| ��
��ǰ����û��һ�ױȽ�������NoSQL���ݿ����ϣ��кܶ��������������˺ܶ࣬�����Ǻ�ϵͳ�����ij����Ž����ҵ���������һ�£�����д��һЩ�Լ��ļ��⡣
����д��һЩĿǰ��NoSql��һЩ��Ҫ�������㷨��˼�롣ͬʱ�о��˴��������е����ݿ�ʵ��������ȫƪ�����Ŷ����NoSQL���ݿ��˽����š�
�����һ�������һ����Դ�ڴ����ݿ�galaxydb.����Ҳ��Ϊ������ݿ��ṩһЩ�ܹ����ϡ�
˼��ƪ
CAP��BASE������һ������NoSQL���ݿ���ڵ������ʯ��������ӷ������ڴ����ݴ洢���������ݡ������һ�е�Դͷ��
CAP
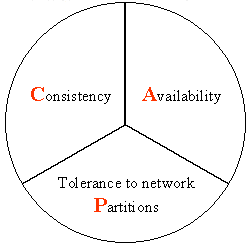
- C: Consistency һ����
- A: Availability ������(ָ���ǿ��ٻ�ȡ����)
- P: Tolerance of network Partition ����������(�ֲ�ʽ)
10��ǰ��Eric Brewer����ָ����������CAP���ۣ�����Seth Gilbert �� Nancy lynch����֤����CAP���۵���ȷ�ԡ�CAP���۸������ǣ�һ���ֲ�ʽϵͳ����������һ���ԣ������Ժͷ����ݴ����������������ֻ��ͬʱ����������
�������㲻�ɼ��Ҳ����ע����һ���ԣ���ô������Ҫ������Ϊϵͳ�����ö����µ�д����ʧ�ܵ���������������ע���ǿ����ԣ���ô��Ӧ��֪��ϵͳ��read�������ܲ��ܾ�ȷ�Ķ�ȡ��write����д�������ֵ�����ϵͳ�Ĺ�ע�㲻ͬ����Ӧ�IJ��õIJ���Ҳ�Dz�һ���ģ�ֻ��������������ϵͳ�������п������ú�CAP���ۡ�
��Ϊ�ܹ�ʦ��һ������������������CAP����
- key-value�洢����Amaze Dynamo�ȣ��ɸ���CAP��ԭ�����ѡ��ͬ��������ݿ��Ʒ��
- ����ģ�� + �ֲ�ʽ���� + �洢 ��Qi4j��NoSql�˶������ɸ���CAP��ԭ�����Լ���Ŀ�������ķֲ�ʽ�������Ѷȸߡ�
�����ṩ�����ַ�����ʵ�ֿ�������CAP�����ݿ⣬��̬����CAP��
- CA����ͳ��ϵ���ݿ�
- AP��key-value���ݿ�
���Դ�����վ����������������������ȼ�Ҫ��������һ���ԣ�һ��ᾡ������ A��P �ķ�����ƣ�Ȼ��ͨ�������ֶα�֤����һ���Ե��������ܹ����ʦ��Ҫ�����˷������������������ߵ������ֲ�ʽϵͳ������Ӧ�ý���ȡ�ᡣ
��ͬ���ݶ���һ���Ե�Ҫ���Dz�ͬ�ġ������������û����۶Բ�һ���Dz����еģ�����������Խϳ�ʱ��IJ�һ�£����ֲ�һ�²�����Ӱ�콻���û����顣����Ʒ�۸��������Ƿdz����еģ�ͨ���������̳���10��ļ۸�һ�¡�
CAP���۵�֤����Brewer's CAP Theorem
����һ����
һ���Ա�֮�������ɣ�����������ս�����뱣��һ����
Ϊ�˸��õ������ͻ���һ���ԣ�����ͨ�����µij��������У���������а���������ɲ��֣�
�洢ϵͳ��������Ϊһ���ں��ӣ���Ϊ�����ṩ�˿����Ժͳ־��Եı�֤��
ProcessA��Ҫʵ�ִӴ洢ϵͳwrite��read����
ProcessB��C�Ƕ�����A������B��CҲ������ģ�����ͬʱҲʵ�ֶԴ洢ϵͳ��write��read������
����������ij����������²�ͬ�̶ȵ�һ���ԣ�
ǿһ���ԣ���ʱһ���ԣ� ����A��д����һ��ֵ���洢ϵͳ���洢ϵͳ��֤����A,B,C�Ķ�ȡ����������������ֵ
����A��д����һ��ֵ���洢ϵͳ���洢ϵͳ���ܱ�֤����A,B,C�Ķ�ȡ�����ܶ�ȡ������ֵ�������������һ������һ���Դ��ڡ��ĸ������ָ��Aд��ֵ������������A,B,C��ȡ������ֵ��һ��ʱ�䡣
����һ��������һ���Ե�һ������������A����write��һ��ֵ���洢ϵͳ���洢ϵͳ��֤�����A,B,C������ȡ֮ǰû������д��������ͬ����ֵ�Ļ����������еĶ�ȡ���������ȡ����Aд�������ֵ����������£����û��ʧ�ܷ����Ļ�������һ���Դ��ڡ��Ĵ�С���������µļ������أ������ӳ٣�ϵͳ�ĸ��أ��Լ����Ƽ�����replica�ĸ����������������Ϊmaster/salveģʽ�У�salve�ĸ�����������һ���Է����������ϵͳ����˵��DNSϵͳ��������һ��������IP�Ժ������ò����Լ�������Ʋ��ԵIJ�ͬ���������еĿͻ����ῴ�����µ�ֵ��
����
- Causal consistency�����һ���ԣ�
���Process A֪ͨProcess B���Ѿ����������ݣ���ôProcess B�ĺ�����ȡ�������ȡAд�������ֵ������Aû�������ϵ��C���������һ���ԡ�
-
Read-your-writes consistency
���Process Aд�������µ�ֵ����ôProcess A�ĺ������������ȡ������ֵ�����������û�����Ҫ��һ��ſ��Կ�����
����һ����Ҫ��ͻ��˺ʹ洢ϵͳ�����������Ự�α�֤Read-your-writes consistency.Hibernate��session�ṩ��һ���Ա�֤�����ڴ���һ���ԡ�
-
Monotonic read consistency
����һ����Ҫ�����Process A�Ѿ���ȡ�˶����ij��ֵ����ô���������������ȡ�������ֵ��
-
Monotonic write consistency
����һ���Ա�֤ϵͳ�����л�ִ��һ��Process�е�����д������
BASE ˵��������Ȥ��BASE��Ӣ�������Ǽ��ACID���ᡣ�����ˮ���ݰ���
- Basically Availble --��������
- Soft-state --��״̬/��������
"Soft state" ��������Ϊ"������"��, �� "Hard state" ��"��������"��
-
Eventual Consistency --����һ����
����һ���ԣ� Ҳ���� ACID ������Ŀ�ġ�
BASEģ�ͷ�ACIDģ�ͣ���ȫ��ͬACIDģ�ͣ�������һ���ԣ���ÿ����Ի�ɿ��ԣ� Basically Available�������á�֧�ַ���ʧ��(e.g. sharding��Ƭ�������ݿ�) Soft state��״̬ ״̬������һ��ʱ�䲻ͬ�����첽�� Eventually consistent����һ�£�����������һ�µľͿ����ˣ�������ʱʱһ�¡�
BASE˼�����Ҫʵ����
1.�����ܻ������ݿ�
2.sharding��Ƭ
BASE˼����Ҫǿ�������Ŀ����ԣ��������Ҫ�߿����ԣ�Ҳ���Ǵ���ĸ����ܣ���ô��Ҫ��һ���Ի��ݴ���Ϊ������BASE˼��ķ����������ϻ�����DZ�����ڵġ�
����
I/O������ӷ���
�� 1987 �꣬Jim Gray �� Gianfranco Putzolu ���������"����ӷ���"�Ĺ۵㣬�����֮�����һ����¼Ƶ�������ʣ���Ӧ�÷ŵ��ڴ������Ļ���Ӧ�ô���Ӳ���ϰ���Ҫ�ٷ��ʡ�����ٽ���������ӡ� ����ȥ��һ�������Եķ���ʵ��������ӵ��������Ǹ���Ͷ��ɱ��жϵģ����ݵ�ʱ��Ӳ����չˮ�����ڴ��б��� 1KB �����ݳɱ��൱��Ӳ���д�� 400 ��Ŀ���(�ӽ������)����������� 1997 �����ҵ�ʱ����й�һ�λعˣ�֤ʵ������ӷ�����Ȼ��Ч��Ӳ�̡��ڴ�ʵ����û���ʵķ�Ծ)������εĻع�������� SSD ���"�µľ�Ӳ��"���ܴ�����Ӱ�졣
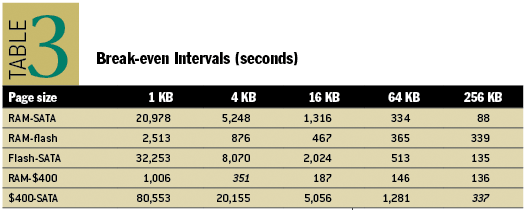
��������ʱ�������٣�����ӷ���һ��Ϊ�����ǰ� SSD ���ɽ������ڴ棨extended buffer pool ��ʹ�û��ǵ��ɽϿ��Ӳ�̣�extended disk��ʹ�á�С�ڴ�ҳ���ڴ������֮����ƶ��Աȴ��ڴ�ҳ������ʹ���֮����ƶ�������������״������ 20 ��֮��������ʱ����5 ���ӷ�����Ȼ��Ч��ֻ�����ʺϸ�����ڴ�ҳ(�ʺ� 64KB ��ҳ�����ҳ��С�ı仯ǡǡ�����˼����Ӳ�����յķ�չ���Լ���������ʱ)��
��Ҫɾ������
Oren Eini������Ayende Rahien�����鿪���߾����������ݿ����ɾ�����������߿��������ΪӲɾ���Ǻ�����ѡ����Ϊ��Ayende���µĻ�Ӧ��Udi Dahanǿ�ҽ�����ȫ��������ɾ����
��ν��ɾ�������ڱ�������һ��IsDeleted���Ա����������������ijһ��������IsDeleted��־�У���ô��һ�оͱ���Ϊ����ɾ���ġ�Ayende�������ַ��������������⡢����ʵ�֡�����ͨ�������������Ǵ��ġ����������ڣ�
ɾ��һ�л�һ��ʵ�弸���ܲ��Ǽ��¼���������Ӱ��ģ���е����ݣ�����Ӱ��ģ�͵���ۡ��������Dz�Ҫ�����ȥȷ��������֡������С�û�ж�Ӧ�ĸ�������������������������ֻ������������������
��������ɾ����ʱ���������Ƿ���Ը���������׳����������𣬱���˭���������һ��С�������Ϳ���ʹ���ͻ����ġ����¶�����ָ��һ���Ѿ���ɾ���Ķ�����
��������߽ӵ���Ҫ����Ǵ����ݿ���ɾ�����ݣ�Ҫ�Dz���������ɾ�����Ǿ�ֻ��Ӳɾ���ˡ�Ϊ�˱�֤����һ���ԣ������߳���ɾ��ֱ���йص������У���Ӧ�ü�����ɾ��������ݡ���Udi Dahan���Ѷ���ע�⣬��ʵ�����粢���Ǽ����ģ�
�����г�����������ƷĿ¼��ɾ��һ����Ʒ�����Dz���˵���а����˸���Ʒ�ľɶ�����Ҫһ����ʧ���ټ�����ȥ����Щ������Ӧ�����з�Ʊ�Dz���Ҳ��ɾ������ôһ����ɾ��ȥ�����ǹ�˾�����汨���Dz���Ӧ�������ˣ�
û�����ˡ�
�����ƺ����ڶԡ�ɾ������ʵĽ���ϡ�Dahan���������������ӣ�
��˵�ġ�ɾ������ʵ��ָ���Ʒ��ͣ�ۡ��ˡ������Ժ��������ֲ�Ʒ���������Ժ��ٽ������Ժ�˿�������Ʒ���߷���Ŀ¼��ʱ���ٿ���������Ʒ�����ֿܲ������ʱ���ü����������ǡ���ɾ�����Ǹ�̰�����˵����
�����ž���һЩվ���û��Ƕȵ���ȷ�����
�������DZ�ɾ���ģ��DZ���ȡ�����ġ�����ȡ����̫��������������ѡ�
Ա�����DZ�ɾ���ģ��DZ�����͡��ģ�Ҳ�����������ˣ���������Ӧ�IJ�����Ҫ������
ְλ���DZ�ɾ���ģ��DZ�������ģ�������Ƹ���뱻���أ���
��������Щ�����У����ǵ����۵�Ӧ�÷����û�ϣ����ɵ������ϣ����Ƿ�����ij��
ʵ�����ϵļ������������������е�����£���Ҫ���ǵ�ʵ���ܲ�ֹһ����
Ϊ�˴���IsDeleted��־��Dahan������һ�������������״̬���ֶΣ���Ч��ͣ�á�ȡ�������õȵȡ��û����Խ�������һ��״̬�ֶλع˹�ȥ�����ݣ���Ϊ���ߵ����ݡ�
ɾ�����ݳ����ƻ�����һ���ԣ�������������ĺ����Dahan������������ݶ��������ݿ������ɾ�������DZ�
ɾ������
RAM��Ӳ��,Ӳ���ǴŴ�
Jim Gray�ڹ�ȥ40���жԼ�����չ�й���Ĺ��ף����ڴ����µ�Ӳ�̣�Ӳ�����µĴŴ������������ԡ���ʵʱ��WebӦ�ò���ӿ�֣��ﵽ������ģ��ϵͳԽ��Խ�࣬���ֺ�����ǰ�˵ķ�չģʽ����Ӳ�����к�Ӱ�죿
Tim Bray������������Ϊ���Ż���֮ǰ�������۹���RAM������Ϊ���ĵ�Ӳ���ṹ�����ƣ�����������Ӳ�������ȴ��̼�Ⱥ�ٶȸ����RAM��Ⱥ��
�������ݵ�������ʣ��ڴ���ٶȱ�Ӳ�̸�������������ʹ����߶˵Ĵ��̴洢ϵͳҲֻ����ǿ�ﵽ1,000��Ѱ��/�룩����Σ� �����������ĵ������ٶ���ߣ������ڴ�ijɱ�����һ�����͡�ͨ�����������һ̨�������ڴ�ȷ��ʴ��̳ɱ����͡�������д����λ���ʱ��Sun�� Infiniband��Ʒ������һ��߱�9��ȫ�����������˿ڽ�������ÿ���˿ڵ��ٶȿ��Դﵽ30Gbit/sec��Voltaire��Ʒ�Ķ˿��������ࣻ��ֱ����������������˽����೬��������������½�չ�����עAndreas Bechtolsheim��Standford����Ŀγ̡���
���ֲ�����ʱ�䣬��2001���ļ����������õ� 1GHz ���˼����Ϊ����

Tim��ָ��Jim Gray��
�����к�����������������������������ʣ�Ӳ�����ò������ܣ���������Ӳ�̵��ɴŴ����ã��������������ݵ������������������ʺ���������RAMΪ����Ӧ������־��logging and journaling������
ʱ����������֮��Ľ��죬���Ƿ���Ӳ���ķ�չ������RAM������������ͷ����������Ӳ��������ֹ����ǰ��Bill McColl�ᵽ���ڲ��м���������ڴ�ϵͳ�Ѿ�������
�ڴ����µ�Ӳ�̣�Ӳ���ٶ���������ڴ�оƬ����ָ��������in-memory�����ܹ����������������ܼ���Ӧ�ô���������������������С�ͻ��ܷ�������1U��2U���ܿ�ͻ�߱�T�ֽڡ��������������ڴ棬�⽫��ı�������ܹ����ڴ��Ӳ��֮���ƽ�⡣Ӳ�̽���Ϊ�µĴŴ�����Ŵ�һ����Ϊ˳��洢����ʹ�ã�Ӳ�̵�˳������൱���٣���������������洢���ʣ��dz����������������Ŵ����Ļ��ᣬ�²�Ʒ�������������10����100����
Dare Obsanjoָ���������������Ե����£������ʲô���Ķ��Ӻ������ Ҳ����Twitter�����ٵ��鷳���ۼ�Twitter�����ݹ�����Obsanjo˵�������һ�����ֻ�Ǽط�ӳ��������������ȥʵ�����ͻ�������� I/O�ĵ�������������Ruby on Rails��Cobol on Cogs��C++������д��һ������д���������Ầ���㡣������֮��Ӧ�ð���������Ƹ�RAM��ֻ��Ӳ������˳�������
Tom White��Hadoop Core��Ŀ���ύ�ߣ�Ҳ��Hadoop��Ŀ����ίԱ��ij�Ա������Gray�������С�Ӳ�����µĴŴ����������˸������̽�֡�White������MapReduce���ģ�͵�ʱ��ָ����Ϊ�ζ���Hadloop�������˵��Ӳ����Ȼ�ǿ��е�Ӧ�ó������ݴ洢���ʣ�
�����ϣ���MapReduce�Ĺ�����ʽ�У�������ʽ�ض�����д��Ӳ�̣�MapReduce����Ӳ�̵Ĵ������ʲ��ϵض���Щ���ݽ�������ͺϲ��� ��֮��ȣ����ʹ�ϵ���ݿ��е����ݣ�����������Ӳ�̵�Ѱ�����ʣ�Ѱ��ָ�ƶ���ͷ�������ϵ�ָ��λ�ö�ȡ��д�����ݵĹ��̣���ΪʲôҪǿ����һ�㣿�뿴��Ѱ��ʱ��ʹ��̴����ʵķ�չ���ߡ�Ѱ��ʱ��ÿ���Լ���5%�������ݴ�����ÿ���Լ���20%��Ѱ��ʱ��Ľ��������ݴ�������������˲��������ݴ����ʾ������ܵ�ģ���������ġ�MapReduce������ˡ�
��Ȼ��̬Ӳ�̣�SSD���ܷ�ı�Ѱ��ʱ��/�����ʵĶԱȻ��д��۲죬White���µĸ��������ܶ��˶���ΪSSD���ΪRAM/Ӳ��֮���е�ƽ��������
Nati Shalom���ڴ��Ӳ�������ݿⲿ���ʹ���еĽ�ɫ����һ�������оݵ������� Shalom����ָ�������ݿ⼯Ⱥ�ͷ�����������ܺͿ������Եľ��ޡ���˵�������ݿ⸴�ƺ����ݿ������������ͬ�Ļ������⣬���Ƕ��������ļ�ϵͳ/Ӳ�� �����ܣ��������ݿ⼯ȺҲ�dz����ӡ���������ķ�����ת��In-Memory Data Grid��IMDG������Hibernate�����������GigaSpaces Spring DAO֮��ļ�����֧�ţ����־û���Ϊ����Persistence as a Service���ṩ��Ӧ�ó���Shalom����˵��IMDG
�ṩ���ڴ��еĻ��ڶ�������ݿ�������֧�ֺ��ĵ����ݿ�ܣ�����������Ͳ�ѯ���������������IMDG����Ӧ�ó���Ĵ����г���������ݵ����ˡ�ͨ�������ķ�ʽ�����ݿⲻ����ȫ��ʧ��ֻ��Ų���ˡ���ȷ�ġ�λ�á�
IMDG���ֱ��RDBMS���ʵ������о����£�
- λ���ڴ��У��ٶȺͲ������������ļ�ϵͳ��Խ�ö�
- ���ݿ�ͨ�����÷���
- ֱ�Ӷ��ڴ��еĶ���ִ�����ݲ���
- �������ݵ�����
- ���еľۺϲ�ѯ
- �����ڣ�In-process���ľֲ�����
- ����˶���-��ϵӳ�䣨ORM��
���Ƿ���Ҫ�ı��Ӧ�ú�Ӳ����˼ά��ʽ������ȡ������Ҫ��������ɵĹ��������ƺ�������Ϊ�������߽�����ܺͿ������Ե�˼·�Ѿ����˸ñ�һ���ʱ��
Amdahl���ɺ�Gustafson����
������Ƕ���S(n)��ʾn��ϵͳ�Ծ������ļ��ٱȣ�K��ʾ���в��ּ���ʱ�������
Amdahl ���ɵļ��ٱȣ�S(n) �� ʹ��1���������Ĵ��м���ʱ�� / ʹ��n���������IJ��м���ʱ��
S(n) = 1/(K+(1-K)/n) = n/(1+(n-1)K)
Gustafson���ɵļ��ٱȣ�S(n) �� ʹ��n���������IJ��м����� / ʹ��1���������Ĵ��м�����
S(n) = K+(1-K)n
�е����Dz��ǣ�
ͨ�Ľ���Amdahl ���ɽ�����������1����n��Ҳֻ�ֵܷ�1-K�Ĺ���������Gustafson�������˹���������1����n�ˣ��Ϳ�������n(1-K)�Ĺ�������
����û�п��������ֲ�ʽ�����Ŀ�������������ͼ������ɱ�����Ҫ��ϸ����ģ�����Խ�ֲ�Խ�á�
�����㷨�ĸ������ڳ�����Χ֮�ڡ�
������̫��
�ֶ�ƪ
һ���Թ�ϣ
Ҫ��ֲ�ʽ�ܹ��ķ�չ˵��
��һ��
���ǵ������������ܳ��أ����ʹ���˷ֲ�ʽ�ܹ���������㷨Ϊ hash() mod n, hash()ͨ��ȡ�û�ID��nΪ�ڵ������˷�������ʵ�����ܹ�������ӪҪ��ȱ���ǵ����㷢������ʱ��ϵͳ���Զ��ָ���
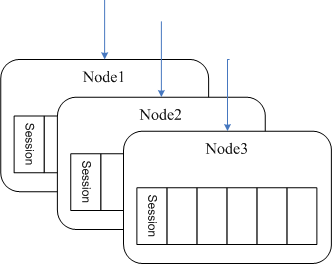
�ڶ���
Ϊ�˽��������ϣ�ʹ�� hash() mod (n/2), ��������һ���û�����2����������ѡ������client���ѡȡ�����ڲ�ͬ������֮����û���Ҫ�˴˽������������еķ�������Ҫȷ�е�֪���û����ڵ�λ�á�����û�λ�ñ����浽memcached�С�
��һ̨�������ϣ�client�����Զ��л�����Ӧbackup�������л�ǰ����1̨û���û���session�������Ҫclient�������µ�¼��
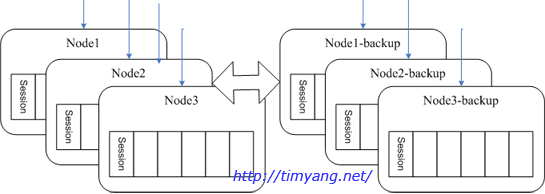
����ε���ƴ�����������
���ز����⣬�����ǵ�̨�������Ϻ�ʣ��һ̨��ѹ������
���ܶ�̬��ɾ�ڵ�
�ڵ㷢������ʱ��Ҫclient���µ�¼
������
����ȥ��Ӳ�����hash() mod n �㷨������һ���Թ�ϣ(consistent hashing)�ֲ�
�������Dynamo�е�strategy 1
���ǰ�ÿ̨server�ֳ�v������ڵ㣬�ٰ���������ڵ�(n*v)������䵽һ���Թ�ϣ��Բ���ϣ��������е��û����Լ�Բ���ϵ�λ��˳ʱ������ȡ����һ��vnode�����Լ������ڵ㡣���˽ڵ���ڹ���ʱ����˳ʱ��ȡ��һ����Ϊ����ڵ㡣
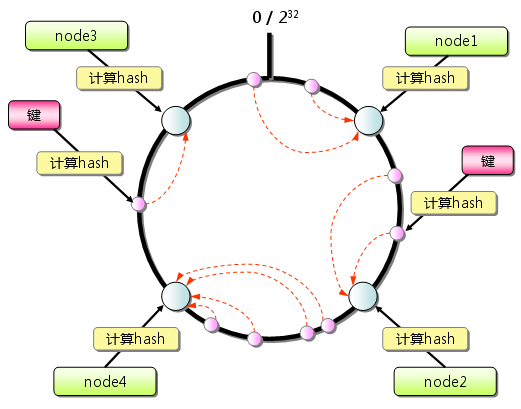
�ŵ㣺�����������ʱ���ػ�����ɢ���������нڵ㣬����ʵ��Ҳ�Ƚ����š�
����ѷ����״
aw2.0��˾��Alan Williamsonд��һƪ��������Ҫ�ǹ�������Amazon EC2�ϵ�����ģ�����Թ˵��Amazon�ǹ�˾Ψһʹ�õ����ṩ�̣����������ڿ�ʼʱ�ܹ���Ӧ�úܺã�������һ���ٽ�㣺
�ڿ�ʼ��������Amazon�ı��ַdz�����ʵ���ڼ�����������������û�������κ����⣬���������ǵ�Сʵ����SMALL INSTANCE��Ҳ�ܽ�׳������֧���ʵ�ʹ�õ�MySQL���ݿ⡣��20�����ڣ�Amazon��ϵͳһ����ת���ã�����Ҫ�κεĹ��ĺͱ�Թ��
����
Ȼ���������İ˸������ң����ǡ����ס��ڵ�©����ʼ���ֳ����ˡ���һ������ǰ���ǣ��¼����Amazon SMALLʵ�������ܳ��������⡣�������ǵļ�أ��ڷ��������������ӵĻ�������ԭ�ȵ���Щ������������½�����ʼ������Ϊ������Ȼ���ֵĹ�����ֻ���� �ɷ����ڡ����ֵ��ھӡ���Noisy Neighbors���Աߡ������������һ�ο��ٵ�ͣ�����������������ͻ������ǻص����������ھӡ��Աߣ��������ǿ��ԴﵽĿ�ġ�
���� Ȼ����������һ�������У����Ƿ��֣���������Щ��ʹ�ø�CPU���е�ʵ����Ҳ��������Сʵ����ͬ�����ˣ����У��µ�ʵ�����ܴ���ʲôλ�ã��������ƺ������ֵ�һ�����������飬���ǻ�������һ�������⣬���Ѿ�����������Amazon�������У��Ǿ����ڲ������ӳ١�
�㷨��ѡ��
��ͬ�Ĺ�ϣ�㷨���Ե������ݷֲ��IJ�ͬλ�ã����ʮ�־��ȣ���ôһ��MapReduce���漰�ڵ�϶࣬���ȵ���ȣ������������֮���ȵ㲻��������»���Ч�ʷ��Ӳ���ȫ��
Quorum NRW
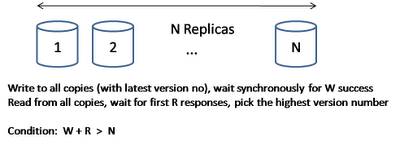
- N: ���ƵĽڵ�����
- R: �ɹ�����������С�ڵ���
- W: �ɹ�д��������С�ڵ���
ֻ��W + R > N���Ϳ��Ա�֤ǿһ���ԡ�
��һ���ؼ������� N����� N ָ�������ݶ������Ƶ� N ̨�����ϣ�N ��ʵ���������ã�Э��������������ݸ��Ƶ� N-1 ���ڵ��ϡ�N �ĵ���ֵ����Ϊ 3.
�� ���е�һ���ԣ����������� Quorum ϵͳ��һ����Э��ʵ�֡����Э���������ؼ�ֵ��R �� W��R ����һ�γɹ��Ķ�ȡ��������С����ڵ�������W ����һ�γɹ���д��������С����ڵ�������R + W>N ������������ quorum ��Ч������ģ���еĶ�(д)�ӳ��������� R(W)���ƾ�����Ϊ�õ��Ƚ�С���ӳ٣�R �� W �е�ʱ��ĺ������ñ� N С��
���N�е�1̨�������ϣ�Dynamo����д�뵽preference list����һ̨��ȷ����Զ��д��
�� ��W+R>N����ô�ֲ�ʽϵͳ�ͻ��ṩǿһ���Եı�֤����Ϊ��ȡ���ݵĽڵ�ͱ�ͬ��д��Ľڵ������ص��ġ���һ��RDBMS�ĸ���ģ���� ��Master/salve)������N=2,��ôW=2,R=1��ʱ��һ��ǿһ����,����������ɵ�������ǿ����Եļ��ͣ���ΪҪ��д�����ɹ�������Ҫ�� 2���ڵ㶼����Ժ�ſ��ԡ�
�ڷֲ�ʽϵͳ�У�һ�㶼Ҫ���ݴ��ԣ����һ��N���Ǵ���3�ģ���ʱ����CAP���ۣ�һ���ԣ������Ժͷ����ݴ� �����ֻ��������������ô���Ǿ���Ҫ��һ���Ժͷ����ݴ���֮����һƽ�⣬���Ҫ�ߵ�һ���ԣ���ô������N=W��R=1,���ʱ������Ծͻ��͡���� ��Ҫ�ߵĿ����ԣ���ô��ʱ����Ҫ����һ���Ե�Ҫ��ʱ��������W=1������ʹ��д�����ӳ���ͣ�ͬʱͨ���첽�Ļ��Ƹ���ʣ���N-W���ڵ㡣
���洢ϵͳ��֤����һ����ʱ���洢ϵͳ������һ����W+R<=N,��ʱ��ȡ��д������Dz��ص��ģ���һ���ԵĴ��ھ������ڴ洢ϵͳ���첽ʵ�ַ�ʽ����һ���ԵĴ��ڴ�СҲ�͵��ڴӸ��¿�ʼ�����еĽڵ㶼�첽�������֮���ʱ�䡣
(N,R,W) ��ֵ��������Ϊ (3, 2 ,2),�������������ԡ�R �� W ֱ��Ӱ�����ܡ���չ�ԡ�һ���ԣ���� W ���� Ϊ 1����һ��ʵ����ֻҪ��һ���ڵ���ã�Ҳ����Ӱ��д��������� R ����Ϊ 1 ��ֻҪ��һ���ڵ���ã�Ҳ����Ӱ�������R �� W ֵ��С��Ӱ��һ���ԣ�����Ҳ���ã�������ֵҪƽ�⡣��������ϵͳ�ĵ��͵� SLA Ҫ�� 99.9% �Ķ�д������ 300ms ����ɡ�
�� ����Read-your-writes-consistency,Session consistency,Monotonic read consistency,���Ƕ�ͨ�������stickiness)�ͻ��˵�ִ�зֲ�ʽ����ķ���������ʵ�ֵģ����ַ�ʽ���Ǽ�������ʹ�ø��ؾ����� �������ݴ���ĸ������ڹ�������ʱ��Ҳ����ͨ���ͻ�����ʵ��Read-your-writes-consistency��Monotonic read consistency,��ʱ��Ҫ��д�IJ��������ݼӰ汾�ţ������ͻ��˾Ϳ��������汾��С����������İ汾�ŵ����ݡ�
��ϵͳ�������� �У�����CAP���ۣ������Ժ�һ������һ�����ͷ����ݴ���ϵͳ��ֻ������һ�������Ϊ�˸߿����ԣ����DZ���ŵ�һ���Ե�Ҫ���Dz�ͬ��ϵͳ��֤��һ���� �����в��ģ����Ҫ����Ҫ����Լ��õ�ϵͳ�ṩʲô���ӵ�����һ���Եı�֤��һ���dz����е����Ӿ���webӦ��ϵͳ���ڴ������webӦ��ϵͳ�ж� �С��û��ɸ�֪һ���ԡ��ĸ����Ҳ����˵����һ�����еġ�һ���Դ���"��СҪС���û���һ�ε��������´ζ�ȡ������֮ǰ�����ݿ����ڴ洢�ĸ����ڵ�֮ �临�ơ����������洢ϵͳ�ṩ��
read-your-write-consistencyһ���ԣ���ô��һ���û�д��������Ժ�������������Լ��ĸ� �£������������û�Ҫ��һ��ſ��Կ������¡�
�������������
W = 1, R = N,��д����Ҫ������ܸ߿��á�
R = 1, W = N , �Զ�����Ҫ������ܸ߿��ã���������cache֮��ҵ��
W = Q, R = Q where Q = N / 2 + 1 һ��Ӧ�����ã���д����֮��ȡ��ƽ�⡣��N=3,W=2,R=2
Vector clock
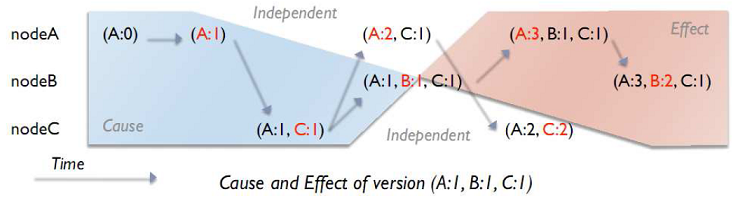
vector clock�㷨���������vector clock�����ÿ���ڵ㶼��¼�Լ��İ汾��Ϣ����һ�����ݣ�����������Щ�汾��Ϣ������һ�����ӣ�����һ��д����һ�α��ڵ�A�����ˡ��ڵ�A������һ���汾��Ϣ(A��1)�����ǰ����ʱ������ݼ���D1(A��1)�� Ȼ������һ����ͬ��key(��һ�����۶������ͬ����key��)�������DZ�A������������D2(A��2)��
���ʱ��D2�ǿ��Ը���D1�ģ������г�ͻ�������������Ǽ���D2�����������нڵ�(B��C)��B��C�յ������ݲ��Ǵӿͻ������ģ����DZ��˸��Ƹ����ǵģ��������Dz������µİ汾��Ϣ����������B��C����������D2(A��2)���ã���������һ������B�����ˣ���������D3(A��2;B��1)����Ϊ����һ���°汾�����ݣ���B����������Ҫ����B�İ汾��Ϣ��
����D3û�д�����C��ʱ����һ������C��������D4(A��2;C��1)����������Щ�汾û�д���������ǰ����һ����ȡ����������Ҫ�ǵã����ǵ�W=1 ��ôR=N=3������R������������ڵ��϶�������������н����������汾��A�ϵ�D2(A��2);B�ϵ�D3(A��2;B��1);C�ϵ�D4(A��2;C��1)���ʱ������жϳ���D2�Ѿ��Ǿɰ汾����������������D3��D4�����°汾����ҪӦ���Լ�ȥ�ϲ���
�����Ҫ�߿�д�ԣ���Ҫ�������ֺϲ����⡣�ü���Ӧ������˳�������������Ǻϲ�D3��D4�汾��Ȼ����������д�룬������B�����������������D5(A��2;B��2;C��1);����汾�����Ը��ǵ�D1-D4���ĸ��汾���������ֻ����һ���ͻ��������ڱ���ͬ�ڵ㴦��ʱ�������� ����ÿ��д���¶��ǿɽ��ܵģ���ҿ����Լ������������һ�¼��������ͻ���������Լ���һ���ɰ汾�����µ������
�������⿴�ƺ������ͨ���������ڵ���ѡ��һ�����ڵ�����������еĶ�ȡ��д�붼�����ڵ������С�����������Υ����W=1���Լ����ʵ���ϻ����˻���W=N������ˡ��������ϵͳ����Ҫ�ܴ�ĵ��ԣ�W=NΪ����Ӧ�ö����ܣ���ôϵͳ������Ͽ��Եõ��ܴ�ļ�Dynamo Ϊ�˸�����ֵĵ��Զ�����Ƴ���ȫ�ĶԵȼ�Ⱥ(peer to peer)�������е��κ�һ���ڵ㶼��������ġ�
Virtual node

����ڵ㣬δ���
gossip
GossipЭ����һ��Gossip˼���P2Pʵ�֡��ִ��ķֲ�ʽϵͳ����ʹ�����Э�飬��������Ψһ���ֶΡ���Ϊ�ײ�Ľṹ�dz����ӣ�����GossipҲ����Ч��
GossipЭ��Ҳ��Ϸ��Ϊ����ʽ��������Ϊ������Ϊ�����IJ��������ơ�
Gossip (State Transfer Model)
��״̬ת�Ƶ�ģʽ�£�ÿ���ظ��ڵ㶼���ֵ�һ��Vector clock��һ��state version tree��ÿ���ڵ��״̬������ͬ��(based on vector clock comparison),���仰˵��state version tree������ȫ���ij�ͻupdates.
At query time, the client will attach its vector clock and the replica will send back a subset of the state tree which precedes the client's vector clock (this will provide monotonic read consistency). The client will then advance its vector clock by merging all the versions. This means the client is responsible to resolve the conflict of all these versions because when the client sends the update later, its vector clock will precede all these versions.
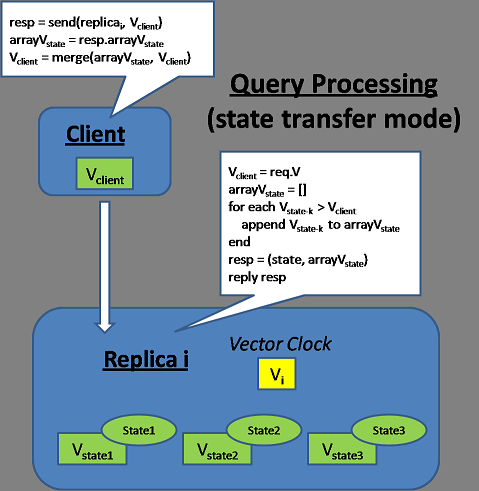
At update, the client will send its vector clock and the replica will check whether the client state precedes any of its existing version, if so, it will throw away the client's update.
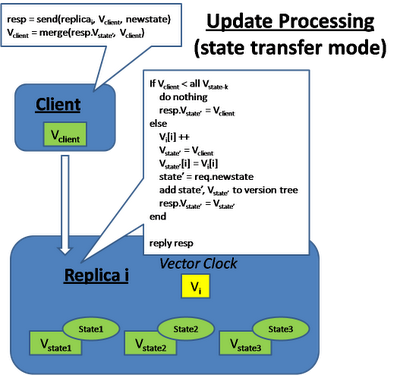
Replicas also gossip among each other in the background and try to merge their version tree together.
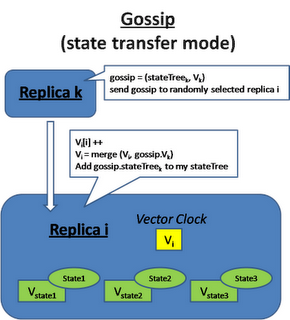
Gossip (Operation Transfer Model)
In an operation transfer approach, the sequence of applying the operations is very important. At the minimum causal order need to be maintained. Because of the ordering issue, each replica has to defer executing the operation until all the preceding operations has been executed. Therefore replicas save the operation request to a log file and exchange the log among each other and consolidate these operation logs to figure out the right sequence to apply the operations to their local store in an appropriate order.
"Causal order" means every replica will apply changes to the "causes" before apply changes to the "effect". "Total order" requires that every replica applies the operation in the same sequence.
In this model, each replica keeps a list of vector clock, Vi is the vector clock the replica itself and Vj is the vector clock when replica i receive replica j's gossip message. There is also a V-state that represent the vector clock of the last updated state.
When a query is submitted by the client, it will also send along its vector clock which reflect the client's view of the world. The replica will check if it has a view of the state that is later than the client's view.
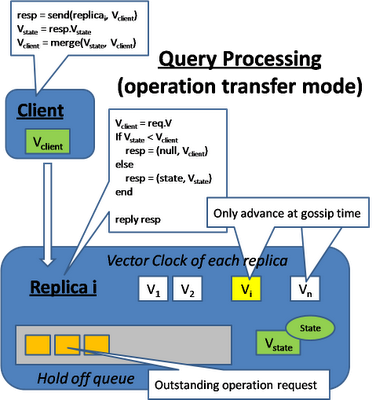
When an update operation is received, the replica will buffer the update operation until it can be applied to the local state. Every submitted operation will be tag with 2 timestamp, V-client indicates the client's view when he is making the update request. V-@receive is the replica's view when it receives the submission.
This update operation request will be sitting in the queue until the replica has received all the other updates that this one depends on. This condition is reflected in the vector clock Vi when it is larger than V-client
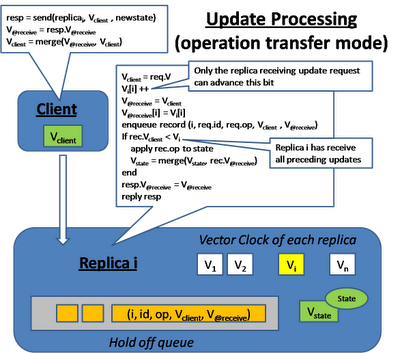
On the background, different replicas exchange their log for the queued updates and update each other's vector clock. After the log exchange, each replica will check whether certain operation can be applied (when all the dependent operation has been received) and apply them accordingly. Notice that it is possible that multiple operations are ready for applying at the same time, the replica will sort these operation in causal order (by using the Vector clock comparison) and apply them in the right order.
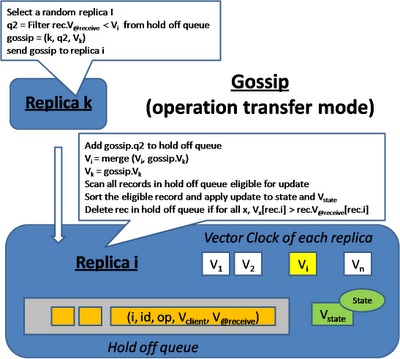
The concurrent update problem at different replica can also happen. Which means there can be multiple valid sequences of operation. In order for different replica to apply concurrent update in the same order, we need a total ordering mechanism.
One approach is whoever do the update first acquire a monotonic sequence number and late comers follow the sequence. On the other hand, if the operation itself is commutative, then the order to apply the operations doesn't matter
After applying the update, the update operation cannot be immediately removed from the queue because the update may not be fully exchange to every replica yet. We continuously check the Vector clock of each replicas after log exchange and after we confirm than everyone has receive this update, then we'll remove it from the queue.
Merkle tree
�����ݴ洢����״�ṹ��ÿ���ڵ��Hash���������ӽڵ��Hash��Hash��Ҷ�ӽڵ��Hash�������ݵ�Hash������һ��ij���ڵ㷢���仯����Hash�ı仯��Ѹ�ٴ��������ڵ㡣��Ҫͬ����ϵͳֻ��Ҫ���ϲ�ѯ���ڵ��hash��һ���б仯��˳����״�ṹ���ܹ���logN�����ʱ���ҵ������仯�����ݣ�����ͬ����
Paxos
paxos��һ�ִ���һ���Ե��ֶΣ���������Ϊ����ɡ�
�������ֶβ�ҪGoogle GFSʹ�õ�Chubby��Lock service���Ҳ���ϲ���������͵���ƾͲ��ѱ�ī�ˡ�
����
����ģԽ��Խ���ʱ��
һ��Master/slave
����Ƕ�������ݷ�����õķ�����һ��������ô˷������ɡ���˴��Ҳ�����ᵽ��premature optimization is the root of all evil����
�ŵ㣺����mysql replication����ʵ�֣������ȶ���
ȱ�㣺д�������ڵ�����ϣ�master����֮��slave����д������slave���ӳ�Ҳ�Ǹ������˵�С���⡣
����Multi-master
Multi-masterָһ��ϵͳ���ڶ��master, ÿ��master������read-write�����������ʱ�����ҵ�����ϲ��汾������ֲ�ʽ�汾����ϵͳgit���������multi-masterģʽ���߱�����һ���ԡ���汾�����Ŀ��Խ��Dynamo��vector clock�ȷ�����
�ŵ㣺����˵�����ϡ�
ȱ�㣺����ʵ��һ���ԣ��ϲ��汾�������ӡ�
����Two-phase commit(2PC)
Two-phase commit��һ���Ƚϼ�һ�����㷨������һ�����㷨ͨ������(��Paxos��The Part-Time Parliament����)�������������⣬����Ҳ�ٸ����������ӡ�
ij��Ҫ��֯һ��ͬѧ�ۻᣬǰ�����������в�����ͬ�������У�����һ�˾ܾ���ȡ������2PC�㷨��ִ�й�������
Phase 1
Prepare: ��֯��(coordinator)��绰�����в�����(participant) ��ͬʱ��֪�������б���
Proposal: �������2pm-5pm�ٰ���
Vote: participant��vote�����coordinator��accept or reject��
Block: ���accept, participant��ס����2pm-5pm��ʱ�䣬���ٽ�����������
Phase 2
Commit: ������в����߶�ͬ�⣬��֯��coodinator֪ͨ���в�����commit, ����֪ͨabort��participant���������
Failure ����ʧ���������
Participant failure:
��һ����������Ӧ��coordinatorֱ��ִ��abort
Coordinator failure:
Takeover: ���participantһ��ʱ��û�յ�cooridnatorȷ��(commit/abort)������Ϊcoordinator�����ˡ���ʱ����Զ���ΪCoordinator����(watchdog)
Query: watchdog����phase 1���յ�participant�б�����query
Vote: ����participant�ظ�vote�����watchdog, accept or reject
Commit: ������ж�ͬ�⣬��commit, ����abort��
�ŵ㣺ʵ�ּ�
ȱ�㣺���в�������Ҫ����(block)��throughput�ͣ����ݴ����ƣ�һ�ڵ�ʧ������������ʧ�ܡ�
�ġ�Three-phase commit (3PC)
Three-phase commit��һ��2PC�ĸĽ��档2PC��һЩ�����Ե�ȱ�㣬������coordinator����commit���߲���ʼ����commit֮��ij��participantͻȻcrash����ʱ��û��abort transaction, ��ʱ��Ⱥ��ʵ���Ͼʹ��ڲ�һ�µ������crash�ָ���Ľڵ�������ڵ������Dz�ͬ�ġ����3PC��2PC��commit�Ĺ���1��Ϊ2,�ֳ�preCommit��commit, ��ͼ��
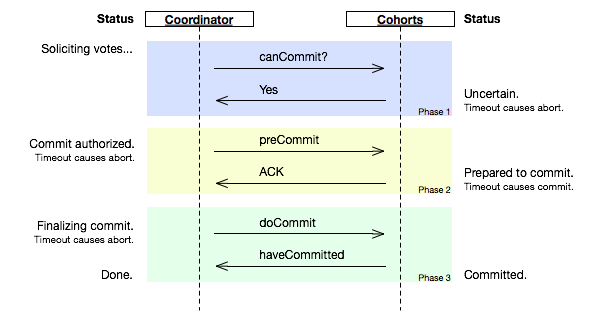
(ͼƬ��Դ��http://en.wikipedia.org/wiki/File:Three-phase_commit_diagram.png)
��ͼ������cohorts(participant)�յ�preCommit֮�����û�յ�commit, Ĭ��Ҳִ��commit, ��ͼ�ϵ�timeout cause commit��
���coodinator������һ��preCommit crash, watchdog�ӹ�֮��ͨ��query, �������һ�ڵ��յ�commit, ����ȫ���ڵ��յ�preCommit, ��ɼ���commit, ����abort��
�ŵ㣺��������������Ϻ�������һ�¡�
ȱ�㣺����������⣬����preCommit��Ϣ���ͺ�ͻȻ���������Ͽ�����ʱ��coodinator���ڻ�����abort, ����ʣ��replicas������commit��
Google Chubby������Mike Burrows˵���� ��there is only one consensus protocol, and that��s Paxos�� �C all other approaches are just broken versions of Paxos. �⼴������ֻ��һ��һ�����㷨���Ǿ���Paxos������������һ�����㷨����Paxos�㷨�IJ������档���2PC/3PC, Paxos�㷨�ĸĽ�
P1a. ÿ��Paxosʵ��ִ�ж�����һ����ţ������Ҫ������ÿ��replica�����ܱȵ�ǰ�����С���
P2. һ��һ�� value v ��replicaͨ������ô֮���κ������� value ������ v����û�а�ռͥ����(Byzantine)���⡣��������͵ı�����˵������һ��������һ��accept����2pm-5pm��proposal, �Ͳ��ܸı����⡣�Ժ�˭���ʶ���accept���value��
һ��proposalֻ��Ҫ������ͬ�⼴��ͨ������˱�2PC/3PC������һ��2f+1���ڵ�ļ�Ⱥ�У�������f���ڵ㲻���á�
����Paxos���кܶ�Լ����ϸ�ڣ��ر���Google��chubby�ӹ���ʵ�ֵĽǶȽ�Paxos��ϸ�ڲ���÷dz�������������α���Byzantine���⣬���ڽڵ�ij־ô洢���ܻᷢ�����ϣ�Byzantine����ᵼ��Paxos�㷨P2Լ��ʧЧ��
���ϼ��ַ�ʽԭ���Ƚ�����
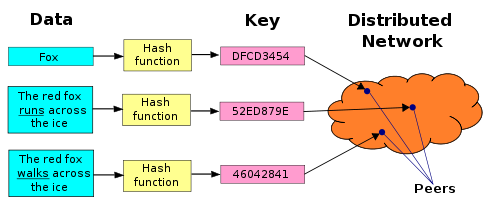
DHT
Distributed hash table
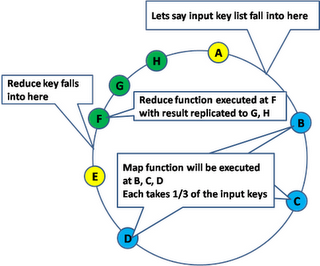
Map Reduce Execution
Map Reduce�Ѿ��ô���ˣ���������Ҫ��һ�¡�
���http://zh.wikipedia.org/wiki/MapReduce
Handling Deletes
������ִ��ɾ��������ʱ�����dz��������Է���ʧ����Ӧ�İ汾��Ϣ��
ͨ�����Ǹ�һ��Object��ע��"��ɾ��"�ı�ǩ�����㹻��ʱ��֮��������ȷ���汾һ�µ�����¿��Խ�������ɾ�����������Ŀռ䡣
�洢ʵ��
One strategy is to use make the storage implementation pluggable. e.g. A local MySQL DB, Berkeley DB, Filesystem or even a in memory Hashtable can be used as a storage mechanism.
Another strategy is to implement the storage in a highly scalable way. Here are some techniques that I learn from CouchDB and Google BigTable.
CouchDB has a MVCC model that uses a copy-on-modified approach. Any update will cause a private copy being made which in turn cause the index also need to be modified and causing the a private copy of the index as well, all the way up to the root pointer.
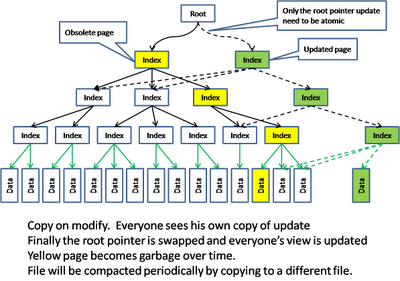
Notice that the update happens in an append-only mode where the modified data is appended to the file and the old data becomes garbage. Periodic garbage collection is done to compact the data. Here is how the model is implemented in memory and disks
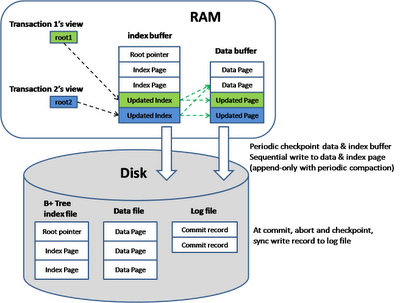
In Google BigTable model, the data is broken down into multiple generations and the memory is use to hold the newest generation. Any query will search the mem data as well as all the data sets on disks and merge all the return results. Fast detection of whether a generation contains a key can be done by checking a bloom filter.
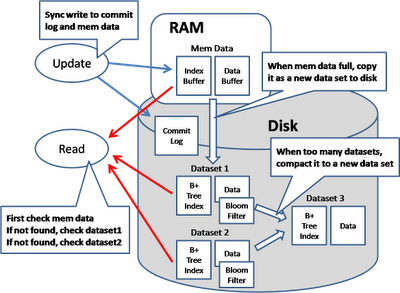
When update happens, both the mem data and the commit log will be written so that if the
�ڵ�仯
Notice that virtual nodes can join and leave the network at any time without impacting the operation of the ring.
When a new node joins the network
- �¼���Ľڵ������Լ��Ĵ���(�㲥���������ֶ�)
- �����ھӽڵ�Ҫ����Key�ķ�����ƹ�ϵ���������ͨ����ͬ����
- ����¼���Ľڵ��첽�Ŀ�������
- ����ڵ�仯�IJ����������������ڵ�
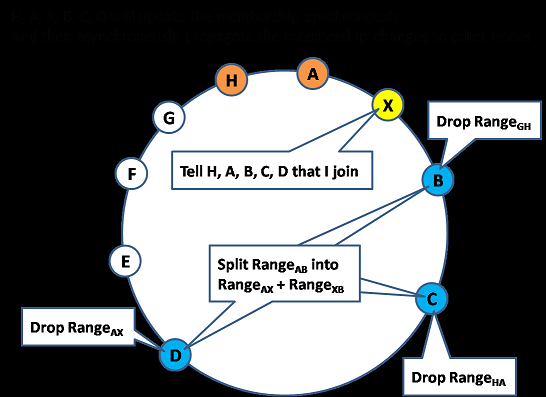
Notice that other nodes may not have their membership view updated yet so they may still forward the request to the old nodes. But since these old nodes (which is the neighbor of the new joined node) has been updated (in step 2), so they will forward the request to the new joined node.
On the other hand, the new joined node may still in the process of downloading the data and not ready to serve yet. We use the vector clock (described below) to determine whether the new joined node is ready to serve the request and if not, the client can contact another replica.
When an existing node leaves the network (e.g. crash)
The crashed node no longer respond to gossip message so its neighbors knows about it.�����Ľڵ㲻�ٷ���Gossip Message�Ļ�Ӧ�����������ھӶ�֪��������
The neighbor will update the membership changes and copy data asynchronously�������ھӴ������£������Ļ�ָ����˸ɣ�ͬʱ�����ڵ��ϵ��
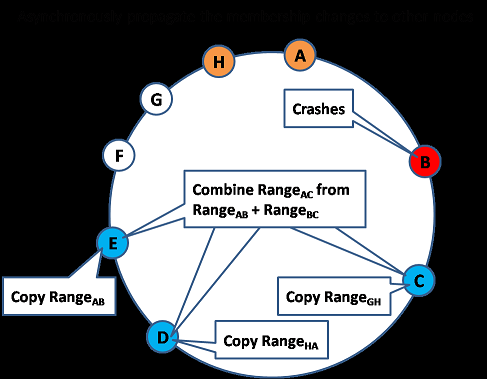
We haven't talked about how the virtual nodes is mapped into the physical nodes. Many schemes are possible with the main goal that Virtual Node replicas should not be sitting on the same physical node. One simple scheme is to assigned Virtual node to Physical node in a random manner but check to make sure that a physical node doesn't contain replicas of the same key ranges.
Notice that since machine crashes happen at the physical node level, which has many virtual nodes runs on it. So when a single Physical node crashes, the workload (of its multiple virtual node) is scattered across many physical machines. Therefore the increased workload due to physical node crashes is evenly balanced.
�д�
����
���ݿ����С��еĶ�ά������ʽ�洢���ݣ�����ȴ��һά�ַ����ķ�ʽ�洢���������µ�һ������

����ı�����Ա������(EmpId), �����ֶ�(Lastname and Firstname)������(Salary).
������洢�ڵ��Ե��ڴ�(RAM)�ʹ洢(Ӳ��)�С���Ȼ�ڴ��Ӳ���ڻ����ϲ�ͬ�����ԵIJ���ϵͳ����ͬ���ķ�ʽ�洢�ġ����ݿ����������ά���洢��һϵ��һά�ġ��ֽڡ��У��ֲ���ϵͳд���ڴ��Ӳ���С�
��ʽ���ݿ��һ���е�����ֵ����һ��洢������Ȼ���ٴ洢��һ�е����ݣ��Դ����ơ� 1,Smith,Joe,40000;2,Jones,Mary,50000;3,Johnson,Cathy,44000;
��ʽ���ݿ��һ���е�����ֵ����һ��洢������Ȼ���ٴ洢��һ�е����ݣ��Դ����ơ� 1,2,3;Smith,Jones,Johnson;Joe,Mary,Cathy;40000,50000,44000;
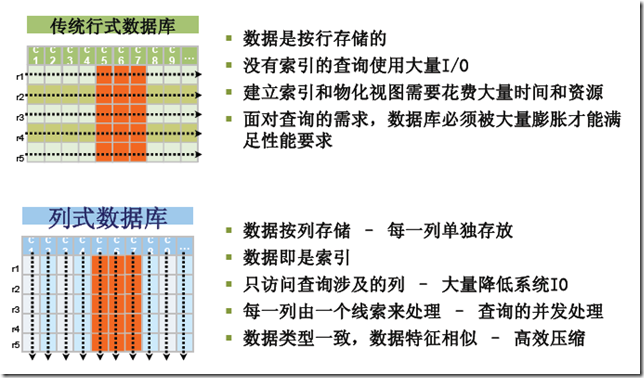
�ص�
- ���õ�ѹ���ȡ����ڴ�������ݿ���ƶ������࣬���һ����ѹ���ȷdz��ߣ���40��M�����ݵ���infobright��û�뵽�����ļ�ֻ��1M��
- ���ϵļ���dz��Ŀ졣
- ����MapReduce��Key-valueģ�͵��ں�
- ��ȡ���е����ݽ��������������ݽϿ�
������Դ��
����ƪ
�����ݿ�
�ҷ������¸�����dzƲ������ݿ��һЩ���ݿ������������ָ���档
MemCached
Memcached��danga.com����ӪLiveJournal�ļ����Ŷӣ�������һ�ֲ�ʽ�ڴ����ϵͳ�������ڶ�̬ϵͳ�м������ݿ� ���أ��������ܡ�
�ص�
- ���
- ����libevent���¼�����
- �����ڴ�洢��ʽ
- memcached������ͨ�ŵķֲ�ʽ
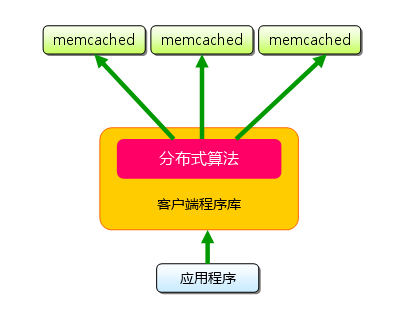
Memcached������ԭ����ÿһ����key��value���ԣ����¼��kv�ԣ���key��ͨ��һ��hash�㷨ת����hash-key�����ڲ��ҡ��Ա��Լ����������ܵ�ɢ�С�ͬʱ��memcached�õ���һ������ɢ�У�ͨ��һ�Ŵ�hash����ά����
Memcached���������������ɣ�����ˣ�ms���Ϳͻ��ˣ�mc������һ��memcached�IJ�ѯ�У�mc��ͨ������key��hashֵ�� ȷ��kv�������ڵ�msλ�á���msȷ���ͻ��˾ͻᷢ��һ����ѯ�������Ӧ��ms������������ȷ�е����ݡ���Ϊ��֮��û�н����Լ��ಥЭ�飬���� memcached�������������Ӱ������С���ġ�
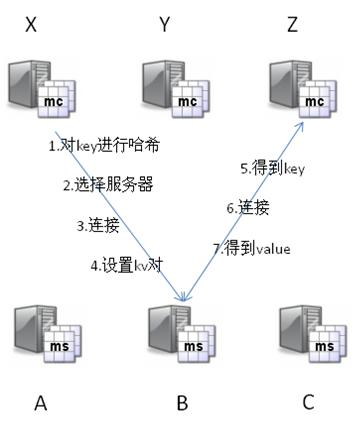
�ڴ����
Ĭ������£�ms����һ�����õĽС����������������������ڴ�ġ�����c++����malloc/free���ڴ���䣬�����ÿ����������ҪĿ�� ��Ϊ�˱����ڴ���Ƭ���������ϵͳҪ���Ѹ���ʱ����������Щ�����������ڴ�飨ʵ�����ǶϿ��ģ������˿��������ms�������Ķ��ڴ���д��ķ��䣬�� �������á���Ȼ���ڿ�Ĵ�С������ͬ�������ݴ�С�Ϳ��С��̫���������£������п��ܵ����ڴ���˷ѡ�
ͬʱ��ms��key��data������Ӧ�����ƣ�key�ij��Ȳ��ܳ���250�ֽڣ�dataҲ���ܳ������С������ --- 1MB��
��Ϊmc��ʹ�õ�hash�㷨�������ῼ�ǵ�ÿ��ms���ڴ��С��������mc���������ϵ�����kv�Ը�ÿ��ms���������ÿ��ms���ڴ涼��̫һ������ ���ܻᵼ���ڴ�ʹ���ʵĽ��͡�����һ������Ľ�������ǣ�����ÿ��ms���ڴ��С���ҳ����ǵ����Լ����Ȼ����ÿ��ms�Ͽ�n������=���Լ���� instance�������͵���ӵ���˶��������Сһ������ms���Ӷ��ṩ������ڴ�ʹ���ʡ�
�������
��ms��hash������֮���µIJ������ݻ�����ϵ����ݣ����µIJ�����LRU���������ʹ�ã����Լ�ÿ��kv�Ե���Чʱ�ޡ�Kv�Դ洢��Чʱ������mc����app���ò���Ϊ��������ms�ġ�
ͬʱms������͵���������ms���Ὺ����Ľ�����ʵʱ����ʱ��kv�Բ�ɾ�������ǵ��ҽ���������һ����������ݣ�����ʱ��û�ж���Ŀռ���ˣ��Ż�������������
�������ݿ��ѯ
����memcached�����е�һ��ʹ�÷�ʽ�ǻ������ݿ��ѯ�������һ��������˵����
App��Ҫ�õ�userid=xxx���û���Ϣ����Ӧ�IJ�ѯ������ƣ�
��SELECT * FROM users WHERE userid = xxx��
App��ȥ��cache����û�С�user:userid����key�����Ԥ�ȶ���Լ���ã������ݣ�����У��������ݣ����û�У�App������ݿ��ж�ȡ���ݣ�������cache��add�����������ݼ���cache�С�
��ȡ��������Ҫ���£�app�����cache��update���������������ݿ���cache������ͬ����
���������������Ҳ���Է��֣�һ�����ݿ�����ݷ��ֱ仯������һ��Ҫ��ʱ����cache�е����ݣ�����֤app��������ͬ������ȷ���ݡ���Ȼ���ǿ� ��ͨ����ʱ����ʽ��¼��cache�����ݵ�ʧЧʱ�䣬ʱ��һ���ͻἤ���¼���cache���и��£�����֮���ܻ���ʱ���ϵ��ӳ٣�����app���ܴ� cache���������ݣ���Ҳ����Ϊ�������⡣���Ժ��һ�ר�������о�������⣩
�������������Ԥ��
����ƽǶ��ϣ�memcached��û����������ڵģ�����������һ�����ģ�ĸ�����cache�㣬���������������ܴ�����ֻ����Ƶĸ����Ժ����ϵͳ�Ŀ�֧��
��һ��ms�϶�ʧ������֮��app���ǿ��Դ����ݿ���ȡ�����ݡ���������������������ijЩms������������ʱ���ṩ�����ms��֧��cache�������Ͳ�����Ϊapp��cache��ȡ�������ݶ�һ���Ӹ����ݿ��������ĸ��ء�
ͬʱΪ�˼���ij̨ms������������Ӱ�죬����ʹ�á��ȱ��ݡ�������������һ̨�µ�ms��ȡ���������ms����Ȼ�µ�ms����Ҫ��ԭ��ms��IP��ַ��������������װ��һ�顣
����һ�ַ�ʽ�����������ms�Ľڵ�����Ȼ��mc��ʵʱ���ÿ���ڵ��״̬���������ij���ڵ㳤ʱ��û����Ӧ���ͻ��mc�Ŀ���server�б��� ɾ��������server�ڵ��������hash��λ����Ȼ����Ҳ����ɵ������ǣ�ԭ��key�洢��B�ϣ���ɴ洢��C���ˡ����Դ˷�������Ҳ�������㣬��� �ܺ͡��ȱ��ݡ��������ʹ�ã��Ϳ���ʹ������ɵ�Ӱ����С����
Memcached�ͻ��ˣ�mc��
Memcached�ͻ����и������Եİ汾�����ʹ�ã�����java��c��php��.net�ȵȣ�����ɲμ�memcached api page [2]��
��ҿ��Ը����Լ���Ŀ����Ҫ��ѡ����ʵĿͻ��������ɡ�
����ʽ��WebӦ�ó���ܹ�
���˻����֧�֣����ǿ����ڴ�ͳ��app���db��֮�����cache�㣬ÿ��app������������һ��mc��ÿ�����ݵĶ�ȡ�����Դ�ms��ȡ�ã���� û�У��ٴ�db���ȡ����������Ҫ���и���ʱ������Ҫ����update��sql��db�㣬ͬʱҲҪ�����µ����ݷ���mc����mcȥ����ms�е����ݡ�
���ܲ���
Memcached д�ٶ�
ƽ���ٶ�: 16222 ��/��
����ٶ� 18799 ��/��
Memcached ���ٶ�
ƽ���ٶ�: 20971 ��/��
����ٶ� 22497 ��/��
Memcachedb д�ٶ�
ƽ���ٶ�: 8958 ��/��
����ٶ� 10480 ��/��
Memcachedb ���ٶ�
ƽ���ٶ�: 6871 ��/��
����ٶ� 12542 ��/��
Դ���뼶��ķ���
�dz��õ���������
dbcached
- dbcached ��һ����� Memcached �� NMDB �ķֲ�ʽ key-value ���ݿ��ڴ滺��ϵͳ��
- dbcached = Memcached + �־û��洢������ + NMDB �ͻ��˽ӿ�
- Memcached ��һ������ܵģ��ֲ�ʽ���ڴ����ϵͳ�������ڶ�̬Ӧ���м������ݿ⸺�أ����������ٶȡ�
- NMDB ��һ���Э���������ݿ�(dbm��)�������������ڴ滺��ʹ��̴洢�����ֹ��ɣ�ʹ�� QDBM �� Berkeley DB ��Ϊ������ݿ⡣
- QDBM ��һ���������ݿ�����̿⣬������ GDBM Ϊ����������������������ߵĴ����ٶȣ���С�����ݿ��ļ���С������API��QDBM ��д�ٶȱ� Berkeley DB Ҫ�죬��ϸ�ٶȱȽϼ���Report of Benchmark Test����
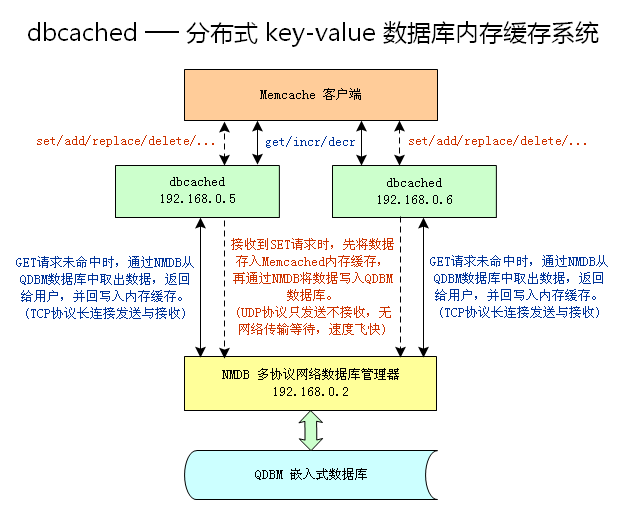
Memcached �� dbcached �ڹ�����һ����?
- ���ݣ�Memcached �����ģ�dbcached ������������֮�⣬dbcached ������Memcached���־û��洢��������NMDB �ͻ��˽ӿڡ���һ�������н�����������κ�ԭ�� Memcached �ͻ���������dbcached �Ծ��Ǹ� Memcached �ڴ����ϵͳ�����ǣ��������ݿ��Գ־ô洢�������������������ϵ� QDBM �� Berkeley DB ���ݿ��С�
- ���ܣ�ǰ�� dbcached �IJ������������� Memcached ��ͬ����� NMDB �� Memcached һ����������libevent ��������IO������ӵ���Լ����ڴ滺����ƣ����ܲ������¡�
- д�룺����dbcached �� Memcached ���֡����յ�һ�� set(add/replace/...) ������ key-value ���ݵ��ڴ��к�dbcached �־û��洢���������ܹ��� key-value ����ͨ����NMDB �ͻ��˽ӿڡ����浽 QDBM �� Berkeley DB ���ݿ��С�
- �ٶȣ�������ϡ�-z������������ UDP Э�顰ֻ���Ͳ����ա�ģʽ�� set(add/replace/...) ����д������ݴ��ݸ� NMDB �������ˣ��� Memcache �ͻ���д�ٶȵ�Ӱ�켸�����Ժ��Բ��ơ���ǧ��������ͬһ�������·�����֮��� UDP ���䶪���������������е�����£���ȡ���ݵ��ٶȸ���ͨ�� Memcached ����ٶ�һ���졣
- ��ȡ������dbcached �� Memcached ���֡����յ�һ�� get(incr/decr/...) ����������dbcached �� Memcached ���֡���ѯ�������ڴ滺��δ���У���dbcached �־û��洢����������ͨ����NMDB �ͻ��˽ӿڡ��� QDBM �� Berkeley DB ���ݿ���ȡ�����ݣ����ظ��û���Ȼ�浽 Memcached �ڴ��С�������û��ٴ�������� key�����ֱ�Ӵ� Memcached �ڴ��з��� Value ֵ��
- �־ã�ʹ�� dbcached�����õ��� Memcached �������������������������ݶ�ʧ��
- �����ʹ�� dbcached����ʹ��Ϊ����ת�ƣ����ӡ����� Memcached �������ڵ���ƻ��ˡ�key ��Ϣ�����Ӧ��Memcached ����������ӳ���ϵҲ���¡�
- �ֲ���dbcached �� NMDB �ȿ���װ��ͬһ̨�������ϣ�Ҳ����װ�ڲ�ͬ�ķ������ϣ���̨ dbcached ���������Զ�Ӧһ̨ NMDB ��������
- �س���dbcached ���ڡ��������ڡ�д����Ӧ���������á�
- ��������dbcached �Ĺ���ת��֧�֡���Ʒ����Լ��� Memcachedb �IJ�֮ͬ����
�д�ϵ��
Hadoop֮Hbase
Hadoop / HBase: API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3]
Ү³��ѧ֮HadoopDB
GreenPlum
FaceBook֮Cassandra
Cassandra: API: many Thrift ? languages, Protocol: ?, Query Method: MapReduce, Replicaton: , Written in: Java, Concurrency: eventually consistent , Misc: like "Big-Table on Amazon Dynamo alike", initiated by Facebook, Slides ? , Clients ?
Cassandra��facebook��Դ������һ���汾��������Ϊ��BigTable��һ����Դ�汾��Ŀǰtwitter��digg.com��ʹ�á�
Cassandra�ص�
- ����schema������Ҫ�����ݿ�һ��Ԥ�����schema�����ӻ���ɾ���ֶηdz����㣨on the fly����
- ֧��range��ѯ�����Զ�Key���з�Χ��ѯ��
- �߿��ã�����չ��������ϲ�Ӱ�켯Ⱥ����������չ��
Cassandra����Ҫ�ص����������һ�����ݿ⣬������һ�����ݿ�ڵ㹲ͬ���ɵ�һ���ֲ�ʽ�������Cassandra��һ��д�������� �����Ƶ������ڵ���ȥ����Cassandra�Ķ�������Ҳ�ᱻ·�ɵ�ij���ڵ�����ȥ��ȡ������һ��CassandraȺ����˵����չ�����DZȽϼ��� �飬ֻ����Ⱥ���������ӽڵ�Ϳ����ˡ��ҿ���������˵Facebook��CassandraȺ���г���100̨���������ɵ����ݿ�Ⱥ����
CassandraҲ֧�ֱȽϷḻ�����ݽṹ����ǿ��IJ�ѯ���ԣ���MongoDB�Ƚ����ƣ���ѯ���ܱ�MongoDB����һЩ��twitter��ƽ̨�ܹ������쵼Evan Weaverд��һƪ���½���Cassandra��http://blog.evanweaver.com/articles/2009/07/06/up-and-running-with-cassandra/���зdz���ϸ�Ľ��ܡ�
Cassandra�Ե����ڵ�����������ڵ�IJ�����д���ܲ����ر�ã�������˵��������Cassandraÿ���Լ����1��ζ�д������Ҳ�� ��һЩ���������������ɵ����ۣ���������Cassandra�����ڵ��������û������ģ���ʵ�ķֲ�ʽ���ݿ����ϵͳ��Ȼ��n����ڵ㹹�ɵ�ϵͳ���䲢 ������ȡ��������ϵͳ�Ľڵ�������·��Ч�ʣ����������ǵ��ڵ�IJ�������������
Keyspace
Cassandra�е������֯��Ԫ�����������һϵ��Column family��Keyspaceһ����Ӧ�ó�������ơ������������ΪOracle�����һ��schema��������һϵ�еĶ���
Column family��CF��
CF��ij���ض�Key�����ݼ��ϣ�ÿ��CF�����ϱ�����ڵ������ļ��С��Ӹ����Ͽ���CF�е������ݿ��е�Table.
Key
���ݱ���ͨ��Key�����ʣ�Cassandra������Χ��ѯ�����磺start => '10050', :finish => '10070'
Column
��Cassandra���ֶ�����С�����ݵ�Ԫ��column��value����һ���ԣ����磺name:��jacky����column��name��value��jacky��ÿ��column:value����һ��ʱ�����timestamp��
�����ݿⲻͬ���ǣ�Cassandra��һ���п�����������column������ÿ�е�column�����Dz�ͬ�ġ������ݿ���ƵĽǶȣ���������� Ϊ�����������ֶΣ���һ����Key���ڶ����dz��ı����ͣ�������źܶ��column����Ҳ��Ϊʲô˵Cassandra�߱��dz����schema��ԭ ��
Super column
Super column��һ�������column��������Դ����������ͨ��column������һ��CF��ͬ��������������Super column��һ��CFֻ�ܶ���ʹ��Column����Super column�����ܻ��á�������Super column��һ�����ӣ�homeAddress���Super column�������ֶΣ��ֱ���street��city��zip�� homeAddress: {street: "binjiang road",city: "hangzhou",zip: "310052",}
Sorting
��ͬ�����ݿ����ͨ��Order by�����������Cassandraȡ��������˳��������һ���ģ����ݱ���ʱ�Ѿ����ն���Ĺ����ţ�����ȡ������˳���Ѿ�ȷ���ˣ�����һ������������ơ�����˼���ǣ�Cassandra����column name������column value������������ ���������¼���ѡ�BytesType, UTF8Type, LexicalUUIDType, TimeUUIDType, AsciiType, ��LongType������������ΰ���column name������ʵ���ϣ����ǰ�column nameʶ���Ϊ��ͬ�����ͣ��Դ����ﵽ��������Ŀ�ġ�UTF8Type�ǰ�column nameת��ΪUTF8��������������LongTypeת����Ϊ64λlong�ͣ�TimeUUIDType�ǰ��ջ���ʱ���UUID���������磺
Column name����LongType����
{name: 3, value: "jacky"},
{name: 123, value: "hellodba"},
{name: 976, value: "Cassandra"},
{name: 832416, value: "bigtable"}
Column name����UTF8Type����
{name: 123, value: "hellodba"},
{name: 3, value: "jacky"},
{name: 832416, value: "bigtable"}
{name: 976, value: "Cassandra"}
�������ǿ�twitter��Schema��
<Keyspace Name="Twitter">
<ColumnFamily CompareWith="UTF8Type" Name="Statuses" />
<ColumnFamily CompareWith="UTF8Type" Name="StatusAudits" />
<ColumnFamily CompareWith="UTF8Type" Name="StatusRelationships"
CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" />
<ColumnFamily CompareWith="UTF8Type" Name="Users" />
<ColumnFamily CompareWith="UTF8Type" Name="UserRelationships"
CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" />
</Keyspace>
���ǿ���һ����Twitter��keyspace���������ɸ�CF������StatusRelationships�� UserRelationships������Ϊ����Super column��CF��CompareWith������column���������CompareSubcolumnsWith������subcolumn������ ��������ʹ�������֣�TimeUUIDType��UTF8Type������û�п����κ��й�column�Ķ��壬����ζ��column�ǿ���������ġ�
Ϊ�˷��������⣬�һ᳢�����ù�ϵ�����ݿ�Ľ�ģ����ȥ����Twitter��Schema����ǧ��Ҫ����Ϊ�����Cassandra������ģ�ͣ�����Cassandra��˵��ÿһ�е�colunn������������ģ������������ݿ�һ����Ҫ�ڽ���ʱ�ʹ����á�
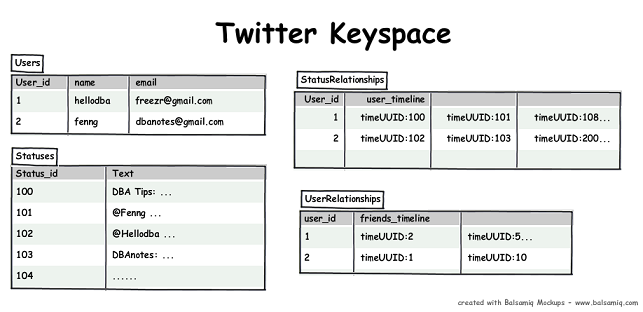
Users CF��¼�û�����Ϣ��Statuses CF��¼tweets�����ݣ�StatusRelationships CF��¼�û�������tweets��UserRelationships CF��¼�û�������followers������ע�����ʽ��TimeUUIDType����������ǰ���ʱ����������UUID�ֶΣ�column name����UUID�����������������������һ��UUID�����UUID��ӳ�˵�ǰ��ʱ�䣬���Ը������UUID�������е�������timestamp һ���������Եõ�����ǰ���ʱ��������ġ�ʹ�ù�twitter���˶�֪���������ǿ��Կ����Լ����µ�tweets�������µ�friends.
�洢
Cassandra�ǻ����д洢��(BigtableҲ��һ��)������ͻ����е����ݿ���һ��������

API
���������ݿ⣬Bigtable��Cassandra API�ĶԱȣ� Relational SELECT `column` FROM `database`.`table` WHERE `id` = key;
BigTable table.get(key, "column_family:column")
Cassandra: standard model keyspace.get("column_family", key, "column")
Cassandra: super column model keyspace.get("column_family", key, "super_column", "column")
�Ҷ�Cassandra����ģ�͵����⣺
1.column name���������ֵ����value�ǿա���ΪCassandra�ǰ���column name�������ǰ��д洢�ģ�������������column name���������ֵ����value�������ǿա����磺��jacky��:��null������fenng��:��null��
2.Super column���Կ�����һ���������е����ϵ�����ݿ��е����������super column����ʵ�ֿ��ٶ�λ����Ϊ�����Է���һ��column���������ź���ġ�
3.�����ڶ���ʱ��ȷ���ˣ�ȡ�������ݿ϶��ǰ���ȷ����˳�����еģ�����һ������������ơ�
4. �dz�����schema��column�������塣ʵ���ϣ�colume name�ںܶ�����£�����value���Dz����е��ƣ���
5.ÿ��column�����timestamp���Ҳ�û���ҵ���ȷ��˵�����Ҳ²���������ݶ�汾�������ǵײ���������ʱ��Ҫ����Ϣ��
���˵˵�ܹ�������Ϊ�ܹ��ĺ��ľ�������ȡ�ᣬ������CAP����BASE�����Ķ������ԭ�ܹ�֮������û���κ�һ�ּܹ����������Ľ���������⣬���ݿ��NoSQL������Ӧ�ó���������Ҫ���ľ���Ϊ�Լ��ҵ����ʵļܹ���
Hypertable
Hypertable: (can you help?) Open-Source Google BigTable alike.
�����������湫˾Zvents����Google��9λ�о���Ա��2006�귢����һƪ���ġ�Bigtable���ṹ�����ݵķֲ��洢ϵͳ�� ������һ�Դ�ֲ�ʽ���ݴ���ϵͳ��Hypertable�ǰ���1000�ڵ������ƣ��� C++д���ɼ��� HDFS �� KFS �ϡ����ܻ��ڳ��ڽΣ������в�����Ч�ܣ�д�� 28M �е����ϣ����ڵ�д�����ʿɴ�7MB/s����ȡ���ʿɴ� 1M cells/s��HypertableĿǰһֱû��̫��߸��غʹ�洢��Ӧ��ʵ�������������Hypertable��Ŀ�õ��˰ٶȵ�����֧�֣���������и��õķ�չ��
Google֮BigTable
�о�Google�IJ�Ʒ���Ǹм�Google�����Լ���ô��㣬����ϲ��֮��

Google AppEngine Datastore ����BigTable֮�Ͻ�������ģ���Google���ڲ��洢ϵͳ�����ڴ����ṹ�����ݡ�AppEngine Datastore�����������ڲ�������ֱ�ӷ���BigTable��ʵ�ֻ��ƣ��ɱ���ΪBigTable֮�ϵ�һ���ӿڡ�
AppEngine Datastore��֧�ֵ���Ŀ����������Ҫ��SimpleDB�ḻ�ö࣬Ҳ�����˰�����һ����Ŀ�ڵ����ݼ��ϵ��б��͡�
����������Google AppEngine֮�ڽ���Ӧ�õĻ����������Կ϶�Ҫ�õ�������ݴ洢��Ȼ��������SimpleDB��ʹ�ùȸ��������ƽ̨֮���Ӧ�ã��㲢���ܲ�������AppEngine Datastore���нӿ� (��ͨ��BigTable)��
Yahoo֮PNUTS
Yahoo!��PNUTS��һ���ֲ�ʽ�����ݴ洢ƽ̨������Yahoo!�Ƽ���ƽ̨��Ҫ��һ���֡������ϲ��Ʒͨ��Ҳ��ΪSherpa�����չٷ��� ��������PNUTS, a massively parallel and geographically distributed database system for Yahoo!��s web applications.�� PNUTS��Ȼ������CAP֮�������ǵ���webӦ�ö�һ���Բ���Ҫ��dz��ϸ�������Ϸ����˶�ǿһ���Ե������������ߵ� availability���ݴ��������ٵ���Ӧ��������ȡ�
�ص�
- �����ֲ�ʽ���ֲ���ȫ�����������ġ����ڴ�WebӦ�ö�����Ӧʱ��Ҫ��ߣ������÷��������������û�����ı��ػ�����
- ����չ����¼����֧�ִӼ��������������������������Ӳ���Ӱ�����ܡ�
- schema-free�����ǹ̶����ṹ��ʵ��ʹ��key/value�洢�ģ�һ����¼�Ķ���ֶ�ʵ������json��ʽ�ϲ�����value�С����delete��update����ָ��primary key����Ҳ֧��������ѯ��
- �߿����Լ��ݴ����ӵ����洢�ڵ㵽�����������IJ����ö�����Ӱ��ǰ��Web���ʡ�
- �ʺϴ����С�͵ļ�¼�����ʺϴ洢���ļ�����ý��ȡ�
- ��һ���Ա�֤��
PNUTSʵ��
Record-level mastering ��¼�������ڵ�
ÿһ����¼����һ������¼������һ��ӡ�ȵ��û�����ļ�¼master��ӡ�Ȼ�����ͨ���Ķ������ӡ�ȡ������ط��������û�������û������ϵ��� ���������������ĵ����ϣ��п���ȡ�����Ǿɰ�����ݡ���master����Ҳ�ɶԼ�¼�����ģ�����Ҫmaster��ͳһ������ÿ�����ݶ����Լ��İ汾�� �ƣ�����ͼ��ʾ��

PNUTS�Ľṹ
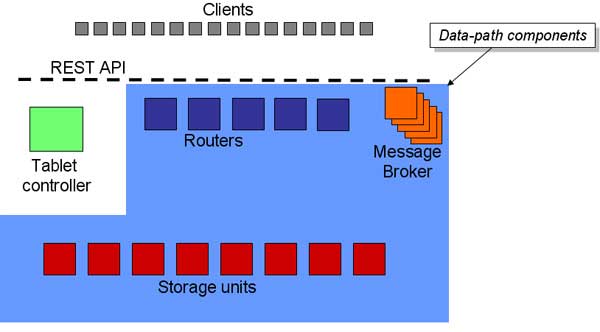
ÿ���������ĵ�PNUTS�ṹ���IJ��ֹ���
Storage Units (SU) �洢��Ԫ
�����Ĵ洢��������ÿ���洢���������溬�ж��tablets��tablets��PNUTS�ϵĻ����洢��Ԫ��һ ��tablets��һ��yahoo�ڲ���ʽ��hash table���ļ�(hash table)����һ��MySQL innodb��(ordered table)��һ��Tabletͨ��Ϊ����M��һ��SU��ͨ������ڼ��ٸ�tablets��
Routers
ÿ��tablets���ĸ�SU����ͨ����ѯrouter��á�һ������������routerͨ��������̨˫�����ݵĵ�Ԫ�ṩ��
Tablet Controller
router��λ��ֻ�Ǹ��ڴ���գ�ʵ�ʵ�λ����Tablet Controller��Ԫ������
Message Broker
��Զ�����ݵ�ͬ������YMB�ṩ������һ��pub/sub���첽��Ϣ����ϵͳ��
TabletsѰַ���з�
�洢��hash��ordered data store��
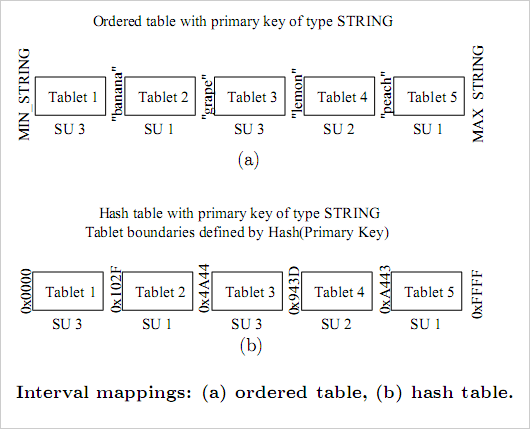
��hashΪ�����ܣ��ȶ����е�tablets��hashֵ��Ƭ������1-10,000����tablets 1, 10,000��20,000����tablets 2���������Ʒ��������е�hash��Χ��һ�����͵�IDCͨ�������100�����µ�tablets, 1,000̨���ҵ�SU��tablets�����ĸ�SU��routersȫ�����ص��ڴ����棬���router�����ٶȼ��죬ͨ�������Ϊƿ�������չٷ��� ˵����ϵͳ��ƿ��ֻ���ڴ����ļ�hash file�����ϡ�
��ij��SU������������ɽ�SU�в���tablets�Ƶ���Կ��е�SU������tablet controller��ƫ�Ƽ�¼��router��λtabletʧЧ֮����Զ�ͨ��tablet controller���¼��ص��ڴ档�����з�Ҳ�������ʵ�֡�
TimҲ������MySQLʵ�ֹ����ƴ��ģ�洢��ϵͳ����ʱ�������ǰ�ÿ����¼��key�����ĸ�SU����Ϣ���浽 һ���ֵ����棬�ô����зֿ��Ի�ø��������ԣ����Զ�̬�����µ�tablets,������Ҫ�з־ɵ�tablets����ȱ������ֵ�û����router�� �������Ը�Ч��ȫ�����ص��ڴ��С����ԱȽ϶��ԣ���ʵ�ʵ�Ӧ���У����η�Ƭ��������Ѿ��㹻ʹ�á�
Write����ʾ��ͼ
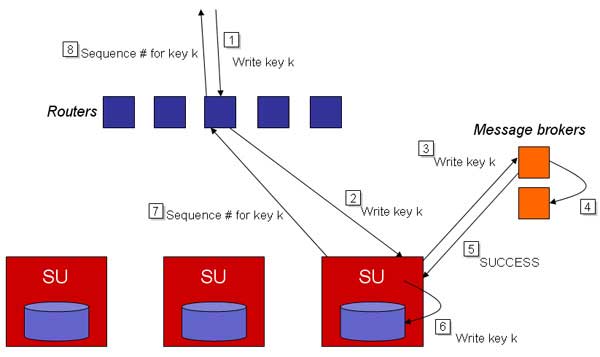
PNUTS����
2006��Greg Linden��˵I want a big, virtual database
What I want is a robust, high performance virtual relational database that runs transparently over a cluster, nodes dropping in an out of service at will, read-write replication and data migration all done automatically.
I want to be able to install a database on a server cloud and use it like it was all running on one machine.
��ϸ���ϣ�
http://timyang.net/architecture/yahoo-pnuts/
��֮SQL���ݷ���
SQL���ݷ��� ���� Azure �� �����ƽ̨��һ���֡���SDS����Ҳ�Ǵ��ڲ��ԽΣ����Ҳ����ѵģ��������ݿ��С�����ơ� SQL���ݷ���������ʵ������һ�������SQL������֮�ϵ�Ӧ�ã���ЩSQL�����������SDSƽ̨�ײ�����ݴ洢���㲻��Ҫ���ʵ����ǣ���Ȼ�ײ���� �ݿ�����ǹ�ϵʽ�ģ�SDS��һ����/ֵ�Ͳִ��������������������۹�������ƽ̨һ����
����������ͬ��ǰ������Ӧ�̣���Ϊ��Ȼ��/ֵ�洢���ڿ�����???�Էdz����������RDBMS�������ݹ�����ȴ�����ѡ����ķ����ƺ�����ľ���֣���ʵ�ֿ����Ժͷֲ����Ƶ�ͬʱ������ʱ������ƣ������������ԣ��ڼ�/ֵ�洢��ϵ���ݿ�ƽ̨�ĺ蹵֮�����һ��������
���Ʒ�������
����֮�⣬Ҳ��һЩ���Զ�����װ�ļ�/ֵ���ݿ�������Ʒ���ֶ��������ᣬ����alpha�����beta�棬�����ǿ�Դ�ģ�ͨ���������Ĵ��룬�����ڷǿ�Դ��Ӧ�������Ҳ��������ʶ��DZ�ڵ���������ơ�
�ĵ��洢
CouchDB
CouchDB: API: JSON, Protocol: REST, Query Method: MapReduceR of JavaScript Funcs, Replication: Master Master, Written in: Erlang, Concurrency: MVCC, Misc:
Links: 3 CouchDB books ?, Couch Lounge ? (partitioning / clusering), ...
����Apache�������� Erlang/OTP �����ĸ����ܡ��ֲ�ʽ�ݴ��ǹ�ϵ�����ݿ�ϵͳ��NRDBMS������������� Erlang �������ṩ�ĸ߲������ֲ�ʽ�ݴ�����ƽ̨�����Ҳο� Lotus Notes ���ݿ�ʵ�֣����ü��ĵ��������ͣ�document-oriented���������ڲ����ĵ����ݾ��� JSON ��ʽ�洢�����⣬��ͨ������ HTTP �� REST Э��ʵ�ֽӿڣ�������ʮ�������Խ������ɲ�����
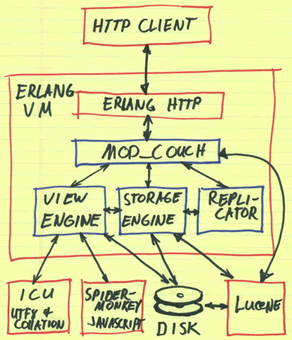
CouchDBһ�ְ�ṹ�������ĵ��ķֲ�ʽ�����ݴ������ݿ�ϵͳ�����ṩRESTFul HTTP/JSON�ӿڡ���ӵ��MVCC���ԣ��û�����ͨ���Զ���Map/Reduce�������ɶ�Ӧ��View��
��CouchDB�У���������JSON�ַ��ķ�ʽ�洢���ļ��С�
����
- RESTFul API��HTTP GET/PUT/POST/DELETE + JSON
- �����ĵ��洢������֮��û�й�ϵ��ʽҪ��
- ÿ�����ݿ��Ӧ�������ļ�(��JSON����),Hot backup
- MVCC��Multi-Version-Concurrency-Control������д�����������ݿ�
- �û��Զ���View
- �ڽ����ݻ���
- ֧�ָ���
- ʹ��Erlang��������������ԣ�
Ӧ�ó��� �����ǵ������У��кܶ�document�������ż����˵����ʼǵȣ�����ֻ�Ǽ���Ϣ��û�й�ϵ���������ǿ��ܽ�����Ҫ�洢��Щ���ݡ� ����������£�CouchDBӦ���Ǻܺõ�ѡ��Ȼ����ʹ�ù�ϵ�����ݿ�Ļ�����Ҳ����ʹ��CouchDB�������
����CouchDB�����ԣ���ijЩż �����������Ӧ���У����ǿ�����CouchDB�ݴ����ݣ�������ͬ����Ҳ������Cloud�����У���Ϊ�ֲ�ʽ�����ݴ洢��CouchDB�ṩ���� HTTP��API���������еij������Զ�����ʹ��CouchDB��
ʹ��CouchDB����ζ�����Dz���Ҫ����ʹ��RMDBSһ���������Ӧ��ǰ������Ƹ�������Table�����ǵĿ������ӿ��٣���
��ϸ�μ���
http://www.javaeye.com/topic/319839
Riak
Riak: API: JSON, Protocol: REST, Query Method: MapReduce term matching , Scaling: Multiple Masters; Written in: Erlang, Concurrency: eventually consistent (stronger then MVCC via Vector Clocks), Misc: ... Links: talk ?,
MongoDB
MongoDB: API: BSON, Protocol: lots of langs, Query Method: dynamic object-based language, Replication: Master Slave, Written in: C++,Concurrency: Update in Place. Misc: ... Links: Talk ?,
MongoDB��һ�����ڹ�ϵ���ݿ�ͷǹ�ϵ���ݿ�֮��IJ�Ʒ���Ƿǹ�ϵ���ݿ�й�����ḻ�������ϵ���ݿ�ġ���֧�ֵ����ݽṹ�dz���ɢ���� ����json��bjson��ʽ����˿��Դ洢�Ƚϸ��ӵ��������͡�Mongo�����ص�����֧�ֵIJ�ѯ���Էdz�ǿ������е��������������IJ�ѯ�� �ԣ���������ʵ�����ƹ�ϵ���ݿⵥ����ѯ�ľ��ֹ��ܣ����һ�֧�ֶ����ݽ���������
Mongo��Ҫ������Ǻ������ݵķ���Ч�����⣬���ݹٷ����ĵ������������ﵽ50GB���ϵ�ʱ��Mongo�����ݿ�����ٶ���MySQL�� 10�����ϡ�Mongo�IJ�����дЧ�ʲ����ر��ɫ�����ݹٷ��ṩ�����ܲ��Ա�������Լÿ����Դ���0.5��1.5�ζ�д������Mongo�IJ����� д���ܣ��ң�robbin��Ҳ�����пյ�ʱ��úò���һ�¡�
��ΪMongo��Ҫ��֧�ֺ������ݴ洢�ģ�����Mongo���Դ���һ����ɫ�ķֲ�ʽ�ļ�ϵͳGridFS������֧�ֺ��������ݴ洢������Ҳ������Щ������ΪGridFS���ܲ��ѣ���һ�㻹���д����������������֤�ˡ�
�������Mongo����֧�ָ��ӵ����ݽṹ�����Ҵ���ǿ������ݲ�ѯ���ܣ���˷dz��ܵ���ӭ���ܶ���Ŀ��������MongoDB�����MySQL��ʵ�ֲ����ر��ӵ�WebӦ�ã��ȷ�˵why we migrated from MySQL to MongoDB����һ����ʵ�Ĵ�MySQLǨ�Ƶ�MongoDB�İ���������������ʵ��̫������Ǩ�Ƶ���Mongo���棬���ݲ�ѯ���ٶȵõ��˷dz�������������
MongoDBҲ��һ��ruby����ĿMongoMapper����ģ��Merb��DataMapper��д��MongoDB�Ľӿڣ�ʹ�������dz���������DataMapperһģһ�������ܷdz�ǿ�����á�
Terrastore
Terrastore: API: Java & http, Protocol: http, Language: Java, Querying: Range queries, Predicates, Replication: Partitioned with consistent hashing, Consistency: Per-record strict consistency, Misc: Based on Terracotta
ThruDB
ThruDB: (please help provide more facts!) Uses Apache Thrift to integrate multiple backend databases as BerkeleyDB, Disk, MySQL, S3.
Key Value / Tuple �洢
Amazon֮SimpleDB
Amazon SimpleDB: Misc: not open source, Book ?
SimpleDB ��һ������ѷ�������ƽ̨��һ���������Եļ�/ֵ���ݿ⡣SimpleDB�Դ��ڹ��ڲ��ԽΣ���ǰ���û�������ע���䡰��ѡ��� --��ѵ���˼��˵ֱ������ʹ������Ϊֹ��
SimpleDB�м���������ơ����ȣ�һ�β�ѯ���ֻ��ִ��5���ӡ���Σ������ַ������ͣ����������������͡�һ�ж����ַ�����ʽ���洢����ȡ�� �Ƚϣ���˳�������������ڶ�תΪISO8601���������ڱȽϽ��������á��������κ��ַ������ȶ����ܳ���1024�ֽڣ�������������һ���������ܴ洢 ���ı��Ĵ�С������˵��Ʒ�����ȣ������������ڸ�ģʽ��̬�������ͨ���ӡ���Ʒ����1��������Ʒ����2�������ƹ��������ơ�һ����Ŀ�������� 256�����ԡ����ڴ��ڲ��ԽΣ�SimpleDB�����ܴ���10GB���������������ܳ���1TB��
SimpleDB��һ��ؼ���������ʹ��һ������һ����ģ�͡� ���һ����ģ�ͶԲ����Ժ��кô�������ζ������ı�����Ŀ����֮����Щ�ı��п��ܲ���������ӳ�����Ķ������ϡ������������ʵ�ʷ����ļ��ʺܵͣ���Ҳ ���������ǡ�����˵��������ݳ���Ʊϵͳ��㲻��������һ�����ֻ���Ʊ����5���ˣ���Ϊ���۳�ʱ��������Dz�һ�µġ�
Chordless
Chordless: API: Java & simple RPC to vals, Protocol: internal, Query Method: M/R inside value objects, Scaling: every node is master for its slice of namespace, Written in: Java, Concurrency: serializable transaction isolation, Links:
Redis
Redis : (please help provide more facts!) API: Tons of languages, Written in: C, Concurrency: in memory and saves asynchronous disk after a defined time. Append only mode available. Different kinds of fsync policies. Replication: Master / Slave,
Redis��һ�����µ���Ŀ���ոշ�����1.0�汾��Redis��������һ��Key-Value���͵��ڴ����ݿ⣬����memcached���������ݿ�ͳ ͳ�������ڴ浱�н��в���������ͨ���첽���������ݿ�����flush��Ӳ���Ͻ��б��档��Ϊ�Ǵ��ڴ������Redis�����ܷdz���ɫ��ÿ����Դ������� 10��ζ�д����������֪������������Key-Value DB��
Redis�ij�ɫ֮�������������ܣ�Redis����������֧�ֱ���List������Set���ϵ����ݽṹ�����һ�֧�ֶ�List���и��ֲ������� ���List����push��pop���ݣ�ȡList���䣬����ȵȣ���Set֧�ָ��ּ��ϵIJ����������������ⵥ��value�����������1GB������ memcachedֻ�ܱ���1MB�����ݣ����Redis��������ʵ�ֺܶ����õĹ��ܣ��ȷ�˵������List����FIFO˫��������ʵ��һ���������ĸ��� ����Ϣ���з���������Set�����������ܵ�tagϵͳ�ȵȡ�����RedisҲ���ԶԴ����Key-Value����expireʱ�䣬���Ҳ���Ա�����һ �����ܼ�ǿ���memcached���á�
Redis����Ҫȱ�������ݿ������ܵ������ڴ�����ƣ����������������ݵĸ����ܶ�д��������û��ԭ���Ŀ���չ���ƣ�������scale������չ�� ������Ҫ�����ͻ�����ʵ�ֲַ�ʽ��д�����Redis�ʺϵij�����Ҫ�����ڽ�С�������ĸ����ܲ����������ϡ�Ŀǰʹ��Redis����վ�� github��Engine Yard��
Scalaris
Scalaris: (please help provide more facts!) Written in: Erlang, Replication: Strong consistency over replicas, Concurrency: non blocking Paxos.
Tokyo cabinet / Tyrant
Tokyo Cabinet / Tyrant: Links: nice talk ?, slides ?, Misc: Kyoto Cabinet ?
�����ձ�����SNS�罻��վmixi.jp������ Tokyo Cabinet key-value���ݿ�����ӿڡ���ӵ��Memcached����Э�飬Ҳ����ͨ��HTTPЭ��������ݽ��������κ�ԭ��Memcached�ͻ��������� ���Խ�Tokyo Tyrant������һ��Memcached�����ǣ����������ǿ��Գ־ô洢�ġ�Tokyo Tyrant ���й���ת�ơ���־�ļ����С�����������±��ֳ�ɫ�����ƣ������http://blog.s135.com/post/362.htm
Tokyo Cabinet 2009��1��18�շ������°汾��Version 1.4.0���Ѿ�ʵ�� Table Database����key-value���ݿ�����չ��һ��������MySQL�ȹ�ϵ�����ݿ�ı����ֶεĸ�����Ų��õĽ�����Tokyo Tyrant Ҳ��֧����һ���ܡ�ֵ���ڴ���
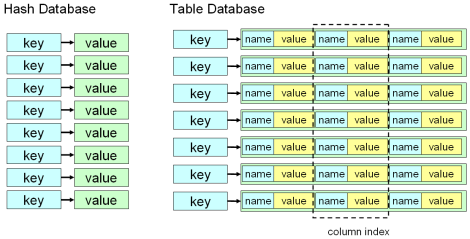
������
| 

