| ����ƪNoSQL���ݿ��̸��һ��
TC����֧��Key-Value�洢֮�⣬��֧�ֱ���Hashtable�������ͣ���˺���һ�������ݿ�������һ�֧�ֻ���column���� ����ѯ����ҳ��ѯ�������ܣ��������൱��֧�ֵ����Ļ�����ѯ�����ˣ����Կ��Լ������ϵ���ݿ�ĺܶ��������Ҳ��TC�ܵ���һ�ӭ����Ҫԭ��֮һ�� ��һ��Ruby����Ŀmiyazakiresistance��TT��hashtable�IJ�����װ�ɺ�ActiveRecordһ���IJ������������dz�ˬ��
TC/TT��mixi��ʵ��Ӧ�õ��У��洢��2000�������ϵ����ݣ�ͬʱ֧����������������ӣ���һ���þ��������Ŀ��TC�ڱ�֤�˼��ߵIJ��� ��д���ܵ�ͬʱ�����пɿ������ݳ־û����ƣ�ͬʱ��֧�����ƹ�ϵ���ݿ���ṹ��hashtable�Լ�����������ҳ�������������һ���ܰ��� NoSQL���ݿ⡣
TC����Ҫȱ�������������ﵽ���ڼ����Ժ���д�������ܻ������½���NoSQL: If Only It Was That Easy�ᵽ�����Ƿ�����TC�������1.6����2-20KB���ݵ�ʱ��д�����ܿ�ʼ�����½��������ǵ���������������ʱ��TC���ܿ�ʼ������½�����TC�����Լ��ṩ��mixi����������������ǧ������������ʱ��û��������ô���Ե�д������ƿ����
�����Tim Yang����һ��Memcached��Redis��Tokyo Tyrant�ļ��������⣬�����ο�
CT.M
GT.M: API: M, C, Python, Perl, Protocol: native, inprocess C, Misc: Wrappers: M/DB for SimpleDB compatible HTTP ?, MDB:X for XML ?, PIP for mapping to tables for SQL ?, Features: Small footprint (17MB), Terabyte Scalability, Unicode support, Database encryption, Secure, ACID transactions (single node), eventual consistency (replication), License: AGPL v3 on x86 GNU/Linux, Links: Slides ?,
Scalien
Scalien: API / Protocol: http (text, html, JSON), C, C++, Python, Concurrency: Paxos.
Berkley DB
Berkley DB: API: Many languages, Written in: C, Replication: Master / Slave, Concurrency: MVCC, License: Sleepycat, BerkleyDB Java Edition: API: Java, Written in: Java, Replication: Master / Slave, Concurrency: serializable transaction isolation, License: Sleepycat
MemcacheDB
MemcacheDB: API: Memcache protocol (get, set, add, replace, etc.), Written in: C, Data Model: Blob, Misc: Is Memcached writing to BerkleyDB.
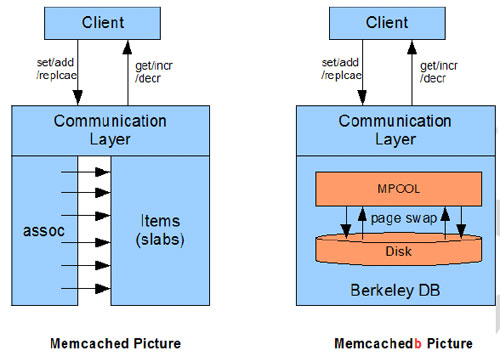
�������˻���������ҵ��Ϊ��Memcached�����ϣ�����Berkeley DB�洢�������һ��֧�ָ߲����ķֲ�ʽ�־ô洢ϵͳ�����κ�ԭ��Memcached�ͻ������������Ծ��Ǹ�Memcached�����ǣ����������ǿ��Գ־ô洢�ġ�
Mnesia
Mnesia: (ErlangDB ?)
LightCloud
LightCloud: (based on Tokyo Tyrant)
HamsterDB
HamsterDB: (embedded solution) ACID Compliance, Lock Free Architecture (transactions fail on conflict rather than block), Transaction logging & fail recovery (redo logs), In Memory support �C can be used as a non-persisted cache, B+ Trees �C supported [Source: Tony Bain ?]
Flare
TC���ձ���һ��SNS��վmixi�����ģ���Flare���ձ��ڶ���SNS��վgreen.jp�����ģ�����˼�ɡ�Flare��˵���Ǹ� TC������scale���ܡ����滻����TT���֣��Լ������TCд�������������Flare����Ҫ�ص����֧��scale������������������֮ǰ������ һ��node server����������˵Ķ���������ڵ㣬��˿��Զ�̬�������ݿ����ڵ㣬ɾ���������ڵ㣬Ҳ֧��failover��������ʹ�ó�������Ҫ��TC�� ��scale����ô���Կ���flare��
flareΨһ��ȱ�������ֻ֧��memcachedЭ�飬��˵���ʹ��flare��ʱ�Ͳ���ʹ��TC��table���ݽṹ�ˣ�ֻ��ʹ��TC��key-value���ݽṹ�洢��
����һ����Key Value�洢
Amazon֮Dynamo
Amazon Dynamo: Misc: not open source (see KAI below)
������ɫ
- �߿���
- ����չ
- ���ǿ�д
- ���Ը���Ӧ�������Ż�(�����ԣ��ݴ��ԣ���Ч������)
�ܹ���ɫ
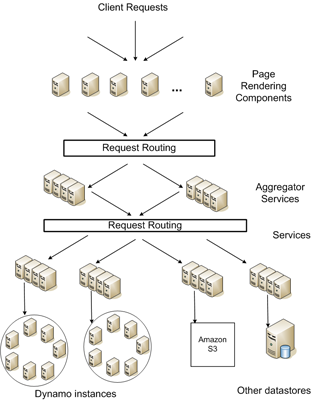
- ��ȫ�ķֲ�ʽ
- ȥ���Ļ�(�˹�����������С)
- Key Ψһ����һ�����ݶ��Ը����ݶ���Ķ�д��ͨ�� Key �����.
- ͨ����һ̨�Դ�Ӳ�̵�������ÿ���ڵ������� Java д�����������Э����(request coordination)����Ա��ʧ�ܼ�⡢���س־�����(local persistence engine)
- ���ݷ������øĽ���һ���Թ�ϣ(consistent hashing)��ʽ���и��ƣ��������ݶ���İ汾��ʵ��һ���ԡ�����ʱ��Ϊ���²�����һ���������ά����ȡ���� quorum �Ļ����Լ�ȥ���Ļ��ĸ���ͬ��Э�顣
- ÿ��ʵ����һ��ڵ���ɣ���Ӧ�õĽǶȿ���ʵ���ṩ IO ������һ��ʵ���ϵĽڵ����λ�ڲ�ͬ������������, ����һ���������ij�����Ҳ���ᵼ�����ݶ�ʧ��
BeansDB
���
BeansDB ��һ����Ҫ��Դ����������߿����Եķֲ�ʽKeyValue�洢ϵͳ������HashTree�ͼİ汾��������ͬ����֤����һ���ԣ�������һ�����Dynamo��
����������memcached��ȥ���Ļ��ṹ���ڿͻ���ʵ������·�ɡ�Ŀǰֻ�ṩ��Python�汾�Ŀͻ��ˣ��������ԵĿͻ��˿�����memcached�Ŀͻ����ԼӸ���õ���
Google Group: http://groups.google.com/group/beandb/
����
2009.12.29 ��һ�������汾 0.3
����
�߿��ã�ͨ������ɶ�д�����ڱ���ʵ�ָ߿���
����һ���ԣ�ͨ����ϣ��ʵ�ֿ�����������ͬ������ʱ�������ݿ��ܲ�һ�£�
������չ�������ڲ��жϷ��������½���������չ��
�����ܣ��첽IO�����ܵ�KeyValue����TokyoCabinet �����õ�
�����Ժ�һ���ԣ�ͨ��N,W,R�������� ��Э�飺Memcache����Э�飬�������ÿͻ���
����
��С���ݼ��ϣ�����memcachedһ���죺 # memstorm -s localhost:7900 -n 1000
Num of Records : 10000
Non-Blocking IO : 0
TCP No-Delay : 0
Successful [SET] : 10000
Failed [SET] : 0
Total Time [SET] : 0.45493s
Average Time [SET] : 0.00005s
Successful [GET] : 10000
Failed [GET] : 0
Total Time [GET] : 0.28609s
Average Time [GET] : 0.00003s
ʵ�ʲ�������µ����ܣ��ͻ��˲������� 􀂄 ������ ������ ����ʱ��(ms) ��λ��(ms) 99% (ms) 99.9%(ms)
􀂄 get A:7900 n=151398, avg=8.89, med=5.94, 99%=115.5, 99.9%=310.2
􀂄 get B:7900 n=100054, avg=6.84, med=0.40, 99%=138.5, 99.9%=483.0
􀂄 get C:7900 n=151250, avg=7.42, med=5.34, 99%=55.2, 99.9%=156.7
􀂄 get D:7900 n=150677, avg=7.63, med=5.09, 99%=97.7, 99.9%=284.7
􀂄 get E:7900 n=3822, avg=3.07, med=0.18, 99%=44.3, 99.9%=170.0
􀂄 get F:7900 n=249973, avg=8.29, med=6.36, 99%=46.8, 99.9%=241.5
􀂄 set A:7900 n=10177, avg=18.53, med=12.78,99%=189.3, 99.9%=513.6
􀂄 set B:7900 n=10431, avg=12.85, med=1.19, 99%=206.1, 99.9%=796.8
􀂄 set C:7900 n=10556, avg=17.29, med=12.97,99%=132.2, 99.9%=322.9
􀂄 set D:7900 n=10164, avg=7.34, med=0.64, 99%=98.8, 99.9%=344.4
􀂄 set E:7900 n=10552, avg=7.18, med=2.33, 99%=73.6, 99.9%=204.8
􀂄 set F:7900 n=10337, avg=17.79, med=15.31, 99%=109.0, 99.9%=369.5
BeansDB���ʵ�֣��dz��ѵõ��������ϣ�
PPT
Nuclear
�������з��е����ݿ�
�����
http://ugc.renren.com/2010/01/21/ugc-nuclear-guide-use/
http://ugc.renren.com/2010/01/28/ugc-nuclear-guide-theory/
��������ϵ�Tips
1. ���½��첽
�����ڱ���Ĺ���������һЩ��·��ͬ���IJ����ڸ߲���������´����������½��Ƿdz��ֲ��ģ����Ǻ���Nuclearϵͳ���κεĸ߲���������������Block��no waiting, no delay��
2. ����ϵͳ���ؿ��ƺ�̨�̵߳���Դռ��
Nuclearϵͳ���в��ٵĺ�̨�߳�ĬĬ���ŵ����Ÿ�������Ĺ�������������ͬ����ռ��ϵͳ��Դ�����ǵĽ�������Ǹ���ϵͳ���ض�̬�����̵߳����к�ֹͣ�����ﵽƽ�⡣
Voldemort
Voldemort: (can you help)
Voldemort�Ǹ���Cassandra���Ƶ�������scale����ķֲ�ʽ���ݿ�ϵͳ��Cassandra������Facebook��� SNS��վ����Voldemort��������Linkedin���SNS��վ��˵����SNS��վΪ���ǹ�����n���NoSQL���ݿ⣬���� Cassandar��Voldemort��Tokyo Cabinet��Flare�ȵȡ�Voldemort�����ϲ��Ǻܶ࣬�����û���ر���ϸȥ���У�Voldemort�ٷ�����Voldemort�IJ����� д����Ҳ�ܲ�����ÿ�볬����1.5��ζ�д��
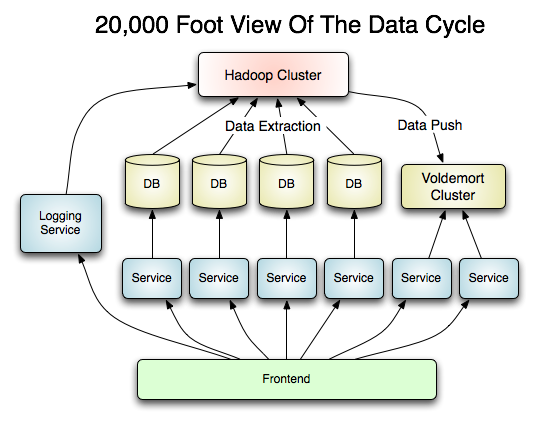
��ʵ���ںܶ˾���ܶ��������������ܹ�ͼ�е��������⡣�� Hadoop ��Ϊ��˵ļ��㼯Ⱥ������ó������������Ҫ�����Ƶ�ǰ��ȥ����ʲô��ʽ�洢��Ϊǡ��? �ٷŵ� DB ����Ļ��������������鷳�£��ŵ� Memcached ֮��� Key-Value �ֲ�ʽϵͳ�У��Ͼ�ֻ�����ڴ��������������Voldemort ����һ�������ĸ���������
ֵ�ý���ļ���:
- ��(Key)�ṹ����ƣ��е㼼�ɣ�
- �ܹ�ʦ��֪Ӳ���ṹ�����õġ�Խ���ϵͳԽ����ˡ�
- �úò��С�Amdahl �����Ժ���ֵij��ϻ���ࡣ
��ϸ��
http://www.dbanotes.net/arch/voldemort_key-value.html
http://project-voldemort.com/blog/2009/06/building-a-1-tb-data-cycle-at-linkedin-with-hadoop-and-project-voldemort/
Dynomite
Dynomite: (can you help)
Kai
KAI: Open Source Amazon Dnamo implementation, Misc: slides ,
���
Skynet
ȫ�µ�Ruby MapReduceʵ��
2004�꣬Google������ڷֲ�ʽ���ݴ�����MapReduce���ģʽ��ͬʱ���ṩ�˵�һ��C++��ʵ�֡����ڣ�һ����ΪSkynet��Rubyʵ���Ѿ���Adam Pisoni������
Skynet�ǿ����䡢���ݴ��ġ������Ҹ��µģ�������ȫ
�Ƿֲ�ʽ��ϵͳ�������ڵ�һ��ʧ�ܽڵ㡣
Skynet��Google���������������Ҫ������
Skynet�������ߣ�Worker������ԭ�����루Raw code����
Skynet���ý�Իָ�ϵͳ����ͬ�Ĺ����ụ�����Է�ʧ�ܣ�
�����һ������������ij��ԭ���뿪���߷����ˣ��ͻ�����һ�������߷��ֲ��ӹ���������Skynet Ҳû����ν�ġ������������̣�ֻ�й����ߣ��������κ�ʱ�䶼���Գ䵱�κ���������������̡�
Skynet��ʹ�ú����ö������ף���Ҳ����MapReduce���������������ơ�Skynet����չ��ActiveRecord��������MapReduce�����ԣ�����distributed_find��
��ҪΪStarfish��дһЩС�������ǵĴ������㽫Ҫ�������еġ������û��Ū���Ļ���������ͬһ̨���������ж������͵�MapReduce��ҵ��Skynet��һ����ȫ���MRϵͳ���������ж������͵Ķ����ҵ�����磬���ֲ�ͬ�Ĵ��롣
SkynetҲ����ʧ�ܡ������ụ����ա����һ��������ʧ���ˣ�����ʱ���������һ�������߽����������������������SkynetҲ֧��map_data����Ҳ����˵����ʹij�����ݼ��dz��Ӵ�����������һ�����ݽṹ�У�SkynetҲ���Դ�����
ʲô��map_data���������ʱ������������һ��map_reduce��ҵʱ�������ṩһ�����ݵĶ��У���Щ�����Ѿ������벢�������д���������� �й�������������Ӧ���ڴ���ô�죿����������£����Ҫ�������ö��У���Ӧ��ʹ��ö�٣�Enumerable����Skynet֪��ȥ����ĵ� ��:next����:each������Ȼ��ʼΪ��ÿһ����each���������map_task����ͨ�������ķ�ʽ��������������ͼͬʱ�������������ݽṹ��
�� �кܶ�����ֵ��һ�ᣬ�����������Ѵ�ҵ��ǣ�Skynet�ܹ��������е�Ӧ�÷dz������ؼ��ɵ�һ��������Ȼ����RailsӦ�á�Skynet�� �����ṩ��һ��ActiveRecord����չ���������ģ�����Էֲ�ʽ����ʽִ��һЩ������Geni�У�����ʹ��������������ر��ӵ���ֲ����ͨ ���漰�����������ģ����ִ��Ruby���롣
Model.distributed_find(:all, :conditions => "id > 20").each(:somemethod)��������Skynet��ʱ��������ÿ��ģ����ִ��:somemethod���������Էֲ�ʽ�ķ�ʽ������� ӵ�ж��ٸ���������أ���������ģ�ͷַ�����ǰ���ؽ��г�ʼ��������������ǰ��ȡ���е�id����������Բ�����������ݼ��� �û��ķ�����Σ�
Drizzle
Drizzle�� ����Ϊ�Ǽ�/ֵ�洢Ҫ���������ķ�����Drizzle������MySQL��6.0����ϵ���ݿ�IJ�֡��ڹ�ȥ����������Ŀ������Ѿ������˴����Ǻ� �ĵĹ��ܣ�������ͼ�����������ѱ�����䡢�洢���̡���ѯ���塢ACL�Լ�һЩ�������ͣ�����Ŀ����Ҫ����һ��������������ݿ�ϵͳ��Drizzle ���ܴ�Ź�ϵ���ݣ�����MySQL/Sun��Brian Aker��˵��������û������ϴ��ˮʱ������Ҳ������������Ŀ����ǣ����������16�ˣ������ϣ�ϵͳ�ϵ����������Ϊ������Ӧ�ã�����һ�����ϵ������ ��ƽ̨��
�Ƚ�
����չ��
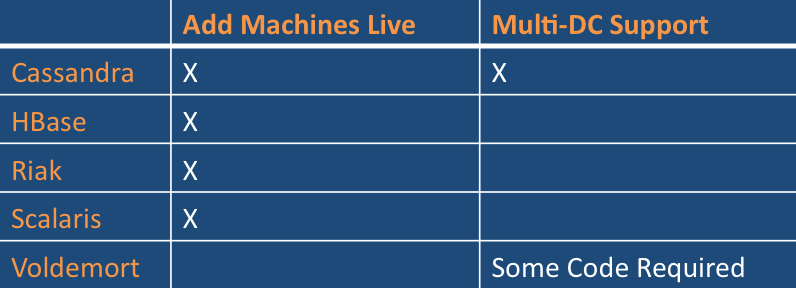
���ݺͲ�ѯģ��
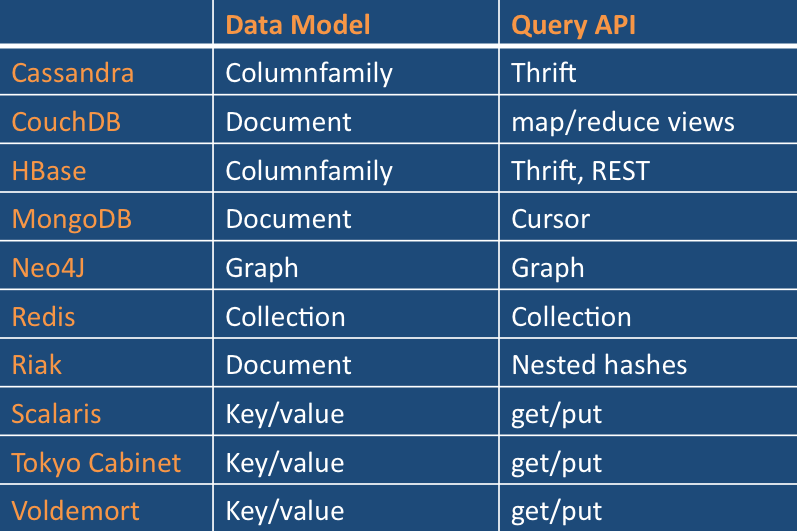
������Ҫ��ѯ�����һ��ֵ��һ����ʱ��Key/valueģ���������Чʵ�֡�
�����ı����ݿ���Key/value����һ��, ������Ƕ��Key������ֵ. ֧�ֲ�ѯ��Щֵ���ݣ���ȼ�ÿ�η�������blob��������Ҫ��Ч�öࡣ
Neo4J��Ψһ�Ĵ洢�����ϵ��Ϊ��ѧͼ���еĽڵ�ͱ�. ������Щ�������ݵIJ�ѯ�������ܹ������������߿�1000s
Scalaris��Ψһ�ṩ��Խ���key�ķֲ�ʽ����
�־û����

�ڴ����ݿ��Ƿdz���ģ�(Redis�ڵ��������Ͽ������ÿ��100,000���ϲ������������ݼ������ڴ�RAM��С�Ͳ���. ���� Durability (�����������ָ�����)Ҳ��һ������
Memtables��SSTables���� buffer�����ڴ���д(��memtable��)�� д֮ǰ����һ������durability����־��.
�����㹻��д���Ժ����memtable��������Ȼ��һ������Ϊ��sstable.��д������У�����ṩ�˽����ڴ����ܣ���Ϊû�д��̵IJ�ѯseeks����, ͬʱ�ֱ����˴��ڴ������durability����.(���˵��� ��ʵJava�е�Terracotta���ʵ�������߽��)
B-Trees�ṩ��׳���������������ܺܲһ�������������������
Ӧ��ƪ
eBay �ܹ�����
1�� Partition Everything �����
2�� Asynchrony Everywhere �����첽
3�� Automate Everything ȫ���Զ�
4�� Remember Everything Fails ��¼ʧ��
5�� Embrace Inconsistency �ײ�ͬ��ν��ͬ
6�� Expect (R)evolution Ԥ���ݱ�
7�� Dependencies Matter ��������
8�� Be Authoritative ����ר��
9�� Never Enough Data
10��Custom Infrastructure �Զ��������ʩ
�Ա��ܹ�����
1���ʵ�����һ����
2�����ݺ������ȶ�������
3���ָ���첽�����������(���� eBay �� Asynchrony Everywhere)
4���Զ������������ɱ�(���� eBay �� Automate Everything)
5����Ʒ������
Flickr�ܹ�����
- ʹ�û����Զ����� (Teach machines to build themselves)
- ʹ�û����Լ��(Teach machines to watch themselves)
- ʹ�û�������(Teach machines to fix themselves)
- ͨ�����̼��� MTTR (Reduce MTTR by streamlining)
Twitter������
�������������һ������Twitter��������Ƶ[Slides] [Video (GFWed)]������Twitter��John Adams��Velocity 2009��һ���ݽ�����Ҫ������Twitter��ϵͳ��ά����һЩ���顣 ���Ĵ������Ĺ۵㶼��Twitter(@xmpp)�Ϸ���������ȫ����������������������
Twitterû���Լ���Ӳ����������NTTA���ṩ��ͬʱNTTA����Ӳ����ص����硢���������ؾ����ҵ��Twitter operations teamֻ��ע���ĵ�ҵ����Performance��Availability��Capacity Planning�����滮�����ù����ȣ�������ܸ�����һ��Ļ�������˾��������
������
Metrics
Twitter�ļ�غ�̨��������ͼ��(critical metrics)�����Ƽ�ʻ�ҵ�ת�ٱ���ʱ�ٱ����ò����߿���Ѹ�ٵ��˽�ϵͳ��ǰ������״̬�����뵽�����������Ƽ�غ�̨�����ݺܶ࣬����������Ҫ����� �����η����жϣ���������������ͼ���ķ������û�����������ѧϰ���ⷽ�澭�顣 ��John���ܿ��Դ�ͼ���Ͽ���ϵͳ��ƿ��-ϵͳ�����Ļ���(web, mq, cache, db?)
����ͼ�����Կ�ѧ���ƶ�ϵͳ�����滮���������º�Ȼ�
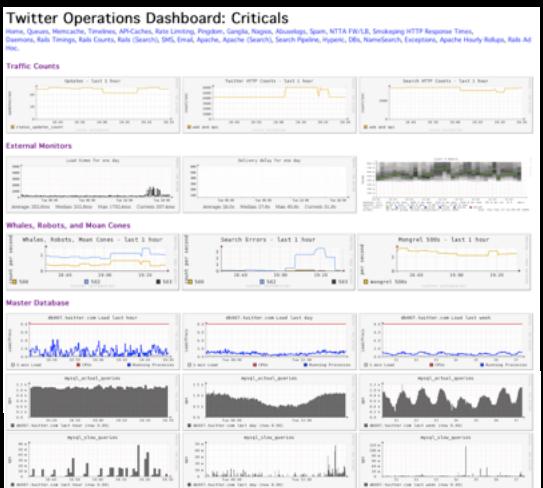
���ù���
ÿ��ϵͳ����Ҫһ���Զ����ù���ϵͳ��Խ��Խ�ã�����һ��������Twitter��ȥ֮������ܶ��Ӧ��
Darkmode
���ý������enable/disable �������Ļ��I/O�Ĺ��ܣ�Ҳ�൱�����Ž�����ϵͳѹ������ʱȡ��һЩ�Ǻ��ĵ�������Դ��Ĺ��ܡ�
���̹���
Twitter����һ����Seppaku�� patch, ���ǽ�Daemon�������n��requests֮������kill�����Ա��ֽ�����low memory״̬�������������˽����Ҳ�в��ٹ�˾����������
Ӳ��
Twitter��CPU��AMD����Xeon֮���30%������������CPU��˫��/4�˻���8��֮������40%��CPU, ����JohnҲ˵�������������ʺ��Լ�����Ӳ���Ĺ�˾��
����Эͬ����
Review�ƶ�
Twitter���ϰٸ�ģ�飬���û��һ���õ��ƶȣ�������������ij�ͻ������������������û�������Twitter��һǿ�Ƶ�source code review�ƶ�, ����ύ�Ĵ����svn commentû�С�reviewed by xxx��, ��pre-commit�ű������ύʧ��, review���Ĵ����ύ���ͨ���Զ����ù���ϵͳӦ�õ��ϰ�̨�������ϡ� ��@xiaomicsͬѧ��Twitter�����Ͼ��ʣ�ʱ��ɱ��ܷ���ܣ�����н���������ô�죿������Ϊ������ʱ�������ڳ���һ����һ�� reviewҲ����ʲô���¡�
�������
�Ӳ���ͼ�����Կ���ÿ�������汾��CPU��latency�仯�����ij���°汾latencyͼ�������Ե�������Ծ����˵���÷����汾�������⡣�����ڼ����ҳ�г�����ģ�����deploy�汾��ʱ�䣬��������Ŀ�����������״��
�Ŷӹ�ͨ
Campfire��Эͬ������campfire�е���Ⱥ�����Ǹ��ʺ�Эͬ����������Campfire�Ͳ���������ܣ��ɲο�Campfire�ٷ�˵����
Cache
- Memcache key hash, ʹ��FNV hash ���� MD5 hash����ΪFNV���졣
- ������Cache Money plugin(Ruby), ��Ӧ�ó����ṩread-through, write-through cache, ����һ��db���ʵĹ��ӣ�����д���ݿ��ʱ����Զ�����cache, �����˷�����cache���´��롣
- ��Evictions make the cache unreliable for important configuration data����Twitterʹ��memcache��һ�������ǣ���ͬ���͵���������ڲ�ͬ��mc,����eviction��������ǰ��Memcached���ݱ���(evictions>0)��������е�һЩ����һ�¡�
- Memcached SEGVs, Memcached����(cold cache problem)�ݳƻ�����ָ߶�����Cache��Web 2.0ϵͳ�������ѣ���֪��Twitter������ô�����
- ��Web��Twitterʹ����Varnish��Ϊ������������������۽ϸߡ�
�Ƽ���ܹ�
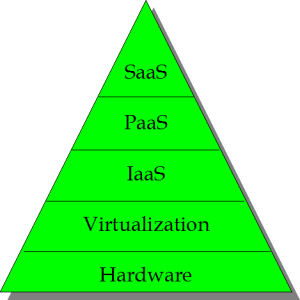
������Ϊ����������������˵��ÿһ��Ĵ�С����Ҳ������ÿ ����������ǰ�����Ϣ���ݡ��ڸ����ϣ�Ӳ���ǻ����㷺�㡣SaaS���Ƕ��壬Ҳ������㡣���ֹ۵��������ڽ�����SaaS�ĵ������û��Ƕȡ�����һ���� �������ҵ�ڲ���PaaSƽ̨�㽫�Ƕ��塣ʹ���ڲ��������������ڲ������Ž�ʵ�����ǵĶ���SaaS����Ҫע�⣺��С�Ͳ�λ�ò���һ����ͬ����Ҫ�ԡ�Ӳ�� �����������Ҫ�ģ���Ϊ�������г���һ�������Ʒ��
Ӳ����The Hardware Layer
���뿼���ݴ������࣬������Ϊû���ݴ�Ӳ��������Ʒ��������ݴ��������������ڣ�Ӳ��Ԥ��Ҫʧ�ܵģ���Ȼ���϶��Դ�ݴ���������RAID��������Ҳ�DZ�Ҫ�ġ�
�����The Virtualization Layer
���ڲ���ϵͳOS�����⻯�㣬������Դ�ܹ�����ʱ������չ��������Ӧ���ṩ������ʩ��Ϊ����(SaaS)��VMware��Citrix��˾��Sun���ṩ���⻯��Ʒ��
The IaaS Layer
�� ���Ϳ��ƵĻ��������ļ��㷽ʽ���ն��û��ܹ���ȷ����ÿ�������û����ÿСʱ�ķѶ���Ǯ�������ṩһ����ͬ�Ľӿڣ����Ż���վ��¶��API������������ �����������������ģ������������û������Կ��ƺ�ʱ���ƻ���������Լ���������������������������������Ҫ����������������ѷ�������� EC2��S3�����ݿ����
The PaaS Layer
��һ���Ŀ���Ǿ������ٲ����Ƶĸ����Ժ��鷳�������û� ���úͿ���������API�ͱ�����ԡ������ܺõ������ǹȸ��App Engine ��Force.comƽ̨����App Engine�У��ȸ蹫���ƴ洢��ƽ̨�����ݿ⣬�Լ�ʹ��Python��Java������Ե�API��������Ա�ܹ���дӦ�ó�������һ���У���˿������Լܹ������ȫ�����ȸ踺�������û���ȫ���ص��Ĺ���������ʩ��Force.comƽ̨���ƣ����������Զ���ı��������ΪApex���������һ��������ҵѰ���ڲ�����Ӧ�õIJ����������Ķ��塣
The SaaS Layer
�� ��������С����ҵ��SME���ʹ���ҵ��ϣ�������Լ���Ӧ�ó���ʱ��SaaS�IJ�����Ķ��壨���㽫ֱ����Եģ�����ֻ�ǽ�������Ȥ�زɹ�������ʼ���ͻ� ��ϵ����������Щ���ܷ����Ѿ�����Ӧ�̿����ɹ����������ƻ������ˣ���ֻ����֤��Ӧ���Ƿ�������ʹ����Ҫ���ʵ����Ի��ڰ�����ѵȸ�����ʽ������Ϊ �����û������������������ά����չӦ�ó����������κγɱ���Խ��Խ�����ҵ����Salesforce.com��Sugar CRM��SaaS��Ʒ��
��ģʽ
����ʧ�ܣ�Single Point of Failure��=
�ֵ��˶�����ڵ�һ���豸�ϲ������ǵ�Ӧ�ã���Ϊ��������ķ��û�Ƚϵͣ���������Ҫ����κε�Ӳ���豸������ʧ�ܵķ��յģ����ֵ���ʧ�ܻ����ص�Ӱ���û������������Ͽ����Ӧ�ã���˳������Ӧ��������ʧ�ܴ�������ʧ������û�Ӧ�þ����ı��ⵥ����գ����������࣬�ȱ��ȡ�
ͬ������
ͬ���������κ�����ϵͳ�ж��Dz��ɱ���ģ�����������������ʦ��������ͬ�����ø�����ϵͳ���������⡣������ǽ�Ӧ�ó�����������ôϵͳ�Ŀ����Ծͻ�����κ�һ����һ����Ŀ����ԡ��������Aͬ�����������B�����A�Ŀ�����Ϊ99.9%�����B�Ŀ�����Ϊ99.9%,��ô���Aͬ���������B�Ŀ����Ծ���99.9% * 99.9%=99.8%��ͬ������ʹ��ϵͳ�Ŀ������ܵ������д�����������Ե�Ӱ�죬���������ϵͳ��Ƶ�ʱ��Ӧ�������Щ�ط�Ӧ��ͬ�����ã��ڲ���Ҫͬ�����õ�ʱ�����Ľ����첽�ĵ��ã�����������˵���첽��һ�ֻ���Ӧ�õ��첽����һ������ϵ��첽����ΪJ2EEĿǰ�ĵײ�ϵͳ����JMS���첽API���⣬������API����ͬ�����õģ���������Ҳ�Ͳ��������ڵײ�J2EEƽ̨�������ṩ�첽�ԣ����DZ����Ӧ�ú���ƵĽǶ������첽�ԣ�
���߱��ع�����
��Ȼ��Ӧ�õ�ÿ���汾���лع����������Ƿdz���ʱ�Ͱ���ģ���������Ӧ������κε�ҵ��������п���ʧ�ܣ���ô���DZ���Ϊ����ʧ������������Ҫ��ϵͳ���û��������Ҫ��ϵͳһ��Ҫ���лع�����������ʧ�ܵ�ʱ���ܽ��м�ʱ�Ļع�����˵���ع���ҿ��ܵ�һʱ���뵽��������Ļع�����ʵ����Ļع�Ӧ����һ�ָ���������Ļع����������Ǽ�¼ÿһ�ε�ʧ�ܵ�ҵ������������ڳ��ִ����ʱ��Ͳ����������������ּ������ֶΣ�����ͨ��ϵͳ�����Ļع����������лع�ʧ��ҵ���������
����¼��־
��־��¼����һ�������ȶ���ϵͳ�Ƿdz���Ҫ�ģ�������Dz�������־��¼����ô�Ҿͺ���ͳ��ϵͳ����Ϊ��
���зֵ����ݿ�
����ϵͳ��ģ������������Ǿ���Ҫ���Ƶ�һ���ݵ����ƣ���Ҫ��������з֡�
���зֵ�Ӧ��
ϵͳ�ڹ�ģС��ʱ��Ҳ���о��������зֵ�Ӧ�ô��������⣬������Ŀǰ���������ٷ�չ��ʱ����˭�ܱ�֤һ��СӦ����һҹ�����Ǽ�ҹ�Ժ���СӦ���أ�˵�������죬���Ǿͷ���Ӧ����ͻ�������ķ����������֧�����顣������Ǿ���Ҫ�����ǵ�ϵͳ������һ��������������Ҫ����ϵͳ����Ӧ�����ص����������Ҫ�����ǵ�Ӧ�þ��кܺõ������ԣ���Ҳ��Ҫ��Ӧ����Ҫ�����õ��з֣�ֻ�н������з֣����Dz��ܶԵ�һ�IJ��Ž������������Ӧ����һ������Ļ���������û�а취���������ġ��ͺñȻ�һ������������֮���Ͱ��������Ϊһ��ģ���ô���ǻ���ô�Իij�����вü������һ��û���зֵ�Ӧ����һ��û�������Ժ�û�п����Ե�Ӧ�á�
�������������ڵ���������
������ǵ�Ӧ��ϵͳ�������������ڵ������ij��̣��������������ݿ⼯Ⱥ����ô���Ǿ�Ϊϵͳ��������������һ����ʱը������Ϊֻ�������Լ�����������Լ���Ӧ�ã�����Ӧ�ô�Ӧ�ú���ƵĽǶȳ���ȥ�������ǵ�Ӧ�ã������������ڵ��������̵����ԡ�
OLAP
������������ (OLAP) �ĸ����������ɹ�ϵ���ݿ�֮��E.F.Codd��1993������ģ���ͬʱ����˹���OLAP��12����OLAP����������˺ܴ�ķ��죬OLAP��Ϊһ���Ʒͬ���������� (OLTP) �������ֿ�����
OLAP������Ʒ�����ѵ������
Ŀǰ�������������ѵ㲻���ڱ�������ʽ����б�ߵȣ�����ʽ��Ϸ��������DZ������ѡ���������ѵ�����ҵ�� ����֪�������������������壬ȴ��֪������������ͳ��ģ��ģ�ͣ���IT����ͨ������ҵ���ŵ������������ݿ�˽�����������ͳ��ģ�ͣ�ȴ�Ա������������� �ļ�ֵ�������⡣
˵�����е���£���ʵ�������ӣ�OLAP������ĸ���ֻ����������ά�۲졢������ȡ��CUBE���㡣
����CUBE���㣺OLAP���������ԭʼ�������Ƿdz��Ӵ�ġ�һ������ģ�ͣ��������漰��������ǧ�������ݣ��������ࣻ������ģ���а������ά���ݣ���Щά�ֿ�������������������ȡ��ϡ������Ľ�����Ǵ�����ʵʱ���㵼��ʱ������͡�
���ǿ������룬һ��1000������¼�ķ���ģ�ͣ����һ����ȡ4��ά�Ƚ�����Ϸ�������ôʵ�ʵ���������� �ﵽ4��1000�η�����������������������������ʮ�������������ĵȴ�ʱ�䡣����û���ά��ϴ�����е����������ӡ������ijЩά�ȵĻ����ֽ���һ���� �µļ�����̡�
������ķ����У����ǿ��Եó����ۣ�������ܽ��OLAP����Ч������Ļ���OLAP����һ������ʵ�ü�ֵ�ĸ����ô��һ�������Ʒ����ν�����������أ����漰��OLAP��һ���dz���Ҫ�ļ�����������CUBEԤ���㡣
һ��OLAPģ���У��������ݺ�ά��������Ӧ������ȷ����һ������ȷ�����������ǿ��Զ����ݽ���Ԥ�ȵĴ���������ʽ����֮ǰ�������ݸ���ά�������
�ȵľ������㣬�����лῼ�ǵ�����ά��������������������һ������CUBE���������ڷ������ϡ�
�������������û��ڵ����������ģ�͵�ʱ�Ϳ���ֱ��ʹ�����CUBE���ڴ˻����ϸ����û���άѡ���ά��Ͻ��и����㣬�Ӷ��ﵽʵʱ��Ӧ��Ч����
NOSQL�DZ���Ĺ���ԭ��
��������֮ǰ����д��һƪ���������˳������� NOSQL ��һ���������ݿ�ı�����������������֮ǰ������Qcon�Ϸ�����һ���ݽ������У��ҽ�����һ����������scalable���� twitter Ӧ�õĹ���ģʽ�������ǵ������У�һ���Զ���������������ݿ�Ŀ���չ�����⡣Ҫ���������⣬����ͼѰ�������ڸ��� NOSQL ֮��Ĺ���ģʽ����չʾ��������ν�����ݿ����չ������ġ��ڱ����У��ҽ��������ճ���Щ���е�ԭ��
����ʧЧ�DZ�Ȼ������
��������ǰͨ������Ӳ��֮����ֶξ���ȥ����ʧЧ���ֶβ�ͬ��NOSQLʵ�ֶ�������Ӳ�̡����������綼��ʧЧ��Щ����֮�ϡ�������Ҫ�϶������Dz� �ܳ�����ֹ��ЩʱЧ���෴��������Ҫ�����ǵ�ϵͳ�ܹ��ڼ�ʹ�dz����˵�������Ҳ��Ӧ����ЩʧЧ��Amazon S3 ����������Ƶ�һ�������ӡ������������������� Why Existing Databases (RAC) are So Breakable! ���ҵ���һ������������ҽ�����һЩ���� Jason McHugh �Ľ��ݵ�����ʧЧ�ļܹ���Ƶ����ݣ�Jason ���� Amazon �� S3 ��ع����ĸ�����ʦ����
�����ݽ��з���
ͨ�������ݽ��з�����������С����ʧЧ������Ӱ�죬Ҳ����д�����ĸ��طֲ����˲�ͬ�Ļ����ϡ����һ���ڵ�ʧЧ�ˣ�ֻ�иýڵ��ϴ洢�������ܵ�Ӱ�죬������ȫ�����ݡ�
����ͬһ���ݵĶ������
�� NOSQL ʵ�ֶ��������ݸ������ȱ�������֤�����ĸ߿����ԡ�һЩʵ���ṩ�� API�����Կ��Ƹ����ĸ��ƣ�Ҳ����˵������洢һ�������ʱ��������ڶ���ָ����ϣ������ĸ��������� GigaSpaces�����ǻ�������������һ���µĸ����������ڵ㣬�����ڱ�Ҫʱ����һ̨�»������������Dz�����ÿ���ڵ��ϱ���̫������ݸ������Ӷ����� �ܴ洢���Խ�Լ�ɱ���
�㻹���Կ��Ƹ���������ͬ�������첽�ģ����������С����������ļ�Ⱥ��һ���ԡ����������������ߡ�����ͬ�����ƣ������������ܱ���һ���ԺͿ��� �ԣ�д����֮�����������������Ա�֤�õ���ͬ�汾�����ݣ���ʹ�Ƿ���ʧЧҲ����ˣ�������Ϊ������ GigaSpaces ��������ͬ�����������ֽ�㣬�첽�洢����˴洢��
��̬����
Ҫ�ƿز������������ݣ��� NOSQL ʵ���ṩ�˲�ͣ������ȫ���·�������չ��Ⱥ�ķ�����һ����֪�Ĵ������������㷨��Ϊһ�¹�ϣ���кܶ��ֲ�ͬ�㷨����ʵ��һ�¹�ϣ��
һ���㷨���ڽڵ�����ʧЧʱ֪ͨijһ�������ھӡ�������Щ�ڵ��ܵ���һ�仯��Ӱ�죬������������Ⱥ����һ��Э�������ƿ���Ҫ��ԭ�м�Ⱥ���½ڵ�֮�����·ֲ������ݵı任���䡣
��һ�����ࣩܶ���㷨ʹ�������������������У������������ǹ̶��ģ��������ڻ����ϵķֲ�ʽ��̬�ġ����ǣ���������̨������1000���� ��������ôÿ500�������������һ̨�����ϡ������Ǽ����˵���̨������ʱ�ͳ���ÿ 333 ����������һ̨�������ˡ���Ϊ���������������ģ������ڴ��еĹ�ϣ�������ֲ���Щ�������dz����ס�
�ڶ��ַ����������������ǿ�Ԥ�Ⲣ��һ�µģ���ʹ��һ�¹�ϣ����������֮������·ֲ����ܲ���ƽ�ȣ���һ���½ڵ��������ʱ���ܻ����ĸ���ʱ�䡣һ���û�����ʱѰ������ת�Ƶ����ݻ�õ�һ���쳣��������������ȱ���ǿ���������������������������
����һ���Ĺ�����һ��������ۣ������Ķ� Ricky Ho ������ NOSQL Patterns ��
��ѯ֧��
��������棬��ͬ��ʵ�����൱���ʵ����𡣲�ͬʵ�ֵ�һ���������ڹ�ϣ���е� key/value ƥ�䡣һЩ�����ṩ�˸����IJ�ѯ֧�֣����������ĵ��ķ��������������� blob �ķ�ʽ�洢������һ����ֵ�������б�������ģ����һ����Ԥ����ṹ�ģ�schema-less���洢����һ���ĵ����ӻ�ɾ�����Էdz����ף����迼���ĵ��� �����ݽ����� GigaSpaces ֧�ֺܶ� SQL ��������� SQL��ѯû��ָ���ض��ļ�ֱ����ô�����ѯ�ͻᱻ���е� map �����еĽڵ�ȥ���ɿͻ�����ɽ���Ļ�ۡ�������Щ���Ƿ�����Ļ��ģ��û����������ע��Щ��
ʹ�� Map/Reduce �������
Map/Reduce ��һ���������������и��ӷ�����ģ�ͣ�������� Hadoop ��ϵ��һ�� map/reduce �����������Dz��л�۲�ѯ��һ��ģʽ���� NOSQL ʵ�ֲ����ṩ map/reduce ���ڽ�֧�֣���Ҫһ���ⲿ�Ŀ����������Щ��ѯ������ GigaSpaces ��˵�������� SQL ��ѯ�������˶� map/reduce ��֧�֣�ͬʱҲ��ʽ���ṩ��һ����Ϊ executors �� API ��֧�� map/reduce��������ģ���У�����Խ����뷢�͵��������ڵصط������ڸýڵ���ֱ�����и��ӵIJ�ѯ��
�ⷽ��ĸ���ϸ�ڣ������Ķ� Ricky Ho ������ Query Processing for NOSQL DB ��
���ڴ��̵ĺ��ڴ��е�ʵ��
NOSQL ʵ�ַ�Ϊ�����ļ��ķ������ڴ��еķ�������Щʵ���ṩ�˻��ģ�ͣ����ڴ�ʹ��̽��ʹ�á������������Ҫ��������ÿ GB �ɱ��Ͷ�д���ܡ�
�����˹̹����һ���Ϊ��The Case for RAMCloud���ĵ��飬�Դ��̺��ڴ����ַ���������һЩ���ܺͳɱ��������Ȥ�ıȽϡ�������˵���ɱ�Ҳ�����ܵ�һ�����������ڽϵ����ܵ�ʵ�֣����̷� ���ijɱ�Զ���ڻ����ڴ�ķ����������ڸ���������ij��ϣ��ڴ淽����������ۡ�
�ڴ��Ƶ��Զ�����ȱ����ǵ�λ�����ĸ߳ɱ����ܺġ�������Щָ�꣬�ڴ��ƻ�ȴ���Ĵ���ϵͳ��50��100 ������ʹ�������ϵͳ��5-10�����������������ָ��μ��ο�����[1]�����ڴ���ͬʱ���Ȼ��ڴ��̺������ϵͳ��Ҫ����Ļ�����������������һ��Ӧ ����Ҫ�洢�������������ݣ�����Ҫ���ٷ��ʣ���ô���ڴ��ƽ��������ѡ��
Ȼ�������ڸ������������Ӧ�ã��ڴ��ƽ����о��������� ʹ��ÿ�β����ijɱ���������Ϊ�������ص�ʱ���ڴ��Ƶ�Ч���Ǵ�ͳӲ��ϵͳ�� 100 �� 1000 ����������ϵͳ�� 5-10 ������ˣ����ڸ������������ϵͳ��˵���ڴ��Ʋ����ṩ�˸����ܣ�Ҳ�ṩ�˸���ԴЧ�ʡ�ͬʱ�����ʹ�� DRAM оƬ�ṩ�ĵ���ģʽ��Ҳ���Խ����ڴ��ƵĹ��ģ��ر�����ϵͳ���е�ʱ���⣬�ڴ��ƻ���һЩȱ�㣬һЩ�ڴ�����֧����Ҫ�������� �����������֮��������ݸ��ơ�������Щ���������µ�ʱ�ӽ���Ҫȡ�����������ļ����ݴ����ʱ�����ģ����ɥʧ���ڴ��Ƶ�ʱ�ӷ�������ơ����⣬�������� �ĵ����ݸ��ƻ����ڴ�������һ���Ը����ѱ�֤���������ڴ�����Ȼ�����ڿ��������ĵ�������ṩ��ʱ�ӵĶ����ʡ�
�����dz���?
�����Ҽ���������������� ��NOSQL �Dz��Ǿ��dz������� �� ��NOSQL ���ȡ�����ڵ����ݿ⣿��
�ҵĻش��ǡ���NOSQL ����ʼ�ڽ��ա��ܶ� NOSQL ʵ�ֶ��Ѿ�������ʮ�����ˣ��кܶ�ɹ��������������кܶ�ԭ���������������������ܻ�ӭ�ˡ�������������ữ������Ƽ���ķ�չ��һЩԭ��ֻ�кܸ߶˵� ��֯�Ż����ٵ����⣬����Ѿ���Ϊ�ձ������ˡ���Σ����еķ����Ѿ�����������������һ����չ�ˡ����ң��ɱ���ѹ���úܶ���֯��ҪȥѰ�Ҹ����Լ۱ȵķ� ���������о�֤ʵ������ͨ����Ӳ���ķֲ�ʽ�洢����������������ڵĸ߶����ݿ���ӿɿ�������һ���Ķ���������Щ�����˶����ࡰ���������������ݿ⡱��������������� AWS�ŶӵĽӴ�����ʦ��VP�� James Hamilton ���������� One Size Does Not Fit All �е�һ�λ���
������������Ӧ������Щ����߱����������Ե�Ӧ�ã��ܹ��������Ƶ���չ�ȸ��ḻ�Ĺ��ܸ�����Ҫ����ЩӦ�ð����ܶ���Ҫ�� �������Ե���վ���� Facebook, MySpace, Gmail, Yahoo �Լ� Amazon.com����Щվ��ʵ����ʹ���˹�ϵ�����ݿ⣬����ʵ���ϲ�δʹ�á���Щ����Ĺ������ڿ���չ�Աȹ��ܹ���Ҫ������������һ����һ�� RDBMS �ϡ���
�ܽ�һ�¡�������Ϊ�����е� SQL ���ݿ���ܲ���ܿ쵭����ʷ��̨����ͬʱ����Ҳ���ܽ�����ϵ��������⡣NOSQL �����������Ҳ����� Not Only SQL������仯�������ҵĹ۵㡣
��
���鲻������ֻͼѧ��֮�㡣��л��λ��ţд����ô������ϣ��������Ը�ⱻ���ã�ѧ������д��Ӧ���½ڡ�
������־��ƪ�����ں���̫������һһУ�ӣ��ش���Ǹ��
��л
��лJdon,dbanotes,infoq��Timyang.���Ƿ�����д����ô�����õ����ϡ�
�汾־
V0.1�汾��2010.2.21�������ṩ�˱����������
v0.2�汾��2010.2.24��������ΪһЩ���ԭ����ǰ���������Ƹ���ʾ���������벿�����ݡ�
v0.3�汾����3�·ݻ�֮��
����
http://www.jdon.com/jivejdon/thread/37999
http://queue.acm.org/detail.cfm?id=1413264
http://www.dbanotes.net/arch/five-minute_rule.html
http://www.infoq.com/cn/news/2009/09/Do-Not-Delete-Data
http://www.infoq.com/cn/news/2010/02/ec2-oversubscribed
http://timyang.net/architecture/consistent-hashing-practice
http://en.wikipedia.org/wiki/Gossip_protocol
http://horicky.blogspot.com/2009/11/nosql-patterns.html
http://snarfed.org/space/transactions_across_datacenters_io.html
http://research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf
http://en.wikipedia.org/wiki/Distributed_hash_table
http://hi.baidu.com/knuthocean/blog/item/cca1e711221dcfcca6ef3f1d.html
http://zh.wikipedia.org/wiki/MapReduce
http://labs.google.com/papers/mapreduce.html
http://nosql-database.org/
http://www.rackspacecloud.com/blog/2009/11/09/nosql-ecosystem/
http://www.infoq.com/cn/news/2008/02/ruby-mapreduce-skynet
http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
http://labs.google.com/papers/bigtable.html
http://www.allthingsdistributed.com/2008/12/eventually_consistent.html
http://www.rackspacecloud.com/blog/2009/11/09/nosql-ecosystem/
http://timyang.net/tech/twitter-operations/
http://blog.s135.com/read.php?394
http://www.programmer.com.cn/1760/
| 

