00
�C ��������
����������ͬʱ����һ����Դ��ʱ���п��ܵ������ݲ�һ�¡������Ҫһ���»�����������˳��
���������е�һ�ֻ��ơ��������̳������¼�����һ�����������¼乩����������ʹ�á���˿����ж��������ͬʱҪ���·���Ϊ�˱����ͻ�����¼������װ���������·������������ס�������˾Ͳ��ܴ���ߴ��ˡ�ֻ����ߵ��˿��ų�������ߵ��˲��ܽ�ȥ��
- ���Ļ�������
���ݿ��ϵIJ������Թ���Ϊ���У�����д���������ͬʱ��һ�������ʱ���Dz����г�ͻ�ġ�
ͬʱ����д����ͬʱд�Ż������ͻ�����Ϊ����߲����ԣ�ͨ��������������
A. ������(Shared Lock) Ҳ�ж���.
��������ʾ�����ݽ��ж���������˶���������ͬʱΪһ������ӹ�������
B. ������(Exclusive Lock) Ҳ��д��.
��������ʾ�����ݽ���д���������һ������Զ����������������������Ͳ����ٸ������κ����ˡ�
- S��X���ļ����Ծ���
��������ͨ������һ����������������֮��ij�ͻ��ϵ��
S X
S + �C
X - -
+ �������ݣ� -����������
- ��������
A. ����(Table Lock)
��������������Ӱ��������м�¼��ͨ������DDL����У���DELETE
TABLE,ALTER TABLE�ȡ�
B. ����(Row Lock)
��һ�м�¼������ֻӰ��һ����¼��ͨ������DML����У���INSERT,
UPDATE, DELETE�ȡ�
�����ԣ�����Ӱ�������������ݣ���˲����Բ��������á�
- ��������Intention Lock)
��Ϊ�������������������ݣ����Ա���������Ҳ�������ͻ����:
A. trx1 BEGI
B. trx1 �� T1 ��X�����ı��ṹ��
C. trx2 BEGIN
D. trx2 �� T1 ��һ�м�¼��S��X���������������ȴ������ɹ�)��
trx1Ҫ��������������ס������������ôtrx2�Ͳ����ٶ�T1�ĵ�����¼��X��S����ȥ��ȡ����������¼��
Ϊ�˷�������������м���֮��ij�ͻ������������������
A. ��������Ϊ�������(IS)������д��(IX)��
B. �������DZ�����������ȴ��ʾ�������ڶ���дijһ�м�¼����������������
����������֮�䲻�������ͻ�������ij�ͻ�ڼ�����ʱ��顣
C. �ڸ�һ�м�¼����ǰ������Ҫ���ñ�����������Ҳ����Ҫͬʱ�ӱ���������������
����������������������Ӿͱ���ˣ�
A. trx1 BEGIN
B. trx1 �� T1 ��X�����ı��ṹ��
C. trx2 BEGIN
D. trx2 �� T1 ��IX���������������ȴ������ɹ�)
E. trx2 �� T1 ��һ�м�¼��S��X��.
- �����ļ����Ծ���
IS IX S X
IS + + + �C
IX + + - -
S + - + -
X - - - -
+ �������ݣ� -����������
A. ������֮�䲻���ͻ, ��Ϊ��������������Ҫ��ij�м�¼���в������ڼ�����ʱ�����ж��Ƿ��ͻ��
01 �C ����
ֱ�۵����⣬��������Ҫ��סһ�м�¼����ֹ��������������м�¼��������һ����������:
A. ���������Զ���ᱻ��ֹ����Ϊ��������������һ�����ڵļ�¼(���ﲻ����Insert
duplicate�Ĵ���)��������ǶԵ��� ����û���ʹ�������أ���Щ��������û��ܽ��ܵģ���Щ��������û����ܽ��ܵġ�
- �ö�(Phantom Read)
�������ֹINSERT�������ͻ�����ö�.MySQL�ֲ����лö��Ľ���.
A. MVCC ���Ա���ö�.����MVCCֻ��SELECT�����Ч������SELECT
�� [LOCK IN SHARE MODE | FOR UPDATE], UPDATE, DELETE�������
B. Ϊ���ܹ�ͨ��������ö���������next-key�Ļ��ơ�next-keyͨ����ס2����¼֮��ļ�϶������ֹINSERT������
- ������ģʽ
����S��X��������һЩ��ȷ��ϸ�֣��ڴ����г���Precise Mode����Щ��ȷ��ģʽ,ʹ���������ȸ�ϸС�����Լ��ٳ�ͻ��
A. ��϶��(Gap Lock),ֻ����϶��
B. ��¼��(Record Lock) ֻ����¼��
C. Next-Key Lock(�����г�ΪOrdinary Lock)��ͬʱ��ס��¼�ͼ�϶.
D. ������ͼ��(Insert Intention Lock),����ʱʹ�õ������ڴ����У�������ͼ����
ʵ������GAP���ϼ���һ��LOCK_INSERT_INTENTION�ı��.
MySQL�ֲ����Щģʽ����ϸ�Ľ���.
- ����ģʽ�ļ����Ծ���
G I R N (�Ѿ����ڵ���,�����ȴ�����)
G + + + +
I - + + -
R + + - -
N + + - -
+ �������ݣ� -����������. I����������ͼ��,
G����Gap����I����������ͼ��,R������¼����N����Next-Key��.
S����S������ȫ���ݵģ�������б������ʱ����Ҫ�ԱȾ�ȷģʽ��
��ȷģʽ�ļ�⣬����S��X��X��X֮�䡣
��������Ǵ�lock0lock.c:lock_rec_has_to_wait()�Ĵ����Ƴ����ġ������������Կ��������ص㣺
A. INSERT����֮�䲻���г�ͻ��
B. GAP,Next-Key����ֹInsert��
C. GAP��Record,Next-Key�����ͻ
D. Record��Record��Next-Key֮�����ͻ��
E. ���е�Insert������ֹ�κ����ӵ�����
ͬʱҲ�м������ʣ�
A. Ϊʲô������ͼ������ֹ��϶�������ض�������»ᵼ��INSERT�������������ӳ١�

B. �������ֹ�κ�������������б�Ҫ������
- Ŀǰ�����������ǣ�ͨ�������ķ�ʽ�����ѵȴ��̡߳�
- ���Ⲣ����ζ�ţ������Ѻ����ֱ������������ˡ���Ҫ�ٴ��ж��Ƿ�������ͻ��
C. GAP+LOCK_INSERT_INTENTION��ǵķ�ʽ���ܷ�ֱ�ӱ��INSERT_INTENTION����
Ŀǰ���ڿ���
- B+Tree ����
InnoDB�����������Ǽ����������ĸ������ָÿ��B+Tree�ϵ�������Ҳ��������Ϊÿ��Index�ϵ���������˲���һ�м�¼ʱ���п��ܻ�Ӷ�������ڲ�ͬ��B+Tree�ϡ���:
CREATE TABLE t1(c1 INT KEY, c2 int,
c3 int, INDEX(c2));
INSERT INTO t1 VALUES(1, 1, 1), (3,
3, 3)
UPDATE t1 c3 = 10 WHERE c2 <= 2
UPDATE����ͬʱ��Secondary Index��Clustered
Index�ϼ�����
- ����ģʽ��ʹ��
��������Щģʽ����ʲô�����ʹ���أ� MySQL�ֲ�����ϸ�Ľ��ܡ�
A. Next-Key ʹ���ڱ�WHERE�����õ��������ϣ�ȷ��˵��������Search��������)��
����������У�Index(c2)��ʹ�� Next-Key Lock.
B. Record Lockʹ����û�б�WHERE����ʹ�õ������ϡ�����������У���������ʹ��Record
Lock.��������UPDATE����ͬʱ�ڼ�Index(c2)�ļ�1�ϼ�Next-Key,������1�ϼ�record��������һ��session��������(2,5,2),(3,5,2)ʱ���Գɹ�������(2,2,2)ʱ�ᱻ������
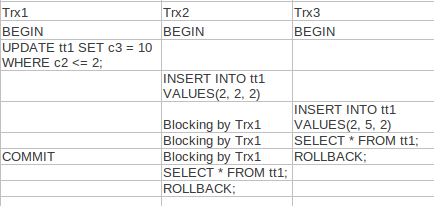
Next-Key And Record
����ʱ���֣�SELECT��[FOR UPDATE |LOCKIN SHARE
MODE]���ܻᵼ��ȫ����¼����ס��
������Сʱ��SELECT�����ȫ��ɨ��ķ�������ʹ�����ַ���ʱ�����������е����ݣ�����������ݶ�����ס�ˡ����ܶԲ����������ļ�¼������ha_innobase::unlock_row(),������Repeatable
Read����ʱ���ᱻ�ͷš�Ҳ������һ��Bug.
C. A��Bͬʱ������SELECT��[FOR UPDATE | LOCK
IN SHARE MODE]�� UPDATE��DELETE��䡣
D. GAP����ȻҲ��ʹ����WHERE����ʹ�õ������ϡ���Next-Key��ͬ���ǣ�GAP��ֻ�����ϱ߽�(��һ�����ڷ��������ļ�¼)�ϡ���Next-Key�������з��������ļ�¼�ϡ����������е�����c2=2�ļ�¼����Ҫ��c2=3�ϼ�һ��GAP����
�� �����ѯʱ��InnoDB��ʵ�����ڱ߽��ϼӵ���Next-Key����
���������ʵ�ֵ����ơ�
Ŀǰʹ��GAP����У�
�C Supremum��¼��ʼ����һ��GAP��
�C �����ѯ(ORDER BY DESC)ʱ.
�C ��ֵƥ��һ��ȷ�еļ�ֵʱ,����һ����¼��GAP����
�C ��ֵƥ��һ��ȷ�еļ�ֵ��ǰʱ,����һ����¼��GAP������
E. INSERTʱ��ͨ����������ֻ�е����������ڲ�������Gap��Next-key����Ҫ�ȴ�ʱ���Żᴴ��һ��������ͼ�������������waiting״̬��
- ���뼶���Next-Key����Ӱ��
A. Read Uncommitted��Read Committedʱ,����Ҫ�ڼ�϶�ϼ���,Nexk-Key���Record����
B. Repeatable Reads �� Serializableʱ��ͨ�������ʹ��Next-key����
��2���������Ҫ�Լ�϶����:
�C ��ѯһ��Ψһ��ֵ���� WHERE c1 = 1, c1 ��������Ψһ�������Ҳ�ѯ����в���NULL�ֶΡ�
�C ��innodb_locks_unsafe_for_binlog�����������ﻹ����һЩֵ��˼��������:
- ��������������UPDATE��DELETEʱ�Ӽ�϶����ȫ��Ϊ�˷�ֹMaster��Slave���ݲ�һ�¡���ô��ʹ��binlogʱ��û�б�Ҫ��DELETE,
UPDATE�Ӽ�϶����
- Row Format Binlogʱ�����Ӽ�϶���Ƿ������Master, Slave��һ����
- ����������innodb_locks_unsafe_for_binlog,SELECT��[]�Ƿ���Բ��Ӽ�϶����
�жϼ�ʲô������Ҫ������row0sel.c:row_search_for_mysql()�С�
02 �C �ӳټ�������
���һ�����кܶ����������ô����һ����¼ʱ������Ҫ�Ӻܶ�������ͬ��B-Tree����
������һ�������״̬��Ϣ:
CREATE TABLE t1(c1 INT KEY, c2 INT);
BEGIN;
INSERT INTO t1 VALUES(1, 1);
INSERT INTO t1 VALUES(2, 2);
SHOW ENGINE INNODB STATUS;
״̬��Ϣ:
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 501, ACTIVE 0 sec
1 lock struct(s), heap size 376, 0 row
lock(s), undo log entries 2
�C ��ʽ��
Lock ��һ�ֱ��۵�˳���ơ�������ܿ��ܷ�����ͻ������ڲ�������ʱ���ͼ�����
�����ͻ�Ŀ����Ժ�С�������������Dz���Ҫ�ġ�
Innodb ʵ����һ���ӳټ����Ļ��ƣ������ټ������������ڴ����г�Ϊ��ʽ��(Implicit
Lock)��
��ʽ�����и���Ҫ��Ԫ��,����ID��trx_id).��ʽ�������������£�
A. InnoDB��ÿ����¼�ж�һ��������trx_id�ֶΣ�����ֶδ����ڴ�������B+Tree�С�
B. �ڲ���һ����¼ǰ�����ȸ��ݼ�¼�е�trx_id���������Ƿ��ǻ������(δ�ύ��ع�).
����ǻ���������Ƚ���ʽ��ת��Ϊ��ʽ��(����Ϊ����������һ����)��
C. ����Ƿ�������ͻ������г�ͻ����������������Ϊwaiting״̬�����û�г�ͻ������,����E��
D. �ȴ������ɹ��������ѣ����߳�ʱ��
E. д���ݣ������Լ���trx_idд��trx_id�ֶΡ�Page Lock���Ա�֤��������ȷ�ԡ�
��ش��룺
A. lock_rec_convert_impl_to_expl()����ʽ��ת������ʾ����
B. �����Ͳ���������ͻ����lock_rec_lock(),���ĵ�һ��������ʾ�Ƿ�����ʽ��������Ҫ�ر�ע��������������ΪTRUE����û�г�ͻʱ�����������
C. ���������ij�ͻ�ľ���������lock_rec_has_wait()
D. ����waiting����lock_rec_enqueue_waiting()
E. ����������lock_rec_add_to_queue()
�C ��ʽ�����ص�
A. ֻ���ںܿ��ܷ�����ͻʱ�ż���������������������
B. ��ʽ������Ա��ĵ�B+Tree��¼����˶���Record���͵�������������Gap��Next-Key���͡�
�C ��ʽ����ʹ��
A. INSERT����ֻ����ʽ��������Ҫ��ʾ������
B. UPDATE,DELETE�ڲ�ѯʱ��ֱ�ӶԲ�ѯ�õ�Index������ʹ����ʾ��������������ʹ����ʽ����
������˵�����Զ�����ʹ����ʽ���ġ���ǰʹ����ʾ��Ӧ����Ϊ�˼��������Ŀ����ԡ�
INSERT��UPDATE��DELETE��B+Tree�ǵIJ������Ǵ�������B+Tree��ʼ����˶���������������Ч����ֹ������
�C Secondary Index�ϵ���ʽ��
ǰ��˵��, trx_idֻ�����������ϣ���ô���������������ʵ����ʽ�����أ�
��Ȼ��Ҫͨ�����������е�����ֵ��������B+Tree�Ͻ��ж��β��ҡ���������Ǻܴ�ġ�
InnoDB�����������һ���Ż���
A. ÿ��ҳ����һ��MAX_TRX_ID,ÿ���ĸ��������ļ�¼ʱ�������������������ID��
B. ���ж��Ƿ�Ҫ����ʽ����Ϊ��ʽ��ʱ���Ƚ�ҳ���max_trx_id�������б�����Сtrx_id�Ƚϡ����max_trx_id�������б�����Сtrx_id��С����ô�Ͳ���Ҫת��Ϊ��ʾ���ˡ�
������lock_sec_rec_some_has_impl_off_kernel()��
/* Some transaction may have an implicit
x-lock on the record onlyif the max trx id for the page
>= min trx id for the trx list, ordatabase recovery
is running. We do not write the changes of a page max
trx id to the log, and therefore during recovery, this
value for a page may be incorrect. */
if (page_get_max_trx_id(page) <
trx_list_get_min_trx_id()
&& !recv_recovery_is_on()) {
return(NULL);
}
03 �C ����ʵ��
�C ���Ĵ��
A. table->locks ���һ���������б�������
B. lock_sys->rec_hash������б���������Hashֵ����(spaceid,
pageno)�����㡣
C. trx->trx_locks�����������������������������м�����һ������������������������ʱ��һ���ͷš�������lock_release_off_kernel().����еȴ��������Ա���Ȩ����Ὣ�ȴ�����,ת��Ϊ����Ȩ��������������Ӧ������
�C ������Ψһʶ��
��һӡ���뵽���ǣ���ÿ�м�¼�ļ�ֵ����������Ψһʶ��.���Ǽ�ֵռ�ÿռ�Ƚϴ�
InnoDBʹ��Page NO.+Heap NO.����������Ψһʶ�����ǿ��Խ�Heap
no.����Ϊҳ���ϵ�һ��������ֵ��ÿ��������¼�ڱ�����ʱ���������һ��Ψһ��heap no.
A. ��ֵ��������Ϊһ����ֵ��page no. + heap no.
�������ġ�
B. ��������Ȼռ�ÿռ�С�����Ǵ���Ҫ����һЩ���磺�ڷ���һ��B+Treeҳ��ʱ��һ��ļ�¼Ҫ�Ƶ��µ�ҳ���У����Ҫ�Դ��ڵ�������Ǩ�ơ�
���ƶ���d�����У�lock_move_reorganize_page(),
lock_move_rec_list_start(),
lock_move_rec_list_end().
��ɾ���Ͳ�������ʱ��ҲҪ����GAP���ļ̳С�lock_rec_inherit_to_gap()
lock_rec_inherit_to_gap_if_gap_lock().
�C ����(Deadlock)
A. ��ʱ���ơ���Ҫ�ӵ�������������ͻʱ������һ��waiting�������ҷ���DB_LOCK_WAIT����
row_mysql_handle_error����srv_suspend_mysql_thread������һ���̡߳�
B. �����������ơ�ÿ������waiting������Ҫ����lock_deadlock_occurs()���������ļ�⡣
������ⷽ����Waits-For Graph.��lock_deadlock_recursive()��ʵ�֡�
������������Ҫѡ�����е�һ��������ع��������������ѡ����һ������ع��ܣ�
�C ���һ����������non-transactional��(��MyISAM�����IJ��ܻع�),��һ����û�С�
��û����non-transactional�Ļᱻ�ع���
�C ���2����������non-transactional�����߶�û�С���Ƚ�2�������ĵļ�¼���ͼӵ����������ܺ�С������ᱻ�ع���trx_weight_ge()ʵ���������
|


