简介:
语义网旨在让机器可以理解信息,旨在让网络更加智能,如提供信息获取、信息过滤、Web 自动服务等。语义网的实现有多种技术,如
HTML5 的 Microdata、RDF、Microformat 等。本文以 HTML5 的 Microdata
为核心展开介绍。
语义网简介
伯纳斯・李(Bemers-Lee)在 2002 年描绘了下一代互联网的前景,并将下一代互联网称为“语义网”(Semantic
Web)。他描述道:“语义网是当前网络的延伸,信息在其中被赋予明确含义,从而实现人与计算机的更好协作。”与仅与人可读的万维网不同,语义网是一种智能网络,它的目标是对现行互联网进行扩展,使整个互联网能够自动处理,使全部内容易于使用,建立一个可理解的全球平台。或者说,语义网是机器可理解的信息,是数据网,更是全球性的数据库,在语义网中,一切可以确定的内容,例如人、时间、事件、物体等都作为实体分布在网络中,每个实体都有一个统一资源标识。语义网的核心是元数据,使得原来
Web 环境下难以实现的许多应用成为可能或变得更有效,如信息获取、信息过滤、Web 自动服务等。
如果将当前的 Web 网络理解为一种语法树,它所具有的功能仅仅是将我们输入的信息以某种格式显示出来,这种网络所做的工作只是显示信息。语义网就是在此基础上的进一步发展,是按照我们对于信息理解,从语法到语义、语用的层次过程,将更复杂的理解过程赋于计算机完成,因此可以名副其实地称为“下一代互联网”。
概括地说,语义网是按照能表达页面内容的“词语”链接起来的全球信息网;换言之,是用机器很容易理解和处理的方式连接起来的全球数据库。它是现有的万维网的变革和延伸,它将使“理解网上信息的含义”不再是只有人类才能做到的事情,计算机在一定程度上也能做到,从而有助于信息与智能的共享,并使网络有能力提供动态与主动的服务,从而更利于人机之间的对话和协同工作。例如,对于天气预报的数字人看到就明白其含义,而计算机并不知道哪个数字表示温度,哪个数字表示湿度。语义网的意义就是在隐藏的编码中,指明哪个数字代表温度,哪个数字代表湿度,并说明“温度”和“湿度“的含义。
语义网最大的好处就是让计算机对网络空间所存储的数据进行智能化评估。这样,计算机就可以像人脑一样“理解”信息的含义,完成“智能代理”的功能。另外,使用语义网搜索引擎的结果也将比万维网更为精确。
语义网可以使用 Microformats, RDF, 或 Microdata
等技术实现,以上技术各有所长,本文将以 Microdata 为主进行展开。
HTML5 Microdata 介绍
Microdata 以自定义的词汇表(vocabulary)为中心,可以想象
HTML5 中所有的元素集合为一个词汇表,这个词汇表包含描述段落(section) 或文章(article)的元素,但是不包含描述事件(event)
或组织(organization)的元素。如果想在 Web 页面中表示一个事件或组织,则需要定义自己的词汇表,Microdata
允许你这么做,任何人都可以定义自己的词汇表,并且将其包含在自己的 Web 页面中。
Microdata 由名字 / 值(name/value)对组成,每一个词汇表定义一组命名的属性。例如,对于人这个词汇表,可以定义名字、头像、地址等属性。为了在页面中包含特定的
Microdata 属性值(value),需要在特定的地方提供 Microdata 属性名(name)。根据你声明属性名的位置,Microdata
有提取属性值的规则。
Microdata 中范围(scoping)的概念很重要,对于这个概念,可以想象
DOM 中元素的父子关系。元素 <HTML> 通常包含两个子元素,<HEAD>
和 <BODY>,元素 <BODY> 可以有很多子元素,这些子元素又可以有自己的子元素。Microdata
重用 DOM 的等级结构提供一种方式表达:这个元素(element)中所有的属性(properties)都来自这个词汇表(vocabulary)。它允许在一个页面中使用多个词汇表(vocabulary),而且词汇表之间可以内嵌,这些全部通过对
DOM 自有结构的使用完成。
现在已经提及到 DOM,这里再赘述下。Microdata 是用来对 Web
页面上已经存在的数据提供附加的语义,它并不是被设计用来作为独立的数据格式,它是对 HTML 的一种补充。下面的章节中你将看到:如果能正确地使用
HTML,Microdata 将很好的工作,但是 HTML 的词汇表表达能力并不是很强。
Microdata 的意义及优势
Microdata 的意义
对于那些喜欢语义网的人来说,HTML5 是非常吸引人的。Microdata
使得以前旧的表现元素有了新的语义意义。基于页面的内容,我们可以使用属性来定义一组内嵌的名字 - 值对来表达页面内容元素的语义,它给我们一种新的方式来添加额外的语义信息。
对于 HTML 页面有两个主要的消费者:
Web 浏览器
搜索引擎
对于浏览器来说,HTML5 定义了一些 DOM API,用来从 Web
页面中提取 Microdata 的项,属性,属性值。但是就目前来说,没有浏览器支持 HTML5 规范中的这些
API,一个也没有。听起来有些不乐观,不过相信浏览器会赶上来并实现这些 API。
另一个主要消费 HTML 的就是搜索引擎。搜索引擎使用 Microdata 的属性能做些什么呢?想象一下这样的场景:搜索引擎的结果除了简单地展示一个页面的标题,或一篇文章的段落,还能够整合一些结构化信息并展示他们。全名、工作名称、雇佣者、地址甚至是一个小小的肖像图片。这些会引起你的兴趣吗?我想会吸引我的眼球。
Google 有自己的一些词汇表,包含如下一些简单的数据:
people
businesses and organizations
events
products
reviews
recipes
通过在自己的页面中添加这些语义信息并不会影响网页搜索的排名,但是这些语义会被搜索引擎显示在搜索结果中。例如在
Google 中搜索 Dive Into HTML5,会得到如下的显示结果:
图 1.Google 中 Dive Into HTML5
的搜索结果
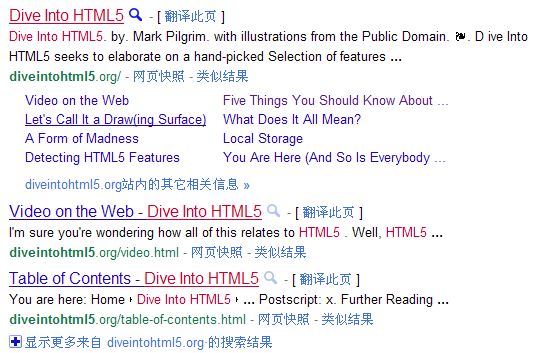
相比于其他搜索结果,可以看到第一条搜索结果除了简单的内容摘录片段,还有结构化信息的显示。同样在
Google 中搜索 Anna ’ s Pizzeria: review,会得到如下的结果:
图 2. Google 中 Anna ’ s Pizzeria:
review 的搜索结果
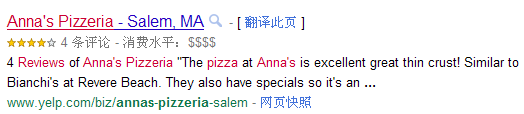
我们可以看到有四星的评价,评价信息的数目:4 条,消费水平等额外信息的显示。
从中我们可以看出,对 Microdata 的支持可以影响搜索结果的显示,使得显示结果更加丰富,虽然不能影响搜索结果的排名,但更多的信息更能捕获使用者的眼球。上面显示的抓图结果随时间的不同会有所不同,仅用作显示示例。
Microdata 的优势
Microformats 在 HTML4.01/XHTML1.0 中本身就是可用的,这也是为什么
class 属性在这里以一种新的方式使用。虽然在 HTML4.01 规范中提到 class 可以有更广泛的应用,但它只是被
CSS 用作风格样式选择器。这意味着我们工作在单一的一个全局命名空间中,而这个命名空间已经被 CSS 类名所污染。
Microformats 和随机的 CSS 类名唯一不同的就在于树结构。这种树结构也有局限性,这意味着你需要为所有的元素找到一个公共祖先。Microformat
的存在似乎是在加重系统化技术的负债。
RDF 模型使用主语 -- 谓语 -- 宾语的三元组结构。如下面的例子:
<p xmlns:foaf="http://xmlns.com/foaf/0.1/"
about="#me">
I'm <span property="foaf:name">Philip
J?genstedt</span> at
<a rel="foaf:homepage" href="http://foolip.org/">foolip.org</a>.
</p>
这里 XML 命名空间的使用有些奇怪。在 XML 中前缀是被用于元素和属性名,而这里却被用于属性值。
相比之下,Microdata 基于 HTML 现有的元素添加语义,不久的将来可以使用
DOM API 来获取这些语义,能够被搜索引擎用来组合更加结构化的搜索结果,并且 Google 已经致力于测试
Microdata 语法,Google 搜索结果已经支持 Microdata。
Microdata 数据模型
定义自己的 Microdata 词汇表(vocabulary)很简单,首先,需要一个
URL 形式的命名空间(namespace)。这个 URL 可以实际上指向一个可用的 Web 页面,但这个
URL 并不是必须的。假如我们要创建一个 Microdata 词汇表(vocabulary)来表示一个人(Person)。如果拥有一个
data-vocabulary.org 的域,可以使用 URL(http://data-vocabulary.org/Person)来表示我们的
Microdata 词汇表(vocabulary)的命名空间(namespace)。通过在自己控制的域上选择一个
URL 就能很容易地创建一个全世界唯一的标识符。
在这个词汇表(vocabulary)中,要定义一些命名的属性,这里从三个基本的属性开始:
name (your full
name)
photo (a link to a picture of you)
url (a link to a site associate to you, like a weblog
or Gooogle profile)
这些属性中一些为 URL,一些是纯文本(plain text)。想象一下你拥有一个“关于”的页面或者人物简介页面,你的名字可能以标题(heading)标识,像一个
<h1> 元素,你的头像是一个 <img> 元素,因为你需要人们看到它,任何和你关联的人物简介可能被标识为超链接(hyperlinks),因为你希望人们可以点击它们。假如你的整个人物简介(profile)就包含在
<section>(section 是 HTML5 中的标签)元素中,如下所示:
清单 1
<section>
<h1>Mark Pilgrim</h1>
<p><img src="http://www.example.com/photo.jpg"
alt="[me smiling]"></p>
<p><a href="http://diveintomark.org/">weblog</a></p>
</section>
Microdata 的数据模型是名字 / 值对(name/value pairs),Microdata
的属性名(比如这个例子中的 name,photo,url)总是在 HTML 元素中声明,相应的属性值从
DOM 元素中取得。对于大多数 HTML 元素,属性值就是元素对应的文本内容(text content),但是也有一些例外:
表 1.Microdata 属性值来源
| Element |
Value |
| <meta> |
content attribute |
<audio>
<embed>
<iframe>
<img>
<source>
<video> |
src attribute |
<a>
<area>
<link> |
href attribute |
| <object> |
data attribute |
| <time> |
datetime attribute |
| all other elements |
text content |
在你的页面中添加 Microdata 就是在已有的 HTML 元素上添加一些属性。首先要做的是声明使用的
Microdata 词汇表(vocabulary)的命名空间,通过添加一个 itemtype 属性完成;另外声明词汇表的范围,通过添加一个
itemscope 属性完成。在这个例子中,所有的数据都在元素 <section> 中,所以我们在
<section> 元素上声明 itemtyp 和 itemscope:
<section itemscope itemtype="http://data-vocabulary.org/Person">
元素 <section> 中的第一个数据是你的名字(name),它内嵌在
<h1> 元素中,<h1> 元素在 HTML5 Microdata 数据模型中没有特殊的处理,所以它遵循“all
other elements”的规则,即它的属性值只是 HTML 相应元素的简单文本内容。(当然,如果你的名字内嵌在
<p>,<div>, 或者 <span> 等元素中,这个规则同样有效。)
<h1 itemprop="name">
Mark Pilgrim </h1>
上面的语句可以这么表述:这里是 http://data-vocabulary.org/Person
词汇表的一个 name 属性,它的属性值是 Mark Pilgrim。
接下来:photo 属性,它应该是一个 URL。根据 HTML5 Microdata 数据模型的规则,<img>
元素的值是 src 属性。可以看出,你的 photo 的 URL 已经在 <img src>
中了,你需要做的就是声明 <img> 元素是 photo 属性。
<p><img itemprop="photo"
src="http://www.example.com/photo.jpg" alt="[me
smiling]"></p>
上面的语句可以这样表述:这里是 http://data-vocabulary.org/Person
词汇表的一个 photo 属性,它的属性值为
http://www.example.com/photo.jpg。
最后,属性 url 同样是一个 URL。根据 HTML5 Microdata
数据模型的规则,元素 <a> 的值是它的 <href> 属性。同样,它完全符合现有的标识,你所需要做的就是声明现有的
<a> 元素是 url 属性:
<a itemprop="url" href="http://diveintomark.org/">
dive into mark </a>
上面的语句可以这么表述:这里是 http://data-vocabulary.org/Person
词汇表的一个 url 属性,它的值为
http://diveintomark.org。
当然,如果你的标识符(markup)看起来有一些不一样,这也不是问题。你可以添加
Microdata 属性和属性值到任何 HTML 元素中。虽然不推荐这么做,但你仍然可以添加它。看下面的例子:
清单 2
<TABLE>
<TR><TD>Name<TD>Mark Pilgrim
<TR><TD>Link<TD>
<A href=# onclick=goExternalLink()>http://diveintomark.org/</A>
</TABLE>
为了标识 name 属性,只需要添加 itemprop 属性到包含 name
属性的表格单元(table cell)中。表格单元没有特殊的规则,所以它的属性只是简单的文本内容。
<TR><TD>Name<TD itemprop="name">Mark
Pilgrim
添加 url 属性看起来有些棘手,这个标识不是按普通的方式使用 <a>
元素。它并不是直接将链接放在 href 属性中,在 href 属性中没有任何有用信息,它通过在 onclick
属性上调用 JavaScript 代码提取 URL 并访问它。
不过你同样可以将它转变为 Microdata 属性,只是直接使用 <a>
元素并不能解决问题。链接地址并不在 href 属性中,没有办法重写规则来表达这个意思:在 <a>
元素中,寻找 <href> 属性的 Microdata 属性值。但是你可以在外面添加一个包装元素,通过这个元素来添加
url Microdata 属性:
清单 3
<TABLE itemscope
itemtype="http://data-vocabulary.org/Person">
<TR><TD>Name<TD>Mark Pilgrim
<TR><TD>Link<TD>
<span itemprop="url">
<A href=# onclick=goExternalLink()>http://diveintomark.org/</A>
</span>
</TABLE>
由于 <span> 元素没有特殊的处理,可以使用默认的规则:它的
Microdata 属性是文本内容。
总结起来可以这么说:你可以给任何 HTML 中的标识符添加 Microdata
属性。如果正确地使用 HTML,你会发现很容易添加 Microdata 属性,如果有些 HTML 标识符比较棘手,它同样可以被完成。
添加 People Microdata 到你的 Web 页面中
这里看一个添加 People Microdata 到你的 Web 页面中的例子,首先看一个不添加任何
Microdata 属性的例子。
清单 4
<section>
<img width="204" height="250"
src="http://diveintohtml5.org/examples/2000_05_mark.jpg"
alt="[Mark Pilgrim, circa 2000]">
<h1>Contact Information</h1>
<dl>
<dt>Name</dt>
<dd>Mark Pilgrim</dd> <dt>Position</dt>
<dd>Developer advocate for Google, Inc.</dd>
<dt>Mailing address</dt>
<dd>
100 Main Street<br>
Anytown, PA 19999<br>
USA
</dd>
</dl>
<h1>My Digital Footprints</h1>
<ul>
<li><a href="http://diveintomark.org/">weblog</a></li>
<li><a href="http://www.google.com/profiles/pilgrim">Google
profile</a></li>
<li><a href="http://www.reddit.com/user/MarkPilgrim">Reddit.com
profile</a></li>
<li><a href="http://www.twitter.com/diveintomark">Twitter</a></li>
</ul>
</section>
首先要做的是声明一个词汇表,和它的使用范围。需要做的是在包含所有数据的最外层标识中添加
itemscope 和 itemtype 属性,在这个例子中那个最外层标识是 <section>
元素:
<section itemscope itemtype="http://data-vocabulary.org/Person">
现在可以从 http://data-vocabulary.org/Person
词汇表中定义 Microdata 属性。你可以打开 http://data-vocabulary.org/Person
去查看属性的列表,Microdata 规范并不要求这么做,不过为了清晰每个属性的含义,这里加上这个属性。毕竟为了开发人员能够使用这个词汇表,你需要记载你的词汇表。Table2
列出了 Person 词汇表的属性:
表 2. Person 词汇表
| Property |
Description |
| name |
Name |
| nickname |
Nickname |
| photo |
An image link |
| title |
The person ’ s title (for example, “Financial
Manager”) |
| role |
The person ’ s role (for example, “Accountant”) |
| url |
Link to a web page, such as the
person ’ s home page |
| affiliation |
The name of an organization with which the person
is associated (for example, an employer) |
| friend |
Identifies a social relationship between the person
described and another person |
| contact |
Identifies a social relationship between the person
described and another person |
| acquaintance |
Identifies a social relationship between the person
described and another person |
| address |
The location of the person (can have the subproperties
street-address, locality, region, postal-code, and
country-name) |
这里例子中的第一个元素是我的图片,通常它用 <img> 元素标识,为了声明
<img> 元素标识的是我的图片,只需要给 <img> 添加 itemprop="photo":
清单 5
<img itemprop="photo"
width="204" height="250"
src="http://diveintohtml5.org/examples/2000_05_mark.jpg"
alt="[Mark Pilgrim, circa 2000]">
从表 1 中可以看出,<img> 的属性值就是 src 属性,每个
<img> 元素都有一个 src 属性,并且 src 通常是一个 url。
这里 <img> 元素并不是单独的,它是 <section> 元素的一个子元素,我们刚在
<section> 中声明了 itemscope 属性。Microdata 重用元素的父子关系来定义
Microdata 属性的范围(scoping)。简单地说,<section> 代表一个人(person),任何在
<section> 能找到的子元素都是人(preson)的属性。可以这么认为,将 <section>
作为句子的主语,itemprop 属性作为句子的谓语,而 Microdata 属性值代表句子的宾语:
清单 6
This person [explicit,
from <section itemscope itemtype="...">]
is pictured at [explicit, from <img itemprop="photo">]
http://diveintohtml5...000_05_mark.jpg [implicit, from
<img src> attribute]
主语只需要定义一次,通过在最外层的 <section> 元素中添加
itemscope 和 itemtype 属性完成,谓语通过在 <img> 元素中添加 itemprop="photo"属性完成,宾语不需要特殊的标识,因为
Table1 中规定了 <img> 元素的属性值是 src 属性。
接下来看到标题 <h1> 标签和 <dl> 列表标签,<h1> 或
<dl> 都必须要被 Microdata 标识,并不是每一个 HTML 标签都需要一个 Microdata
属性,Microdata 用来描述属性本身,而不是包含属性的标题或列表。<h1> 并不是一个属性,它只是一个标题,同样,<dl>
表示"name"只是一个标签,不是一个属性:
清单 7
<h1>Contact
Information</h1>
<dl>
<dt>Name</dt>
<dd>Mark Pilgrim</dd>
哪里才是真正的信息呢?在 <dd> 元素中,这里才是需要添加
itemprop 属性的地方。使用哪个属性呢?正是 name 属性。那么属性值呢?就是在 <dd>
元素中的文本内容。它需要被标识起来吗?根据 Table1 的规定,<dd> 元素不需要特殊的处理,所以它的属性值只是它包含的纯文本:
<dd itemprop="name">Mark
Pilgrim</dd>
接下来的两个属性比较棘手,先看使用 Microdata 前的代码片段:
<dt>Position</dt>
<dd>Developer advocate for Google,
Inc.</dd>
看一下 Person 词汇表的定义,你会发现文本“Developer advocate
for Google, Inc.”实际上包含两个属性:title(“Developer advocate”)和
affiliation(“Google, Inc”)。怎么在 Microdata 中表示这两个属性呢?答案是你不能,Microdata
没有办法将文本分为多个属性,你不能说前 18 个字符是一个 Microdata 属性,剩下的 12 个字符是另外一个
Microdata 属性。
想象一下,你想让前 18 个字符用一种风格,剩下 12 个字符用另一种风格,CSS
可以做到吗?答案也是不能。不过你可以把前 18 个字符内嵌到一个元素中,像 <span>,剩下
12 个字符内嵌到另一个 <span> 中,然后对不同的 <span> 使用不同的
CSS 样式。
这种技术同样适用于 Microdata,这里有两段不同的信息:title
和 affiliation,如果分别将两段信息内嵌到不同的 <span> 元素中,你可以声明每个
<span> 为独立的 Microdata 属性。
清单 8
<dt>Position</dt>
<dd><span itemprop="title">Developer
advocate</span> for
<span itemprop="affiliation">Google,
Inc.<span></dd>
同样这个技术也可以用于组合街道地址。Person 词汇表定义了 address
属性,而这个属性本身也是一个词汇表,并且定义自己的属性(properties):street-address,
locality, region, postal-code, 和 country-name。
你可能对用点标识对象和属性的方式很熟悉,想象这样的关系:
Person
Person.address
Person.address.street-address
Person.address.locality
Person.address.region
Person.address.postal-code
Person.address.country-name
这个例子中,所有的街道地址信息都包含在一个 <dd> 元素中。标识
address 属性比较简单,只需要在 <dd> 元素上添加 itemprop 属性。
<dt>Mailing address</dt>
<dd itemprop="address">
但是要注意,address 本身也是一个 Microdata 项,所以我们需要还需要定义
itemscope 和 itemtype 属性:
清单 9
<dt>Mailing
address</dt>
<dd itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
Address 同样遇到前面 title 和 affiliation 的问题,address
是一长串的字符串,但是我们想把它分割成几部分。解决办法是一样,我们把不同的部分内嵌到不同的 <span>
中,然后在 <span> 上声明不同的 Microdata 属性:
清单 10
<dd itemprop="address"
itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="street-address">100
Main Street</span><br>
<span itemprop="locality">Anytown</span>,
<span itemprop="region">PA</span>
<span itemprop="postal-code">19999</span>
<span itemprop="country-name">USA</span>
</dd>
</dl>
还有一个需要关注的就是一系列的 URL。Person 词汇表有个叫做 url
的属性,url 的定义很宽松,可以是任何你想跟一个人关联的 url:一个博客,一个照片。
值得注意的是一个人可以有很多的 url 属性。从技术上讲,任何属性都可以出现多次,比如,你可以拥有两张图像,每个用不同的
url 表示。这里我们要列出四个不同的 url。在 HTML 中,它是一系列 url 的列表:四个 <a>
元素,每个在 <li> 元素中。在 Microdata 中,每个 <a> 元素有一个
itemprop="url"属性:
清单 11
<h1>My Digital
Footprints</h1>
<ul>
<li><a href="http://diveintomark.org/"
itemprop="url">weblog</a></li>
<li><a href="http://www.google.com/profiles/pilgrim"
itemprop="url">Google profile</a></li>
<li><a href="http://www.reddit.com/user/MarkPilgrim"
itemprop="url">Reddit.com profile</a></li>
<li><a href="http://www.twitter.com/diveintomark"
itemprop="url">Twitter</a></li>
</ul>
根据表 1 知道,<a> 元素需要特别处理。它的 Microdata
属性值是 href 属性,而不是子元素的文本内容。
结束语
本文介绍了 HTML5 中的 Microdata,它的特点、数据模型和一个将
People Microdata 加入到自己的 Web 页面中的例子。Microdata 可以作为语义网的实现技术,当然还有其他的实现技术,比如
Microformats、RDF 等,有兴趣的读者可以阅读参考资料中的资源。
参考资料
学习
关于 HTML5 Microdata 的参考资料,请参考 HTML5
Microdata in <Dive Into HTML5>
关于 HTML5 Microdata 的例子,请参考 Microdata
example
关于 Microformat 的参考资料,请参考 Microformat
关于 RDF 的语法资料,请参考
RDF
关于 RDF Use Case 的资料,请参考 RDFa
Use Cases
关于 Microdata,RDF,Microformats 的比较,请参考
Microformats
vs RDFa vs Microdata和 RDFa
and HTML5's Microdata
“使用
Dojo 的 Ajax 应用开发进阶教程:富含语义的 HTML”(developerWorks,2009
年 7 月):HTML 语言是互联网的基础。如何正确合理的编写 HTML 文档,是很多 Web
开发人员关心的问题。富含语义的 HTML 是一种 Web 应用开发的实践,它强调从文档所需要表达的语义出发,使用
HTML 语法中表示文档结构和富含语义的元素来编写 HTML 文档,从而使得 Web 应用的结构与展示分离,降低各部分之间的耦合度。随着
Ajax 应用的流行,这种实践越来越为 Web 开发人员所接受。本文详细介绍富含语义的 HTML 这一开发实践,供
Web 开发人员参考。
“借助语义技术构建
Wikipedia 查询表单”(developerWorks,2009 年 9 月):通过提供对大量
Linked Data 的开放访问,公共的 SPARQL 端点为您的应用程序提供了很棒的数据,进而推动了语义
Web 的发展。正如很多其他受数据驱动的 Web 站点一样,可以通过向这些端点发送一个查询、然后再将结果包装在
HTML 标签内的方式创建一个 Web 页面;SPARQL 端点的一个与众不同之处在于这些新数据是公开可用的,可用在您的应用程序中。本文展示了如何通过简单的
CGI 脚本从两个不同的 SPARQL 端点获得数据并构建应用程序以解答用户的两个问题:在两个导演的电影中都出现过的演员有哪些以及哪些艺人发布过哪些专辑。
“使用
HBase 发现通往语义 Web 的道路”(developerWorks,2009 年 10 月):Hadoop
Database(HBase) 非常适于创建一个语义 Web 并提取现有知识或计算知识。学习如何在 HBase
数据库中为科学文章表示 RDF/XML 断言,了解 HBase 和 Bigtable 如何发起一种存储和处理数据的新方法。
“利用语义
Web 技术集成异构数据”(developerWorks,2010 年 10 月):不同的 RDF
数据集比其他常见格式的不同数据集要容易组合得多。您可以轻松地将异构的非 RDF 数据集转换成 RDF,然后再组合起来创建增强的新内容。在本文中,学习如何将电子表格数据、来自
web 服务的 CSV 数据和来自网站的字段数据集成到单个报表中。
developerWorks
Web development 专区:通过专门关于 Web 技术的文章和教程,扩展您在网站开发方面的技能。
developerWorks
Ajax 资源中心:这是有关 Ajax 编程模型信息的一站式中心,包括很多文档、教程、论坛、blog、wiki
和新闻。任何 Ajax 的新信息都能在这里找到。
developerWorks
Web 2.0 资源中心,这是有关 Web 2.0 相关信息的一站式中心,包括大量 Web 2.0
技术文章、教程、下载和相关技术资源。您还可以通过 Web 2.0 新手入门栏目,迅速了解 Web 2.0
的相关概念。
查看
HTML5 专题,了解更多和 HTML5 相关的知识和动向。 | 