| 为什么我们使用搜索引擎时,不同的用户搜索同样的关键词看到的广告却不同?为什么我们到电子商务网站购物时,每次浏览同样的商品时都可以得到不同的商品推荐?作为网站服务的开发者,你有没有想过,你所拥有的数据蕴含着怎样的价值?当你准备对自己的网站数据进行深入分析时,是否曾面对着成百上千的数据不知如何下手?
如果上面的问题会让你连连点头,那么请跟随我们,展开一段数据分析之旅。希望沿途的见闻,会让你在下次进行数据挖掘操作时,更加得心应手。
借用一下本刊前面的一篇文章――《借助OTS快速构建LBS服务》中的故事。假设你利用OTS构建了一个很不错的LBS网站,公司业务蒸蒸日上,积累了大量的活跃用户,还拥有了北京地区大部分餐馆的物理信息和用户评价信息;如果你的广告业务也发展得很好,说不定你的公司已经收支平衡,并且小有盈余。可以说,这时的你已不满足于仅仅为用户提供餐馆信息,而且希望能够利用你拥有的数据为客户创造更大的价值。
对了,在开始前,我们也要介绍一下本次旅行的交通工具:阿里云开放数据处理服务(Open Data Processing Service,简称ODPS)。ODPS是构建在大规模分布式计算系统上的海量数据处理服务,以REST API的形式支持描述性查询语言SQL的数据处理,适用于海量数据统计、数据模型、数据挖掘、数据商业智能等诸多互联网应用。
一个简单的数据分析示例
你拥有的数据可以支持很多复杂精彩的分析任务,我们从最简单的一个开始:希望利用所有用户的点评数据计算餐馆的综合评分,进而统计“北京最受欢迎的十大餐馆”。由于这个榜单相对固定,我们可以每天重新计算一次,看是否有黑马杀入。
如果你的业务发展得比上文描述的还要好,那么你此刻可能会有点烦恼了:假设你已有8000万用户,按10%的活跃用户平均每人30条点评,其他90%的用户平均每人2条点评计算,用户点评数据约有4亿条;如果每条点评信息平均0.5KB,那么点评数据总计有200GB。利用传统数据库来完成数据分析会显得力不从心;而大数据处理的商业解决方案极为昂贵,开源的解决方案又需要非常专业的开发和运维知识。在这种场景下,就要靠ODPS大显身手了。
第一个数据分析的SQL
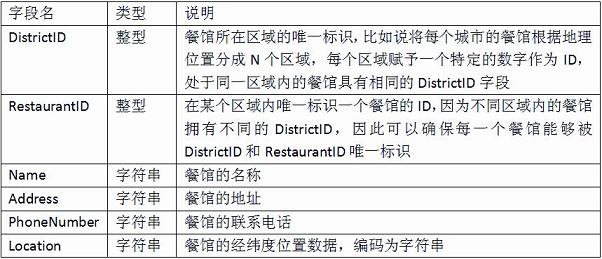
表1 RestaurantInfo表存储餐馆的数据
让我们回顾一下你的原始数据,它们都已经存储在OTS的表格中了(为了ODPS的计算需要,表的schema略有修改),如表1和表2所示。
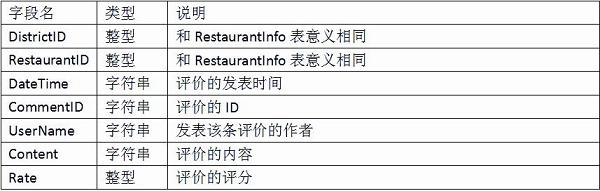
表2 RestaurantComment表存储用户对餐馆的评价数据
为了使用ODPS服务,你还需要到ODPS的管理中心申请数据存储所需的存储空间、数据分析所需的计算资源、用于确保数据和计算安全的AccessID和AccessKey【注:ODPS使用这一加密对来保证开发者的数据、作业和工作流不能被别人访问,因此开发者需要小心保管AccessId和AccessKey,不要对任何人泄露】的安全加密对,以及开发所需的SDK安装包(什么,你还没有注册?别担心,阿里云支持统一用户登录,你在使用OTS时已经注册过,此时仅仅需要开通ODPS服务就可以了)。
在ODPS的SDK安装包中,提供了一个命令行工具odpscmd【注:随ODPS SDK一同发布的命令行操作工具,其安装过程参见http://odps.aliyun.com】。odpscmd封装了ODPS的REST API,支持ODPS服务的绝大部分功能,可以帮助你尽快了解并熟悉ODPS的常用操作。SQL的构造流程分为以下五步。
- 用odpscmd来配置一下你的安全加密对(odpscmd要求所有命令以“;”结尾):
$ odpscmd SET ACCESSID=AccessID ACCEESSKEY=AccessKey;
- 将OTS中的两张表的schema和数据复制到ODPS中(以下以大写字母表示关键字,斜体字母表示用户自定义标识符;odpscmd对所有关键词和标识符不区分大小写):
$ odpscmd CREATE TABLE RestaurantInfo AS SELECT * FROM OTS.RestaurantInfo;
$ odpscmd CREATE TABLE RestaurantComment AS SELECT * FROM OTS.RestaurantComment;
在HangMode【注:odpscmd处理SQL命令的一种模式,与NoneHangMode相对】模式下,odpscmd会同步串行处理提交的一系列SQL命令,直到最后一个SQL命令结束,结果表数据生成后才会返回。根据表中的数据量多少和运算的复杂性,等待时间可能会是几秒钟到几个小时不等。当OTS中的源表数据量很大、数据被分片保存时,ODPS服务会启动多个任务并发读取OTS中的数据,以缩短数据复制时间。存储在ODPS中的数据也会分片保存,以便后续的数据分析操作可以快速地读取数据。
- 你还需要在ODPS中创建一张新表TopTenRestaurants,存储十大餐馆的统计信息,如表3所示。
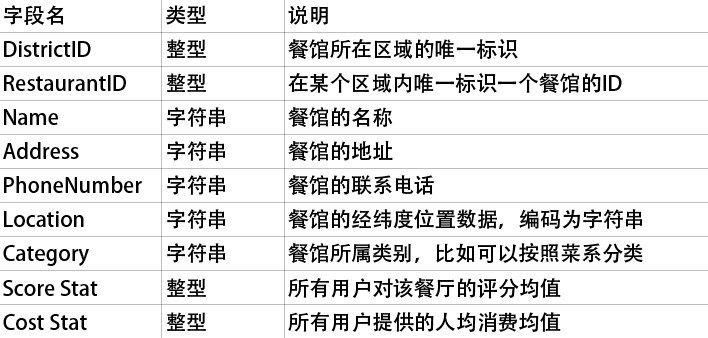
表3 TopTenRestaurants表存储十大餐馆的统计数据
建表命令为:
$ odpscmd CREATE TABLE IF NOT EXISTS TopTenRestauransts (DistrictID INT, RestaurantID INT, Name STRING, Address STRING, PhonenNmber STRING, Location STRING, Category STRING, ScoreStat INT, CostStat INT);
- 我们将用户对每个餐馆评分的平均值定义为该餐馆的口碑,取评分最高的前十名餐馆作为“北京最受欢迎的十大餐馆”。构造相应的SQL语句后,在odpscmd中提交:
$ odpscmd INSERT OVERWRITE TABLE TopTenRestaurants SELECT a.DistrictID, a.RestaurantID, a.Name, a.Address, a.PhoneNumber, a.Location, a.Category, b.ScoreStat, b.CostStat FROM RestaurantInfo a JOIN (SELECT DistrictID, RestaurantID, AVG(Score) AS ScoreStat, AVG(Cost) AS CostStat FROM RestaurantComment GROUP BY DistrictID, RestaurantID) b ON a.DistrictID = b. DistrictID AND a.RestaurantID = b.RestaurantID ORDER BY b.ScoreStat DESC LIMIT 10;
- SQL语句运算完成后,我们可以查阅表中的结果数据:
$ odpscmd READ TABLE TopTenRestaurants;
在ODPS中计算的结果数据需要被外部应用访问,我们可以借助于OTS的实时查询功能。假设在OTS中利用相同的schema也创建了TopTenRestaurants表,你可以通过下面的命令将ODPS的数据推送到OTS中:
$ odpscmd EXPORT DATA TO OTS TopTenRestaurants FROM TABLE TopTenRestaurants;
自动定期分析
至此,我们已完成一次数据分析操作:从OTS导入原始数据到ODPS中,进行数据分析操作,再将结果数据导出到OTS供查询。但这个过程是手工完成的,如果希望“十大餐馆”的数据每天更新一次,那么有没有什么办法可以自动完成上面的操作呢?
我们将上面的流程整理一下,形成一个SQL命令脚本,保存到CalTopTenRestaurants.sql中:
DROP TABLE RestaurantInfo;
DROP TABLE RestaurantComment;
CREATE TABLE RestaurantInfo AS SELECT * FROM OTS.RestaurantInfo;
CREATE TABLE RestaurantComment AS SELECT * FROM OTS.RestaurantComment;
CREATE TABLE IF NOT EXISTS TopTenRestaurants (DistrictID INT, RestaurantID INT, Name STRING, Address STRING, PhoneNumber STRING, Location STRING, Category STRING, ScoreStat INT, CostStat INT);
INSERT OVERWRITE TABLE TopTenRestaurants SELECT a.DistrictID, a.RestaurantID, a.Name, a.Address, a.PhoneNumber, a.Location, a.Category, b.ScoreStat, b.CostStat FROM RestaurantInfo a JOIN (SELECT DistrictID, RestaurantID, AVG(Score) AS ScoreStat, AVG(Cost) AS CostStat FROM RestaurantComment GROUP BY DistrictID, RestaurantID) b ON a.DistrictID = b. DistrictID AND a.RestaurantID = b.RestaurantID ORDER BY b.ScoreStat DESC LIMIT 10;
EXPORT DATA TO OTS TopTenRestaurants FROM TABLE TopTenRestaurants;
为了定期执行上面的SQL命令脚本,我们在ODPS中创建一个作业(QUERY)【注:由用户定义的一系列串行执行的SQL命令,保存在ODPS中,用来对ODPS中的表完成某个特定的数据分析操作】:
$ odpscmd CREATE QUERY CalTopTenRestaurants FROM
./CalTopTenRestaurants.sql;
CalTopTenRestaurants这个作业包含了计算“十大餐馆”的全部数据分析操作,我们需要这个作业每天运行一次,在odpscmd中进行如下设置:
$ odpscmd SET QUERY CalTopTenRestaurants EXECTIME=00:00:00 EVERY DAY;
好了,现在这个作业会从设置的第二天零点开始,每天执行一次。你的前端应用程序可以直接在OTS中访问结果表数据,ODPS会在后台自动完成作业的运行和监控,并会在出现问题时,通过ODPS管理中心向你发出警报。你可以随时查询这个作业的状态,了解它的上次运行时间、总运行次数等信息。
$ odpscmd DESCRIBE QUERY TopTenRestaurants;
构造复杂的数据挖掘任务
利用上面的流程,你可以完成很多简单的数据分析操作,让你的网站能够为客户提供更丰富的服务;但你的数据蕴含的价值远不止如此。下面再来试个稍微复杂一点的例子:你的用户在网站上发表的点评暗示了他/她的消费轨迹和偏好,我们希望通过分析用户的点评数据,为他/她推荐喜爱的餐馆。
首先需要做点准备工作。在《借助OTS快速构建LBS服务》一文中没有提及用户信息如何保存,由于后续的计算需要用到用户数据,不妨假设你的用户信息都存放在表4中。

然后我们来分析如何向用户推荐他/她喜欢的餐馆。
DROP TABLE RestaurantInfo; #(1)
CREATE TABLE RestaurantInfo AS SELECT * FROM OTS.RestaurantInfo; #(2)
DROP TABLE RestaurantComment; #(3)
CREATE TABLE RestaurantComment AS SELECT * FROM OTS.RestaurantComment; #(4)
DROP TABLE UserInfo; #(5)
CREATE TABLE UserInfo AS SELECT * FROM OTS.UserInfo; #(6)
- 在上一节中计算的结果依然有用:首先得到所有餐馆的用户口碑,接下来可以计算每类餐馆中口碑最好的一家。
DROP TABLE RestaurantStat; #(7)
CREATE TABLE RestaurantStat AS SELECT a.DistrictID, a.RestaurantID, a.Name, a.Address, a.PhoneNumber, a.Location, a.Category, b.ScoreStat, b.CostStat FROM RestaurantInfo a JOIN (SELECT DistrictID, RestaurantID, AVG(Score) AS ScoreStat, AVG(Cost) AS CostStat FROM RestaurantComment GROUP BY DistrictID, RestaurantID) b ON a.DistrictID = b. DistrictID AND a.RestaurantID = b.RestaurantID; #(8)
DROP TABLE BestRestaurantInCategory; #(9)
CREATE TABLE BestRestaurantInCategory AS SELECT Category, DistrictID, RestaurantID, Name, Address, PhoneNumber, Location, MAX(ScoreStat) AS BestScoreStat, CostStat FROM RestaurantStat GROUP BY Category; #(10)
- 找到每个用户最后发表点评的餐馆,假设他/她刚刚去过那家餐馆,并且比较喜欢那个餐馆所在类别的餐馆;计算这些餐厅所属的类别。
DROP TABLE UserLatestCategory; #(11)CREATE TABLE UserLatestCategory AS SELECT a.UserName, b.Category FROM (SELECT DistrictID, RestaurantID, MAX(DateTime) AS LatestDateTime, UserName FROM RestaurantComment GROUP BY UserName) a JOIN RestaurantInfo b ON a.DistrictID = b.DistrictID AND a.RestaurantID = b.RestaurantID; #(12)
#计算为每位用户推荐的餐厅
DROP TABLE UserRecommandedRestaurant; #(13)
CREATE TABLE UserRecommandedRestaurant AS SELECT a.UserId, a.UserName, b.Category, c.Name, c.Address, c.PhoneNumber, c.Location, c.BestScoreStat, c.CostStat FROM UserInfo a LEFT OUTER JOIN UserLatestCategory b ON a.UserName = b.UserName LEFT OUTER JOIN BestRestaurantInCategory c ON b.Category = c.Category; #(14)
EXPORT DATA TO OTS UserRecommandedRestaurant FROM TABLE UserRecommandedRestaurant; #(15)
我们可以将上述SQL命令保存为一个作业,提交给ODPS服务执行。但这样一个作业中的所有SQL命令是顺序执行的,对于RestaurantComment和UserInfo这类含有千万甚至亿条数据的表而言,执行GROUP BY和MULTI-JOIN操作需要花费大量时间。如果数据模型的复杂度提升,时间还会进一步增加,难以满足数据分析对时效性的要求。有什么好办法吗?通过观察不难发现,上述15个SQL语句之间是有依赖关系的,其依赖关系可以构成一张有向无环图,如图1所示。每个节点的编号与SQL语句后面的编号一一对应。
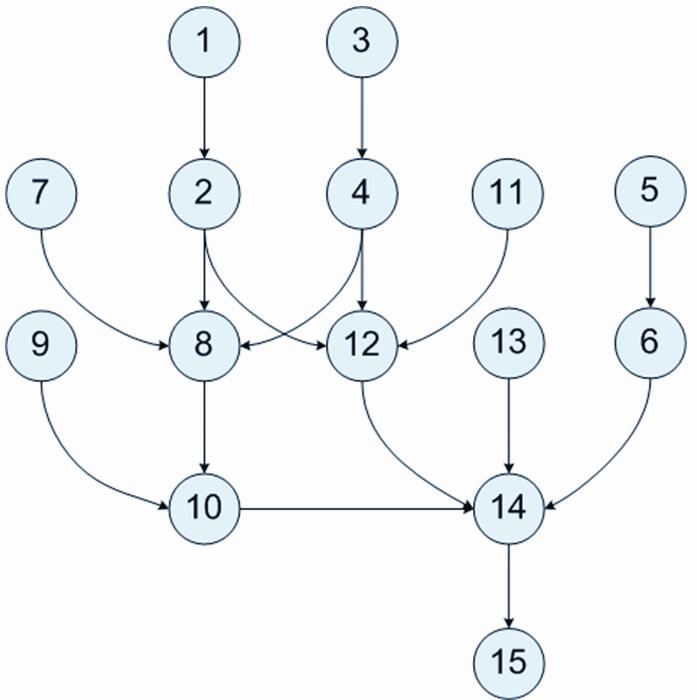
图1 计算向用户推荐的餐馆的SQL语句的依赖关系
ODPS支持按作业的依赖关系并发调度作业,因此,我们根据这15个SQL语句的依赖关系将它们整理成如下作业(冒号前面是作业名称,冒号后面是该作业包含的SQL语句,此处省略了在odpscmd中定义作业的命令):
QUERY GenRestaurantInfo: 1, 2
QUERY GenRestaurantComment: 3, 4
QUERY GenUserInfo: 5, 6
QUERY CalBestRestaurantInCategory: 7, 8, 9, 10
QUERY CalUserLatestCategory: 11, 12
QUERY CalUserRecommandedRestaurant: 13, 14
QUERY Finish: 15
定义好作业后,我们可以在ODPS中定义一个工作流 【注:由用户定义的作业集合,集合中的作业满足特定的执行依赖关系。利用ODPS的并发调度功能,使用工作流可以更高效地执行多个作业】。这个工作流包括上述全部作业以及它们之间的依赖关系,通过执行这个工作流,可以完成向用户推荐餐馆的全部数据分析操作。
$ odpscmd CREATE WORKFLOW CalUserRecommandedRestaurant { GenRestaurantInfo -> CalBestRestaurantInCategory, GenRestaurantInfo -> CalUserLatestCategory, GenRestaurantComment -> CalBestRestaurantInCategory, GenRestaurantComment -> CalUserLatestCategory, CalBestRestaurantInCategory -> CalUserRecommandedRestaurant, CalUserLatestCategory -> CalUserRecommandedRestaurant, GenUserInfo -> CalUserRecommandedRestaurant, CalUserRecommandedRestaurant};
工作流CalUserRecommandedRestaurant定义的作业之间的依赖关系如图2所示。
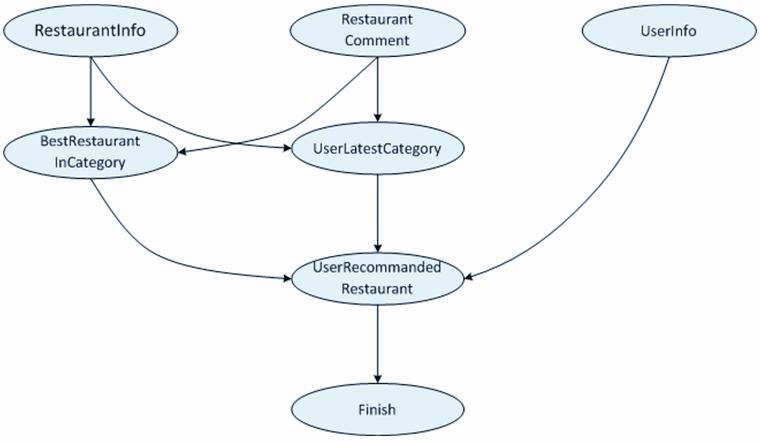
图2 计算向用户推荐餐馆的作业的依赖关系
定义好工作流之后,就可以像执行作业一样执行它了。我们现在就来计算为每个用户推荐的最喜欢的餐厅,并将结果表导出到OTS。或者,你也可以为该工作流定义执行计划,这需要综合考虑用户的登录频率和该工作流的执行时间。
$ odpscmd EXEC WORKFLOW UserRecommandedRestaurant;
后记
ODPS拥有出色的数据离线处理能力,并提供了丰富的命令让用户可以灵活地管理海量数据和多个并发计算作业,以帮助用户快速构建复杂的数据分析和数据挖掘应用。借助于数据分片存储和分片计算等分布式数据处理技术,ODPS可以游刃有余地处理TB甚至PB级别的数据分析任务。除了提供丰富的数据导入/导出命令外,ODPS还与阿里云的其他服务进行了深度集成,允许用户轻松地将在其他服务中沉淀的数据导入到ODPS中进行分析和处理,并回流到原服务中供其他应用访问。
拥有出色的处理能力仅仅是ODPS的冰山一角,未来我们将会把业务伙伴在ODPS上沉淀的数据开放出来,供更多的组织机构使用,让ODPS成为一个数据分享和数据分析的开放式服务平台,同时满足数据生产者、加工者和消费者等多方面的需求。
| 

