| БрМЭЦМі: |
БОЮФРДздibmЃЌЮФеТДгИХФюЕФНЧЖШНщЩмАцБОПижЦЯЕЭГЁЂGit
КЭ GitHubЃЌВЂзХжиЭЈЙ§вЛаЉЪЕбщРДбнЪО Git ЕФЛљДЁЬиадЁЃ |
|
ЧАбд
Git ЪЧФПЧАвЕНчзюСїааЕФАцБОПижЦЯЕЭГЃЈVersion Control SystemЃЉЃЌЖј GitHub
ЪЧПЊдДДњТыЭаЙмЦНЬЈЕФЧЬГўЁЃдНРДдНЖрЕФДгвЕепЁЂДгвЕЭХЖгвдМАПЊдДЙБЯзепЪзбЁЖўепгУгкЙмРэЯюФПДњТыЁЃБОЮФЪзЯШДгИХФюЕФНЧЖШНщЩмАцБОПижЦЯЕЭГЁЂGit
КЭ GitHubЃЌВЂзХжиЭЈЙ§вЛаЉЪЕбщРДбнЪО Git ЕФЛљДЁЬиадЃЌЪЙФњФмЙЛЖд Git КЭ GitHub
гаИќЧхЮњЕФШЯЪЖЁЃ
Git КЭ GitHub ЧјБ№КЭСЊЯЕ
вЛаЉГѕДЮНгДЅ Git КЭ GitHub ЕФДгвЕепГЃГЃНЋ Git КЭ GitHub ЖўепЛьЯ§ЖјЬИЁЃЖўепЫфШЛСЊЯЕЩѕНєЃЌЕЋДгБОжЪЩЯЪЧСНИіВЛЭЌЕФИХФюЁЃ
Git ЪЧвЛИіПЊдДЕФЗжВМЪНАцБОПижЦЯЕЭГЁЃЖј GitHub БОжЪЩЯЪЧвЛИіДњТыЭаЙмЦНЬЈЃЌЫќЬсЙЉЕФЪЧЛљгк
Git ЕФДњТыЭаЙмЗўЮёЁЃЖдгквЛИіЭХЖгРДЫЕЃЌМДЪЙВЛЪЙгУ GitHubЃЌЫћУЧвВПЩвдЭЈЙ§здМКДюНЈКЭЙмРэ Git
ЗўЮёЦїРДНјааДњТыПтЕФЙмРэЃЌЩѕжСЛЙгавЛаЉЦфЫќЕФДњТыЭаЙмЩЬПЩЙЉбЁдёЃЌШч GitLabЃЌBitBucket
ЕШЁЃжЕЕУвЛЬсЕФЪЧ Git зїЮЊвЛИіПЊдДЯюФПЃЌЦфДњТыБОЩэОЭБЛЭаЙмдк GitHub ЩЯЃЌШчЙћФњИааЫШЄЃЌПЩвдЩЯШЅвЛЙлЦфецШнЁЃGit
ЯюФПЕижЗЃКhttps://github.com/git
АцБОПижЦЯЕЭГМђНщ
дкЯжДњШэМўЯюФПжаЃЌАцБОПижЦЯЕЭГЪЧЯюФПХфжУЙмРэВЛПЩЛђШБЕФвЛВПЗжЃЌЩѕжСЪЧЦфКЫаФЙЄОпЁЃАцБОПижЦзюжївЊЕФШЮЮёЪЧзЗзйЮФМўЕФБфИќЃЌЮоТлЪЧгІгУЯЕЭГдДДњТыЁЂЯюФПХфжУЮФМўЃЌЛЙЪЧЯюФПЙ§ГЬЕФПЊЗЂЮФЕЕЃЌЩѕжСЪЧЭјеОНчУцЭМЦЌЁЂLogoЃЌЖМПЩвдЧвгІИУБЛАцБОПижЦЯЕЭГЫљЙмРэЦ№РДЃЌвдЗНБуЮвУЧдкЯюФПЕФЩњУќИїжмЦкФмЙЛзЗзйЁЂВщПДЕНШэМўЯЕЭГЕФБфИќКЭбнНјЁЃАцБОПижЦЯЕЭГСэвЛИіживЊЕФзїгУЪЧЗНБуПЊЗЂепНјаааЭЌПЊЗЂЃЌЪЙЕУЯюФПжаИїПЊЗЂепФмЙЛдкБОЕиЭъГЩПЊЗЂЖјзюжеЭЈЙ§АцБОПижЦЯЕЭГНЋИїПЊЗЂепЕФЙЄзїКЯВЂдквЛЦ№НјааЙмРэЁЃ
МЏжаЪНАцБОПижЦЯЕЭГ
дчЦкЕФАцБОПижЦЯЕЭГДѓЖрЪЧМЏжаЪНЃЈCentralizedЃЉАцБОПижЦЯЕЭГЁЃЫљЮНМЏжаЪНЃЌМДЪЧДЫРрЯЕЭГЖМгавЛИіЕЅвЛЕФМЏжаЙмРэЕФЗўЮёЦїЁЃдкИУЗўЮёЦїЩЯБЃДцзХЯюФПЫљгаЮФМўвдМАЮФМўЕФРњЪЗАцБОЃЌЖјИїПЊЗЂепПЩвдЭЈЙ§СЌНгЕНИУЗўЮёЦїЖСШЁВЂЯТдиЕНЮФМўЕФзюаТАцБОЃЌвВПЩвдМьЫїЮФМўЕФРњЪЗАцБОЁЃПЊЗЂепГЃГЃПЩвджЛашвЊЯТдиЫћУЧЫљашвЊЕФЮФМўЁЃЭЈЙ§СЌНгМЏжаЪНЗўЮёЦїРДЛёШЁЮФМўКЭЮФМўИќаТЪЧМЏжаЪНАцБОПижЦЯЕЭГЕФБъзМзіЗЈЁЃвЕНчжїСїЕФМЏжаЪНАцБОПижЦЯЕЭГАќРЈ
CVSЁЂSVNЁЂPerforce ЕШЁЃ
МЏжаЪНАцБОПижЦКмДѓГЬЖШЩЯНтОіСЫАцБОПижЦКЭаЭЌПЊЗЂЕФЮЪЬтЃЌЕЋЪЧЫќвВгажиДѓЕФШБЕуЁЃШчЙћжабыЗўЮёЦїГіЯжхДЛњЃЌФЧУДПЊЗЂепНЋЮоЗЈЬсНЛДњТыЃЌвВЮоЗЈНјаааЭЌЙЄзїЃЌИќЮоЗЈВщПДЮФМўРњЪЗЁЃШчЙћЗўЮёЦїГіЯжИќбЯжиЕФДХХЬЫ№ЛЕЃЌгжУЛгаНјааЧЁЕБЕФБИЗнЃЌФЧУДКмДѓПЩФмНЋЖЊЪЇЕєЯюФПЮФМўвдМАЯюФПЕФБфИќРњЪЗЁЃЖјИїаЭЌПЊЗЂепдкздМКБОЕивђЮЊвВжЛгаЕБЧААцБОЕФЮФМўЃЌЛђепжЛгаВПЗжЮФМўЃЌКмФбИљОнИїПЊЗЂепЕФБОЕиПтЖдЯюФПЕФРњЪЗМЧТМНјааЛжИДЁЃ
ЗжВМЪНАцБОПижЦЯЕЭГ
ЯрБШНЯМЏжаЪНЕФАцБОПижЦЃЌФПЧАвЕНчзюСїааЕФАцБОПижЦЯЕЭГЪЧЗжВМЪНЃЈDistributedЃЉАцБОПижЦЯЕЭГЃЌЦфзюДѓЕФЬиЕуЪЧИїПЊЗЂепБОЕиЫљИДжЦЕФВЛНіНіЪЧЕБЧАзюаТАцБОЕФЮФМўЃЌЖјЪЧАбДњТыВжПтЭъећЕиДгЗўЮёЦїЩЯПЫТЁСЫЯТРДЁЃИїПЊЗЂепБОЕигЕгаДњТыВжПтЫљгаЕФЮФМўвдМАЮФМўРњЪЗКЭБфИќаХЯЂЁЃетбљМДЪЙЗўЮёЦїГіЯжхДЛњЃЌвВВЛгАЯьПЊЗЂепБОЕиПЊЗЂЃЌПЊЗЂепвВПЩвдЫцЪБВщПДЮФМўЕФИїРњЪЗАцБОЁЃЩѕжСЗўЮёЦїГіЯжЙЪеЯЕМжТЪ§ОнЖЊЪЇЪБЃЌЯюФПзщвВКмШнвзИљОнПЊЗЂепЕФБОЕиДњТыПтЛжИДГіЫљгаЮФМўКЭЮФМўЕФРњЪЗБфИќМЧТМЁЃ
Git ЪЧвЕНчФПЧАзюЮЊСїааЕФЗжВМЪНАцБОПижЦЯЕЭГЃЌГ§ДЫжЎЭтЛЙга MercurialЁЂBitKeeper
ЕШЁЃGit ЦфЪЕОЭЪЧ Linus Torvalds ИљОн BitKeeper ЕФЩшМЦРэФюЖјжиаТЩшМЦВЂжїЕМПЊЗЂЖјГЩЕФЁЃдкЫцКѓЕФеТНкжаЛсвд
Git ЮЊР§НјвЛВННщЩмЗжВМЪНАцБОПижЦЯЕЭГЕФЛњжЦЁЃШчЙћФњИааЫШЄПЩвдШЅВщдФвЛЯТ Linus TorvaldsЁЂBitKeeper
КЭ Git жЎМфЕФШЄЪТЁЃ
РэНт Git ЕФЗжВМЪНАцБОПижЦ
дчЦкЮвдкНгДЅ Git ЪБЃЌГЃГЃЮЊЦфЫљЮНЕФЗжВМЪНИаЕНРЇЛѓЁЃДѓВПЗжШЫаФФПжаЕФЗжВМЪНЕФИХФюПЩФмИќЖрРДздгкЗжВМЪНМЦЫуЁЃЗжВМЪНМЦЫуЪЙЕУГЬађПЩвдЭЈЙ§ФГжжЛњжЦЗжВМЕидЫаадкЖрЬЈМЦЫуЛњЩЯДгЖјзюДѓЛЏЕиРћгУЖрЬЈМЦЫуЛњЕФМЦЫуФмСІЁЂДцДЂФмСІЁЃЗжВМЪНМЦЫуЪЧНЋМЦЫуШЮЮёЗжИюГЩЖрИіПЩвдЖРСЂдЫааЕФзгШЮЮёЃЌШЛКѓНЋзгШЮЮёЗжВМдкЖрЬЈМЦЫуЛњЖРСЂВЂаадЫааЃЌзюКѓЭЈЙ§ФГжжКЯВЂЛњжЦНЋЫљгаМЦЫуЛњЕФМЦЫуНсЙћзюжеКЯВЂЦ№РДЁЃвђДЫЕЅЖРРДПДетЖрЬЈМЦЫуЛњжаЦфжаФГвЛЬЈЃЌЫќВЂУЛгагЕгаГЬађЕФЫљгаЪ§ОнКЭЫљашзЪдДЁЃДгБэУцПДетЫЦКѕКЭЗжВМЪНАцБОПижЦЯЕЭГжаЕФЗжВМЪНИХФюНиШЛЯрЗДЁЃБЯОЙЗжВМЪНАцБОПижЦЯЕЭГ"КХГЦ"ПЫТЁвЛДЮДњТыПтБОЕиОЭгЕгаСЫвЛИіЭъећЕФДњТыПтИББОЃЌетЬ§Ц№РДгааЉКЇШЫЬ§ЮХЁЃ
ЦфЪЕЮвУЧПЩвдГЂЪдДгвдЯТСНИіЗНУцРДРэНтЃК
ЦфвЛЃЌдкЗжВМЪНАцБОПижЦЯЕЭГжаЃЌПЫТЁСЫДњТыПтЕФИїБОЕиПЊЗЂепгЕгаСЫЗўЮёЦїЗжЗЂЙ§РДЃЈDistributedЃЉЕФЭъећЕФДњТыПтИББОЃЌЪЙЕУПЊЗЂепУЧПЩвдЖРСЂгкжїЗўЮёЦїжЎЭтНјааПЊЗЂШЮЮёЃЌетКЭЗжВМЪНМЦЫуИХФюжаЃЌИїМЦЫуЛњЖРСЂНјааМЦЫуШЮЮёЕФРэФюВЛФБЖјКЯЁЃЭЌЪБвВЗћКЯЗжВМЪНДцДЂЕФРэФюЃКвЛИіЮФМўЖрЗнИББОЁЃ
ЦфЖўЃЌИїПЊЗЂепдкЭъГЩПЊЗЂШЮЮёКѓгжашвЊНЋздМКБОЕиаоИФКѓЕФДњТыПтКЯВЂЃЈMergeЃЉЕНжїЗўЮёЦїЩЯЁЃетвВгыЗжВМЪНМЦЫуИХФюжазюжеашвЊНЋИїМЦЫуЛњЕФМЦЫуНсЙћКЯВЂЦ№РДЕФИХФюЪЧЯрЗћЕФЁЃ
вђДЫетвВОЭВЛФбРэНтЗжВМЪНАцБОПижЦжаЕФЗжВМЪНИХФюСЫЁЃ
ЯТУцЭЈЙ§ Git ЕФвЛИіЪЕбщРДГЂЪдРэНтЪВУДЪЧПЫТЁСЫЭъећЕФДњТыПтИББОЁЃ
ЪзЯШЮвдк GitHub ЩЯНЈСЂСЫвЛИігУгкЪЕбщЕФЙЋПЊДњТыПтЁЃДњТыПтжаФПЧАжЛАќКЌгаЩйСПЕФдДЮФМўКЭЬсНЛМЧТМЃЌШчЧхЕЅ
1 ЫљЪОЁЃЪЕбщВжПтЕижЗЃКhttps://github.com/caozhi/repo-for-developerworks
ЧхЕЅ 1. ВщПДБОЕиДњТыПтжаЫљгЕгаЕФЮФМў
caozhi @ repo-for-developerworks$
ls -al
total 24
drwxr-xr-x 7 caozhi staff 224 8 4 23:43 .
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 ..
drwxr-xr-x 13 caozhi staff 416 8 4 23:43 .git
-rw-r--r-- 1 caozhi staff 278 8 4 23:43 .gitignore
-rw-r--r-- 1 caozhi staff 39 8 4 23:43 README.md
-rw-r--r-- 1 caozhi staff 56 8 4 23:43 helloworld.sh
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 src |
зЂвтДњТыПтжа .git ФПТМжаАќКЌСЫДњТыПтЫљгаЕФДцДЂЖдЯѓКЭМЧТМЁЃШчЙћЯывЊБИЗнЛђИДжЦвЛИіДњТыПтЃЌдђжЛашвЊНЋетИіФПТМПНБДЯТРДМДПЩЁЃ
вђДЫИУДњТыПтжажЛга .gitignoreЁЂREADME.mdЁЂhelloworld.sh вдМА src
ФПТМЪЧДњТыПтЫљЙмРэЕФдДЮФМўЁЃЮвУЧНЋГ§ .git ФПТМжЎЭтЕФЫљгаЮФМўШЋВПЩОГ§ЃЌШчЧхЕЅ 2 ЫљЪОЃК
ЧхЕЅ 2. ЩОçç .git ФПТМжЎЭтЕФШЋВПдДЮФМў
| caozhi@ repo-for-developerworks$
rm -rf .gitignore README.md helloworld.sh src |
НгЯТРДЮвУЧЖЯЕєЕчФдЕФЭјТчСЌНгЪЙЕУБОЕиДњТыПтЮоЗЈгыЗўЮёЦїНјааНЛЛЅЃЌвдбщжЄЪЧЗёЫљгаЕФЮФМўПЩвджЛДгБОЕиОЭНјааЛжИДЁЃЖЯЭјжЎКѓжДаа
git pull ГЂЪдгыЗўЮёЦїНјааЭЌВНЃЌУќСюНсЙћЬсЪОЃКNetwork is downЃЌШчЧхЕЅ 3 ЫљЪОЃК
ЧхЕЅ 3. ЖЯЭјжЎКѓГЂЪд git pull ЭЌВНДњТы
caozhi@ repo-for-developerworks$
git pull
ssh: connect to host github.com port 22: Network
is down
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists. |
ВЛгУЕЃаФДњТыПтБЛЦЦЛЕЃЌШчЧАЫљЪіЃЌ.git ФПТМжаАќКЌгаДњТыПтЫљгаЕФЮФМўЖдЯѓКЭМЧТМЃЌвђДЫЮвУЧПЩвдКмШнвзЕФЭЈЙ§УќСюНЋЦфНјааЛжИДЁЃ
ЪзЯШЃЌЫфШЛЮФМўБЛЩОГ§ЧвЭјТчЮоЗЈСЌНгЃЌЮвУЧвРШЛПЩвдВщбЏЕНРњЪЗЬсНЛМЧТМЃЌШчЭМ 1 ЫљЪОЃК
ЭМ 1. ВщПДЬсНЛРњЪЗ
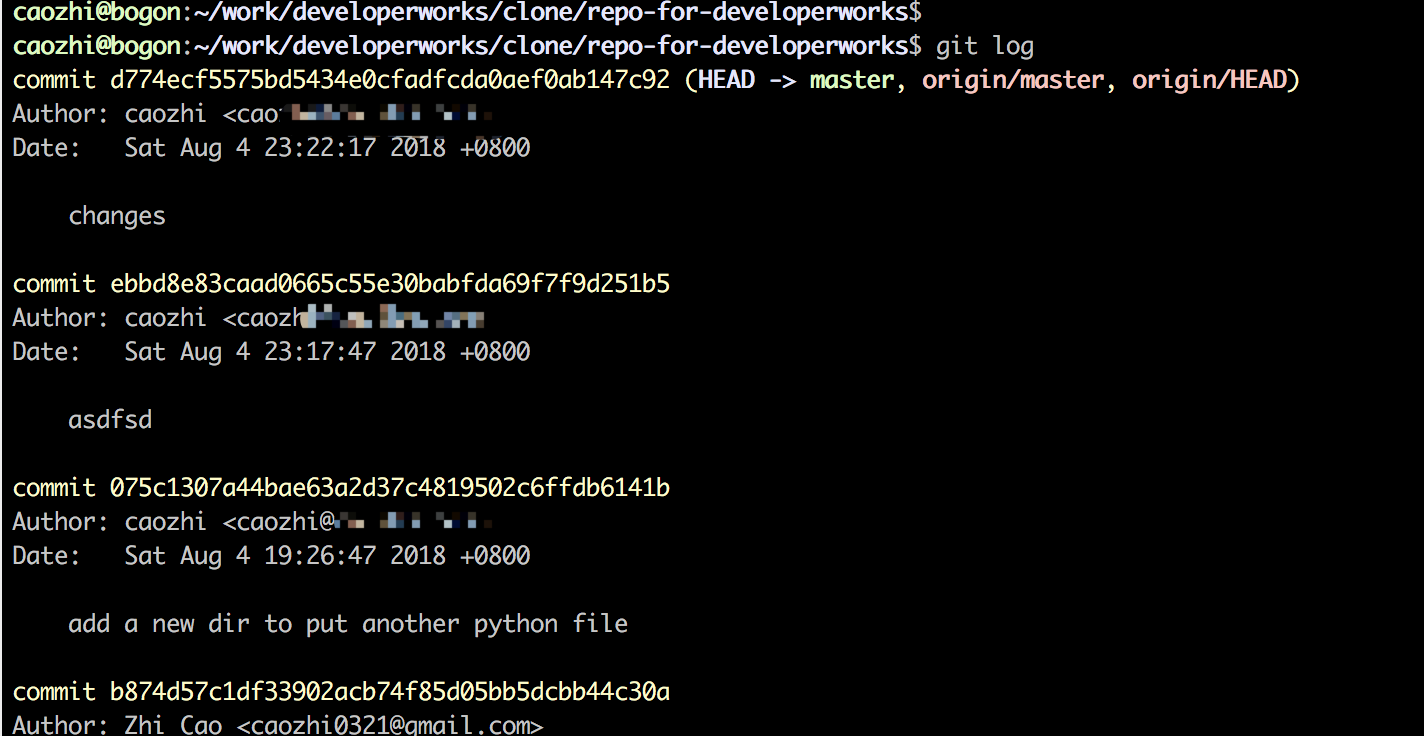
ШЛКѓЮвУЧПЩвдЭЈЙ§ git reset --hard commit_id УќСюЛжИДЕБЧАДњТыПтЕНФПБъ
commit ЕФзДЬЌЃЌШчЧхЕЅ 4 ЫљЪОЃК
ЧхЕЅ 4. жДаа git reset --hard УќСю
caozhi@ repo-for-developerworks$
git reset --hard d774ecf5575bd5434e0cfadfcda0aef0ab147c92
HEAD is now at d774ecf changes
caozhi@ repo-for-developerworks$ ll -a
total 24
drwxr-xr-x 7 caozhi staff 224 8 5 10:48 .
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 ..
drwxr-xr-x 15 caozhi staff 480 8 5 10:48 .git
-rw-r--r-- 1 caozhi staff 278 8 5 10:48 .gitignore
-rw-r--r-- 1 caozhi staff 39 8 5 10:48 README.md
-rw-r--r-- 1 caozhi staff 56 8 5 10:48 helloworld.sh
drwxr-xr-x 3 caozhi staff 96 8 5 10:48 src |
ДгдЫааНсЙћЮвУЧПЩвдПДГіЃЌДњТыПтжаБЛЩОГ§ЕФЮФМўвбОБЛЛжИДЛиРДЃЌЖјЧвЪЧдкЮоШЮКЮЭјТчСЌНгЁЂУЛгаКЭЗўЮёЦїНјааНЛЛЅЕФЧщПіЯТНјааЕФЛжИДЃЁ
ЭЈЙ§етИіЪЕбщЯраХФњЖд Git ПЫТЁСЫЭъећЕФДњТыПтИББОгаИќМгжБЙлЕФРэНтЁЃШчгааЫШЄЃЌФњвВПЩГЂЪдЭЈЙ§ git
reset УќСюНЋДњТыПтЛжИДЕНШЮвтФПБъ commit ЕФзДЬЌЁЃБОЮФОЭВЛдйзИЪіЁЃ
Git ЛљДЁЬиад
БОеТНЋЛсНщЩм Git зїЮЊАцБОПижЦЯЕЭГЕФМИДѓЛљДЁЬиадВЂЛсНшжњвЛаЉЪЕбщРДАяжњРэНтетаЉЬиадЁЃзЂвтЃКБОеТНкНщЩмЕФЛљДЁЬиадЦфФкШнзмНсзд
ProGit етБОЪщЃЌШчгааЫШЄФњвВПЩздааВщдФдЮФЁЃ
ПЫТЁвЛДЮМДЛёЕУДњТыПтЕФЭъећИББО
етИіЬиадЪЧЫљгаЗжВМЪНАцБОПижЦЯЕЭГЕФЬиаджЎвЛЁЃGit вВВЛР§ЭтЁЃБОЮФдкЩЯвЛИіеТНкжавбОЖдИУЬиадНјааСЫЯъЯИЕФУшЪіКЭЗжЮіЃЌдкДЫОЭВЛдйзИЪіЁЃ
жБНгМЧТМПьееЖјЗЧВювьБШНЯ
АцБОПижЦЯЕЭГжаВЩШЁКЮжжВпТдРДЙмРэЮФМўЕФРњЪЗАцБОЪЧЯЕЭГЕФКЫаФММЪѕжЎвЛЁЃФПЧАКмЖрДЋЭГЕФАцБОПижЦЯЕЭГШч SVNЁЂPerforce
ЕШВЩгУЛљгкдіСПЕФЗНЪНРДМЧТМУПДЮБфИќЁЃУПДЮБфИќВњЩњМДЩњГЩвЛИіВювьЖдЯѓЃЌзюжезюаТАцБОЕФЮФМўПЩвдгЩзюГѕЕФЛљДЁЮФМўКЭетИіЮФМўЫљРлЛ§ЕФВювьРДзщГЩЁЃШчЭМ
2 ЫљЪОЃЈНиШЁзд ProGit вЛЪщЃЉЃК
ЭМ 2. діСПЗНЪН
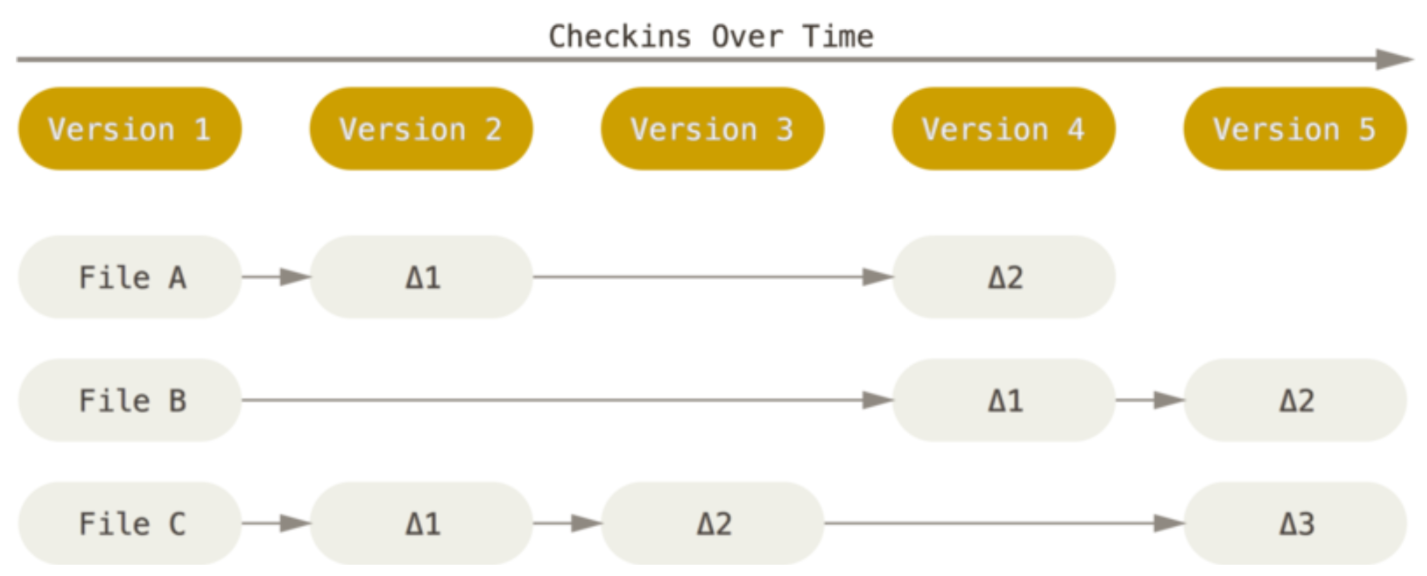
Жј Git ВЩгУЕФЪЧРрЫЦгкПьееСїЃЈStreams of SnapshotЃЉЕФЗНЪНРДДцДЂЪ§ОнЁЃGit
дквЛИіЮФМўЗЂЩњаоИФЪБЛсЩњГЩвЛИіаТЕФЭъећЕФЮФМўЖдЯѓЃЌЕБШЛОЩЕФЮФМўЖдЯѓвВЛсБЃСєЯТРДзїЮЊРњЪЗАцБОЁЃЖдгкЮДЗЂЩњИќИФЕФЮФМўЃЌGit
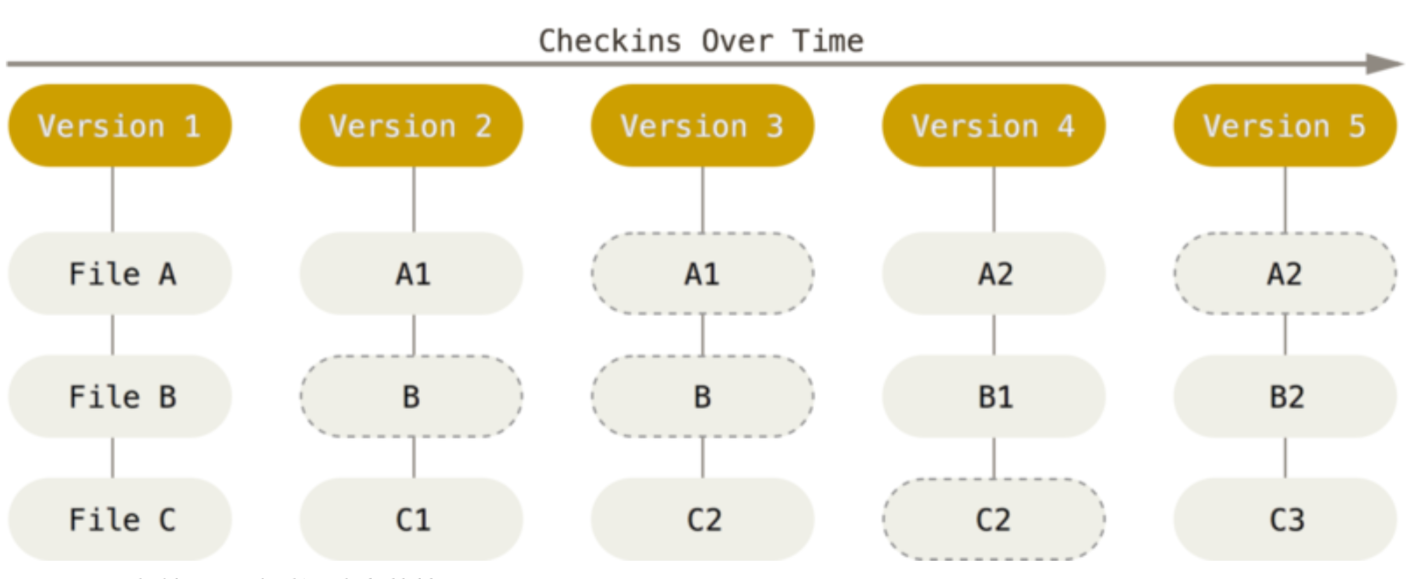
дкаТАцБОЕФДњТыПтжажЛЪЧБЃСєСЫвЛИіСДНгжИЯђжЎЧАДцДЂЕФЮФМўЁЃР§ШчЭМ 3 ЃЈНиШЁзд ProGit вЛЪщЃЉЫљЪОАцБО
2 жаЃЌЖд A ЮФМўКЭ C ЮФМўЖМНјааСЫаоИФЃЌGit ЩњГЩСЫСНИіаТЕФЭъећЕФЮФМўЖдЯѓ A1 КЭ C1ЃЌЖј
B ЮФМўЮДЗЂЩњИќИФЃЌФЧУДАцБО 2 жаОЭжЛМЧТМСЫвЛИіжИЯђ B ЮФМўЕФСДНгЁЃЛљгкЮФМўЖдЯѓ A1 КЭ C1
вдМАСЌНг BЃЌGit ОЭЩњГЩСЫвЛИіАцБО 2 ЕФПьееЁЃ
ЭМ 3. ПьееЗНЪН
ДњТыПтЕФДцДЂКЭИДжЦВЂЗЧАцБОПижЦЯЕЭГЕФЦПОБЫљдкЃЌЗжЮіЮФМўЕФВювьЁЂВщПДДњТыПтЕФИїРњЪЗАцБОГЃГЃЪЧеце§ЕФЦПОБЫљдкЁЃЛљгкетжжПьееСїЕФЩшМЦЃЌGit
ПЩвдПьЫйЕиЛёШЁЕНФГвЛЪБПЬЕФДњТыПтЫљгаЮФМўЃЌЭЌЪБвВПЩвдПьЫйЕиНјааЮФМўИїИіРњЪЗАцБОЕФВювьБШЖдЃЌЩѕжСЪЧИїРњЪЗАцБОЛђепИїЗжжЇЕФДњТыПтећЬхВювьБШЖдЁЃЯыЯёвЛЯТШчЙћЪЧДЋЭГЕФдіСПДцДЂЗНЪНЃЌвЛИіДњТыПтОЙ§ГЄЦкЕФПЊЗЂЃЌМйЩшДњТыПтвбОга
10 ЭђИіЮФМўЃЌУПИіЮФМўЦНОљОРњСЫ 100 ДЮаоИФЃЌФЧУДвЊМьЫїзюаТЕФДњТыПтКЭдЪМЕФДњТыПтЕФВювьЃЌОЭашвЊМьЫїГі
1000 ЭђИідіСПВХФмзюжеГЩЙІБШЖдЃЌеташвЊФбвдЯыЯѓЕФЪБМфГЩБОЁЃЖј Git ОЭВЛДцдкетИіЮЪЬтЃЌGit
жЛашвЊМьЫїГізюаТЕФДњТыПтПьееКЭдЪМДњТыПтПьеежБНгНјааБШЖдМДПЩЃЌдйвРЭагк Git ЕФ diff ЫуЗЈЃЈMyers
ЫуЗЈЃЉЃЌGit ПЩвдИпаЇПьЫйЕиМьЫїГіЖўепЕФВювьРДЁЃ
НќКѕЫљгаВйзїЖМЪЧБОЕижДаа
Git СэвЛИіЪЎЗжИпаЇЕФдвђЪЧЫќМИКѕЫљгаЕФВйзїЖМЪЧдкБОЕижДааЃЌГ§СЫМИИіМЋЩйЕФашвЊИњЗўЮёЦїЭЌВНДњТыЕФВйзїЃЈpushЁЂpullЁЂfetchЃЉЁЃетжжБОЕижДааЕФФмСІе§ЪЧРДздгкПЫТЁвЛДЮМДЛёЕУДњТыПтЕФЭъећИББОетвЛЬиадЁЃдкБОЮФЧАУцЕФеТНкжаЖд
Git ЕФБОЕиВйзївВНјааСЫЪЕбщЃЌЫљвддкДЫврВЛНјаазИЪіЁЃ
ГЯШЛЃЌРрЫЦ SVN КЭ Perforce вЛРрЕФМЏжаЪНЗжВМЯЕЭГЃЌЕБУЛгаЭјТчСЌНгЪБЮвУЧвРШЛПЩвдЖдБОЕиДњТыНјаааоИФЃЌЕЋШДЮоЗЈЬсНЛДњТыЃЌИќВЛгУЫЕВщбЏЬсНЛРњЪЗЃЌБШЖдАцБОВювьЁЃдкШеГЃЕФПЊЗЂЙЄзїжаЃЌаоИФДњТыжЛЪЧЙЄзїЕФвЛВПЗжЃЌЛЙгаКмДѓВПЗжЙЄзїашвЊВЛЖЯгыДњТыПтИїРњЪЗАцБОНјааНЛЛЅЁЃдкМЏжаЪНЗжВМЯЕЭГжаЃЌЕБЗЂЩњЭјТчвьГЃЪБЃЌетРрЙЄзїОЭМИКѕЮоЗЈНјааДгЖјКмПЩФмЕМжТПЊЗЂжаЖЯЁЃМДЪЙЪЧЭјТче§ГЃЕФЧщПіЯТЃЌМЏжаЪНЗжВМЯЕЭГЕФЙЄзїаЇТЪвВдЖЕЭгк
Git ЕФБОЕиЛЏжДааЁЃ
ЪЙгУ SHA-1 ЙўЯЃжЕБЃжЄЭъећад
Git жаЫљгаЪ§ОнЖдЯѓЃЈЯъМћЯТЮФЃЉдкДцДЂЧАЖМЛсМЦЫу SHA-1 аЃбщКЭЃЌЩњГЩвЛИі 40 ЮЛЕФЪЎСљНјжЦЕФЙўЯЃжЕзжЗћДЎЁЃЛљгкДЫаЃбщКЭЃЌОЭВЛПЩФмдк
Git ВЛжЊЧщЕФЧщПіЯТИќИФШЮКЮЮФМўФкШнЁЃGit жаКмЖрЕиЗНЛсЪЙгУЕНетжжЙўЯЃжЕЃЌШчЧАУцЪЕбщжаЮвУЧЪЕМЪЩЯОЭгУЕНСЫ
commit ЕФЙўЯЃжЕ id РДЛЙдДњТыПтЁЃ
НгЯТРДЮвУЧгУСэвЛЯЕСааЁЪЕбщРДбнЪОВЂбщжЄ Git ЕФВПЗжЛљДЁЬиадЃК
МЧТМЕФПьееКЭИїРњЪЗЕФЭъећФкШнЃЌЖјЗЧМЧТМВювьБШНЯ
ЙўЯЃжЕдк Git жаЕФживЊзїгУ
БОНкШдШЛвд repo-for-developerworks ЮЊР§згЁЃ
ЧАЮФЬсЕНЃЌДњТыПтжа.git ФПТМДцДЂСЫДњТыПтЕФЫљгаЮФМўКЭаХЯЂЁЃЮвУЧПЩвдВщПД .git ФПТМНсЙЙЃЌШчЧхЕЅ
5 ЫљЪОЃК
ЧхЕЅ 5. ВщПД Git ФПТМНсЙЙ
caozhi@.git$
tree -L 1
.
ЉРЉЄЉЄ FETCH_HEAD
ЉРЉЄЉЄ HEAD
ЉРЉЄЉЄ ORIG_HEAD
ЉРЉЄЉЄ branches
ЉРЉЄЉЄ config
ЉРЉЄЉЄ description
ЉРЉЄЉЄ hooks
ЉРЉЄЉЄ index
ЉРЉЄЉЄ info
ЉРЉЄЉЄ logs
ЉРЉЄЉЄ objects
ЉРЉЄЉЄ packed-refs
ЉИЉЄЉЄ refs |
дкБОЯЕСаЕФЫцКѓЮФеТжаЛсЖдИУФПТМУПИізгЯюНјааЩюШыНщЩмЃЌФњЯждкжЛашЙизЂ objects ФПТМЁЃobjects
ФПТМДцДЂСЫБОЕиВжПтЕФЫљгаЪ§ОнЖдЯѓЃЌGit ДцДЂЕФЪ§ОнЖдЯѓвЛЙВгавдЯТЫФжжЃК
TreeЃКРрЫЦ Unix ЮФМўЯЕЭГЕФЮФМўзщжЏЗНЪНЃЌTree ЖдЯѓжаМЧТМСЫЖрИі Blob ЖдЯѓЛђепЦфЫќзг
Tree ЖдЯѓЙўЯЃжЕЁЂЮФМўУћФПТМУћЕШдЊЪ§ОнЁЃЭЈЙ§ Tree ЖдЯѓПЩвдЛЙдГіДњТыПтЕФФПТМНсЙЙЁЃ
CommitЃКМЧТМвЛИі commit ЕФЫљгааХЯЂЁЃ
BlobЃКМЧТМСЫДњТыПтдДЮФМўЕФФкШнЃЌВЛМЧТМдДЮФМўЕФШчЮФМўУћвЛРрЕФдЊЪ§ОнЁЃ
TagЃКЮЊФГвЛИіЪБПЬЕФДњТыПтДђвЛИі TagЃЌЗНБуМьЫїЬиЖЈЕФАцБОЁЃTag дк Git жавВЪЧвдвЛжжЪ§ОнЖдЯѓЕФЗНЪННјааДцДЂЁЃ
objects ФПТМЯТДцЗХСЫЖрИівд 2 ЮЛзжЗћУќУћЕФФПТМЃЌдкетаЉФПТМЯТгжДцЗХСЫ 38 ЮЛзжЗћУќУћЕФЮФМўЃЌ2
ЮЛЕФЧАзККЭ 38 ЮЛЕФЮФМўУћОЭзщГЩСЫ Git жаЕФвЛИіЪ§ОнЖдЯѓЕФЙўЯЃжЕЃЌШчЧхЕЅ 6 ЫљЪОЃК
ЧхЕЅ 6. ВщПД objects ФПТМНсЙЙ
caozhi@ objects
$ tree -L 2
.
ЉРЉЄЉЄ 06
ЉІ ЉИЉЄЉЄ dad60f87d28d220216f5891dddfdfe4af5f1a0
ЉРЉЄЉЄ 07
ЉІ ЉИЉЄЉЄ 5c1307a44bae63a2d37c4819502c6ffdb6141b
ЉРЉЄЉЄ 16
ЉІ ЉИЉЄЉЄ d0e292c43ca35d4ab36da6b3e1913288477076
ЉРЉЄЉЄ 22
ЉІ ЉИЉЄЉЄ 783d07955986cab0d2195eb131d8e0047acb59
ЉРЉЄЉЄ 40
ЉІ ЉИЉЄЉЄ 6714df7708534f67d9373821de5948ab3f5d9a
ЉРЉЄЉЄ 6d
ЉІ ЉИЉЄЉЄ 1f98e1a9bede453ab16d6ba90428a994ebf147
ЉРЉЄЉЄ ae
ЉІ ЉИЉЄЉЄ e311888e5572cc3d7d8b00e8f400216d26d320
ЉРЉЄЉЄ b3
ЉІ ЉИЉЄЉЄ adac68e8b6a22f88003c226fc4746a5269a496
ЉРЉЄЉЄ b8
ЉІ ЉИЉЄЉЄ 74d57c1df33902acb74f85d05bb5dcbb44c30a
ЉРЉЄЉЄ d4
ЉІ ЉИЉЄЉЄ eec9c19502086dd0f42f8bb7f26feb77377d5c
ЉРЉЄЉЄ d6
ЉІ ЉИЉЄЉЄ 96feb980566a3c03fd0f22c4b806e34a312de6
ЉРЉЄЉЄ info ## can be ignored right now
ЉИЉЄЉЄ pack ## can be ignored right now
ЉРЉЄЉЄ pack-eff5463c4b0c56c3ea5e5c381941541d76d8e143.idx
ЉИЉЄЉЄ pack-eff5463c4b0c56c3ea5e5c381941541d76d8e143.pack
8 directories, 8 files |
ЧхЕЅ 7 ЕФНХБОКЫаФЪЙгУСЫ git cat-file -t УќСюРДВщПДЖдЯѓЮФМўЕФРраЭЁЃгЩДЫПЩвдПДГіЃЌдк
Git ФкВПЪЙгУЙўЯЃжЕзїЮЊЮФМўУћРДДцДЂЫљгаЕФЪ§ОнЖдЯѓЁЃ
ЧхЕЅ 7. жДааНХБОСаГіЖдЯѓЮФМўМАЦфЖдгІЕФРраЭ
caozhi@ objects$
find . -type f | grep -v pack | \
while read line; \
do \
var=${line//"."/""}; \
var=${var////""}; \
echo $line `git cat-file -t $var`; \
done
./b3/adac68e8b6a22f88003c226fc4746a5269a496 tree
./d6/96feb980566a3c03fd0f22c4b806e34a312de6 tree
./ae/e311888e5572cc3d7d8b00e8f400216d26d320 tree
./16/d0e292c43ca35d4ab36da6b3e1913288477076 commit
./07/5c1307a44bae63a2d37c4819502c6ffdb6141b commit
./6d/1f98e1a9bede453ab16d6ba90428a994ebf147 blob
./06/dad60f87d28d220216f5891dddfdfe4af5f1a0 blob
./d4/eec9c19502086dd0f42f8bb7f26feb77377d5c blob
./b8/74d57c1df33902acb74f85d05bb5dcbb44c30a commit
./40/6714df7708534f67d9373821de5948ab3f5d9a tree
./22/783d07955986cab0d2195eb131d8e0047acb59 tag |
СэЭтПЩвдПДЕН 16d0e292Ё етИіЖдЯѓБэЪОЦфЪЧвЛИі commitЁЃНсКЯЬсНЛРњЪЗМЧТМПЩвдПДЕНЃЌетИіЙўЯЃжЕШЗЪЕЖдгІгквЛИі
commit idЃЌШчЧхЕЅ 8 ЫљЪОЃК
ЧхЕЅ 8. ВщПДЬсНЛРњЪЗ
caozhi@ repo-for-developerworks/.git/objects$
git log
commit d774ecf5575bd5434e0cfadfcda0aef0ab147c92
(HEAD -> master, origin/master, origin/HEAD)
Author: caozhi <caozhi0321@gmail.com>
Date: Sat Aug 4 23:22:17 2018 +0800
changes
Ё ## Ignored some useless history
commit 16d0e292c43ca35d4ab36da6b3e1913288477076
Author: Zhi Cao <caozhi0321@gmail.com>
Date: Fri Aug 3 22:15:02 2018 +0800
Create a shell script
Ё ## Ignored some useless history |
дкЧхЕЅ 9 жаПЩвдПДЕН 6d1f98e1Ё етИіЖдЯѓЪЧвЛИі blob ЖдЯѓЃК
ЧхЕЅ 9. ВщПД blob ЖдЯѓЕФРраЭКЭФкШн
caozhi@ objects$
git cat-file -t 6d1f98e1a9bede453ab16d6ba90428a994ebf147
blob
caozhi@ objects$ git cat-file -p 6d1f98e1a9bede453ab16d6ba90428a994ebf147
#!/bin/bash
echo hello world!
caozhi@ objects$ git cat-file -t d4eec9c19502086dd0f42f8bb7f26feb77377d5c
blob
caozhi@ objects$ git cat-file -p d4eec9c19502086dd0f42f8bb7f26feb77377d5c
#!/bin/bash
echo hello world!
echo hello world again! |
ВщПДИУЮФМўФкШнЃЌПЩвдПДЕН 6d1f98e1Ё ЦфЪЕЪЧ helloworld.sh етИідДДњТыЕФФкШнЃЌЕЋЖдЯѓ
6d1f98e1Ё ЪЧ helloworld.sh ЕФЩЯвЛИіАцБОЃЌЖјдкЫцКѓВщПДЕФ d4eec9c1Ё
ВХЪЧЦфзюаТАцБОЁЃДгетРявВФмПДЕН Git дкДцДЂЮФМўВЛЭЌАцБОЪБЃЌШЗЪЕЪЧДцДЂСЫИїРњЪЗАцБОШЋСПЕФЮФМўЖјЗЧЦфдіСПЁЃ
зЂвтЃКЪЕМЪВйзїжавВПЩвдЪЙгУЙўЯЃжЕЕФЧААЫЮЛЫѕаДЃЌШчЃКgit cat-file -t 6d1f98e1ЁЃШчгааЫШЄЃЌФњПЩвдГЂЪдвЛЯТЁЃ
жСДЫЃЌЮвУЧПДЕН SHA1 ЙўЯЃжЕдк Git ЕзВуЕФОоДѓзїгУЃЌЫљгаЖдЯѓЖМвдЙўЯЃжЕРДУќУћВЂДцДЂЃЌЫљгаЖдЯѓвВПЩвдЭЈЙ§ЙўЯЃжЕРДНјааМьЫїЁЃЭЌЪБЮвУЧвВДг
Git ЕзВудйДЮбщжЄСЫ Git дкБОЕиДцДЂСЫЮФМўЕФЫљгаШЋСПРњЪЗАцБОЁЃ
Git вЛАужЛЬэМгЪ§Он
етИіЬиаджИЕФЪЧе§ГЃЧщПіЯТЮвУЧжДааЕФ Git ВйзїЃЌМИКѕжЛЭљ Git РядіМгЪ§ОнЁЃвђДЫКмФбШУ Git
жДааШЮКЮВЛПЩФцЕФВйзїЃЌЛђепШУЫќвдШЮКЮЗНЪНЧхГ§Ъ§ОнЁЃЭЌЦфЫќАцБОПижЦЯЕЭГвЛбљЃЌУЛгаЬсНЛЕФИќаТгаПЩФмГіЯжЖЊЪЇЕФЧщПіЃЌЕЋЪЧвЛЕЉЮвУЧНЋИќИФЬсНЛЕН
Git жажЎКѓЃЌОЭКмФбдйЖЊЪЇЪ§ОнЁЃ
етИіЬиадЪЙЕУЮвУЧПЩвдЗХаФЧвгфдУЕиЪЙгУ GitЃЌЮвУЧПЩвдОЁЧщЕизіШЮКЮГЂЪдЁЃМДЪЙЮѓВйзїГіЯжЪ§ОнЖЊЪЇЃЌЮвУЧвВПЩвдЭЈЙ§ИїжжЪжЖЮНЋЦфНјааПьЫйЛжИДЁЃ
дк ProGit вЛЪщжаЛЙЬсЕНСЫ Git ЕФСэвЛИіЬиад"Ш§жжзДЬЌ"ЃЌИУЬиадЪЧжИ
Git жаЕФЮФМўвЛАугаШ§жжзДЬЌЃКвбЬсНЛЃЈcommittedЃЉЁЂвбаоИФЃЈmodifiedЃЉКЭвбднДцЃЈstagedЃЉЁЃдкЫцКѓЕФЯЕСаЮФеТжаНЋЛсНсКЯ
Git ЕФШеГЃЪЙгУРДзХжиНщЩмвдАяжњФњРэНтетШ§жжзДЬЌЃЌЛЙЛсЖд Git ФПТМвдМА Git ЕФЖдЯѓДцДЂФЃаЭНјааЯъЯИЕиЗжЮіКЭНВНтЁЃ
GitHub МђНщ
GitHub ЪЧШЋЧђзюДѓЕФПЊдДДњТыЭаЙмЦНЬЈЃЌдкПЊдДНчгазХВЛПЩКГЖЏЕФЖЈЮЛЃЌвВЩюЪмПЊдДАЎКУепЕФЯВАЎЁЃGitHub
ЦНЬЈБОЩэЪЎЗжжБЙлвзгУЃЌЦфЪЙгУЗНЗЈдкДЫОЭВЛНјааЯъЪіЁЃБОеТМђЕЅСаОйвЛЯТЮвШЯЮЊЕФ GitHub вЛаЉКмгавтЫМЛђепКмгагУЕФЙІФмЃК
ШчЙћжЛЪЙгУУтЗбАцЃЌФЧУДЮоЗЈДДНЈЫНШЫВжПтЃЈRepositoryЃЉЃЌжЛФмДДНЈПЊЗХВжПтЃЛПЊЗХВжПтПЩБЛШЮКЮШЫПЫТЁЛђ
ForkЁЃ
ПЩвдзїЮЊЖРСЂПЊЗЂепНЈСЂздМКЕФДњТыВжПтЃЌЭХЖгазїЕФЛАвВПЩвдЭЈЙ§НЈСЂзщжЏЃЈOrganizationЃЉРДЙмРэзщжЏЯТЕФВжПтЁЂЭХЖгЁЂГЩдБЁЂШЈЯоЕШЁЃШчЭМ
4 ЫљЪОЃК
ЭМ 4. ЬэМгВжПтЛђзщжЏ
ШчЙћЪЧПЊдДЯюФПЃЌПЩвдКмШнвз Fork ЦфЫќПЊдДЯюФПЕФДњТыПтЕНздМКЕФеЫКХЯТЃЛвВПЩвдЯђБ№ШЫЗЂЦ№ Pull
Request ЧыЧѓЃЌЧыЧѓзїепНЋ Fork ЯТРДжЎКѓЕФДњТыаоИФКЯВЂЕНдДњТыПтжаЁЃШчЭМ 5 КЭЭМ 6
ЫљЪОЃЌЮвУЧПЩвдНЋ Linux ЕФдДТыПт Fork ЕНздМКЕФеЫЛЇЛђзщжЏЯТЁЃ
ЭМ 5. Fork Linux ДњТыПт

ЭМ 6. бЁдё Fork ЕФФПБъ
Pull Request ЬсЙЉСЫЧПДѓЕФДњТыЦРЩѓЁЂДњТыКЯВЂЕФЛњжЦЁЃЭЈЙ§ДДНЈ Pull Request
ЯђПЊдДЯюФПЕФзїепЛђепЙмРэепЗЂЦ№КЯВЂздМКДњТыЕФЧыЧѓЃЌЮвУЧПЩвдЧсЫЩЕиЯђПЊдДЯюФПЙБЯзДњТыЁЃДњТыЦРЩѓКЭ Pull
Request НЋдкЫцКѓЕФЯЕСаЮФеТжаЯъЯИНщЩмЁЃ
ЪЙгУ Gist ПЩвдЙмРэвЛаЉздМКГЃгУЕФДњТыЦЌЖЮЁЂГЃгУЕФУќСюЃЌвВПЩвдЗжЯэИјЦфЫћПЊЗЂепЁЃ
GitHub ЩЯвВПЩвдЙмРэЙГзгЃЈHookЃЉЃЌПЩгУгкздЖЏЙЙНЈЙ§ГЬЃЌР§Шчв§Шы Jenkins ЕФ WebHookЃЌЪЙЕУ
Jenkins ПЩвддкУПДЮЗЂЯжДњТыЬсНЛКѓСЂМДДЅЗЂвЛДЮЯюФПЙЙНЈЁЃ
GitHub вВЬсЙЉСЫКмЖрПЩбЁЕФМЏГЩЗўЮёЃЈIntegration & ServiceЃЉЪЙгУЃЌР§ШчМЏГЩ
ZenHub ВхМўЃЌПЩвдНјааУєНнЪНЯюФПЙмРэЁЃ
БОеТМђЕЅТоСаСЫВПЗж GitHub ЕФЬиЕуЃЌдкЫцКѓЕФЯЕСаЮФеТжаЃЌЮвНЋЛсЖд GitHub ВЛЭЌЕФжїЬтНјааЯъЯИЕФНщЩмЃЌР§ШчШЈЯоПижЦЁЂPull
Request ЕШЁЃ
НсЪјгя
Git КЭ GitHub ЖМЪЧЯждквЕНчзюСїааЕФДњТыЙмРэЙЄОпЁЃGit ЬсЙЉСЫЧПДѓЕФАцБОПижЦЙІФмЃЌЖј GitHub
зїЮЊзюДѓЕФПЊдДДњТыДњТыЭаЙмЦНЬЈЃЌЬсЙЉСЫЧПДѓЕФЭаЙмФмСІЁЂаЭЌКЯзїФмСІЁЃGitHub ЕФХюВЊЗЂеЙгыПЊдДЯюФПЕФХюВЊЗЂеЙЯЂЯЂЯрЙиЃЌGitHub
гЕБЇПЊдДЕФПЊЗХЬЌЖШЪЙЦфГЩЮЊСЫПЊЗЂепаФФПжазюЮЊЯВАЎЕФДњТыЭаЙмЦНЬЈЁЃЯЃЭћФњдкЖСЭъБОЮФжЎКѓЖд Git КЭ
GitHub ФмгаЧхЮњЕФРэНтЃЌЭЌЪБдкНёКѓЕФЙЄзїжаЯэЪмЕН Git КЭ GitHub ДјРДЕФРжШЄЁЃ |









