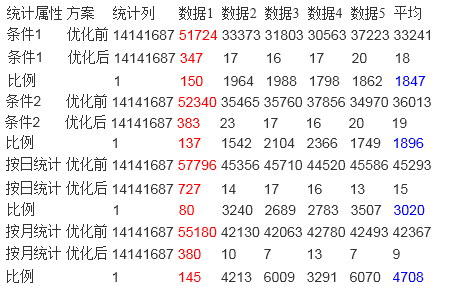
统计优化测试数据:
数据量 14141687
单位(ms)
测试计算机配置:
CPU:Inter(R) Celeron(R) CPU 430 @ 1.80GHz
1.79GHz
Memory:2G (计算机存在其他服务,SQL Server 可利用的内存实际在1G左右)
每进行一次数据检索操作,均重启SQL Server服务。
优化前后数据库均已建立相关索引,索引在这里就不列出了。
由于数据库存在数据预热的阶段,所以平均值的计算方式为去掉最大值后计算的平均值,表中红色为去掉的测试时间。
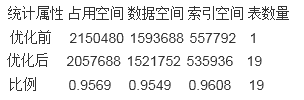
存储空间占用统计:
数据量14141687
单位(KB)
数据日期区间2011-11-25 ~ 2011-12-29
信息查询优化测试数据:
数据量 14141687
单位(ms)
每页行数:50
由于数据库存在数据预热的阶段,所以平均值的计算方式为去掉最大值后计算的平均值,表中红色为去掉的测试时间。
条件属性为:
1.统计时间:2011-11-16 0:00:00 ~ 2011-12-30
0:00:00
2.条件1:xxxx
3.条件2:xxxx
测试1:以时间为筛选条件
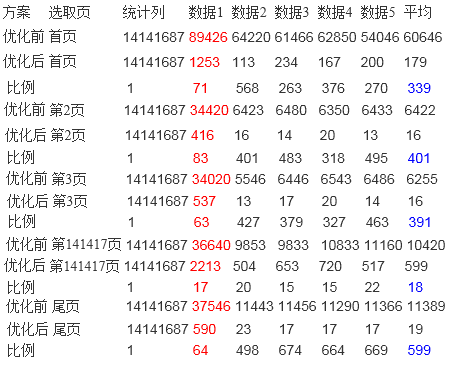
测试2:以时间和条件1为筛选条件
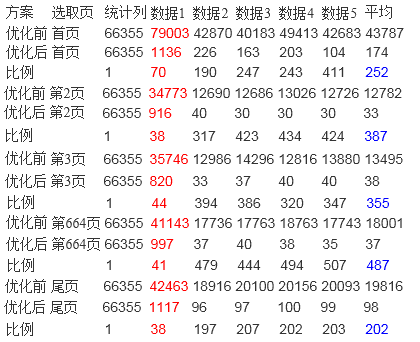
测试3:以时间和条件2为筛选条件
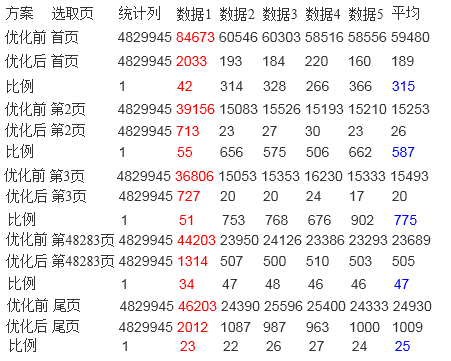
测试4:以时间和条件1、条件2为筛选条件
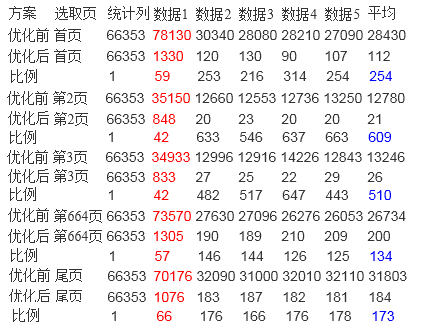
测试结果分析:
从统计功能来看,数据库的响应速度提升很大,从30秒左右提升到20毫秒左右,速度最大提升了4700多倍,效果明显。
从查询功能来看,数据库的响应速度提升没有统计功能明显,但是也从30多秒提高到200毫秒左右,提升了约400-500倍左右。
原因分析:统计功能利用本算法可以完全避免对于原始数据表的读取操作,所以对于该功能来说,只是操作几张4-5千条数据的表,所以响应时间快,但是对于查询功能来说,最终返回给用户的信息是具体的消息,所以无法避免的要对数据表进行查找,所以时间上消耗的多了些。但是基本上也都控制在200毫秒以下就可以做出响应。
代价:
本机制采用的是复杂度换时间的方法,即数据库结构和选取方式的复杂度增加了,从而减少了在选取时消耗的时间,并且有一部分统计工作提到了选取操作以外进行,将时间分块,从而在感觉上降低了响应时间。
对于,日表及月表的数据填充工作可以使用数据库的作业,在业务不繁忙的时间进行原始表的划分工作。
对于测试数据来说,1千4百万的数据初始化需要十分钟左右的时间进行,可以选择凌晨1点开始,这样最长1-2个小时就可以把数据处理完毕。并且大量表的初始化只在第一次更换数据库结构时产生,以后每天进行的数据统计工作基本上只有200w左右,这个数量级只需要几分钟就可以完成,完全不影响软件每天的正常使用。 |


